1. Introduction
Land cover modeling plays a critical role in understanding and managing Earth’s surface dynamics, with applications ranging from agricultural planning to climate change mitigation. Traditional approaches, such as cellular automata (CA) [
1,
2], CLUE [
3], and stochastic element augmentation [
4], have laid important foundations for this field. However, these approaches often struggle to capture the full complexity of spatiotemporal processes. Methods such as deep neural networks (DNNs) [
5,
6,
7] and convolutional neural networks (CNNs) [
8] often rely on data-driven methods, which face several limitations, including over-reliance on training data, limited spatiotemporal transferability and generalization, a lack of interpretability regarding underlying physical processes, and challenges in balancing overfitting on linear relationships with underfitting on complex nonlinear relationships.
Partial differential equations (PDEs) have emerged as a powerful tool for modeling spatiotemporal processes, offering a balance between physical interpretability and mathematical rigor. PDEs are frequently used to explicitly describe the laws governing dynamic systems in various fields of natural sciences and are of fundamental significance in many disciplines and engineering applications. For instance, the Navier–Stokes equation is used to describe the velocity and pressure distribution of a fluid [
9], the heat conduction equation describes the distribution of temperature inside an object over time and space [
10], and the wave equation and elasticity equation can be used to model the vibration behavior of buildings, bridges, and other structures [
11]. These PDEs were initially constructed based on observed phenomena and the empirical understanding of the problem by scientists and showed that temporal derivatives can describe the evolution of variables along the direction of time while spatial derivatives can be regarded as variations in different regions of location. Subsequently, a correlation model is mathematically analyzed or numerically approximated to capture the system’s evolution.
AI for Science, a new research paradigm that integrates artificial intelligence (AI) methodologies into scientific discovery, brings tremendous promise for various disciplines due to a series of breakthroughs in deep learning and big data science. Scholars have begun to shift their focus from purely theoretical derivation to machine-based computing. Accordingly, data-driven equation discovery has become a research hotspot. One of the most typical methods is PDE-FIND [
12], which discusses in detail how to discover partial differential equations from data. To achieve this, a library of candidate functions is constructed, consisting of all the relevant terms to be determined. Then, a sparse regression algorithm is used to select a small number of appropriate terms from the library and obtain their corresponding coefficients. Chen et al. [
13] proposed a more robust deep learning symbolic genetic algorithm (SGA-PDE) that uses symbolic mathematics to discover free-form equations, thereby realizing the self-mining of governing equations from data. At the same time, scholars are committed to exploring the use of neural networks to characterize partial differential equations. Physics-informed neural networks (PINNs) [
14,
15,
16] are proposed to approximate the solution of an equation while satisfying physical constraints, even when some coefficients are unknown. This approach is useful when the form of the right-hand term of the equation is known but not all coefficients are known. The unknown system can then be solved. Long et al. [
17,
18] proposed a data-driven feedforward neural network, named PDE-Net, to approximate the right-hand term of equations of unknown form. PDE-Net can be used to construct a system that approximates the partial differential equation and predicts its solution for a long time. However, these AI-driven PDE discovery frameworks focus on low-dimensional systems or simplified models that do not effectively scale to high-dimensional real-world problems, such as land cover dynamics. Addressing these limitations requires a more holistic approach that combines the strengths of data-driven learning with physical modeling principles.
The rapid advances of data-driven modeling methods have brought about a technological change in the way that partial differential equations are discovered. This change makes it possible to explore land cover dynamical systems from remotely sensed data, and the large volume of data just characterize the remote sensing discipline. Remote sensing images are the “photographs” of the Earth’s surface. The Earth’s surface can be considered as a complex giant dynamical system, but it is highly challenging to obtain a concise yet precise description of its internal laws under non-ideal conditions through mathematical derivation or experience. Therefore, data-driven methods gain more importance and are more suitable for extracting the main control equations of land cover dynamics.
There are many features regarding the description of land cover, and the normalized difference vegetation index (NDVI) is a comprehensive and representative one. The NDVI is a commonly used indicator for monitoring vegetation cover and growth patterns in various ecological, agricultural, and climate change studies. Concretely, the NDVI has been employed in diverse applications such as drought conditions monitoring [
19,
20], agricultural production predicting [
21], land cover classification [
22,
23], etc. Therefore, continuous and accurate NDVI time series data are crucial for understanding vegetation dynamics and their response to land surface environmental changes. However, various factors often cause NDVI time series to be incomplete or noisy, requiring reconstruction efforts.
