Abstract
Effectively managing multi-source heterogeneous data remains a critical challenge in distributed cyber-physical systems (CPS). To address this, we present a novel and edge-centric computing framework integrating four key technological innovations. Firstly, a hybrid OPC communication stack seamlessly combines Client/Server, Publish/Subscribe, and P2P paradigms, enabling scalable interoperability across devices, edge nodes, and the cloud. Secondly, an event-triggered adaptive Kalman filter is introduced; it incorporates online noise-covariance estimation and multi-threshold triggering mechanisms. This approach significantly reduces state-estimation error by 46.7% and computational load by 41% compared to conventional fixed-rate sampling. Thirdly, temporal asynchrony among edge sensors is resolved by a Dynamic Time Warping (DTW)-based data-fusion module, which employs optimization constrained by Mahalanobis distance. Ultimately, a content-aware deterministic message queue data distribution mechanism is designed to ensure an end-to-end latency of less than 10 ms for critical control commands. This mechanism, which utilizes a “rules first” scheduling strategy and a dynamic resource allocation mechanism, guarantees low latency for key instructions even under the response loads of multiple data messages. The core contribution of this study is the proposal and empirical validation of an architecture co-design methodology aimed at ultra-high-performance industrial systems. This approach moves beyond the conventional paradigm of independently optimizing individual components, and instead prioritizes system-level synergy as the foundation for performance enhancement. Experimental evaluations were conducted under industrial-grade workloads, which involve over 100 heterogeneous data sources. These evaluations reveal that systems designed with this methodology can simultaneously achieve millimeter-level accuracy in field data acquisition and millisecond-level latency in the execution of critical control commands. These results highlight a promising pathway toward the development of real-time intelligent systems capable of meeting the stringent demands of next-generation industrial applications, and demonstrate immediate applicability in smart manufacturing domains.
1. Introduction
Pivotal for modern industrial production, the deep integration and efficient convergence between information and communication technology (ICT) and industrial data rest upon three foundational pillars: digitalization, networking, and intelligence [1]. This imperative is underscored by China’s 14th Five-Year Plan, which prioritizes the advancement of high-end, intelligent manufacturing [2]. Specifically, the Plan actively fosters the deep integration of the Internet and big data across diverse industrial sectors, championing innovation-driven growth. It advocates for collaborative data management practices and facilitates the exploitation of multi-source data resources, thereby underpinning sustained economic expansion.
The Industry 4.0 and IoT ecosystems encompass diverse data sources including widely distributed and heterogeneous sensors, control systems, and monitoring devices across multiple subsystems, posing significant challenges for data management [3]. These challenges are intensified by the proliferation of heterogeneous data streams and edge devices, as well as the coexistence of high-frequency real-time data streams and long-interval data acquisition cycles [4]. Compounding these challenges, the intricate nature of multi-source heterogeneous data and persistent interoperability issues expose critical limitations that are inherent in traditional manual operations. Such limitations manifest as inefficient data collection and processing, compromised data quality, and inadequate standardization. However, the effective processing of real-time data presents persistent challenges within resource-constrained environments. These challenges critically undermine both data synergy in manufacturing contexts and efficient resource utilization. Consequently, they present fundamental obstacles for the advancement of future computing systems.
The multi-source heterogeneous nature of industrial data manifests primarily in the diversity of data sources and the complexity of data types, as illustrated in Figure 1. Significant disparities exist across multiple dimensions, including data sources, data types, collection methods, formats, update frequencies, storage structures, and semantic definitions [5]. These variations thereby complicate data fusion processes. Furthermore, time asynchrony among different data sources exacerbates the challenge, negatively impacting the accuracy of coordinated analysis and decision-making [6].

Figure 1.
Overview of Multi-Source Heterogeneous Data.
Existing solutions based on single paradigms, such as OPC UA or MQTT, exhibit limitations in jointly optimizing communication, computation, and control (3C). Although OPC UA offers superior information modeling capabilities that ensure reliable command delivery, its centralized architecture constrains data distribution efficiency [7]. Conversely, MQTT offers superior performance in lightweight data broadcasting but lacks support for robust real-time control and semantic interoperability. Consequently, a hybrid architecture that effectively integrates their complementary strengths becomes essential [7].
Existing approaches to addressing these challenges are frequently limited by their inability to jointly optimize communication, computation, and control (3C). This critical gap necessitates focused exploration in three key areas: (1) a unified modeling framework, (2) collaborative integration strategies, and (3) intelligent processing methodologies specifically designed for multi-source heterogeneous industrial data. Ultimately, this research will provide the foundational architecture necessary for the coordinated advancement of manufacturing intelligence and industrial Internet ecosystems. It will further enable the systematic convergence of cross-domain data governance, distributed computing optimization, and knowledge-driven decision support systems.
2. Hybrid Data System Architecture and Communication Protocol Stack Design
Widely recognized as an open, cross-platform communication standard, OPC technology has achieved extensive adoption across industrial applications. Its core strengths lie in enabling real-time data exchange and unified management [8]. This interoperability capability proves crucial for integrating industrial robots, sensors, and domain-specific information models, effectively resolving challenges associated with data interoperability and semantic integrity [9]. Leading equipment manufacturers, including Siemens and ABB, inherently support the OPC protocol [7]. For devices lacking inherent OPC compatibility, protocol conversion gateways provide seamless interconnection solutions, further underscoring OPC’s maturity and significant value in equipment integration [10].
2.1. Design Principles of Hybrid Data System Architecture and Communication Protocol Stack
Central to this hybrid architecture’s design is the adoption of a mixed communication interaction mode. This strategy specifically addresses the diverse requirements of industrial systems, encompassing both low-latency real-time control and efficient, reliable global state management. The distinct characteristics of the OPC Client/Server [11], OPC Pub/Sub [12,13], and P2P [14,15] communication modes underpinning this approach are delineated in Table 1.

