1. Introduction
Accurate and efficient digital meter reading is fundamental to the metering and management of utilities such as water, electricity, and gas [
1]. Traditional manual meter reading methods are labor-intensive and time-consuming, requiring significant on-site effort, which makes them highly inefficient and unsuitable for real-time monitoring. Furthermore, these methods are prone to inaccuracies caused by human error or subjective judgment, leading to potential billing disputes. Although smart meters capable of remote automatic reading and data transmission have been widely adopted in developed regions [
2], improving both efficiency and accuracy, their large-scale deployment remains impractical in many underdeveloped areas due to cost constraints [
3]. As an alternative, automatic meter reading (AMR) technologies that take advantage of mobile devices or fixed cameras have recently gained traction for their cost-effectiveness and efficiency. However, these systems face several challenges in real-world applications, including pixelation, foggy blur, and extreme illumination variations of images. Limitations in shooting angles and distances often result in perspective distortions and deformations in the captured meter region as well, further complicating the recognition process [
4]. Developing a stable and reliable AMR system that can operate effectively under such complex conditions is a critical field with significant research value and application prospects.
AMR is essentially a natural text detection and recognition task. A comprehensive understanding of AMR systems requires a systematic analysis of both text-detection and text-recognition components. Text detection, as the initial step in AMR, focuses on localizing and identifying text regions within images. Early research in text detection primarily relied on traditional methods such as Connected Components Analysis (CCA) [
5,
6,
7] and sliding window approaches [
8,
9] along with Conditional Random Fields (CRFs) [
10] and graph-based algorithms [
11]. Some of them showed some improvement in challenging scenarios. For instance, Neumann et al. [
5] proposed a method based on Maximally Stable Extremal Regions (MSERs), whereas Yin et al. [
12] developed a multi-scale feature extraction framework. However, these approaches still faced significant challenges when dealing with extreme lighting conditions, complex backgrounds, and multi-angle text. With the development of deep learning, object-detection-based models have been widely adopted for digital meter region detection. Liu et al. [
13] employed Fast R-CNN for meter region detection, whereas Wu et al. [
14] achieved high-precision detection through modifications to Mask R-CNN. However, these methods inherited the real-time performance limitations of the R-CNN architecture. To address perspective distortion, Lin et al. [
15] combined Polygon-YOLOV5 and YOLOV5s to extract meter regions and reading areas, though this two-step detection approach resulted in suboptimal performance. Peng et al. [
16] later proposed the YOLO-CPDM model, an improvement on YOLOV5, achieving a better balance between real-time performance and detection accuracy, yet still showing limitations under extreme lighting variations and image distortion. Some researchers have attempted to enhance model robustness through image preprocessing and data augmentation. For instance, Lin et al. [
15] incorporated FFT and DeblurGAN for blur removal during preprocessing, whereas Hou et al. [
17] evaluated YOLOX trained with data augmentation across various extreme conditions. However, most of these studies are confined to object detection models or corner detection methods, lacking in-depth research on detecting irregular boundaries. This gap led some researchers to explore scene text detection models, such as Carvalho et al. [
18] fine-tuning the EAST model for digital water meter detection and Zheng et al. [
19] applying DBNet to X-ray weld image detection, though few studies focused on structural improvements specifically for extreme meter reading scenarios. These studies indicate that relying solely on either object-detection-based algorithms or scene text detection algorithms is insufficient to overcome challenges such as reading perspective distortion and performance degradation in extreme scenarios [
20].
Following text detection, the subsequent challenge lies in text recognition, which transforms the detected text regions into characters. Traditional text recognition approaches can be broadly categorized into feature-based methods and sequential decomposition methods. Feature-based approaches utilize direct feature extraction through character segment-based algorithms [
21] and label embedding techniques [
22], whereas the sequential decomposition paradigm breaks recognition into sub-problems, including text binarization [
23], character segmentation [
24], and word correction [
25]. These approaches shared common limitations in their heavy dependence on handcrafted features, which had shown limited performance on challenge scenarios such as curved text or complex image backgrounds. The introduction of deep learning methods significantly enhanced text recognition performance. Some researchers employed object detection models for digit recognition, such as Liang et al. [
26], using YOLOV3-based segmentation and Martinelli et al. [
27], improving segmentation recognition performance with YOLOV5s. Peng et al. [
16] proposed the YOLO-EERRM model by integrating CBAM attention mechanisms into YOLOV5’s C3 structure, achieving state-of-the-art performance on private datasets. However, object detection methods typically require integration with segmentation algorithms for complete reading recognition, resulting in complex post-processing and potential segmentation errors [
20]. In contrast, scene text recognition algorithms are more suitable for automatic meter reading tasks, offering end-to-end recognition of complete text sequences. Some researchers [
18,
28,
29] employed CRNN or its variants (such as LSTM) for digit recognition. Li et al. [
29] enhanced recognition performance by embedding CBAM modules in LSTM, whereas Zhang et al. [
19] significantly improved performance by incorporating CA and CBAM modules into the MASTER model. These studies demonstrate that scene text recognition methods show greater potential and better text recognition capabilities for meter reading tasks compared to object-detection-based models.
In summary, current automatic meter reading approaches face several critical limitations: (1) Object-detection-based methods typically rely on rectangular or four-points polygon anchor boxes, which are inherently inadequate to capture the irregular and asymmetrical reading regions in AMR tasks [
30], leading to significant prediction deviations under perspective distortions. (2) Most robustness improvements focus on extensive data preprocessing such as image enhancement, normalization, and aggressive data augmentation during training, which often compensate for rather than address the intrinsic shortcomings of the model architectures themselves in challenging scenarios. (3) Object-detection-based approaches for digit recognition often require complex post-processing and are prone to segmentation errors. (4) Existing methods typically address either detection or recognition challenges separately, lacking an integrated approach for both tasks. These limitations highlight the need for an end-to-end framework that leverages the strengths of scene text detection and recognition algorithms to handle the unique challenges of meter reading in natural scenes, particularly under extreme conditions [
4].