A range of methods have been developed for NDVI time series reconstruction or prediction, such as an autoregressive integrated moving average model combined with climatic data [
24] and the Holt–Winters model in high- and low-vegetation regions [
25]. However, these methods usually assume that NDVI time series exhibit linearity and smoothness, but they often fail to effectively capture the nonlinearities and irregularities hidden in NDVI time series during the forecasting process [
26].
In recent years, more advanced machine learning and deep learning methods have been adopted to improve the accuracy of NDVI prediction. Tong et al. [
27] introduced a pixel space gap-filling approach for soil moisture estimation on the Tibetan Plateau based on machine learning and geostatistics. In contrast to traditional statistical prediction techniques, machine learning methods excel at capturing nonlinear relationships between dependent and independent variables through extensive training, effectively addressing intricate prediction challenges posed by noisy data [
28]. Roy et al. [
29] employed four supervised machine learning algorithms—support vector machine regression (SVR), random forests (RFs), linear regression, and polynomial regression—to forecast NDVI data. Their findings revealed that the random forest and linear regression methods achieved superior prediction accuracy. However, it was also observed that these methods exhibited a certain sensitivity to mutations. Gao et al. [
30] established a new NDVI prediction model by combining time series decomposition (TSD), a CNN, and long short-term memory (LSTM), called TSD-CNN-LSTM; Cui et al. [
31] proposed SF-CNN, a new NDVI prediction model that combines a CNN and historical data statistical features. However, the majority of these methodologies employ temporal features and deep learning to improve prediction accuracy, yet they neglect to consider the spatial dependence of vegetation status. To augment spatial dependency, Xu et al. [
32] captured long-range dependencies of NDVI time series by combining a non-local attention module and spatial autocorrelation modeling based on the local Moran index to learn spatial dependence, where a convolutional LSTM network (ConvLSTM) with spatial autocorrelation and non-local attention modules (ConvLSTM-SAC-NL) is proposed. Theoretically, the ConvLSTM-SAC-NL method improves the spatial dependence, but it still has some shortcomings in long-term prediction. How to integrate the spatial dependence of the surface state while achieving long-term prediction remains an unsolved issue. Moreover, there is still the question of how to explicitly interpret or to find the physical meaning behind these deep learning models.
Based on the above considerations, in this paper, we propose a temporal–spatial partial differential equation modeling (TS-PDE) method for land cover dynamics. TS-PDE can discover the governing equations behind long-term satellite image time series and establish the corresponding land cover dynamic system. Since the computation of the spatial partial derivative term involves spatial neighborhood information, it therefore has neighborhood recursion capabilities. By introducing temporal and spatial differential terms into the equations, the TS-PDE method captures the interactions between temporal changes and spatial patterns, which are often intertwined in land cover dynamics. This approach demonstrates the advantage of focusing on spatial dependence and temporal features during the prediction of full images compared to conventional methods as it integrates the contextual information from neighboring pixels and temporal trends across the image series. In other words, the discovered equations not only describe the local changes at individual pixels but also generalize the underlying rules governing the entire temporal–spatial domain of the training images. This generalization capability allows the equations to represent the common patterns and dynamics shared across the study area, making them applicable to broader spatial and temporal contexts.
The remainder of this paper is organized as follows:
Section 2 introduces the two datasets used for experiments and details the proposed TS-PDE method.
Section 3 presents the experimental results by showing the discovered equations and quantitatively evaluating the prediction performance of these equations.
Section 4 discusses the physical significance, limitations, and future work of TS-PDE. Finally, conclusions are given in
Section 5.
2. Materials and Methods
2.1. Research Data
The NDVI is a widely recognized and extensively used vegetation index in remote sensing. It exploits the unique spectral characteristics of vegetation, specifically the strong reflection of near-infrared (NIR) light and the significant absorption of red light by chlorophyll. The NDVI is calculated as the normalized difference between the reflectance values of the NIR and red bands, providing a quantitative measure of vegetation health and vigor:
The NDVI ranges from to 1, where higher values typically indicate healthier and denser vegetation while lower or negative values suggest sparse vegetation, bare soil, or other non-vegetative surfaces.
