
Quadrotor Autonomous Navigation in Semi-Known Environments Based on Deep Reinforcement Learning †


Abstract
:
1. Introduction
2. Related Works
3. Proposed Method
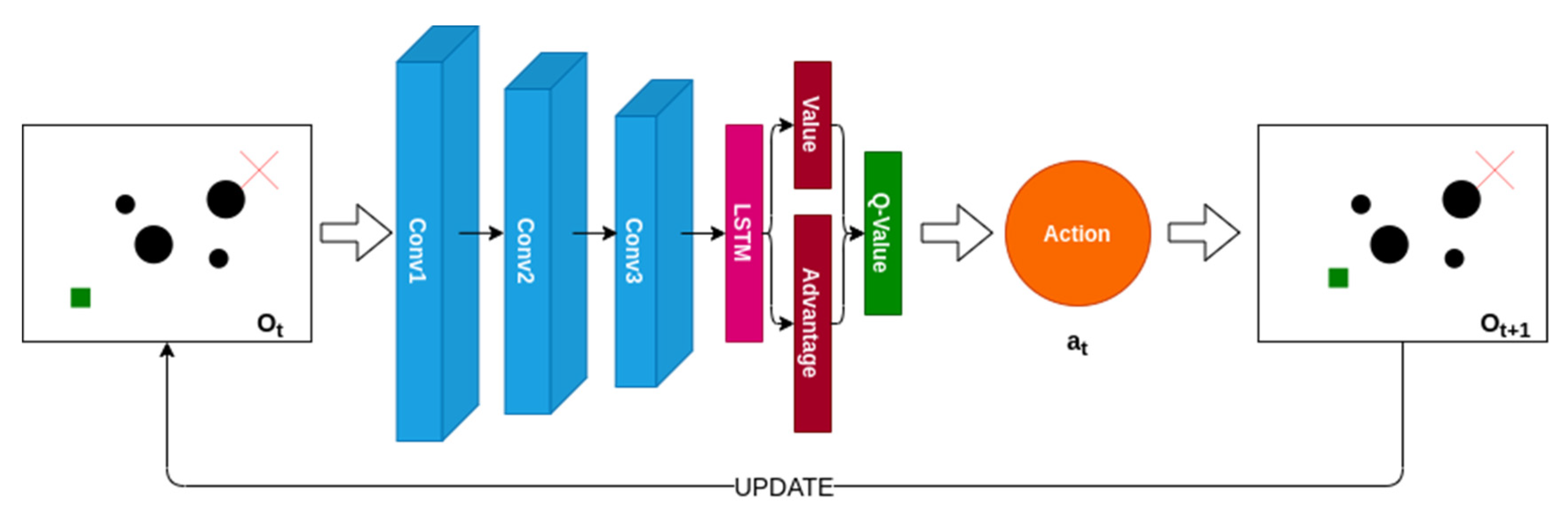
3.1. Dueling Double Deep Recurrent Q-Learning
3.1.1. Problem Formulation
3.1.2. Network Structure
3.1.3. Value Function Estimation
3.2. Global Path Planning
3.2.1. Planner Network
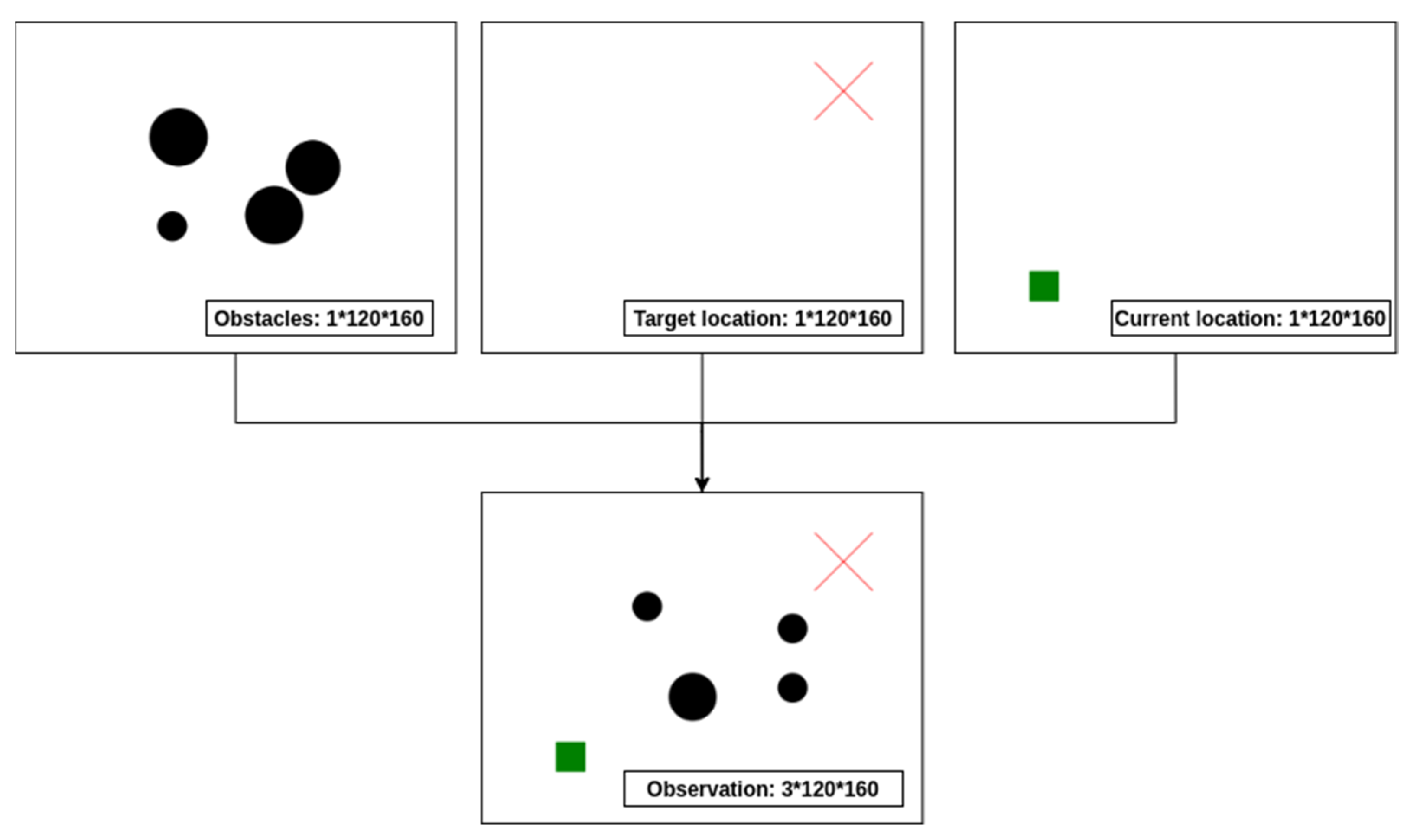
3.2.2. Observation Space
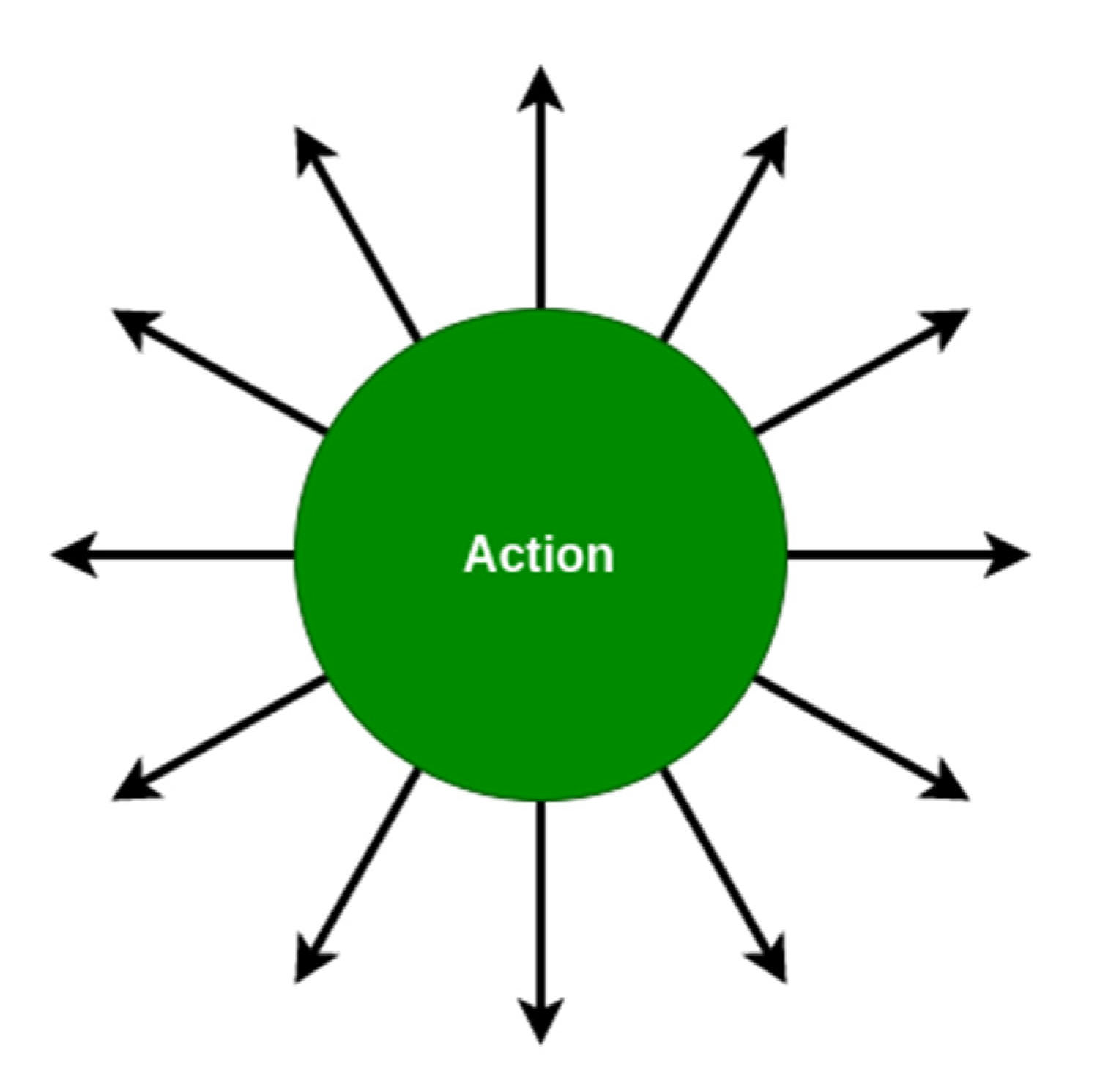
3.2.3. Action Space
3.2.4. Reward Function
3.3. Autonomous Obstacle Avoidance
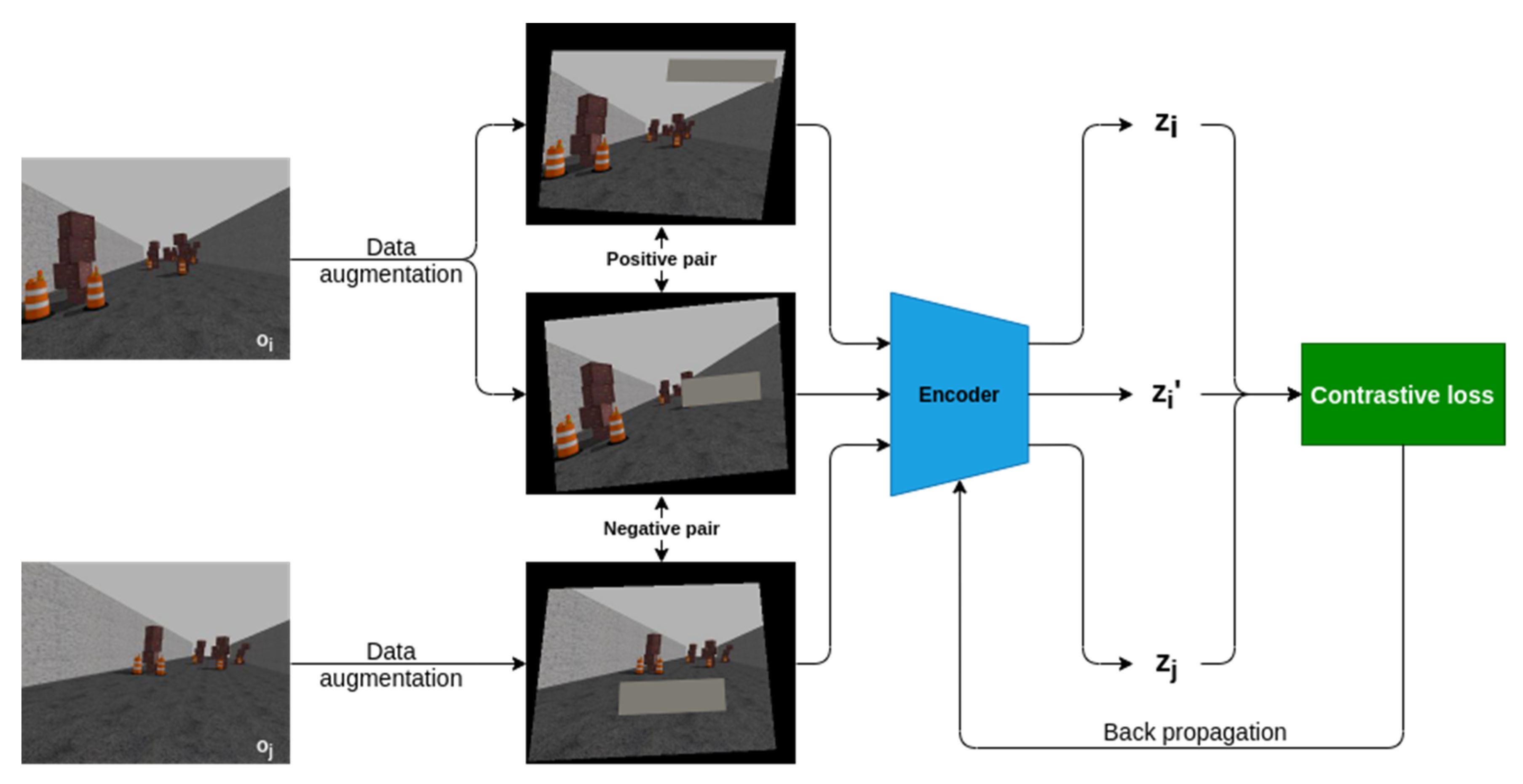
3.3.1. Random Data Augmentation
3.3.2. Feature Extraction Network
3.3.3. Contrastive Loss
3.3.4. Decision Making Network