Based on the limitations of existing research, the main contributions of this work are as follows.
- (1)
A novel and robust AMR framework, EDPNet, is proposed, which integrates scene text detection and recognition algorithms instead of traditional object-detection-based methods. The framework achieves state-of-the-art performance on challenge scenarios compared with methods lacking specific optimization on meter detection and recognition.
- (2)
EDNet, an excellent detection network replacing backbone with EfficientNetV2-s and incorporating EMA and MSKA attention mechanisms, is proposed. The network achieves significantly enhanced and superior detection results on multiple challenge scenarios, especially irregular reading regions and perspective distortion.
- (3)
EPNet, an improved recognition network that integrates DropKey attention mechanisms into vision transformer encoders of PARSeq, is proposed. This design enhances recognition performance while effectively mitigating overfitting issues.
- (4)
Through extensive comparative and ablation experiments, the effectiveness and generalization capabilities of the proposed EDPNet framework across diverse and challenging automatic meter reading scenarios are validated. These results demonstrate that the proposed network achieves an excellent balance between real-time performance and precision while significantly reducing parameters.
The remainder of this paper is organized as follows.
Section 2 briefly introduces the principles and implementation details of the proposed method.
Section 3 presents the experimental setup in detail.
Section 4 provides comprehensive comparative experiments and ablation studies, demonstrating that the proposed method achieves state-of-the-art performance in both conventional and challenging scenarios, thus validating its feasibility and effectiveness. Finally,
Section 5 is a summary and outlook.
2. Proposed Method
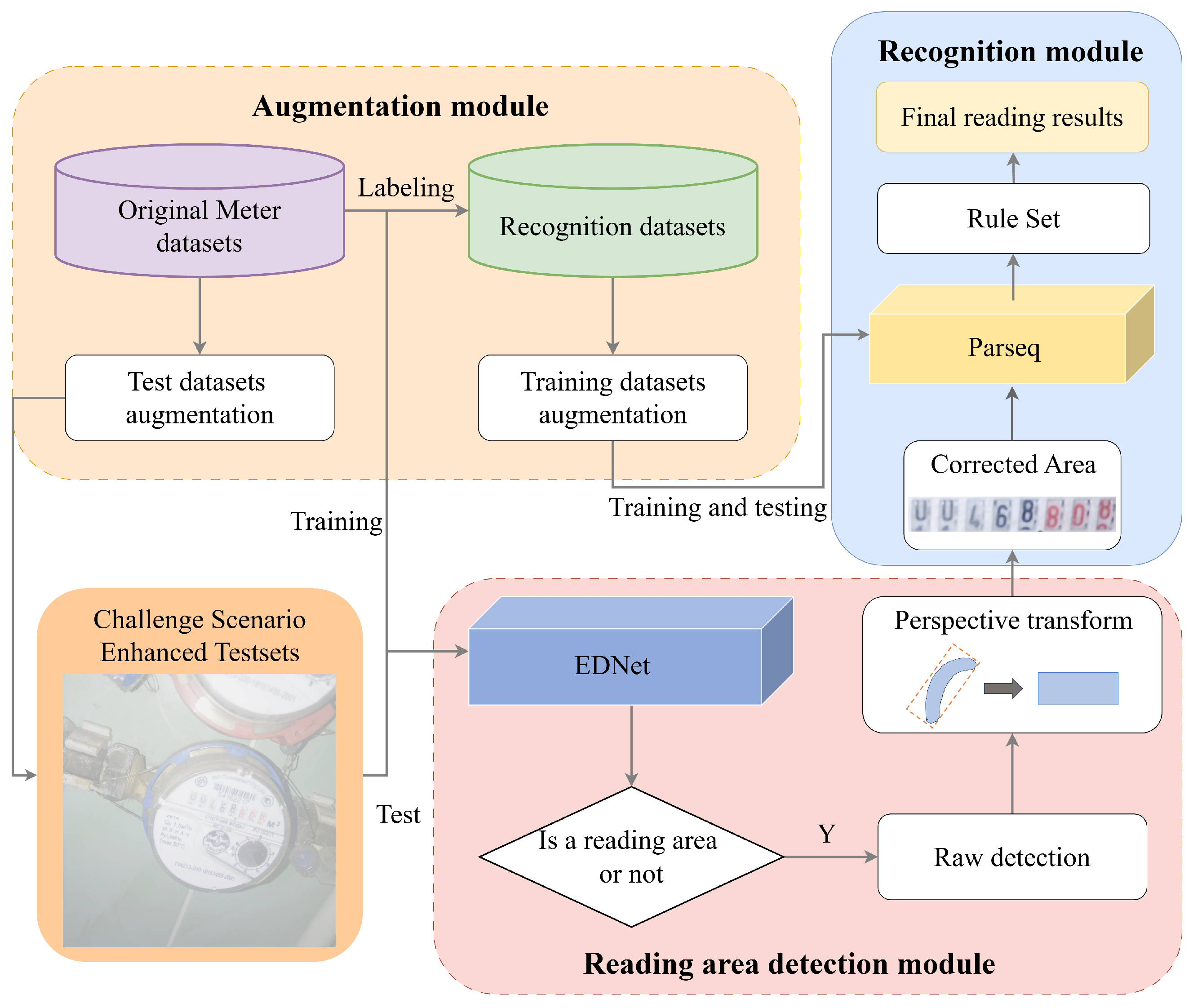
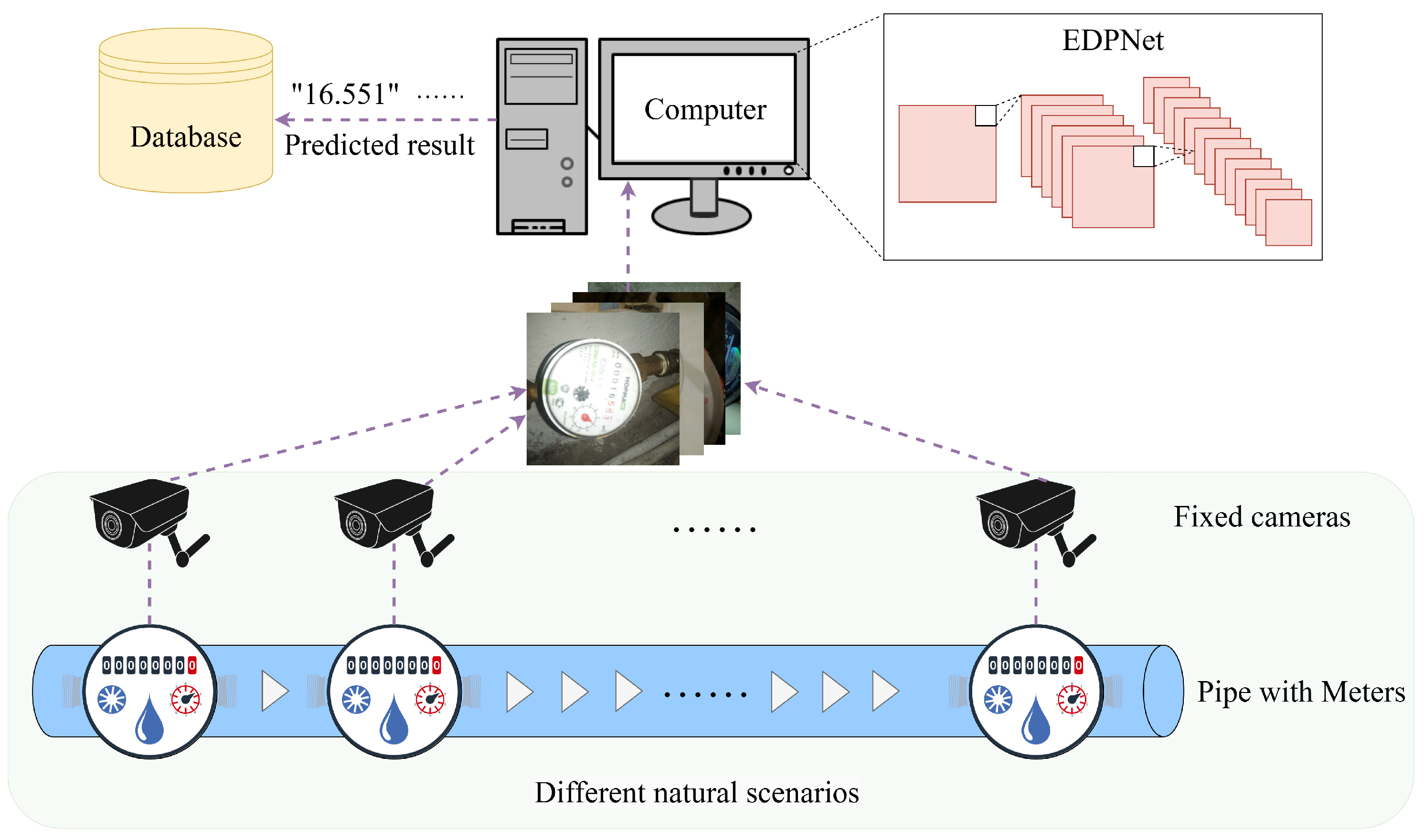
EDPNet is a real-time digital meter reading system for natural scenes based on deep learning, which integrates EDNet and EPNet. As illustrated in
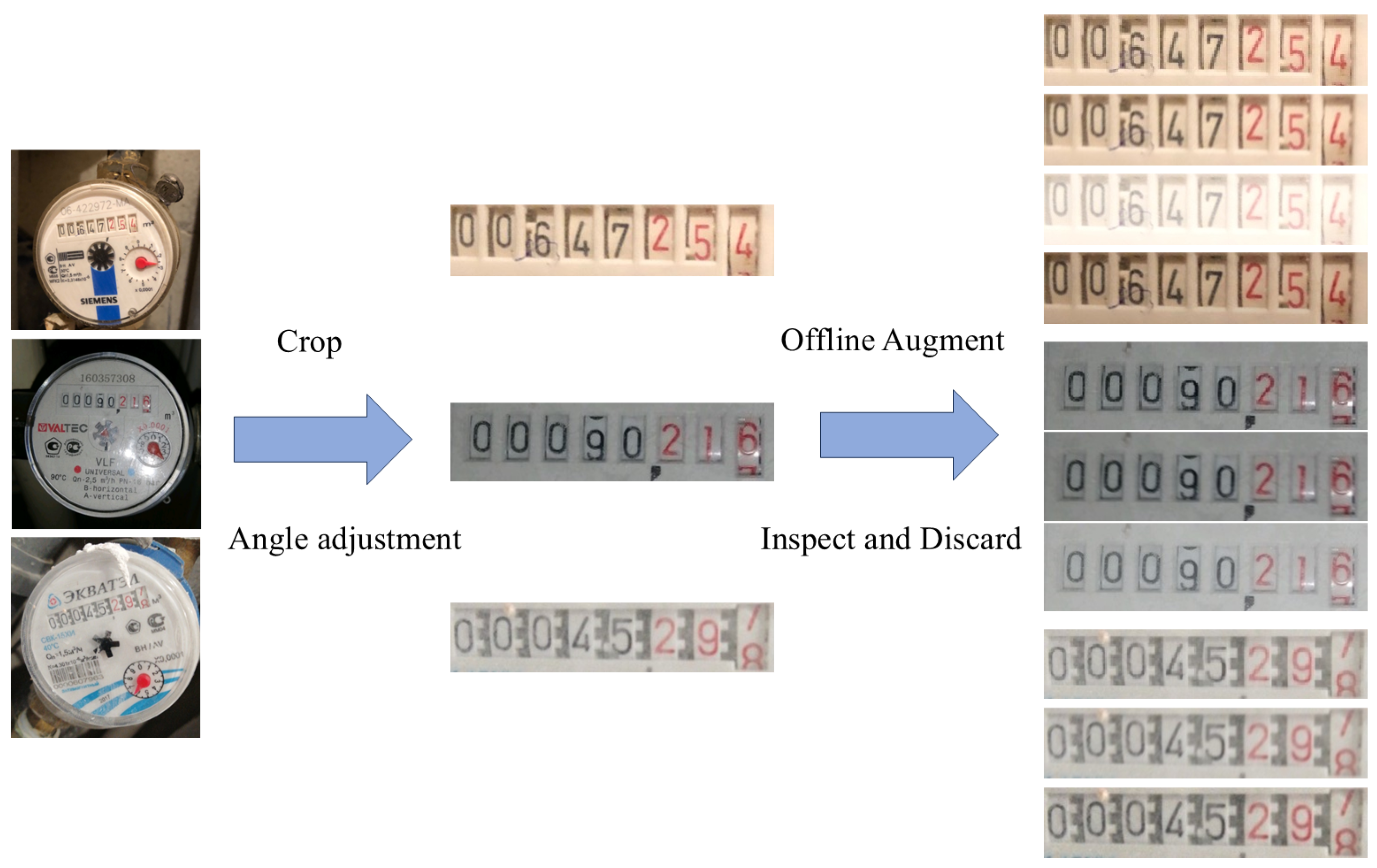
