Abstract
Methane steam reforming (MSR) is the most widely used industrial process for hydrogen production. However, catalyst deactivation, carbon emissions, and energy inefficiencies limit its sustainable performance. Therefore, improving catalyst selection and optimizing operating conditions are essential for efficient hydrogen generation. This study proposes an artificial intelligence-driven framework to optimize catalyst–condition combinations in MSR systems. The framework integrates Hybrid Golden Beetle Optimization (HGBO), VIKOR-based multi-criteria decision making, and Convolutional Long Short-Term Memory (ConvLSTM) modeling. HGBO explores the solution space and generates Pareto-optimal combinations of catalysts and operating conditions. These solutions are then ranked using the VIKOR method. The ranking considers hydrogen yield, methane conversion, energy efficiency, CO2 emissions, and catalyst lifetime. Economic feasibility is also included in the decision process. ConvLSTM modeling captures spatiotemporal relationships in catalyst and process data and predicts catalyst degradation under different operating conditions. The framework is evaluated using 620 experimentally reported MSR cases collected from the published literature within industrial ranges of 600–1200 °C, 1–40 bar, and H2O/CH4 ratios of 1–6. The optimized configurations achieve hydrogen yields up to 98.5%, energy efficiency approaching 99%, and reduced CO2 emissions of about 0.85 kg h−1. The results provide practical guidance for catalyst selection and process optimization in industrial hydrogen production systems.
1. Introduction
Methane steam reforming (MSR) is the predominant industrial method for hydrogen production, where methane reacts with steam in the presence of a catalyst to produce hydrogen and carbon monoxide [1]. The key difficulty in the process is the possibility to have high hydrogen selectivity and, at the same time, to reduce unwanted byproducts like CO2 and carbon deposits on the catalyst surface [2]. Recent developments show that artificial intelligence (AI) under the condition of implementing methods of deeper reactor and process optimization can significantly increase the activity of catalysts and the overall efficiency of the process [3]. Optimization with the assistance of AI allows decreasing carbon footprint and operating expenses, which contributes to the switch to a low-carbon hydrogen economy [4].
The traditional methods, like the trial-and-error-based methods using experimental trials, density functional theory (DFT), and detailed kinetic modeling, are still confined by expensive, lengthy development time and a lack of generalization to operating conditions. Even though AI-based approaches such as artificial neural networks (ANNs) and GA are showing promise in modeling and optimization in MSR, they are often prone to premature convergence, lack sensitivity to limited datasets, and lack interpretability [5]. As a result, there is an increasing demand to use AI frameworks that are robust and interpretable, as well as to include mechanistic awareness to achieve reliable and sustainable catalyst optimization in MSR [6].
This requirement aligns with the global transition toward low-carbon and sustainable hydrogen generation routes [7]. According to Figure 1, AI-based optimization enhances the catalyst micro-activity and performance of MSR through higher hydrogen production, less energy use, and less carbon dioxide emission. This type of synergistic combination of AI with catalytic process optimization has quantifiable environmental and economic impacts, and it is a future perspective of scalable and sustainable hydrogen generation.
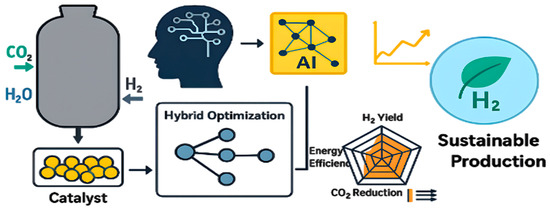
Figure 1.
AI-driven catalyst optimization framework for MSR within industrial operating ranges (600–1200 °C, 1–40 bar, H2O/CH4 = 1–6).
This study introduces HGBO, which represents a hybridization of Golden Jackal Optimization (GJO) and Dung Beetle Optimizer (DBO), adapted in this work for multi-objective catalyst optimization in MSR [8]. The main pillars of the research are scientific validity and repeatability; thus, the framework is applied to the 620-entry experimental dataset, where each entry corresponds to a unique catalyst–operating-condition combination collected from published methane steam reforming experiments, made up of Ni-based, Rh-based, Ru-based, perovskite, and bimetallic catalysts that have been systematically collected. Experimental conditions include 600–1200 °C, 1–40 bar pressure, and H2O/CH4 ratios of 1–6, which are industry-relevant operating ranges. The decision variables in the current formulation comprise a combination of catalyst-related (e.g., Ni loading, promoter content, type of support, and dispersion index) and process-operating (reactor temperature, system pressure, and ratio of H2O/CH4 = 1–6) variables within experimentally reported industrial constraints (600–1200 °C, 1–40 bar, and H2O/CH4 = 1–6). The optimization thus provides a combined solution to the composition of the catalyst and the choice of operating window within prescribed limits [9]. The catalyst is also compared to these well-defined criteria: optimization of the hydrogen yield, enhancement of energy efficiency, minimization of CO2 release, and extended catalyst life.
The combination of the HGBO with VIKOR (VlseKriterijumska Optimizacija i Kompromisno Resenje) and ConvLSTM offers a complete, consistent, and information-driven model performance, which increases performance control and sustainability trade-offs and catalyst degradation at the same time [10]. It is this synthesizing framework that renders the current study unique, as it integrates hybrid metaheuristic optimization, structured multi-criteria decision making, and spatiotemporal degradation modeling within a unified data-driven pipeline [11].
In contrast to a first-ever framework, the contribution made here is a coherent fusion of these approaches and the simultaneous application of all of them to discuss the question of catalyst selection, sustainability trade-offs, and the analysis of long-term stability. Such collective form of treatment is the reverse of prior AI-focused optimization work, which has explored such aspects individually. Convolutional Long Short-Term Memory (ConvLSTM) network is created and is applied to detect changes in spatiotemporal patterns of catalyst process data, and this can be utilized to draw predictive models on degradation and performance trends [12].
Multi-domain feature fusion is also used as part of the strategy, which combines physicochemical, operational, statistical, and spectral descriptors to give a full picture of catalyst process interactions in MSR. A comprehensive list of Ni-based, noble-metal-based, perovskite-based, and bimetallic catalysts were collected, including physicochemical, operational, and environmental characteristics [13]. The multi-domain feature engineering retrieves both static and dynamic trends in catalyst performance. Pareto-optimal catalyst rankings are obtained with the combination of HGBO and VIKOR, which elucidates trade-offs among hydrogen yield, energy efficiency, CO2 emissions, and economic viability. According to the model-based analysis, hydrogen yield predictions reach up to 98.5% under specified operating conditions, demonstrating better robustness than baseline methods (Random Search, GA, PSO, and SVR) under similar computational conditions.
Although numerous studies have utilized artificial neural networks, genetic algorithms, particle swarm optimization, and other metaheuristic methods in methane steam reforming, most reported studies focus on catalyst screening, optimization of operating parameters, or degradation analysis individually. The current study stands out in that it incorporates hybrid global–local optimization (HGBO), formal compromise-based multi-criteria ranking (VIKOR), and spatiotemporal degradation-aware modeling (ConvLSTM) into a single structure within a realistic industrial operating framework. This synchronized integration supports simultaneous performance optimization and lifetime-conscious sustainability assessment under uniform decision criteria.
The current research is structured as follows. Section 2 discusses existing approaches to catalyst optimization and the application of AI in methane steam reforming, highlighting current limitations and research gaps. Section 3 presents the proposed AI-based framework, detailing the hybrid HGBO–VIKOR optimization approach, data preprocessing, multi-domain feature extraction, and the ConvLSTM-based predictive model for catalyst performance and degradation assessment. Section 4 provides the experimental evaluation of the framework, including comparative analysis with baseline optimization and predictive methods under industrially relevant operating conditions. Finally, Section 5 summarizes the main findings and outlines future research directions aimed at improving catalyst selectivity, process efficiency, and sustainable hydrogen production via methane reforming.
2. Literature Survey
Recent studies have explored the role of artificial intelligence in improving energy efficiency and reducing emissions in hydrogen and energy production systems [14]. These studies highlight the growing importance of AI-driven optimization approaches in supporting sustainable hydrogen production pathways.
Several strategies of multi-objective optimization have also been created to achieve CO2 emission reduction and enhance the thermal efficiency of hydrogen production systems. DNN-based methods with Pareto-front analysis have claimed CO2 emissions of 577.9 to 597.6 t/y and a thermal efficiency of 77.5 to 87.0, which proves that machine learning can be useful in the trade-off analysis [15]. ANNs have simulated the process of methane steam reforming by estimating the outlet of the reactor as per the operating conditions and catalyst parameters [16]. In the same way, the application of the computed fluid dynamic (CFD) models has proposed optimum working conditions of the membrane-based SMR systems, such as optimal gas hourly space velocity, pressure, and inlet temperature [17].
The developments of catalyst design have been directed towards the enhancement of dispersion, promoter effects and support interactions. It has been found that porous Ni-Cu/Al2O3 catalysts are more efficient in the production of hydrogen during bioethanol reforming [10]. Recent catalyst research has also explored heterogeneous catalytic systems for hydrogen generation and storage materials, highlighting the importance of catalyst design and reaction mechanisms in improving hydrogen production efficiency [18]. Ni-based catalysts have been modified with promoters such as Ni/CeO2/Al2O3 and La promotion of Ni/Al2O3 systems, which have proven to be more stable and active, as demonstrated by advanced characterization methods [19].
Multi-objective evolutionary algorithms such as NSGA-II have seen wide application on an optimization front in constructing Pareto fronts in energy systems and provide a structured trade-off control between competing objectives [20,21,22]. Further, interpretable machine learning methods such as SHAP have been applied to improve transparency in catalyst and process modeling by evaluating the contribution of input features in hydrogen production systems [11,14]. Recent studies have also employed time-series deep learning models, such as LSTM-based frameworks, for dynamic modeling of hydrogen energy systems, including automotive proton exchange membrane fuel cell (PEMFC) applications. These approaches demonstrate the capability of recurrent neural networks to capture temporal dependencies in hydrogen system performance data and highlight the importance of advanced temporal modeling techniques. Such developments motivate the adoption of spatiotemporal architectures, such as ConvLSTM, for modeling catalyst performance and process dynamics in methane steam reforming [18].
Even with such developments, the current literature often discusses the composition of catalysts, the conditions of the process, and the behavior of degradation separately. Co-optimization of multi-objective optimization, structured decision-making and the spatiotemporal degradation modeling in a single MSR catalyst process co-optimization framework is limited [23]. In turn, it is necessary to have a methodology that would be able to deal with nonlinear trade-offs, balanced exploration–exploitation dynamics, and prediction that would consider degradation in catalyst selection under industry-constrained conditions [24].
The global transition toward low-carbon energy systems highlights the growing need to produce hydrogen in a reliable, efficient, and sustainable manner [25]. With the increasing adoption of hydrogen in downstream energy applications, particularly proton exchange membrane fuel cells (PEMFCs), hydrogen purity, supply stability, and catalyst durability have become critical performance requirements [26]. Fuel cell systems require high-quality hydrogen to maintain efficiency, long-term stability, and safe operation in energy conversion applications. Consequently, improvements in catalyst performance and process optimization in methane steam reforming are important for supporting hydrogen energy infrastructures and fuel cell technologies. Such evolving requirements emphasize the importance of advanced AI-based optimization frameworks that integrate physicochemical properties, operating constraints, and sustainability considerations in methane steam reforming processes [27].
