
Towards Automated Situational Awareness Reporting for Disaster Management—A Case Study



Abstract
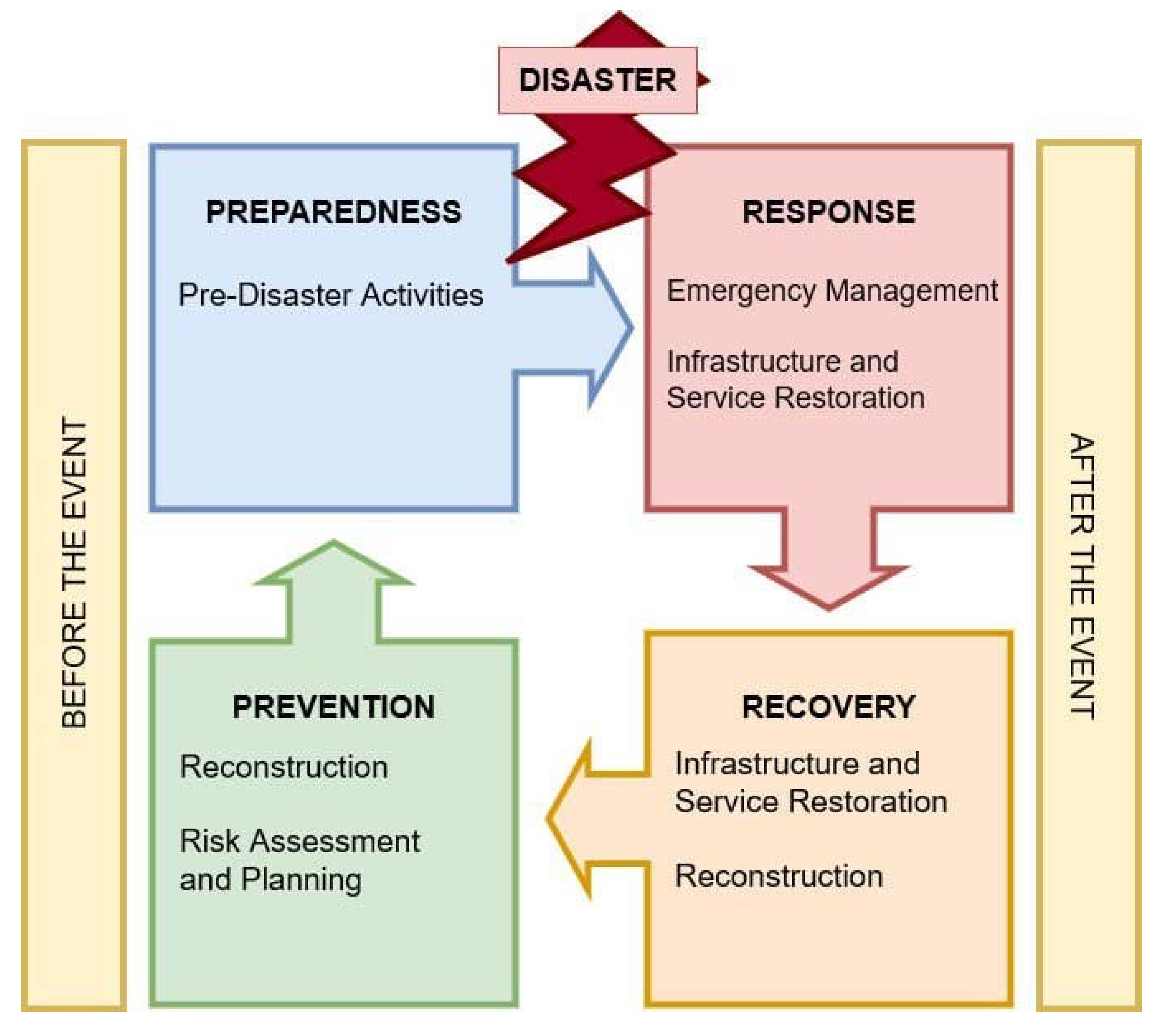
1. Introduction
- Plan
- The planning phase basically covers the entire cycle. The strategic and operational planning carried out in this section defines requirements and provides a benchmark for evaluating implementations. The planning elements show which capacities must be available during a major disaster [7].
