
RLita: A Region-Level Image–Text Alignment Method for Remote Sensing Foundation Model

Abstract

1. Introduction
- This paper proposes a novel region-level image–text alignment method for foundation models designed for remote sensing object interpretation tasks, which is designed by a multi-granularity CLIP module and a parameter-efficient tuning strategy.
- For better generalization of remote sensing objects, a region-level image–text alignment optimization module named multi-granularity CLIP is proposed.
- To reduce computational resources, a parameter-efficient tuning strategy is designed to adapted to remote sensing images, which is the vision adapter (VAP) module.
- To mitigate the cost of image annotation, region-level image–text pairs are constructed based on annotated data by contrastive learning for segmenting object mask features.
2. Related Works
2.1. Vision Pretraining for Remote Sensing
2.2. Multimodal Pretraining for Remote Sensing
2.3. Parameter Efficient Fine-Tuning
3. Methodology
3.1. Multi-Granularity CLIP Module
3.2. VAP Module
4. Experiments
4.1. Comparison Methods and Experiment Settings

4.2. Experiments on Object Detection
4.2.1. Datasets and Evaluation Metrics
4.2.2. Comparison with the SOTA
4.2.3. Ablation Experiments



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Local Image-Text Loss | Global Image-Text Loss | mAP (%) |
|---|---|---|---|
| ✓ | 45.39 | ||
| FAIR1M [12] | ✓ | 69.42 | |
| ✓ | ✓ | 73.80 | |
| ✓ | 52.07 | ||
| DIOR [13] | ✓ | 78.31 | |
| ✓ | ✓ | 85.24 |
| Dataset | VAP | Para./FLOPs | Training Time | mAP(%) |
|---|---|---|---|---|
| FAIR1M [12] | / | 9.68 M/114 G | 234.71 h | 74.69 |
| MHA version | 5.36 M/95 G | 144.82 h | 74.25 | |
| MLP version | 4.07 M/76 G | 98.60 h | 73.89 | |
| fully version | 0.38 M/76 G | 46.25 h | 73.80 | |
| DIOR [13] | / | 9.68 M/114 G | 205.03 h | 85.93 |
| MHA version | 5.36 M/95 G | 118.32 h | 85.57 | |
