Highlights
What are the main findings?
- We propose the Causal Attention Transformer (CAT), the first framework to integrate causal inference with a hybrid CNN-Transformer backbone for hyperspectral image (HSI) classification, enabling explicit modeling of spectral–spatial causality without external discovery pipelines.
- CAT introduces a novel Causal Attention Mechanism that enforces temporal and spatial causality through triangular masking and axial decomposition, effectively eliminating spurious spectral–spatial correlations and enhancing model robustness.
What are the implications of the main findings?
- The architecture features a Dual-Path Hierarchical Fusion module with learnable gating to adaptively integrate complementary spectral and spatial causal features in an end-to-end trainable manner.
- A Linearized Causal Attention (LCA) module reduces computational complexity from O(N2) to O(N) while preserving causal constraints, enabling scalable high-resolution HSI processing.
- Extensive experiments on three benchmark datasets (Indian Pines, Pavia University, Houston2013) demonstrate that CAT achieves state-of-the-art classification accuracy, with significant improvements over leading CNN, Transformer, and Mamba-based models.
Abstract
Hyperspectral image (HSI) classification is pivotal in remote sensing, yet deep learning models, particularly Transformers, remain susceptible to spurious spectral–spatial correlations and suffer from limited interpretability. These issues stem from their inability to model the underlying causal structure in high-dimensional data. This paper introduces the Causal Attention Transformer (CAT), a novel architecture that integrates causal inference with a hierarchical CNN-Transformer backbone to address these limitations. CAT incorporates three key modules: (1) a Causal Attention Mechanism that enforces temporal and spatial causality via triangular masking and axial decomposition to eliminate spurious dependencies; (2) a Dual-Path Hierarchical Fusion module that adaptively integrates spectral and spatial causal features using learnable gating; and (3) a Linearized Causal Attention module that reduces the computational complexity from to via kernelized cumulative summation, enabling scalable high-resolution HSI processing. Extensive experiments on three benchmark datasets (Indian Pines, Pavia University, Houston2013) demonstrate that CAT achieves state-of-the-art performance, outperforming leading CNN and Transformer models in both accuracy and robustness. Furthermore, CAT provides inherently interpretable spectral–spatial causal maps, offering valuable insights for reliable remote sensing analysis.
1. Introduction
Hyperspectral images (HSIs) capture detailed surface information across hundreds of contiguous spectral bands, forming rich three-dimensional data cubes that enable precise material discrimination in applications such as mineral exploration and precision agriculture [1]. Consequently, HSI classification, which aims to assign land cover labels based on spectral–spatial characteristics, is a fundamental remote sensing task.
Traditional machine learning approaches, including support vector machines (SVMs) [2] and random forests [3], primarily rely on handcrafted features. While computationally efficient, these methods are fundamentally limited in modeling the complex, non-linear spectral–spatial interactions inherent in HSIs due to their reliance on manual feature engineering and their vulnerability to the curse of dimensionality, leading to pronounced sensitivity to noisy and redundant spectral bands [4].
The advent of deep learning revolutionized HSI classification by enabling automatic feature extraction. Convolutional Neural Networks (CNNs), particularly 2D-CNNs [5] and 3D-CNNs [6], excelled at capturing local spectral–spatial patterns through hierarchical convolutions. Hybrid architectures [7,8] further enhanced multi-scale feature fusion. However, CNNs are inherently limited by their local receptive fields, struggling to model long-range spatial dependencies crucial for large-scale scenes. Recently, Transformers [8,9] have addressed this by leveraging global self-attention mechanisms to model long-range dependencies. Despite their success, standard self-attention computes dependencies between all token pairs indiscriminately, making it susceptible to spurious correlations from high-dimensional spectral redundancies. Furthermore, its quadratic computational complexity with respect to sequence length limits its scalability for high-resolution HSIs. Meanwhile, emerging State Space Models (SSMs) such as Mamba [9] offer a promising alternative with linear complexity, as demonstrated by [10] with regard to remote sensing data processing. Concurrently, Causal Attention Mechanisms have shown potential in mitigating confounding biases, with ref. [11] developing causal attention for vision–language tasks, and ref. [12] employing causal meta-reinforcement learning for multimodal remote sensing data classification.
Beyond correlation-based models, causal inference has emerged as a powerful framework for enhancing model robustness and interpretability by modeling cause–effect relationships. Causal networks, such as Causal Bayesian Networks (CBNs) [13], aim to identify directional dependencies, mitigating confounding biases. Parallelly, Causal Attention Mechanisms have been developed to integrate these principles directly into deep learning architectures. For instance, masked attention [14] and front-door adjustment [15] restrict attention to causally relevant features, effectively reducing spurious correlations in tasks like vision–language reasoning and improving out-of-distribution generalization in language models [16]. These works demonstrate the potential of causal attention to provide a principled approach to feature selection and robustness. However, their application to HSI classification remains largely unexplored and faces significant domain-specific challenges.
Parallelly, causal attention networks have been developed to integrate causal principles into attention mechanisms, primarily to mitigate confounding biases and spurious correlations. The core innovation lies in restricting attention to causally relevant features through mechanisms like masked attention [11] or front-door adjustment [17]. For instance, Yang et al. proposed Causal Attention (CATT) for vision–language tasks, employing in-sample and cross-sample attention modules to eliminate confounding effects without requiring explicit confounder observations. In large language models, Causal Attention Tuning (CAT) has been introduced to inject fine-grained causal knowledge into attention distributions, effectively reducing reliance on spurious correlations and improving out-of-distribution generalization [18]. Recent work like CASTLE further enhanced causal attention with lookahead keys, enabling better global context understanding while maintaining causal constraints [19]. These approaches demonstrate that causal attention can significantly improve model interpretability and robustness across diverse domains.
Despite these advancements, current deep learning approaches for HSI classification face three unresolved challenges: (1) susceptibility to spurious spectral–spatial correlations due to unconstrained attention in high-dimensional spaces; (2) inadequate modeling of causal dependencies between spectral bands and spatial contexts, leading to interpretability bottlenecks and noise sensitivity; and (3) limited scalability imposed by the quadratic complexity of standard Transformers. Existing causal models are either not designed for HSI or require extensive, separate causal discovery pipelines. To address these limitations holistically, we propose the Causal Attention Transformer (CAT). Our approach directly tackles these issues: a Causal Attention Mechanism eliminates spurious correlations via structured masking; a Dual-Path Hierarchical Fusion module jointly models spectral and spatial causality; and a Linearized Causal Attention module reduces complexity to O(N) for scalable processing.
To address these limitations, we propose the Causal Attention Transformer (CAT), a novel hybrid architecture that integrates causal inference with hierarchical feature fusion for robust and interpretable HSI classification. Our approach introduces three key innovations: (1) a Causal Attention Mechanism that eliminates spurious interactions by establishing counterfactual dependencies through triangular masking and axial decomposition; (2) a Dual-Path Hierarchical Fusion module that implements a spectral–spatial fusion framework with learnable gating to progressively integrate causal features from orthogonal domains; and (3) a Linearized Causal Attention module that leverages kernelized cumulative summation to reduce computational complexity from to while maintaining causal constraints for high-resolution HSI processing. These components are integrated within a multi-scale CNN-Transformer backbone that extracts both local patterns and global dependencies while preserving causal relationships.
