Abstract
In this tutorial paper the Gull–Skilling kangaroo problem is revisited. The problem is used as an example of solving an under-determined system by variational principles, the maximum entropy principle (MEP), and Information Geometry. The relationship between correlation and information is demonstrated. The Kullback–Leibler divergence of two discrete probability distributions is shown to fail as a distance measure. However, an analogy with rigid body rotations in classical mechanics is motivated. A table of proper “geodesic” distances between probability distributions is presented. With this paper the authors pay tribute to their late friend David Blower.
1. Introduction
On my (RB) first meeting with Dr. John Skilling and Dr. Steve Gull in Cambridge in 1987, I was posed the following problem [1,2,3]:
Having no clue about the use of their shorter forelegs, let alone any handedness, nor of the colour of their eyes, I assumed that:In Australia, of the kangaroos are right-handed and have blue eyes. Can you construct the probability table?
- a kangaroo is right-handed or left-handed; and
- a kangaroo has blue eyes or green eyes.
This means that there are four distinct possibilities: right-handed with blue eyes, right-handed with green eyes, left-handed with blue eyes, and left-handed with green eyes. The statement space is of dimension 2 × 2 and has 4 cells, and a bare probability table looks like Table 1, showing the two given marginal values and the sum.

Table 1.
Probability table: version 1.
The two other marginal values result from normalizing the sum of the joint probabilities. Filling in the table a little more, we obtain Table 2. The notation for probabilities originates with David Blower, who avoids the overused P-symbol. In this paper we follow Blower’s notation closely [4].
Table 2.
Probability table: version 2.
I thought about this problem for a short while and filled in the table by multiplying the row and column marginal values, as in Table 3.
Table 3.
Probability table, version 3.
However, then I was presented with the following set of equations
There are only three equations in four unknowns, leaving any other (consistent) equations relating to the redundant. This is an under-determined system. In my proposed solution, I must have used a fourth equation. So, where did this fourth equation come from? My answer was that I assumed that handedness and eye colour are independent, and thus the marginal probabilities could be multiplied. “Aah”, they said, “you have applied the Maximum Entropy Principle!”
Jaynes discussed and extended the kangaroo problem in the Fourth Maximum Entropy Workshop in 1984 [3].
This under-determined system has one free variable. Choosing as the free variable, the equations reduce to
A symbolic solution can be obtained by using Wolfram Mathematica’s Reduce[] function [5] as shown in Figure 1.

Figure 1.
Wolfram Mathematica code for solving the under-determined problem (2).
In this code snippet, the three equations can be recognized as well as the positivity condition. The solution is
With this solution the probability table can be filled in as in Table 4.
Table 4.
Probability table, version 4.
Figure 2 shows a range of solutions to this problem. This figure illustrates the correlation and anti-correlation between the various -s. Since and have to maintain their sum as , they must be anti-correlated. Therefore the coloured lines cross each other between and . Similarly, is anti-correlated with . Therefore, and have to be correlated, and the coloured lines between them do not cross. Finally, is correlated with , which can be seen from the repeated -axis at the right.
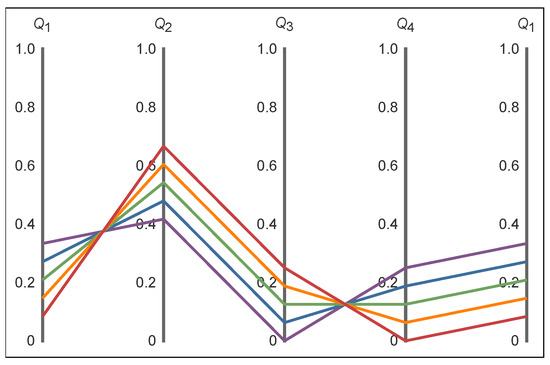
Figure 2.
Parallel-axis plot of the , , , and , for between (red) and (purple) in equidistant steps of . For clarity, the axis is repeated on the right.
2. Variational Principles
A possible solution for an under-determined problem can be found by adopting a variational principle. This is a function of the joint probabilities to be optimized (maximized or minimized) under some constraints, whose free parameters correspond to the missing equations. Sivia considers four variational functions: the entropy, the sum of squares, the sum of logarithms, and the sum of square roots, as shown in Table 5 [1].
