Abstract
Healthcare researchers have been working on mortality prediction for COVID-19 patients with differing levels of severity. A rapid and reliable clinical evaluation of disease intensity will assist in the allocation and prioritization of mortality mitigation resources. The novelty of the work proposed in this paper is an early prediction model of high mortality risk for both COVID-19 and non-COVID-19 patients, which provides state-of-the-art performance, in an external validation cohort from a different population. Retrospective research was performed on two separate hospital datasets from two different countries for model development and validation. In the first dataset, COVID-19 and non-COVID-19 patients were admitted to the emergency department in Boston (24 March 2020 to 30 April 2020), and in the second dataset, 375 COVID-19 patients were admitted to Tongji Hospital in China (10 January 2020 to 18 February 2020). The key parameters to predict the risk of mortality for COVID-19 and non-COVID-19 patients were identified and a nomogram-based scoring technique was developed using the top-ranked five parameters. Age, Lymphocyte count, D-dimer, CRP, and Creatinine (ALDCC), information acquired at hospital admission, were identified by the logistic regression model as the primary predictors of hospital death. For the development cohort, and internal and external validation cohorts, the area under the curves (AUCs) were 0.987, 0.999, and 0.992, respectively. All the patients are categorized into three groups using ALDCC score and death probability: Low (probability < 5%), Moderate (5% < probability < 50%), and High (probability > 50%) risk groups. The prognostic model, nomogram, and ALDCC score will be able to assist in the early identification of both COVID-19 and non-COVID-19 patients with high mortality risk, helping physicians to improve patient management.
1. Introduction
The Coronavirus Disease 2019 (COVID-19) pandemic continues to strike the globe with second and third waves of infections, as the emerging variants of Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) are more transmissible and deadly [1]. Different countries are vaccinating their population with several vaccines to reduce the disease burden and mitigate the pandemic, but, in this race, all countries are not at the same level [2,3]. COVID-19 vaccine production, distribution, and administration have not reached the needed vaccine coverage globally [2,3]. Therefore, the spread of emerging SARS-CoV-2 variants is exceeding the speed of vaccination campaigns resulting in a continuous global burden of COVID-19 disease. As of today, 7 August 2021, there have been a total number of approximately 201 million cases worldwide with 4.27 million deaths [4].
COVID-19 has a spectrum of clinical presentations ranging from asymptomatic patients to critically ill patients. According to several studies [5,6,7,8,9], the severity of the disease depends mostly on age and comorbid conditions. Moreover, genetic factors are also being studied to identify the relationship of COVID-19 with severity [10]. In one particular study, a link was found between genes encoding blood groups, specifically type A, with serious clinical manifestations [11,12]. There are many complications associated with COVID-19 and patients may present with symptoms affecting multiple systems including respiratory, cardiovascular, and gastrointestinal (GI), in addition to affecting coagulability [13,14]. COVID-19 is known to affect coagulation profile and cardiac biomarkers. The rates of cardiac injury among COVID-19 patients are between 19.7% and 27.8% of admitted cases and the associated mortality rates are between 23% and 51.2% [15]. An analysis of coagulopathy, inflammation, and troponin can help to explain the mechanism of myocardial injury. Notably, raised troponin levels among critically ill patients point to cardiac injury and are a sign of poor prognosis. It is a clear indication that the cytokine divulgence syndrome potentially mediates myocardial injury. Longitudinal follow-up insinuates a notable divergence between critically ill patients who die and those who do not. Lastly, cardiac injury during admission relates to severe outcomes. On the third day, C-reactive protein (CRP), a blood marker, measures the level of inflammation. CRP is a protein made by the liver and sent into the bloodstream in response to inflammation. Interleukin-6 (IL-6) is also an inflammatory marker, which is an indicator of disease severity [16], and it was found that the IL-6 peak among critically ill survivors falls between the fourth and seventh days [15]. By contrast, this increases continuously among those who do not survive. D-dimer, a marker of coagulopathy, remains high in those who do not survive in contrast to those who do. COVID-19 is also associated with changes in levels of various circulatory inflammatory coagulation biomarkers including fibrinogen and D-dimer. D-dimer levels have been noticed to be within normal ranges or slightly increased in the early stages of the disease. As the disease and severity progress, levels of D-dimer are significantly increased [17]. Fibrinogen, a protein produced by the liver, also increases with inflammation and a coagulation bio-marker. Creatinine, Lactate Dehydrogenase (LDH) levels, Lymphocyte count, D-Dimer, Troponin, IL-6 and CRP are shown to be important biomarkers for the severity prognosis of COVID-19. Creatinine is a chemical compound leftover from energy-producing processes in the muscles, which a healthy kidney filters out of the blood. LDH is an enzyme involved in energy production, which is found in almost all cells in the body, used to monitor tissue damage associated with a wide range of disorders, including liver disease and interstitial lung disease. The increase of LDH reflects tissue damage, which suggests a viral infection or lung damage, such as the pneumonia induced by SARS-CoV-2 [18].
Assessing COVID-19 severity and prognosis has been of great importance in clinical patient management. Machine learning has played a noteworthy role in detecting COVID-19 using clinical data and chest X-ray and computer tomography images in patients [19,20,21,22,23,24,25]. Banerjee et al. in [26] used full blood counts to recognize COVID-positive cases, instead of the traditional identification of symptoms, and have found that positive patients exhibit lower amounts of leukocytes, platelets, and lymphocytes. Brinati et al. [27] used routine blood biomarkers to test a sample of 279 COVID patients using machine learning models, which results in accuracy ranging between 82% and 86%, and sensitivity ranging between 92% and 95%. Yang et al. [28] evaluated the use of machine learning in routine laboratory blood tests to predict COVID-19, which offers an opportunity for early detection of the illness in areas where RT-PCR tests are not available. Machine learning was also used to predict mortality and critical events in patients with COVID-19. Rahman et al. [29] used easily available complete blood count (CBC) parameters to predict the severity of COVID-19 patients and the developed model was validated on another external dataset reporting very high classification accuracy. Chowdhury et al. [24] investigated demographic and clinical characteristics and patient outcomes using machine learning tools to identify key biomarkers in order to predict the mortality of the individual patient. A nomogram was developed for predicting the mortality risk among COVID-19 patients. Lactate dehydrogenase, neutrophils (%), lymphocyte (%), highly sensitive C-reactive protein, and age (LNLCA), information acquired at hospital admission, were identified as key predictors of death by the multi-tree XGBoost model. The area under the curve (AUC) of the nomogram for the derivation and validation cohort was 0.961 and 0.991, respectively. An integrated score was calculated with the corresponding death probability. COVID-19 patients were divided into three subgroups: low-, moderate- and high-risk groups. Vaid et al. in [30] claim that with the XGBoost classifier, such trends as acute kidney injury, elevated LDH, tachypnea, hyperglycemia, higher age, anion gap, and C-reactive protein were the strongest drivers associated with mortality and critical events. Aladag and Atabey [31] have attempted to predict mortality risk for critical COVID-19 patients using coagulopathy markers. Terwangne et al. in [32] showed the predictive accuracy of severity classification of COVID-19 using a model based on Bayesian network analysis with the help of five important parameters: acute kidney injury, age, Lactate Dehydrogenase Levels (LDH), lymphocytes and activated prothrombin time (aPTT).
Huang et al. [5] used nine independent risk factors at admission to the hospital to quantify the risk score and stratify the patients into various risk groups in a retrospective, multicenter analysis of 336 confirmed COVID-19 patients and 139 control patients. This research did not use any external validation. The independent relationship between the baseline level of four indicators (Neutrophil to Lymphocyte Ratio (NLR), LDH, D-dimer, and CT score) on admission and the severity of COVID-19 was assessed using logistic regression. The presence of high levels of NLR and LDH in serum could help in the early detection of COVID-19 patients who are at high risk. It was shown that the usage of LDH and NLR together increased detection sensitivity [6]. This model, however, is based on a CT image-based ranking, which is not available for all patients. In a limited number of hospitalized patients (84) with COVID-19 pneumonia, Liu et al. [7] suggested combining the NLR and CRP to predict 7-day disease severity. A retrospective cohort of 80 COVID-19 patients treated at Beijing You’an Hospital was analyzed to identify risk factors for serious and even fatal pneumonia and establish a scoring system for prediction, which was later validated in a group of 22 COVID-19 patients [8]. Age, diabetes, coronary heart disease (CHD), percentage of lymphocytes (LYM percent), procalcitonin (PCT), serum urea, CRP, and D-dimer were found to be correlated with mortality by LASSO binary logistic regression in a total of 2529 COVID-19 patients. The researchers then used multivariable analysis to determine that old age, CHD, LYM percent, PCT, and D-dimer independently posed risks for mortality. A COVID-19 scoring system (CSS) was developed based on the above variables to classify patients into low-risk and high-risk categories with discrimination of AUC = 0.919 and calibration of p = 0.64 [9].
Although there have been recent works utilizing machine learning approaches for early mortality prediction of patients using biomarkers [5,7,8,9,33,34,35,36,37,38], to the best of the authors’ knowledge, there has been no work to develop a generalized and reliable model for both COVID-19 and non-COVID-19 patients, which is the motivation behind this study, and important to develop during the pandemic situation when medical personnel are dealing with both types of patient. It is critical for both resource planning and treatment planning to identify and prioritize the patients at high risk. In addition, it should be possible for high-risk patients to be constantly tracked during their hospital stay using a reliable scoring method. The patients at risk, who typically end with ill outcomes, require treatment in an intensive care unit (ICU), which can be identified by the proposed tool, helping in saving the lives of a significant number of people during this pandemic. Thus, the novelty of the work in this paper can be stated as the development of a generalized and reliable early mortality risk predicting technique for identifying the patients with high risk among both COVID-19 and non-COVID patients. It also adds to the body of knowledge for developing a framework of prognostic models using machine-learning approaches. This paper not only develops a nomogram-based scoring technique but also validates the performance on a completely unseen dataset from different countries and populations.
The rest of the paper is organized as follows: Section 2 discusses the methodology of the study by describing the datasets used in this paper, the details of data pre-processing stages for machine learning classifiers, and the nomogram-based scoring technique. Section 3 discusses the result of the classification models and nomogram-based scoring techniques. Section 4 discusses the result and validates the performance of the developed nomogram-based scoring technique and, finally, the article is concluded in Section 5.