The main contributions of this work are summarized as follows:
- We propose a novel Causal Attention Transformer (CAT) that first integrates causal inference with a hybrid CNN-Transformer architecture for hyperspectral image classification, enabling explicit modeling of spectral–spatial causality without external causal discovery pipelines.
- We design a Causal Attention Mechanism with triangular masking and axial decomposition to explicitly disentangle spectral–spatial causality via front-door adjustment, enhancing model robustness and generalization capability, which enforces temporal and spatial causality to eliminate spurious correlations—a principled approach not previously applied to HSI.
- We develop a Dual-Path Hierarchical Fusion framework with learnable gating, which adaptively merges spectral and spatial causal features in an end-to-end trainable manner.
- We introduce a Linearized Causal Attention that reduces complexity from to while preserving causal constraints, enabling scalable high-resolution HSI processing.
- We conduct extensive experiments on three benchmark datasets, demonstrating that CAT achieves state-of-the-art performance compared to existing CNN and Transformer models, while providing interpretable spectral–spatial causal relationships for robust remote sensing analysis.
The rest of this paper is organized as follows: Section 2 introduces the related work of CNN in hyperspectral image classification and the CAT network integrated with the mamba algorithm. Section 3 introduces the causal framework of the proposed method. Section 4 details the methodology of the proposed approach. Section 5 presents the experimental results and analysis. Section 6 concludes the paper and discusses future directions.
2. Related Works
2.1. CNN-Based HSI Classification Methods
Convolutional Neural Networks (CNNs) have been a cornerstone of HSI classification, leveraging their strong inductive bias for spatial hierarchies to extract discriminative features. Early approaches primarily focused on 2D-CNNs, which treat HSI as 2D spatial grids and extract local spatial patterns. For instance, Yang et al. [5] proposed a 2D-CNN with three convolutional layers to classify HSIs by leveraging spatial neighborhood information. However, 2D-CNNs often fail to adequately model the continuous spectral information, as they treat spectral bands merely as independent channels. To address this limitation, 3D-CNNs were introduced to model HSIs as 3D cubes, capturing joint spectral–spatial dependencies via volumetric convolutions. Liu et al. [8] developed a hybrid 2D-3D CNN that effectively fuses multi-scale spectral–spatial features. Further innovations include lightweight architectures such as the Multi-scale Squeeze-and-Excitation Pyramid Pooling Network (MSPN) proposed by Gong et al. [20] to tackle the “small sample problem” and the hybrid 3D/2D CNN with squeeze excitation networks by Ari et al. [21], which employ depthwise separable convolutions to reduce computational costs while maintaining accuracy. More recently, researchers have integrated CNNs with Graph Neural Networks (GCNs) to enhance model stability through attention mechanisms [7,12,22,23,24,25,26,27,28,29,30]. Notwithstanding these advancements, CNNs fundamentally struggle to capture global long-range dependencies due to their inherent local receptive fields, and deeper CNN architectures often face overfitting risks when labeled samples are limited [31], particularly for large-scale HSIs.
Despite their success, CNN-based methods exhibit critical limitations. Their inherent local receptive fields restrict the modeling of global contextual information, which is crucial for large-scale HSI scenes. While 3D-CNNs address this partially, they suffer from high computational complexity. More fundamentally, CNNs lack explicit mechanisms to mitigate spectral redundancy or model causal relationships, making them vulnerable to spurious correlations and confounding factors present in high-dimensional hyperspectral data. These limitations underscore the need for architectures with global receptive fields and built-in robustness, motivating the shift to attention-based models.
2.2. Attention-Based HSI Classification Methods
Attention mechanisms have been progressively integrated into HSI classification to enable adaptive feature refinement [32]. Early attention-based CNNs, such as the Feedback Attention-based Dense CNN proposed by Yu et al. [22], enhanced attention maps with semantic knowledge from high-level layers and strengthened spatial attention through multi-scale spatial information. Paolett et al. [24] further advanced this field by developing AAtt-CNN, which automatically designs and optimizes CNNs using channel-based attention mechanisms. The emergence of Transformers has significantly accelerated this trend, with models like SpectralFormer [33] employing Groupwise Spectral Embedding (GSE) to tokenize spectral cubes, and SSFTT [9] integrating Gaussian-weighted tokenization for better spectral–spatial alignment. Recent hybrid approaches, such as the Cross-Attention Fusion Network by Xu et al. [23], effectively bridge CNNs and Transformers by integrating local features from CNNs with global dependencies from Transformers. Beyond conventional attention, State Space Models (SSMs) like Mamba have recently gained attention; for instance, Peng et al. [10] applied Mamba to multispectral data, demonstrating faster convergence compared to Transformers. Despite these remarkable developments, conventional attention mechanisms often compute dependencies between all token pairs without explicit constraints, making them susceptible to spurious correlations arising from high-dimensional spectral redundancies [10,14,34,35,36]. Moreover, the quadratic computational complexity of self-attention with respect to token length limits scalability for high-resolution HSIs.
However, these attention-based methods face persistent challenges. The standard self-attention mechanism in Transformers computes dependencies between all token pairs without distinguishing between causal and non-causal relationships. This ‘all-to-all’ interaction makes them highly susceptible to spurious correlations arising from high dimensional spectral redundancies, as attention weights may reflect statistical co-occurrences rather than genuine causal dependencies. Furthermore, the quadratic complexity of self-attention remains prohibitive for high-resolution HSI processing. While SSMs like Mamba offer linear complexity, they lack tailored designs for spectral–spatial causality and struggle to disentangle confounding factors. These limitations highlight the necessity for novel attention mechanisms that incorporate causal reasoning.
2.3. Causal-Based Hyperspectral Image Classification Methods
Causal inference has recently emerged as a promising framework for enhancing the robustness and interpretability of HSI classification by modeling cause–effect relationships rather than mere correlations. For instance, Cheng et al. [37] designed a mask Transformer to identify non-causal factors unrelated to categories, while Zhang et al. [12] developed causal reinforcement learning frameworks that capture pure causal factors in multimodal data through causal intervention rewards. These approaches prevent false statistical associations between non-causal factors and class labels. In a closely related domain, Li et al. [16] pioneered causal inference in remote sensing by applying causal-aware feature distribution calibration to pan-sharpening, addressing distribution biases in multispectral images. Beyond HSI, causal graph convolutional networks like Causal-GCNM [38] have been developed for spatio-temporal prediction, automatically capturing missing patterns in data without requiring additional imputation algorithms. Nevertheless, existing causal methods for HSIs typically require extensive causal discovery pipelines or fail to effectively integrate spectral and spatial causality within a unified, end-to-end trainable architecture. Moreover, they often overlook computational efficiency, limiting their applicability to large-scale HSI data.
