Highlights
What are the main findings?
- Compared with the deep learning method for surface defect detection, the proposed SLRTD-based detection method is simpler and more effective in a galvanized strip steel production line.
What is the implication of the main finding?
- The proposed SLRTD-based detection method of surface defect can be applied for other industrial products, such as glass, fabric, LCD, and AMOLED.
Abstract
Accurate and efficient white-spot defects detection for the surface of galvanized strip steel is one of the most important guarantees for the quality of steel production. It is a fundamental but “hard” small target detection problem due to its small pixel occupation in low-contrast images. By fully exploiting the low-rank and sparse prior information of a surface defect image, a Schatten-p norm-based low-rank tensor decomposition (SLRTD) method is proposed to decompose the defect image into low-rank background, sparse defect, and random noise. Firstly, the original defect images are transformed into a new patch-based tensor mode through data reconstruction for mining valuable information of the defect image. Then, considering the over-shrinkage problem in the low-rank component estimation caused by a vanilla nuclear norm and a weighted nuclear norm, a nonlinear reweighting strategy based on a Schatten -norm is incorporated to improve the decomposition performance. Finally, a solution framework is proposed via a well-designed alternating direction method of multipliers to obtain the white-spot defect target image by a simple segmenting algorithm. The white-spot defect dataset from a real-world galvanized strip steel production line is constructed, and the experimental results demonstrate that the proposed SLRTD method outperforms existing state-of-the-art methods qualitatively and quantitatively.
1. Introduction
Galvanized strip steel is widely used in automobile manufacturing, household electrical appliances, and other daily-use products; surface defects might lead to some product quality issues for both in-progress and downstream products. The white-spot defects mainly caused by random zinc dross and ash in the hot dip or electro galvanizing process are considered the most serious threat to the steel surface quality due to their high concurrence and typical periodicity. This defect can be detected and recorded by the surface defect inspection based on machine vision, and then the quality issues with strip steel will be controlled at the early stage [1,2]. In fact, industrial production images frequently contain some prior information; for example, if a defect rarely appears, the vast majority of images show no defects. The white-spot defects are always ultra-tiny in size, occupying less than 5% of the whole raw image. The inherent issues of tiny size and low-contrast of white-spot defects under complex clutters and heavy noise constitute the significant obstacle in the detection and segmentation of the defect target: (a) they are sensitive to tiny defects because of their extreme small sizes, and (b) they cannot accurately locate the random appeared defects whose semantic relationship with the background context is weak.
In industrial machine vision, small or tiny object detection has always been a significantly studied issue, especially in industrial applications [3,4,5,6,7]. The research can be classified into three categories: traditional filtering-based methods, sparse and low-rank representation-based methods, and data-driven methods [8]. Filtering-based methods typically design relevant filtering operators in either grayscale or derivative spaces to suppress background noise and enhance targets. While these methods offer a certain level of real-time performance, they often require manual design of operators tailored to specific scenes when facing complex backgrounds, which limits their generalization ability and adaptability. Unlike the methods above that rely on manually designed features based on data priors, data-driven approaches utilize convolutional neural networks (CNNs) for deep feature extraction automatically [9,10]. Although these methods perform well and can extract deeper information, they depend heavily on image samples, which affects their real-time applicability. Due to the size limitations of small targets, which typically consist of only a few pixels, there is a risk of losing critical information during target detection, which may be ineffective or even degrade detection performance. In contrast, some traditional methods offer strong interpretability and maintain a certain level of robustness when faced with complex scenarios, maintaining certain advantages.
In recent years, tensor decomposition-based sparse and low-rank representation methods have achieved remarkable success, especially in infrared or remote sensing small target detection [11,12,13,14,15]. These methods leverage the low-rank nature of the infrared background and the sparse characteristics of small infrared targets; the background is modeled as a low-rank component, while the infrared targets are typically modeled as sparse components. The tensor model effectively preserves spatial structures and utilizes temporal information across multiple frames, which helps achieve more accurate target detection. These methods can combine spatial and temporal local information and iteratively optimize to approach the optimal detection results, significantly improving robustness to detect small targets in complex scenes. As the defect is random in the production line of strip steel, different image frames are irrelated, and the spatial and temporal information between different image frames are lost. As single-frame information is limited, these methods often miss targets or retain excessive false alarms when dealing with edge overlapping or complex backgrounds, thus failing to provide optimal decomposition guidance without temporal information across frames [16]. As shown in Figure 1, the white-spot defect of galvanized steel sheet is random and keeps changing all the time; small or tiny white-spot defects among 4096 × 2048 raw images are still easily ignored due to insufficient appearance information. At the same time, the highly varied nature of the background image and small target characteristics make the detection process extremely difficult.

Figure 1.
White-spot defects on the surface of galvanized steel sheet: the rightmost is the proportion of defective pixels in the whole image.
Motivated by the above discussions, we establish the adaptive tensor model to accurately detect white-spot defects on galvanized steel sheet. The main contributions of this article are outlined as follows:
- We propose an SLRTD method by digging out inter-patch correlation-ships of surface defect images of galvanized strip steel. The separated defect foreground target information with sparse outliers is embedded in the background of low-rank representation.
