Abstract
Controllable Image Captioning (CIC) aims to generate coherent and semantically faithful textual descriptions of images while adhering to user-specified constraints. Existing methods have achieved promising results under individual constraints such as sentimental style or sentence length. However, they typically fail to handle and satisfy multiple constraints simultaneously, as the controls often interact and interfere with one another. To overcome these challenges, we propose Internal–External Multi-Agent Steering (IE-MAS) for CIC. IE-MAS introduces an internal multimodal steering (IMS) strategy to control affective coherence within the caption, and an external multi-agent collaboration system (EMCS) to guide visual grounding and contextual alignment. From an information-theoretic view, IMS reduces uncertainty in the generation process, while EMCS strengthens the dependency between captions and visual inputs, converting the length and sentiment constraints into information gains. Together, they produce a stable balance among semantic consistency, affective expression, and length control through an adaptive steering process that dynamically balances internal linguistic control and external perceptual grounding. Experimental results demonstrate that IE-MAS effectively coordinates multiple constraints, producing captions that satisfy the length constraint and are sentimental expressive and visually faithful.
1. Introduction
Image Captioning (IC) [1] aims to automatically generate coherent and semantically rich natural language descriptions for visual inputs. Controllable Image Captioning (CIC) [2] extends IC tasks by incorporating additional predefined constraints into the caption generation process, such as enforcing particular sentimental tones or regulating textual length [3,4]. The ability to satisfy fine-grained constraints over both linguistic and affective properties positions CIC as a valuable technology for diverse real-world applications, including personal multimedia recommendation systems [5] and adaptive human–computer interaction platforms [6].
The sentiment of generated captions serves as a core constraint in CIC and has attracted considerable research attention. Large language models (LLMs) achieve controllable captioning by conditioning the decoding process on explicit control signals; zero- and few-shot strategies such as prompt tuning [3] and post hoc polishing [4] provide partial control in sentiment. Recent multimodal large language models (MLLMs), including Qwen2.5-VL [7] and LLaMA3.2-vision [8], demonstrate strong cross-modal understanding and generation capabilities. However, prompt-based strategies remain inadequate for precisely identifying and modulating sentiment-relevant internal representations within these models, leading to unstable or inconsistent control effects [9]. Insufficient exploration of the latent sentiment representation space within MLLMs limits their effectiveness in achieving fine-grained controllable sentiment captioning. Thus, a key challenge lies in analyzing and adjusting the internal representations to enable precise and sentiment-consistent caption generation.
Beyond sentiment, as shown in Figure 1, CIC may incorporate additional constraints such as text length. Prior research on length control in non-sentiment text generation propose techniques including positional prompting and fine-tuning to guide token allocation [10,11,12], as well as post hoc sampling and rewriting methods that operate without retraining [13,14]. However, directly applying these methods in sentiment-constrained cases often distorts or even inverts the intended sentiment, revealing their fragility when multiple constraints must be satisfied simultaneously. For instance, caption length inherently affects expressive granularity: shorter captions tend to emphasize high-level visual cues, whereas longer ones enable richer affective detail but increase the likelihood of mixed or ambiguous sentiment [15]. Multi-Agent Systems (MASs) provide an alternative framework for achieving multi-constraint control in generative modeling. Recent studies have applied MASs to image captioning tasks, demonstrating that collaborative or role-specialized agents can enhance generation diversity, factual consistency, and contextual alignment [16,17,18,19]. Nevertheless, effective coordination among agents remains difficult due to conflicts arising from heterogeneous conditional objectives and potentially competing constraints [20]. Such conflicts can further lead to issues such as hallucination [17,21]. Therefore, jointly managing external constraints including sentiment, length, and visual grounding, while balancing their inherent conflicts remains an open challenge for current MAS-based captioning architectures.
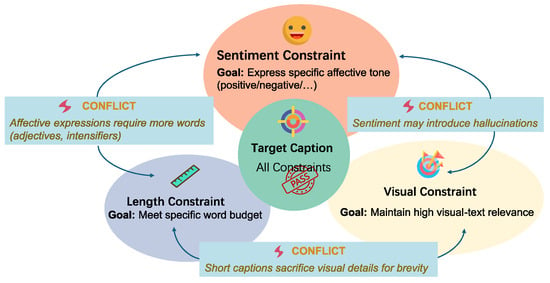
Figure 1.
An example showing conflicts among multiple constraints in controllable image caption.
Under the information-theoretic perspective, CIC is formulated as the regulation of conditional uncertainty during caption generation [22]. Given visual features and user constraints, a desired system should simultaneously minimize the conditional entropy while maximizing mutual information [23,24]. Prior studies [3,4,16] primarily operated through prompt-level control and rarely quantified or constrained uncertainty within internal representations, leading to unstable information flow and degraded caption quality when multiple constraints interact.
To address these challenges, we propose IE-MAS (Internal–External Multi-Agent Steering), a synergistic collaborative framework that integrates internal representation steering with an external multi-agent coordination system. (1) To overcome the inherent limitations of prompt-based control, we introduce Internal Multimodal Steering (IMS). IMS employs contrastive activation addition and sparse autoencoders to extract sentiment-relevant steering vectors and enhance their interpretability. By analyzing the distribution of affective correlation vectors within MLLMs and selectively injecting these vectors into the cross-modal attention layers, IMS enables fine-grained and interpretable sentiment modulation without retraining. (2) To balance competing objectives across multiple constraints, we design the External Multi-Agent Collaboration System (EMCS), comprising four cooperative agents: a Generator, a Reviewer, an Arbitrator, and a Contactor. The Contactor, serving as the mediator between external evaluation and internal steering, dynamically translates high-level feedback from the Reviewer into adaptive injection intensities for the Generator. Thus, the EMCS effectively harmonizes multiple constraints and generates coherent captions.
Experiments across distinct sentiment and length constraints show that IE-MAS consistently achieves significant improvements over strong baselines. Compared with backbone model, IE-MAS raises sentiment accuracy by over , and reduces length deviation by more than , while maintaining strong image–text alignment. The layer-wise analysis reveals that the deep cross-modal layers of MLLMs are most effective for fine-grained sentiment steering. Ablation studies further confirm that both the IMS and the EMCS are essential. Together, these results demonstrate that IE-MAS achieves a balanced integration of controllability, semantic consistency, and interpretability.
To summarize, our contributions are as follows.
- Internal Multimodal Steering (IMS) for fine-grained sentiment control. IMS extracts sentiment-related steering vectors and injects these vectors into the cross-modal attention layers of the base MLLM, enabling fine-grained modulation of affective tone without retraining.
- External Multi-Agent Collaboration System (EMCS) for multi-constraint controllable captioning. The EMCS balances conflicts from multiple constraints by the novel Contactor, who translates high-level external feedback into internal steering intensity. By integrating IMS and the EMCS, the proposed IE-MAS achieves adaptive coordination between internal representational control and external agent collaboration.
