
SF-CNN: Signal Filtering Convolutional Neural Network for Precipitation Intensity Estimation



Abstract
:1. Introduction
2. Related Works
3. Signal Filtering Convolutional Neural Network
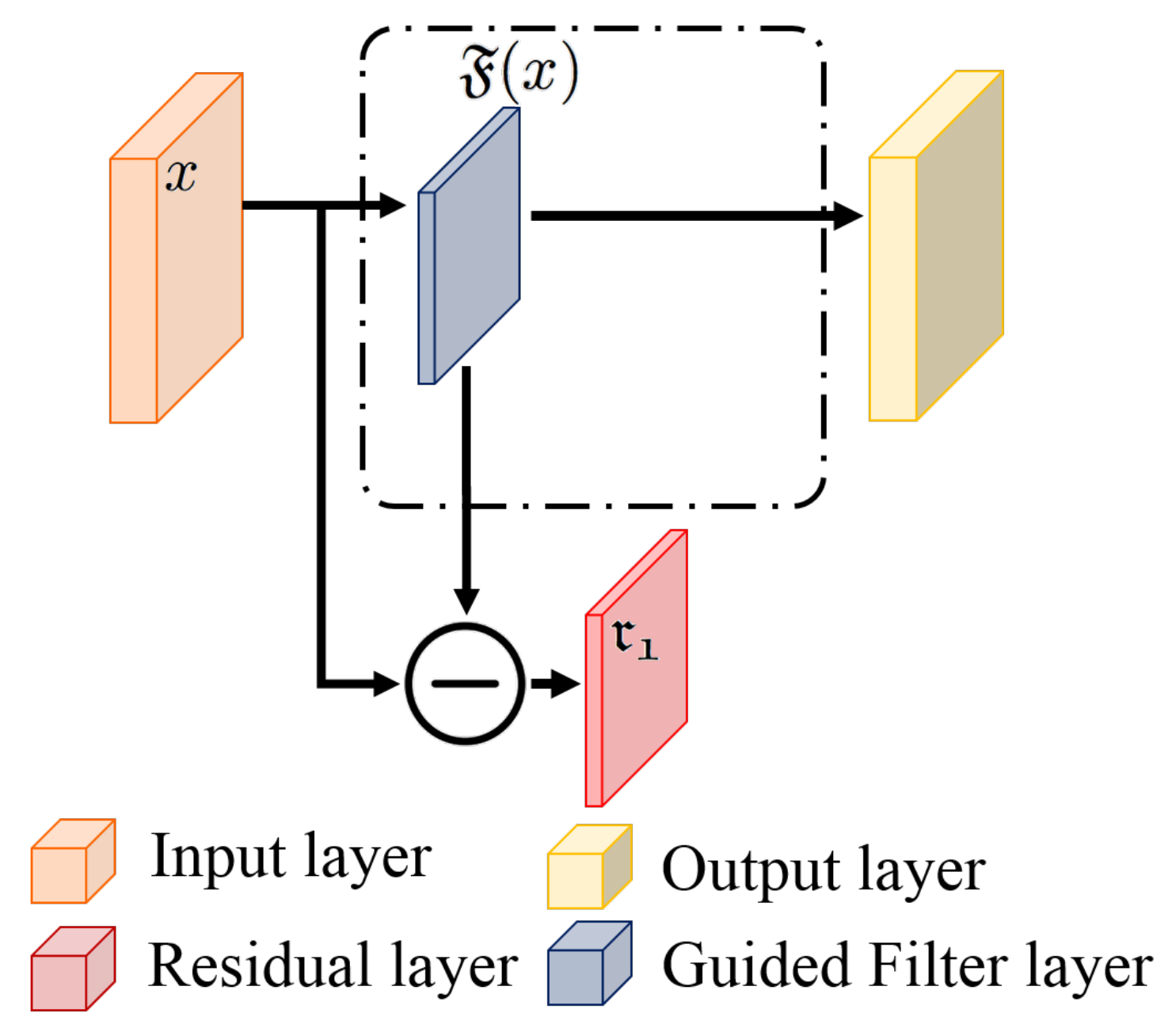
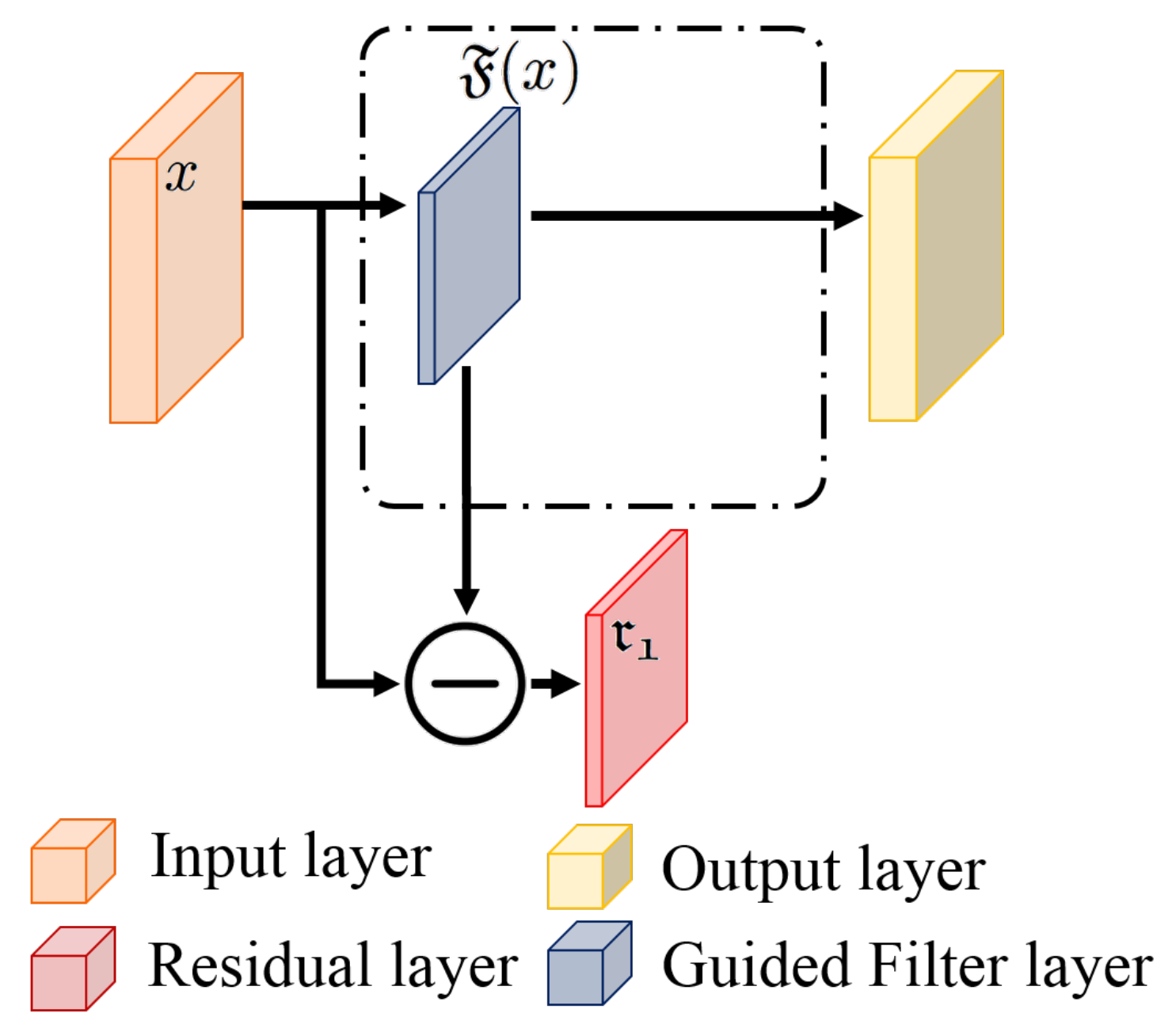
3.1. Signal Filtering Block
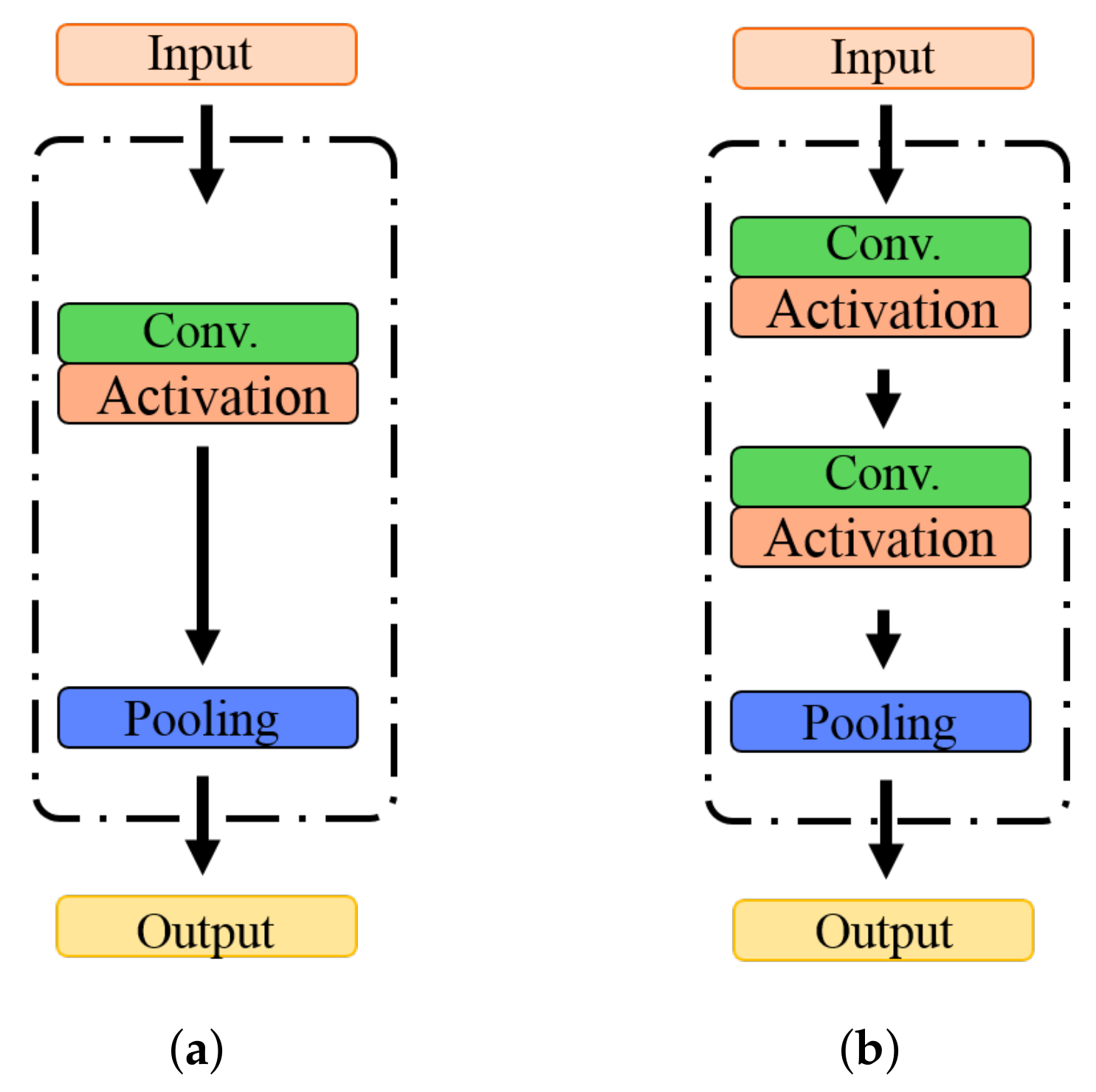
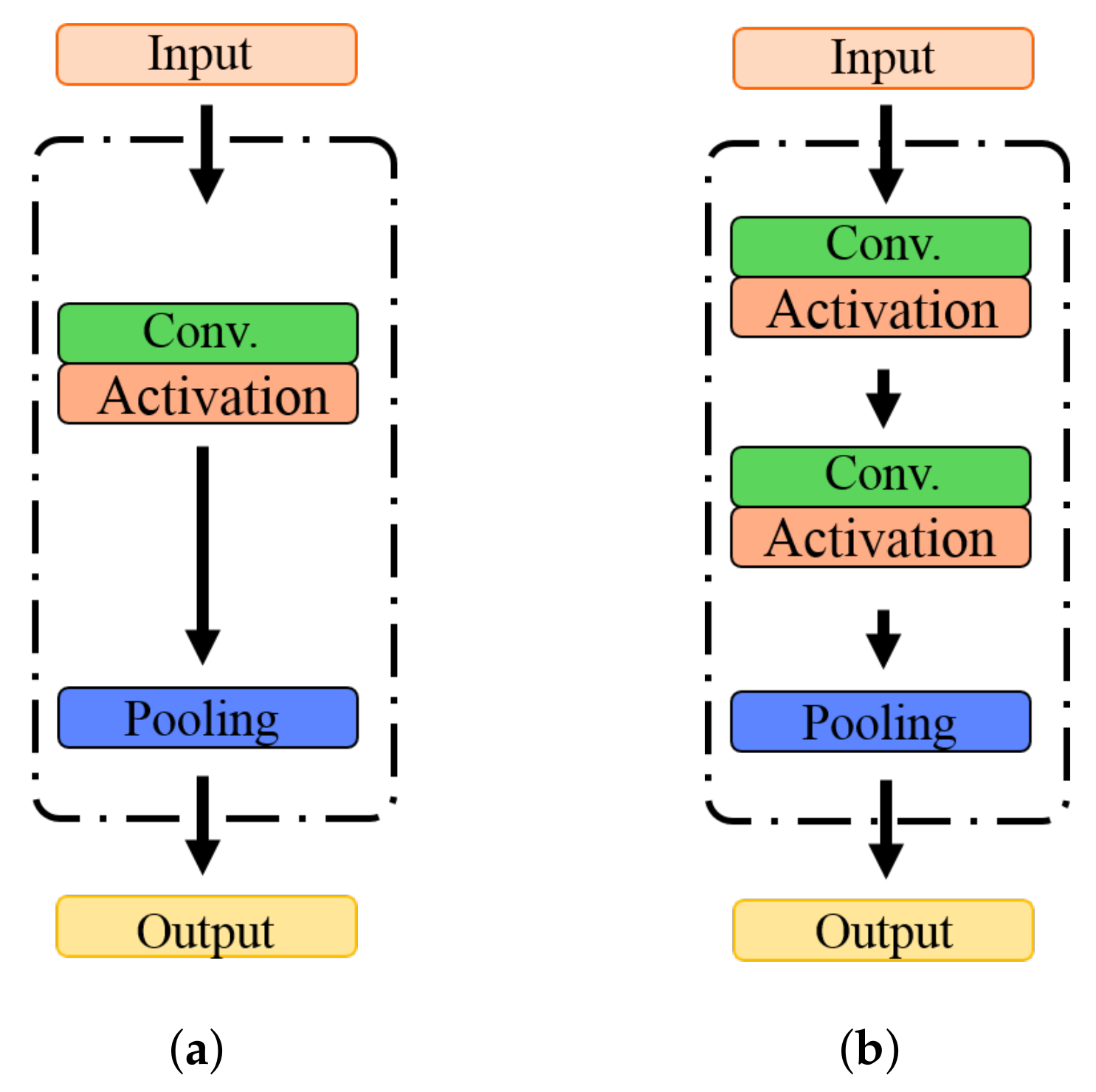
3.2. Gradually Decreasing Dimensional Block
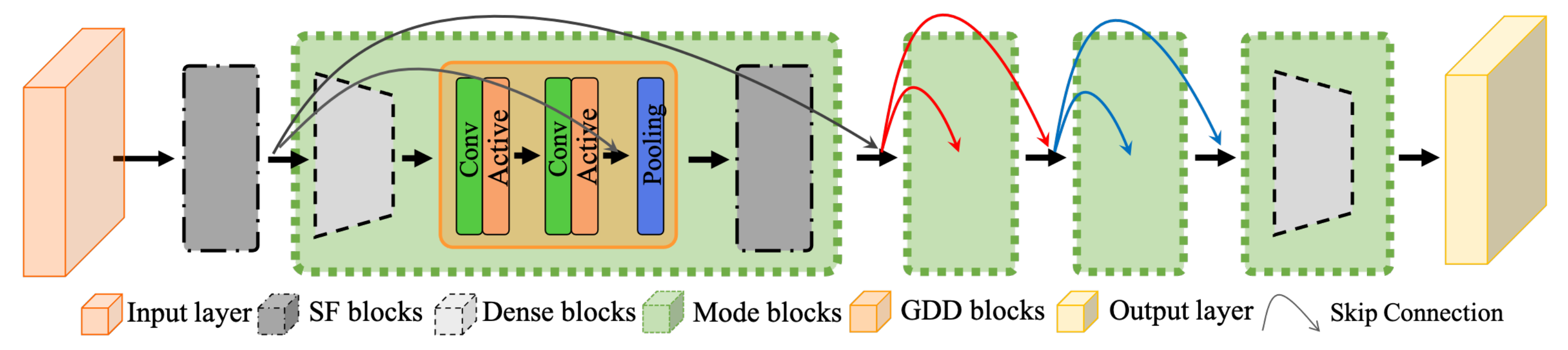
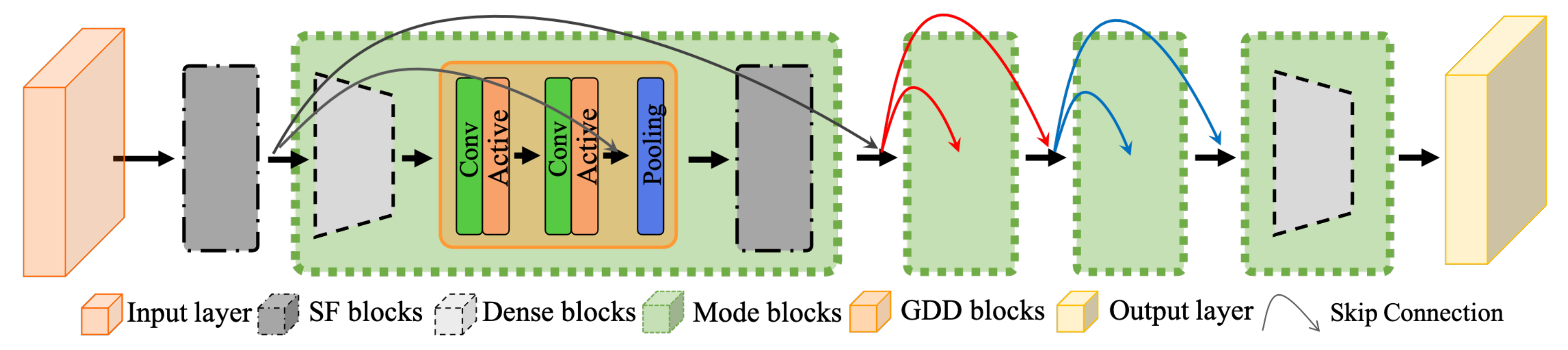
3.3. Network Structure
4. Experimental Results
4.1. Experimental Environments and Benchmarks
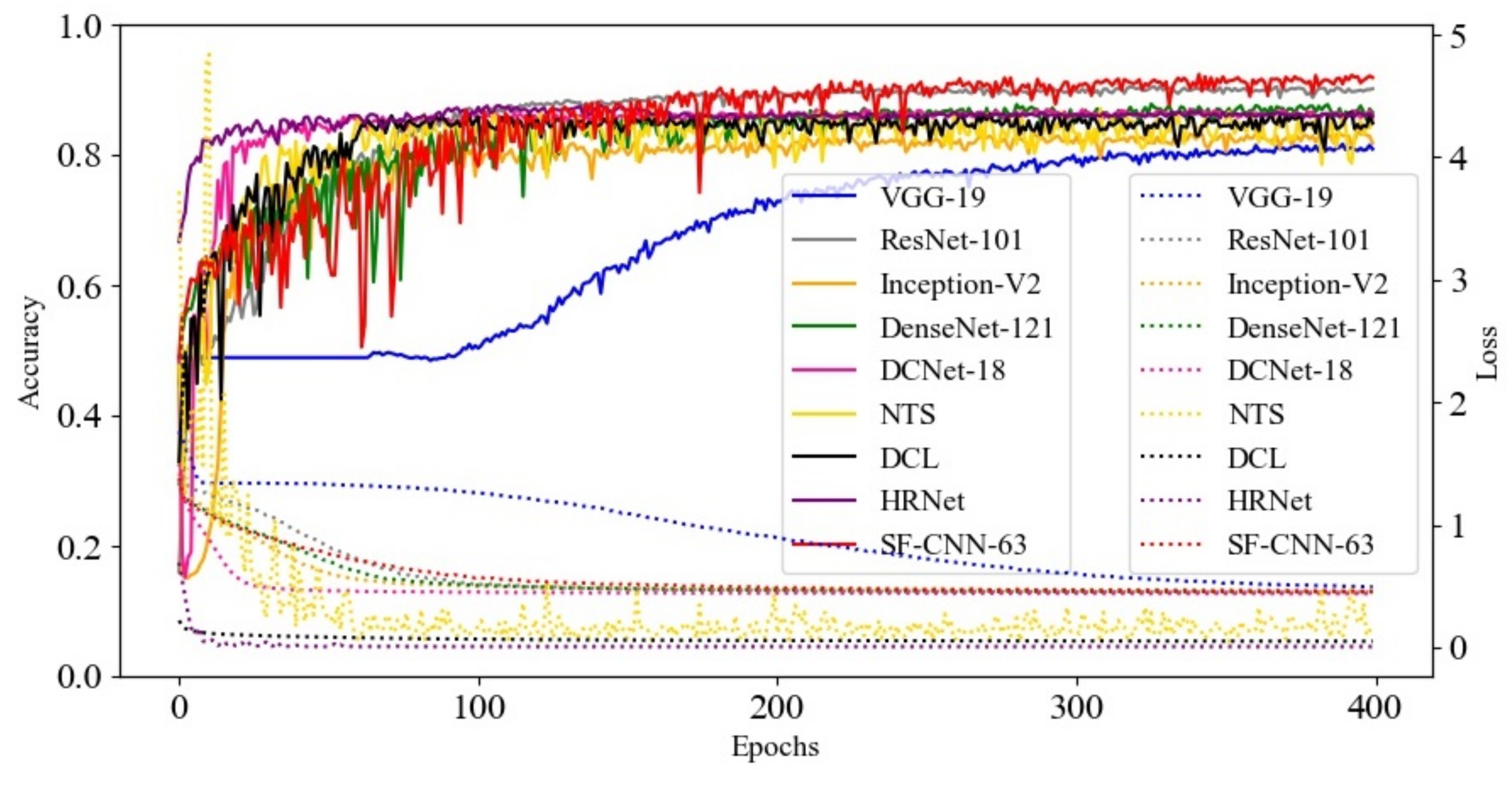
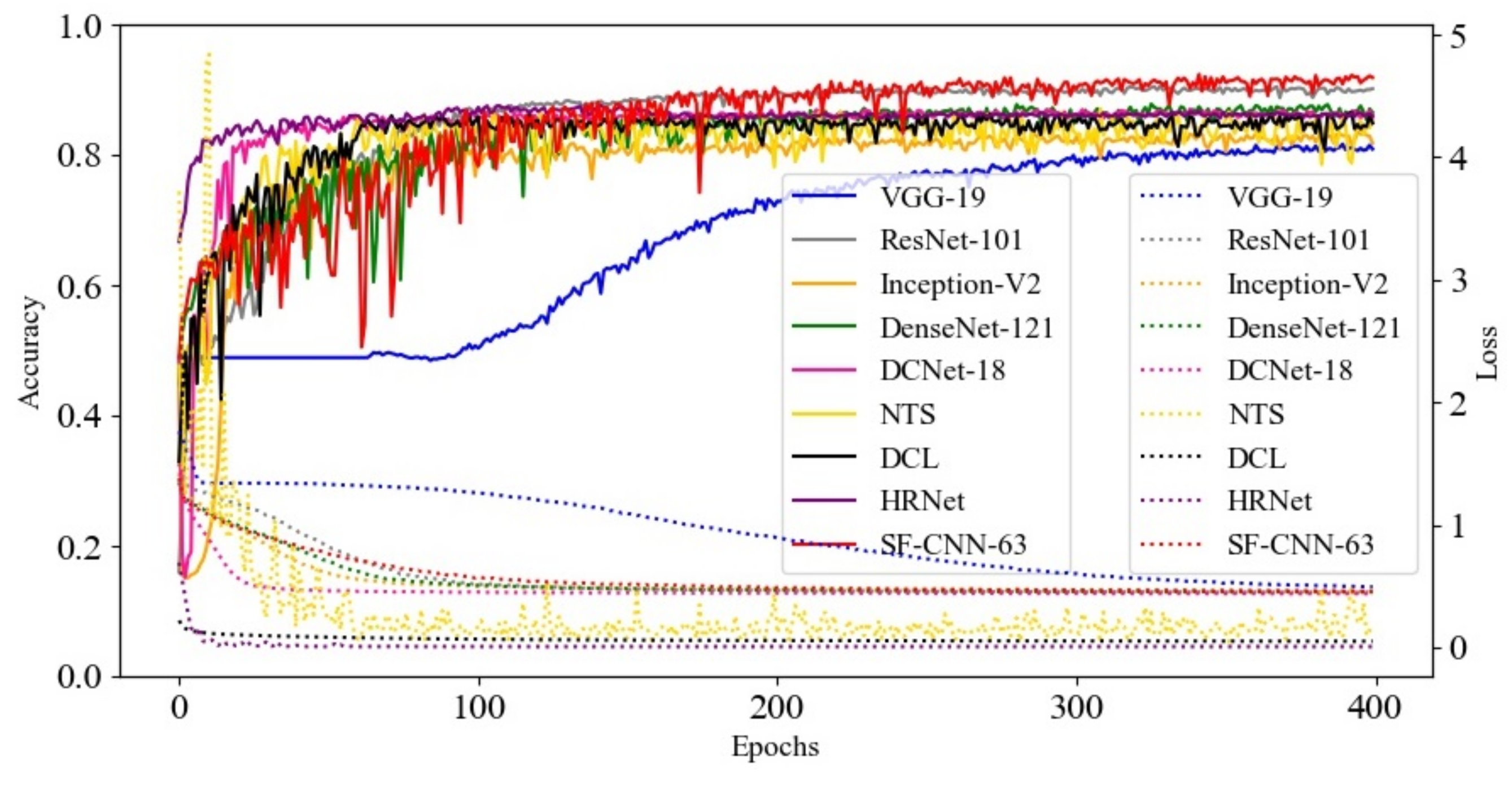
4.2. Experimental Analysis on Various Networks
4.3. Ablation Experimental Analysis of the Proposed Network
5. Discussion
5.1. Analysis of the GDD Block
5.2. Analysis of the SF Block
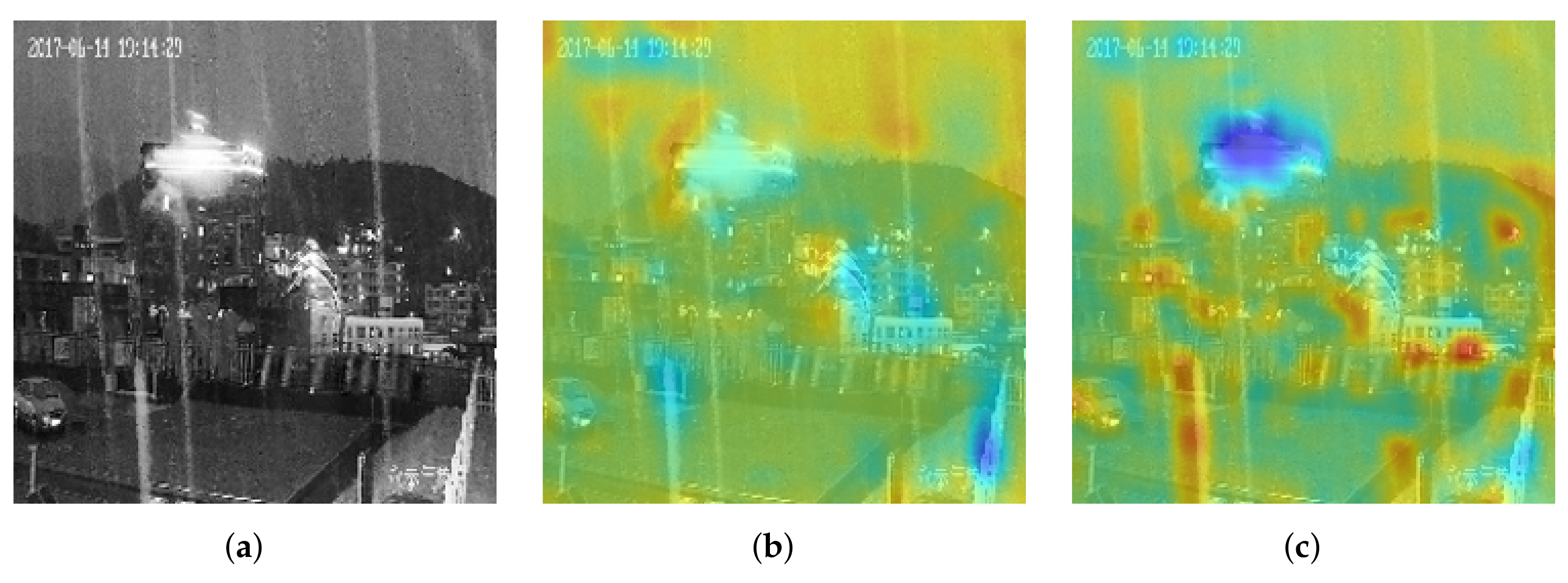
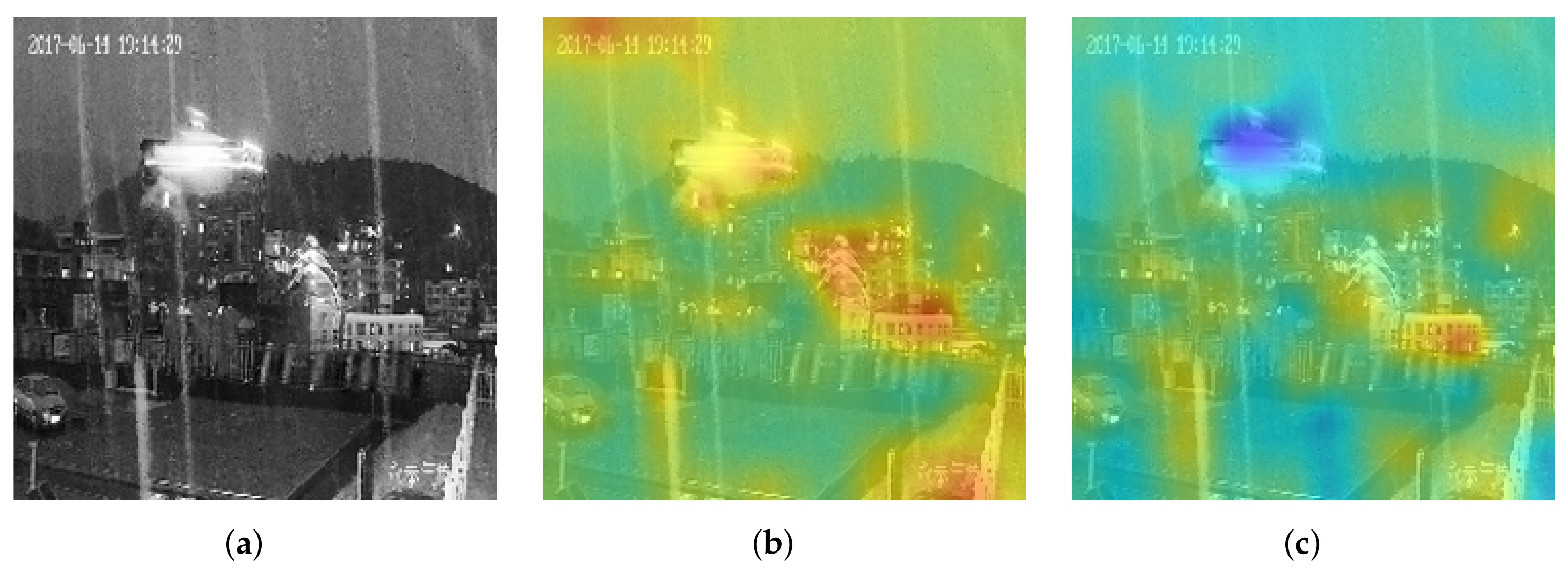
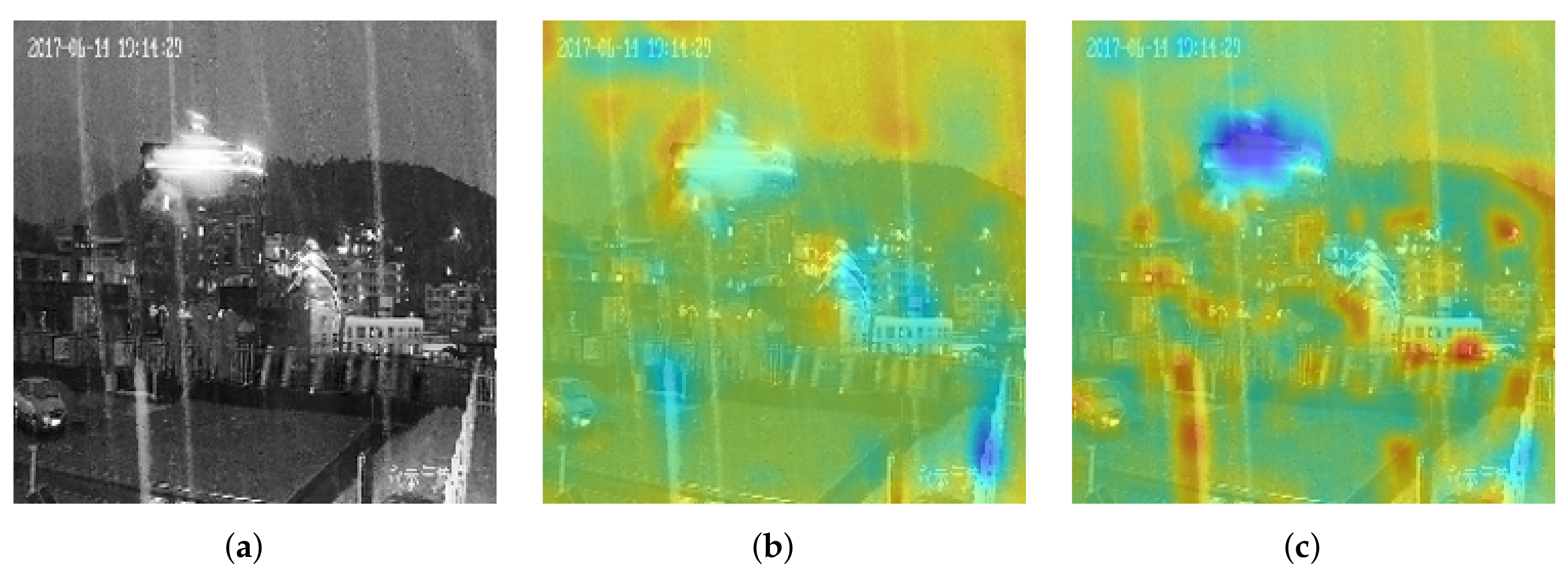
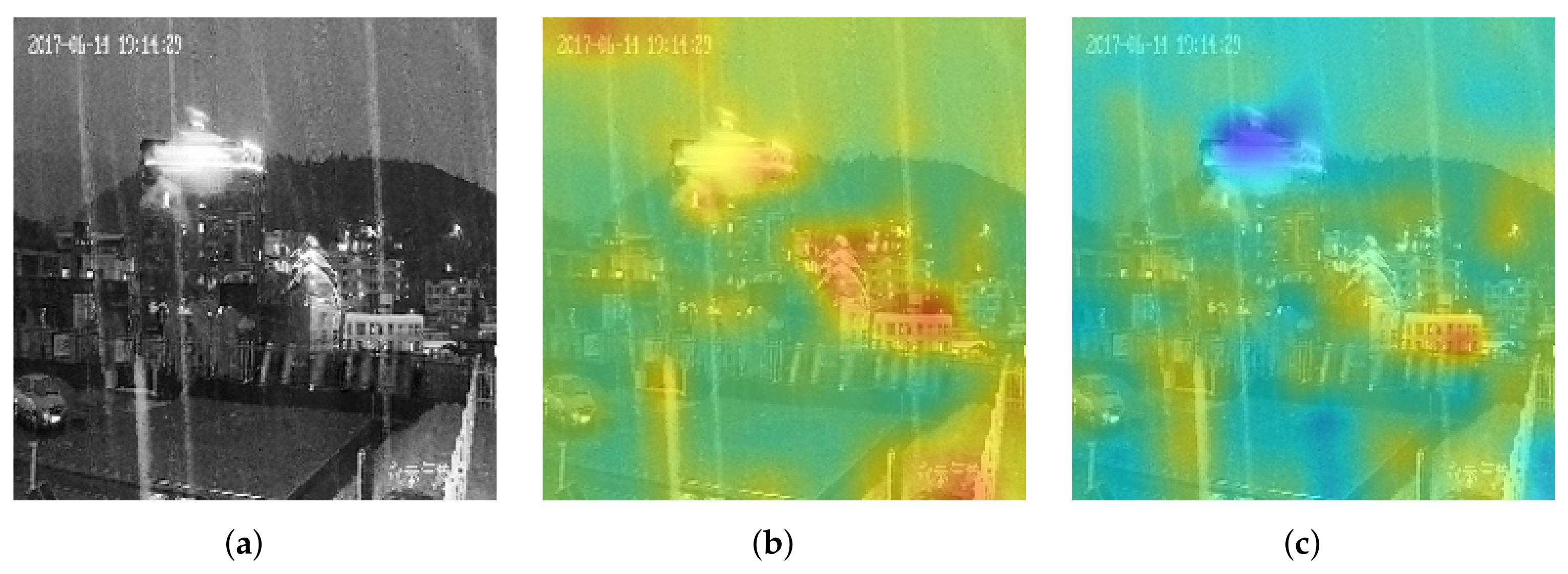
5.3. Characteristic of the DNN’s Black Box
5.4. Limitation and Outlook
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xie, P.; Chen, M.; Yang, S.; Yatagai, A.; Hayasaka, T.; Fukushima, Y.; Liu, C. A gauge-based analysis of daily precipitation over East Asia. J. Hydrometeorol. 2007, 8, 607–626. [Google Scholar] [CrossRef]
- Chen, M.; Shi, W.; Xie, P.; Silva, V.B.; Kousky, V.E.; Wayne Higgins, R.; Janowiak, J.E. Assessing objective techniques for gauge-based analyses of global daily precipitation. J. Geophys. Res. Atmos. 2008, 113. [Google Scholar] [CrossRef]
- Wilson, J.W.; Brandes, E.A. Radar measurement of rainfall—A summary. Bull. Am. Meteorol. Soc. 1979, 60, 1048–1060. [Google Scholar] [CrossRef] [Green Version]
- Germann, U.; Galli, G.; Boscacci, M.; Bolliger, M. Radar precipitation measurement in a mountainous region. Q. J. R. Meteorol. Soc. 2006, 132, 1669–1692. [Google Scholar] [CrossRef]