Figure 1, the system’s overall architecture consists of three primary modules: augmentation, reading area detection, and recognition. The augmentation module serves to validate the trained reading area detection module and train the recognition module. By applying data augmentation techniques that simulate challenge scenarios to the original data, the generalization capability and accuracy of the recognition module are effectively enhanced. After the detection module identifies the reading area, perspective-transform algorithms are employed to locate the minimum bounding rectangle of the irregular region and apply perspective correction. The corrected image is then fed into the reading recognition module to produce the final meter reading result. Given the diversity of water meter formats in the dataset, a rule-set mapping is implemented to process decimal points in the recognition results before generating the final output. The subsequent sections provide an in-depth analysis of the architectural design and core methodologies of EDNet and EPNet, highlighting their respective contributions to the overall system.
2.1. EDNet
Considering the real-time requirements of water meter reading tasks and the detection characteristics of complex scenarios, this work selects DBNet [
31] as the baseline model and makes improvements. DBNet can accurately detect curved text, which is particularly suitable for the common cases of perspective distortion and deformation of reading areas in water meter reading tasks. DBNet mainly consists of three parts: Backbone, FPN neck, and DBHead.
Backbone: The input is a three-channel image. The backbone network extracts features through convolution, generating feature maps with resolutions corresponding to 1/2, 1/4, 1/8, 1/16 and 1/32 of original size, respectively, with the number of channels gradually increasing. When selecting different backbone networks, the number of channels in the feature maps may vary; therefore, it is necessary to adjust the configuration accordingly to ensure correct forward propagation.
Neck: Through a top-down process that involves progressive upsampling, residual connections, and convolutional operations,
is reshaped to new feature sets
, which are subsequently concatenated to form the fused feature map
DBHead:
