
CNN and Attention-Based Joint Source Channel Coding for Semantic Communications in WSNs



Abstract
1. Introduction
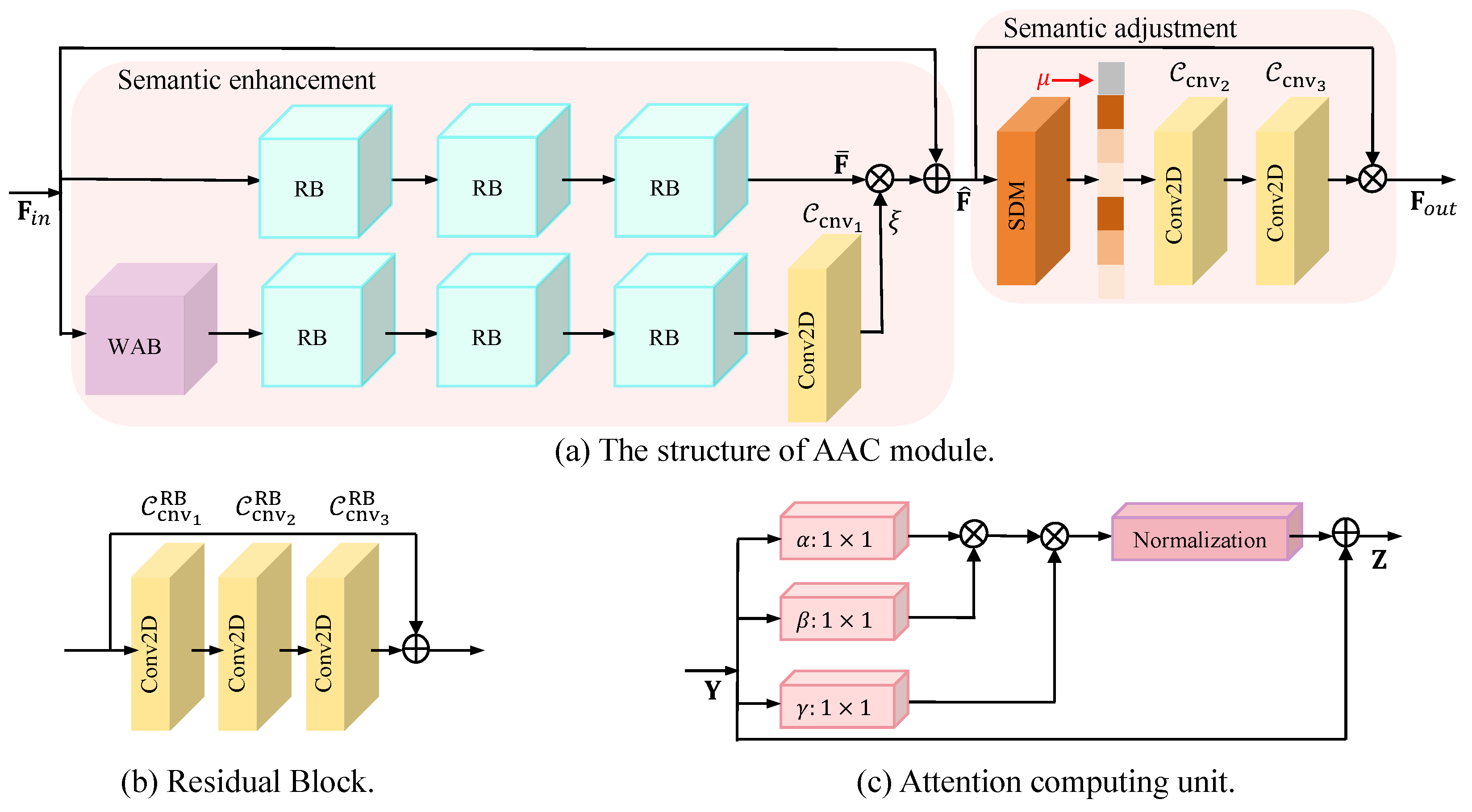
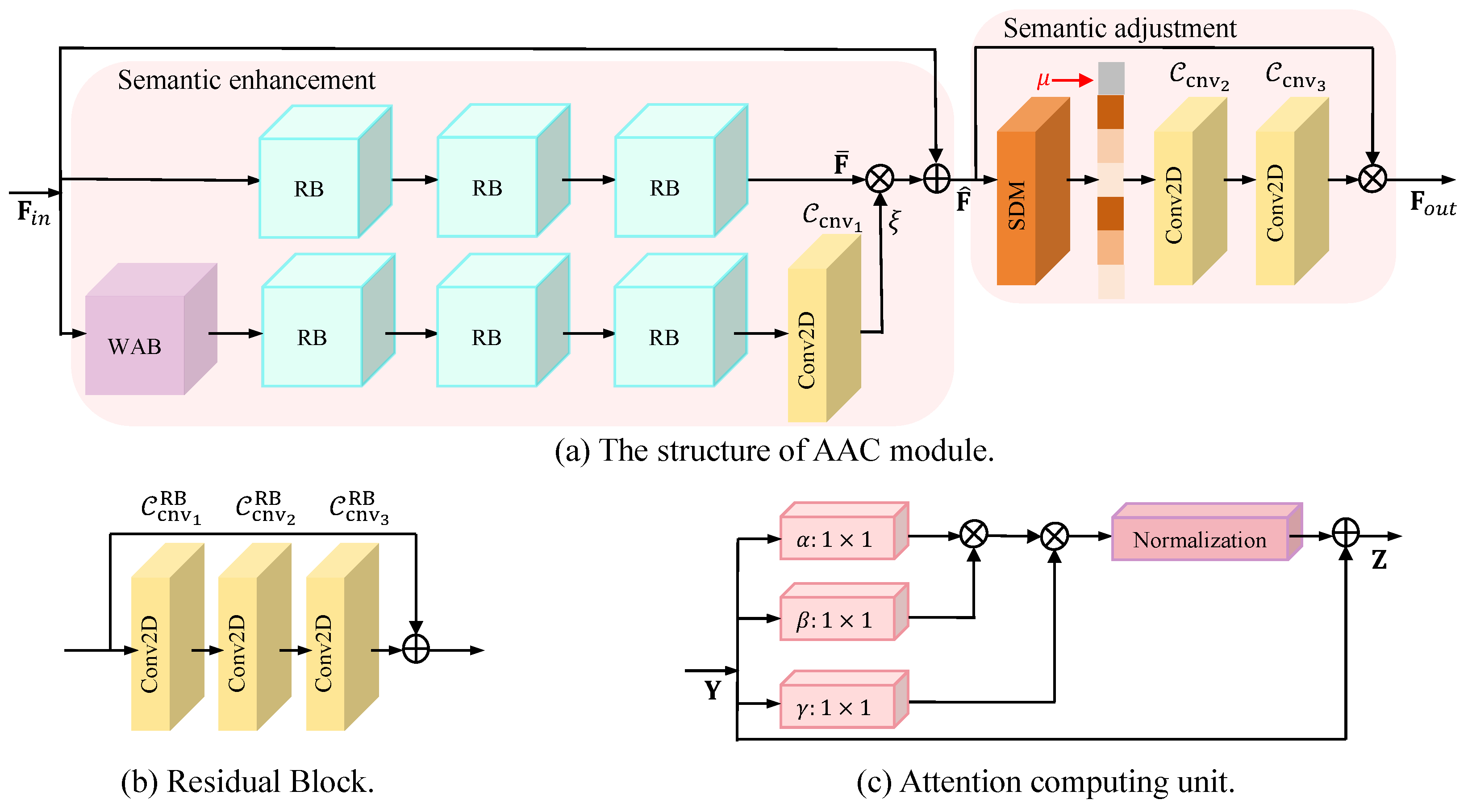
- We propose a flexible AAC module. Considering the resource-limited nature of WSN devices, it is able to capture the correlation between spatial neighboring elements to dynamically weight key local semantic information without sacrificing too many computational resources and is able to dynamically adjust the model output based on the current channel state information, which is capable of adapting/training a single model for a wide range of SNRs.
- We propose a novel JSCC model based on AAC modules and CNNs for ISC. Experimental results show that our model is more robust than the baseline model when compared to the current state-of-the-art methods, even in the case of channel mismatch.