3.3.5. Observation and Action Space
3.3.6. Reward Function
4. Experiments
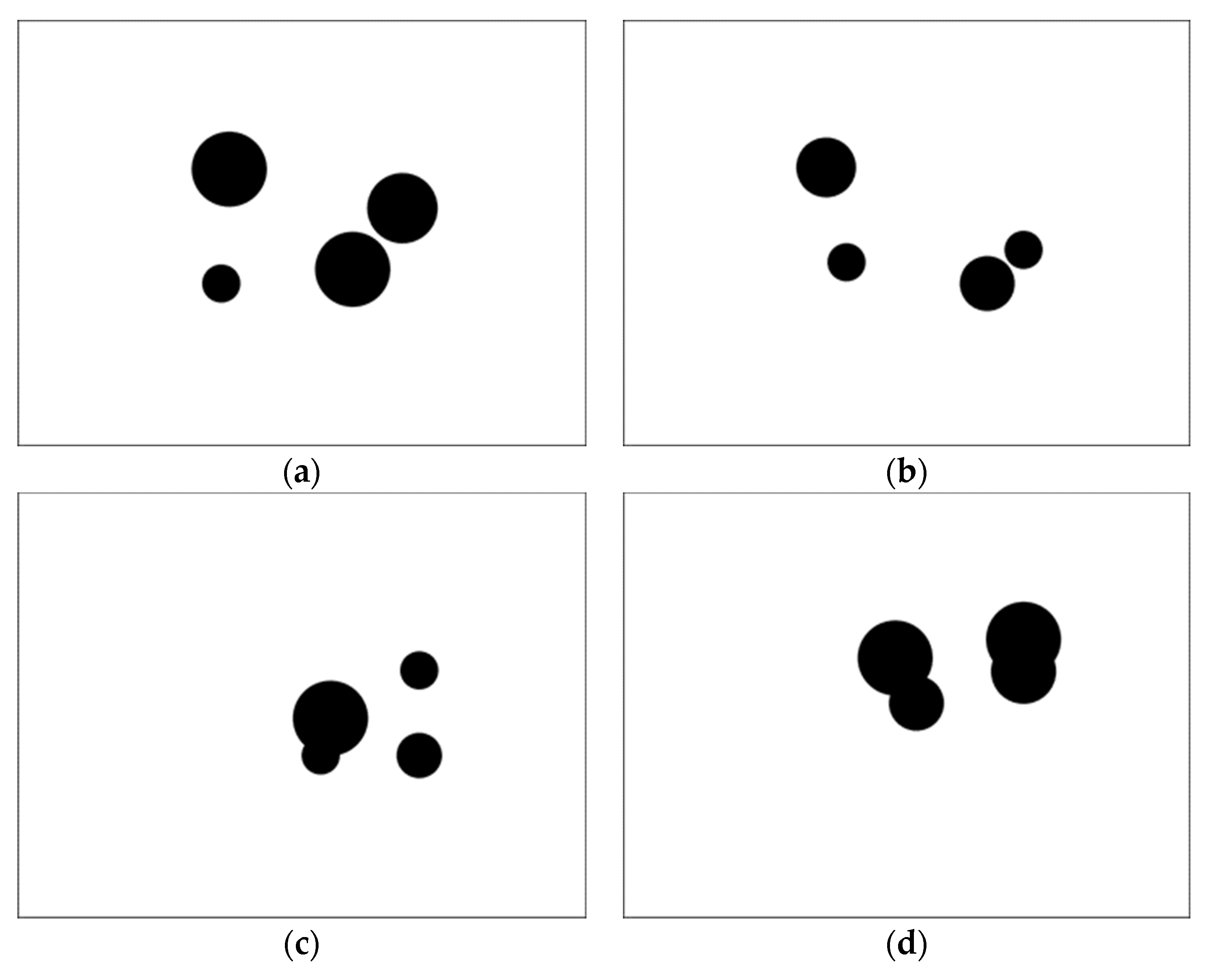
4.1. Global Path Planning
4.1.1. Training Setup
| Algorithm 1. Algorithm for global path planning |
| Require: max epoch number |
| Require: planner network and parameters of planner network |
| Require: random action rate |
| Require: current location and goal location |
| Training phase |
| while do |
| Reset the initial state |
| , local memory = [] |
| while do |
| Obtain current observation |
| Randomly generate |
| if then |
| Randomly choose an action |
| else |
| Choose action based on and Equation (6) |
| end if |
| Update current location |
| Receive reward and in environment |
