





Sensors 2026, 26(8), 2569; https://doi.org/10.3390/s26082569 - 21 Apr 2026
Viewed by 678
Abstract
►
Show Figures
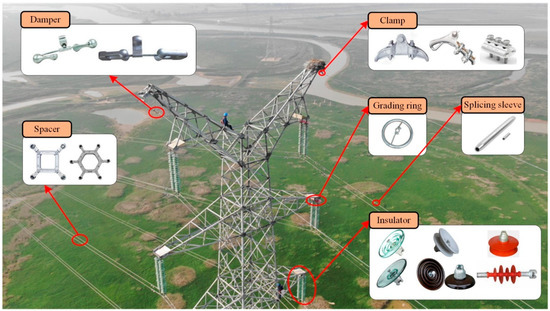
Vulnerable road users in informal urban environments confront a distinct set of hazards that standard computer vision datasets are ill-equipped to represent: artisanal speed bumps constructed without regulatory compliance, deteriorated road markings, and the mototaxi—a three-wheeled motorized vehicle that constitutes the primary informal
[...] Read more.
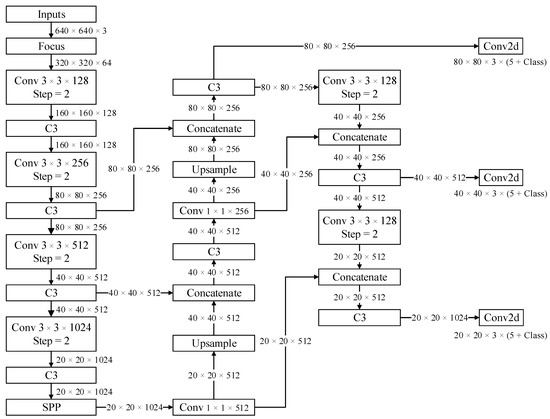
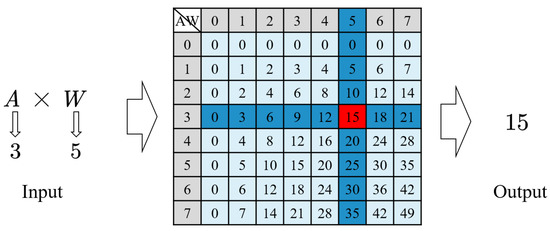
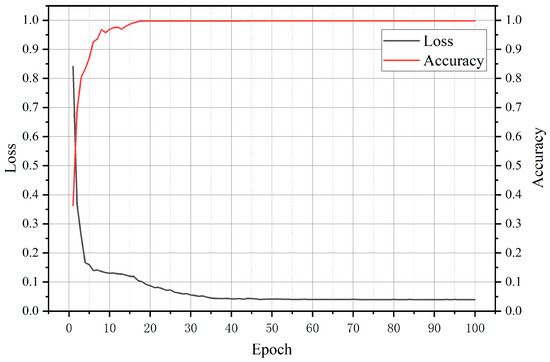