is processed through a series of convolutions and transposed convolutions to generate the probability map (
P) and the threshold map (
T). These maps are then passed through Differentiable Binarization to obtain the final binary map. The operations can be represented as
where
represents the Sigmoid function and
k denotes the amplifying factor for Differentiable Binarization. Though the computation of
P and
T are based on
,
P is primarily used to generate the probability distribution of text regions, while
T is mainly used to generate a threshold map that aligns with
P, facilitating subsequent binarization. DBNet offers significant advantages over traditional binarization methods. Traditional approaches typically rely on fixed thresholds or global probability distributions, which struggle to handle complex backgrounds, irregularly shaped text regions, and geometric distortions in images. In contrast, DBNet generates a probability map
and a dynamic threshold map
, and their combination is used to compute the final binary map
. This allows the binarization process to adaptively adjust based on the actual scene. Specifically, the threshold map
can dynamically adjust the binarization standard according to the local information of the input features, improving robustness in complex scenarios.
The adaptive binarization capability of DBNet makes it particularly efficient for region detection in water meter reading tasks. Water meter reading regions in natural scenes often exhibit irregular shapes and are subject to perspective distortion and viewpoint shifts due to varying shooting angles and lighting conditions. The dynamic threshold mechanism of DBNet allows for robust adaptation to varying regional characteristics, enabling the efficient detection of irregular areas. Furthermore, its robust boundary segmentation capability ensures high detection accuracy even in complex scenes, providing reliable technical support for water meter readings.
To address the challenges posed by geometric distortions (including angular distortion and perspective shifts) and adverse imaging conditions (e.g., pixelation, foggy blur, or extreme lighting) frequently encountered in water meter reading tasks, this study proposes EDNet, an efficient detection model built upon the architecture of DBNet.