2. Methodology
The study consists of two important phases: the model development and model validation phase using two datasets. Dataset-1 [39] (Day-0 patient’s data) is used for the prediction model development and Dataset-2 [40] is used for external validation of the developed model. The code for machine learning pipeline used in this study can be found in [41]. As further illustrated in the methodology diagram (Figure 1), Day-3 and Day-7 patients’ data from dataset 1 is also used for external validation. Pre-processing, and feature selection and reduction were important parts of the feature-engineering task. In the model development phase, the authors have divided the training dataset (Day-0 patients’ data from dataset 1) with the selected features into training, validation and testing data. The validation dataset is used for the tuning of hyper parameters in the machine learning process, and the testing dataset is used for model evaluation. The best-trained model is used to develop the scoring technique to classify the patients into three mortality risk categories: Low, Medium and High. Finally, the developed model is validated using external datasets and the results are reported. The remaining part of the section will provide details of the datasets, pre-processing techniques, performance metrics for machine learning model and the nomogram based scoring technique.
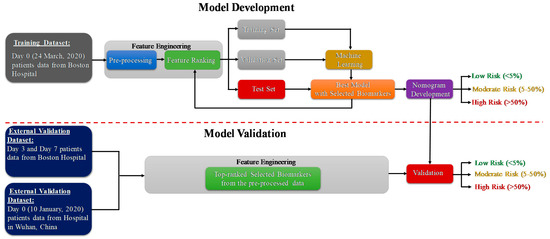
Figure 1.
Methodology of the study.
2.1. Study Population
In this study, two clinical biomarker datasets from two different countries were used. The first dataset (Dataset-1) was used to develop and validate an early death prediction model and the second dataset (Dataset-2) was used as an external validation model. The first dataset was created from the Emergency Department (ED) of a metropolitan and academic hospital in Boston during the first wave of the COVID-19 pandemic from 24 March 2020 to 30 April 2020. The study was carried out with institutional ethical approval [39]. Patients 18 years or older with clinical concern at the time of hospital admission with acute respiratory illness were included in the study, with at least one of the following conditions: (1) tachypnea (about 22 breaths per minute), (2) oxygen saturation ≤ 92% on room air, (3) supplemental oxygen requirement or (4) positive pressure ventilation requirement. The patients were monitored up to 28 days after registration for the clinical outcome or discharged if the patient recovered. The dataset consists of the biomarkers for three separate days (0, 3, and 7 days). There are six groups of patients available in the enrolled 384 patients. Among them, the first group (Class 1) were the patients with death outcomes (49 (12.76%) patients) and the other groups (Class 2–6) were the patients in the survived class (335 (87.24%) patients). Among the 384 patients, 78 (20%) patients tested as SARS-CoV-2 negative and 306 (80%) patients tested as SARS-CoV-2 positive by RT-PCR. Table 1 shows the description of the first dataset (Dataset-1).

Table 1.
Description of different variables in the Dataset-1.
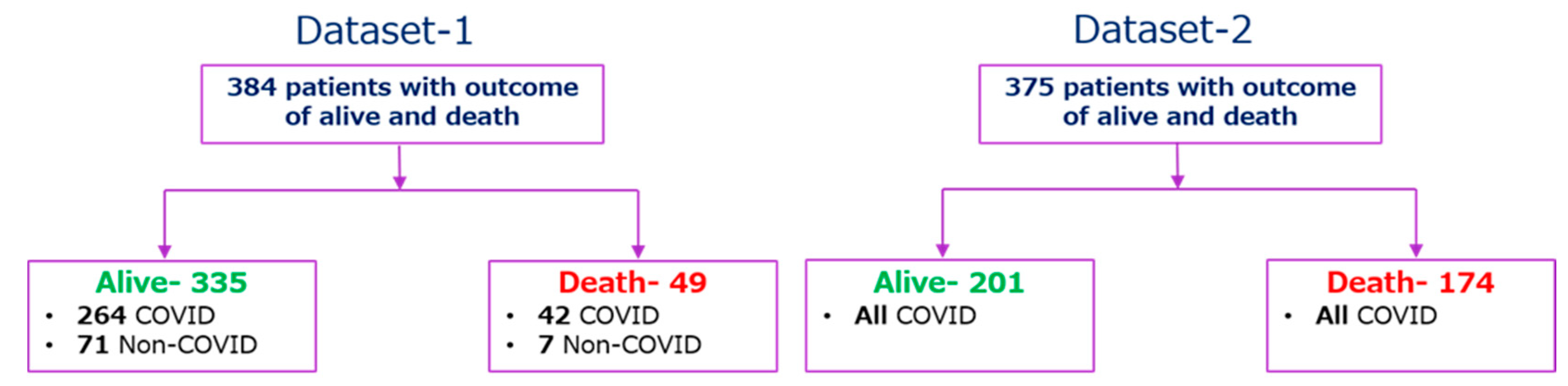
The second dataset (Dataset-2) was collected retrospectively from 375 patients in Wuhan, China between 10 January and 18 February 2020 to find valid and relevant clinical markers of mortality risk. Standard case report forms were used to collect medical records, which included information on epidemiological, demographic, clinical, laboratory, and mortality results. Yan et al. [18] have published the dataset along with their article, and the original study was approved by the Tongji Hospital Ethics Committee. 187 (49.9%) patients had fever symptoms among 375 patients, while cough, weariness, dyspnea, chest discomfort, and muscular pain were reported for 52 (13.9%), 14 (3.7%), 8 (2.1%), 7 (1.9%), and 2 (0.5%) patients, respectively. Among 375 COVID-19 positive patients, 174 and 201 patients were classified as (‘1′) for those who died and (‘0′) for those who survived respectively. Patients’ outcomes with the condition of COVID-19 positive and negative are summarized in Figure 2. There are 76 parameters present in the dataset; the common parameters of Dataset-1, 2 were used for this study, and the parameters from Dataset-2 were normalized in the same way as they appear in Dataset-1, as shown in Table 1, so that Dataset-2 can be used as an external validation set.
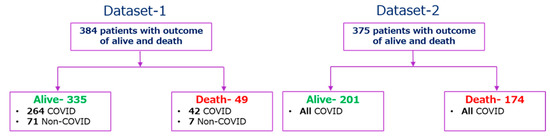
Figure 2.
Outcome tree for the patients of Dataset-1 and Dataset-2.
2.2. Statistical Analysis
Python 3.7 and Stata/MP 13.0 were used to conduct the statistical analysis. Continuous variables, age, and other biomarkers were reported with the number of missing data, and frequency for each biomarker in death and survival groups. Chi-square univariate test was conducted to identify the statistically significant different features among the dead and survived group and the difference is considered significant if the p-value is <0.05. There were 20 features present in the original dataset; the top five features using the feature selection method were identified as promising (reported in the later section) and are summarized in Table 2A,B for Dataset-1, and Dataset-2, respectively. The ranked five features were Age, Lymphocyte count, D-dimer, Creatinine, and CRP.
Table 2.
Statistical Analysis of the Characteristic of the subjects’ data for (A) Dataset-1 and (B) Dataset-2.
2.3. Data Preprocessing
While patient’s blood sample data were available for multiple days, the study used first-day data (from Dataset-1) for model training and validation to identify the primary predictors of the severity of the disease. The model also helps to differentiate between patients who need urgent medical support. Clinical data always suffer from missing data problems that contribute to either biased models or degradation in model performance. This problem can be tackled by deleting the corresponding rows of data for further investigation, but it is stated in [38] that this easy method of removing missing data rows can often lead to the loss of important data that would have been useful in the study, and can also lead to skewed estimates. To fix the missing data, many standard data imputation techniques are available. The most common technique for clinical data imputation is multiple imputations using the chained equations (MICE) data imputation technique [42]. Based on the other variables present in the dataset, the missing data is estimated using multiple regression models. The technique often takes into account the data form of the missing variables before imputing them. Using logistic regression, binary variables are predicted, while continuous variables are predicted using statistical mean matching [38]. Supplementary Figure S1 shows the number of missing values in different features in Dataset-1. Most of the features appear to be completely populated, while Lymphocyte count, d-dimer, creatinine, LDH, monocyte, CRP, and neutrophils seem spottier. The spark-line at right summarizes the general shape of the data completeness in the dataset. The imbalanced data can result in a biased model and, therefore, the dataset needs to be balanced. The synthetic minority oversampling technique (SMOTE) is a powerful approach to tackle the imbalance problem [43]. In this study, alive patients are about seven times more frequent than dead patients, so SMOTE was used for balancing the data.
Twenty different features present in Dataset-1 were checked to identify the correlation among different features. Feature reduction, with the help of the removal of highly correlated features, has always helped in improving the classifier performance [44]. Supplementary Figure S2 shows the heat map of correlation and it is found that most of them are not correlated with each other. The maximum correlation found between creatinine and kidney parameters is 0.56. Therefore, no feature can be removed based on correlation; rather feature ranking and identifying the best feature combination for stratifying the dead and survived group is required.
2.4. Development and Validation of Classification Model
The authors have investigated different machine learning classifiers: Random Forest [45], Support Vector Machine (SVM) [46], K-nearest neighbor (KNN) [47], XGBoost [48], Extra-tree [49] and Logistic regression [50]. Logistic regression was the best performing machine learning classifier and has been used in this study (Table 3). Logistic Regression is also a commonly used model for clinical investigation and is a supervised machine learning method for classification tasks [50]. When we want to estimate the likelihood of a binary classification problem (i.e., survival or death of a patient), this technique is very popular [51]. The logistic function is a sigmoid function and shrinks continuous inputs into a probability value. The logistic regression classifier is used to classify the data into two classes: Death and Survived using the ranked features, and the best feature combination is identified for both COVID and NON-COVID data and COVID data alone.
Table 3.
Performance Comparison between different Machine Learning Classifiers.
Dataset-1 was divided into training and validation sets (80% of the data) and testing sets (20%). Different machine learning models were investigated using five-fold cross-validation. The performance of different models was evaluated on the test dataset using several performance metrics, including sensitivity, specificity, precision, accuracy, and F1-score as shown in Equations (1)–(5). The receiver operating characteristic curve, or ROC curve, is used to measure the area under the curve (AUC) separately for single predictors as well as for a combination of them. To determine the performance of various top-ranked parameters in stratifying dead and survived patients, the AUC values for different individual features and their combinations’ contributions were evaluated. The performance of unseen (test) folds was combined to create the overall confusion matrix for the five-fold.
