Abstract
Autonomous driving (AV) technology has elicited discussion on social dilemmas where trade-offs between individual preferences, social norms, and collective interests may impact road safety and efficiency. In this study, we aim to identify whether social dilemmas exist in AVs’ sequential decision making, which we call “sequential driving dilemmas” (SDDs). Identifying SDDs in traffic scenarios can help policymakers and AV manufacturers better understand under what circumstances SDDs arise and how to design rewards that incentivize AVs to avoid SDDs, ultimately benefiting society as a whole. To achieve this, we leverage a social learning framework, where AVs learn through interactions with random opponents, to analyze their policy learning when facing SDDs. We conduct numerical experiments on two fundamental traffic scenarios: an unsignalized intersection and a highway. We find that SDDs exist for AVs at intersections, but not on highways.
1. Introduction
Despite significant efforts in artificial intelligence (AI) being focused on computer vision, the intelligence of autonomous vehicles (AVs) lies in their optimal decision-making abilities in the motion-planning stage while driving alongside human drivers [1,2,3]. The question of how individual AVs should develop the ability to survive in a complex traffic environment is a prerequisite to realizing the anticipated societal benefits of AVs [4,5], such as improved traffic safety [6,7,8,9], efficiency [10,11,12,13], and the promotion of sustainable human–machine ecologies. One major advantage that AVs have over human drivers is their ability to promptly assess situations with a greater amount of information, allowing them to react in an optimal way.
However, AVs still lack the ability to deal with sequential decision-making when facing complex driving scenarios, which may result in underperformance compared to humans. To elaborate, the self-driving technology remains unclear about how to handle the conflicts between individual self-interest and the collective interest of a group, the so-called “social dilemma”. Social dilemmas can arise when individual AVs prioritize their own safety and efficiency, potentially compromising the safety and efficiency of other AVs or human-driven vehicles on the road. For instance, when changing lanes on highways, AVs must consider the speed and trajectory of surrounding vehicles while prioritizing their own utility. If each AV prioritizes its self-interest, it may lead to car accidents and decreased the overall efficiency on the road. Understanding social dilemmas involving AVs is critical at the early stage of AV adoption.
The aim of this paper is to study social dilemmas that arise when AVs make sequential decisions in a dynamic driving environment (as shown in Figure 1). To achieve this, we propose a social learning framework in which AVs learn cooperation and defection strategies in a Markov game through interactions with random opponents selected from an agent pool. By obtaining the empirical payoff matrix of the Markov game using these strategies, we can identify the specific dilemma the game belongs to. These dilemmas, which we refer to as “sequential driving dilemmas” (SDDs), can aid policymakers in creating regulations that promote safe and efficient driving behavior, as well as designing incentive mechanisms that encourage cooperative driving strategies that benefit the group as a whole.
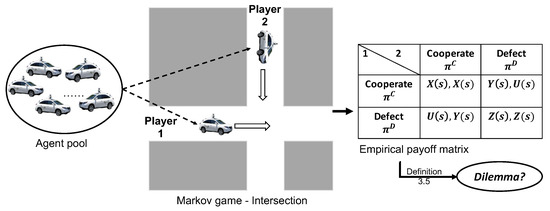
Figure 1.
SDD framework (adapted from [14]).
2. Related Work
Social dilemmas have been widely studied to understand cooperative and defective behaviors among players, as seen in the works of Allen et al. [15], Alex et al. [16], Qi et al. [17], and Hilbe et al. [18]. While recent studies have investigated social dilemmas in the context of autonomous vehicles (AVs), such as the Trolley problem, which aims to investigate how AVs can make moral decisions [19,20], these studies are limited to matrix games. Matrix games are stateless and cannot capture the sequential decision-making process in dynamic traffic environments. Moreover, they do not account for other road users that may affect the state of the traffic environment. To overcome these limitations, this paper focuses on Markov games, which allow for sequential decision-making and cumulative rewards over time, making them suitable for modeling AVs’ behavior in traffic environments.