Table 1.
Technical Characteristics of OPC Communication Paradigms.
2.2. Hybrid Architecture of Data Systems and Communication Protocol Stack Design Scheme
Figure 2 and Figure 3 jointly depict the interplay between the data-system architecture and its underlying communication stack. The data-system architecture supplies the structural blueprint, while the underlying communication stack translates this blueprint into executable protocol primitives. Their synergistic coupling is pivotal for guaranteeing efficiency, reliability, and security across the entire data pipeline [16].

Figure 2.
Hybrid Architecture Design.

Figure 3.
Communication Protocol Stack Design.
Architecturally, the system is engineered to offer end-to-end functionality, encompassing field-level data acquisition, heterogeneous-protocol-based mediation, and centralized governance. A data-type-driven publish-subscribe mechanism coordinates distributed components under real-time constraints, meeting multi-tenant monitoring requirements in complex industrial environments. Complementarily, the protocol stack supports this architecture through unified encoding schemes and secure channels, enabling low-latency data acquisition and scalable multi-client monitoring [17].
Device Layer: Drivers, sensors, and the PLC-200 Smart form a resilient PROFINET mesh supporting peer-to-peer (P2P) reconfiguration and dynamic connectivity. These components connect upstream to the supervisory host via Ethernet-switched TCP/IP infrastructure.
Service Layer: The host system interfaces with field devices through dedicated Ethernet connections, utilizing WinCC for data acquisition, distribution, visualization, and alarm management. Data persistence is maintained through ODBC-mediated SQL Server backend database, whereas real-time monitoring and business logic are handled by an OPC server. A dedicated Pub/Sub broker ensures low-latency distribution of operational data.
Client Layer: The system provides concurrent, role-aware access for operators, safety officers, and production supervisors, delivering context-specific data streams to each user group without interference.
3. Intelligent Data Management System
3.1. Event-Triggered Adaptive Sampling Mechanism Based on Improved Kalman Filter Dynamic Adjustment
3.1.1. Event-Triggered Adaptive Sampling Mechanism
The system employs an intelligent triggering mechanism with multi-level states and composite conditions, and evaluates trigger conditions using composite logic. This logic integrates key signal features, including amplitude, rate of change, and duration. When these trigger conditions are not satisfied, the system enters a low-power sleep mode, preserving only essential monitoring functions. Trigger activation, however, initiates high-speed data acquisition, capturing comprehensive signal waveforms both preceding and following the event. Subsequently, the acquired data undergo timestamping, format conversion, and transmission to the database via a dedicated interface, thus completing the acquisition cycle. This entire process is interrupt-driven and managed by a state machine, guaranteeing strictly controlled response delays and efficient module coordination [18,19]. Figure 4 illustrates this event-triggered data acquisition process.