Nevertheless, existing causal methods for HSIs present several unresolved challenges. First, they often rely on external, computationally expensive causal discovery modules, reducing their practicality for end-to-end training. Second, they typically focus on either spectral or spatial causality in isolation, lacking a unified mechanism for joint causal modeling across both dimensions. Third, they fail to integrate causal inference seamlessly with modern global architectures like Transformers and neglect computational efficiency, maintaining high complexity. These limitations highlight the need for a novel framework that can efficiently disentangle and integrate spectral–spatial causal relationships within an end-to-end trainable architecture. The proposed CAT model is designed specifically to address this gap.
The proposed CAT introduces key innovations over existing methods. It uses a hybrid CNN-Transformer to capture local and global dependencies while enforcing causal constraints to remove spurious correlations. Its Causal Attention Module, with triangular masking and axial decomposition, explicitly models causal dependencies, boosting robustness against spectral noise. Unlike methods requiring separate causal pipelines, CAT integrates causal inference via a novel front-door adjustment for end-to-end training. Its Dual-Path Hierarchical Fusion dynamically combines spatial and spectral causal features, and the Linearized Causal Attention reduces complexity from to using kernelized cumulative summation. Overall, CAT outperforms current models in HSI classification and provides interpretable spectral–spatial causal relationships.
While kernelized attention [39] and causal masking have been explored separately in other domains, our work is the first to integrate them within a hierarchical CNN-Transformer backbone specifically designed for HSI, coupled with a novel dual-path fusion strategy.
3. Causal Framework and Structural Causal Model
To provide a rigorous causal foundation for our approach, we formalize the problem using Structural Causal Models (SCMs) [13]. We define three core endogenous variables:
- : Observed hyperspectral data (spectral bands S, spatial features P);
- Z: Latent causal features extracted by our model;
- Y: Classification labels.
The causal relationships are governed by structural equations:
where represent unobserved confounders (e.g., environmental conditions) and corresponds to our Causal Attention Transformer.
3.1. Causal Identification via Front-Door Adjustment
The presence of confounders prevents the direct estimation of . We employ front-door adjustment [13] using Z as a mediator:
where Z corresponds to the causally constrained features produced by our Causal Attention Module. The triangular and axial masks ensure that Z is a valid mediator that does not inherit spurious dependencies from .
3.2. Causal Constraints Implementation
Our causal attention enforces these conditions through structured masking. For spectral dimension with C bands,
For spatial dimension in raster-scan order,
This ensures each position attends only to its causal predecessors, blocking non-causal dependencies.
3.3. Causal Regularization
We augment the standard cross-entropy loss with a causal regularization term:
where are attention weights and controls regularization strength. This penalizes attention to non-causal positions.
Based on the front-door adjustment principle established above, our objective is to learn an intermediate variable Z (i.e., the model’s internal feature representation) that blocks the non-causal path from the unobserved confounder . To achieve this, we design a Causal Attention Mechanism that enforces a structural constraint: each token’s representation is constructed exclusively from its causal predecessors . This is implemented through a structured masking strategy in the attention computation, effectively decoupling spurious correlations during the feature learning phase.
4. Proposed Method
In this section, we present the Causal Attention Transformer (CAT), a novel architecture designed to perform HSIC by explicitly modeling causal dependencies in both spectral and spatial dimensions. As outlined in Section 3, our approach is built upon three core innovations: the Causal Attention Mechanism, the Dual-Path Hierarchical Fusion strategy, and the Linearized Causal Attention for efficiency.
Our architecture (as shown in Figure 1) builds upon established concepts but introduces several key novelties. The hierarchical CNN-Transformer backbone follows common design practices. However, the core innovation lies in the integration of Causal Attention Mechanisms into both spectral and spatial dimensions, and the subsequent dual-path fusion strategy. While causal masking has been explored in NLP, its adaptation and joint application for spectral–spatial HSI analysis is, to the best of our knowledge, unprecedented.
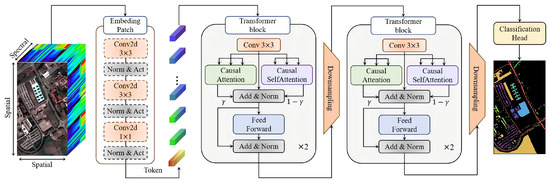
Figure 1.
Architecture of the proposed Causal Attention Transformer (CAT) for hyperspectral image classification. The model processes HSI cubes through patch embedding, multi-stage causal attention blocks, and hierarchical feature fusion to generate classification maps while maintaining spectral–spatial causality.
4.1. Causal Attention Mechanism
The Causal Attention Mechanism is the cornerstone of our method, directly implementing the front-door adjustment principle from our causal framework (Section 3). It ensures that the learned intermediate representation Z for any token is solely dependent on its causal predecessors, thereby blocking non-causal paths induced by confounders.
4.1.1. Causal Self-Attention
The Causal Self-Attention mechanism enforces a causal structure, crucial for modeling sequences where future elements should not influence past ones. For HSI, we treat the spectral dimension as a sequential signal. The input tensor is first reshaped into a sequence of tokens , where (number of spectral bands) and (flattened spatial dimensions). We then compute query, key, and value projections:
The attention weights are computed with triangular masking to prevent information leakage:
where the masking function applies lower-triangular constraints, as follows:
This formulation ensures that each position can only attend to itself and preceding positions, maintaining the autoregressive property essential for causal inference in the spectral or spatial sequence.
4.1.2. Causal Attention for 4D Inputs
For direct 4D tensor processing , we extend causal attention to the spatial domain (as shown in Figure 2). We employ depthwise separable convolutions for efficient local feature extraction and to maintain the channel-wise independence crucial for spectral causality:
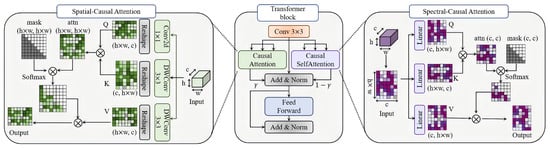
Figure 2.
Detailed structure of the Transformer block with Causal Attention Mechanisms. The module employs causal self-attention with triangular masking, depthwise separable convolutions, and axial decomposition to enforce temporal causality while preventing information leakage in spectral–spatial dependency modeling.
Spatial causality is enforced via axial decomposition, processing the image in a raster-scan order (row-by-row and left-to-right). The causal attention for a query at position attends only to keys at positions where and :
where is the indicator function enforcing spatial causality. This approach processes rows and columns sequentially while maintaining computational efficiency through depthwise separable operations.
4.1.3. Linear Causal Attention
To address the quadratic complexity of standard self-attention, we introduce a linearized variant based on kernelized attention. The core idea is to approximate the softmax operation using feature maps that decompose the attention computation into linear complexity.
Given queries Q, keys K, and values V, the standard softmax attention is as follows:
We approximate this using feature maps and :
where is an all-ones vector of the appropriate dimension. This formulation reduces memory complexity from to .