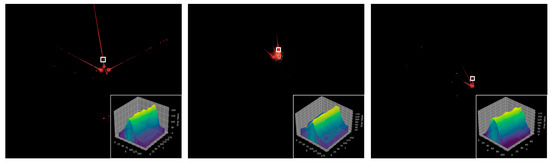
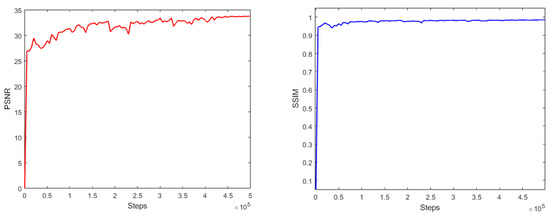
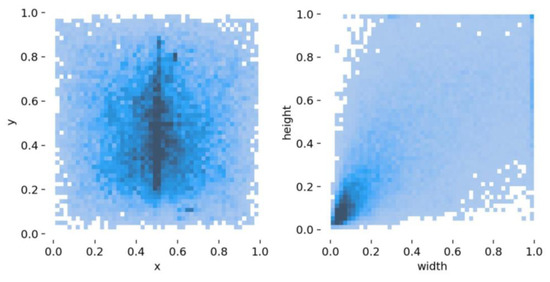
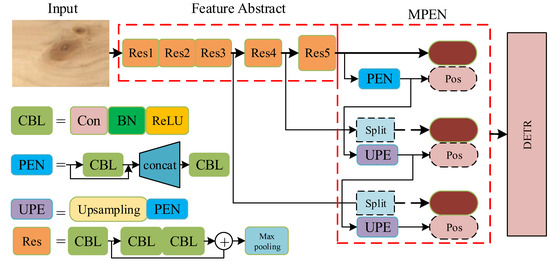
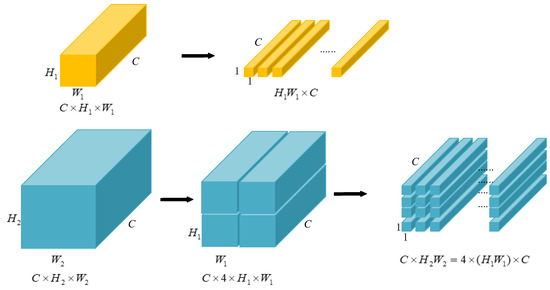
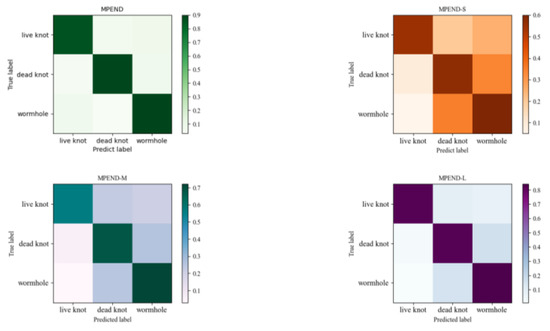
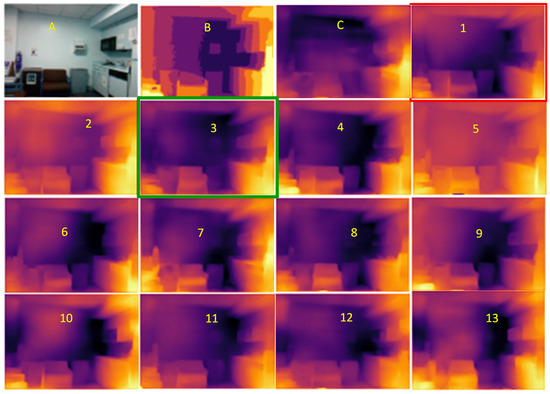
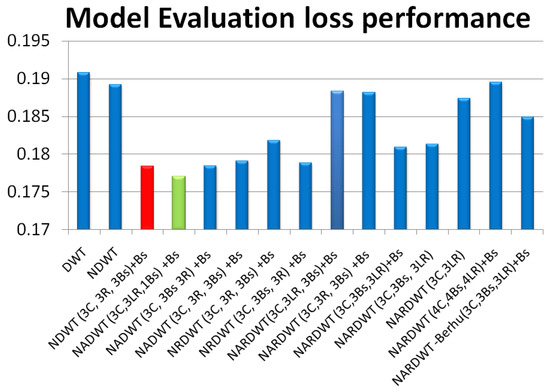
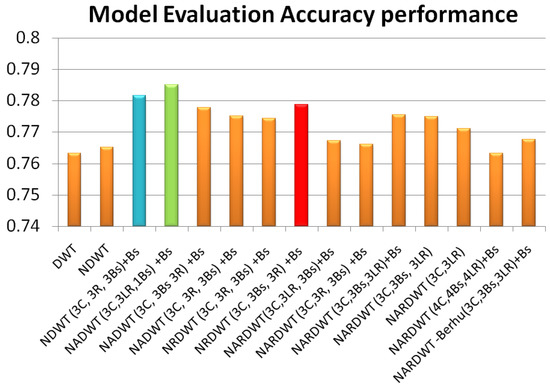
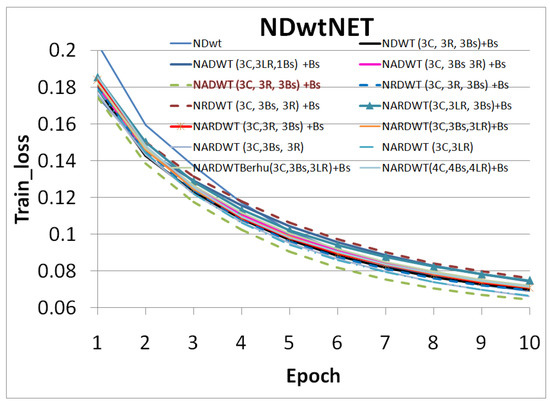
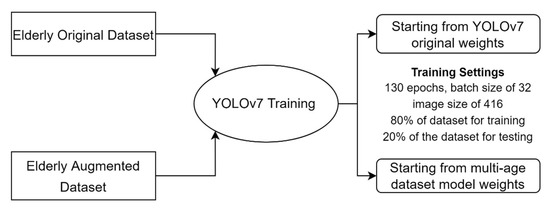
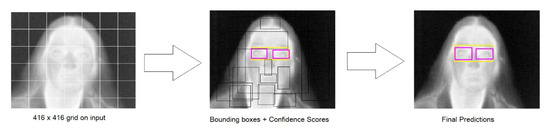
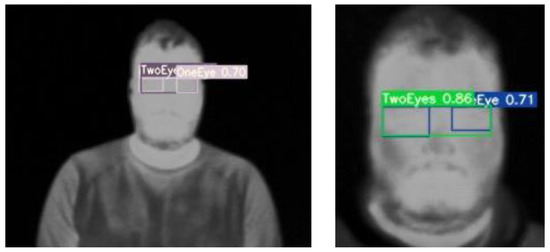
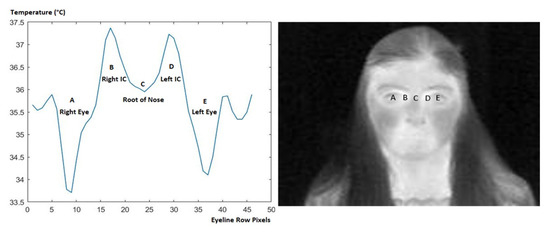
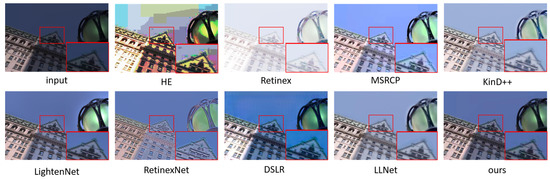
