Although we have already obtained several solutions to the kangaroo problem by the optimization of various variational functions, the procedure may be seen as ad hoc. The Maximum Entropy Principle (MEP) is a versatile problem-solving method based on the work of Shannon and Jaynes ([
6], Ch. 11; [
3,
7]). The MEP is a method with highly desirable features for making numerical assignments, and, most importantly, all conceivable legitimate numerical assignments may be made, and are made, via the MEP. The book by Blower [
4] is entirely devoted to the MEP.
5.1. Interactions
Blower defines the interaction between two (or more) constraints as the product of their constraint function vectors. Here we have two constraints, which can have only one interaction, namely between “right-handed” and “blue eyes”. In problems with more dimensions, higher-dimensional interactions can be defined by the product of three or more constraint function vectors.
The interaction vector is the element-wise product of the relevant constraint function vectors
From
Table 12, we see how
selects the interaction between “right-handed” and “blue eyes”. This interaction singles out the
statement in the state space and, consequently, the
joint probability. Keeping our terminology simple, this interaction vector is also called a constraint function vector.
There are now three constraint function vectors
which can be combined to form the
constraint function matrix
The constraint function matrix has dimensions
. As in
Section 4, the expectation value of the interaction
is
The three expectation values are combined to form the
constraint function average vector
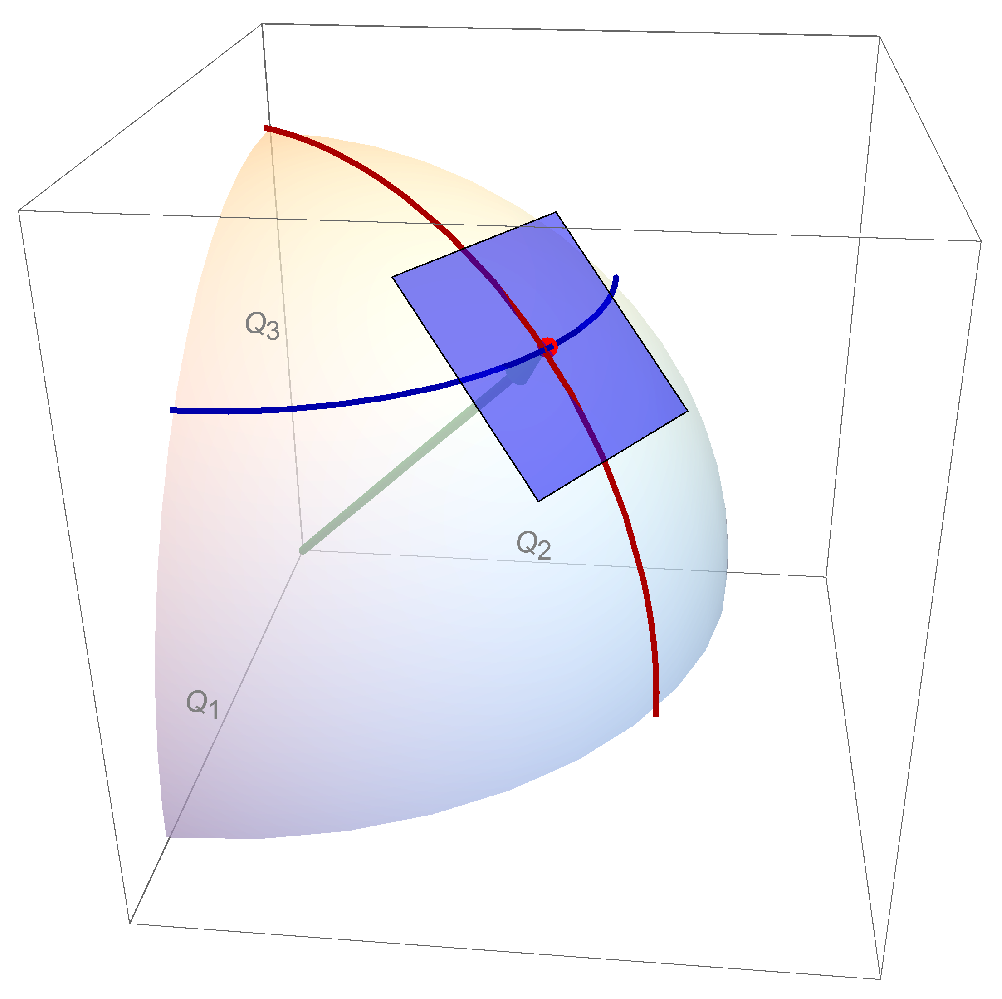
The constraint function average vector
is related to the contravariant coordinates
in information geometry in
Section 6.