The NDVI serves as a critical parameter for assessing vegetation health, growth stages, and coverage. It is widely applied in precision agriculture, forestry, and ecological research, offering valuable insights into crop health, stress detection, and land use changes. Furthermore, its integration with modern remote sensing technologies has enhanced its utility in addressing global challenges such as food security, biodiversity conservation, and sustainable land management.
In summary, the NDVI provides a reliable and interpretable measure of vegetation status, contributing significantly to advancements in precision agriculture, ecological studies, and environmental monitoring. Moreover, the NDVI is a univariate index rather than the multiple spectral bands of raw satellite images, which helps us to concentrate on the modeling methodology itself without concerns about the relation among different variables. Therefore, this study employs NDVI data to validate the feasibility and accuracy of the proposed model. Two datasets with different spatial and temporal resolutions, the MODIS dataset and Planet dataset, are used to demonstrate the robustness and adaptivity of the proposed TS-PDE method.
2.1.1. MODIS Dataset
Moderate-resolution imaging spectroradiometer (MODIS) data are a typical satellite image data source that lasts for decades and is widely used by many large-scale environmental applications. The dataset used in this study comprises the MOD13Q1 NDVI data products (orbit number H26V05), which have a spatial resolution of 250 m and a temporal resolution of 16 days. This dataset spans from January 2001 to December 2010, providing a continuous and comprehensive temporal range for analysis. The primary form of our experiment is to predict NDVI values derived from this MODIS dataset. To evaluate our model’s performance, ten sub-datasets, each with a dimension of pixels, are randomly selected from the larger dataset. These sub-datasets are then divided into training and testing sets by time. Specifically, a training-to-testing ratio of 9:1 is employed, meaning that data from the first 9 years (approximately 90% of the total time length of the dataset) are used for training while data from the remaining 1 year (10% of the total time length) are used to assess the model’s predictive capabilities.
This setting allows for a rigorous evaluation of the model’s generalizability and performance across different subsets of the dataset, ensuring that the model is trained on a substantial portion of the data while being tested on unseen data to accurately evaluate its predictive accuracy.
2.1.2. Planet Dataset
To enhance the diversity of experimental data, another dataset that is complementary to the MODIS dataset from the perspective of both spatial and temporal resolutions is employed in this study. The main source of imagery of this dataset is the fusion monitoring product by Planet Labs, a commercial provider of high-resolution satellite imagery. The dataset comprises a sequence of images based on cadastral data from Brandenburg, Germany for the training tiles from 2018. The product has a spatial resolution of 3 m and collects 4 spectral bands (RGB + NIR). According to Equation (
1), band operations are performed to calculate the NDVI, where
NIR represents the reflectance value in the near-infrared band and
R represents the reflectance value in the red light band. In contrast to MODIS data, it provides dense imagery in a daily time interval. Also, the time series is an analysis-ready data (ARD) source, level 3 product, that delivers a temporally consistent collection of images with removed clouds and shadows. For the sake of maintaining the proportion of the training and testing time length to be consistent with the MODIS dataset, for this dataset, we still divide the time series length as 9:1 for the training and testing parts.
