
Uncertainties Involved in the Use of Thresholds for the Detection of Water Bodies in Multitemporal Analysis from Landsat-8 and Sentinel-2 Images

 ,
,  , , , ,
, , , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data-Sets
2.2.1. Digital Elevation Model
2.2.2. Data Acquirement and Image Pre-Processing
- Landsat-8 Surface Reflectance Tier 1 collection provided by United States Geological Survey (USGS), a Level-1 precision and terrain corrected product, atmospherically corrected surface reflectance using LaSRC algorithm, with a 30 m resolution, 16-day temporal resolution. Bands B3 (green) and B6 (SWIR) were used in the MNDWI composition. We used 19 free-of-cloud images available from 14 April 2013 to 24 September 2020;
- Sentinel-2 collection provided by the European Space Agency (ESA), a Level-2A orthorectified product, atmospherically corrected surface reflectance using the Sen2Cor algorithm. Along with a 5-day temporal resolution, SWIR band (B11) available with 20 m spatial resolution, and Green band (B3) available with the 10 m and resampled to 20 m were used in the MNDWI composition. We used 24 free-of-cloud images available from 22 December 2018 to 17 September 2020.
2.2.3. Hydrological Monitoring Data
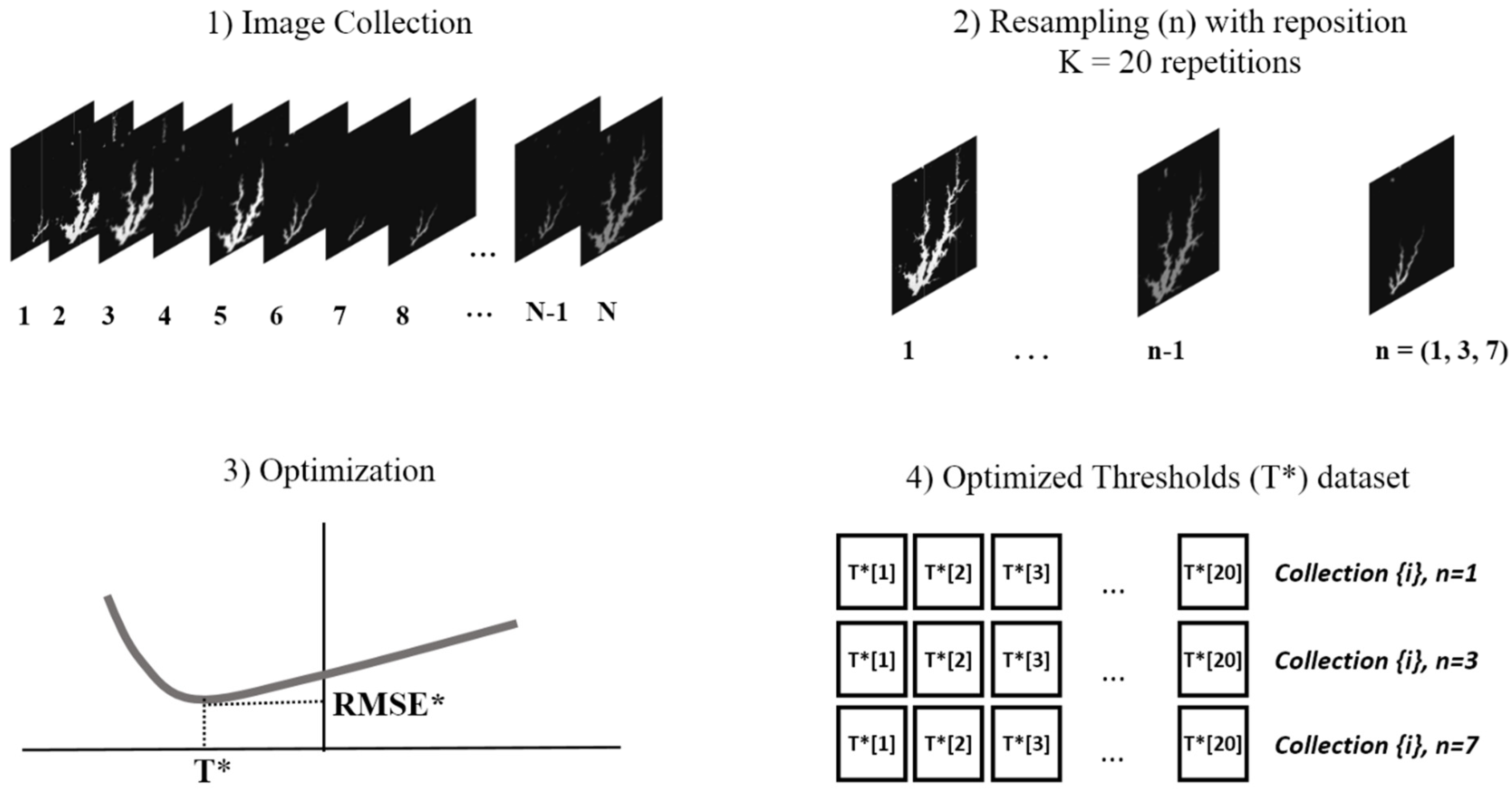
2.3. Threshold Optimization and Uncertainty Analysis
2.3.1. Image Segmentation and Water Level Estimation
2.3.2. Threshold Optimization and Accuracy Evaluation
2.3.3. Uncertainty Analysis
- Our interest is to support constructing a model capable of predicting WL on independent test data;
- A fitting method typically adapts to training data, and hence the training error is commonly an optimistic estimate of test error (generalization error) [33];
- Once each image produces only one WL (Yc) to compare with each observed gauges (Yc), our training set was limited to the number of Landsat-8 and Sentinel-2 scenes available (Section 2.2.2);
- With a restricted number of training instances (19 Landsat 8 and 24 Sentinel 2 images), we are not in a data-rich situation to divide the training and a test set;
- The computational effort required to tune our model (enumerative search) is considerable due to the complexity of the WL estimative process described in Figure 2;