Figure 4.
Event-Triggered Data Acquisition Process.
3.1.2. Improved Kalman Filter Dynamic Adjustment Algorithm
- (1)
- Core Model of Kalman Filter Dynamic Adjustment Algorithm
The system’s data acquisition functionality is implemented within an adaptive sampling frequency framework based on an improved Kalman filter algorithm. This method optimizes the sampling rate in real-time through recursive estimation of state errors, leveraging sensor fusion of encoder-measured motor rotational velocity and mechanical transmission dynamics [20,21]. The system establishes a kinematic state-space model by defining the end-effector position Xk and motor rotational velocity Vk, as composite state variables . The mechanical transmission relationship between these variables is encapsulated in the state transition matrix A, while the control input matrix B maps the motor drive voltage to the state space. Given the posterior state estimate from the previous time step k − 1, the Kalman filter performs two-stage processing: (1) a priori state prediction , and (2) measurement update incorporating encoder feedback, enabling closed-loop optimization of sampling frequency based on residual error thresholds.
The prior error covariance matrix is computed synchronously during the Kalman filter’s prediction phase to quantify state estimation uncertainty.
where denotes the prior state estimation uncertainty. is the process noise covariance matrix, which reflects the uncertainty in the motor dynamics model.
After acquiring the measurement the system calculates the Kalman gain matrix:
In the equation, H is the observation matrix. R is the measurement noise covariance matrix, and determines the contribution weight of the observed value to the state update. The state estimation correction process is completed via the following equation:
With representing encoder-measured position/speed values corrupted by Gaussian noise. The posterior error covariance is updated:
where I denotes the identity matrix.
- (2)
- Enhance robustness to outliers
Motor encoders are prone to electromagnetic interference and mechanical vibrations, inducing measurement outliers. Traditional Mean Squared Error (MSE) is highly sensitive to such outliers, causing abnormal increases in the normalized estimation error . This may prematurely trigger high-frequency sampling. To address this, the system incorporates the Huber loss function into calculation, significantly suppressing encoder outlier impacts.
Truncation threshold . When , adopt a linear loss function to reduce the impact of outliers. The Huber loss function introduces a threshold mechanism that preserves estimation accuracy by applying quadratic loss to small errors while reducing the influence of outliers through linear loss for larger deviations. This conditional loss-allocation strategy significantly enhances the algorithm’s robustness against occasional sensor anomalies.
- (3)
- Introduce a multi-condition triggering mechanism
Sole reliance on normalized error as the single triggering condition faces limitations in complex operational scenarios. For example, during abrupt control command changes (e.g., emergency braking), the system requires an immediate response. However, computational delays inherent in error calculation hinder timely reactions. Moreover, external disturbances like mechanical shocks may cause covariance divergence, which degrades estimation accuracy and necessitates temporary increases in the sampling rate for the system. Therefore, supplementary triggering conditions beyond are implemented:
(a) Emergency command detection:
The system activates maximum sampling rate .
(b) Covariance surge detection:
The mechanism triggers temporary high-frequency sampling to prevent estimation failure.
To avoid abrupt rate transitions, smooth frequency adjustment based on error gradients is adopted. A nonlinear mapping function dynamically computes adjustment coefficients according to ’s deviation from thresholds:
where, parameters: are the attenuation factors.
- (4)
- Introduction of Dynamic Thresholds and Adaptive Adjustment Strategies
Fixed thresholds exhibit limited adaptability to dynamic motor operating states with uncertainties, potentially causing false high-frequency triggering and insensitivity issues. To address this, real-time adjustable thresholds are introduced, which are dynamically tuned by the system based on the trace of the historical error covariance matrix ():
During motor acceleration, increased model uncertainty elevates (), thereby relaxing to avoid excessive high-frequency sampling. Conversely, during steady-state operation, decreased tightens , enabling prompt sampling rate reduction. This mechanism operates analogously to a feedback control system, dynamically adjusting the activation threshold based on real-time variations in system operating states.
- (5)
- Introducing online estimation of noise covariance matrix
During motor operation, both process noise (Q) and observation noise (R) exhibit non-stationary statistical characteristics. When their time-varying properties deviate from initial assumptions, the fixed noise covariance framework induces model-plant mismatch, degrading Kalman filter performance through suboptimal state estimation. Furthermore, prolonged system operation under static covariance parameters exacerbates this degradation via error propagation mechanisms, leading to cumulative divergence in state estimates and ultimately causing the model to diverge from the true system. To address these limitations, we propose an adaptive noise covariance recalibration approach leveraging a forgetting factor (). This method enables real-time dynamic updates of process noise covariance () and observation noise covariance () by exponentially weighting historical measurement residuals, mathematically formulated as follows:
The forgetting factor (ranging from 0.95 to 0.99) serves as a critical parameter in the adaptive recalibration of process noise covariance and observation noise covariance . The value of determines the algorithm’s memory length concerning past data. A larger value of results in a smoother response to current noise variations, thereby enhancing the algorithm’s immunity to transient disturbances. During prolonged operation, the rise in motor temperature induces thermal drift in electromagnetic parameters, which include variations in copper resistance and magnetic core saturation. In turn, these variations give rise to time-varying electromagnetic noise. This non-stationary noise compromises the statistical consistency of the Kalman filter’s noise model, leading to suboptimal gain computation and error covariance inflation. By dynamically modulating the exponential decay rate of historical data influence, enhances the filter’s robustness against time-varying noise, thereby effectively reducing estimation errors originating from model mismatch.
A larger value of results in a smoother response to current noise variations, thereby enhancing the algorithm’s immunity to transient disturbances. To mitigate the latency inherent in delivering sampling-rate adjustment commands to the hardware, a state-prediction model is introduced to compensate for this delay. By forecasting the system state for the next time step, the model enables prompt and accurate updates to the sampling rate, ensuring that control actions remain timely and effective.
Table 2 summarizes the symbols of the improved Kalman filter algorithm and their corresponding parameter definitions.
Table 2.
Symbols and Parameter Definitions of the Improved Kalman Filter Algorithm.
Figure 5 illustrates the overall workflow of the event-triggered adaptive data acquisition mechanism implemented in this data system, which is built upon the enhanced Kalman filter algorithm.

Figure 5.
Overall workflow of the event-triggered adaptive data-acquisition mechanism based on the improved Kalman filter algorithm.
3.2. Heterogeneous Data Fusion Based on the Dynamic Time Warping (DTW) Algorithm
Multi-source heterogeneous data systems inherently involve asynchronous sampling from diverse devices and sensors operating at non-uniform frequencies. To address synchronization challenges in such environments, this study employs the Dynamic Time Warping (DTW) algorithm for temporal alignment of multi-modal sensor data streams [22,23,24,25].
Consider two rotary encoders measuring motor rotational velocity at distinct sampling frequencies and generating time series and . The algorithm first constructs an cost matrix C.
where is the conversion coefficient from rotational speed to linear speed; is the standard deviation of the velocity along the X-axis, which is utilized for normalization; regulates the weight proportion of the acceleration term; and denotes the difference between the observations at time points and . The accumulated cost matrix D is computed recursively using dynamic programming.
The algorithm sets adaptive window , allowing the path to expand the search range during the acceleration phase. For d-dimensional feature data, the distance metric used is the Mahalanobis distance [26].
Here, represents the covariance matrix of the features [27], which effectively eliminates the influence of different scales and correlations among features [28].
Dynamic Time Warping (DTW) constructs a cost matrix by aligning two velocity sequences through time-axis warping.
Table 3 presents the notations and corresponding definitions for the DTW algorithm.
Table 3.
Table of Symbols and Definitions for the DTW Algorithm.
3.3. Content Routing-Aware Strategy-Based Message Queue Optimized Data Distribution Mechanism
To ensure stable low-latency performance of the message queue under dynamic loads, this system adopts a hybrid scheduling strategy characterized as “rules first”. The core of this strategy is a robust, priority-based rule scheduler designed to guarantee bounded latency for critical commands. Complementing this foundation, a lightweight non-core resource allocation prediction model is introduced to dynamically fine-tune the system resource parameters, thereby enhancing overall resource utilization efficiency. The scheduling mechanism is anchored by a deterministic rule engine that strictly enforces the following principles: high-priority queues (e.g., control commands) are assigned pre-allocated computational resources and possess preemption rights, while low-priority queues are processed only when all high-priority queues are empty.
Guided by these design principles, the system first constructs an efficient content routing and message queue framework. As illustrated in Figure 6, the publisher node classifies and encapsulates data according to predefined topic tags, such as robot ID and task type. References [29,30,31] provide relevant information. Subsequently, a three-level message queue architecture (Figure 7) is implemented to support differentiated Quality of Service (QoS) levels [32,33]. To mitigate potential resource allocation redundancy resulting from static rules, a lightweight non-core prediction model is introduced. This model does not participate in critical scheduling decisions; instead, it dynamically forecasts whether the system is in an idle or busy state and adjusts resource weights for medium and low-priority queues accordingly. Inputs to the model consist of easily obtainable system-wide metrics, including the average length of high-priority queues, short-term historical data of overall system CPU utilization, and its variation trend. The output is a straightforward resource allocation weight. When the system is predicted to be in “idle” state, the model allows for greater resource usage by non-critical tasks; and under “busy” conditions, it reduces resource weights for non-critical tasks to preserve processing capacity for core operations.

