Abstract
The slow propagation speed of acoustic waves in water leads to significant variations and random fluctuations in communication delays among underwater acoustic sensor network (UASN) nodes. Conventional deep reinforcement learning (DRL)-based underwater acoustic network access methods can adaptively adjust their parameters and improve network communication efficiency by effectively utilizing inter-node delay differences for concurrent communication. However, they still suffer from shortcomings such as not accounting for random delay fluctuations in underwater acoustic links and low learning efficiency. This paper proposes a DRL-based delay-fluctuation-resistant underwater acoustic network access method. First, delay fluctuations are integrated into the state model of deep reinforcement learning, enabling the model to adapt to delay fluctuations during learning. Then, a double deep Q-network (DDQN) is introduced, and its structure is optimized to enhance learning and decision-making in complex environments. Simulations demonstrate that the proposed method achieves an average improvement of 29.3% and 15.5% in convergence speed compared to the other two DRL-based methods under varying delay fluctuations. Furthermore, the proposed method significantly enhances the normalized throughput compared to conventional Time Division Multiple Access (TDMA) and DOTS protocols.
1. Introduction
The propagation speed of underwater acoustic signals ranges from approximately 1460 m/s to 1520 m/s, which is much lower than that of radio frequency signals ( m/s). This dramatically reduced propagation speed introduces two critical challenges for underwater acoustic sensor networks (UASNs). First, the slow signal velocity creates significant end-to-end latency, with one-way delays often reaching hundreds of milliseconds even for moderate distances. Second, environmental factors including temperature gradients, salinity variations, and dynamic water currents cause temporal variations in propagation speed, leading to significant propagation delay fluctuation. These physical characteristics make the collision patterns in UASNs completely different from those on land and significantly affect the performance of the Medium Access Control (MAC) protocol in UASNs.
To address the propagation delay variations caused by the different distances between source nodes and target nodes, some MAC protocols for UASNs regard them as parallel opportunities in time. By strategically scheduling the transmission times of source nodes, these protocols enable collision-free concurrent transmission in time division multiple access (TDMA) [1,2,3,4] or handshake-based [5,6,7] schemes, or reduce the collision probability in random access protocols [8]. However, these protocols generally depend on accurate propagation delay estimation, and the dynamic underwater environments often undermine delay estimation accuracy and protocol reliability.
In recent years, DRL [9,10] has introduced a novel paradigm for enhancing communication protocols in UASNs. DRL algorithms allow network nodes to learn through environment interaction, thereby optimizing key functions such as routing, resource allocation, and dynamic spectrum access. This capability improves the adaptability and overall performance of the network. Currently, research on DRL-based MAC protocols for UASNs is still in the early stage. Only a limited number of such protocols have been proposed, which aim to enhance network throughput by efficiently utilizing the idle time slots resulting from propagation delay differences among nodes. In [11], a DRL-based MAC protocol for UASNs named DR-DLMA (Delayed Reward Deep Reinforcement Learning Multiple Access) was first introduced. It formalized the state, action, and reward structures within the UASN access process and integrated propagation delay into the DRL framework. In the DR-DLMA protocol, nodes apply deep reinforcement learning to select the optimal channel access strategy. This approach effectively utilizes the idle time slots caused by the propagation delay differences or unused slots from other nodes to improve data transmission efficiency. In [12], the AUMA (Adaptive Underwater Medium Access Control based on Deep Reinforcement Learning) protocol was proposed. Leveraging DRL techniques, it effectively utilizes the high propagation delay of UASNs to learn the optimal round-trip transmission delay and window size, and adjusts the congestion window mechanism to improve the overall throughput and channel utilization of high-mobility underwater acoustic communication networks. In [13], the issue of unfair channel allocation and energy-constrained nodes in heterogeneous hybrid optical–acoustic UASNs was addressed through a new DRL-based MAC protocol.
Although conventional DRL-based MAC protocols for UASNs account for propagation delay in reward acquisition, most do not consider the delay fluctuations during an agent’s transition from the current state to the next. Specifically, during state transition, an agent must wait for a duration equivalent to round-trip propagation delay to obtain state observations. Due to the low propagation speed of underwater acoustic signals, the actual delay may vary within this waiting period, thereby affecting the convergence speed and stability of the network. Additionally, the DRL networks employed in these protocols are relatively simple, which consequently results in insufficient learning efficiency. To address these problems, this paper proposes a DRL-based delay-fluctuation-resistant UASN access method. First, delay fluctuations are integrated into the state model of deep reinforcement learning, enabling the model to adapt to delay fluctuations during learning. Then, a double deep Q-network (DDQN) is introduced, and its structure is optimized to enhance learning and decision-making in complex environments.
The structure of this paper is organized as follows: Section 2 reviews the works related to MAC protocols for UASNs. Section 3 introduces the new delay-fluctuation-resistant DRL model; Section 4 describes the proposed delay-fluctuation-resistant UASN access method based on DDQN; Section 5 presents and discusses the simulation results; Finally, Section 6 concludes the paper.
2. Related Work
2.1. Conventional MAC Protocols for UASNs
The MAC protocol, which manages access to the shared broadcast channel among nodes in a network, is a key technology for UASNs. These MAC protocols are generally classified into three categories: non-contention-based, contention-based, and hybrid.
Non-contention-based MAC protocols, such as TDMA [14], frequency division multiple access (FDMA) [15], and code division multiple access (CDMA) [16], divide spectrum resources into subchannels by time, frequency, or code and allocate them statically to nodes. These protocols typically manage uplink and downlink communications through centralized resource allocation. This avoids collisions and suits heavy, continuous, and balanced traffic, but may waste resources under light or bursty loads.