The number of patients with death outcome classified as death, the number of survived patients identified as survivors, the number of survived patients incorrectly identified as death, and the number of death patients incorrectly identified as survivors, respectively, are denoted by the true positive (TP), true negative (TN), false positive (FP), and false-negative (FN).
2.5. Development and Validation of Logistic Regression-Based Nomogram
The study proposed a diagnosis nomogram based on multivariate logistic regression analysis and Stata/MP software version 13.0, which was developed using Alexander Zlotnik’s Nomolog [52]. Nomograms are graphic representations of complicated mathematical formulas. Medical nomograms graphically represent a statistical prognostic model that predicts a likelihood of a clinical event, such as cancer recurrence or death, for a specific individual, using biologic and clinical data such as tumor grade and patient age. Each variable is listed separately in a nomogram, with a corresponding number of points allocated to each variable’s magnitude. The total point score for all factors is then matched to an outcome scale [53]. A binary regression is used in logistic (logit) regression to estimate the parameter. The dependent variable, generally labeled ‘0′ and ‘1′, is the response variable. Those that survived are marked with a ‘0′, while those who died are marked with a ‘1′. Equation (6) shows the odds, which shows the ratio of probability (Pr) of occurring death and not occurring death (1 − Pr). While the probability can vary from 0 to 1, the odds can vary from 0 to . The logarithm of odds is a linear combination of one or more independent variables (predictors) in the logistic regression. The independent variables can be a binary variable (e.g., gender) and a continuous variable (e.g., age). The log of odds can be termed as linear prediction (LP), as seen in Equation (7), and can be related to the probability of a particular outcome (e.g., death). Equations (6)–(9) are used to create a relationship between death probability and the key predictors using logistic regression.
The logistic regression-based nomogram was created using the top-ranked independent variables with the best performance. The clinical parameters from Dataset-1′s Day-0 data were utilized for model creation, while day-3, day-7, and data upon hospital admission from Dataset-2 were used for model validation. Internal calibration curves, with the first dataset, and external calibration curves, with the second dataset, are used to compare the performance of the developed model. To determine the threshold values at which nomograms will be clinically relevant, the study used Decision Curve Analysis (DCA).
2.6. Nomogram-Based Scoring System
Nomograms are widely used for clinical prognosis as they can help in simplifying statistical predictive models into probability of an event, i.e., mortality in this study. They are preferred by clinicians due to their user-friendly graphical interfaces [54]. The nomogram represents many independent variables as a numerated horizontal axis scale, with the patient’s values placed on that scale. From the many parameters numerated and arranged scales, a vertical line was traced down to a horizontal score axis. On the score axis, all of the scores from the independent variables were combined to create a total score, which was then linked to a death probability, which was a horizontal axis scaled from 0 to 1. It should be emphasized that, according to the nomogram, a greater score indicates a higher risk of mortality. The model was created using the patients’ Day-0 data. However, it can be used to longitudinally validate the model to predict death probability using biomarkers acquired later during the patients’ hospital stay.
3. Results
This section discusses the following results: (i) identification of the best feature combinations using logistic regression classifier, (ii) developed and validation of the proposed nomogram-based model in predicting death outcomes for the best feature combinations, and finally (iii) a detailed prognostic evaluation of the nomogram.
3.1. Univariate and Multivariate Analysis Using Logistic Regression
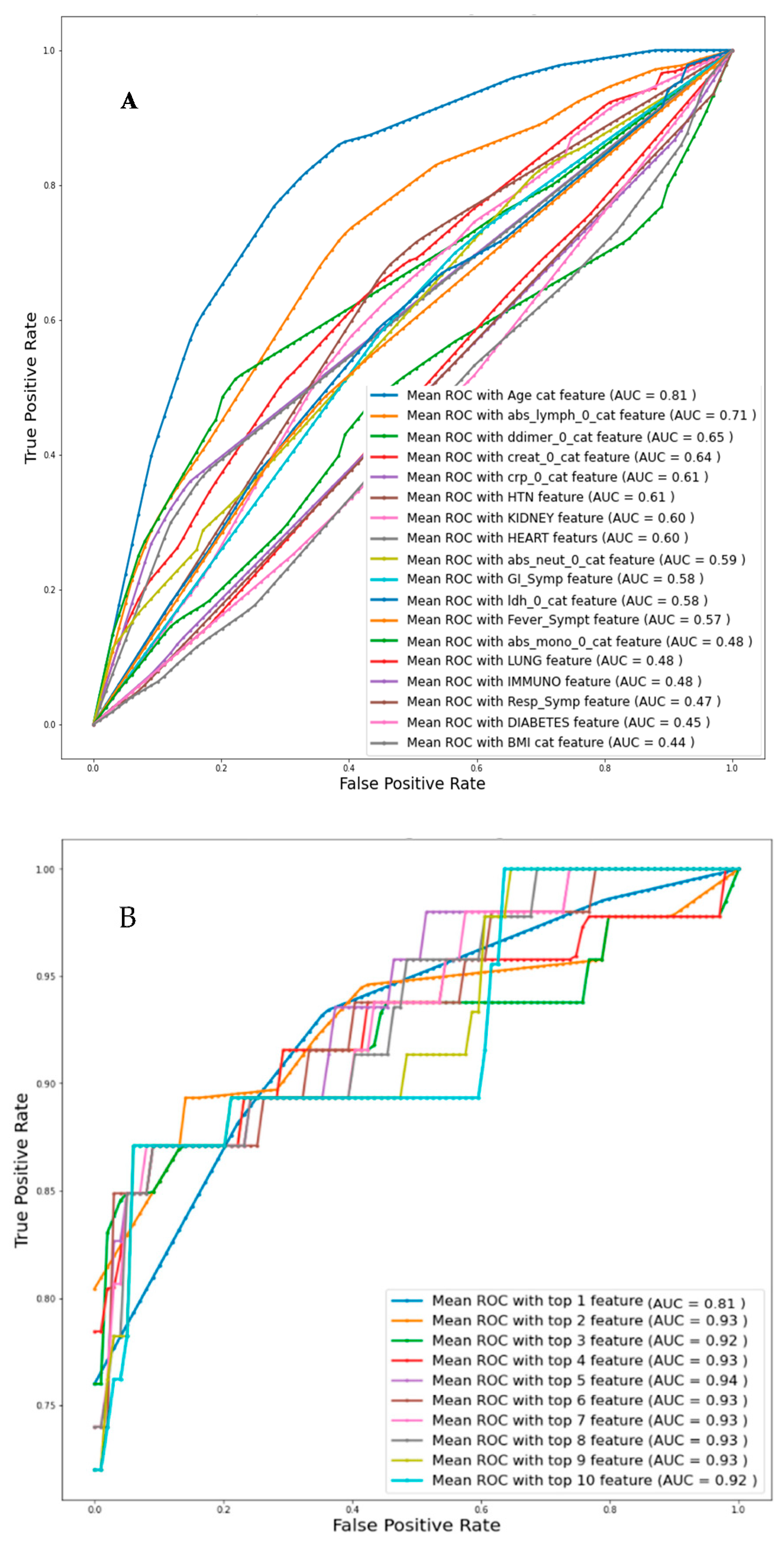
Univariate logistic regression analysis with individual features was used to identify the independent variables related to death, and then the Top-1, Top-2, and up to Top-10 features were identified based on AUC values for Day-0 data from Dataset-1 as can be seen from Table 4A. Figure 3A represents the ROC curve for all the features individually and the corresponding AUC value is mentioned. Figure 3B presents the ROC curve for the combinations of the top ranked features and it is found that the combination of top ranked five features had a maximum AUC of 0.94. Overall accuracies and weighted average performance matrices for different models using Top-1 to 10 features individually and in combination using five-fold cross-validation for the logistic regression classifier are shown in Table 4A,B respectively. Each of the cases is reported with the confusion matrices so that the false positive and negative cases can be reported.
Table 4.
Comparison of the average performance matrix and confusion matrix from five-fold cross-validation for (A) Individual top 10 feature, (B) Combined top 1 to 10 features.
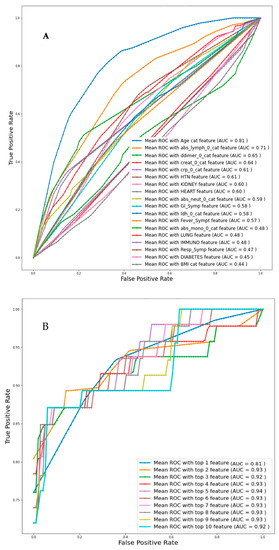
Figure 3.
Comparison of the receive operating characteristic (ROC) plots for (A) individual feature (Imputation-Mice, Classifier-Logistic regression), (B) top-ranked 1 up to 10 features (Imputation-Mice, Classifier-Logistic regression).
The top-ranked five independent variables: Age, Lymphocyte count, D-dimer, CRP, and Creatinine (in short ALDCC) have exhibited the best performance. Therefore, in the rest of the study, these five variables were used for nomogram creation and scoring technique development and validation.
3.2. Nomogram-Based Scoring System
The top-ranked five biomarkers were found to be statistically significant using an ML-based classifier to develop a multivariate logistic regression-based nomogram for predicting mortality. Table 5 shows the multivariable logistic regression analysis of the correlation between linear death prediction and biomarkers with the regression coefficient, z-value, standard error, and statistical significance, as well as the 95% confidence interval. The ratio of the regression coefficient to its standard error is known as the z-value. In logistic regression, the z-value typically identifies strong and weak contributors, with a high z-value indicating a strong relationship between the dependent and independent variables and a z-value near to zero indicating a weak relationship. Creatinine is not a particularly powerful predictor from the five variables, while age and Lymphocyte count are. A null hypothesis for a certain regression coefficient can be used to calculate the p-value, which is used to identify the significance of a specific X-variable in relation to the Y-variable. The X-variables with a strong correlation to the Y-variables are those with a p < 0.05. The p-value also shows that Creatinine is only weakly connected to the Y-variable. However, the logistic regression classifier in Table 4B shows that the five variable model outperforms the four variable models. As a consequence, no variable from these five variables was deleted when developing the nomogram.