To identify dilemmas in Markov games, sequential social dilemmas have been proposed to capture cooperative and defective behaviors in a dynamic environment, building on the concept of social dilemmas in two-player matrix games [14,21,22,23]. Prior research assumes that agents play with a fixed opponent in Markov games, which does not work for real-world scenarios in which AVs may randomly interact with each other. To tackle this challenge, this paper leverages a social learning framework where a population of agents [24] learn policies through repeated interactions with randomly selected opponents in multi-agent systems. In this study, we aim to identify sequential social dilemmas for AVs in traffic scenarios, utilizing a social learning scheme for Markov games.
Many other studies focus on enhancing coordination and cooperation among players at game equilibrium. One approach to guiding players’ cooperative behavior in a social group is through social norms or conventions, which are shared standards of acceptable behavior by groups [25,26,27,28] and can lead to desired social outcomes [24]. It is important to note that social dilemmas depict a game where there is a conflict between collective and individual interests, while social norms denote a game equilibrium that can lead to desired social outcomes. We provide a summary of related work on social dilemmas and social norms in Table 1.

Table 1.
Literature on social dilemmas and social norms.
Contributions of This Paper
The contributions of this paper include:
- We propose a social learning framework to investigate sequential driving dilemmas (SDD) in autonomous driving systems.
- We develop a reinforcement learning algorithm for AVs’ policy learning to estimate SDDs in traffic scenarios.
- We apply the proposed algorithm to two traffic scenarios: an unsignalized intersection and a highway, in order to identify SDDs.
The remainder of this paper is organized as follows. In Section 3, we first present preliminaries regarding social dilemmas in matrix games. In Section 4, we introduce a social learning framework to model interactions among random AV players in dynamic driving environments. In Section 5, we conduct several numerical experiments to identify SDDs in traffic scenarios. Section 6 concludes and discusses the future work.
3. Preliminaries
3.1. Social Dilemma in a Matrix Game
In this subsection, we briefly introduce social dilemmas in a traditional matrix game. Table 2 demonstrates the payoff matrix of a game between two players. Both players can choose cooperative and defective policies, which are defined as follows.
Table 2.
Matrix game.
Definition 1.
Define and as cooperative and defective policies, respectively. Players choose to cooperate with opponents when conducting and defect with opponents when conducting . and denote policy sets.
Definition 2.
The game is a social dilemma if the payoff satisfies the following conditions [35]:
- : Agents prefer mutual cooperation to mutual defection;
- : Agents prefer mutual cooperation to unilateral cooperation;
- : Agents prefer mutual cooperation over an equal probability of unilateral cooperation and defection;
- : Agents prefer unilateral defection to mutual cooperation,: Agents prefer mutual defection to unilateral cooperation.
Definition 3.
According to Definition 2, we can identify three types of social dilemmas:
- : Prisoner’s dilemma;
- : Chicken game;
- : Stag hunt game.
Note that social dilemma in Definition 2 is a one-shot matrix game. The cooperative and defective policies are static strategies, which are not applicable to real-world scenarios. We will extend it to sequential driving dilemmas with dynamic settings in the following subsection.
3.2. Sequential Driving Dilemma in a Markov Game
We first introduce a Markov game to model the sequential decision making of agents in a dynamic driving environment. We assume the Markov game is a non-cooperative game in which each agent aims to maximize their own cumulative payoff. The Markov game is denoted by . We specify each component of the Markov game as follows:
- m. There are m adaptive AVs in the agent pool, denoted by .
- . The environment state s in the driving environment, denoted by , refers to global information such as the spatial distribution of all road users and road conditions. It is important to note that there may also be other road users, such as background vehicles, who are non-strategic players in the Markov game. The environment state space is denoted by . However, it should be noted that the environment state s is not fully observable to agents, making the Markov game a partially observable Markov decision process (POMDP).
- . Each agent draws a private observation from their neighborhood environment, which is a subset of the global environment state s. Specifically, agent draws a private observation denoted by , where is the observation space of agent i. The joint observation space for all agents is denoted by , which captures the overall observation of the driving environment by all agents. It is important to note that each agent is limited to only observing their surroundings and not the entire environment state.