2.3.4. Threshold Stability Analysis
3. Results and Discussion
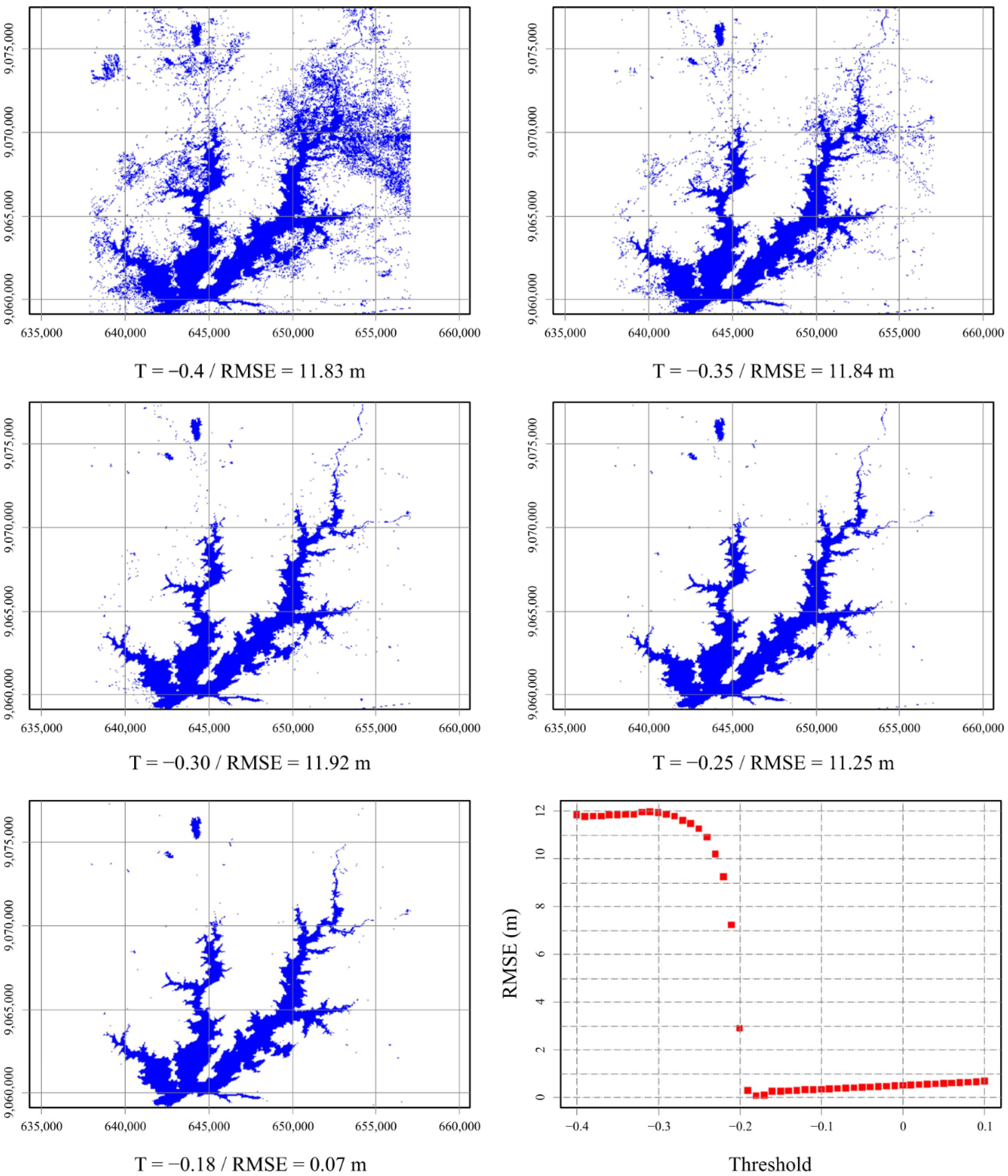
3.1. Errors Involving Single Threshold
- Thresholds values are not constant in space and time and vary due to subpixel water-land-cover composition [18] and due to environmental optical complexity [7] that affects reflected spectral profile such as biological water characteristics, presence of aquatic vegetation, and complex land-covers near water boundary;
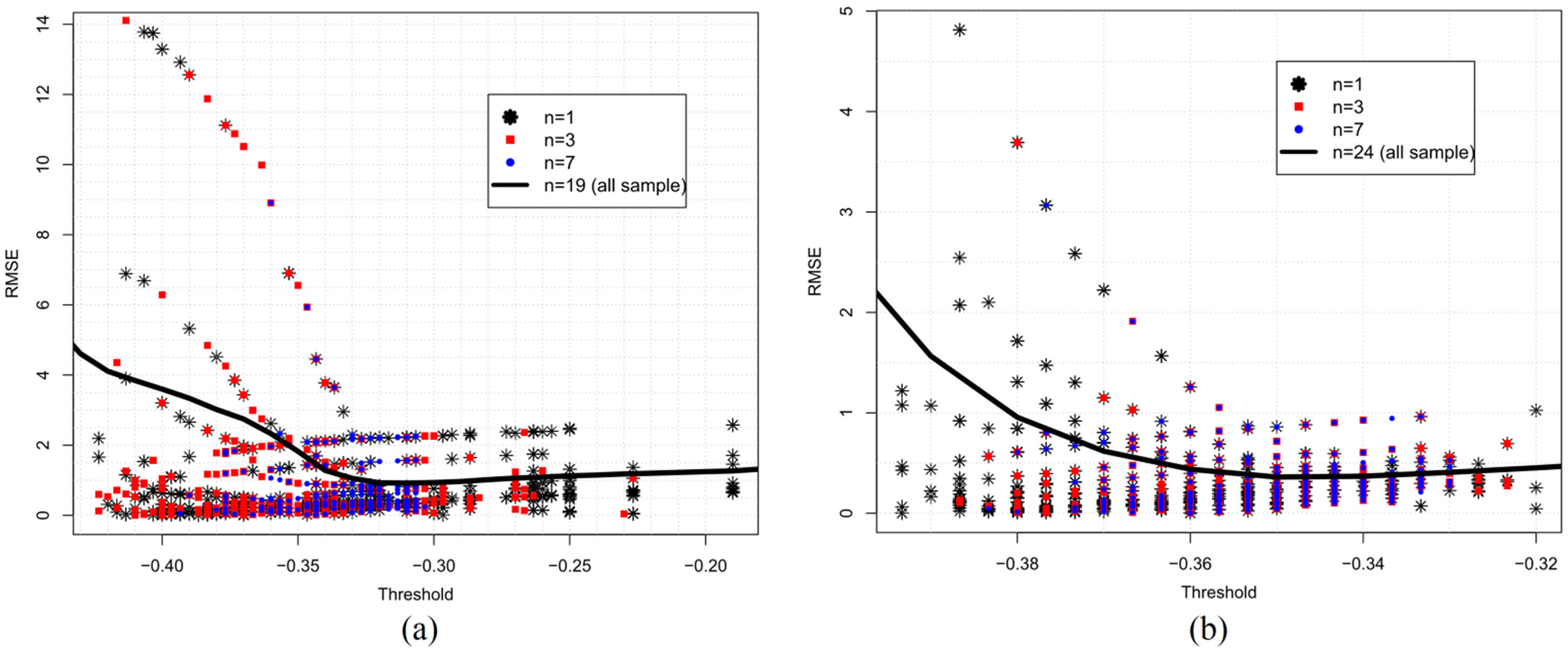
3.2. Accuracy, Stability, and Precision
3.3. The Non-Optimistic Error
3.4. Comparison between Otsu and Single Optimized Threshold
3.5. Ensemble as Alternative to Single Threshold Approach
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Weekley, D.; Li, X. Tracking Multidecadal Lake Water Dynamics with Landsat Imagery and Topography/Bathymetry. Water Resour. Res. 2019, 55, 8350–8367. [Google Scholar] [CrossRef]
- Ogilvie, A.; Belaud, G.; Massuel, S.; Mulligan, M.; Le Goulven, P.; Calvez, R. Surface water monitoring in small water bodies: Potential and limits of multi-sensor Landsat time series. Hydrol. Earth Syst. Sci. 2018, 22, 4349–4380. [Google Scholar] [CrossRef] [Green Version]
- Rokni, K.; Ahmad, A.; Selamat, A.; Hazini, S. Water Feature Extraction and Change Detection Using Multitemporal Landsat Imagery. Remote Sens. 2014, 6, 4173–4189. [Google Scholar] [CrossRef] [Green Version]
- Deus, D.; Gloaguen, R. Remote Sensing Analysis of Lake Dynamics in Semi-Arid Regions: Implication for Water Resource Management. Lake Manyara, East African Rift, Northern Tanzania. Water 2013, 5, 698–727. [Google Scholar]
- Gao, H.; Birkett, C.; Lettenmaier, D.P. Global monitoring of large reservoir storage from satellite remote sensing. Water Resour. Res. 2012, 48. [Google Scholar] [CrossRef] [Green Version]
- Bai, J.; Chen, X.; Li, J.; Yang, L.; Fang, H. Changes in the area of inland lakes in arid regions of central Asia during the past 30 years. Environ. Monit. Assess. 2011, 178, 247–256. [Google Scholar] [CrossRef]
