
Double Augmentation: A Modal Transforming Method for Ship Detection in Remote Sensing Imagery


Abstract
1. Introduction
- The proposed method achieves effective modal transforming and generalization of detection, the method only needs little images from a target domain and no labeled images are required. This makes it convenient to use the existing dataset in training.
- The proposed method is run in a transparent way without changing the network, no matter what kind of backbone network is used. So, an open-source light-weight model can be easily used, which significantly reduces the requirements and difficulty of training and deployment, making it suitable for running in edge node.
- The proposed method can effectively reduce the false-alarm rate in detection and improve the confidence of detection.
2. Related Works
3. Research Methodology
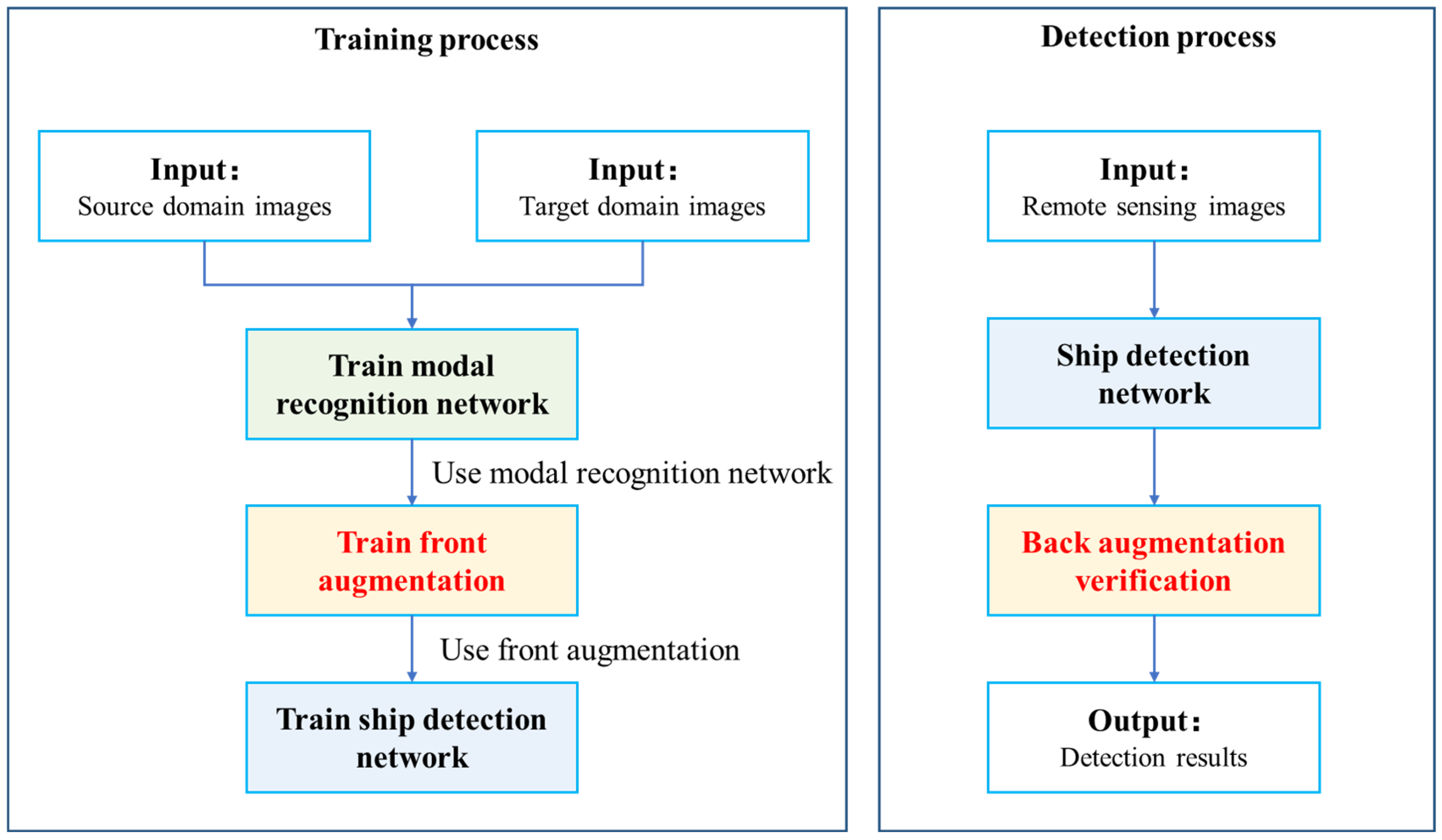
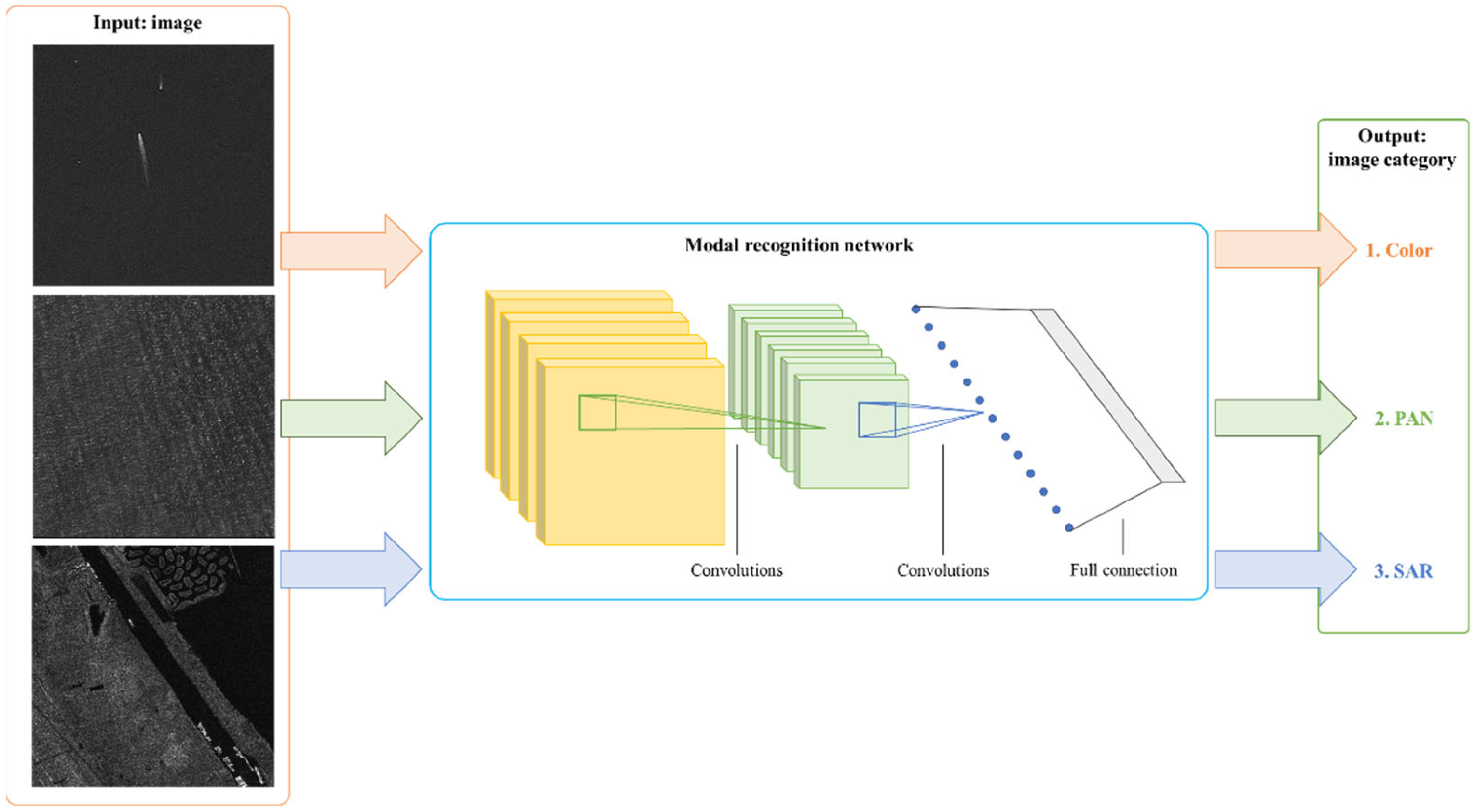
3.1. Overview of the Framework
- A large color-image dataset for training the ship detection network given the barely available PAN datasets for ship detection;
- The modal difference between images causes great performance deterioration;
- Deployment for edge nodes needs a light-weight model.