Contention-based protocols allow nodes to dynamically compete for channel access, making them suitable for light, bursty, or unbalanced traffic. These protocols primarily focus on uplink access cases where multiple nodes compete to send data to a common receiver. However, since channel competition may lead to collisions which significantly reduce transmission efficiency, how to mitigate or eliminate collisions remains a key research focus in contention-based protocols. Contention-based protocols are further divided into random access protocols (e.g., ALOHA [17] and CSMA (Carrier Sense Multiple Access) [18]), where nodes transmit without coordination and risk collisions, and handshake-based protocols (e.g., MACA (Multiple Access with Collision Avoidance) [19] and FAMA (Floor Acquisition Multiple Access) [20]), which use RTS/CTS exchanges to avoid collisions.
Hybrid MAC protocols are mainly designed for uplink access in UASNs. They combine multiple mechanisms (e.g., non-contention with contention, or different subtypes within each category [21]) and adaptively switch between them to leverage their respective advantages, aiming for improved overall performance in varying network conditions.
2.2. UASN MAC Protocols Based on Reinforcement Learning
The advancement of intelligent algorithms, such as Reinforcement Learning (RL) and DRL, has opened new pathways for enhancing communication protocols. These sophisticated algorithms enable nodes to autonomously optimize tasks like routing, resource allocation, and dynamic spectrum access through interaction with the environment. However, research on intelligent MAC protocols for UASNs remains in its early stages, often involving adaptations of protocols originally designed for terrestrial wireless networks. RL-based intelligent MAC protocols learn optimal behaviors through reward feedback, making them suitable for simple environments. Yet, their effectiveness is limited by the size of the state space. In contrast, DRL-based protocols integrate deep learning to handle more complex environments and broader state spaces, albeit at the cost of increased computational resources and data requirements.
In the study of RL-based intelligent MAC protocols for UASNs, several innovative approaches have been proposed. For instance, a new method that combines reinforcement learning with Slotted-CSMA was proposed in [22]. This protocol focuses on uplink access cases where sensor nodes transmit data toward surface stations. It divides the underwater acoustic channel into multiple subchannels and employs Q-learning to help nodes select both the optimal relay node and the most suitable subchannel for data transmission. Another study introduced RL-MAC (Reinforcement Learning-based MAC) [23], which is designed to address challenges such as propagation delay, error probability, node mobility, and low data rates in underwater multimedia sensor networks. By applying Q-learning, this protocol optimizes the contention mechanism during the initial phase of multimedia transmission, thereby improving both transmission efficiency and overall network performance. Additionally, the ALOHA-QUPAF (Packet flow ALOHA with Q-learning) protocol [24] was developed as a packet-flow-based reinforcement learning MAC protocol. To address linear multi-hop uplink cases, it uses an improved two-phase Q-learning process to extract implicit reward signals, further optimizing data transmission in underwater acoustic sensor networks. The DR-ALOHA-Q (Delayed-reward ALOHA-Q) protocol proposed in [17] is a MAC protocol based on reinforcement learning within the ALOHA framework. This protocol supports asynchronous network operations and leverages long propagation delays to enhance network throughput.
Turning to DRL-based intelligent MAC protocols for UASNs, researchers have developed more advanced solutions capable of handling greater complexity. The research and design of these protocols primarily focus on uplink access cases, as the uplink concentrates the most challenging network issues (e.g., multi-node competition, energy efficiency optimization). Ye et al. pioneered the DR-DLMA protocol [11], which aims to maximize network throughput. Using deep reinforcement learning, DR-DLMA enables nodes to collaborate effectively within the network. It intelligently selects optimal channel access strategies, making efficient use of idle slots or unused slots caused by long propagation delays or other nodes’ activities, thereby optimizing overall network performance. Similarly, Geng et al. proposed the DL-MAC (Deep-reinforcement Learning-based Medium Access Control) protocol [25], which leverages deep reinforcement learning to exploit long propagation delays in underwater acoustic communication. This protocol adopts both synchronous and asynchronous transmission modes to enhance system throughput. Notably, its asynchronous mode adapts to spatiotemporal variations in UASNs by adjusting the start time of transmission slots, further refining network performance. Moreover, Liu et al. investigated efficient channel bandwidth utilization in heterogeneous hybrid optical–acoustic underwater sensor networks and proposed a novel MAC protocol based on deep reinforcement learning [26], demonstrating the continued evolution and application of DRL techniques in challenging underwater environments.
3. Delay-Fluctuation-Resistant DRL Model
To simplify the system design and focus on the performance analysis of the MAC layer mechanism, we assume that the physical layer can provide a stable bitstream service to the upper layer (MAC layer). Therefore, when constructing the DRL model and designing the access strategy, we do not consider specific underwater acoustic channel models (e.g., multipath, attenuation), but concentrate on MAC layer influencing factors such as propagation delay and delay fluctuations caused by variations in propagation speed.
In the DR-DLMA model, the system state is determined by the action and the observation , where denotes the one-way propagation delay between the agent node and the master node. Specifically, represents the action taken at timeslot , and represents the observation obtained after executing action . However, due to the slow propagation speed of underwater acoustic signals, the value of is subject to random fluctuations during the agent’s transition from the current state to the next. These variations can be caused by environmental and dynamic factors such as water currents, node mobility, and changes in sound speed. DR-DLMA does not account for the impact of such delay fluctuations, which limits its ability to adapt to dynamic underwater delay conditions and affects the convergence speed and stability of the model.
In this paper, we incorporate a propagation delay fluctuation feature, , into the DRL framework by redefining the system state. The new state is a tuple composed of the delay fluctuation , the historical action , and the corresponding observation , denoted as:
The state of the agent node in time slot is defined as follows:
where represents the historical length of the state.
The reinforcement learning elements [11] in this paper are defined as follows:
Agent: A network node that runs the DRL protocol.
Action: Each node can choose between two types of actions: transmitting and waiting. Therefore, the action set is defined as . In each time slot , the node running the DRL protocol selects an action .
State: The system state is defined using Equations (1) and (2), incorporating the propagation delay fluctuations, the historical actions, and the corresponding observations.
