Abstract
This paper introduces a deep learning-based framework for video watermarking that achieves robust, imperceptible, and fast embedding under a wide range of visual and temporal conditions. The proposed method is organized into seven modules that collaboratively perform frame encoding, semantic region analysis, block selection, watermark transformation, and spatiotemporal injection, followed by decoding and multi-objective optimization. A key component of the framework is its ability to learn a visual importance map, which guides a saliency-based block selection strategy. This allows the model to embed the watermark in perceptually redundant regions while minimizing distortion. To enhance resilience, the watermark is distributed across multiple frames, leveraging temporal redundancy to improve recovery under frame loss, insertion, and reordering. Experimental evaluations conducted on a large-scale video dataset demonstrate that the proposed method achieves high fidelity, while preserving low decoding error rates under compression, noise, and temporal distortions. The proposed method operates processing 38 video frames per second on a standard GPU. Additional ablation studies confirm the contribution of each module to the system’s robustness. This framework offers a promising solution for watermarking in streaming, surveillance, and content verification applications.
1. Introduction
The exponential growth in video-based communications, driven by the proliferation of social media platforms, video streaming services, remote surveillance systems, and user-generated content, has fundamentally reshaped the digital landscape. Alongside these benefits, the vulnerability of video content to unauthorized copying, tampering, and illegal redistribution has increased dramatically. Consequently, the development of robust techniques for protecting ownership rights, ensuring content integrity, and preserving authenticity has become a critical research focus [1,2,3].
Traditional video watermarking techniques, often operating in the spatial or frequency domains through transformations such as Discrete Cosine Transform (DCT) or Discrete Wavelet Transform (DWT), have historically achieved a reasonable balance between imperceptibility and resistance to common manipulations, including compression, cropping, and filtering [4,5,6,7,8]. However, these methods frequently fall short when dealing with complex distortions specific to video, particularly those that exploit temporal redundancy across frames or involve sophisticated attacks such as frame dropping, frame rate conversion, or collusion [9,10]. These limitations have prompted the research community to explore alternative paradigms capable of learning data-driven, context-aware representations that go beyond hand-crafted heuristics.
In recent years, deep learning has demonstrated transformative potential across a wide range of computer vision tasks, including motion estimation, object tracking, and perceptual enhancement, by leveraging large datasets and hierarchical feature learning [11,12,13]. Within the domain of digital watermarking, several deep neural network (DNN)-based schemes have been proposed, primarily for images, where architectures such as convolutional autoencoders, generative adversarial networks (GANs), and invertible neural networks have shown encouraging results in terms of robustness, payload capacity, and invisibility [14,15,16]. Nevertheless, the application of deep learning to video watermarking remains comparatively underdeveloped. Most existing methods either adapt still-image models to video by independently processing frames or employ limited spatiotemporal modeling through shallow extensions, thereby failing to capture the full temporal dynamics of video streams [17,18].
Several recent contributions have attempted to close this gap. For instance, Ye et al. proposed ItoV, a technique that flat-tens the temporal axis into spatial channels, allowing conventional convolutional layers to embed watermarks while preserving frame-level consistency [19]. Luo et al. introduced DVMark, a multi-scale deep framework that incorporates a differentiable distortion simulation layer and exploits 3D convolutional architectures to enhance robustness against temporal attacks and high-efficiency compression codecs [20]. Meanwhile, Mansour et al. presented a GAN-inspired model that transforms video sequences into mosaic-style composite images to improve resistance against frame-level manipulations and collusion attacks [21]. Additionally, emerging methods have explored embedding in alternative frequency domains using dual-tree complex wavelet transforms combined with DNNs to achieve a stronger trade-off between invisibility and robustness [22].
Despite these advances, several fundamental challenges persist. Maintaining temporal coherence during watermark embedding, especially under dynamic scene changes and motion, remains a difficult task. Deep models capable of capturing long-range temporal dependencies are often computationally expensive, limiting their deployment in real-world applications. Furthermore, achieving joint optimization of competing objectives, such as visual fidelity, watermark capacity, and extraction robustness, within an end-to-end framework continues to pose significant difficulties. Many current models also lack adequate resilience when subjected to real-world distortions such as collusion, adaptive re-encoding, or adversarial attacks targeting temporal inconsistencies [23].
In response to these challenges, this paper proposes a unified deep learning-based framework for video watermarking that jointly addresses robustness, imperceptibility, and efficient spatial embedding. The proposed architecture is composed of a set of interdependent modules that operate collaboratively to embed binary watermarks into video frames while preserving high perceptual quality. A U-Net backbone processes the input video to extract semantic features and guides a learned block importance estimator, which identifies low-saliency spatial regions suitable for watermark injection. A lightweight encoder transforms the binary watermark vector into a structured spatial representation, which is then injected into selected blocks across frames using a spatiotemporal modulation strategy. A multistage decoder re-constructs the watermark from potentially distorted sequences. The entire system is optimized via a multi-objective loss function that balances binary cross-entropy for watermark fidelity, structural similarity (SSIM) [24] for perceptual quality, and a sparsity regularization term to limit embedding to the most suitable regions.
The proposed framework is evaluated on Kinetics-600 dataset [25], which includes high-resolution and motion-rich videos, and subjected to a comprehensive suite of simulated and real-world distortions such as H.264 video compression, frame dropping, noise contamination, and temporal reordering. Our results demonstrate consistent improvements over state-of-the-art approaches in terms of imperceptibility, robustness, and watermark recoverability, confirming the viability of our approach for practical deployment in digital video ecosystems.
Main contributions of this work are summarized as follows:
- We propose a modular end-to-end framework for blind video watermarking that jointly optimizes imperceptibility and robustness through unified training.
- We introduce a content-adaptive embedding strategy based on an importance-guided block selection mechanism, which steers watermark injection away from perceptually sensitive or semantically dominant regions.
- We incorporate spatiotemporal injection with temporal redundancy to improve resilience against video-specific distortions such as compression, frame dropping, and temporal editing.
- We provide a comprehensive evaluation against recent baselines under diverse attack conditions, including multi-strength settings, demonstrating improved robustness–quality trade-offs.
The remainder of this paper is organized as follows. Section 2 reviews existing literature in traditional and deep learning-based video watermarking. Section 3 introduces the proposed framework, detailing the design of its components and training strategy. Section 4 presents experimental configuration, datasets, and evaluation metrics. Section 5 discusses empirical results and comparative analyses, while Section 6 presents complementary experiments to reinforce the robustness, efficiency, and design rationale of our method. Section 7 concludes the paper with final insights and future research directions.
2. Related Work
The emergence of deep learning has revolutionized digital watermarking, especially for images. Architectures like convolutional autoencoders, GANs, and invertible neural networks can learn complex feature representations that hide payloads imperceptibly while maintaining robustness [26,27,28,29]. Comprehensive surveys on deep watermarking have underscored significant performance gains in image domains and the potential for transfer to video [30,31,32]. Nonetheless, adaptation to video watermarking remains limited, as many methods either treat each frame independently or incorporate only limited temporal modeling (e.g., short-range aggregation or simple inter-frame consistency constraints), which does not fully leverage the dynamics of video streams.
Several pioneering works have sought to bridge this gap. Luo et al. introduced DVMark, proposing an end-to-end train-able deep learning solution tailored for video. DVMark employs a multi-scale design that distributes watermark information across spatial and temporal scales, augmented by a differentiable distortion simulation layer to mimic common attacks. A proxy for non-differentiable processes such as compression is also included. Experimental results on a wide range of distortions, covering compression, frame loss, geometric transformation, and noise, confirmed that DVMark outperforms both traditional video watermarking methods and state-of-the-art deep image watermarking techniques, all while preserving high perceptual quality [20].
In 2023, Ye et al. proposed ItoV [19], which confronts the assumption that temporal convolutions are necessary for video watermarking. Instead, ItoV merges the temporal axis into the channel dimension, enabling standard 2D convolutions to handle video data as if it were static imagery. The authors found that spatial convolutions alone were sufficient for embedding robust watermarks and achieved significant reductions in computational cost using depth wise separable convolutions. A novel “frame loss” term was introduced to promote consistency of watermark intensity across frames. ItoV exhibited imperceptibility and robust performance on datasets like Kinetics 600 [25] and Inter4K [33].
Separately, Mansour et al. [21] presented an innovative mosaic-based method. They convert video clips into mosaic-style composite images, which aggregate multiple frames spatially. This conversion permits embedding within a unified image, enhancing resistance to frame-level attacks such as collusion or temporal tampering. Their CNN–GAN pipeline for both embedding and extraction outperformed benchmarks in robustness under severe distortions.
Another important strand of research involves embedding watermarks in alternative transform domains. Chang et al. [22] embedded watermarks within the dual-tree complex wavelet transform (DT-CWT) domain and coupled this approach with deep neural networks. DT-CWT offers near shift invariance and directional selectivity, enabling high im-perceptibility and robustness to a variety of attacks. The study confirmed that this hybrid frequency–deep network approach achieves superior invisibility and strong resilience in challenging test scenarios.
Even with these improvements, challenges remain. DVMark [20] contributes a robust framework that leverages multiscale spatial-frequency injection, but it entails multiple distortion simulations and significant computational overhead. ItoV [19] offers a simplified image-to-video adaptation pipeline that reduces architectural complexity, yet it lacks temporal modeling mechanisms, which can impair performance in fast-moving scenes. The mosaic-based method by Mansour et al. [21] improves robustness against frame-level distortions by embedding across coarse spatial regions, though at the cost of potential visual artifacts. Finally, the DT-CWT-based approach [22] benefits from frequency-domain resilience via wavelet transformations, but its reliance on hand-engineered features limits adaptability and integration with modern end-to-end learning frameworks.
