1. Introduction
The capability of seeing through occlusions in heavily-cluttered scenes is beneficial to many practical computer vision application fields, ranging from hidden object imaging to detection, tracking and recognition in surveillance. Since traditional imaging methods use a simple camera to acquire the 2D projection of the 3D world from a single viewpoint, they are unable to directly resolve the occlusion problem.
A fundamental solution to the problem is to exploit new imaging procedures. For example, emerging computational photography techniques based on generalized optics provide plausible solutions to capture additional visual information. Many different camera arrays have been built over the past few years (as shown in
Figure 1), and the camera array synthetic aperture imaging or SAI [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17] provides a unique capability of seeing through occlusions. SAI warps and integrates the multiple view images to simulate a virtual camera with an ultra-large convex lens, and it can focus on different frontal-parallel [
1] or oblique [
2] planes with a narrow depth of field. As a result, objects laying on the virtual focus plane, even if being occluded in reality, would be clearly imaged.
In practice, however, getting a good imaging result is still challenging. For one thing, we really can’t find the focus plane of an object for all of those cameras without sufficient visibility analysis. Actually, the indiscriminate averaging of the projection of the foreground occluder often significantly blurs the images of focused occluded objects. Additionally, objects laying on different focus planes in the scene always fail to be present in one single synthetic image.
1.1. Our Approach
To overcome the weakness above, we present a novel synthetic aperture imaging algorithm, which aims at generating a depth-free all-in-focus synthetic image (as shown in
Figure 2c). Here, the all-in-focus image refers to a synthetic one that contains not only objects laying on the virtual focus plane, but also those that are not. Depth-free means that, given a certain depth, the algorithm can see through occluders and generate a clear all-in-focus image of the scene contents behind it.
Figure 1.
Examples of camera array synthetic aperture imaging sensors. NPU, Northwestern Polytechnical University.
Figure 1.
Examples of camera array synthetic aperture imaging sensors. NPU, Northwestern Polytechnical University.
Figure 2.
Comparison results of occluded object synthetic aperture imaging methods. (a) One camera view in the Stanford camera array; (b) Result of traditional synthetic image focused on the CD case; (c) Result of occluded object all-in-focus image by our method.
Figure 2.
Comparison results of occluded object synthetic aperture imaging methods. (a) One camera view in the Stanford camera array; (b) Result of traditional synthetic image focused on the CD case; (c) Result of occluded object all-in-focus image by our method.
Different from in-painting algorithms [
18,
19], which can generate visually-plausible results, but not guarantee the correctness of the result, our technique is based on the light field visibility analysis. For every 3D point, we trace all rays passing through it back to the camera array and then construct a visibility layer in which the 3D point is visible in all active cameras. To recover the all-in-focus image behind a specific depth layer, we partition the scene into multiple visibility layers to directly deal with layer-wise occlusion and apply an optimization framework to propagate the visibility information between multiple layers. On each layer, visibility and optimal focus depth estimation is formulated as a multiple label energy minimization problem. The energy integrates the visibility mask from previous layers, multi-view intensity consistency and the depth smoothness constraint. We compare our method with state-of-the-art solutions on publicly-available Stanford [
20] and UCSD (University of California, San Diego) [
21] light field datasets and three datasets captured by ourselves with multiple occluders. As illustrated in
Figure 2, conventional synthetic aperture imaging algorithms only focus on a particular depth and result in poor quality (see
Figure 2b), while our approach, which creatively segments the scene into multiple visibility layers and uses an optimization framework to propagate the visibility information between multiple layers, can produce the all-in-focus image even under occlusion (see
Figure 2c). Extensive experimental results with qualitative and quantitative analysis further demonstrate the performance.
1.2. Related Work
Tremendous efforts have been made on developing light field imaging systems and post-processing algorithms. On the hardware front, light field camera arrays with different numbers of cameras, resolution and effective aperture size have been built (as shown in
Figure 1), e.g., Stanford [
3], CMU [
4], UCSD [
5], Alberta [
6], Delaware [
7], Northwestern Polytechnical University (NPU) [
8,
16], PiCam [
15], Tokyo [
17],
etc., and the camera array synthetic aperture imaging technique has been proven to be a powerful way to see objects through occlusion. Similar camera array techniques have been adopted in producing movie special effects. For instance, in the 1999 movie The Matrix, a 1D camera array is used to create an impressive bullet dodging scene that freezes time, but changes viewpoint towards the character.