- Organize/Equip
- Organization and equipment provide the human and technical resources needed to build and meet modernization and sustainability requirements. Organization and equipment include identifying the competencies and skills that staff should have and ensuring that an organization has the proper personnel. It also includes identifying and procuring standard equipment that an organization might need in emergencies [7].
- Train
- Training provides first responders, homeland security officials, emergency management officials, private and non-governmental partners, and other personnel with the knowledge, skills, and abilities needed to perform key tasks required during a specific emergency situation [6].
- Exercise
- Exercises enable entities to identify strengths and incorporate them within best practices to sustain and enhance existing capabilities. They also provide an objective assessment of gaps and shortfalls within plans, policies, and procedures to address areas for improvement prior to a real-world incident [7].
- Evaluate
- The final phase of the preparedness cycle is evaluation. In this phase, organizations gather lessons learned, develop improvement plans, and pursue corrective actions to address gaps and deficiencies identified during exercises or real-world events [6].
- Is the system able to process the data of the previous time window in the current time window?
- What percentage of the events in a dataset that is as realistic as possible is the system able to detect?
- Which of the three libraries for automated text summarization provides the best results?
- How could the results be improved?
2. Related Works
2.1. Event Detection
2.2. Text Summarization
2.3. Summary
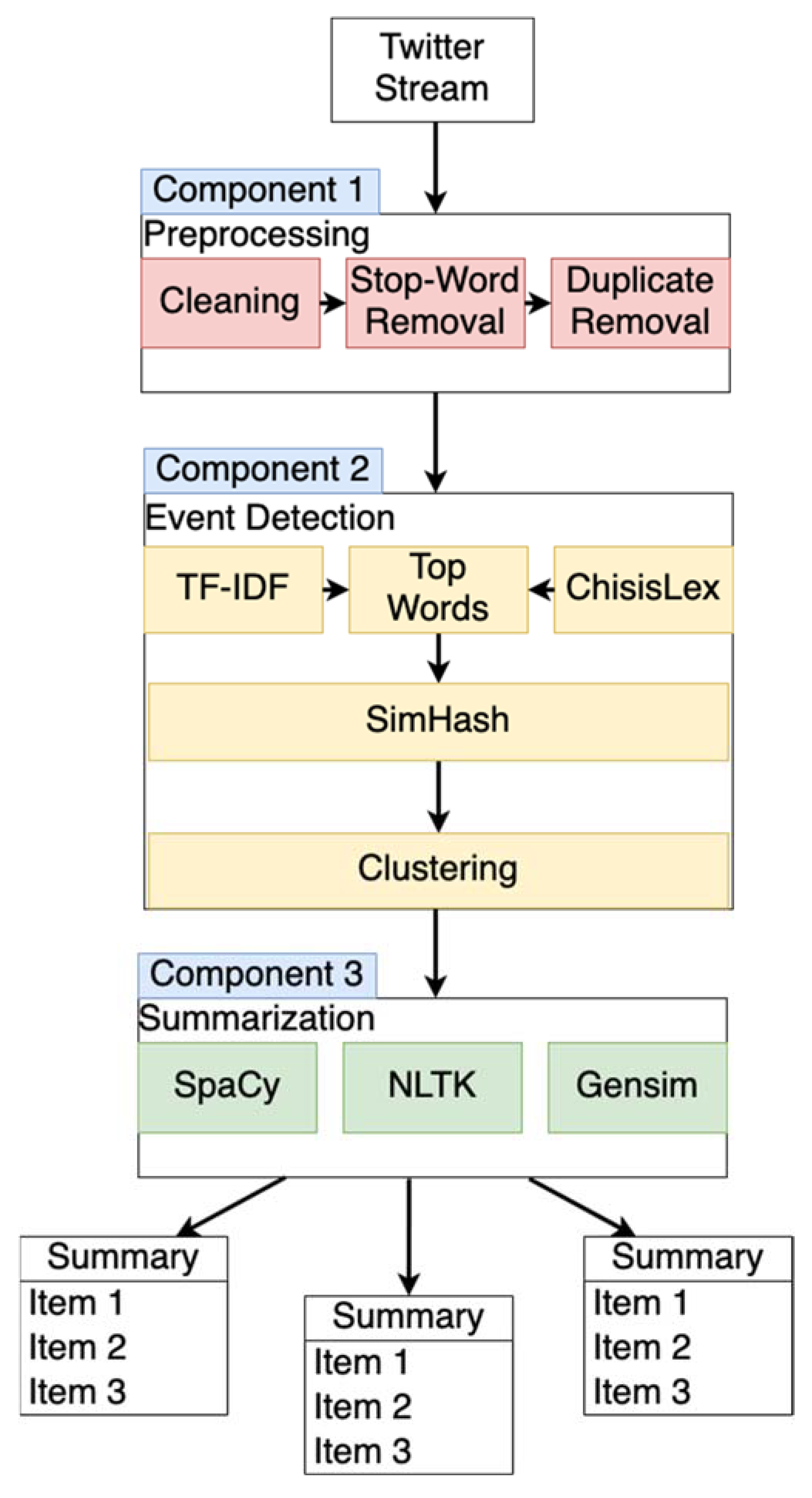
3. Proposed Approach
3.1. Preprocessing
3.2. Event Detection
3.3. Summarization
4. Experiment
5. Discussion
- Is the system able to process the data of the previous time window in the current time window?
- What percentage of the events in a dataset that is as realistic as possible is the system able to detect?
- Which of the three libraries for automated text summarization provides the best results?
- How could the results be improved?
6. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al-Madhari, A.F.; Keller, A.Z. Review Of Disaster Definitions. Prehosp. Disaster Med. 1997, 12, 17–21. [Google Scholar] [CrossRef] [PubMed]
- Zibulewsky, J. Defining Disaster: The Emergency Department Perspective. Bayl. Univ. Med. Cent. Proc. 2001, 14, 144–149. [Google Scholar] [CrossRef]
- Hanna Sawalha, I. Behavioural Response Patterns: An Investigation of the Early Stages of Major Incidents. Foresight 2018, 20, 337–352. [Google Scholar] [CrossRef]