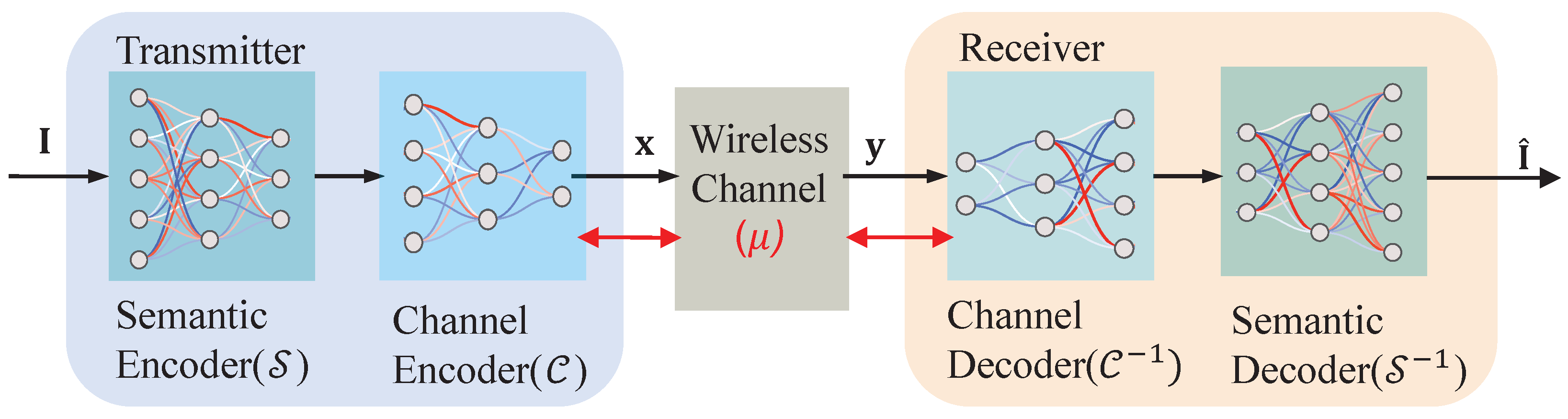
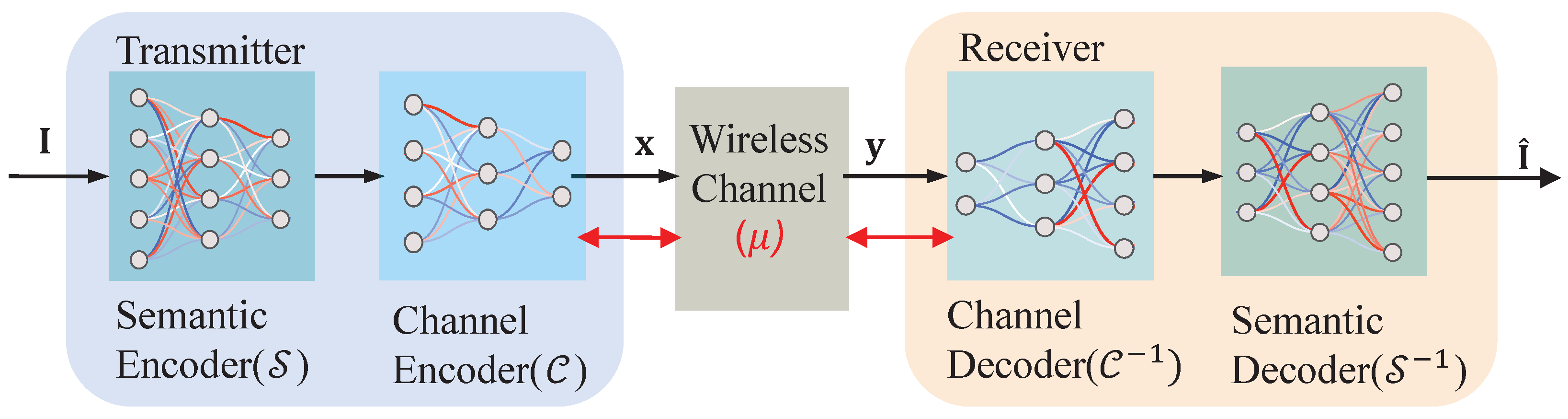
2. System Model
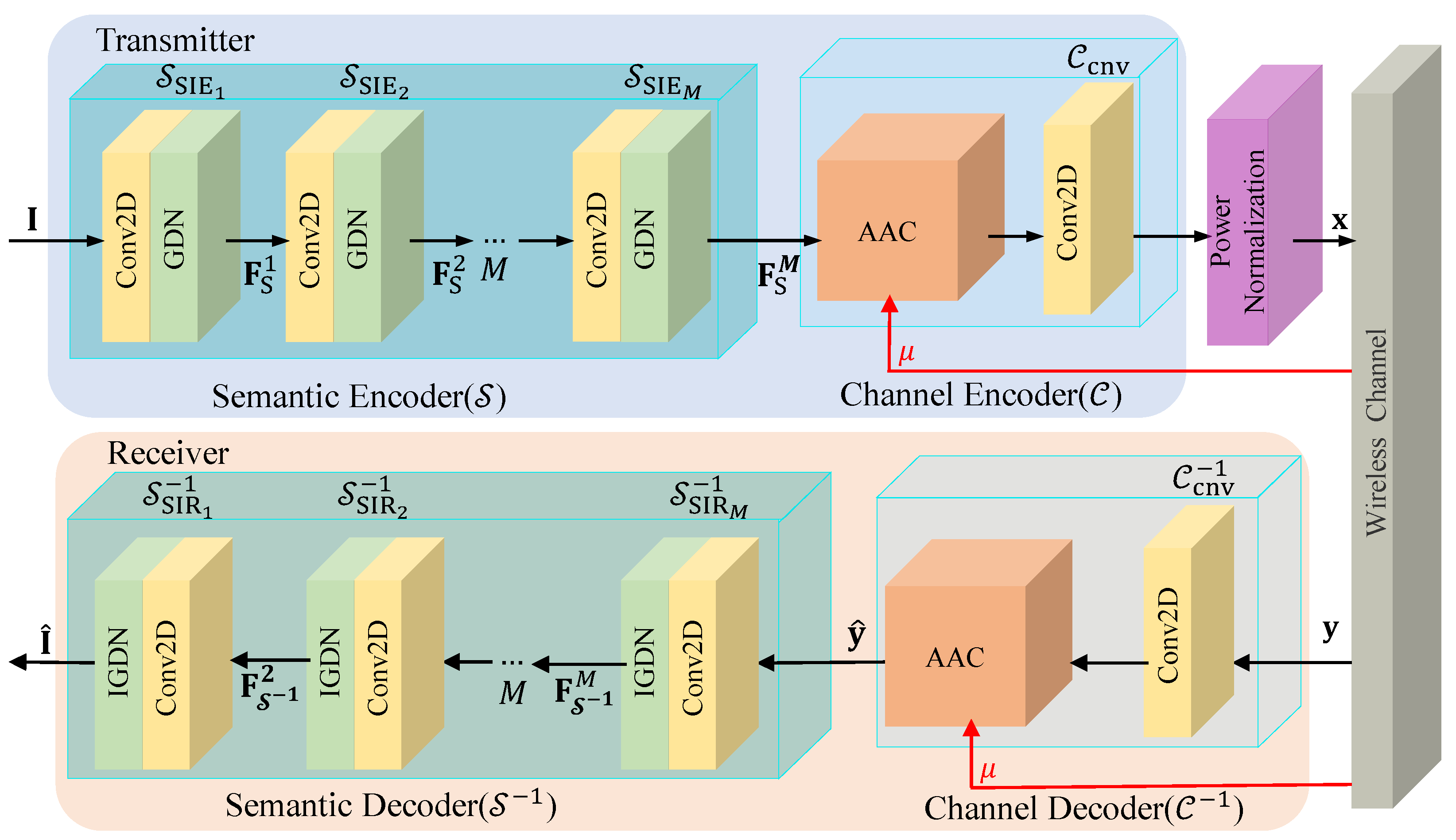
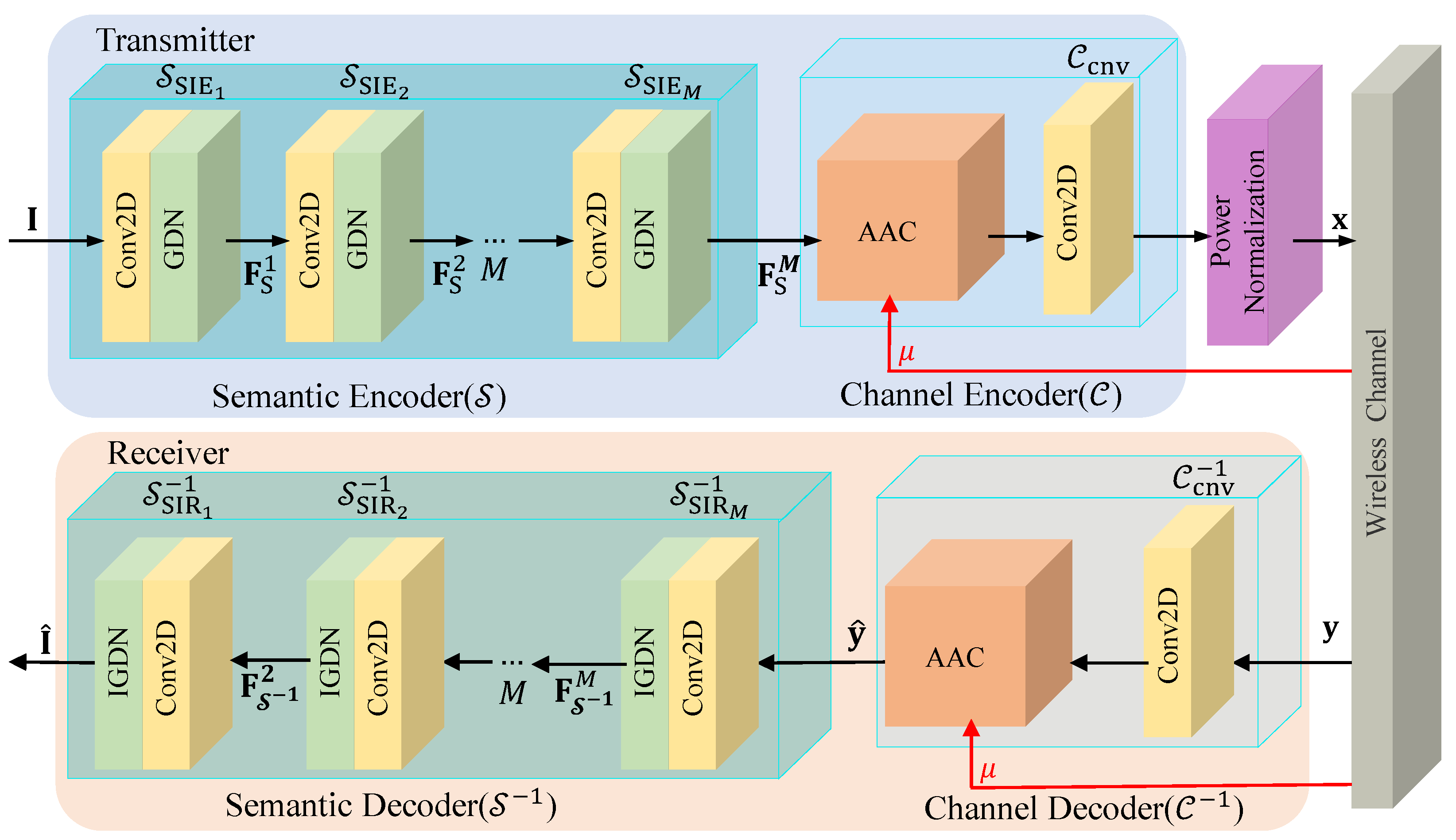
3. The Proposed JSCC Scheme
3.1. The Design of and
3.2. The Design of and
3.3. The Training Algorithm
| Algorithm 1 Training Algorithm for |
|
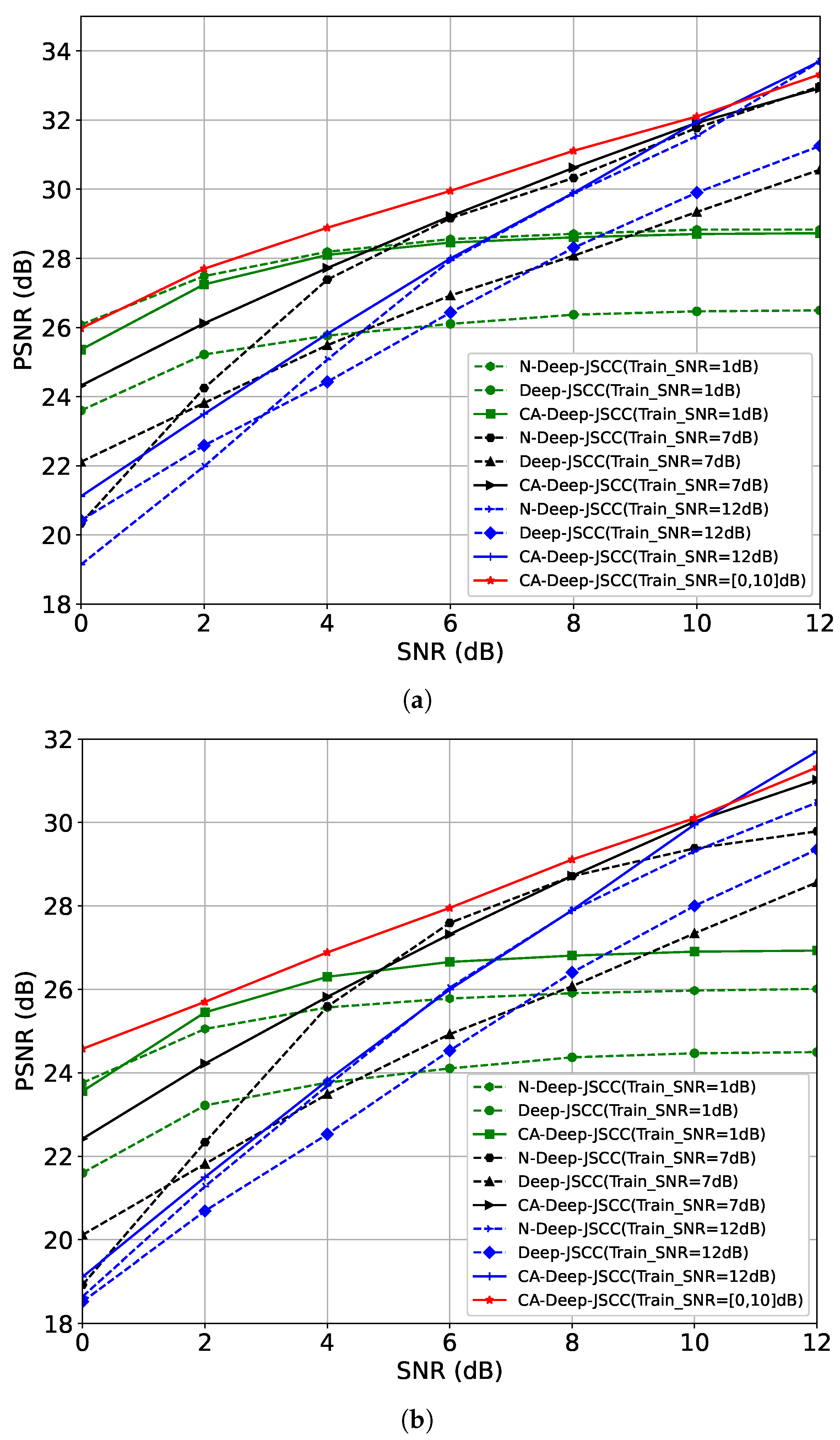
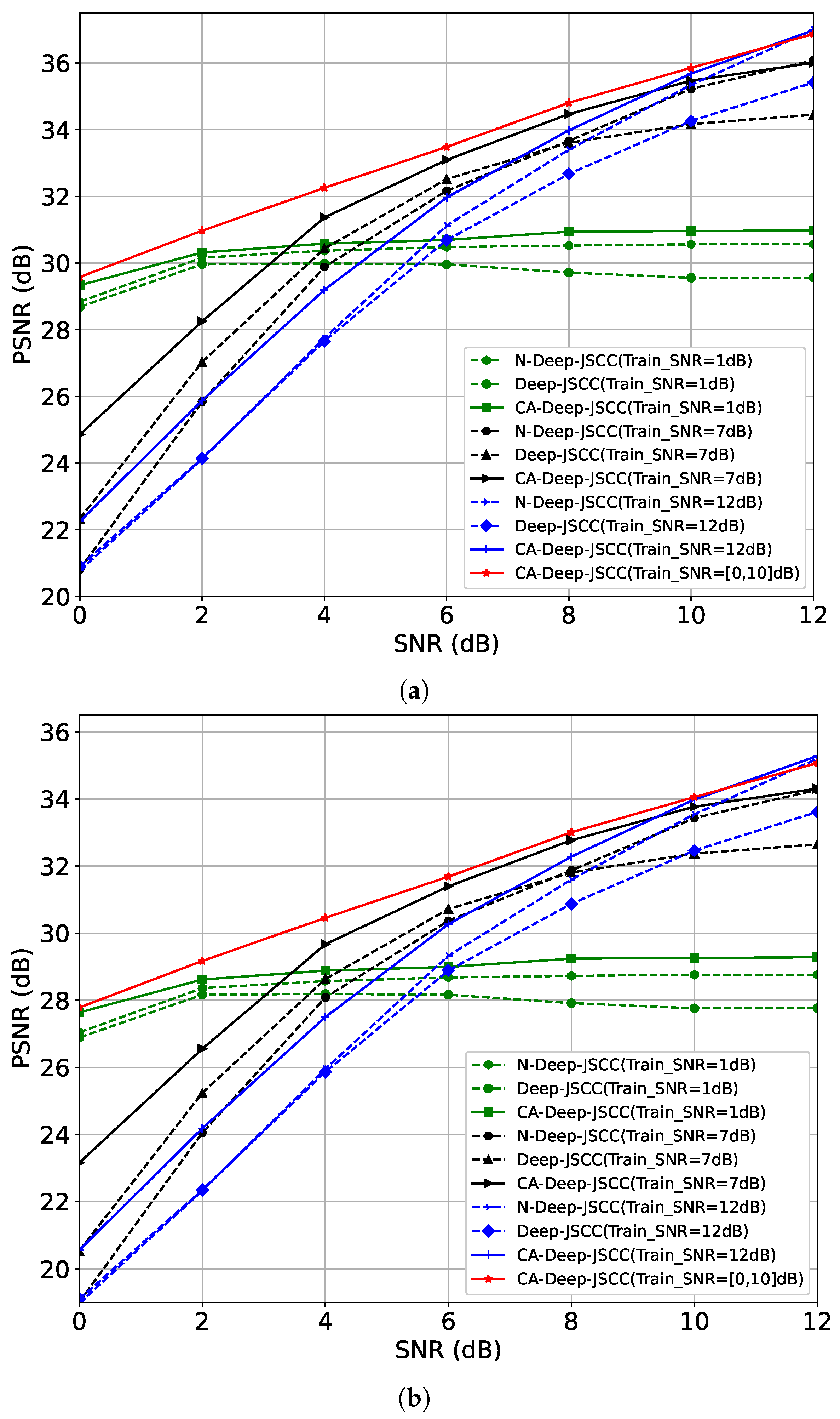
4. Simulation Results
4.1. Simulation Settings
4.2. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Compton, M.; Henson, C.; Neuhaus, H.; Lefort, L.; Sheth, A. A Survey of the Semantic Specification of Sensors. In Proceedings of the 2nd International Workshop on Semantic Sensor Networks, at 8th International Semantic Web Conference, Chantilly, VA, USA, 25–29 October 2009; pp. 17–32. [Google Scholar] [CrossRef]
- Akyildiz, I.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. A survey on sensor networks. IEEE Commun. Mag. 2002, 40, 102–114. [Google Scholar] [CrossRef]