- Feyisa, G.L.; Meilby, H.; Fensholt, R.; Proud, S.R. Automated Water Extraction Index: A new technique for surface water mapping using Landsat imagery. Remote Sens. Environ. 2014, 140, 23–35. [Google Scholar] [CrossRef]
- Fisher, A.; Flood, N.; Danaher, T. Comparing Landsat water index methods for automated water classification in eastern Australia. Remote Sens. Environ. 2016, 175, 167–182. [Google Scholar] [CrossRef]
- Guo, Q.; Pu, R.; Li, J.; Cheng, J. A weighted normalized difference water index for water extraction using Landsat imagery. Int. J. Remote Sens. 2017, 38, 5430–5445. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Bangira, T.; Alfieri, S.M.; Menenti, M.; Van Niekerk, A. Comparing Thresholding with Machine Learning Classifiers for Mapping Complex Water. Remote Sens. 2019, 11, 1351. [Google Scholar]
- Schaffer-Smith, D.; Swenson, J.J.; Barbaree, B.; Reiter, M.E. Three decades of Landsat-derived spring surface water dynamics in an agricultural wetland mosaic; Implications for migratory shorebirds. Remote Sens. Environ. 2017, 193, 180–192. [Google Scholar] [CrossRef] [Green Version]
- Acharya, T.D.; Lee, D.H.; Yang, I.T.; Lee, J.K. Identification of Water Bodies in a Landsat 8 OLI Image Using a J48 Decision Tree. Sensors 2016, 16, 1075. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, W.; Du, Z.; Ling, F.; Zhou, D.; Wang, H.; Gui, Y.; Sun, B.; Zhang, X. A Comparison of Land Surface Water Mapping Using the Normalized Difference Water Index from TM, ETM+ and ALI. Remote Sens. 2013, 5, 5530–5549. [Google Scholar] [CrossRef] [Green Version]
- Schwatke, C.; Scherer, D.; Dettmering, D. Automated Extraction of Consistent Time-Variable Water Surfaces of Lakes and Reservoirs Based on Landsat and Sentinel-2. Remote Sens. 2019, 11, 1010. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Chen, L. Evaluation of automated urban surface water extraction from Sentinel-2A imagery using different water indices. J. Appl. Remote Sens. 2017, 11, 26016. [Google Scholar] [CrossRef]
- Ji, L.; Zhang, L.; Wylie, B. Analysis of Dynamic Thresholds for the Normalized Difference Water Index. Photogramm. Eng. Remote Sens. 2009, 11, 1307–1317. [Google Scholar] [CrossRef]