- To achieve an accurate estimation of non-defect background rank, we incorporate weighted Schatten -norm regularization for the background component, allowing for better noise removal while preserving edges, ultimately leading to improved detection results. Concurrently, a nonlinear reweighting strategy and tensor singular value decomposition (t-SVD) are adopted to help the model more delicately balance the low-rank and sparse components throughout the iterative process, which elevates the separation accuracy between the defect target and non-defect background.
- According to the alternating direction method of multipliers (ADMM), we solve the sparse and low-rank decomposition problem. Experiment results demonstrate the feasibility and effectiveness of the proposed SLRTD method.
The remainder of this paper is structured as follows: Section 2 provides a concise overview of related work. Section 3 presents a comprehensive introduction to the architecture and components of the proposed SLRTD approach. Section 4 demonstrates numerical comparisons and module analysis. Finally, Section 5 concludes the paper. In our paper, tensors, matrices, and vectors are denoted using calligraphic letters, uppercase, and lowercase italics.
2. Related Works
In this section, we provide a brief overview of existing defect detection methods based on filtering, data-driven, and tensor decomposition methods.
2.1. Filtering-Based Methods
Generally, filter-based methods design relevant filtering operators in grayscale or derivative spaces to suppress background clutter and enhance the target. These methods can be further classified into the threshold method (e.g., Otsu, cross-entropy), morphological method (e.g., morphological operations, template matching), and spectral method (e.g., Fourier transform, Gabor transform, wavelet transform). However, the threshold and morphological methods often need manual adjustments to find the defect regions, especially when the distributions of scene intensity and texture are complicated. The images are transformed to frequency–domain in the spectral method, which often miss some small defects targets. These methods show poor adaptability and robustness [17].
2.2. Data-Driven-Based Methods
During the past few years, tremendous efforts have been devoted to small defect target detection based on deep learning [18]. Zhang et al. [19] constructed a novel feature enhancement network to improve the performance of small object detection. Hou et al. [20] proposed a contextual information and spatial attention that is based on a network for detecting small defects in the manufacturing industry. Yang et al. [21] introduced an RSADUnet model for metal surface tiny defect inspection. However, the satisfactory performance of these methods relies heavily on expensive labeled images, large numbers of parameters, and computational complexity to obtain strong feature awareness. Additionally, they are always used for natural or medical scenes where the shape of the specific object does not change much. Thus, these methods may not be suitable for steel surface defect detection in which the defect is random, especially for small defects with varied shapes and sizes. At the same time, a small defect occupies small pixels and lacks obvious texture and structure characteristics, thus it is difficult to provide reliable defect features.
2.3. Tensor Decomposition-Based Methods
In contrast, the tensor decomposition-based sparse and low-rank model always transforms the detection problem into an iterative optimization task by exploring new representations of the target and background features. Each patch is directly used as the obverse side slice to construct tensor data, which can guarantee the local features of the defect image can be reserved and is conductive to withdrawing the prior information. Many methods proposed different types of regularization to constrain low-rank and sparse attributes. The reweighted infrared patch-tensor (RIPT) model proposed by Dai et al. [22] utilizes the target sparse prior and background nonlocal self-correlation prior, and the local structure weight is designed for the target tensor term and serves as an edge indicator in the weighted model. However, RIPT still has limitations because the nuclear norm cannot accurately estimate the background. To alleviate this issue, inspired by t-SVD and a non-convex approximation of rank based on the tensor nuclear norm, Lu et al. [23] exploited the tensor robust principal component (TRPCA) method, which regularizes all singular values of tensor data equally and shrinks all singular values with the same parameter. Zhang et al. [24] introduced a novel nonconvex low-rank constraint, the partial sum of the tensor nuclear norm (PSTNN), combined with a weighted l1 norm to effectively suppress the background while effectively preventing target over-shrinkage. Gao et al. [25] developed an enhanced TRPCA (ETRPCA) model by the weighted tensor Schatten -norm minimization, which makes the large singular values shrink less in the tensor nuclear norm minimization. The Schatten -norm can better approximate the NP-Hard problem, optimize the recovery of its convex relaxation, and will not over-shrink the low-rank components of the data. Chen et al. [26] introduced logarithmic norm regularization as the nonconvex surrogate of matrix and tensor rank, which achieves more accurate low-rank approximation and high computational efficiency.
As it does not consider the influence from noise and clutter, the target detection effect will be reduced greatly in the face of the defect image in a more complex background. Luo et al. [27] utilized the sparse components of small targets along with a background dictionary, employing the fully connected tensor nuclear norm for low-rank estimation. Wang et al. [28] built a unique regularization term as a tensor-correlated total variation, which essentially encodes both low-rank and sparse priors of a tensor simultaneously. Geng et al. [29] developed a nonconvex and nonlocal TRPCA (NN-TRPCA) model based on the tensor adjustable logarithmic norm, which adaptively shrinks small singular values more and shrinks large singular values less. Huang et al. [30] introduced a two-stage feature complementary improved tensor low-rank sparse decomposition method, which is divided into two stages: tensor initialization and tensor decomposition, effectively integrating local and nonlocal features. Based on above analysis, the detection capability of these methods is dependent on the contrast between the target and the background. When there is strong contrast, these methods yield good detection results; otherwise, they tend to have a high false-positive rate. Moreover, these methods depend on the measurement of background rank in terms of accuracy, and obviously reduce performance and are time-consuming in the face of dim targets with complex backgrounds.
