
Exploring the Landscape of Data Analysis: A Review of Its Application and Impact in Ecuador



Abstract
Highlights
- Latin America has shown increased big data adoption since 2012; Ecuador is now entering this transformative field.
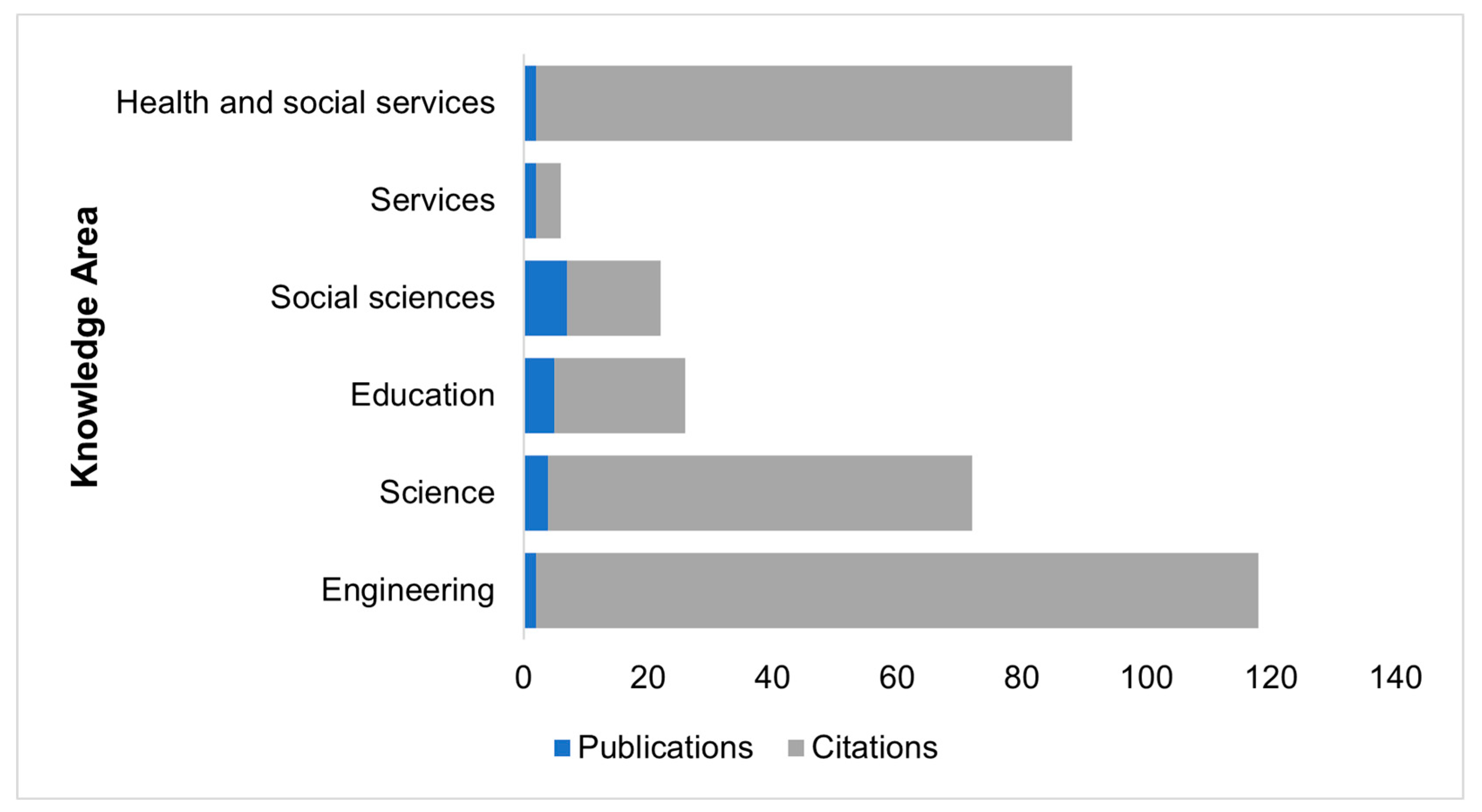
- Science and engineering in Ecuador have benefited most from data analysis, with untapped potential in health and services sectors.
- Big data is shaping sectors in Ecuador, including disaster prediction, agriculture, smart city development, and electoral data analysis.
- Despite public sector inefficiencies, residential ICT adoption provides opportunities for Ecuador’s smart city advancements.
- Despite some data underutilization, big data’s transformative potential is evident in Ecuador’s healthcare and education advancements.