Table 5.
Sivia’s four variational functions: entropy, sum of squares, sum of logarithms, sum of square roots.
In the case of the Least Squares variational function we have
This is a quadratic function and has a unique minimum at
which yields the exact solution of
For the Maximum Entropy, the variational function
has to be maximized, subject to the constraints. This function has a unique maximum at
which yields the exact solution of
The solutions for for the Maximum logarithms and Maximum square roots variational equations only can be obtained via numerical optimization. For each solution , the other three values follow directly from (2). The Variational Principle solutions are tabulated in Table 6 and visualized in Figure 3.
Table 6.
The Variational Principle solutions.
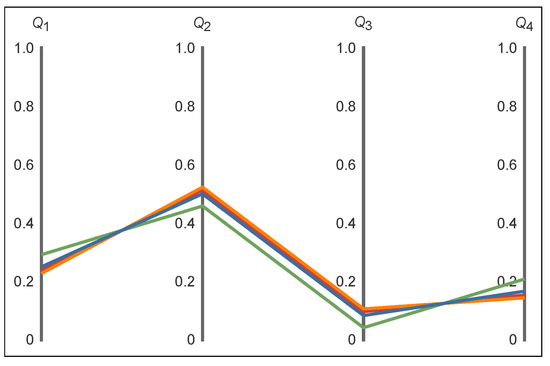
Figure 3.
Parallel axis plot of the Variational Principle solutions: is blue, is green, is orange, and is red.
However, given these four different solutions to the kangaroo problem, we need a rationale for choosing one of them. Which one is ’best’? Sivia states that barring some evidence about a gene-linkage between handedness and eye colour for kangaroos, the MaxEnt model is preferred because this model provides the only uncorrelated assignment of the . This is shown in Section 4.
3. State Space and Constraint Functions
In the kangaroo problem, we have two traits: handedness and eye colour. Each trait has a set of features; for the handedness they are “right-handed” and “left-handed”; for the eye colour “blue” and “green”. Mixtures of features are not allowed. Therefore, for every trait, one, and only one, feature applies; the features are mutually exclusive.
More abstractly, the features can be represented as statements. The combined features from different traits form joint statements. The joint statements define a state space of dimension . The n cells uniquely number the joint statements. Table 7 shows the general setup.
Table 7.
The n cells of the state space uniquely number the joint statements.
Any joint statement about a kangaroo can be placed in one and only one cell of the state space. For example, a left-handed and blue-eyed kangaroo is uniquely defined by the joint statement . In this notation, the X denotes the two traits, and the specifies the features in cell 3. The state space is congruent to the probability table of Table 1, but it has a different role. The joint statements, , are logical statements which can be either True or False.
A constraint function is defined over the state space, as shown in Table 8. The function F assigns a Boolean value to each joint statement and returns a vector of values ([4], Ch. 21)
The constraint function vector specifies the operation of a constraint.
Table 8.
The constraint function is a function defined on the space of joint statements.
The constraint function for our first constraint, “In Australia of the kangaroos are right-handed ...,” is shown in Table 9. Writing out the constraint function vector for , we have
The corresponding constraint function vector for the left-handed kangaroos is its complement, .
Table 9.
The constraint function for the constraint “ of the kangaroos are right-handed.”
The constraint function for the second constraint, “... and have blue eyes,” is shown in Table 10. Writing out the constraint function vector , we obtain
The constraint function vector for the blue-eyed kangaroos is , and for the green-eyed ’roos.
Table 10.
The constraint function vector for the second constraint ( of the kangaroos have blue eyes).
The probability distribution is normalized, which means that the sum of all joint probabilities is unity. This is also a constraint. The overall normalization is a universal constraint function vector
This whole business of creating constraint function vectors for assigning probabilities may seem overly elaborate but conceptually, and operationally, we need a way to connect a statement with a numerical value. Technically, F is an operator that accepts a joint statement as its variable and returns a Boolean value. Furthermore, the constraint function vectors become the basis vectors in the vector space of the information geometry in Section 6.
4. Correlation, Covariance, and Entropy
What do correlation and covariance actually mean, and what is the difference? Sometimes the two terms are used interchangeably.