- Ebert, E.E.; Janowiak, J.E.; Kidd, C. Comparison of near-real-time precipitation estimates from satellite observations and numerical models. Bull. Am. Meteorol. Soc. 2007, 88, 47–64. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Peters-Lidard, C.D.; Eylander, J.B.; Joyce, R.J.; Huffman, G.J.; Adler, R.F.; Hsu, K.l.; Turk, F.J.; Garcia, M.; Zeng, J. Component analysis of errors in satellite-based precipitation estimates. J. Geophys. Res. Atmos. 2009, 114. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Zhang, C.; Gu, R.; Li, P.; Yang, B. Vehicle detection and recognition for intelligent traffic surveillance system. Multimed. Tools Appl. 2017, 76, 5817–5832. [Google Scholar] [CrossRef]
- Liu, L.; Stroulia, E.; Nikolaidis, I.; Miguel-Cruz, A.; Rincon, A.R. Smart homes and home health monitoring technologies for older adults: A systematic review. Int. J. Med. Inform. 2016, 91, 44–59. [Google Scholar] [CrossRef]
- Yuan, P.H.; Yang, K.F.; Tsai, W.H. Real-time security monitoring around a video surveillance vehicle with a pair of two-camera omni-imaging devices. IEEE Trans. Veh. Technol. 2011, 60, 3603–3614. [Google Scholar] [CrossRef]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Deep joint rain detection and removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1357–1366. [Google Scholar]
- Fu, X.; Huang, J.; Ding, X.; Liao, Y.; Paisley, J. Clearing the skies: A deep network architecture for single-image rain removal. IEEE Trans. Image Process. 2017, 26, 2944–2956. [Google Scholar] [CrossRef] [Green Version]
- Shedekar, V.S.; King, K.W.; Fausey, N.R.; Soboyejo, A.B.; Harmel, R.D.; Brown, L.C. Assessment of measurement errors and dynamic calibration methods for three different tipping bucket rain gauges. Atmos. Res. 2016, 178, 445–458. [Google Scholar] [CrossRef] [Green Version]
- Niemczynowicz, J. The dynamic calibration of tipping-bucket raingauges. Hydrol. Res. 1986, 17, 203–214. [Google Scholar] [CrossRef]
- Tang, H.; Kuang, L.; Shi, P. Design of a high precision weighing rain cauge based on WSN. Meas. Control Technol. 2014, 33, 200–204. [Google Scholar]
- Knechtl, V.; Caseri, M.; Lumpert, F.; Hotz, C.; Sigg, C. Detecting temperature induced spurious precipitation in a weighing rain gauge. Meteorol. Z. 2019, 28, 215–224. [Google Scholar] [CrossRef]
