Affiliated Fusion Conditional Random Field for Urban UAV Image Semantic Segmentation

 , ,
, , 


Abstract
1. Introduction
2. Preliminary
2.1. Conditional Random Field
2.2. General CRF Model
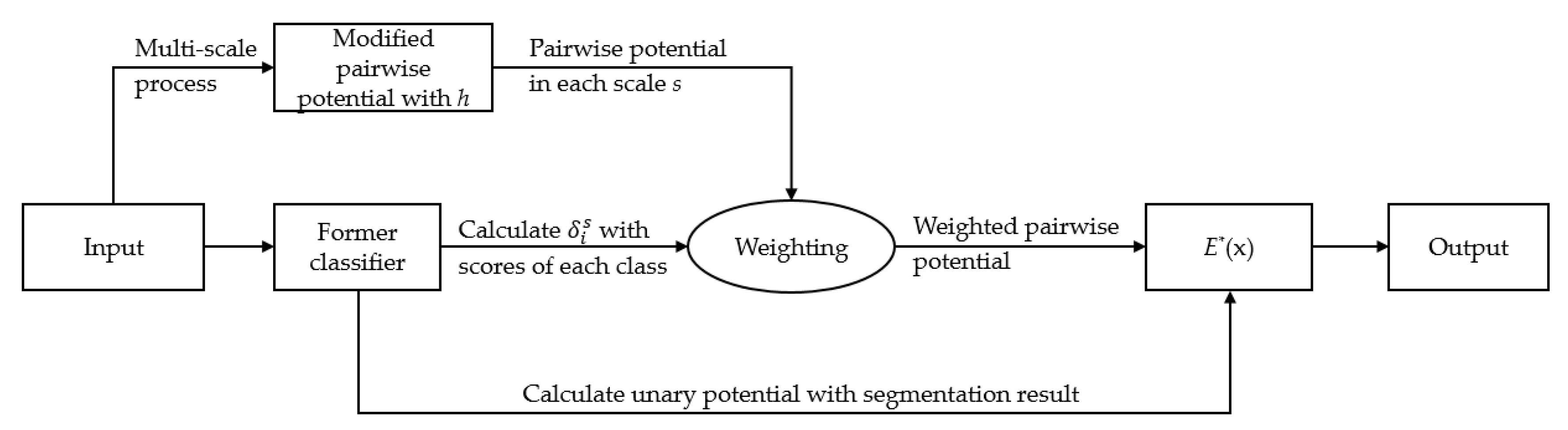
3. Affiliated Fusion Conditional Random Fields
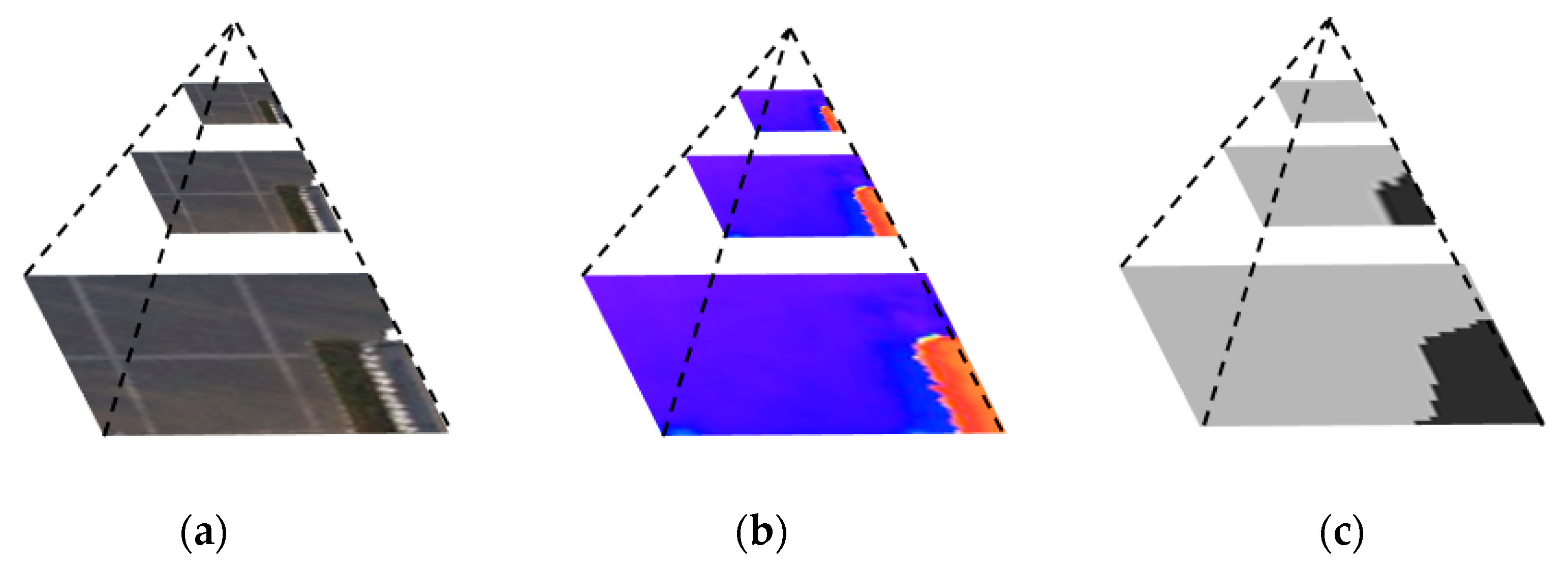
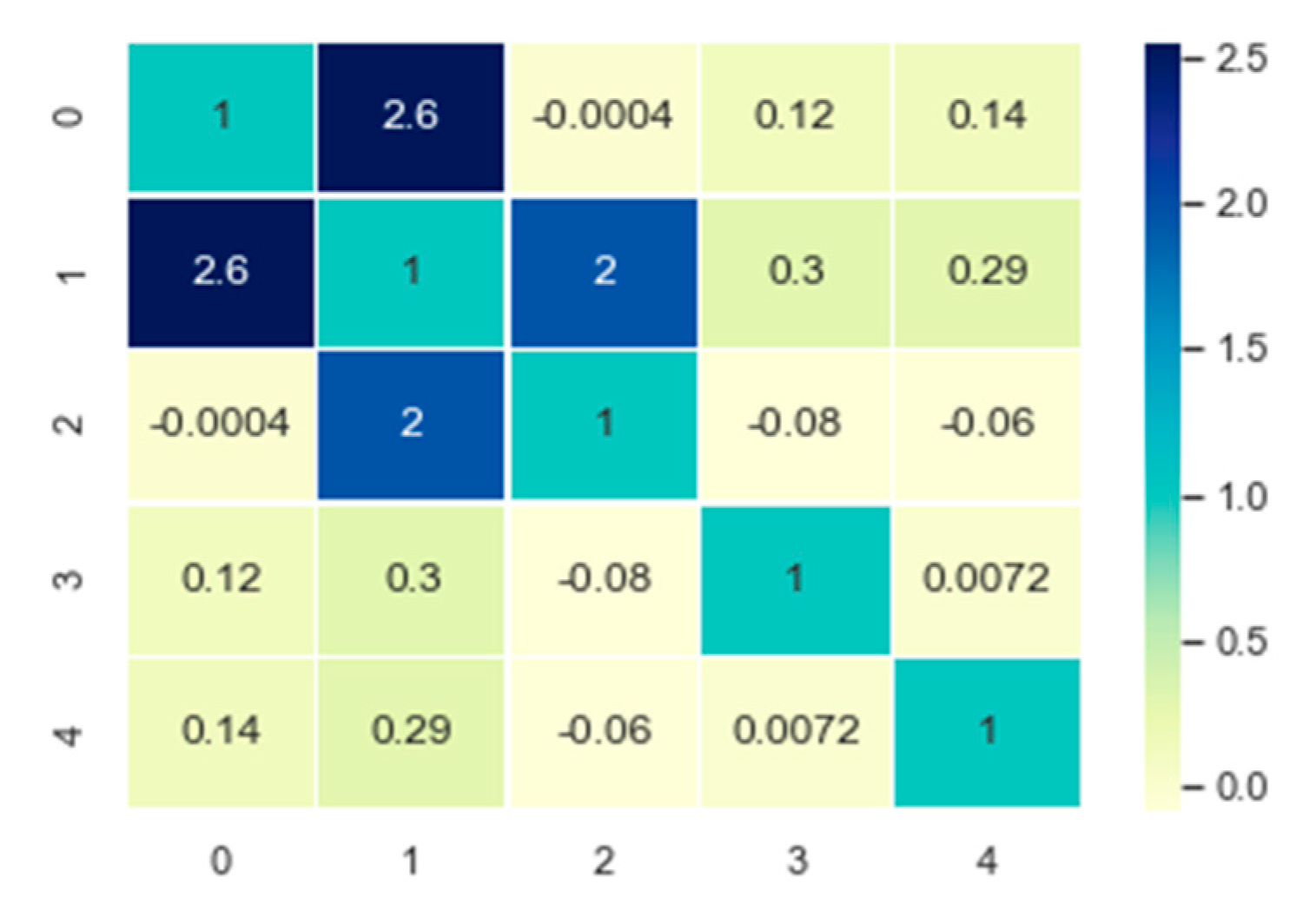
3.1. Multi-Scale Analysis
3.2. AF-CRF
4. Inference and Learning of the Model
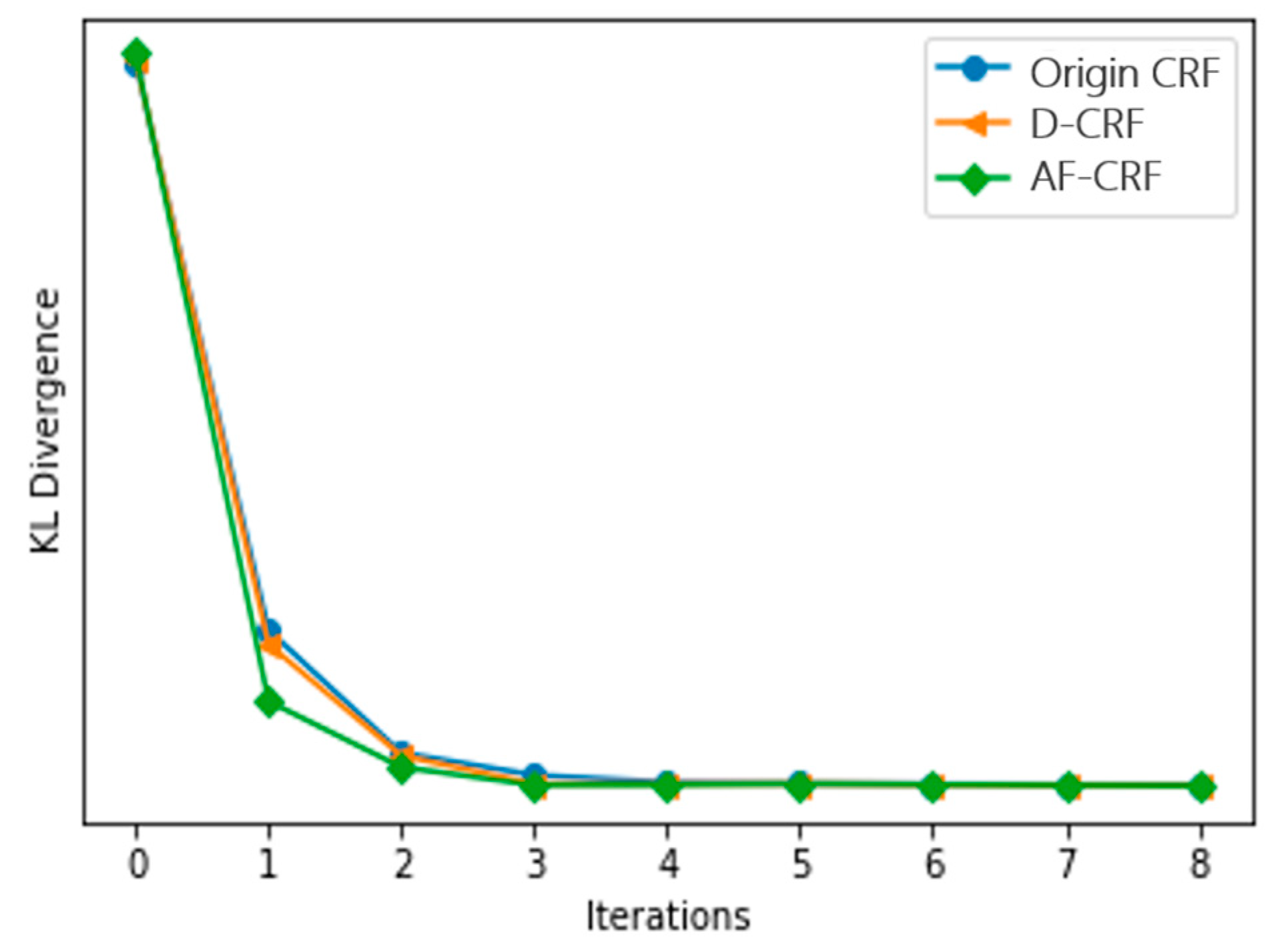
4.1. Inference
4.2. Learning
5. Experiments and Analysis
5.1. Dataset
5.2. Implement Details
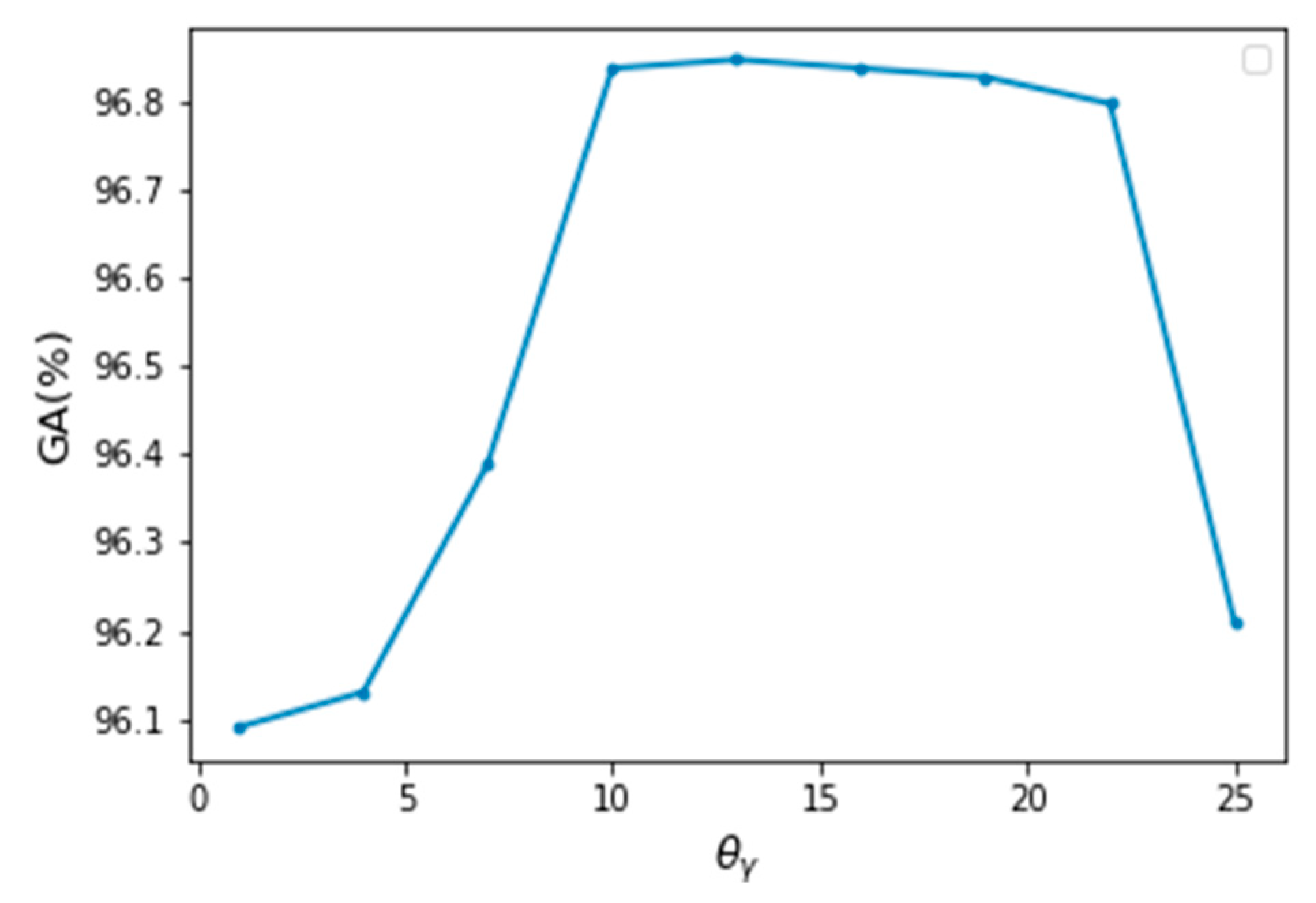
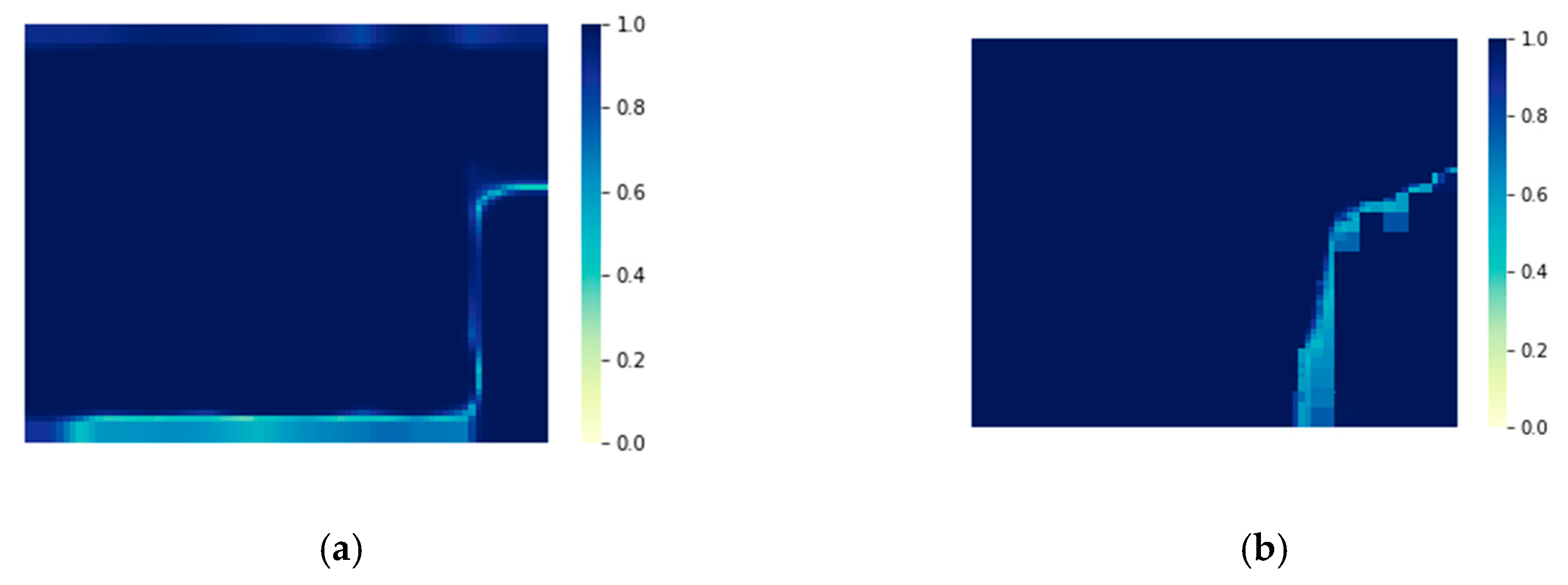
5.3. Results and Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lafferty, J.D.; Mccallum, A.; Pereira, F.C.N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the 18th International Conference on Machine Learning (ICML), Williamstown, MA, USA, 28 June 2001. [Google Scholar]