The overall structure of EDNet is shown in
Figure 2. EDNet achieves significantly enhanced detection performance through architectural modifications. Specifically,
- (1)
The backbone network is replaced with the lightweight yet high-performance EfficientNetV2-s to improve feature extraction in challenge scenarios. This substitution is particularly effective because DBNet’s foundation architecture excels at detecting irregular text boundaries [
31], and the proposed EDNet leverages this strength while enhancing it with a superior compound scaling method of EfficientNetV2-s. EfficientNetV2-s systematically balances network depth, width, and resolution, resulting in more robust feature representation and excellent detection performance, particularly for perspective-distorted or irregular meter readings.
- (2)
The Efficient Multi-scale Attention (EMA) module introduced between the Backbone and Neck addresses the critical issue of feature degradation in foggy and low-contrast environments. By efficiently processing multi-scale feature maps, EMA performs adaptive recalibration of channel-wise features while maintaining computational efficiency. This mechanism specifically enhances the network’s capability to distinguish meter readings from foggy backgrounds by amplifying discriminative feature regions while suppressing irrelevant environmental noise. The multi-scale approach ensures that both fine-grained details (critical for digit recognition) and broader contextual information (essential for boundary detection) are preserved even under challenging visibility conditions.
- (3)
A Multi-Scale KeyDrop Attention (MSKA) module is proposed. This module integrates channel attention, spatial attention, and enhanced attention mechanisms to hierarchically optimize feature maps, focusing on critical regions. By inserting MSKA between the Neck and Head, EDNet prevents overfitting to specific lightning condition, thus enhancing the capability to tackle extreme illumination challenges in real-world meter reading tasks.
2.1.1. EfficieNetV2
EfficientNetV2, proposed by the Google team at CVPR 2021 [
32], is an efficient backbone network that further optimizes training speed and parameter size compared to its predecessor, EfficientNet, achieving significant improvements in multiple performance metrics. EfficientNetV2 adopts a modular stacked design and incorporates dilated convolutions and optimized residual connections, greatly enhancing training efficiency. Experiments demonstrate that EfficientNetV2 achieves an 11-fold increase in training speed and reduces parameters to 1/6.8 of the original size while achieving a higher Top-1 accuracy on the ImageNet dataset compared to traditional backbone networks. Although its inference latency is slightly higher, optimizations for CPU and mobile devices make it superior to traditional backbone networks for mobile deployments [
33]. The stacked design of EfficientNetV2 is challenging to visualize directly. Therefore, the detailed structure of EfficientNetV2-s used in this study is presented in
Table 1.
In the official release, DBNet++ [
34] often employs ResNet or MobileNet variants as backbone networks. However, these networks may struggle to effectively extract features in complex scenarios encountered in meter reading tasks, such as pixelation, foggy blur, and extreme lighting conditions. In contrast, EfficientNetV2 demonstrates outstanding performance in feature extraction and fusion, due to its advanced multi-scale feature pyramid structure and built-in SE attention mechanism. Additionally, its efficient training strategy significantly reduces model training time and resource requirements, making it highly suitable for resource-constrained environments.
Based on these advantages, this study incorporates EfficientNetV2-s as the backbone network to further enhance DBNet. As shown in
Figure 3, the input image
is processed through multiple stages in EfficientNetV2-s, where
represents the i-th
. Specifically, when
i = 2, 3, 4, 5, the output feature maps are denoted as
with channel dimensions of 48, 64, 160, and 1280, respectively. Instead of being directly fed into the Neck, are first processed by four separate Efficient Multi-scale Attention (EMA) modules. Then the outputs of these EMA modules serve as inputs to the Neck.
In summary, the challenge scenarios imposes greater demands on the feature-extraction capability of backbone networks. Within both image classification and object detection domains, EfficientNetV2-s outperforms conventional backbone architectures while notably reducing parameters. The modular stacked design and optimized training strategy of EfficientNetV2 enable it to maintain an excellent balance between accuracy and light weight, which serve as two key criteria of meter reading.
