Abstract
As a typical visual foundation model, SAM has been extensively utilized for optical image segmentation tasks. However, synthetic aperture radar (SAR) employs a unique imaging mechanism, and its images are very different from optical images. Directly transferring a pretrained SAM from optical scenes to SAR image instance segmentation tasks can lead to a substantial decline in performance. Therefore, this paper fully integrates the SAR scattering mechanism, and proposes a SAR image target segmentation method guided by the SAR scattering mechanism-based visual foundation model. First, considering the discrete distribution features of strong scattering points in SAR imagery, we develop an edge enhancement morphological adaptor. This adaptor is designed to incorporate a limited set of trainable parameters aimed at effectively boosting the target’s edge morphology, allowing quick fine-tuning within the SAR realm. Second, an adaptive denoising module based on wavelets and soft-thresholding techniques is implemented to reduce the impact of SAR coherent speckle noise, thus improving the feature representation performance. Furthermore, an efficient automatic prompt module based on a deep object detector is built to enhance the ability of rapid target localization in wide-area scenes and improve image segmentation performance. Our approach has been shown to outperform current segmentation methods through experiments conducted on two open-source datasets, SSDD and HRSID. When the ground-truth is used as a prompt, SARSAM improves by more than 10%, and by more than 5% from the baseline. In addition, the computational cost is greatly reduced because the number of parameters and FLOPs of the structures that require fine-tuning are only 13.5% and 10.1% of the baseline, respectively.
1. Introduction
As an active Earth observation platform, synthetic aperture radar (SAR) acquires detailed information about target surfaces by emitting pulsed electromagnetic waves and receiving reflected signals. Unlike traditional optical imaging, weather and light conditions do not affect SAR imaging results, provide excellent penetration, and produce high-resolution images [1]. These characteristics have led to the widespread application of SAR technology in marine monitoring, geographic mapping, and military fields [2]. In the field of marine monitoring, ship detection is a critical task, where the precise localization of ship targets is essential. Although object detection techniques can achieve localization, they often struggle to accurately delineate the contours of these targets. However, instance segmentation technology [3], which combines the strengths of both object detection and segmentation, can more accurately locate and classify individual target instances in remote sensing images while clearly delineating the boundaries of the targets [4]. Although the initial instance segmentation methods were designed primarily for optical images, SAR images are prone to coherent interference during the imaging process, leading to an increase in speckle noise, side-lobe effects, and complex background interference in the images. These challenges make instance segmentation of ships in SAR imagery particularly difficult. Traditional SAR ship segmentation methods perform well in simple scenarios but may be limited in complex backgrounds, or when multiple scales and occlusions are present. The advancement of deep learning technology has sparked increasing interest in the use of methods such as convolutional neural networks (CNNs) [5] to improve ship segmentation in SAR images.
In the field of segmentation tasks, researchers have introduced numerous deep learning methods, some of which are tailored specifically for SAR image instance segmentation. Wei et al. published the high-resolution SAR ship instance dataset (HRSID) [6], which serves as a valuable resource for research in this area. However, their work did not include any specific instance segmentation methods for SAR images. Ke et al. [7] improved the localization accuracy of bounding boxes for better segmentation by modeling global contextual information and carefully designing bounding box-aware predictions; however, the research failed to comprehensively consider the distinctions between the segmentation task and the detection task. Gao et al. [8] designed a feature fusion module that enables feature decoupling while constraining the loss function on the basis of the center of mass and angle. The method, although excellent in some cases, still has shortcomings in complex ocean scenarios. By increasing the resolution of the feature map and optimizing the information flow between mask branches, Su et al. [9] improved the accuracy of mask prediction. They verified the validity of their approach using the SSDD dataset [10].
The growth in data volume and increase in model depth have made linguistic, visual, and multimodal foundation models a hot research topic. In 2023, Meta AI introduced the Segment Anything Model (SAM) [11], an interactive segmentation foundation model. Yet, experiments show that SAM’s accuracy in segmenting ship targets in SAR images is low and its performance is poor. This is mainly because SAM’s training dataset comes from natural scenes, which are very different from SAR images and lack an understanding and effective processing of SAR image features. So, visual foundation models (VFMs) in SAR face many challenges, such as domain differences between optical and SAR images, limited dataset sizes, and complex scattering characteristics. As a result, some scholars have started to study VFMs for SAR. Chen et al. proposed RSPrompter [12], which automatically generates prompts and fine-tunes the decoder while freezing the encoder, achieving great performance on the SSDD dataset. By using SAM, Pu et al. developed the lightweight CWSAM, which allows effective parameter fine-tuning and has a classification mask decoder. This model ultimately achieved land-cover classification in SAR images, showing the potential of VFMs in the SAR domain [13]. From the perspective of imaging mechanism and target characteristics, RingMo constructs a multi-mission model by combining optical and SAR remote sensing data [14]. With a large scale SAR dataset, Li et al. developed the first SAR target recognition algorithm using an embedding-prediction self-supervised learning framework [15].
In summary, for the SAR ship segmentation task, this paper addresses the performance degradation issue of the SAM in the SAR domain by introducing a novel SAR ship instance segmentation model based on SAM, named SARSAM. By utilizing parameter efficient fine-tuning (PEFT) [16] technology, this algorithm enhances the model’s ability to segment ship targets in SAR images, with the need to update only a limited number of parameters.