As summarized in Table 1, existing AI-driven MSR studies primarily address either process optimization, catalyst screening, or predictive modeling independently [1,8,15,16,20,25]. While multi-objective strategies have been reported, formal compromise-based decision-making and degradation-aware predictive modeling are rarely integrated within a unified framework.

Table 1.
Comparative assessment of AI-driven MSR optimization frameworks.
The present study distinguishes itself through
- Hybrid global–local metaheuristic optimization (HGBO);
- Formal VIKOR-based compromise ranking;
- Spatiotemporal degradation-aware ConvLSTM modeling;
- Strict enforcement of industrially realistic operating bonds.
This coordinated integration enables simultaneous catalyst–process co-optimization under five explicitly defined objectives, providing a structured and industrially interpretable decision framework beyond prior approaches, as shown in Table 1.
3. Materials and Methods
3.1. AI-Driven Catalyst Selection in Methane Steam Reforming
The operational window of MSR was limited to a temperature range of 600–1200 °C, system pressure between 1 and 40 bar, and H2O/CH4 molar ratios between 1 and 6. Feed inlet temperatures were maintained at 200–400 °C, while the gas hourly space velocity (GHSV) was maintained within 5000–20,000 h−1, which is consistent with industrial operating conditions. These limits were established based on reported conditions where catalyst deactivation, coke formation, and efficiency trade-offs are most significant.
The assembled database primarily represents fixed-bed tubular reactor designs commonly used in laboratory-scale and pilot-scale MSR experiments. The catalyst mass in the reactor bed ranged from 0.5 g to 5 g, with gas residence times between 0.25 s and 2.5 s under GHSV conditions of 5000–20,000 h−1. Reactor geometry (tube diameter and bed length) and catalyst morphology (pelletized or supported particles) influence heat transfer, pressure drop, and effective contact time. These factors were considered indirectly through the reported GHSV, pressure drop, and conversion data.
To achieve scientific reproducibility, a sample of 620 experimental entries was compiled systematically based on peer-reviewed literature and industrial data. It comprises Ni-based (Ni/Al2O3, Ni–CeO2, and Ni–MgO), noble-metal-based (Rh/Al2O3, Ru/MgO), and perovskite and bimetallic catalysts over selected temperature, pressure, and steam-to-carbon ratios. Cases were selected as examples of the practical application of the framework. In each case hydrogen yield, CO2 emission, energy efficiency and catalyst life are measured.
The dataset undergoes structured preprocessing. Physicochemical properties and process variables are extracted as model features. Missing values are imputed using the MissForest algorithm to preserve nonlinear relationships. Outliers are identified using the IQR method; however, physically valid extreme operating conditions within industrial MSR ranges are retained after verification. Z-score normalization is applied as the final and consistent feature scaling method across all experiments.
The proposed AI-based catalyst selection model architecture is depicted in Figure 2. It shows the gradual flow from MSR performance data collection to final catalyst ranking through preprocessing, feature engineering, optimization, and predictive modeling. Each step is represented one after the other in the order of data collection, preprocessing, feature extraction, prediction, and evaluation, thus delineating the logical flow from raw data to final catalyst ranking. Furthermore, Figure 2 indicates that the descriptors from four domains, i.e., statistical, time-domain, frequency-domain and material features, are combined with ConvLSTM predictions to achieve strong performance even in unseen conditions. After preprocessing, the feature extraction produces descriptors in four different domains:
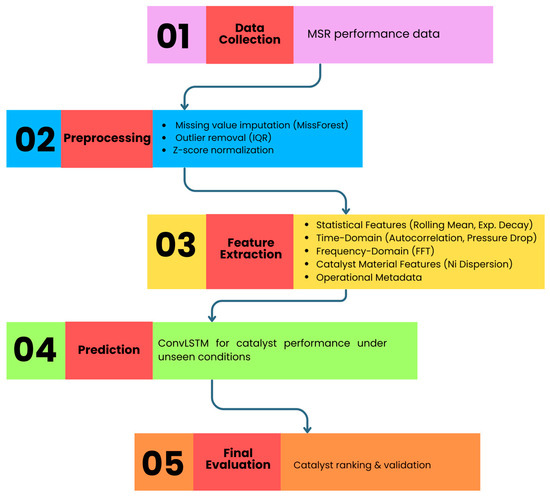
Figure 2.
Architecture of the proposed AI-based catalyst selection model.
- Statistical properties (moving average and decay of exponentially);
- Time-based properties (autocorrelation and total pressure drop);
- Frequency-based properties (FFT-oscillatory pattern);
- Catalyst material characteristics (dispersed Ni, promoter content, and support type) together with the operational metadata.
These characteristics together form an all-encompassing view of the catalyst’s performance. The HGBO algorithm is used for optimization, which is a method that fuses global exploration with local exploitation in generating Pareto-optimal solutions. There are four objectives, specifically defined in the first place, from the basis for evaluation of the combinations of catalyst and conditions: (i) achieving a hydrogen yield of over 90% at maximum conditions, (ii) heat duty reduction per H2 produced to increase energy efficiency, (iii) CO2 emission minimization with respect to the baseline SMR for better sustainability, and (iv) catalyst lifetime prolongation for deactivation, sintering, and coking resistance. Economic feasibility is added as one of the secondary constraints to ensure that the performance and cost-effectiveness optimization results are balanced. MCDM through VIKOR subsequently prioritizes such Pareto-optimal solutions over the defined objectives, and ConvLSTM demonstrates the performance of catalysts under unknown operating conditions by capturing both spatiotemporal and spatial dynamics within the processes. This hybrid pipeline proves useful in streamlining an optimization of catalyst–condition sets in relation to methane steam reforming, and as such the structure is robust, repeatable and applicable to industry.
3.2. Methane Steam Reforming
Steam reforming of methane (SRM) is widely regarded as the most used method for hydrogen production. In this proven process, methane reacts with steam to produce CO and H2 (Equation (1)), which is further converted through the water–gas shift reaction (Equation (2)) into hydrogen and CO2 (Equation (3)).
The primary steam reforming reaction (Equation (1): CH4 + H2O ⇌ CO + 3H2) is highly endothermic (ΔG > 0 below 600 °C at 1 bar) due to methane’s strong C–H bond energy (435 kJ/mol). Efficient hydrogen conversion requires Ni-based catalysts, commonly Ni/Al2O3, although issues such as carbon deposition (Equation (4): 2CO ⇌ C + CO2; Equation (5): CH4 ⇌ C + 2H2) and Ni sintering persist.
Extensive research has targeted improved Ni catalysts through novel supports and promoter modifications, while costly noble metals like Ru and Rh offer alternatives.
Figure 3 shows how the MSR process works: methane reacts with steam to produce hydrogen and carbon monoxide. It also illustrates that the reaction requires a high amount of heat and often runs into issues like high operating temperatures and coke buildup. Due to these challenges, researchers are exploring ways to run the reaction at a lower temperature and improve catalyst efficiency.
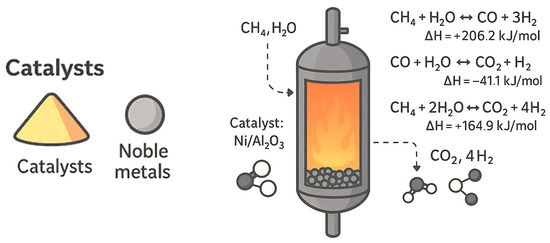
Figure 3.
Reaction scheme of methane steam reforming (MSR) showing primary reforming (600–1200 °C) and associated side reactions under 1–40 bar.
Figure 4 demonstrates the process of the production of hydrogen based on the MSR process, explaining how methane is steadily transformed into the syngas and then enriched to produce hydrogen. It also points out the importance of better catalysts because better catalyst performance translates to increased hydrogen production under normal industrial conditions.
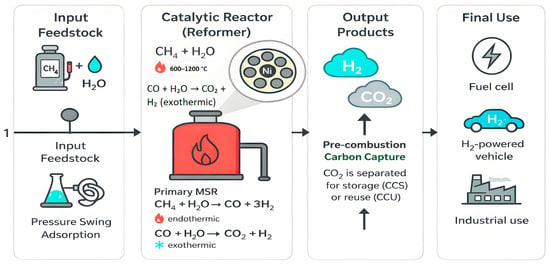
Figure 4.
Hydrogen production pathway in methane steam reforming (MSR) under H2O/CH4 ratios of 1–6 and operating temperatures of 600–1200 °C.
3.3. Thermodynamic Analysis
The Gibbs free energy minimization process is used to test the thermodynamic feasibility of the MSR process. This method calculates the equilibrium composition without requiring the specification of all individual reactions. The total Gibbs free energy is computed as shown in Equation (6).
Aspen Plus uses the RGIBBS reactor module to perform equilibrium calculations by minimizing Gibbs free energy under phase and chemical equilibrium conditions. The Peng–Robinson property method is applied for accurate representation of hydrocarbons, light gases, and their mixtures. All species are considered simultaneously, namely CH4, CO2, CO, H2, H2O, and solid carbon, which enables the identification of stable equilibrium states over a wide operating range.
Figure 5 represents thermodynamic analysis expressed by the minimization of the Gibbs free energy and demonstrates the distribution of the major species at equilibrium. As the number 5 indicates, temperature and pressure play an important role in the manufacturing of hydrogen and development of carbon, and the choice of working conditions to rely on is a crucial decision in making the hydrogen production process a successful and effective one.
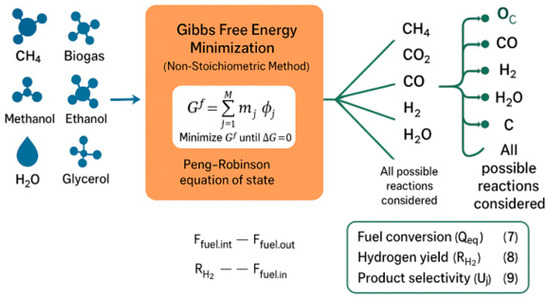
Figure 5.
Thermodynamic equilibrium composition obtained via Gibbs free energy minimization over 600–1200 °C and 1–40 bar.
3.4. CO2 Emission and Energy Efficiency Calculation
CO2 emissions are estimated from steady-state molar flow rates obtained through Gibbs free energy minimization. The mass flow rate of CO2 is calculated as
where n˙CO2 is the outlet molar flow rate and MCO2 is the molar mass of CO2.
Energy efficiency is defined on a lower heating value (LHV) basis as
where n˙H2 is the hydrogen molar production rate and Qinput represents the modeled reformer heat duty under defined operating conditions. Heat duty values are obtained from equilibrium-based Aspen Plus simulations using the RGIBBS reactor module.
All reported energy efficiency values correspond to equilibrium-optimized steady-state conditions within the defined industrial operating window (600–1200 °C, 1–40 bar).
3.5. Hydrogen Yield, Fuel Conversion and Selectivity
The established criteria for assessing the efficacy of the steam reforming system include the different fuels’ equilibrium conversions, , the hydrogen yield, , and the selectivity to product, , as defined as follows in Equations (7)–(9):
where and are the molar flow rates at the intake and the outflow, respectively, is the molar flow rate of hydrogen out of the outlet, is the product’s molar flow rate exiting the reactor, excluding steam and unconverted fuel, and represents a correction factor for the hydrogen flow.
