1. Introduction
Optical remote sensing image ship target detection technology plays an important role in sea area monitoring, marine pollution detection, maritime traffic management, and military reconnaissance. Research on ship target detection technology is of great significance. Due to the great success of object detection algorithms based on convolutional neural networks [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10], many researchers use similar techniques to achieve ship detection [
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21]. However, it is still a very challenging task to accurately locate small ships from optical remote sensing images.
Small ship targets in remote sensing images have fewer pixels and blurry details, making them difficult to successfully detect. Most of the existing ship detection methods generate multi-scale feature maps via the feature pyramid structure [
22], and then set anchors with different sizes on shallow feature maps that have more detailed information to detect small ships. During the training process, the anchor is only matched with nearby ships that have a similar size (that is, the IoU reaches the preset threshold) to generate positive samples for regression, which reduces the difficulty of parameter prediction and improves the localization accuracy of the detection.
However, small ships have fewer pixels and the IoU changes caused by size and location offset are drastic, which greatly increases the difficulty of matching with the anchor. When predefined sizes of the anchor are not close to the ground-truth bounding box, it is difficult for the algorithm to match a sufficient number of positive samples for small ship targets during the training process. In this way, the training is insufficient, resulting in a decrease in detection performance and even misdetections. Different from anchor-based methods, anchor-free methods do not require predefined anchors and can freely match objects of different sizes without IoU restrictions during training. This enables the anchor-free method to match more positive samples for small ship targets beyond the predefined size of the anchor, making the training more adequate and reducing misdetections. However, due to the lack of prior size information, the localization accuracy of anchor-free methods is usually lower than that of anchor-based methods.
To resolve this contradiction, we propose a small ship detection method based on hybrid anchor structure and feature super-resolution. The proposed method combines the advantages of both anchor-based methods and anchor-free methods. Firstly, an adaptive feature pyramid is proposed, which combines the rich detail information of shallow features to predict the spatial location weight of deep features, so as to enhance the information of important locations in a more targeted manner, making it easier for small ships to be classified and located. Then, based on the shallow features of the adaptive feature pyramid, two parallel anchor-based and anchor-free detection branches are set to detect small ships. The two detection branches give full play to the high localization accuracy of anchor-based methods and the high recall of anchor-free methods.
During training, the network minimizes the losses of the two detection branches to extract ship features with complementary advantages, thereby improving the detection accuracy of both branches. During the test phase, in order to preserve better detection results of each branch, the output results need to be merged according to the classification scores of the two branches. However, due to the different definitions of positive samples, the classification scores of the anchor-based branch and anchor-free branch have different meanings and cannot be directly used for comparison. Although they have complementary advantages, the difference in output evaluation makes it difficult for the two branches to obtain their respective optimal outputs.
To solve this problem, we propose a label reassignment strategy. The proposed strategy comprehensively considers the localization accuracy before and after regression to reassign the sample labels in each iteration, so that the two detection branches can obtain unified output evaluations. The classification score after label reassignment is able to better reflect the localization accuracy of the bounding box, which further narrows the difference between the classification and regression tasks, thereby optimizing the training process. When the training is completed, the algorithm retains ship proposals with higher accuracy according to the classification scores of the two branches, making use of the complementary roles of the anchor-based branch and the anchor-free branch.
In addition, although the hybrid anchor structure can effectively reduce misdetections, small ships in remote sensing images still lack detail information, which limits further improvement of the detection. To solve this problem, we perform feature super-resolution on the RoI features of small ships to recover the missing details. Specifically, a feature super-resolution network is proposed, which is composed of recursive residual modules and densely connected structures. The feature super-resolution network maps RoI features of small ships into super-resolution features with more detailed information, while avoiding a lot of computation caused by super-resolution reconstruction to the whole image. With help of the more detailed information of super-resolution features, the proposed method is able to accurately locate small ship targets and obtain better detection results.
The rest of this paper is organized as follows. The related work is introduced in
Section 2.
Section 3 describes the proposed method in detail. Experimental analysis and comparisons are given in
Section 4 to verify the superiority of our method.
Section 5 concludes this paper.
3. The Proposed Method
Following the two-stage detection pipeline, the overall framework of our method is shown in
Figure 1 and consists of four parts: backbone network, adaptive feature pyramid, hybrid anchor detection structure, and RoI feature super-resolution.
The ResNet-50 [
41] model is used as the backbone network. Firstly, an adaptive feature pyramid is constructed based on the output feature maps of different depths of the backbone network. The spatial information is adaptively enhanced via an adaptive enhancement module to highlight the features of important locations. Then, a hybrid anchor detection structure is proposed to take full advantages of both anchor-based methods and anchor-free methods. In hybrid anchor structure, an anchor-based detection branch and an anchor-free detection branch are set based on the output feature maps of the
layer to detect small ships. Since the definitions of positive and negative samples of the two detection branches are different, directly merging the output results according to the prediction score will lead to a performance drop. Therefore, we proposes a label reassignment strategy, which reassigns the label of training samples according to their localization accuracy before and after regression. After label reassignment, the two different detection branches can obtain a unified output evaluation, so as to better merge the output results.
Next, in the RoI feature super-resolution part, the feature super-resolution network performs super-resolution reconstruction on the RoI features of small ships. The feature super-resolution process supplements missing details of small ships, which is beneficial for further classification and regression. During training, the high-resolution feature extraction network extracts high-resolution RoI features of small ships from high-resolution images as the ground-truth of the feature super-resolution network. Moreover, to obtain more realistic super-resolution features, the feature super-resolution network is optimized by means of generative adversarial training with the help of the feature discriminator. Finally, the super-resolution RoI features generated by the feature super-resolution network are classified and regressed to obtain the final detection result.