2.1.2. Efficient Multi-Scale Attention Module
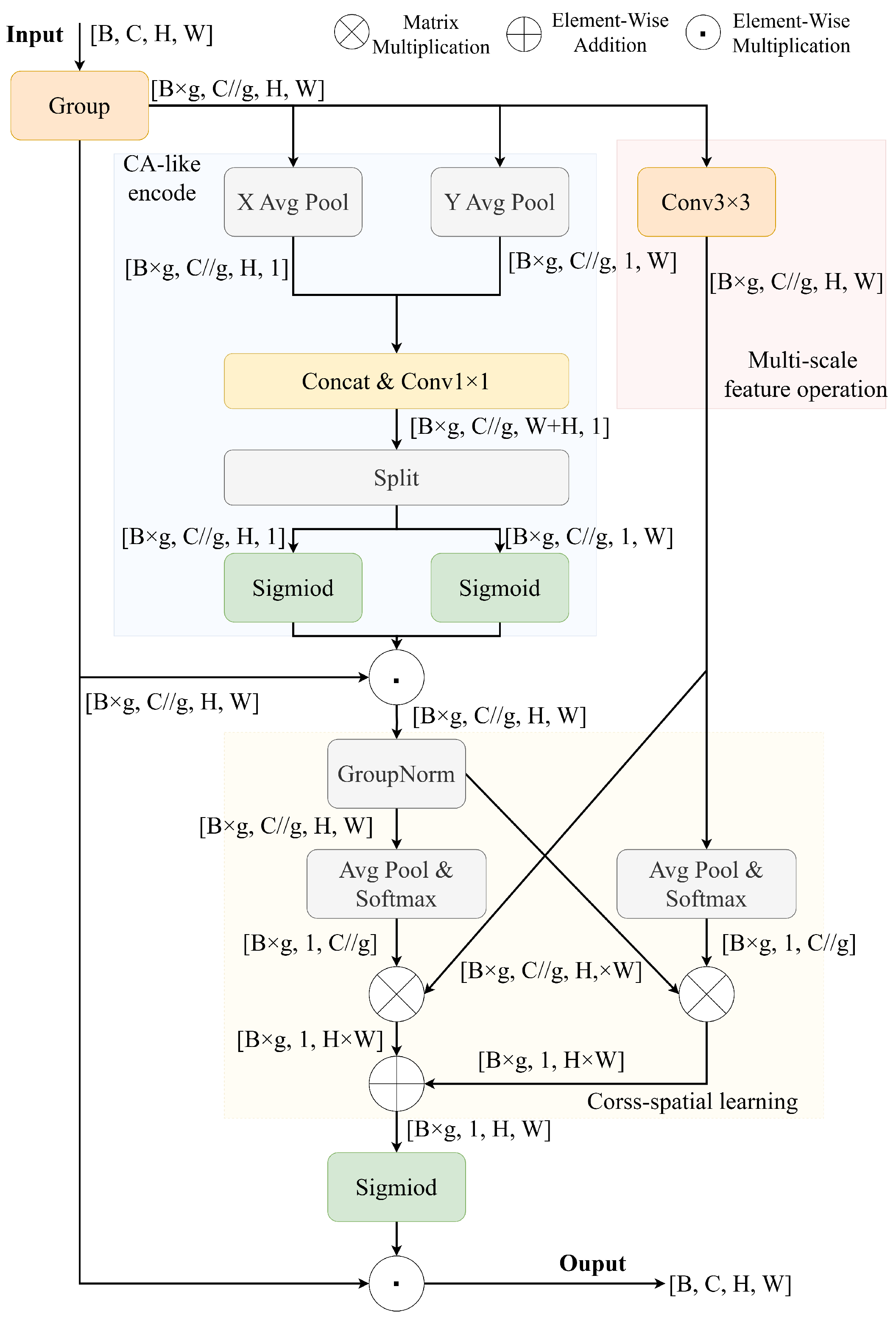
To address common challenges in water meter reading tasks, including pixelation and foggy blur of the image, an Efficient Multi-scale Attention (EMA) [
35] module is introduced. As shown in
Figure 4, the EMA module builds upon Coordinate Attention and enhances its performance. Unlike traditional methods, which use convolution for channel dimension reduction, EMA reconstructs partial channels into batch dimensions and groups channel dimensions into multiple sub-features, thereby avoiding information loss from dimensionality reduction while significantly reducing computational overhead. Specifically, EMA comprises three parallel branches: two branches are computed along the width and height directions of the feature maps, respectively, capturing long-range dependencies; the third branch introduces 3 × 3 convolution to capture local cross-channel interactions, enhancing feature representation capabilities. The outputs from these three branches are fused through a cross-spatial learning strategy to generate the final attention weights.
The EMA module is applied to the four feature maps extracted by EfficientNetV2-s to enhance key feature responses while preserving their original resolution. Unlike conventional attention mechanisms such as CA, SA, CBAM, and ECA, which typically rely on convolution for channel reduction, EMA employs grouped channel reorganization to avoid information loss from dimensionality compression. This design reduces computational overhead and preserves rich channel interactions, making it well-suited for lightweight, real-time models.
Besides the structural design, the choice of EMA is further based on extensive comparisons in its original study [
35], where it outperformed the attention mechanisms mentioned above across various tasks. Its ability to model multi-scale dependencies makes it particularly effective in addressing challenges such as pixelation, foggy blur, and geometric distortion, which are common in meter reading scenarios. By improving feature representation with minimal cost, EMA enables a better balance between detection accuracy and inference efficiency. The feature maps processed by EMA are then fed into the Neck for further feature fusion, providing more refined feature input to DBHead, thus improving the model’s performance in automatic meter reading tasks.
2.1.3. Multi-Scale KeyDrop Attention Module
To enhance DBNet’s performance in meter reading detection tasks, particularly in challenging scenarios involving pixelation, foggy blur, and extreme lighting, an MSKA module is proposed. MSKA is designed to enhance the feature processing capabilities of DBHead by integrating channel attention, spatial attention, and DropKey-based enhanced attention mechanisms, hierarchically optimizing feature maps to generate high-quality probability maps.
The structure of MSKA is illustrated in
Figure 5,where different colors represent the initial data used for residual addition at different stages. Taking the output from Neck as input
, MSKA first aggregates global cross-channel information through a channel attention mechanism. It extracts channel features using global average pooling and adjusts channel weights through a lightweight convolutional network while preserving original feature information through residual connections. Subsequently, the spatial attention mechanism focuses on the spatial dimensions of feature maps, generating spatial features through channel averaging and applying convolution operations to highlight key spatial regions, effectively capturing the spatial arrangement information of the meter reading area. These two attention mechanisms work in concert to initially enhance feature representation.
To further improve the performance of the model and reduce overfitting, MSKA incorporates a DropKey-based enhanced attention mechanism. This mechanism draws inspiration from DropKey [
36], applying probabilistic masking operations during the training phase to features that have been integrated with channel and spatial attention, simulating a feature regularization process. DropKey encourages the model to attend to different attention regions by randomly dropping certain attention values, reducing dependence on specific dominant features and thereby enhancing model generalization capability. Specifically, given input feature maps x, the DropKey computation is formulated as
where
attn_map denotes the initial attention map derived from the enhanced attention module, and
mask denotes the probabilistic masking generated based on Bernoulli distribution and the fixed dropkey ratio. The output attention map serves as input to the DBHead for generating the final probability map.