- Comprehensive experimental validation. Extensive experiments under different sentiment types and length settings demonstrate that IE-MAS consistently outperforms strong baselines. Layer analysis further confirms the effectiveness of internal modulation, while ablation studies verify the complementary roles of IMS and the EMCS in achieving balanced and stable Controllable Image Captioning.
The remainder of this paper is organized as follows. Section 2 reviews related work in Controllable Image Captioning, steering strategies, and multi-agent system. Section 3 illustrates the problem formulation and essential preliminaries. Section 4 introduces the proposed IE-MAS methodology. Section 5 reports experimental results and analysis. Finally, Section 6 concludes the paper and discusses future directions.
2. Related Work
We organize the related studies into three directions: Controllable Image Captioning (CIC), steering for CIC, and multi-agent systems. Together, these research lines trace the evolution from early constraint-based captioning to recent adaptive control frameworks for MLLMs, highlighting the progress and gaps that motivate our IE-MAS framework.
2.1. Controllable Image Captioning
Beyond ensuring factual grounding as an inherent requirement of image captioning, Controllable Image Captioning (CIC) extends conventional caption generation by introducing auxiliary constraints such as sentiment and length.
Sentiment Constraint. Early studies mainly inject sentiment signals into caption decoders through specialized embeddings or adaptive attention to balance emotional tone with visual fidelity. Mathews et al. [25] introduced SentiCap in 2016, the first RNN-based model that learns to generate captions by disentangling factual and affective words. StyleNet [26] introduces a style embedding mechanism to disentangle and control stylistic features in generated captions, while MSCap [27] incorporates multiple style representations to flexibly generate captions with diverse sentimental tones. With the rapid advancement of textual [28] and visual pretrained models [29,30], controllable captioning has been further enhanced through large-scale representation learning [3], making pretraining-based approaches the prevailing direction in affective captioning. For example, Tian et al. [31] leveraged unsupervised pretraining on large-scale unlabeled image–text data to capture both semantic and affective cues, while Wang et al. [3] employed pretraining on massive vision–language corpora to improve caption quality. Recent methods further integrate contrastive learning [32], reinforcement learning [33,34], and instruction fine-tuning [35], achieving high controllability on emotions without sacrificing linguistic quality.
Length Constraint. Beyond sentiment constraint, length constraint regulating the number of tokens/words has been explored through several paradigms. Representative approaches include length-conditioned RNNs that incorporate target length embeddings into the decoder to regulate sequence generation [36], positional encoding strategies that guide token allocation during decoding [37], and explicit length-level modeling for image captioning that achieves precise control without retraining [10].
Parallel research has explored length constraint in non-affective text generation. Representative approaches include guiding token allocation during decoding through positional prompts or fine-tuning strategies [10,11,12], as well as post hoc adjustment methods such as sampling or rewriting that modify outputs without retraining [13,14]. However, when these techniques are directly applied to CIC, they often satisfy word-length constraints at the expense of affective coherence and visual grounding.
Multiple Constraints. With the rise of LLMs in CIC, prompt engineering [38] has emerged as a pivotal technique for caption generation [39]. Recent approaches leverage prompt engineering to enable controllable captioning. Wang et al. [3] embedded learnable prompts into a pretrained captioner to enable flexible control over style and length. ConZIC [4] introduced GibbsBERT, a sampling-based non-autoregressive model that iteratively refines tokens to satisfy constraints in a zero-shot manner.
While these zero- or few-shot strategies allow partial manipulation of sentiment or length through natural-language conditioning, they remain limited to single-constraint optimization and fail to explicitly model the interplay among multiple constraints such as length, affect, and visual grounding. Moreover, although recent multimodal LLMs [7,8] have substantially expanded cross-modal reasoning capabilities, jointly satisfying multiple controllable constraints without task-specific fine-tuning remains an open challenge.
2.2. Steering for Controllable Image Captioning
Steering is a common method for controlling large models by adjusting internal activations or latent representations to guide model behavior [40]. The foundations of steering lie in manipulating intermediate representations to control semantics, progressively developing in recent years.
Subramani et al. demonstrated that latent steering vectors can be extracted from pretrained decoders, enabling parameter-free control of semantic attributes [41]. Building on this idea, Turner et al. formalized activation addition (ActAdd) operations that inject semantic directions into residual streams and that are effective for attribute control such as sentiment and style [40,42]. To improve robustness and interpretability, subsequent work moved toward contrastive and feature-aware methods: Contrastive Activation Addition (CAA) uses contrastive signals to derive more stable control directions [40], Feature-Guided Activation Additions (FGAA) introduce feature selection for more targeted interventions [43], and Sparse Steering confines steering vectors to sparse, interpretable subspaces via autoencoders [44]. Together, these developments trace a clear progression from discovering latent semantic directions to performing precise, stable, and interpretable interventions in model activations.
A few recent works have extended activation-level interventions directly to image captioning, primarily to mitigate object hallucination. Su et al. [45] proposed an activation–intervention decoding framework that integrates activation steering into the caption generation process, with empirical evaluations using CHAIR metrics demonstrating that activation-level modulation can effectively reduce hallucination without retraining. Extensions of ActAdd and CAA to image captioning confirm the feasibility of semantic correction through latent manipulation, but also expose limitations in cross-modal generalization and visual–textual alignment.
2.3. Multi-Agent System for Controllable Image Captioning
Multi-agent systems (MASs) have recently emerged as an effective paradigm for decomposing complex generation tasks into specialized, cooperative subtasks. Several studies explore the potential of agent-based collaboration for the image captioning generation task.
MAS for image captions. MosAIC [16] provided a multi-agent multimodal framework for cultural image captioning, where agents represent different cultural views and a central aggregator combines their outputs. MoColl [18] is a collaboration framework that mixes general and specialized agents to balance accuracy and style control. Other multi-LLM pipelines [46] adopted staged agent workflows (generation, screening, and rewriting) to improve coherence and readability. HuggingGPT [19] offered a general orchestration idea that uses an LLM controller to coordinate different expert models.
MAS for grounding captions. CapMAS [17] coordinated planner, generator, and critic agents to improve factual completeness in detailed captions and reduce hallucination. Jiang et al. [47] explored relational reasoning for image captioning and combined retrieval-augmented generation with hallucination detection to strengthen entity-level grounding. Several works focus on reducing hallucination and on grounding captions to image facts by adding retrieval, verification, or specialized critics. It shows way to make captions more faithful to the image and to user controls.
These works show that MAS architectures enhance interpretability, adaptability, and factual robustness in image captioning generation. However, their coordination mechanisms remain prompt- or response-level, focusing on surface optimization through inter-agent dialogue rather than direct internal representation control. Consequently, while MASs provide a promising foundation for multi-constraint generation, current designs neglect to directly manipulate or interpret the latent dynamics of multimodal large language models.