3.1. Adaptive Feature Pyramid
The feature pyramid structure fuses deep features to shallow layers step by step, supplementing rich semantic information for the shallow features with more detailed information. The traditional feature pyramid structure fuses the features of two adjacent layers by element-wise addition. However, this fusion approach cannot adaptively adjust the weight according to the changes of input features. In the layer-by-layer process of feature fusion, the semantic information of different spatial locations cannot be distinguished, so the important location information transmitted to the bottom layer is weakened, thus affecting the detection performance for small ship targets.
Aiming at this defect of the traditional feature pyramid, we propose an adaptive feature pyramid structure. The core of the adaptive feature pyramid is the adaptive feature enhancement module. This module uses shallow features with rich spatial information to adaptively enhance the different locations of the deep features, so that the features on important locations in the fusion result are more salient, which is convenient for detecting small ship targets.
The structure of the adaptive feature pyramid is shown in
Figure 2.
,
,
, and
represent the output feature maps from the second stage to the fifth stage of the ResNet-50 network model, respectively. The feature map of the
layer goes through the
convolutional layer to reduce the number of channels, and the top-level feature map of the pyramid
is obtained. Then,
is 2× upsampled to match the spatial size of
, while
is channel-reduced by 8 to get the same number of channels as
. Next,
together with
are used as the input of the adaptive enhancement module. Since
has low resolution and less spatial information, while
has high resolution and richer spatial information, the adaptive enhancement module combines the information of
to enhance the spatial information of
to obtain the enhanced feature map. The enhanced feature map is added to the feature map of the
layer after dimension reduction, and the fused sub-top layer feature map
is obtained. The method then iterates in the same way to get
and the bottom-level feature map
.
The structure of the adaptive enhancement module is shown in
Figure 3. The input feature maps
and
are both
in size. First,
and
(
i = 2, 3, 4) are spliced along the channel, and a
convolutional layer is set for channel fusion to obtain the
size output feature map. Then, channel reduction is performed through a
convolutional layer to halve the number of channels. Next, a spatial weight map of size
is obtained via channel average pooling and sigmoid activation function. Finally, the spatial weight map is used to weight
to get the enhanced feature
. The adaptive enhancement module predicts the fusion weight for each location of high-level features according to the feature map to be fused. In this way, features of important locations are enhanced while features of irrelevant locations are ignored, thereby achieving better feature fusion.
3.2. Hybrid Anchor Detection Structure
Mainstream object detection algorithms widely use anchor boxes to locate objects. These methods predefine anchors with different scales and aspect ratios as initial candidates for objects, providing prior information about the object size. The design of anchors can effectively improve the localization accuracy of the detection, but there are still two main defects: (1) Since the size of the object is unknown, the algorithm needs to set multiple anchor boxes of different sizes at each pixel location, which increases the computational burden of the network. (2) The anchor introduces the two hyperparameters of scale and aspect ratio. When these hyperparameters are not set properly, the object cannot be matched to a sufficient number of positive samples, resulting in a decrease in detection performance.
The anchor-free method improves on these defects. This kind of method directly predicts the distance from the object bounding box to the current pixel location without predefining the size of the bounding box. Since it is not limited by the size of the object, anchor-free methods can better match small objects that are difficult to cover by the anchor, thus effectively reducing misdetections.
The anchor-based method can better detect ships of regular size. However, for small ships, especially those with large aspect ratios, a small offset may lead to a dramatic change in the IoU between the anchor and ground-truth bounding boxes. In this case, it is difficult to reach the threshold of positive samples, which can easily cause misdetections. Therefore, in order to take full advantages of both anchor-based methods and anchor-free methods, we set two parallel anchor-based and anchor-free detection branches at the bottom of the adaptive feature pyramid. Among them, the anchor-based detection branch can improve the localization accuracy of small ships, and the anchor-free detection branch can help to avoid misdetections. On this basis, a label reassignment strategy is proposed to unify the output evaluations of the two branches, so as to better combine the detection results of the two branches and make full use of their complementary advantages.
3.2.1. Anchor-Based Detection Branch
The anchor-based detection algorithms predefine a variety of anchors with different sizes, which reduces the difficulty of regression and can more accurately locate the object. Therefore, anchor-based detection branches are set at the , , , and layers of the adaptive feature pyramid to detect ships of different sizes. In remote sensing images, rotated bounding boxes can provide accurate localization descriptions for regular sized ship targets. However, unlike regular sized ships, small ships have small bounding boxes and weak directionality. Predicting rotated bounding boxes is far less important for small ships than for regular-sized ships. Therefore, the anchor-based detection branch of the layers predicts rotated proposals, while both the anchor-based and anchor-free detection branches of the layer predict horizontal proposals for small ships.
Specifically, the scales of the anchors at the
–
layers are
,
,
,
, and
, respectively. Each scale has three aspect ratios of 1:5, 1:1, and 5:1. Among them, the anchors for the
layer are horizontal anchors. For the
–
layers, we set rotated anchors with six predefined orientations of
,
,
,
,
, and
, as described in [
42].
3.2.2. Anchor-Free Detection Branch
In order to better detect small ships, we set an anchor-free detection branch at the
layer. Different from the anchor-based branch, the anchor-free branch does not need to predefine the width and height of the bounding box, and it directly regresses the distance from the current location to the four sides of the object bounding box. Assuming that the coordinates of the top left corner and the bottom right corner of the object bounding box are
and
, respectively, and the coordinates corresponding to the current location are
. Then, as shown in
Figure 4, the offset predicted by the anchor-free branch is
.