Taken together, these methods illustrate complementary design philosophies, yet they differ not only in architecture but also in the underlying conceptual assumptions about where watermark energy should be placed and how it should persist under spatial and temporal distortions. While the compared methods are learning-based, they pursue robustness and imperceptibility through different core principles. DVMark [20] mainly seeks robustness via multiscale spatio-temporal feature injection coupled with distortion-aware training, trading off complexity for invariance. ItoV [19] focuses on efficient adaptation by folding temporal information into channel space to reuse 2D image-watermarking backbones, but it does not explicitly enforce content-aware embedding admissibility or dedicated temporal redundancy. Mansour et al. [21] improve resilience through mosaic-style coarse embedding, which spreads information spatially but may introduce block-level artifacts and lacks fine-grained, content-adaptive gating. The DT-CWT approach [22] gains robustness by encoding watermark bits in hand-crafted transform-domain coefficients, which improves frequency-domain stability but reduces end-to-end adaptability. In contrast, our framework is conceptually driven by content-aware admissible embedding—learning where watermark energy is allowed via an importance/semantic gate—and by explicit learned temporal redundancy, distributing the payload across frames to maintain recoverability under temporal edits. This conceptual coupling between embedding admissibility and temporal persistence distinguishes our approach beyond a mere combination of modules.
To better contextualize the contributions and limitations of prior works in deep learning-based video watermarking, Table 1 provides a comparative overview of four representative state-of-the-art approaches: ItoV [19], DVMark [20], the mosaic-based method by Mansour et al. [21], and the DT-CWT-based method proposed in [22]. The comparison considers key characteristics including the domain of watermark embedding, the presence of temporal modeling capabilities, the extent of learnable components, and observed performance in terms of robustness and imperceptibility. This structured summary highlights the trade-offs between design complexity, attack resilience, and visual quality, thereby motivating the need for a more integrated and adaptive framework capable of addressing these factors simultaneously.

Table 1.
Comparative summary of related deep learning-based video watermarking methods.
Considering these limitations, our proposed method integrates the strengths of previous approaches into a fully learnable and modular design. We adopt an efficient spatial injection mechanism guided by semantic block selection, inspired by ItoV’s localized encoding. Robustness is enhanced through spatiotemporal redundancy and multi-level representations obtained from a U-Net backbone, capturing both global and fine-grained features. Unlike traditional frequency-domain techniques, our system learns all feature transformations in the spatial domain, enabling flexible optimization. This design aims to deliver improved imperceptibility, resilience under compression and noise, and general robustness in real-world video scenarios.
3. Proposed Method
This section details the architecture and mechanisms of the proposed deep learning-based watermarking framework, which is illustrated in Figure 1. The process begins with two parallel inputs: the original video and the binary watermark. The video is fed into the Frame Encoding module, which extracts semantically rich features from each frame using a deep convolutional backbone. In parallel, the watermark is passed through the Watermark Encoding module, which projects the binary vector into a spatial tensor aligned with the frame dimensions.
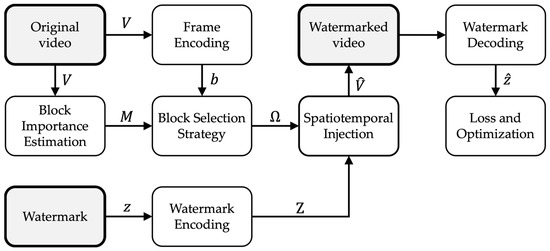
Figure 1.
Overall architecture of the proposed deep learning-based video watermarking framework. The pipeline is applied over frames in a clip; subscripts t are omitted in the diagram for readability.
Independently, the original video frames are also processed by the Block Importance Estimation module, which outputs an importance map capturing the perceptual sensitivity of different spatial regions. This importance map is then fused with semantic activation measures derived from the frame encoding in the Block Selection Strategy. The fusion results in a saliency map , which is binarized to obtain a selection mask , indicating where the watermark should be embedded. Here, the subscript denotes the frame (time) index within a clip.
The Spatiotemporal Injection module uses the encoded watermark Ζ and applies it to the selected spatial blocks , guided by temporal redundancy strategies to ensure robustness across frames. This process yields the Watermarked Video, which is then passed to the Watermark Decoding module. The decoder attempts to recover the original watermark even in the presence of distortions. Finally, the Loss and Optimization module compares the recovered watermark to the ground truth and jointly minimizes reconstruction error, perceptual distortion, and mask sparsity through backpropagation. Overall, this architecture implements a fully trainable pipeline where each module contributes to balancing imperceptibility, robustness, and embedding efficiency in complex video environments. Each module is explained in the subsections below.
3.1. Frame Encoding
The watermarking process begins with the encoding of raw video frames into a compact, informative representation suitable for subsequent analysis and manipulation. This step is crucial as it transforms each input frame into a high-level feature representation that captures both semantic and structural cues, which are later used for perceptual block selection and watermark integration.
Let us denote a video as a temporal sequence of frames , where each frame corresponds to the pixel intensities at time , with height , width , and three color channels. The first step in the pipeline involves passing each frame through a frame encoder , implemented as a convolutional neural network (CNN), which progressively downsamples the input and increases the depth of the representation. The encoder captures spatial patterns such as edges, textures, and objects, which are critical for assessing where the watermark can be safely embedded. Mathematically, the encoded representation of a frame is given by:
The encoder is designed to satisfy two main requirements: (1) semantic richness, ensuring that the encoded features contain meaningful information about the content of the frame (e.g., presence of objects or scene context), and (2) computational efficiency, which allows near-real-time performance. To achieve this, the architecture typically includes several convolutional blocks of the form:
The choice of kernel size k, stride, and number of filters in each block is tuned to balance resolution with feature discriminability. The down sampling process via max pooling reduces spatial resolution while retaining dominant structures and discarding noise, which is advantageous for both robustness and imperceptibility of the watermark.
The output provides a condensed yet informative map of the visual content of the frame. Each spatial location encodes local information about a region (or patch) of the original frame . This enables subsequent modules, such as block selection, to reason over the scene in terms of semantic features rather than raw pixels, facilitating adaptive and intelligent watermark placement.
Additionally, this encoding process supports spatial alignment with later operations such as importance mapping and watermark modulation. Specifically, since and the importance map will share the same spatial resolution , their correspondence allows for efficient fusion and joint analysis. In summary, the frame encoding stage transforms high-resolution visual data into structured, semantically rich tensors, serving as the backbone for perceptually aware watermarking. The learned features not only enable context-aware embedding decisions but also provide robustness to distortions by operating at a level abstracted from raw pixel intensity.
3.2. Block Importance Estimation
An essential aspect of any robust and imperceptible watermarking system is its ability to adaptively decide where in the video content the watermark should be embedded. This decision must account for both the perceptual sensitivity of different image regions and their structural characteristics. In our method, this is achieved through the estimation of an importance map for each frame , which quantifies the perceptual relevance of every spatial location within the frame. The goal is to avoid embedding watermarks in regions that are critical to human visual attention, such as faces, logos, or text, and instead target areas where alterations are less likely to be noticed.
To compute this importance map, each input frame is passed through a dedicated convolutional neural network , implemented using a U-Net architecture. The U-Net is particularly well-suited for this task due to its encoder–decoder structure with skip connections, which allows the model to combine global contextual information with precise spatial localization. This ensures that the output map can detect and preserve semantically important features such as object boundaries or motion areas.
The output of this network is a normalized 2D map , where each element represents the relative importance of the corresponding cell in the featured grid. Each cell approximately maps to a region of size pixels of the original frame, determined by the network downsampling and receptive field. Formally,
To ensure that the map is meaningful in a relative sense, we normalize it using a SoftMax operation across all spatial locations:
where denotes the raw importance logits produced by the U-Net before normalization. This SoftMax normalization has two key benefits: (1) it guarantees that , allowing the map to be interpreted as a probability distribution over the frame; and (2) it forces the model to focus its capacity on discriminating between relatively more and less sensitive regions, rather than producing uniformly high values.
We use SoftMax in Equation (3) to obtain a relative importance distribution that is comparable across frames and scenes with different contrast, motion intensity, or feature magnitude. In practice, the block selector operates on ranked importance rather than absolute values; SoftMax provides a stable scaling where a fixed selection budget (e.g., top K blocks or a sparsity target) can be applied consistently without requiring per-video tuning. Importantly, should not be interpreted as a semantic probability map; instead, it acts as a normalized allocation of embedding risk across spatial locations, which is later combined with semantic features in the selection stage.
A known behavior of SoftMax is that it may become peaky when a few locations dominate the logits, which can occur in scenes with prominent faces, text, or high-contrast edges. In such cases, most mass concentrates on a small region, and moderately important regions may receive near-zero scores. Conversely, in highly cluttered scenes, SoftMax may spread mass more evenly, reducing contrast between important and unimportant areas. To reduce this sensitivity, we employ a simple calibration in practice (temperature scaling or clipping of logits before normalization), which prevents overly concentrated maps and stabilizes the resulting selection mask across diverse content.
