
A Cloud-Based Data Collaborative to Combat the COVID-19 Pandemic and to Solve Major Technology Challenges



Abstract
1. Introduction
- Comprising a collection of unique datasets and AI tools, this Data Collaborative would democratize data and the tools to analyze them, enabling virtually anyone, anywhere to use data to solve the world’s grandest challenges.
- It would provide access to the massive amounts of data that have been organized and cleaned so that it can be accessed in an accountable, transparent, and responsible manner.
- Data owners across industries and topic areas will feel safe in sharing their data while maintaining ownership, privacy, and security. Data scientists, as well as Machine Learning and Artificial Intelligence systems, will all have access to the Data Collaborative, resulting in enhanced problem-solving models and innovative approaches to solving Grand Challenges posed by XPRIZE competitions.
2. Materials and Methods
2.1. Research Questions and Motivations
- Are applications developed in the Cloud moving to only use containers? How are the Cloud technologies ranging from VMs to containers SDIs used and why?
- How has the COVID-19 pandemic affected application development and deployment?
- Are there any noticeable trends in Cloud Computing deployment that became apparent during the development, and if so, what are they?
2.2. Methodology
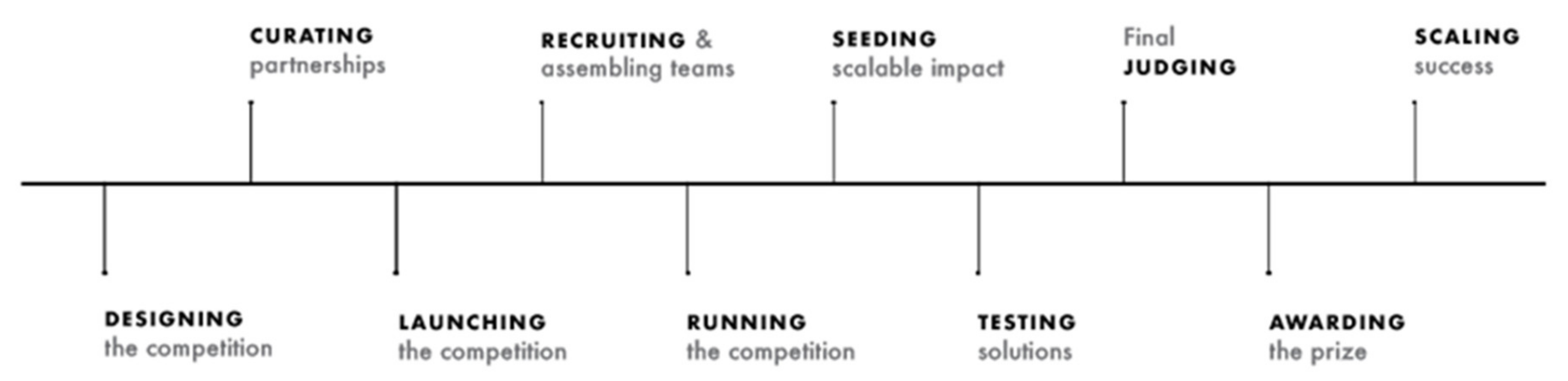
2.3. Contest Lifecycle
2.4. Data Collaborative Detailed Requirements
- A highly scalable, accessible, and elastic infrastructure: A single competition could involve as many as thousands of teams at one time, and as each competition milestone is reached, the number could be reduced by one or two orders of magnitude. Teams can be from almost anywhere in the world. The ability to rapidly scale up and down is required.
- A stable and highly usable analytics software platform: Teams in XPRIZE competitions will need to be able to not just access data but analyze it. It should be familiar to many users and extendable.
- Isolated and secure analytics software platform: Since awards in XPRIZE competitions can be multi-millions of dollars, teams and their work need to be effectively isolated from each. In addition, since we are providing the infrastructure for teams to run arbitrary code, we need to make sure that what we provide is not abused—not used as a base for attacks or noncompetition-related work such as crypto-mining.
- A scalable analytics compute platform: While the common goal is to democratize data access and the ability to analyze that data, should a team wish to purchase more capacity, the platform should enable that.