- Al-Wagdany, A. Inconsistency in rainfall characteristics estimated from records of different rain gauges. Arab. J. Geosci. 2016, 9, 410. [Google Scholar] [CrossRef]
- Grimes, D.; Pardo-Iguzquiza, E.; Bonifacio, R. Optimal areal rainfall estimation using raingauges and satellite data. J. Hydrol. 1999, 222, 93–108. [Google Scholar] [CrossRef]
- Gat, J.R.; Airey, P.L. Stable water isotopes in the atmosphere/biosphere/lithosphere interface: Scaling-up from the local to continental scale, under humid and dry conditions. Glob. Planet. Chang. 2006, 51, 25–33. [Google Scholar] [CrossRef]
- Yan, J.; Bárdossy, A.; Hörning, S.; Tao, T. Conditional simulation of surface rainfall fields using modified phase annealing. Hydrol. Earth Syst. Sci. 2020, 24, 2287–2301. [Google Scholar] [CrossRef]
- Suseno, D.P.Y.; Yamada, T.J. Simulating flash floods using geostationary satellite-based rainfall estimation coupled with a land surface model. Hydrology 2020, 7, 9. [Google Scholar] [CrossRef] [Green Version]
- Sevruk, B. Regional dependency of precipitation-altitude relationship in the Swiss Alps. In Climatic Change at High Elevation Sites; Springer: Dordrecht, The Netherlands, 1997; pp. 123–137. [Google Scholar]
- Barnes, S.L. A technique for maximizing details in numerical weather map analysis. J. Appl. Meteorol. Climatol. 1964, 3, 396–409. [Google Scholar] [CrossRef] [Green Version]
- Foehn, A.; Hernández, J.G.; Schaefli, B.; De Cesare, G. Spatial interpolation of precipitation from multiple rain gauge networks and weather radar data for operational applications in Alpine catchments. J. Hydrol. 2018, 563, 1092–1110. [Google Scholar] [CrossRef]
- Ryzhkov, A.; Zrnic, D. Radar polarimetry at S, C, and X bands: Comparative analysis and operational implications. In Proceedings of the 32nd Conference on Radar Meteorology, Norman, OK, USA, 22–29 October 2005. [Google Scholar]
- Huang, H.; Zhao, K.; Zhang, G.; Hu, D.; Yang, Z. Optimized raindrop size distribution retrieval and quantitative rainfall estimation from polarimetric radar. J. Hydrol. 2020, 580, 124248. [Google Scholar] [CrossRef]