In practice, the importance map highlights regions of the frame that are visually salient or semantically critical, such as human faces, object edges, or areas of motion. These regions are then avoided in the block selection stage to minimize perceptual artifacts. Conversely, low-importance areas, such as homogeneous textures, shadows, or out-of-focus backgrounds, are identified as suitable locations for embedding. To make this behavior explicit, Figure 2 provides an example of the predicted importance map for a representative frame. We show (a) the input frame , and (b) the estimated importance map rendered as a heatmap over [0, 1]. The example highlights that semantically salient structures receive higher importance values, whereas homogeneous or low-detail background regions tend to receive lower importance, aligning with our goal of avoiding perceptually sensitive areas during block selection.

Figure 2.
Example visualization of the estimated importance map for a representative frame from the Kinetics-600 dataset. (a) Input video frame . (b) Predicted importance map rendered as a heatmap (higher values indicate more perceptually/semantically important regions).
From an architectural perspective, the encoder part of the U-Net progressively reduces the spatial resolution while increasing the number of feature channels, allowing the model to capture coarse semantic information. The decoder then reconstructs the map to the original (reduced) resolution , leveraging skip connections to preserve fine details. This structure makes it possible to maintain high spatial precision, which is essential for block-level watermark embedding.
By learning to produce such importance maps in a data-driven fashion, the model adapts to diverse visual scenes and content types, from static backgrounds to dynamic, cluttered environments. Moreover, since the importance map shares spatial dimensions with the encoded feature map from Section 3.1, the two can be directly aligned and fused during the block selection phase.
3.3. Block Selection Strategy
Once the method has obtained both a semantically rich representation of the input frame and an importance map , the next step is to determine where the watermark should be inserted. This task is entrusted to the Block Selection Strategy, which plays a critical role in balancing imperceptibility and robustness by carefully identifying the regions of the frame that are most suitable for embedding.
The fundamental idea behind this module is to exclude from embedding those regions that are either perceptually sensitive (according to ) or semantically rich (according to ), since any distortion in those areas is more likely to be detected by the human visual system or to interfere with content recognition. Conversely, the module prioritizes less important or visually redundant areas as candidates for watermarking. A natural concern is whether prioritizing visually redundant regions could enable a malicious attacker to remove the watermark by selectively replacing or inpainting those regions. In principle, targeted region editing is a plausible threat model, particularly if the attacker can estimate which areas are being modified. In our framework, this risk is mitigated by distributing the watermark across multiple spatial locations and across consecutive frames through spatiotemporal redundancy, so that removing the watermark would require sustained, coordinated editing of many regions over time. Such extensive manipulation typically induces noticeable artifacts or temporal inconsistencies, and partial corruption is further handled by the decoder due to robustness-oriented training with stochastic distortions. Nevertheless, we acknowledge that fully adaptive, content-aware watermark removal is an important direction for future work and could be further addressed by incorporating stronger attack models into the adversarial training loop.
To this end, we define a composite saliency score for each block located at spatial position by linearly combining the normalized importance value from and a semantic activation measure derived from the encoded features:
where is a tunable hyperparameter that controls the trade-off between perceptual and semantic sensitivity. The function is implemented as the entropy of the feature vector at each location, capturing the variability or uncertainty in local content:
We use feature entropy as a simple proxy for local semantic complexity because it measures the dispersion of intermediate feature responses within a region. Regions with higher entropy typically exhibit richer structure and heterogeneous patterns, which are more likely to correspond to semantically informative content, whereas low-entropy regions tend to be homogeneous and visually redundant. Importantly, this signal is lightweight and does not require additional supervision, and it remains comparatively stable under common distortions because it is computed in the feature space rather than directly from raw pixels. Alternative indicators such as gradient magnitude or attention-derived saliency may capture complementary cues, and we consider their systematic comparison a natural direction for future work.
This entropy-based formulation allows the model to detect locations with high semantic complexity, such as object contours or areas of motion, which are more vulnerable to perceptual degradation. Combining this measure with the learned importance map results in a unified saliency estimation.
Once all the saliency scores have been computed, we applied a thresholding rule to generate a binary block selection mask :
where is a predefined threshold that controls the sparsity of the mask. A lower value of leads to fewer selected blocks and higher imperceptibility, while a higher increases watermark coverage at the cost of greater visual impact. The resulting mask thus identifies the blocks where the watermark will be embedded.
Crucially, the block selection process operates at the feature map resolution , which is lower than the original frame resolution. This makes it efficient for large-scale video processing while maintaining alignment with the outputs of both the encoder and the U-Net . During training, the model implicitly learns to balance the aggressiveness of embedding with the need for stealth by optimizing the full loss function introduced in Section 3.7.
In this way, the Block Selection Strategy acts as a spatial gatekeeper, synthesizing perceptual and semantic signals into a mask that guides the downstream watermark injection process. Its design ensures that only suitable regions are modified, preserving the visual quality of the video while enhancing the resilience of the embedded watermark against both perceptual and algorithmic attacks.
Figure 3 illustrates the internal steps of the block selection process applied to a representative video frame from the Kinetics-600 dataset. In Figure 3a, we show the original frame used as input to the block selection modules. Figure 3b presents the saliency map which combines the importance map, derived from low-level visual cues such as edge density and motion gradients, with semantic activations extracted from the encoder to guide spatial attention. Figure 3c, the binary mask is generated by applying a threshold to the saliency map, resulting in a discrete representation that determines where watermark information may be safely embedded. Finally, Figure 3d overlays the selected blocks onto the original frame, highlighting the regions chosen for embedding via red rectangles. These regions are usually located in areas of low semantic importance and spatial redundancy, ensuring a favorable balance between imperceptibility and robustness. Together, these visualizations provide an intuitive understanding of how the model dynamically adapts its embedding strategy to the video content, allowing the watermark to be placed in visually stable and low-attention areas without requiring handcrafted rules.

Figure 3.
Visual example of the block selection pipeline using a frame from the Kinetics-600 dataset: (a) original input frame; (b) saliency map combining the estimated importance map and semantic activations; (c) binarized selection mask obtained by thresholding the saliency map; (d) selected embedding blocks overlaid on the original frame (red rectangles).
3.4. Watermark Encoding
The watermark encoding module is responsible for transforming the input watermark vector into a spatially structured format suitable for injection into the selected video blocks. This step is critical because it ensures that the watermark information aligns with the spatial resolution and semantic layout of the carrier frame, enabling both robust embedding and accurate recovery.
Let the binary watermark be denoted as a one-dimensional vector , where represents the number of watermark bits. To make this vector compatible with the visual embedding process, we project it into a higher-dimensional feature representation. Specifically, the encoder transforms into a multi-channel 2D tensor , where is the number of feature channels, and , matches the height and width of the importance mask . This ensures spatial alignment between the watermark features and the regions selected for embedding.
The encoding process is realized via a compact convolutional neural network composed of fully connected layers followed by upsampling and convolution blocks. The transformation is formalized as
where is trained jointly with the rest of the network to optimize both imperceptibility and robustness. The design ensures that preserves the semantic structure of the watermark bits while conforming to the spatial embedding constraints defined by . To promote better generalization and resilience, we also introduce controlled redundancy in the encoding step. The encoder is designed to distribute watermark information across spatial regions with overlapping, thereby increasing resistance to localized attacks or noise. This is applied by introducing Gaussian noise and dropout layers within , encouraging the network to learn robust encoding patterns that are not overfitted to specific locations.
3.5. Spatiotemporal Injection
Once the spatial representation of the watermark has been generated by the encoder, it must be seamlessly embedded into the original video frame following the structure provided by the block importance map and the selection mask . This process is carried out by the Spatiotemporal Injection Module, which modifies the video content in selected regions while preserving the visual quality and achieving robustness across multiple frames. The key idea is to perform additive modulation of the input frame using the encoded watermark , guided by both spatial importance and temporal consistency. The formulation of the embedding process is as follows:
where is the watermarked video, is a learnable or tunable scaling factor controlling embedding strength, represents element-wise multiplication, and acts as a binary spatial mask ensuring that modifications are restricted to selected blocks. Here, controls the embedding strength. Although can be defined as a learnable parameter, in this work we treat as a fixed scalar hyperparameter and set for all experiments, selected to preserve imperceptibility while maintaining reliable watermark recovery. This value is kept constant during both training and inference.
This formulation guarantees that only the regions explicitly selected for embedding are altered, while the rest of the frame remains untouched, preserving overall image fidelity. Moreover, the feature map contains redundant watermark representations that enhance the likelihood of successful recovery even under partial destruction of the signal.
To improve robustness across time, especially under compression and frame-skipping attacks, the framework distributes portions of the watermark across multiple consecutive frames. Suppose we consider a window of frames centered around a target frame ; then the full watermarked sequence is
for . In each of these frames, a different spatial subset of is embedded, ensuring temporal redundancy. This temporal spreading of watermark bits reduces the impact of occlusion or lossy processing on any single frame and contributes significantly to extraction reliability, particularly in real-world applications like streaming video or online broadcasting. Finally, to enhance imperceptibility, the injection module includes a lightweight convolutional refinement layer that adjusts the output to compensate for local contrast and luminance variations, reducing the visual footprint of the watermark.
The watermark injection is implemented via a U-Net-like encoder–decoder architecture [34] that fuses the selected video regions with the encoded watermark signal. Table 2 provides the configuration of the convolutional stages used in this component, including kernel dimensions and channel depths.
Table 2.
Video Embedder Architecture (U-Net variant).
3.6. Watermark Decoding
The Watermark Decoding module is responsible for extracting the embedded information from one or more watermarked frames . It must accomplish this task even under adverse conditions, such as compression, noise, or geometric transformations, making it a critical component of the proposed system’s robustness.