We all have an intuitive interpretation. For instance, people’s heights and weights are correlated, which means that generally, tall persons weigh more than short ones. The two variables vary together; they are co-varying. However, this does not necessarily reflect a causal relationship. Gaining weight does not automatically imply becoming taller, as we all know.
4.1. Expectation
Suppose that a function is defined over the state space and returns a numerical value for each joint statement. The expectation of V is
The sum is over all values in the state space, whereas the are from the probability table. The expectation value, , is a numerical quantity.
With this definition, let’s compute the expectation for “right-handedness”. The constraint function vector for right-handedness, , acts as the quantity V
In the last step, we have used the information given in Table 2. The expectation for right-handedness thus equals its marginal value.
Similarly for “blue eyes”, with
Furthermore, the expectation value for blue eyes again equals its marginal value.
4.2. Variance
The variance of the values is defined as
Notice that there are two nested sets of brackets involved. The is defined by (14).
By expanding the square, this can be rewritten as
We have used the properties and in the above derivation, because is a constant.
So what is the variance of “right-handedness”? Taking , we obtain
The variance of “blue eyes” is
We conclude that both variances are independent of .
4.3. Covariance
The covariance between two variables and is defined by
By a similar expansion as above, the product can be written as
What does this give for the ? Expanding the sum and substituting the constraint function vectors and , we obtain
We find that does depend on .
The variances and covariances can be combined in the variance-covariance matrix, which is defined by
The variance-covariance matrix is related to the metric tensor g from information geometry in Section 6.
4.4. Correlation
The correlation coefficient is a single value derived from the variance and covariance values. It is defined as
Therefore the correlation between the eye colour and the handedness of the kangaroos is
This finally confirms that indeed, the MaxEnt solution, with , has zero correlation. We agree with Sivia that the other variational functions yield a positive or negative correlation between handedness and eye colour. (Notice that our correlation coefficients have the opposite sign, because Sivia correlates the left-handedness with blue eyes [1].) Table 11 shows the model solutions and the corresponding correlation values.
Table 11.
The numerical details for the variational principle solutions.
One may have gotten the impression that the constraint function values are always 0 or 1, but these are specific for the problem treated in this paper. In general, a constraint function may yield any numerical value. The construction of a constraint function can be intricate; see, for example, Blower ([4], p. 63).
4.5. Entropy
The information entropy is a measure of the amount of missing information in a probability distribution. The information entropy of a discrete probability distribution is
Of all possible probability distributions, the discrete uniform distribution has the maximum missing information. Thus for , we have with
When the natural logarithm is used, the units of entropy are nats. However, the entropy can also be defined in terms of the more familiar bits when is used. The conversion of to bits by multiplying by gives
Maximum missing information of two bits exactly describes our minimum state of knowledge in a state space with four equally probable states. We need one bit to choose a column and another bit to choose a row. Combined, we have fully specified one of four equally probable states or cells in the state space.
Absolute certainty is described by zero bits of missing information. This is attained when one and all other . Then our state of knowledge is fully specified and there is no missing information. For example, a “certain distribution” is , for which the entropy is
Here we have used
and = 0.
The table in Table 11 shows the values for , in bits, in the last column. Although all models have an entropy that is smaller than two bits, the numerical values of the entropy are not easily assessed intuitively. Jaynes gives an excellent explanation to guide one’s intuition ([6], Ch. 11.3).
Suppose we were first told about the kangaroos’ handedness, namely versus . The information entropy of this binary case is
Next, we learn that the first alternative consists of two possibilities, namely blue and green eyes, with , where and . The information entropy for the ternary case becomes
Finally, the second alternative also consists of two possibilities, namely , with and . The information entropy becomes
We recognize the same value as for in Table 11. In this example, the state space is gradually expanded and, as the number of cells increases one’s ambivalence also increases, which is reflected in an increase in the entropy. The example also shows that the subsequent are additive. Notice that the above partitioning of the and is proportional to the blue- and green-eyed kangaroos ratio.
For a given set of constraints, of all possible models, the maximum entropy solution has the highest information entropy ([4], Ch. 24.2), which is confirmed in Table 11. This means that the solution has the most missing information. Consequently, in one way or another, some extra information was introduced by the other variational functions. From the example above, one may surmise that the additional information originates from a different partitioning of the and into the -s.