- Malilay, J.; Heumann, M.; Perrotta, D.; Wolkin, A.F.; Schnall, A.H.; Podgornik, M.N.; Cruz, M.A.; Horney, J.A.; Zane, D.; Roisman, R.; et al. The Role of Applied Epidemiology Methods in the Disaster Management Cycle. Am. J. Public Health 2014, 104, 2092–2102. [Google Scholar] [CrossRef] [PubMed]
- Anderson, A.I.; Compton, D.; Mason, T. Managing in a Dangerous World—The National Incident Management System. Eng. Manag. J. 2004, 16, 3–9. [Google Scholar] [CrossRef]
- Gujral, U.P.; Johnson, L.; Nielsen, J.; Vellanki, P.; Haw, J.S.; Davis, G.M.; Weber, M.B.; Pasquel, F.J. Preparedness Cycle to Address Transitions in Diabetes Care during the COVID-19 Pandemic and Future Outbreaks. BMJ Open Diabetes Res. Care 2020, 8, e001520. [Google Scholar] [CrossRef]
- Ramsbottom, A.; O’Brien, E.; Ciotti, L.; Takacs, J. Enablers and Barriers to Community Engagement in Public Health Emergency Preparedness: A Literature Review. J. Community Health 2018, 43, 412–420. [Google Scholar] [CrossRef]
- Arias-Aranda, D.; Molina, L.-M.; Stantchev, V. Integration of Internet of Things and Blockchain to Increase Humanitarian Aid Supply Chains Performance. Dyna 2021, 96, 653–658. [Google Scholar] [CrossRef]
- Rudra, K.; Ganguly, N.; Goyal, P.; Ghosh, S. Extracting and Summarizing Situational Information from the Twitter Social Media during Disasters. ACM Trans. Web. 2018, 12, 1–35. [Google Scholar] [CrossRef]
- Lamsal, R.; Kumar, T.V.V. Twitter-Based Disaster Response Using Recurrent Nets. Int. J. Sociotechnol. Knowl. Dev. 2021, 13, 133–150. [Google Scholar] [CrossRef]
- Mukhtiar, W.; Rizwan, W.; Habib, A.; Afridi, Y.S.; Hasan, L.; Ahmad, K. Relevance Classification of Flood-Related Twitter Posts via Multiple Transformers. arXiv 2022, arXiv:2301.00320. [Google Scholar]
- Karimiziarani, M.; Jafarzadegan, K.; Abbaszadeh, P.; Shao, W.; Moradkhani, H. Hazard Risk Awareness and Disaster Management: Extracting the Information Content of Twitter Data. Sustain. Cities Soc. 2022, 77, 103577. [Google Scholar] [CrossRef]
- Karimiziarani, M.; Moradkhani, H. Social Response and Disaster Management: Insights from Twitter Data Assimilation on Hurricane Ian. SSRN Electron. J. 2022. [Google Scholar] [CrossRef]
- Lamsal, R.; Harwood, A.; Read, M.R. Socially Enhanced Situation Awareness from Microblogs Using Artificial Intelligence: A Survey. ACM Comput. Surv. 2022, 55, 1–38. [Google Scholar] [CrossRef]
- Takahashi, B.; Tandoc, E.C.; Carmichael, C. Communicating on Twitter during a Disaster: An Analysis of Tweets during Typhoon Haiyan in the Philippines. Comput. Hum. Behav. 2015, 50, 392–398. [Google Scholar] [CrossRef]
- Phengsuwan, J.; Shah, T.; Thekkummal, N.B.; Wen, Z.; Sun, R.; Pullarkatt, D.; Thirugnanam, H.; Ramesh, M.V.; Morgan, G.; James, P.; et al. Use of Social Media Data in Disaster Management: A Survey. Future Internet 2021, 13, 46. [Google Scholar] [CrossRef]