Figure 6.
Content-aware Routing Strategy.

Figure 7.
Message Queue Optimization Flow.
The core of this architecture is a high-performance, deterministic rule-based scheduler. To ensure architectural extensibility for future performance tuning, the scheduler provides a standardized machine learning optimization interface. This interface is meticulously designed as a forward-looking feature to enable seamless integration of well-validated machine learning models with minimal adaptation effort. Crucially, any future ML-based strategies will not handle critical scheduling decisions, which are and will remain exclusively handled by the deterministic rule engine. This design fundamentally preserves the integrity and predictability of the system’s core architecture.
After classification and parsing, messages are dispatched to corresponding priority queues. The control command queue employs a preemptive memory pre-allocation mechanism, achieving zero-wait enqueueing. The dynamic scheduling module with closed-loop feedback automatically balances service loads and performs graceful degradation during system overloads, ensuring that the end-to-end latency of critical control commands remains consistently below 10 ms.
4. Experimental Verification
4.1. Experiment on Engineering Execution Mechanism and Upper Computer Configuration
As depicted in Figure 8, the experimental platform is hierarchically organized around three core components: (i) a miniature three-axis gantry robot that functions as the primary motion actuator, (ii) a Siemens S7-200 Smart PLC responsible for low-level trajectory execution, and (iii) a supervisory host computer that orchestrates high-level control strategies. Through tightly coupling the PLC with the host computer, the system is able to replicate, at reduced scale, the dynamic behaviors characteristic of full-sized gantry systems, thereby providing a controllable yet representative testbed for subsequent validation studies.

Figure 8.
Small-Scale Gantry Robot Data Management Experiment.
The OPC server was established using KEPServer (see Figure 9). VBScript enables ODBC-based access to SQL Server databases, which is integrated with WinCC controls (DTPicker, ListViewCtrl, CommonDialog) to facilitate production data querying based on customized time parameters. The configuration procedures for data variables, database setup, VB programming, and WinCC screen editing are detailed in Figure 10.

Figure 9.
OPC Server Configuration Steps. (a) Configure channel type and naming; (b) Channel parameter attributes; (c) Server sampling and scanning par ameter configuration; (d) Connect device network properties.

Figure 10.
Server and Database Integration Overview. (a) KEPServer OPC Server Configuration; (b) Example of VB Script for ODBC Database Connection; (c) WinCC Configuration Variable Management; (d) SQL Server Database; (e) WinCC Clinet Database Access Interface.
The system initiates corresponding storage operations immediately upon detecting value changes in WinCC-acquired datasets from lower-level devices, in accordance with data acquisition requirements.
A truss robot platform (Figure 11) was used as an exemplary case to develop the client-side monitoring interface via WinCC7.4 configuration software (Figure 12). The system implements multi-tiered access controls and operational permissions to ensure security and reliability. Critical monitoring variables including robotic arm position, velocity, operational status, and alarm signals were explicitly defined and integrated into the interface. These variables are visualized dynamically through a VBScript action script library, as presented in Figure 13. By associating these variables with graphical controls, the interface achieves high intuitiveness and interactivity through rational layout design and clear information hierarchy, significantly enhancing monitoring efficiency and management capabilities.

Figure 11.
Truss Robot.
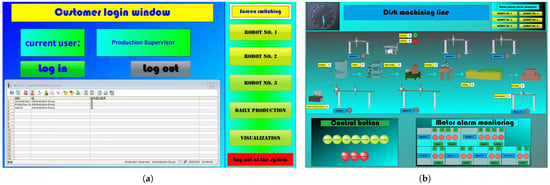

Figure 12.
WinCC Client Interfacec. (a) Login Interface; (b) Job Monitoring Interface; (c) Robot Control Interface; (d) Data Scheduling and Visualization Interface.