This extra information also shows up as non-zero correlations; the higher the absolute value of the correlation, the lower the information entropy. Therefore, correlation induces information, reducing the amount of missing information.
5. Maximum Entropy Principle
Although we have already obtained several solutions to the kangaroo problem by the optimization of various variational functions, the procedure may be seen as ad hoc. The Maximum Entropy Principle (MEP) is a versatile problem-solving method based on the work of Shannon and Jaynes ([6], Ch. 11; [3,7]). The MEP is a method with highly desirable features for making numerical assignments, and, most importantly, all conceivable legitimate numerical assignments may be made, and are made, via the MEP. The book by Blower [4] is entirely devoted to the MEP.
5.1. Interactions
Blower defines the interaction between two (or more) constraints as the product of their constraint function vectors. Here we have two constraints, which can have only one interaction, namely between “right-handed” and “blue eyes”. In problems with more dimensions, higher-dimensional interactions can be defined by the product of three or more constraint function vectors.
The interaction vector is the element-wise product of the relevant constraint function vectors
From Table 12, we see how selects the interaction between “right-handed” and “blue eyes”. This interaction singles out the statement in the state space and, consequently, the joint probability. Keeping our terminology simple, this interaction vector is also called a constraint function vector.
Table 12.
selects the interaction between “right-handed” and “blue eyes”.
There are now three constraint function vectors
which can be combined to form the constraint function matrix
The constraint function matrix has dimensions . As in Section 4, the expectation value of the interaction is
The three expectation values are combined to form the constraint function average vector
The constraint function average vector is related to the contravariant coordinates in information geometry in Section 6.
In an under-determined problem, the number of constraints (primary and interaction) is . In our case , therefore combined with the normalization of the probability distribution, we have a linear system of four equations with four unknowns. However, in this paper, we take a general approach as if we had an under-determined system with .
Returning to our kangaroo problem, from the MEP perspective, we will obtain four models defined by their constraint function averages . The set-up of the problem fixes values of and , whereas the third value, , is taken as the -s from the model solutions, as shown in Table 11.
5.2. The Maximum Entropy Principle
The MEP involves a constrained optimization problem utilizing the method of Lagrange multipliers. According to Jaynes, the MEP provides the most conservative, non-committal distribution where the missing information is as ‘spread-out’ as possible, yet which accords with no other constraints than those explicitly taken into account.
The MEP solution in its canonical form is ([4], p. 50)
Here is the probability for the joint statement . The is the j-th constraint function operator acting on the i-th joint statement. The are the Lagrange multipliers, each corresponding to a constraint function. The summation is over all m constraints. The in the denominator normalizes the joint probabilities and is called the partition function
For our kangaroo problem the MEP solution can be written as
with
The arguments of the exponents can be written in vector-matrix notation, using the constraint function matrix (37)
The partition function then becomes
The joint probabilities (42) are expressed in full as
and the three Lagrange parameters are the solutions of the three constraint equations
This is a non-linear problem in three unknowns. Solving the Lagrange parameters usually requires an advanced numerical approximation technique. The Legendre transform provides such a method, which is described in detail by Blower ([4], Ch. 24), and demonstrated in the code example in Figure 4. In some cases, the can be obtained exactly, as we will see below.

Figure 4.
Wolfram Mathematica code for finding the Lagrange parameters (47) using the Legendre transform as a function of .
Our four models are distinguished only by their constraint function average, , in (39). The details are shown in Table 13.
Table 13.
MEP-solution of the kangaroo problem.
The constraint function vectors are shown in the second column. The three Lagrange parameters are shown in the third column. From this column one can learn that all three Lagrange parameters vary, even when only the value of is varied. Substituting these in (46), the probability distributions of the last column are obtained. In our case, these MEP solutions are the same as those obtained by the variational principle methods in table in Table 6, but this need not be so in general. The Lagrange parameters are related to the covariant coordinates of information geometry in Section 6.
Close inspection of the table in Table 13 reveals that the Lagrange multiplier for solution. This is an important observation because it signals that the constraint function is redundant and, consequently, can be removed. The solution for the joint probabilities using only is identical to the one with . Actually, we knew this already, as this was the basis of the solution in Table 3, but the MEP provides a systematic method for detecting redundancies ([6], p. 369, [8], p. 108).