| MLP version | 4.07 M/76 G | 77.19 h | 85.31 | |
| fully version | 0.38 M/76 G | 21.98 h | 85.24 |

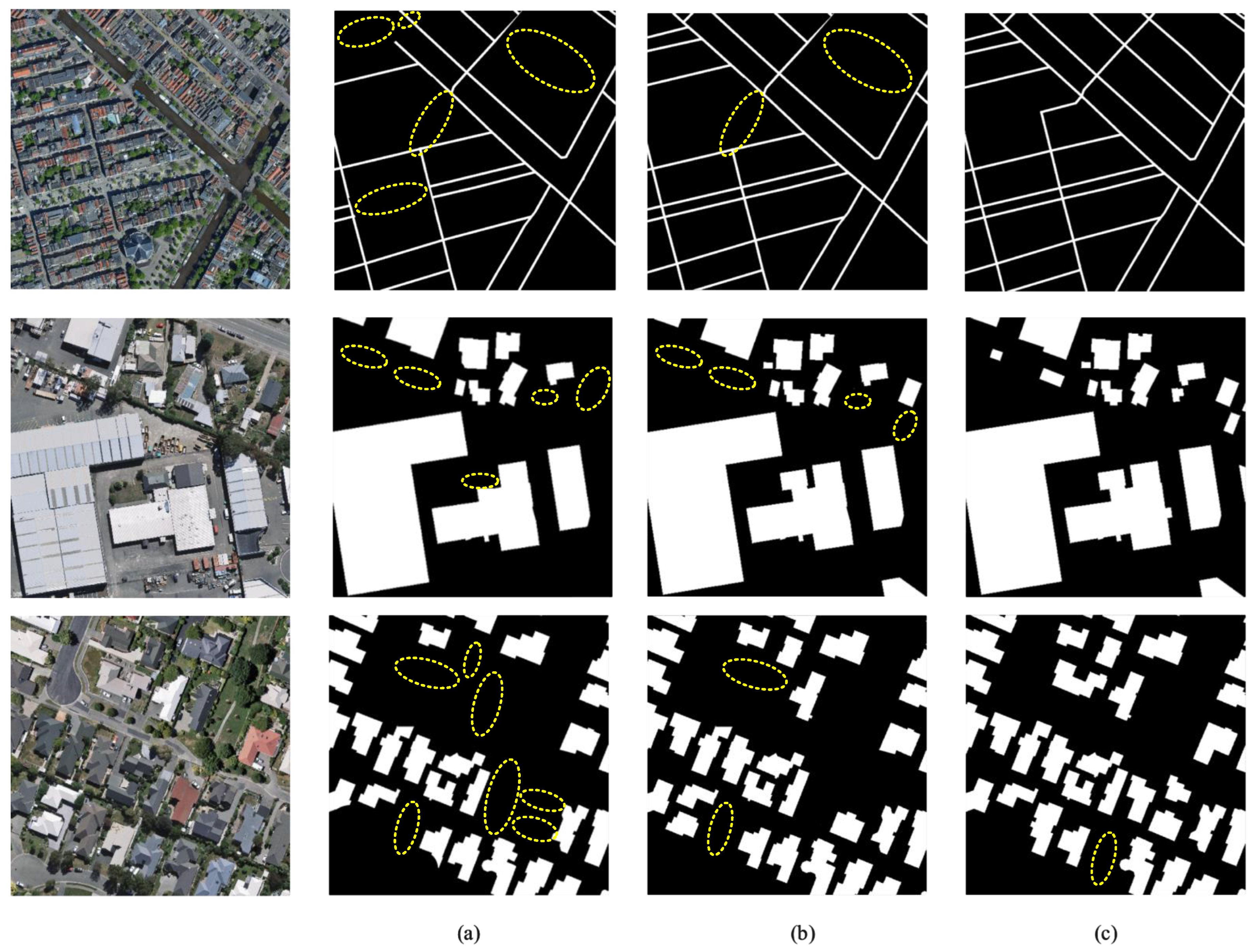
4.3. Experiments on Semantic Segmentation
4.3.1. Datasets and Evaluation Metrics
4.3.2. Comparison with the SOTA
4.3.3. Ablation Experiments
| Dataset | Local Image-Text Loss | Global Image-Text Loss | mIoU (%) |
|---|---|---|---|
| ✓ | 69.42 | ||
| iSAID [15] | ✓ | 78.35 | |
| ✓ | ✓ | 80.96 | |
| ✓ | 66.82 | ||
| Vaihingen [16] | ✓ | 73.39 | |
| ✓ | ✓ | 75.44 |
| Dataset | VAP | Para./FLOPs | Training Time | mIoU (%) |
|---|---|---|---|---|
| iSAID [15] | / | 7.12 M/138 G | 127.30 h | 82.04 |
| MHA version | 3.88 M/115 G | 90.68 h | 81.36 | |
| MLP version | 3.01 M/92 G | 69.45 h | 81.17 | |
| fully version | 0.29 M/92 G | 5.29 h | 80.96 | |
| Vaihingen [16] | / | 7.12 M/138 G | 203.97 h | 77.13 |
| MHA version | 3.88 M/115 G | 109.34 h | 76.05 | |
| MLP version | 3.01 M/92 G | 78.36 h | 75.80 | |
| fully version | 0.29 M/92 G | 17.82 h | 75.44 |
4.4. Experiments on Change Detection
4.4.1. Datasets and Evaluation Metrics
4.4.2. Comparison with the SOTA
4.4.3. Ablation Experiments

| Method | |
|---|---|
| ChangeFormer | 90.40 |
| RingMo | 91.86 |
| SkySense | 92.58 |
| Our RLita | 94.08 |
| Dataset | Local Image-Text Loss | Global Image-Text Loss | F1 (%) |
|---|---|---|---|
| ✓ | 79.36 | ||
| LEVIR-CD [17] | ✓ | 91.79 | |
| ✓ | ✓ | 94.08 |
| Dataset | VAP | Para./FLOPs | Training Time | F1(%) |
|---|---|---|---|---|
| LEVIR-CD [17] | / | 13.3 M/121 G | 149.33 h | 94.41 |
| MHA version | 7.94 M/100 G | 67.32 h | 94.13 | |
| MLP version | 5.02 M/81 G | 44.80 h | 93.66 | |
| fully version | 0.52 M/81 G | 5.78 h | 94.08 |