- . For simplicity, we adopt discrete action space. Joint action is , where and is the action set. Actions in different traffic scenarios will be detailed in Section 5.
- . After taking action a in state s, an agent arrives at a new state with transition probability . The agent interacts with the environment to gain state transition experiences, i.e., .
- . Agent receives a reward at each time step, which can be the travel cost in the driving environment.
- . The discount factor is used to discount the future reward. In this study, we take , because drivers usually complete trips in a finite horizon and they value future and immediate rewards equally.
Agent uses a policy to choose actions after drawing observation . The policy is designed to maximize the agent’s expected cumulative reward by selecting an optimal action. This process of observing the environment, selecting an action, and receiving a reward repeats until the agents reach their own terminal state, which occurs when either a crash happens or the agents complete their trips. In a multi-agent system, the optimal policy for agent i is denoted as , and is defined as the agent’s best response to the policies of other agents when those policies are held constant. For all agents , the value achieved by agent i from any state s is maximized given the other agents’ policies.
where, is the joint action of agent i’s opponents. We denote the value function of agent i starting from state s as given a policy of agent i and policies of her random opponents in the environment. This study employs independent reinforcement learning to facilitate individual agents’ optimal policy learning. Each agent is trained with its own policy networks.
We now present how agents learn the cooperative policy and defective policy in the Markov game, as well as the method for calculating the empirical payoff matrix of the agents with respect to these policies. To obtain the cooperative policy and defective policy within the social learning framework, we introduce a weight parameter w to represent the desired level of social outcomes [29] in an agent’s reward. Specifically, we define the weight associated with desired social behaviors for the cooperative policy as and that for the defective policy as . The reward obtained by agent i at each time step in a dynamic environment is then calculated as follows:
where, is the reward associated with the selected action and is the reward associated with some desired social outcome (e.g., road safety). Note that the weight parameter w is used to balance the importance of these two types of rewards. We have , which means agents prefer collective interest to self-interest when adopting and vice versa. Cooperative and defective policies are trained based on and , respectively (See the learning algorithm in Section 4.2). There are many other ways to obtain and . For instance, a cooperative agent is defined as a driver who always yields at the intersection, and a defective agent is a driver who crosses the intersection aggressively without taking into account other road users [36]. The level of aggressiveness is utilized for each agent via social behavior metrics [14] to determine and .
Definition 4.
Define an empirical payoff matrix for a pair of agents i and j who play a Markov game starting from state in Table 3:
Table 3.
Empirical payoff matrix in a Markov game.
Each cell in the matrix denotes the payoff regarding and . Mathematically,
where, . is the payoff of agent i when agents i and j adopt and , respectively.
Definition 5.
A Markov game is a sequential driving dilemma (SDD) when there exist states for a pair of agents whose empirical payoff matrix satisfies the following social dilemma conditions (Definition 2):
- : Agents prefer mutual cooperation to mutual defection when starting from state;
- : Agents prefer mutual cooperation to unilateral cooperation when starting from state;
- : When starting from state , agents prefer mutual cooperation over an equal probability of unilateral cooperation and defection;
- : When starting from state , agents prefer unilateral defection to mutual cooperation,: Agents prefer mutual defection to unilateral cooperation.
Note that the empirical payoff matrix in a Markov game is utilized to identify the existence of dilemmas. We will investigate game equilibrium in sequential driving dilemmas in the future.
4. Social Learning Framework
In this section, we introduce a social learning framework that utilizes a Markov game to model interactions among autonomous vehicles (AVs) that are randomly selected from an agent pool.
4.1. Social Learning Scheme
In order to understand road users’ behaviors in the traffic environment, each AV must learn through interactions with its opponents. In traditional learning schemes, an agent repeatedly interacts with a fixed opponent until a stable equilibrium is reached. However, in the context of navigating the traffic environment, AVs encounter different opponents dynamically instead of a fixed one.