- Wen, W.; Cui, Y.; Zheng, F.C.; Jin, S.; Jiang, Y. Random caching based cooperative transmission in heterogeneous wireless networks. IEEE Trans. Commun. 2018, 66, 2809–2825. [Google Scholar] [CrossRef]
- Wen, W.; Fu, Y.; Quek, T.Q.; Zheng, F.C.; Jin, S. Joint uplink/downlink sub-channel, bit and time allocation for multi-access edge computing. IEEE Commun. Lett. 2019, 23, 1811–1815. [Google Scholar] [CrossRef]
- Yarinezhad, R.; Hashemi, S.N. A sensor deployment approach for target coverage problem in wireless sensor networks. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 5941–5956. [Google Scholar] [CrossRef]
- Wang, J.; Wang, S.; Dai, J.; Si, Z.; Zhou, D.; Niu, K. Perceptual learned source-channel coding for high-fidelity image semantic transmission. In Proceedings of the GLOBECOM 2022–2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil, 4–8 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 3959–3964. [Google Scholar] [CrossRef]
- Wang, S.; Dai, J.; Liang, Z.; Niu, K.; Si, Z.; Dong, C.; Qin, X.; Zhang, P. Wireless deep video semantic transmission. IEEE J. Sel. Areas Commun. 2022, 41, 214–229. [Google Scholar] [CrossRef]
- Bourtsoulatze, E.; Burth Kurka, D.; Gündüz, D. Deep Joint Source-Channel Coding for Wireless Image Transmission. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 567–579. [Google Scholar] [CrossRef]
- Kurka, D.B.; Gündüz, D. DeepJSCC-f: Deep joint source-channel coding of images with feedback. IEEE J. Sel. Areas Inf. Theory 2020, 1, 178–193. [Google Scholar] [CrossRef]
- Ding, M.; Li, J.; Ma, M.; Fan, X. SNR-adaptive deep joint source-channel coding for wireless image transmission. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1555–1559. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Jia, Y.; Huang, Z.; Luo, K.; Wen, W. Lightweight Joint Source-Channel Coding for Semantic Communications. IEEE Commun. Lett. 2023, 27, 3161–3165. [Google Scholar] [CrossRef]