The hydrogen yields of the various fuels (as shown in Figure 6) are also compared at an equal water-to-C ratio, as given in Equation (10). Specifically, the water-to-methane ratio, which is often seen in commercial SRMs, is set at 3. The hydrogen yield for each fuel is computed for a water-to-fuel ratio of x • 3, as shown in Equation (11), to compare the yield for the same water-to-C atom ratio.
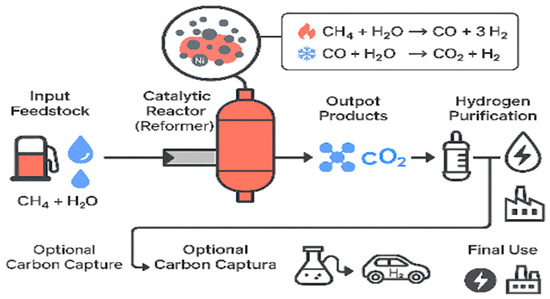
Figure 6.
Comparative hydrogen yield under equal water-to-carbon ratio (H2O/C = 3) within 600–1000 °C equilibrium conditions.
Figure 6 illustrates hydrogen production and its practical applications. The figure shows that when conditions are kept the same, methane provides one of the highest hydrogen yields compared to other common fuels, which is a major reason for its continued widespread industry use. It also demonstrates that changing the water-to-carbon ratio can significantly affect both the amount of hydrogen produced and the selectivity of the process. This helps guide researchers towards better ways to design cleaner and more efficient hydrogen production systems.
3.6. Optimal Catalyst Selection
3.6.1. Overview
The demand for hydrogen production through the MSR process depends on the use of catalysts with high activity, selectivity, stability, and low cost, while the catalyst design must also minimize the adverse effects of coke formation and sintering. Nickel-based catalysts still hold the position of the industrial standard due to their economic viability, although their performance is reduced due to carbon accumulation and almost total loss of catalytic activity. Several modifications have been made in the forms of altered supports (MgO, CeO2), the addition of promoters (K2O, CaO, lanthanides), and synthesis techniques that lead to better dispersion of Ni. Noble metals (Ru, Rh, Pt, and Pd) have high activity but also high prices; hence, they are only used as dopants. Newcomers like perovskites and Cu/Co-based systems, together with AI-driven models, are being investigated to find the optimal operation point.
Figure 7 emphasizes the selection of catalysts in MSR: Ni-based (low cost, coking problems), Rh/Ru (high activity, expensive), and perovskites (stable, regenerable). They allow a compromise among cost, activity, and durability.
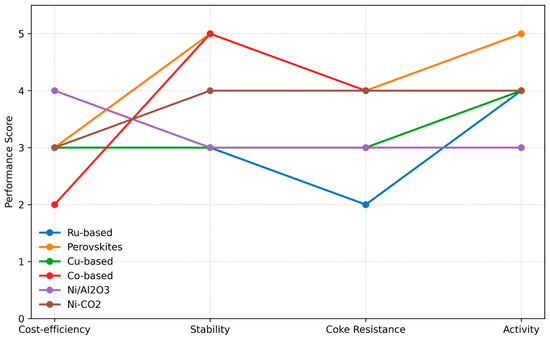
Figure 7.
Catalyst selection map for MSR activity.
Boundary Conditions and Selection Criteria
To achieve a clear methodological understanding and scientific rigor, the parameters of boundary conditions, the criteria of catalyst selection, and MSR cases, which are examined in the current study, are well defined. The bases of these options are both typical industrial practice and experimentally reported values; hence, the findings are realistic and can be replicated by other researchers.
- Boundary Conditions
The MSR process conditions were constrained within industrially relevant limits to ensure realistic simulation scenarios. Reactor temperatures were considered in the range of 600–1200 °C, system pressures between 1 and 40 bar, and H2O/CH4 feed ratios from 1 to 6. In addition, feed inlet temperatures were maintained between 200 and 400 °C, while the gas hourly space velocity (GHSV) varied from 5000 to 20,000 h−1. These parameter ranges were selected based on reported industrial and experimental studies where catalyst deactivation, carbon deposition, and process efficiency trade-offs are most pronounced.
- b.
- Selection Criteria
Four primary objectives were used to evaluate the catalyst condition combinations:
- Hydrogen yield (↑): maximizing H2 selectivity above 90% under benchmark conditions.
- Energy efficiency (↑): reducing heat duty per unit of H2 produced.
- CO2 emissions (↓): minimizing the environmental impact relative to the baseline SMR.
- Catalyst lifetime (↑): ensuring stability against deactivation, sintering, and coking.
In the present research, the definition of catalyst lifetime that is used directly is the time during which hydrogen selectivity declines to under the lowest acceptable rate of 70%. This threshold is chosen according to commonly available industrial deactivation conditions in the literature on methane steam reforming. The lifetime values are directly derived from published time-on-stream experimental data of catalysts. In cases where lifetime values are not explicitly reported, the exponential degradation model in the form of Equations (16) through (18) is employed to determine the lifetime of the catalyst using the calculated decay rate constant (k_d). This guarantees uniformity and transparency in lifetime labeling throughout the dataset that must be gathered.
In addition, economic feasibility was also introduced as a supportive constraint, thus contributing to the balance between sustainability and cost-effectiveness within the framework. It is necessary to emphasize that these requirements are directly related to industrial concerns: more efficient work and higher hydrogen production will result in a decrease in operating costs; a longer catalyst life will result in the reduction of replacement costs and downtimes; and a decrease in CO2 emission will be needed to comply with environmental policies and carbon-neutrality goals.
- c.
- Number of Cases Examined
It is constructed on a dataset of 620 experimental records obtained out of peer-reviewed literature and industrial records. These entries comprise different families of catalysts such as Ni/Al2O3, Ni/CeO2, Rh/MgO, and perovskites, working under different temperatures, pressures, and steam-to-carbon ratios. Representative case studies (e.g., Ni/Al2O3 at 700 °C, Rh/Al2O3 at 600 °C, and Ru/MgO at 800 °C) of this dataset were the examples of practically applied implementation of the framework.
These arguments, along with the definition and characterization of the same, ensure that the optimization of the catalysts in the present study is not limited to theoretical discourse but is based on well-selected experimental evidence under realistic operational regimes. The study identifies the operational limits and can be used as validation cases that show that the framework has been constructed and tested over reproducible experimental limits.
3.6.2. Data Collection
The experimental data pertaining to methane steam reforming have been systematically gathered from peer-reviewed experimental works published in the transparent scientific literature. There were no proprietary or confidential industrial datasets employed in the current work. All the entries are based on publicly available experimental studies to achieve transparency and reproducibility. Each dataset record is the combination of a catalyst and operating condition, where unique catalysts are used with operating-condition parameters and reported indicators of performance.
The input variables in the AI model are
- Operating variables, including reactor temperature (°C) and system pressure (bar), the H2O/CH4 molar ratio, inlet temperature, and gas hourly space velocity (GHSV);
- Catalyst descriptors, including catalyst family, metal loading (wt%), promoter content, support type, Ni particle size, and the dispersion index;
- Characterization parameters, including the BET surface area, XRD crystallinity, SEM/TEM morphology descriptors, and H2-TPR reducibility.
All these variables make up the input features used by the AI-based catalyst optimization framework. Hydrogen selectivity, methane conversion, the CO2 emission rate, energy efficiency, and catalyst lifetime are the output performance metrics that undergo optimization and predictive modeling.
The processed dataset and the scripts employed to execute data processing used in this study are publicly available in the repository mentioned in the Data Availability Statement. The compiled dataset is a result of numerous independent literature sources and experimental campaigns; therefore, stringent screening and harmonization processes were undertaken to regulate heterogeneity. Only experiments that functioned within the industrially relevant boundaries (600–1200 °C, 1–40 bar, H2O/CH4 = 1–6, and GHSV = 5000–20,000 h−1) were kept. Furthermore, only fixed-bed tubular reactor designs were retained to ensure consistent behavior in terms of heat and mass transfer across studies. These limits diminish systematic differences caused by essentially different reactor designs and measurement procedures. Research that used considerably different reactor geometries or non-comparable microreactor systems was eliminated to provide cross-study comparability.
Under benchmark operating conditions, the most significant target variables are hydrogen selectivity, CO2 emissions, and heat duty. The AI-based catalyst modeling and optimization model is based on these standardized datasets [16]. The dataset contained 620 experimental entries meeting the filtering criteria. In this work, the term entry describes one data point corresponding to a specific operating condition and catalyst in experimental methane steam reforming studies. The individual data entries thus indicate a distinct set of catalyst material characteristics and operating conditions of the reactor, such as temperature, pressure, the steam-to-methane ratio, and catalyst composition. These entries relate to the reported performance outputs such as hydrogen selectivity, methane conversion, CO2 emission, energy efficiency, and catalyst lifetime.
The dataset was split into 70% training, 15% validation, and 15% testing portions, with proportional representation of the various catalyst families maintained to preserve statistical balance during model development.
The data were preprocessed using MissForest imputation, IQR-based outlier filtering, and Z-score normalization, after which the parameters learned using the training data were applied to the validation and testing data. Time-series data were separated into blocks to ensure that information was not leaked into model training. Normalization of all numerical measures using Z-score standardization was performed to minimize the influence of outliers and control inter-study variance due to inconsistent reporting standards and variation in analytical instrumentation. This standardization reduces bias arising from differences in measurement scales, definitions of catalyst loading, and reporting units across literature sources.
Rather than determining performance measurements using direct numerical comparisons on heterogeneous literature datasets, performance measures were evaluated within standardized industrial operating ranges and normalized feature spaces to provide statistically consistent model training. The 620 samples were selected to provide sufficient diversity and statistical power, representing different catalyst chemistries, reactor configurations, and representative MSR operating windows. Such data volume is sufficient to capture adequate catalyst family and operating-condition coverage so that modeling trends are not based on isolated experimental observations.
A methodical synthesis of literature sources was performed considering bibliographic ranges, reactor configurations, experimental scales, and widely used analytical techniques to increase the traceability of dataset provenance.
Cross-Validation Strategy
The training data was cross-validated five times, which guaranteed statistical strength and minimized the error in variation of one data division. The data was separated into five equal portions, four of which were put in training and the remaining one in validation in every iteration. Mean performance measures in all five folds (MSE, RMSE, MAE, and R2) were determined. The obtained results are given in the form of the mean and standard deviation of the folds, thus guaranteeing the credibility and reproducibility of the model assessment. The cross-validation approach also reduces possible bias of heterogenous-literature-derived data by making the performance of the model remain unchanged under varying randomized partitions of the filtered data.
As Table 2 summarizes, some of the entries have performance measures because the reporting was not fully made in the original literature sources. It considers the missing data using MissForest imputation that was only used on the training partition when the data was being preprocessed so that no information leakage was created and the statistical validity was not compromised. The temperature, pressure, and H2O/CH4 ratio of the experiment differed in the literature sources; hence, the raw performance measures of various entries were not directly compared. Rather, modeling and optimization were done under standardized industrial operating conditions (600–1200 °C, 1–40 bar, and H2O/CH4 = 1–6), and all numerical variables were standardized using Z-score normalization. This preprocessing provides comparability stability across the learning structure in a statistically consistent way as well as considering the experimental variations residual in Table 3.
Table 2.
Key collected data for methane steam reforming.
Table 3.
Catalytic performance metrics.