- Sarp, G.; Ozcelik, M. Water body extraction and change detection using time series: A case study of Lake Burdur, Turkey. J. Taibah Univ. Sci. 2017, 11, 381–391. [Google Scholar] [CrossRef] [Green Version]
- Herndon, K.; Muench, R.; Cherrington, E.; Griffin, R. An Assessment of Surface Water Detection Methods for Water Resource Management in the Nigerien Sahel. Sensors 2020, 20, 431. [Google Scholar] [CrossRef] [Green Version]
- Du, Y.; Zhang, Y.; Ling, F.; Wang, Q.; Li, W.; Li, X. Water Bodies’ Mapping from Sentinel-2 Imagery with Modified Normalized Difference Water Index at 10-m Spatial Resolution Produced by Sharpening the SWIR Band. Remote Sens. 2016, 8, 354. [Google Scholar] [CrossRef] [Green Version]
- Pereira, M. Relatório de Elaboração da CAV. ANA CAV-Açudes. Lote 02-Açude Poço da Cruz; ANA-Agência Nacional de Águas: Brasília, Brazil, 2018; p. 98. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Pebesma, E. Simple Features for R: Standardized Support for Spatial Vector Data. R J. 2018, 10, 439–446. [Google Scholar] [CrossRef] [Green Version]
- Hijmans, R.J. Raster: Geographic Data Analysis and Modeling; R Core Team: Vienna, Austria, 2020. [Google Scholar]
- Wickham, H.; François, R.; Henry, L.; Müller, K. Dplyr: A Grammar of Data Manipulation; R Core Team: Vienna, Austria, 2021. [Google Scholar]
- Wickham, H. Ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016. [Google Scholar]
- Wickham, H. Reshaping Data with the reshape Package. J. Stat. Softw. 2007, 21, 1–20. [Google Scholar] [CrossRef]
- Van Leeuwen, B.; Tobak, Z.; Kovács, F. Sentinel-1 and -2 Based near Real Time Inland Excess Water Mapping for Optimized Water Management. Sustainability 2020, 12, 2854. [Google Scholar] [CrossRef] [Green Version]
- Kannan, K.S.; Manoj, K.; Arumugam, S. Labeling Methods for Identifying Outliers. Int. J. Stat. Syst. 2015, 10, 231–238. [Google Scholar]
- Jones, J.W. Improved Automated Detection of Subpixel-Scale Inundation—Revised Dynamic Surface Water Extent (DSWE) Partial Surface Water Tests. Remote Sens. 2019, 11, 374. [Google Scholar] [CrossRef] [Green Version]