| Append data to local memory |
| end while |
| Push local memory into replay buffer M |
| Randomly select one batch of training data in M |
| Calculate loss based on Equation (4) |
| Upate to minimize loss |
| end while |
| Return and |
| Testing phase |
| Reset the initial state |
| while do |
| Obtain current observation |
| Choose optimal action based on and Equation (6) |
| Update current location and append it into path |
| end while |
| Return path |
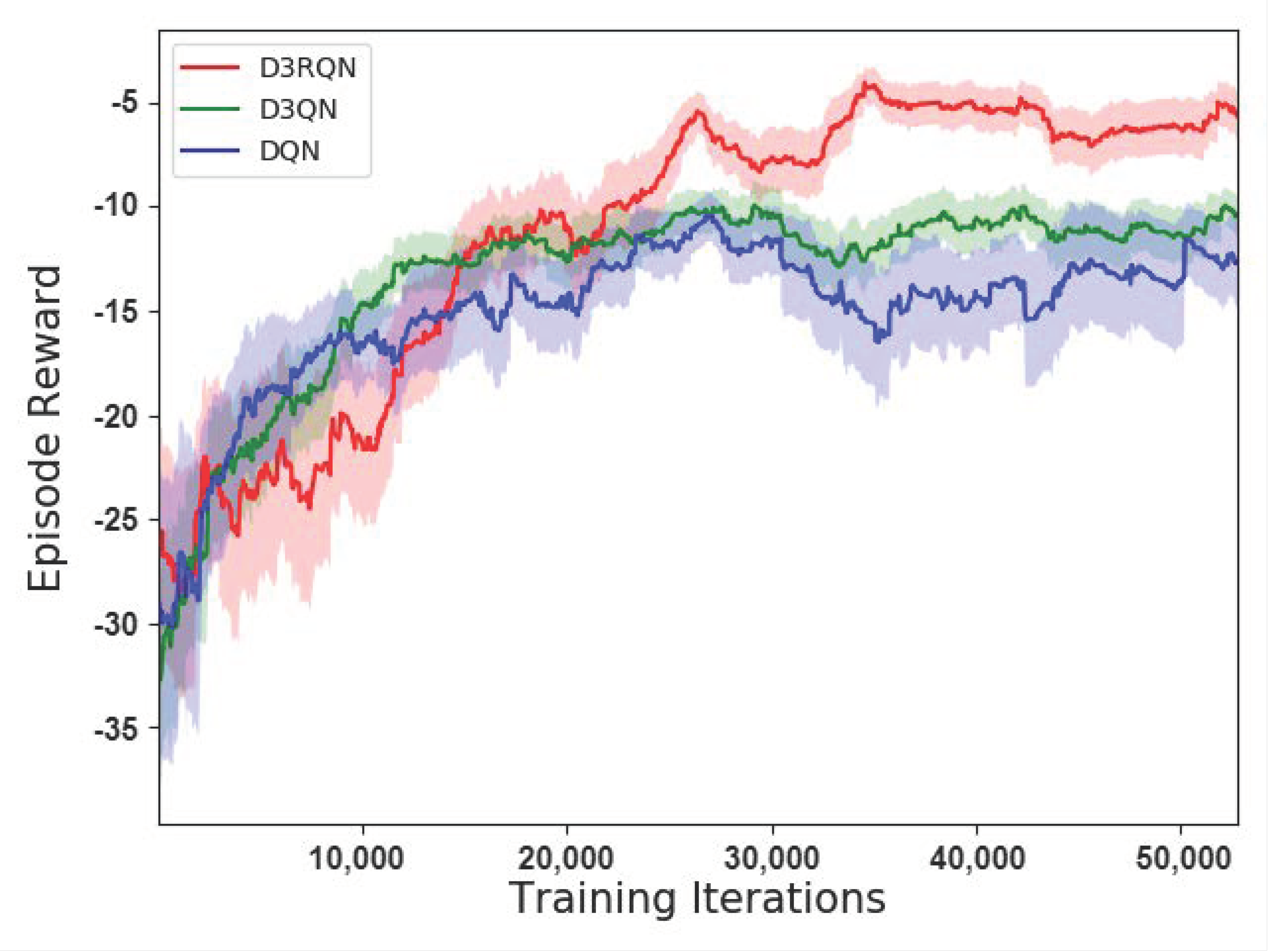
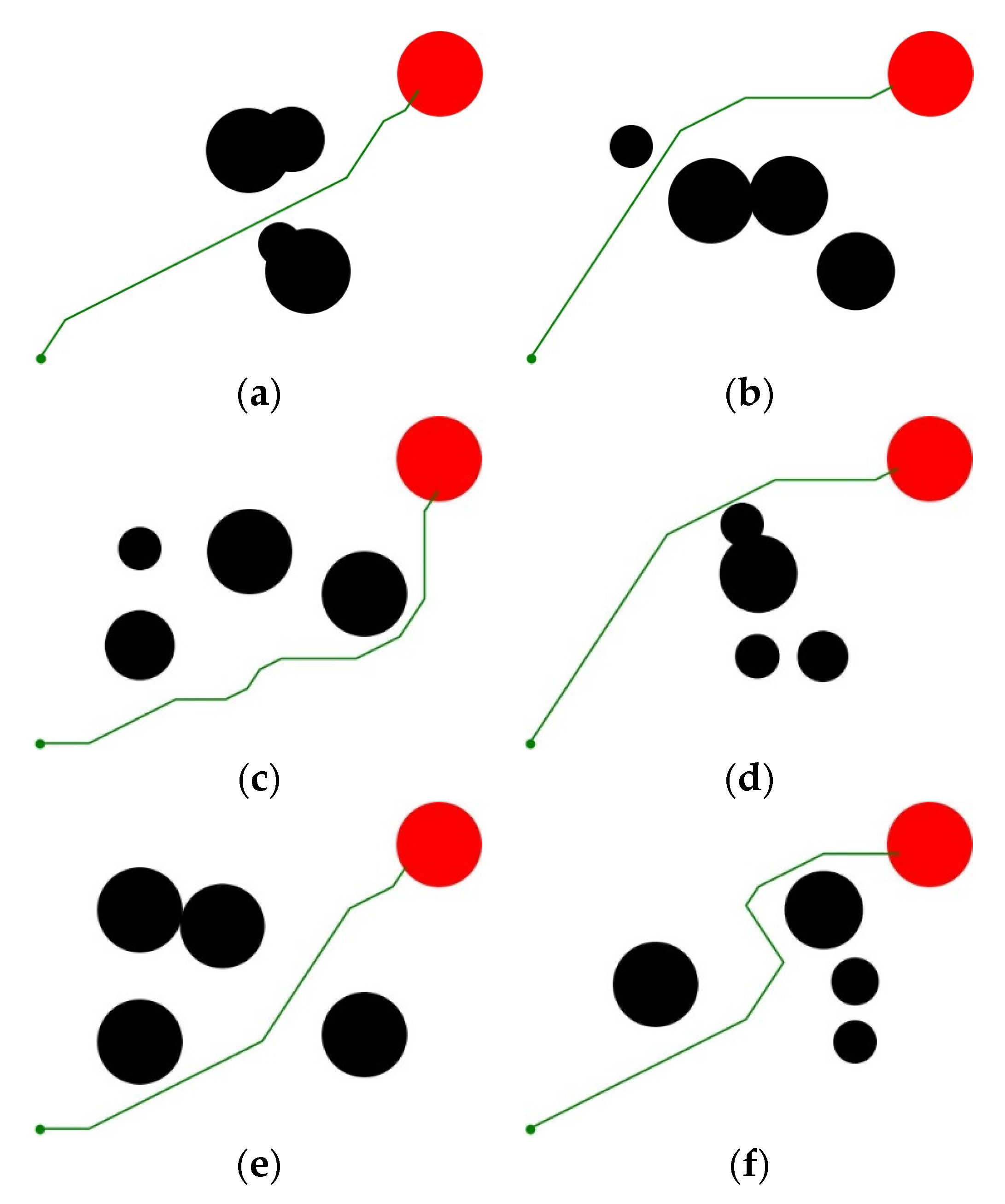
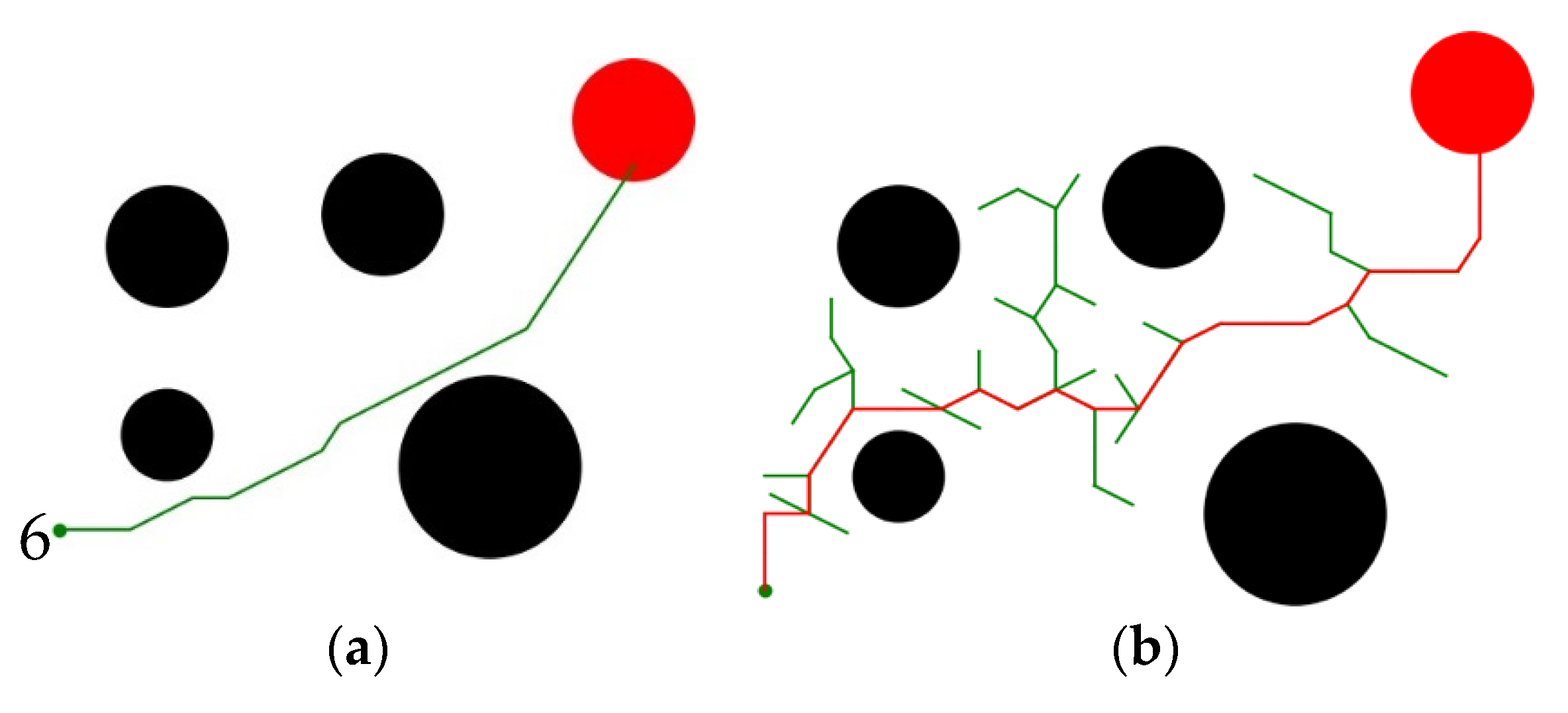
4.1.2. Results Analysis
4.2. Autonomous Obstacle Avoidance
4.2.1. Training Setup
| Algorithm 2. Algorithm for obstacle avoidance |