Abstract
1. Introduction
2. Methodology
2.1. Objective
2.2. Protocol
2.3. Search Strategy
2.4. Inclusion Criteria
2.5. Exclusion Criteria
2.6. Data Sources and Search Strategies
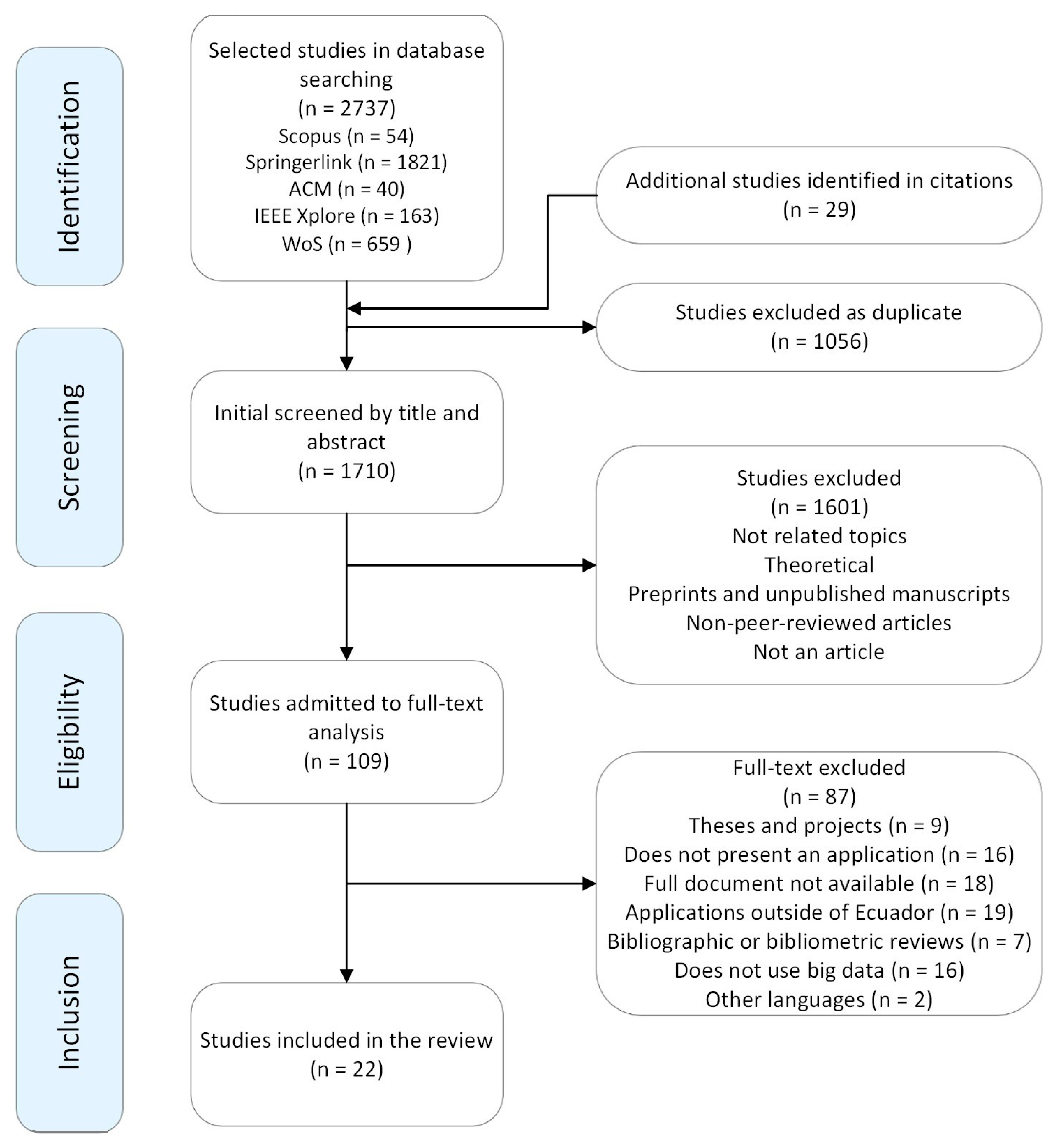
2.7. Identification and Selection of Studies
3. Results
3.1. Sciences
3.2. Engineering
3.3. Social
3.4. Services
3.5. Health
3.6. Education
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ogunsola, L. Information and Communication Technologies and the Effects of Globalization: Twenty-First Century “Digital Slavery” for Developing Countries—Myth or Reality? E-JASL 1999–2009 (volumes 1–10). Electron. J. Acad. Spec. Librariansh. 2005, 58, 6. [Google Scholar]
- Bergeaud, A.; Cette, G.; Lecat, R. Productivity Trends in Advanced Countries between 1890 and 2012. Rev. Income Wealth 2016, 62, 420–444. [Google Scholar] [CrossRef]
- Kolb, J.; Kolb, J. Secrets of the Big Data Revolution; Applied Data Labs: Chicago, IL, USA, 2013; ISBN 978-1490403809. [Google Scholar]
- Hilbert, M. Big Data for Development: A Review of Promises and Challenges. Dev. Policy Rev. 2016, 34, 135–174. [Google Scholar] [CrossRef]
- Knudsen, E.S.; Lien, L.B.; Timmermans, B.; Belik, I.; Pandey, S. Stability in Turbulent Times? The Effect of Digitalization on the Sustainability of Competitive Advantage. J. Bus. Res. 2021, 128, 360–369. [Google Scholar] [CrossRef]
- Ruiz-Palmero, J.; Colomo-Magaña, E.; Ríos-Ariza, J.M.; Gómez-García, M. Big Data in Education: Perception of Training Advisors on Its Use in the Educational System. Soc. Sci. 2020, 9, 53. [Google Scholar] [CrossRef]
- Foresti, R.; Rossi, S.; Magnani, M.; Guarino Lo Bianco, C.; Delmonte, N. Smart Society and Artificial Intelligence: Big Data Scheduling and the Global Standard Method Applied to Smart Maintenance. Engineering 2020, 6, 835–846. [Google Scholar] [CrossRef]
- Zhu, S.; Dong, T.; Luo, X. A Longitudinal Study of the Actual Value of Big Data and Analytics: The Role of Industry Environment. Int. J. Inf. Manag. 2021, 60, 102389. [Google Scholar] [CrossRef]
- De Godoy, J.; Otrel-Cass, K.; Toft, K.H. Transformations of Trust in Society: A Systematic Review of How Access to Big Data in Energy Systems Challenges Scandinavian Culture. Energy AI 2021, 5, 100079. [Google Scholar] [CrossRef]
- Da Ueti, R.M.; Espinosa, D.F.; Rafferty, L.; Hung, P.C.K. Case Studies of Government Use of Big Data in Latin America: Brazil and Mexico. In Big Data Applications and Use Cases; Springer: Cham, Switzerland, 2016; pp. 197–214. [Google Scholar]
- Novikov, S.V. Data Science and Big Data Technologies Role in the Digital Economy. TEM J. 2020, 9, 756–762. [Google Scholar] [CrossRef]
- Baig, M.I.; Shuib, L.; Yadegaridehkordi, E. Big Data in Education: A State of the Art, Limitations, and Future Research Directions. Int. J. Educ. Technol. High. Educ. 2020, 17, 44. [Google Scholar] [CrossRef]
- Seles, B.M.R.P.; de Sousa Jabbour, A.B.L.; Jabbour, C.J.C.; de Camargo Fiorini, P.; Mohd-Yusoff, Y.; Thomé, A.M.T. Business Opportunities and Challenges as the Two Sides of the Climate Change: Corporate Responses and Potential Implications for Big Data Management towards a Low Carbon Society. J. Clean. Prod. 2018, 189, 763–774. [Google Scholar] [CrossRef]
- Kalogiannakis, M.; Papadakis, S.; Zourmpakis, A.-I. Gamification in Science Education. A Systematic Review of the Literature. Educ. Sci. 2021, 11, 22. [Google Scholar] [CrossRef]
- August, S.E.; Tsaima, A. Artificial Intelligence and Machine Learning: An Instructor’s Exoskeleton in the Future of Education BT-Innovative Learning Environments in STEM Higher Education: Opportunities, Challenges, and Looking Forward; Ryoo, J., Winkelmann, K., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 79–105. ISBN 978-3-030-58948-6. [Google Scholar]
- Zalat, M.M.; Hamed, M.S.; Bolbol, S.A. The Experiences, Challenges, and Acceptance of e-Learning as a Tool for Teaching during the COVID-19 Pandemic among University Medical Staff. PLoS ONE 2021, 16, e0248758. [Google Scholar] [CrossRef]