Table 4 summarizes the operating windows of methane steam reforming, including reactor temperature, system pressure, inlet H2O/CH4 molar ratio, inlet temperature, and gas hourly space velocity (GHSV). It also presents the standard and extended operating ranges commonly encountered in industrial and experimental MSR systems.
Table 4.
Process operating conditions.
Table 5 shows the collective thermodynamic and environmental performance parameters at different operating conditions such as heat duty, CO2 emissions, hydrogen yield and the overall process energy efficiency. The relationship between the operating conditions and the sustainability indicators is determined using these values.
Table 5.
Energy and emissions data.
Table 6 shows the deactivation characteristics of Ni/Al2O3 at 700 °C at different times. A reduction in the pressure gradient across the reactor is associated with the reduction in hydrogen selectivity and the conversion of CH4. This is an indication of gradual catalyst fouling and deactivation as the catalyst gets used. The time-on-stream behavior has been experimentally reported, and this data is factored into the dataset to build degradation-related features into the AI framework.
Table 6.
Time series and catalyst degradation.
Table 7 indicates the characteristics applied in the AI-based catalyst prediction models. These are catalyst physicochemical properties, reactor design variables, impurities in feedstock and dynamic operation variables like thermal cycling. These variables improve the behavior predictive power of the model in different situations.
Table 7.
Additional parameters for AI modeling.
Although the absolute measurement conditions differ among studies, performance measures are only taken into consideration with the identical preprocessing pipeline and specified filtering criteria, which makes sure that the performance measures are only taken under similar industrial operating conditions. The bibliographic clustering, reactor design and scale of the experiment on which the collected data were based is further explained by the systematic provenance record that is presented in Table 8. This method of harmonization reduces the inter-study bias and increases the strength of the further AI-based optimization analysis.
Table 8.
Dataset provenance summary.
3.6.3. Phase 1: Data Cleaning and Normalization in AI-Driven Catalyst Optimization for Methane Steam Reforming
Experimental, literature, and operational log datasets of MSR catalysts must be standardized before training AI models for catalyst optimization. These datasets often contain missing values, inconsistent units, and outliers. Preprocessing (Figure 8) addresses these issues through (i) MissForest imputation to handle nonlinear dependencies, (ii) IQR-based anomaly filtering, and (iii) Z-score normalization for feature scaling. These steps form a standardized preprocessing pipeline applied consistently across the dataset to ensure reproducible model inputs and minimize bias introduced by heterogeneous experimental reporting standards.
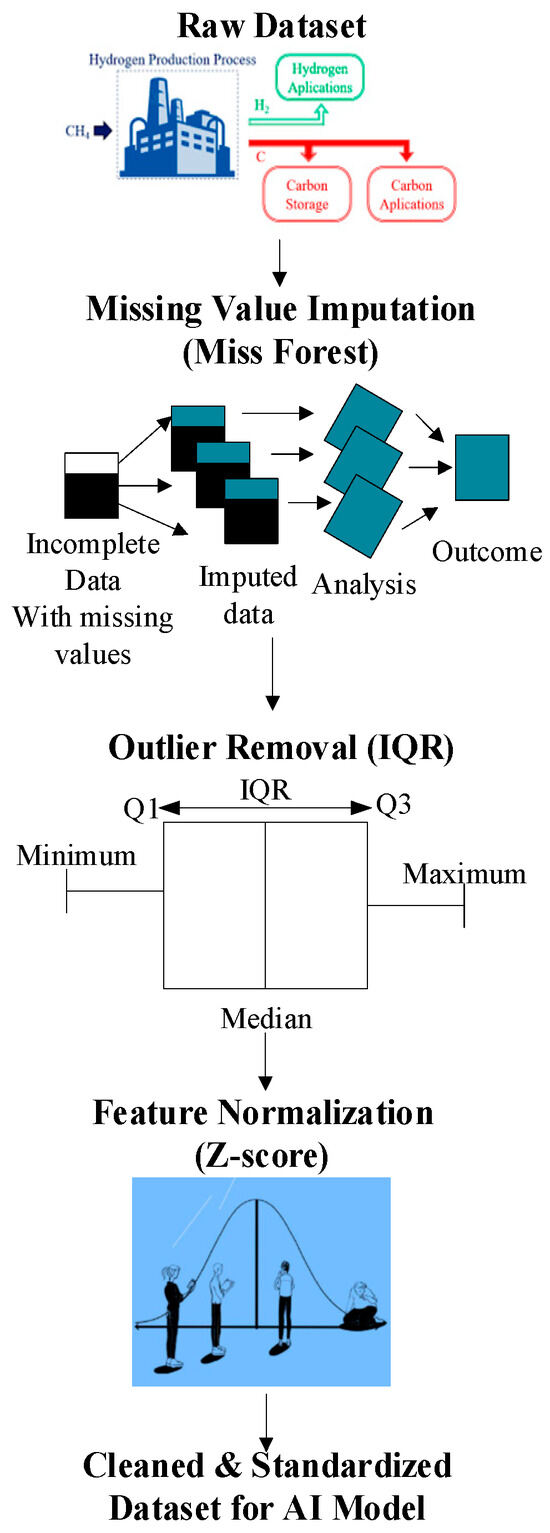
Figure 8.
Stages of data processing: transition from raw data to processed data.
Handling Missing Values via Miss Forest
Experimental datasets for MSR often contain missing values due to irregular measurements or incomplete records, such as missing CO selectivity at high temperatures. Missing values were addressed using the MissForest algorithm, which iteratively applies Random Forest modeling to predict and replace missing entries while preserving nonlinear dependencies. It works as described in the Equation (12).
Initialization: Missing values are filled with the mean.
For a dataset with p features and missing values at positions m, replace missing with the mean (continuous) and the mode (categorical):
Iterative prediction via RF: Iterative prediction using Random Forest imputes missing values by updating estimates until convergence, preserving nonlinear patterns such as the link between Ni particle size and H2 selectivity. For instance, it effectively fills gaps in Rh/Al2O3 CO selectivity data at 600 °C by correlating with pressure and temperature, maintaining physicochemical trends include Arrhenius relationships.
Outliers, often from sensor errors or transient spikes, are removed using the Interquartile Range (IQR), with valid data restricted to [Q1 − 1.5 × IQR, Q3 + 1.5 × IQR].
Finally, Z-score normalization standardizes diverse variables (e.g., pressure 1–40 bar, and Ni loading 5–20 wt%), balancing feature influence for robust AI model training.
Z-score: Transforms data to have zero mean and unit variance:
Normalizing the reactor temperature (μ = 900°, σ = 200°) and pressure (μ = 10.5 bar, σ = 8.2 bar) ensures equal weighting in clustering algorithms.
In the absence of normalization, methods such as k-means or gradient descent can be biased towards large-value features (e.g., pressure over Ni particle size). In comparing CeO2-doped (0–15 wt%) and undoped catalysts, normalized features allow for an unbiased comparison of the effect of doping on H2 selectivity. AI models consistently classify optimal catalysts (e.g., 10 wt% Ni-CeO2/Al2O3) based on equally considering all concerned parameters. The ablation study in Table 9 shows that successive preprocessing steps in MissForest, IQR filtering, and Z-score normalization progressively improved accuracy from 82.14% to 94.88%, reduced Root Mean Squared Error (RMSE), and optimized training efficiency for MSR catalyst modeling. In addition, results are presented as averages across ten independent runs with standard deviations, ensuring statistical robustness, as shown in Table 9.
Table 9.
Ablation study preprocessing stage.
3.6.4. Phase 2: Feature Extraction for AI-Driven Catalyst Optimization in Methane Steam Reforming
Feature extraction connects the preprocessed MSR data with the AI model. It extracts significant characteristics from the raw input data that represent the catalyst and the process. Preprocessing enhances the quality of data, and feature extraction generates parameters that are beneficial for the model in terms of better predictions and good performance under various conditions.
It helps in four key ways: it reduces the complexity of the data, captures behavior at different scales, makes the results easier to interpret by trying to capture real physical behavior, and ensures the method works reliably across different catalysts and operating conditions. The descriptors cover a wide range, including statistical, temporal, spectral, material, and operational aspects.
Statistical Features: Quantifying Performance Trends
Catalyst degradation trends are quantified using statistical descriptors.
Rolling mean: To reveal the underlying trend in selectivity, the rolling mean’s smooth, short-term fluctuation is revealing.
The rolling mean is calculated over the w-hour window for such time-series performance metric selectivity and conversion, which is given in Equation (14)
The performance value at time t is represented by x(t), whereas the rolling window size (number of time points) is represented by w and (t) by the smoothed value at time t. This can be depicted in continuous time through Equation (15):
The application of a rolling mean function is akin to a low-pass filter; it reduces noise and short-term variations and keeps long-term degradation. In the case of MSR, it points out the slow selectivity decline, for example, Ni/Al2O3 by dropping from 79.76% to 72.89% over a period of 400 h, certainly giving a clear lifetime prediction indicator notwithstanding small recovery bumps.
The importance of this experiment is that it shows that H2 selectivity is gradually declining (for instance, the selectivity of Ni/Al2O3 decreases from 79.76% to 72.89% during 400 h of operation), and at the same time, it establishes a direct connection between the catalyst deactivation process due to coking or sintering.
Exponential decay rate (α): It reflects the speed of performance reduction. If the α value is low, it indicates the deactivation process is slower—this is vital for industrial applications. The performance decrease of a catalyst in the course of time usually corresponds to an exponential model, which is mathematically represented in Equation (16):
where x(t) corresponds to the performance metric H_2 selectivity) at any time t, x_0 indicates the initial performance at t = 0, α is the exponential decay rate h^(−1)) and t is the time (hours of operation).
- Decay rate α quantifies the rate of deactivation.
- A low α means slow degradation, indicating a catalyst with high operational stability.
- A high α means rapid performance loss, suggesting susceptibility to coking or sintering.
In connection with the catalyst lifetime, if is the minimum performance that is acceptable (70% selectivity), then the catalyst lifetime can be estimated in accordance with Equation (18):
The following is an example in MSR.
For a catalyst with and , if regression yields , then can be expressed in Equation (19):
This establishes a straightforward connection between the value of the feature and the economic consequences, as a slower decay allows for less frequent catalyst replacement shutdowns.
AI uses statistical attributes to categorize the catalysts in terms of durability and to estimate their remaining useful life, which is an economic factor in hydrogen production.
Time-Domain Features: Catalyst Degradation and Process Stability Indicators
Time-domain characteristics are important variables that indicate catalyst state and process stability, as they reflect both short- and long-term variations in the MSR reactor. Two important descriptors are introduced, namely autocorrelation and cumulative pressure drop, along with their precise mathematical formulations, estimation procedures, interpretation, and practical guidance for incorporating them as robust attributes in AI models.
Time-Domain Features: Autocorrelation and Pressure-Drop Analysis
Time-domain signatures represent real-time changes in catalyst performance indicators, such as temporal variations in methane conversion and reactor pressure drop ΔP(t). These features enable AI models to detect operational instabilities at fine temporal scales that might otherwise remain unnoticed. The autocorrelation function, which indicates the degree to which a signal resembles a time-shifted version of itself, is one of the primary descriptors considered and is expressed by the following Formula (20):
where stands for or ∆P at the ith time step and is the average value and ∆t is the time lag. Unique peaks in R(∆t) at the intervals like ∆t = 50 h usually indicate planned regeneration cycles or regular process disturbances. This can uncover cyclic coking-regeneration patterns that are hidden in steady-state averages.