- Bellerby, T.; Todd, M.; Kniveton, D.; Kidd, C. Rainfall estimation from a combination of TRMM precipitation radar and GOES multispectral satellite imagery through the use of an artificial neural network. J. Appl. Meteorol. 2000, 39, 2115–2128. [Google Scholar] [CrossRef]
- Behrangi, A.; Hsu, K.L.; Imam, B.; Sorooshian, S.; Kuligowski, R.J. Evaluating the utility of multispectral information in delineating the areal extent of precipitation. J. Hydrometeorol. 2009, 10, 684–700. [Google Scholar] [CrossRef]
- Hong, Y.; Hsu, K.L.; Sorooshian, S.; Gao, X. Precipitation estimation from remotely sensed imagery using an artificial neural network cloud classification system. J. Appl. Meteorol. 2004, 43, 1834–1853. [Google Scholar] [CrossRef] [Green Version]
- Kummerow, C.; Olson, W.S.; Giglio, L. A simplified scheme for obtaining precipitation and vertical hydrometeor profiles from passive microwave sensors. IEEE Trans. Geosci. Remote Sens. 1996, 34, 1213–1232. [Google Scholar] [CrossRef]
- Lazri, M.; Labadi, K.; Brucker, J.M.; Ameur, S. Improving satellite rainfall estimation from MSG data in Northern Algeria by using a multi-classifier model based on machine learning. J. Hydrol. 2020, 584, 124705. [Google Scholar] [CrossRef]
- Ouallouche, F.; Lazri, M.; Ameur, S. Improvement of rainfall estimation from MSG data using Random Forests classification and regression. Atmos. Res. 2018, 211, 62–72. [Google Scholar] [CrossRef]
- Tao, Y.; Hsu, K.; Ihler, A.; Gao, X.; Sorooshian, S. A two-stage deep neural network framework for precipitation estimation from bispectral satellite information. J. Hydrometeorol. 2018, 19, 393–408. [Google Scholar] [CrossRef]
- Wang, C.; Xu, J.; Tang, G.; Yang, Y.; Hong, Y. Infrared precipitation estimation using convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8612–8625. [Google Scholar] [CrossRef]
- Bossu, J.; Hautiere, N.; Tarel, J.P. Rain or snow detection in image sequences through use of a histogram of orientation of streaks. Int. J. Comput. Vis. 2011, 93, 348–367. [Google Scholar] [CrossRef]