In an under-determined problem, the number of constraints (primary and interaction) is . In our case , therefore combined with the normalization of the probability distribution, we have a linear system of four equations with four unknowns. However, in this paper, we take a general approach as if we had an under-determined system with .
Returning to our kangaroo problem, from the MEP perspective, we will obtain four models
defined by their constraint function averages
. The set-up of the problem fixes values of
and
, whereas the third value,
, is taken as the
-s from the
model solutions, as shown in
Table 11.
5.2. The Maximum Entropy Principle
The MEP involves a constrained optimization problem utilizing the method of Lagrange multipliers. According to Jaynes, the MEP provides the most conservative, non-committal distribution where the missing information is as ‘spread-out’ as possible, yet which accords with no other constraints than those explicitly taken into account.
The MEP solution in its canonical form is ([
4], p. 50)
Here
is the probability for the joint statement
. The
is the
j-th constraint function operator acting on the
i-th joint statement. The
are the Lagrange multipliers, each corresponding to a constraint function. The summation is over all
m constraints. The
in the denominator normalizes the joint probabilities and is called the
partition function
For our kangaroo problem the MEP solution can be written as
with
The arguments of the exponents can be written in vector-matrix notation, using the constraint function matrix (
37)
The partition function then becomes
The joint probabilities (
42) are expressed in full as
and the three Lagrange parameters
are the solutions of the three constraint equations
This is a non-linear problem in three unknowns. Solving the Lagrange parameters usually requires an advanced numerical approximation technique. The Legendre transform provides such a method, which is described in detail by Blower ([
4], Ch. 24), and demonstrated in the code example in
Figure 4. In some cases, the
can be obtained exactly, as we will see below.
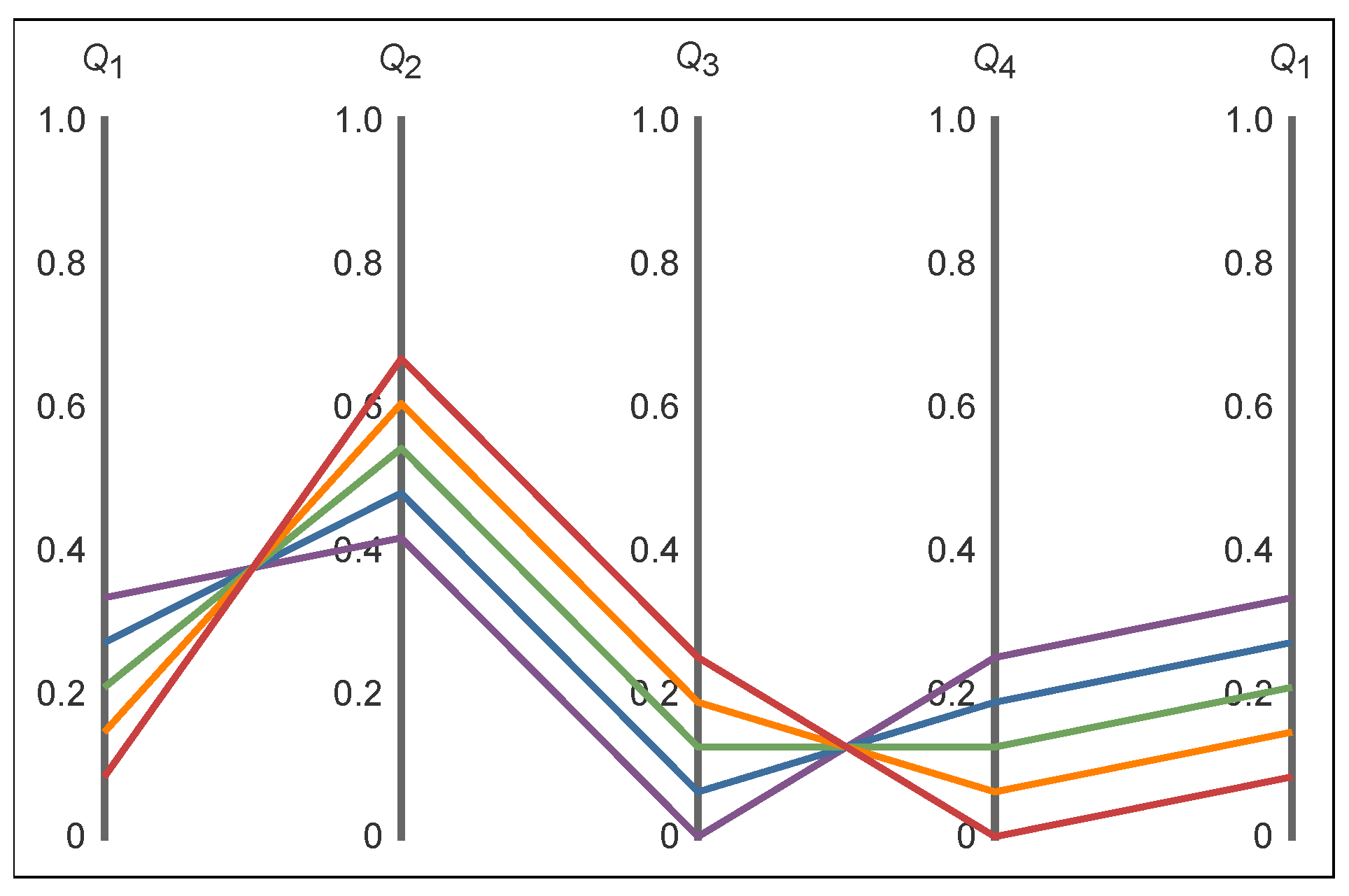
Our four models are distinguished only by their constraint function average,
, in (
39). The details are shown in
Table 13.