Table 5.
The logistic regression model.
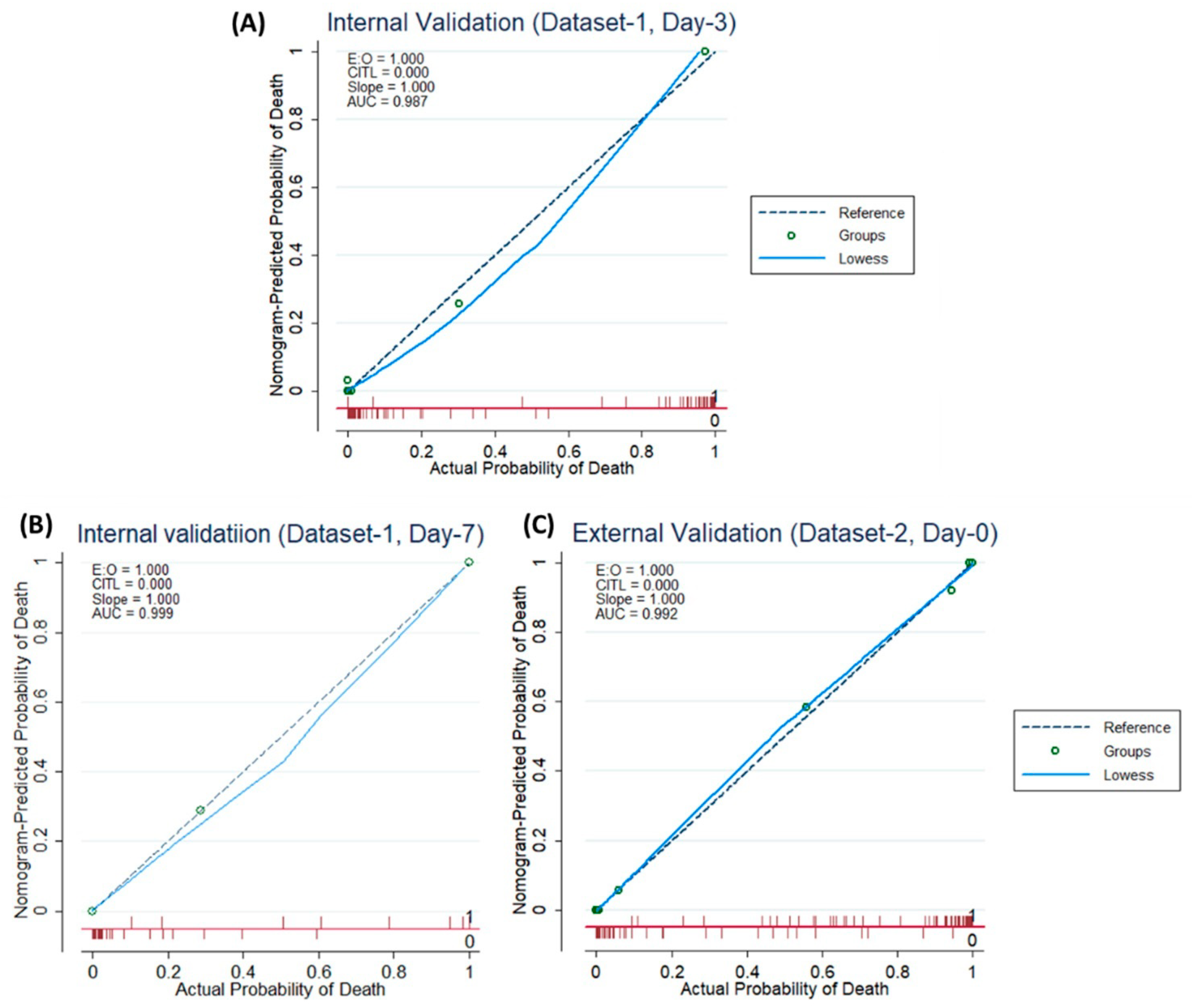
According to Figure 4A–C, both for internal and external validation, the calibration curve matches closely with the diagonal line which is representative of the ideal model. Supplementary Figure S3 shows that the net gain of single Age and Lymphocyte count predictor models are positive, once the threshold of 0.85 is reached. This means that they both contributed the most to the prediction of the results. Interestingly, the complete model showed the best results, which also reinforced the need to combine the model with five predictors.
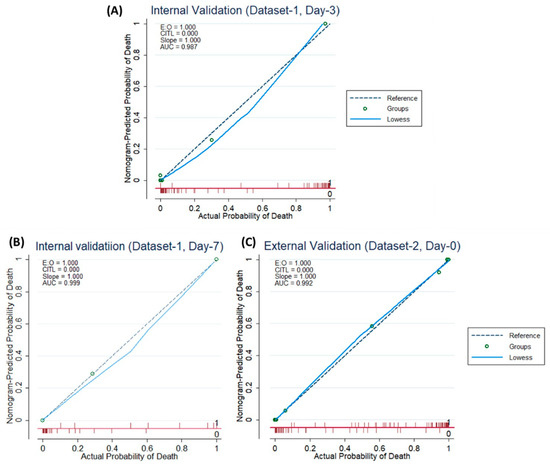
Figure 4.
Internal Validation Curve (A,B) and the External validation (C).
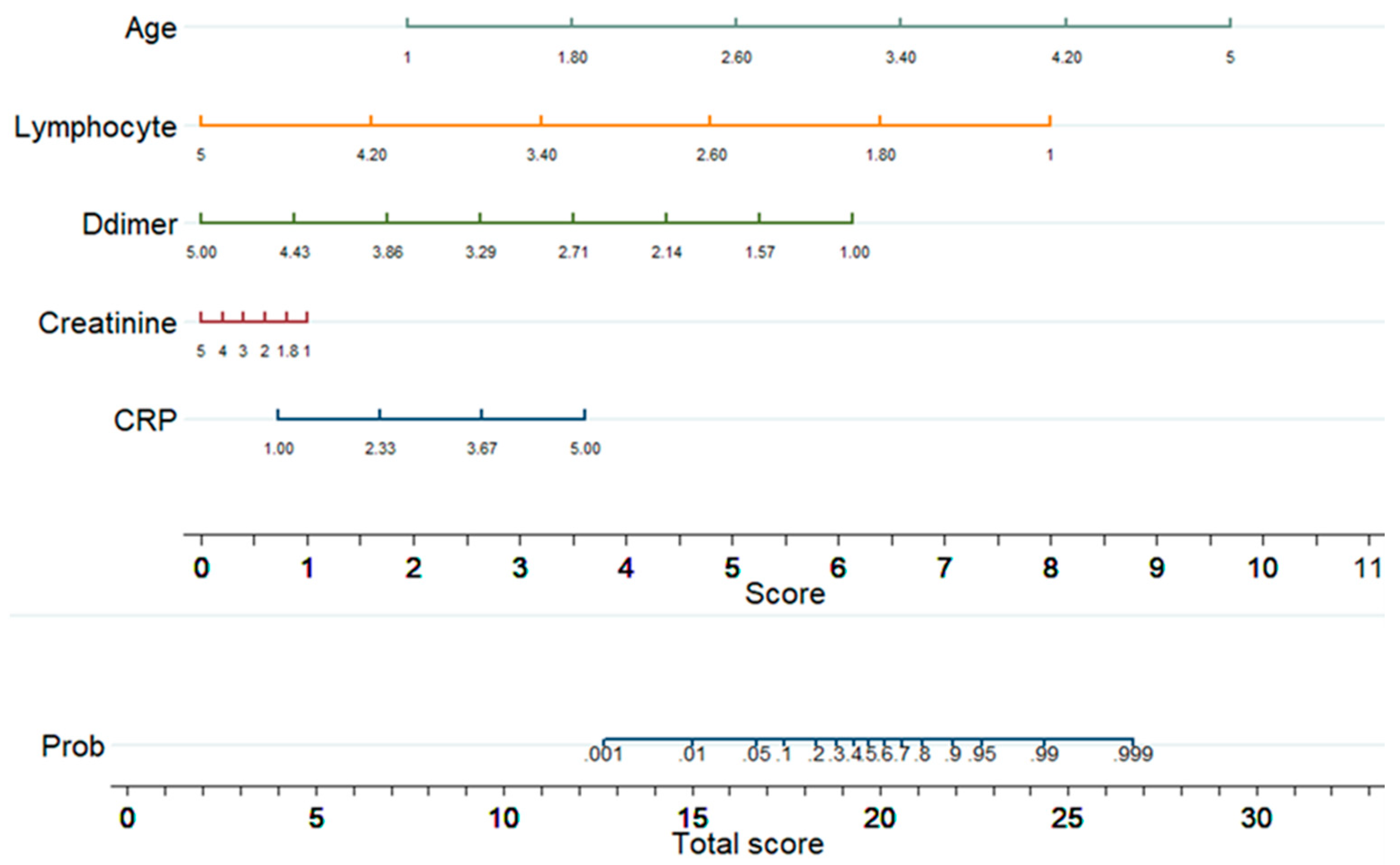
Figure 5 shows a nomogram with eight rows with different colors so that they are distinguishable, with rows 1–5 representing independent variables. Each variable was assigned a score by drawing a downward vertical line from the value on the variable axis to the ‘points’ axis using patient data. The score (row 6) corresponds to the points of the five variables, and the scores are added to the overall score (row 8). A line could then be drawn from the ‘Total Score’ axis to the ‘Prob’ axis to calculate the death risk of patients (row 7). However, the mathematical equations explaining the total score, linear prediction, and death probability based on which the ALDCC score is produced can be derived using the corresponding equations found earlier in Equations (5)–(8). The ALDCC score cut-off values of 16.6 and 19.8 correspond to 5% and 50% of the probability of mortality, respectively. This can be used to categorize all patients into three groups: low, moderate, and high-risk. The death probability was less than 5%, between 5% and 50%, and more than 50% for the low-risk group (ALDCC < 16.6), moderate risk group (16.6 ≤ ALDCC ≤ 19.8), and high-risk group (ALDCC > 19.8), respectively.