In order to normalize the offsets between objects of different sizes, the IoU loss is usually used for network optimization during training in anchor-free detection algorithms. The IoU loss is defined as follows:
where
represents the IoU between the predicted box and the ground-truth bounding box. Since small ships in remote sensing images usually have unclear outlines, it is particularly important to accurately locate their center points. Therefore, a center point distance loss term is introduced to better locate the center point of the ship. The IoU loss
with center point distance loss term is defined as follows:
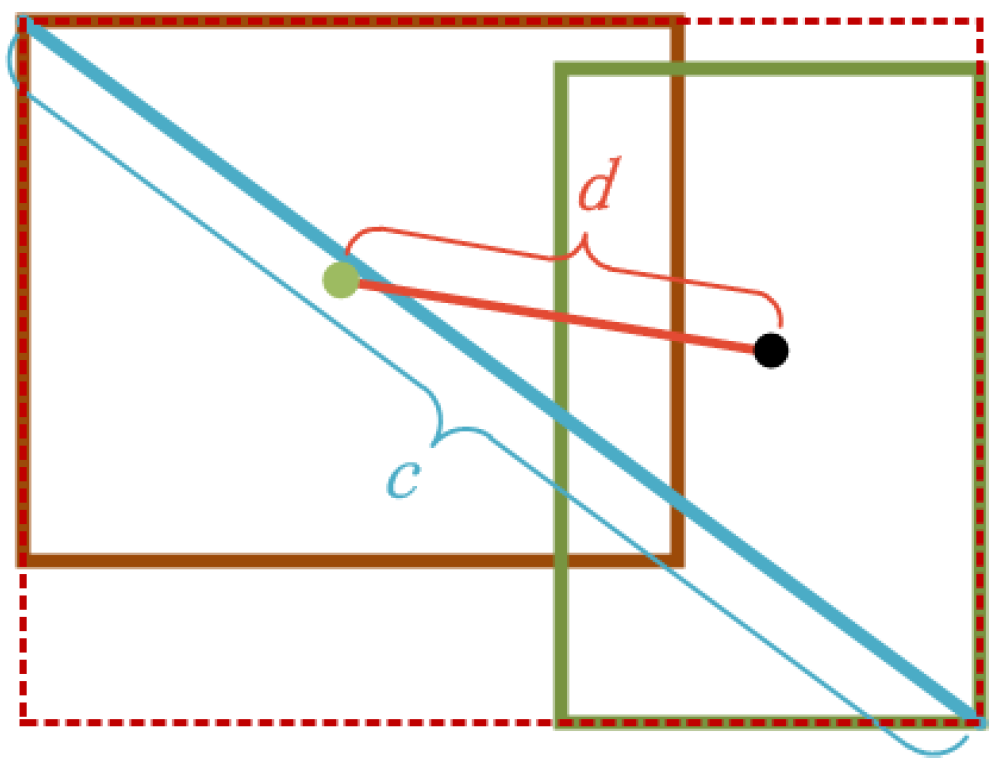
where
represents the square of the distance between the predicted box and the center point of the ground-truth bounding box, and
c represents the diagonal length of the combined rectangle composed of the predicted box and the ground-truth bounding box, as shown in the
Figure 5.
Another important difference between the anchor-free branch and the anchor-based branch is the definition of positive and negative samples during training. The anchor-based branch needs to calculate the IoU between the anchor and ground-truth bounding boxes, and then compare it with the IoU threshold. However, IoU not only requires the location of the anchor to be accurate, but also needs to be similar in size to the ground-truth bounding boxes, which greatly limits the number of positive samples. In contrast, the anchor-free branch only needs to consider the geometric relationship between the current location and ground-truth bounding boxes, which can effectively increase the number of positive samples of small ship targets.
Specifically, for the anchor-free detection branch, a positive sample falls within the constraint rectangle. A constraint rectangle is a rectangular region with the same center point as the ground-truth bounding box, but 0.9 times its width and height. The constraint rectangle is set here to alleviate the imbalance offset regression when the pixel is too close to the boundary of the ground-truth bounding box. The samples between the constraint rectangle and the ground-truth bounding box are ignored, and the samples outside the ground-truth bounding box are negative samples. When adjacent ground-truth bounding boxes have overlap, the corresponding constraint rectangles may also overlap. For this case, the samples in the overlapped region will be matched to the closest ground-truth bounding box.
Since the output of anchor-based and anchor-free branches may highly overlap, it is necessary to eliminate redundancy through the non-maximum suppression (NMS) post-processing process and merge the prediction results of the two branches. The NMS algorithm ranks all proposals according to the classification scores, gradually eliminating the redundancy around the region with the highest scores. For the anchor-free branch and the anchor-based branch, the different definitions of positive and negative samples lead to different meanings of the classification scores of the two branches: the classification score of the anchor-free branch represents the probability that the current pixel location falls within the constraint rectangle, while the classification score of the anchor-based branch reflects the degree of overlap between the anchor and the ground-truth bounding box. Therefore, the classification scores of the two branches cannot be used in the NMS process.
In order to solve this problem and obtain the same output evaluation of the two branches, we proposes a label reassignment strategy that re-selects positive and negative samples according to the harmonic IoU before and after regression. The specific process of the label reassignment strategy is as follows:
- (1)
The anchor-based and anchor-free detection branches first generate positive and negative samples according to their respective rules. Then, the IoU between these samples and the ground-truth bounding boxes is calculated, denoted as the a priori IoU, .
- (2)
The two branches respectively perform location correction according to the output offsets to obtain ship proposals.
- (3)
The IoU between proposals and the ground-truth bounding boxes is calculated, denoted as posterior IoU,
. Then,
and
are weighted and summed to get the harmonic IoU:
in which
is the weighting coefficient.