In this paper, the following improvements are made in how to achieve target segmentation in SAR images via visual foundation models:
(1) Unlike optical remote sensing, SAR suffers from severe coherent speckle noise interference, which involves different frequency components. To address this issue, this paper introduces an adaptive wavelet soft thresholding (AWST) denoising module. AWST decomposes shallow features with noise into different frequency and directional subbands on the basis of a two-dimensional discrete wavelet transform, and then employs an attention mechanism to autonomously determine the most suitable threshold values for individual subbands. With these threshold values, the subbands can be soft-thresholded separately and then reconstructed via an inverse wavelet transform, which ultimately suppresses the coherent speckle noise and enhances the image quality.
(2) Targets in SAR images are often composed of multiple strong scattering points, which exhibit discrete distribution characteristics and incomplete structures, with blurred edges and weak contour information. Moreover, the SAM is large scale, and fine-tuning it directly on SAR datasets is computationally expensive. To solve this problem, this paper introduces an edge-enhanced morphological adapter (M-Adapter). The M-Adapter, which is based on the standard adapter, uses group convolutions to simulate morphological opening operations, thereby automatically obtaining the shape of structural elements and enhancing the edge features of the targets. During training, the original model parameters are frozen, and only the M-Adapter parameters need to be updated to achieve fine-tuning.
(3) The segmentation performance of the SAM architecture is heavily dependent on the quality of the prompts. However, SAR scenes often contain numerous interfering targets, which complicates the segmentation process. Accurately locating target areas and providing reliable prompts are crucial. Preliminary experiments indicate that bounding box prompts are far more effective than point prompts. Therefore, this paper constructs a prompter based on a deep object detector. This prompter, trained on SAR datasets, can provide reliable bounding box prompts for the methods proposed in this paper, thereby assisting in the precise segmentation of targets in SAR images.
2. Related Work
2.1. Instance Segmentation
The objective of instance segmentation is to precisely determine the position of individual objects, identify their category, and generate the corresponding pixel-level mask. In simpler terms, instance segmentation can be viewed as a blend of object detection and semantic segmentation duties. Currently, deep learning-based instance segmentation consists of two types of methods: single-stage and two-stage. They are developed on the basis of single-stage and two-stage object detectors. The difference between them is that the single-stage methods are fast and have a small model size, but the segmentation results are not very fine, while the two-stage methods can achieve finer segmentation results, but they tend to have a larger number of model parameters and slower inference speeds. Given the hardware resource constraints and the need for real-time performance, single-stage methods are more prevalent in practical applications.
For example, algorithms such as YOLOv8 [17] and Yolact [18] not only ensure rapid inference but also exhibit excellent instance segmentation capabilities. Furthermore, with the widespread application of the Transformer architecture in visual tasks, instance segmentation methods based on the Vision Transformer (ViT), such as Cell-DETR [19] and Mask Transfiner [20], are gaining attention from researchers. However, most existing instance segmentation methods were developed for natural scene tasks and do not account for the unique characteristics of SAR images, resulting in a performance decline when applied to the SAR domain. Currently, general visual foundation models are emerging as new research hotspots that are capable of being transferred to various downstream tasks, providing new strategies for solving instance segmentation tasks.
2.2. Segment Anything Model
In the swift evolution of artificial intelligence, foundational models in language and vision have demonstrated exceptional generalization capabilities by extracting complex feature representations from vast datasets, showcasing their efficient performance across a spectrum of downstream tasks. Language foundational models are dedicated to the comprehension and generation of natural language, with models such as Chat-GPT [21] and LaMDA [22] being representative of this domain. On the other hand, visual foundational models emphasize the in-depth analysis and understanding of image and video content, with models such as CogVLM [23] and LVM [24] exerting significant influence in their respective fields. Moreover, multimodal large models have achieved advanced task processing capabilities by integrating linguistic and visual information, with models such as CLIP [25] and stable diffusion [26] being paragons in this regard.
Developed by Meta AI in 2023, SAM is an interactive vision model that has been extensively trained on tens of millions of images and billions of masks using an internal cyclic data engine to annotate the data, giving the model superior generalization capabilities for a broad spectrum of visual tasks. The SAM framework’s interactive characteristics enable it to employ a diverse array of prompts, including points, bounding boxes, and masks, to achieve accurate segmentation of targets. This high level of flexibility opens up broad prospects for applying SAM to a variety of visual tasks. The architecture of the SAM comprises three fundamental components: an image encoder, a prompt encoder, and a mask decoder. The image encoder is based on a large-scale Vision Transformer (ViT) model, whereas the prompt encoder and mask decoder are constructed via comparatively smaller models. This strategic design ensures the model’s efficiency while also maintaining its capacity for fine-grained feature extraction and processing.
2.3. Parameter-Efficient Fine-Tuning
As the scale of deep learning models continues to expand, PEFT has increasingly emerged as an essential methodology. PEFT facilitates the rapid and economical adaptation of pretrained models to particular tasks, eliminating the necessity for extensive and resource-demanding retraining of the entire network architecture. The primary benefit of this methodology lies in its ability to adapt new tasks by adjusting only a limited subset of the model’s parameters, thereby considerably decreasing the demand for computational resources. Therefore, PEFT has become a key means of transferring large models to other tasks.