- Azeem, M.; Haleem, A.; Bahl, S.; Javaid, M.; Suman, R.; Nandan, D. Big Data Applications to Take up Major Challenges across Manufacturing Industries: A Brief Review. Mater. Today Proc. 2021, 49, 339–348. [Google Scholar] [CrossRef]
- Chang, K.-H.; Tsai, C.-C.; Wang, C.-H.; Chen, C.-J.; Lin, C.-M. Optimizing the Energy Efficiency of Chiller Systems in the Semiconductor Industry through Big Data Analytics and an Empirical Study. J. Manuf. Syst. 2021, 60, 652–661. [Google Scholar] [CrossRef]
- Ying, S.; Sindakis, S.; Aggarwal, S.; Chen, C.; Su, J. Managing Big Data in the Retail Industry of Singapore: Examining the Impact on Customer Satisfaction and Organizational Performance. Eur. Manag. J. 2021, 39, 390–400. [Google Scholar] [CrossRef]
- Correa, C.M. Transfer of Technology in Latin America: A Decade of Control. J. World Trade 1981, 15, 388–409. [Google Scholar] [CrossRef]
- Toapanta, S.M.T.; Quimi, F.G.M.; Lambogglia, L.M.R.; Gallegos, L.E.M. Impact on the Information Security Management Due to the Use of Social Networks in a Public Organization in Ecuador. Smart Innov. Syst. Technol. 2020, 165, 51–64. [Google Scholar] [CrossRef]
- Pazmiño-Maji, R.; Conde, M.; García-Peñalvo, F. Learning Analytics in Ecuador: A Systematic Review Supported by Statistical Implicative Analysis. Univers. Access Inf. Soc. 2021, 20, 495–512. [Google Scholar] [CrossRef]
- Pazmiño-Maji, R.; Naranjo-Ordoñez, L.; Conde-González, M.; García-Peñalvo, F. Learning Analytics in Ecuador: An Initial Analysis Based in a Mapping Review. In Proceedings of the ACM International Conference Proceeding Series; Association for Computing Machinery: New York, NY, USA, 2019; pp. 304–311. [Google Scholar]
- García, L.J.P. La Minería De Procesos Y Su Aplicación En Ecuador: Una Revisión Sistemática. Rev. Espamciencia 2019, 10, 1–7. [Google Scholar]
- Ayala-Chauvin, M.; Maigua, P.; Medina-Enríquez, A.; Buele, J. Socio-Spatial Segregation Using Computational Algorithms: Case Study in Ambato, Ecuador. In Trends in Artificial Intelligence and Computer Engineering—ICAETT 2022; Botto-Tobar, M., Gómez, O.S., Rosero Miranda, R., Díaz Cadena, A., Luna-Encalada, W., Eds.; Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2023; Volume 619, pp. 64–75. ISBN 9783031259418. [Google Scholar]
- López-Fierro, S. Querying on Google Sheets Designing a Sentiments Analysis Alternative for Rating Tweets Regarding the Ecuadorian 2021 Presidential Campaigns. IX Jorn. Cloud Comput. Big Data Emerg. Top. 2021, 37–41. [Google Scholar]
- López-Fierro, S.; Chiriboga-Calderon, C.; Pacheco-Villamar, R. If It Looks, Retweets and Follows like a Troll; Is It a Troll?: Targeting the 2021 Ecuadorian Presidential Elections Trolls. In Proceedings of the 2021 IEEE International Conference on Big Data, Big Data 2021, Orlando, FL, USA, 15–18 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2503–2509. [Google Scholar]
- Cruz, E.; Vaca, C.; Avendano, A. Mining Top-up Transactions and Online Classified Ads to Predict Urban Neighborhoods Socioeconomic Status. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 4055–4062. [Google Scholar] [CrossRef]
- Martinez-Mosquera, D.; Luján-Mora, S. Framework for Big Data Integration in E-Government. DYNA 2019, 86, 215–224. [Google Scholar] [CrossRef]
- Toapanta, S.M.; Mafla Gallegos, L.E.; Ordoñez Baldeon, P.; Trivino Trivino, F.D. Blockchain Analysis Applied to a Process for the National Public Data System for Ecuador. In Proceedings of the 3rd International Conference on Information and Computer Technologies, ICICT 2020, San Jose, CA, USA, 9–12 March 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020; pp. 258–265. [Google Scholar]
- Tenesaca Luna, G.A.; Imba, D.; Mora-Arciniegas, M.-B.B.; Segarra-Faggioni, V.; Ramírez-Coronel, R.L. Use of Apache Flume in the Big Data Environment for Processing and Evaluation of the Data Quality of the Twitter Social Network. Adv. Intell. Syst. Comput. 2019, 884, 314–326. [Google Scholar] [CrossRef]
- Herrera, N.I.H. Big Data Architecture Proposal for Vehicular Traffic Detection. In Proceedings of the 2020 International Conference of Digital Transformation and Innovation Technology (Incodtrin), Quito, Ecuador, 28–30 October 2020; pp. 118–122. [Google Scholar] [CrossRef]