On the algorithm front, one of the most important techniques is synthetic aperture imaging (SAI). By integrating appropriate rays in the camera array, SAI can generate a view that would be captured by a virtual camera having a large aperture. In addition, through shearing or warping the camera array images before performing this integration, SAI can focus on different planes in the scene. For example, the Stanford LF (Light Field) camera array by Levoy
et al. [
3] consists of 128 Firewire cameras, and for the first time, aligns multiple cameras to a focus plane to approximate a camera with a very large aperture. The constructed synthetic aperture image has a shallow depth of field, so that objects off the focus plane disappear due to significant blur. This unique characteristic makes synthetic aperture imaging a powerful tool for occluded object imaging.
Taking advantage of the geometry constraints of the dense camera array, Vaish
et al. [
11] present a convenient plane + parallax method for synthetic aperture imaging. A downside of their work, however, is that all rays from the camera array are directly integrated without further analysis. Thus, the clarity and contrast of their imaging result would be reduced by rays from the foreground occluders.
Visibility analysis through occlusion is a difficult, but promising way to improve the occluded object imaging quality, and many algorithms have been developed in this way. Vaish
et al. [
12] study four cost functions, including color medians, entropy, focus and stereo, for reconstructing an occluded surface using synthetic apertures. Their method achieves encouraging results under slight occlusion; however, the cost functions may fail under severe occlusion. Joshi
et al. [
10] propose a natural video matting algorithm using a camera array. Their method uses high frequencies present in natural scenes to compute mattes by creating a synthetic aperture image that is focused on the foreground object. Their result is inspiring, and it has the potential to be used for visibility analysis. However, this algorithm may fail in the case of a textureless background and cannot deal with occluded object matting. Pei
et al. [
13] propose a background subtraction method for segmenting and removing foreground occluders before synthetic aperture imaging. Their result is encouraging in a simple static background; however, since this approach is built on background subtraction, it cannot handle static occluders. In addition, their performance is very sensitive to a cluttered background and may fail under crowded scenes.
The most relevant method to ours would be the work of Pei
et al. [
6], which solves the foreground segmentation problem through binary labeling via graph cuts. Instead of labeling the visibility and focusing depth, they label whether a point is in focus at a particular depth and aggregate these focus labels in a given depth range to get a visibility mask for occluded object imaging. Although the result is encouraging, this method can only deal with front occluder (whose depth range needs to be provided as a prior) labeling problem and may fail if the occluder has severe self-occlusion or there are multiple occluded objects due to a lack of visibility propagation. In addition, the result of the method in [
6] can only focus on a particular depth of the scene instead of all-in-focus imaging, and the performance will be decreased in a textureless background.
A graph cut [
22,
23,
24,
25] is one of the most popular methods to solve the Markov random field (MRF) energy minimization problem due to its efficiency. In this paper, we formulate the entire scene synthetic aperture imaging as a multi-layer multi-labeling problem, which can be solved via graph cuts. Different from most works using graph cuts for 3D scene reconstruction, in our algorithm, we creatively apply the graph cuts in solving the visibility property and optimal focus depth labeling energy minimization problems. In order to solve the visibility property labeling energy minimization problem, we carefully design a key energy function with a different data term, which can measure the cost of assigning a visibility label to a pixel, and a different smoothness term, which can encourage neighboring pixels to belong to the same visibility label. Additionally, in order to solve the optimal focus depth labeling energy minimization problem, we carefully design another key energy function whose data term can measure the cost of assigning a depth layer to a pixel and whose smoothness term can courage neighboring pixels to share the same label.
The organization of this paper is as follows.
Section 2 presents the visibility layer propagation-based imaging model.
Section 3 details the visibility optimization algorithm.
Section 4 details the visibility optimization algorithm.
Section 5 describes the dataset, implementation details and the experimental results. We conclude the paper and point out the future work in
Section 6.