Table 1 summarizes representative methods in Controllable Image Captioning, activation steering, and multi-agent captioning system. In contrast to methods that typically focus on a single constraint or enforce control only at the surface text or agent level, IE-MAS combines multimodal steering with an external multi-agent coordination system to jointly handle sentiment, length, and visual grounding during caption generation. This internal–external design improves controllability under multiple constraints while preserving the generality of the underlying MLLMs.

Table 1.
Summary of representative related work on Controllable Image Captioning, steering, and multi-agent captioning systems.
3. Preliminaries
3.1. Problem Formulation
Notations. Controllable Image Captioning (CIC) aims to generate captions that are factually grounded in a given input image while satisfying predefined constraints, such as sentiment s [3,48] and caption length L [10]. The input image is encoded by a vision encoder [49] into a visual representation , the target sentiment polarity specifies the desired affective tone (e.g., positive or negative), and defines the target word budget. Prior work typically addresses only a single constraint at a time, neglecting potential interactions across multiple objectives. In contrast, we handle a set of constraints .
Autoregressive factorization. A generative model produces a caption sequence , where denotes the token generated at time step t and T represents the sequence length. Following the standard autoregressive factorization [2], the conditional probability distribution is defined as
where sentiment s dominates the token distribution at each decoding step, while length L and visual grounding v provide soft constraints to maintain caption quality. Specifically, we enforce the hard length constraint by setting and prioritize sentiment alignment through internal representation steering, allowing the model to trade off between visual fidelity and affective coherence when conflicts arise.
3.2. Steering
Contrastive Activation Addition (CAA) and the Sparse Autoencoder (SAE) provide the foundation for steering. CAA supplies a directional control vector, while the SAE isolates a concise, interpretable basis within the activation subspace. Their integration enables precise and layer-aware sentiment modulation within MLLMs without extra fine-tuning.
Contrastive Activation Addition (CAA). CAA derives directional control vectors by aggregating activations from contrastive sample pairs, grounded in the linear representation hypothesis [50,51]. Let denote the mapping from the input to the activation space at layer l of a pretrained LLM. Given a positive set and a negative set , the activations at layer l are denoted as and . The CAA vector for layer l is computed as
which represents the semantic direction separating positive and negative samples in the representation space.
Sparse Autoencoder (SAE). To refine the CAA vector and reduce redundancy, we adopt a Sparse Autoencoder (SAE) that transforms into a compact and interpretable representation [40,52]. Formally, the SAE first encodes the CAA vector as
Then, it reconstructs a refined steering vector through the decoder:
The SAE is optimized by minimizing the reconstruction objective:
where the first term preserves semantic fidelity and the second promotes sparsity. Finally, the refined vector is injected into the model activations for controllable generation:
where controls the steering strength.
3.3. Multi-Agent System
Multi-agent systems (MASs) consist of multiple autonomous agents that collaborate or compete to accomplish tasks beyond the capability of a single agent [53,54]. In the context of controllable caption generation, basic MAS frameworks typically include two core types of agents: (1) Generation agents (Generator) produce candidate outputs according to task specifications, such as generating captions [16,17]. (2) Discrimination agents (Evaluator or Reviewer) assess the outputs with respect to predefined criteria, including factual correctness, stylistic constraints, or task-specific rules [18,46].
A typical communication among agents involves the following: the Generator proposes outputs, the Evaluators provide feedback, and optionally, decisions are passed to a mediator for selection or iteration [19]. This iterative interaction enables the system to improve output quality.
4. Methodology
As shown in Figure 2, IE-MAS achieves multi-constraint controllable captioning by two key components: (1) Internal Multimodal Steering (IMS) modifies the semantic activation patterns of a pretrained MLLM to achieve fine-grained sentiment modulation; and (2) the External Multi-agent Collaboration System (EMCS) performs iterative refinement to jointly satisfy sentiment, length, and image–semantic alignment. By incorporating both, IE-MAS internally overcomes the limitation of prompt-based control by operating at the representation level (by IMS); and externally reconciles multiple potentially conflicting constraints by combining steering with iterative evaluations and arbitrations (by the EMCS). IE-MAS operates purely at inference time: we do not retrain the backbone MLLM or the sentiment classifier, and all modules run as plug-in components, making it easy to integrate into existing captioning pipelines.
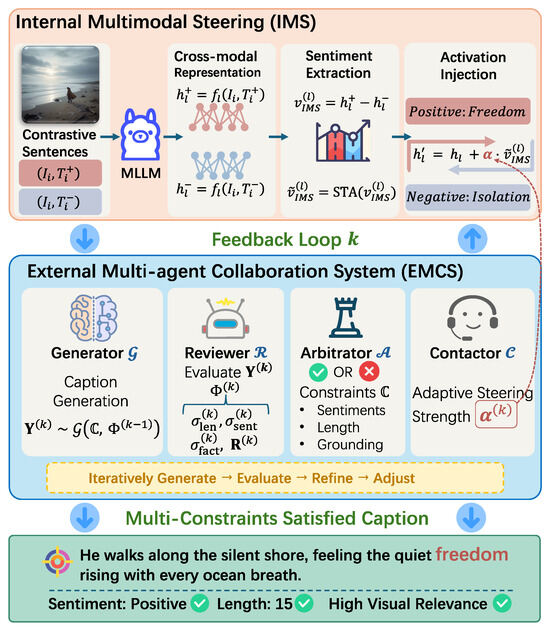
Figure 2.
Overview of the IE-MAS framework. The IE-MAS framework integrates two complementary components: (1) Internal Multimodal Steering (IMS) extracts contrastive activation vectors from positive–negative caption pairs to steer internal representations of the multimodal large language model. (2) The External Multi-Agent Collaboration System (EMCS) consists of a Generator, Reviewer, Arbitrator, and Contactor, which iteratively generate, evaluate, and refine captions under sentiment, length, and visual constraints. The feedback loop between IMS and the EMCS enables IE-MAS to produce captions that jointly satisfy multiple control objectives.
4.1. Internal Control: Multimodal Activation Steering for Cic
Existing steering studies focus on text-only LLMs, whereas steering in MLLMs differs in fundamental ways. In textual models, steering manipulates hidden activations within a purely linguistic representation space to adjust style or sentiment. In contrast, MLLMs jointly integrate visual and textual embeddings through cross-modal attention mechanisms, where activations simultaneously capture linguistic semantics and visual grounding. Consequently, steering in MLLMs affects not only sentiment expressed in language generation but also the model’s interpretation of visual cues.
Sentiment Direction Extraction and Refinement. To capture this joint representation, we compute the contrastive activation differences over paired image–caption inputs , rather than text-only data. The paired inputs are extracted from a small, randomly sampled set of contrastive caption pairs. Formally, at the layer l, the multimodal sentiment direction is
where and represent positive and negative sentiment image–caption pairs, respectively. This cross-modal sentiment vector captures both affective and visual alignment shifts, serving as the foundation of the internal control signal within IE-MAS.