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Earthquake Shakes Twitter Users. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26 April 2010; ACM: New York, NY, USA, 2010; pp. 851–860. [Google Scholar]
- Shan, S.; Zhao, F.; Wei, Y.; Liu, M. Disaster Management 2.0: A Real-Time Disaster Damage Assessment Model Based on Mobile Social Media Data—A Case Study of Weibo (Chinese Twitter). Saf. Sci. 2019, 115, 393–413. [Google Scholar] [CrossRef]
- Muzamil, S.A.H.B.S.; Zainun, N.Y.; Ajman, N.N.; Sulaiman, N.; Khahro, S.H.; Rohani, M.M.; Mohd, S.M.B.; Ahmad, H. Proposed Framework for the Flood Disaster Management Cycle in Malaysia. Sustainability 2022, 14, 4088. [Google Scholar] [CrossRef]
- Pastor-Galindo, J.; Nespoli, P.; Gomez Marmol, F.; Martinez Perez, G. The Not Yet Exploited Goldmine of OSINT: Opportunities, Open Challenges and Future Trends. IEEE Access 2020, 8, 10282–10304. [Google Scholar] [CrossRef]
- Hasan, M.; Orgun, M.A.; Schwitter, R. A Survey on Real-Time Event Detection from the Twitter Data Stream. J. Inf. Sci. 2018, 44, 443–463. [Google Scholar] [CrossRef]
- Yu, X.; Li, C.; Yen, G.G. A Knee-Guided Differential Evolution Algorithm for Unmanned Aerial Vehicle Path Planning in Disaster Management. Appl. Soft. Comput. 2021, 98, 106857. [Google Scholar] [CrossRef]
- Rabiei, P.; Arias-Aranda, D. Introducing a Novel Multi-Objective Optimization Model for Vehicle Routing and Relief Supply Distribution in Post-Disaster Phase: Combining Fuzzy Inference Systems with NSGA-II and NRGA. In Proceedings of the 6th International Conference on Transportation Information and Safety: New Infrastructure Construction for Better Transportation, ICTIS 2021, Wuhan, China, 22–24 October 2021; pp. 1226–1243. [Google Scholar] [CrossRef]
- Rabiei, P.; Arias-Aranda, D.; Stantchev, V. Introducing a Novel Multi-Objective Optimization Model for Volunteer Assignment in the Post-Disaster Phase: Combining Fuzzy Inference Systems with NSGA-II and NRGA. Expert Syst. Appl. 2023, 226, 120142. [Google Scholar] [CrossRef]
- Garg, P.K.; Chakraborty, R.; Dandapat, S.K. OntoDSumm: Ontology Based Tweet Summarization for Disaster Events. arXiv 2022, arXiv:cs.SI/2201.06545. [Google Scholar]
- Garg, P.K.; Chakraborty, R.; Dandapat, S.K. EnDSUM: Entropy and Diversity Based Disaster Tweet Summarization. arXiv 2022, arXiv:2203.01188. [Google Scholar]
- Wu, K.; Li, L.; Li, J.; Li, T. Ontology-Enriched Multi-Document Summarization in Disaster Management Using Submodular Function. Inf. Sci. 2013, 224, 118–129. [Google Scholar] [CrossRef]
- Banerjee, S.; Mukherjee, S.; Bandyopadhyay, S.; Pakray, P. An Extract-Then-Abstract Based Method to Generate Disaster-News Headlines Using a DNN Extractor Followed by a Transformer Abstractor. Inf. Process. Manag. 2023, 60, 103291. [Google Scholar] [CrossRef]