- Herrera, N.H.; Santamaria, H.S.; Macias Macias, M.; Gomez, E. Analysis of the Factors Generating Vehicular Traffic in the City of Quito and Its Relation to the Application of Sensorial and Social Data with Big Data as a Basis for Decision Making. In Proceedings of the 2016 3rd International Conference on eDemocracy and eGovernment, ICEDEG 2016, Sangolqui, Ecuador, 30 March–1 April 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 133–137. [Google Scholar]
- Reyes Reyes, F.A.; Cruz Felipe, M.D.R.; Parraga-Alava, J. Prediction of Diseases in the Elderly in Manabí Through Big Data Technologies. Lect. Notes Netw. Syst. 2022, 511, 600–611. [Google Scholar] [CrossRef]
- Yacchirema, D.C.; Sarabia-Jacome, D.; Palau, C.E.; Esteve, M. A Smart System for Sleep Monitoring by Integrating IoT with Big Data Analytics. IEEE Access 2018, 6, 35988–36001. [Google Scholar] [CrossRef]
- Ponce-Guevara, K.L.; Palacios-Echeverria, J.A.; Maya-Olalla, E.; Dominguez-Limaico, H.M.; Suarez-Zambrano, L.E.; Rosero-Montalvo, P.D.; Peluffo-Ordonez, D.H.; Alvarado-Perez, J.C. GreenFarm-DM: A Tool for Analyzing Vegetable Crops Data from a Greenhouse Using Data Mining Techniques (First Trial). In Proceedings of the 2017 IEEE 2nd Ecuador Technical Chapters Meeting, ETCM 2017, Salinas, Ecuador, 16–20 October 2017; IEEE: Piscataway, NJ, USA, 2018; Volume 2017, pp. 1–6. [Google Scholar]
- Estupiñán, J.; Menéndez, J.J.D.; Arias, I.F.B.; Bermúdez, J.M.M.; Lemus, N.M. Neutrosophic K-Means for the Analysis of Earthquake Data in Ecuador. Neutrosophic Sets Syst. 2021, 44, 255–262. [Google Scholar]
- Andrade, X.; Layedra, F.; Vaca, C.; Cruz, E. RiSC: Quantifying Change after Natural Disasters to Estimate Infrastructure Damage with Mobile Phone Data. In Proceedings of the 2018 IEEE International Conference on Big Data, Big Data 2018, Seattle, WA, USA, 10–13 December 2018; IEEE: Piscataway, NJ, USA, 2019; pp. 3383–3391. [Google Scholar]
- Castro, R.; Tierra, A.; Luna, M. Assessing the Horizontal Positional Accuracy in Openstreetmap: A Big Data Approach. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2019; Volume 931, pp. 513–523. ISBN 9783030161835. [Google Scholar]
- Guaman, A.; Ramirez, J.; Mayorga, B.; Aviles, F.; Gallardo, C. Short-Term Load Forecasting in the Distribution System of the Electric Company of Ambato (EEASA) Based on Big Data Criteria. In Proceedings of the 2019 International Conference on Information Systems and Computer Science (INCISCOS), Quito, Ecuador, 20–22 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 23–30. [Google Scholar]
- Villegas-Ch, W.; Palacios-Pacheco, X.; Luján-Mora, S. Application of a Smart City Model to a Traditional University Campus with a Big Data Architecture: A Sustainable Smart Campus. Sustainability 2019, 11, 2857. [Google Scholar] [CrossRef]
- Espinosa-Pinos, C.A.; Ayala-Chauvín, I.; Buele, J. Predicting Academic Performance in Mathematics Using Machine Learning Algorithms. In Communications in Computer and Information Science; Springer: Cham, Switzerland, 2022; Volume 1658, pp. 15–29. [Google Scholar]
- Villegas-Ch, W.; Roman-Cañizares, M.; Jaramillo-Alcázar, A.; Palacios-Pacheco, X. Data Analysis as a Tool for the Application of Adaptive Learning in a University Environment. Appl. Sci. 2020, 10, 7016. [Google Scholar] [CrossRef]
- Tejedor, S.; Ventin, A.; Martinez, F.; Tusa, F. Emerging Lines in the Teaching of University Communication the Inclusion of Data Journalism in Universities in Spain, Colombia and Ecuador. In Proceedings of the 2020 15th Iberian Conference on Information Systems and Technologies (CISTI), Sevilla, Spain, 24–29 June 2020; IEEE: Piscataway, NJ, USA, 2020; Volume 2020, pp. 1–9. [Google Scholar]
- Baldeon Egas, P.F.; Gaibor Saltos, M.A.; Toasa, R. Application of Data Mining and Data Visualization in Strategic Management Data at Israel Technological University of Ecuador. Adv. Intell. Syst. Comput. 2020, 1066, 419–431. [Google Scholar] [CrossRef]