To refine and suppress noisy activations, we draw upon the idea of Steering Target Atoms (STA), leveraging its advantage of selecting atoms in the SAE-decoupled space [9]. This enables our model to achieve finer-grained and stabler control. Specifically, we first encode through the SAE:
We then select the top- most discriminative latent dimensions (atoms) according to the absolute activation strength :
Finally, the refined steering vector is reconstructed through the SAE decoder:
This process isolates the most sentiment-relevant atoms in the latent space, effectively removing redundant and visually irrelevant components.
Activation Injection. During caption generation, the refined vector is injected into selected cross-modal representation to guide sentiment expression:
where is typically a predefined hyper-parameter in existing work. In contrast, in response to other constraints, such as factual grounding, we employ an agent (Contactor ) to dynamically adapt in the k-th refinement iteration.
Through this process, IMS enables the model to generate captions that convey the target sentiment with stable affective tone and preserved visual semantics, establishing a foundation for multi-constraint coordination in IE-MAS.
4.2. External Control: Multi-Agent Collaboration System for Cic
The external multi-agent collaboration system (EMCS) manages the controllable caption generation process. It comprises four primary agents: the Generator , Reviewer , Arbitrator , and Contactor . The system defines a communication protocol in which diagnostic feedback from the Reviewer and judgments from the Arbitrator are transmitted into actionable guidance for the Generator, while the Contactor bridges external assessments with internal steering parameters.
Generator. At iteration k, given the control specification and the guidance message from the previous step (with as the initial prompt), the Generator produces candidate captions via autoregressive sampling:
Reviewer. For the candidate caption , the Reviewer conducts multi evaluations, including length compliance, sentiment alignment, and image–text factual consistency. independently assess and returns diagnostic indicators, including a length deviation , agreement score , factuality score , and a concise rationale highlighting potential errors. Formally,
where , , and are auxiliary models. Here, quantifies the signed deviation of the generated caption’s length from the specified target L, measures the alignment between the affective expression of and the desired sentiment polarity s, and captures the degree of semantic consistency between and the visual content of the input image Img.
In addition, the Reviewer generates a rationale identifying tokens with weak or unsupported visual grounding. These diagnostic signals are then integrated into a unified guidance message:
where performs structured summarization rather than naive concatenation. Specifically, identifies the primary constraint violation and produces actionable instructions, such as “Reduce by words” or “Remove hallucinated tokens: [objects from ]”.
Arbitrator. The Arbitrator enforces acceptance criteria for candidate captions based on evaluation signals. A caption is accepted before reaching the iteration limit only if all checks pass:
where and are sentiment and grounding thresholds, respectively. Length is enforced exactly, while sentiment and factuality are evaluated with soft margins to preserve linguistic naturalness. If no candidate satisfies all constraints after iterations, selects the final caption from the history by the priority ordering: factual grounding, sentiment alignment, and length accuracy.
During the refinement, identifies the dominant failure mode in and updates both the prompt and the steering strength via the Contactor .
Contactor. The Contactor serves as a communication interface between the external multi-agent system and the internal steering mechanism. It dynamically regulates the steering strength based on sentiment deviation, thereby adapting internal control intensity based on external evaluation feedback. The existing fixed-intensity steering [9] lacks temporal adaptability: they cannot provide strong modulation in early iterations to accelerate sentiment convergence, nor can they gradually attenuate adjustments in later stages to prevent over-correction and maintain linguistic naturalness.
Formally, the adaptive steering strength is updated via a non-linear mapping:
where represents the sentiment deviation, indicating the divergence of the generated caption from the target affective polarity. and denote the lower and upper bounds of the steering coefficient, and controls the smoothness of adjustment. When the deviation is large, approaches for strong corrective influence; as the deviation decreases, gradually converges toward for stable refinement.
Through this adaptive coordination, integrates the external feedback signals into the internal control process, achieving balanced regulation across sentiment, length, and visual grounding. The complete iterative coordination procedure is outlined in Algorithm 1.
| Algorithm 1 The proposed IE-MAS framework |
|
4.3. Information-Theoretic Interpretation of IE-MAS
From an information-theoretic view, CIC can be formulated as modeling the conditional distribution . IE-MAS concentrates probability mass on captions that are consistent with both the image and the specific constraints, thereby reducing the conditional entropy and stabilizing generation. Formally, for fixed constraints ,
where lower entropy reflects higher certainty and stronger adherence to constraints.
Conditional uncertainty and token-level entropy. During decoding, uncertainty can be estimated through token-level entropy. At refinement iteration k, the stepwise softmax probabilities of the generated caption yield an empirical estimate of . The entropy reduction between consecutive iterations is given by
where a positive indicates a reduction in uncertainty and improved alignment of the conditional distribution with the target constraints from round to k.
IMS refines latent activations of the MLLMs to shift toward sentiment-consistent and visually grounded candidates. It follows the information bottleneck principle [55] by preserving mutual information that is most predictive of the desired caption while discarding irrelevant variability. Specifically, through the selective activation mechanism (STA in Equation (9)), IMS retains informative components in (and thus ) and suppresses noise in the latent space, thereby reducing entropy and enhancing stability in the generation process.
The EMCS further regulates the effective conditional distribution through iterative feedback. At each round, , , and from the Reviewer quantify mutual dependencies between the generated caption and each control signal. These signals could be viewed as proxies of measurement of mutual information between captions and corresponding constraints.
The feedback mechanism effectively reallocates probability mass toward outputs with higher joint information across modalities and constraints. We experimentally explore the correlation between mutual information and these proxies in Section 5.7.
5. Experiment
5.1. Experimental Settings
Dataset. Experiments are conducted on the SentiCap benchmark [25], which contains 2000 images, each annotated with three human-written captions expressing either positive or negative sentiment.
Metrics. To evaluate length controlability, three quantitative metrics are employed. Mean Absolute Error (MAE) [11] measures the average absolute deviation between the generated caption lengths and the predefined length constraint; Exact Match (EM) [14] denotes the proportion of captions whose lengths exactly match the prescribed constraint; and Length Compliance (LC) [14] reports the fraction of captions whose lengths fall within a tolerance of word. Sentiment expression is evaluated by Sentiment Classification Accuracy (Cls.) [27], which predicts the sentiment of the caption using a pretrained BERT-based classifier [56]. Image-semantic alignment is assessed using CLIPScore (ClipS) and Reference CLIPScore (RefClipS) [57], which are known to provide robust correlation with human judgments. Unlike n-gram-based metrics (e.g., BLEU [58], CIDEr [59]), which exhibit unreliable in zero-shot LLM outputs [60], CLIPScore directly quantifies image–caption correspondence in the joint vision–language embedding space. RefCLIPScore further incorporates human references to yield a more comprehensive evaluation of semantic consistency.
Baseline Methods. Our IE-MAS is compared against two backbone MLLMs: Qwen2.5-VL (7B) [7] and LLaMA 3.2 Vision (11B) [8] (without our multi-agent control). Additionally, two representative control-oriented methods are included for comparison: ConZIC [4], a Gibbs-sampling-based controllable captioner, and PositionID [11], a positional-prompting method for explicit length regulation.