3. Methodology
The overall framework of the proposed SLRTD method is shown in Figure 2, which consists of construction of tensor model for defect image, model solution, and model analysis.
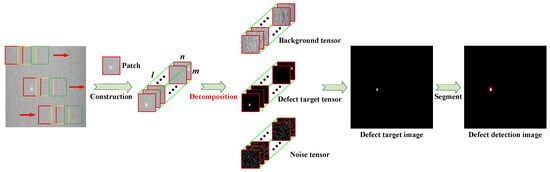
Figure 2.
The flowchart of the proposed SLRTD method for surface defect detection.
3.1. Construction of Tensor Model for Defect Image
Tensor can be expanded into matrix along n-modes and its i-th frontal slice are denoted as . We denote as the result of Discrete Fourier Transformation (DFT) along its third dimension by using , that is, . The inverse operator computes from , that is, . The tensor nuclear norm is defined as , where and are the entries on the diagonal of the first slice of , which has a decreasing order property. And we denote the l0 norm, the l1 norm, and the Frobenius norm as , , , respectively.
The defect image is mainly composed of defect target, background, and noise, which can be expressed as follows:
where , , , and represent the input of original defect image, defect image, background image, and noise defect, respectively.
The original defect image is two-dimensional data, which can be converted to tensor data. Assume original defect image and the tensor structure obtained after data reconstruction is . The image will be browsed by sliding window from left to right and from top to bottom; the total sliding time is ; the small patch obtained each time as the frontal slice of is shown in Figure 2. The tensor model of defect image can be constructed as follows:
where , , , and represent defect image patch-tensor, defect target patch-tensor, background patch-tensor, and random noise patch-tensor, respectively.
Defect target patch-tensor :
For defect image from the strip steel production line, defects with fewer pixels with respect to the whole image, it is sparse compared to most of the normal background regions. Thus, the corresponding defect target patch-tensor is an extremely sparse tensor, which can be depicted as follows:
where is an integer that is related with defect target characteristics of number and size.
Background patch-tensor :
As illustrated in Figure 1, the gray-value of normal regions is almost uniform, which means that the local patches are highly correlated with each other. Actually, the mode-1, mode-2, and mode-3 unfolding matrices of the background patch-tensor are also low-rank. In Figure 3b–d, the horizontal axes denote the number of singular values; the vertical axes denote the singular values. Assuming the defect image is 200 × 200, the patch is 40 × 40 and the step size is 10, the patch-tensor , the size of mode-1, mode-2, and mode-3 unfolding matrices are 40 × 11,560, 40 × 11,560, 289 × 1600, respectively. From Figure 3, it can be observed that the singular values of three mode-unfolding matrices all exhibit a sharp decreasing trend and decline into approximate zero rapidly, with only a small fraction being significantly greater than zero. It indicates that the background patch-tensor is correlated along each mode direction and further reflects its inherent low-rank structure within the subspaces corresponding to each mode [31,32]. Based on this property, we can consider the background patch-tensor as a low-rank tensor, and their unfolding matrices are also all low-rank defined as follows:
where , , and denote model-1, model-2, and model-3 unfolding matrices of , respectively; , , and denote the background complexity.
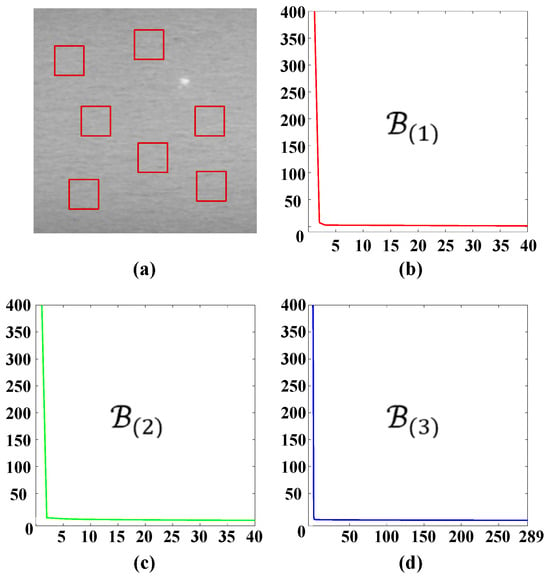
Figure 3.
Illustration of the nonlocal similarity and the low-rank property of background patch-tensors: (a) one representative defect image; (b–d) corresponding singular values distributions curve of the mode-1, mode-2, and mode-3 unfolding matrices of background patch-tensors.
Noise patch-tensor :
The noise is usually modeled as additive white Gaussian noise, and it satisfies , where denotes the Gaussian noise level.
Based on above analysis, the small white-spot defects detection on galvanized strip steel based on tensor decomposition can be formulated as follows:
where denotes matrix rank and denotes norm, denotes norm, and denote regularization parameters to balance the low-rank and sparse characteristics.