3.2. Training Process
3.3. Detection Process
4. Experiments and Discussion
4.1. Comparison Experiments
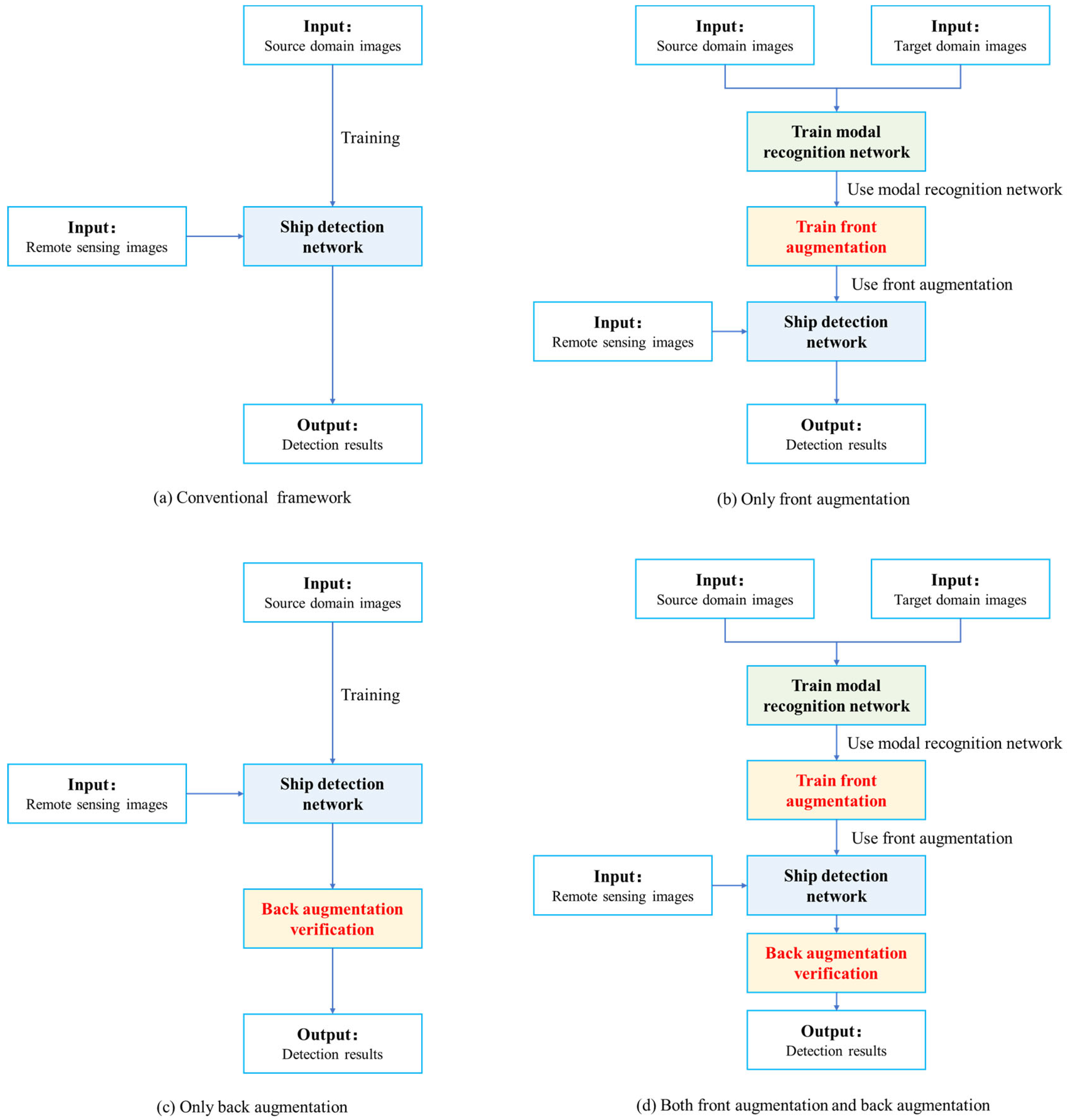
4.2. Ablation Study
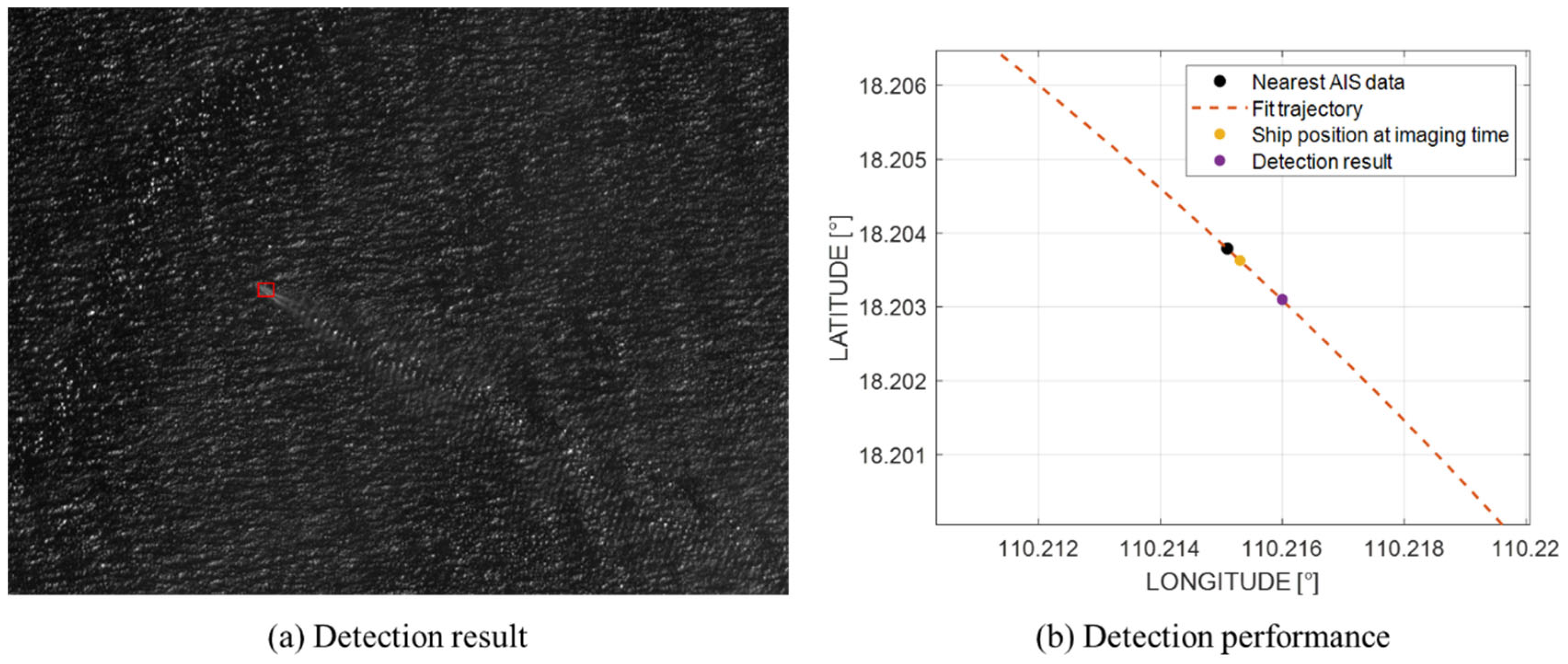
4.3. Detection Precision
4.4. Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chaturvedi, S.K. Study of synthetic aperture radar and automatic identification system for ship target detection. J. Ocean Eng. Sci. 2019, 4, 173–182. [Google Scholar] [CrossRef]
- Shi, H.; He, G.; Feng, P.; Wang, J. An On-Orbit Ship Detection and Classification Algorithm for Sar Satellite. In IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Ma, J.; Zhou, H.; Zhao, J.; Gao, Y.; Jiang, J.; Tian, J. Robust feature matching for remote sensing image registration via locally linear transforming, IEEE Trans. Geosci. Remote Sens. 2015, 53, 6469–6481. [Google Scholar] [CrossRef]
- Shao, Z.; Cai, J.; Fu, P.; Hu, L.; Liu, T. Deep learning-based fusion of landsat-8 and sentinel-2 images for a harmonized surface reflectance product. Remote Sens. Environ. 2019, 235, 111425. [Google Scholar] [CrossRef]
- Thomas, C.; Ranchin, T.; Wald, L.; Chanussot, J. Synthesis of multispectral images to high spatial resolution: A critical review of fusion methods based on remote sensing physics. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1301–1312. [Google Scholar] [CrossRef]
- Ghassemian, H. A review of remote sensing image fusion methods. Inf. Fusion 2016, 32, 75–89. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Chen, C.; Liang, P.; Guo, X.; Jiang, J. Pan-GAN: An unsupervised pan-sharpening method for remote sensing image fusion. Inf. Fusion 2020, 62, 110–120. [Google Scholar] [CrossRef]