The decoding process begins with the same feature encoder , previously used to analyze the original frame content. Each received (possibly degraded) watermarked frame is passed through to generate an intermediate representation:
This encoded representation contains both semantic features of the visual content and distortions caused by the watermark signal. However, since the watermark was injected in structured and selected regions only, the decoder must focus on these regions to retrieve the embedded data reliably.
To achieve this, the system uses a spatiotemporal attention mechanism that aggregates feature responses across the block locations originally marked for embedding. Let be the binary mask indicating the selected blocks at frame , then the aggregated watermark estimate is computed as:
where is a multi-layer perceptron (MLP) that maps the aggregated feature vector back to the estimated watermark vector, and the sum aggregates information over selected spatial positions in the encoded feature map.
To further improve accuracy, the system performs temporal fusion by repeating the decoding process across multiple frames in the neighborhood of . The final recovered watermark is obtained by majority voting or averaging across these multiple predictions:
where denotes the indices of the selected neighboring frames. Equation (12) implements temporal fusion by aggregating frame-level watermark estimates over a short temporal neighborhood. In our experiments, we consider two standard fusion rules: uniform averaging of the predicted bit probabilities and majority voting after binarization. Uniform averaging provides a stable estimate when individual frames are mildly degraded, while majority voting can reduce the impact of sporadic frame-level outliers. A weighted averaging variant, where each frame contribution is scaled by a confidence score derived from the decoder output, is also a plausible alternative for scenarios with non-uniform temporal corruption. A comprehensive comparison of these fusion mechanisms is an interesting direction for future work. The fusion strategy improves stability by aggregating evidence across frames, so that sporadically degraded blocks, missing frames, or localized corruptions have reduced influence on the final watermark estimate. Finally, a binary decision is applied to convert the continuous estimate into discrete watermark bits:
where is a decision threshold, typically set to 0.5 during inference.
3.7. Loss and Optimization
The training of the proposed deep watermarking framework is guided by a multi-objective loss function that balances three key properties: robustness, imperceptibility, and capacity. Each of these aspects is addressed by a dedicated loss component, and the objective of global optimization is their weighted combination.
This loss directly penalizes incorrect bit predictions and ensures the encoder–decoder pair learns a discriminative mapping for watermark recovery. To ensure imperceptibility, we use a perceptual similarity loss that compares the original and watermarked frames. Instead of relying solely on pixel-wise errors like MSE, we adopt the SSIM loss:
This loss penalizes structural and luminance changes that would be visible to human observers, helping preserve high visual quality. In some configurations, an additional feature loss may be added by comparing intermediate feature maps from a pre-trained CNN, but this is optional depending on training complexity.
To prevent the network from embedding across the entire frame and instead concentrate watermark information in low-importance regions, we introduce a sparsity regularization over the selection mask :
This encourages the selection of a minimal number of embedding blocks, thereby reinforcing perceptual invisibility and preserving more of the original signal. The total objective function combines these components:
where , , are hyperparameters tuned empirically to balance the trade-offs. In our experiments, a typical configuration is , and . Training is performed using the Adam optimizer with an initial learning rate of 10−4, batch size of 8 video clips (each containing 5 consecutive frames), and data augmentation including rotation, scaling, and compression artifacts to simulate real-world distortions.
In summary, the optimization process jointly tunes all modules, encoder, decoder, selector, and injection layers, to achieve a watermarking system that is accurate, invisible, and resilient, even in complex video environments.
3.8. Implementation Summary
To bring the proposed framework into practice, all network components were implemented using the PyTorch deep learning library (PyTorch v2.0.1). The system operates on short video clips composed of 16 consecutive frames (), with each frame resized to a resolution of 224 × 224 pixels and normalized per channel. The architecture processes two parallel inputs: raw video frames and a binary watermark vector. A latent embedding of 512 dimensions is used to represent the watermark payload, ensuring sufficient capacity for binary message encoding.
Each submodule, including the frame encoder, block importance estimator, watermark encoder, and injection module, was initialized with He initialization and trained end-to-end using the Adam optimizer. To improve generalization, the model was trained with various data augmentation strategies and adversarial attack simulation plugins, allowing robustness to be learned directly through gradient descent.
Further details regarding training protocols, loss functions, and attack configurations are provided in Section 4.
4. Experimental Setup and Evaluation Protocol
Building upon the modular architecture and implementation strategy described in Section 3.8, this section presents the experimental configuration used to evaluate the proposed framework. We detail the dataset preparation, performance metrics, attack scenarios, and baseline methods used for comparison. Our goal is to assess the system’s ability to embed and recover watermarks under diverse conditions while maintaining imperceptibility and computational feasibility. The evaluation protocol is designed to ensure consistency with prior works in video watermarking and to enable reproducibility of our results.
4.1. Dataset and Preprocessing
We evaluate our method using the Kinetics-600 dataset [25], a large-scale human action video collection widely used for training and benchmarking video analysis models. From the training split, we randomly sample 5000 clips representing a diverse range of scenes, motions, and lighting conditions. Each video is converted into a sequence of 16 consecutive frames (), resized to 224 × 224 pixels, and normalized per RGB channel. Data augmentation is applied during training to enhance generalization and robustness. These augmentations include random horizontal flipping, slight brightness and contrast perturbations, and Gaussian blur. A fixed-length binary watermark of 512 bits is generated per clip and embedded using the proposed method. Although the payload is fixed to 512 bits here for controlled benchmarking across methods, Section 6 briefly discusses how capacity variations influence imperceptibility and robustness and how the proposed framework can be configured for different payload sizes.
4.2. Performance Metrics
We evaluate watermarking performance along three main axes: imperceptibility, robustness, and computational efficiency. Visual imperceptibility is evaluated using PSNR and SSIM, comparing original and watermarked frames. Although perceptual losses such as SSIM and sparsity regularization are minimized during training (as explained in Section 3.7), final evaluations are reported using PSNR and SSIM to ensure fair comparison with existing works. Robustness is evaluated by computing the BER of recovered watermark vectors under various distortions. Finally, computational efficiency is reported in terms of frames per second (FPS) during inference on a standard GPU.
4.3. Attack Models
To validate the robustness of the proposed framework, we subjected the watermarked videos to a comprehensive suite of real-world and adversarial distortions. These attacks simulate both common signal degradations and deliberate attempts to disrupt watermark integrity. Spatial perturbations included Gaussian blur with a standard deviation of 1.0, and salt-and-pepper noise with a corruption probability of 0.01.
Temporal modifications were also introduced, such as frame dropping at a rate of 20%, insertion of random frames, duplication of existing frames, and reordering of temporal sequences. To assess codec-level resilience, the watermarked videos were re-encoded using H.264 at a reduced bitrate, mimicking typical streaming degradation. Additionally, a composite distortion was applied by combining Gaussian noise with frame skipping to simulate more aggressive real-world interference.
These attack scenarios were selected to match the evaluation protocols used in related state-of-the-art frameworks, including ItoV [19], DVMark [20], the mosaic-based watermarking approach by Mansour et al. [21], and the DT-CWT-based CNN method [22]. Each attack was applied independently, and the system’s performance was measured in terms of BER and PSNR and SSIM across the full test set.
Beyond compression and noise, geometric transformations including small rotations constitute a relevant threat model because they can introduce spatial misalignment between the embedded signal and the decoder’s sampling grid. However, in this study the quantitative robustness benchmark focuses on codec recompression, signal degradation, and temporal attacks, which represent common real-world distribution and editing conditions. Prior work on robustness against geometric attacks [35] provides useful context for this threat model and motivates extending the evaluation protocol in future work.
4.4. Baseline Methods
We conducted comparative evaluations against four recent deep learning-based video watermarking methods selected for their diversity in embedding strategy and domain. The first method, DVMark [20], uses a multiscale spatial-frequency architecture to insert watermarks at different resolution levels, providing strong robustness but at the cost of high computational complexity due to its multi-path design and distortion simulation layers. The second baseline, ItoV [19], offers a lightweight image-to-video adaptation framework based on patch wise embedding, which achieves low visual distortion but lacks temporal redundancy and tends to underperform in dynamic scenes. The third method [22] is a hybrid approach based on the dual-tree complex wavelet transform (DT-CWT) combined with a convolutional decoder. It provides robustness to compression artifacts but partially reintroduces handcrafted feature design, limiting its adaptability. Lastly, we included the mosaic-based watermarking technique proposed by Mansour et al. [21], which inserts information in low-frequency coarse regions to improve resilience against cropping and temporal jitters. However, this method may produce perceptual artifacts due to the granularity of the mosaic encoding. All baseline methods were either reimplemented based on their published specifications or reproduced from publicly available code, and were evaluated under identical datasets, attack scenarios, and performance metrics to ensure fair comparison.
4.5. Evaluation Protocol and Metrics Summary
All experiments are conducted on a single NVIDIA RTX 3090 GPU with 24 GB of memory. The system is trained using the Adam optimizer with a learning rate of 10−4, a batch size of 8, and early stopping based on validation BER. For each test configuration, we report average PSNR, SSIM, and BER across 100 video sequences. Further implementation details are provided in Section 4.1, while the loss definition and weighting are described in Section 3.7.