The constraint function vectors are shown in the second column. The three Lagrange parameters are shown in the third column. From this column one can learn that all three Lagrange parameters
vary, even when only the value of
is varied. Substituting these
in (
46), the probability distributions
of the last column are obtained. In our case, these MEP solutions are the same as those obtained by the variational principle methods in table in
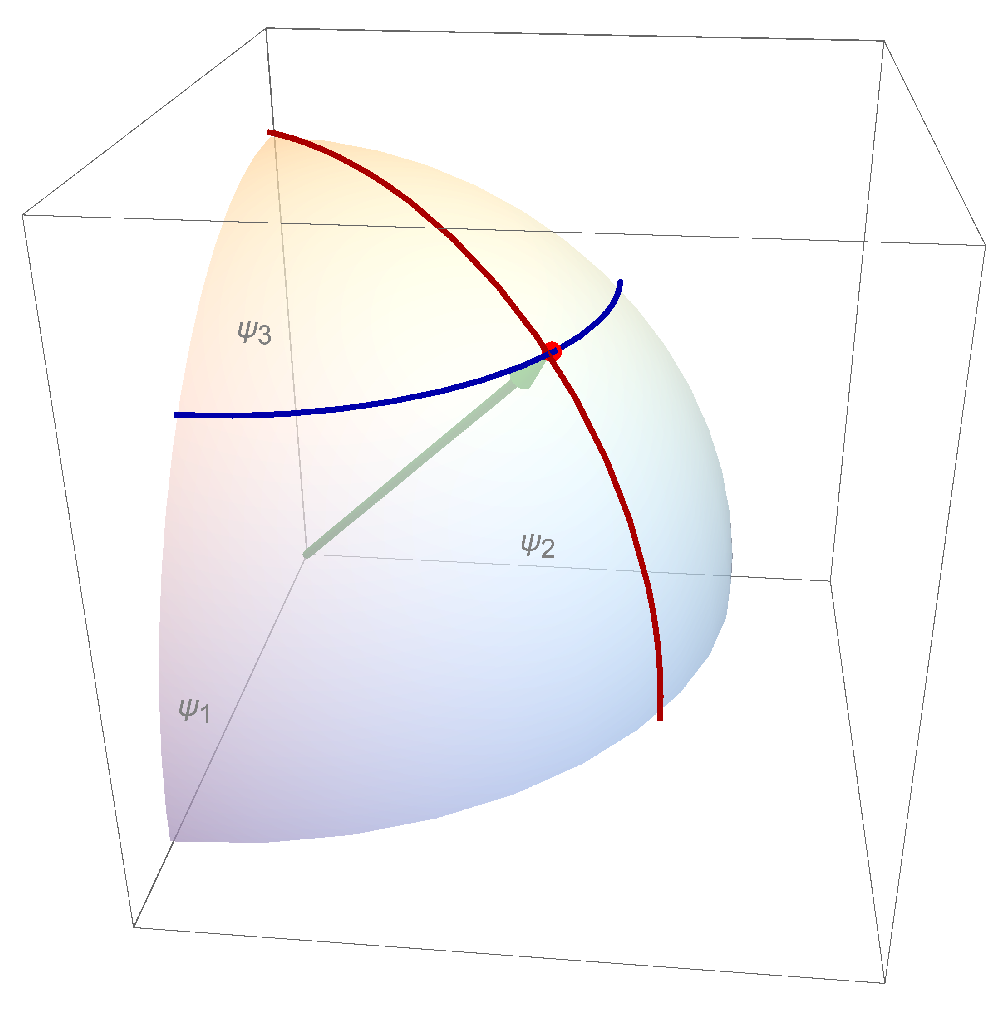
Table 6, but this need not be so in general. The Lagrange parameters
are related to the covariant coordinates
of information geometry in
Section 6.