- Saini, N.; Saha, S.; Bhattacharyya, P. Microblog Summarization Using Self-Adaptive Multi-Objective Binary Differential Evolution. Appl. Intell. 2022, 52, 1686–1702. [Google Scholar] [CrossRef]
- Vitiugin, F.; Castillo, C. Cross-Lingual Query-Based Summarization of Crisis-Related Social Media: An Abstractive Approach Using Transformers. In Proceedings of the HT 2022: 33rd ACM Conference on Hypertext and Social Media—Co-located with ACM WebSci 2022 and ACM UMAP 2022, Barcelona, Spain, 1 July–28 June 2022; pp. 21–31. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Rudra, K. Towards an Interpretable Approach to Classify and Summarize Crisis Events from Microblogs. In Proceedings of the ACM Web Conference 2022, Virtual, 29 April 2022. [Google Scholar] [CrossRef]
- Mukherjee, R.; Vishnu, U.; Peruri, H.C.; Bhattacharya, S.; Rudra, K.; Goyal, P.; Ganguly, N. MTLTS: A Multi-Task Framework to Obtain Trustworthy Summaries from Crisis-Related Microblogs. In Proceedings of the 15th ACM International Conference on Web Search and Data Mining (WSDM), Tempe, AZ, USA, 21–25 February 2022; pp. 755–763. [Google Scholar] [CrossRef]
- Rudra, K.; Ghosh, S.; Ganguly, N.; Goyal, P.; Ghosh, S. Extracting Situational Information from Microblogs during Disaster Events: A Classification-Summarization Approach. In Proceedings of the International Conference on Information and Knowledge Management, Proceedings, Melbourne, Australia, 19–23 October 2015; pp. 583–592. [Google Scholar] [CrossRef]
- Unankard, S.; Nadee, W. Sub-Events Tracking from Social Network Based on the Relationships between Topics. In Proceedings of the 2020 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering (ECTI DAMT & NCON), Pattaya, Thailand, 11–14 March 2020; pp. 1–6. [Google Scholar]
- Hasan, M.; Orgun, M.A.; Schwitter, R. Real-Time Event Detection from the Twitter Data Stream Using the TwitterNews+ Framework. Inf. Process. Manag. 2019, 56, 1146–1165. [Google Scholar] [CrossRef]
- Li, Q.; Chao, Y.; Li, D.; Lu, Y.; Zhang, C. Event Detection from Social Media Stream: Methods, Datasets and Opportunities. In Proceedings of the 2022 IEEE International Conference on Big Data, Osaka, Japan, 17–20 December 2022; pp. 3509–3516. [Google Scholar] [CrossRef]
- Osborne, M.; Moran, S.; McCreadie, R.; von Lunen, A.; Sykora, M.; Cano, E.; Ireson, N.; Macdonald, C.; Ounis, I.; He, Y.; et al. Real-Time Detection, Tracking, and Monitoring of Automatically Discovered Events in Social Media. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations; Association for Computational Linguistics, Stroudsburg, PA, USA, 23–24 June 2014; pp. 37–42. [Google Scholar]
- Petrovic, S.; Osborne, M.; Lavrenko, V. Streaming First Story Detection with Application to Twitter. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics (HLT ’10), Los Angeles, CA, USA, 2–4 June 2010; Association for Computational Linguistics: Seattle, WA, USA, 2010; pp. 181–189. [Google Scholar]