Reward: At time slot and corresponding state , the node executes action . Then, at time slot , it evaluates the performance of action and obtains a reward . The node transitions to a new state simultaneously. The reward is determined based on the reception result of the master node, defined as follows:
when , it indicates that the node has successfully transmitted, and the corresponding reward is 1; when , it indicates that the node was idle or a collision occurred in that time slot, so the reward is 0.
4. Delay-Fluctuation-Resistant UASN Access Method Based on DDQN
In the DR-DLMA, the Deep Q-Network (DQN) algorithm [27,28] is employed. The DQN architecture consists of fully connected layers with residual connections. However, this neural network structure presents several limitations in practice. First, during Q-value updates, DQN selects the action corresponding to the maximum expected reward in the next state. This approach may result in a systematic overestimation of future rewards, as it consistently prioritizes the highest estimated values without accounting for potential uncertainties or environmental dynamics. Such overestimation leads to inaccurate policy evaluation during training, ultimately affecting the quality and performance of the learned policy. Second, the network structure in DQN is relatively simple and lacks an explicit mechanism for separating state values and action advantages of reinforcement learning, which may lead to low learning efficiency. Third, during updates, the neural network modifies the Q-value only for the executed action, and does not affect the Q-values of other actions. This update strategy limits the network’s ability to learn across the entire action space. To address these issues, this paper introduces the DDQN algorithm into the proposed delay-fluctuation-resistant DRL model. We also optimize the deep neural network structure in DDQN by separately modeling state values and action advantages, thereby enhancing its overall learning efficiency and policy performance.
4.1. Delay-Fluctuation-Resistant DRL Model Based on DDQN
Compared with the DQN, DDQN employs two networks with the same structure but different parameters to alleviate the issue of Q-value overestimation [29,30]. One network, called the main network, is responsible for selecting actions, while the other network, called the target network, is used to evaluate the value of these actions. DDQN utilizes the main network to select the optimal action for the next state as:
where denotes the parameters of the main network, and denotes the action selected in the state . Then, the target network is used to calculate the target Q-value for this chosen action as:
where denotes the reward obtained at time slot , denotes the discount factor, and denotes the parameters of the target network.
To adapt DDQN to the proposed model, we modify its experience replay mechanism by adopting the delayed experience replay mechanism proposed in [11]. During the training process, a predefined number of real experiences are randomly sampled from the experience buffer to update the parameters of the main network. is defined as:
where is constructed by combining the state and the action of the sequential experience with the reward and next state of the sequential experience . The state is given by (1) and (2). To account for the round-trip propagation delay between the agent node and the master node, the reward and the state in (4) and (5) are replaced by and respectively. (4) and (5) are adjusted as follows:
4.2. Optimization of Neural Network Structure
To address the issues of a simplistic neural network architecture and low learning efficiency in DR-DLMA, this paper proposes an improved network structure, as illustrated in Figure 1. Compared with DR-DLMA, a long short-term memory (LSTM) and a centralized processing module are added.
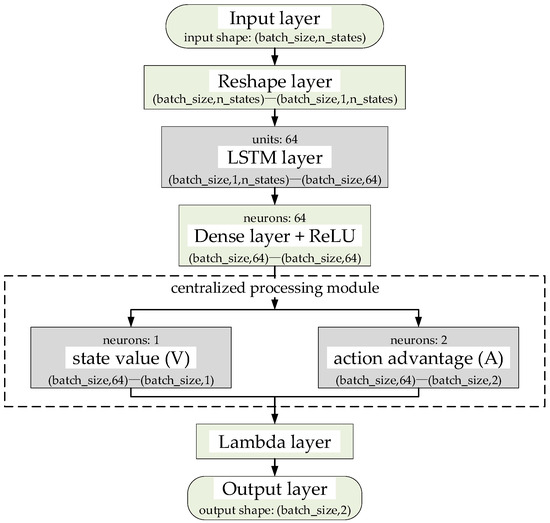
Figure 1.
The improved neural network structure.
The proposed neural network takes a state vector of shape as input, where denotes the state history length. This vector is reshaped into a 3D tensor of to fit the LSTM input format. The LSTM layer contains 64 LSTM units and outputs a 64-dimensional feature vector. Then, a Dense layer with 64 neurons follows, performing feature extraction and non-linear transformation. The processed features then flow into the centralized processing module, which consists of two parallel Dense layers and is responsible for separately estimating the state value and action advantage. The state value stream uses 1 neuron to output a scalar representing the overall quality of the state, while the action advantage stream employs 2 neurons to output the advantage of each action relative to the average level. Finally, the Q-values are computed through the Lambda layer, and a 2-dimensional Q-value vector is output for action selection.
The LSTM layer is positioned between the input layer and the fully connected layer to process sequential input states and capture dependencies in the time-series data. In typical reinforcement learning scenarios, the environment is usually assumed to follow a Markov decision process, where the future state is only related to the current state and the action taken. However, the actual environments are often more complex and may not strictly adhere to the Markov property [31]. In such cases, the incorporation of an LSTM layer enhances the model’s ability to retain and integrate historical information, thereby enabling the network to learn from long-term sequential data and improve its capacity for optimizing cumulative rewards over extended periods.
The design of the centralized processing module follows the method proposed in [32]. The centralized processing module consists of two parallel fully connected layers, which decompose the input state into a state value function and an action advantage function . The module then performs centralized processing on the action advantage function to calculate the final Q-value as follows:
where denotes the Q-value when the input state is and the corresponding action is ; denotes the state value function when the input state is ; denotes the action advantage function when the input state is and the corresponding action is ; denotes the number of selectable actions; denotes the sum of action advantage functions when the input state is ; and denote the network parameters of the two fully connected layers, respectively; denotes the network parameters of the DDQN main network; and and denote action parameters. This structure enables the network to update the state value function in each training step while simultaneously influencing the Q-values of all actions. As a result, the proposed neural network structure can learn the state-value function more frequently and accurately.
