3.1. Overview of the Network Architecture
The overview of the network architecture is shown as
Figure 1. RatioNet is an anchor-free detector constructed with the backbone network and two task-specific subnets, classification and regression.
In the proposed architecture, a feature pyramid network is applied for optimal detection of multi-scale objects, especially the small ones, with features from different levels. Following [
19], five levels from P
to P
is used, where
l is defined as the pyramid level. At the same time, P
also means that the resolution of the feature map in this level is 1/2
of the input image, that is to say, the strides of 8, 16, 32, 64 and 128 are assigned to the levels of P
, P
, P
, P
, P
, respectively. To be specific, when
l is in {3, 4, 5}, P
is generated from the backbone network’s feature maps called C
, which is followed by a 1 × 1 convolutional layer. Moreover, P
is produced from P
rather than C
through a convolutional layer with a stride of 2, and then P
is produced from P
through the similar operation. As in [
19], experiment have been conducted with higher AP and less memory cost with the application of P
compared to C
to generate the feature level of P
. Each level of the feature pyramid network handles different objects with corresponding scales directly, instead of utilizing anchors with different areas in anchor-based detectors.
As shown in
Figure 1, every feature level is followed by a detection head. Each head has two fundamental branches, classification and regression. Suppose the size of input image is (W
, H
), and the bounding box of the object in the input image is (
x,
y,
w,
h,
c), where (
x,
y), (
w,
h),
c denote the center coordinate, width and height, and the category of the box, respectively. In addition, (
x,
y,
w,
h,
c) is defined as the relative ground-truth box in the P
, and it is equal to (
x/2
,
y/2
,
w/2
,
h/2
,
c). Each branch following the detection head is firstly equipped with four 3 × 3 convolutional layers, where the resolution of the input feature map is the same as the output feature map, to further extract deep features.
Classification Subnet: As aforementioned, one of the subnets attached to each feature level is the classification subnet. The shape of the classification output for the
lth level is (W
, H
, C), where (W
, H
) equal to (W
/2
, H
/2
) denotes the size of each feature map and C denotes the channels of feature maps as well as the total number of classes, which is 80 for COCO dataset [
22]. Each spatial location of the classification output predicts the probability of belonging to specific category of objects. We regard all the spatial locations falling into the ground-truth box region, i.e., (
x,
y,
w,
h) in the classification output of P
, as the positive samples, so as many positive samples as possible are utilized in training. To some extent, it alleviates the quantitative imbalance of positive and negative samples, and achieves easier training and better performance compared to the keypoint-based approach. Let
Pijc be the predicted score at the location (
i,
j) for class c, and let
Yijc be the corresponding ground-truth. Following focal loss [
25], the classification loss is defined as:
where
and
are hyper-parameters equal to 0.25 and 2, respectively, and
N is the number of positive samples.
Regression Subnet: The other subnet attached to each feature level is the regression subnet. The final layers are mainly the w-h regression and the ratio regression, which are in parallel with each other. The shape of either w-h regression or ratio regression is (W
/2
, H
/2
, 2) for the
l-th level of the feature pyramid network. We utilize the w-h regression, merged with the ratio-regression, to generate the bounding box, which is introduced in detail in
Section 3.2. Moreover, there is another output branch, in parallel with the w-h regression and ratio regression, named ratio-center with the shape of (W
/2
, H
/2
, 1). With the help of ratio-center, a large amount of low-quality bounding boxes are suppressed so that the high-quality bounding boxes get high scores for better performance.
3.2. W-H Regression and Ratio Regression
In general, detectors [
19,
27,
31], the regression branch predicts distances from the current location in the corresponding feature maps to the top, bottom, left and right sides of the bounding box. In experiments, this regression pattern primarily considers single oriented features of objects in each channel, that is to say, during inference it’s easy to form false boxes due to the neglect of global features of the object. For better utilization of the overall features, we adopt two branches, w-h regression and ratio regression, to predict the width and height of the boxes and the relative ratios to determine the final boxes.
Particularly, the branches of w-h regression and ratio regression are attached to the four 3 × 3 convolutional layers with the shape of (W
/2
, H
/2
, 2). For w-h regression, the pair of values of each pixel location in the feature maps with two channels indicate the width and height of the corresponding box. On the other hand, due to the uncertain position of the point, which falls into the bounding box, the predicted target still cannot be determined. So we need one more constraint, i.e., ratio regression. It is worth noting that ratio regression has the same shape as w-h regression, especially the same number of channels. Firstly, we define l_ratio as the ratio of the distance (from the point in the box to the left boundary) to the width of the box. Similarly, t_ratio is defined as the ratio of the distance (from the point to the top boundary) to the height of the box. Specifically, l_ratio and t_ratio represent the two-channel feature maps of ratio regression. Hence, as shown in
Figure 2, if the location (x, y) is associated with a bounding box, the formula of the regression target is defined as,
With the above four values and the location (x, y), a certain bounding box can be determined. What is more, we add a sigmoid function attached to the ratio-regression to guarantee that the values of l_ratio and t_ratio are in [0, 1]. During training, we apply IoU loss [
27] generally used in box regression at the positive locations,
where N is the number of positive samples and
Pij and
Yij are the predicted box and the ground-truth, respectively.