- (4)
The anchors and initial locations corresponding to the proposals with larger than 0.5 in the two detection branches are reselected as positive samples, while the regions where is less than 0.3 are negative samples. The rest are ignored.
In step (1), since the anchor-free branch does not have predefined anchors, each pixel location is regarded as a virtual anchor with the same width and height as the ground-truth bounding box to calculate the prior IoU of the anchor-free branch. The harmonic IoU adds the prior IoU before regression, which enhances the stability of the training. During training, we set to strengthen the effect of posterior IoU. After reassigning labels according to the harmonic IoU, the classification and regression losses are calculated according to the reselected positive and negative samples. At this time, the classification scores of the two branches both reflect the localization accuracy of the ship proposals, so that the outputs have unified evaluations. The classification scores are used for merging the output in the NMS post-processing process to obtain better detection results for each branch.
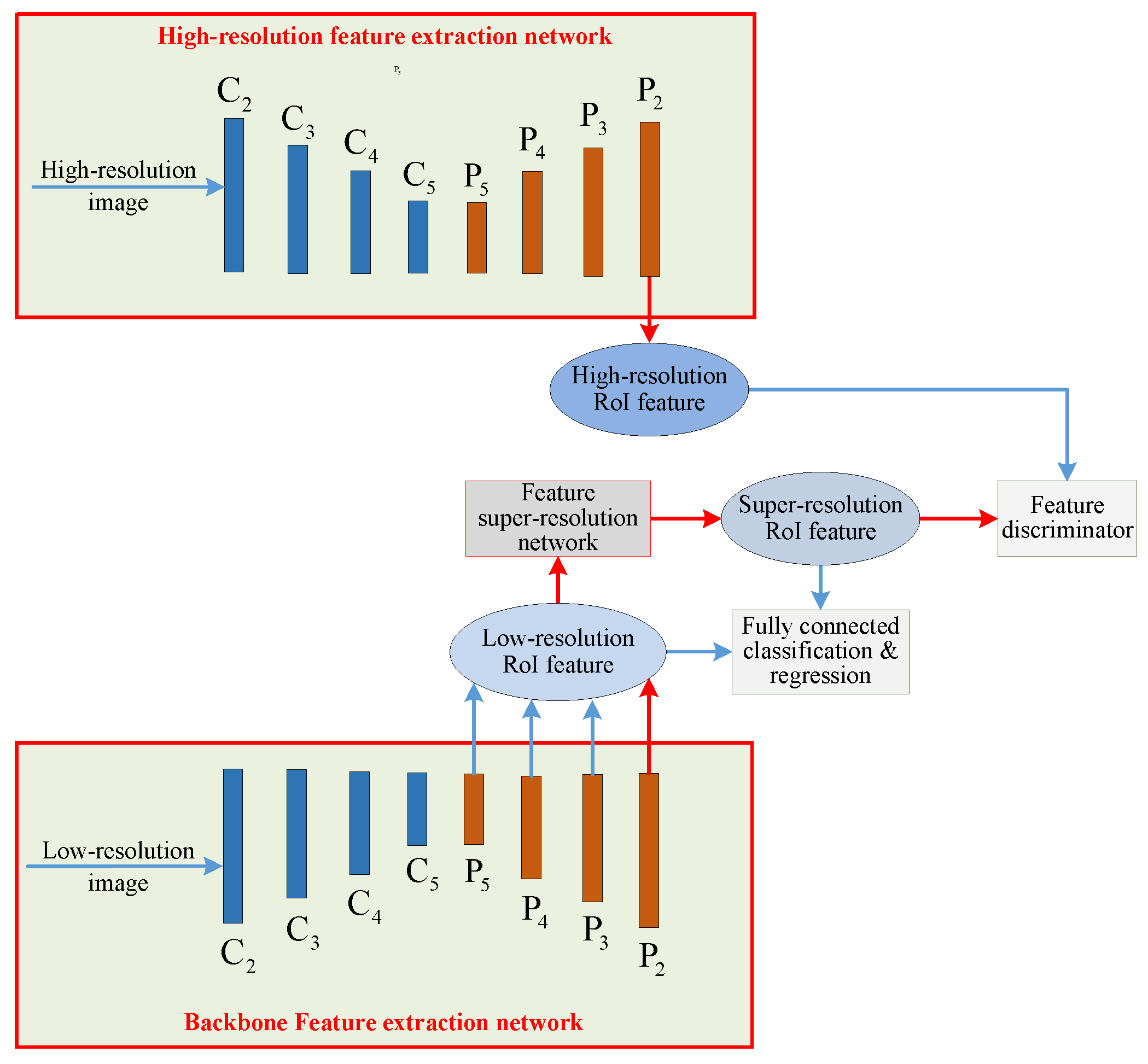
3.3. RoI Feature Super-Resolution
One of the important reasons why small ships are difficult to detect is the lack of detail information. Although the feature map at the bottom of the feature pyramid has relatively rich details, it still cannot make up for the missing information in the original image. A common method to solve this problem is to enlarge the image and supplement the missing details through image super-resolution technology to obtain high-resolution images. Since regular-sized ships and irrelevant background regions do not require sharper details, image super-resolution results in many unnecessary redundant computations. Taking high-resolution images as input significantly increases the computational burden of convolutional neural networks.
The idea of feature super-resolution is similar to image super-resolution, which reconstructs low-resolution features into high-resolution features with more detail information. Compared with image super-resolution, feature super-resolution is closer to object discrimination, which can maximize shared computing and reduce the computation cost. Therefore, we adopt feature super-resolution to obtain the super-resolution RoI features of the small ship proposals. Then, the second-stage classification and regression are performed on the basis of the super-resolution RoI features to obtain more accurate detection results.