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf (accessed on 27 April 2025).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. 2019. Available online: https://storage.prod.researchhub.com/uploads/papers/2020/06/01/language-models.pdf (accessed on 27 April 2025).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Du, Z.; Qian, Y.; Liu, X.; Ding, M.; Qiu, J.; Yang, Z.; Tang, J. GLM: General Language Model Pretraining with Autoregressive Blank Infilling. arXiv 2021, arXiv:2103.10360. [Google Scholar]
- Chowdhury, M.; Zhang, S.; Wang, M.; Liu, S.; Chen, P.Y. Patch-level Routing in Mixture-of-Experts is Provably Sample-efficient for Convolutional Neural Networks. arXiv 2023, arXiv:2306.04073. [Google Scholar]
- Rajbhandari, S.; Li, C.; Yao, Z.; Zhang, M.; Aminabadi, R.Y.; Awan, A.A.; Rasley, J.; He, Y. DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale. arXiv 2022, arXiv:2201.05596. [Google Scholar]
- Zhang, Y.; Cai, R.; Chen, T.; Zhang, G.; Zhang, H.; Chen, P.Y.; Chang, S.; Wang, Z.; Liu, S. Robust Mixture-of-Expert Training for Convolutional Neural Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023. [Google Scholar]
- Lin, K.; Wang, L.; Liu, Z. End-to-End Human Pose and Mesh Reconstruction with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Sun, X.; Wang, P.; Yan, Z.; Xu, F.; Wang, R.; Diao, W.; Chen, J.; Li, J.; Feng, Y.; Xu, T.; et al. FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery. ISPRS J.Photogramm. Remote Sens. 2022, 184, 116–130. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, J.; Li, K.; Xie, X.; Lang, C.; Yao, Y.; Han, J. Anchor-Free Oriented Proposal Generator for Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Waqas Zamir, S.; Arora, A.; Gupta, A.; Khan, S.; Sun, G.; Shahbaz Khan, F.; Zhu, F.; Shao, L.; Xia, G.-S.; Bai, X. isaid: A large-scale dataset for instance segmentation in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 28–37. [Google Scholar]
- International Society for Photogrammetry and Remote Sensing.2D Semantic Labeling. Available online: https://www.itc.nl/ISPRS_WGIII4/tests_datasets.html (accessed on 27 April 2025).
