Abstract
The Full Bayesian Significance Test (FBST) has been proposed as a convenient method to replace frequentist p-values for testing a precise hypothesis. Although the FBST enjoys various appealing properties, the purpose of this paper is to investigate two aspects of the FBST which are sometimes observed as measure-theoretic inconsistencies of the procedure and have not been discussed rigorously in the literature. First, the FBST uses the posterior density as a reference for judging the Bayesian statistical evidence against a precise hypothesis. However, under absolutely continuous prior distributions, the posterior density is defined only up to Lebesgue null sets which renders the reference criterion arbitrary. Second, the FBST statistical evidence seems to have no valid prior probability. It is shown that the former aspect can be circumvented by fixing a version of the posterior density before using the FBST, and the latter aspect is based on its measure-theoretic premises. An illustrative example demonstrates the two aspects and their solution. Together, the results in this paper show that both of the two aspects which are sometimes observed as measure-theoretic inconsistencies of the FBST are not tenable. The FBST thus provides a measure-theoretically coherent Bayesian alternative for testing a precise hypothesis.
1. Introduction
Statistical hypothesis testing is an important method in a broad range of sciences [1]. However, the recent problems with the validity of research results have been termed a scientific replication crisis [2,3], at the core of which lie some fundamental flaws in the statistical analysis of data [4]. Various papers have discussed the reproducibility of research and often the inadequate use of null hypothesis significance tests (NHST) substantiates a major cause of the replication crisis [5]. This holds in particular in the biomedical and cognitive sciences [6,7], where the p-value is the gold standard for quantifying the evidence against a precise null hypothesis.
Bayesian hypothesis testing has become increasingly popular in the biomedical and cognitive sciences due to the above problems [8,9,10]. It is well known that Bayesian data analysis solves some of the problems of NHST by allowing researchers to make use of optional stopping [11,12] and by simplifying the interpretation of censored data [13]. Together, these aspects are consequence of Bayesian inference being consistent with the likelihood principle [13]. An appealing proposal for a Bayesian test of a precise hypothesis is the Full Bayesian Significance Test (FBST), which has been applied in a wide range of domains [8,14,15,16,17,18]. The FBST advocates the e-value as a Bayesian replacement of the frequentist p-value for quantifying the statistical evidence against a precise hypothesis [19]. The FBST is a fully Bayesian procedure [19], accords with the likelihood principle [15], and enjoys attractive asymptotic properties [20] next to transformation invariance [16]. However, the FBST seems to suffer from two aspects which are studied in detail in this paper. First, the reference criterion in the FBST is only defined up to Lebesgue null sets, which seems to be make the evidential threshold arbitrary. Thus, it seems that the FBST statistical evidence, the e-value, lacks a calibration. Second, the statistical evidence in the FBST seems to have no prior probability, which contradicts common Bayesian reasoning. For other criticisms on the FBST see Ly & Wagenmakers [21] and for a more optimistic perspective Kelter [22]. In this paper it is shown that both aspects can be solved by fixing a version of the posterior distribution for statistical inference, and assigning one of two possible interpretations to the prior probability of the statistical evidence in the FBST. These aspects have not yet been discussed extensively in the literature and present a further justification of the FBST as an attractive replacement of frequentist p-values to remedy the ongoing problems with the replication of scientific results. The plan of the paper is as follows: The next section outlines the theory behind the FBST. After that, the two problematic aspects mentioned above are detailed and illustrated by an example from medical research. The following section elaborates on the problems and provides solutions to them. After that, a conclusion is provided.
2. The Full Bayesian Significance Test
This section outlines the theory behind the FBST. First, the required notation is introduced.
2.1. Notation
In contrast to the frequentist approach, in the Bayesian approach the parameter is modelled as a random variable, and the data are fixed. Denote by the parameter space and as the -algebra on , and let be the prior probability measure on , leading to the triple . The observed sample is modelled by the random variable which takes values in the measurable space , where is endowed with a -algebra . The uncertainty in the data generating mechanism producing a sample for is modelled via the assumption of a statistical model which is dominated by a -finite measure . In practice, often is the Lebesgue measure . The latter requirement guarantees the existence of Radon-Nikodým derivatives . Let be the product space defined as , and the product measure induced by the selection of and , where must be a measurable function on for every y on . Thus, is the marginal distribution of with respect to the parameter , and the marginal distribution with respect to Y is the prior predictive for any . The parameter, as noted above, is modelled mathematically as a random variable . The resulting operational models from a Bayesian point of view are thus given as
- (1)
- the prior model
- (2)
- the statistical model on , leading to , and
- (3)
- the posterior model
The existence of the posterior distribution is guaranteed on Polish spaces [23] and inference about is conducted with respect to the posterior distribution with density , which exists under the assumption that where denotes absolute-continuity of with respect to the measure .