4.3. UASN MAC Protocol Based on the Proposed DRL Model
Based on the proposed delay-fluctuation-resistant DRL model, we develop a MAC protocol for centralized UASNs named DFR-DLMA (Delay-Fluctuation-Resistant Deep Reinforcement Learning Multiple Access). The centralized UASN consists of a master node and slave nodes. The master node, typically a surface buoy, performs preliminary processing on the ocean data collected from the slave nodes before forwarding it to an onshore remote base station or monitoring center for in-depth analysis and storage. The slave nodes are underwater sensors responsible for acquiring marine environmental data and transmitting it to the master node via uplink underwater acoustic channels. The slave nodes are categorized into two types: the first type operates using the TDMA protocol, transmitting data packets within specific time slots allocated by the master node. The second type employs the DRL protocol, utilizing idle time slots that are not occupied by TDMA nodes to send data. In the TDMA protocol, both data packets and acknowledgment (ACK) signals are of fixed length. Each time slot is divided into two parts: the first part is used by the slave node to transmit data packets, and the second part is used by the master node to broadcast ACK signals. A guard interval, which may span one or multiple time slots, is set to exceed the maximum transmission delay in the sensor network to avoid interference between packets from different nodes during propagation. The DFR-DLMA protocol is similar to DR-DLMA [11] but incorporates the proposed DRL model and involves the following steps:
- Network Initialization: The master node first broadcasts a beacon packet. Each slave node calculates the number of propagation time slots between itself and the master node based on the received packet.
- DFR-DLMA Node Initialization: Initialize the DDQN algorithm by defining its key components (agent, action, state, and reward). Also, initialize the experience replay buffer for these nodes.
- Action Selection and Coordination: Each DFR-DLMA node inputs the initial state into the DDQN main network to obtain Q-values for all possible actions. Using the ε-greedy strategy, the node selects an action, either “Transmit” or “Wait”. One DFR-DLMA node is designated as the gateway, which is connected to all other DFR-DLMA nodes via a control channel for coordination. In each time slot, the gateway determines whether DFR-DLMA nodes should transmit. If the action chosen is “Transmit”, the gateway selects one node via polling to send a data packet to the master node. Otherwise, all nodes remain in the waiting state.
- Acknowledgement Handling: After the master node successfully receives a data packet, it broadcasts an ACK signal to confirm reception. If no ACK is broadcasted, it indicates that a collision occurred during the transmission in Step 3.
- Experience Processing and Training: After transmitting, each DFR-DLMA node observes the presence or absence of an ACK signal, computes the corresponding reward, and transitions to the next state. These sequential experiences are stored in the replay buffer and are used to train the DDQN network. The Q-values are continually updated to optimize the transmission strategy. ACK failures are handled differently based on their nature: persistent failures are treated as communication interruptions, while occasional failures are corrected through subsequent algorithm training.
- Strategy Execution: Each DFR-DLMA node transmits data packets to the master node according to the optimal transmission strategy obtained in Step 5.
- Convergence Assurance: Execute the protection training mechanism [11] to drive the average reward to a steady state, thereby maximizing sensor network throughput.
5. Simulations and Results
5.1. Simulation Setup
In the simulations, we consider the same centralized UASN model with the same configuration as in [11]. The master node and slave nodes are fully connected and communicate in half-duplex mode. Each slave node operates its own MAC protocol and transmits data packets to the master node in a time-slotted manner. Nodes are randomly distributed within a monitoring area. The underwater acoustic speed is fixed at 1500 m/s and the time slot duration is set to 200 ms. The data packet size is 256 bits and the ACK packet size is 16 bits, with a data transmission rate of 1600 bit/s.
To evaluate the robustness of the proposed protocol against delay fluctuations, we introduce variations into the propagation delay by modeling it as a Gaussian-distributed random variable [1,33,34]. The mean of the delay is set to the number of time slots required for information propagation between any two nodes in the absence of delay fluctuations. Considering that longer propagation delays between nodes are more susceptible to environmental interference and thus exhibit greater fluctuations, the variance of the delay is set as a percentage of the mean delay in the simulations.
The proposed DRL network is implemented using the Python 3.9.12 programming language and the Keras [35] deep learning framework. We referred to the parameter ranges commonly used in DR-DLMA [11] and DRL related works. Building on this, we conducted systematic parameter sensitivity analysis and ablation experiments on the validation set for the proposed DRL network, ultimately determining the parameters. The parameter settings of the proposed DRL network are shown in Table 1.

Table 1.
Settings of the proposed DRL network.
5.2. Performance Evaluation Metrics
To comprehensively evaluate the performance of the proposed DFR-DLMA protocol, the following three key metrics are employed: average training time, short-term average network throughput and normalized throughput [36,37].
Average training time of the algorithm refers to the average time required for the algorithm to converge, measured in time slots. In this paper, an algorithm is considered to have converged when its short-term average network throughput reaches 0.996. The value 0.996 is used exclusively for result analysis and performance evaluation, while a dynamic convergence detection mechanism is employed during model training. The mechanism employs a 1600-slot window to monitor the average reward. It maintains the most recent 1600 time slots of data and computes the corresponding average reward. Convergence is considered achieved when the fluctuation of the average reward within the window remains below 5%. This method overcomes the limitations of fixed thresholds and adapts to varying load conditions.