A reweighted strategy is always adopted to solve low-rank and sparse tensor decomposition. The principle of weighted Schatten -norm minimization (WSNM) is to assign different weights to different singular values [33,34], which can recover the low-rank component and separate target from background more accurately by adjusting . Therefore, we incorporate the WSNM to improve the detection accuracy of defect target. It can be defined as follows:
where is the number of patches, denotes a weight tensor, which is defined in Algorithm 1; represents the singular values of , is a parameter, is a positive constant.
| Algorithm 1: Solving Equation (11) |
| Input: ,
Output: step 1: Conduct FFT operation: step 2: Conduct SVD operation on each frontal slice of for do , Compute for do end for , end for for do end for step 3: Compute |
Additionally, norm is replaced by norm for solving the model. Hence, Equation (5) can be transformed as follows:
3.2. Model Solution
In order to solve Equation (7), the ADMM are selected to solve the separable convex optimization problem. The Lagrange function can be constructed as shown in Equation (8), which can be converted to Equation (9), where, , and denote the Lagrangian multiplier tensor, inner product among tensors, respectively.
Based on ADMM, can be broken into several sub-problems for iterative update:
(i) Fix the rest of the variables and update of , which is defined by Equation (10):
It can be solved by Generalized Soft-Thresholding (GST) and tensor singular value thresholding (t-SVT) [35] as follows:
where denotes solving WSNM-tensor problem, and the detailed process is provided in Algorithm 1. represents the value of variables in k-th iteration.
(ii) Fix the rest of the variables and update of , which is confirmed by Equation (12):
As -norm of is defined as the sum of -norm of each mode-2 fiber, we matricize each tensor along the 2nd mode, so . It can be transformed into the matrix form with Equation (13):
Let , so
According to [36], it has the following close-form solution with Equation (15):
where represents the j-th column of the matrix .
After is solved, it can be transformed into tensor form .
(iii) Fix the rest of the variables and update of is obtained by Equation (16):
Differentiating it with respect to , and let it be zero:
Then, we have the following:
(iv) Fix the rest of the variables and update of
(v) Update of :
where , .
(vi) Iteration termination condition:
where .
Finally, we summarize the algorithmic process of the proposed SLRTD method in Algorithm 2.
From target-background separation, the tensor is decomposed into the defect target and background . The defect target image and background image are reconstructed from and , respectively. Finally, the defect targets can be extracted and segmented by the adaptive thresholding segmentation method.
| Algorithm 2: Solving Equation (7) by ADMM |
| Input: Original defect image sequence tensor
,
,
Output: , , Initialize: , , , , , , While: not converged, do step 1: Update by Equation (11) step 2: Update by Equation (15) step 3: Update by Equation (16) step 4: Update by Equation (19) step 5: Update by Equation (20) step 6: Check the convergence condition step 7: Update end While |
3.3. Model Analysis
3.3.1. Computational Complexity
For surface defect image D, it could be constructed into the tensor with sliding window’s size and times . The computation complexity of the solution of includes three operations [34] of FFT, SVD, and GST; FFT operation is , SVD operation is , GST operation is , where denotes iterations number in Algorithm 1, denotes iterations number in GST. Thus, the computation complexity of solution is . For solution , the computation complexity is . Therefore, the whole computation complexity of model is , where is the iterations number in ADMM.
3.3.2. Convergence of Algorithm
The convergence of model Equation (9) has been proven in [25]. We evaluate the convergence of the proposed SLRTD method to empirically show the convergence through experiments in different iterations. We set a convergence error value of and found that the algorithm takes approximately 0.5 s per frame for small target detection. Figure 4 shows the variation in convergence error as the number of iterations progresses from 0 to 30. It can be observed that after 10 iterations, the error of our algorithm gradually decreases, and the convergence curve stabilizes, indicating that our method meets the convergence requirements and successfully achieves optimal or near-optimal solutions.
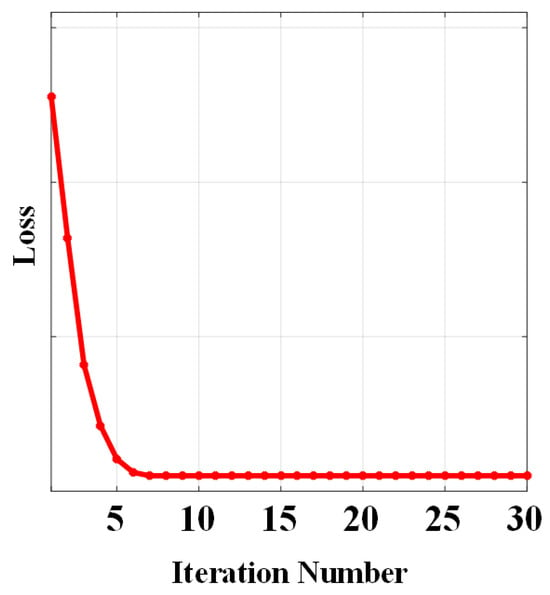
Figure 4.
Convergence curve of the proposed SLRTD method.
4. Experiment
To evaluate the effectiveness of the proposed SLRTD method, we conduct a series of qualitative and quantitative experiments. Firstly, the details of data collection and preprocessing, and evaluation metrics are described. Secondly, the key parameters and robustness are analyzed. Finally, the performance comparison is conducted between our method and the other four typical methods.