- DeVries, B.; Huang, C.; Lang, M.W.; Jones, J.W.; Huang, W.; Creed, I.F.; Carroll, M.L. Automated Quantification of Surface Water Inundation in Wetlands Using Optical Satellite Imagery. Remote Sens. 2017, 9, 807. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning. In Unsupervised Learning; Springer: New York, NY, USA, 2009. [Google Scholar]
- Kushler, R.H. Computational Statistics Handbook With MATLAB®. Technometrics 2002, 44, 405–406. [Google Scholar] [CrossRef]
- Efron, B.T.; Robert, J. An Introduction to Bootstrap; Chapman & Hall: London, UK, 1993. [Google Scholar]
- Pau, G.; Fuchs, F.; Sklyar, O.; Boutros, M.; Huber, W. EBImage—An R package for image processing with applications to cellular phenotypes. Bioinformatics 2010, 26, 979–981. [Google Scholar] [CrossRef]
- Yang, X.; Qin, Q.; Grussenmeyer, P.; Koehl, M. Urban surface water body detection with suppressed built-up noise based on water indices from Sentinel-2 MSI imagery. Remote Sens. Environ. 2018, 219, 259–270. [Google Scholar] [CrossRef]
- Brownlee, J. Master Machine Learning Algorithms: Discover How They Work and Implement Them from Scratch; Machine Learning Mastery: Vermont, VIC, USA, 2016. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling, 1st ed.; Springer: New York, NY, USA, 2013; Volume 26, p. 600. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite | Image Acquisition Date | CDAY | ΔT (Days) | OWL_CDAY (m) | Filled OWL (m) |
|---|---|---|---|---|---|
| Landsat-8 | 14 April 2013 | 16 April 2013 | 2 | 424.31 | 424.35 |
| 13 September 2016 | 5 October 2016 | 22 | 417.62 | 416.97 | |
| 29 September 2016 | 5 October 2016 | 6 | 417.62 | 417.44 | |
| 15 October 2016 | 5 October 2016 | 10 | 417.62 | 417.28 | |
| 2 December 2016 | 21 December 2016 | 19 | 415.00 | 415.65 | |
| 4 February 2017 | 10 February 2017 | 6 | 414.31 | 414.46 | |
| 12 June 2017 | 31 July 2017 | 49 | 413.60 | 413.16 | |
| 15 August 2017 | 31 July 2017 | 15 | 413.60 | 413.44 | |
| 2 October 2017 | 31 October 2017 | 29 | 412.59 | 412.91 | |
| 5 December 2017 | 20 November 2017 | 15 | 412.29 | 412.84 | |
| 6 January 2018 | 19 February 2018 | 44 | 415.64 | 414.02 | |
| 2 June 2019 | 3 June 2019 | 1 | 420.61 | 420.62 | |
| Sentinel-2 | 1 January 2019 | 31 December 2018 | 1 | 419,18 | 419,17 |