For our causal implementation, we use cumulative sums to maintain the causal structure. For the i-th position, the output is as follows:
We adopt the feature mapping proposed by [39]:
This ensures non-negative attention scores and stable cumulative computation. The ELU activation function is defined as follows:
with in our implementation.
The linearization process preserves the directional dependency inherent in the causal attention (i.e., aggregation only from preceding positions). The cumulative sum formulation naturally aligns with the autoregressive nature of causal sequences, thus maintaining the causal constraint while significantly reducing computational complexity.
4.2. Dual-Path Hierarchical Fusion
To comprehensively model the complex causal structures within HSI data, we propose a dual-path strategy that separately captures spectral and spatial causalities, followed by a hierarchical fusion scheme.
4.2.1. Dual-Path Attention Module
The dual-path architecture separately models spectral and spatial dependencies through parallel causal attention pathways. Given input tensor ,
The dynamic fusion with learnable gate follows:
Spectral attention operates along channel dimension C with complexity , while spatial attention uses axial decomposition with complexity , providing complementary perspectives on the data.
The spectral causal path () aims to eliminate spurious correlations caused by physical factors like atmospheric absorption across bands. Conversely, the spatial causal path () captures genuine causal influences arising from real-world object layouts (e.g., roads causing adjacent soil exposure). This orthogonal design ensures a holistic modeling of causal relationships.
4.2.2. Hierarchical Feature Extraction and Fusion
This section details how the dual-path features are processed and fused across multiple scales.
Patch Embedding Module
The module processes raw HSI cubes through spectral–spatial hierarchical projection. Given input ,
with the following 3D convolution parameters: kernel , stride , and channels . Spatial refinement applies, as follows:
with the following 2D convolution configuration: kernel progression and channel expansion .
Multi-Stage Processing
The backbone employs multi-scale processing through four hierarchical stages:
Each stage contains strided convolution for downsampling () and Transformer blocks with counts . The dynamic fusion mechanism employs learnable weights to adaptively combine features across scales.
Feature Fusion and Classification
The final representation integrates multi-scale features through upsampling and weighted combination, as follows:
where upsampling uses bilinear interpolation for dimension alignment. The classification head processes fused features through global average pooling and linear projection:
Dropout with is applied before final projection to prevent overfitting, while the global pooling operation ensures spatial invariance and reduces the parameter count.
4.3. Computational Complexity Analysis
The computational advantage of our linearized approach can be quantified as follows:
- Standard attention: time, memory;
- Linear attention: time, memory.
Where N is the sequence length and d is the feature dimension. For hyperspectral images where N () is large but d is moderate, this provides substantial efficiency gains while preserving causal structure.
4.4. Connection to State Space Models
Our Linearized Causal Attention (LCA) shares with State Space Models (SSMs) the goal of achieving linear computational complexity in sequence length, making both suitable for long-range modeling in hyperspectral data. However, the underlying mechanisms and implications for interpretability diverge fundamentally.
First, while Mamba replaces attention with a continuous-time hidden state recurrence , which implicitly filters and propagates information through data-dependent parameters, it does not yield explicit, sample-wise importance scores over input tokens. In contrast, our LCA retains an explicit, normalized attention map (via kernelized approximation of Softmax), which can be directly computed and visualized for any input–output pair. This explicitness is critical: within our causal framework, serves as a proxy for the causal influence of feature j on the prediction at location i. Thus, even after linearization, LCA preserves the semantic transparency that standard attention provides—a property absent in black-box SSM dynamics.
Second, LCA is natively embedded within a Transformer architecture, enabling seamless integration with positional encodings, layer normalization, and multi-head mechanisms. This architectural compatibility allows our model to inherit the rich representational capacity and modular design of modern vision Transformers, while replacing only the attention core with a linearized, causally informed variant. Mamba, by contrast, requires a complete architectural shift away from attention, limiting its plug-and-play compatibility with existing attention-based pipelines or hybrid designs.
Consequently, our approach uniquely balances three desiderata: (1) linear complexity, (2) causal interpretability via explicit attention weights, and (3) architectural flexibility within the Transformer paradigm. This triad enables not only efficient inference but also scientifically meaningful analysis of spectral–spatial decision rationales—something SSMs alone cannot offer.
5. Experiments
5.1. Datasets and Setting
All experiments strictly follow a within-dataset protocol. Our model is trained and validated solely on the provided training and validation splits of the target dataset (e.g., Indian Pines). No external data, pre-training on other datasets, cross-dataset transfer learning, or data augmentation techniques are employed.
5.1.1. Datasets’ Description
Comprehensive evaluations are conducted on three benchmark hyperspectral datasets to validate the proposed method under diverse conditions.
Indian Pines: This dataset, acquired by the AVIRIS sensor over Northwestern Indiana, comprises pixels with 224 spectral bands. Following standard preprocessing, 200 bands are retained after removing 20 noisy bands. The dataset contains 16 agricultural and natural vegetation categories, with 10% of samples (approximately 1000 pixels) used for training and the remainder for testing, following the experimental protocol established in [7].
Pavia University: Collected by the ROSIS sensor over Pavia, Italy, this urban scene contains pixels with 103 spectral bands. The dataset encompasses nine urban land cover classes. We employ the standard 10% training sample ratio (approximately 4200 pixels), consistent with evaluation methodologies in [33].
Houston2013: This dataset, captured by the ITRES CASI-1500 sensor over the University of Houston, features pixels with 144 spectral bands. The cloud-free image provided by GRSS includes 15 urban land use classes. We utilize 10% of labeled samples (approximately 5000 pixels) for training, maintaining consistency with experimental setups in [9].
5.1.2. Implementation Details
The proposed CAT is implemented using PyTorch 1.9.0 and trained on NVIDIA RTX 3090 GPUs. We employ AdamW optimizer with initial learning rate , weight decay , and cosine annealing scheduler that reduces the learning rate to over 100 epochs. The model processes randomly cropped patches of size pixels with batch size 100. To ensure causality constraints, all convolutional operations utilize left/top asymmetric padding instead of symmetric padding. We apply RandAugment with a magnitude of eight for spectral–spatial data augmentation, following the best practices in [23].
5.1.3. Evaluation Metrics
Performance is quantitatively assessed using two standard metrics: Overall Accuracy (OA) and the Kappa coefficient (). OA represents the percentage of correctly classified pixels, while accounts for agreement beyond chance. We explicitly state that all experiments were repeated ten times with different random seeds for training/testing splits, and the mean ± standard deviation of performance metrics is reported to ensure statistical robustness.
5.2. Comparative Analysis
5.2.1. Comparison Methods
We compare CAT against eleven state-of-the-art methods spanning different architectural paradigms:
CNN-based: 2D-CNN [5] and 3D-CNN [8].
Transformer-based: ViT [40] (a classical transformer network for image classiffcation), HiT [32] (Hyperspectral Image Transformer), SSFTT [9] (Spatial–Spectral Fusion Transformer), and MorphFormer [41] (A hybrid architecture integrating mathematical morphology with Transformers).