Short-term average network throughput is a normalized value defined as the ratio of the average amount of data correctly received by the master node over the past time slots to the transmission rate. It is calculated as follows:
Normalized throughput is defined as the ratio of the throughput to the transmission rate, calculated as follows:
5.3. Comparison with DRL-Based Protocols
Compared to DR-DLMA, the main improvements of the proposed method include integrating delay fluctuation characteristics into the DRL framework and replacing the DQN used in DR-DLMA with an optimized DDQN. To evaluate the effectiveness of these enhancements, simulations were conducted comparing the proposed DFR-DLMA against both the original DR-DLMA and a variant (denoted as DDQN-DLMA) that employs DDQN but does not incorporate delay fluctuation features. The underwater propagation delays for the three protocols follow a Gaussian distribution, with the standard deviations set to 5%, 10%, 20%, and 30% of the mean value, respectively. All three protocols are based on DRL, hence they achieve similar performance upon convergence. However, differences exist in their convergence speed and stability. In the simulations, the average training time and the short-term average throughput are used to evaluate the convergence speed and stability of the algorithms. To simulate the application scenario where DRL-based protocols capture idle time slots, the slave nodes in the underwater acoustic network are divided into two categories in the experiment: DRL nodes and TDMA nodes, with a ratio set to 2:3. The DRL nodes operate using one of the three compared protocols. Experimental results are obtained by averaging over 200 independent simulation runs.
5.3.1. Convergence Speed
This paper employs the average training time of the algorithms to evaluate the convergence speed, considering the algorithm converged when the throughput reaches 0.996. The convergence speeds of the three protocols are compared under different propagation delay fluctuations and different numbers of nodes. The experimental results are shown in Figure 2.
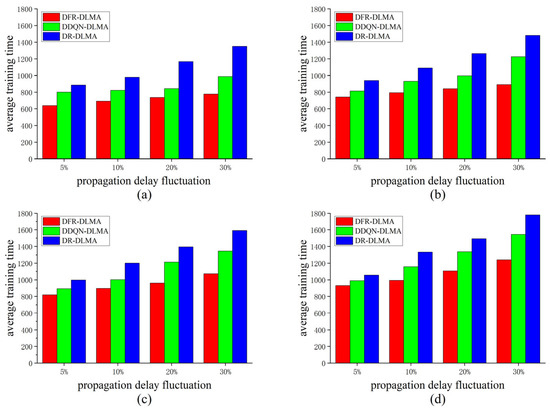
Figure 2.
Average training times of the three protocols under different propagation delay fluctuations and different numbers of nodes. (a) N = 5; (b) N = 10; (c) N = 15; (d) N = 20.
As shown in Figure 2, DFR-DLMA requires the fewest training times under the same number of nodes and same propagation delay fluctuation. In terms of training speed, it achieves an average improvement of 29.3% and 15.5% over DR-DLMA and DDQN-DLMA, respectively, demonstrating superior learning efficiency and convergence performance. When the number of nodes is fixed, the training times of DFR-DLMA do not increase significantly as the propagation delay fluctuation grows. Similarly, under a fixed delay fluctuation, although all protocols require more training times as the number of nodes increases, the rate of increase for DFR-DLMA is notably lower than that of the other two protocols. These results suggest that due to the incorporation of the propagation delay fluctuation feature, the proposed protocol exhibits enhanced robustness and better adaptability to dynamic network conditions. Additionally, the faster convergence speed of DDQN-DLMA compared to DR-DLMA further demonstrates that the proposed network architecture achieves higher learning efficiency than the conventional DQN used in DR-DLMA.
5.3.2. Stability
The short-term average network throughput is employed to evaluate the stability of different algorithms after convergence. The number of nodes in the experiment is set to 5. The experimental results are shown in Figure 3. As shown in the figure, DFR-DLMA converges faster than the other two protocols. The short-term average network throughputs of all three protocols approach 1 after convergence, and the throughput of DFR-DLMA at convergence is slightly higher than that of the other two protocols. As the propagation delay fluctuation increases, the convergence speed of all three protocols decreases as the fluctuation increases. This is because the heightened delay fluctuation leads to greater environmental uncertainty, requiring the algorithms more time for exploration and learning. Moreover, both DFR-DLMA and DDQN-DLMA maintain relatively stable throughput levels after convergence. In contrast, the throughput of DR-DLMA still fluctuates significantly after convergence. This difference can be attributed to the use of DDQN in the first two protocols, which mitigates Q-value overestimation bias and thus enhances stability.
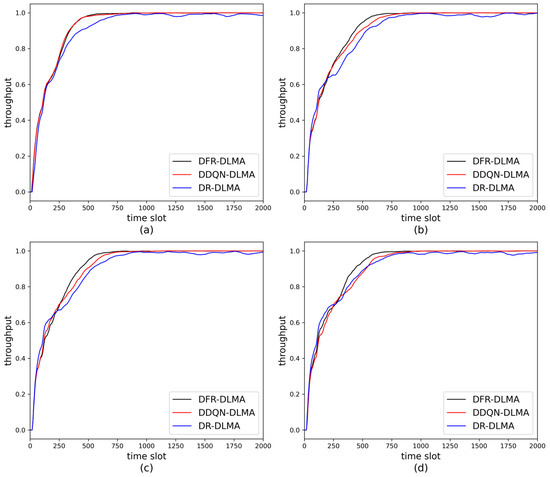
Figure 3.
Short-term average network throughput of the three protocols under different propagation delay fluctuations. (a) 5%; (b) 10%; (c) 20%; (d) 30%.
5.3.3. Ablation Experiments
To more clearly isolate the contribution of each component to the model performance, we conducted ablation experiments on individual components. The ablation experiments were performed under the conditions of 5 nodes and 5% delay fluctuation, using the average training time as the metric. All experiments maintained the same experimental environments and parameter settings to ensure validity and comparability of the results. Experimental results are presented in Table 2, where a “” indicates that the corresponding component was included in the experimental configuration.
Table 2.
Ablation experiment results.
Through a comprehensive analysis of the ablation experiment results, we can draw the following conclusions. We adopted the original DR-DLMA algorithm as the baseline (Experiment 1), with an average training time of 885. Experiment 3 introduced delay fluctuation on DR-DLMA, which increased the average training time by 9.9%. It demonstrates that the DR-DLMA protocol has limited resistance to delay fluctuations. From the single-component experiments (Experiments 2, 4, and 5), it can be observed that DDQN, LSTM, and the centralized processing module (CPM) contributed positively to resisting delay fluctuation. Experiment 6 employed DDQN under delay fluctuation and reduced the average training time by 12.4%, indicating that DDQN is effective in resisting delay fluctuation. Experiments 7 and 8 combined DDQN with LSTM and the centralized processing module, respectively, leading to reductions in average training time of 10.7% and 11.6%. Experiment 9 implemented the complete DFR-DLMA model proposed in this paper, achieving the lowest average training time, thereby validating the effectiveness of the full model in resisting delay fluctuation.