The cumulative pressure drop is another important metric in the time domain, which is defined as in Equation (21):
S(t), which is the cumulative pressure drop, serves as a way of indicating the fouling of the catalyst bed, where sudden increases can be interpreted as pore blockage due to the carbon deposited. By continuously observing these patterns, the AI algorithm can detect the occurrence of fouling at the onset stage and recommend intervention measures. The time-domain analysis, which employs the pair of signals R(Δt) and S(t), is effective in capturing those instabilities that necessitate correction actions, which are regarded as proactive in extending the life of the catalyst and thus the production of hydrogen.
Frequency-Domain Features—Detecting Harmful Oscillations
Frequency-domain features are extracted only when sufficiently sampled time-series data are available from experimental degradation studies or operational logs. For datasets with limited temporal observations, spectral analysis is not applied. Instead, statistical and time-domain descriptors are used to preserve methodological validity.
In MSR reactors, small oscillations in parameters such as pressure, temperature, or gas composition may indicate early operational instabilities that accelerate catalyst deactivation. When regularly sampled time-series data are available, the reactor temperature profile TR(t) can be analyzed in the frequency domain using Fast Fourier Transform (FFT) to identify periodic trends.
In mathematical form, the continuous Fourier Transform of the reactor temperature signal is expressed as
The only way to obtain signals is by using discrete measurements, hence the application of Discrete Fourier Transform (DFT) in the analysis part:
FFT analysis is performed only when the temporal resolution and sequence length satisfy minimum sampling requirements. Peaks in |X[k]| indicate dominant oscillation frequencies. Such oscillations may correspond to burner fluctuations, feed variations, or thermal instabilities that contribute to hot spots, sintering, or carbon deposition.
Accordingly, frequency-domain descriptors serve as auxiliary exploration features rather than primary optimization drivers within the proposed framework.
Catalyst Material Features—Linking Structure to Activity
Catalyst material features characterize the inherent structural and compositional parameters, which lead to access to active sites, reaction kinetics and long-term stability. In the case of MSR, they are nickel dispersion, support composition, and promoter loading, and each of them affects activity by the alteration of surface chemistry and reactant–adsorbate interactions.
Mathematical Representation of Ni Dispersion Index (D_Ni)
The Ni dispersion index (D_Ni) represents the fraction of surface-exposed Ni atoms relative to the total Ni atoms and is used as a structural descriptor within the AI framework. It is defined as
where is defined as the number of Ni atoms located on the catalyst surface and is defined as the total number of Ni atoms in the bulk + surface. If particle size is known and particles are assumed spherical, can be approximated by Equation (25):
Here, k is a shape-dependent proportionality constant, and d_p is the average Ni particle diameter. This relationship serves as a first-order approximation rather than a rigorous physicochemical dispersion calculation.
When experimentally measured dispersion values derived from chemisorption, TEM, or other characterization techniques are available, those reported values are incorporated directly into the dataset. Simplified approximation is applied only in cases where detailed dispersion measurements are not explicitly reported.
Here, k is defined as the shape-dependent proportionality constant (for spheres, k ≈ 0.96 nm), and d_p is the average Ni particle diameter (nm).
An example calculation for 5 nm Ni particles is described in Equation (26):
An example for 50 nm Ni particles is shown in Equation (27):
Smaller Ni particles exhibit ~10× higher dispersion, yielding more accessible active sites, which chemically enhances hydrogen yield but also increases susceptibility to sintering under prolonged operation. In AI-driven catalyst design, the Ni dispersion index (DNi) is used alongside the support composition ratio (Sox) and promoter loading (Pwt%), where high basic supports (e.g., MgO and CeO2) reduce coke deposition and lanthanide promoters enhance stability. Real chemical implications for H2 yield, CH4 conversion, and long-term coke resistance are linked to the numerical features through this. The exposition of active sites is more due to high Ni dispersion, which leads to an increase in hydrogen yield; however, it also poses a risk of particle sintering in a prolonged operation. Supports with a higher basicity such as MgO or CeO2 countermeasure carbon deposition by neutralizing acidic intermediates, which in turn leads to better stability. This is the same with FFT-based time-domain signals, that when associated with oscillatory pressure and temperature patterns provide alertness to hot spots and carbon accumulation, which are direct contributors to the deactivation of the catalyst. A high dispersion often leads to an increase in turnover frequency (TOF); however, the interactions with support acidity/basicity also play a role in this, as expressed in Equation (28):
Here, f represents a nonlinear function learned by the AI model.
Operational Metadata—Contextualizing Reactor Performance
Space–time yield (STY) is a method that quantifies the rate of hydrogen production in relation to the weight of the catalyst and the duration of its operation and is given as . This method allows for a valid comparison of different catalysts, the quick identification of deactivation through a decreasing trend, and the optimization process by aligning the hydrogen yield with CO2 emissions, energy utilization, and the catalyst’s operational lifetime.
3.6.5. Enhancing Catalytic Selectivity in Methane Steam Reforming Using HGBO–VIKOR Framework
In the process of selecting a catalyst for MSR, a complex multi-objective optimization problem arises, which requires the concurrent optimization of hydrogen selectivity (S_H2), CO2 emissions (E_CO2), energy consumption (Q_req), and catalyst lifetime (τ_cat). The conventional approach of trial-and-error screening is not only expensive and time-consuming but also does not take advantage of the large amount of data that is readily available.
To solve the problem, the HGBO approach is utilized. HGBO merges with the global strategy of GJO’s and DBO’s local improvement capability, thus achieving a good mix of global search and local exploitation. Such versatility avoids early convergence and makes the system more robust in complicated fitness scenarios.
HGBO catalyzes the systematic exploration of trade-offs through the formalization of MSR catalyst design as a multi-objective optimization problem. Hence, the results are higher hydrogen yield, less emissions, and performing catalysts that are environmentally friendly.
The following is an optimization problem on a formal multi-objective.
Let the vector’s decision be
The design and catalyst synthetic parameters are represented by .
The objective vector is
where
F(x) = [f1(x), f2(x), f3(x), f4(x), f5(x)] T
- f1(x) = Hydrogen yield;
- f2(x) = CH4 conversion;
- f3(x) = CO2 emissions;
- f4(x) = Catalyst lifetime;
- f5(x) = Energy efficiency.
The multi-objective optimization (MOO) is formulated as follows.
F is Pareto-optimal to find , where
Typical constraints are as follows.
:
Tmin ≤ T ≤ Tmax
Material safety limits:
Economic constraints:
Minimization of heat duty per unit hydrogen produced is
reflecting energy cost intensity.
Enforcement of minimum space-time yield is
to avoid economically impractical low-throughput solutions.
Implicit reduction of catalyst replacement frequency through lifetime maximization () directly influences operational expenditure.
Solutions violating defined economic thresholds are penalized during feasibility evaluation using a constraint-based penalty term added to the objective function.
Objectives have mixed senses (min/max) and are converted into a consistent optimization form during algorithm implementation.
3.6.6. HGBO
The HGBO is a proposed hybrid metaheuristic algorithm that combines the global search attributes of Golden Jackal Optimization (GJO) with the local improvement capability of DBO, and henceforth, an adaptive convergence control factor and prey–exploration dynamics are introduced to balance between global search and local exploitation. This ensures that no solution gets chosen too soon, diversity in solutions is increased, and more robust Pareto fronts are formed in comparison with other hybrid metaheuristics. Furthermore, HGBO is coupled with the VIKOR multi-criteria decision-making method and ConvLSTM predictive modeling, resulting in a unified framework that optimizes catalyst performance, systematically balances sustainability trade-offs, and predicts catalyst degradation concurrently. The combined formulation represents a structured approach compared to previously reported AI-based optimization studies that addressed these aspects individually. The GJO component is based on cooperative hunting behavior to facilitate broad search capability and minimize premature convergence, whereas the DBO component refines local candidate solutions. Both exploration and exploitation mechanisms are defined by Equations (32) and (33), respectively.
where X_i refers to the position of the ith candidate, X_(prey) refers to the position of prey, α(t) refers to the convergence control factor, and X_best refers to the best known solution.
where β refers to the local exploitation coefficient and X_rand refers to the randomly selected solution.
Implementation Parameters and Constraint Handling
To ensure methodological reproducibility, the HGBO algorithm is executed with a population size of N = 40 candidate solutions and a maximum of 100 iterations, consistent with the computational budget used for all benchmark algorithms. The termination criterion is defined as either reaching the maximum iteration limit or observing negligible improvement in the global best objective value over ten consecutive iterations. The termination criterion is either reaching the maximum iteration limit or observing insignificant changes in the global best objective value (tolerance less than 10−6 for 10 consecutive iterations).
A feasibility-based penalty approach is used for constraint handling. Violations of operating limits (temperature, pressure, and steam-to-carbon ratio), material limits (maximum Ni loading), and economic limits are penalized by introducing a large constraint violation term into the objective function. Pareto-front construction retains only feasible solutions to ensure compliance with physically realistic MSR operating domains.
Initial candidate solutions are generated randomly within defined feasible bounds to ensure unbiased exploration of the search space. The penalty coefficient is set sufficiently large (103 multiplier) to prevent infeasible solutions from dominating the selection process.
The VIKOR approach ranks alternatives based on their proximity to an optimal trade-off between group utility and individual regret. When combined with HGBO, it further refines the Pareto front of catalyst-condition solutions, enabling the selection of the most balanced compromise solution in multi-objective MSR optimization.
In this described process, S denotes the minimum of , the maximum of , the minimum of and the maximum of .
Weight Selection and Sensitivity Analysis
In this analysis, the four primary goals are assigned equal weights (w = 0.25 each) at the initial stage, namely hydrogen yield, energy efficiency, CO2 emissions, and catalyst lifetime. This ensures neutrality and avoids subjective prioritization in the baseline evaluation.
A sensitivity analysis is performed to assess robustness by allowing individual weights to vary within ±20%, while adjusting the remaining criteria proportionally to maintain a unity sum. These perturbations are used to evaluate the ranking consistency of the top catalyst–condition combinations.
The findings show that the relative ranking of the top three solutions remains unchanged under the tested weight variations. This indicates that the HGBO–VIKOR ranking is not highly sensitive to moderate weight changes and confirms the stability of the developed decision framework.
Model Architecture and Training Configuration
To enable spatial convolution, tabular catalyst–process descriptors are reshaped into structured 2D feature maps. Each sample is organized into a tensor of shape:
where
(T, H, W, C)
- T = temporal sequence length;
- H = grouped feature rows (e.g., material, operational, statistical, and degradation descriptors);
- W = feature columns within each group;
- C = number of channels (set to 1 in this study).
In implementation, feature maps are arranged as 6 × 6 matrices per time step, constructed by grouping related catalyst and operating variables. Temporal stacking forms the sequential dimension required by ConvLSTM.
The ConvLSTM network architecture is explicitly defined to enable reproducibility. The implemented architecture consists of
- One ConvLSTM layer with 32 filters and a 3 × 3 kernel;
- One batch-normalization layer;
- A dropout layer with rate 0.2;
- A fully connected dense layer with 64 neurons and ReLU activation;
- And a final regression output layer.