4.1. Experimental Setup
4.1.1. Data Collection and Preprocessing
The proposed SLRTD method is validated on a dataset from a real-world galvanized strip steel production line, and the image acquisition platform can be observed in Figure 5. We crop the raw images’ 4096 × 1024 pixels into 200 × 200 pixels to make the dataset. In total, we obtain 100 defect images and 100 non-defect images. For each image, the pixel-level ground-truth is manually marked by using “1” to denote defective pixels and “0” to denote defect-free pixels. The size of the white-spot defect in the production line is about 1 mm to 3 mm, which is about 5 to 8 pixels in the 200 × 200 image. Defect samples and the corresponding masks of the constructed datasets are shown in Figure 6.

Figure 5.
Industrial image acquisition platform in the galvanized strip steel production line: (a) strip steel production line; (b) image captured from the steel surface.
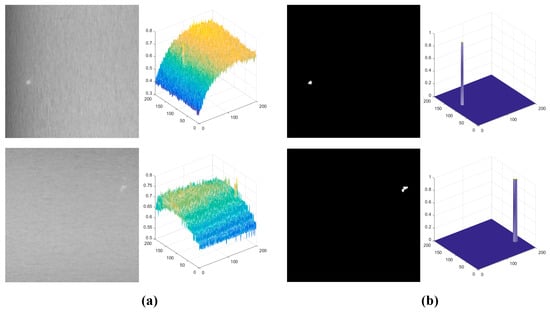
Figure 6.
Three-dimensional maps of defect samples and the corresponding ground-truth: (a) original image; (b) ground-truth.
4.1.2. Evaluation Metrics
In order to evaluate the detection performance of the proposed SLRTD model, Precision, Recall, Precision-Recall (P-R) curve, receiver operating characteristic (ROC) curve, area under ROC curve (AUC) average F-Measure (Fζ), and mean square error (MAE) are adopted as evaluation metrics.
Precision is used to evaluate how many positive pixels are correctly classified. It can be defined as follows:
where true positive () indicates the number of defect pixels which are correctly classified as defect, false positive () indicates the number of background pixels mistakenly identified as defect.
Recall is used to evaluate how many pixels are correctly classified. It can be defined as follows:
where false negative () indicates the number of defect pixels that are not classified to defect class.
represents the weighted harmonic mean of precision and recall. It can be defined as follows:
MAE measures the dissimilarity between segmentation images and corresponding ground-truth image . It can be defined as follows:
where and denote height and width of surface defect image.
Using Otsu’s threshold, we determine the Precision and Recall by changing the thresholds from 0 to 255 to obtain pairs of Precision and Recall.
4.2. Validation of the Proposed SLRTD Method
4.2.1. Parameter Analysis
For the proposed SLRTD method, the patch size, sliding step size, and value of Schatten- are evaluated by the AUC and MAE, where the regularized parameter is set to , which is adaptive to the patch size and number of patches.
- Patch size
To balance the detection performance and computational complexity, we change the patch size from 20 to 50 with 10 intervals and provide the corresponding AUC and MAE in Table 1. As the patch size increases, the detection performance of the SLRTD method decreases. When the patch size is 50 × 50, the degradation is more serious. The reason is the larger patch size may destroy the low-rank and sparsity between the different patches, and influence the decomposition of the defect target and background.

Table 1.
Experimental results of AUC and MAE with different patch sizes and step sizes.
- b.
- Step size
In practice, we hope to take a larger step in exchange for the reduction in computational complexity. We fix the patch size and vary the step size from 10 to 40 with 10 intervals. The evaluation results are shown in Table 1. It could be observed that the performances of larger steps are always better than that of smaller ones, but when the step size is similar with the patch size, the performance becomes worse.
- c.
- Value of Schatten-
As shown in Table 2, the AUC and MAE with change from 0.1 to 1 with 0.1 intervals. The detection performance of is worse than lower as the over-shrinkage is serious. When is decreased, the low-rank background may be closer to true rank, while more high-rank components would become zeros [34]. When is too small, it would also make some low-rank backgrounds become zeros to lead the bad detection performance. Therefore, in order to make the tradeoff between detection accuracy and error, is set to 0.7 in the following experiments.
Table 2.
Experiment of AUC and MAE with different .
4.2.2. Robustness to Noise
The noise conditions of a real-world galvanized strip steel production line are complex and random; we evaluate the proposed SLRTD method’s performance in the noise case with different levels. Additive Gaussian noise with different signal-to-noise ratios (SNRs) are introduced to the original defect image, including 36 dB, 32 dB, and 28 dB. The experimental results are shown in Figure 7 and Table 3. It can be observed that the SLRTD is robust to noise in most cases; binarization defect images obtained by SLRTD are clear and accurate. When SNR decreases gradually, the AUC and MAE metrics can remain a relatively high level; for example, AUC still remains around 0.85 under the condition of , which is considered as less sensitive to noise. However, some pixels of the background are misclassified for defects, which is still a great challenge for the SLRTD method.

Figure 7.
Detection results of binarization by Otsu’s method in different noise cases: (a) original image; (b) ground-truth; (c) 0 dB; (d) 36 dB; (e) 32 dB; (f) 28 dB.