- Eikvil, L.; Aurdal, L.; Koren, H. Classification-based vehicle detection in high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2009, 64, 65–72. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; CVPR: Columbus, OH, USA, 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision; ICCV: Santiago, Chile, 2015; pp. 1440–1448. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar] [CrossRef]
- Jiang, H.; Learned-Miller, E. Face detection with the faster R-CNN. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 650–657. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision; ICCV: Venice, Italy, 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Dong, X.; Yan, S.; Duan, C. A lightweight vehicles detection network model based on YOLOv5. Eng. Appl. Artif. Intell. Int. J. Intell. Real-Time Autom. 2022, 113, 113. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision; ICCV: Venice, Italy, 2017; pp. 2980–2988. [Google Scholar]
- Al-saad, M.; Aburaed, N.; Panthakkan, A.; Al Mansoori, S.; Al Ahmad, H.; Marshall, S. Airbus ship detection from satellite imagery using frequency domain learning. In Image and Signal Processing for Remote Sensing XXVII; SPIE: Bellingham, WA, USA, 2021; pp. 267–273. [Google Scholar]
- Li, Q.; Mou, L.; Liu, Q.; Wang, Y.; Zhu, X.X. HSF-Net: Multiscale deep feature embedding for ship detection in optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7147–7161. [Google Scholar] [CrossRef]
- Jiao, J.; Zhang, Y.; Sun, H.; Yang, X.; Gao, X.; Hong, W.; Fu, K.; Sun, X. A densely connected end-to-end neural network for multiscale and multi-scene SAR ship detection. IEEE Access 2018, 6, 20881–20892. [Google Scholar] [CrossRef]
