
A Hybrid Sailfish Whale Optimization and Deep Long Short-Term Memory (SWO-DLSTM) Model for Energy Efficient Autonomy in India by 2048

 , ,
, ,  ,
, 
Abstract
:1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Share in Primary Energy Supply | 2012 | 2022 | 2030 | 2047 |
|---|---|---|---|---|
| Coal | 47% | 52% | 51% | 52% |
| Oil | 27% | 28% | 29% | 28% |
| Gas | 8% | 9% | 9% | 8% |
| Nuclear, Renewables and hydro | 10% | 6% | 6% | 6% |
| Others | 6% | 5% | 5% | 6% |
Research Gap and Motivation
- Data preprocessing and extraction of technical indicators is done using Box-Cox transformation.
- The optimal features are selected from the extracted features using HSIC.
- The output of integrated optimization algorithm (SWO) is fed into the Deep LSTM model for training. This hybrid approach leads to improved accuracy with faster convergence rate.
- A detailed analysis of electricity prediction of the proposed model in terms of install capacity, village electrified prediction, length of R & D lines, the prediction of Hydro, gas, coal, nuclear, etc. is made, and the results are compared with the existing methods to show the improved accuracy.
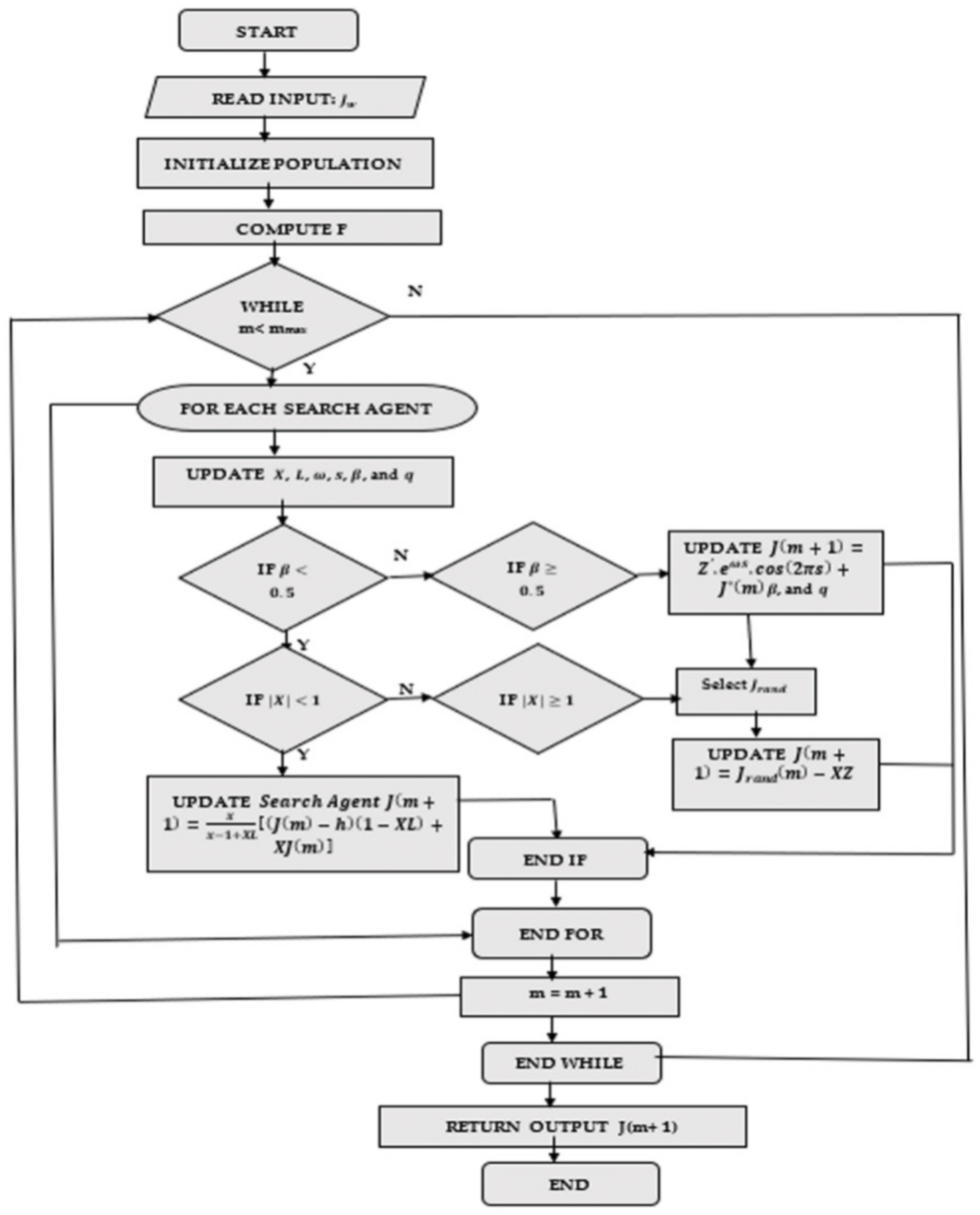
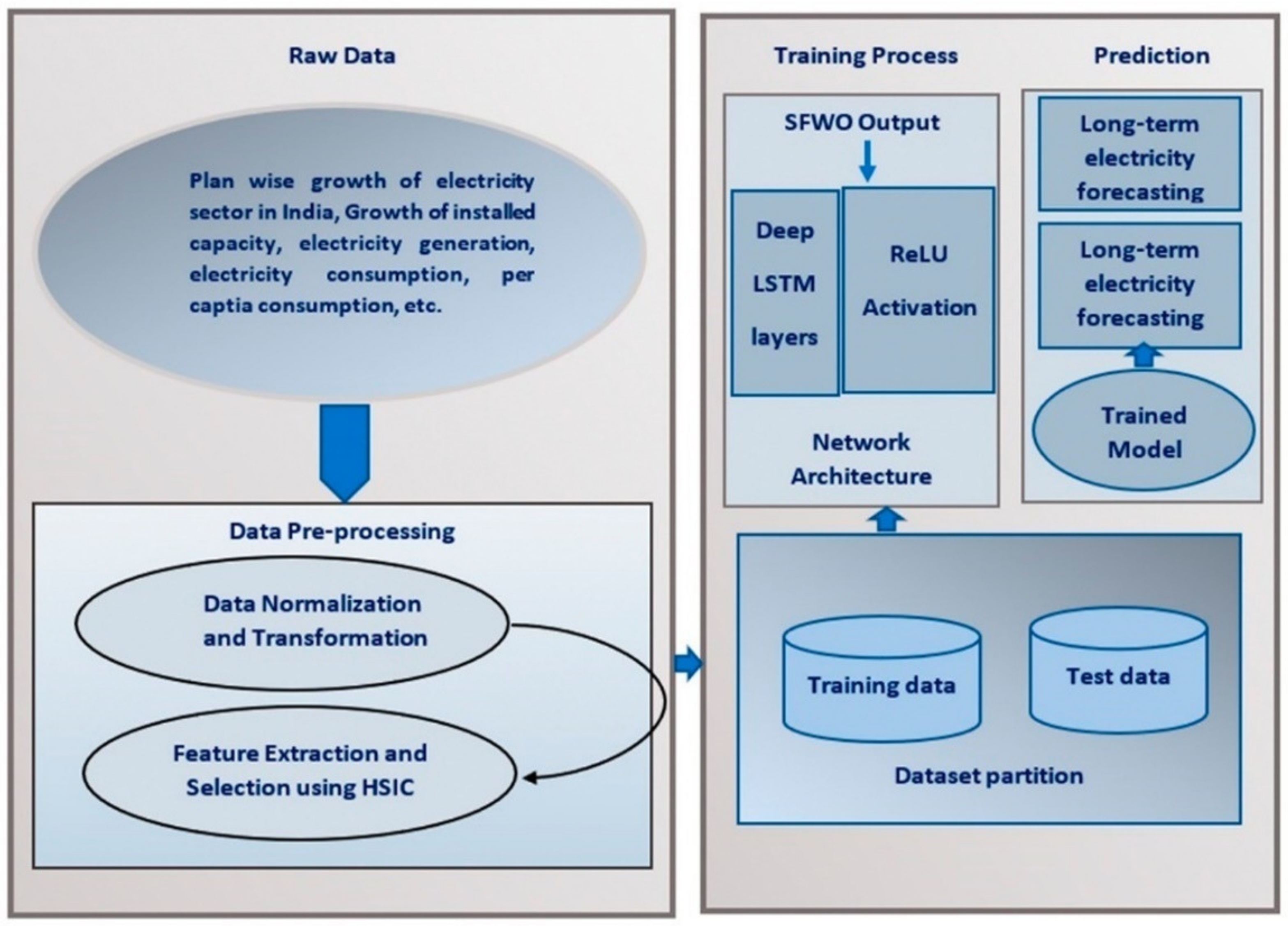
2. Proposed Sailfish Whale Optimization-Based Deep LSTM Approach for Power Generation Forecasting
2.1. Acquisition of the Input Time-Series Data
2.2. Data Preprocessing and Feature Extraction
2.3. Data Transformation Using Box-Cox Transformation
2.4. Extraction of Technical Indicators
2.5. Feature Selection Using Hilbert-Schmidt Independence Criterion (HSIC)
| Algorithm 1: HSIC |
| Input: Entire set of features Q |
| Output: An ordered set of features Q’ |
Q’  ϕ ϕ |
| Repeat |
| σ ≡ |
| U argmaxu Σsєu HSIC (σ, Q\{s}), U є Q |
| Q Q\U |
| Q’ (Q’, U) |
| Until Q = ϕ |
3. Forecasting Power Generation Using the Proposed SWO-Based Deep LSTM
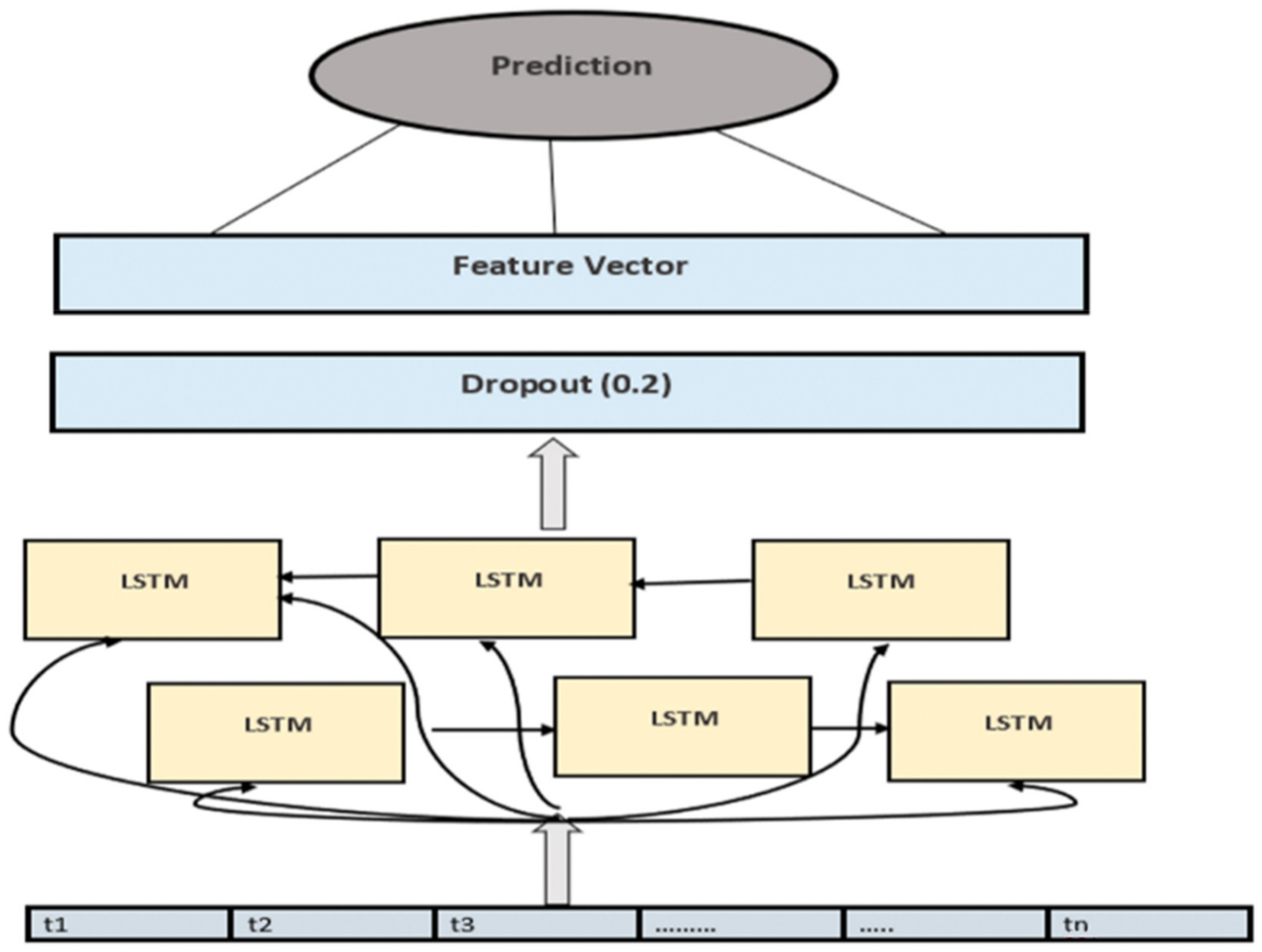
3.1. Structure of Deep LSTM
3.2. Selection of Nodes and Hyper Parameters for Deep LSTM
3.3. Proposed Sailfish Optimization Algorithm
3.4. Experimental Setup and Dataset Description
3.5. Inspection of Model Quality
3.5.1. Mean Squared Error (MSE)
3.5.2. Root Mean Squared Error (RMSE)
3.5.3. Normalized Mean Squared Error (nMSE)
3.5.4. Normalized Root Mean Squared Error (nRMSE)
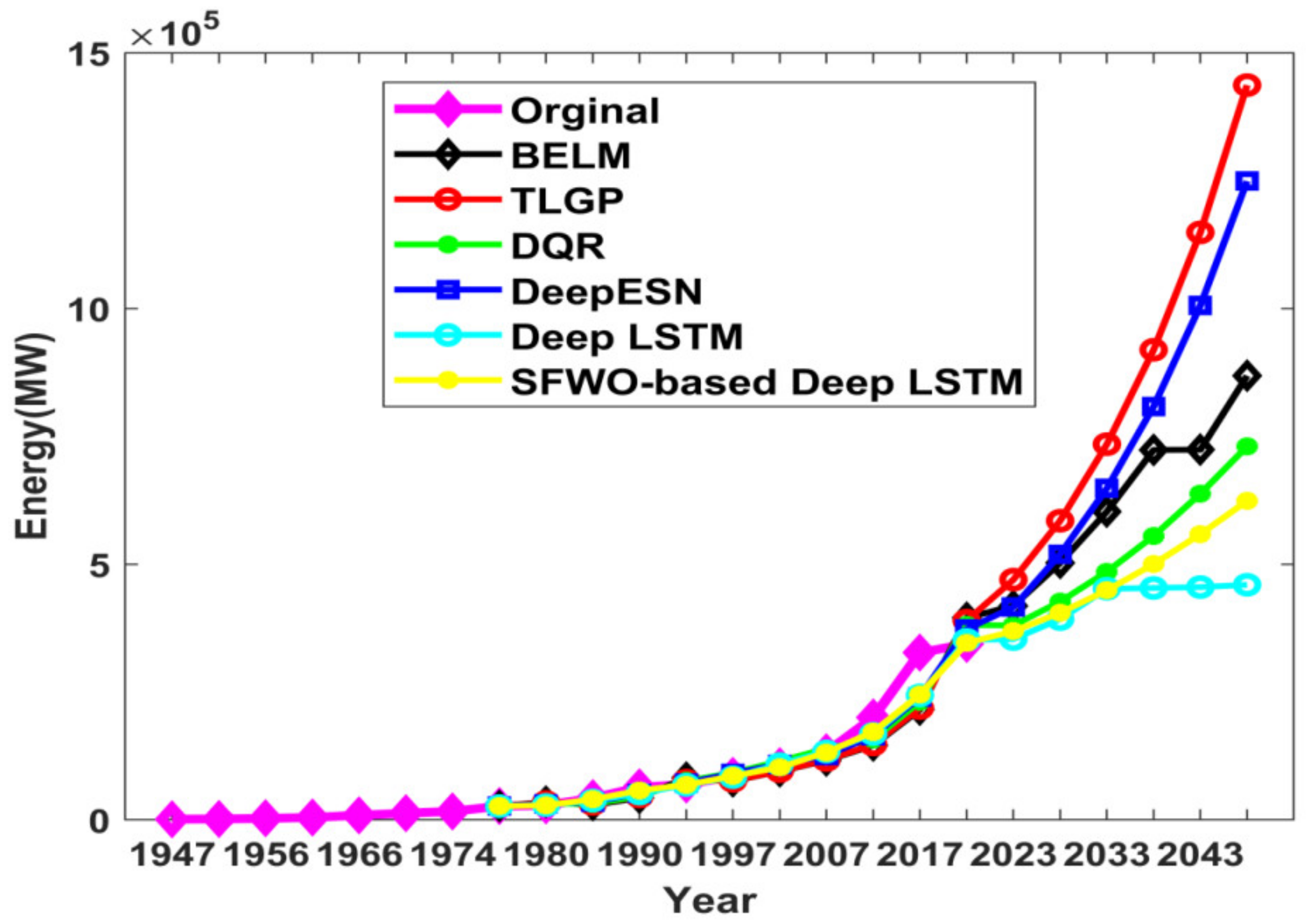
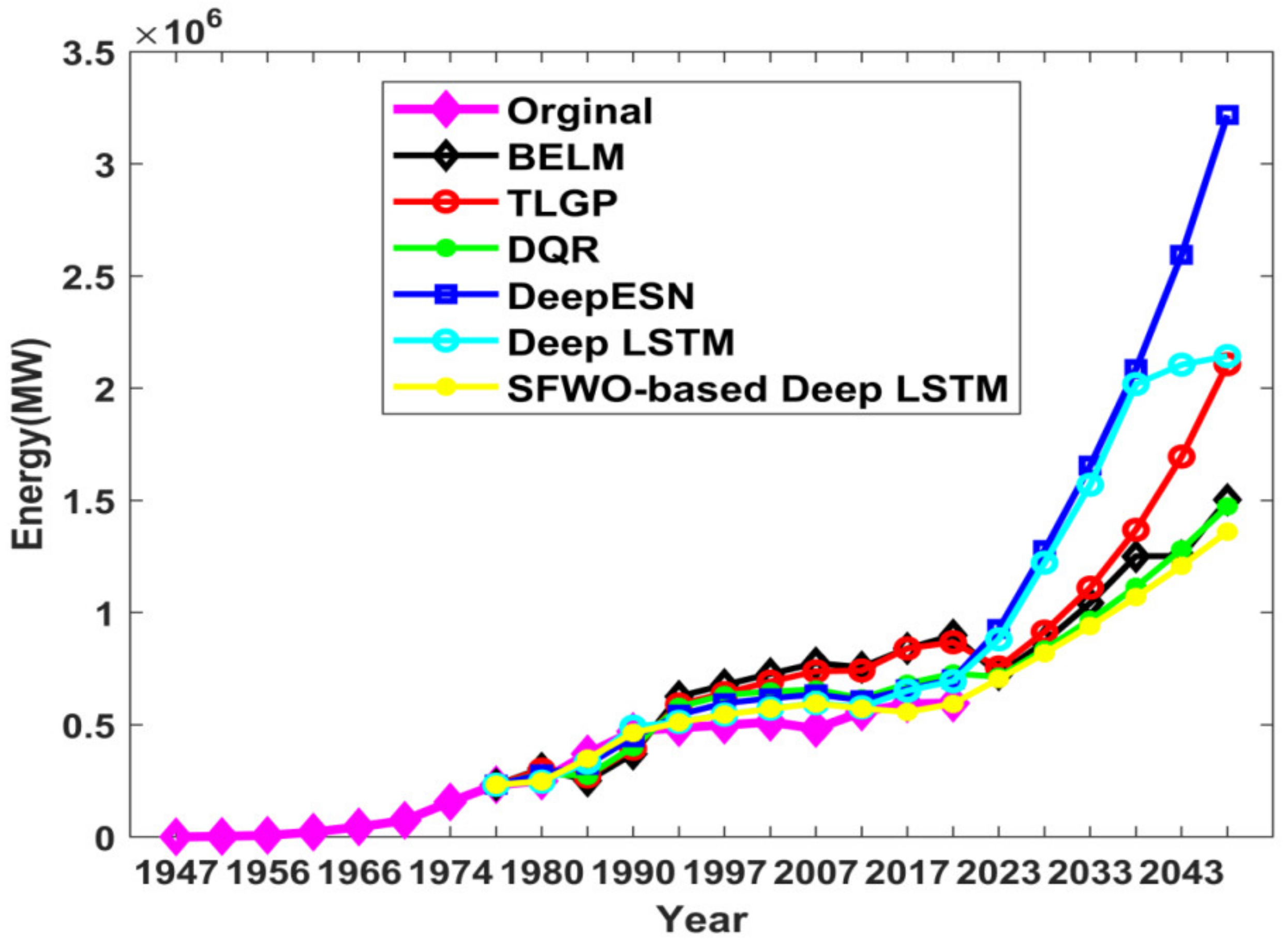
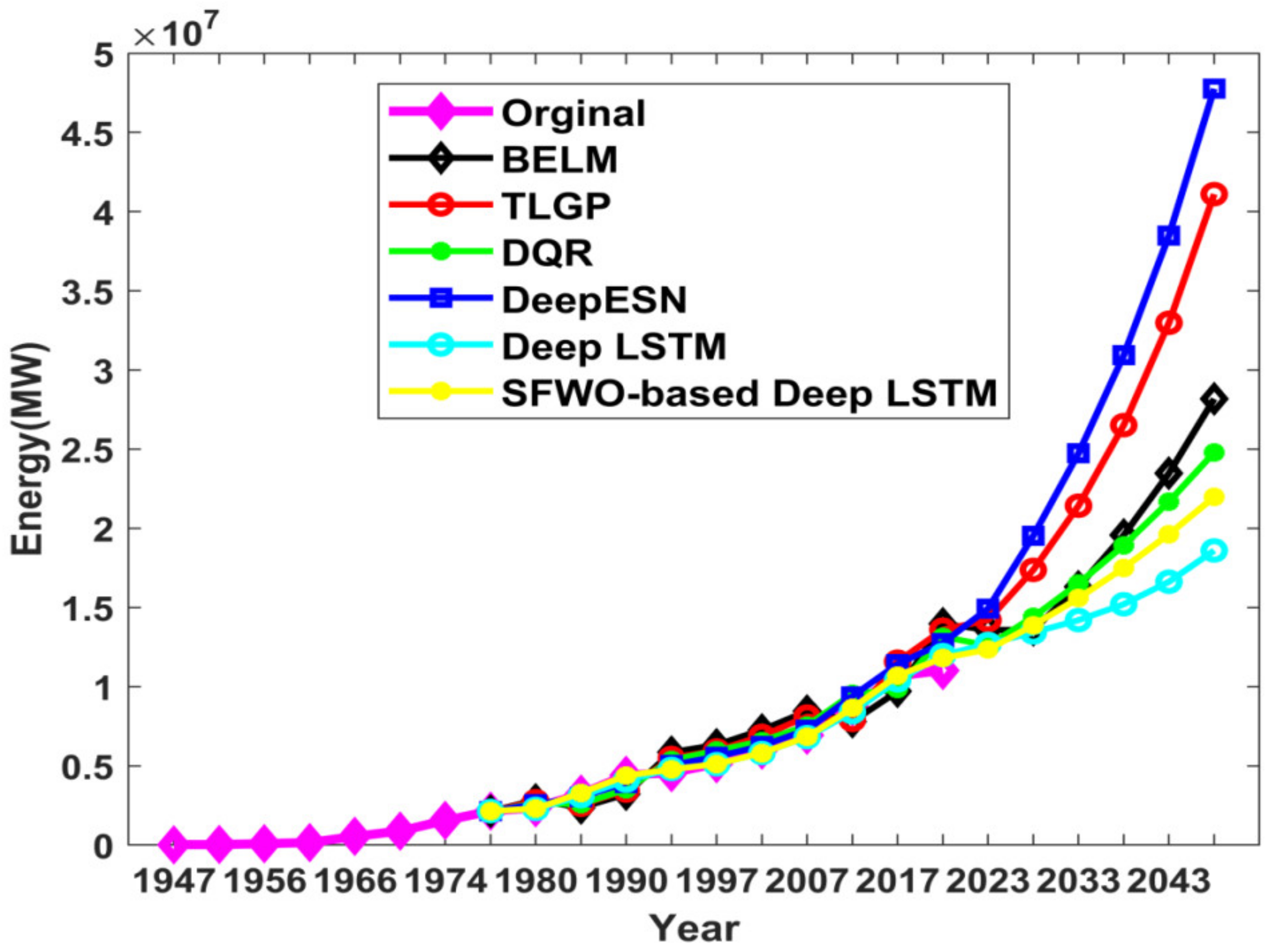
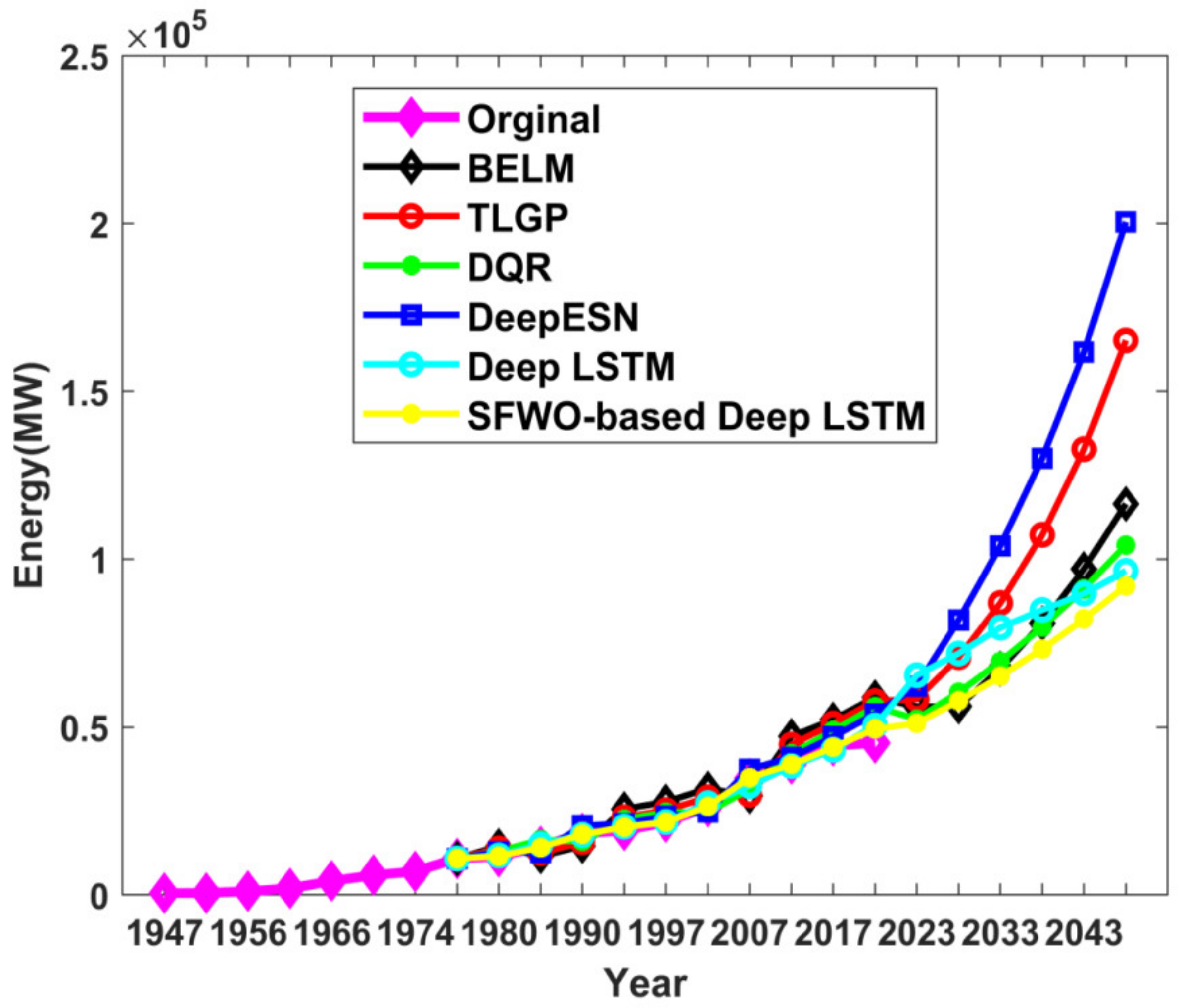
4. Results and Discussion
4.1. Comparative Analysis of Energy Prediction
4.2. Research Results and Outcome Analysis
4.3. Statistical Results Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| ANN | Artificial Neural Network | NWP | Numerical Weather Prediction |
| CNN | Convolutional Neural Network | OBV | On Balance Volume |
| Deep ESN | Deep Echo State Network | PMSG | Permanent Magnet Synchronous Generator |
| DQR | Direct Quantile Regression | PV | Photo Voltaic |
| ELM | Extreme Learning Machine | RKHS | Reproducing Kernel Hilbert Spaces |
| EMA | Exponential Moving Average | RMSE | Root Mean Square Error |
| FFNN | Feed Forward Neural Networks | RNN | Recurrent Neural Network |
| GW | Giga Watt | SARIMA | Seasonal Autoregressive Integrated Moving Average |
| HSIC | Hilbert-Schmidt Independence Criterion | SMA | Simple Moving Average |
| IEA | International Energy Agency | SMI | Stochastic Momentum Index |
| LMBNN | Levenberg Marquardt Back Propagation Neural Networks | SO | Sailfish Optimizer |
| LSTM | Long Short-Term Memory | SVAR | Sparse Vector Auto Regressive |
| MAPE | Mean Absolute percentage Error | SVM | Support Vector Machines |
| MFO | Moth Flame optimization | SWO-DLSTM | Sailfish Whale Optimization and Deep Long Short-Term Memory |
| MGWO-SCA-CSA | Micro Grid Wolf Optimizer-Sine cosine Algorithm- Crow Search Algorithm | TLGP | Temporally Local Gaussian Process |