5.4. Comparison with Conventional Protocols
To evaluate the performance of the proposed protocol, the normalized throughput of DFR-DLMA was compared with that of DR-DLMA [11], TDMA [38], and DOTS [39] under different network loads and different numbers of nodes. To more accurately assess the maximum capability of each protocol, all slave nodes in the network employed the same MAC protocol to avoid the performance evaluation being affected by a hybrid network environment.
5.4.1. Normalized Throughput Under Different Network Loads
Figure 4 presents the normalized throughput of the four protocols across various network loads. The experiment was conducted with 5 nodes and propagation delay fluctuation was set to 5%. The results were averaged over 200 simulation runs.
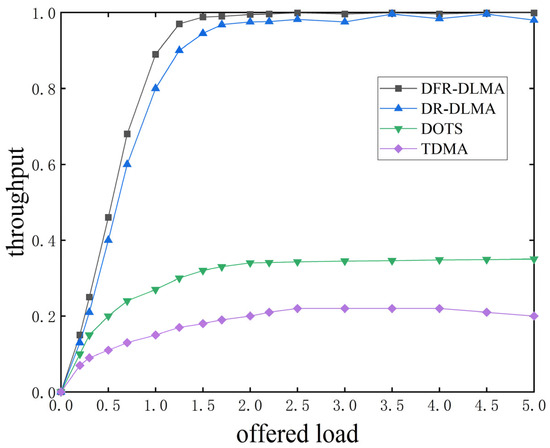
Figure 4.
Normalized throughput of the four protocols under different network loads.
As shown in Figure 4, the throughput of each protocol increases continuously with rising network load until reaching saturation. After stabilization, the throughput of the DFR-DLMA protocol is 355% and 186% higher than that of the traditional TDMA and DOTS protocols, respectively. The TDMA protocol rigidly allocates channel time to each node, leading to wasted channel resources when nodes have no data to transmit. This inflexibility prevents full utilization of all available time slots, significantly limiting overall network throughput. The DOTS protocol requires notifying other nodes of the transmission schedule via control packets (such as RTS and CTS) before each transmission. This process generates a large amount of overhead, thereby reducing the overall network throughput. Furthermore, the normalized throughput of the DFR-DLMA protocol is slightly higher than that of the DR-DLMA protocol. This improvement can be attributed to the incorporation of delay fluctuation characteristics and the improvement in the DFR-DLMA network architecture.
5.4.2. Normalized Throughput Under Different Numbers of Nodes
Figure 5 shows the normalized throughput of the four protocols under different numbers of nodes, with the network load fixed at 1.5. The normalized throughput of DFR-DLMA remains consistently high between 0.98 and 1.0 across all tested network scales. Although the normalized throughput of DFR-DLMA is only slightly higher than that of DR-DLMA, it demonstrates advantages in adapting to networks of different sizes. Even as the number of nodes increases, DFR-DLMA is able to maintain high throughput performance. In contrast, the throughput of traditional TDMA and DOTS protocols ceases to increase and stabilizes at a relatively low level once the network size reaches a certain threshold. When the number of nodes exceeds 20, the throughput of TDMA stabilizes at approximately 0.21 and DOTS saturates around 0.35.
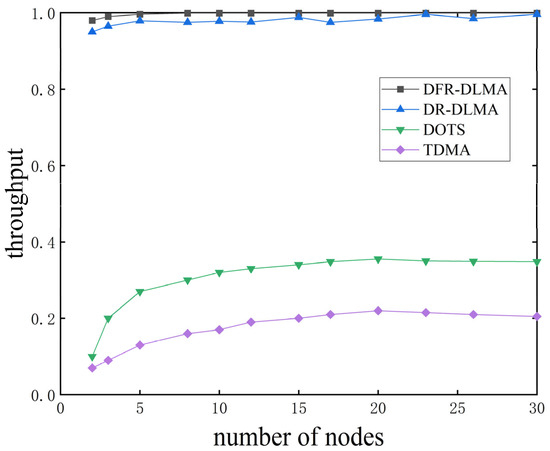
Figure 5.
Normalized throughput of the four protocols under different numbers of nodes.
5.5. Computational Complexity
The computational complexity metric is the total number of floating point operations (FLOPs) during algorithm execution [40]. To provide an intuitive computational complexity benchmark between the proposed method (DFR-DLMA) and the baseline method (DR-DLMA), both the DFR-DLMA and DR-DLMA were executed for 200 runs on an Ubuntu platform (CPU: Intel Core i9-9900K, GPU: NVIDIA GeForce RTX 2080 Ti). The number of nodes is 5, and the delay fluctuation is set to 5%. The FLOPs and average single-run time (AST) are presented in Table 3.
Table 3.
Computational complexity.
As shown in Table 3, the proposed method requires 57,034 FLOPs, representing an approximately 25% increase over the baseline method. This indicates that DFR-DLMA performs more complex computations. The AST of DFR-DLMA is 13.168 s, significantly longer than the 8.028 s required by DR-DLMA. However, DFR-DLMA demonstrates a lower standard deviation of 0.259 s in single-run time, compared to 0.420 s for DR-DLMA. Correspondingly, the 95% confidence interval (CI) width for DFR-DLMA is 0.073 s, compared to 0.119 s for DR-DLMA, demonstrating that the DFR-DLMA results are more concentrated and exhibit better stability and predictability. In summary, the proposed method achieves enhanced performance stability at the cost of increased computational complexity and extended execution time.