The ConvLSTM architecture comprises a single spatiotemporal convolutional layer with 32 filters and 3 × 3 kernels, followed by a batch-normalization layer, a dropout layer (rate = 0.2), and a fully connected dense layer with 64 neurons prior to the final regression output. The total number of trainable parameters in the model is approximately 58,000, ensuring a balanced trade-off between model complexity and computational efficiency.
The model is trained using the Adam optimizer (learning rate = 0.001) with Mean Squared Error (MSE) as the loss function for a maximum of 100 epochs. To prevent overfitting and ensure stable convergence, early stopping with a patience of 10 epochs is employed.
Hyperparameters including number of filters (32), kernel size (3 × 3), dense layer size (64), dropout rate (0.2), and learning rate (0.001) were selected using grid search combined with five-fold cross-validation on the training set. The configuration producing the lowest validation loss was retained for the final model.
This formulation enables ConvLSTM to capture local feature correlations through convolution operations and temporal degradation trends through recurrent gating, allowing effective spatiotemporal learning even when the original catalyst dataset is tabular.
The HGBO–VIKOR framework integrates optimization and decision-making mechanisms to identify optimal catalyst–operating-condition combinations. First, the HGBO algorithm performs global exploration followed by local refinement to generate a set of Pareto-optimal candidate solutions. Subsequently, the VIKOR method ranks these solutions based on weighted criteria including hydrogen yield, energy efficiency, CO2 emissions, and economic considerations, enabling the identification of balanced compromise solutions. The overall optimization workflow is illustrated in Figure 9.
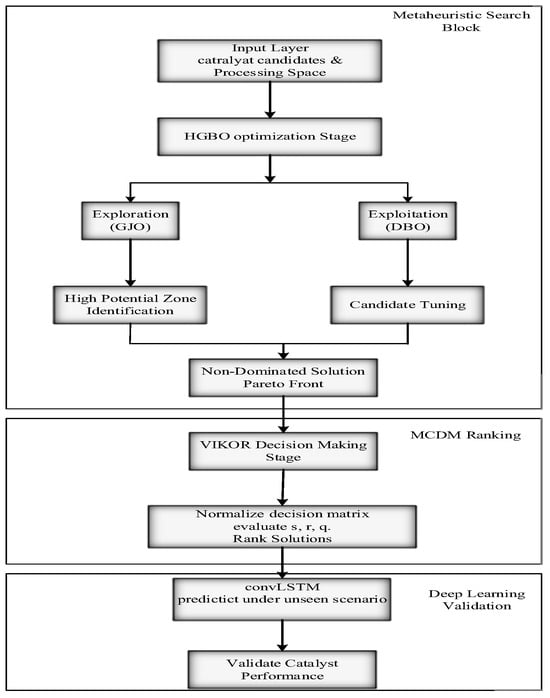
Figure 9.
HGBO–VIKOR optimization flowchart.
The HGBO–VIKOR framework, as displayed in Figure 9, is successful in maintaining a proper balance between global search and local exploitation, thus preventing getting stuck in a local optimum position or premature convergence. Moreover, the global best optimizer (HGB) produces a variety of Pareto-optimal solutions that reflect the compromises reached between the competing objectives, and the Selection of the Best from the Ranks (VIKOR) ranks them impartially according to the criteria and worst-case scenarios. This guarantees that the decision-making process is transparent, trustworthy, and adaptable to unexpected operating conditions, leading to the provision of a strong and sustainable catalyst–condition pairing.
ConvLSTM for Catalyst Property Identification
The ConvLSTM network is a deep learning model of spatiotemporal nature that uses convolutional layers for spatial feature extraction and LSTM units for temporal sequence modeling at the same time. This teaches catalyst structure–process correlations and long-term operational dynamics together, and thus it is very effective in predicting catalyst properties in MSR.
The ConvLSTM framework integrates convolutional filters with LSTM units, where it, ft, and ot denote the input, forget, and output gates, respectively, allowing the model to learn spatial correlations and temporal dynamics in catalyst behavior. The descriptors like pore structure, active site distribution, surface area maps, and dopant densities provide spatial correlations, thereby connecting the nanoscale morphology with catalytic activity and selectivity. Temporal dynamics are modeled through LSTM units, which learn sequential dependencies reflecting long-term changes such as deactivation, sintering, coke deposition, or poisoning. By combining these within its recurrent gate structure, ConvLSTM simultaneously learns spatial structures and temporal transition dynamics under steam reforming conditions. The model accepts multi-domain inputs including catalyst descriptors, temperature, pressure, and gas composition time series and outputs predictions for performance metrics such as H2 yield, CO2 reduction efficiency, energy efficiency, and stability. Furthermore, ConvLSTM can function as a classifier, distinguishing catalysts (e.g., high vs. low activity or stable vs. unstable) and uncovering hidden structure–property–performance relationships critical to methane steam reforming optimization.
Figure 10 shows the ConvLSTM network architecture. The integration of convolutions with LSTM recurrent gates has formed a ConvLSTM network and contributes greatly to predicting catalyst properties, as it captures spatial correlations of structural physical features and temporal dependencies of the reaction dynamics and provides a better means of properly defining and accurately predicting the catalyst performance of methane steam reforming processes.
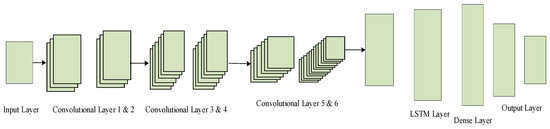
Figure 10.
ConvLSTM network structure.
Spatiotemporal Input Construction and Data Representation
Experimental data are collected from discrete literature sources; however, temporal sequences are constructed using two complementary approaches. First, published time-on-stream degradation data (e.g., hydrogen selectivity, methane conversion, and pressure drop trends) are directly used to represent catalyst performance evolution over operational hours. Second, for steady-state datasets without explicit time-series reporting, operating conditions are arranged into ordered sequences based on temperature progression and reaction exposure levels. This enables structured temporal learning while preserving experimental realism.
The spatial aspect of the ConvLSTM model is a geometric physical grid. Instead, it relates to structured feature maps created by combining catalyst physicochemical features (e.g., Ni dispersion, support type, and promoter loading), reactor features (temperature, pressure, and steam–carbon ratio), and derived statistical features into a two-dimensional feature map. This organized representation enables convolutional filters to capture local associations among correlated process descriptors related to the catalysts.
In application, each catalyst–condition instance is reformulated into a structured feature tensor, where rows represent clusters of related descriptor categories and columns represent closely related process variables. These tensors are sequentially stacked over time to form the sequential dimension of the LSTM component. Although the underlying dataset is primarily tabular with attached temporal characteristics, ConvLSTM was selected because catalyst process descriptors were deliberately arranged into structured two-dimensional feature maps rather than treated as independent scalar quantities. This design allows convolutional kernels to learn local inter-feature covariance (e.g., among Ni dispersion, temperature, pressure, and steam ratio) before temporal gating. Standard LSTM or GRU models operate on flattened feature vectors and do not explicitly compute such local structural relationships. Temporal CNN (TCN) architectures lack recurrent memory gating mechanisms, which are important for long-term degradation modeling. Transformer-based architectures typically require larger datasets to stabilize attention weights and avoid overfitting; therefore, with the medium-sized dataset (n = 620), ConvLSTM provides a more balanced trade-off between spatial correlation learning and temporal dependency modeling.
Accordingly, the ConvLSTM model learns time-varying relationships across degradation cycles and sequential operating conditions while simultaneously capturing spatial relationships among organized catalyst characteristics and process variables. This formulation achieves effective spatiotemporal learning without relying on a physical spatial grid and makes the architecture suitable for catalyst performance prediction in methane steam reforming.
3.6.7. Benchmark Algorithm Configuration and Parameter Tuning
The benchmark algorithms (GA, PSO, and SVR) were configured under consistent experimental conditions and subjected to a uniform tuning process to ensure a fair and transparent comparison.
For GA and PSO, the population size (N = 40) and the maximum number of iterations (100) were kept the same as those used in HGBO to ensure equal computational budgets. The crossover probability in GA was fixed at 0.8 and the mutation probability at 0.1, which are commonly adopted values in the multi-objective optimization literature. For PSO, the inertia weight was set to 0.7, while the cognitive and social coefficients were both set to 1.5.
In the case of SVR, a radial basis function (RBF) was used. The hyperparameters were identified by grid search (using five-fold cross-validation on the training data) by searching for parameters such as the penalty parameter (C) and the width of the kernel (γ). The best values were picked according to the least validation error.
Each benchmark algorithm was run ten times to present stochastic variation. All optimization algorithms (HGBO, GA, PSO, and Random Search) were subjected to the same population size (N = 40), maximum number of iterations (100), termination criteria, and objective formulation to be fair. There are performance measures in the form of mean and standard deviation between ten runs. It was statistically tested by means of the Wilcoxon signed-rank test (p < 0.05) to guarantee that the observed improvements were due to the properties of the algorithm but not to uneven computational budget or the termination conditions.
4. Results and Discussion
The HGBO-VIKOR method generates a Pareto front of catalyst–condition pairs, identifying balanced compromises between hydrogen yield, efficiency, CO2 reduction, and cost and evaluating the selected catalyst under new conditions.
4.1. Evaluation of Catalyst Performance
Operating at 600–1200 °C, 1–40 bar, and H2O/CH4 = 1–6, the HGBO–VIKOR framework predicted hydrogen yield values up to 98.5% under modeled equilibrium conditions within the defined industrial operating ranges. This result is typical of the representative case studies drawn from the 620-entry dataset, which are Ni/Al2O3 at 700 °C, Rh/Al2O3 at 600 °C, and Ru/MgO at 800 °C. While the framework covers a wide range of 620 catalyst–condition entries, it does not depend on isolated case studies but rather methodically includes a wide range of operating ranges and catalyst chemistries. Therefore, the observed performance enhancement is not attributed to dataset bias but to consistent catalytic behavior within defined industrial operating ranges. The hybrid model not only obtains higher yields but also corroborates performance against experimental trends of catalysts compared to baseline optimization methods like Random Search (93%), GA (92%), PSO (94.5%), and SVR (92%). The reason for this is the balanced mixture of exploiting and exploring phases of the HGBO algorithm, which is then combined with VIKOR’s compromise ranking, resulting in greater robustness.
As shown in Figure 11, with the benchmark conditions (700 °C, 10 bar, and H2O/CH4 = 3), the framework predicts CO2 emissions below 0.85 kg/h under the modeled benchmark feed conditions. These values are computed using steady-state mass balance within the specified operating window and should be interpreted as scaled model predictions rather than direct industrial measurements. The calculated reduction in CO2 emissions is consistent with experimental reports on promoted Ni-based catalysts such as Ni–CeO2/Al2O3 and La-modified Ni/Al2O3 systems, in which improved dispersion and enhanced support basicity inhibit coke formation and enhance catalytic stability.
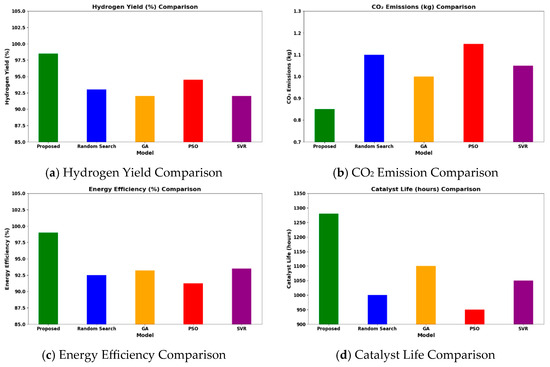
Figure 11.