In the existing methodology of PEFT, the frozen layer method is a widely adopted strategy. Methods such as BitFit [27] and AutoFreeze [28] are based on freezing the majority of the parameters of the initial model and training only a few parameters in certain layers of the network to achieve rapid adaptation to new tasks. Additionally, the adapter [29] fine-tuning technique effectively achieves efficient parameter updating by introducing adapter layers (e.g., AdapterFusion [30] and AdapterDrop [31]) with low parameter counts in the model. These adapters, despite their limited parameters, allow the model to be substantially adapted to new tasks. LoRA [32] employs low-rank approximation to add a low-rank matrix within the model’s weight matrices, achieving fine-tuning by updating the low-rank matrix. Furthermore, there are methods that introduce additional prompts, such as prompt-tuning [33] and VPT [34]. Despite the achievements made, PEFT still faces many challenges. In the future, to better develop PEFT techniques, researchers may focus on developing more effective fine-tuning strategies and exploring deeper model structures.
3. Methods
In this work, we first provide a full description of the problem setup associated with the task of instance segmentation in SAR imagery, as well as the implementation of the baseline SAM. In light of the unique attributes of the SAR images, we draw upon the Medical SAM Adapter [35] to develop a segmentation methodology for ship instances in SAR imagery. This approach, termed SARSAM, is illustrated in Figure 1. Finally, we explain the working principle of each component in SARSAM in detail.
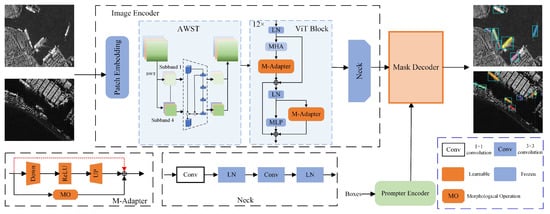
Figure 1.
Overall structural framework of SARSAM.
3.1. Problem Formulation
(1) Problem formulation: Instance segmentation is recognized as an effective paradigm for precisely localizing targets. Consequently, we utilize instance segmentation methodologies to identify and localize ship targets within SAR imagery. In the context of instance segmentation, given an image, the objective is to identify all object instances within the image and generate an accurate two-dimensional mask for each instance, which aligns precisely with the object’s contour. Unlike class-agnostic segmentation approaches, such as semantic segmentation, instance segmentation necessitates the differentiation of objects that belong to the same category but represent distinct instances.
(2) Baseline Model: The baseline model utilized in this study is the SAM model, which has garnered increasing attention from researchers because of its robust generalizability. In addition, in all experiments on the baseline model, the ground-truth box was used as a prompt; this was done to highlight more visually how good or bad the model was at the model level, and to exclude the influence of the quality of the prompt on the analysis of the model.
3.2. Morphological Adapter
Currently, large vision models (LVMs) in computer vision research, including Swin Transformer V2 [36] and DINOv2 [37], employ the Transformer architecture and have demonstrated excellent efficacy in a variety of visual tasks. This enhancement in performance is largely attributed to their substantial model size, enabling them to more accurately capture and fit complex data distributions. However, when these pretrained LVMs are directly applied to downstream data, there is often a significant decrease in performance. To address this issue, it is standard practice to conduct retraining of the model utilizing the downstream dataset. However, the extensive number of model parameters involved in this retraining process results in a significant waste of computational resources and requires a substantial investment of time. Therefore, the adoption of PEFT methods to fine-tune these LVMs is of particular urgency.
In this paper, we choose the ViT-B model from the SAM as the foundational architecture. Despite being the smallest model in the SAM series, the parameter count of ViT-B is close to 90 million. Furthermore, considering the peculiarities of SAR imaging, targets within SAR images are generally composed of numerous strong scattering points. These scattering points, caused by different parts of the target, exhibit a discrete distribution in the image, leading to the weakening of the target edge information. To achieve effective model fine-tuning in the SAR domain, this paper introduces a morphological processing mechanism on the basis of the standard Adapter module and designs an innovative M-Adapter. This M-Adapter is integrated into the structure of each layer of the image encoder, especially after the multihead attention (MHA) mechanism, and in parallel with the multilayer perceptron (MLP). This design of the M-Adapter facilitates not only the fine-tuning of models but also the augmentation of edge features within the target, thereby improving the model’s performance in SAR image processing. The specific architecture of the M-Adapter is illustrated in Figure 2a.
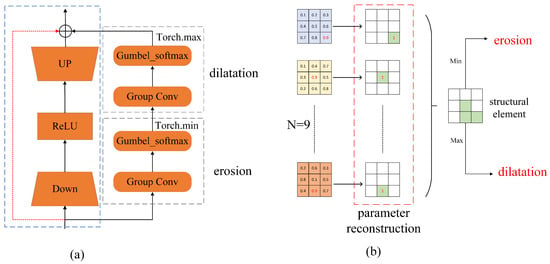
Figure 2.
(a) The structure of the M-Adapter. (b) Constructive processes of morphological operations.
(1) Adapter: In parameter-efficient fine-tuning, the adapter is an effective and widely used method. An adapter is typically characterized by a bottleneck architecture comprising two feedforward layers, a non-linear activation function, and a skip connection. The initial feedforward layer transforms the original features from a higher-dimensional space d to a lower-dimensional space m, while the subsequent feedforward layer restores the feature dimension to its original size. The structure means that parameter adjustments are made only in low-rank subspaces, effectively capturing specific changes to the task. It is important to note that the dimension m is significantly smaller than d, as delineated in Equations (1) and (2), where denotes the linear layer and and denote the ascending and descending dimensions, respectively. Inserting an adapter into the model is equivalent to introducing a small number of trainable parameters. This allows for the fine-tuning of the entire model’s weights by training only these few parameters while keeping the original parameters unchanged, which has achieved significant effects in downstream tasks. In this research, the adapter positioned subsequent to the multi-head attention mechanism includes a shortcut that facilitates the direct transfer of input to output, thereby preserving the integrity of the original feature information. Conversely, the adapter that operates in parallel with the multi-layer perceptron (MLP) does not include a shortcut, as illustrated by the red dashed line in Figure 2a.