Implementation Details. The Generator is instantiated using either Qwen2.5-VL (7B) [7] or LLaMA 3.2 Vision (11B) [8]. The initial prompt is formatted as “Please produce a single caption at {length_constraint} words. Use a {sentiment_constraint} tone.” Other default settings are shown in Table 2. All experiments are executed on a single NVIDIA A800 GPU.
Table 2.
Parameter settings for IE-MAS.
5.2. Analysis of Main Results
Table 3 reports results concerning positive and negative sentiment constraints, respectively. IE-MAS improves both backbones and delivers the strongest overall performance with the LLaMA variant. The gains hold across all metric groups, showing that combining an external multi-agent loop with internal steering is effective regardless of the base model.
Table 3.
Comprehensive evaluation on the SentiCap dataset concerning positive and negative sentiment constraints, respectively. The winners are highlighted in bold. Lower values are preferable for MAE; higher values are better for all other metrics.
Sentiment control. Both IE-MAS variants raise sentiment accuracy over their bases. IE-MAS (LLaMA) keeps high accuracy for both positive and negative captions, and IE-MAS (Qwen) pushes the positive case to the top. Importantly, the negative caption collapse seen in the Qwen base is largely mitigated, showing that IE-MAS can protect affect while meeting other constraints.
Length control. IE-MAS (LLaMA) achieves tight length control in both sentiments, with an of 0.785 and length compliance achieving 0.901. Other systems either drift in length or match length less reliably. The results indicate that the external feedback loop stabilizes length while the internal steering keeps edits local.
Image–text alignment. IE-MAS maintains strong grounding. ClipS and RefClipS are commonly better than the base models and specialized controllable captioners. The reference-based scores confirm that constraint satisfaction does not come at the cost of semantic fidelity.
Joint optimization. Competing methods tend to trade one objective for another (e.g., better length but weaker affect, or strong affect with poor length control). IE-MAS achieves tight length, accurate sentiment, and solid grounding at the same time, with the LLaMA instantiation offering the best balance.
5.3. Ablation Study: Component Contributions to Multi-Constraint Control
To evaluate the role of each component in IE-MAS, we conduct ablation experiments by removing the Internal Multimodal Steering (IMS) or the External Multi-Agent Collaboration System (EMCS) individually. As shown in Table 4, removing either component leads to clear performance degradation under both positive and negative sentiment constraints.
Table 4.
Ablation study: evaluating IMS and EMCS components by removing them individually.
Without the EMCS, the model struggles to coordinate multiple constraints, resulting in a noticeably higher MAE and reduced LC scores. This indicates that external iterative feedback plays a key role in stabilizing length control and improving overall consistency. Without IMS, performance on sentiment-related metrics (Cls.) declines, suggesting that internal representation-level steering is essential for maintaining accurate emotional tone. Although both variants still preserve some degree of caption quality, neither can match the balanced performance of the full IE-MAS. These results collectively demonstrate that IMS and the EMCS complement each other: IMS provides fine-grained semantic control, while the EMCS ensures cooperative optimization across constraints. Their integration allows IE-MAS to achieve stable and interpretable controllable captioning.
5.4. Internal Layer Analysis
In contrast to text-only LLMs, MLLMs integrate both visual and textual modalities, naturally enabling affective modulation to operate across heterogeneous feature spaces but also introducing greater structural complexity. Therefore, to better understand how sentimental control works within such architectures, we deeply explore the internal behavior of MLLMs. Specifically, we take LLaMA as the backbone, which alternates between self-attention layers for linguistic encoding and cross-attention layers for vision–language fusion. Each layer thus encodes a distinct level of semantic and multimodal abstraction, providing potential sites for controllable modulation.
Inter-layer similarity analysis. Figure 3 presents the cosine similarity heatmap of IMS vectors across all Transformer layers. Each matrix entry represents the pairwise cosine similarity between the activation-based steering directions of two layers, while the average similarity (shown at the top right) summarizes their overall alignment. Both axes correspond to layer indices (L3–L38), ordered from shallow to deep, encompassing self- and cross-attention modules.
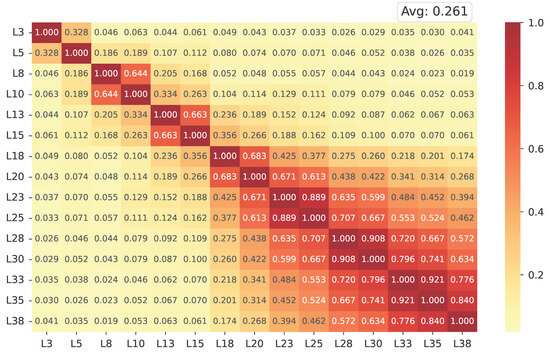
Figure 3.
Cosine similarity heatmap of IMS vectors for distinct layers within LLaMA.
Overall, the heatmap reveals a low similarity (0.261), indicating that the IMS vectors extracted from different layers capture distinct, largely independent directions in the representation space. Slightly higher similarities appear among the topmost layers, suggesting a gradual convergence as the network approaches the output space. This layer-wise divergence demonstrates that affective information is not encoded at a single locus but refined hierarchically throughout the model depth. The observed inter-layer independence validates the rationale of specific-layer steering: by modulating selected subsets of layers rather than all of them uniformly, the model can leverage diverse yet complementary sentimental representations while preserving representational stability.
IMS vector distribution analysis. Figure 4 shows that vector norms steadily increase with depth, meaning that higher layers respond more strongly to steering perturbations. This reflects the progressive abstraction of semantic features, where affective modulation gains greater representational influence near the language–vision fusion and output stages.
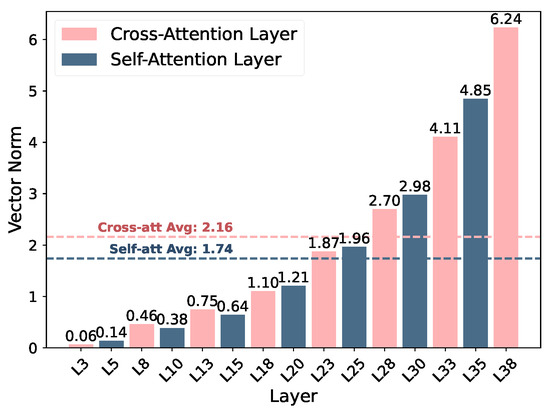
Figure 4.
IMSvector normal distribution across layers, showing that cross-attention layers maintain higher and more variable magnitudes than self-attention layers, especially in deeper stages.
A distinct contrast emerges between the two attention types: cross-attention layers demonstrate stronger and more fluctuating activations, peaking at 6.24 with an average of 2.16, while self-attention layers show comparatively subdued and consistent responses, with corresponding values of 4.85 and 1.74. This implies that the fusion layers, where visual and linguistic features interact, are the primary loci for effective emotional control, while self-attention layers mainly stabilize linguistic structure and syntactic coherence.