| Require: Encoder network and parameters of the Encoder Require: D3RQN and parameters of D3RQN Require: max epoch number for training the Encoder Require: max epoch number for training the D3RQN Require: random data augmentation Require: max step number Require: random action rate Encoder training phase while do Randomly select two batch of training data and Extract feature vector , , Calculate loss based on Equation (8) Update to minimize loss end while Return and D3RQN training phase while do Reset the initial state , local memory = [] while no collide do Obtain current observation Randomly generate if then Randomly choose an action else Choose action based on and Equation (6) end if Update current quadrotor location Receive reward and in environment Append data to local memory end while Push local memory into replay buffer Randomly select one batch of training data in Calculate loss based on Equation (4) Upate to minimize loss end while Return and Testing phase Reset the initial state while and no collide do Obtain current observation Choose optimal action based on and Equation (6) Update quadrotor location end while if then Return success end if |
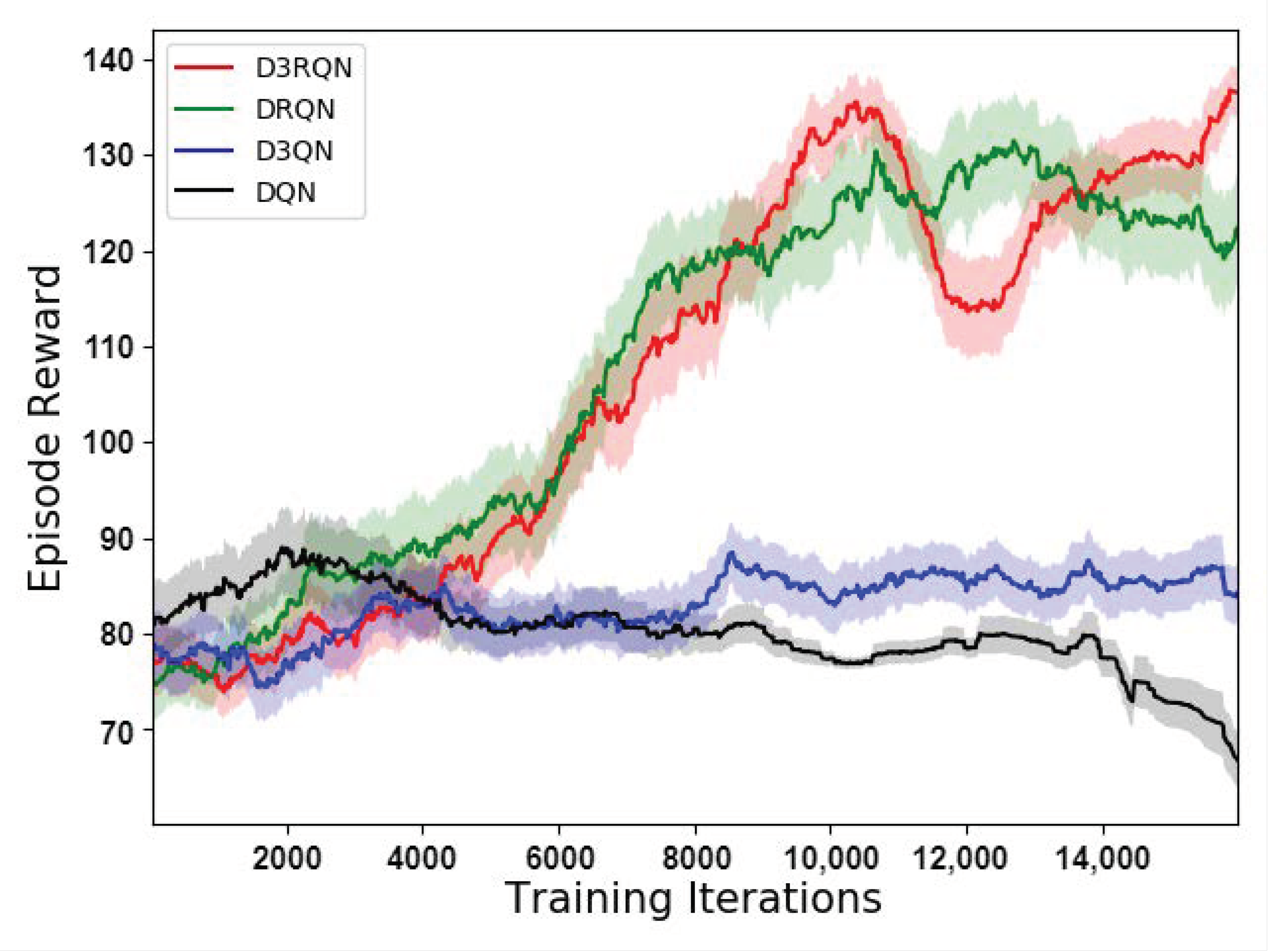
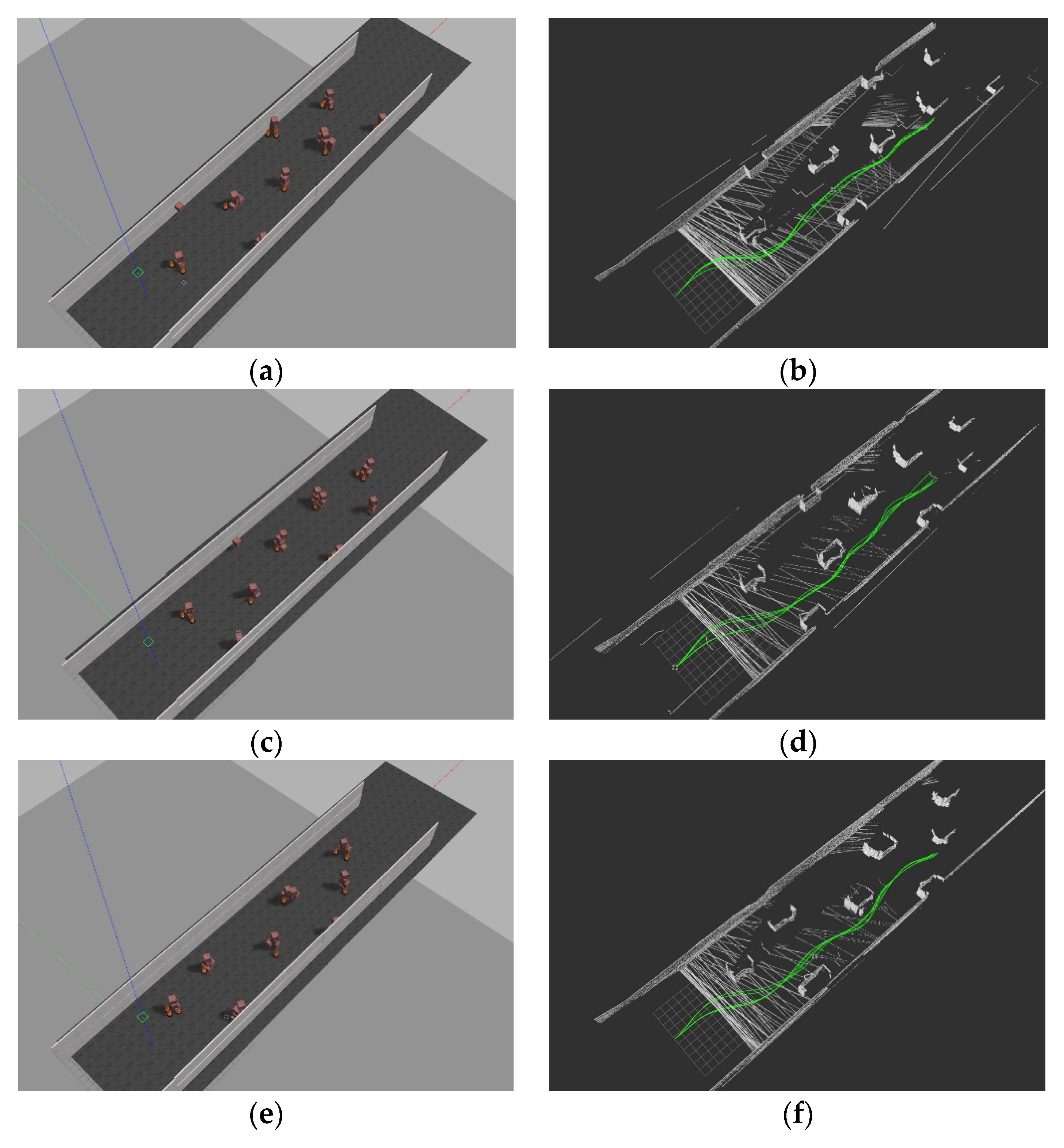
4.2.2. Results Analysis
5. Discussion
- In this paper, an multi-layer CNN based encoder is used for extracting the visual representation of onboard camera observations, which is trained with unsupervised contrastive learning. The trained encoder is applied to autonomous obstacle avoidance of the quadrotor. Its training requires no groundtruth or special format for the training dataset, while some other perception methods based on depth estimation via unsupervised learning require a special format for training datasets such as left-right consistency or sequence consistency [23,24,25,26]. Moreover, the trained encoder in this paper is only 42.2 MB, and the total number of parameters is 4,379,680. The depth estimation model is 126.4 MB in [24] with a total number of 31,596,900 parameters. So the proposed encoder model is more lightweight, making it more suitable for quadrotor applications.