The Lagrange parameters can be solved algebraically for the and the models. Recall that the and models gave exact solutions for the , namely from substituting (8) and (5) in (2). From (46), we see that , therefore the value of the partition function is exactly known. Subsequently, the can be solved algebraically from (46).
Since the and the model results turn out to be identical, the distinction based on their solution method can now be dropped. For consistency, we keep the redundant constraint function in the model.
6. Information Geometry
6.1. Coordinate Systems
In Information Geometry (IG), a discrete probability distribution is represented by a point in a manifoldS. A manifold of dimension n is denoted by ; in our case . The probability distribution is parameterized by two dual coordinate systems, namely a covariant system denoted by superscripts and a contravariant system denoted by subscripts . This notation corresponds to the work of Amari [9]. The book by Blower [8] is entirely devoted to IG, and in this section we follow his notation.
The contravariant coordinate system corresponds to the constraint function averages
whereas the covariant coordinates are the Lagrange multipliers
The normalization of the probability distribution is given by
This definition yields for the first covariant coordinate
where Z is the partition function (41). For example, the uniform distribution q in the covariant coordinate system is
and in the contravariant coordinate system
In IG, the normalization is always implicitly assumed; therefore the coordinates and are never shown explicitly. In the remainder of this paper, only three coordinates are used, namely
and
6.2. Tangent Space
All modeling takes place in a sub-manifold , which is tangent to the manifold . This is illustrated in Figure 5. In our kangaroo problem .
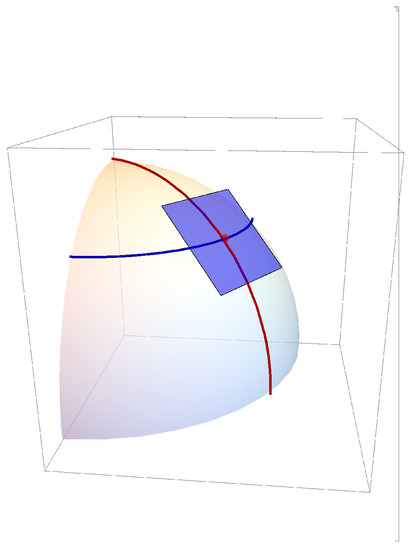
Figure 5.
The sub-manifold (blue) is tangent to the manifold . The red line is a meridian of longitude and the blue line is a parallel of latitude through the point of tangency.
Perhaps it is tempting to think of a probability distribution Q as a vector in , with a coordinate system along the axes as in Figure 6. However, this notion is conceptually wrong because the probability distribution is normalized by
and not as
We will return to the issue of normalization in Section 6.6.
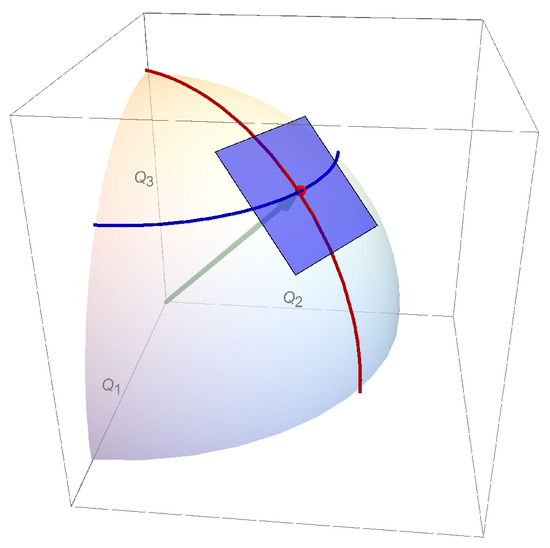
Figure 6.
Incorrect view of the probability distribution as a vector (green) to the point of tangency in , with a coordinate system along the axes.
The manifold has no familiar extrinsic set of coordinate axes by which all points can be referenced. All we have is this austere representation of points mapped to a coordinate system ([8], p.46). The tangent space is spanned by a set of m basis vectors. The natural basis vectors of the tangent space are
where we recognize the constraint function vector and the corresponding constraint function average . Notice that the constraint function average is subtracted from every element of the constraint function vector . For the least squares model solution , the basis vectors are
where we have used (36) and (39), and substituted the using (5).