2. Visibility Layer Propagation-Based Imaging Model
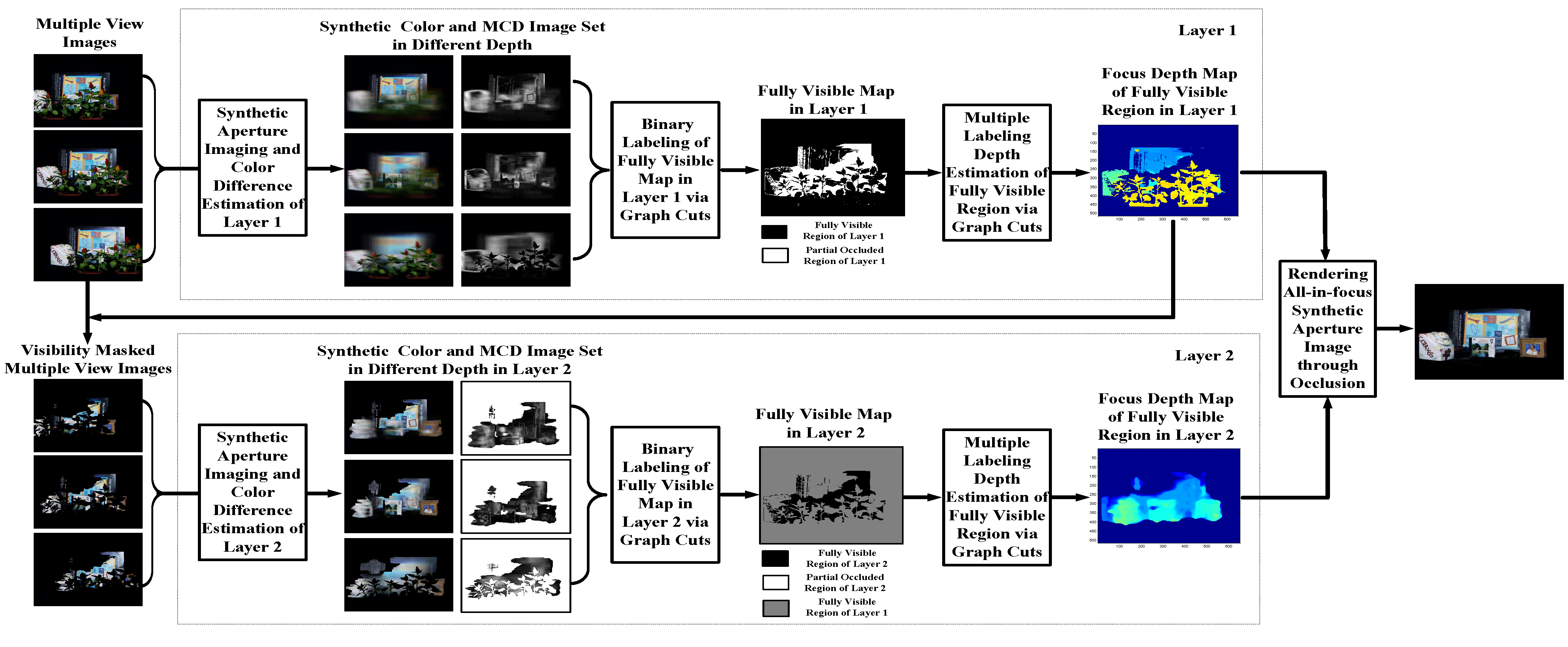
In this section, we will introduce our multiple-layer propagation-based synthetic aperture imaging method. The framework of our method is an iterated process (as shown in
Figure 3). The scene is divided into different visibility layers. For each layer, we have two steps, visibility labeling and depth estimation, which will be discussed in
Section 3 and
Section 4, respectively.
Figure 3.
Framework of our active synthetic aperture imaging algorithm. MCD, maximal color difference.
Figure 3.
Framework of our active synthetic aperture imaging algorithm. MCD, maximal color difference.