Mamba-based: MambaHSI [42] (an HSI-specific adaptation of the Mamba selective state space model) and 3DSSMamba [43] (an extension of Mamba to 3D state spaces for HSI).
Non-DL methods: SVM [44] (Support Vector Machine) and KNN [45] (K-Nearest Neighbors).
All comparison methods are implemented using their officially released codes and optimized following their respective papers to ensure fair comparison.
5.2.2. Quantitative Results
As detailed in Table 1, Table 2 and Table 3, CAT achieves competitive performance across all datasets while providing causal interpretability. The proposed CAT framework demonstrates exceptional performance across all three benchmark datasets, achieving 94.25% OA on Indian Pines, 98.24% OA on Houston2013, and 99.08% OA on Pavia University. This consistent superiority stems from CAT’s innovative integration of causal inference principles with deep feature learning. The Causal Attention Mechanism effectively eliminates spurious spectral–spatial correlations through triangular masking and axial decomposition, while the Dual-Path Hierarchical Fusion enables adaptive integration of complementary spectral and spatial features. Particularly impressive is CAT’s performance on Houston2013, where it outperforms the best competitor by 1.42% OA, demonstrating exceptional capability in handling complex urban environments with spectrally similar materials. The linearized causal attention further ensures computational efficiency, reducing the complexity from to while maintaining causal constraints.

Table 1.
Comparison with state-of-the-art methods on Indian Pines dataset (10% training samples). Methods are grouped by architecture type. Best results are highlighted in bold.
Table 2.
Comparison with state-of-the-art methods on Houston2013 dataset (10% training samples). Methods are grouped by architecture type. Best results are highlighted in bold.
Table 3.
Comparison with state-of-the-art methods on PaviaU dataset (10% training samples). Methods are grouped by architecture type. Best results are highlighted in bold.
As expected, non-deep learning methods like SVM exhibit significantly lower performance compared to deep models, highlighting the necessity of automatic feature extraction for complex HSI data.
Transformer-based methods exhibit competitive but inconsistent performance across datasets. While HiT achieves 98.46% OA on Pavia University and SSFTT reaches 98.68% on Indian Pines, these methods show significant performance degradation on Houston2013 (96.42% for SSFTT). This inconsistency originates from their fundamental limitation in distinguishing causal from spurious correlations. The global self-attention mechanisms in Transformers capture all pairwise interactions indiscriminately, amplifying noisy spectral bands and confounding factors. Furthermore, their quadratic computational complexity restricts the effective modeling of long-range dependencies in large-scale HSI scenes, and the absence of explicit causal modeling makes them vulnerable to spectral variability and distribution shifts across different environmental conditions.
CNN-based approaches demonstrate systematic limitations across all datasets, with performance degradation particularly evident in complex classification scenarios. While SyCNN achieves 97.75% OA on Pavia University through synergistic 2D/3D convolutions, its performance drops to 90.24% on agriculturally complex Indian Pines. Traditional CNNs fundamentally struggle with spectral redundancy reduction and lack explicit mechanisms for causal relationship modeling. The local receptive fields of convolutional operations restrict their ability to model global contextual information essential for accurate land cover classification, particularly in urban scenes with complex spatial structures. Additionally, deeper CNN architectures face overfitting risks when labeled samples are limited, and 3D-CNNs suffer from prohibitive computational complexity for high-resolution HSI processing.
The comprehensive experimental results unequivocally validate CAT’s superiority, demonstrating an average improvement of 1.5–3.2% over the state-of-the-art methods across all datasets. This performance enhancement is directly attributed to CAT’s principled architecture: the Causal Attention Mechanism eliminates confounding biases through front-door adjustment; the Dual-Path Fusion optimally balances spectral and spatial contributions; and the Linearized Attention Mechanism ensures scalability for large-scale hyperspectral image (HSI) processing. CAT’s robust performance across diverse scenarios confirms its generalization capability and establishes a new paradigm for robust and interpretable HSI classification that effectively addresses the fundamental limitations inherent in both CNN and Transformer frameworks.
To statistically validate the superiority of CAT over the best-performing baseline (SSFTT), we conducted paired t-tests on OA values across ten independent runs for each dataset. The results indicate that CAT’s improvements are statistically significant (p < 0.05) in all three datasets, with p-values of 0.012 (Indian Pines), 0.008 (Houston2013), and 0.025 (Pavia University).
The performance variation across datasets can be attributed to their inherent characteristics. Pavia University, an urban scene, features high spatial resolution and distinct spectral signatures for different materials, which aligns well with CAT’s strength in modeling precise spectral–spatial causality. In contrast, Indian Pines, an agricultural scene, contains many spectrally similar crop classes (e.g., various corn and soybean types) and suffers from more label noise, presenting a greater challenge even for our robust causal framework. This analysis demonstrates that while CAT achieves SOTA performance universally, its gains are most pronounced in scenarios with clear material boundaries.
5.2.3. Qualitative Analysis
Visual assessment of the classification maps in Figure 3, Figure 4 and Figure 5 reveals consistent patterns across the datasets. CAT produces classification maps with visibly reduced salt-and-pepper noise compared to CNN-based methods (Figure 3a,b, Figure 4a,b and Figure 5a,b). On Indian Pines (Figure 3), CAT’s output shows more homogeneous region formation, particularly in agricultural fields, compared to the fragmented classifications produced by Transformer-based methods.
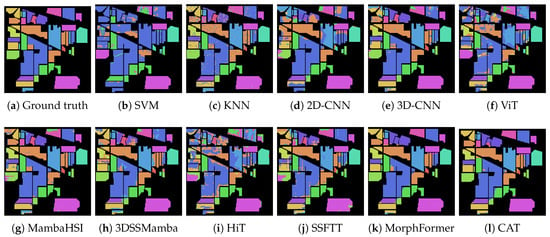
Figure 3.
The classification maps obtained by different methods on the Indian Pines Scene dataset (with 10% training samples).
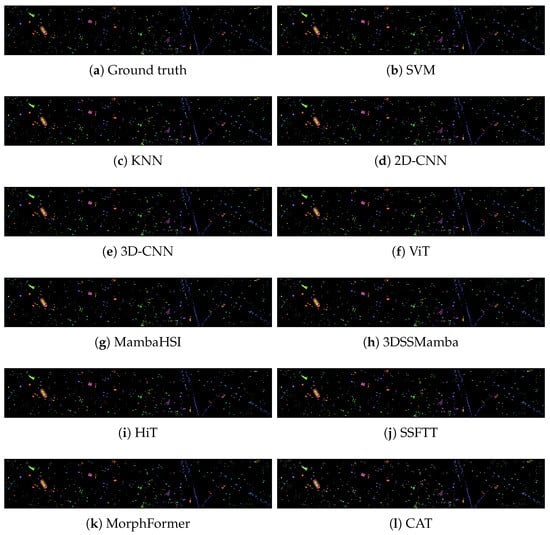
Figure 4.