These basis vectors are not orthogonal. The angle between two vectors and is given by
This gives for the angles in degrees between and , and , and and : , , and respectively. The basis vectors are also not normalized; their lengths are defined as and found to be , , and , respectively. However, the of (57) are perpendicular to the probability distribution (6) from the model
all mutual angles are .
Since the basis vectors do not form an orthogonal coordinate system, for an arbitrary vector there are two possible projections. Covariant coordinates are obtained by a projection parallel to the basis vectors, while contravariant coordinates are obtained by a perpendicular projection onto the basis vectors.
6.3. Metric Tensor
Each probability distribution p in the manifold has an associated metric tensor . The metric tensor is an additional structure that allows the definition of distances and angles in the manifold.
The metric tensor is a symmetric matrix, and it comes in covariant and contravariant forms which are each other’s matrix inverse. The contravariant metric tensor turns out to be the same as the variance-covariance matrix ([8], p. 50). In our notation the covariant form is , and the contravariant form is , where the superscripts and subscripts r and c refer to the matrix row and column index.
The elements of the contravariant metric tensor are defined as inner products
The sum is over all state space cells, whereas the r and c are fixed. Notice that this is the same computation as (22) for the covariance between two vectors.
In the locally flat tangent space , the two coordinate systems are non-orthogonal, and the metric tensor forms the local transformation between the two coordinate systems,
and its inverse
In Blower’s notation the contravariant and covariant vector indices do not follow the common Einstein convention.
The metric tensor can be computed by
with Z the partition function (43)
The contravariant metric tensor for our kangaroo problem is most easily expressed in the covariant coordinates
The Wolfram Mathematica [5] code which yields this symbolic expression is surprisingly compact, as shown in Figure 7. This short piece of code demonstrates the indispensability of a good symbolic tool when doing IG.

Figure 7.
Wolfram Mathematica code for calculating the metric tensor (65).
Substituting the appropriate Lagrange parameters from Table 13, the metric tensor for the least squares model solution is
and for the maximum entropy model , we obtain
Here we can see that the upper-left sub-matrices are identical to the variance-covariance matrix of (24). The extension to the matrices is due to the added interactions .
6.4. Kullback–Leibler Divergence
The Kullback–Leibler divergence allows for the determination of the differences in information content between two probability distributions. The Kullback–Leibler divergence between two discrete probability distributions p and q is defined as
The divergence is not a distance because the expression is not symmetric in p and q. A common way to refer to Kullback–Leibler divergence (KL) is as the relative entropy of p with respect to q or the information gained from p over q.
For example, with and we have
where we have used the limit expression (31) again. However, when we interchange p and q we obtain
Therefore, figuratively speaking, we have gained a finite amount of information when learning that we are certain, but we have lost an “infinite” amount when we lose our certainty. Learning and forgetting are asymmetric.
Therefore, the notion of the KL-divergence as a distance measure between distinct probability distributions is flawed. Rewriting (68) we obtain
where is the entropy of p. The first term on the right is the expectation of with respect to p. When , and are strictly positive quantities.
The KL-divergence can be expressed in bits when (68) is multiplied by . Table 14 shows the values for our four models. As expected, the table is not symmetric.
Table 14.
The Kullback–Leibler divergence (bits) between the models , where p and q are the models in the rows and columns, respectively.
When the distributions p and are infinitesimally close, writing
we have
Expanding the KL-divergence for small
This expansion is a sum of squares, which is symmetric. Therefore, the KL-divergence is commutative for infinitesimal separations between p and q.
This property of the Kullback–Leibler divergence has an analogy in classical mechanics, namely that two infinitesimal rotations of a rigid body along different principal axes are commutative, while finite rotations are not.
6.5. Distances
What is the distance between two discrete probability distributions p and q in the manifold ? This is at the heart of Information Geometry. For a distance we need a curve connecting the two points. There are many possibilities. What would be the length of such curves? Which one is the shortest? The shortest of all possible curves is called a geodesic. Suppose that s is a curve connecting p and q, then any point t on the curve s is a probability distribution. Therefore, we have a continuum of probability distributions along s in the manifold .
For two close-by points p and , their distance is a function of the KL-divergence, namely ([8], pp. 77–78)
The same distance is given by
where the covariant coordinates and of p and q are used, and the metric tensor is evaluated as in (65). However, there is a subtle difference here, namely the KL-divergence in (75) is computed in the full manifold , whereas in (76) is computed in the tangent space , with .