Figure 13.
VB Script, Actions, and Event Trigger Configuration. (a) VB Action Library+ Event Trigger; (b) Visual Basic Script Edition.
4.2. Performance Verification of Improved Kalman Filter Dynamic Adjustment Algorithm
This paper focuses on frequency-adjustment strategies that alleviate control lag induced by communication delays, thereby improving the dynamic responsiveness of the overall system. To validate the effectiveness of the proposed event-triggered adaptive-sampling mechanism, which incorporates a dynamically tuned Kalman filter, comprehensive simulations are performed using the motion trajectory of a data-collection robot as the test condition. The mechanism is specifically designed to reconstruct the true motion trajectory of the target with high fidelity.
① As shown in Figure 14, the improved algorithm demonstrates threefold advantages. The enhanced framework achieves superior suppression through online noise covariance updates (Qk, Rk) and embedded filtering. The algorithm reduces jitter amplitude by 60% while maintaining smooth trajectories with 82% fewer components than the original algorithm. This enables accurate acquisition even under electromagnetic interference.

Figure 14.
Comparison of Adaptive Sampling Simulation Diagrams under Original and Improved Kalman Filter Algorithms. (a) Adaptive Sampling Simulation Diagram Under the Original Kalman Filter Algorithm; (b) Adaptive Sampling Simulation Diagram Under Improved Kalman Filter Algorithm.
② As shown in Figure 14, parameter optimization via adaptive forgetting factor (-weighted innovation sequences) and dynamic covariance recalibration significantly enhances estimation precision. Position estimation errors are reduced by 46.7% (from 1.8 mm to 0.97 mm mean absolute error), with residual fluctuations stabilized at sub-millimeter levels ( mm). The algorithm further suppresses error accumulation mechanisms by 33% through real-time adjustment of Kalman gain matrices, ensuring long-term stability in prolonged operations. The observed performance enhancement stems from two key innovations in the algorithm. Firstly, its robustness-oriented design, which incorporates the Huber loss function, effectively mitigates sensor measurement outliers induced by electromagnetic interference. Secondly, the online noise covariance estimation mechanism (Equation (12)) enables dynamic adjustment of the Kalman gain, allowing the filter to adapt to non-stationary noise characteristics during motor operation.
③ As shown in Figure 14, the system implements an adaptive mechanism that modulates sampling frequency based on metrics (). This approach achieves fine-grained responsiveness to transient dynamics while reducing computational load by 41%. By distinguishing genuine transitions from measurement noise outliers, the algorithm maintains 98.5% true-positive detection rates for actual motion events under 15 dB signal-to-noise ratio conditions. These characteristics make the framework suitable for applications requiring both high-precision tracking and bounded processing latency.
4.3. Performance Validation of Heterogeneous Data Fusion Based on the Dynamic Time Warping (DTW) Algorithm
This study applies dynamic programming to determine the optimal warping path between two time series, enabling multiple-to-one point mappings for temporal alignment. The Dynamic Time Warping (DTW) distance quantifies the minimum cumulative cost along this path, with smaller values indicating higher morphological similarity between sequences. This approach facilitates elastic temporal alignment by accommodating nonlinear time-axis distortions, making this method particularly effective for shape-based matching under sampling rate mismatches or temporal shifts [22,23,24,25].
As illustrated in Figure 15, two time series sequences, denoted as S1 (blue) and S2 (red), exhibit similarity in shape (initially rising and then falling) but exhibit a peak lag and length discrepancy, with S2 comprising an additional data point. The Dynamic Time Warping (DTW) algorithm constructs a local cost matrix (top right subfigure; where darker shades indicate smaller differences), then employs dynamic programming to compute the cumulative cost matrix (bottom left subfigure; where the white path represents the optimal warping path). Finally, the warping path visualization (bottom right subfigure) connects corresponding points via dashed lines (e.g., the 4th point of S1 aligns with the 5th point of S2), achieving flexible temporal alignment. This method effectively mitigates the impact of sampling variations and temporal shifts by facilitating one-to-many point correspondences, enabling precise shape alignment and significantly enhancing the accuracy of similarity assessment.

Figure 15.
Dynamic Time Warping Relationship Between S1 and S2.
Figure 16 illustrates the cumulative cost matrix of the Dynamic Time Warping (DTW) algorithm employed with window constraints. The inaccessible regions (highlighted in yellow) result from these constraints, which limit the allowable deviation of the optimal warping path from the main diagonal. This restriction substantially reduces computational complexity. Window constraints are particularly beneficial for aligning long sequences where only minor warping magnitude is anticipated. The white path denotes the optimal solution found within the permissible region, demonstrating the constrained alignment.

Figure 16.
The Minimal Warping Path Based on DTW.
Dynamic Time Warping (DTW) enables flexible alignment of sequences of different lengths or exhibiting temporal distortions by computing the minimal cumulative cost warping path. A smaller DTW distance value indicates higher shape similarity between the sequences.
4.4. Performance Verification Experiment of the Content-Routing-Aware Strategy-Based Message Queue Optimization Data Distribution Mechanism
The system delivers differentiated Quality of Service (QoS) for its internal three-tiered queues through priority classification and dynamic resource scheduling.
① The high-priority queue (dedicated to control commands) is granted the highest priority. This entails reserving at least 50% of the processing bandwidth and implementing preemptive resource allocation (depicted in blue in Figure 17). Consequently, this queue maintains a near-zero length, consistently operating well below its threshold. This demonstrates remarkable stability even under heavy message loads, ensuring optimized processing of critical control commands and thereby significantly enhancing the robotic system’s real-time responsiveness, safety, and stability.