- Stern, D.H.; Graepel, T.; MacKay, D. Modelling uncertainty in the game of Go. In Proceedings of the 2004 International Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 13–18 December 2004. [Google Scholar]
- Bernal, A.; Crammer, K.; Hatzigeorgiou, A.G.; Pereira, F.C. Global discriminative learning for higher-accuracy computational gene prediction. PLoS Comput. Biol. 2005, 3, 346–354. [Google Scholar] [CrossRef] [PubMed]
- Taskar, B.; Guestrin, C.; Koller, D. Max-margin Markov networks. In Proceedings of the 2004 International Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 13–18 December 2004. [Google Scholar]
- Sun, X.; Nan, X. Chinese base phrases chunking based on latent semi-CRF model. In Proceedings of the 6th International Conference on Natural Language Processing and Knowledge Engineering (NLP-KE), Beijing, China, 21–23 August 2010. [Google Scholar]
- Martinez, O.; Tsechpenakis, G. Integration of active learning in a collaborative CRF. In Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 223–228 June 2008. [Google Scholar]
- Desmaison, A.; Bunel, R.; Kohli, P.; Torr, P.H.S.; Kumar, M.P. Efficient Continuous Relaxations for Dense CRF. In Proceedings of the 2016 European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 17 September 2016. [Google Scholar]
- He, X.; Zemei, R.S.; Carreira-Perpiñán, M.Á. Multiscale conditional random fields for image labeling. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Kohli, P.; Kumar, P.K.; Torr, P.H.S. P³ & Beyond: Move Making Algorithms for Solving Higher Order Functions. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1645–1656. [Google Scholar] [PubMed]