- Kang, L.W.; Lin, C.W.; Fu, Y.H. Automatic single-image-based rain streaks removal via image decomposition. IEEE Trans. Image Process. 2011, 21, 1742–1755. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.H.; Sim, J.Y.; Kim, C.S. Video deraining and desnowing using temporal correlation and low-rank matrix completion. IEEE Trans. Image Process. 2015, 24, 2658–2670. [Google Scholar] [CrossRef] [PubMed]
- Sawant, S.; Ghonge, P. Estimation of rain drop analysis using image processing. Int. J. Sci. Res. 2015, 4, 1981–1986. [Google Scholar]
- Hsieh, C.W.; Chi, P.W.; Chen, C.Y.; Weng, C.J.; Wang, L. Automatic Precipitation Measurement Based on Raindrop Imaging and Artificial Intelligence. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10276–10284. [Google Scholar] [CrossRef]
- Roser, M.; Moosmann, F. Classification of weather situations on single color images. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 798–803. [Google Scholar]
- Zhang, S.; Chi, C.; Lei, Z.; Li, S.Z. Refineface: Refinement neural network for high performance face detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4008–4020. [Google Scholar] [CrossRef]
- Li, X.; Yu, L.; Chang, D.; Ma, Z.; Cao, J. Dual cross-entropy loss for small-sample fine-grained vehicle classification. IEEE Trans. Veh. Technol. 2019, 68, 4204–4212. [Google Scholar] [CrossRef]
- LeBien, J.; Zhong, M.; Campos-Cerqueira, M.; Velev, J.P.; Dodhia, R.; Ferres, J.L.; Aide, T.M. A pipeline for identification of bird and frog species in tropical soundscape recordings using a convolutional neural network. Ecol. Inform. 2020, 59, 101113. [Google Scholar] [CrossRef]
- Hossain, M.; Rekabdar, B.; Louis, S.J.; Dascalu, S. Forecasting the weather of Nevada: A deep learning approach. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–6. [Google Scholar]
- Sadeghi, M.; Asanjan, A.A.; Faridzad, M.; Nguyen, P.; Hsu, K.; Sorooshian, S.; Braithwaite, D. PERSIANN-CNN: Precipitation estimation from remotely sensed information using artificial neural networks–convolutional neural networks. J. Hydrometeorol. 2019, 20, 2273–2289. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Guided image filtering. In Proceedings of the European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–14. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef]