5.5. Sentiment-Specific SAE Feature Distribution
Figure 5 presents the PCA projections of SAE-learned features from layers L8, L18, L28, and L38 in the LLaMA backbone. The x- and y-axes correspond to the first and second principal components, capturing the major variance in the latent feature space. Each point denotes a neuron’s feature activation within the sparse representation.
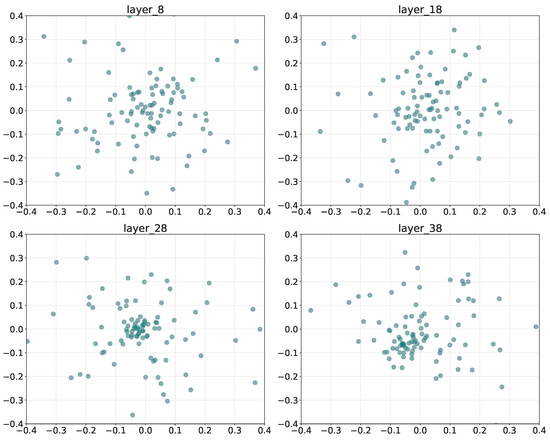
Figure 5.
Layer-wise PCA projections of SAE-learned features, illustrating the progressive consolidation of sentimental representations from shallow to deep layers.
The shallow layer (L8) exhibits a dispersed and scattered feature distribution, suggesting that affective cues remain entangled with general semantic features. By the middle layer (L18, L28), features begin to cluster loosely, reflecting partial disentanglement as sentiment-related neurons start to specialize. At the deep layer (L38), the distribution becomes compact and centralized with reduced variance, implying that sentimental information has been integrated into a unified semantic representation. Overall, the transition from dispersion to concentration reveals the hierarchical consolidation of sentimental encoding in MLLMs.
5.6. Sensitivity Analysis
To explore the impact of length constraints as well as the trade-off among constraints, we conduct a series of sensitivity analyses.
Impact of length constraint. Figure 6 shows the impact of length constraints on sentiment accuracy under both positive (red) and negative (blue) generation settings, respectively. Each pair of bars compares the baseline LLaMA-V model (solid color) against IE-MAS (hatched pattern) under conditions with or without a 15-word length limit.
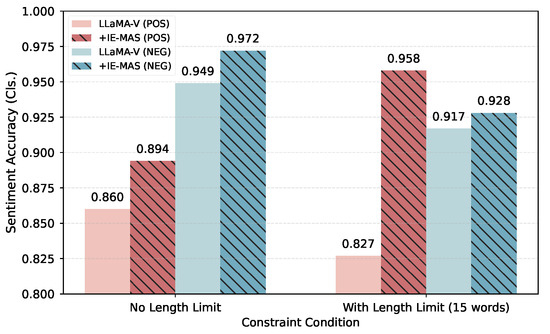
Figure 6.
The sentiment accuracy of generated captions with or without length constraint.
Imposing a strict length constraint consistently reduces sentiment accuracy for the baseline, indicating that restricted word budgets limit expressive flexibility and complicate the satisfaction of multiple constraints. Nevertheless, IE-MAS outperforms the baseline across all settings, confirming its controllability under various scenarios.
Conflict between sentiment and length. Table 5 analyzes the sensitivity of sentiment accuracy and image–text alignment across varying caption lengths.
Table 5.
Performance under different length and sentiment constraints.
As the length budget increases, Cls. declines while ClipS improves. This inverse relationship indicates that longer captions dilute affective focus but enhance visual grounding by incorporating more scene details. The trend highlights an inherent trade-off among length budget, emotional precision, and visual completeness.
5.7. Information-Theoretic Analysis
As discussed in Section 4.3, we approximate token-level entropy by averaging the stepwise softmax entropy over each caption. For each sample, the reduction in entropy equals the entropy in the first-round caption minus the one in accepted captions after iterative refinement. As a result, the average token-level entropy across the dataset decreases from 1.5245 to 1.0452 for positive captions, and from 1.7602 to 1.1254 for negative captions, yielding reductions of 0.4793 and 0.6348, respectively.
Figure 7 illustrates how the empirical behavior of IE-MAS corresponds to the information-theoretic interpretation discussed in Section 4.3. In Round 1, all constraints are severely violated, resulting in high entropy and diffuse probability allocation. In Round 2, as sentiment and grounding constraints become progressively satisfied, entropy drops sharply, reflecting reduced conditional uncertainty . Rounds 3–4 exhibit localized increases in entropy, where sentiment and grounding remain stable but length deviations persist, indicating transient constraint conflicts. By the final round, Round 5, all constraints are satisfied and entropy attains its minimum, corresponding to strong image–text alignment and elevated mutual information under fixed conditioning inputs.
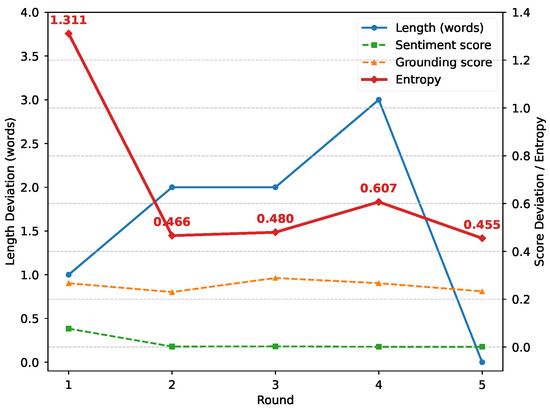
Figure 7.
Trends of constraint deviations and approximated entropy across rounds.
5.8. Qualitative Comparison
As shown in Figure 8, this section summarizes the results of the qualitative comparison under different sentiment and length constraints. PositionID is a position-aware embedding method that often produces captions with mixed numeric markers under sentiment conditioning. When the sequence reaches the maximum length, the generation stops directly and the caption remains incomplete. Prompt-based models such as ConZIC tend to produce fixed and repetitive sentences, often beginning with phrases like “Image of”. This reduces the naturalness of expression and wastes limited word space, making the generated captions less informative. Qwen2.5-VL and LLaMA3.2-V can express the correct sentimental tone in many cases, but it remains sensitive to length limits. When the caption length is restricted, the sentimental tone may become inaccurate or incomplete. In contrast, IE-MAS performs reliably across all conditions. It produces captions that accurately express the target sentiment, remain fluent, and preserve strong visual alignment even when the sentence length is limited. Notably, captions generated by IE-MAS exhibit richer sentimental expression, featuring vivid affective cues such as “quiet freedom rising,” “pure feline excitement,” and “the tide’s endless ache,” which convey powerful sentiment nuances beyond literal description. These results indicate that the coordinated control between internal steering and external agent modules effectively improves emotional accuracy and stability, allowing IE-MAS to balance expressive emotion with multimodal consistency.

Figure 8.