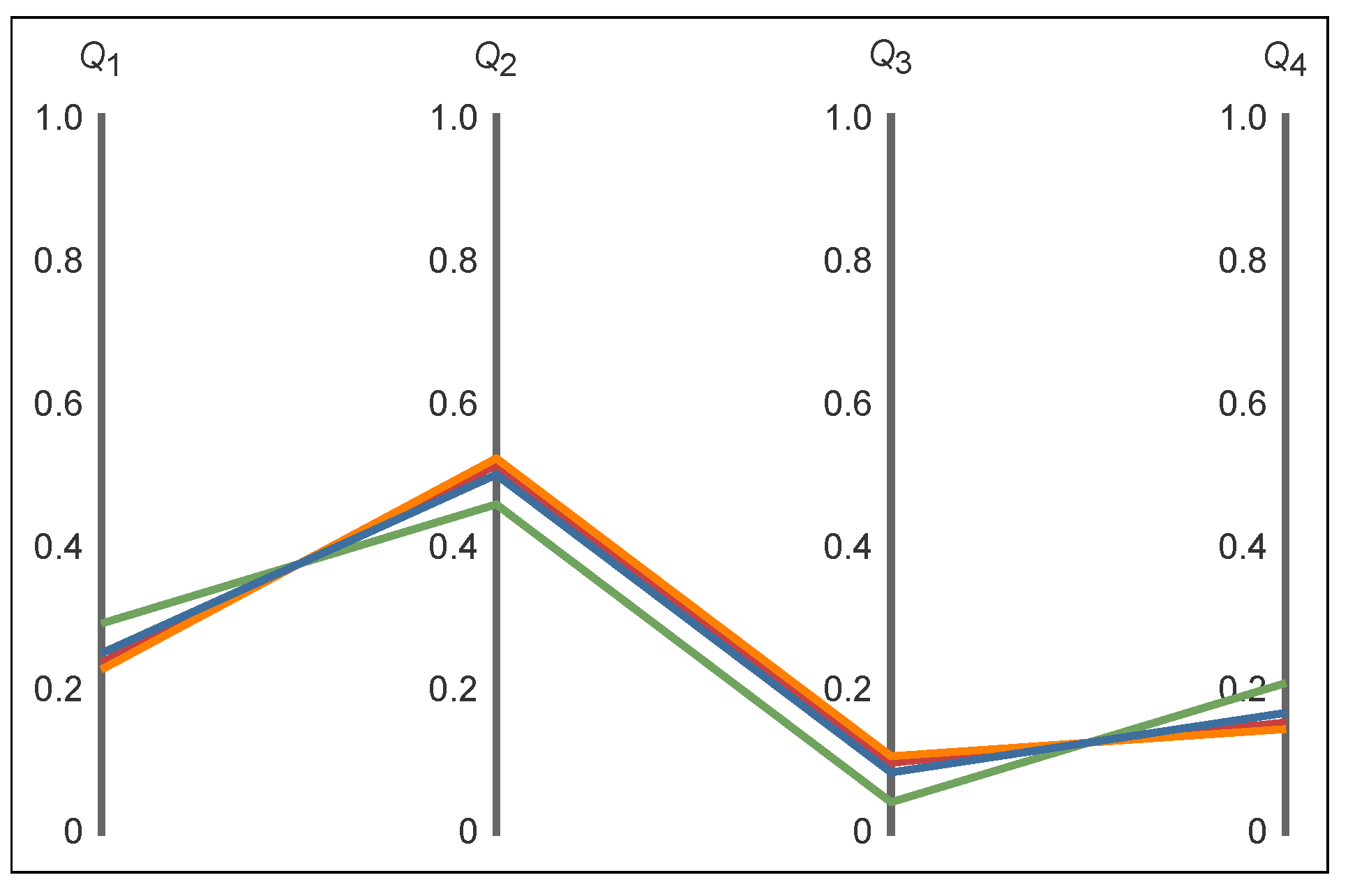
Close inspection of the table in
Table 13 reveals that the Lagrange multiplier
for
solution. This is an important observation because it signals that the
constraint function is redundant and, consequently, can be removed. The solution for the joint probabilities
using only
is identical to the one with
. Actually, we knew this already, as this was the basis of the solution in
Table 3, but the MEP provides a systematic method for detecting redundancies ([
6], p. 369, [
8], p. 108).
The Lagrange parameters can be solved algebraically for the
and the
models. Recall that the
and
models gave exact solutions for the
, namely from substituting (
8) and (
5) in (
2). From (
46), we see that
, therefore the value of the partition function is exactly known. Subsequently, the
can be solved algebraically from (
46).
Since the and the model results turn out to be identical, the distinction based on their solution method can now be dropped. For consistency, we keep the redundant constraint function in the model.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}