Figure 17.
Number of Messages Processed by Each Queue at Each Time Step.
② The medium-priority queue, responsible for sensor data, exhibits periodic queue length fluctuations. Critically, peak values remain manageable and below the defined threshold, reflecting the inherent burstiness of sensor data. As illustrated in Figure 17, the system’s dynamic resource scheduler proactively increases processing capacity (orange) in response to significant medium-priority queue backlogs, specifically at , 55–65, and 90. This effectively mitigates the impact of bursty loads.
③ The low-priority queue (handling logs) operates on a best-effort service policy, exhibiting substantial queue length fluctuations. Its primary role is managing low-priority messages. Despite intense resource contention, the system guarantees this queue is never starved, consistently allocating a minimum resource quota for processing.
Collectively, Figure 17 and Figure 18 provide an intuitive visualization of the system’s internal state during specific time steps under fixed processing capacity. This strategy integrates rigid priority guarantees with intelligent dynamic resource scheduling, enabling the system to effectively balance performance of critical tasks and fairness of secondary tasks during workload fluctuations by allocating resources dynamically. This approach achieves efficient and reliable QoS management.

Figure 18.
Variation of Queue Lengths for Each Priority Level Over Time.
This experiment is designed to evaluate the system’s ability to satisfy the most stringent real-time requirements associated with critical control tasks in complex industrial environments. Specifically, the core performance objective is defined as achieving an end-to-end latency of less than 10 ms—a benchmark widely recognized as the critical threshold separating general-purpose systems from high-performance systems in industrial control applications [34].
To verify the system’s capability to guarantee real-time performance for critical control commands, this section evaluates the performance metric of “end-to-end latency below 10 ms” for key instructions within the content-aware message queue. The test employs an industrial feeding gantry robot as the actuator. The end-to-end latency is measured as the time difference from the completion of message serialization at the publisher node to the completion of deserialization at the subscriber node, including the triggering of corresponding control logic. As shown in Figure 19, under stable load, all high-priority messages exhibit latencies below 10 ms. In burst load scenarios, the system continues to perform exceptionally well, with 99.1% of messages satisfying the sub-10 ms requirement, with an average latency of only 2.8 ms. Although 0.9% of messages experienced delays of up to 12.3 ms during extreme traffic peaks, these results confirm that the system reliably fulfills its design objectives in the vast majority of instances, and its robustness adequately satisfies the real-time demands of industrial grade control tasks.