| MSE | Mean Squared Error | VMD | Variational Mode Decomposition |
| MW | Mega Watt | WECS | Wind Energy Conversion System |
| nMSE | normalized Mean Squared Error | WHO | World Health Organization |
| nRMSE | normalized Root Mean Squared Error | WOA | Whale Optimization Algorithm |
Appendix A
| Prediction | Statistical Analysis | BELM [21] | TLGP [24] | DQR [42] | Deep ESN [47] | Deep LSTM [45] | Proposed SWO-Based Deep LSTM |
|---|---|---|---|---|---|---|---|
| Install capacity prediction | Best | 20.792 | 20.697 | 20.395 | 20.129 | 19.938 | 19.855 |
| Mean | 20.790 | 20.694 | 20.392 | 20.128 | 19.936 | 19.854 | |
| Variance | 0.002 | 0.003 | 0.003 | 0.001 | 0.002 | 0.001 | |
| Number of villages electrified prediction | Best | 23.830 | 23.589 | 22.622 | 22.076 | 21.380 | 20.868 |
| Mean | 23.827 | 23.588 | 22.620 | 22.073 | 21.378 | 20.866 | |
| Variance | 0.003 | 0.001 | 0.002 | 0.003 | 0.002 | 0.002 | |
| Length of L&D lines prediction | Best | 27.720 | 27.327 | 26.949 | 26.329 | 25.054 | 24.415 |
| Mean | 27.717 | 27.326 | 26.947 | 26.327 | 25.051 | 24.414 | |
| Variance | 0.003 | 0.001 | 0.002 | 0.002 | 0.003 | 0.001 | |
| Hydro prediction | Best | 17.094 | 16.650 | 16.168 | 15.664 | 14.523 | 13.855 |
| Mean | 17.093 | 16.648 | 16.166 | 15.661 | 14.521 | 13.853 | |
| Variance | 0.001 | 0.002 | 0.002 | 0.003 | 0.002 | 0.002 | |
| Coal prediction | Best | 19.889 | 19.784 | 19.583 | 19.374 | 19.049 | 18.975 |
| Mean | 19.887 | 19.781 | 19.851 | 19.372 | 19.047 | 18.974 | |
| Variance | 0.002 | 0.003 | 0.002 | 0.002 | 0.002 | 0.001 | |
| Gas prediction | Best | 16.495 | 15.777 | 15.494 | 15.155 | 14.446 | 13.821 |
| Mean | 16.492 | 15.775 | 15.492 | 15.154 | 14.442 | 13.819 | |
| Variance | 0.003 | 0.002 | 0.002 | 0.001 | 0.004 | 0.002 | |
| Diesel prediction | Best | 11.712 | 11.182 | 11.066 | 10.821 | 10.759 | 10.309 |
| Mean | 11.710 | 11.180 | 11.063 | 10.820 | 10.757 | 10.307 | |
| Variance | 0.002 | 0.002 | 0.003 | 0.001 | 0.002 | 0.002 | |
| Nuclear prediction | Best | 20.045 | 19.950 | 19.657 | 19.455 | 19.234 | 19.149 |
| Mean | 20.042 | 19.948 | 19.656 | 19.453 | 19.232 | 19.148 | |
| Variance | 0.003 | 0.002 | 0.001 | 0.002 | 0.002 | 0.001 | |
| Total utility prediction | Best | 15.083 | 14.368 | 12.756 | 12.420 | 11.319 | 10.579 |
| Mean | 15.081 | 14.365 | 12.153 | 12.418 | 11.317 | 10.577 | |
| Variance | 0.002 | 0.003 | 0.003 | 0.002 | 0.002 | 0.002 | |
| Res prediction | Best | 18.246 | 18.227 | 18.207 | 18.168 | 18.020 | 17.467 |
| Mean | 18.244 | 18.226 | 10.205 | 18.166 | 18.018 | 17.466 | |
| Variance | 0.002 | 0.001 | 0.002 | 0.002 | 0.002 | 0.001 | |
| Total prediction | Best | 20.792 | 20.697 | 20.395 | 20.129 | 19.938 | 19.855 |
| Mean | 20.790 | 20.694 | 20.392 | 20.127 | 19.936 | 19.853 | |
| Variance | 0.002 | 0.003 | 0.003 | 0.002 | 0.002 | 0.002 |
| Prediction | Statistical Analysis | BELM [21] | TLGP [24] | DQR [42] | Deep ESN [47] | Deep LSTM [45] | Proposed SWO-Based Deep LSTM |
|---|---|---|---|---|---|---|---|
| Install capacity prediction | Best | 4.5598 | 4.5494 | 4.5161 | 4.4865 | 4.4652 | 4.4559 |
| Mean | 4.5595 | 4.5492 | 4.5158 | 4.4863 | 4.4650 | 4.4557 | |
| Variance | 0.0003 | 0.0002 | 0.0003 | 0.0002 | 0.0002 | 0.0002 | |
| Number of villages electrified prediction | Best | 4.8816 | 4.8568 | 4.7562 | 4.6985 | 4.6238 | 4.5682 |
| Mean | 4.8813 | 4.8566 | 4.7560 | 4.6984 | 4.6236 | 4.5681 | |
| Variance | 0.0003 | 0.0002 | 0.0002 | 0.0001 | 0.0002 | 0.0001 | |
| Length of L&D lines prediction | Best | 5.2650 | 5.2276 | 5.1913 | 5.1312 | 5.0054 | 4.9411 |
| Mean | 5.2648 | 5.2275 | 5.1910 | 5.1310 | 5.0050 | 4.9409 | |
| Variance | 0.0002 | 0.0001 | 0.0003 | 0.0002 | 0.0004 | 0.0002 | |
| Hydro prediction | Best | 4.1345 | 4.0804 | 4.0210 | 3.9578 | 3.8109 | 3.7222 |
| Mean | 4.1342 | 4.0801 | 4.0208 | 3.9576 | 3.8107 | 3.7221 | |
| Variance | 0.0003 | 0.0003 | 0.0002 | 0.0002 | 0.0002 | 0.0001 | |