6. Conclusions
Conventional DRL-based UASN access schemes often overlook the variability of underwater acoustic link delays and suffer from low learning efficiency. This paper proposes a deep reinforcement learning-based access method for mitigating the impact of propagation delay fluctuations in UASNs. The proposed method explicitly incorporates propagation delay fluctuations into the DRL framework and further employs an optimized neural network architecture to enhance learning efficiency. Simulation results demonstrate that the proposed protocol not only accelerates convergence in environments with variable delays, but also significantly improves the adaptability and stability of the sensor network. Although the proposed method enhances performance, its increased structural complexity leads to higher computational and storage requirements. Future work will focus on reducing energy consumption and balancing performance and efficiency.
Author Contributions
Conceptualization and methodology, J.Z.; software and validation, J.S. and K.T.; formal analysis and data curation, J.S., J.Z. and K.T.; writing—original draft preparation, J.S. and J.Z.; supervision, J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
The National Natural Science Foundation of China, grant number of 61372083.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Morozs, N.; Mitchell, P.; Zakharov, Y.V. TDA-MAC: TDMA without Clock Synchronization in Underwater Acoustic Networks. IEEE Access 2018, 6, 1091–1108. [Google Scholar] [CrossRef]
- Zhang, X.; Liang, Y. An Energy-Saving MAC Protocol for Underwater Acoustic Sensor Networks Based on TDMA. In Proceedings of the 2024 2nd International Conference on Signal Processing and Intelligent Computing (SPIC), Guangzhou, China, 20–22 September 2024; pp. 207–210. [Google Scholar] [CrossRef]
- Sun, W.; Gao, X. Pre-Allocated MAC Protocol Based on Underwater Acoustic Communication Network. In Proceedings of the 2023 8th International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 8–10 July 2023; pp. 935–939. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, J.; Ming, W.; Sun, D. Adaptive TDMA Protocol Based on LSTM Network for Underwater Acoustic Networks. In Proceedings of the 2022 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Xi’an, China, 25–27 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Qian, L.; Zhang, S.; Liu, M.; Zhang, Q. A MACA-Based Power Control MAC Protocol for Underwater Wireless Sensor Networks. In Proceedings of the 2016 IEEE/OES China Ocean Acoustics (COA), Harbin, China, 9–11 January 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, D. A Power Control Based Handshake-Competition MAC Protocol for Underwater Acoustic Networks. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Information Systems (ICAIIS), Dalian, China, 20–22 March 2020; pp. 665–669. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, H.; Dan, F.; Yang, X.; Yan, B. A Handshake-Based Low Delay MAC Protocol in Hybrid Topology for Urban Lake Monitoring. IEEE Sens. J. 2022, 22, 21342–21354. [Google Scholar] [CrossRef]
- Yang, S.; Cheng, E.; Chen, K.; Feng, W.; Cao, W.; Xiao, L. A Link Quality-Aware Adaptive MAC Protocol Based on Clustering for Underwater Acoustic Network. In Proceedings of the OCEANS 2024—Singapore, Singapore, 15–18 April 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Yang, H.; Geng, X.; Kong, N. A MAC Protocol for Wireless Networks Using Dueling-DDQN Algorithm. J. Beijing Univ. Posts Telecommun. 2023, 46, 25–30. [Google Scholar] [CrossRef]
- Ye, X.; Yu, Y.; Fu, L. Deep Reinforcement Learning Based MAC Protocol for Underwater Acoustic Networks. IEEE Trans. Mob. Comput. 2022, 21, 1625–1638. [Google Scholar] [CrossRef]
- Wang, S.; Wei, Y. Adaptive Underwater Medium Access Control Protocol Based on Reinforcement Learning. In Proceedings of the 2024 IEEE 6th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 24–26 May 2024; pp. 902–906. [Google Scholar] [CrossRef]
- Han, X.; Zhang, Y.; Li, M.; Feng, X. Deep reinforcement learning based proportional-fair optimized cross-layer MAC protocol for underwater acoustic network. Mod. Electron. Technol. 2024, 47, 1–9. [Google Scholar] [CrossRef]
- Eri¸s, Ç.; Gül, O.M.; Bölük, P.S. A Novel Medium Access Policy Based on Reinforcement Learning in Energy-Harvesting Underwater Sensor Networks. Sensors 2024, 24, 5791. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Qiao, G.; Zhang, Y.; Sun, W. A frequency division multiple access based dual-channel media access control protocol for underwater acoustic communication network. Appl. Acoust. 2013, 32, 395–400. [Google Scholar]
- Guo, J.; Song, S.; Liu, J.; Wan, L.; Yu, Y.; Han, G. An MC-CDMA-Based MAC Protocol for Efficient Concurrent Communication in Mobile Underwater Acoustic Networks. IEEE Trans. Mob. Comput. 2024, 23, 12428–12443. [Google Scholar] [CrossRef]
- Tomovic, S.; Radusinovic, I. DR-ALOHA-Q: A Q-Learning-Based Adaptive MAC Protocol for Underwater Acoustic Sensor Networks. Sensors 2023, 23, 4474. [Google Scholar] [CrossRef] [PubMed]
- Iqbal, B.; Liu, S.; Ullah, K.I. Multiple RTS and DATA Receptions in a Loop-Based Underwater Propagation Delay Aware MAC Protocol. In Proceedings of the 2021 OES China Ocean Acoustics (COA), Harbin, China, 14–17 July 2021; pp. 665–669. [Google Scholar] [CrossRef]