2.2. Methods
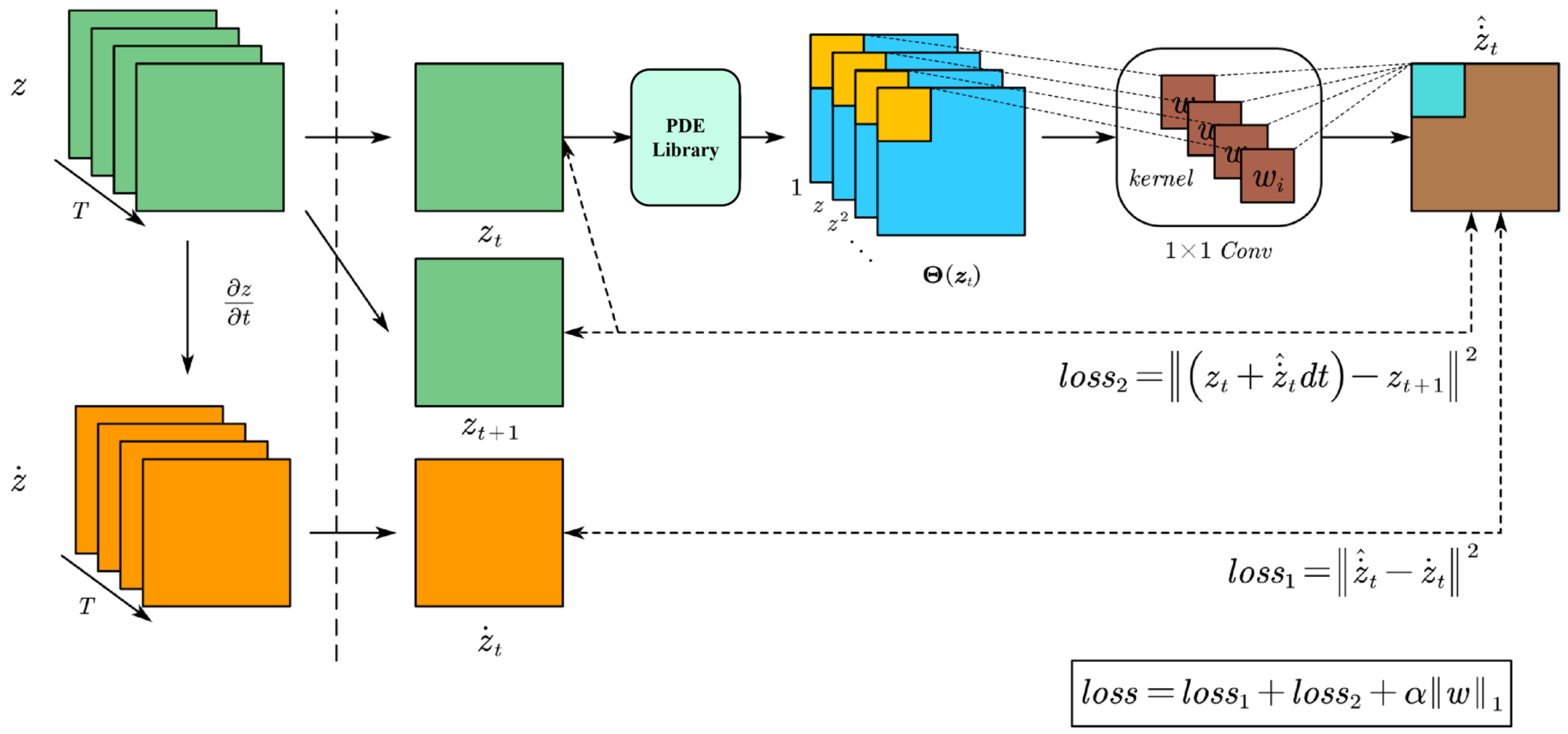
Regarding the derivation of equations from the NDVI time series, our approach fundamentally involves constructing a candidate dictionary comprising simple functions and partial derivatives that could potentially appear in the unknown control equation. We build the model based on the nonlinear response form of known partial differential equations. Subsequently, we use convolutional neural network algorithms to select the terms that best capture the intricacies present in the data. The model-building process is shown in
Figure 1.
Let us consider the model formed as
. Since the long-term time series is taken into account, the partial differentiation of time
is used to replace the difference value
on the left side of the equality during the construction of the model, and the following equality is obtained:
where
represents the coordinates of the pixel at time
t,
z represents the value of the NDVI, the subscripts denote partial differentiation in either time or space—for example,
is the second-order partial derivative of the NDVI for
x—and
is an unknown right-hand side that is generally a nonlinear function of
. Other related derivatives and parameters are retained in
. (To simplify the model,
is set to zero in this study.) With this setting, discovering the nonlinear functions
becomes our main goal in the next step. Furthermore, it is acknowledged that the NDVI is subject to cyclical variation with the seasons, and trigonometric functions have this cyclic nature. In consideration of this phenomenon, the decision was taken to incorporate a trigonometric term into the candidate function library. Then, taking into account the model’s capacity to express as many unknown situations as possible while maintaining interpretability and computational efficiency, we chose the base function dictionary as follows:
Let
, where ⊗ represents the tensor product; then, Equation (
2) is expressed in matrix form:
that is, for
, one can obtain the following:
The derivative with respect to time
t on the left side of Equation (
5) can be approximated using the finite difference method, i.e.,
. Likewise, derivatives with respect to spatial coordinates
x or
y can be approximated by calculating differences between spatial neighborhood pixels.