- Control of data: Contest sponsors and others want to be able to protect the data they provide and know who accesses it. The data should remain within the analytics platform, with it being difficult and time consuming to copy it outside of the analytics platform. Access to data needs to be recorded and attributable to a team.
- Manageability: The common infrastructure needs to be maintainable by a relatively small staff.
- Reasonably fast implementation: The infrastructure needs to be scaled up in a reasonably fast amount of time in order to make a difference in the pandemic.
- Costs: Costs should be minimized when possible.
- User Analytics Software Platform
- Team Isolation
- Naming Design and Infrastructure
- User Authentication
- Protecting Data in Transit
- Logging and Monitoring
- Team Infrastructure Instantiation Process
2.5. Design Choices
2.5.1. User Analytics Software Platform
2.5.2. Team Isolation
2.5.3. Naming Design and Infrastructure
2.5.4. User Authentication
- Password
- Authentication token
2.5.5. Protecting Data in Transit
- On each notebook container
- On a sidecar container
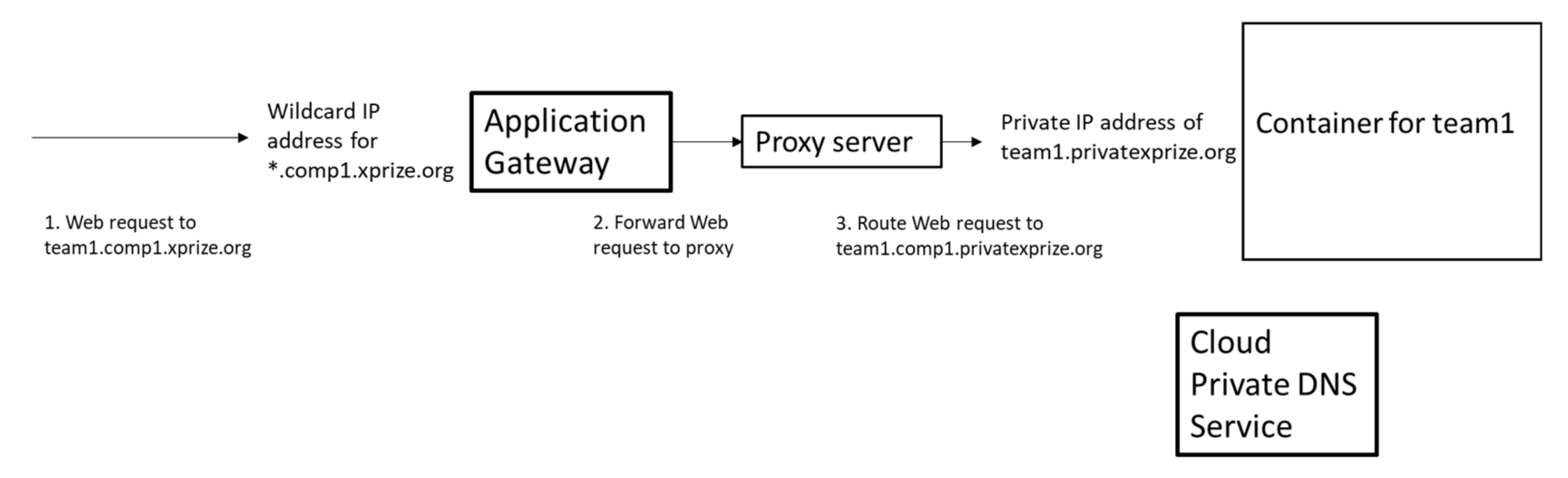
- Proxy
- Application gateway
2.5.6. Logging and Monitoring
2.5.7. Instantiating Team Environment
- Run the instantiation scripts on XPRIZE portal.
- Create a dedicated VM or container to run the scripts.
- Define a function to run the scripts and launch it in the Cloud (serverless).