Instead of segmenting the observed scene into various depth layers, our approach segments the entire scene into multiple visibility layers, for example the Stanford Light Field dataset shown in
Figure 3 is divided into two visibility layers. The visibility layer is defined on each layer as all of the rays that are not occluded in any cameras and computed by energy minimization. Points on each visibility layer do not necessarily need to correspond to the same object or surface. By modeling the scene as multiple visibility layers and propagating visibility information through layers, we can obtain the focusing depth and corresponded cameras for all of the objects in the scene, including the occlusion object and occluded objects. Therefore, each visibility layer consists of pixels that are visible in all active cameras. The word active refers to the fact that the pixel position of the camera has not been labeled as visible by the previous visibility layers, e.g., not labeled as visible by Layer 1 in
Figure 3. Extraction of each visibility layer is based on the information of previous visibility layers. More precisely, according to the occlusion mask information of previous layers, we firstly obtain the current visibility layer, then estimate the depth map of this layer and, finally, update the occlusion mask. For better understanding of the proposed method, we provide an example workflow with the Stanford Light Field data in
Figure 3.
There are mainly two reasons why we introduce the concept of the visibility layer. First, by taking advantage of the introduced visibility layer, the occlusion problem can be tackled more directly. The visibility information is propagated from layer to layer, and in each layer, the occlusion mask needs to be updated only once. Second, segmenting the scene into visibility layers instead of depth layers is more beneficial, as neighboring pixels in the same layer tend to belong to the same object, and the depth smoothness constraint can be enforced when estimating the depth map.
Let L denote the number of visibility layers in the scene. For each layer, we need to find a labeling function , where Ω refers to the set of all unmasked pixels in all images and denotes the set of possible labels of these pixels. represents the depth range of our scene. For a pixel x, if , then x is fully visible in all active camera views. Otherwise, if , then x is partially occluded.
Considering the labeling redundancy of camera array (the labels in different cameras are highly related), the problem can be further simplified. Instead of labeling all of the unmasked pixels of all of the cameras, we label all of the pixels of the reference camera equivalently (not only the unmasked pixels, as a masked pixel of the reference camera may still be fully visible in all of the other active cameras). This means that if there are
N cameras in the camera array, we only label all of the pixels of the reference camera view instead of labeling all of the unmasked pixels of all cameras. Specifically, instead of finding the above labeling function, we seek a more succinct labeling,
, where
refers to the whole image area of the reference camera. In our implementation, the visibility and depth map is calculated first on the reference image, then the visibility and depth maps of all of the other cameras are derived based on the calibration information of the camera array (as shown in
Figure 3, the visibility masked multiple view images).
Therefore, for each layer
ℓ, the problem of estimating fully-visible pixels and corresponding depths can be formulated as the following energy minimization problem:
where the data term
is a data penalty function, which can measure the cost of assigning the label
g to the pixel, and the smooth term
is a regularizer that encourages neighboring pixels to share the same label, while the visibility information
from previous layers is used to encode and block the occluded rays. In our algorithm, the estimation of visibility information is coupled to the depth value, and it is difficult to minimize energy Function (1) directly, so we let the label
g represent two kinds of labeling information, including visibility labeling information and depth labeling information. Additionally, if we want to get the visible map of each visibility layer, we can make
, so Equation (1) can be transformed into Equation (2) and can be solved in
Section 3 through the carefully-designed data term and smoothness term. Additionally, if we want to get all depth maps of each visibility layer, we can make
, so Equation (1) can be transformed into Equation (9) and can be solved in
Section 4 with the well-designed data term and smoothness term.
As the estimation of visibility information is coupled to depth value and can only be obtained by analyzing synthetic images of different depths of focus, it is difficult to minimize energy Function (1) directly. In this paper, we solve for
by the following two optimization modules: (1) optimize the visible map
in the reference camera (as shown in
Figure 3, the fully-visible map in Layers 1 and 2); (2) calculate the depth map
of visible pixels (as shown in
Figure 3, the focus depth map of the fully-visible region in Layers 1 and 2).
In the first module, in order to obtain the fully-visible map, we formulate this problem as a binary energy minimization problem, which can be optimized by graph cuts [
22]. The energy function used in the first module is composed of an energy function with a unary data term, which represents the cost of assigning a visibility label to a pixel, and a pairwise smoothness term, which accounts for the smoothness prior of the visibility layer. More details about the first module will be discussed in the
Section 3.
In the second optimization module, estimation of the optimal focus depth for pixels in each visible layer is formulated as a multiple-label energy minimization problem and is also solved via graph cuts [
22]. The energy function is composed by a unary data term, which indicates the cost of assigning a depth label to a pixel, and a pairwise smoothness term, which accounts for the smoothness constraint of the depth map. More details about the second optimization module will be discussed in the
Section 4.