| 2 November 2019 | 3 November 2019 | 1 | 419.52 | 419.53 | |
| 17 November 2019 | 18 November 2019 | 1 | 419.38 | 419.39 | |
| 12 December 2019 | 13 December 2019 | 1 | 419.30 | 419.32 | |
| 10 April 2020 | 17 April 2020 | 7 | 431.82 | 431.43 | |
| 4 July 2020 | 3 July 2020 | 1 | 432.42 | 432.41 |
| MNDWI | n | T* | RMSE* | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Min. | Max. | Mean | SD | CV | Min. | Max. | Mean | SD | CV | ||
| Landsat-8 | 1 | −0.440 | −0.190 | −0.325 | 0.097 | −0.299 | 0.000 | 0.208 | 0.050 | 0.064 | 1.281 |
| 3 | −0.430 | −0.190 | −0.335 | 0.062 | −0.177 | 0.005 | 1.368 | 0.611 | 0.478 | 0.783 | |
| 7 | −0.410 | −0.300 | −0.328 | 0.033 | −0.101 | 0.073 | 1.354 | 0.848 | 0.355 | 0.418 | |
| Sentinel-2 | 1 | −0.393 | −0.320 | −0.365 | 0.030 | −0.082 | 0.001 | 0.093 | 0.022 | 0.021 | 0.955 |
| 3 | −0.387 | −0.323 | −0.353 | 0.023 | −0.065 | 0.040 | 0.501 | 0.227 | 0.130 | 0.573 | |
| 7 | −0.383 | −0.330 | −0.351 | 0.017 | −0.048 | 0.091 | 0.466 | 0.315 | 0.109 | 0.346 | |
| MNDWI | n | RMSE | RMSE/ RMSE* | RMSE [Ti ≤ T≤ Tf] | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Min. | Max. | Mean | CI95% | Min. | Max. | Mean | CI95% | |||
| Landsat-8 | 1 | 0.002 | 13.783 | 1.041 | [0.027;6.039] | 20.8 | 0.014 | 2.574 | 0.794 | [0.063;2.392] |
| 3 | 0.000 | 14.108 | 1.043 | [0.021;6.427] | 1.71 | 0.041 | 2.362 | 0.653 | [0.046;2.267] | |
| 7 | 0.012 | 8.908 | 0.746 | [0.067;2.263] | 0.88 | 0.088 | 2.290 | 0.691 | [0.100;2.243] | |
| Sentinel-2 | 1 | 0.001 | 4.813 | 0.422 | [0.014;2.392] | 19.2 | 0.023 | 1.025 | 0.317 | [0.044;0.860] |
| 3 | 0.001 | 3.693 | 0.301 | [0.023;0.915] | 1.33 | 0.000 | 1.257 | 0.308 | [0.038;0.902] | |
| 7 | 0.001 | 3.067 | 0.314 | [0.023;0.910] | 0.99 | 0.003 | 1.052 | 0.309 | [0.044;0.902] | |
| MNDWI | n | P (RMSE < X) × 100 | P (RMSE [Ti < T < Tf] < X) × 100 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| <0.5 m | <1.0 m | <1.25 m | <2.0 m | <0.5 m | <1.0 m | <1.25 m | <2.0 m | ||
| Landsat-8 | 1 | 46.6 | 75.2 | 77.0 | 85.8 | 38.7 | 79.3 | 80.5 | 88.0 |
| 3 | 59.2 | 73.0 | 75.8 | 85.4 | 61.1 | 83.3 | 84.9 | 90.5 | |
| 7 | 59.6 | 78.8 | 79.4 | 88.0 | 61.2 | 81.6 | 81.6 | 87.3 | |