- Wang, L.; Li, D.; Zhu, Y.; Tian, L.; Shan, Y. Dual super-resolution learning for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3774–3783. [Google Scholar]
- Bae, K.I.; Park, J.; Lee, J.; Lee, Y.; Lim, C. Flower classification with modified multimodal convolutional neural networks. Expert Syst. Appl. 2020, 159, 113455. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Liu, W.; Liu, Z.; Yu, Z.; Dai, B.; Lin, R.; Wang, Y.; Rehg, J.M.; Song, L. Decoupled Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2771–2779. [Google Scholar]
- Yang, Z.; Luo, T.; Wang, D.; Hu, Z.; Gao, J.; Wang, L. Learning to navigate for fine-grained classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 420–435. [Google Scholar]
- Chen, Y.; Bai, Y.; Zhang, W.; Mei, T. Destruction and construction learning for fine-grained image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5157–5166. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef] [Green Version]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Zheng, Q.; Yang, M.; Tian, X.; Wang, X.; Wang, D. Rethinking the Role of Activation Functions in Deep Convolutional Neural Networks for Image Classification. Eng. Lett. 2020, 28, 80–92. [Google Scholar]
- Kuo, C.C.J. Understanding convolutional neural networks with a mathematical model. J. Vis. Commun. Image Represent. 2016, 41, 406–413. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine learning interpretability: A survey on methods and metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef] [Green Version]
- Du, M.; Liu, N.; Hu, X. Techniques for interpretable machine learning. Commun. ACM 2019, 63, 68–77. [Google Scholar] [CrossRef] [Green Version]
- Buhrmester, V.; Münch, D.; Arens, M. Analysis of explainers of black box deep neural networks for computer vision: A survey. Mach. Learn. Knowl. Extr. 2021, 3, 48. [Google Scholar] [CrossRef]