| Coal prediction | Best | 4.4597 | 4.4479 | 4.4253 | 4.4016 | 4.3645 | 4.3561 |
| Mean | 4.4596 | 4.4477 | 4.4251 | 4.4013 | 4.3642 | 4.3559 | |
| Variance | 0.0001 | 0.0002 | 0.0002 | 0.0003 | 0.0003 | 0.0002 | |
| Gas prediction | Best | 4.0615 | 3.9720 | 3.9362 | 3.8929 | 3.8008 | 3.7177 |
| Mean | 4.0613 | 3.9717 | 3.9360 | 3.8928 | 3.8006 | 3.7176 | |
| Variance | 0.0002 | 0.0003 | 0.0002 | 0.0001 | 0.0002 | 0.0001 | |
| Diesel prediction | Best | 3.4223 | 3.3440 | 3.3266 | 3.2896 | 3.2801 | 3.2108 |
| Mean | 3.4220 | 3.3438 | 3.3265 | 3.2894 | 3.2800 | 3.2106 | |
| Variance | 0.0003 | 0.0002 | 0.0001 | 0.0002 | 0.0001 | 0.0002 | |
| Nuclear prediction | Best | 4.4772 | 4.4665 | 4.4336 | 4.4107 | 4.3856 | 4.3760 |
| Mean | 4.4770 | 4.4662 | 4.4334 | 4.4105 | 4.3854 | 4.3759 | |
| Variance | 0.0002 | 0.0003 | 0.0002 | 0.0002 | 0.0002 | 0.0001 | |
| Total utility prediction | Best | 3.8837 | 3.7906 | 3.5715 | 3.5242 | 3.3643 | 3.2526 |
| Mean | 3.8835 | 3.7903 | 3.5712 | 3.5240 | 3.3641 | 3.2524 | |
| Variance | 0.0002 | 0.0003 | 0.0003 | 0.0002 | 0.0002 | 0.0002 | |
| Res prediction | Best | 4.2715 | 4.2693 | 4.2670 | 4.2623 | 4.2450 | 4.1794 |
| Mean | 4.2713 | 4.2692 | 4.2668 | 4.2620 | 4.2448 | 4.1793 | |
| Variance | 0.0002 | 0.0001 | 0.0002 | 0.0003 | 0.0002 | 0.0001 | |
| Total prediction | Best | 4.5598 | 4.5494 | 4.5161 | 4.4865 | 4.4652 | 4.4559 |
| Mean | 4.5596 | 4.5490 | 4.5160 | 4.4862 | 4.4650 | 4.4558 | |
| Variance | 0.0002 | 0.0004 | 0.0001 | 0.0003 | 0.0002 | 0.0001 |
References
- Rathor, S.; Saxena, D. Energy management system for smart grid: An overview and key issues. Int. J. Energy Res. 2020, 44, 4067–4109. [Google Scholar] [CrossRef]
- The Editor SR of Energy W. Statistical Review of World Energy, 69th ed.; bp: London, UK, 2020; Available online: https://www.bp.com/content/dam/bp/business-sites/en/global/corporate/pdfs/energy-economics/statistical-review/bp-stats-review-2020-full-report.pdf (accessed on 31 March 2021).
- Government of India, Central Electricity Authority M of power. All India Installed Capacity (in MW) of Power Stations Installed Capacity (in Mw) of Power Utilities in the States/Uts Located. Cent Electricity Authority. Minist. Power 2020, 4, 1–7. Available online: https://cea.nic.in/wp-content/uploads/installed/2021/03/installed_capacity.pdf (accessed on 31 March 2021).
- IEA. Global Energy Review 2020. Paris: 2020. Available online: https://www.iea.org/reports/global-energy-review-2020 (accessed on 31 March 2021).
- De la Rue du Can, S.; Khandekar, A.; Abhyankar, N.; Phadke, A.; Khanna, N.; Fridley, D.; Zhou, N. Modeling India’s energy future using a bottom-up approach. Appl. Energy 2019, 238, 1108–1125. [Google Scholar] [CrossRef]
- Padmanathan, K.; Govindarajan, U.; Ramachandaramurthy, V.K.; Rajagopalan, A.; Pachaivannan, N.; Sowmmiya, U. A sociocultural study on solar photovoltaic energy system in India: Stratification and policy implication. J. Clean. Prod. 2019, 216, 461–481. [Google Scholar] [CrossRef]
- Ali, S. Indian Electricity Demand How Much, by Whom, and under What Conditions? Brookings India 2018. Available online: https://www.brookings.edu/wp-content/uploads/2018/10/The-future-of-Indian-electricity-demand.pdf (accessed on 31 March 2021).
- Elavarasan, R.M.; Shafiullah, G.M.; Kumar, N.M.; Padmanaban, S. A State-of-the-Art Review on the Drive of Renewables in Gujarat, State of India: Present Situation, Barriers and Future Initiatives. Energies 2020, 13, 40. [Google Scholar] [CrossRef] [Green Version]
- NITI Aayog and IEEJ. Energizing India, A Joint Project Report of NITI Aayog and IEEJ. 2017. Available online: https://niti.gov.in/writereaddata/files/document_publication/Energy%20Booklet.pdf (accessed on 31 March 2021).
- Sood, N. India’s Power Sector Calls for A Multi-Pronged Strategy. Bus World 2017. Available online: https://cea.nic.in/wp-content/uploads/2020/04/nep_jan_2018.pdf (accessed on 31 March 2021).