Linear prediction = −0.7606855 + 1.904726 × age − 1.964625 × lymphocyte count − 1.508334 × d-dimer + 0.709297 × CRP + 0.2467726 × creatinine
Death probability = 1/(1 + exp (−Linear Prediction))
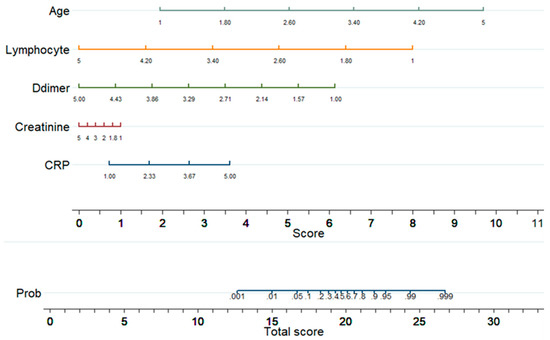
Figure 5.
Developed Nomogram.
3.3. Performance Evaluation of the ALDCC Scoring Technique
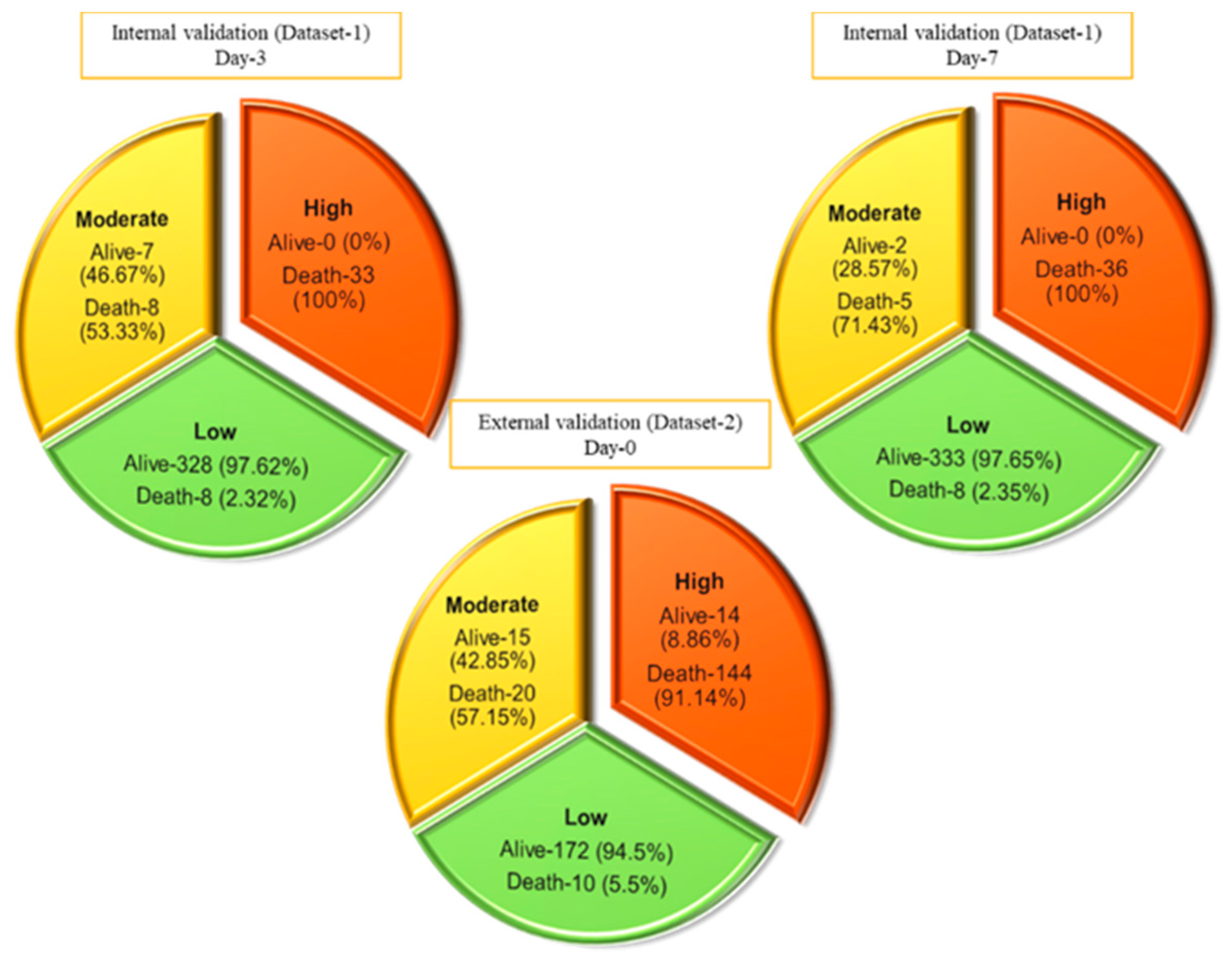
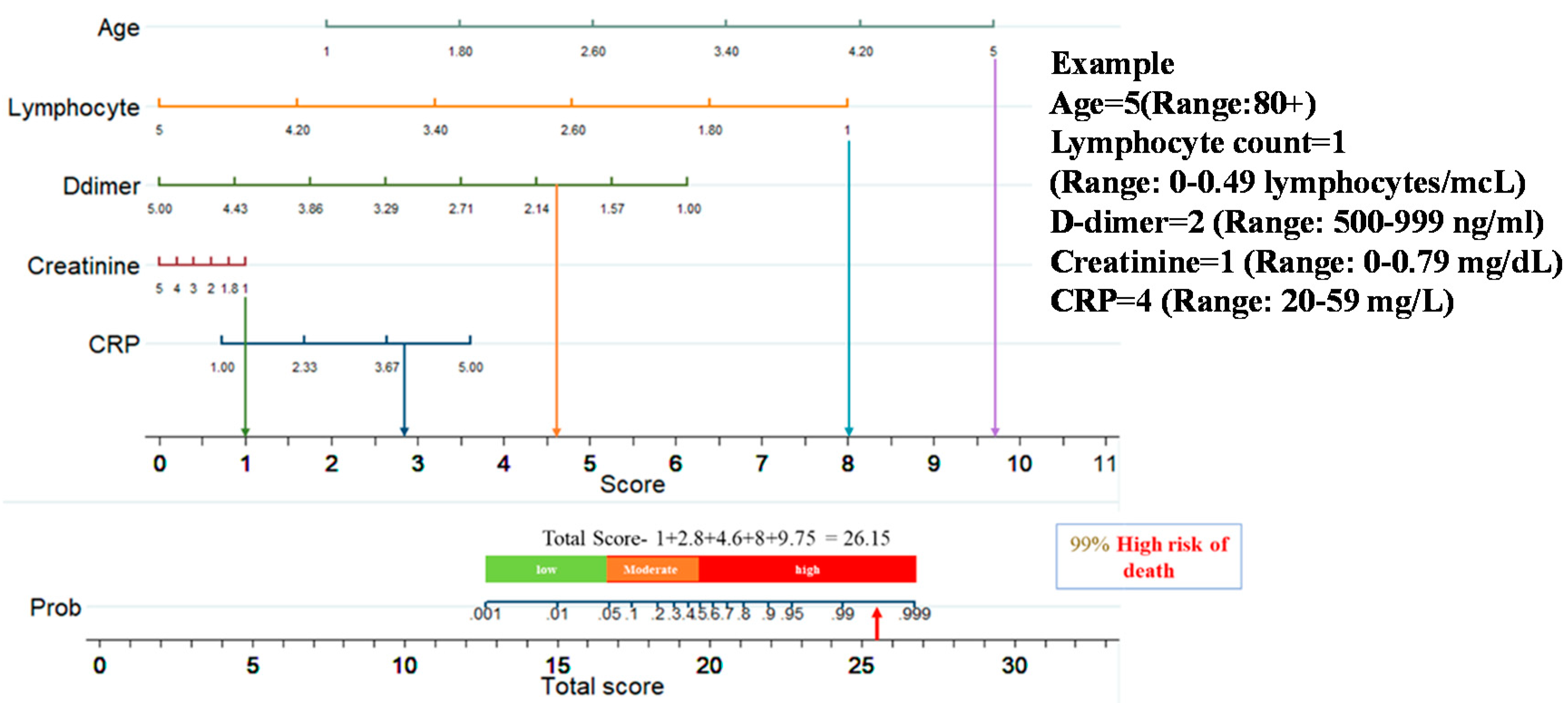
This nomogram-based scoring technique can be used to anticipate patient outcomes early by categorizing them into low, moderate, and high-risk categories. The thresholds for ALDCC score, which can be used to find the death probability using Equation (11), for the different categories are illustrated in Figure 6, prioritizing patients in the moderate and high-risk groups. We have categorized the patients from internal (Dataset-1, Day-3′ and Day-7 data) and external validation (Dataset-2, data on admission) into three subgroups (low, moderate, and high-risk) by associating actual outcome with the predicted outcome using the ALDCC score. For internal validation (Dataset-1 at Day-3), the proportions of death were 2.38% (8/336) (p < 0.001) for low-risk group, 53.33% (8/15) (p-value = 0.0025) for moderate-risk group and 100% (33/33) (p < 0.001) for high-risk group. For Dataset-1 at Day-7, the proportions of death were 2.35% (8/341) (p < 0.001) for low-risk group, 71.43% (5/7) (p < 0.001) for moderate-risk group and 100% (36/36) (p < 0.001) for high-risk group, while for external validation from different hospital (Dataset-2), the proportions of death were 5.5% (10/172) (p < 0.001) for low-risk group, 57.15% (20/35) (p < 0.001) for moderate-risk group and 91.14% (144/158) (p < 0.001) for high-risk group as shown in Figure 7. The actual death rates among the three categories were found to differ significantly (p < 0.001). Figure 8 illustrates a nomogram-based scoring system for a COVID-19 patient with admission variables. Individual scores for each predictor were calculated and added together to create a total score, with a death probability of 99%. This can be done as early as three weeks before the patient’s actual outcome.

Figure 6.
ALDCC score from nomogram and corresponding death probability of COVID-19 and non-COVID-19 patients where ALDCC score ≤ 16.6 and death probability ≤ 5% are shown for low risk group and ALDCC score > 19.8 and death probability > 50% are shown for high risk group.