When the two distributions are finitely separated, as is the case for our models , the length of the curve is the integral from p to q of
where is the curve in parameterized by the probability distribution t, and is its first derivative. The tangent sub-manifold follows t along from p to q, and the Lagrange parameters and the metric tensor vary with t. However, finding the distance is an Euler–Legendre variational problem beyond the scope of this paper [10].
6.6. Angular Distances
The distance between two probability distributions can also be found as the arc length of a great circle on a sphere in . This is known as the Bhattacharyya angle.
Substituting (74) in (75) we can write
with a metric tensor
Using the transformation
we define as a point on the positive orthant of the unit sphere with
This effectively restricts to a sub-manifold of dimension . The geometry is illustrated by Figure 8. In the -coordinate system, the infinitesimal distance becomes
or
Notice that in this coordinate system the metric tensor is the Euclidean metric tensor
With this transformation the probability distributions become points on a hypersphere with a unit radius in dimensions. However, it is well known that geodesics on a sphere are great circles. Therefore, the distance can be obtained by the path integral (77) along a great circle connecting the two points. The arc length between two points is the subtended angle between two points and on the unit hypersphere
This remarkable result is the Bhattacharyya angle between two probability distributions [11]. The distance D between p and q is twice the arc length from (83)
The units of D are radians. The maximum distance of radians is achieved between two orthogonal distributions.
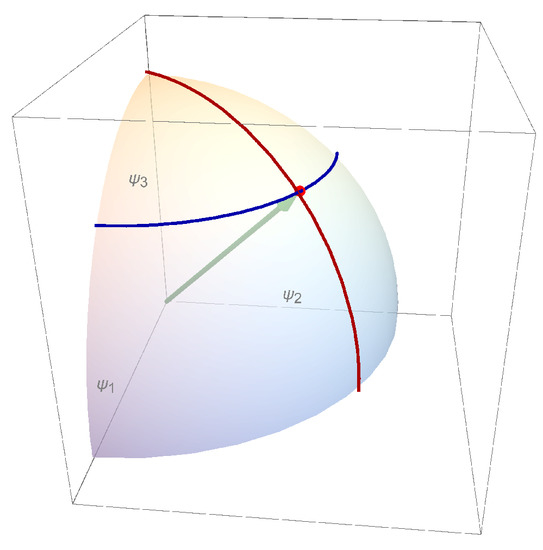
Figure 8.
Positive orthant . In the -coordinate system, the are orthonormal coordinates.
With this result we can compute the symmetric distance table for our four Kangaroo models, shown in Table 15; the numerical values are converted from radians to degrees. From this table we see that the largest distance is between the models and . This observation corresponds with these models having the biggest difference in their correlation coefficients in Table 11.
Table 15.
The distance D (in degree) between the models .
Interestingly, when we define lower and upper bounds
all the distances from Table 15 have values
Although we have no proof, this observation suggests that the two forms of the KL-divergence may act as lower and upper limits for the true distance .
6.7. Geodesics
The arc of the great circle connecting the two points can be found as follows [12]. Let and be two points on the dimensional hypersphere, then
Then
traces out a great circle through and . It starts at when , it reaches at , and returns to when . Here we recognize the Bhattacharyya angle again.
When and represent two probability distributions, they must remain on the positive orthant of the hypersphere. For ,
is a probability distribution in on the geodesic connecting and .
Our under-determined problem is parametrized by a single variable, namely from (3), which implies that there is only one dimension involved. Therefore it seemed reasonable to surmise that varying traces out probability distributions t along the shortest distance between the various models, but this turned out to be incorrect. The distributions t on the geodesic connecting, for example, to , do not comply with the constraint function average vector (39)
except for the endpoints.
6.8. Distances Revisited
Our knowledge of the geodesic allows us to verify (75) with (76). The arc length of the geodesic between p and q is
where we have substituted (76). Notice that the metric tensor as well as the covariant coordinates depends on t. This integral can be approximated by a sum of many small steps in t ([8], p.78).
By taking K small segments, the distance s is approximated by
Here corresponds to the probability distribution and is the distribution . The intermediate points are obtained by dividing the arc of the hypersphere into K equal angular segments. The corresponding probability distributions are , using (92).