- Xie, N.; Ras, G.; van Gerven, M.; Doran, D. Explainable deep learning: A field guide for the uninitiated. arXiv 2020, arXiv:2004.14545. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Qin, S.; Zhong, Y.M. A new envelope algorithm of Hilbert–Huang transform. Mech. Syst. Signal Process. 2006, 20, 1941–1952. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Baigorria, G.A.; Jones, J.W.; O’Brien, J.J. Understanding rainfall spatial variability in southeast USA at different timescales. Int. J. Climatol. A J. R. Meteorol. Soc. 2007, 27, 749–760. [Google Scholar] [CrossRef]
- Razmkhah, H.; AkhoundAli, A.M.; Radmanesh, F.; Saghafian, B. Evaluation of rainfall spatial correlation effect on rainfall-runoff modeling uncertainty, considering 2-copula. Arab. J. Geosci. 2016, 9, 323. [Google Scholar] [CrossRef]
- Wu, K.; Shen, Y.; Wang, S. 3D convolutional neural network for regional precipitation nowcasting. J. Image Signal Process. 2018, 7, 200–212. [Google Scholar] [CrossRef]
- Ayzel, G.; Scheffer, T.; Heistermann, M. RainNet v1. 0: A convolutional neural network for radar-based precipitation nowcasting. Geosci. Model Dev. 2020, 13, 2631–2644. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grade of Precipitation (mm/hr) | |||||||
|---|---|---|---|---|---|---|---|
| Amount | Grade | Scattered Rain (<0.1) | Drizzle (0.1–0.5) | Moderate Rain (1.6–6.9) | Heavy Rain (7.0–14.9) | Rainstorm (15.0–39.9) | Large Rainstorm (40.0–49.9) |
| Station | (I) | (II) | (III) | (IV) | (V) | (VI) | |
| WS1 | 209 | 467 | 410 | 96 | 12 | 0 | |
| WS2 | 232 | 518 | 380 | 36 | 48 | 12 | |
| WS3 | 136 | 545 | 389 | 72 | 8 | 0 | |
| WS4 | 101 | 579 | 367 | 78 | 12 | 0 | |
| WS5 | 121 | 651 | 363 | 68 | 12 | 0 | |
| WS6 | 170 | 616 | 339 | 24 | 0 | 0 | |
| WS7 | 224 | 694 | 207 | 24 | 0 | 0 | |
| WS8 | 219 | 504 | 415 | 36 | 0 | 0 | |
| Total | 1412 | 4574 | 2870 | 434 | 92 | 12 | |
| Model | Source | Year | Depth | I (%) | II (%) | III (%) | IV (%) | V (%) | VI (%) | (%) | Params(M) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VGG | ICLR | 2015 | 19 | 89.05 | 86.56 | 75.99 | 48.00 | 60.00 | 0.00 | 81.64 | 0.7121 | 10.16 |
| Inception-V2 | PMLR | 2015 | 32 | 89.05 | 88.53 | 76.57 | 59.20 | 80.00 | 0.00 | 83.46 | 0.7411 | 10.16 |
| ResNet | CVPR | 2016 | 50 | 92.86 | 94.08 | 85.78 | 56.80 | 72.00 | 0.00 | 89.39 | 0.8326 | 23.52 |
| 101 | 96.19 | 93.43 | 87.30 | 67.20 | 72.00 | 33.33 | 90.54 | 0.8519 | 42.51 | |||