- Urena-Torres, J.-P.; Tenesaca-Luna, G.-A.; Arciniegas, M.B. Analysis and Processing of Academic Data from a Higher Institution with Tools for Big Data. In Proceedings of the 2017 12th Iberian Conference on Information Systems and Technologies (CISTI), Lisbon, Portugal, 14–17 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Rivadeneira, F.; Segovia, M.; Alvarado, A.; Egred, J.; Troncoso, L.; Vaca, S.; Yepes, H. Breves Fundamentos Sobre Los Terremotos En El Ecuador; Instituto Geofísico de la Escuela Politécnica Nacional, Corporación Editora Nacional: Quito, Ecuador, 2007; ISBN 978-9978-84-460-1. [Google Scholar]
- Banco Interamericano de Desarrollo. Perfil de Riesgo de Desastres Por Evento Sísmico de Ecuador; BID: Madrid, Spain, 2020. [Google Scholar] [CrossRef]
- Sánchez, M.; Urquiza, L. Security Enhancement through Effective Encrypted Communication Using ELK. In Proceedings of the ACM International Conference Proceeding Series; Association for Computing Machinery: New York, NY, USA, 2019; pp. 88–92. [Google Scholar]
- Khan, N.; Yaqoob, I.; Hashem, I.A.T.; Inayat, Z.; Mahmoud Ali, W.K.; Alam, M.; Shiraz, M.; Gani, A. Big Data: Survey, Technologies, Opportunities, and Challenges. Sci. World J. 2014, 2014, 712826. [Google Scholar] [CrossRef]
- Zikoupoulos, P.; Eaton, C. Understanding Big Data: Analytics for Enterprise Class Hadoop and Streaming; McGraw-Hill Osborne Media: New York, NY, USA, 2016; Volume 11, ISBN 9780071790536. [Google Scholar]
- Macfadyen, L.P.; Dawson, S.; Pardo, A.; Gaševic, D. Embracing Big Data in Complex Educational Systems: The Learning Analytics Imperative and the Policy Challenge. Res. Pract. Assess. 2014, 9, 17–28. [Google Scholar]
- Segarra, J.; Ortiz, J.; Gualan, R.; Saquicela, V. Discovering Research Trends in the Computer Science Area of Ecuador: An Approach Using Semantic Knowledge Bases. In Proceedings of the 2019 XLV Latin American Computing Conference (CLEI), Panama City, Panama, 30 September–4 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–9. [Google Scholar]
- Flores, A.; Ramirez, S.; Toasa, R.; Vargas, J.; Urvina-Barrionuevo, R.; Lavin, J.M. Performance Evaluation of NoSQL and SQL Queries in Response Time for the E-Government. In Proceedings of the 2018 International Conference on eDemocracy & eGovernment (ICEDEG), Quito, Ecuador, 4–6 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 257–262. [Google Scholar]
- Quelal, R.; Villavicencio, M. A Survey of Big Data Use in Large and Medium Ecuadorian Companies. In Big Data—BigData 2018; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2018; Volume 10968, pp. 334–342. ISBN 9783319943008. [Google Scholar]
- Toapanta, S.M.T.; Quintana, T.F.P.; Arellano, M.R.M.; Gallegos, L.E.M. Hyperledger Technology in Public Organizations in Ecuador. In Proceedings of the 2020 3rd International Conference on Information and Computer Technologies (ICICT), San Jose, CA, USA, 9–12 March 2020; pp. 294–301. [Google Scholar] [CrossRef]
- Argüelles-Cruz, A.-J.; García-Peñalvo, F.-J.; Ramírez-Montoya, M.-S. Education in Latin America: Toward the Digital Transformation in Universities. In Radical Solutions for Digital Transformation in Latin American Universities; Lecture Notes in Educational Technology; Springer: Singapore, 2021; pp. 93–108. [Google Scholar]
- Hillier, D.; Mitchell, A.; Millwood, R. “Change of Heart!”: A New e-Learning Model Geared to Addressing Complex and Sensitive Public Health Issues. Innov. Educ. Teach. Int. 2005, 42, 277–287. [Google Scholar] [CrossRef]
- Schintler, L.A.; Kulkarni, R. Big Data for Policy Analysis: The Good, the Bad, and the Ugly. Rev. Policy Res. 2014, 31, 343–348. [Google Scholar] [CrossRef]
- Morales, D.E.P. Analysis of Digital Government in Ecuador: Review of Ecuadorian Agenda with Regard to the Digital Government Stage Framework. In Proceedings of the 2018 International Conference on eDemocracy & eGovernment (ICEDEG), Quito, Ecuador, 4–6 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 345–350. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Author | Year | Knowledge Area/Sub-Area | Application | Main Findings | Limitations/Future Work |