In a social learning scheme, agents learn through interactions with opponents randomly selected from an agent pool. As a result, each agent plays games repeatedly with random opponents and develops its own policy based on personal experience. This approach allows AVs to learn from a diverse set of opponents and adapt to changing circumstances, which is critical for ensuring safe and efficient driving behavior in real-world scenarios. In contrast to the fixed agents in traditional learning schemes, the agents in a social learning scheme are randomly selected from a pool in each episode. These agents then play a Markov game and update their policies based on the outcomes.
4.2. Social Learning Algorithm
In this section, we introduce a multi-agent reinforcement learning algorithm based on Deep Q-network (DQN) [37] to learn the cooperative policy and defective policy for AVs in the social learning scheme. The proposed algorithm is summarized in Algorithm 1.
We first initialize deep Q-networks for each agent. Q-networks for cooperative and defective policies are denoted as , parameterized by and , respectively. Their target networks are and . Hyperparameters, including exploration rate , learning rate , update period and update parameter , are predetermined (See Table 4). For each run in one episode, two agents are randomly selected and removed till the agent pool is empty. When an agent is selected to participate in a Markov game, she randomly chooses to either cooperate or defect with her opponent. If agent i chooses cooperation, her cooperative Q-network and target cooperative Q-network will be updated with the weight parameter of rewards in the Markov game. Similarly, if agent i chooses defection, her defective Q-network and target defective Q-network will be updated with the weight parameter of rewards in the Markov game. From an initial environmental state , agent i draws private observation and taking action according to the widely used -greedy method (i.e., agent i chooses action randomly with probability and greedily from optimal policy with probability ), until reaching some terminal state. The joint action is executed in the environment, which results in a state transition . After the state transition, each agent i receives a new private observation and a corresponding reward according to Equation (2). This process is repeated until a terminal state is reached, which occurs when a crash happens or agents complete their trips. The experience tuple of agent i is stored in a replay buffer, which is used to update the target network every time steps.
| Algorithm 1 DQN-SDD |
|
Table 4.
Hyperparameters.
After the training process, the trained Q-networks are utilized to calculate the empirical payoff matrix. First, each pair of agents from the agent pool is randomly selected. Then, the pair executes four Markov games, corresponding to the combinations of cooperative and defective policies, namely , , , and , according to their own Q-networks and . The empirical payoff for agent i is calculated as cumulative rewards received over a fixed number of iterations. Each cell in the resulting payoff matrix is calculated based on Equation (4), which represents the average reward obtained by agent i when the pair of agents takes actions , given the current state s and policies and .
5. Numerical Experiments
In this section, we investigate two traffic scenarios (Figure 2): unsignalized intersections and highways. In each traffic scenario, we first introduce the environment set-up and then discuss SDD results.
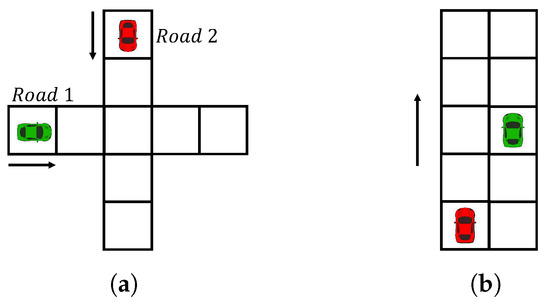
Figure 2.
Traffic scenarios. (a) Unsignalized intersection. (b) Highway.
5.1. Scenario 1: Unsignalized Intersection
5.1.1. Environment Set-Up
The traffic environment is an unsignalized intersection (Figure 2a) comprising two intersecting roads, Road 1 and Road 2. Vehicles represented by green and red colors navigate Road 1 and Road 2, respectively. The intersection is discretized into uniform cells, and the state s is defined by the locations of the agents. Each agent is able to observe only the road she navigates, and the action set consists of two actions: “Go” and “Stop”. The “Go” action corresponds to moving forward by one cell, while the “Stop” action represents taking no action. In each time step, agents receive a negative reward for taking either the “Go” or “Stop” action, denoting the instantaneous travel time, in order to encourage them to complete the game quickly. If a collision occurs at the intersection cell, each agent incurs a negative reward to reflect the cost of the collision. On the other hand, if no collision occurs, agents complete their trips and the game terminates. The desired social outcome is that no collision occurs, and agents successfully complete their trips.