- The proposed method can be used in global path planning. Compared with other traditional methods like RRT, our method has the ability to generate feasible paths more effectively. In the process of path planning, our method does not need detection or random path exploration, so it has higher execution efficiency. In each step of path planning, it selects the optimal action according to the trained policy. In the evaluation, it successfully plans the path with an average of 22.31 steps, which is much lower than the 39.68 steps of RRT. Also, its path planning success rate is also better than its competitors DQN and D3QN.
- In this paper, the conduction of autonomous obstacle avoidance of the quadrotor was undertaken based on the image data captured by a fixed on-board monocular camera. The autonomous obstacle avoidance can be considered as POMDP. The incomplete observation of the sensor leads to the significant performance degradation of the DQN and D3QN models. In the evaluation, the success rate of the DQN and D3QN was only slightly higher than 10%. By adding a recurrent neural network layer, the DRQN and D3RQN model can reduce the negative impact of incomplete observation, and significantly improve the success rate. By combining the dueling and double technique, the performance of the D3RQN model is further improved, reaching more than 99% in the evaluation. Moreover, the whole obstacle avoidance model, combined with the preprocessing encoder, can run at a maximum frequency of 15 Hz on the test computer, so it is possible to control an actual quadrotor.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef] [Green Version]
- LaValle, S.M. Rapidly-Exploring Random Trees: A New Tool for Path Planning. Research Report. 1999. Available online: https://www.cs.csustan.edu/~xliang/Courses/CS4710-21S/Papers/06%20RRT.pdf (accessed on 22 October 2021).
- Zhang, Z. Microsoft kinect sensor and its effect. IEEE Multimed. 2012, 19, 4–10. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Montemerlo, M.; Thrun, S. Simultaneous localization and mapping with unknown data association using FastSLAM. In Proceedings of the 2003 IEEE International Conference on Robotics and Automation (Cat. No. 03CH37422), Taipei, Taiwan, 14–19 September 2003; Volume 2, pp. 1985–1991. [Google Scholar]
- Kalogeiton, V.S.; Ioannidis, K.; Sirakoulis, G.C.; Kosmatopoulos, E.B. Real-time active SLAM and obstacle avoidance for an autonomous robot based on stereo vision. Cybern. Syst. 2019, 50, 239–260. [Google Scholar] [CrossRef]
- Song, K.T.; Chiu, Y.H.; Kang, L.R.; Song, S.H.; Yang, C.A.; Lu, P.C.; Ou, S.Q. Navigation control design of a mobile robot by integrating obstacle avoidance and LiDAR SLAM. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 1833–1838. [Google Scholar]
- Wen, S.; Zhao, Y.; Yuan, X.; Wang, Z.; Zhang, D.; Manfredi, L. Path planning for active SLAM based on deep reinforcement learning under unknown environments. Intell. Serv. Robot. 2020, 13, 263–272. [Google Scholar] [CrossRef]
- Li, J.; Bi, Y.; Lan, M.; Qin, H.; Shan, M.; Lin, F.; Chen, B.M. Real-time simultaneous localization and mapping for uav: A survey. In Proceedings of the International Micro Air Vehicle Competition and Conference, Beijing, China, 17–22 October 2016; pp. 237–242. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 2016, 17, 1334–1373. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Xia, Y.; Shen, G. A novel learning-based global path planning algorithm for planetary rovers. Neurocomputing 2019, 361, 69–76. [Google Scholar] [CrossRef] [Green Version]
- Qureshi, A.H.; Simeonov, A.; Bency, M.J.; Yip, M.C. Motion planning networks. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2118–2124. [Google Scholar]
- Yu, X.; Wang, P.; Zhang, Z. Learning-Based End-to-End Path Planning for Lunar Rovers with Safety Constraints. Sensors 2021, 21, 796. [Google Scholar] [CrossRef]
- Wu, K.; Esfahani, M.A.; Yuan, S.; Wang, H. TDPP-Net: Achieving three-dimensional path planning via a deep neural network architecture. Neurocomputing 2019, 357, 151–162. [Google Scholar] [CrossRef]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. arXiv 2014, arXiv:1406.2283. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chil, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Hua, Y.; Tian, H. Depth estimation with convolutional conditional random field network. Neurocomputing 2016, 214, 546–554. [Google Scholar] [CrossRef]
- Kuznietsov, Y.; Stuckler, J.; Leibe, B. Semi-supervised deep learning for monocular depth map prediction. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6647–6655. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Yin, Z.; Shi, J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1983–1992. [Google Scholar]
- Chen, L.; Tang, W.; Wan, T.R.; John, N.W. Self-supervised monocular image depth learning and confidence estimation. Neurocomputing 2020, 381, 272–281. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- Laskin, M.; Srinivas, A.; Abbeel, P. Curl: Contrastive unsupervised representations for reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Montréal, QC, Canada, 6–8 July 2020; pp. 5639–5650. [Google Scholar]