|---|---|---|---|---|---|
| Ayala et al. [25] | 2023 | Social sciences/social and behavioral sciences | To evaluate the existence of spatial segregation in Ambato, Ecuador. | The most resource-rich people live west of the city and represent a quarter of the population. Most of the population is concentrated in the southwest, with access to below-average resources. | Data and algorithmic limitations, contextual factors, spatial resolution, and generalizability to other cities or contexts. Future work includes collecting more data, examining causal mechanisms, comparing findings with other cities, and developing interventions. |
| López-Fierro et al. [26] | 2021 | Social sciences/social and behavioral sciences | Sentiment analysis of tweets in the 2021 Ecuador presidential election. | There was a pattern between the number of tweets per candidate and sentiment (for or against specific candidates). | Small sample, limited sentiment analysis, not validated externally, and biased sample selection. Consider diverse sentiment analysis methods, include more tweets, validate them externally, and explore implications for political communication and public opinion. |
| López-Fierro et al. [27] | 2021 | Social sciences/social and behavioral sciences | Analysis of tweets related to the 2021 Ecuador presidential elections through a script. | Tweets from the 2021 Ecuador presidential campaign were retrieved, and positive and negative sentiments towards the candidates were identified. | The study only analyzed activity on Twitter and did not examine the impact of trolls on actual voting behavior. Explore the effectiveness of countermeasures against trolls and their impact on democratic processes. |
| Cruz E. et al. [28] | 2019 | Social sciences/business education and administration | Prediction of socioeconomic status of urban neighborhoods in Guayaquil, Ecuador, through the mining of cell phone electronic recharge transactions. | Transactional information from electronic recharges allowed for predicting socioeconomic status with a prediction rate of up to 71% for urban neighborhoods. | Small sample size, limited geographical scope, and lack of data on income levels. Validating the model in other countries and using it to design more targeted marketing strategies. |
| Martínez-Mosquera D. et al. [29] | 2019 | Social sciences/business education and administration | Integration of big data in e-government decision making. | It was found that there is a need for a waste management policy aimed at energy-saving luminaires that use small amounts of mercury; otherwise, there may be adverse environmental effects. | Future work includes data privacy, security, scalability, and the integration of big data in e-government systems. |
| Toapanta Toapanta, S., et al. [30] | 2020 | Social sciences/business education and administration | Implementation of a blockchain model for the national public data system. | It provides transparency on the procedures carried out by public and private entities. In addition, data immutability and traceability. | Need for robust network infrastructure, privacy concerns, and potential for centralization. Future work includes exploring scalability, interoperability, user adoption, and integration with other emerging technologies such as artificial intelligence (AI) and the Internet of Things (IoT). |
| Tenesaca-Luna G. et al. [31] | 2019 | Social sciences/social and behavioral sciences | Evaluation of the quality of tweets in the 2017 presidential election in Ecuador. | Tweet traffic was analyzed, where 21.33% of the content was related to presidential candidates. | Limited comparison with other tools and exploration of scalability challenges. Future work includes benchmarking with other tools, exploring performance optimization techniques, and addressing scalability challenges. |