- Padmanathan, K.; Kamalakannan, N.; Sanjeevikumar, P.; Blaabjerg, F.; Holm-Nielsen, J.B.; Uma, G. Conceptual Framework of Antecedents to Trends on Permanent Magnet Synchronous Generators for Wind Energy Conversion Systems. Energies 2019, 12, 2616. [Google Scholar] [CrossRef] [Green Version]
- Elavarasan, R.M. The Motivation for Renewable Energy and its Comparison with Other Energy Sources: A Review. Eur. J. Sustain. Dev. Res. 2019, 3, em0076. [Google Scholar] [CrossRef]
- IEA; IRENA; UNSD; World Bank; WHO. Tracking SDG 7: The Energy Progress Report. World Bank 2020, 176. Available online: https://www.irena.org/publications/2021/Jun/Tracking-SDG-7-2021 (accessed on 31 March 2021).
- Devaraj, J.; Elavarasan, R.M.; Pugazhendi, R.; Shafiullah, G.M.; Ganesan, S.; Jeysree, A.J.; Khan, I.A.; Hossian, E. Forecasting of COVID-19 cases using deep learning models: Is it reliable and practically significant? Results Phys. 2021, 21, 103817. [Google Scholar] [CrossRef]
- Ahmad, T.; Chen, H. Potential of three variant machine-learning models for forecasting district level medium-term and long-term energy demand in smart grid environment. Energy 2018, 160, 1008–1020. [Google Scholar] [CrossRef]
- Weron, R. Electricity price forecasting: A review of the state-of-the-art with a look into the future. Int. J. Forecast 2014, 30, 1030–1081. [Google Scholar] [CrossRef] [Green Version]
- Krishnamoorthy, R.; Udhayakumar, U.; Raju, K.; Elavarasan, R.M.; Mihet-Popa, L. An Assessment of Onshore and Offshore Wind Energy Potential in India Using Moth Flame Optimization. Energies 2020, 13, 3063. [Google Scholar] [CrossRef]
- Dey, B.; Bhattacharyya, B.; Ramesh, D. A novel hybrid algorithm for solving emerging electricity market pricing problem of microgrid. Int. J. Intell. Syst. 2021, 36, 919–961. [Google Scholar] [CrossRef]
- Pinson, P.; Kariniotakis, G.N. Wind power forecasting using fuzzy neural networks enhanced with on-line prediction risk assessment. In Proceedings of the IEEE 2003 IEEE Bologna Power Tech, Bologna, Italy, 23–26 June 2003; Volume 2, p. 8. [Google Scholar] [CrossRef] [Green Version]
- Dowell, J.; Pinson, P. Very-Short-Term Probabilistic Wind Power Forecasts by Sparse Vector Autoregression. IEEE Trans. Smart Grid 2016, 7, 763–770. [Google Scholar] [CrossRef] [Green Version]
- Wan, C.; Xu, Z.; Pinson, P.; Dong, Z.Y.; Wong, K.P. Probabilistic Forecasting of Wind Power Generation Using Extreme Learning Machine. IEEE Trans. Power Syst. 2014, 29, 1033–1044. [Google Scholar] [CrossRef] [Green Version]
- Pinson, P.; Kariniotakis, G. Conditional Prediction Intervals of Wind Power Generation. IEEE Trans. Power Syst. 2010, 25, 1845–1856. [Google Scholar] [CrossRef] [Green Version]
- Pinson, P.; Nielsen, H.A.; Møller, J.K.; Madsen, H.; Kariniotakis, G.N. Non-parametric probabilistic forecasts of wind power: Required properties and evaluation. Wind Energy 2007, 10, 497–516. [Google Scholar] [CrossRef]
- Yan, J.; Li, K.; Bai, E.; Zhao, X.; Xue, Y.; Foley, A.M. Analytical Iterative Multistep Interval Forecasts of Wind Generation Based on TLGP. IEEE Trans. Sustain. Energy 2019, 10, 625–636. [Google Scholar] [CrossRef] [Green Version]
- Lago, J.; de Ridder, F.; de Schutter, B. Forecasting spot electricity prices: Deep learning approaches and empirical comparison of traditional algorithms. Appl. Energy 2018, 221, 386–405. [Google Scholar] [CrossRef]
- Yang, Z.; Mourshed, M.; Liu, K.; Xu, X.; Feng, S. A novel competitive swarm optimized RBF neural network model for short-term solar power generation forecasting. Neurocomputing 2020, 397, 415–421. [Google Scholar] [CrossRef]
- Zafirakis, D.; Tzanes, G.; Kaldellis, J.K. Forecasting of Wind Power Generation with the Use of Artificial Neural Networks and Support Vector Regression Models. Energy Procedia 2019, 159, 509–514. [Google Scholar] [CrossRef]