- Yang, S.; Meng, Z.; Chen, X.; Xie, R. Real-time obstacle avoidance with deep reinforcement learning Three-Dimensional Autonomous Obstacle Avoidance for UAV. In Proceedings of the 2019 International Conference on Robotics, Intelligent Control and Artificial Intelligence, Shanghai, China, 20–22 September 2019; pp. 324–329. [Google Scholar]
- Han, X.; Wang, J.; Xue, J.; Zhang, Q. Intelligent decision-making for 3-dimensional dynamic obstacle avoidance of UAV based on deep reinforcement learning. In Proceedings of the 2019 11th International Conference on Wireless Communications and Signal Processing (WCSP), Xi’an, China, 23–25 October 2019; pp. 1–6. [Google Scholar]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3357–3364. [Google Scholar]
- Ou, J.; Guo, X.; Zhu, M.; Lou, W. Autonomous quadrotor obstacle avoidance based on dueling double deep recurrent Q-learning with monocular vision. Neurocomputing 2021, 441, 300–310. [Google Scholar] [CrossRef]
- Singla, A.; Padakandla, S.; Bhatnagar, S. Memory-based deep reinforcement learning for obstacle avoidance in UAV with limited environment knowledge. IEEE Trans. Intell. Transp. Syst. 2021, 22, 107–118. [Google Scholar] [CrossRef]
- Xie, L.; Wang, S.; Markham, A.; Trigoni, N. Towards monocular vision based obstacle avoidance through deep reinforcement learning. arXiv 2017, arXiv:1706.09829. [Google Scholar]
- Shin, S.Y.; Kang, Y.W.; Kim, Y.G. Reward-driven U-Net training for obstacle avoidance drone. Expert Syst. Appl. 2020, 143, 113064. [Google Scholar] [CrossRef]
- Hausknecht, M.; Stone, P. Deep recurrent q-learning for partially observable mdps. In 2015 AAAI Fall Symposium Series; AAAI: Menlo Park, CA, USA, 2015. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Van Hasselt, H.; Lanctot, M.; De Freitas, N. Dueling network architectures for deep reinforcement learning. arXiv 2015, arXiv:1511.06581. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Input Size | Output Size | Kernel | Stride | Padding |
|---|---|---|---|---|---|
| Conv1 | 3 | 6 | 8 | 4 | 0 |
| Conv2 | 6 | 12 | 4 | 2 | 0 |
| Conv3 | 12 | 24 | 3 | 2 | 0 |
| LSTM | 1152 | 1152 | - | - | - |
| FC (advantage) | 1152 | 12 | - | - | - |
| FC (value) | 1152 | 1 | - | - | - |
| Layer | Input Size | Output Size | Kernel | Stride | Padding |
|---|---|---|---|---|---|
| Conv1 | 3 | 32 | 7 | 2 | 3 |
| Conv2 | 32 | 32 | 7 | 0 | 3 |
| Conv3 | 32 | 64 | 5 | 2 | 2 |
| Conv4 | 64 | 64 | 5 | 0 | 2 |
| Conv5 | 64 | 128 | 3 | 2 | 1 |
| Conv6 | 128 | 128 | 3 | 0 | 1 |
| Conv7 | 128 | 256 | 3 | 2 | 1 |
| Conv8 | 256 | 256 | 3 | 0 | 1 |
| Conv9 | 256 | 128 | 3 | 2 | 1 |
| Conv10 | 128 | 128 | 3 | 0 | 1 |
| FC | 10,240 | 256 | - | - | - |
| Layer | Input Size | Output Size |
|---|---|---|
| FC1 | 256 | 1024 |
| FC2 | 1024 | 1024 |
| FC3 | 1024 | 1024 |
| LSTM | 1024 | 1024 |
| FC (advantage) | 1024 | 5 |
| FC (value) | 1024 | 1 |
| Action Number | Linear Velocity (m/s) | Angular Velocity (rad/s) |
|---|---|---|
| (x, y, z) | (x, y, z) | |
| 1 | (2, 0, 0) | (0, 0, 0) |
| 2 | (2, 0, 0) | (0, 0, 0.25) |
| 3 | (2, 0, 0) | (0, 0, −0.25) |
| 4 | (2, 0, 0) | (0, 0, 0.5) |
| 5 | (2, 0, 0) | (0, 0, −0.5) |
| Parameters | Value |
|---|---|
| Map size | 120*160 |
| Obstacle number | 4 |
| Batch size | 32 |
| Discount factor | 0.99 |
| Learning rate | 0.00005 |
| Input sequence length | 5 |
| Action number | 12 |
| Step length | 7 |
| Target network update frequency | 1000 |
| Optimizer | Adam |
| Policy | SR (30 Steps) | SR (50 Steps) | SR (100 Steps) | AS |
|---|---|---|---|---|
| Random | 0 | 0 | 0 | - |
| DQN | 0.612 | 0.625 | 0.629 | 24.22 |
| D3QN | 0.735 | 0.738 | 0.740 | 23.95 |
| RRT | 0.926 | 0.968 | 0.997 | 39.68 |
| D3RQN | 0.972 | 0.973 | 0.973 | 22.31 |
| Parameters | Value |
|---|---|
| Image number | 10,000 |
| Batch size | 64 |
| Learning rate | 0.00005 |
| Image size | 3*240*320 |
| Feature dim | 256 |
| Optimizer | Adam |
| Parameters | Value |
|---|---|
| Batch size | 32 |
| Discount factor | 0.99 |
| Learning rate | 0.00005 |
| Input sequence length | 5 |
| Action time interval | 0.4 s |
| Target network update frequency | 400 |
| Optimizer | Adam |
| Policy | Training Time | Execution Frequency | Success Rate |
|---|---|---|---|
| Straight | - | - | 0 |
| Random | - | - | 0.002 |
| DQN | 10.2 h | 15 Hz | 0.113 |
| D3QN | 11.5 h | 15 Hz | 0.144 |
| DRQN | 16.1 h | 15 Hz | 0.732 |
| D3RQN | 16.0 h | 15 Hz | 0.996 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ou, J.; Guo, X.; Lou, W.; Zhu, M. Quadrotor Autonomous Navigation in Semi-Known Environments Based on Deep Reinforcement Learning. Remote Sens. 2021, 13, 4330. https://doi.org/10.3390/rs13214330
Ou J, Guo X, Lou W, Zhu M. Quadrotor Autonomous Navigation in Semi-Known Environments Based on Deep Reinforcement Learning. Remote Sensing. 2021; 13(21):4330. https://doi.org/10.3390/rs13214330
Chicago/Turabian StyleOu, Jiajun, Xiao Guo, Wenjie Lou, and Ming Zhu. 2021. "Quadrotor Autonomous Navigation in Semi-Known Environments Based on Deep Reinforcement Learning" Remote Sensing 13, no. 21: 4330. https://doi.org/10.3390/rs13214330
APA StyleOu, J., Guo, X., Lou, W., & Zhu, M. (2021). Quadrotor Autonomous Navigation in Semi-Known Environments Based on Deep Reinforcement Learning. Remote Sensing, 13(21), 4330. https://doi.org/10.3390/rs13214330