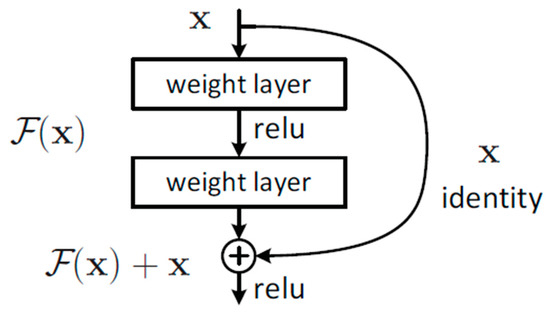
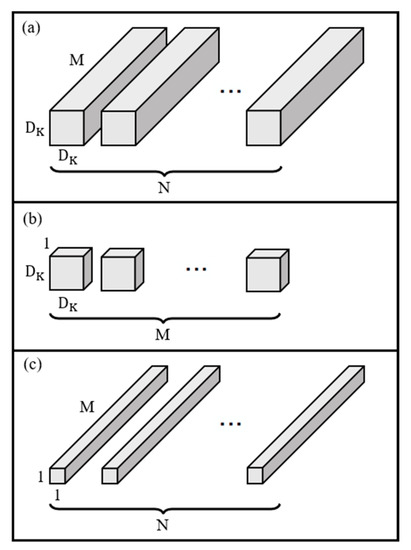
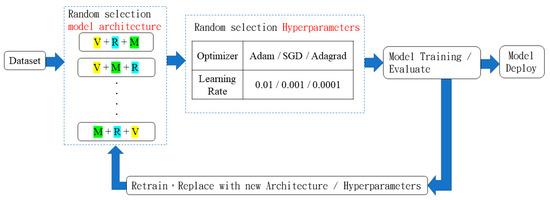
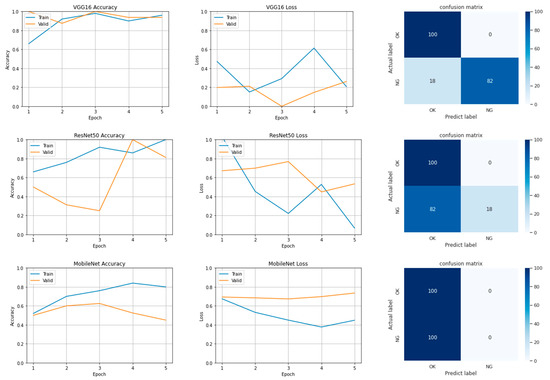
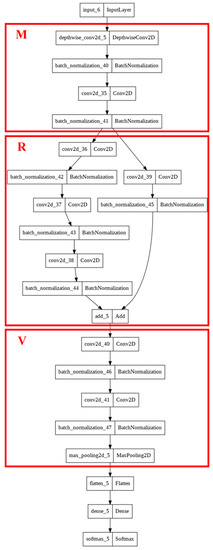
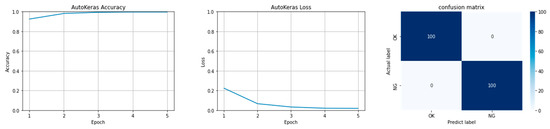
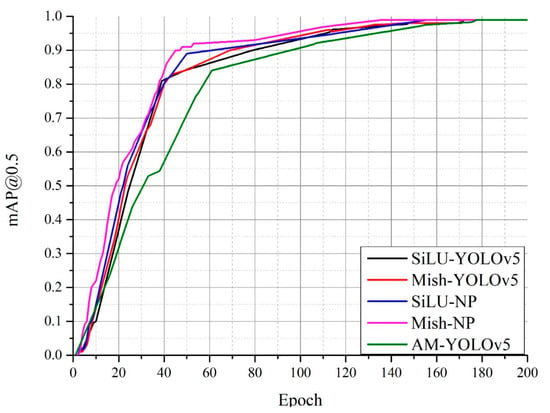
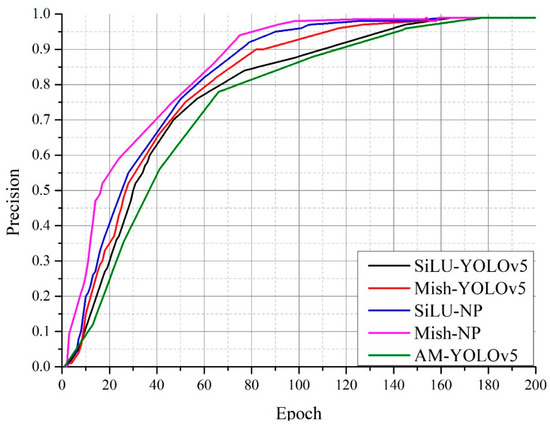
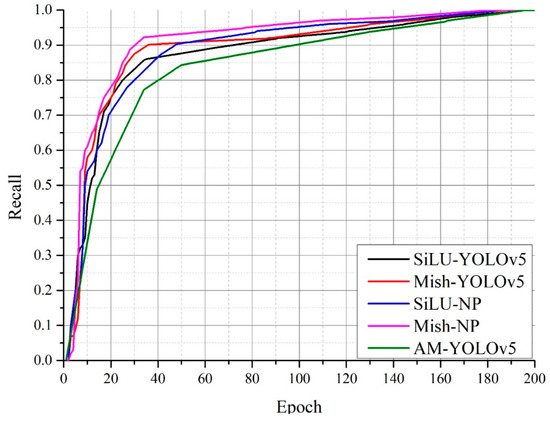
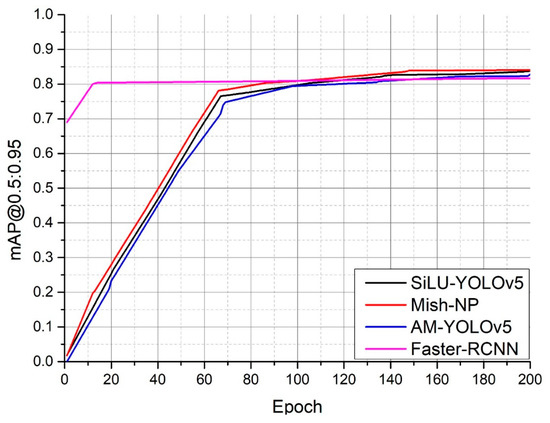
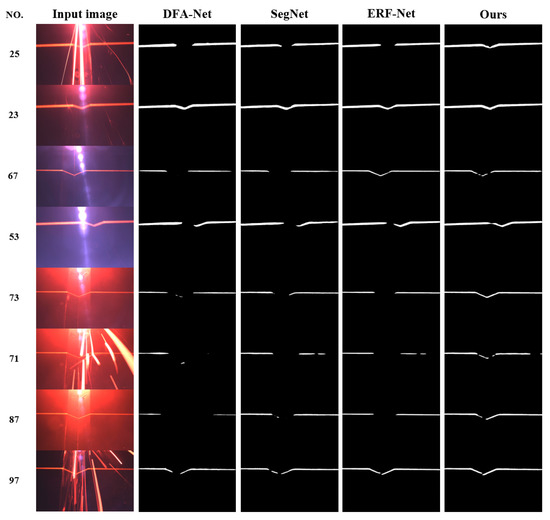
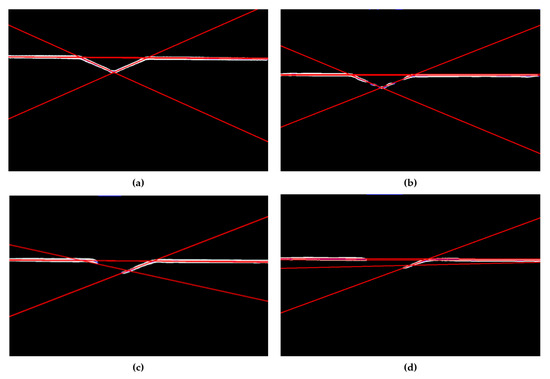
Vulnerable road users in informal urban environments confront a distinct set of hazards that standard computer vision