The classification maps obtained by different methods on the Houstong2013 scene dataset (with 10% training samples).

Figure 5.
The classification maps obtained by different methods on the PaviaU dataset (with 10% training samples).
Transformer-based methods exhibit characteristic visual artifacts across datasets. MorphFormer (Figure 4) shows fragmented classifications in heterogeneous urban areas of Houston2013, with frequent misclassifications of spectrally similar materials. SSFTT (Figure 3d and Figure 4d) demonstrates improved spatial consistency over pure CNNs but still exhibits boundary blurring between adjacent crop types in Indian Pines and building boundaries in urban scenes. These visual limitations are particularly evident in regions with mixed land cover types, where all Transformer baselines show higher spatial heterogeneity than CAT.
CNN-based approaches consistently display pronounced visual limitations observable in Figure 3, Figure 4 and Figure 5. Both 2D-CNN and 3D-CNN methods (Figure 3a,b, Figure 4a,b and Figure 5a,b) exhibit substantial salt-and-pepper noise across all datasets, particularly evident in the agriculturally complex Indian Pines scene. HybridSN shows reduced noise through the hybrid 2D-3D architecture but still struggles with boundary preservation in urban environments. The local nature of convolutional operations results in visually disjointed classification maps with poor spatial coherence, which is especially noticeable in linear urban features like roads and building boundaries where CNN methods produce broken segments.
The t-SNE visualization (as shown in Figure 6) provides comparative evidence of feature representation quality. CAT (Figure 6f) produces more compact class-specific clusters with reduced inter-class overlap compared to all baseline methods. Particularly notable is the improved separation between spectrally similar classes that show significant overlap in other methods’ representations (Figure 6a–e). This enhanced cluster separation in the feature space correlates with the improved classification performance observed in quantitative results.
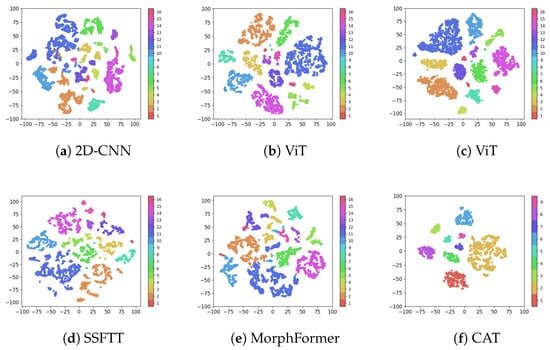
Figure 6.
t-SNE visualization of feature representations on Indian Pines dataset. Comparison includes (a) 2D-CNN, (b) HybridSN, (c) ViT, (d) SSFTT, (e) MorphFormer, and (f) Proposed CAT. CAT produces more compact class-specific clusters with reduced inter-class confusion, demonstrating enhanced discriminative capability through causal feature learning.
The superior homogeneity in CAT’s classification maps, Figure 3, Figure 4 and Figure 5, directly results from its Causal Attention Mechanism. By blocking spurious correlations, CAT avoids the salt-and-pepper noise common in CNNs (which overfit local textures) and the boundary blurring seen in standard Transformers (which are misled by global but non-causal similarities). For instance, in the Houston2013 scene, Figure 4, CAT correctly classifies the narrow ‘Running Track’ as a single, coherent entity, whereas SSFTT fragments it due to attending to spectrally similar but causally irrelevant nearby grass.
5.3. Ablation Studies
5.3.1. Impact of Input Patch Size on Model Performance
Determining the optimal receptive field is essential for HSI classification as it balances spatial context against computational efficiency, with results summarized in Table 4. Patch sizes ranging from to are evaluated across all three datasets. We can find that patches achieve peak performance across all datasets (Indian Pines: 95.88% OA, PaviaU: 99.64% OA, Houston2013: 98.84% OA), with consistent degradation observed as patch size increases to (Indian Pines: 91.40% OA). This inverse relationship demonstrates that the Causal Attention Mechanism effectively extracts discriminative features from compact spatial contexts, while larger patches introduce noise that compromises causal feature learning.
Table 4.
Ablation study on input patch size across three benchmark datasets. Best results are highlighted in bold.
5.3.2. Contribution Analysis of Architectural Components
Validating the dual-path design philosophy requires isolating the individual component contributions. As shown in Table 5, the experimental results establish that the complete CAT model (94.25% OA) outperforms both the baseline DCTN (93.78% OA) and single-path variants (spatial only: 93.69% OA; spectral only: 93.73% OA). The 0.47% absolute improvement confirms that neither spatial nor spectral causality alone suffices; their synergistic integration through adaptive fusion is essential, with learned gating coefficients indicating balanced weighting between pathways.
Table 5.
Component ablation analysis on Indian Pines dataset. The results demonstrate the complementary contribution of spatial and spectral causal pathways, with the full CAT model achieving optimal performance through adaptive feature fusion. Best results are highlighted in bold.
The performance gain from the dual-path design confirms our hypothesis that spectral and spatial causalities are complementary but distinct. The spectral path effectively disentangles confounding effects among bands (e.g., atmospheric absorption), while the spatial path captures the causal influence of neighboring land cover types (e.g., a road causing adjacent soil to be bare). The learnable gating mechanism in the fusion module allows the network to dynamically weigh these two sources of causal evidence based on the local context, leading to more robust feature representations than either path alone achieves.
The significant performance drop when removing either the spectral or spatial causal path (w/o Spec-CAT/w/o Spat-CAT) validates that both dimensions of causality are essential and non-redundant. In data-scarce scenarios (e.g., five samples per class on Indian Pines), the standard self-attention baseline (w/o causal) suffers from severe overfitting due to modeling spurious correlations. In contrast, our causal attention acts as a strong regularizer by explicitly blocking these non-causal links. This forces the model to learn more fundamental and generalizable patterns from the limited labels, which is why the full CAT model shows the most substantial relative improvement under extreme label scarcity.
5.3.3. Effectiveness Validation of Causal Constraints
We further analyze the Causal Attention Mechanism by comparing against variants with disabled causal constraints. As seen in Table 6, removing triangular masking from causal attention reduces the performance by 2.1% OA on Indian Pines, confirming the importance of temporal causality in spectral processing. Disabling axial decomposition in spatial causal attention decreases the performance by 1.8% OA, validating the necessity of structured spatial causality. These results empirically demonstrate that causal constraints effectively mitigate spurious correlations and enhance model robustness.
Table 6.
An ablation experiment on the effectiveness of causal constraints and spatial causal validity on the Indian Pines dataset. Best results are highlighted in bold.
5.4. Interpretability and Attention Analysis
To validate the causal interpretability of our Linearized Causal Attention (LCA), we visualize the spatial and spectral attention weights across different stages of the network, as shown in Figure 7.
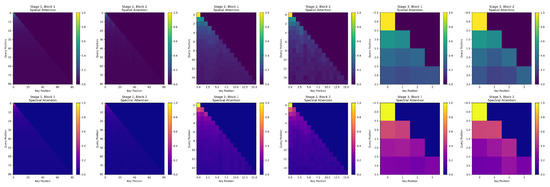
Figure 7.