3.3.1. High-Resolution Feature Extraction Network
Learning the super-resolution representation of low-resolution RoI features for small ships requires using the corresponding real high-resolution features as supervision. The high-resolution feature extraction network takes high-resolution images as input to obtain high-resolution output feature maps, and then the high-resolution RoI feature of small ships can be obtained through the RoI pooling operation. In order to have consistent correspondence between RoI features of different resolutions, the high-resolution RoI features must have the following properties: (1) The channel information is consistent with the low-resolution RoI features, so that the features have the same meaning. (2) The relative receptive field is consistent with the low-resolution RoI features, so that the features cover the same image region.
Directly using the backbone network as the high-resolution feature extraction network can ensure that the channel information is consistent, but it will lead to a mismatch in the relative receptive fields [
43]. As the size of RoI decreases, the mismatch of the relative receptive field also increases. That is, low-resolution RoI features contain a wider range of information in the image, while high-resolution RoI features cover a smaller range, which causes the generated super-resolution features to lose part of the receptive field information and affects the subsequent detection results. Therefore, the high-resolution feature extraction network needs to enlarge the receptive field while maintaining parameter sharing with the backbone feature extraction network to reduce the mismatch of the relative receptive fields between RoI features. In our implementation, we replace all
convolutional layers in the backbone feature extraction network with the corresponding convolutional layer in the high-resolution feature extraction network.