- Xie, H.; Qin, Z.; Li, G.Y.; Juang, B.H. Deep Learning Enabled Semantic Communication Systems. IEEE Trans. Signal Process. 2021, 69, 2663–2675. [Google Scholar] [CrossRef]
- Yao, S.; Niu, K.; Wang, S.; Dai, J. Semantic coding for text transmission: An iterative design. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 1594–1603. [Google Scholar] [CrossRef]
- Weng, Z.; Qin, Z. Semantic communication systems for speech transmission. IEEE J. Sel. Areas Commun. 2021, 39, 2434–2444. [Google Scholar] [CrossRef]
- Bian, C.; Shao, Y.; Gunduz, D. Wireless Point Cloud Transmission. arXiv 2023, arXiv:2306.08730. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Horé, A.; Ziou, D. Image Quality Metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Huang, X.; Chen, X.; Chen, L.; Yin, H.; Wang, W. A Novel Convolutional Neural Network Architecture of Deep Joint Source-Channel Coding for Wireless Image Transmission. In Proceedings of the 2021 13th International Conference on Wireless Communications and Signal Processing (WCSP), Changsha, China, 20–22 October 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Available online: http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 18 January 2024).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Franzen, R. Kodak Lossless True Color Image Suite. 1999, Volume 4, p. 9. Available online: http://r0k.us/graphics/kodak (accessed on 18 January 2024).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Layer | Input | Output | K_Size | Stride | Activation | |
|---|---|---|---|---|---|---|---|
| () | () | 3(256) | 256(3) | 9(9) | 2(2) | PReLU(PReLU) | |
| () | 256(256) | 256(256) | 5(5) | 2(2) | PReLU(PReLU) | ||
| () | 256(256) | 256(256) | 5(5) | 1(1) | PReLU(PReLU) | ||
| () | 256(256) | 256(256) | 5(5) | 1(1) | PReLU(PReLU) | ||
| () | () | 256() | (256) | 3 | 1 | PReLU(PReLU) | |
| AAC | 256 | 128 | 1 | 1 | GELU | ||
| 128 | 128 | 3 | 1 | GELU | |||
| 128 | 256 | 1 | 1 | None | |||