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Han, J.; Ding, J.; Xue, N.; Xia, G.S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Niu, R.; Sun, X.; Tian, Y.; Diao, W.; Chen, K.; Fu, K. Hybrid multiple attention network for semantic segmentation in aerial images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- He, Q.; Sun, X.; Yan, Z.; Fu, K. DABNet: Deformable contextual and boundary-weighted network for cloud detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- He, Q.; Sun, X.; Yan, Z.; Li, B.; Fu, K. Multi-object tracking in satellite videos with graph-based multitask modeling. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Bao, J.; Chen, K.; Sun, X.; Zhao, L.; Diao, W.; Yan, M. Siamthn: Siamese target highlight network for visual tracking. IEEE Trans. Circuits Syst. Video Technol. 2023. [Google Scholar] [CrossRef]
- Cui, Y.; Hou, B.; Wu, Q.; Ren, B.; Wang, S.; Jiao, L. Remote sensing object tracking with deep reinforcement learning under occlusion. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Stojnic, V.; Risojevic, V. Self-supervised learning of remote sensing scene representations using contrastive multiview coding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Ayush, K.; Uzkent, B.; Meng, C.; Tanmay, K.; Burke, M.; Lobell, D.; Ermon, S. Geography-aware self-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; Hu, H. Simmim: A simple framework for masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Cong, Y.; Khanna, S.; Meng, C.; Liu, P.; Rozi, E.; He, Y.; Burke, M.; Lobell, D.; Ermon, S. Satmae: Pre-training transformers for temporal and multi-spectral satellite imagery. Adv. Neural Inf. Process. Syst. 2022, 35, 197–211. [Google Scholar]
- Sun, X.; Wang, P.; Lu, W.; Zhu, Z.; Lu, X.; He, Q.; Li, J.; Rong, X.; Yang, Z.; Chang, H.; et al. RingMo: A Remote Sensing Foundation Model With Masked Image Modeling. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–22. [Google Scholar] [CrossRef]
- Yan, Z.; Li, J.; Li, X.; Zhou, R.; Zhang, W.; Feng, Y.; Diao, W.; Fu, K.; Sun, X. RingMo-SAM: A Foundation Model for Segment Anything in Multimodal Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, T.; Zhao, L.; Hu, L.; Wang, Z.; Niu, Z.; Cheng, P.; Chen, K.; Zeng, X.; Wang, Z.; et al. RingMo-lite: A Remote Sensing Lightweight Network with CNN-Transformer Hybrid Framework. IEEE Trans. Geosci. Remote Sens. 2024. [Google Scholar] [CrossRef]
- Cha, K.; Cha, K.; Seo, J.; Lee, T. A Billion-scale Foundation Model for Remote Sensing Images. arXiv 2023, arXiv:2304.05215. [Google Scholar] [CrossRef]
- Guo, X.; Lao, J.; Dang, B.; Zhang, Y.; Yu, L.; Ru, L.; Zhong, L.; Huang, Z.; Wu, K.; Hu, D.; et al. Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery. arXiv 2023, arXiv:2312.10115. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Liu, F.; Chen, D.; Guan, Z.; Zhou, X.; Zhu, J.; Ye, Q.; Fu, L.; Zhou, J. RemoteCLIP: A Vision Language Foundation Model for Remote Sensing. arXiv 2023, arXiv:2306.11029. [Google Scholar] [CrossRef]
- Mikriukov, G.; Ravanbakhsh, M.; Demir, B. Deep unsupervised contrastive hashing for large-scale cross-modal text-image retrieval in remote sensing. arXiv 2022, arXiv:2201.08125. [Google Scholar]
- Xu, J.; Liu, S.; Vahdat, A.; Byeon, W.; Wang, X.; De Mello, S. Open-vocabulary panoptic segmentation with text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Yu, Q.; He, J.; Deng, X.; Shen, X.; Chen, L.C. Convolutions die hard: Open-vocabulary segmentation with single frozen convolutional clip. arXiv 2023, arXiv:2308.02487. [Google Scholar]
- El-Nouby, A.; Izacard, G.; Touvron, H.; Laptev, I.; Jegou, H.; Grave, E. Are large-scale datasets necessary for self-supervised pre-training? arXiv 2021, arXiv:2112.10740. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Zaken, E.B.; Ravfogel, S.; Goldberg, Y. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv 2021, arXiv:2106.10199. [Google Scholar]