5. Experimental Results
This section presents a comprehensive evaluation of the proposed watermarking framework across a range of metrics and adversarial scenarios. We assess the visual imperceptibility of the watermarked video, the system’s robustness to signal degradation and temporal attacks, and its comparative performance relative to four recent baselines. Results are reported using standard metrics such as PSNR, SSIM, and BER. All evaluations are based on 100 randomly sampled video clips from the Kinetics-600 dataset, each processed with an embedded binary watermark of 512 bits. For fairness, we configure all baseline methods to embed the same payload size (512 bits) whenever their public implementations allow; otherwise, we use the closest supported configuration and explicitly report the deviation in the corresponding baseline setup.
5.1. Visual Quality Under Distortion
To evaluate the perceptual impact of watermark embedding, we measure PSNR and SSIM between the original and watermarked video frames under various levels of visual distortion. These metrics provide insight into the trade-off between watermark robustness and visual fidelity.
Figure 4 shows the results in terms of PSNR after five distortion conditions: no attack (NONE), H.264 compression at QP = 28 (QP28) and QP = 40 (QP40), Gaussian noise (GN), and a composite distortion combining noise and temporal skipping (GN + FS). The proposed method achieves an average value of 38.6 dB under clean conditions, indicating minimal distortion and nearly lossless embedding. Under moderate compression (QP = 28), PSNR drops to 35.4 dB, and further to 32.3 dB at QP = 40, remaining above the perceptibility threshold of 30 dB across all conditions. Under Gaussian noise (σ = 5), the system retains 34.2 dB, and under composite distortion (Gaussian noise combined with frame skipping), it still delivers 32.1 dB. While ItoV [19] attains the highest PSNR values in all scenarios, owing to its minimal injection footprint, the proposed method achieves a favorable trade-off by maintaining strong perceptual quality with significantly higher robustness. DVMark [20] and DT-CWT [22] perform acceptably, though they exhibit sharper degradation under compression. The mosaic-based method of Mansour et al. [21] consistently exhibits the lowest PSNR values, due to the visible block artifacts introduced by its coarse embedding strategy.
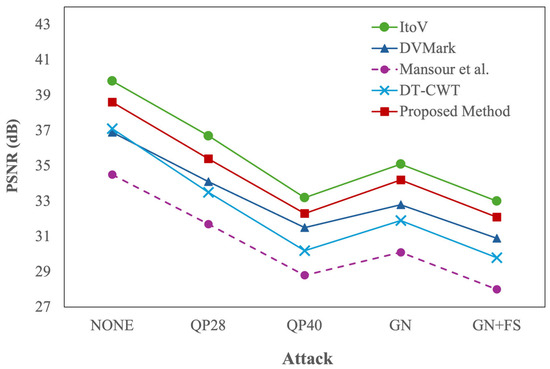
Figure 4.
PSNR comparison under different attacks for the proposed method and four baselines: ItoV [19], DVMark [20], Mansour et al. [21], and DT-CWT [22].
The SSIM results (Figure 5) mirror the PSNR trends but offer finer insight into the structural preservation of the image. Under clean conditions, the proposed method reaches an SSIM of 0.962, confirming that the embedded content causes negligible structural alteration. Under QP = 28 and QP = 40, SSIM remains high at 0.945 and 0.928, respectively. Even with additive Gaussian noise, the model maintains 0.940, and under the composite distortion scenario, SSIM remains at 0.921. These results are only slightly behind ItoV [19], which leads with SSIM values up to 0.975, yet significantly ahead of DVMark [20], DT-CWT [22], and Mansour et al. [21], particularly under aggressive or mixed distortions. These outcomes confirm that the saliency-aware block selection mechanism not only avoids high-frequency and semantically important areas but also achieves consistent structural preservation across a variety of degradation types.
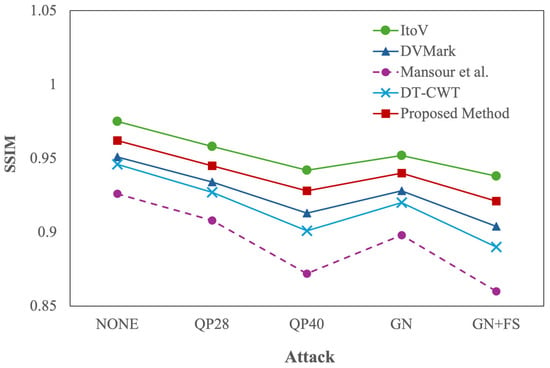
Figure 5.
SSIM Comparison under different attacks for the proposed method and four baselines: ItoV [19], DVMark [20], Mansour et al. [21], and DT-CWT [22].
5.2. Watermark Robustness and Retrieval Accuracy
A central requirement for any watermarking system is its robustness, that is, its ability to accurately recover the embedded watermark even after the video has undergone significant transformations. In this section, we evaluate robustness using the BER, defined as the percentage of watermark bits incorrectly decoded after the video is subjected to an attack. Ten different distortion scenarios are considered, spanning spatial, temporal, codec, and combined domains. Each attack is applied independently to the test set of 100 video clips, and average BER values are reported for the proposed method and four baseline systems (Table 3). A lower BER indicates higher robustness. The following paragraphs present a detailed analysis of the results obtained under each attack condition.
Table 3.
Average BER (%) under each attack. Best results are shown in bold and second-best results are underlined.
Compression using H.264 with a quantization parameter of 28 (QP = 28) represents a typical video delivery scenario, introducing moderate visual degradation while preserving frame structure. The proposed method performs exceptionally well under this condition, achieving an average BER of just 0.5%. This demonstrates that the watermark remains largely unaffected by quantization artifacts, thanks to the content-aware block selection strategy that avoids perceptually and semantically sensitive regions. In contrast, DVMark [20] and DT-CWT [22] report BERs of 1.7% and 1.9%, respectively, while ItoV [19] and the mosaic method by Mansour et al. [21] yield higher errors, suggesting their embeddings are more sensitive to compression noise.
To directly address robustness under increasing compression strength, Table 3 also reports results under QP = 34 and QP = 40. Increasing the compression level represents a more aggressive quantization scenario, often encountered in mobile streaming or low-bandwidth environments. As expected, stronger quantization increases BER for all methods, yet the proposed approach exhibits a notably gradual degradation: BER increases from 0.5% (QP = 28) to 1.0% (QP = 34) and 1.6% (QP = 40). In contrast, ItoV [19] grows from 2.3% to 4.1% and 5.8%, and Mansour et al. [21] increases from 3.2% to 4.5% and 6.0%. Even the strongest competing baselines degrade more sharply than our model (e.g., DVMark [20]: 1.7%, 2.6%, 3.5%; DT-CWT [22]: 1.9%, 2.6%, 3.2%). These results indicate that the proposed spatiotemporal injection combined with selective embedding yields stronger resilience to progressive quantization, which is particularly relevant for low-bitrate streaming environments. Recompression may also introduce non-aligned quantization patterns and grid misalignment effects that complicate reliable recovery, and related work has investigated alignment recovery and quantization-step estimation under non-aligned recompressed content, providing complementary context for this scenario [36].
Gaussian noise simulates sensor and transmission perturbations by introducing random pixel-level variation. At σ = 5, the proposed model attains a BER of 0.6%, outperforming DVMark [20] (1.8%) and DT-CWT [22] (1.5%), while ItoV [19] and Mansour et al. [21] degrade further (2.1% and 2.9%). The same trend holds across lower and higher noise levels: at σ = 3, the BER remains as low as 0.4% for the proposed approach, and at σ = 8 it increases modestly to 0.9%, whereas ItoV [19] rises from 1.3% to 3.4% and Mansour et al. [21] from 1.7% to 4.6%. This smooth increase across noise severities supports the interpretation that distributing watermark information across selected stable regions and training with perturbation-based augmentation improves tolerance to stochastic corruption.
Salt-and-pepper noise introduces impulsive corruption by randomly flipping a fraction of pixels to extreme values, which represents a harsher form of localized pixel damage. At p = 1.0%, the proposed method achieves a BER of 1.1%, again outperforming DVMark [20] (2.6%), DT-CWT [22] (2.2%), ItoV [19] (3.5%), and Mansour et al. [21] (4.0%). The multi-strength results further highlight the robustness trend: at p = 0.5% the BER is 0.6%, and even at p = 2.0% it remains limited to 2.0%, while competing baselines show substantially larger increases (e.g., ItoV [19]: 1.8%, 3.5%, 6.8%; Mansour et al. [21]: 2.0%, 4.0%, 7.9%). This suggests that the decoding stage can leverage contextual redundancy to recover watermark bits even when sparse but severe pixel-level corruption is present.
Frame dropping directly targets temporal consistency by removing a fraction of frames, simulating packet loss or editing operations. At the reported 20% drop rate, the proposed method records a BER of 2.4%, reflecting the benefit of embedding redundancy across time. The same mechanism is evidenced more clearly: the BER is 1.1% at 10% drop and increases to 3.4% at 30% drop, showing a controlled degradation as temporal information is progressively removed. Baselines degrade more sharply under the same conditions (e.g., ItoV [19]: 3.7%, 7.9%, 11.6%; DT-CWT [22]: 2.4%, 5.0%, 7.6%), confirming that approaches lacking explicit temporal redundancy are less resilient when the frames carrying watermark evidence are partially missing. Overall, the extended multi-strength evaluation in Table 3 reinforces that the proposed design achieves consistently lower BER across both spatial and temporal attack families and maintains robustness trends under increasing attack severity.