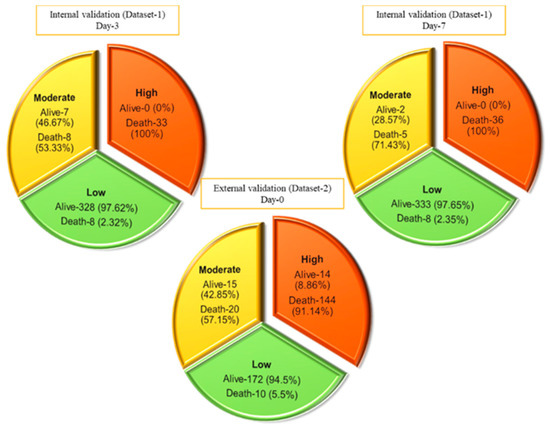
Figure 7.
Prediction of internal and external validation with Dataset-1 and Dataset-2 using ALDCC score.
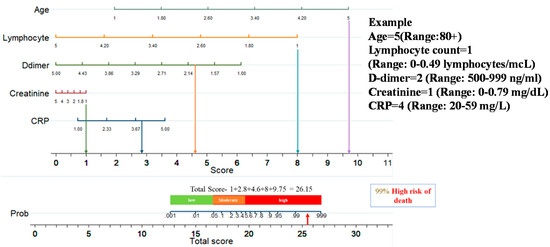
Figure 8.
An example of nomogram-based ALDCC score to predict the probability of death of a patient from the test set (3 weeks before the actual outcome).
4. Discussion
The association between the severity of the disease and the clinical evidence was explored in the current analysis. Based on the data acquired at hospital admission time, ten predictors were defined by the logistic regression algorithm as death probability predictors. Ten different classification models were trained, validated, and evaluated using this technique for the Top 1 to 10 features. The AUC and performance matrices for the top five features with the highest AUC of 0.94 were observed. A logistic regression-based nomogram was then developed utilizing these five variables. An overall score known as ALDCC has been proposed for early categorization of death severity. Moreover, the results obtained in the paper are better than in some recent similar works, as can be seen from Table 6.
Table 6.
Performance comparison with similar recent works.
Age has been identified as a primary predictor of death in earlier research on the coronavirus family, including SARS [59], Middle East respiratory disease (MERS) [60] and COVID-19 [61]. Immuno-senescence and/or various medical problems appear to make individuals more sensitive to significant COVID-19 disease with older age [55]. Increased Lymphocytes, according to Liu et al. [62], can aid in the early detection of COVID-19 disease severity. Lymphocytes, a type of immune cell, play a critical role in host defense and infection clearance. Lymphopenia, defined as a decrease in the number of blood lymphocytes, is a common biologic finding in COVID-19 patients and may play a role in disease progression and death [63]. Patients with community-acquired pneumonia have considerable immune system activation and/or immunological malfunction, leading to alterations in their levels, according to earlier studies. It has been observed [64,65] that reducing creatinine levels, due to kidney problems occurring due to COVID-19 is an indicator of COVID-19 severity and mortality. It was observed in this study that Lymphocytes and creatinine parameters were small for high-risk patients. CRP testing at the time of admission, according to Lu et al. in [66], can help to predict COVID-19-associated mortality. CRP is an acute-phase protein generated by hepatocytes in response to infection, inflammation, or tissue damage-induced cytokines from leukocytes [63,66,67,68,69,70]. This study found similar findings, with higher CRP rates estimated upon admission for COVID-19/Non-COVID individuals with high mortality risk. This indicated that these patients had severe lung inflammation or, more likely, a subsequent bacterial infection [61]. Weng et al. [55] recently indicated that individual primary predictors associated with death probability were age, Lymphocyte count, D-dimer, and CRP. A nomogram for death prediction was developed using these key predictors. In this study, a logistic regression model, using the selected five key predictors reported at admission, was used to construct a nomogram-based prognostic model that exhibits excellent calibration and discrimination in predicting the probability of death of patients with COVID-19 and non-COVID-19. An unseen external cohort was used for validation and the model also showed an outstanding performance on the external dataset. Additionally, several blood sample data obtained from patients during their hospital stay were analyzed, and the model outperformed the competition on longitudinal data. To the best of our knowledge, the AUC values for the development, internal, and external validation cohorts were 0.987, 0.999, and 0.992, respectively, which is superior to all previous nomogram-based mortality prediction methods.
Furthermore, this nomogram-derived ALDCC score provided a simple, easy-to-understand, and interpretable early warning method for stratifying and thus assisting clinical management of high-risk patients at admission. Using the ALDCC score assessed and determined at admission, all patients were grouped into three risk groups. The patients who are in the low-risk category can be isolated and handled in an isolation unit, while the isolation ward could be treated as a specialized facility with moderate-risk patients. On the other hand, patients in the high-risk community should be closely monitored and, if possible, transferred to vital care facilities or ICU for emergency treatment.
This research has scope for improvement in future. Firstly, the article suggests that clinical data on both COVID-19 and non-COVID-19 could be used to aid in the estimation of early mortality. The model can be improved much more with the help of a larger dataset. Secondly, unlike the first dataset where a limited number of parameters are present, if we have access to large features set (like Dataset-2), the machine learning model can be used to identify the best features in multi-center and multi-country data to create a more generalized model that can be used in any country.
Being able to predict the risk of mortality for patients is needed for allocating the right resources during a crisis. Indeed, very high mortality patients might not be the target for receiving the highest level of support and might need comfort care in a situation of crisis, as we have seen during the first period of the pandemic in many countries.
On the contrary, the low risk mortality patients should not be directed to demanding resources units such as ICU and can be treated outside the hospital, easing the strong pressure on the healthcare facilities. This tool might be used too in research to evaluate its ability to predict in a prospective manner the death of COVID-19 patients and refine this by including other parameters. The limitation of this kind of tool is that it takes into consideration clinical and biological parameters and does not integrate treatments, and is obviously exposed to bias.
5. Conclusions
In summary, the developed nomogram can be deployed for rapid and reliable mortality prediction of patients with both COVID-19 and non-COVID-19, based on multiple risk factors, such as Age, Lymphocyte count, D-dimer, CRP, and Creatinine. The model can predict the patient’s prognosis with a high accuracy, well in advance of the actual clinical outcomes. As a result, the use of ALDCC can assist physicians in developing an effective and optimized patient management strategy without overloading healthcare resources, as well as minimizing death, through an increased and expected response. The authors have also created a webpage as App [71] to assist healthcare personnel in predicting early mortality using the developed model and easily accessible ALDCC scoring results (Supplementary Figure S4). We hope to improve the model’s performance even more with the help of a larger dataset comprising data from other centers and countries.
Supplementary Materials
The following are available online at https://www.mdpi.com/article/10.3390/diagnostics11091582/s1, Figure S1: The number of missing fata for different features in Dataset-1. Figure S2: Heatmap of correlation among different features. Figure S3: Decision curves analysis stating the performance of the individual parameters and the developed model. Figure S4: Mortality risk prediction App.
Author Contributions
Conceptualization, M.E.H.C. and S.M.Z.; methodology, T.R., K.R.I. and A.K.; validation, F.A.A.-I., F.S.A.-M., R.S.M., M.H.A.-H.; formal analysis, A.A.H., S.A.-M., M.E.H.C. and S.M.Z. All authors have worked in the investigation and drafting of the paper. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Qatar National Research under Grant UREP28-144-3-046. The statements made herein are solely the responsibility of the authors.
Institutional Review Board Statement
This article uses the clinical data which was made publicly available by [39,40]. Therefore, the authors of this study were not involved with human participants or animals. However, the original retrospective studies carried out by [39,40] were approved by the respective local Ethics Committees.
Informed Consent Statement
Not applicable.
Data Availability Statement
Datasets are publicly available in [39,40].
Acknowledgments
We would like to thank the authors of [39,40] for sharing the datasets publicly, which give researchers opportunity to conduct more research on these datasets.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Vaidyanathan, G. Coronavirus variants are spreading in India—What scientists know so far. Nature 2021, 593, 321–322. [Google Scholar] [CrossRef]
- Black, M.; Lee, A.; Ford, J. Vaccination against COVID-19 and inequalities–avoiding making a bad situation worse. Public Health Pract. 2021, 2, 100101. [Google Scholar] [CrossRef]
- Kluge, H.; McKee, M. COVID-19 vaccines for the European region: An unprecedented challenge. Lancet 2021, 397, 1689–1691. [Google Scholar] [CrossRef]
- COVID-19 Coronavirus Pandemic. Available online: https://www.worldometers.info/coronavirus/ (accessed on 19 April 2020).