Now, the problem becomes finding a sparse weight-vector
satisfying the following:
Each term in
w corresponds to a coefficient associated with a term in the equation. However, in practical applications, equations often involve only a few nonlinear terms. Accordingly, the coefficient matrix
w should exhibit high sparsity in the nonlinear function space, and this sparsity plays a pivotal role in maintaining a delicate balance between the model’s complexity and its accuracy. Therefore, solving the coefficient matrix is transformed into addressing the following sparse regression problem for an approximate solution:
where
w collects the coefficients of candidate function
, which is the goal of minimization. Symbols
represent the
norm, and
is a regularization term.
Equation (
7) can be solved using convex optimization algorithms, such as the least absolute shrinkage and selection operator (LASSO). Alternatively, the method of sequential threshold least squares can be employed. However, traditional convex optimization algorithms often struggle to capture the intricate nonlinear properties inherent in complex systems. In contrast, neural networks have demonstrated remarkable success in learning and representing such complex features. To address this limitation, we employ
convolutional kernels to approximate derivatives in the following ways:
Spatial Derivatives: By applying kernels to neighboring pixels, the CNN solver can compute finite differences, which approximate spatial derivatives (e.g., and ).
Temporal Derivatives: Similarly, kernels can be applied across consecutive time steps to approximate temporal derivatives (e.g., ). This allows the model to capture changes in land cover dynamics over time.
Higher-Order Derivatives: By stacking multiple convolutional layers or combining them with nonlinear activation functions, the CNN solver can approximate higher-order derivatives, which are essential for modeling complex interactions in the TS-PDE framework.
Based on these advantages, we propose a CNN-based method to solve the coefficients of the governing equations. This approach preserves the nonlinearity of the model while significantly improving solution accuracy. The architecture of the CNN and the solution process are illustrated in
Figure 2, where the convolutional kernel size is set to
. Specifically, we approximate the derivative of the time series data
z using the output of the CNN, denoted as
. The loss function is then constructed based on the residuals as follows:
where
is a regularization term.
At the same time, sparsity is introduced through the application of the sequential threshold least squares method, which involves iteratively setting all coefficients less than the tolerance to 0. By choosing a specific tolerance and , this approach provides a sparse approximation for w.
2.3. Accuracy Evaluation
In order to accurately and objectively assess the model’s performance, this study utilizes three evaluation metrics from two distinct perspectives.
The first perspective involves time series regression evaluation metrics, specifically mean squared error (MSE), which is used to evaluate the temporal accuracy of the model’s predictions:
In this equation, i represents the i-th sample point, denotes the NDVI value at the i-th time point for the time series of the given pixel, and and represent the predicted and mean NDVI values, respectively. To eliminate the influence of spatial variations across different pixels, the MSE is computed for each pixel at different time points within the study area, and the average MSE across all pixels is used as the final evaluation metric. This procedure allows for a comprehensive assessment of the model’s temporal prediction accuracy.
The second perspective concerns image quality assessment metrics, namely the structural similarity index (SSIM) and peak signal-to-noise ratio (PSNR). Unlike traditional pixel-by-pixel prediction, the model generates predictions for the entire image at each time point, making it crucial to compare the predicted image with the original image at the same time. The SSIM and PSNR metrics provide valuable measures for assessing image quality at each time point. The formulas for these metrics are as follows:
1. Structural similarity index (SSIM):
In this formula, and represent the mean values of images x and y, and are their variances, and is the covariance between x and y. Constants and are used to stabilize the calculation.
2. Peak signal-to-noise ratio (PSNR):
Here, is the maximum pixel value in the image and is the mean squared error.
The SSIM and PSNR metrics provide critical insight into the spatial accuracy of the model, comparing the structural and signal-to-noise relationships between the predicted and original images. These metrics are essential for evaluating how well the model preserves spatial features and image integrity during the prediction process.
4. Discussion
4.1. Physical Significance
In this study, convolutional neural networks (CNNs) combined with sparse regression methods are utilized to analyze datasets at varying spatial resolutions, enabling the extraction of governing equations that describe the underlying dynamics. For low-resolution MODIS images, as shown in
Table 7, the extracted equations comprise ten different terms, indicating a relatively higher level of complexity, likely due to the coarser spatial resolution and additional variability in the data (e.g., cloud and shadow pixels).