Qualitative case study illustrating caption generation under different sentiment and length constraints. IE-MAS consistently produces sentimental accurate and semantically coherent captions, even under strict length limitations. Blue indicates bugs related to “PositionID”, purple highlights the fixed prompt structure in “ConZIC”, orange marks positive sentiment words, and black marks negative sentiment words.
6. Conclusions and Future Work
6.1. Conclusions
In conclusion, this paper introduces Internal–External Multi-Agent Steering (IE-MAS) for Controllable Image Captioning, a framework that coordinates internal representation-level control with external symbolic reasoning to achieve simultaneous satisfaction of multiple constraints in image captioning. From the information-theoretic perspective, IE-MAS lowers the entropy of generation under multiple constraints and increases the mutual information between captions and images, thereby conveying more image-relevant content with lower uncertainty. The internal multimodal steering strategy leverages CAA combined with SAE-based feature decomposition to manipulate sentiment-related representations. The external multi-agent collaboration system provides structured evaluation and iterative refinement through specialized agents for length, sentiment, and visual alignment, while an adaptive strength adjustment mechanism dynamically balances internal and external control based on real-time feedback.
Our comprehensive experiments demonstrate that IE-MAS effectively coordinates multiple constraints without the performance trade-offs observed in baseline methods. The ablation studies confirm that all components are essential and synergistic, with removing any single component leading to substantial performance degradation. The layer-wise analysis of CAA vectors and SAE features provides theoretical and empirical insights into sentiment representation in MLLMs.
6.2. Future Work
Looking forward, we plan to introduce entropy-aware adaptive decoding at inference and explore more autonomous agent interaction mechanisms, allowing uncertainty-driven dynamic communication among agents to better balance multiple constraints. We will also further investigate the internal representations of MLLMs to enhance their controllability and generalization in the field of image captioning.
Author Contributions
Conceptualization, T.C. and C.C.; methodology, T.C.; validation, T.C. and S.J.; data curation, T.C. and S.L.; writing—original draft preparation, T.C.; writing—review and editing, T.C., C.C., and X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China, under grant number 62476060.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original data presented in the study are openly available at https://users.cecs.anu.edu.au/~u4534172/senticap.html (SentiCap, accessed on 1 November 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Farhadi, A.; Hejrati, M.; Sadeghi, M.; Young, P.; Rashtchian, C.; Hockenmaier, J.; Forsyth, D. Every picture tells a story: Generating sentences from images. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 15–29. [Google Scholar]
- Chen, S.; Jin, Q.; Wang, P.; Wu, Q. Say as you wish: Fine-grained control of image caption generation with abstract scene graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9962–9971. [Google Scholar]
- Wang, N.; Xie, J.; Wu, J.; Jia, M.; Li, L. Controllable image captioning via prompting. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2617–2625. [Google Scholar]
- Zeng, Z.; Zhang, H.; Lu, R.; Wang, D.; Chen, B.; Wang, Z. Conzic: Controllable zero-shot image captioning by sampling-based polishing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 23465–23476. [Google Scholar]
- Danescu-Niculescu-Mizil, C.; Gamon, M.; Dumais, S. Mark my words! Linguistic style accommodation in social media. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 745–754. [Google Scholar]
- Ghandi, T.; Pourreza, H.; Mahyar, H. Deep learning approaches on image captioning: A review. ACM Comput. Surv. 2023, 56, 1–39. [Google Scholar] [CrossRef]
- Bai, S.; Chen, K.; Liu, X.; Wang, J.; Ge, W.; Song, S.; Dang, K.; Wang, P.; Wang, S.; Tang, J.; et al. Qwen2.5-vl technical report. arXiv 2025, arXiv:2502.13923. [Google Scholar] [CrossRef]
- Meta, A. Llama 3.2: Revolutionizing edge ai and vision with open, customizable models. Meta AI Blog. Retrieved Dec. 2024, 20, 2024. [Google Scholar]
- Wang, M.; Xu, Z.; Mao, S.; Deng, S.; Tu, Z.; Chen, H.; Zhang, N. Beyond Prompt Engineering: Robust Behavior Control in LLMs via Steering Target Atoms. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vienna, Austria, 27 July–1 August 2025; Che, W., Nabende, J., Shutova, E., Pilehvar, M.T., Eds.; pp. 23381–23399. [Google Scholar] [CrossRef]
- Deng, C.; Ding, N.; Tan, M.; Wu, Q. Length-controllable image captioning. In Proceedings of the European conference on computer vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 712–729. [Google Scholar]
- Wang, N.; Duan, F.; Zhang, Y.; Zhou, W.; Xu, K.; Huang, W.; Fu, J. PositionID: LLMs can Control Lengths, Copy and Paste with Explicit Positional Awareness. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 16877–16915. [Google Scholar]
- Butcher, B.; O’Keefe, M.; Titchener, J. Precise length control for large language models. Nat. Lang. Process. J. 2025, 11, 100143. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, W.; Feng, X.; Zhong, W.; Zhu, K.; Huang, L.; Liu, T.; Qin, B. Length Controlled Generation for Black-box LLMs. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, 27 July–1 August 2025; Association for Computational Linguistics: Stroudsburg, PA, USA, 2025; pp. 16878–16895. [Google Scholar]
- Retkowski, F.; Waibel, A. Zero-Shot Strategies for Length-Controllable Summarization. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2025, Albuquerque, NM, USA, 29 April–4 May 2025; Association for Computational Linguistics: Stroudsburg, PA, USA, 2025; pp. 551–572. [Google Scholar]
- Sweller, J. Cognitive load during problem solving: Effects on learning. Cogn. Sci. 1988, 12, 257–285. [Google Scholar] [CrossRef]
- Bai, L.; Borah, A.; Ignat, O.; Mihalcea, R. The Power of Many: Multi-Agent Multimodal Models for Cultural Image Captioning. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Albuquerque, NM, USA, 29 April–4 May 2025; pp. 2970–2993. [Google Scholar]
- Lee, S.; Yoon, S.; Bui, T.; Shi, J.; Yoon, S. Toward Robust Hyper-Detailed Image Captioning: A Multiagent Approach and Dual Evaluation Metrics for Factuality and Coverage. In Proceedings of the Forty-second International Conference on Machine Learning, Vancouver, WC, Canada, 13–19 July 2025. [Google Scholar]
- Yang, P.; Dong, B. Mocoll: Agent-based specific and general model collaboration for image captioning. arXiv 2025, arXiv:2501.01834. [Google Scholar]
- Shen, Y.; Song, K.; Tan, X.; Li, D.; Lu, W.; Zhuang, Y. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. Adv. Neural Inf. Process. Syst. 2023, 36, 38154–38180. [Google Scholar]
- Zhang, X.; Dong, X.; Wang, Y.; Zhang, D.; Cao, F. A Survey of Multi-AI Agent Collaboration: Theories, Technologies and Applications; Association for Computing Machinery: New York, NY, USA, 2025. [Google Scholar]
- Yang, J.; Sun, Y.; Liang, J.; Ren, B.; Lai, S.H. Image captioning by incorporating affective concepts learned from both visual and textual components. Neurocomputing 2019, 328, 56–68. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1999.