| Herrera Herrera N. [32] | 2020 | Services/transportation services | Architecture proposal for the implementation of vehicular traffic detection software. | Particular phases were identified for processing vehicle traffic records collected in the city of Quito, Ecuador. | Comparative evaluation with other traffic detection systems. Future work includes exploring scalability and security challenges. |
| Herrera Herrera et al. [33] | 2016 | Services/transportation services | To determine the causes of traffic congestion in Quito based on social networks. | Using tweets such as “traffic” or “congestion”, it was possible to identify the georeferencing points where the most traffic exists. | The small sample size of the survey. Future work includes expanding the survey to a larger population and exploring other potential solutions. |
| Reyes Reyes F. et al. [34] | 2022 | Health and social services/medicine | Predicting CVD risk in the population of Manabí, Ecuador. | The variables that most influence CVD are shortness of breath, height, regular intake of medications, and persistent dizziness. | Limited variables and ethical implications. Future work includes expanding the study to other populations, exploring additional variables. |
| Yacchirema, D. et al. [35] | 2018 | Health and social services/medicine | An IoT and big data system to monitor and treat sleep apnea in the elderly in real time. | A smart system for monitoring and treating obstructive sleep apnea (OSA) in elderly people using IoT and big data technologies. The system was successfully implemented and tested, showing potential for improving the quality of life for elderly people with OSA. | Cost of implementing and maintaining the system, the need for reliable Internet connectivity, and the potential for false positives or false negatives in detecting OSA episodes. Future work includes improving the system’s accuracy in detecting OSA episodes, expanding the system’s interoperability with other IoT devices, and integrating the system with electronic health records. |
| Ponce-Guevara et al. [36] | 2017 | Science/life sciences | Analysis of factors influencing the growth of vegetable crops in a greenhouse. | The factors that most influence plant photosynthesis are soil moisture, relative humidity, ambient temperature, light level, and CO2. This will allow greater nutrient absorption and produce better fruit. | Develop and extend to other crops and environments, as well as incorporating real-time data collection and more advanced visualization techniques. |
| Estupiñán J. et al. [37] | 2021 | Science/physical science | Applying data segmentation methods (clustering) to a dataset with information on earthquakes in Ecuador for disaster prevention. | The month’s most prone to earthquakes are the first months of the year (March–May). In later months, there are fewer and less intense earthquakes (July–September). | Limited earthquake data. Explore the use of the algorithm for analyzing other types of geospatial data, such as satellite imagery. |
| Andrade X. et al. [38] | 2019 | Science/physical science | To relate human mobility patterns after an earthquake in Ecuador. | People moved to less affected areas but also tended to stay close to their homes after a disaster. | Potential bias in mobile phone data, a large sample size needed, and privacy concerns. Further validation of the RiSC metric, exploration of other data types (e.g., social media), and wider implementation. |
| Castro R. et al. [39] | 2019 | Science/physical science | Evaluation of inconsistencies in a map of the “Manuela Sáenz” area in Quito, Ecuador using two pieces of software. | OSM and a script in RStudio were used, where intersections of roads that need corrections were identified. Using the two pieces of software together was considered necessary for better positional accuracy. | Limited scope, and potential for errors in the reference dataset. Exploration of factors affecting accuracy, such as community involvement and mapping tools, and application to improve other GISs. |