Frame insertion introduces new, unrelated frames into the video sequence, disrupting temporal consistency and potentially desynchronizing the decoding pipeline. This attack is particularly challenging because it breaks continuity without altering the original watermark-bearing frames. The proposed method achieves a BER of 3.0%, demonstrating strong temporal generalization capabilities. This is achieved using a spatiotemporal decoding strategy that can distinguish signal from noise across adjacent frames. DVMark [20] and DT-CWT [22] are moderately affected, while ItoV’s [19] performance degrades sharply to 8.6% BER due to the absence of temporal modeling.
Frame duplication repeats existing frames, creating artificial redundancy in the video timeline. Though this does not directly corrupt the watermark-carrying frames, it alters the rhythm of the sequence and can mislead temporal feature extraction. The proposed method maintains a BER of 2.6% in this condition. The decoder’s use of inter-frame correlations and learned spatiotemporal patterns allows it to distinguish genuine frame transitions from repetitions. Baseline methods such as DVMark [20] and DT-CWT [22] show elevated BERs above 4.5%, and ItoV [19] once again proves highly susceptible to temporal manipulations, with an error rate of 8.2%.
Frame reordering, one of the most aggressive temporal attacks, alters the sequence of frames, effectively desynchronizing the spatial content from its original temporal order. This type of manipulation is particularly damaging for systems that rely on frame continuity. Even under this harsh condition, the proposed method maintains a BER of 7.3%, significantly better than DVMark [20] (8.5%), DT-CWT [22] (9.2%), and the other baselines. The decoder’s design allows flexible reconstruction, even when the watermark appears in a scrambled sequence, showcasing the advantage of distributing watermark bits over multiple locations and frames.
Re-encoding using H.264 at low bitrate simulates common post-processing pipelines such as transcoding or platform-specific recompression. This process introduces noise quantization and changes the chroma subsampling. The proposed BER method remains low at 1.2%, indicating strong resilience to such codec-level transformations. This is enabled by the adaptive injection strategy that targets visually redundant regions, less prone to quantization loss. Other methods such as DVMark [20] and DT-CWT [22] perform reasonably, but Mansour et al. [21] suffer due to their reliance on low-frequency block-level information, which is typically discarded or severely compressed in such scenarios.
Finally, the composite attack combines Gaussian noise with frame skipping, producing a challenging scenario where both spatial and temporal signals are degraded. The proposed system achieves a BER of 2.9%, demonstrating that it can maintain robustness even when multiple forms of distortion are present simultaneously. The combined effect of adversarial training, saliency-aware injection, and temporal redundancy allows the system to recover the watermark despite complex interference. In comparison, all baseline methods experience substantial degradation, with ItoV [19] reaching nearly 10% BER and others fluctuating between 5.7% and 7.8%.
Overall, the results in Table 3 demonstrate that the proposed method achieves a strong balance between imperceptibility and robustness. Its consistently low BER values across a wide range of distortions reflect the effectiveness of combining spatial selectivity, temporal redundancy, and adversarial training. This robustness, even under compound attacks, underscores its suitability for real-world applications such as video streaming, surveillance, and copyright protection. At the same time, our evaluation emphasizes practical recompression and temporal editing conditions, while specialized defenses against geometric misalignment remain a complementary direction highlighted in prior watermarking literature and left as a future extension of the benchmark [35].
6. Discussion
This section complements the quantitative results presented earlier by offering a deeper analysis of the internal behavior of the proposed method. While Section 5 reveals strong performance in terms of imperceptibility and robustness, this section addresses three essential aspects for validating the method’s consistency and practicality: (1) sensitivity to block selection quality, (2) temporal embedding strategy and inference speed, and (3) ablation of architectural components. Together, these analyses highlight the contributions of each design choice to the overall performance of the system.
6.1. Sensitivity to Block Selection Quality
The watermark embedding strategy proposed in this work relies on selectively modifying spatial regions that are less critical to the visual semantics of the video. This block selection process is guided by an importance map , estimated via a U-Net-based encoder, which is then refined into a binary mask that determines which blocks receive portions of the watermark. Because only a subset of spatial regions is used for injections, the accuracy and consistency of this selection mechanism are vital for preserving imperceptibility and ensuring robustness under distortion.
To evaluate the impact of the block selection quality, we designed an experiment comparing three configurations of the system, each using a different block selection strategy but identical watermark encoding, injection, and decoding components. The first configuration corresponds to the proposed method using the learned saliency-guided mask. The second configuration uses a fixed central block, a common choice in traditional methods. The third configuration applies a random binary mask of the same sparsity, simulating non-adaptive selection.
Table 4 reports both imperceptibility (PSNR and SSIM, measured under benign/no-attack conditions) and robustness (BER under two representative distortions: H.264 compression at QP = 28 and Gaussian noise with σ = 5) for three block selection strategies. The proposed learned, content-aware mask achieves the best visual fidelity, reaching 38.6 dB PSNR and 0.962 SSIM, confirming that avoiding perceptually sensitive regions reduces visible embedding artifacts. In contrast, the fixed central-block strategy yields the lowest perceptual quality (35.8 dB, 0.935 SSIM), which is consistent with forcing embedding into salient object-centered content. The random mask produces intermediate visual quality (36.5 dB, 0.948 SSIM) but performs poorly in robustness, as its non-adaptive selection often places watermark energy into unstable or noise-sensitive regions.
Table 4.
Impact of block selection strategy on imperceptibility and robustness under H.264 compression (QP = 28) and Gaussian noise (σ = 5). Higher PSNR/SSIM indicate better imperceptibility, while lower BER indicates better robustness. Best results are shown in bold and second-best results are underlined.
The same trend is reflected in robustness. The proposed method attains the lowest BER under both distortions (0.5% at QP = 28 and 0.6% under Gaussian noise), substantially outperforming the fixed central-block baseline (1.9%, 2.1%) and the random mask variant (3.4%, 3.1%). Overall, these results validate that content-aware block selection is essential not only for invisibility but also for robustness, by steering watermark injection toward visually redundant yet structurally stable regions.
In practice, the learned selection mask consistently avoids embedding in high-attention regions such as faces, motion boundaries, and overlaid text, and instead targets visually stable areas. This behavior is learned through gradient-based supervision and adversarial training, allowing the system to automatically discover regions that optimize both invisibility and robustness. The experiment confirms that block selection is not merely a design choice, but a critical functional component of the watermarking pipeline, whose omission or simplification leads to significantly weaker performance under real-world perturbations.
6.2. Temporal Redundancy and Robustness
Video watermarking methods must address temporal inconsistencies introduced by real-world editing or network disruptions. Unlike image-based approaches, video sequences may suffer from dropped, duplicated, inserted, or reordered frames, each of which can severely disrupt watermark integrity. To address this, the proposed method introduces temporal redundancy by embedding the watermark over a sliding window of consecutive frames. The goal is to increase resilience without compromising visual quality or decoding accuracy.
To evaluate this strategy, we conducted an experiment that varied the number of frames used for embedding, specifically 4, 8, 12, and 16, while keeping the watermark payload constant. Two attacks were considered: 20% frame drop and full-frame reordering. These attacks represent common distortions in streaming and editing pipelines that can misalign the embedded signal across time.
The results, shown in Figure 6, demonstrate that increasing the number of embedding frames significantly improves robustness. With only 4 frames, the system experiences a BER of 6.7% under frame drop and 10.1% under frame reordering, reflecting a limited capacity to recover the watermark when frame-level changes occur. As the number of frames increases, performance improves consistently: at 12 frames, BER drops to 2.7% and 5.2%, respectively; and at 16 frames, BER stabilizes at 2.4% and 4.3%. These improvements confirm that spreading the watermark across multiple locations in time not only distributes risk but also enhances decoder reliability, especially when trained with variable-length temporal data.
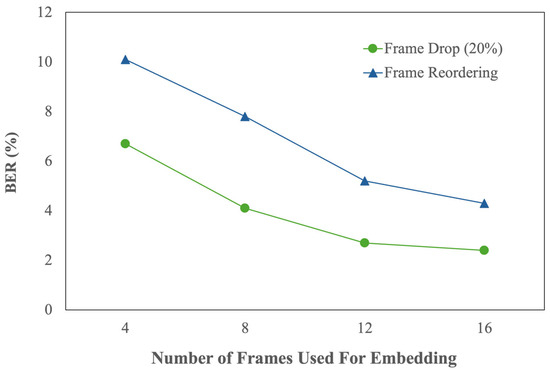
Figure 6.
Effect of Temporal Redundancy on Robustness.
This analysis underscores the importance of temporally redundant design in video watermarking. Embedding longer sequences allows the system to tolerate a wider variety of disruptions while retaining the embedded signal’s structure. Unlike strategies that inject watermark information in a single frame or use frame-agnostic decoders, our approach benefits from temporal consistency and recovery mechanisms that are tuned to spatiotemporal cues.
These findings underscore the importance of temporal redundancy. Embedding the same latent watermark across several well-chosen regions in multiple frames provides natural robustness to partial corruption. Moreover, the system is trained to exploit these temporal dependencies: the decoder aggregates spatiotemporal features, allowing it to recover the original signal even when some frames are missing or out of sequence.
In conclusion, the combination of temporal redundancy and spatiotemporal learning enables the proposed method to achieve a rare balance: high robustness under temporal distortion and low latency during deployment. This feature makes the system particularly well-suited for real-world environments where videos are often re-encoded, trimmed, or edited before playback or distribution.