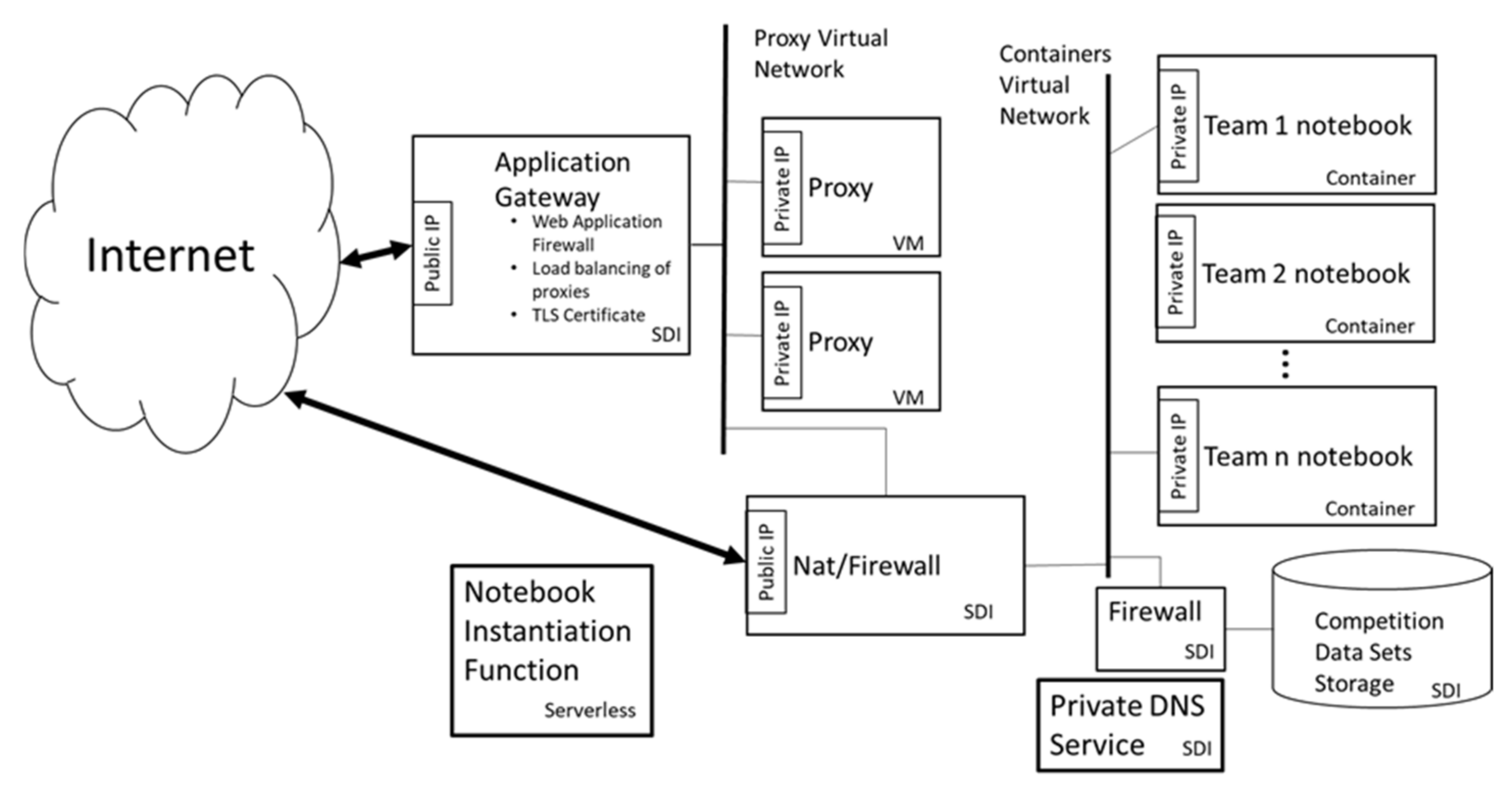
2.6. Architecture and Component Layout
3. Results
3.1. Implementation Time and Resource Usage
3.2. Evaluation of the Design and Implementation against Requirements
3.3. Revisiting Our Research Questions
3.3.1. Are Applications Developed in the Cloud Moving to Only Use Containers?
3.3.2. How Has the COVID-19 Pandemic Affected Application Development and Deployment?
- Portability between Clouds: Extensive work has been done try to create technology that makes applications portable between Cloud Service Providers [43] and avoiding vendor lock-in [44,45]. This goal was simply not a priority in our efforts to get the Data Collaborative up and running. We chose to use the Cloud Service Provider that we were most familiar with to get the service to production as soon as possible.