(2) Adaptive Morphological Processing: Morphological processing, a commonly used tool in image processing, encompasses operations such as dilation, erosion, opening, and closing. The opening operation, defined as erosion followed by dilation, smooths the edges of an object and removes protrusions from the edges. However, ship targets in SAR images exhibit multiscale and directional characteristics. The traditional opening operation requires a fixed structural element, making it challenging to achieve optimal results. For this reason, in this paper, the morphological operation is simulated via 2D convolution, and the desired shape of the structural element can be learned automatically during the network training process.
As shown in Figure 2b, a 3 × 3 2D group convolution is constructed with the same number of groups as the number of input feature channels, and the number of output channels in each group is nine. First, the parameters in these 9 convolutions with channel number 1 are reconstructed using the gumbel softmax function, as shown Equations (3) and (4). In this function, takes a very small value and as approaches 0, the closer z is to one-hot coding. Thus, in each convolution, the position with the largest parameter is reconstructed as 1. Nine convolutional layers cover each position of a 3 × 3 convolution, and, in approximation, all the positions where the parameter is reconstructed as 1 simulate a structural element. In morphology, the erosion operation takes the minimum value in the region covered by the structural element; corresponding to this process, we take the minimum value in each set of output features in the group convolution. Conversely, the expansion operation takes the maximum value.
In summary, we can use group convolution to simulate the opening operation in morphology and automatically obtain the appropriate shape of the structural element during training, thereby enhancing the target edge of the SAR image.
Here, z denotes the set of parameter values after reconstruction, denotes the i-th parameter value after reconstruction, N denotes the number of parameters, denotes gumble noise, denotes the i-th parameter value before reconstruction, denotes the j-th parameter value before reconstruction, and denotes the temperature coefficient.
3.3. Adaptive Wavelet Soft Threshold Denoising (AWST)
During the imaging process of SAR images, the radar receives the scattered echoes and coherently superimposes them, which results in coherent spot noise on the image due to the presence of random fading of the echo signals from the scattering points in both the amplitude and phase. Owing to the presence of this noise, the target in the image tends to become blurred, which makes image segmentation extremely difficult. Second, the frequency characteristics of scattering noise are more complex and can manifest as high-frequency noise or low-frequency noise. In response to the aforementioned issues, this study presents an adaptive wavelet soft threshold denoising module, as illustrated in Figure 3. This module realizes the denoising process of shallow features through the wavelet transform and soft threshold function to improve the model segmentation performance.
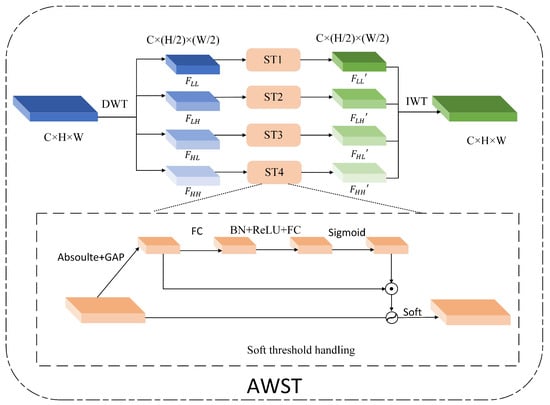
Figure 3.
Structural details of the adaptive wavelet denoising module.
The wavelet transform’s multi-resolution analysis allows simultaneous time and frequency domain signal analysis. By selecting suitable wavelet bases, the signal can be decomposed into different frequency ranges to precisely capture local features. Soft thresholding offers smooth processing, maintaining signal continuity without abrupt changes near the threshold, and involves a relatively small computation. Common wavelet bases include Harr, Biorthogonal, Daubechies, and Coiflets. The Harr wavelet is simple and computationally efficient but has limited denoising capability. Biorthogonal wavelets’ symmetry helps prevent image geometric distortion and preserves edge and texture details, yet they have higher computational complexity. Daubechies wavelets have good smoothing properties, but their asymmetry may introduce distortion during signal reconstruction. Coiflets can retain a lot of detailed information, but some high-frequency information may still be lost. To summarize, Biorthogonal wavelet are generally more effective for SAR image denoising. However, considering the need to balance computational efficiency and denoising performance in this paper, the Harr wavelet is chosen.
First, this paper employs the Haar wavelet to perform a two-dimensional discrete wavelet transform on shallow features. As an orthogonal transformation, the Haar wavelet does not introduce additional information distortion. Through this transformation, shallow features can be decomposed into subbands with different frequencies and directions. Specifically, in the feature space, let the shallow feature be denoted as . Initially, high-pass and low-pass filters are applied in the horizontal direction to acquire the horizontal low-frequency component and the horizontal high-frequency component . These two components are subsequently passed through a high-pass and low-pass filter in the vertical direction to ultimately obtain four components with different frequencies and directions: , , , . The calculation formulas are shown in Equation (5), where (x,y) represents the coordinates of a point in the feature map.