- Kohli, P.; Ladický, L.; Torr, P.H.S. Robust Higher Order Potentials for Enforcing Label Consistency. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 24 January 2009. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. In Proceedings of the 2012 International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Li, H. Statistical Learning Method; Tsinghua University Press: Beijing, China, 2012. [Google Scholar]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Paris, S.; Durand, F. A Fast Approximation of the Bilateral Filter Using a Signal Processing Approach. Int. J. Comput. Vis. 2009, 81, 24–52. [Google Scholar] [CrossRef]
- Jaud, M.; Passot, S.; Le Bivic, R.; Delacourt, C.; Grandjean, P.; Le Dantec, N. Assessing the Accuracy of High Resolution Digital Surface Models Computed by PhotoScan and MicMac in Sub-Optimal Survey Conditions. Remote Sens. 2017, 8, 465. [Google Scholar] [CrossRef]
- Zhang, B.; Kong, Y.; Chen, Y.; Leung, H.; Xing, S. Urban UAV Images Semantic Segmentation Based on Fully Convolutional Networks with Digital Surface Models. In Proceedings of the 10th International Conference on Intelligent Control and Information Processing (ICICIP), Marrakesh, Morocco, 11–16 December 2019. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing & Computer Assisted Intervention (MICCAI), Munich, Germany, 18 November 2015. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
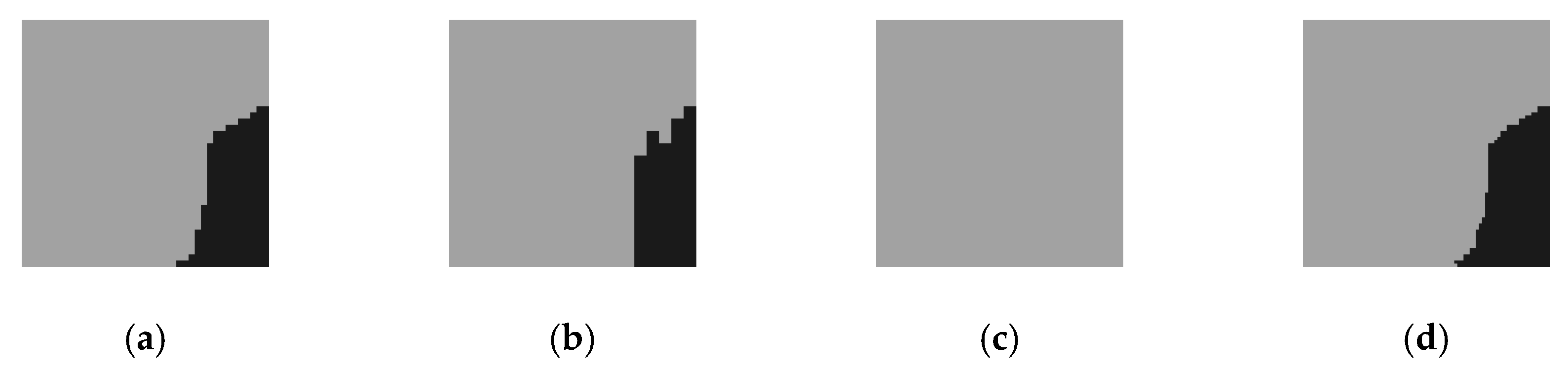{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | GAT (%) | GAV (%) | IoUcls1 (%) | IoU cls2 (%) | IoU cls3 (%) | IoU cls4 (%) | mIoU (%) |
|---|---|---|---|---|---|---|---|
| DeepLabv3 + -ds-ss [17] | 94.62 | 91.55 | 79.36 | 57.36 | 65.16 | 59.76 | 63.16 |
| PSPNet-ds-ss | 97.79 | 96.83 | 92.67 | 74.90 | 81.12 | 72.14 | 80.27 |