6.3. Ablation Study of Core Modules
To quantify the individual contribution of each architectural component, we conduct an ablation study in which specific modules are disabled or replaced with simplified alternatives. We evaluate five variants of the system: (1) baseline without block importance estimation (fixed grid mask), (2) without saliency map refinement (random attention), (3) without temporal redundancy (embedding in a single frame), (4) without adversarial noise simulation during training, and (5) full model.
Each variant is trained from scratch and evaluated using the QP = 40 and frame drop attacks. As shown in Table 5, the absence of the block importance module leads to a 1.7× increase in BER, while removing the saliency map results in a 2.1× increase. Disabling temporal redundancy causes the most severe drop in robustness under frame drop (BER increases from 2.4% to 6.8%). Excluding adversarial training leads to poor generalization under compression, confirming that simulated noise during training enhances resilience.
Table 5.
Ablation study: BER (%) under QP = 40 and Frame Drop (20%). Best results are shown in bold and second-best results are underlined.
These results highlight the complementary roles of each module. While the learned attention maps improve spatial localization, temporal redundancy handles dynamic content variation, and adversarial loss improves robustness under unforeseen degradations. The ablation study supports the modular design of the system and shows that each component contributes meaningfully to the overall resilience of the framework.
6.4. Computational Efficiency
While robustness and visual fidelity are critical in evaluating video watermarking systems, computational efficiency remains a key factor for real-world deployment. Applications such as streaming protection, broadcast monitoring, and edge-device surveillance demand models that not only perform well but also operate in real time. In this subsection, we compare the inference speed of the proposed method with four baseline systems by measuring the average number of FPS during embedding and decoding.
Figure 7 presents the comparative results obtained on a single NVIDIA RTX 3090 GPU. The proposed system achieves an average inference speed of 38 FPS, confirming its ability to operate in real-time scenarios with minimal latency. This performance is made possible using single-pass encoder–decoder architecture for both the importance map and the watermark injection, avoiding computationally intensive operations such as adversarial refinement or frequency decomposition.
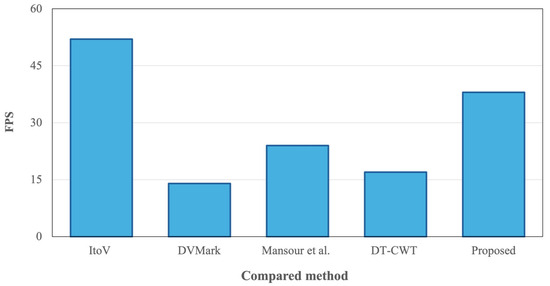
Figure 7.
Inference speed (FPS) comparison among methods (ItoV [19], DVMark [20], Mansour et al. [21], DT-CWT [22], and the proposed method).
In contrast, DVMark [20], which incorporates multiscale frequency-domain injection and internal distortion simulations, achieves only 14 FPS, making it significantly slower in inference despite its robustness advantages. Similarly, DT-CWT [22], which depends on complex wavelet transformations and convolutional decoding in the transform domain, processes videos at 17 FPS on average. The mosaic-based method by Mansour et al. [21] operates at 24 FPS, reflecting its simpler architecture but also its lower resilience to complex distortions. ItoV [19] achieves the highest speed among all methods compared, with a throughput of 52 FPS. This is expected given its lightweight patch wise embedding and absence of temporal modeling. However, this gain in speed comes at the cost of lower robustness under frame-level attacks, as shown in Section 5.2.
To provide additional implementation-oriented indicators, we report the parameter count and inference latency of the proposed model under the default evaluation resolution of 224 × 224. The proposed network contains approximately 4.5 million trainable parameters. Based on the measured throughput of 38 frames per second on an NVIDIA RTX 3090 GPU, the average inference latency is approximately 26 ms per frame. Since the main encoding, embedding, and decoding stages are convolutional, the computational cost scales approximately with the number of processed pixels; therefore, increasing the input resolution increases runtime proportionally to in practice. These indicators complement the FPS comparison already reported in Figure 7 and provide a clearer view of deployment feasibility. A full FLOPs profiling across multiple resolutions can be obtained via standard profiling tools and is left as a future extension, while the reported FPS and latency capture the practical runtime behavior.
Overall, the proposed system offers a balanced profile: it maintains real-time capability while delivering significantly higher resilience and imperceptibility than both faster and slower alternatives. This efficiency-performance trade-off makes it particularly suitable for deployment in scenarios where video integrity must be verified quickly and reliably, such as live broadcasts, on-device watermarking, or automated copyright enforcement pipelines.
We examined the stability of the proposed framework with respect to three hyperparameters that control the robustness and imperceptibility trade-off. The parameter , which balances the contribution of the importance signal and the semantic cue in the selection policy, primarily affects how conservatively the method avoids perceptually sensitive content and therefore influences visual fidelity. The threshold , used to obtain the binary selection mask, regulates the sparsity of selected blocks, with higher selectivity typically favoring imperceptibility while reducing embedding redundancy. The embedding-strength scaling factor controls the magnitude of the injected watermark signal and directly governs the trade-off between extraction reliability and distortion. Overall, the method remains stable under moderate variations around the chosen defaults, showing consistent qualitative trends across attacks and no need for content-specific re-tuning.
Payload size affects both imperceptibility and robustness because higher capacities require allocating more information per clip. In practice, increasing the payload typically demands either selecting a larger set of embedding blocks or increasing the embedding-strength scaling factor, which can increase visible distortion and reduce PSNR and SSIM. Conversely, lower payloads reduce the injected signal and generally improve perceptual fidelity, while also making recovery more stable under strong distortions. In our framework, capacity changes can be handled without modifying the architecture by controlling the sparsity of the binary selection mask through the threshold parameter and by tuning the embedding-strength scaling factor, allowing additional payload to be distributed across more blocks and frames rather than concentrating energy locally.
Finally, from a deployment perspective, the proposed framework is compatible with near real-time operation in typical streaming pipelines when GPU acceleration is available, as indicated by the measured throughput and latency previously reported. In practical settings, watermark embedding may be applied offline at ingest time for content distribution platforms, while decoding can be performed either continuously on sampled segments or on demand for watermark tracing and dispute resolution. The modular design also enables selective activation of components depending on application constraints, for example prioritizing robustness for tracing or prioritizing imperceptibility for consumer-er-facing streaming. Nevertheless, several limitations should be noted. Runtime scales with input resolution and hardware availability, and CPU-only deployment may not meet real-time constraints. In addition, although the method is robust to recompression, noise, and temporal edits evaluated in this work, extreme geometric misalignment or heavy post-production transformations may require dedicated alignment handling, and the use of a fixed payload length motivates future extensions toward payload-adaptive configurations. These considerations highlight both the practical viability of the method and the conditions under which further engineering or training adaptations may be required.
7. Conclusions and Future Work
This work introduced a unified, deep learning-based framework for robust and imperceptible video watermarking, structured around seven modular components: frame encoding, block importance estimation, saliency-driven block selection, watermark encoding, spatiotemporal injection, watermark decoding, and multi-objective optimization. Together, these modules enable a trainable, end-to-end system capable of learning content-aware embedding strategies and recovering watermarks even under severe distortions. The model leverages spatial attention, temporal redundancy, and adversarial training to optimize both perceptual quality and watermark resilience.
Extensive experiments demonstrated that the proposed method outperforms four state-of-the-art baselines across a wide spectrum of attack scenarios, including compression, noise, frame manipulation, and composite distortions. It consistently maintains BER values below 3% in most scenarios, with extraction accuracies exceeding 96%, while preserving perceptual fidelity with average PSNR above 38 dB and SSIM over 0.96 under clean conditions. Notably, the system remains effective even under compound attacks and aggressive temporal alterations, such as frame reordering and skipping, highlighting the importance of its temporally redundant embedding strategy.
Analyses of sensitivity and ablation further validated the functional contributions of key modules, particularly the block importance estimation and selection mechanisms, which were shown to significantly impact robustness and invisibility. The method also demonstrates near real-time performance, achieving 38 FPS in inference on a single GPU, balancing complexity and practicality. These characteristics make it suitable for deployment in content authentication, streaming protection, and copyright enforcement pipelines.
Looking ahead, several avenues for extension are promising. First, future iterations could enable dynamic payload encoding, allowing the system to adjust watermark content in real time according to user ID, content features, or application constraints. Additionally, the importance estimation stage could be strengthened for semantically dense or cluttered scenes by incorporating more robust semantic representation learning strategies inspired by recent advances in human parsing, which explicitly address the transition from simple to complex scenes. Beyond watermark robustness, complementary directions in multimedia security include video encryption and steganography-based information hiding, which can provide additional insights on security-oriented embedding control and perceptual imperceptibility. Incorporating such perspectives, for example by encrypting the payload prior to embedding or by adopting chaos-inspired parameterization strategies, is a promising direction for future work in security-critical deployment settings [37,38,39]. Second, incorporating learnable frequency-domain embeddings, such as wavelet-like neural filters, may enhance robustness under heavy compression or down sampling. Lastly, expanding the adversarial training regime through reinforcement learning agents or self-supervised attack generation could improve generalization to unseen distortions and real-world manipulations.
In summary, the proposed framework delivers a robust, efficient, and extensible solution for modern video watermarking. Its modularity and empirical performance position it as a strong foundation for further research into secure, trustworthy multimedia content authentication, including future extensions that incorporate a secret parameter to enable authorized embedding and deter unauthorized watermark insertion or forgery.