- Korprasertsak, N.; Leephakpreeda, T. Robust short-term prediction of wind power generation under uncertainty via statistical interpretation of multiple forecasting models. Energy 2019, 180, 387–397. [Google Scholar] [CrossRef]
- Kushwaha, V.; Pindoriya, N.M. A SARIMA-RVFL hybrid model assisted by wavelet decomposition for very short-term solar PV power generation forecast. Renew. Energy 2019, 140, 124–139. [Google Scholar] [CrossRef]
- Eseye, A.; Lehtonen, M.; Tukia, T.; Uimonen, S.; Millar, R.J. Machine Learning Based Integrated Feature Selection Approach for Improved Electricity Demand Forecasting in Decentralized Energy Systems. IEEE Access 2019, 7, 91463–91475. [Google Scholar] [CrossRef]
- Devaraj, J.; Ganesan, S.; Elavarasan, R.M.; Subramaniam, U. A Novel Deep Learning Based Model for Tropical Intensity Estimation and Post-Disaster Management of Hurricanes. Appl. Sci. 2021, 11, 4129. [Google Scholar] [CrossRef]
- Sardianos, C.; Varlamis, I.; Chronis, C.; Dimitrakopoulos, G.; Alsalemi, A.; Himeur, Y.; Bensaali, F.; Amira, A. The emergence of explainability of intelligent systems: Delivering explain, able and personalized recommendations for energy efficiency. Int. J. Intell. Syst. 2021, 36, 656–680. [Google Scholar] [CrossRef]
- Devaraj, J.; Elavarasan, R.M.; Shafiullah, G.M.; Jamal, T.; Khan, I. A holistic review on energy forecasting using big data and deep learning models. Int. J. Energy Res. 2021, 45, 13489–13530. [Google Scholar] [CrossRef]
- Piotrowski, P.; Baczyński, D.; Kopyt, M.; Szafranek, K.; Helt, P.; Gulczyński, T. Analysis of forecasted meteorological data (NWP) for efficient spatial forecasting of wind power generation. Electr. Power Syst. Res. 2019, 175, 105891. [Google Scholar] [CrossRef]
- Elavarasan, R.M.; Shafiullah, G.M.; Padmanaban, S.; Kumar, N.M.; Annam, A.; Vetrichelvan, A.M. A Comprehensive Review on Renewable Energy Development, Challenges, and Policies of Leading Indian States with an International Perspective. IEEE Access 2020, 8, 74432–74457. [Google Scholar] [CrossRef]
- Kumar, J.C.R.; Majid, M.A. Renewable energy for sustainable development in India: Current status, future prospects, challenges, employment, and investment opportunities. Energy Sustain. Soc. 2020, 10, 2. [Google Scholar] [CrossRef]
- Bilgili, M.; Ozbek, A.; Sahin, B.; Kahraman, A. An overview of renewable electric power capacity and progress in new technologies in the world. Renew. Sustain. Energy Rev. 2015, 49, 323–324. [Google Scholar] [CrossRef]
- Joaquin, J.; Jimenez, M.; Stokes, L.; Moss, C.; Yang, Q.; Livina, V.N. Modelling energy demand response using long short-term memory neural networks. Energy Effic. 2020, 13, 1263–1280. [Google Scholar] [CrossRef]
- Kang, T.; Lim, D.Y.; Tayara, H.; Chong, K.T. Forecasting of Power Demands Using Deep Learning. Appl. Sci. 2020, 10, 7241. [Google Scholar] [CrossRef]
- Real, A.J.D.; Dorado, F.; Durán, J. Energy Demand Forecasting Using Deep Learning: Applications for the French Grid. Energies 2020, 13, 2242. [Google Scholar] [CrossRef]
- Choi, E.; Cho, S.; Kim, D.K. Power Demand Forecasting Using Long Short-Term Memory (LSTM) Deep-Learning Model for Monitoring Energy Sustainability. Sustainability 2020, 12, 1109. [Google Scholar] [CrossRef] [Green Version]
- Wan, C.; Lin, J.; Wang, J.; Song, Y.; Dong, Z.Y. Direct Quantile Regression for Nonparametric Probabilistic Forecasting of Wind Power Generation. IEEE Trans. Power Syst. 2017, 32, 2767–2778. [Google Scholar] [CrossRef]
- Debnath, K.; Mourshed, M. Forecasting methods in energy planning models. Renew. Sustain. Energy Rev. 2018, 88, 297–325. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, T.; Chen, H. A review on machine learning forecasting growth trends and their real-time applications in different energy systems. Sustain. Cities Soc. 2020, 54, 102010. [Google Scholar] [CrossRef]