2.2. Theory behind the Full Bayesian Significance Test (FBST)
The Full Bayesian Significance Test (FBST) was originally developed by Pereira and Stern [14] as an alternative to frequentist null hypothesis significance tests based on the p-value. It was created under the assumption that a significance test of a sharp hypothesis had to be conducted, where a sharp hypothesis refers to any submanifold of the parameter space of interest [20]. This includes, in particular, precise hypotheses like for [15]. The FBST assumes a standard parametric statistical model, where is a (possibly vector-valued) parameter of interest, is the density corresponding to the model distribution and is the prior density corresponding to the prior distribution , where we again assume a dominating measure to guarantee the existence of Radon-Nikodým densities. A hypothesis H makes the statement that the parameter lies in the corresponding null set , where for simple (or precise) hypotheses , where is the value specified in . The Full Bayesian Significance Test (FBST) then defines two quantities: ev, which is the e-value supporting (or in favour of) the hypothesis H, and , the e-value against H, also called the Bayesian evidence value against H [14]. First, the posterior surprise function and its maximum restricted to the null set are introduced:
Definition 1
(Posterior surprise function). The posterior surprise function for a reference function from Θ to a measurable space is defined as
In the definition of the posterior surprise function , the denominator serves as a reference density, and often the measurable space is equal to . When the improper flat reference function is used, the surprise function becomes the posterior density . Otherwise, a weakly informative prior density can be used as a reference function, see Pereira and Stern [16]. Then,
is defined as the supremum of the surprise function over the null hypothesis support. For a precise null hypothesis, is simply . Next, the tangential set is introduced:
Definition 2
(Tangential set). The tangential set is defined as
where
Thus, includes all parameter values which attain a surprise function value smaller or equal to the threshold . The tangential set is then the set complement and includes all parameter values which yield a surprise function value larger than . Fixing yields , which is called the tangential set to the hypothesis H. This set contains the points of the parameter space with higher surprise (or corroboration relative to the reference function ) than the point in the null set . Then, the cumulative surprise function is introduced which is required to compute the e-value in the final step:
Definition 3
(Cumulative surprise function). The map given by
is called the complementary cumulative surprise function, and
is called the cumulative surprise function.
Thus, the complementary cumulative surprise function is the integral of the posterior density over the set , and the cumulative surprise function is simply the integral of the posterior density over the tangential set . The final step towards the e-value is to integrate the posterior density over this set:
Definition 4
(e-value). The e-value against a sharp null hypothesis is defined as
and can be interpreted as the Bayesian evidence against .
Clearly, is the integral of the density over the tangential set , which can be interpreted as the integral of the posterior density over all parameter values which fulfill the condition . The e-value ev supporting H is obtained as ev under . Large values of thus indicate that the hypothesis H traverses low-density regions (or equivalently, that the alternative hypothesis traverses high-density regions) so that the evidence against is large. For the argument is identical as traverses low posterior-surprise regions then.
For theoretical properties of the FBST and the e-value see Pereira and Stern [16] and Kelter [18]. The FBST then uses ev to reject H if ev is sufficiently small (or when is large) [14,15].
3. On Two Aspects of the FBST
Now, this section demonstrates the two aspects briefly mentioned in the introduction based on an illustrative example.
3.1. The Reference Criterion
To illustrate the first problem, data of Rosenman et al. [24] of the Western Collaborative Group Study about coronary heart disease is used.