However, since coherent patch noise contains components of different frequencies, performing the denoising process only in the low- or high-frequency range is obviously not reasonable. Therefore, these feature subbands need to be denoised separately. In the field of image denoising, threshold denoising is favored for its computational efficiency. The technique can be divided into two main categories: hard threshold denoising and soft threshold denoising. As shown in Equations (6) and (7) and Figure 4, T represents the threshold value and X represents the pixel value. Soft thresholding differs from hard thresholding in that it is not is not simply keeping pixel points that are larger than the threshold. Instead, it performs threshold subtraction on those pixels. This approach effectively diminishes noise while enhancing the retention of the edge and detail information within the image, thereby improving the overall performance in the preservation of image quality.
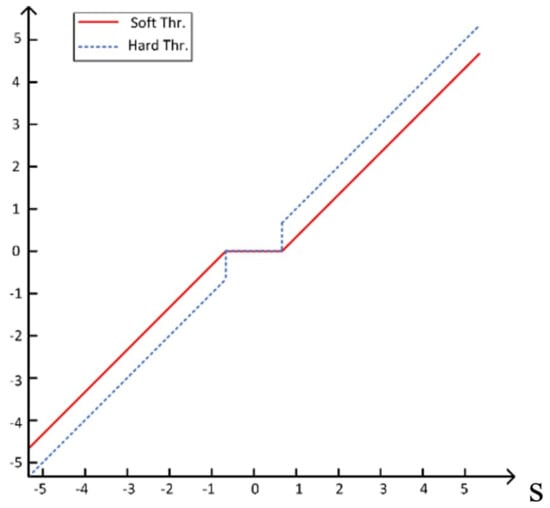
Figure 4.
Soft threshold function.
Inspired by the deep residual shrinkage network [38], this paper uses the attention mechanism as a means to automatically obtain thresholds. Notably, each subband has a certain number of channels, which are not the same as each other, and it is obviously unreasonable to use the same threshold for denoising all the channels. Therefore, it is necessary to determine a threshold for each channel. Assuming that a feature subband is F, the ST module first takes the absolute value operation on F and then performs global average pooling to derive a vector with dimensions . Subsequently, is input in sequence into two fully connected layers. Since the final threshold is a positive number and cannot be too large, this paper applies sigmoid activation to the output of the last fully connected layer, scaling its output value to between (0, 1) and obtaining a scale vector with the same dimensions . Finally, is multiplied by to obtain the threshold T required for each channel. Soft thresholding is subsequently implemented across various channels of the feature subbands in accordance with the threshold, thereby finalizing the comprehensive threshold denoising process.
The function consists of a series of operations, starting with a vector passing through a fully connected layer with an invariant number of channels and then undergoing batch normalization and the activation function before being input into another fully connected layer with a constant number of channels.
3.4. Box Prompter
The segmentation effect of the SAM on a target depends largely on the quality of the prompts, and higher-quality prompts produce better segmentation effects. Unlike ordinary optical images, SAR images have complex scenes and are usually interfered with by many nontarget objects. In addition, some targets may have discrete features and incomplete details on SAR images due to their complex structures, all of which can make it difficult to identify and localize targets. As a result, it is difficult for some people who are not specialized in the field to provide reasonable hints when SAM is used for interactive segmentation of ship targets, which leads to incorrect segmentation results. To help most people use SARSAM to accomplish ship segmentation in the field of SAR, this paper conducts a simple validation experiment in the early stage. As shown in Figure 5, when segmenting ship targets in SAR images, box prompts are much better than point prompts. This is because the object in the SAR image is a collection of some scattering points, which will show a discontinuous state. When using point prompts that provide only the location of the target and no information about the target range, they are susceptible to interference from similar objects in the vicinity as well as from their own structural discretization. Bounding box prompts, on the other hand, provide both target location and range information through explicit rectangular regions, reducing the ambiguity of segmentation. In addition, the target edges are blurred in dense scenes. YOLOv8 is widely used because of its fast and accurate target detection ability. In this paper, the YOLOv8 algorithm is chosen to train the dataset, which is used as a prompter to provide reliable bounding box prompts for researchers, and it is fed into the SARSAM to perform ship segmentation. This part is defined as follows:
where , , , represent the prompter, image encoder, prompt encoder, and mask decoder, respectively. I denotes the input image, denotes the output of prompter, is the output feature of the image encoder, is the sparse embedding obtained from the output of prompter, and is the final output mask.

Figure 5.
The effect of SAM using different prompts.
4. Experiments
This study initially introduces two SAR image datasets that include instance segmentation annotations, namely SSDD and HRSID. We subsequently outline the evaluation metrics employed in the experiments, along with the specific setup details. Ultimately, we analyze and substantiate the experimental outcomes associated with our proposed SARSAM model.
4.1. Datasets
(1) SSDD: SSDD represents the inaugural publicly accessible SAR image dataset focused on both domestic and international vessels, which is specifically tailored for tasks related to target detection and instance segmentation. This dataset encompasses a total of 1160 SAR images, with resolutions varying from 1 m to 15 m, and features 2546 distinct ship instances that include both inshore and offshore environments. The specific parameters of the dataset are shown in Table 1.

Table 1.
Introduction to SSDD dataset parameters.
(2) HRSID: HRSID is a publicly accessible dataset designed for the purposes of target detection and instance segmentation. It consists of 5604 cropped SAR images, encompassing a total of 16,951 ship instances. The dataset features a diverse range of resolutions, polarization modes, sea states, maritime regions, and coastal ports. The specific parameters of the dataset are shown in Table 2.
Table 2.