5.1.2. SDD Results
We investigate whether SDD exists at the unsignalized intersection. In Figure 3, each point represents the empirical payoff matrix (Table 3) obtained by a pair of agents randomly selected from the pool and play the intersection game from some initial state s. For example, to estimate one cell in the payoff matrix, we simulate the game between these two agents driven by policies and for 1000 times and compute the average payoff. The x-axis represents and the y-axis represents in the empirical payoff matrix. The squares and circles represent cases satisfying and violating SDD conditions, respectively. According to Definition 4, the intersection game is an SDD. The cooperation and defection performance in two scenarios are summarized in Table 5.
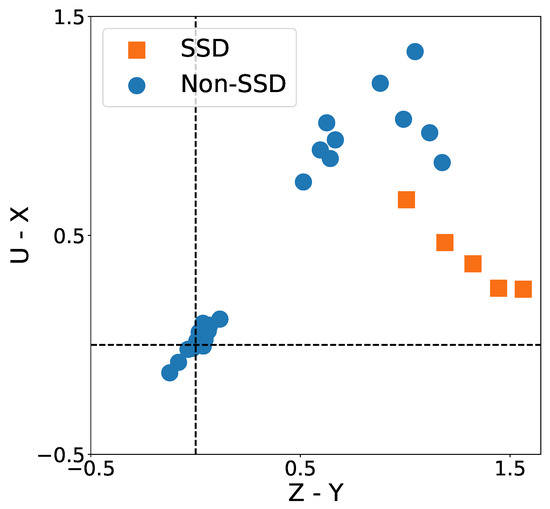
Figure 3.
SDD—unsignalized intersection.
Table 5.
Cooperation and defection.
We look into points satisfying SDD conditions (orange squares). Note that these points are in the first quadrant where and . According to Definition 4, means agents prefer unilateral defection to mutual cooperation. It implies that when AVs encounter those who choose to yield at the intersection, they prefer crossing the intersection aggressively over yielding to others. means agents prefer mutual defection to unilateral cooperation. It implies that when AVs encounter aggressive agents, they prefer crossing the intersection aggressively over yielding to others. According to Definition 3, the intersection game is a prisoner’s dilemma.
5.2. Scenario 2: Highway
5.2.1. Environment Set-Up
The traffic environment is a highway (Figure 2b) with two lanes, going from south to north. Vehicles in green and red colors represent AV players in a Markov game. The environment is discretized into uniform cells, and the state space is defined by the locations of the agents. The initial locations of the agents on two lanes are randomized. Agents are capable of observing both lanes. The action set comprises three actions, namely, “Go”, “Stop”, and “Lane-change”. The “Go” action is associated with moving forward by one cell, whereas the “Stop” action is associated with taking no action. The “Lane-change” action allows switching to the other lane. At each time step, agents receive a negative reward that denotes their travel time for taking any of the three actions. Agents receive a positive reward for formulating a car platoon, which refers to a group of vehicles that travel in a coordinated manner, with one leading vehicle and the others following behind [38].
5.2.2. SDD Results
Figure 4 displays the empirical payoff matrices obtained by simulating the platoon game. The points in the plot are located in the fourth quadrant where and , indicating that the platoon game does not satisfy the SDD condition. Specifically, implies that agents prefer mutual cooperation over unilateral defection, indicating that AVs are more likely to form a platoon when interacting with cooperative agents. On the other hand, implies that agents prefer unilateral cooperation over mutual defection, suggesting that AVs are more likely to change lanes and form a platoon with defective agents.