| Guaman A. et al. [40] | 2019 | Engineering/engineering and related professions | Forecasting electricity demand in a city in Ecuador. | Improved short-term load forecasting in the electric distribution system with more than 82% accuracy. | Reliance on historical data may not be representative of future conditions. Application to other distribution systems, inclusion of economic indicators, and the use of real-time data to improve accuracy. |
| Villegas-Ch W. et al. [41] | 2019 | Engineering/architecture and construction | Analysis of mobility data, machine purchases, and student concentration for decision-making. | Increased knowledge of student behavior. This allows for better scheduling for teachers and students, reducing on-campus travel. | Single campus study. Extend the framework to multiple campuses and integrate with IoT technologies for more comprehensive data monitoring and analysis. |
| Espinosa-Pinos C. et al. [42] | 2022 | Education/teacher training | Assessment of variables influencing mathematics achievement in a school. | Numerical variables contribute to the development of the classification model. The most influential variables are grades in other subjects, graduation, and college entrance exam. | Analysis of academic tests only. Sociodemographic variables did not influence the study. For future work, economic variables will be evaluated. |
| Villegas-Ch W. et al. [43] | 2020 | Education/teacher training | Integral model for detecting student needs in a private university in Ecuador. | The information obtained from intelligent sensors on campus makes it possible to identify patterns in students and propose new educational models adaptive to emergencies (COVID-19). | The small sample size limits the generalizability. Designing and implementing an adaptive learning model based on students’ learning styles and preferences. |
| Tejedor S. et al. [44] | 2020 | Education/teacher training | Content analysis of communication faculty programs at six universities. | At these universities, there are no compulsory subjects that address data journalism, but some are implementing it. | The lack of diversity and the limited generalizability of findings. Studying new teaching approaches and addressing the needs of underrepresented groups in data journalism education. |
| Baldeon Egas P. et al. [45] | 2020 | Education/teacher training | Analysis of the performance of undergraduate students in a private university in Ecuador. | Approximately 78.5% of undergraduate students pass, with the second and third levels being the most complicated and the nineth with the highest number of passes. In the future, there will be an increase in blended education, mostly men. | Limited data quality control. Developing real-time data collection methods, improving data quality control, and refining data interpretation techniques. |
| Urena-Torres J. et al. [46] | 2017 | Education/teacher training | Analysis of undergraduate enrollment data from a private university in Ecuador. | It allows one to make predictions and decisions about opening up new careers, sources of income, and better education services for students. | Limited to one institution. Explore other data mining and visualization techniques to gain more insights and make better decisions. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ayala-Chauvin, M.; Avilés-Castillo, F.; Buele, J. Exploring the Landscape of Data Analysis: A Review of Its Application and Impact in Ecuador. Computers 2023, 12, 146. https://doi.org/10.3390/computers12070146
Ayala-Chauvin M, Avilés-Castillo F, Buele J. Exploring the Landscape of Data Analysis: A Review of Its Application and Impact in Ecuador. Computers. 2023; 12(7):146. https://doi.org/10.3390/computers12070146
Chicago/Turabian StyleAyala-Chauvin, Manuel, Fátima Avilés-Castillo, and Jorge Buele. 2023. "Exploring the Landscape of Data Analysis: A Review of Its Application and Impact in Ecuador" Computers 12, no. 7: 146. https://doi.org/10.3390/computers12070146
APA StyleAyala-Chauvin, M., Avilés-Castillo, F., & Buele, J. (2023). Exploring the Landscape of Data Analysis: A Review of Its Application and Impact in Ecuador. Computers, 12(7), 146. https://doi.org/10.3390/computers12070146