- Mujeeb, S.; Javaid, N.; Ilahi, M.; Wadud, Z.; Ishmanov, F.; Afzal, M. Deep Long Short-Term Memory: A New Price and Load Forecasting Scheme for Big Data in Smart Cities. Sustainability 2019, 11, 987. [Google Scholar] [CrossRef] [Green Version]
- Bedi, J.; Toshniwal, D. Energy load time-series forecast using decomposition and autoencoder integrated memory network. Appl. Soft. Comput. 2020, 93, 106390. [Google Scholar] [CrossRef]
- Hu, H.; Wang, L.; Lv, S.-X. Forecasting energy consumption and wind power generation using deep echo state network. Renew. Energy 2020, 154, 598–613. [Google Scholar] [CrossRef]
- Shadravan, S.; Naji, H.R.; Bardsiri, V.K. The Sailfish Optimizer: A novel nature-inspired metaheuristic algorithm for solving constrained engineering optimization problems. Eng. Appl. Artif Intell. 2019, 80, 20–34. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Raymaekers, J.; Rousseeuw, P.J. Transforming variables to central normality. Mach. Learn 2021, 1–23. [Google Scholar] [CrossRef]
- Vaiz, J.S.; Ramaswami, M. Forecasting Stock Trend Using Technical Indicators with R. Int. J. Comput. Intell. Inform. 2016, 6, 3. [Google Scholar]
- Gangeh, M.J.; Zarkoob, H.; Ghodsi, A. Fast and Scalable Feature Selection for Gene Expression Data Using Hilbert-Schmidt Independence Criterion. IEEE/ACM Trans. Comput. Biol. Bioinform. 2017, 14, 67–81. [Google Scholar] [CrossRef]
- Zhu, W.; Lan, C.; Xing, J.; Zeng, W.; Li, Y.; Shen, L. Co-Occurrence Feature Learning for Skeleton Based Action Recognition Using Regularized Deep LSTM Networks. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence AAAI, Phoenix, AZ, USA, 12–17 February 2016; pp. 3697–3703. [Google Scholar]
- Yu, Y.; Liu, F. Effective Neural Network Training with a New Weighting Mechanism-Based Optimization Algorithm. IEEE Access 2019, 7, 72403–72410. [Google Scholar] [CrossRef]
- General Electricity Authority, Government of India M of P. Growth of electricity sector in INDIA from 1947–2020. Available online: https://cea.nic.in/wp-content/uploads/pdm/2020/12/growth_2020.pdf (accessed on 31 March 2021).


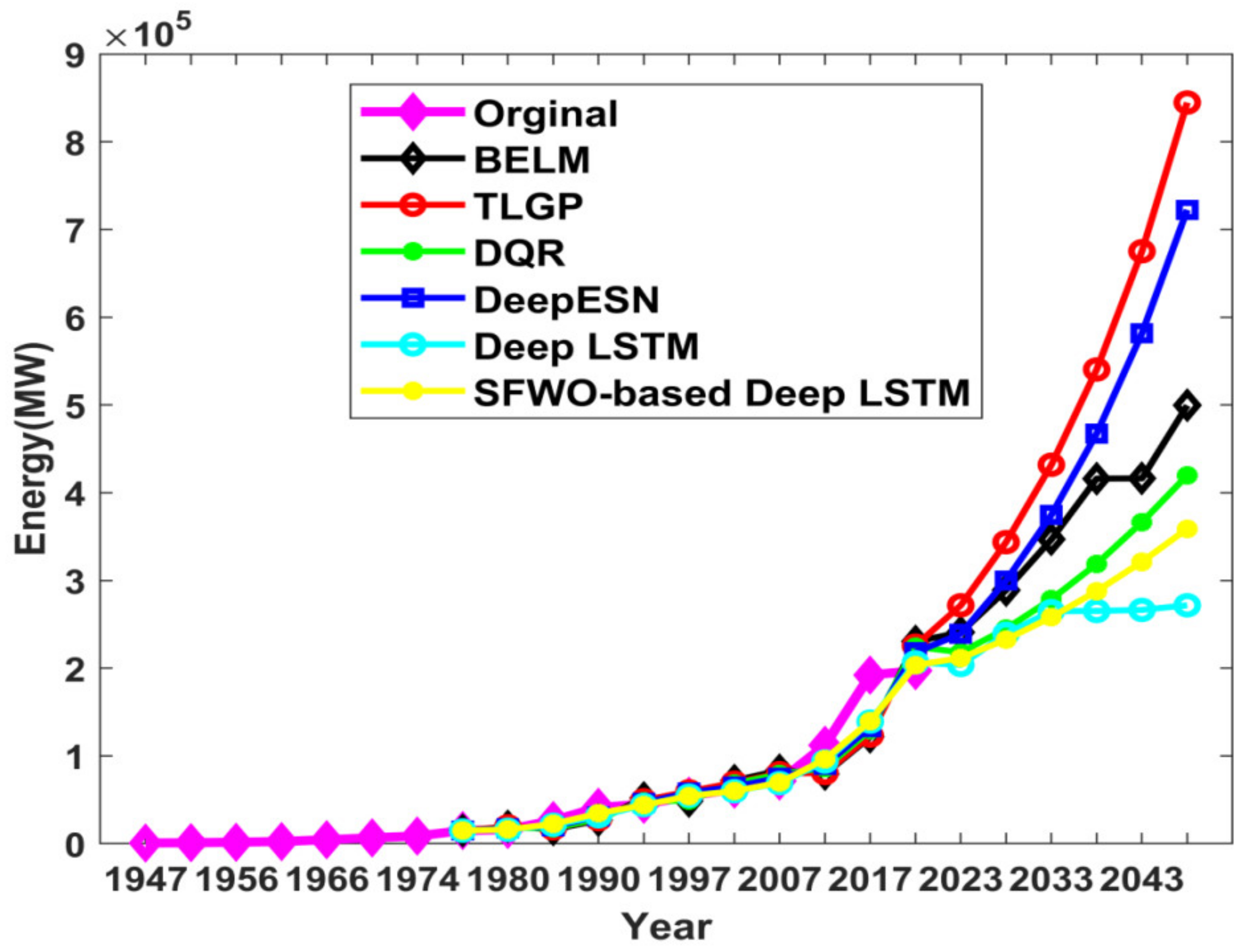
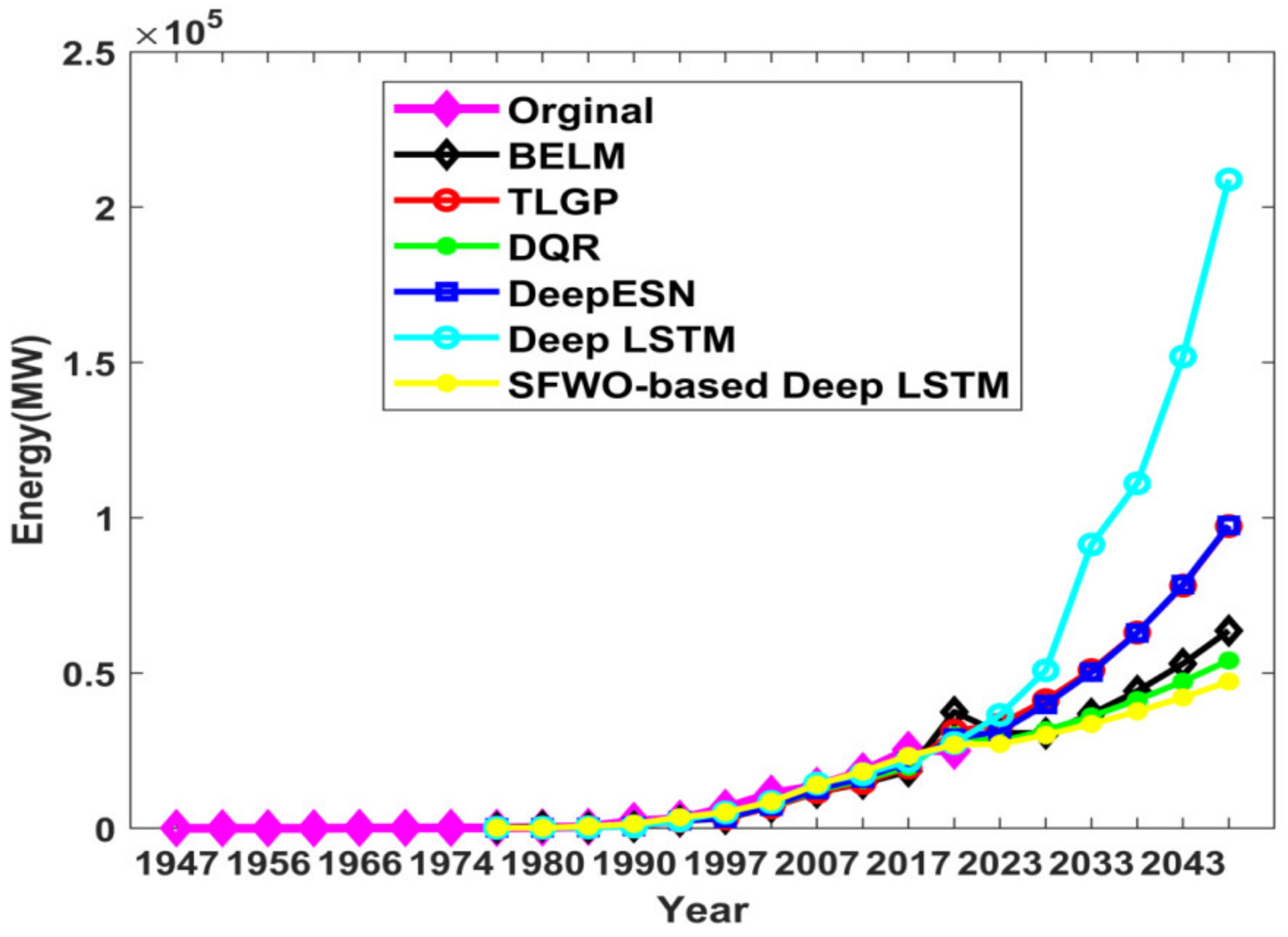
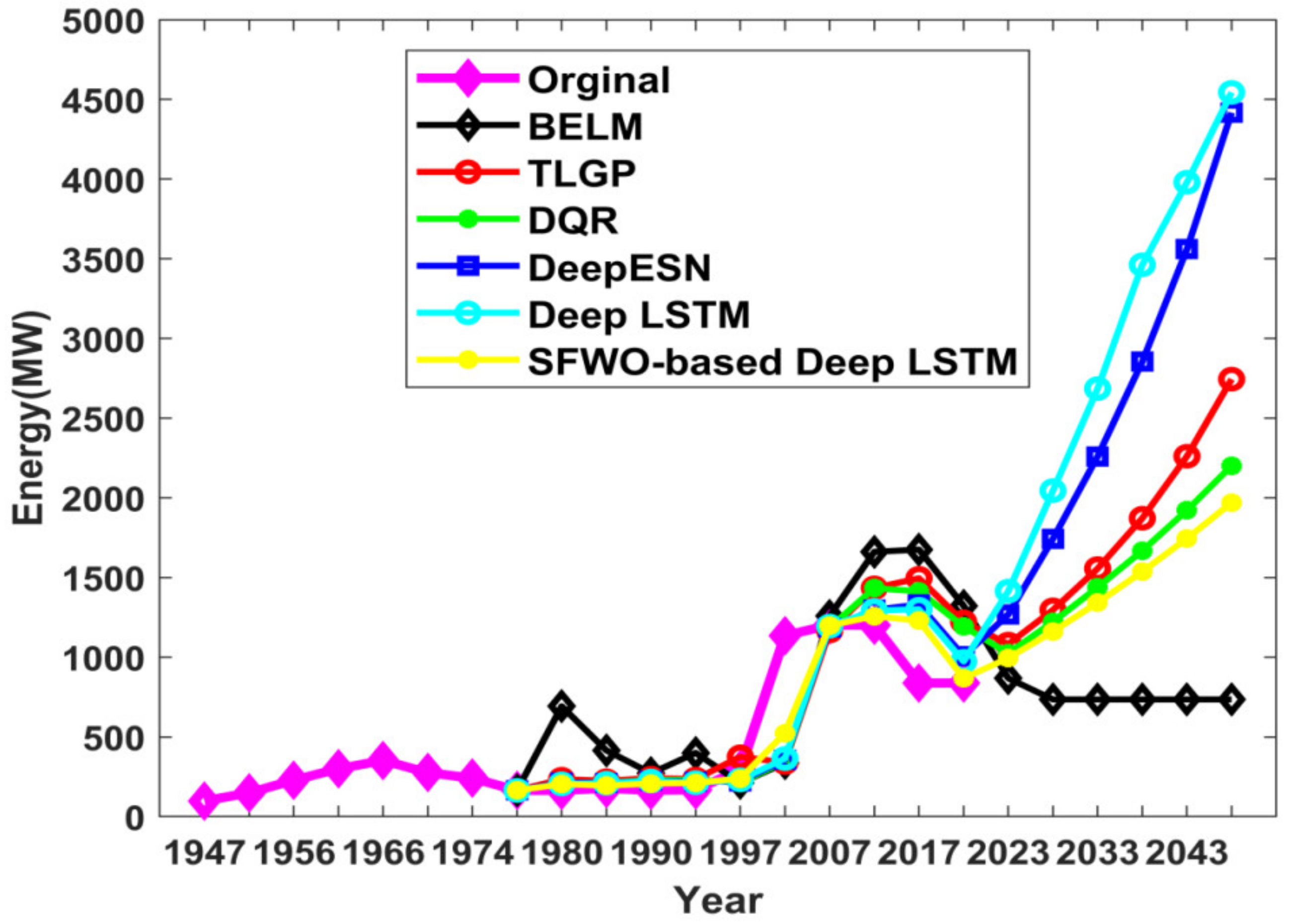
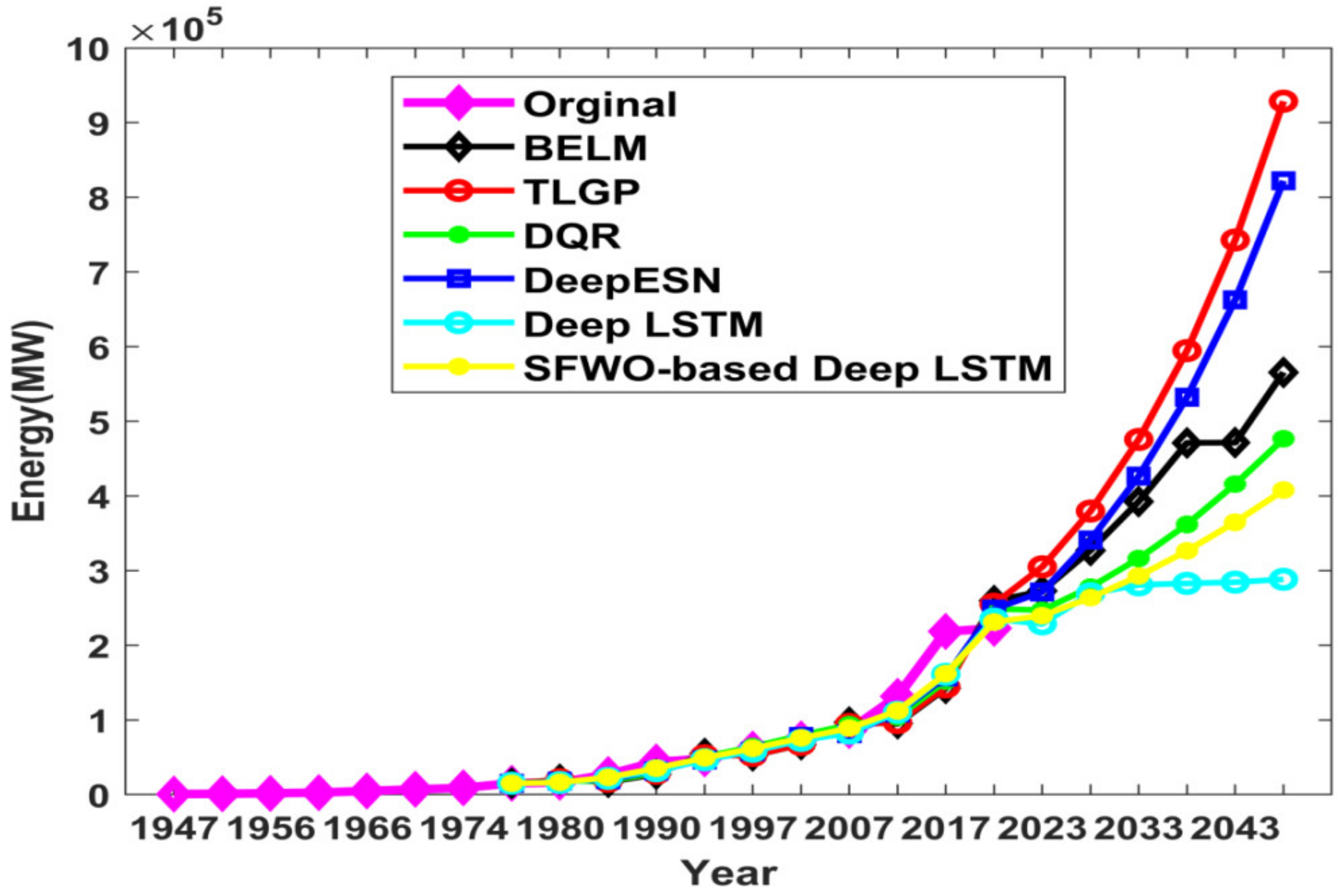
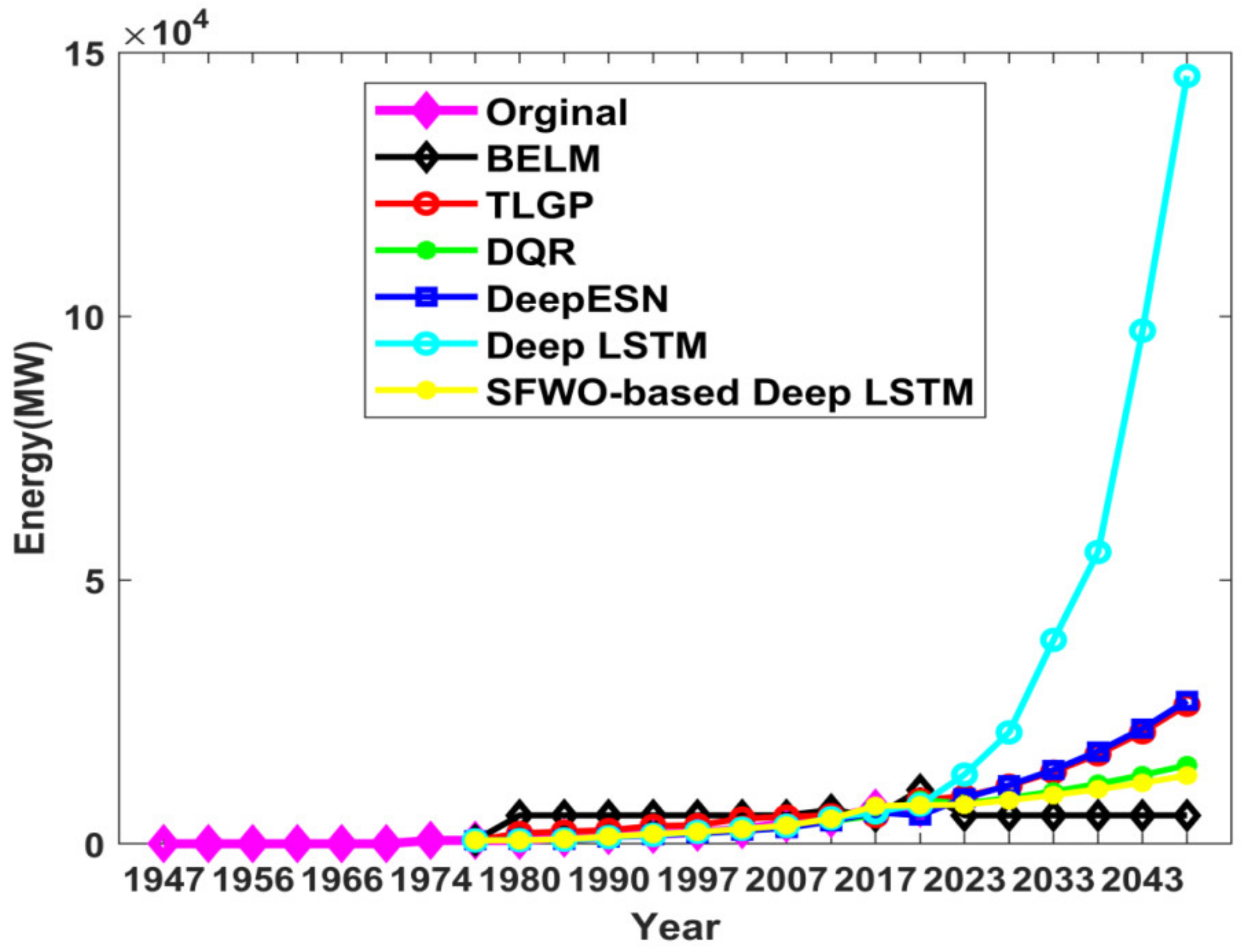
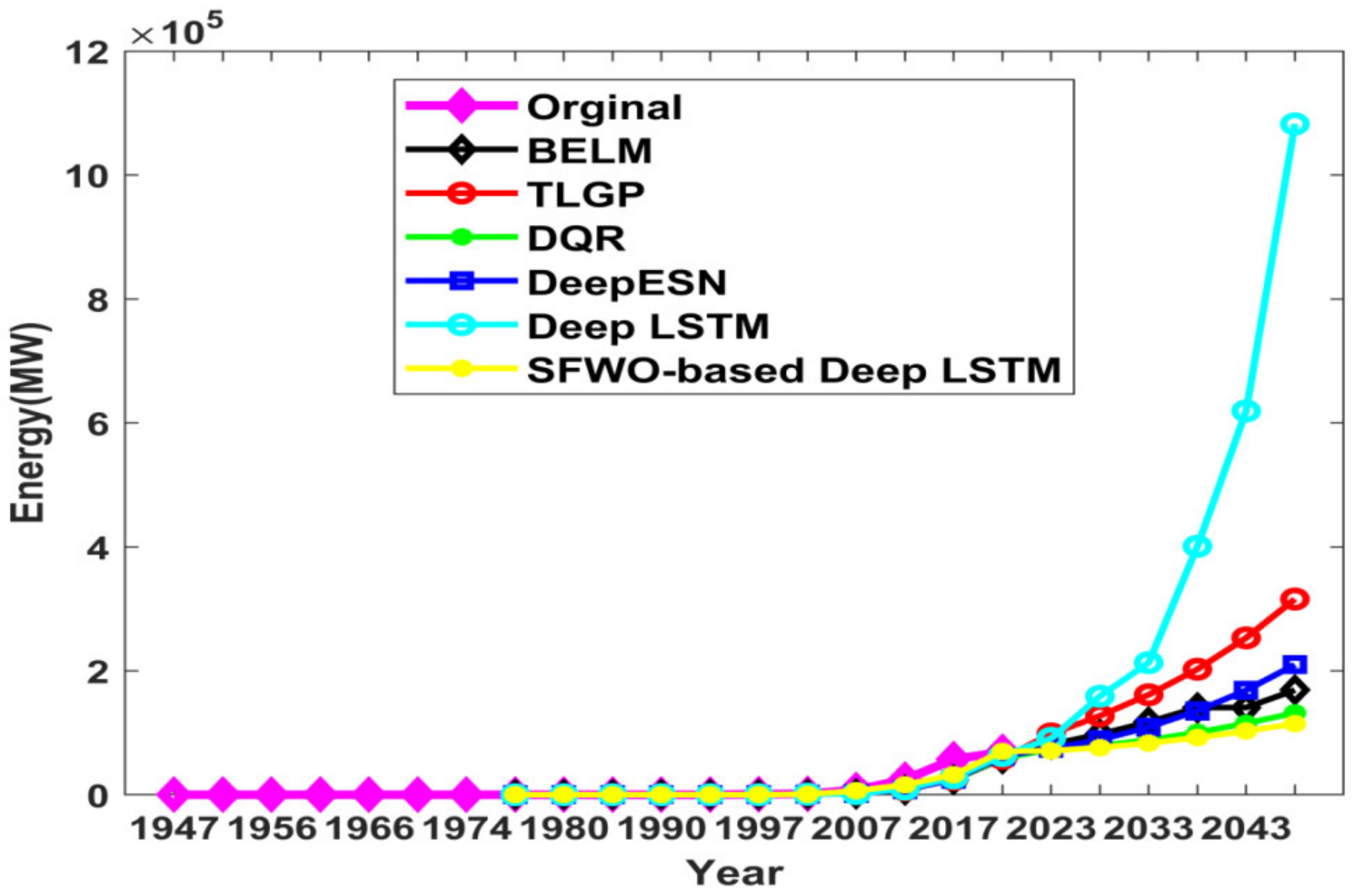

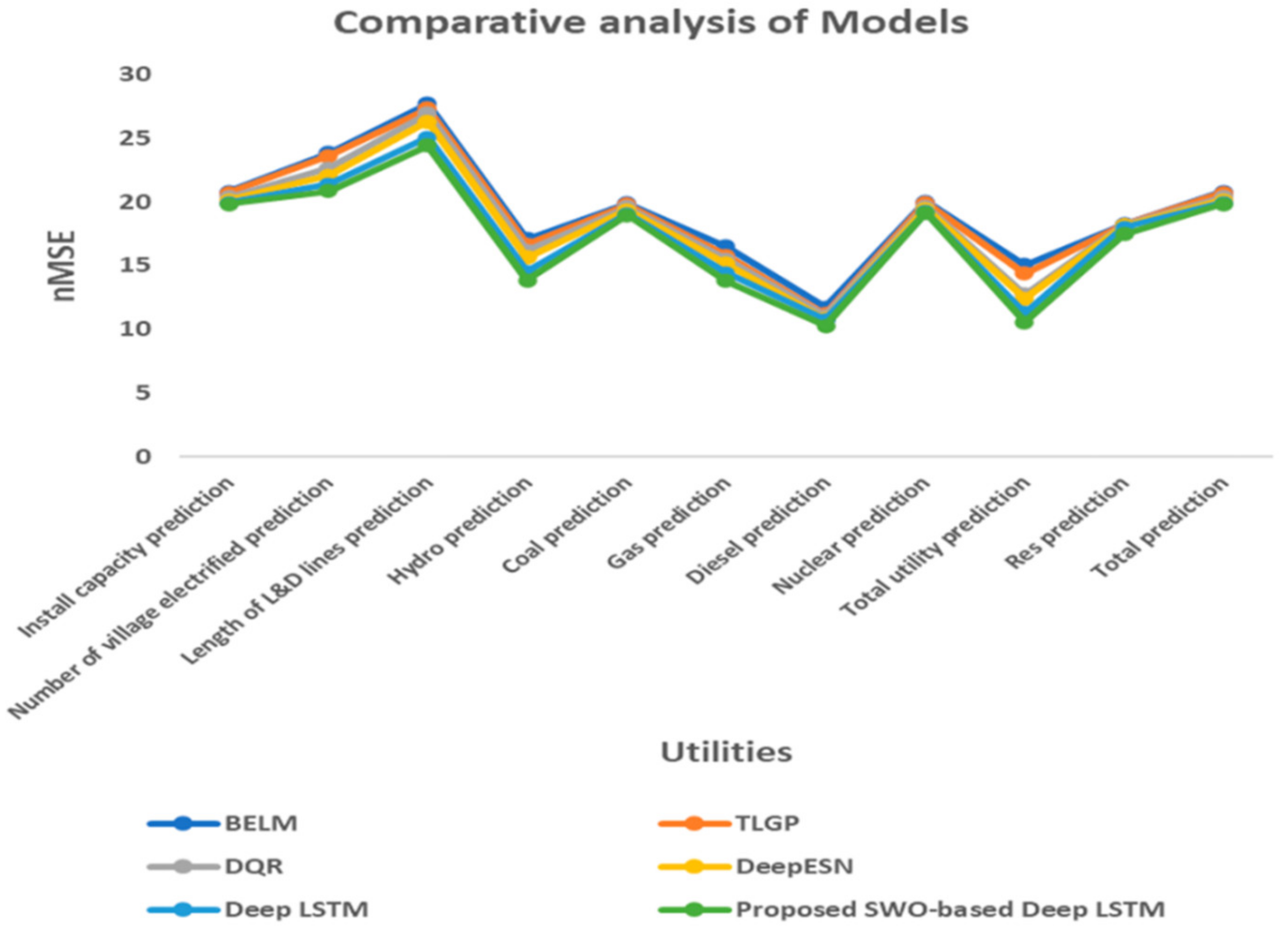
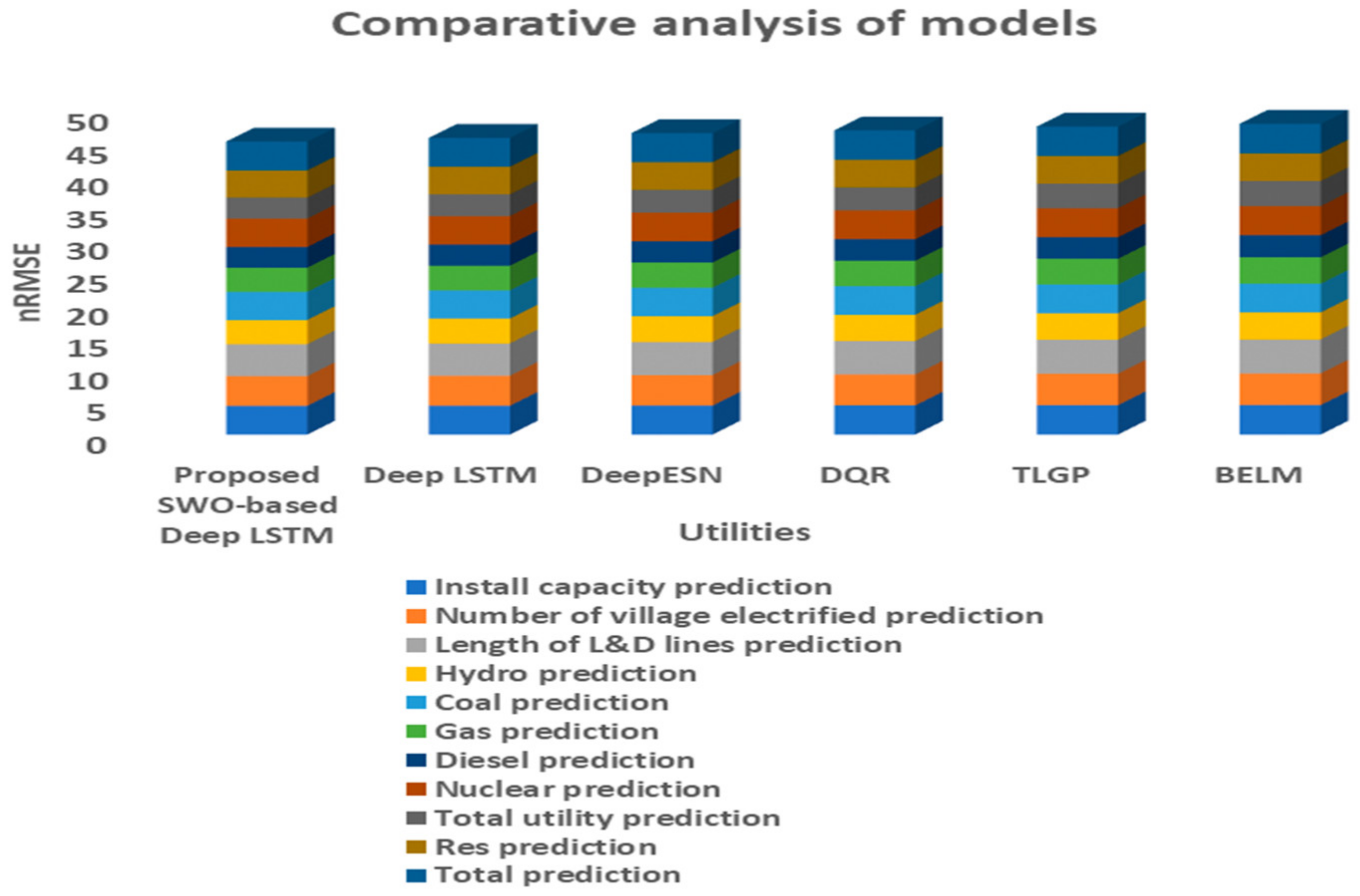
| Ref. | Dataset Used | Forecasting Model | Methodology Used | Outcome |
|---|---|---|---|---|
| [38] | Four years of data from 2014 to 2018 of UK Triads. | Long Short-Term Memory (LSTM). | The proposed methodology is used to produce the triad signals 48 h ahead. 250 number of epochs with the batch size of 6 days of data are used for training the model. | LSTM outperforms other models like ANN and SVM in electricity demand forecasting. The model achieves RMSE (MW) value of 759.66. |
| [39] | Korea Power Exchange data from 1 January 2003 to 22 May 2020is used for forecasting. 11 years of data from 2003 to 2013 is used for training. | A hybrid model of Convolutional Neural Networks (CNN) and Recurrent Neural Network (RNN) is used. | The proposed hybrid model is used for electricity power forecasting like facility capacity, supply capacity and power consumption. | The hybrid model consists of 1D conv layer with 32 filters combined with bidirectional LSTM of 16 nodes and grid search algorithm. CNN achieves 0.025 for full capacity (MW), 0.214 for supply capacity (MW) and 0.314 for power capacity (MW). |
| [40] | Historical power data from French energy consumption is taken 2012 to 2020.Weather forecast data from Action de Recherche Petite Echelle Grande Echelle (ARPEGE). | Energy demand forecasting using CNN-ANN. | The proposed model combines the feature extraction using Convolutional Neural Network (CNN) and the regression capabilities of ANN. | Accurate energy demand forecasting achieves lower Mean Absolute Error MAE (%) value of 1.4934 when compared to other models. The errors were uniformly distributed for monthly forecasting. |