- Li, J.; Selvaraju, R.; Gotmare, A.; Joty, S.; Xiong, C.; Hoi, S.C.H. Align before fuse: Vision and language representation learning with momentum distillation. Adv. Neural Inf. Process. Syst. 2021, 34, 9694–9705. [Google Scholar]
- Mathews, A.; Xie, L.; He, X. Senticap: Generating image descriptions with sentiments. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AR, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Gan, C.; Gan, Z.; He, X.; Gao, J.; Deng, L. Stylenet: Generating attractive visual captions with styles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3137–3146. [Google Scholar]
- Guo, L.; Liu, J.; Yao, P.; Li, J.; Lu, H. MSCap: Multi-Style Image Captioning with Unpaired Stylized Text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, Z.; Lin, W.; Shi, Y.; Zhao, J. A robustly optimized BERT pre-training approach with post-training. In Proceedings of the China National Conference on Chinese Computational Linguistics, Hohhot, China, 13–15 August 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 471–484. [Google Scholar]
- Radford, A.; Kim, J.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 19730–19742. [Google Scholar]
- Tian, J.; Yang, Z.; Shi, S. Unsupervised style control for image captioning. In Proceedings of the International Conference of Pioneering Computer Scientists, Engineers and Educators, Chengdu, China, 19–22 August 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 413–424. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Wei, J.; Bosma, M.; Zhao, V.Y.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned language models are zero-shot learners. arXiv 2021, arXiv:2109.01652. [Google Scholar]
- Kikuchi, Y.; Neubig, G.; Sasano, R.; Takamura, H.; Okumura, M. Controlling Output Length in Neural Encoder-Decoders. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, Texas, USA, 1–4 November 2016. [Google Scholar]
- Takase, S.; Okazaki, N. Positional Encoding to Control Output Sequence Length. In Proceedings of the 2019 Conference of the North. Association for Computational Linguistics, Minneapolis, MN, USA, 3–5 June 2019. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Li, J.; Zhang, L.; Zhang, K.; Hu, B.; Xie, H.; Mao, Z. Cascade semantic prompt alignment network for image captioning. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 5266–5281. [Google Scholar] [CrossRef]
- Rimsky, N.; Gabrieli, N.; Schulz, J.; Tong, M.; Hubinger, E.; Turner, A. Steering Llama 2 via Contrastive Activation Addition. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 11–16 August 2024; pp. 15504–15522. [Google Scholar]
- Subramani, N.; Suresh, N.; Peters, M.E. Extracting Latent Steering Vectors from Pretrained Language Models. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 566–581. [Google Scholar]
- Turner, A.M.; Thiergart, L.; Leech, G.; Udell, D.; Vazquez, J.J.; Mini, U.; MacDiarmid, M. Steering language models with activation engineering. arXiv 2023, arXiv:2308.10248. [Google Scholar]
- Soo, S.; Teng, W.; Balaganesh, C.; Tan, G.; Yan, M. Interpretable Steering of Large Language Models with Feature Guided Activation Additions. In Proceedings of the Building Trust Workshop at ICLR 2025, Singapore, 24 April 2025. [Google Scholar]
- Bayat, R.; Rahimi-Kalahroudi, A.; Pezeshki, M.; Chandar, S.; Vincent, P. Steering large language model activations in sparse spaces. arXiv 2025, arXiv:2503.00177. [Google Scholar] [CrossRef]
- Su, J.; Chen, J.; Li, H.; Chen, Y.; Qing, L.; Zhang, Z. Activation steering decoding: Mitigating hallucination in large vision-language models through bidirectional hidden state intervention. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vienna, Austria, 27 July–1 August 2025; pp. 12964–12974. [Google Scholar]
- Kim, J.; Lee, J.; Choi, H.J.; Hsu, T.Y.; Huang, C.Y.; Kim, S.; Rossi, R.; Yu, T.; Giles, C.L.; Huang, T.H.; et al. Multi-LLM Collaborative Caption Generation in Scientific Documents. In Proceedings of the International Workshop on AI for Transportation, Philadelphia, PA, USA, 25 February–4 March 2025; Springer: Berlin/Heidelberg, Germany, 2025; pp. 142–160. [Google Scholar]
- Jiang, A.; Wang, D.; Peng, C.; Wang, M. Relational Reasoning Image Captioning via Multi-Agent Retrieval-Augmented Generation. Knowl.-Based Syst. 2025, 114977. [Google Scholar] [CrossRef]
- Wu, X.; Li, T. Sentimental visual captioning using multimodal transformer. Int. J. Comput. Vis. 2023, 131, 1073–1090. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Elhage, N.; Hume, T.; Olsson, C.; Schiefer, N.; Henighan, T.; Kravec, S.; Hatfield-Dodds, Z.; Lasenby, R.; Drain, D.; Chen, C.; et al. Toy models of superposition. arXiv 2022, arXiv:2209.10652. [Google Scholar] [CrossRef]
- Zou, A.; Phan, L.; Chen, S.; Campbell, J.; Guo, P.; Ren, R.; Pan, A.; Yin, X.; Mazeika, M.; Dombrowski, A.K.; et al. Representation engineering: A top-down approach to ai transparency. arXiv 2023, arXiv:2310.01405. [Google Scholar] [CrossRef]
- Huben, R.; Cunningham, H.; Riggs Smith, L.; Ewart, A.; Sharkey, L. Sparse Autoencoders Find Highly Interpretable Features in Language Models. In Proceedings of the Twelfth International Conference on Learning Representations (ICLR 2024), Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Wooldridge, M. An introduction to Multiagent Systems; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Ferber, J.; Weiss, G. Multi-Agent Systems: An Introduction to Distributed Artificial Intelligence; Addison-Wesley Reading: Boston, UK, 1999; Volume 1. [Google Scholar]
- Tishby, N.; Pereira, F.C.; Bialek, W. The Information Bottleneck Method. In Proceedings of the 37th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 4–6 October 2000; pp. 368–377. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT: A Distilled Version of BERT—Smaller, Faster, Cheaper and Lighter. In Proceedings of the 5th Workshop on Energy Efficient Machine Learning and Cognitive Computing, Vancouver, BC, Canada, 8 December 2019. [Google Scholar]
- Hessel, J.; Holtzman, A.; Forbes, M.; Choi, Y. CLIPScore: A Reference-Free Evaluation Metric for Image Captioning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP 2021), Online. Punta Cana, Dominican Republic, 7–11 November 2021; pp. 7514–7528. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Tewel, Y.; Shalev, Y.; Schwartz, I.; Wolf, L. Zerocap: Zero-shot image-to-text generation for visual-semantic arithmetic. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17918–17928. [Google Scholar]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).