- Huang, D.; Wang, T.; Chen, Z.; Yang, H.; Yao, R.; Liang, Z. A novel risk score to predict diagnosis with coronavirus disease 2019 (COVID-19) in suspected patients: A retrospective, multicenter, and observational study. J. Med. Virol. 2020, 92, 2709–2717. [Google Scholar] [CrossRef]
- Cai, Y.-Q.; Zhang, X.-B.; Zeng, H.-Q.; Wei, X.-J.; Zhang, Z.-Y.; Chen, L.-D.; Wang, M.-H.; Yao, W.-Z.; Huang, Q.-F.; Ye, Z.-Q. Prognostic Value of Neutrophil-to-Lymphocyte Ratio, Lactate Dehydrogenase, D-Dimer and CT Score in Patients with COVID-19. Res. Sq. 2020, 1–13. [Google Scholar] [CrossRef]
- Liu, Y.-P.; Li, G.-M.; He, J.; Liu, Y.; Li, M.; Zhang, R.; Li, Y.-L.; Wu, Y.-Z.; Diao, B. Combined use of the neutrophil-to-lymphocyte ratio and CRP to predict 7-day disease severity in 84 hospitalized patients with COVID-19 pneumonia: A retrospective cohort study. Ann. Transl. Med. 2020, 8, 635. [Google Scholar] [CrossRef]
- Zhang, C.; Qin, L.; Li, K.; Wang, Q.; Zhao, Y.; Xu, B.; Liang, L.; Dai, Y.; Feng, Y.; Sun, J. A novel scoring system for prediction of disease severity in COVID-19. Front. Cell. Infect. Microbiol. 2020, 10, 318. [Google Scholar] [CrossRef]
- Shang, Y.; Liu, T.; Wei, Y.; Li, J.; Shao, L.; Liu, M.; Zhang, Y.; Zhao, Z.; Xu, H.; Peng, Z. Scoring systems for predicting mortality for severe patients with COVID-19. EClinicalMedicine 2020, 24, 100426. [Google Scholar] [CrossRef]
- Initiative, C.-H.G. The COVID-19 host genetics initiative, a global initiative to elucidate the role of host genetic factors in susceptibility and severity of the SARS-CoV-2 virus pandemic. Eur. J. Hum. Genet. 2020, 28, 715. [Google Scholar] [CrossRef]
- Zhao, J.; Yang, Y.; Huang, H.; Li, D.; Gu, D.; Lu, X.; Zhang, Z.; Liu, L.; Liu, T.; Liu, Y. Relationship between the ABO Blood Group and the COVID-19 Susceptibility. Clin. Infect. Dis. 2020, 73, 328–331. [Google Scholar] [CrossRef]
- Göker, H.; Karakulak, E.A.; Demiroğlu, H.; Ceylan, Ç.M.A.; Büyükaşik, Y.; Inkaya, A.Ç.; Aksu, S.; Sayinalp, N.; Haznedaroğlu, I.C.; Uzun, Ö. The effects of blood group types on the risk of COVID-19 infection and its clinical outcome. Turk. J. Med. Sci. 2020, 50, 679–683. [Google Scholar] [CrossRef]
- Leung, T.; Chan, A.; Chan, E.; Chan, V.; Chui, C.; Cowling, B.; Gao, L.; Ge, M.; Hung, I.; Ip, M. Short-and potential long-term adverse health outcomes of COVID-19: A rapid review. Emerg. Microbes Infect. 2020, 9, 2190–2199. [Google Scholar] [CrossRef] [PubMed]
- Zheng, K.I.; Feng, G.; Liu, W.Y.; Targher, G.; Byrne, C.D.; Zheng, M.H. Extrapulmonary complications of COVID-19: A multisystem disease? J. Med. Virol. 2021, 93, 323–335. [Google Scholar] [CrossRef]
- Imran, A.; Posokhova, I.; Qureshi, H.N.; Masood, U.; Riaz, M.S.; Ali, K.; John, C.N.; Hussain, M.I.; Nabeel, M. AI4COVID-19: AI enabled preliminary diagnosis for COVID-19 from cough samples via an app. Inform. Med. Unlocked 2020, 20, 100378. [Google Scholar] [CrossRef]
- Zhang, J.; Hao, Y.; Ou, W.; Ming, F.; Liang, G.; Qian, Y.; Cai, Q.; Dong, S.; Hu, S.; Wang, W. Serum interleukin-6 is an indicator for severity in 901 patients with SARS-CoV-2 infection: A cohort study. J. Transl. Med. 2020, 18, 1–8. [Google Scholar] [CrossRef]
- Grobler, C.; Maphumulo, S.C.; Grobbelaar, L.M.; Bredenkamp, J.C.; Laubscher, G.J.; Lourens, P.J.; Steenkamp, J.; Kell, D.B.; Pretorius, E. COVID-19: The rollercoaster of fibrin (ogen), d-dimer, von willebrand factor, p-selectin and their interactions with endothelial cells, platelets and erythrocytes. Int. J. Mol. Sci. 2020, 21, 5168. [Google Scholar] [CrossRef] [PubMed]
- Yan, L.; Zhang, H.-T.; Goncalves, J.; Xiao, Y.; Wang, M.; Guo, Y.; Sun, C.; Tang, X.; Jing, L.; Zhang, M. An interpretable mortality prediction model for COVID-19 patients. Nat. Mach. Intell. 2020, 2, 283–288. [Google Scholar] [CrossRef]
- Rahman, T.; Khandakar, A.; Kadir, M.A.; Islam, K.R.; Islam, K.F.; Mazhar, R.; Hamid, T.; Islam, M.T.; Kashem, S.; Mahbub, Z.B. Reliable tuberculosis detection using chest X-ray with deep learning, segmentation and visualization. IEEE Access 2020, 8, 191586–191601. [Google Scholar] [CrossRef]
- Tahir, A.; Qiblawey, Y.; Khandakar, A.; Rahman, T.; Khurshid, U.; Musharavati, F.; Islam, M.; Kiranyaz, S.; Chowdhury, M.E. Coronavirus: Comparing COVID-19, SARS and MERS in the eyes of AI. arXiv 2020, arXiv:2005.11524. [Google Scholar]
- Rahman, T.; Akinbi, A.; Chowdhury, M.E.; Rashid, T.A.; Şengür, A.; Khandakar, A.; Islam, K.R.; Ismael, A.M. COV-ECGNET: COVID-19 detection using ECG trace images with deep convolutional neural network. arXiv 2021, arXiv:2106.00436. [Google Scholar]
- Chowdhury, M.E.; Rahman, T.; Khandakar, A.; Mazhar, R.; Kadir, M.A.; Mahbub, Z.B.; Islam, K.R.; Khan, M.S.; Iqbal, A.; Al Emadi, N. Can AI help in screening viral and COVID-19 pneumonia? IEEE Access 2020, 8, 132665–132676. [Google Scholar] [CrossRef]
- Rahman, T.; Chowdhury, M.E.; Khandakar, A.; Islam, K.R.; Islam, K.F.; Mahbub, Z.B.; Kadir, M.A.; Kashem, S. Transfer learning with deep convolutional neural network (CNN) for pneumonia detection using chest X-ray. Appl. Sci. 2020, 10, 3233. [Google Scholar] [CrossRef]
- Chowdhury, M.E.; Rahman, T.; Khandakar, A.; Al-Madeed, S.; Zughaier, S.M.; Doi, S.A.; Hassen, H.; Islam, M.T. An early warning tool for predicting mortality risk of COVID-19 patients using machine learning. Cogn. Comput. 2021, 1–16. [Google Scholar] [CrossRef]
- Rahman, T.; Khandakar, A.; Qiblawey, Y.; Tahir, A.; Kiranyaz, S.; Kashem, S.B.A.; Islam, M.T.; Al Maadeed, S.; Zughaier, S.M.; Khan, M.S. Exploring the effect of image enhancement techniques on COVID-19 detection using chest X-ray images. Comput. Biol. Med. 2021, 132, 104319. [Google Scholar] [CrossRef]
- Banerjee, A.; Ray, S.; Vorselaars, B.; Kitson, J.; Mamalakis, M.; Weeks, S.; Baker, M.; Mackenzie, L.S. Use of machine learning and artificial intelligence to predict SARS-CoV-2 infection from full blood counts in a population. Int. Immunopharmacol. 2020, 86, 106705. [Google Scholar] [CrossRef]
- Proctor, E.A.; Dineen, S.M.; van Nostrand, S.C.; Kuhn, M.K.; Barrett, C.D.; Brubaker, D.K.; Yaffe, M.B.; Lauffenburger, D.A.; Leon, L.R. Coagulopathy signature precedes and predicts severity of end-organ heat stroke pathology in a mouse model. J. Thromb. Haemost. 2020, 18, 1900–1910. [Google Scholar] [CrossRef]
- Bhattacharyya, R.; Iyer, P.; Phua, G.C.; Lee, J.H. The interplay between coagulation and inflammation pathways in COVID-19-associated respiratory failure: A narrative review. Pulm. Ther. 2020, 6, 1–17. [Google Scholar] [CrossRef]
- Brinati, D.; Campagner, A.; Ferrari, D.; Locatelli, M.; Banfi, G.; Cabitza, F. Detection of COVID-19 infection from routine blood exams with machine learning: A feasibility study. J. Med. Syst. 2020, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.S.; Hou, Y.; Vasovic, L.V.; Steel, P.A.; Chadburn, A.; Racine-Brzostek, S.E.; Velu, P.; Cushing, M.M.; Loda, M.; Kaushal, R. Routine laboratory blood tests predict SARS-CoV-2 infection using machine learning. Clin. Chem. 2020, 66, 1396–1404. [Google Scholar] [CrossRef]
- Tawsifur Rahman, A.K.; Hoque, M.E.; Ibtehaz, N.; Kashem, S.B.; Masud, R.; Shampa, L.; Hasan, M.M.; Islam, M.T.; Al-Madeed, S.; Zughaier, S.M.; et al. Development and Validation of an Early Scoring System for Prediction of Disease Severity in COVID-19 using Complete Blood Count Parameters. IEEE Access 2021, 9, 112565–112576. [Google Scholar]
- Vaid, A.; Somani, S.; Russak, A.J.; De Freitas, J.K.; Chaudhry, F.F.; Paranjpe, I.; Johnson, K.W.; Lee, S.J.; Miotto, R.; Richter, F. Machine Learning to Predict Mortality and Critical Events in a Cohort of Patients with COVID-19 in New York City: Model Development and Validation. J. Med. Internet Res. 2020, 22, e24018. [Google Scholar] [CrossRef]
- Aladağ, N.; Atabey, R.D. The role of concomitant cardiovascular diseases and cardiac biomarkers for predicting mortality in critical COVID-19 patients. Acta Cardiol. 2020, 76, 1–8. [Google Scholar] [CrossRef]
- de Terwangne, C.; Laouni, J.; Jouffe, L.; Lechien, J.R.; Bouillon, V.; Place, S.; Capulzini, L.; Machayekhi, S.; Ceccarelli, A.; Saussez, S. Predictive accuracy of COVID-19 world health organization (Who) severity classification and comparison with a bayesian-method-based severity score (epi-score). Pathogens 2020, 9, 880. [Google Scholar] [CrossRef]
- Liang, W.; Yao, J.; Chen, A.; Lv, Q.; Zanin, M.; Liu, J.; Wong, S.; Li, Y.; Lu, J.; Liang, H. Early triage of critically ill COVID-19 patients using deep learning. Nat. Commun. 2020, 11, 1–7. [Google Scholar] [CrossRef]
- Wang, C.; Deng, R.; Gou, L.; Fu, Z.; Zhang, X.; Shao, F.; Wang, G.; Fu, W.; Xiao, J.; Ding, X. Preliminary study to identify severe from moderate cases of COVID-19 using combined hematology parameters. Ann. Transl. Med. 2020, 8, 593. [Google Scholar] [CrossRef]
- McRae, M.P.; Simmons, G.W.; Christodoulides, N.J.; Lu, Z.; Kang, S.K.; Fenyo, D.; Alcorn, T.; Dapkins, I.P.; Sharif, I.; Vurmaz, D. Clinical decision support tool and rapid point-of-care platform for determining disease severity in patients with COVID-19. Lab Chip 2020, 20, 2075–2085. [Google Scholar] [CrossRef]
- Zhang, L.; Yan, X.; Fan, Q.; Liu, H.; Liu, X.; Liu, Z.; Zhang, Z. D-dimer levels on admission to predict in-hospital mortality in patients with COVID-19. J. Thromb. Haemost. 2020, 18, 1324–1329. [Google Scholar] [CrossRef] [PubMed]
- Hegde, H.; Shimpi, N.; Panny, A.; Glurich, I.; Christie, P.; Acharya, A. MICE vs. PPCA: Missing data imputation in healthcare. Inform. Med. Unlocked 2019, 17, 100275. [Google Scholar] [CrossRef]
- Filbin, M.R.; Mehta, A.; Schneider, A.M.; Kays, K.R.; Guess, J.R.; Gentili, M.; Fenyves, B.G.; Charland, N.C.; Gonye, A.L.; Gushterova, I. Plasma proteomics reveals tissue-specific cell death and mediators of cell-cell interactions in severe COVID-19 patients. BioRxiv 2020. [Google Scholar] [CrossRef]
- Tawsifur Rahman, F.A.A.-I.; Al-Mohannadi, F.S.; Mubarak, R.S.; Al-Hitmi, M.H.; Islam, K.R.; Khandaker, A.; Hssain, A.A.; al Maadeed, S.A.; Zughaier, S.M.; Chowdhury, M.E.H. Mortality-Severity-Prediction-Using-Blood-Biomarkers. Available online: https://github.com/tawsifur/Mortality-severity-prediction-using-blood-biomarkers (accessed on 5 June 2021).