| [41] | Power demand data set from Jan 2017–Dec 2017 with 5 min resolution. | Short-term Power demand forecasting using LSTM. | Mixed Data Sampling Technique MIDAS for data preprocessing and DeepLearning4J is used for constructing the power demand forecasting model. | LSTM+MIDAS model achieves lower RMSE values of 7.330, 14.4, 53.6 and 36.8 for Residential, City Hall, Factory and hospital locations respectively. |
| [42] | Direct Quantile Regression (DQR) for Nonparametric Probabilistic Forecasting of Wind Power Generation. | Multi-step ahead forecasting of 10-min wind power generation. | The proposed technique is used to minimize operation cost and increase the reliability of power system with large wind energy penetration through a reliable and accurate forecasting technique. | The forecasting errors are approximated through different parametric probability distribution methods and achieves computational efficiency of 63.89(s). Addresses the issues from the perspective of power system stability and balance. |
| [43] | Forecasting methods in energy planning models. | A systematic and critical review on forecasting techniques used in 483 energy planning models. | The proposed study emphasizes the various statistical methods and the computational intelligence methods like machine learning algorithms. | With large scale penetration, probabilistic forecast is integrated into different decision-making activities in the power systems. Hybrid models and the computational intelligence techniques yields higher accuracy than the other stand-alone models. |
| [44] | A review on machine learning forecasting growth trends and their real-time applications in different energy systems. | A comprehensive and critical review that compares the different forecasting models for energy consumption prediction with climate data were addressed. | The proposed review analyzes the best models for forecasting future load and demand, geothermal, wind and solar energy forecasting. | Bayesian regularization back propagation neural networks (BRBBNNs) and the Levenberg Marquardt back propagation neural networks (LMBNNs) provides higher accuracy and achieves the correlation coefficient of 0.972 and 0.971 respectively. |
| [45] | Deep Long Short-Term Memory: A New Price and Load Forecasting Scheme for Big Data in Smart Cities. | Deep Long Short-Term Memory (DLSTM) for price and demand forecasting. | For all the months, 1-day ahead and 1-week ahead forecasting was analyzed using the hybrid forecasting model. | DNN and LSTM (DLSTM) outperforms with 1.94 and 0.08 for price forecast and 2.9 and 0.087 for load forecast in terms of Mean Absolute Error (MAE) and 0.08 for Normalized Root Mean Squared Error (NRMSE) respectively. |
| [46] | Energy load time-series forecast using decomposition and auto-encoder integrated memory network. | Hybrid approach of Variational Mode Decomposition (VMD) and LSTM model is used for load and demand forecasting. | VMD and auto-encoder is integrated for extracting the features from the dataset. LSTM model is used for training the extracted features. | Spatio-temporal correlations are captured using the hybrid model using agglomerative clustering algorithm. Hybrid model is implemented on the energy consumption data of Himachal Pradesh (HP) and achieves Mean Absolute percentage Error (MAPE) of 3.04% |
| [47] | Forecasting energy consumption and wind power generation using deep echo state network. | Deep Echo State Network (Deep ESN) is used to generate wind power and forecast energy consumption based on the stacked hierarchy of reservoir. | The non-linear stability of the echo state network and the deep learning capability are combined using Deep ESN. | Deep ESN outperforms ESN framework improves the performance accuracy of 51.56%, 51.53%, and 35.43% in terms of mean absolute error, root mean square error, and mean absolute percentage error respectively. |