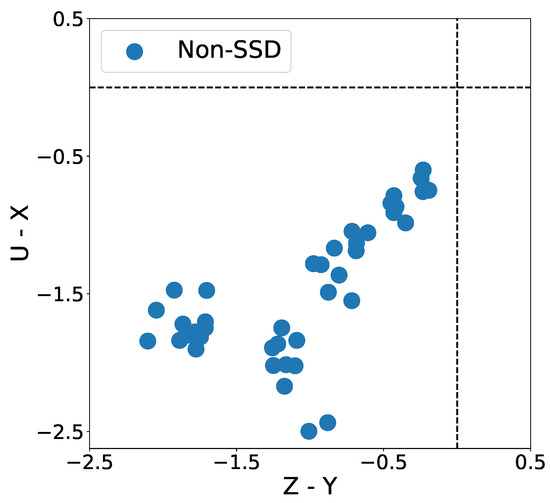
Figure 4.
SDD—highway.
Summarizing the two games, we find that the intersection game is an SDD but the platoon game is not. The intuitive explanation is: In the intersection game, the collective interest for agents is to avoid crashes at the intersection and individual interest is to minimize travel time. If agents want to avoid crashes, they need to stop and wait till one of them crosses the intersection, which increases travel time. It is shown that there exists a conflict between the collective and individual interests. In the presence of defective agents, the intersection game becomes a Prisoner’s dilemma where agents may defect to gain individual advantages at the cost of collective interest.
6. Conclusions
In this study, we employ a social learning scheme for Markov games to identify SDDs in AVs’ policy learning. We propose a learning algorithm to train cooperative and defective policies and evaluate SDDs in traffic scenarios. We investigate the existence of SDDs in intersection and platoon games. The overall findings include: (1) The intersection game is an SDD, while the platoon game on highways is not. (2) The Markov game at an unsignalized intersection resembles a Prisoner’s dilemma, where agents may defect to gain individual advantages, but at the cost of the collective interest.
We briefly discuss the limitations of this work: (1) AVs’ decision making in driving environments are simplified as discretized action sets. There are many continuous decision variables for AV players, including velocity, brake rate and headway. (2) The number of agents who randomly encounter in Markov games is limited. The number of agents and their interactions in real-world traffic scenarios can be larger and more complex.
This work can be extended in the following ways: (1) We will leverage multi-agent reinforcement learning (MARL) and identify SDDS in more complex real-world scenarios with many road users (e.g., pedestrians). (2) Addressing SDDs for AVs will require policymakers and road planners to design policies and incentives that encourage AVs to make decisions that benefit the public good. This may involve the creation of regulations that enforce safe and efficient behavior, in line with established traffic rules and social norms. Incentive mechanisms such as gifting in a multi-agent system can be explored to study how to enhance AVs’ cooperative behaviors.
Author Contributions
Conceptualization, X.C. and X.D.; methodology, X.C.; validation, X.C. and Z.L.; writing—original draft preparation, X.C.; writing—review and editing, X.D.; visualization, X.C. and Z.L.; supervision, X.D.; project administration, X.D.; funding acquisition, X.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work is partially supported by the National Science Foundation CAREER under award number CMMI-1943998.
Data Availability Statement
Not applicable.
Conflicts of Interest
We confirm that neither the manuscript nor any parts of its content are currently under consideration or published in another journal.