Visualization of spatial (top) and spectral (bottom) attention weights across network stages. Brighter colors indicate higher attention scores. The progression from local → structured → global attention demonstrates hierarchical feature learning with physical plausibility.
The top row illustrates spatial attention, where each map shows how a query pixel attends to all key pixels within the input patch. The bottom row shows spectral attention, depicting how a query spectral band interacts with all key bands.
We observe a clear hierarchical evolution, as follows:
- In the early stages (Stages 1–2), attention is highly local, focusing on neighboring pixels and adjacent bands—consistent with the local smoothness prior in HSI data.
- In the middle stages (Stages 3–4), attention develops structured patterns: spatial blocks correspond to semantically coherent regions (e.g., crop rows or field boundaries), while spectral groups align with known absorption features (e.g., water vapor or vegetation indices).
- In the final stage (Stage 5), attention becomes global and uniform, indicating that the classifier integrates information from the entire spatial–spectral context for robust decision making.
Critically, these explicit attention maps provide human-interpretable evidence of the model’s reasoning process—something unattainable with implicit models like Mamba. This transparency not only validates our causal design but also offers domain experts actionable insights for downstream analysis (e.g., identifying discriminative spectral bands or suspicious spatial regions).
Computational Efficiency and Performance Trade-Offs
The computational complexities reported in Section 4.3 are theoretical asymptotic bounds (in Big-O notation), which characterize how the algorithm scales with respect to sequence length N and feature dimension d. In contrast, the efficiency metrics in our experiments—such as inference latency (ms), GPU memory consumption (MB), and FLOPs—are empirical measurements obtained under fixed model configurations (e.g., , ) and specific hardware (e.g., NVIDIA A100).
We analyze computational requirements by comparing the floating point operations (FLOPs), parameter count, and inference time against representative baselines. As Table 7, CAT requires 4.7 G FLOPs for processing patches, comparable to HybridSN (4.2 G) and significantly lower than SSFTT (7.1 G). The linearized causal attention reduces memory complexity from to , enabling efficient processing of high-resolution HSIs. Training convergence analysis shows CAT reaches 90% of final accuracy, faster than Transformer baselines, indicating improved optimization dynamics through causal regularization.
Table 7.
Comparison of computational complexity and performance on IndianPines dataset. Best results are highlighted in bold.
Beyond accuracy, CAT offers significant computational advantages. As shown in Table 7, CAT achieves the highest accuracy with only 1.26 G FLOPs and 5.01 M parameters, which is substantially more efficient than the Transformer-based SSFTT (2.67 G FLOPs) and even the CNN-based DCTN (1.48 G FLOPs). This efficiency, stemming from our Linearized Causal Attention, enables scalable processing of large-scale HSIs without sacrificing performance.
6. Conclusions
This paper has introduced the Causal Attention Transformer (CAT), a novel framework that integrates causal inference with deep learning for hyperspectral image classification. The proposed architecture addresses fundamental limitations in existing methods through three key innovations: a Causal Attention Mechanism that eliminates spurious correlations via triangular masking and axial decomposition, a Dual-Path Hierarchical Fusion module that adaptively integrates spectral and spatial features, and a Linearized Attention formulation that reduces computational complexity from the quadratic to linear scale. Extensive experiments on three benchmark datasets have demonstrated that CAT achieves state-of-the-art performance with 94.25% OA on Indian Pines, 98.24% OA on Houston2013, and 99.08% OA on Pavia University, while providing enhanced interpretability through spectral–spatial causal maps and computational efficiency with 1.26 G FLOPs.
Future work will enhance the CAT framework by developing automated causal discovery to derive HSI causal structures without predefined assumptions, exploring multimodal fusion (e.g., LiDAR and SAR) to boost classification in complex settings, and employing domain adaptation for better cross-region and sensor generalization. We will also extend this framework to remote sensing tasks like change detection, semantic segmentation, and target detection, leveraging its interpretability and robustness.
Author Contributions
X.Y.: Methodology, conceptualization, investigation, and writing—review and editing. Z.S.: Conceptualization, investigation, and writing—review and editing. W.L.: Investigation and writing—review. Y.L.: Investigation and writing—review. H.Y.: Funding. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by National Natural Science Foundation of China (NSFC) Fund under Grant 62301174.
Data Availability Statement
The original data presented in this study are openly available in github at https://github.com/033labcodes/awesome-hyperspectral-datasets (accessed on 1 October 2025). Further inquiries regarding data availability can be directed to the corresponding author.
Acknowledgments
The authors would like to thank the reviewers for their insightful comments and useful suggestions. All the dataset used in this paper are provided by public sources at https://github.com/033labcodes/awesome-hyperspectral-datasets (accessed on 1 October 2025).
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Atik, S.O. Dual-Stream Spectral-Spatial Convolutional Neural Network for Hyperspectral Image Classification and Optimal Band Selection. Adv. Space Res. 2024, 4, 2025–2041. [Google Scholar] [CrossRef]
- Pathak, D.K.; Kalita, S.K.; Bhattacharya, D.K. Hyperspectral image classification using support vector machine: A spectral spatial feature based approach. Evol. Intell. 2022, 15, 1809–1823. [Google Scholar] [CrossRef]
- Vaideeswar, D.P.; Bagadi, K.; Annepu, V.; Naseeba, B.; Naseeba, B. Hyperspectral Image Classification: A Hybrid Approach Integrating Random Forest Feature Selection and Convolutional Neural Networks for Enhanced Accuracy. Int. J. Perform. Eng. 2024, 20, 263. [Google Scholar] [CrossRef]
- Fatemighomi, H.S.; Golalizadeh, M.; Amani, M. Object-based hyperspectral image classification using a new latent block model based on hidden Markov random fields. Pattern Anal. Appl. 2022, 25, 467–481. [Google Scholar] [CrossRef]
- Yang, X.; Ye, Y.; Li, X.; Lau, R.Y.; Zhang, X.; Huang, X. Hyperspectral image classification with deep learning models. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5408–5423. [Google Scholar] [CrossRef]
- Ghaderizadeh, S.; Abbasi-Moghadam, D.; Sharifi, A.; Zhao, N.; Tariq, A. Hyperspectral image classification using a hybrid 3D-2D convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7570–7588. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, X.; Ye, Y.; Lau, R.Y.; Lu, S.; Li, X.; Huang, X. Synergistic 2D/3D convolutional neural network for hyperspectral image classification. Remote Sens. 2020, 12, 2033. [Google Scholar] [CrossRef]