3. Multiple-Layer Visibility Optimization
Since our method propagates the binary visible map between multiple layers, for a certain layer
, occluders in front of this layer have been labeled and can be easily removed in the images of all cameras. To make the notation uncluttered, we do not write previous visibility layers
explicitly unless necessary. As a result, the visibility energy function can be written as follows:
Data term: If a pixel is fully visible in the current layer, it should be in focus for some depth value, and at the same time, corresponding pixels that form the synthetic aperture image should be related by the same point of an object (except those occluded by previous layers). If a scene point is in focus, its corresponding pixel in the synthetic aperture image will have good clarity and contrast, which can be measured by state-of-the-art focusing metrics. In addition, the corresponding pixels that form the synthetic aperture image should have a similar intensity value, which can be measured by various intensity constance metrics. In this paper, focusing metrics and intensity constance metrics are all referred to as focusing metrics. We define the cost of labeling a pixel as fully visible based on its corresponding curve of focusing metrics in synthetic images of different depths of focus.
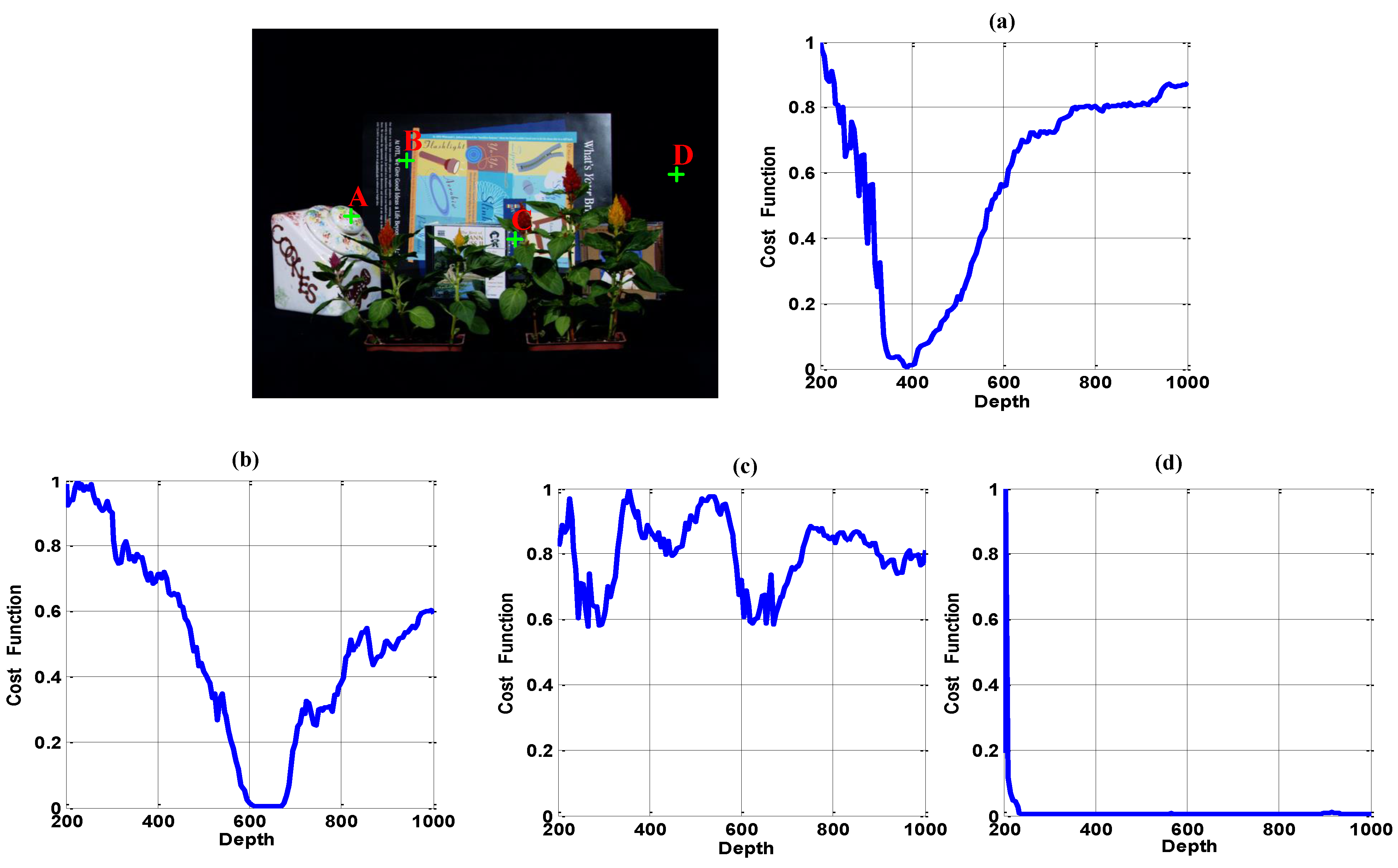
The ideal curve of a fully-visible pixel (
Figure 4, Point A) should satisfy the following two constraints: (1) it is unimodal throughout the focus depth scope; and (2) the curve reaches a global minimal, if and only if all visible rays intersect at the same point on an object in the scene. In contrast, a partially-occluded pixel or a free point without focus should always have a large value through the entire focus depth scope (
Figure 4, Point C). That is because these points are only visible in some of the cameras, thus for unfocused depth and even for focused depth, the cost of those points is high. A textureless object pixel should have a small value in a small range of depths around the focusing depth (
Figure 4, Point B), while a textureless background pixel should have a small value over a broad focus range due to its similarity with the neighborhood pixels (
Figure 4, Point D). Besides,
Figure 4, Point D gives a sharp peak near the origin. That is caused by the position of focusing depth plane: when it is too close to the camera, the out-of-focus problem results in an unexpected value.
Reasonably, we cannot estimate the depth of the textureless background pixels. Thus, according to the width of the low value depth range, we remove the textureless background region before our binary visibility optimization.