Introduction to HRSID dataset parameters.
4.2. Evaluation Metrics
In this paper, we employ the metric, which is frequently used in segmentation tasks, as well as the COCO standard metric to quantitatively and comprehensively assess the capabilities of instance segmentation methods. is the average of the intersection and union ratios for each category; a higher value indicates a closer alignment between the predicted mask and the ground-truth, thereby reflecting greater segmentation accuracy. Among the COCO standard metrics, we use , which represents the average accuracy at an IoU threshold of 0.5, with larger values indicating a better instance segmentation performance. The formulas for these two indicators are shown in Equations (15)–(17):
where is true positive, is false positive, is false negative, and k is the number of categories of the target.
4.3. Implementation Details
(1) Structural Detail: The method we propose is built upon the SAM framework, which can generate multiple prediction masks for a single prompt. However, for segmentation tasks, only one mask per instance is needed. Therefore, we choose the first prediction mask as the actual output. In image encoder, the first module is the patch-embedding block with a patch size of 16; notably, the window size is 14 × 14. After that, the shallow features are denoised after passing through the adaptive wavelet soft threshold denoising module. In each ViT block, two M-Adapters are introduced for parameter fine-tuning, where the M-Adapter introduced after MHA contains a residual connection.
(2) Training detail: In the training phase, we freeze the original parameters in the SAM, and train only the new parameters introduced by the above improvements. The input image dimensions for the network were standardized at 1024 × 1024 pixels to conform to the input specifications of the SAM model. All the experimental procedures were executed on an NVIDIA A100 GPU, encompassing a total of 300 training epochs utilizing the SSDD dataset. The Adam optimizer was employed in conjunction with a learning rate decay strategy that was evenly distributed over the training period. The initial learning rate was 0.0001, and the mini-batch size utilized during the training process was set to 1.
4.4. Comparison with Other Algorithms
In this section, we assess the segmentation performance and effectiveness of the proposed SARSAM by comparing it with several existing methods. We selected several relatively recent instance segmentation models, including Mask R-CNN [39], HQ-ISNet, YOLOv8, RSPrompter, PatchDCT [40], and Mask2Form [41]. As presented in Table 3 and Table 4, our method demonstrates a significantly better segmentation performance on both the SSDD and HRSID datasets than these existing methods.
Table 3.
Comparison of quantitative results of our method with existing methods on SSDD dataset, with the best results are bolded.
Table 4.
Comparison of quantitative results of our method with existing methods on HRSID dataset.
(1) Results on the SSDD Dataset: The findings of the experiment are illustrated in Table 3, which demonstrates that our SARSAM achieves a significantly better segmentation performance than the other established methodologies. Specifically, when the prompter is used, and improve by 14.72% and 3.18%, respectively, relative to the baseline. In addition, both metrics are improved relative to YOLOv8. This further indicates that the method in this paper is more accurate for segmentation in the same detection range case. When the ground-truth box is used, and reach 88.48% and 98.95%, which are improved by 17.07% and 5.5%, respectively,relative to the baseline. Through the two different prompting methods, we further observe that the segmentation performance of the model utilizing the SAM framework is significantly influenced by the quality of the prompts provided.
In addition to the aforementioned quantitative analysis, we conducted a visualization of the instance segmentation outcomes produced by SARSAM and other methodologies on the SSDD dataset, as illustrated in Figure 6. Our SARSAM is more effective in segmenting ship targets with unclear edges, such as those close to the shore and neighboring other ships, which is attributed to the enhancement of the target edges achieved by M-Adapter.

Figure 6.
Comparison of visualization results on SSDD.
(2) Experimental Results on the HRSID Dataset: We conducted experiments utilizing the HRSID dataset under the same training conditions to further elucidate the benefits of our proposed method. The results are presented in Table 4. Consistent with the outcomes observed in the SSDD dataset, the findings demonstrate that our SARSAM method significantly outperforms other existing approaches.
Specifically, when using the ground-truth box as a prompt, SARSAM’s and both show the best performance, reaching 90.29% and 96.56%, respectively. However, when using the prompter, SARSAM’s decreases compared to the baseline, while increases significantly. Our analysis suggests that this is because the bounding box output from the prompter is not as accurate as the ground-truth box. However, this small decrease does not negate the advantages of our method. Compared with YOLOv8, SARSAM has higher metrics in both categories, which suggests that the method in this paper is more accurate in segmenting the same detection area.
Along with the quantitative analysis mentioned above, we also visualized the instance segmentation results of SARSAM and other methods on the HRSID dataset, as shown in Figure 7. Similarly, our method demonstrates superior segmentation capabilities.

Figure 7.
Comparison of visualization results on HRSID.
(3) Modeling Efficiency: As shown in Table 5, our proposed method increases the number of parameters by only 13.5% and the number of FLOPs by 10.1% compared with SAM (ViT-Base), but the segmentation performance is greatly improved.
Table 5.
Number of parameters and FLOPs of the model.
4.5. Albation Studies
To verify the effectiveness of SarSAM as well as the designed modules, we perform ablation experiments on two SAR ship datasets.
(1) baseline*: To verify the effectiveness of the designed module, a baseline* is established. Two standard adapters are integrated into each block of the image encoder, positioned after the MHA, and connected in parallel with the MLP. During model training, the original parameters are frozen, and only the Adapters are fine-tuned. According to Table 6 and Table 7, the segmentation ability of the strong baseline shows considerable improvement.
Table 6.