References
- Sadigh, D.; Sastry, S.; Seshia, S.A.; Dragan, A.D. Planning for Autonomous Cars that Leverage Effects on Human Actions. In Proceedings of the Robotics: Science and Systems, Ann Arbor, MI, USA, 12–16 July 2016. [Google Scholar]
- Fisac, J.F.; Bronstein, E.; Stefansson, E.; Sadigh, D.; Sastry, S.S.; Dragan, A.D. Hierarchical Game-Theoretic Planning for Autonomous Vehicles. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9590–9596. [Google Scholar] [CrossRef]
- Di, X.; Shi, R. A survey on autonomous vehicle control in the era of mixed-autonomy: From physics-based to AI-guided driving policy learning. Transp. Res. Part Emerg. Technol. 2021, 125, 103008. [Google Scholar] [CrossRef]
- Huang, K.; Chen, X.; Di, X.; Du, Q. Dynamic driving and routing games for autonomous vehicles on networks: A mean field game approach. Transp. Res. Part Emerg. Technol. 2021, 128, 103189. [Google Scholar] [CrossRef]
- Shou, Z.; Chen, X.; Fu, Y.; Di, X. Multi-agent reinforcement learning for Markov routing games: A new modeling paradigm for dynamic traffic assignment. Transp. Res. Part Emerg. Technol. 2022, 137, 103560. [Google Scholar] [CrossRef]
- Pedersen, P.A. A Game Theoretical Approach to Road Safety; Technical Report, Department of Economics Discussion Paper; University of Kent: Canterbury, UK, 2001. [Google Scholar]
- Pedersen, P.A. Moral hazard in traffic games. J. Transp. Econ. Policy (JTEP) 2003, 37, 47–68. [Google Scholar]
- Chatterjee, I.; Davis, G. Evolutionary game theoretic approach to rear-end events on congested freeway. Transp. Res. Rec. J. Transp. Res. Board 2013, 2386, 121–127. [Google Scholar] [CrossRef]
- Chatterjee, I. Understanding Driver Contributions to Rear-End Crashes on Congested Freeways and Their Implications for Future Safety Measures. PhD Thesis, University of Minnesota, Minneapolis, MN, USA, 2016. [Google Scholar]
- Yoo, J.H.; Langari, R. Stackelberg game based model of highway driving. In Proceedings of the ASME 2012 5th Annual Dynamic Systems and Control Conference joint with the JSME 2012 11th Motion and Vibration Conference, Fort Lauderdale, FL, USA, 17–19 October 2012; American Society of Mechanical Engineers: New York, NY, USA, 2012; pp. 499–508. [Google Scholar]
- Yoo, J.H. A Game Theory Based Model of Human Driving with Application to Autonomous and Mixed Driving. Doctoral Dissertation, Texas A & M University, College Station, TX, USA, 2014. [Google Scholar]
- Talebpour, A.; Mahmassani, H.; Hamdar, S. Modeling Lane-Changing Behavior in a Connected Environment: A Game Theory Approach. Transp. Res. Part Emerg. Technol. 2015, 59, 216–232. [Google Scholar] [CrossRef]
- Yu, H.; Tseng, H.E.; Langari, R. A human-like game theory-based controller for automatic lane changing. Transp. Res. Part Emerg. Technol. 2018, 88, 140–158. [Google Scholar] [CrossRef]
- Leibo, J.Z.; Zambaldi, V.; Lanctot, M.; Marecki, J.; Graepel, T. Multi-agent Reinforcement Learning in Sequential Social Dilemmas. In Proceedings of the AAMAS ’17, 16th International Conference on Autonomous Agents and MultiAgent Systems, Sao Paulo, Brazil, 8–12 May 2017. [Google Scholar]
- Allen, B.; Lippner, G.; Chen, Y.T.; Fotouhi, B.; Momeni, N.; Yau, S.T.; Nowak, M.A. Evolutionary dynamics on any population structure. Nature 2017, 544, 227–230. [Google Scholar] [CrossRef]
- McAvoy, A.; Allen, B.; Nowak, M.A. Social goods dilemmas in heterogeneous societies. Nat. Hum. Behav. 2020, 4, 819–831. [Google Scholar] [CrossRef]
- Su, Q.; McAvoy, A.; Wang, L.; Nowak, M.A. Evolutionary dynamics with game transitions. Proc. Natl. Acad. Sci. USA 2019, 116, 25398–25404. [Google Scholar] [CrossRef]
- Hilbe, C.; Štěpán Šimsa, Š.; Chatterjee, K.; Nowak, M.A. Evolution of cooperation in stochastic games. Nature 2018, 559, 246–249. [Google Scholar] [CrossRef] [PubMed]