For each in (95), the constraint function averages are obtained through the multiplication by the constraint function vectors (36). The corresponding covariant coordinates are computed by solving the set of equations in (47), as illustrated by Figure 4. Finally, the metric tensor is obtained through substitution of in (65). By taking segments and performing the computation of (95) we have confirmed all the numerical values in Table 15. This confirms the equivalence of (75) and (76).
7. Conclusions
The Gull–Skilling kangaroo problem provides a useful setting for illustrating the solution of under-determined problems in probability. The Variational Principle—in conjunction a variational function—effectively creates enough missing information for a complete solution, but not necessarily the minimum amount. In this paper four different Variational Principle solutions are shown, only one of which introduces the minimum amount, when the variational function is the Shannon–Jaynes entropy function.
The Maximum Entropy Principle is an alternative method for solving under-determined problems, which however avoids any implicit introduction of extra information not in the original problem. This information manifests itself in our examples as added correlations in the solutions.
The Kullback–Leibler divergence allows for the determination of the differences in information content between two probability distributions, but it cannot be used as a distance measure. It is symmetrical for infinitesimal separations. We point out an analogy with infinitesimal rigid body rotations.
Through the lens of Information Geometry, the actual geometric distance between two probability distributions along a geodesic path, can also be expressed as twice the Bhattacharyya angle in a hypersphere. In this paper, we illustrate the equivalence of these two geometrical concepts.
We also find that the mutual differences in distance between any two models, are directly reflected in the difference of their correlation coefficients.
Our understanding of the kangaroo problem and its implications has been particularly facilitated by the symbolic programming capabilities of Wolfram Mathematica.
Author Contributions
The authors R.B. and B.J.S. contributed equally to the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
This paper was written to honor our late friend David Blower. The reader may benefit from his books, as we have. We acknowledge the comments of John Skilling, who pointed out the Bhattacharyya angle to us. Further we thank Ann Stokes, Ali Mohammad-Djafari and two anonymous referees for supporting comments.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sivia, D.S.; Skilling, J. Data Analysis, 2nd ed.; Oxford University Press: Oxford, UK, 2006; pp. 111–113. [Google Scholar]
- Gull, S.F.; Skilling, J. Maximum entropy method in image processing. IEE Proc. 1984, 131, 646–659. [Google Scholar] [CrossRef]
- Jaynes, E.T. Monkeys, kangaroos and N. In Maximum Entropy and Bayesian Methods in Applied Statistics; Justice, J. H., Ed.; Cambridge University Press: Calgary, AB, Canada, 1984; pp. 27–58. [Google Scholar]
- Blower, D.J. Information Processing, Volume II, The Maximum Entropy Principle; Third Millennium Inferencing: Pensacola, FL, USA, 2013. [Google Scholar]
- Wolfram Mathematica. Available online: www.wolfram.com (accessed on 7 December 2022).
- Jaynes, E.T. Probability Theory: The Logic of Science; Bretthorst, G.L., Ed.; Cambridge University Press: New York, NY, USA, 2003. [Google Scholar]
- Buck, B; Macaulay, V. A. Maximum Entropy in Action; Oxford University Press: Oxford, UK, 1991. [Google Scholar]
- Blower, D.J. Information Processing, Volume III, Introduction to Information Geometry; Third Millennium Inferencing: Pensacola, FL, USA, 2016. [Google Scholar]
- Amari, S.; Nagaoka, H. Methods of Information Geometry; Originally Published in Japanese by Iwanami Shoten Publishers, Tokyo, Ed.; Translated by D. Harada; Oxford University Press: Oxford, UK, 1993. [Google Scholar]
- Mathews, J.; Walker, R.L. Mathematical Methods of Physics, 2nd ed.; Addison-Wesley Publ.: Menlo Park, CA, USA, 1973; pp. 322–344. [Google Scholar]
- Bhattacharyya, A. On a Measure of Divergence between Two Multinomial Populations. Sankhyā 1946, 7, 401–406. [Google Scholar]
- Mathematics Stack Exchange. Available online: https://math.stackexchange.com/questions/1883904/a-time-parameterization-of-geodesics-on-the-sphere (accessed on 15 September 2022).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).