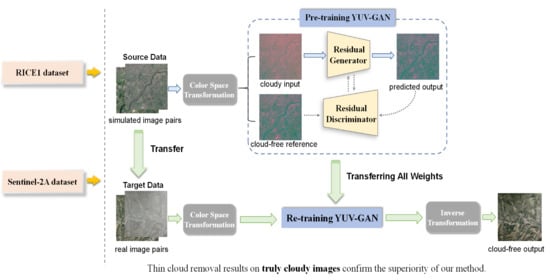
Figure 1.
Overall framework of our method.
Figure 1.
Overall framework of our method.
Figure 2.
The failures of RSC-Net when predicting cloud-free images with some bright and dark pixels. Bright pixels are predicted to be turquoise and dark pixels are predicted to be red.
Figure 2.
The failures of RSC-Net when predicting cloud-free images with some bright and dark pixels. Bright pixels are predicted to be turquoise and dark pixels are predicted to be red.
Figure 3.
Architecture of the residual block.
Figure 3.
Architecture of the residual block.
Figure 4.
Architecture of the generator.
Figure 4.
Architecture of the generator.
Figure 5.
Architecture of discriminator.
Figure 5.
Architecture of discriminator.
Figure 6.
Synthesis of cloudy images: (a) reference cloud-free images, (b) simulated clouds using Perlin Fractal noise, and (c) cloudy images synthesized by alpha blending.
Figure 6.
Synthesis of cloudy images: (a) reference cloud-free images, (b) simulated clouds using Perlin Fractal noise, and (c) cloudy images synthesized by alpha blending.
Figure 7.
The thin cloud removal results of two RICE1 samples reconstructed in different color spaces: (a1,a2) input cloudy image, (b1,b2) output images reconstructed in RGB color space, (c1,c2) output images reconstructed in YUV color space, and (d1,d2) reference cloud-free image.
Figure 7.
The thin cloud removal results of two RICE1 samples reconstructed in different color spaces: (a1,a2) input cloudy image, (b1,b2) output images reconstructed in RGB color space, (c1,c2) output images reconstructed in YUV color space, and (d1,d2) reference cloud-free image.
Figure 8.
The thin cloud removal results of two Sentinel-2A samples reconstructed in different color spaces: (a1,a2) input cloudy image, (b1,b2) output images reconstructed in YUV color space, (c1,c2) output images reconstructed in YUV color space, and (d1,d2) reference cloud-free image.
Figure 8.
The thin cloud removal results of two Sentinel-2A samples reconstructed in different color spaces: (a1,a2) input cloudy image, (b1,b2) output images reconstructed in YUV color space, (c1,c2) output images reconstructed in YUV color space, and (d1,d2) reference cloud-free image.
Figure 9.
The thin cloud removal results of a RICE1 sample reconstructed with different fidelity losses: (a) input cloudy image, (b) reconstructed image with the loss, (c) reconstructed image with the loss, and (d) reference cloud-free image.
Figure 9.
The thin cloud removal results of a RICE1 sample reconstructed with different fidelity losses: (a) input cloudy image, (b) reconstructed image with the loss, (c) reconstructed image with the loss, and (d) reference cloud-free image.
Figure 10.
The thin cloud removal results of a Sentinel-2A sample reconstructed with different fidelity losses: (a) input cloudy image, (b) reconstructed image with the loss, (c) reconstructed image with the loss, and (d) reference cloud-free image.
Figure 10.
The thin cloud removal results of a Sentinel-2A sample reconstructed with different fidelity losses: (a) input cloudy image, (b) reconstructed image with the loss, (c) reconstructed image with the loss, and (d) reference cloud-free image.
Figure 11.
The thin cloud removal results under the influence of adversarial training: (a1,a2) input cloudy image, (b1,b2) reconstructed images without adversarial training, (c1,c2) reconstructed images with adversarial training, and (d1,d2) reference cloud-free image.
Figure 11.
The thin cloud removal results under the influence of adversarial training: (a1,a2) input cloudy image, (b1,b2) reconstructed images without adversarial training, (c1,c2) reconstructed images with adversarial training, and (d1,d2) reference cloud-free image.
Figure 12.
The trend of the PSNR values with increasing training sets.
Figure 12.
The trend of the PSNR values with increasing training sets.
Figure 13.
Thin cloud removal results of various methods on a cloudy image from the RICE1 test set: (a) input cloudy image, (b) result of DCP, (c) result of McGAN, (d) result of RSC-Net, (e) result of our method, and (f) reference cloud-free image.
Figure 13.
Thin cloud removal results of various methods on a cloudy image from the RICE1 test set: (a) input cloudy image, (b) result of DCP, (c) result of McGAN, (d) result of RSC-Net, (e) result of our method, and (f) reference cloud-free image.
Figure 14.
Thin cloud removal results of various methods on a cloudy image from the Sentinel-2A test set: (a) input cloudy image, (b) result of DCP, (c) result of McGAN, (d) result of RSC-Net, (e) result of our method, and (f) reference cloud-free image.