Table 3.
Experiment with different noise levels.
4.3. Comparison with the State-of-the-Art Methods
The proposed SLRTD method is compared with four state-of-the-art algorithms, including TRPCA [23], PSTNN [24], ETRPCA [25], and NN-TRPCA [29].
4.3.1. Qualitative Comparison
To facilitate a more intuitive comparison of the performance of each algorithm, we selected representative defect images from the dataset. The false-detected targets are highlighted with green circles, which are shown in Figure 8. The qualitative comparison results between the proposed SLRTD method and the other four methods are shown in Figure 8. These images show various illumination and gray levels. NN-TRPCA and PSTNN can enhance defect targets, but they also enhance many clutters and noises of the background and the defect object cannot be uniformly highlighted, which can cause a high false alarm rate. These methods may lose the targets with heavy noise. NN-TRPCA exhibits poor robustness in detecting small targets against complex backgrounds, resulting in considerable background residue. The TRPCA and ETRPCA methods can detect the targets in the 2nd and 4th rows, but some background residue still remains. There are many pixels that belong to the background and are misjudged by defects, which leads to low accuracy. By contrast, SLRTD separates the defect objects from the image background successfully and locates various defects precisely. It more efficiently highlights the whole defect object with well-defined boundaries than the other methods. It can be concluded that WSNM regularization could improve the performance. In addition, WSNM regularization of SLRTD contributes to good performance, and thus, is the important factor to obtain more precise segmentation results than other methods. What is more, it is reasonable to conclude that treating the matrix singular values differently is the method by which the most important characteristics of the defects or background can be preserved. The superiority of the proposed SLRTD method can suppress the noise and detect the defect targets clearly, which can generate high-quality binary segmentation results by a simple threshold method.
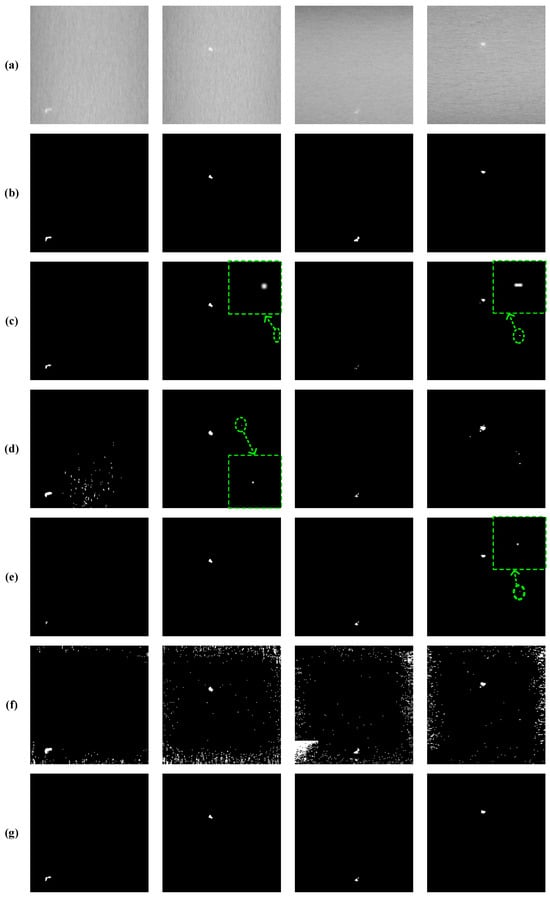
Figure 8.
Qualitative comparison results: (a) input image; (b) ground-truth image; (c) TRPCA; (d) ETRPCA; (e) NN-TRPCA; (f) PSTNN; (g) ours.
4.3.2. Quantitative Comparison
To further demonstrate the superiority of the proposed SLRTD method, four competitive methods of TRPCA, ETRPCA, NN-TRPCA, PSTNN are selected for comparison. From the P-R and ROC curves demonstrated in Figure 9, for the same false alarm ratio, our method can achieve the highest detection performance. By imposing a -norm to the patch-image, SLRTD can suppress background noise effectively for all defect images and lay a good foundation for the subsequent target segmentation. Table 4 summarizes the quantitative results of five methods, and the best results are marked in bold. It demonstrates that SLRTD also has better performance than the other four methods. Most of the AUC results are higher than 85%, and SLRTD achieves 0.9560. MAE of SLRTD is typically the lowest among all the methods. Compared with TRPCA, it is increased by 2.08% and 1.55% in AUC and MAE, respectively. Based on the above qualitative and quantitative analyses, it confirms that our proposed SLRTD method consistently outperforms some state-of-the-art methods and verifies the effectiveness of the proposed SLRTD method.
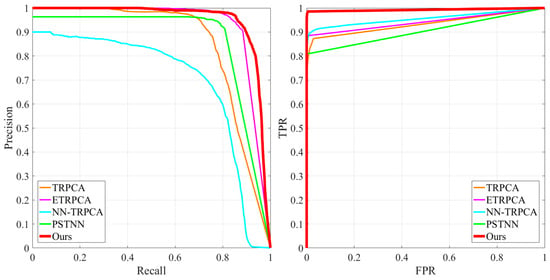
Figure 9.