Example 1
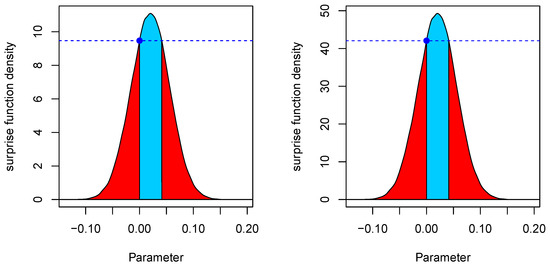
(Coronary heart disease data). The Western Collaborative Group Study began in 1960 with 3524 male volunteers who were 39 to 59 years old and free of heart disease as determined by electrocardiogram. After the initial screening, the study population dropped to 3154 because of various exclusions. Multiple endpoints were studied and average follow-up continued for years with repeat examinations. As an illustrative example, suppose interest lies in testing for differences in systolic blood pressure between light smokers and heavy smokers. Thus, we test the hypothesis against the alternative where we classify participants with more than 5 cigarettes per day as heavy smokers. A Bayesian two-sample t-test using the model of Rouder et al. [25] is conducted, and the left plot in Figure 1 shows the results of the FBST using a flat reference function . The model is parameterized in the effect size δ of Cohen [26], and the e-value is given as , which equals the posterior probability mass visualized as the blue area in the left plot of Figure 1. Thus, 43.62% of the posterior probability indicate evidence against the null hypothesis, and the situation is inconclusive. The right plot in Figure 1 shows the result of the FBST when replacing the flat reference function with a Cauchy density (note the different scaling on the y-axis), which is also used as the prior on δ in the two-sample t-test. In this case, the e-value indicates a similarly inconclusive situation and changes the result barely.
Figure 1.
Results of the Full Bayesian Significance Test using a flat reference function (left) and a Cauchy density as reference function (right) for testing the hypothesis of no difference in terms of systolic blood pressure between smokers and non-smokers.
Now, the above example shows that calculation of the e-value is straightforward and universally applicable. However, the parameter space is continuous in the example (the effect size is a continuous quantity) and any usual prior distribution assigned to is absolutely continuous with respect to the Lebesgue measure . It is well-known that the posterior distribution is absolutely continuous with respect to the prior distribution [27], and thus any -null-set with is also a -null-set with . Problematically, the set which is used in the precise null hypothesis is a -null-set under both the improper flat and Cauchy prior, as both of these are absolutely continuous with respect to the Lebesgue measure , and submanifolds are Lebesgue-null-sets [28]. Thus, implies due to , which implies in turn that the posterior probability of the value is a -null-set due to . As a consequence, the value of the posterior density which is shown as the blue point in the left plot of Figure 1 could be chosen arbitrarily. Problematically, this value is used as the reference criterion in the calculation of the e-value in the computation of the tangential set . Thus, one could assign an entirely different value, say, , and obtain a different e-value than the one calculated from the value . This seems to render the calculation of the statistical evidence in the FBST arbitrary, questioning the use of the procedure.
3.2. Prior Probability of the e-Value
The second issue with the FBST may be phrased as the e-value having no valid prior probability. In fact, the e-value in Equation (7) is based on the cumulative surprise function , which itself depends on the tangential set and the posterior density . Before data are observed, the posterior has not been realized as and thus there exists no prior probability which is associated with the e-value. Even the tangential set which is a subset of seems to have no prior probability, because it depends on the surprise function which itself depends on the posterior density , compare Equation (1). Thus, the statistical evidence in the FBST seems to escape the natural Bayesian transition from prior to posterior probability.
4. Solutions to the Two Aspects
4.1. The Reference Criterion
If the above criticism that the reference criterion in the FBST is arbitrary would hold, the procedure would be of little use in practice. However, the solution to the problem is given by fixing a specific version of the posterior distribution and performing all calculations conditional on fixing such a version. It is well known that probability distributions (which are probability measures corresponding to a random variable) are defined up to Lebesgue-null-sets (when they are dominated by the Lebesgue measure). The values on null-sets do not influence these probability measures and therefore they are identified with each other whenever they only differ on Lebesgue-null-sets [28]. Technically, this corresponds to the shift from the vector space
on a probability space , for to the quotient space , see Bauer [28]. The latter space is defined as , where
and the elements in are equivalence classes. Thus, two elements are equal if and only if they differ only on -null-sets, that is, . Thus, the arbitrariness of the reference criterion in the FBST exists only unless a specific representant of the equivalence class, in which the posterior density is located, is selected. In the context of Example 1, this implies that a specific version of the posterior density needs to be chosen, which fixes the densities value on (and the other values ). Thus, setting explicitly by definition fixes one representant of the equivalence class of and bypasses the problem that the reference threshold in the FBST is arbitrary. Whenever the posterior is obtainable as a closed-form solution, that is, follows a well-known probability density with Lebesgue-density , setting as the value of this known probability density for the posterior density p in the FBST by definition solves the first problem. Whenever numerical techniques like Markov-Chain-Monte-Carlo (MCMC) are used to produce the posterior, the resulting posterior distribution and the posterior density approximate the true posterior distribution and the posterior Lebesgue-density . Thus, setting by definition for a fixed numerical technique like MCMC with given random number generator seed fixes a version of the posterior density and renders the reference threshold in the FBST unique. In Example 1 this equals the choice of by definition (as MCMC sampling was used), and for all . In summary, the above considerations provide the following result:
Theorem 1.