- Tian, L.; Cao, Y.; He, B.; Zhang, Y.; He, C.; Li, D. Image enhancement driven by object characteristics and dense feature reuse network for ship target detection in remote sensing imagery. Remote Sens. 2021, 13, 1327. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part I 16; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Shin, H.C.; Lee, K.I.; Lee, C.E. Data augmentation method of object detection for deep learning in maritime image. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Busan, Republic of Korea, 19–22 February 2020; pp. 463–466. [Google Scholar]
- Hu, J.; He, J.; Jiang, P.; Yin, Y. SOMC: A Object-Level Data Augmentation for Sea Surface Object Detection. J. Phys. Conf. Ser. 2022, 2171, 012033. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, D.; Zhang, Y.; Cheng, X.; Zhang, M.; Wu, C. Deep learning for autonomous ship-oriented small ship detection. Saf. Sci. 2020, 130, 104812. [Google Scholar] [CrossRef]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; ICCV: Las Vegas, NV, USA, 2016; pp. 845–853. [Google Scholar]
- Zhang, S.; Cao, Y.; Sui, B. DF-Mask R-CNN: Direction Field-Based Optimized Instance Segmentation Network for Building Instance Extraction. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Zhu, Z.; Sun, X.; Diao, W.; Chen, K.; Xu, G.; Fu, K. AOPDet: Automatic Organized Points Detector for Precisely Localizing Objects in Aerial Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5606816. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise; AAAI Press: Washington, DC, USA, 1996. [Google Scholar]
- Aissen, M.I. Some remarks on Stirling formula. Am. Math. Mon. 1954, 61, 687–691. [Google Scholar] [CrossRef]
- Inversion; Faudi, J.; Martin. Airbus Ship Detection Challenge. Kaggle. 2018. Available online: https://kaggle.com/competitions/airbus-ship-detection (accessed on 16 July 2023).