Quantitative comparison results with P-R curves and ROC curves.
Table 4.
Comparison of AUC and MAE of different methods.
5. Conclusions
In order to detect small white-spot surface defects of galvanized strip steel accurately and rapidly, the SLRTD method is proposed in this paper. The nonlinear reweighting strategy based on Schatten -norm is adopted to separate the defect image into a smooth non-defect background and random noise. A solution framework is proposed by the ADMM algorithm to obtain the defect target image. Based on the self-constructed defect dataset, experiments are conducted by the qualitative and quantitative method, which achieves the best performance among the state-of-the-art defect detection methods. In the future, we will focus on improving the ability of the proposed SLRTD method to detect the other tiny defects under weak illumination conditions or irregular defect-like texture surfaces. In the future, we will conduct binocular and structured-light stereo vision to obtain three-dimensional information of surface defects in industrial production.
Author Contributions
S.Z. designed the SLRTD model and performed the evaluation experiments. X.Y. collaborated closely and contributed equally to this work. H.L. arranged the datasets, as well as reviewed the article. C.G. developed the automatic optical inspection procedure. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China, grant number 52205537 and 51805386, the open fund of State Key Laboratory of Intelligent Manufacturing Equipment and Technology (Huazhong University of Science and Technology), grant number IMETKF2025024, and the Innovative Research Group Project of the National Natural Science Foundation of Hubei Province of China, grant number 2024AFA026.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data are not publicly available due to privacy issues.
Acknowledgments
The authors would like to thank the editor and anonymous reviewers.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Diers, J.; Pigorsch, C. A survey of methods for automated quality control based on images. Int. J. Comput. Vision 2023, 131, 2553–2581. [Google Scholar] [CrossRef]
- Zhu, J.P.; He, G.H.; Zhou, P. MFNet: A novel multilevel feature fusion network with multibranch structure for surface defect detection. IEEE Trans. Instrum. Meas. 2023, 72, 1–11. [Google Scholar] [CrossRef]
- Cheng, G.; Yuan, X.; Yao, X.W.; Yan, K.B.; Zeng, Q.H.; Xie, X.X.; Han, J.W. Towards large-scale small object detection: Survey and benchmarks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13467–13488. [Google Scholar] [CrossRef]
- Li, J.; Wu, R.; Zhang, S.; Chen, Y.L.; Dong, Z.C. FASCNet: An edge-computational defect detection model for industrial parts. IEEE Internet. Things. 2023, 11, 6622–6637. [Google Scholar] [CrossRef]
- Luo, Q.W.; Chen, Y.W.; Su, J.J.; Yang, C.H.; Silvén, O.; Liu, L. Prior-guided YOLOX for tiny roll mark detection on strip steel. IEEE Sens. J. 2024, 24, 15575–15587. [Google Scholar] [CrossRef]
- Ameri, R.; Hsu, C.C.; Band, S.S. A systematic review of deep learning approaches for surface defect detection in industrial applications. Eng. Appl. Artif. Intel. 2023, 130, 107717. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M.; Hill, R.; Allen, P. A comprehensive review of convolutional neural networks for defect detection in industrial applications. IEEE Access 2024, 12, 94250–94295. [Google Scholar] [CrossRef]
- Zou, Z.X.; Chen, K.Y.; Shi, Z.W.; Guo, Y.H.; Ye, J.P. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Jha, S.B.; Babiceanu, R.F. Deep CNN-based visual defect detection: Survey of current literature. Comput. Ind. 2023, 14, 103911. [Google Scholar] [CrossRef]
- Liu, G.H.; Chu, M.X.; Gong, R.F.; Zheng, Z.H. Global attention module and cascade fusion network for steel surface defect detection. Pattern Recogn. 2024, 158, 110979. [Google Scholar] [CrossRef]
- Zare, A.; Ozdemir, A.; Iwen, M.A.; Aviyente, S. Extension of PCA to higher order data structures: An introduction to tensors, tensor decompositions, and tensor PCA. Proc. IEEE 2018, 106, 1341–1358. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, J.G.; An, W. Infrared dim and small target detection via multiple subspace learning and spatial-temporal patch-tensor model. IEEE T. Geosci. Remote. 2020, 59, 3737–3752. [Google Scholar] [CrossRef]
- Yu, Q.; Yang, M. Low-rank tensor recovery via non-convex regularization, structured factorization and spatio-temporal characteristics. Pattern Recogn. 2023, 137, 109343. [Google Scholar] [CrossRef]
- Wang, M.H.; Hong, D.F.; Han, Z.; Li, J.X.; Yao, J.; Gao, L.R.; Zhang, B.; Chanussot, J. Tensor decompositions for hyperspectral data processing in remote sensing: A comprehensive review. IEEE Geosci. Remote Sens. Mag. 2023, 11, 26–72. [Google Scholar] [CrossRef]