| 152 | 92.38 | 91.89 | 82.63 | 49.60 | 76.00 | 0.00 | 87.00 | 0.7954 | 58.16 | |||
| DenseNet | CVPR | 2017 | 63 | 93.10 | 89.70 | 86.25 | 50.40 | 84.00 | 0.00 | 87.25 | 0.8010 | 2.31 |
| 121 | 93.81 | 91.02 | 84.85 | 56.80 | 76.00 | 0.00 | 87.79 | 0.8095 | 6.96 | |||
| 169 | 92.38 | 90.72 | 82.75 | 61.60 | 84.00 | 0.00 | 87.07 | 0.7981 | 12.49 | |||
| DCNet | CVPR | 2018 | 18 | 92.38 | 90.36 | 83.68 | 60.80 | 68.00 | 0.00 | 87.00 | 0.7962 | 41.93 |
| 101 | 93.10 | 91.38 | 79.60 | 52.80 | 56.00 | 33.33 | 85.93 | 0.7784 | 42.58 | |||
| NTS | ECCV | 2018 | 50 | 93.81 | 91.60 | 84.83 | 36.80 | 68.00 | 0.00 | 87.07 | 0.7962 | 26.25 |
| DCL | CVPR | 2019 | 50 | 96.90 | 89.92 | 79.14 | 69.60 | 80.00 | 0.00 | 86.57 | 0.7923 | 23.50 |
| HRNet | PAMI | 2020 | 50 | 95.00 | 90.07 | 83.57 | 66.40 | 72.00 | 66.67 | 87.57 | 0.8081 | 39.20 |
| SF-CNN | - | 2021 | 63 | 95.95 | 95.33 | 88.81 | 76.80 | 76.00 | 33.33 | 92.36 | 0.8804 | 1.99 |
| 121 | 97.14 | 94.23 | 90.68 | 71.20 | 84.00 | 33.33 | 92.39 | 0.8814 | 5.27 | |||
| 169 | 96.67 | 95.98 | 89.04 | 75.20 | 80.00 | 33.33 | 92.82 | 0.8879 | 9.12 |
| SF-CNN-63-W-GDD | SF-CNN-63-W-SF | SF-CNN-63 | |
|---|---|---|---|
| (%) | 91.57 | 87.64 | 92.36 |
| 0.8684 | 0.8049 | 0.8804 | |
| Params (M) | 1.85 | 1.99 | 1.99 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, C.-W.; Huang, X.; Lin, M.; Hong, S. SF-CNN: Signal Filtering Convolutional Neural Network for Precipitation Intensity Estimation. Sensors 2022, 22, 551. https://doi.org/10.3390/s22020551
Lin C-W, Huang X, Lin M, Hong S. SF-CNN: Signal Filtering Convolutional Neural Network for Precipitation Intensity Estimation. Sensors. 2022; 22(2):551. https://doi.org/10.3390/s22020551
Chicago/Turabian StyleLin, Chih-Wei, Xiuping Huang, Mengxiang Lin, and Sidi Hong. 2022. "SF-CNN: Signal Filtering Convolutional Neural Network for Precipitation Intensity Estimation" Sensors 22, no. 2: 551. https://doi.org/10.3390/s22020551
APA StyleLin, C.-W., Huang, X., Lin, M., & Hong, S. (2022). SF-CNN: Signal Filtering Convolutional Neural Network for Precipitation Intensity Estimation. Sensors, 22(2), 551. https://doi.org/10.3390/s22020551