Ablation experiments on SSDD, where × represents no use and ✓ represents use.
Table 7.
Ablation experiments on HRSID, where × represents no use and ✓ represents use.
(2) AWST validity analysis: To explore the effectiveness of the AWST module, we integrated the AWST module into the baseline during the training phase. Compared with the baseline, the addition of the module significantly improves the segmentation performance of the baseline, where and are improved by 9.78% and 5.35% on the SSDD dataset, and 2.35% and 1.59% on the HRSID dataset, respectively. Since both datasets contain data with different polarization modes, different resolutions, and different scenarios, it is known that the proposed AWST module has the ability to suppress the noise in the face of different types of SAR data, allowing the model to better be focused on the target itself. We also visualize the AWST denoising effect, as shown in Figure 8. The denoising feature map is less noisy than before denoising, suggesting that AWST has somewhat attenuated the impact of speckle noise.

Figure 8.
AWST module denoising effect.
(3) M-Adapter Effectiveness Analysis: Standard adapters enable efficient model fine-tuning and greatly improve model performance but lack an understanding of SAR image properties. In contrast, the M-Adapter takes into account the problems of weak target edge information and the incomplete structure of SAR images and makes some improvements. According to Table 6 and Table 7, after the introduction of M-Adapter alone, and are improved by 16.98% and 5.45% on the SSDD dataset and 13.46% and 6.49% on the HRSID dataset, respectively, compared with the baseline. Compared with the strong baseline, the M-Adapter also works better.
In addition, to demonstrate the advantages of the opening operation over other morphological processing methods, we changed the morphological operations (dilation, erosion, opening, closing) in the M-Adapter while using all modules, and conducted multiple sets of experiments for verification. The results are shown in Table 8. It can be seen from the table that the best performance is achieved when the opening operation is selected in the M-Adapter.
Table 8.
Morphological operation ablation experiment.
(4) Prompter Analysis: SARSAM depends on high-quality prompts, with the box prompter’s detection results directly impacting segmentation. As shown in Figure 9, it presents multiple detection cases of the prompter and corresponding segmentation results. The yellow circle marks missed detections, and the red circle marks misdetections. The figure shows that correct detection of prompter leads to accurate SARSAM segmentation. Misdetections cause wrong masks, and missed detections result in no mask at the target location.

Figure 9.
(a) Prompter detection results. (b) Corresponding segmentation results.
5. Discussion
In summary, the SARSAM method proposed in this paper significantly improves the performance of SAM in SAR ship segmentation tasks. In comparative experiments, SARSAM outperformed other methods. Among them, the indicator is particularly prominent, which has improved greatly compared with the baseline. In the ablation experiment, the effectiveness of each module was verified in turn. Specifically, the AWS module is able to reduce the interference of speckle noise in the image on segmentation. Secondly, M-Adapter efficiently fine-tunes the model by introducing a small number of parameters. In addition, M-Adapter uses group convolution to simulate the opening operation in morphology to enhance the target edge.
6. Conclusions
In this work, a SAR image target segmentation method guided by the SAR scattering mechanism, called SARSAM, is introduced in detail. The method is designed for complex SAR scenarios with interference, and addresses the problem of performance degradation when applying pretrained SAM models from optical scenarios to the SAR domain. First, we design the M-Adapter in response to the discrete distribution characteristics of strong SAR scatterers, enhancing the edge features of the targets by adding a few learnable parameters, and achieving fine-tuning in the SAR domain. Second, the proposed AWST module can suppress the effect of coherent speckle noise on the model from the different frequency and directional scales, improving the representation capability of the target features. Furthermore, a bounding box prompter based on a deep object detector is constructed, which can provide high-quality box prompts for this method under complex target interference in SAR scenarios, assisting in the precise segmentation of targets. Finally, extensive experiments conducted on the SSDD and HRSID datasets show that our SARSAM is clearly superior to existing methods. When true bounding boxes are used as prompts, the is increased by more than 10% compared with the baseline SAM, and the is increased by more than 5%. Additionally, when the prompter is used, the segmentation performance of this method is slightly worse, further confirming the importance of high-quality prompts. Moreover, in this approach, the trainable parameters account for merely 13.5% of the baseline, and the FLOPs are just 10.1% of the baseline. This significantly reduces the computational resources needed for fine-tuning.