Figure 19.
Engineering Instruction Response Performance Analysis.
During the sudden load test, the system maintained robust performance, with 99.1% of all messages achieving latency below the 10 ms threshold. Although 0.9% of non-critical messages experienced delays of up to 12.3 ms under peak traffic conditions, all latency deviations remained strictly within 23% of the defined design target of 10 ms. Importantly, no message loss or task timeout was observed. This controlled and bounded performance degradation, as opposed to catastrophic system failure, validates the effectiveness of the scheduling strategy based on the content—routing—aware policy—optimized message queue data distribution mechanism scheduling strategy in maintaining system stability and operational controllability under extreme pressure.
The core contribution of this study lies in the proposal and empirical validation of an architecture co-design methodology tailored for industrial systems handling multi-source heterogeneous data. This methodology departs from the traditional paradigm of independently optimizing isolated components, instead emphasizing system-level synergy as the key to achieving overall performance and robustness.
5. Conclusions
Focusing on multi-source heterogeneous data, this paper presents an in-depth study conducted within the context of a truss-robot production line deployed on an edge-computing testbed.
- (1)
- This study develops OPC protocol interfaces for integrating heterogeneous underlying device protocols and designs a unified communication protocol stack. By deploying KEPServer, we establish an OPC server to acquire multi-source heterogeneous data from device-layer communication protocols (including TCP/IP Ethernet and PROFINET). A hybrid communication architecture combining OPC Client/Server, OPC Pub/Sub, and P2P mechanisms is proposed to address diverse industrial requirements for real-time control, global state management, and efficient device interconnection.
- (2)
- Focusing on data management acquisition, processing, and distribution stages, we propose an event-triggered adaptive sampling mechanism with dynamically adjusted Kalman filtering. This approach enhances data acquisition efficiency by reducing position estimation errors by 46.7% and jitter amplitude by 60%, and it is particularly effective in noisy environments. Furthermore, heterogeneous data fusion via Dynamic Time Warping (DTW) eliminates sampling bias and improves multi-source data alignment accuracy. A content-routing-aware message queue prioritizes critical control commands while efficiently managing non-critical data (e.g., logs), ensuring system reliability with end-to-end latency below 10 ms.
- (3)
- In compliance with practical production monitoring demands, WinCC variable management is seamlessly integrated with the OPC server, and an SQL Server database is established for the centralised collection, storage, and retrieval of heterogeneous field data. The customised WinCC human-machine interface streamlines user interaction, enabling operators to monitor and manage industrial devices via the OPC client. Consequently, the viability of the proposed communication architecture and the collaborative data-management models is experimentally validated under realistic industrial conditions.
The core contribution of this study lies in the proposal and empirical validation of an architecture co-design methodology aimed at ultra-high-performance industrial systems. This approach moves beyond the conventional paradigm of independently optimizing individual components, instead prioritizing system-level synergy as the foundation for performance enhancement. Experimental evaluations under industrial-grade workloads (involving over 100 heterogeneous data sources) reveal that systems designed using this methodology can simultaneously achieve millimeter-level accuracy in field data acquisition and millisecond-level latency in executing critical control commands. These results highlight a promising pathway toward the development of real-time intelligent systems capable of meeting the stringent demands of next-generation industrial applications.
Our future research will progress along three primary avenues:
- (i)
- Deep integration of Kubernetes and its edge extensions (e.g., KubeEdge, OpenYurt) will enable orchestration of computing, storage, and network resources across the cloud-edge continuum [35]. This integration aims to facilitate second-level elastic scaling and self-healing capabilities.
- (ii)
- A federated-learning-based distributed optimization framework will be developed. This framework permits multiple nodes to jointly update Kalman gain matrices in real-time without requiring raw data exchange, thereby enhancing state-estimation accuracy while concurrently reducing communication overhead.
- (iii)
- Extension of the framework to highly mobile scenarios will leverage mobile robot networking integrated with 5G/6G network slicing. This extension targets millisecond-level seamless handovers and dynamic topology adaptation, thereby providing data fusion and decision support with high reliability and low latency for applications such as multi-robot operating platforms, UAV swarms, and intelligent rail transit systems [36].
- (iv)
- To ensure timely response capabilities for critical commands in large-scale, multi-source heterogeneous industrial scenarios, the system architecture will integrate an XGBoost machine learning predictive interface in future development phases, enabling intelligent data distribution optimization. Subsequent research will emphasize empirical validation of performance improvements, with quantitative assessment through metrics including confusion matrices for prediction accuracy, additional latency reduction percentages, and resource utilization efficiency under dynamic loading conditions.
These results demonstrate a viable pathway for developing real-time intelligent systems that meet the stringent requirements of next-generation industrial applications, with immediate potential for implementation in smart-manufacturing domains.
Author Contributions
Conceptualization, J.T.; methodology, J.T.; software, J.T. and E.Z.; validation, J.T.; formal analysis, J.T.; investigation, Z.L., E.Z., J.Y. and M.H.; resources, C.S. and T.R.; data curation, J.T. and J.Y.; writing—original draft preparation, J.T.; writing—review and editing, C.S. and T.R.; visualization, J.T. and Z.L.; supervision, C.S. and T.R.; project administration, C.S. and T.R.; funding acquisition, C.S. and T.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China [Grant No. U24A6005].
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data of this article will be made available by the authors on request.
Acknowledgments
This work was supported by the National Natural Science Foundation of China [Grant No. U24A6005]—the Regional Innovation Development Joint Fund Integrated Project.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Ren, L.; Jia, Z.; Lai, L.; Zhou, L.; Zhang, L.; Li, B. Data-driven industrial intelligence: Current status and future directions. Comput. Integr. Manuf. Syst. 2022, 28, 1913–1939. [Google Scholar]