- van Buuren, S.; Groothuis-Oudshoorn, K. mice: Multivariate imputation by chained equations in R. J. Stat. Softw. 2010, 45, 1–68. [Google Scholar] [CrossRef] [Green Version]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Khandakar, A.; Chowdhury, M.E.; Reaz, M.B.I.; Ali, S.H.M.; Hasan, M.A.; Kiranyaz, S.; Rahman, T.; Alfkey, R.; Bakar, A.A.A.; Malik, R.A. A Machine Learning Model for Early Detection of Diabetic Foot Using Thermogram Images. arXiv 2021, arXiv:2106.14207. [Google Scholar]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Keerthi, S.S.; Shevade, S.K.; Bhattacharyya, C.; Murthy, K.R.K. Improvements to Platt’s SMO algorithm for SVM classifier design. Neural Comput. 2001, 13, 637–649. [Google Scholar] [CrossRef]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN model-based approach in classification. In Proceedings of the OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”, Rhodes, Greece, 21–25 October 2019. [Google Scholar]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y. Xgboost: Extreme Gradient Boosting; R Package Version 0.4-2; 2015; Volume 1, pp. 1–4. [Google Scholar]
- Sharaff, A.; Gupta, H. Extra-tree classifier with metaheuristics approach for email classification. In Advances in Computer Communication and Computational Sciences; Springer: Berlin/Heidelberg, Germany, 2019; pp. 189–197. [Google Scholar]
- Subasi, C. Logistic Regression Classifier. Available online: https://towardsdatascience.com/logistic-regression-classifier-8583e0c3cf9 (accessed on 26 April 2021).
- Anderson, R.P.; Jin, R.; Grunkemeier, G.L. Understanding logistic regression analysis in clinical reports: An introduction. Ann. Thorac. Surg. 2003, 75, 753–757. [Google Scholar] [CrossRef]
- Zlotnik, A.; Abraira, V. A general-purpose nomogram generator for predictive logistic regression models. Stata J. 2015, 15, 537–546. [Google Scholar] [CrossRef] [Green Version]
- Balachandran, V.P.; Gonen, M.; Smith, J.J.; DeMatteo, R.P. Nomograms in oncology: More than meets the eye. Lancet Oncol. 2015, 16, e173–e180. [Google Scholar] [CrossRef] [Green Version]
- Iasonos, A.; Schrag, D.; Raj, G.V.; Panageas, K.S. How to build and interpret a nomogram for cancer prognosis. J. Clin. Oncol. 2008, 26, 1364–1370. [Google Scholar] [CrossRef]
- Weng, Z.; Chen, Q.; Li, S.; Li, H.; Zhang, Q.; Lu, S.; Wu, L.; Xiong, L.; Mi, B.; Liu, D. ANDC: An early warning score to predict mortality risk for patients with coronavirus disease 2019. J. Transl. Med. 2020, 18, 1–10. [Google Scholar] [CrossRef]
- Jianfeng, X.; Daniel, H.; Hui, C.; Simon, T.A.; Shusheng, L.; Guozheng, W.; Yishan, W.; Hanyujie, K.; Laura, B.; Ruiqiang, Z. Development and External Validation of a Prognostic Multivariable Model on Admission for Hospitalized Patients with COVID-19. 2020. Available online: https://www.medrxiv.org/content/medrxiv/early/2020/03/30/2020.03.28.20045997.full.pdf (accessed on 1 June 2021).
- Zhang, B.; Zhou, X.; Qiu, Y.; Song, Y.; Feng, F.; Feng, J.; Song, Q.; Jia, Q.; Wang, J. Clinical characteristics of 82 cases of death from COVID-19. PLoS ONE 2020, 15, e0235458. [Google Scholar] [CrossRef] [PubMed]
- Al Youha, S.; Doi, S.A.; Jamal, M.H.; Almazeedi, S.; Al Haddad, M.; AlSeaidan, M.; Al-Muhaini, A.Y.; Al-Ghimlas, F.; Al-Sabah, S.K. Validation of the Kuwait Progression Indicator Score for predicting progression of severity in COVID19. MedRxiv 2020. [Google Scholar] [CrossRef]
- Chan, J.C.; Tsui, E.L.; Wong, V.C.; Group, H.A.S.C. Prognostication in severe acute respiratory syndrome: A retrospective time-course analysis of 1312 laboratory-confirmed patients in Hong Kong. Respirology 2007, 12, 531–542. [Google Scholar] [CrossRef] [PubMed]
- Assiri, A.; Al-Tawfiq, J.A.; Al-Rabeeah, A.A.; Al-Rabiah, F.A.; Al-Hajjar, S.; Al-Barrak, A.; Flemban, H.; Al-Nassir, W.N.; Balkhy, H.H.; Al-Hakeem, R.F. Epidemiological, demographic, and clinical characteristics of 47 cases of Middle East respiratory syndrome coronavirus disease from Saudi Arabia: A descriptive study. Lancet Infect. Dis. 2013, 13, 752–761. [Google Scholar] [CrossRef] [Green Version]
- Chen, R.; Liang, W.; Jiang, M.; Guan, W.; Zhan, C.; Wang, T.; Tang, C.; Sang, L.; Liu, J.; Ni, Z. Risk factors of fatal outcome in hospitalized subjects with coronavirus disease 2019 from a nationwide analysis in China. Chest 2020, 158, 97–105. [Google Scholar] [CrossRef]
- Liu, J.; Liu, Y.; Xiang, P.; Pu, L.; Xiong, H.; Li, C.; Zhang, M.; Tan, J.; Xu, Y.; Song, R. Neutrophil-to-lymphocyte ratio predicts severe illness patients with 2019 novel coronavirus in the early stage. MedRxiv 2020. [Google Scholar] [CrossRef] [Green Version]
- Huang, I.; Pranata, R. Lymphopenia in severe coronavirus disease-2019 (COVID-19): Systematic review and meta-analysis. J. Intensive Care 2020, 8, 1–10. [Google Scholar] [CrossRef]
- Han, X.; Ye, Q. Kidney involvement in COVID-19 and its treatments. J. Med. Virol. 2021, 93, 1387–1395. [Google Scholar] [CrossRef]
- Ok, F.; Erdogan, O.; Durmus, E.; Carkci, S.; Canik, A. Predictive values of blood urea nitrogen/creatinine ratio and other routine blood parameters on disease severity and survival of COVID-19 patients. J. Med. Virol. 2021, 93, 786–793. [Google Scholar] [CrossRef]
- Adamzik, M.; Broll, J.; Steinmann, J.; Westendorf, A.M.; Rehfeld, I.; Kreissig, C.; Peters, J. An increased alveolar CD4+ CD25+ Foxp3+ T-regulatory cell ratio in acute respiratory distress syndrome is associated with increased 30-day mortality. Intensive Care Med. 2013, 39, 1743–1751. [Google Scholar] [CrossRef]
- Lu, J.; Hu, S.; Fan, R.; Liu, Z.; Yin, X.; Wang, Q.; Lv, Q.; Cai, Z.; Li, H.; Hu, Y. ACP Risk Grade: A Simple Mortality Index for Patients with Confirmed or Suspected Severe Acute Respiratory Syndrome Coronavirus 2 Disease (COVID-19) during the Early Stage of Outbreak in Wuhan, China. SSRN J. 2020. [Google Scholar] [CrossRef]
- Ko, J.-H.; Park, G.E.; Lee, J.Y.; Lee, J.Y.; Cho, S.Y.; Ha, Y.E.; Kang, C.-I.; Kang, J.-M.; Kim, Y.-J.; Huh, H.J. Predictive factors for pneumonia development and progression to respiratory failure in MERS-CoV infected patients. J. Infect. 2016, 73, 468–475. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Wu, X.; Tian, Y.; Li, X.; Zhao, X.; Zhang, M. Dynamic changes and diagnostic and prognostic significance of serum PCT, hs-CRP and s-100 protein in central nervous system infection. Exp. Ther. Med. 2018, 16, 5156–5160. [Google Scholar] [CrossRef] [Green Version]
- Yildiz, B.; Poyraz, H.; Cetin, N.; Kural, N.; Colak, O. High sensitive C-reactive protein: A new marker for urinary tract infection, VUR and renal scar. Eur. Rev. Med. Pharmacol. Sci. 2013, 17, 2598–2604. [Google Scholar] [PubMed]
- Rahman, T. Early COVID-19 Mortality Risk Prediction. Available online: https://covid-19-risk-prediction.herokuapp.com/ (accessed on 1 June 2021).

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).