| Input Parameters | Values |
|---|---|
| Optimizer | Adam |
| Number of hidden units | 200 |
| MaxEpochs | 250 |
| Gradient Threshold | 1 |
| Initial Learning Rate | 0.005 |
| Learn rate schedule | Piece-wise |
| Learn rate drop period | 125 |
| Dropout factor | 0.2 |
| Prediction | BELM [21] | TLGP [24] | DQR [42] | Deep ESN [47] | Deep LSTM [45] | Proposed SWO-Based Deep LSTM |
|---|---|---|---|---|---|---|
| Install capacity prediction | 20.792 | 20.697 | 20.395 | 20.129 | 19.938 | 19.855 |
| Number of village electrified prediction | 23.830 | 23.589 | 22.622 | 22.076 | 21.380 | 20.868 |
| Length of L&D lines prediction | 27.720 | 27.327 | 26.949 | 26.329 | 25.054 | 24.415 |
| Hydro prediction | 17.094 | 16.650 | 16.168 | 15.664 | 14.523 | 13.855 |
| Coal prediction | 19.889 | 19.784 | 19.583 | 19.374 | 19.049 | 18.975 |
| Gas prediction | 16.495 | 15.777 | 15.494 | 15.155 | 14.446 | 13.821 |
| Diesel prediction | 11.712 | 11.182 | 11.066 | 10.821 | 10.759 | 10.309 |
| Nuclear prediction | 20.045 | 19.950 | 19.657 | 19.455 | 19.234 | 19.149 |
| Total utility prediction | 15.083 | 14.368 | 12.756 | 12.420 | 11.319 | 10.579 |
| Res prediction | 18.246 | 18.227 | 18.207 | 18.168 | 18.020 | 17.467 |
| Total prediction | 20.791 | 20.698 | 20.398 | 20.128 | 19.936 | 19.853 |
| Prediction | BELM [21] | TLGP [24] | DQR [42] | Deep ESN [47] | Deep LSTM [45] | Proposed SWO-Based Deep LSTM |
|---|---|---|---|---|---|---|
| Install capacity prediction | 4.5598 | 4.5494 | 4.5161 | 4.4865 | 4.4652 | 4.4559 |
| Number of village electrified prediction | 4.8816 | 4.8568 | 4.7562 | 4.6985 | 4.6238 | 4.5682 |
| Length of L&D lines prediction | 5.2650 | 5.2276 | 5.1913 | 5.1312 | 5.0054 | 4.9411 |
| Hydro prediction | 4.1345 | 4.0804 | 4.0210 | 3.9578 | 3.8109 | 3.7222 |
| Coal prediction | 4.4597 | 4.4479 | 4.4253 | 4.4016 | 4.3645 | 4.3561 |
| Gas prediction | 4.0615 | 3.9720 | 3.9362 | 3.8929 | 3.8008 | 3.7177 |
| Diesel prediction | 3.4223 | 3.3440 | 3.3266 | 3.2896 | 3.2801 | 3.2108 |
| Nuclear prediction | 4.4772 | 4.4665 | 4.4336 | 4.4107 | 4.3856 | 4.3760 |
| Total utility prediction | 3.8837 | 3.7906 | 3.5715 | 3.5242 | 3.3643 | 3.2526 |
| Res prediction | 4.2715 | 4.2693 | 4.2670 | 4.2623 | 4.2450 | 4.1794 |
| Total prediction | 4.5599 | 4.5496 | 4.5163 | 4.4864 | 4.4653 | 4.4558 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rajamoorthy, R.; Saraswathi, H.V.; Devaraj, J.; Kasinathan, P.; Elavarasan, R.M.; Arunachalam, G.; Mostafa, T.M.; Mihet-Popa, L. A Hybrid Sailfish Whale Optimization and Deep Long Short-Term Memory (SWO-DLSTM) Model for Energy Efficient Autonomy in India by 2048. Sustainability 2022, 14, 1355. https://doi.org/10.3390/su14031355
Rajamoorthy R, Saraswathi HV, Devaraj J, Kasinathan P, Elavarasan RM, Arunachalam G, Mostafa TM, Mihet-Popa L. A Hybrid Sailfish Whale Optimization and Deep Long Short-Term Memory (SWO-DLSTM) Model for Energy Efficient Autonomy in India by 2048. Sustainability. 2022; 14(3):1355. https://doi.org/10.3390/su14031355
Chicago/Turabian StyleRajamoorthy, Rajasekaran, Hemachandira V. Saraswathi, Jayanthi Devaraj, Padmanathan Kasinathan, Rajvikram Madurai Elavarasan, Gokulalakshmi Arunachalam, Tarek M. Mostafa, and Lucian Mihet-Popa. 2022. "A Hybrid Sailfish Whale Optimization and Deep Long Short-Term Memory (SWO-DLSTM) Model for Energy Efficient Autonomy in India by 2048" Sustainability 14, no. 3: 1355. https://doi.org/10.3390/su14031355
APA StyleRajamoorthy, R., Saraswathi, H. V., Devaraj, J., Kasinathan, P., Elavarasan, R. M., Arunachalam, G., Mostafa, T. M., & Mihet-Popa, L. (2022). A Hybrid Sailfish Whale Optimization and Deep Long Short-Term Memory (SWO-DLSTM) Model for Energy Efficient Autonomy in India by 2048. Sustainability, 14(3), 1355. https://doi.org/10.3390/su14031355