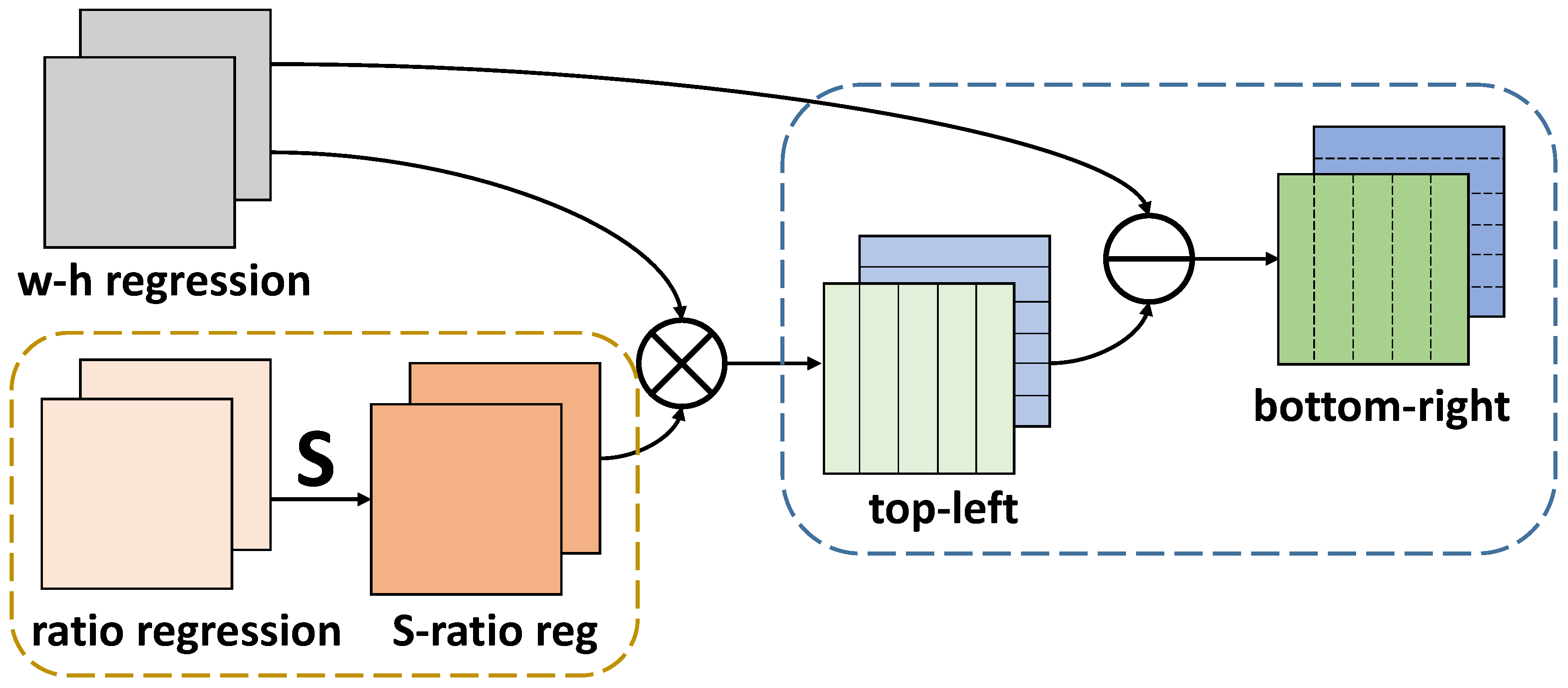
Figure 3 provides the structure of how w-h regression and ratio regression work jointly. Firstly, the ratio regression is processed by the sigmoid function. Then the output feature maps S-ratio reg with two channels are multiplied by w-h regression correspondingly. Finally, w-h regression subtracts top-left to generate the bottom-right with two channels. The total four channels of top-left and bottom-right represent the distances from the current location to the top, left, bottom and right boundaries of the box, respectively.
3.3. Ratio-Center
In general, visual regions close to the center region have higher-quality predictions than those far from the center. So ratio-center is proposed to leverage the locations close to the center region as far as possible. The ratio-center is defined as,
where
l,
r,
t,
b indicate the distances from the location to four boundaries,
is the hyper-parameter, and the value of ratio-center is limited in [0, 1]. As we can see, when the location is closer to the center, the value of ratio-center is approaching to 1. So we can employ ratio-center as the weight of each location. The loss of the ratio-center is binary cross entropy (BCE) loss defined as,
where N is the number of locations and
Pij and
Yij are the prediction of the ratio-center and the ground-truth, respectively.
In order to show the effect of ratio-center mathematically, we draw the function relation curve with different
, as shown in
Figure 4, by assuming that
t is equal to
b and x is defined as the proportion of
l to
r. So ratio-center is changed to,
To illustrate the difference with center-ness [
19], we also change the center-ness into x
with the same settings as the line of dashes shown in
Figure 4. When
is changed from 0.5 to 3, the gradient of the curve increases. One major difference between ratio-center and center-ness [
19] is that when x is 0, center-ness is 0 while ratio-center is larger than 0. Thus, we argue that ratio-center pays softer attention to the location in the marginal region than center-ness. In
Section 4.2, we show that the performance of our ratio-center is better than center-ness.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}