- Rahman, W.U.; Gang, Q.; Feng, Z.; Khan, Z.U.; Aman, M.; Bilal, M. A MACA-Based Energy-Efficient MAC Protocol Using Q-Learning Technique for Underwater Acoustic Sensor Network. In Proceedings of the 2023 IEEE 11th International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 21–22 October 2023; pp. 352–355. [Google Scholar] [CrossRef]
- Dao, V.-P.; Nguyen, P.-Q.; Truong, T.-B.-N.; Le, H.-M.; Bui, T.-T.-D.; Phu, T.-N.-H. A Scheduled and Slotted MAC Protocol for Underwater Acoustic Networks. In Proceedings of the 2022 6th International Conference on Green Technology and Sustainable Development (GTSD), Nha Trang City, Vietnam, 29–30 July 2022; pp. 1064–1069. [Google Scholar] [CrossRef]
- Zhao, H.; Chen, H.; Xie, L. A Scheduling-Based Hybrid Medium Access Control Protocol for Underwater Acoustic Sensor Networks. In Proceedings of the 2023 International Conference on Wireless Communications and Signal Processing (WCSP), Hangzhou, China, 2–4 November 2023; pp. 639–644. [Google Scholar] [CrossRef]
- Jin, L.; Huang, D. A slotted CSMA based reinforcement learning approach for extending the lifetime of underwater acoustic wireless sensor networks. Comput. Commun. 2013, 36, 1094–1099. [Google Scholar] [CrossRef]
- Gazi, F.; Ahmed, N.; Misra, S.; Wei, W. Reinforcement Learning-Based MAC Protocol for Underwater Multimedia Sensor Networks. ACM Trans. Sens. Netw. 2022, 18, 1–25. [Google Scholar] [CrossRef]
- Alhassan, I.B.; Mitchell, P.D. Packet Flow Based Reinforcement Learning MAC Protocol for Underwater Acoustic Sensor Networks. Sensors 2021, 21, 2284. [Google Scholar] [CrossRef] [PubMed]
- Geng, X.; Zheng, Y.R. Exploiting Propagation Delay in Underwater Acoustic Communication Networks via Deep Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 10626–10637. [Google Scholar] [CrossRef]
- Liu, E.; He, R.; Chen, X.; Yu, C. Deep Reinforcement Learning Based Optical and Acoustic Dual Channel Multiple Access in Heterogeneous Underwater Sensor Networks. Sensors 2022, 22, 1628. [Google Scholar] [CrossRef] [PubMed]
- Kim, N.; Na, W.; Lakew, D.S.; Dao, N.N.; Cho, S. DQN-Based Directional MAC Protocol in Wireless Ad Hoc Network in Internet of Things. IEEE Internet Things J. 2024, 11, 12918–12928. [Google Scholar] [CrossRef]
- Bharadwaj, G.S.; Pratap, D.; Darapaneni, N. Optimized Automated Stock Trading Using DQN and Double DQN. In Proceedings of the 2024 International Conference on Intelligent Algorithms for Computational Intelligence Systems (IACIS), Hassan, India, 23–24 August 2024; pp. 1–9. [Google Scholar] [CrossRef]
- He, Y.; Tao, Y. Deep Reinforcement Learning Based Cognitive Equalization Algorithm Research in Underwater Communication. In Proceedings of the 2023 IEEE 3rd International Conference on Computer Communication and Artificial Intelligence (CCAI), Taiyuan, China, 26–28 May 2023; pp. 348–352. [Google Scholar] [CrossRef]
- Du, F.; Wang, X. DDQN-Based Path Planning for Mining Cave Robots. In Proceedings of the 2024 China Automation Congress (CAC), Qingdao, China, 1–3 November 2024; pp. 234–239. [Google Scholar] [CrossRef]
- Gaon, M.; Brafman, R.I. Reinforcement Learning with Non-Markovian Rewards. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 3980–3987. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.V.; Lanctot, M.; Freitas, N.D. Dueling network architectures for deep reinforcement learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1995–2003. [Google Scholar]
- Carevic, D. Tracking target in cluttered environment using multilateral time-delay measurements. J. Acoust. Soc. Am. 2004, 115, 1198–1206. [Google Scholar] [CrossRef]
- Chavhan, J.W.; Sarate, G.G. Channel Estimation Model for Underwater Acoustic Sensor Network. In Proceedings of the 2015 International Conference on Industrial Instrumentation and Control (ICIC), Pune, India, 28–30 May 2015; pp. 978–981. [Google Scholar] [CrossRef]
- Yang, P.; Peng, Z.; Wang, W. Sitting Posture Detection System Based on Keras Framework. In Proceedings of the 2022 3rd International Conference on Computer Vision, Image and Deep Learning & International Conference on Computer Engineering and Applications (CVIDL & ICCEA), Changchun, China, 20–22 May 2022; pp. 170–174. [Google Scholar] [CrossRef]
- Du, H.; Wang, X.; Sun, W.; Zhang, J. An Adaptive MAC Protocol for Underwater Acoustic Networks Based on Deep Reinforcement Learning. In Proceedings of the 2024 6th International Conference on Communications, Information System and Computer Engineering (CISCE), Guangzhou, China, 10–12 May 2024; pp. 1271–1275. [Google Scholar] [CrossRef]
- Huang, J.; Chi, C.; Wang, W.; Huang, H. A Sequence-Scheduled and Query-Based MAC Protocol for Underwater Acoustic Networks with a Mobile Node. J. Commun. Inf. Netw. 2020, 5, 150–159. [Google Scholar] [CrossRef]
- Zhong, Y.; Huang, J.; Han, J. A TDMA MAC Protocol for Underwater Acoustic Sensor Networks. In Proceedings of the 2009 IEEE Youth Conference on Information, Computing and Telecommunication, Beijing, China, 20–21 September 2009; pp. 534–537. [Google Scholar] [CrossRef]
- Noh, Y.; Lee, U.; Han, S.; Wang, P.; Torres, D.; Kim, J. DOTS: A propagation delay-aware opportunistic MAC protocol for mobile underwater networks. IEEE Trans. Mob. Comput. 2014, 13, 766–782. [Google Scholar] [CrossRef]
- Gholami, M.R.; Gezici, S.; Ström, E.G. TW-TOA based positioning in the presence of clock imperfections. Digit. Signal Process. 2016, 59, 19–30. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).