Figure 14.
Thin cloud removal results of various methods on a cloudy image from the Sentinel-2A test set: (a) input cloudy image, (b) result of DCP, (c) result of McGAN, (d) result of RSC-Net, (e) result of our method, and (f) reference cloud-free image.
Figure 15.
The result of removing heavy clouds and cloud shadows with poor performance: (a) input cloudy image, (b) reconstructed image by YUV-GAN, and (c) reference cloud-free image.
Figure 15.
The result of removing heavy clouds and cloud shadows with poor performance: (a) input cloudy image, (b) reconstructed image by YUV-GAN, and (c) reference cloud-free image.
Figure 16.
A failure case: smooth output for an image with overly heavy clouds: (a) input cloudy image, (b) reconstructed image by YUV-GAN, and (c) reference cloud-free image.
Figure 16.
A failure case: smooth output for an image with overly heavy clouds: (a) input cloudy image, (b) reconstructed image by YUV-GAN, and (c) reference cloud-free image.
Table 1.
Sentinel-2A bands used in experiments.
Table 1.
Sentinel-2A bands used in experiments.
| Band Number | Band Name | Central Wavelength (m) | Bandwidth (nm) | Spatial Resolution (m) |
|---|
| Band 2 | Blue | 0.490 | 98 | 10 |
| Band 3 | Green | 0.560 | 45 | 10 |
| Band 4 | Red | 0.665 | 38 | 10 |
Table 2.
The composition of the RICE1 and Sentinel-2A datasets used in experiments.
Table 2.
The composition of the RICE1 and Sentinel-2A datasets used in experiments.
| Dataset | Training Set | Test Set |
|---|
| RICE1 | 700 real pairs | 140 real pairs |
| Sentinel-2A | 100 real pairs + 880 × 700 simulated pairs | 140 real pairs |
Table 3.
Average peak signal-to-noise ratio (PSNR) and similarity index measurement (SSIM) values of images reconstructed with various architectures—the RICE1 test set.
Table 3.
Average peak signal-to-noise ratio (PSNR) and similarity index measurement (SSIM) values of images reconstructed with various architectures—the RICE1 test set.
| Method | Color Space | Fidelity Loss | Adv-T | PSNR (dB) | SSIM |
|---|
| 1 | RGB | | No | 22.973169 | 0.888430 |
| 2 | YUV | | No | 23.579019 | 0.905411 |
| 3 | YUV | | No | 24.506355 | 0.917344 |
| 4 | YUV | | Yes | 25.130979 | 0.918523 |
Table 4.
Average PSNR and SSIM values of images reconstructed with various architectures—the Sentinel-2A test set.
Table 4.
Average PSNR and SSIM values of images reconstructed with various architectures—the Sentinel-2A test set.
| Method | Color Space | Fidelity Loss | Adv-T | PSNR (dB) | SSIM |
|---|
| 1 | RGB | | No | 19.377462 | 0.626397 |
| 2 | YUV | | No | 19.476388 | 0.629305 |
| 3 | YUV | | No | 19.527454 | 0.630686 |
| 4 | YUV | | Yes | 19.584991 | 0.638989 |
Table 5.
Average PSNR and SSIM values of reconstructed images from the RICE1 test set (YUV-GAN with or without TL).
Table 5.
Average PSNR and SSIM values of reconstructed images from the RICE1 test set (YUV-GAN with or without TL).
| Method | PSNR (dB) | SSIM |
|---|
| YUV-GAN without TL | 25.130979 | 0.918523 |
| YUV-GAN with TL | 25.076177 | 0.914382 |
Table 6.
Average PSNR and SSIM values of reconstructed images from the Sentinel-2A test set (YUV-GAN with or without TL).
Table 6.
Average PSNR and SSIM values of reconstructed images from the Sentinel-2A test set (YUV-GAN with or without TL).
| Method | PSNR (dB) | SSIM |
|---|
| YUV-GAN without TL | 22.136661 | 0.677236 |
| YUV-GAN with TL | 22.457308 | 0.694812 |
Table 7.
Average PSNR and SSIM values of images reconstructed with various methods using the RICE1 test set.
Table 7.
Average PSNR and SSIM values of images reconstructed with various methods using the RICE1 test set.
| Method | PSNR (dB) | SSIM |
|---|
| DCP [16] | 20.64042 | 0.797252 |
| McGAN [29] | 21.162399 | 0.873094 |
| RSC-Net [35] | 22.973169 | 0.888430 |
| Ours | 25.130979 | 0.918523 |
Table 8.
Average PSNR and SSIM values of images reconstructed with various methods using the Sentinel-2A test set.
Table 8.
Average PSNR and SSIM values of images reconstructed with various methods using the Sentinel-2A test set.
| Method | PSNR (dB) | SSIM |
|---|
| DCP [16] | 18.684304 | 0.608332 |
| McGAN [29] | 19.777914 | 0.636999 |
| RSC-Net [35] | 22.169535 | 0.669528 |
| Ours | 22.457308 | 0.694812 |





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}