The high-resolution feature extraction network is only used during training and will be removed in the test phase. During training, the high-resolution and low-resolution images are fed into the high-resolution feature extraction network and the backbone feature extraction network, respectively, for parallel computation, and the multi-scale feature maps of the two images are obtained at the same time. According to the prediction result of the hybrid anchor detection structure, high-resolution RoI features are extracted from the high-resolution feature extraction network through the RoI pooling operation. The high-resolution RoI features are then serve as the supervision information for the feature super-resolution network.
3.3.2. Feature Super-Resolution Network
The feature super-resolution network maps low-resolution RoI features to super-resolution RoI features with more detail information. Since RoI features have a fixed spatial size, the output of the feature super-resolution network is the same size as the input feature. The high-resolution features contain low-resolution features and the missing high-frequency detail information. This correspondence can be described well by the residual structure. Therefore, we build the feature super-resolution network based on the residual module.
In general, deep networks have better image super-resolution performance. However, as the number of network layers increases, the number of parameters increases linearly, increasing the risk of overfitting, especially for the RoI feature, whose spatial size is usually only
. Therefore, in order to better balance the network depth and the number of parameters, a recursive residual [
44] module with parameter sharing is used to build the feature super-resolution network.
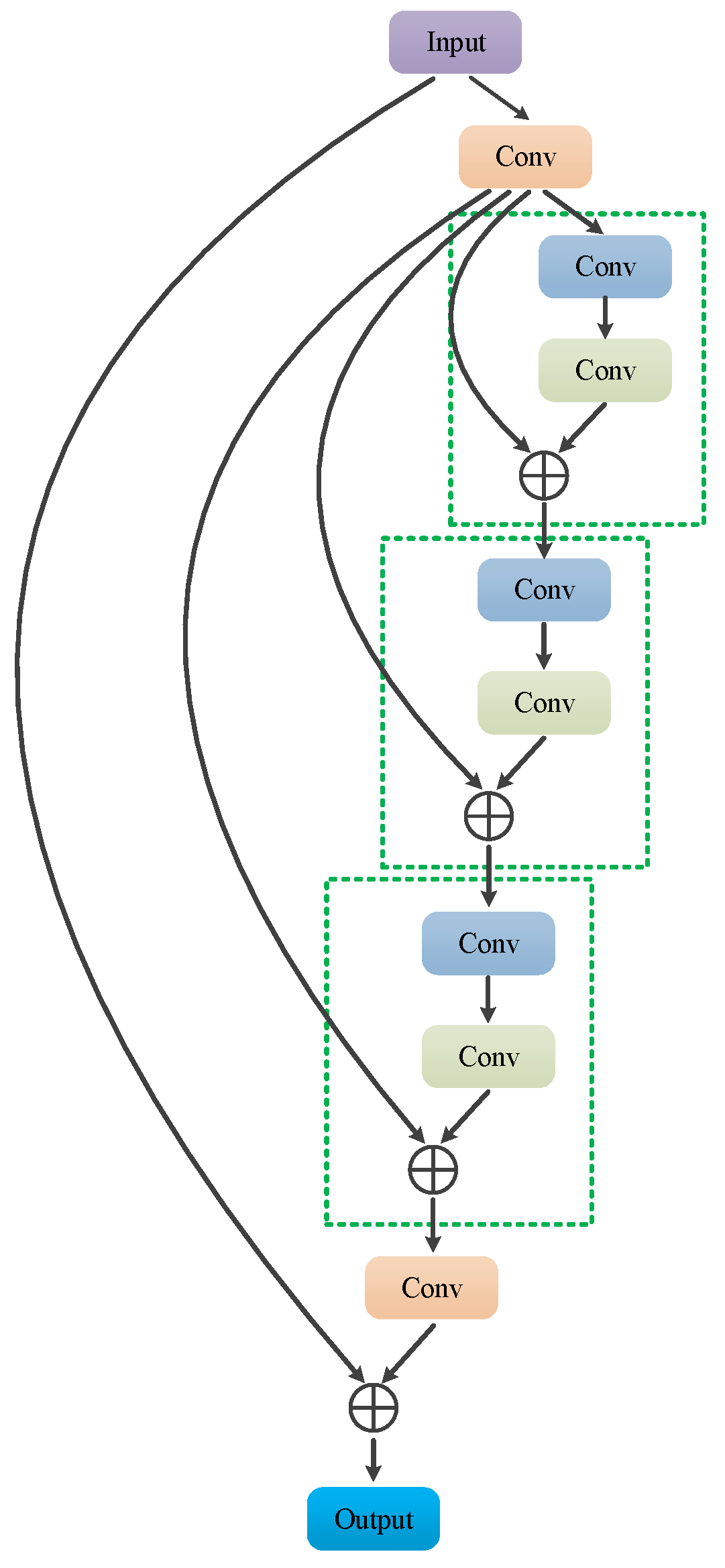
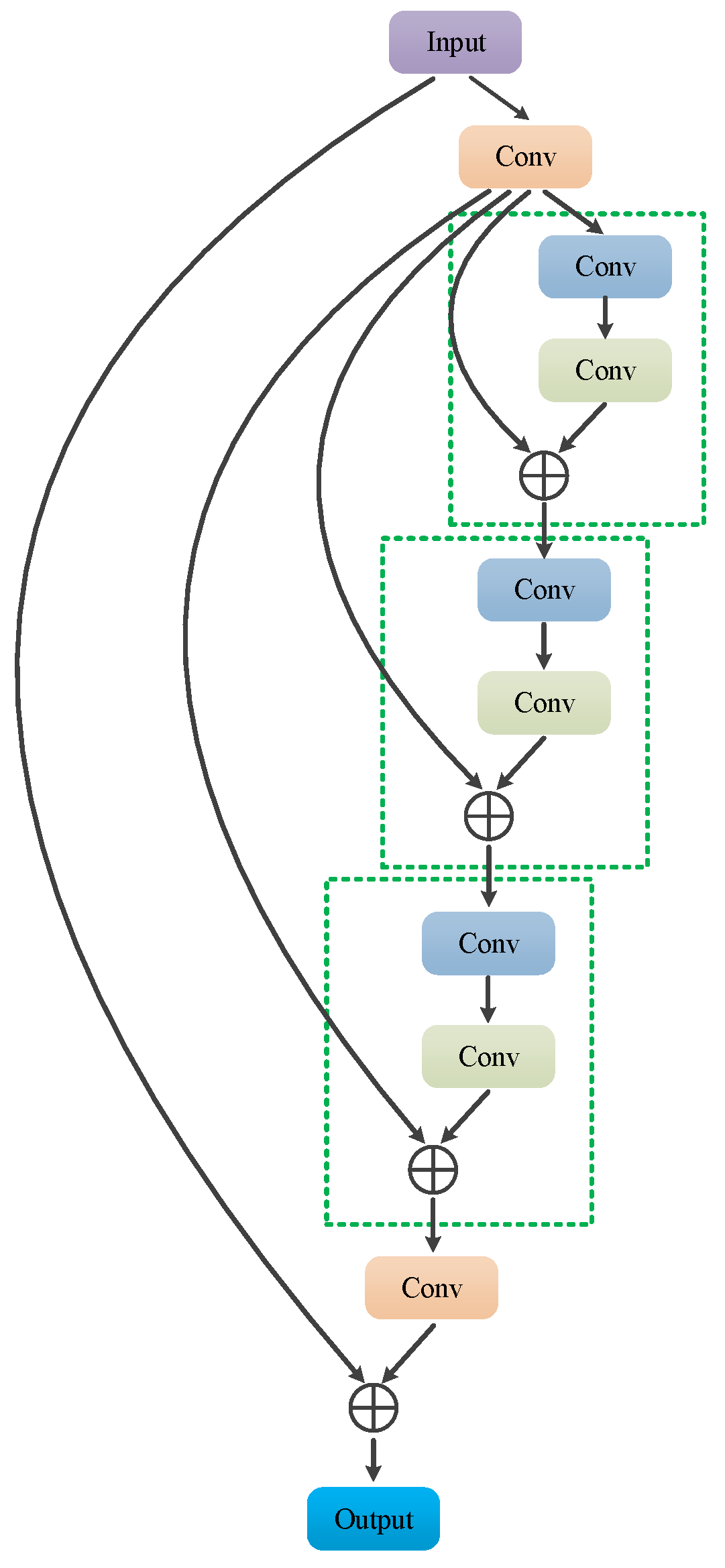
The structure of the recursive residual module is shown in
Figure 6, in which the two consecutive
size convolutional layers in the green dashed boxes are the basic convolutional units. To limit the growth of parameters, the parameters are fully shared between basic convolutional units. The recursive residual module consists of a basic convolution unit and a recursive residual structure, which recursively calls the basic convolution unit to calculate the residual output. Compared with an ordinary residual module, the recursive residual module increases the depth of the network without increasing the number of learnable parameters, so it has less risk of overfitting.