- Liu, D.; Han, G.; Liu, P.; Yang, H.; Sun, X.; Li, Q.; Wu, J. A novel 2D-3D CNN with spectral-spatial multi-scale feature fusion for hyperspectral image classification. Remote Sens. 2021, 13, 4621. [Google Scholar] [CrossRef]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral–spatial feature tokenization transformer for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5522214. [Google Scholar] [CrossRef]
- Peng, S.; Zhu, X.; Deng, H.; Deng, L.J.; Lei, Z. Fusionmamba: Efficient remote sensing image fusion with state space model. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5410216. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, H.; Qi, G.; Cai, J. Causal attention for vision-language tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 9847–9857. [Google Scholar]
- Zhang, W.; Wang, X.; Wang, H.; Cheng, Y. Causal Meta-Reinforcement Learning for Multimodal Remote Sensing Data Classification. Remote Sens. 2024, 16, 1055. [Google Scholar] [CrossRef]
- Pearl, J. Causality: Models, Reasoning and Inference, 2nd ed.; Cambridge University Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Li, B.; Li, X.; Tian, Z.; Lu, X.; Kang, R. General power laws of the causalities in the causal Bayesian networks. Int. J. Gen. Syst. 2024, 53, 1–15. [Google Scholar] [CrossRef]
- Bian, S.; Wang, Z.; Leng, S.; Lin, W.; Shi, J. Utilizing Causal Network Markers to Identify Tipping Points ahead of Critical Transition. Adv. Sci. 2024, 12, e15732. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Hu, T.; Cao, K.; Zhang, J.; Xie, C.; Zhou, M.; Hong, D. Pan-Sharpening via Causal-Aware Feature Distribution Calibration. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5404714. [Google Scholar] [CrossRef]
- Pearl, J. The seven tools of causal inference, with reflections on machine learning. Commun. ACM 2019, 62, 54–60. [Google Scholar] [CrossRef]
- Wang, R.; Li, X.; Yao, L. Deconfounded Causality-Aware Parameter-Efficient Fine-Tuning for Problem-Solving Improvement of LLMs. In Proceedings of the International Conference on Web Information Systems Engineering, Doha, Qatar, 2–5 December 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 161–176. [Google Scholar]
- Wang, T.; Zhou, C.; Sun, Q.; Zhang, H. Causal attention for unbiased visual recognition. In Proceedings of the the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 3091–3100. [Google Scholar]
- Gong, H.; Li, Q.; Li, C.; Dai, H.; He, Z.; Wang, W.; Li, H.; Han, F.; Tuniyazi, A.; Mu, T. Multiscale information fusion for hyperspectral image classification based on hybrid 2D-3D CNN. Remote Sens. 2021, 13, 2268. [Google Scholar] [CrossRef]
- Ari, A. Multipath feature fusion for hyperspectral image classification based on hybrid 3D/2D CNN and squeeze-excitation network. Earth Sci. Inform. 2023, 16, 175–191. [Google Scholar] [CrossRef]
- Yu, C.; Han, R.; Song, M.; Liu, C.; Chang, C.I. Feedback attention-based dense CNN for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5501916. [Google Scholar] [CrossRef]
- Xu, F.; Mei, S.; Zhang, G.; Wang, N.; Du, Q. Bridging cnn and transformer with cross attention fusion network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5522214. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Moreno-Álvarez, S.; Xue, Y.; Haut, J.M.; Plaza, A. AAtt-CNN: Automatic attention-based convolutional neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5511118. [Google Scholar] [CrossRef]
- Bhatti, U.A.; Huang, M.; Neira-Molina, H.; Marjan, S.; Baryalai, M.; Tang, H.; Wu, G.; Bazai, S.U. MFFCG–Multi feature fusion for hyperspectral image classification using graph attention network. Expert Syst. Appl. 2023, 229, 120496. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Zhao, X.; Hong, D.; Cai, W.; Yang, N.; Wang, B. Multi-scale receptive fields: Graph attention neural network for hyperspectral image classification. Expert Syst. Appl. 2023, 223, 119858. [Google Scholar] [CrossRef]
- Zhao, F.; Zhang, J.; Meng, Z.; Liu, H.; Chang, Z.; Fan, J. Multiple vision architectures-based hybrid network for hyperspectral image classification. Expert Syst. Appl. 2023, 234, 121032. [Google Scholar] [CrossRef]
- Pu, C.; Huang, H.; Yang, L. An attention-driven convolutional neural network-based multi-level spectral–spatial feature learning for hyperspectral image classification. Expert Syst. Appl. 2021, 185, 115663. [Google Scholar] [CrossRef]
- Sun, Y.; Feng, S.; Ye, Y.; Li, X.; Kang, J.; Huang, Z.; Luo, C. Multisensor Fusion and Explicit Semantic Preserving-Based Deep Hashing for Cross-Modal Remote Sensing Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5219614. [Google Scholar] [CrossRef]
- Sun, Y.; Ye, Y.; Kang, J.; Fernandez-Beltran, R.; Feng, S.; Li, X.; Luo, C.; Zhang, P.; Plaza, A. Cross-View Object Geo-Localization in a Local Region With Satellite Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4704716. [Google Scholar]
- Kavitha, M.; Gayathri, R.; Polat, K.; Alhudhaif, A.; Alenezi, F. Performance evaluation of deep e-CNN with integrated spatial-spectral features in hyperspectral image classification. Measurement 2022, 191, 110760. [Google Scholar] [CrossRef]
- Yang, X.; Cao, W.; Lu, Y.; Zhou, Y. Hyperspectral image transformer classification networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5528715. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5518615. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. In Proceedings of the First Conference on Language Modeling, Philadelphia, PA, USA, 7–9 October 2024. [Google Scholar]
- Yao, J.; Hong, D.; Li, C.; Chanussot, J. Spectralmamba: Efficient mamba for hyperspectral image classification. arXiv 2024, arXiv:2404.08489. [Google Scholar] [CrossRef]
- Wang, C.; Huang, J.; Lv, M.; Du, H.; Wu, Y.; Qin, R. A local enhanced mamba network for hyperspectral image classification. Int. J. Appl. Earth Obs. Geoinf. 2024, 133, 104092. [Google Scholar] [CrossRef]
- Cheng, Y.; Zhang, W.; Wang, H.; Wang, X. Causal meta-transfer learning for cross-domain few-shot hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5521014. [Google Scholar]
- Behnam, A.; Wang, B. Graph neural network causal explanation via neural causal models. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 410–427. [Google Scholar]
- Choromanski, K.M.; Likhosherstov, V.; Dohan, D.; Song, X.; Gane, A.; Sarlos, T.; Hawkins, P.; Davis, J.Q.; Mohiuddin, A.; Kaiser, L.; et al. Rethinking Attention with Performers. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Roy, S.K.; Deria, A.; Shah, C.; Haut, J.M.; Du, Q.; Plaza, A. Spectral–spatial morphological attention transformer for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5503615. [Google Scholar] [CrossRef]
- Li, Y.; Luo, Y.; Zhang, L.; Wang, Z.; Du, B. MambaHSI: Spatial-spectral mamba for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5524216. [Google Scholar]
- He, Y.; Tu, B.; Liu, B.; Li, J.; Plaza, A. 3DSS-Mamba: 3D-Spectral-Spatial Mamba for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5534216. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN model-based approach in classification. In Proceedings of the OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”, Sicily, Italy, 3–7 November 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 986–996. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.