- Ultra-low cost: While a reasonable cost is a key requirement (#8 above), having an extremely low cost, especially at the expense of having a usable and working solution, was not.
- High Performance: While our requirement for a usable and scalable platform (requirements #1 and #2) demands enough performance to be usable, it did not demand high performance. We need the Data Collaborative in a relatively short time frame that worked and was usable. In addition, the contest time frames should allow for time for analyses to complete.
3.3.3. Are There Any Noticeable Trends in Cloud Computing Deployment That Became Apparent during the Development?
4. Discussion
4.1. Study Limitations
4.2. Other Issues Encountered
5. Conclusions
5.1. Future Work
5.2. Implications for Cloud Native Application Development
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- XPRIZE Foundation. Available online: https://www.xprize.org/ (accessed on 28 October 2020).
- Hossain, M.; Kauranen, I. Competition-Based Innovation: The Case of the X Prize Foundation. J. Organ. Des. 2014, 3, 46–52. [Google Scholar] [CrossRef]
- Haller, J.B.A.; Bullinger, A.C.; Möslein, K.M. Innovation Contests. Bus. Inf. Syst. Eng. 2011, 3, 103–106. [Google Scholar] [CrossRef][Green Version]
- Accelerating Radical Solutions to COVID-19 and Future Pandemics. Available online: https://www.xprize.org/fight-covid19 (accessed on 28 October 2020).
- Mackay, M.J.; Hooker, A.C.; Afshinnekoo, E.; Salit, M.; Kelly, J.; Feldstein, J.V.; Haft, N.; Schenkel, D.; Nambi, S.; Cai, Y.; et al. The COVID-19 XPRIZE and the need for scalable, fast, and widespread testing. Nat. Biotechnol. 2020, 38, 1021–1024. [Google Scholar] [CrossRef] [PubMed]
- Kaggle. Available online: https://kaggle.com/ (accessed on 5 November 2020).
- Yang, X.; Zeng, Z.; Teo, S.G.; Wang, L.; Chandrasekhar, V.; Hoi, S. Deep learning for practical image recognition: Case study on kaggle competitions. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, August 2008; ACM: New York, NY, USA, 2018; pp. 923–931. [Google Scholar]
- CoLab. Available online: https://colab.research.google.com/notebooks/intro.ipynb (accessed on 5 November 2020).
- Bisong, E. Google Colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform; Apress: Berkeley, CA, USA, 2019; pp. 59–64. [Google Scholar]
- CoCalc. Available online: https://cocalc.com/ (accessed on 5 November 2020).
- Bouvin, N.O. From notecards to notebooks: There and back again. In Proceedings of the 30th ACM Conference on Hypertext and Social Media, Hof, Germany, 2019; ACM: New York, NY, USA, 2019; pp. 19–28. [Google Scholar]
- Nextjournal. Available online: https://nextjournal.com/ (accessed on 5 November 2020).
- Baxter, P.; Jack, S. Qualitative Case Study Methodology: Study Design and Implementation For Novice Researchers; The Qualitative Report: Fort Lauderdale, FL, USA, 2013; Volume 13, pp. 544–559. [Google Scholar]
- Baskarada, S. Qualitative Case Study Guidelines; The Qualitative Report: Fort Lauderdale, FL, USA, 2014; Volume 19, pp. 1–25. [Google Scholar]
- Andrikopoulos, V.; Fehling, C.; Leymann, F. Designing for CAP—The Effect of Design Decisions on the CAP Properties of Cloud-native Applications. In Proceedings of the 2nd International Conference on Cloud Computing and Services Science (CLOSER 2012), Porto, Portugal, 18–21 April 2012; pp. 365–374. [Google Scholar]
- Kratzke, N. A Brief History of Cloud Application Architectures. Appl. Sci. 2018, 8, 1368. [Google Scholar] [CrossRef]
- Kratzke, N.; Quint, P.C. Understanding cloud-native applications after 10 years of cloud computing-a systematic mapping study. J. Syst. Softw. 2017, 126, 1–6. [Google Scholar] [CrossRef]
- Gannon, D.; Barga, R.; Sundaresan, N. Cloud-Native Applications. IEEE Cloud Comput. 2017, 4, 16–21. [Google Scholar] [CrossRef]