The core design of the MSKA module aims to enhance feature representation and mitigate overfitting. The former is achieved by integrating both channel-wise and spatial-wise attention mechanisms, while the latter is achieved through the DropKey-based enhanced attention strategy. Although the feature maps produced by the backbone and FPN contain rich information, under challenging scenarios, the model may misinterpret noisy signals as meaningful features. Therefore, MSKA’s joint design of feature reinforcement and feature dropout strategy play a critical role in improving the model’s robustness and generalization in various challenge scenarios.
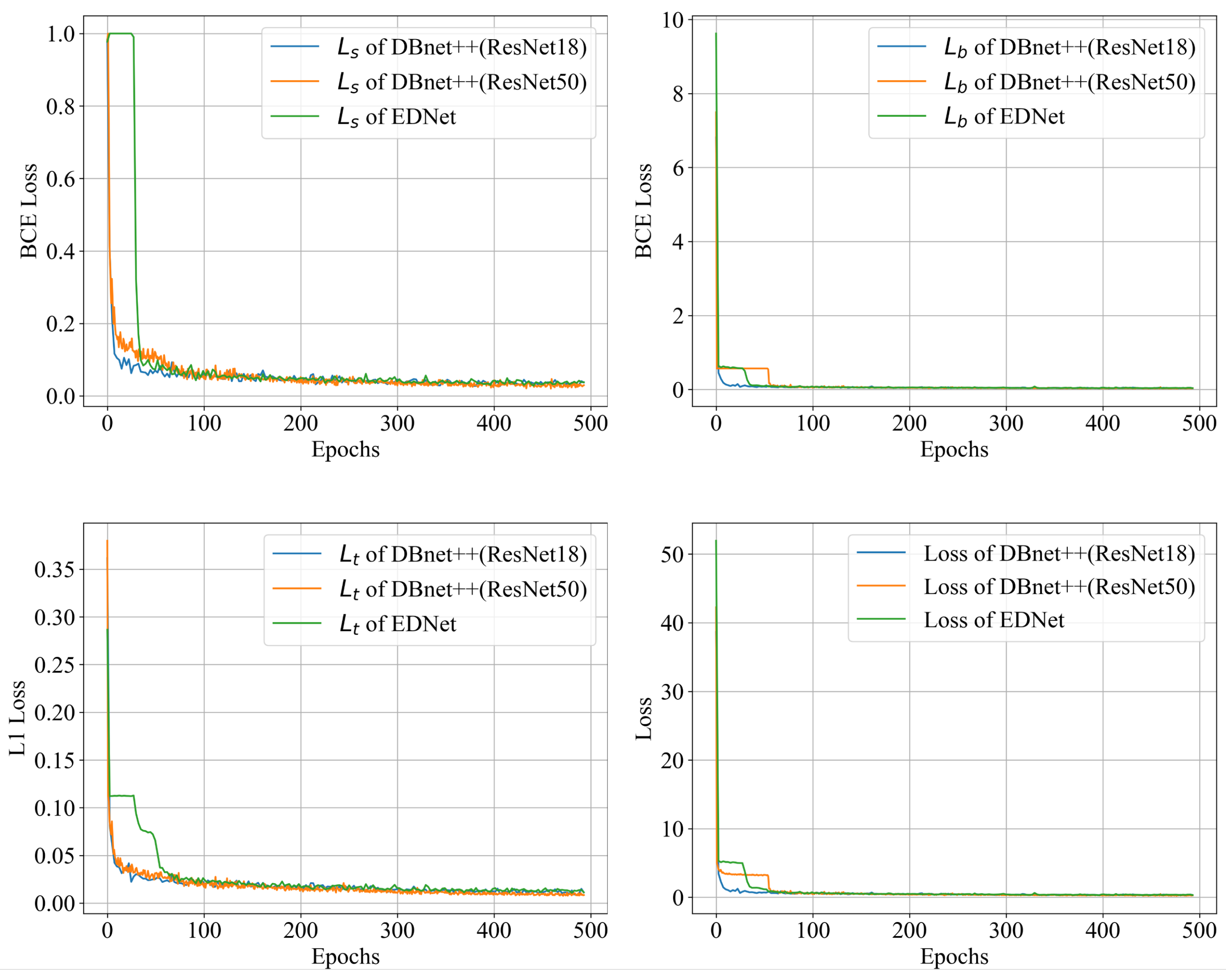
2.1.4. Loss Function
Since EDNet is based on DBNet, it employs the same loss function as DBNet. The loss function is formulated as
where
a and
are empirically set to 5.0 and 10, respectively. The total loss function
L is represented as a weighted sum of the probability map loss
, binary map loss
, and threshold map loss
. Binary Cross-Entropy (BCE) loss is applied to supervise both
and
, whereas
is supervised by
Loss.
2.2. Perspective Transformation
To address common challenges of shooting angle deviation and perspective distortion in meter images, OpenCV-based perspective transformation is employed to correct the polygonal regions output by the EDNet model. Specifically, the minimum bounding rectangle for each polygonal region is computed to effectively delineate the target area. The minimum bounding rectangle is chosen because it encompasses the target region with minimal area, thereby reducing interference from background noise. Subsequently, a perspective transformation matrix is calculated using the four vertices of this rectangle to transform the irregular quadrilateral region into a standardized horizontal rectangle. This step effectively corrects geometric distortions caused by shooting angles, presenting the meter region in a standardized form, thus significantly improving the accuracy and robustness of subsequent reading recognition.