In contrast, as shown in
Table 8, the equations derived from high-resolution Planet images are significantly more concise, consisting of four different terms in total. This simplicity suggests that high-resolution data inherently capture dominant patterns more effectively, minimizing the need for complex mathematical descriptions. Furthermore, if the left-hand side of the equation is interpreted as the first derivative of the NDVI value with respect to time, it can be inferred that the NDVI values of high-resolution Planet images follow a sinusoidal relationship over time. This periodic behavior reflects the regular, cyclic nature of the underlying environmental or vegetation dynamics, such as seasonal growth and decay patterns, which are more precisely captured in high-resolution imagery.
However, the physical significance of these equations requires further exploration and discussion. Understanding the broader implications and connections between the mathematical representations and the underlying physical processes will provide deeper insights into the dynamics of vegetation and environmental systems represented by the extracted equations. For instance, the first-order derivative terms of x or y coordinates may indicate the influence of longitude or latitude on land cover, while the hybrid derivatives of x and y, or their second-order derivative terms, still need more interpretation.
4.2. Limitations
The current approach faces significant challenges in terms of physical interpretability, particularly when applied to low-resolution MODIS data. As
Table 8 shows, the dominant equation of Planet data contains five terms, that is, constant terms, first-order terms, and trigonometric terms. This means that the value of the NDVI approximately exhibits a trigonometric relationship with time. But, unlike high-resolution Planet data, where the dominant equation offers a clear and concise representation of the underlying dynamics, the dominant equation derived from MODIS data is more complex and less intuitive. The complexity of the function is characterized by 10 terms as shown in
Table 7, including the squared term, the trigonometric term, and the derivative terms for x and y. It is acknowledged that the derivative terms frequently possess a physical meaning associated with the rate of change. Consequently, the first-order derivative term for x can be conceptualized as the rate of change in the NDVI value along the latitude axis, while the first-order derivative term for y can be interpreted as the rate of change in the NDVI value along the longitude axis. In addition to this, the dominant equation contains a combination of trigonometric and derivative terms, which we conjecture is since the NDVI values demonstrate a trigonometric trend in time and are influenced by the surrounding environment (i.e., the dominant equation contains terms related to the rate of change in latitude and longitude). However, due to the complexity of the terms, it is difficult for us to obtain a direct physical explanation. Furthermore, the dominant equations vary considerably across the five datasets, with non-zero terms differing significantly between them. This inconsistency adds another layer of difficulty in uncovering a consistent physical meaning from the low-resolution data equations. To address these limitations, future work could explore tailored methods for low- and high-resolution data, such as simplifying equation structures for low-resolution data or leveraging multi-scale modeling techniques to enhance interpretability while maintaining accuracy.
Another limitation lies in the manual construction of the candidate function set used in this study. This restricts the derived equation terms to those predefined in the candidate set, making it impossible to identify more complex or unconventional equation forms. If the true dominant equation involves terms beyond the scope of the manually defined candidate set, the approach will fail to capture these dynamics accurately, leading to incomplete or erroneous results. This limitation highlights the need for automated or adaptive methods to expand the range of candidate functions and improve the robustness of the derived equations.
4.3. Future Work
Future research will endeavor to address several key limitations identified in this study and further improve the effectiveness and applicability of the methodology. Firstly, to improve the physical interpretability of the derived equations, we will explore ways to extract the underlying dynamics more efficiently from low-resolution MODIS data. This includes the development of more advanced techniques to deal with the complexity and variability of the key equations, thereby facilitating the identification of meaningful physical relationships between different datasets. Specifically, future work could improve the sophistication of the technique in terms of the set of candidate functions to explore the underlying equation forms more flexibly and comprehensively by adopting an adaptive approach to ensure that the derived equations more accurately reflect the true dynamics of the system.
Secondly, in order to validate the effectiveness of the method, future work could include evaluating the TS-PDE method using a wider range of remote sensing parameters to assess its accuracy and versatility, such as the enhanced vegetation index (EVI) and the soil-adjusted vegetation index (SAVI), which could be utilized to complement the NDVI, thereby capturing additional aspects of vegetation health and structure. Spectral band data could be employed to assess the capacity of models to capture finer spectral detail and enhance prediction accuracy using multispectral or hyperspectral data.