- Balalaie, A.; Heydarnoori, A.; Jamshidi, P. Microservices architecture enables devops: Migration to a cloud-native architecture. IEEE Softw. 2016, 33, 42–52. [Google Scholar] [CrossRef]
- Burns, B.; Oppenheimer, D. Design patterns for container-based distributed systems. In Proceedings of the 8th {USENIX} Workshop on Hot Topics in Cloud Computing (HotCloud 16), Denver, CO, USA, 20–21 June 2016. [Google Scholar]
- Baldini, I.; Castro, P.; Chang, K.; Cheng, P.; Fink, S.; Ishakian, V.; Mitchell, N.; Muthusamy, V.; Rabbah, R.; Slominski, A.; et al. Serverless Computing: Current Trends and Open Problems. In Research Advances in Cloud Computing; Springer: Singapore, 2017; pp. 1–20. [Google Scholar]
- Eismann, S.; Scheuner, J.; Van Eyk, E.; Schwinger, M.; Grohmann, J.; Herbst, N.; Abad, C.L.; Iosup, A. Serverless Applications: Why, When, and How? IEEE Softw. 2021, 38, 32–39. [Google Scholar] [CrossRef]
- Hong, S.; Srivastava, A.; Shambrook, W.; Dumitraș, T. Go serverless: Securing cloud via serverless design patterns. In Proceedings of the 10th {USENIX} Workshop on Hot Topics in Cloud Computing (HotCloud 18), Boston, MA, USA, 15 June 2020. [Google Scholar]
- Kang, J.-M.; Lin, T.; Bannazadeh, H.; Leon-Garcia, A. Software-Defined Infrastructure and the SAVI Testbed. In Proceedings of the International Conference on Testbeds and Research Infrastructures, Guangzhou, China, 5–7 May 2014; Springer: Berlin/Heidelberg, Germany; pp. 3–13.
- Homer, A.; Sharp, J.; Brader, L.; Narumoto, M.; Swanson, T. Cloud Design Patterns: Prescriptive Architecture Guidance for Cloud Applications; Microsoft Patterns & Practices: Redmond, WA, USA, 2014. [Google Scholar]
- Meyers, A. Data Science Notebooks—A Primer. Available online: https://medium.com/memory-leak/data-science-notebooks-a-primer-4af256c8f5c6/ (accessed on 8 November 2020).
- Estimate of Public Jupyter Notebooks on GitHub. Available online: https://nbviewer.jupyter.org/github/parente/nbestimate/blob/master/estimate.ipynb (accessed on 10 January 2021).
- Jupyter Notebook. Available online: https://jupyter.org/ (accessed on 6 November 2020).
- Apache Zeppelin. Available online: https://zeppelin.apache.org/ (accessed on 7 November 2020).
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 95–101. [Google Scholar]
- Jupyterhub. Available online: https://jupyter.org/hub (accessed on 8 November 2020).
- Mockpetris, P. RFC 1035: Domain Names—Implementation and Specification; RFC Editor: Fremont, CA, USA, 1987. [Google Scholar]
- Rekhter, Y.; Moskowitz, B.; Karrenberg, D.; Groot, G.D.; Lear, E. Rfc 1918: Address Allocation for Private Internets. Available online: https://www.rfc-editor.org/info/rfc1918 (accessed on 24 February 2021).
- Security in the Jupyter Notebook Server. Available online: https://jupyter-notebook.readthedocs.io/en/stable/security.html (accessed on 10 January 2021).
- Sun, S.T.; Beznosov, K. The devil is in the (implementation) details: An empirical analysis of OAuth SSO systems. In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh, NC, USA, October 2012; ACM: New York, NY, USA, 2012; pp. 378–390. [Google Scholar]
- Rescorla, E.; Dierks, T. RFC 8446: The Transport Layer Security (Tls) Protocol Version 1.3. Available online: https://tools.ietf.org/html/rfc8446 (accessed on 11 November 2020).
- Aas, J.; Barnes, R.; Case, B.; Durumeric, Z.; Eckersley, P.; Flores-López, A.; Halderman, J.A.; Hoffman-Andrews, J.; Kasten, J.; Rescorla, E.; et al. Let’s Encrypt: An Automated Certificate Authority to Encrypt the Entire Web. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, November 2019; ACM: New York, NY, USA, 2019; pp. 2473–2487. [Google Scholar]
- Sidecar Pattern. Available online: https://docs.microsoft.com/en-us/azure/architecture/patterns/sidecar (accessed on 9 November 2020).