| 256 | 256 | 1 | 1 | Sigmoid | |||
| 257 | 256 | 1 | 1 | ReLU | |||
| 256 | 256 | 1 | 1 | Sigmoid | |||
| WAB | |||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Huang, Z.; Zhang, Y.; Jia, Y.; Wen, W. CNN and Attention-Based Joint Source Channel Coding for Semantic Communications in WSNs. Sensors 2024, 24, 957. https://doi.org/10.3390/s24030957
Liu X, Huang Z, Zhang Y, Jia Y, Wen W. CNN and Attention-Based Joint Source Channel Coding for Semantic Communications in WSNs. Sensors. 2024; 24(3):957. https://doi.org/10.3390/s24030957
Chicago/Turabian StyleLiu, Xinyue, Zhen Huang, Yulu Zhang, Yunjian Jia, and Wanli Wen. 2024. "CNN and Attention-Based Joint Source Channel Coding for Semantic Communications in WSNs" Sensors 24, no. 3: 957. https://doi.org/10.3390/s24030957
APA StyleLiu, X., Huang, Z., Zhang, Y., Jia, Y., & Wen, W. (2024). CNN and Attention-Based Joint Source Channel Coding for Semantic Communications in WSNs. Sensors, 24(3), 957. https://doi.org/10.3390/s24030957