Moreover, to evaluate the generalizability of the TS-PDE method, its application will be extended to areas exhibiting diverse environmental characteristics, including arid zones, tropical forests, and urban areas. This approach will facilitate the acquisition of knowledge regarding the adaptability and generalizability of the method within varied ecological systems.
Historically, NDVI prediction has predominantly relied on time series analysis methods, including classical statistical approaches like the autoregressive integrated moving average (ARIMA) [
24], deep learning architectures such as LSTM [
33], and hybrid models combining convolutional and temporal networks like TSD-CNN-LSTM [
30] and SF-CNN [
31]. Recent advancements have further enhanced spatial–temporal modeling through integrated frameworks like ConvLSTM-SAC-NL [
32], which couples a CNN with attention mechanisms for improved spatial dependency capture. However, a critical limitation persists: none of these methods provide explicit mathematical equations to describe the NDVI’s intrinsic dynamics. The TS-PDE framework addresses this gap by deriving interpretable partial differential equations that explicitly characterize NDVI evolution. This represents a significant advancement over purely data-driven approaches, offering both predictive capability and mechanistic insights. Despite this progress, TS-PDE currently relies on manually constructed candidate functions for equation discovery, which inherently constrains its flexibility and generalizability. To overcome this limitation, future work will integrate symbolic genetic algorithms [
13]—a class of deep learning-driven evolutionary methods that enable the automated discovery of free-form equations without predefined templates. The integration of deep learning techniques [
12,
17,
18,
34] holds particular promise for advancing NDVI modeling. These methods excel at handling complex nonlinear systems and high-dimensional interactions, potentially enhancing both prediction accuracy and temporal extrapolation capabilities. Our ongoing research focuses on replacing traditional sparse-regression-based equation solvers with deep learning architectures, aiming to develop a unified framework that combines the interpretability of PDE-based modeling with the adaptive power of neural networks. This hybrid approach seeks to transcend the limitations of current methodologies, ultimately enabling a more robust and generalizable modeling of land cover dynamics while preserving physical interpretability.
5. Conclusions
This study introduces a novel approach for dynamic land cover modeling, termed TS-PDE. The TS-PDE method integrates spatiotemporal information by utilizing a combination of convolutional neural networks and sparse regression algorithms to uncover the dynamic equations governing land cover changes from satellite images. The accuracy of the TS-PDE prediction method is evaluated using NDVI time series data, assessing both temporal and spatial prediction capabilities.
The main findings of this study are as follows:
The proposed TS-PDE method effectively overcomes the limitations of short-term and single-pixel prediction in existing land cover time series prediction methods by discovering a global spatiotemporal governing equation.
For low-resolution data (MODIS data), the TS-PDE method generates a governing equation comprising diverse functional terms, offering a more comprehensive representation of land cover dynamics.
For high-resolution data (Planet data), the TS-PDE method produces a more concise and consistent governing equation, consisting of only a constant term and one or two simple terms. This may indicate that spatiotemporal details are more sufficiently exhibited and captured with high spatial and temporal resolution images, while, for low-resolution or unprocessed images, information is mixed in pixels such that unified equations are hard to present.
Furthermore, the derived dominant equations are capable of making long-term predictions, with the differences between predicted results and actual observations remaining minimal, thereby ensuring high prediction accuracy.
In the future, the TS-PDE method is expected to have considerable potential in supporting governments and environmental agencies in land cover monitoring and management. Specifically, it can be applied to assess agricultural land use by enabling policymakers to optimize crop yields, identify areas at risk of degradation, and support precision farming initiatives. Furthermore, the method is poised to play a significant role in climate change mitigation by offering insights into the long-term dynamics of carbon sinks, such as forests and wetlands. This, in turn, will inform strategies for both mitigation and adaptation. To realize these applications, future work will focus on enhancing the scalability and accessibility of the TS-PDE method. This will include the development of user-friendly software tools and the integration of the framework with existing geospatial platforms. The TS-PDE framework is a transformative approach to understanding and managing land cover dynamics that bridges the gap between data-driven learning and physical modeling. Its applications have far-reaching implications for environmental sustainability and policy making, paving the way for more informed and effective decision making in the face of global environmental challenges.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}