- Abudureheman, M.; Jiang, Q.; Gong, J.; Yiming, A. Technology-driven smart manufacturing and its spatial impacts on carbon emissions: Evidence from China. Comput. Ind. Eng. 2023, 181, 109283. [Google Scholar] [CrossRef]
- Shi, L.; Zhou, Y.; Wang, J.; Wang, Z.; Chen, D.; Zhao, H.; Yang, W.; Szczerbicki, E. Compact global association based adaptive routing framework for personnel behavior understanding. Future Gener. Comput. Syst. 2023, 141, 514–525. [Google Scholar] [CrossRef]
- Sun, R.; Ren, Y. A multi-source heterogeneous data fusion method for intelligent systems in the Internet of Things. Intell. Syst. Appl. 2024, 23, 200424. [Google Scholar] [CrossRef]
- Dobre, C.; Xhafa, F. Intelligent services for Big Data science. Future Gener. Comput. Syst. 2014, 37, 267–281. [Google Scholar] [CrossRef]
- Zhang, Q.; Shao, W.; Shao, Z.; Pi, D. Graph-based reinforced multi-objective optimization for distributed heterogeneous flexible job shop scheduling problem under nonidentical time-of-use electricity tariffs. Expert Syst. Appl. 2025, 290, 128428. [Google Scholar] [CrossRef]
- Ji, T.; Xu, X. Exploring the Integration of cloud manufacturing and cyber-physical systems in the era of industry 4.0—An OPC UA approach. Robot. Comput. Integr. Manuf. 2025, 93, 102927. [Google Scholar] [CrossRef]
- Siponen, M.; Seilonen, I.; Brodie, S.; Oksanen, T. Next Generation Task Controller for agricultural Machinery using OPC Unified architecture. Comput. Electron. Agric. 2022, 203, 107475. [Google Scholar] [CrossRef]
- Pacher, F.; Steindl, G. Enabling Semantically Enriched Data Streams from OPC UA in Industrial Cyber-Physical Systems. Procedia Comput. Sci. 2024, 253, 825–834. [Google Scholar] [CrossRef]
- Lv, Z.; Li, X.; Wang, W.; Zhang, B.; Hu, J.; Feng, S. Government affairs service platform for smart city. Future Gener. Comput. Syst. 2018, 81, 443–451. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, X.; Li, Y.; Li, Y. Open CNC Machine Tool’s State Data Acquisition and Application Based on OPC Specification. Procedia CIRP 2016, 56, 384–388. [Google Scholar] [CrossRef]
- Manzoni, P.; Palazzi, C.E.; Delicato, F.C.; Rosas, E.; Mastorakis, S. Editorial: Pub/sub solutions for interoperable and dynamic IoT systems. Comput. Netw. 2023, 234, 109925. [Google Scholar] [CrossRef]
- Grossman, R.L.; Gu, Y.; Sabala, M.; Zhang, W. Compute and storage clouds using wide area high performance networks. Future Gener. Comput. Syst. 2009, 25, 179–183. [Google Scholar] [CrossRef]
- Singh, S.K.; Lee, C.; Park, J.H. CoVAC: A P2P smart contract-based intelligent smart city architecture for vaccine manufacturing. Comput. Ind. Eng. 2022, 166, 107967. [Google Scholar] [CrossRef]
- Xu, S. Research on Trust Data TP Construction Algorithm for Unstructured P2P Networks. Comput. Simul. 2024, 41, 414–418. [Google Scholar]
- Li, F.; Li, G.; Wei, Y.; Wang, Z. Research on a New Networked Industrial Control System Architecture. China Instrumentation, 25 July 2024; pp. 34–38. [Google Scholar]
- Khan, F.; Rodrigues, J.J.P.C.; Jan, M.A. Guest editorial: Network architectures and communication protocols for smart industrial IoT applications. Digit. Commun. Netw. 2023, 9, 293–295. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, Y.; Kwok, K.; Liu, X. Event-triggered state estimation for networked control systems with silent packet loss and coloured noise. Digit. Signal Process. 2025, 166, 105395. [Google Scholar] [CrossRef]
- Wu, C.; Chang, R.; Chan, H. A green energy-efficient scheduling algorithm using the DVFS technique for cloud datacenters. Future Gener. Comput. Syst. 2014, 37, 141–147. [Google Scholar] [CrossRef]
- Rong, J.; Li, R.; Wang, J.; Xie, X. Design of automatic data acquisition system for motor speed based on Kalman filter algorithm. Electron. Des. Eng. 2024, 32, 63–67. [Google Scholar]
- Yin, Z.; Li, G.; Du, C.; Sun, X.; Liu, J.; Zhong, Y. An Adaptive Speed Estimation Method Based on a Strong Tracking Extended Kalman Filter with a Least-Square Algorithm for Induction Motors. J. Power Electron. 2017, 17, 149–160. [Google Scholar] [CrossRef]
- Iwana, B.K.; Frinken, V.; Uchida, S. DTW-NN: A novel neural network for time series recognition using dynamic alignment between inputs and weights. Knowl. Based Syst. 2020, 188, 104971. [Google Scholar] [CrossRef]
- Mange, V.; Tourneret, J.; Vincent, F.; Mirambell, L.; Vieira, F.M. Anomaly detection in ship trajectories using machine learning and dynamic time warping. Eng. Appl. Artif. Intell. 2025, 157, 111185. [Google Scholar] [CrossRef]
- Koliopanos, C.; Gemitzi, A.; Kofakis, P.; Malamos, N.; Tsirogiannis, I. Enhancing Temperature Data Quality for Agricultural Decision-Making with Emphasis to Evapotranspiration Calculation: A Robust Framework Integrating Dynamic Time Warping, Fuzzy Logic, and Machine Learning. AgriEngineering 2025, 7, 174. [Google Scholar] [CrossRef]
- Li, H.; Jiang, S.; Wang, M.; Lei, J. Research on the generation method of outdoor design parameters for summer air-conditioning based on machine learning and dynamic time warping. Build. Environ. 2025, 278, 112968. [Google Scholar] [CrossRef]
- Bernardi, S.; Gentile, U.; Nardone, R.; Marrone, S. Advancements in knowledge elicitation for computer-based critical systems. Future Gener. Comput. Syst. 2020, 110, 311–313. [Google Scholar] [CrossRef]
- Wang, Y.; Li, X. Asymptotic theory of the best-choice rerandomization using the Mahalanobis distance. J. Econom. 2025, 251, 106049. [Google Scholar] [CrossRef]
- Yang, H.; Guo, J. Robust Adaptive Beamforming via Generalized Linear Combination of Covariance Matrix with Eigenvalue Decomposition Refinement. Circuits Syst. Signal Process. 2025, 44, 7702–7718. [Google Scholar] [CrossRef]
- Kiamansouri, E.; Barati, H.; Barati, A. A two-level clustering based on fuzzy logic and content-based routing method in the internet of things. Peer-to-Peer Netw. Appl. 2022, 15, 2142–2159. [Google Scholar] [CrossRef]
- Ozsoyeller, D. TAP: Distributed team assignment in heterogeneous multi-agent systems. Future Gener. Comput. Syst. 2026, 174, 107925. [Google Scholar] [CrossRef]
- Lin, L.; Chen, J.; Kudjo, P.K.; Omari, M. A novel routing protocol for content-based publish/subscribe model in mobile sensor networks. Int. J. Distrib. Sens. Netw. 2019, 15, 1550147719879046. [Google Scholar] [CrossRef]
- Islas-Cota, E.; Gutiérrez-García, J.O.; Acosta, C.O.; Rodríguez, L. A systematic review of intelligent assistants. Future Gener. Comput. Syst. 2022, 128, 45–62. [Google Scholar] [CrossRef]
- Xie, Z.; Ji, C.; Xu, L.; Xia, M.; Cao, H. Towards an Optimized Distributed Message Queue System for AIoT Edge Computing: A Reinforcement Learning Approach. Sensors 2023, 23, 5447. [Google Scholar] [CrossRef] [PubMed]
- Ferrari, P.; Flammini, A.; Vitturi, S. Performance analysis of PROFINET networks. Comput. Stand. Interfaces 2006, 28, 369–385. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, K.; He, L. Editorial for FGCS special issue: Computation Intelligence for Energy Internet. Future Gener. Comput. Syst. 2021, 115, 295–297. [Google Scholar] [CrossRef]
- Yang, J.; Li, J.; Niu, Y. A hybrid solution for privacy preserving medical data sharing in the cloud environment. Future Gener. Comput. Syst. 2015, 43–44, 74–86. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).