Author Contributions
Writing—original draft, C.Z.; Writing—review & editing, J.C.; Supervision, J.C., Z.H. (Zhongling Huang), H.Z., Z.H. (Zhixiang Huang), Y.L., H.X., X.P. and L.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation grant number U23B2007, 62471006, 62101459 and Anhui Provincial Science and Technology Breakthrough Project 202423h08050007.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
Authors Jie Chen and Long Sun were employed by the company 38th Research Institute of China Electronics Technology Group Corporation. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Zhang, J.; Liu, Z.; Jiang, W.; Liu, Y. Application of deep generative networks for SAR/ISAR: A review. Artif. Intell. Rev. 2023, 56, 11905–11983. [Google Scholar] [CrossRef]
- Yasir, M.; Jianhua, W.; Mingming, X. Ship detection based on deep learning using SAR imagery: A systematic literature review. Soft Comput. 2023, 25, 63–84. [Google Scholar] [CrossRef]
- Yang, Q.; Peng, J.; Chen, D. A Review of Research on Instance Segmentation Based on Deep Learning. In Proceedings of the International Conference on Computer Engineering and Networks, Wuxi, China, 3–5 November 2023; pp. 43–53. [Google Scholar]
- Xu, X.; Feng, Z.; Cao, C. An improved swin transformer-based model for remote sensing object detection and instance segmentation. Remote Sens. 2021, 13, 4779. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M. HRSID: A high-resolution SAR images dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Ke, X.; Zhang, X.; Zhang, T. GCBANET: A global context boundary-aware network for SAR ship instance segmentation. Remote Sens. 2022, 14, 2165. [Google Scholar] [CrossRef]
- Gao, F.; Zhong, F.; Sun, J.; Hussain, A. BBox-Free SAR Ship Instance Segmentation Method Based on Gaussian Heatmap. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–18. [Google Scholar] [CrossRef]
- Su, H.; Wei, S.; Liu, S. HQ-ISNet: High-quality instance segmentation for remote sensing imagery. Remote Sens. 2020, 12, 989. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Liu, J. SAR ship detection dataset (SSDD): Official release and comprehensive data analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Kirrillov, A.; Mintun, E.; Ravi, N.; Mao, H. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 4015–4026. [Google Scholar]
- Chen, K.; Liu, C.; Chen, H. RSPrompter: Learning to prompt for remote sensing instance segmentation based on visual foundation model. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–17. [Google Scholar] [CrossRef]
- Pu, X.; Jia, H.; Zheng, L.; Wang, F.; Xu, F. ClassWise-SAM-Adapter: Parameter-Efficient Fine-Tuning Adapts Segment Anything to SAR Domain for Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 4791–4804. [Google Scholar]
- Sun, X.; Wang, P.; Lu, W.; Zhu, Z.; Lu, X.; He, Q.; Li, J.; Rong, X.; Yang, Z.; Chang, H.; et al. RingMo: A Remote Sensing Foundation Model with Masked Image Modeling. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–22. [Google Scholar]
- Li, W.; Yang, W.; Hou, Y.; Liu, L.; Liu, Y.; Li, X. SARATR-X: Toward Building a Foundation Model for SAR Target Recognition. IEEE Trans. Image Process. 2025, 34, 869–884. [Google Scholar]
- Han, Z.; Gao, C.; Liu, J. Parameter-efficient fine-tuning for large models: A comprehensive survey. arXiv 2024, arXiv:2403.14608. [Google Scholar]
- Glenn, J.; Ayush, C.; Jing, Q. Ultralytics YOLOv88.0.0. Available online: https://github.com/ultralytics/ultralytics (accessed on 1 December 2023).
- Bolya, D.; Zhou, C.; Xiao, F. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Prangemeier, T.; Reich, C.; Koeppl, H. Attention-based transformers for instance segmentation of cells in microstructures. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine, Seoul, Republic of Korea, 16–19 December 2020; pp. 700–707. [Google Scholar]
- Ke, L.; Danelljan, M.; Liu, X. Mask transfiner for high-quality instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4412–4421. [Google Scholar]
- OpenAI. ChatGPT (Mar14version) [Largelanguagemodel]. 2023. Available online: https://openai.com/chatgpt/overview/ (accessed on 1 December 2023).
- Thoppilan, R. Lamda: Language models for dialog applications. arXiv 2022, arXiv:2201.08239. [Google Scholar]
- Wang, W.; Lv, Q.; Yu, W. Cogvlm: Visual expert for pretrained language models. arXiv 2023, arXiv:2311.03079. [Google Scholar]
- Bai, Y.; Geng, X.; Mangalam, K. Sequential modeling enables scalable learning for large vision models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 22861–22872. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- EZaken, B.; Ravfogel, S. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv 2021, arXiv:2106.10199. [Google Scholar]
- Liu, Y.; Agarwal, S.; Venkataraman, S. Autofreeze: Automatically freezing model blocks to accelerate fine-tuning. arXiv 2021, arXiv:2102.01386. [Google Scholar]
- Houlsby, N.; Giurgiu, A. Parameter-efficient transfer learning for NLP. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 2790–2799. [Google Scholar]
- Pfeiffer, J.; Kamath, A. Adapterfusion: Non-destructive task composition for transfer learning. arXiv 2020, arXiv:2005.00247. [Google Scholar]
- Rücklé, A.; Geigle, G.; Glockner, M. Adapterdrop: On the efficiency of adapters in transformers. arXiv 2020, arXiv:2010.11918. [Google Scholar]
- Hu, E.J.; Shen, Y. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Lester, B.; Al-Rfou, R.; Constant, N. The power of scale for parameter-efficient prompt tuning. arXiv 2021, arXiv:2104.08691. [Google Scholar]
- Jia, M.; Tang, L.; Chen, B. Visual prompt tuning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 709–727. [Google Scholar]
- Wu, J.; Ji, W.; Liu, Y. Medical sam adapter: Adapting segment anything model for medical image segmentation. arXiv 2023, arXiv:2304.12620. [Google Scholar]
- Liu, Z.; Hu, H.; Yao, Z. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019. [Google Scholar]
- Oquab, M.; Darcet, T.; Moutakanni, T. Dinov2: Learning robust visual features without supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]
- Zhao, M.; Zhong, S.; Fu, X. Deep residual shrinkage networks for fault diagnosis. IEEE Trans. Ind. Inform. 2019, 16, 4681–4690. [Google Scholar]
- He, K.; Gkioxari, G. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Wen, Q.; Yang, J.; Yang, X. Patchdct: Patch refinement for high quality instance segmentation. In Proceedings of the Eleventh International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).