- Luo, Y.; Li, X.R.; Chen, S.H. 5-D spatial-temporal information-based infrared small target detection in complex environments. Pattern Recogn. 2024, 158, 111003. [Google Scholar] [CrossRef]
- Zeng, N.Y.; Wu, P.S.; Wang, Z.D.; Li, H.; Liu, W.; Liu, X.H. A small-sized object detection oriented multi-scale feature fusion approach with application to defect detection. IEEE Trans. Instrum. Meas. 2022, 71, 3507014. [Google Scholar] [CrossRef]
- Wen, X.; Shan, J.; He, Y.; Song, K. Steel surface defect recognition: A survey. Coatings 2023, 13, 17. [Google Scholar] [CrossRef]
- Li, D.; Li, Y.; Xie, Q.; Wu, Y.; Yu, Z.; Wang, J. Tiny defect detection in high-resolution aero-engine blade images via a coarse-to-fine framework. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar] [CrossRef]
- Zhang, H.Y.; Li, M.; Miao, D.Q.; Pedrycz, W.; Wang, Z.G.; Jiang, M.H. Construction of a feature enhancement network for small object detection. Pattern Recogn. 2023, 143, 109801. [Google Scholar] [CrossRef]
- Hou, X.Q.; Liu, M.Q.; Zhang, S.L.; Wei, P.; Chen, B.D. CANet: Contextual information and spatial attention based network for detecting small defects in manufacturing industry. Pattern Recogn. 2023, 140, 109558. [Google Scholar] [CrossRef]
- Yang, B.Y.; Liu, Z.Y.; Duan, G.F.; Tan, J.R. Residual shape adaptive dense-nested Unet: Redesign the long lateral skip connections for metal surface tiny defect inspection. Pattern Recogn. 2023, 147, 110073. [Google Scholar] [CrossRef]
- Dai, Y.; Wu, Y.Q. Reweighted infrared patch-tensor model with both nonlocal and local priors for single-frame small target detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3752–3767. [Google Scholar] [CrossRef]
- Lu, C.Y.; Feng, J.S.; Chen, Y.D.; Liu, W.; Lin, Z.C.; Yan, S.C. Tensor robust principal component analysis with a new tensor nuclear norm. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 925–938. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.D.; Peng, Z.M. Infrared small target detection based on partial sum of the tensor nuclear norm. Remote Sens. 2019, 11, 382. [Google Scholar] [CrossRef]
- Gao, Q.X.; Zhang, P.; Xia, W.; Xie, D.Y.; Gao, X.B.; Tao, D.C. Enhanced tensor RPCA and its application. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2133–2140. [Google Scholar] [CrossRef]
- Chen, L.; Jiang, X.; Liu, X.Z.; Zhou, Z.X. Logarithmic norm regularized low-rank factorization for matrix and tensor completion. IEEE Trans. Image Process. 2021, 30, 3434–3449. [Google Scholar] [CrossRef]
- Luo, Y.; Li, X.R.; Yan, Y.F.; Xia, C.Q. Spatial-temporal tensor representation learning with priors for infrared small target detection. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 9598–9620. [Google Scholar] [CrossRef]
- Wang, H.L.; Peng, J.J.; Qin, W.J.; Wang, J.J.; Meng, D.Y. Guaranteed tensor recovery fused low-rankness and smoothness. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10990–11007. [Google Scholar] [CrossRef]
- Geng, X.Y.; Guo, Q.; Hui, S.X.; Yang, M.; Zhang, C.M. Tensor robust PCA with nonconvex and nonlocal regularization. Comput. Vis. Image Und. 2024, 243, 104007. [Google Scholar] [CrossRef]
- Huang, Z.X.; Zhao, E.W.; Zheng, W.; Peng, X.D.; Niu, W.L.; Yang, Z. Infrared small target detection via two-stage feature complementary improved tensor low-rank sparse decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 17690–17709. [Google Scholar] [CrossRef]
- Liu, C.T.; Wang, H. Research on infrared dim and small target detection algorithm based on low-rank tensor recovery. J. Syst. Eng. Electron. 2023, 34, 861–872. [Google Scholar] [CrossRef]
- Guo, J.; Wu, Y.Q.; Dai, Y.M. Small target detection based on reweighted infrared patch-image model. IET Image Process. 2018, 12, 70–79. [Google Scholar] [CrossRef]
- Xie, Y.; Gu, S.H.; Liu, Y.; Zuo, W.M.; Zhang, W.S.; Zhang, L. Weighted Schatten p-norm minimization for image denoising and background subtraction. IEEE Trans. Image Process. 2016, 25, 4842–4857. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, J.G.; Li, M.; An, W. Infrared small target detection via spatial-temporal infrared patch-tensor model and weighted Schatten p-norm minimization. Infrared Phys. Techn. 2019, 102, 103050. [Google Scholar] [CrossRef]
- Zuo, W.M.; Meng, D.Y.; Zhang, L.; Feng, X.C.; Zhang, D. A generalized iterated shrinkage algorithm for non-convex sparse coding. In Proceedings of the 2013 IEEE International Conference on Computer Vision 2013, Sydney, NSW, Australia, 1–8 December 2013; IEEE: Piscataway, NJ, USA, 2014; pp. 217–224. [Google Scholar] [CrossRef]
- Xie, D.Y.; Yang, M.; Gao, Q.X.; Song, W. Non-convex tensorial multi-view clustering by integrating l1-based sliced-Laplacian regularization and l2,p-sparsity. Pattern Recognit. 2024, 154, 110605. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).