- Bonnefon, J.F.; Shariff, A.; Rahwan, I. The social dilemma of autonomous vehicles. Science 2016, 352, 1573–1576. [Google Scholar] [CrossRef] [PubMed]
- Schwarting, W.; Pierson, A.; Alonso-Mora, J.; Karaman, S.; Rus, D. Social behavior for autonomous vehicles. Proc. Natl. Acad. Sci. USA 2019, 116, 24972–24978. [Google Scholar] [CrossRef] [PubMed]
- Eccles, T.; Hughes, E.; Kramár, J.; Wheelwright, S.; Leibo, J.Z. Learning Reciprocity in Complex Sequential Social Dilemmas. arXiv 2019, arXiv:1903.08082. [Google Scholar]
- Badjatiya, P.; Sarkar, M.; Sinha, A.; Singh, S.; Puri, N.; Subramanian, J.; Krishnamurthy, B. Inducing Cooperative behaviour in Sequential-Social dilemmas through Multi-Agent Reinforcement Learning using Status-Quo Loss. arXiv 2020, arXiv:2001.05458. [Google Scholar]
- Gupta, G. Obedience-Based Multi-Agent Cooperation for Sequential Social Dilemmas. Master Thesis, University of Waterloo, Waterloo, ON, Canada, 2020. [Google Scholar]
- Sen, S.; Airiau, S. Emergence of Norms through Social Learning. In Proceedings of the IJCAI’07, 20th International Joint Conference on Artifical Intelligence, Hyderabad, India, 6–12 January 2007; Morgan Kaufmann Publishers Inc: San Francisco, CA, USA, 2007; pp. 1507–1512. [Google Scholar]
- Lewis, D. Convention: A Philosophical Study; Wiley: Hoboken, NJ, USA, 1970. [Google Scholar]
- Boella, G.; Lesmo, L. A Game Theoretic Approach to Norms and Agents; Universita di Torino: Torino, Italy, 2001. [Google Scholar]
- Boella, G.; van der Torre, L. Norm governed multiagent systems: The delegation of control to autonomous agents. In Proceedings of the IAT 2003, IEEE/WIC International Conference on Intelligent Agent Technology, Halifax, NSA, Canada, 13–17 October 2003; pp. 329–335. [Google Scholar] [CrossRef]
- Epstein, J. Learning to Be Thoughtless: Social Norms and Individual Computation. Comput. Econ. 2001, 18, 9–24. [Google Scholar] [CrossRef]
- O’Callaghan, D.; Mannion, P. Tunable Behaviours in Sequential Social Dilemmas Using Multi-Objective Reinforcement Learning; International Foundation for Autonomous Agents and Multiagent Systems: Richland, SC, USA, 2021; pp. 1610–1612. [Google Scholar]
- Delgado, J. Emergence of social conventions in complex networks. Artif. Intell. 2002, 141, 171–185. [Google Scholar] [CrossRef]
- Villatoro, D.; Sabater-Mir, J.; Sen, S. Social Instruments for Robust Convention Emergence. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; pp. 420–425. [Google Scholar] [CrossRef]
- Yu, C.; Zhang, M.; Ren, F.; Luo, X. Emergence of Social Norms through Collective Learning in Networked Agent Societies. In Proceedings of the AAMAS ’13, 2013 International Conference on Autonomous Agents and Multi-Agent Systems, St. Paul, MN, USA, 6–10 May 2013; International Foundation for Autonomous Agents and Multiagent Systems: Richland, SC, USA, 2013; pp. 475–482. [Google Scholar]
- Franks, H.; Griffiths, N.; Jhumka, A. Manipulating convention emergence using influencer agents. Auton. Agents-Multi-Agent Syst. 2013, 26, 315–353. [Google Scholar] [CrossRef]
- Chen, X.; Li, Z.; Di, X. Social Learning In Markov Games: Empowering Autonomous Driving. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 4–9 June 2022; pp. 478–483. [Google Scholar] [CrossRef]
- Macy, D.; Flache, A. Learning Dynamics in Social Dilemmas. Proc. Natl. Acad. Sci. USA 2002, 99 (Suppl. 3), 7229–7236. [Google Scholar] [CrossRef]
- Bouderba, S.; Moussa, N. Evolutionary dilemma game for conflict resolution at unsignalized traffic intersection. Int. J. Mod. Phys. 2019, 30, 189. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.A.; Fidjeland, A.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Di, X. Legal Framework for Rear-End Crashes in Mixed-Traffic Platooning: A Matrix Game Approach. Future Transp. 2023, 3, 417–428. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).