- Gateway Offloading Pattern. Available online: https://docs.microsoft.com/en-us/azure/architecture/patterns/gateway-offloading (accessed on 9 November 2020).
- Asynchronous Background Processing and Message. Available online: https://docs.microsoft.com/en-us/dotnet/architecture/serverless/serverless-design-examples#asynchronous-background-processing-and-messaging (accessed on 11 November 2020).
- Bulkhead Pattern. Available online: https://docs.microsoft.com/en-us/azure/architecture/patterns/bulkhead (accessed on 9 November 2020).
- AI and Data for the Benefit of Humanity. Available online: https://xprize.org/aialliance (accessed on 9 November 2020).
- Bergmayr, A.; Breitenbücher, U.; Ferry, N.; Rossini, A.; Solberg, A.; Wimmer, M.; Kappel, G.; Leymann, F. A Systematic Review of Cloud Modeling Languages. ACM Comput. Surv. 2018, 51, 1–38. [Google Scholar] [CrossRef]
- Opara-Martins, J.; Sahandi, R.; Tian, F. Critical review of vendor lock-in and its impact on adoption of cloud computing. In Proceedings of the International Conference on Information Society (i-Society 2014), London, UK, 10–12 November 2014; pp. 92–97. [Google Scholar]
- Kratzke, N.; Quint, P.C.; Palme, D.; Reimers, D. Project Cloud TRANSIT—Or to Simply Cloudnative Applications Provisioning for SMEs by Integrating Already Available Container Technologies. In Proceedings of the European Project Space on Smart Systems, Big Data, Future Internet—Towards Serving the Grand Societal Challenges, Rome, Italy, 2016; Kantere, V., Koch, B., Eds.; SciTePress: Setubal, Portugal, 2017; pp. 2–26. [Google Scholar]
- Liu, S.; Schmitt, P.; Bronzino, F.; Feamster, N. Characterizing Service Provider Response to the COVID-19 Pandemic in the United States. arXiv 2020, arXiv:2011.00419. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Goal | Goal Met? | Title 3 |
|---|---|---|
| 1. Scalable Infrastructure | Yes | Scaled to 300 |
| 2. Usable Analytics Platform | Yes | Users for one complete competition and one in progress |
| 3. Isolated Secure Platform | Possibly | Secure as far as we know—no incidents so far |
| 4. Scalable Analytics Compute Platform (self-service capacity adds) | Probably | Put in place but not yet exercised |
| 5. Control of data | Yes | Access to datasets is controlled |
| 6. Manageability | Yes | Manageable by small XPRIZE team |
| 7. Fast Implementation | Yes | Started in late 2019 and first competition started in mid-2020 |
| 8. Cost-controlled | Yes | No evidence of cost issues at this point |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cappellari, M.; Belstner, J.; Rodriguez, B.; Sedayao, J. A Cloud-Based Data Collaborative to Combat the COVID-19 Pandemic and to Solve Major Technology Challenges. Future Internet 2021, 13, 61. https://doi.org/10.3390/fi13030061
Cappellari M, Belstner J, Rodriguez B, Sedayao J. A Cloud-Based Data Collaborative to Combat the COVID-19 Pandemic and to Solve Major Technology Challenges. Future Internet. 2021; 13(3):61. https://doi.org/10.3390/fi13030061
Chicago/Turabian StyleCappellari, Max, John Belstner, Bryan Rodriguez, and Jeff Sedayao. 2021. "A Cloud-Based Data Collaborative to Combat the COVID-19 Pandemic and to Solve Major Technology Challenges" Future Internet 13, no. 3: 61. https://doi.org/10.3390/fi13030061
APA StyleCappellari, M., Belstner, J., Rodriguez, B., & Sedayao, J. (2021). A Cloud-Based Data Collaborative to Combat the COVID-19 Pandemic and to Solve Major Technology Challenges. Future Internet, 13(3), 61. https://doi.org/10.3390/fi13030061