- Nie, X.; Duan, M.; Ding, H.; Hu, B.; Wong, E.K. Attention Mask R-CNN for Ship Detection and Segmentation From Remote Sensing Images. IEEE Access 2020, 8, 9325–9334. [Google Scholar] [CrossRef]
- Li, M.; Cao, C.; Feng, Z.; Xu, X.; Wu, Z.; Ye, S.; Yong, J. Remote Sensing Object Detection Based on Strong Feature Extraction and Prescreening Network. IEEE Geosci. Remote Sens. Lett. 2023, 20, 8000505. [Google Scholar] [CrossRef]
- Zheng, J.-C.; Sun, S.-D.; Zhao, S.-J. Fast ship detection based on lightweight YOLOv5 network. IET Image Process 2022, 16, 1585–1593. [Google Scholar] [CrossRef]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A Small-Object-Detection Model Based on Improved YOLOv8 for UAV Aerial Photography Scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.-Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 10 October 2023).
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mFAR | Runtime [s] | ||
|---|---|---|---|---|
| Mask-R-CNN | 0.6897 | 0.3482 | 0.2364 | 1133 |
| Mask-R-CNN (ours) | 0.8554 | 0.8223 | 0.0121 | 1320 |
| Deformable DETR | 0.8175 | 0.5119 | 0.1459 | 835 |
| Deformable DETR (ours) | 0.8798 | 0.8421 | 0.0087 | 946 |
| YOLOv5 | 0.7025 | 0.4142 | 0.2104 | 157 |
| YOLOv5 (ours) | 0.8602 | 0.8254 | 0.0120 | 162 |
| YOLOv8 | 0.8241 | 0.5315 | 0.1366 | 204 |
| YOLOv8 (ours) | 0.8856 | 0.8513 | 0.0076 | 223 |
| Method | mFAR | Runtime [s] | |||
|---|---|---|---|---|---|
| Conventional framework | 0.6897 | 0.3482 | 0.3364 | 50 | 1133 |
| Only front augmentation | 0.6954 | 0.4021 | 0.2567 | 103 | 1138 |
| Only back augmentation | 0.7335 | 0.6828 | 0.1378 | 49 | 1325 |
| Double augmentation | 0.8554 | 0.8223 | 0.0121 | 103 | 1320 |
| Update Time: | Longitude (°): | Latitude (°): | Course (°): | Speed (kn): | Heading (°): |
|---|---|---|---|---|---|
| 29 June 2023 11:13:03 | 110.2312 | 18.18648 | 327.4 | 7.8 | 82.0 |
| 29 June 2023 11:14:23 | 110.22948 | 18.18898 | 325.8 | 8.2 | 325.8 |
| 29 June 2023 11:23:24 | 110.2151 | 18.20379 | 315.6 | 8.1 | 315.6 |
| 29 June 2023 11:35:30 | 110.19424 | 18.2146 | 112.6 | 7.6 | 235.0 |
| 29 June 2023 11:41:23 | 110.1945 | 18.215475 | 290.0 | 7.5 | 290.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mou, F.; Fan, Z.; Jiang, C.; Zhang, Y.; Wang, L.; Li, X. Double Augmentation: A Modal Transforming Method for Ship Detection in Remote Sensing Imagery. Remote Sens. 2024, 16, 600. https://doi.org/10.3390/rs16030600
Mou F, Fan Z, Jiang C, Zhang Y, Wang L, Li X. Double Augmentation: A Modal Transforming Method for Ship Detection in Remote Sensing Imagery. Remote Sensing. 2024; 16(3):600. https://doi.org/10.3390/rs16030600
Chicago/Turabian StyleMou, Fangli, Zide Fan, Chuan’ao Jiang, Yidan Zhang, Lei Wang, and Xinming Li. 2024. "Double Augmentation: A Modal Transforming Method for Ship Detection in Remote Sensing Imagery" Remote Sensing 16, no. 3: 600. https://doi.org/10.3390/rs16030600
APA StyleMou, F., Fan, Z., Jiang, C., Zhang, Y., Wang, L., & Li, X. (2024). Double Augmentation: A Modal Transforming Method for Ship Detection in Remote Sensing Imagery. Remote Sensing, 16(3), 600. https://doi.org/10.3390/rs16030600