Comparative analysis of proposed models over the existing models.
Under identical computational conditions, the HGBO–VIKOR framework exhibits improved multi-objective balance in terms of hydrogen yield, CO2 mitigation, energy efficiency, and catalyst lifetime compared to GA, PSO, Random Search, and SVR. This improvement is attributed to the balanced exploration–exploitation mechanism of HGBO combined with the structured compromise ranking of VIKOR.
The framework also predicts energy efficiency values approaching 99 percent under thermodynamically optimized modeled conditions within specified industrial limits. Catalyst lifetime extension is estimated using degradation modeling calibrated with reported time-on-stream data. Overall, the findings demonstrate algorithmic robustness and consistency with established catalytic behavior trends reported in the literature.
4.2. Analysis on Optimization Metrics
It is also predicted within the framework that energy efficiencies of nearly 99% are achievable under thermodynamically optimized modeled conditions within the specified industrial limits. Catalyst lifespan is estimated through degradation modeling calibrated using time-on-stream data. Overall, the results demonstrate algorithmic strength and consistency with trends reported in the existing catalyst literature.
The HGBO-VIKOR model achieves a high objective value of 0.98 when applied to the 620-case dataset. The optimization results are validated across different catalyst families (Ni/Al2O3, Rh/Al2O3, Ru/MgO, and perovskites), indicating that the findings are not limited to individual cases but are applicable within defined industrial operating limits. The VIKOR trade-off solution ensures balanced management of trade-offs among hydrogen yield, energy efficiency, CO2 emissions, and catalyst lifecycle. A comparative visualization of objective values, solution spread, and convergence behavior is presented in Figure 12.
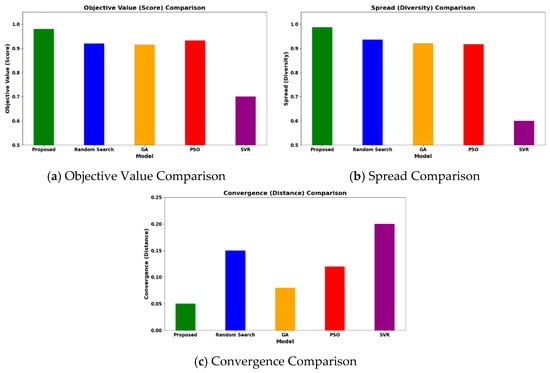
Figure 12.
Comparative analysis of the proposed HGBO-VIKOR model for optimal catalyst identification.
In the same conditions of computing, the HGBO-VIKOR framework reaches a maximum objective value of 0.987, which is better compared to GA, PSO, Random Search and SVR. The solution spread is more widespread, and it implies better exploration with controlled exploitation and a better-defined Pareto front. The convergence distance indicated by the convergence analysis is lower (0.05), indicating quicker and more consistent optimization behavior. A median optimization operation with a population size of 40 and 100 steps, which operates on an Intel i7 processor with 16 GB RAM, takes about 145 s. The LSTM model essentially consists of 58,000 trainable parameters and is trained to a maximum of 100 epochs with the Adam optimizer (learning rate = 0.001). The mean time for training per epoch is approximately 1.9 min on an NVIDIA RTX 3080 card and leads to a total training time of about 3.2 h. Early stopping patience of 10 epochs is used, and convergence is normally attained after 70–85 epochs. Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), and the R2 value are used to evaluate model performance. The accuracy of classification is not considered, and it is a regression task. The convergence success is one in which the validation loss stabilization has been achieved, and the performance is consistent after ten independent runs. Scalability analysis demonstrates that computational time is around linearly proportional to the size of the dataset, and parallelization based on GPUs improves computational efficiency, which supports the applicability of the methods to medium-sized industrial datasets. This better performance of optimization can be at least partially explained by the fact that the HGBO balanced global–local search mechanism avoids premature convergence and VIKOR systematically handles the trade-offs between objectives. The synergistic effect is used to strengthen and stabilize multi-objective MSR catalyst selection.
4.3. Ablation Study: Comparative Evaluation of HGBO, GJO, and DBO
An ablation study was employed to prove the efficiency of the suggested HGBO algorithm by assessing the two key compositions of its Golden Jackal Optimization (GJO) and the Dung Beetle Optimizer (DBO) separately and under the same experimental conditions. The three algorithms were run with an equal population (N = 40), number of iterations (100), objective formulation and constraint settings. Accuracies of each of the methods were assessed based on the full 620-case MSR dataset and averaged across ten independent runs to provide reliability, as shown in Table 10.
Table 10.
Ablation comparison of HGBO, GJO, and DBO.
GJO has an excellent global exploration and a comparatively inferior refinement of subsequent iterations. DBO boosts the local search, but the convergence in the complex search spaces can be slow. Conversely, HGBO incorporates both processes, and better objective values and higher rates and convergence are obtained, as can be seen in Table 10.
The Wilcoxon signed-rank test is used to determine the statistical significance of the performance improvement of HGBO compared to that of GJO and DBO (p < 0.05). These findings prove that the hybridization strategy is not only structural but also functional. Global exploration and local exploitation in HGBO create a balance that guarantees an increased robustness, convergence stability and total optimization performance in multi-objective MSR catalyst selection.
4.4. MCDM Metrics
The integrated HGBO–VIKOR–ConvLSTM framework achieves the highest weighted score (0.982) and the lowest VIKOR Q-value (0.08), indicating superior compromise performance within the defined industrial operating window (600–1200 °C, 1–40 bar, and H2O/CH4 = 1–6). The integration guarantees that the rankings are not abstract but are tied to the reproducible catalyst behavior through representative case studies. The model always tops the ranks by giving equal importance to hydrogen yield, energy efficiency, CO2 mitigation, and economic viability. The combined HGBO–VIKOR–ConvLSTM framework not only reduces experimentations that are costly and time-consuming but also enhances the really durable catalysts and makes the hydrogen yield higher; thus, its impact is not only in terms of method improvement but also in addressing the two aspects of process sustainability and catalyst erosion prediction, providing the opportunity to connect the computational modeling with real catalysis and process engineering. On the other hand, GA shows moderate performance, 0.961, Q = 0.15, and PSO shows moderate performance, 0.93, Q = 0.22; Random Search, 0.95, Q = 0.3, and SVR, 0.94, Q = 0.35, show weak outcomes. Figure 13 shows the MCDM for optical catalyst identification.
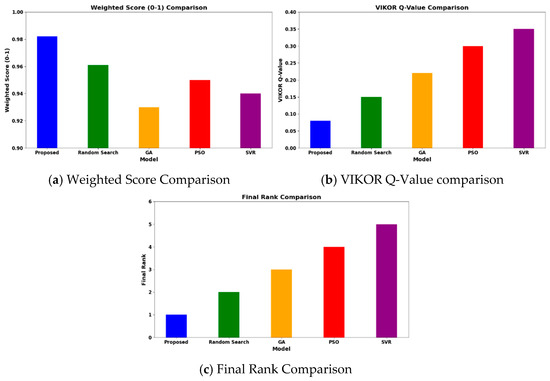
Figure 13.
Analysis of MCDM for optimal catalyst identification.
Combining optimization with deep learning improves prediction accuracy and enables better trade-off management between environmental impact and economic cost [22]. AI-driven optimization also enhances hydrogen production efficiency and catalyst stability. These improvements support downstream hydrogen utilization technologies, including fuel cell systems. High hydrogen purity and stable production are particularly important for applications such as proton exchange membrane fuel cells (PEMFCs), where fuel quality directly affects system efficiency and durability. Consequently, advances in catalyst optimization for methane steam reforming can help strengthen the broader hydrogen energy value chain.
The model proposed produces the best Mean Squared Error (MSE) of 0.012 compared to the MSE for LSTM 0.02, TCN 0.025, CNN 0.03, and RNN 0.035. The model developed has better predictive accuracy due to its greater ability to capture temporal dependencies and engage more complex relationships between the features. This increased ability to depict both increases generalization and decreased error, therefore producing a more reliable model for inference in creating or identifying catalyst properties over the standard deep learning models [23].
The proposed model produces the lowest RMSE value of 0.11 compared to LSTM (0.141), TCN (0.158), CNN (0.173), and RNN (0.187). The model developed a better prediction for the catalyst properties that is more accurate. The proposed model instantiates a hybrid architecture for faults in two phases, while also capturing long-term antecedents for fault occurrence and mitigating noise sensitivity. Therefore, the benefits of capturing the hybrid architecture and properties of accurate values are likely to provide a more stable and accurate estimate of catalyst performance than conventional deep learning models.
where n is the number of time steps and refers to predicted output.
The proposed model achieves the lowest Mean Absolute Error (MAE) of 0.085, demonstrating significantly less deviation between predicted and actual catalyst properties compared with LSTM (0.12), TCN (0.135), CNN (0.145), and RNN (0.16). The fact that the model is capable of reproducing the trends of catalyst degradation, which are already documented (e.g., Ni/Al2O3 at 700 °C), is also one of the aspects contributing to the improvement that it is not only in terms of computation but also in terms of model’s performance with the use of structural descriptors like Ni particle size, promoter content and support type. When the physicochemical features are linked with the time-dependent degradation behavior, the ConvLSTM predictions become interpretable and consistent with the experiments, thus making the model robust, reliable, and applicable to real-world MSR scenarios.
This model achieved the highest R2 value of 0.95, indicating that it explained the greatest variance in the prediction of catalyst properties compared to LSTM (0.90), TCN (0.88), CNN (0.85), and RNN (0.82). The enhanced performance can be attributed to its strong ability to capture nonlinear relationships and long-term temporal patterns. This implies that it produced more reliable predictions and generalized well across a range of datasets.
where refers to the average of the measured output.
Compared to LSTM, TCN, CNN and RNN, the proposed ConvLSTM model has demonstrated high regression when forecasting catalyst properties. The model has reduced error values and a greater coefficient of determination and has the better capacity to describe nonlinear spatiotemporal interactions among catalyst descriptors and operating variables. The improved performance is attributed to enhanced feature representation and more effective learning of temporal dependencies, leading to more stable and general predictions across operating conditions. Table 11 summarizes the comparative regression metrics. The proposed method achieves an MSE of 0.012, an RMSE of 0.11, an MAE of 0.085, and an R2 score of 0.95, outperforming the benchmark deep learning models. These comparative results validate that introducing convolutional operations prior to recurrent temporal modeling improves structured inter-feature correlation learning, which cannot be fully captured by pure LSTM or static ANN architectures operating on flattened feature vectors. These results confirm the robustness and predictive reliability of the proposed framework.
Table 11.
Deep learning metric values.
5. Limitations and Future Work
The present study is computational and data-driven in nature. Although the proposed HGBO–VIKOR–ConvLSTM framework is validated against 620 experimentally reported catalyst–condition entries compiled from peer-reviewed literature, independent pilot-scale or industrial experimental validation has not yet been performed within this work. The predictive results therefore reflect model-optimized outcomes under harmonized industrial operating constraints rather than direct experimental verification conducted by the authors.
In addition, equilibrium-based thermodynamic modeling does not fully capture kinetic limitations, reactor-scale heat transfer effects, or long-term mechanical degradation mechanisms that may arise in industrial reformers. While structured preprocessing and cross-validation mitigate inter-study heterogeneity, residual variability from literature-derived datasets may still influence predictive generalization.