datasets are ill-equipped to represent: artisanal speed bumps constructed without regulatory compliance, deteriorated road markings, and the mototaxi—a three-wheeled motorized vehicle that constitutes the primary informal transport mode in intermediate Andean cities yet is absent from all major international repositories. This paper presents QHAWAY—from Quechua qhaway, a transitive verb meaning “to look; to observe”—an Advanced Driver Assistance System (ADAS) predicated on instance segmentation, monocular distance estimation via the pinhole camera model, and Time-to-Collision (TTC) computation, developed for the road environment of Ayacucho, Peru (2761 m a.s.l.), a city recognised by UNESCO as a Creative City of Crafts and Folk Art since 2019. A hybrid dataset comprising 25,602 images with 127,525 annotated instances across 12 classes was assembled by combining an original local collection of 4598 images (10,701 instances) captured through four complementary acquisition methods across the five urban districts of the Huamanga province with three established international datasets (BDD100K, BSTLD, RLMD; 21,004 images, 116,824 instances). A three-phase progressive training strategy with monotonically increasing resolution (640, 800, and 1024 pixels) was evaluated as an ablation study. A multi-architecture comparison spanning YOLOv8L-seg and the YOLO26 family (nano, small, large) identified YOLO26L-seg as the best-performing model, attaining mAP50 Box of 0.829 and mAP50 Mask of 0.788 at epoch 179. The integration of ByteTrack multi-object tracking with the pinhole equation

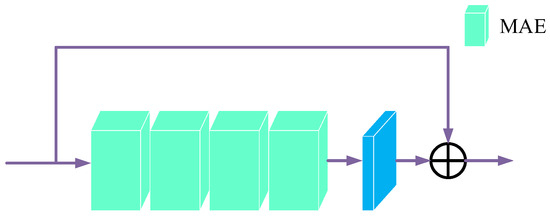
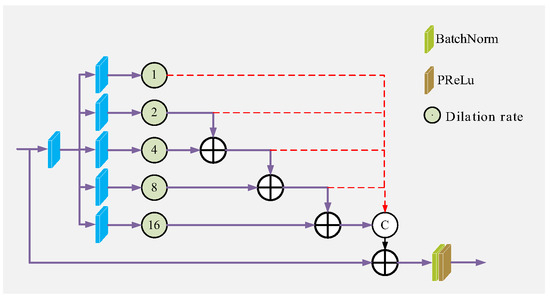
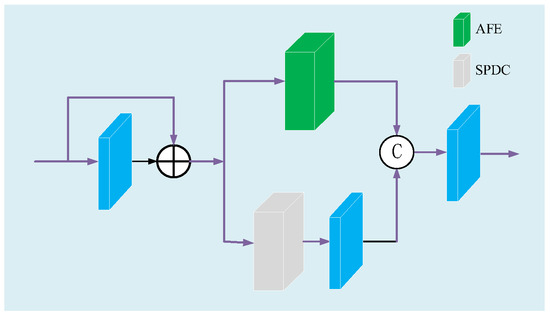
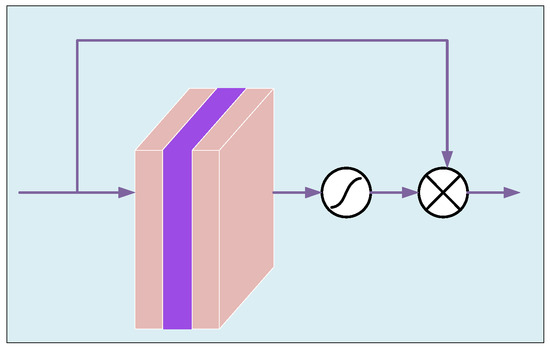
Figure 1




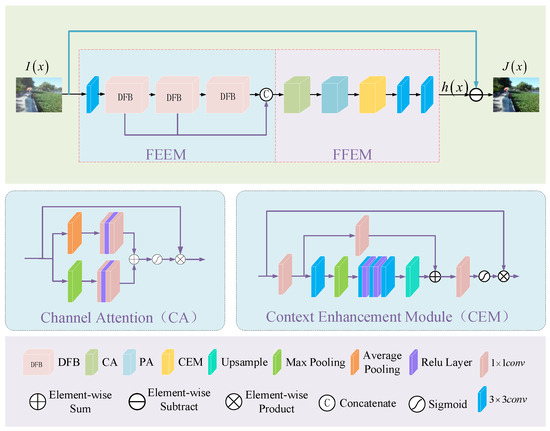



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}