Let be the supremum of the surprise function in the Full Bayesian Significance Test, and and the corresponding vector spaces on with quotient space for . Whenever is a known probability distribution with Lebesgue-density , defining pointwise for all renders the e-value against for well-defined and unique for the choice of .
Proof.
See Appendix A. □
Note that when using numerical methods such as MCMC, ergodic theory ensures that in distribution and , that is, the MCMC posterior density approximates the posterior Lebesgue-density pointwise with increasing precision for increasing number of MCMC samples [29]. Thus, fixing a version of the posterior, Theorem 1 extends also to situations where numerical techniques such as MCMC are required.
4.2. Prior Probability of the e-Value
The solution to the second problem is more involved and less technical. Conceptually, from the above line of thought it is immediate that under absolutely continuous priors with respect to the Lebesgue measure , the prior probability will be zero for any precise null hypothesis with for . The posterior is absolutely continuous with respect to the prior , so . Thus, it is simply not possible to use a natural Bayesian workflow which assigns positive probability mass to a Lebesgue-null-set whenever the statistician uses an absolutely continuous prior distribution with respect to . Traditional Bayesian hypothesis testing and model selection bypasses this inconvenience by introducing an arbitrary mixture prior structure which assigns positive probability mass to the null set , and distributes the rest of the probability mass by means of a probability distribution on the alternative hypothesis space . Early proposals of such a mixture prior structure include Jeffreys [30] and Haldane [31], see also Robert [29] and Kleijn [23]. Such a prior allows computation of a Bayes factor, and furthermore, the Bayes factor itself also has no prior probability which is naturally associated with it. Importantly, this mixture prior structure imposes a dichotomy between hypothesis testing and parameter estimation, because such a mixture prior structure is reasonable only from a hypothesis testing perspective. Whenever parameter estimation is the goal, the assignment of probability mass to a specific value is highly questionable and often contradicts reasonable a priori beliefs. In these cases, prior beliefs are expressed better through a prior which is absolutely continuous with respect to the Lebesgue measure .
The FBST avoids the introduction of such a mixture structure and thus allows for a unified prior elicitation which is coherent both from a Bayesian hypothesis testing and Bayesian parameter estimation stance. Importantly, the e-value is intended to be a Bayesian replacement of the frequentist p-value which measures the statistical discrepancy between the observed data to an assumed precise hypothesis. Thus, the e-value provides the Bayesian evidence against such a precise hypothesis. From a measure-theoretic point of view, every precise null hypothesis is assumed to be false and the FBST thus aligns with the empirical rationalism of Popper [32]. For the use of testing a precise hypothesis as an approximation of a small interval hypothesis see Berger [33], Rousseau [34], Rao & Lovric [35] as well as Kelter [36]: Often, the approximation of a small interval hypothesis via a precise point null hypothesis will be bad, and thus the e-value does not assign positive probability mass to such a precise null hypothesis. Instead, the FBST quantifies the discrepancy between the observed data and the hypothetical precise null value, while simultaneously implementing I.J. Good’s principle of least surprise [37,38,39]. Note further that the mathematical introduction of positive prior probability to a precise value when using a mixture prior does not render such a precise hypothesis more realistic in practice.
Furthermore, next to its measure-theoretic premises, there exists another argument which weakens the criticism that there is no prior probability of the e-value: When a prior distribution is selected and no data has been observed, the posterior distribution can be identified conceptually as the prior distribution. Thus, replacing the posterior density with the -density of the prior yields , which implies that the tangential set for includes those parameter values for which . Using the fact that for a precise hypothesis then, yields . Plugging this tangential set into Equation (6) yields the e-value
which is the integral of the prior density over . When the reference function is chosen as a flat improper prior , this becomes
which is the integral of the prior density over all values which attain higher prior density values than the null value in . Thus, the e-value in such a case quantifies the discrepancy of the precise hypothesis with the prior beliefs . The above line of thought provide the following result:
Theorem 2.