- Rudrapal, D.; Das, A.; Bhattacharya, B. A Survey on Automatic Twitter Event Summarization. J. Inf. Process. Syst. 2018, 14, 79–100. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, Q. Twitter Event Summarization by Exploiting Semantic Terms and Graph Network. Proc. AAAI Conf. Artif. Intell. 2021, 35, 15347–15354. [Google Scholar] [CrossRef]
- Montani, I.; Honnibal, M.; Honnibal, M.; van Landeghem, S.; Boyd, A.; Peters, H.; McCann, P.O.; Samsonov, M.; Geovedi, J.; O’Regan, J.; et al. Explosion/SpaCy: V3.1.6: Workaround for Click/Typer Issues 2022. Available online: https://zenodo.org/record/1212303 (accessed on 3 April 2023).
- Rygl, J.; Pomikálek, J.; Řehůřek, R.; Růžička, M.; Novotný, V.; Sojka, P. Semantic Vector Encoding and Similarity Search Using Fulltext Search Engines. In Proceedings of the 2nd Workshop on Representation Learning for NLP, Vancouver, BC, Canada, 3 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; Volume 3, pp. 81–90. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009; Volume 6. [Google Scholar]
- Navarro, G. A Guided Tour to Approximate String Matching. ACM Comput. Surv. 2001, 33, 31–88. [Google Scholar] [CrossRef]
- Rajaraman, A.; Ullman, J.D. Data Mining. In Mining of Massive Datasets; Cambridge University Press: Cambridge, UK, 2011; pp. 1–17. [Google Scholar]
- Olteanu, A.; Castillo, C.; Diaz, F.; Vieweg, S. CrisisLex: A Lexicon for Collecting and Filtering Microblogged Communications in Crises. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 376–385. [Google Scholar] [CrossRef]
- Manku, G.S.; Jain, A.; das Sarma, A. Detecting Near-Duplicates for Web Crawling. In Proceedings of the 16th international conference on World Wide Web, New York, NY, USA, 12 May 2007; ACM: New York, NY, USA, 2007; pp. 141–150. [Google Scholar]
- McCreadie, R.; Macdonald, C.; Ounis, I. Insights on the Horizons of News Search. Available online: http://terrierteam.dcs.gla.ac.uk/publications/richardmSSM2010.pdf (accessed on 25 April 2023).
- Li, C.; Sun, A.; Datta, A. Twevent: Segment-Based Event Detection from Tweets. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 155–164. [Google Scholar] [CrossRef]
- Stilo, G.; Velardi, P. Efficient Temporal Mining of Micro-Blog Texts and Its Application to Event Discovery. Data Min. Knowl. Discov. 2016, 30, 372–402. [Google Scholar] [CrossRef]
- Osborne, M.; Petrovi’cpetrovi’c, S.; Mccreadie, R.; Macdonald, C.; Ounis, I. Bieber No More: First Story Detection Using Twitter and Wikipedia. In Proceedings of the TAIA’12, Portland, OR, USA, 12–16 August 2012; pp. 16–76. [Google Scholar]
- Timeline of the 2022 Russian Invasion of Ukraine: Phase 3—Wikipedia. Available online: https://en.wikipedia.org/wiki/Timeline_of_the_2022_Russian_invasion_of_Ukraine:_phase_3 (accessed on 1 February 2023).