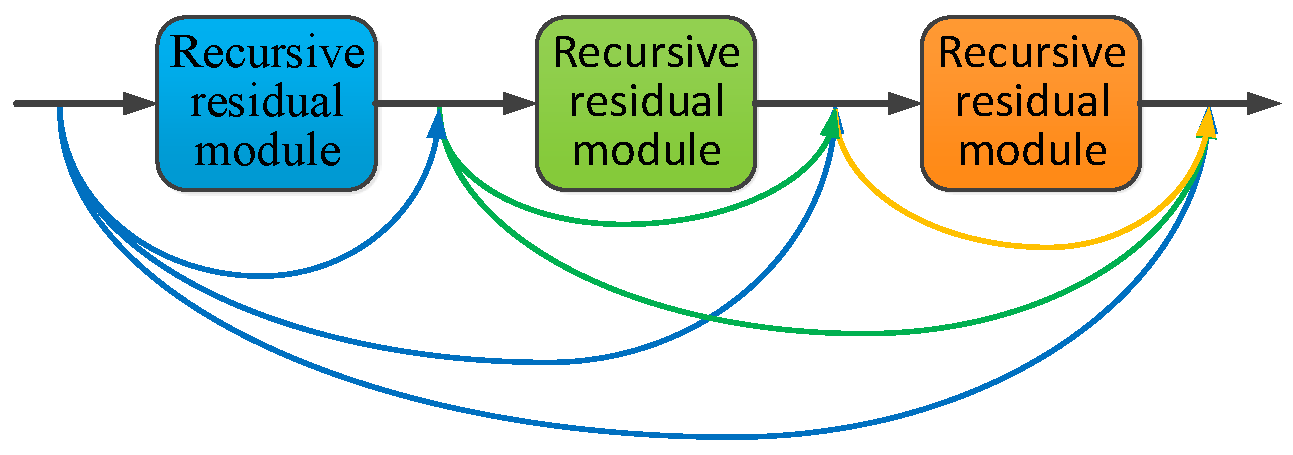
The feature super-resolution network composed of recursive residual modules is shown in
Figure 7. The network consists of three recursive residual modules, and a dense connection structure is added between different residual modules to achieve feature reuse. The densely connected structure enables the input of each layer to fully absorb the outputs of all previous layers, so that the features extracted by different convolutional layers can be fully utilized to reconstruct high-resolution features.
During training, the feature super-resolution network takes high-resolution RoI features output by the high-resolution feature extraction network as learning targets, and updates the network parameters through the feature super-resolution loss. In addition, in order to obtain more realistic super-resolutin features, the idea of a generative adversarial network is used to further optimize the output of the feature super-resolution network. Using the feature super-resolution network as the generator, the discriminator consists of two fully connected layers and a softmax layer to identify whether input features are real high-resolution features. After training, the discriminator is removed in the test phase. The super-resolution RoI features output by the feature super-resolution network are further subjected to second-stage classification and regression prediction to obtain the final detection results for small ships.
3.4. Training
3.4.1. Training Process
Most of the existing object detection methods only use single-resolution images in the training dataset to learn the feature representation of the object. Limited by the image resolution, for small objects, the features obtained by these methods are lacking in detail information, which is not conducive to accurate detection. In order to enrich the details of small ships, we design the feature super-resolution network to generate super-resolution features for the proposal of small ships. Training the feature super-resolution network requires real high-resolution features as supervision. Therefore, as shown in
Figure 8, a parallel structure is used to train the network, generating low-resolution RoI features and the required high-resolution RoI feature at the same time.
During training, the backbone network takes low-resolution images as input. At different layers of the adaptive feature pyramid, the corresponding detection branches generate low-resolution ship RoI features of different sizes. Among them, the feature super-resolution network performs feature super-resolution on the RoI features of small ships generated by the detection branch located at the layer. Based on the super-resolution RoI features, the classification score and regression offset are predicted through the fully connected classification and regression layers. Besides small ships, ships of other sizes contain larger number of pixels, and sufficient detail information can be obtained from the original input image. Therefore, in order to reduce unnecessary computation, the RoI features generated by the detection branch located at the – layers are directly fed into the fully connected classification and regression layers for prediction.
Meanwhile, the high-resolution feature extraction network takes high-resolution images as input, and generates the corresponding high-resolution RoI features of small ships according to the output of the backbone network. The feature super-resolution network takes the generated high-resolution RoI features as the ground-truth, learning the mapping relationship between low-resolution features and real high-resolution features by optimizing the super-resolution loss. In addition, the feature discriminator discriminates super-resolution features from real high-resolution features during training, making the output of the feature super-resolution network more realistic.
In our implementation, the corresponding low-resolution image is obtained by down-sampling the high-resolution image. During training, the training image is directly used as the high-resolution image, and the image downsampled to half the size of the original image is used as the low-resolution image. The two images are input in pairs to the high-resolution feature extraction network and the backbone feature extraction network. The complete training process of the network is as follows:
- (1)
The parameters of the high-resolution feature extraction network and the feature discriminator are fixed, while the backbone network and the fully connected classification and regression layers are trained.
- (2)
The parameters of the backbone network are fixed, while the high-resolution feature generation network and the feature discriminator are alternately trained until they converge.
- (3)
The parameters of all the remaining parts are fixed to exclude the influence of the generative adversarial loss, while the parameters of the fully connected classification and regression layers are fine-tuned to further improve the performance of the detection.
3.4.2. Loss Functions
The loss of the proposed method during training consists of three parts: the detection loss for training the detection model, the super-resolution loss for training the feature super-resolution network, and the discrimination loss for training the feature discriminator.
- (1)
Detection loss
The detection loss
consists of each detection branch of the adaptive feature pyramid and the classification and regression loss of the second stage. In order to facilitate convergence, the regression loss of all anchor-based detection branches in the
–
layers adopt the IoU loss
shown in Equation (
1). Both the anchor-based detection branch and anchor-free detection branch at the
layer adopt the IoU loss
with center point distance loss, as shown in Equation (
2). The classification loss
of each detection branch is consistent with [
3]. The classification and regression losses of the second stage are exactly the same as the detection branches of the first stage.
- (2)
Super-resolution loss
The super-resolution loss computes the deviation between the output of the high-resolution feature generation network and the real high-resolution feature pixel by pixel. It is defined as follows:
In Equation (
4), subscript 2 means 2-norm,
i is the serial number of the RoI feature,
represents the low-resolution RoI feature,
represents high-resolution RoI features,
G represents the high-resolution feature generation network, and
N is the number of samples.