Figure 4.
Typical focusing curve of different kinds of points. (a) Point A: Fully-visible texture region; (b) Point B: Fully-visible region with pure color; (c) Point C: Partially-occluded region or free point; (d) Point D: Textureless region.
Figure 4.
Typical focusing curve of different kinds of points. (a) Point A: Fully-visible texture region; (b) Point B: Fully-visible region with pure color; (c) Point C: Partially-occluded region or free point; (d) Point D: Textureless region.
Based on the above analysis, we have compared different kinds of metrics to obtain the desired ideal curve. Part of the comparison result is shown in
Figure 5.
Figure 5a gives the input images of different cameras, while
Figure 5b–d displays the synthetic aperture imaging result, variance image and maximal color difference (MCD) image in different depths. Comparing
Figure 5c,d, we can see that the MCD image could describe the minimal color difference more accurately than the variance image. Thus, the MCD measurement is more suitable for visibility analysis.
Figure 5e shows the corresponding curves of Points A–C marked in
Figure 5a. The focus measures evaluated include DCTenergy ratio (DCTR) [
26], diagonal Laplacian (LAPD) [
27], steerable filters (SFIL) [
28], variance and MCD. For the first three focus measures, we compute the focus metric using a 5 × 5 pixel block on one hundred sampled focus planes. All of the results are normalized and mapped to [0 1], where a low value represents good focus. The result indicates that for a point in a textured region without occlusion, all focus measures can successfully find the focus point (Point A in
Figure 5e). However, when the textured point is occluded in some cameras (Point B in
Figure 5e), the curves of DCTR, LAPD, SFIL and variance measures are multimodal with multiple local minima. In contrast, the MCD metric is more stable and more insensitive to occlusion. In the low texture region (
Figure 5e, Point C), the first three measures contain many noises. In contrast, both the variance and MCD measure reach the global minimum around the ground truth. In addition, the MCD curve is sharper than the variance and closer to the ideal curve.
Figure 5.
Comparison results of focus measures for different kinds of points; the manually-labeled ground truth focus depth is marked with the red arrow. (a) Multiple view images; (b)Synthetic Aperture Image; (c) Variance Image; (d) Our MCD Image; (e) Comparison results of different focus measures, variance and maximal color difference metric.
Figure 5.