- BwandoWando Ukraine Conflict Twitter Dataset 2023. Available online: https://www.kaggle.com/datasets/bwandowando/ukraine-russian-crisis-twitter-dataset-1-2-m-rows/versions/363 (accessed on 13 February 2023).



{kind=link}
{kind=link}
| Date | Num. of Tweets | Num. of Events | SpaCy | Gensim | NLTK |
|---|---|---|---|---|---|
| Sep 01 | 48,262 | 2 | 2 | 0 | 0 |
| Sep 02 | 53,668 | 4 | 4 | 2 | 3 |
| Sep 03 | 40,732 | 2 | 1 | 0 | 2 |
| Sep 04 | 40,151 | 2 | 3 | 1 | 2 |
| Sep 05 | 44,695 | 0 | 2 | 0 | 1 |
| Sep 06 | 61,619 | 2 | 1 | 0 | 1 |
| Sep 07 | 46,496 | 1 | 3 | 1 | 1 |
| Sep 08 | 47,830 | 0 | 0 | 0 | 0 |
| Sep 09 | 70,401 | 1 | 2 | 0 | 1 |
| Sep 10 | 64,953 | 6 | 9 | 3 | 4 |
| Sep 11 | 67,526 | 8 | 7 | 6 | 8 |
| Sep 12 | 62,944 | 2 | 5 | 3 | 2 |
| Sep 13 | 63,866 | 2 | 3 | 2 | 2 |
| Sep 14 | 75,392 | 2 | 2 | 1 | 2 |
| Sep 15 | 67,230 | 1 | 1 | 0 | 2 |
| Sep 16 | 63,125 | 1 | 2 | 0 | 1 |
| Sep 17 | 49,592 | 1 | 2 | 0 | 2 |
| Sep 18 | 42,426 | 1 | 1 | 0 | 1 |
| Sep 19 | 49,332 | 2 | 3 | 0 | 2 |
| Sep 20 | 57,409 | 3 | 5 | 1 | 3 |
| Sep 21 | 104,313 | 4 | 6 | 3 | 4 |
| Sep 22 | 78,507 | 0 | 2 | 0 | 0 |
| Sep 23 | 77,368 | 3 | 3 | 2 | 3 |
| Sep 24 | 63,866 | 0 | 0 | 0 | 0 |
| Sep 25 | 52,998 | 0 | 1 | 0 | 0 |
| Sep 26 | 60,625 | 1 | 1 | 1 | 1 |
| Sep 27 | 68,866 | 4 | 5 | 3 | 3 |
| Sep 28 | 80,527 | 3 | 3 | 2 | 2 |
| Sep 29 | 66,984 | 3 | 4 | 3 | 2 |
| Sep 30 | 69,930 | 3 | 3 | 1 | 1 |
| 184,1633 | 64 | 134.375% | 54.6875% | 87.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schwarz, K.; Aranda, D.A.; Hartmann, M. Towards Automated Situational Awareness Reporting for Disaster Management—A Case Study. Sustainability 2023, 15, 7968. https://doi.org/10.3390/su15107968
Schwarz K, Aranda DA, Hartmann M. Towards Automated Situational Awareness Reporting for Disaster Management—A Case Study. Sustainability. 2023; 15(10):7968. https://doi.org/10.3390/su15107968
Chicago/Turabian StyleSchwarz, Klaus, Daniel Arias Aranda, and Michael Hartmann. 2023. "Towards Automated Situational Awareness Reporting for Disaster Management—A Case Study" Sustainability 15, no. 10: 7968. https://doi.org/10.3390/su15107968
APA StyleSchwarz, K., Aranda, D. A., & Hartmann, M. (2023). Towards Automated Situational Awareness Reporting for Disaster Management—A Case Study. Sustainability, 15(10), 7968. https://doi.org/10.3390/su15107968