| Sentinel-2 | 1 | 76.0 | 91.2 | 93.4 | 96.0 | 84.3 | 99.4 | 100 | 100 |
| 3 | 86.4 | 98.0 | 99.2 | 99.6 | 87.1 | 98.9 | 99.7 | 100 | |
| 7 | 96.0 | 98.8 | 99.2 | 99.8 | 83.4 | 99.5 | 100 | 100 | |
| MNDWI | OTSU Thresholds | |||||
|---|---|---|---|---|---|---|
| Min. | Max. | Mean | Median | Q1 | Q3 | |
| Landsat-8 | −0.363 | 0.074 | −0.060 | −0.051 | −0.094 | −0.008 |
| Sentinel-2 | −0.215 | 0.082 | −0.116 | −0.121 | −0.154 | −0.094 |
| MNDWI | OTSU Thresholds | |||||
|---|---|---|---|---|---|---|
| Min. | Max. | Mean | Median | Q1 | Q3 | |
| Landsat-8 | 0.168 | 9.924 | 1.751 | 1.143 | 1.046 | 1.602 |
| Sentinel-2 | 0.812 | 1.791 | 1.197 | 1.115 | 0.991 | 1.352 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reis, L.G.d.M.; Souza, W.d.O.; Ribeiro Neto, A.; Fragoso, C.R., Jr.; Ruiz-Armenteros, A.M.; Cabral, J.J.d.S.P.; Montenegro, S.M.G.L. Uncertainties Involved in the Use of Thresholds for the Detection of Water Bodies in Multitemporal Analysis from Landsat-8 and Sentinel-2 Images. Sensors 2021, 21, 7494. https://doi.org/10.3390/s21227494
Reis LGdM, Souza WdO, Ribeiro Neto A, Fragoso CR Jr., Ruiz-Armenteros AM, Cabral JJdSP, Montenegro SMGL. Uncertainties Involved in the Use of Thresholds for the Detection of Water Bodies in Multitemporal Analysis from Landsat-8 and Sentinel-2 Images. Sensors. 2021; 21(22):7494. https://doi.org/10.3390/s21227494
Chicago/Turabian StyleReis, Luis Gustavo de Moura, Wendson de Oliveira Souza, Alfredo Ribeiro Neto, Carlos Ruberto Fragoso, Jr., Antonio Miguel Ruiz-Armenteros, Jaime Joaquim da Silva Pereira Cabral, and Suzana Maria Gico Lima Montenegro. 2021. "Uncertainties Involved in the Use of Thresholds for the Detection of Water Bodies in Multitemporal Analysis from Landsat-8 and Sentinel-2 Images" Sensors 21, no. 22: 7494. https://doi.org/10.3390/s21227494
APA StyleReis, L. G. d. M., Souza, W. d. O., Ribeiro Neto, A., Fragoso, C. R., Jr., Ruiz-Armenteros, A. M., Cabral, J. J. d. S. P., & Montenegro, S. M. G. L. (2021). Uncertainties Involved in the Use of Thresholds for the Detection of Water Bodies in Multitemporal Analysis from Landsat-8 and Sentinel-2 Images. Sensors, 21(22), 7494. https://doi.org/10.3390/s21227494