- Lester, B.; Al-Rfou, R.; Constant, N. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; Association for Computational Linguistics: St, Stroudsburg, PA, USA, 2021. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Jia, M.; Tang, L.; Chen, B.C.; Cardie, C.; Belongie, S.; Hariharan, B.; Lim, S.N. Visual prompt tuning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–24 October 2022; Springer Nature: Cham, Switzerland, 2022. [Google Scholar]
- Yoo, S.; Kim, E.; Jung, D.; Lee, J.; Yoon, S. Improving visual prompt tuning for self-supervised vision transformers. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Tu, C.-H.; Mai, Z.; Chao, W.-L. Visual query tuning: Towards effective usage of intermediate representations for parameter and memory efficient transfer learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Han, C.; Wang, Q.; Cui, Y.; Cao, Z.; Wang, W.; Qi, S.; Liu, D. E2VPT: An Effective and Efficient Approach for Visual Prompt Tuning. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; IEEE Computer Society: Piscataway, NJ, USA, 2023. [Google Scholar]
- Chen, S.; Ge, C.; Tong, Z.; Wang, J.; Song, Y.; Wang, J.; Luo, P. Adaptformer: Adapting vision transformers for scalable visual recognition. Adv. Neural Inf. Process. Syst. 2022, 35, 16664–16678. [Google Scholar]
- Yin, D.; Yang, Y.; Wang, Z.; Yu, H.; Wei, K.; Sun, X. 1% vs 100%: Parameter-efficient low rank adapter for dense predictions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- He, X.; Li, C.; Zhang, P.; Yang, J.; Wang, X.E. Parameter-efficient model adaptation for vision transformers. Proc. AAAI Conf. Artif. Intell. 2023, 37, 817–825. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, K.; Liu, Z. Neural prompt search. arXiv 2022, arXiv:2206.04673. [Google Scholar] [CrossRef]
- Liu, Y.; Xu, L.; Xiong, P.; Jin, Q. Token mixing: Parameter-efficient transfer learning from image-language to video-language. Proc. AAAI Conf. Artif. Intell. 2023, 37, 1781–1789. [Google Scholar] [CrossRef]
- Zhang, B.; Ge, Y.; Xu, X.; Shan, Y.; Shou, M.Z. Taca: Upgrading your visual foundation model with task-agnostic compatible adapter. arXiv 2023, arXiv:2306.12642. [Google Scholar]
- Xu, C.; Zhu, Y.; Zhang, G.; Shen, H.; Liao, Y.; Chen, X.; Wu, G.; Wang, L. DPL: Decoupled Prompt Learning for Vision-Language Models. arXiv 2023, arXiv:2308.10061. [Google Scholar]
- Hu, L.; Yu, H.; Lu, W.; Yin, D.; Sun, X.; Fu, K. AiRs: Adapter in Remote Sensing for Parameter-Efficient Transfer Learning. IEEE Trans. Geosci. Remote Sens. 2024. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Bandara, W.G.C.; Patel, V.M. A Transformer-Based Siamese Network for Change Detection. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 207–210. [Google Scholar]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. Dota: A largescale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]








| Method | mAP(%) |
|---|---|
| RingMo | 46.21 |
| SkySense | 54.57 |
| Oriented RCNN | 44.30 |
| Our RLita | 73.80 |
| Method | DIOR | DIOR-R |
|---|---|---|
| mAP50(%) | mAP50(%) | |
| RingMo | 75.90 | - |
| SkySense | 78.73 | 74.27 |
| Our RLita | 85.24 | 75.90 |
| Method | mIoU |
|---|---|
| RingMo-SAM | 57.99 |
| RingMo | 67.20 |
| SkySense | 70.91 |
| Our RLita | 80.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Wang, D.; Yu, X. RLita: A Region-Level Image–Text Alignment Method for Remote Sensing Foundation Model. Remote Sens. 2025, 17, 1661. https://doi.org/10.3390/rs17101661
Zhang Q, Wang D, Yu X. RLita: A Region-Level Image–Text Alignment Method for Remote Sensing Foundation Model. Remote Sensing. 2025; 17(10):1661. https://doi.org/10.3390/rs17101661
Chicago/Turabian StyleZhang, Qiang, Decheng Wang, and Xiao Yu. 2025. "RLita: A Region-Level Image–Text Alignment Method for Remote Sensing Foundation Model" Remote Sensing 17, no. 10: 1661. https://doi.org/10.3390/rs17101661
APA StyleZhang, Q., Wang, D., & Yu, X. (2025). RLita: A Region-Level Image–Text Alignment Method for Remote Sensing Foundation Model. Remote Sensing, 17(10), 1661. https://doi.org/10.3390/rs17101661