Comparison results of focus measures for different kinds of points; the manually-labeled ground truth focus depth is marked with the red arrow. (a) Multiple view images; (b)Synthetic Aperture Image; (c) Variance Image; (d) Our MCD Image; (e) Comparison results of different focus measures, variance and maximal color difference metric.
Based on the analysis above, we select the MCD measure to define the data cost
for each pixel x in the reference camera:
where
is the depth range of the scene,
is the MCD focus measure value of the pixel x in depth
d:
represents the value of pixel x on the warped image of camera
i in depth
d.
is a binary map of camera
i to mask fully-visible pixels of previous layers.
is the maximum gray intensity, and for a eight-bit camera, its value is 255.
is the visibility layer
of camera
i and can be obtained easily from
of the reference camera. If
, x is occupied by previous layers, otherwise
.
A good energy function should reach a good solution when the energy is low. In order to achieve this, we design the data term of the visibility optimization model as Equation (3), which is introduced to classify all of the pixels as visible or invisible. When min(MCD) is small, or the data term is small, the probability that the point is occluded is low; thus, the cost of assigning it as a visible point is low. In addition, according to the definition of MCD, even if one of the camera views is occluded, the min(MCD) appears to be a large value, and the cost of assigning this point as a visible point is high by Equation (3). Thus, for visibility labeling, it is straightforward to see that our data term should achieve its minimum when it is correctly assigned and achieve a large value for an occluded point, which is the perfect data term that we want.
Smoothness term: The smoothness term
at layer
ℓ is a prior regularizer that encourages overall labeling to be smooth. The prior is that two neighboring pixels have a higher probability to belong to the same object and should be both visible or occluded in the reference camera at the same time. Here, we adopt the standard four-connected neighborhood system and penalize the fact if labels of two neighboring pixels are different:
where
and
denote the maximum and weight of the smoothness term, respectively.
h is a decreasing weighting function that takes into account the MCD measure similarity between neighboring pixels. The more similar the MCD measure is, the weight will be higher, and the smoothness constraint between pixels will be stronger.
Because every two neighboring pixels have a higher probability of belonging to the same object and should be both visible or occluded in the reference camera at the same time, so the MCD measure should be similar between neighboring pixels, which means that the smoothness term will be big between neighboring pixels. In our algorithm, in order to represent the decreasing relationship between the MCD measure and the smoothness term, we simply use the inverse proportional function
as
in our experiments. It is worth noting that other functions that can represent the decreasing relationship should also work well. With the above data term and smoothness term, our energy function can be minimized via graph cuts [
22].
4. Multiple-Layer Depth Optimization
As
is obtained by the visibility optimization in
Section 3, we could estimate the optimal depth of these fully-visible pixels by multiple depth label optimization. Different from the visibility optimization, which applies the graph cuts to get all visibility layers, our multiple-layer depth map optimization model applies the graph cuts to get the optimal focus depth of the fully-visible pixels in each visibility layer. In this model, we also need to find a labeling function:
, where
represents the set of all fully-visible pixels on the reference camera and
is the depth range of the scene. In order to get this labeling function, we use the energy minimization framework to do this work:
Data term: The data term should reflect defocusing and reaches the global minimal at the optimal focusing depth. Just as we have analyzed in
Section 3, the MCD metric outperforms other focus measures; thus, we adopt the MCD measure in the synthetic aperture images as the cost function:
Smoothness term: The smoothness term
of layer
ℓ is a regularizer that encourages the overall depth labeling to be smooth. Similar to
Section 3, we adopt the standard four-connected neighborhood system and penalize the fact that the depth labels of two neighboring pixels are different.
where
and
are as defined in
Section 3. Again, the problem of depth label optimization is solved via graph cuts [
22].
Because we already get all synthetic images of different depths of focus, so after obtaining and , we can get all pixel’s optimal imaging results and each layer’s color information. Combing with the visible information in each visibility layer and removing the visibility layer that contains the occluders, we can get the all-in-focus imaging result just by simply combining the remaining layers.
The above process also can be represented by:
where
x is one pixel in the reference camera,
is the synthetic value of pixel
x in
,
denotes the optimal depth of pixel
x in
and
represents the value of pixel x on the warped image of camera
k at depth
.
N represents the number of camera views. Then, given a depth
, we could generate the all-in-focus synthetic aperture image by combining
with
.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