| DeepLabv3 + -ds-ss + CRF | 95.57 | 93.29 | 85.45 | 57.33 | 69.97 | 62.31 | 65.87 |
| PSPNet-ds-ss + CRF | 97.75 | 96.85 | 93.21 | 74.71 | 83.26 | 72.14 | 81.02 |
| Model | GA (%) | IoUcls1 (%) | IoU cls2 (%) | IoU cls3 (%) | IoU cls4 (%) | mIoU (%) |
|---|---|---|---|---|---|---|
| DeepLabv3 + -ds-ss | 72.37 | 71.24 | 43.20 | 54.81 | 42.55 | 53.24 |
| PSPNet-ds-ss | 77.28 | 80.67 | 61.90 | 69.14 | 53.39 | 67.77 |
| DeepLabv3 + -ds-ss+CRF | 85.34 | 81.47 | 54.27 | 60.72 | 60.55 | 71.09 |
| PSPNet-ds-ss + CRF | 90.97 | 90.12 | 70.01 | 78.21 | 69.85 | 78.82 |
| Model | CRF | GA (%) |
|---|---|---|
| FCN8s [18] | × | 80.3 |
| √ | 85.4 | |
| DeepLab | × | 78.2 |
| √ | 82.5 | |
| U-Net [19] | × | 67.5 |
| √ | 79.3 |
| Metric | PSPNet-ds-ss | AF-CRF |
|---|---|---|
| Aver. Conf (%) | 97.09 | 98.65 |
| Min. Conf (%) | 35.57 | 50.04 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kong, Y.; Zhang, B.; Yan, B.; Liu, Y.; Leung, H.; Peng, X. Affiliated Fusion Conditional Random Field for Urban UAV Image Semantic Segmentation. Sensors 2020, 20, 993. https://doi.org/10.3390/s20040993
Kong Y, Zhang B, Yan B, Liu Y, Leung H, Peng X. Affiliated Fusion Conditional Random Field for Urban UAV Image Semantic Segmentation. Sensors. 2020; 20(4):993. https://doi.org/10.3390/s20040993
Chicago/Turabian StyleKong, Yingying, Bowen Zhang, Biyuan Yan, Yanjuan Liu, Henry Leung, and Xiangyang Peng. 2020. "Affiliated Fusion Conditional Random Field for Urban UAV Image Semantic Segmentation" Sensors 20, no. 4: 993. https://doi.org/10.3390/s20040993
APA StyleKong, Y., Zhang, B., Yan, B., Liu, Y., Leung, H., & Peng, X. (2020). Affiliated Fusion Conditional Random Field for Urban UAV Image Semantic Segmentation. Sensors, 20(4), 993. https://doi.org/10.3390/s20040993