Future work will focus on experimental validation under controlled pilot-scale methane steam reforming conditions, integration of kinetic reactor modeling, and real-time degradation monitoring to further strengthen industrial applicability and model robustness.
6. Conclusions
This study presents an interdisciplinary AI-driven framework for catalyst selection and performance prediction in MSR, with the objective of advancing efficient and lower-emission hydrogen production. The proposed framework integrates experimental and literature-derived datasets, systematic data preprocessing, multi-domain feature extraction, and a hybrid optimization strategy combining decision-making HGBO–VIKOR. This integrated approach simultaneously addresses multiple, often conflicting objectives, including hydrogen yield, CO2 emission reduction, energy efficiency, and catalyst lifetime. The hybrid optimization strategy effectively balances global exploration and local exploitation, while the VIKOR method provides a rational compromise ranking among competing performance criteria. Simultaneously, ConvLSTM predictive modeling has been shown to capture both spatiotemporal correlations in catalyst behavior by which predictable catalyst performance and degradation can be predicted across unbiased operating conditions never seen before. Under industrially relevant operating regimes within the compiled dataset, the framework predicts hydrogen yield values up to 98.5%, energy efficiency approaching 99% (calculated on a lower heating value basis under modeled equilibrium conditions), CO2 emissions of approximately 0.85 kg h−1 under benchmark feed-flow rates, and a catalyst lifetime of about 1280 h estimated via exponential degradation modeling calibrated against reported time-on-stream data. These model-optimized outcomes demonstrate improved multi-objective balance compared to benchmark optimization methods such as Random Search (93%), genetic algorithm (92%), and particle swarm optimization (94.5%), while support vector regression (92%) is employed as a predictive baseline under identical computational settings. Although experimental validation under pilot-scale or industrial conditions remains necessary, the framework shows computational robustness through clearly defined operating constraints, uniform selection criteria, statistical evaluation across ten independent runs, and validation against 620 experimentally reported catalyst–condition entries. The diversity of catalyst families and operating environments represented in the dataset supports the practical relevance of the observed predictive trends for methane steam reforming applications.
Funding
This research received no external funding.
Institutional Review Board Statement
Not Applicable.
Informed Consent Statement
Not Applicable.
Data Availability Statement
The dataset used in this study was compiled exclusively from publicly reported experimental methane steam reforming studies available in the peer-reviewed scientific literature. The processed dataset (CSV format), the complete list of source publications, and the entry-to-reference mapping table linking each dataset entry to its original publication DOI are available in the following repository: https://github.com/code-iot278/Toward-Intelligent-and-Sustainable-Hydrogen-Production accessed on 5 March 2025. The repository also contains the preprocessing scripts and Python 3.10 implementation of the HGBO–VIKOR–ConvLSTM framework to enable full reproducibility of the results presented in this work.
Conflicts of Interest
The author declares no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| Abbreviation | Full Term |
| AI | Artificial Intelligence |
| XRD | X-Ray Diffraction |
| CFD | Computational Fluid Dynamics |
| CH4 | Methane |
| CO | Carbon Monoxide |
| CO2 | Carbon Dioxide |
| ConvLSTM | Convolutional Long Short-Term Memory |
| DBO | Dung Beetle Optimizer |
| SVR | Support Vector Regression |
| DFT | Density Functional Theory |
| LSTM | Long Short-Term Memory |
| PSO | Particle Swarm Optimization |
| MCDM | Multi-Criteria Decision Making |
| RMSE | Root Mean Square Error |
| SMR | Steam Methane Reforming |
| MSR | Methane Steam Reforming |
| Ni | Nickel |
| GA | Genetic Algorithm |
| GHSV | Gas Hourly Space Velocity |
| HGBO | Hybrid Golden Beetle Optimization |
| LHV | Lower Heating Value |
| MAE | Mean Absolute Error |
References
- Hong, S.; Lee, J.; Cho, H.; Kim, M.; Moon, I.; Kim, J. Multi-objective optimization of CO2 emission and thermal efficiency for on-site steam methane reforming hydrogen production process using machine learning. J. Clean. Prod. 2022, 359, 132133. [Google Scholar] [CrossRef]
- Nwosu, C.; Ayodele, O.; Ibrahim, H. Optimization of hydrogen production via catalytic autothermal reforming of crude glycerol using response surface methodology and artificial neural network. Int. J. Energy Res. 2021, 45, 18999–19013. [Google Scholar] [CrossRef]
- Boretti, A.; Banik, B.K. Advances in hydrogen production from natural gas reforming. Adv. Energy Sustain. Res. 2021, 2, 2100097. [Google Scholar] [CrossRef]
- Adeniyi, A.G.; Ighalo, J.O.; Marques, G. Utilisation of machine learning algorithms for the prediction of syngas composition from biomass bio-oil steam reforming. Int. J. Sustain. Energy 2021, 40, 310–325. [Google Scholar] [CrossRef]
- Das, A.; Peu, S.D. A comprehensive review on recent advancements in thermochemical processes for clean hydrogen production to decarbonize the energy sector. Sustainability 2022, 14, 11206. [Google Scholar] [CrossRef]
- Stenina, I.; Yaroslavtsev, A. Modern technologies of hydrogen production. Processes 2023, 11, 56. [Google Scholar] [CrossRef]
- Tahir, M.; Fan, W.K.; Hasan, M. Investigating influential effect of methanol–phenol–steam mixture on hydrogen production through thermodynamic analysis with experimental evaluation. Int. J. Energy Res. 2022, 46, 964–979. [Google Scholar] [CrossRef]
- Kim, H.W.; Lee, S.W.; Na, G.S.; Han, S.J.; Kim, S.K.; Shin, J.H.; Chang, H.; Kim, Y.T. Reaction condition optimization for non-oxidative conversion of methane using artificial intelligence. React. Chem. Eng. 2021, 6, 235–243. [Google Scholar] [CrossRef]
- Fan, Z.; Xiao, W. Electrochemical splitting of methane in molten salts to produce hydrogen. Angew. Chem. 2021, 133, 7742–7746. [Google Scholar] [CrossRef]
- Magazzino, C.; Haroon, M. AI-based modelling and processing technologies for hydrogen creation. J. Sustain. 2025, 1, 1112. [Google Scholar] [CrossRef]
- Du, X.; Gao, S.; Yang, G. Machine learning applications in gray, blue, and green hydrogen production: A comprehensive review. Gases 2025, 5, 9. [Google Scholar] [CrossRef]
- Sethi, H.; Ahmad, I.; Khan, M.M.; Qazi, A.; Ayub, A.; Zulkefal, M.; Shutaywi, M. Applications of computer intelligence in hydrogen production. ACS Omega 2025, 10, 33982–33998. [Google Scholar] [CrossRef]
- Usman, M.; Yamada, T. Methanol reforming for hydrogen production: Advances in catalysts, nanomaterials, reactor design, and fuel cell integration. ACS Eng. Au 2025, 5, 314–346. [Google Scholar] [CrossRef]
- Alatalo, J.; Heilimo, E.; Rantonen, M.; Väänänen, O.; Sipola, T. Reducing emissions using artificial intelligence in the energy sector: A scoping review. Appl. Sci. 2025, 15, 999. [Google Scholar] [CrossRef]
- Pizoń, Z.; Kimijima, S.; Brus, G. Enhancing a deep learning model for the steam reforming process using data augmentation techniques. Energies 2024, 17, 2413. [Google Scholar] [CrossRef]
- Ullah, K.S.; Omer, A.; Rashid, K.; Rehman, N.U.; Rahimipetroudi, I.; Kim, S.D.; Dong, S.K. Modeling and comprehensive analysis of hydrogen production in a newly designed steam methane reformer with membrane system. Comput. Chem. Eng. 2023, 175, 108278. [Google Scholar] [CrossRef]
- Chih, Y.K.; Chen, W.H.; You, S.; Hsu, C.H.; Lin, H.P.; Naqvi, S.R.; Ashokkumar, V. Statistical optimization of hydrogen production from bio-methanol steam reforming over Ni–Cu/Al2O3 catalysts. Fuel 2023, 331, 125691. [Google Scholar] [CrossRef]
- Liu, Z.; Zhou, Q.; Sun, P.; Xu, S. A Multitask Learning Framework With LSTM-TPA for Dynamic Modeling of Automotive Fuel Cell Systems. IEEE Trans. Transp. Electrif. 2025, 12, 1532–1542. [Google Scholar] [CrossRef]
- Pan, Y.; Gao, P.; Tang, S.; Han, X.; Hao, Z.; Chen, J.; Ma, X. Enhancing CO2 methanation via doping CeO2 to Ni/Al2O3 and stacking catalyst beds. Chin. J. Chem. Eng. 2024, 75, 170–180. [Google Scholar] [CrossRef]
- Salahi, F.; Zarei-Jelyani, F.; Esmaeilzadeh, M.; Rahimpour, M.R. Effect of nickel active site position and synthesis method on performance of Ni–La–Al2O3 catalyst in the steam reforming of methane: Optimization by Box–Behnken Design. J. Energy Inst. 2025, 122, 102183. [Google Scholar] [CrossRef]
- Li, X.; Liu, Z.; Shao, S.; Yu, Y.; Wang, W.; Sun, T.; Wu, S. A Ca-modified Ni/CeO2·Al2O3 bifunctional catalyst for two-stage steam reforming of biomass pyrolysis oil for hydrogen production. Ind. Crops Prod. 2025, 228, 120891. [Google Scholar] [CrossRef]
- Shen, Z.; Nabavi, S.A.; Clough, P.T. Design and performance testing of a monolithic nickel-based SiC catalyst for steam methane reforming. Appl. Catal. A Gen. 2024, 670, 119529. [Google Scholar] [CrossRef]
- Salehi, F.; Abbassi, R.; Asadnia, M.; Chan, B.; Chen, L. Overview of safety practices in sustainable hydrogen economy–An Australian perspective. Int. J. Hydrogen Energy 2022, 47, 34689–34703. [Google Scholar] [CrossRef]
- Lueg, L.; Schack, D.; Örs, E.; Schmidt, R.; Bickert, P.; von Kurnatowski, M.; Ludl, P.O.; Ludl, P.O. Data-driven Process Design Exemplified on the Steam Methane Reforming Process. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2021; Volume 50, pp. 1013–1019. [Google Scholar] [CrossRef]
- Benavides-Hernandez, J.; Dumeignil, F. From characterization to discovery: Artificial intelligence, machine learning and high-throughput experiments for heterogeneous catalyst design. ACS Catal. 2024, 14, 11749–11779. [Google Scholar] [CrossRef]
- Liu, Z.; Xu, S.; Zhang, B.; Guo, S. Voltage tracking and regulation of vehicle PEMFC system under low load condition based on fuzzy LQG hybrid strategy. ISA Trans. 2025, 165, 510–523. [Google Scholar] [CrossRef]
- Impemba, S.; Provinciali, G.; Filippi, J.; Caporali, S.; Muzzi, B.; Casini, A.; Caporali, M. Tightly Interfaced Cu2O with In2O3 to Promote Hydrogen Evolution in Presence of Biomass-Derived Alcohols. ChemNanoMat 2024, 10, e202400459. [Google Scholar] [CrossRef]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.