- (3)
Discrimination loss
The loss of the high-resolution feature discriminator is the categorical cross-entropy loss, which is defined as follows:
In Equation (
5),
represents the output probability for the feature discriminator, and
is the category label for the
i-th input feature (
for the real high-resolution feature, and
for the generated super-resolution feature).
To sum up, the network loss
L is equal to the sum of the above losses, as follows:
4. Experiments
4.1. Datasets and Implementation Details
The proposed method is verified on a remote sensing image dataset collected from Google Earth. The dataset contains a total of 3000 images, covering the port and sea environment. The dataset is randomly divided into a training set, validation set, and test set according to the ratio of 6:1:3. In order to more clearly show the detection performance on ships of different sizes, ships in the dataset are divided into three categories of small ships, medium ships, and large ships for evaluation. Among them, the size of the bounding box for small ships is less than pixels, while the medium ships are between pixels and pixels, and the large ships are larger than pixels.
The GPU model in our experiment is NVIDIA 1080Ti, the CPU model is Intel i7-7820X, and the memory is 32 GB. The experiment is carried out on the Ubuntu 16.04 operating system, based on the TensorFlow deep learning framework. The network is optimized by the Adam optimizer, with a total of 80,000 iterations. The learning rate is 0.001 for the first 40,000 iterations and 0.0001 for the second 40,000 iterations. Two images of different resolutions are input for the training in each iteration. The shorter side of the original image is scaled to 600 pixels to obtain the high-resolution input image. During training, the backbone network shares all learnable parameters with the high-resolution feature extraction network. During the test phase, the high-resolution feature extraction network and feature discriminator will be removed.
4.2. Experimental Analysis
4.2.1. Evaluation of the Adaptive Feature Pyramid
The adaptive feature pyramid improves the feature fusion of the original feature pyramid, and enhances the spatial information of deep features through information interaction. To verify the effectiveness of adaptive feature pyramid,
Table 1 shows the evaluation results of different feature pyramid structures. In
Table 1, SAP, MAP, and LAP represent the mean precision (AP) for small ships, medium ships, and large ships, respectively. The original feature pyramid adopts element-wise addition to fuse the adjacent two levels of features. In contrast, the convolution feature pyramid replaces the element-wise addition with a convolution operation after feature concatenation.
From the experimental results, we can see that although the convolution operation can learn the fusion weight, this weight does not bring obvious performance improvement. The adaptive feature pyramid predicts the fusion weight between different layers via the attention mechanism, so the AP of each kind of ship is effectively improved.
4.2.2. Evaluation of the Hybrid Anchor Structure
In this paper, an anchor-free detection branch is set in the hybrid anchor structure to detect small ships, and the training is further optimized with the help of a label reassignment strategy and center point distance IoU loss. For a more adequate comparison, a baseline model that does not contain the hybrid anchor structure is set as the benchmark for comparison. In the baseline model, the anchor-free detection branch is replaced by the anchor-based detection branch.
Table 2 gives the evaluation results of the hybrid anchor box structure. Experimental results show that the anchor-free detection branch, the label reassignment strategy, and the center point distance IoU loss jointly improve the detection accuracy of small ships.
4.2.3. Evaluation of RoI Feature Super-Resolution
In order to verify the effectiveness of the RoI feature super-resolution structure and its components, detailed comparative experiments are conducted on the receptive field matching of the high-resolution feature extraction network, as well as the recursive residual and densely connected structure of the feature super-resolution network. Experiment results are shown in
Table 3. The receptive field matching can significantly improve the detection performance, which demonstrates the importance of maintaining similar receptive fields. In addition, recursive residuals and dense connections further boost the AP.
4.3. Comparison Results and Discussion
In order to further verify the effectiveness of the proposed method, the proposed method is compared with other three representative small object detection algorithms, which are the method from [
40], the method from [
45], and Libra R-CNN [
46].
The method from [
40] first performs the super-resolution operation on the features of the input image, and adds the super-resolution features to original features to obtain the features with enhanced details. Then, the enhanced features are used for detection. Method [
45] first cuts out a suspected target region smaller than a certain size from the input image according to the detection results. Then, the captured image region is super-resolved to obtain the super-resolution image. Finally, the super-resolution images are classified as objects and non-objects to obtain the final result.
Libra R-CNN improves the small object detection performance based on two aspects of the training strategy and network structure. In the training strategy, the negative samples are uniformly extracted according to different IoU intervals to balance the number of positive and negative samples. For the network structure, the multi-scale features are first unified at intermediate size by interpolation and pooling for fusion, and then the original features are enhanced with the fused features.
The detection results of the different methods for small ships are shown in
Figure 9. It can be seen that all three of the other methods have misdetections to some extent. For blurry pictures and unclear ships, the situation is even worse. In contrast, the proposed method combines a number of improved technologies, which effectively avoids misdetection and achieves the best detection performance for small ships.
Besides small ships,
Figure 10 shows multi-scale ship detection results. Under the interference of complex port background, both the method from [
40] and the method from [
45] lost many warships and small ships. Libra R-CNN achieves better detection results than the above two methods by means of the improvements to the training strategy and network structure. However, some heavily disturbed ships failed to be accurately detected. In contrast, the proposed method can not only accurately locate small ships, but also has high detection accuracy for multi-scale ships.
Table 4 provides the quantitative evaluation results of different methods. It can be seen from the evaluation results that the proposed method has better detection performance than other methods on ships of various sizes, especially small-sized ships.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}