Author Contributions
Conceptualization, A.C.-H. and L.V.-G.; methodology, M.C.-H. and F.J.G.-U.; software, A.C.-H.; validation, M.C.-H.; formal analysis, F.J.G.-U.; investigation, L.V.-G.; writing—original draft preparation, A.C.-H. and L.V.-G.; writing—review and editing, A.C.-H. and F.J.G.-U.; funding acquisition, M.C.-H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Secretaria de Ciencia, Humanidades, Tecnologia e Innovacion (SECIHTI) under scholarship numbers 161591 and 205834, and by the Secretaria de Investigación y Posgrado del Instituto Politécnico Nacional (SIP-IPN-20250064).
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed at the corresponding author.
Acknowledgments
The authors wish to thank the Tecnologico de Monterrey, the Instituto Politécnico Nacional, the Universidad Nacional Autonoma de Mexico, and the Secretaria de Ciencia, Humanidades, Tecnologia e Innovacion (SECIHTI) for their support during this research.
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Saoussen, B.J.; Mohamed, B.F. Deep learning-based watermarking techniques challenges: A review of current and future trends. Circuits Syst. Signal Process. 2024, 43, 4339–4368. [Google Scholar] [CrossRef]
- Singh, H.K.; Singh, A.K. Comprehensive review of watermarking techniques in deep-learning environments. J. Electron. Imaging 2023, 32, 031804. [Google Scholar] [CrossRef]
- Zhong, X.; Das, A.; Alrasheedi, F.; Tanvir, A. A brief, in-depth survey of deep learning-based image watermarking. App. Sci. 2023, 13, 11852. [Google Scholar] [CrossRef]
- Aberna, P.; Agilandeeswari, L. Digital image and video watermarking: Methodologies, attacks, applications, and future directions. Multimed. Tools Appl. 2024, 83, 5531–5591. [Google Scholar] [CrossRef]
- Huang, I.C.; Wu, J.Y.; Ooi, W.T. RBMark: Robust and blind video watermark in DT CWT domain. J. Vis. Commun. Image Represent. 2025, 109, 104438. [Google Scholar] [CrossRef]
- Saritas, O.F.; Ozturk, S. A blind CT and DCT based robust color image watermarking method. Multimed. Tools Appl. 2023, 82, 15475–15491. [Google Scholar] [CrossRef]
- Alkanhel, R.; Abdallah, H.A. Securing color video when transmitting through communication channels using DT-CWT-Based watermarking. Electronics 2022, 11, 1849. [Google Scholar] [CrossRef]
- Hou, J.U. MPEG and DA-AD resilient DCT-based video watermarking using adaptive frame selection. Electronics 2021, 10, 2467. [Google Scholar] [CrossRef]
- Sharma, S.; Zou, J.J.; Fang, G.; Shukla, P.; Cai, W. A review of image watermarking for identity protection and verification. Multimed. Tools Appl. 2024, 83, 31829–31891. [Google Scholar] [CrossRef]
- Huan, W.; Li, S.; Qian, Z.; Zhang, X. Exploring stable coefficients on joint sub-bands for robust video watermarking in DT CWT domain. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1955–1965. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Leite, P.N.; Pinto, A.M. Exploiting motion perception in depth estimation through a lightweight convolutional neural network. IEEE Access 2021, 9, 76056–76068. [Google Scholar] [CrossRef]
- Mumuni, A.; Mumuni, F. Robust appearance modeling for object detection and tracking: A survey of deep learning approaches. Prog. Artif. Intell. 2022, 11, 279–313. [Google Scholar] [CrossRef]
- Hosny, K.M.; Magdi, A.; ElKomy, O.; Hamza, H.M. Digital image watermarking using deep learning: A survey. Comput. Sci. Rev. 2024, 53, 100662. [Google Scholar] [CrossRef]
- Chen, H.; Liu, C.; Zhu, T.; Zhou, W. When deep learning meets watermarking: A survey of application, attacks and defenses. Comput. Stand. Interfaces 2024, 89, 103830. [Google Scholar] [CrossRef]
- Zhong, X.; Huang, P.C.; Mastorakis, S.; Shih, F.Y. An automated and robust image watermarking scheme based on deep neural networks. IEEE Trans. Multimed. 2020, 23, 1951–1961. [Google Scholar] [CrossRef]
- Kaczyński, M.; Piotrowski, Z.; Pietrow, D. High-quality video watermarking based on deep neural networks for video with HEVC compression. Sensors 2022, 22, 7552. [Google Scholar] [CrossRef]
- Chen, L.; Wang, C.; Zhou, X.; Qin, Z. Robust and compatible video watermarking via spatio-temporal enhancement and multiscale pyramid attention. IEEE Trans. Circuits Syst. Video Technol. 2024, 35, 1548–1561. [Google Scholar] [CrossRef]
- Ye, G.; Gao, J.; Wang, Y.; Song, L.; Wie, X. ItoV: Efficiently adapting deep learning-based image watermarking to video watermarking. In Proceedings of the 2023 International Conference on Culture-Oriented Science and Technology (CoST), Xi’an, China, 11–14 October 2023; pp. 192–197. [Google Scholar] [CrossRef]
- Luo, X.; Li, Y.; Chang, H.; Liu, C.; Milanfar, P.; Yang, F. Dvmark: A deep multiscale framework for video watermarking. IEEE Trans. Image Process. 2023, 34, 4371–4385. [Google Scholar] [CrossRef]
- Mansour, S.; Jabra, S.B.; Zagrouba, E. A Robust Deep Learning-Based Video Watermarking Using Mosaic Generation. In Proceedings of the 18th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISAPP), Lisbon, Portugal, 19–21 February 2023; Volume 5, pp. 668–675. [Google Scholar] [CrossRef]
- Chang, X.; Chen, B.; Ding, W.; Liao, X. A DNN robust video watermarking method in dual-tree complex wavelet transform domain. J. Inf. Secur. Appl. 2024, 85, 103868. [Google Scholar] [CrossRef]
- Jang, M.; Jang, Y.; Lee, J.; Yang, F.; Oh, G.; Jeong, J.; Kim, S. LVMark: Robust Watermark for latent video diffusion models. arXiv 2024. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Carreira, J.; Noland, E.; Banki-Horvath, A.; Hillier, C.; Zisserman, A. A short note about kinetics-600. arXiv 2018. [Google Scholar] [CrossRef]
- Lee, J.E.; Seo, Y.H.; Kim, D.W. Convolutional neural network-based digital image watermarking adaptive to the resolution of image and watermark. Appl. Sci. 2020, 10, 6854. [Google Scholar] [CrossRef]
- Zhu, J.; Kaplan, R.; Johnson, J.; Li, F.-F. Hiding data with deep networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 657–672. [Google Scholar] [CrossRef]
- Abdelnabi, S.; Fritz, M. Adversarial watermarking transformer: Towards tracing text provenance with data hiding. In Proceedings of the 2021 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 24–27 May 2021; pp. 121–140. [Google Scholar] [CrossRef]
- Luo, Y.; Tan, X.; Cai, Z. Robust Deep Image Watermarking: A Survey. Comput. Mater. Contin. 2024, 81, 133–160. [Google Scholar] [CrossRef]
- Mansour, S.; Jabra, S.B.; Zagrouba, E. A comprehensive overview of deep learning-based video watermarking: Current works, challenges and future trends. Multimed. Tools Appl. 2024, 84, 28013–28060. [Google Scholar] [CrossRef]
- Fernandez, P.; Elsahar, H.; Yalniz, I.Z.; Mourachko, A. Video seal: Open and efficient video watermarking. arXiv 2024. [Google Scholar] [CrossRef]
- Mansour, S.; Jabra, S.B.; Zagrouba, E. A comprehensive review of video watermarking technique in deep learning environments. In Proceedings of the 2023 International Conference on Cyberworlds (CW), Sousse, Tunisia, 3–5 October 2023; pp. 70–77. [Google Scholar] [CrossRef]
- Stergiou, A.; Poppe, R. Adapool: Exponential adaptive pooling for information-retaining downsampling. IEEE Trans. Image Process. 2022, 32, 251–266. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, Q.; Wang, X.; Zhou, L.; Li, Q.; Xia, Z. Light-Field Image Multiple Reversible Robust Watermarking Against Geometric Attacks. IEEE Trans. Dependable Secur. Comput. 2025, 22, 5861–5875. [Google Scholar] [CrossRef]
- Cheng, X.; Wang, H.; Luo, X.; Guan, Q.; Ma, B.; Wang, J. Re-cropping Framework: A Grid Recovery Method for Quantization Step Estimation in Non-aligned Recompressed Images. IEEE Trans. Circuits Syst. Video Technol. 2025. [Google Scholar] [CrossRef]
- Gao, S.; Zhang, Z.; Li, Q.; Ding, S.; Ho-Ching, I.H.; Cao, Y. Encrypt a Story: A Video Segment Encryption Method Based on the Discrete Sinusoidal Memristive Rulkov Neuron. IEEE Trans. Dependable Secur. Comput. 2025, 22, 8011–8024. [Google Scholar] [CrossRef]
- Erkan, U.; Toktas, F.; Toktas, A.; Lai, Q.; Zhou, S.; Lin, Y.; Gao, S. Multi-layer and multi-directional image encryption algorithm based on hyperchaotic 3D Xin-She Yang map. Expert Syst. Appl. 2026, 304, 130808. [Google Scholar] [CrossRef]
- Li, Q.; Ma, B.; Wang, X.; Wang, C.; Gao, S. Image Steganography in Color Conversion. IEEE Trans. Circuits Syst. II Express Briefs 2023, 71, 106–110. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.