Assuming
represent the four vertices of the minimum bounding rectangle, and
are their corresponding vertices after perspective transformation, the mapping relationship is represented as
where
M denotes the perspective transformation matrix. By applying perspective transformation, distorted regions are corrected into standardized rectangles, effectively improving the accuracy of recognition algorithms in automatic meter reading tasks.
2.3. EPNet
PARSeq [
37] is an advanced permuted autoregressive sequence model for scene text recognition that achieves efficient processing without relying on external language models. Its robust architecture demonstrates exceptional capability in handling challenging scenarios such as image blur, text curvature, and angular rotation, making it particularly suitable for complex text recognition in meter reading tasks. Unlike traditional approaches that depend on standalone language models for prediction refinement, PARSeq’s efficient design enables superior performance in resource-constrained environments while maintaining high recognition accuracy.
In this study, water meter reading images corrected through perspective transformation are fed into the PARSeq model for reading recognition. To further enhance the model’s performance in automatic meter reading tasks, EPNet is proposed, which improves the PARSeq model by incorporating the DropKey mechanism [
36] in the encoder of Vision Transformer. This mechanism randomly drops attention keys with a probability
p during training to reduce overfitting and improve the model’s generalization ability. Thus, EPNet enhances the focus on key features, making it better suited for handling the diverse text inputs and complex image backgrounds encountered in automatic meter reading tasks. Let the Query, Key, and Value be denoted as
with a scaling factor of
. The attention score computation is represented as
where
A denotes the attention score matrix.
A random binary matrix
B, generated according to the Bernoulli distribution and specified dropkey rate, is applied to perturb
A to obtain the perturbed attention matrix
.
The normalized attention score matrix
a is obtained by passing
to the softmax function. During training, Dropout is additionally applied to
a, further improving the model’s generalization ability. Finally, the output
y is obtained by performing matrix multiplication with the Value matrix
V.
EPNet improves recognition accuracy and robustness by incorporating the DropKey mechanism into PARSeq’s Encoder, enabling better adaptation to diverse text inputs and complex image backgrounds encountered in meter reading tasks.
Traditional water meters typically comprise digital readings and pointer readings. Due to various meter designs in the market, the length of numerical digits and the position of decimal points are not standardized. Unlike smart water meters with electronic displays, traditional water meters have their decimal points permanently marked during the molding process. In contrast to YOLO-based recognition methods, EPNet offers the advantage of outputting complete numerical strings. Based on the survey of numerical digits and decimal point configurations in mainstream water meters, mapping is developed between digit count and decimal point positions to automatically correct PARSeq’s output by inserting decimal points at appropriate locations. Specifically, a rule set is designed for the model, which is shown in
Table 2. The X and Y represent integers and decimals, respectively.
5. Conclusions
In the detection task, EDNet employs EfficientNetV2-s as its backbone network with the proposed Multi-scale KeyDrop Attention (MSKA) module and introduced Efficient Multi-scale Attention (EMA) module, thereby enhancing boundary detection precision and recall, particularly in challenging scenarios such as pixelation, blur, glare, and dimness conditions. The model’s generalization capability and robustness are effectively enhanced through perspective transformation of the detection results. In the recognition task, EPNet, based on the PARSeq framework, incorporates a DropKey Attention module to mitigate overfitting and improve recognition accuracy. Experimental results demonstrate that EPNet achieves a recognition accuracy of 90.0%, surpassing the current state-of-the-art methods by 0.2%. The following conclusions can be drawn:
- (1)
Superior Detection Performance: EDNet achieves an F1 score of 0.997988 on the original test set, representing a 0.61% improvement over DBNet++. On the four augmented test sets, it demonstrates improvements in accuracy of 0.7~1.9% compared to the existing best methods. Additionally, EDNet reduces parameter count by 20.03% compared to DBNet++ (ResNet50), achieving a superior balance between high precision and lightweight real-time performance.
- (2)
Enhanced Robustness: EDNet exhibits strong adaptability to complex scenarios involving perspective distortion and rotation. It demonstrates exceptional detection performance in challenging scenarios such as pixelation, foggy blur, glare, and dimness, validating its robustness.
- (3)
Enhanced Recognition Performance: With the integration of the DropKey Attention module, EPNet significantly improves recognition accuracy to 90.0% without substantially increasing parameters, demonstrating excellent practicality and reliability.
- (4)
Through statistical analysis with real-world detection data, critical performance thresholds of EDPNet under extreme conditions are found. Typical errors include incomplete segmentation boundaries and digit misrecognition. Performance deteriorates when rotation angles exceed 75° due to perspective distortions causing a rapid IoU decline; brightness variations beyond ±45% trigger significant error rate increases; fogging shows minimal impact even at high intensities owing to preserved semi-transparent features; and pixelation increases over 90% lead to rapid performance degradation from the loss of discriminative features.
In conclusion, the proposed EDPNet demonstrates considerable potential for text extraction and recognition tasks in diverse challenge scenarios, extending beyond digital meter reading to applications such as expiration date detection on food packaging and the automatic parsing of industrial equipment labels. Based on the identified error patterns, future research will focus on two critical directions: (1) Enhancing model robustness at critical thresholds by developing a comprehensive solution that integrates higher-quality composite training datasets with advanced geometric filtering algorithms, addressing both detection limitations under extreme rotational angles (>75°) and illumination variations (±45%), while preserving valid anchor boxes in challenging recognition scenarios. (2) Explore the deployment of the model entirely on mobile devices for real-time automatic meter-reading breakthroughs, which is more emphasized on deployment than the work in this paper.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}