Let . In case no data has been observed, the e-value quantifies the discrepancy between the precise hypothesis for and and the prior distribution , that is,
Proof.
See Appendix A. □
Whenever , the interpretation is more complicated because such a reference function incorporates a surprise element into the tangential set, but the conclusions remain the same. The e-value then quantifies the discrepancy between the precise hypothesis and the prior surprise.
5. Discussion
The Full Bayesian Significance Test (FBST) has been proposed as a convenient method to replace frequentist p-values for testing a precise hypothesis [14,15,16]. Although the FBST enjoys various appealing properties [8,19,20,40], two aspects of the FBST are sometimes observed as measure-theoretic inconsistencies of the procedure and have not been discussed rigorously in the literature. First, the FBST uses the posterior density as a reference for judging the Bayesian statistical evidence against a precise hypothesis. However, under absolutely continuous prior distributions, the posterior density is defined only up to Lebesgue null sets which renders the reference criterion arbitrary. Second, the FBST statistical evidence seems to have no valid prior probability. In this paper, it was shown that the former problem can be circumvented by fixing a version of the posterior density before using the FBST. Theorem 1 demonstrated that then, the e-value is well-defined and unique after observing the data .
The latter aspect is based on the measure-theoretic premises of the FBST. As shown in this paper, the FBST avoids the use of a mixture prior structure which imposes a dichotomy between Bayesian hypothesis testing and parameter estimation. Thus, the FBST is compatible with absolutely continuous priors with respect to the Lebesgue measure (the Bayes factor, for example, is not). As a consequence, there exists no prior probability of the e-value and a precise hypothesis under an absolutely continuous prior . Theorem 2 showed that even then, the e-value has a proper interpretation from a prior perspective: It quantifies the a priori discrepancy of the hypothesis with the prior beliefs which are expressed by whenever the reference function is flat. When , the interpretation is more difficult but the conclusion remains the same.
Together, the results in this paper show that both of the two aspects which are sometimes observed as measure-theoretic inconsistencies of the FBST are not tenable. The FBST thus provides a measure-theoretically coherent Bayesian alternative for testing a precise hypothesis.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The R code to recreate all analyses and plots can be found at the Open Science Foundation at https://osf.io/25vsw/?view_only=e1e243c1e2a44646969fb75cc4c34d57.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| FBST | Full Bayesian Significance Test |
| NHST | Null Hypothesis Significance Testing |
Appendix A
Proof of Theorem 1.
From Definition 1 and Equation (2) it follows that the tangential set becomes , which equals the set
where the first equality uses Definition 2 and the second equality uses for a precise hypothesis for . By assumption, the posterior distribution is known to take the form with Lebesgue-density . Defining the posterior density pointwise as implies that the value is equal to . Thus, the tangential set in Equation (A1) is well-defined and unique for this fixed value . From Definition 3 and Equation (7) it follows that the e-value is well-defined and unique for the choice of . □
Proof of Theorem 2.
Let be the prior distribution and . Suppose no data has been observed, then the posterior distribution can be identified as the prior distribution . Thus, replacing the posterior density with the -density of the prior yields , which implies that the tangential set for includes the parameter values which fulfill the condition . It follows that for a precise hypothesis , and this yields for the tangential set to . Using the latter in Equation (6) yields the e-value
which is the integral of the prior density over . By assumption, , so this becomes
which is the statement in Equation (10). □
References
- Gigerenzer, G. Mindless statistics. J.-Socio-Econ. 2004, 33, 587–606. [Google Scholar] [CrossRef]
- Pashler, H.; Harris, C.R. Is the Replicability Crisis Overblown? Three Arguments Examined. Perspect. Psychol. Sci. 2012, 7, 531–536. [Google Scholar] [CrossRef]
- Baker, M.; Penny, D. Is there a reproducibility crisis? Nature 2016, 533, 452–454. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McElreath, R.; Smaldino, P.E. Replication, communication, and the population dynamics of scientific discovery. PLoS ONE 2015, 10, 1–16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ioannidis, J.P.A. What Have We (Not) Learnt from Millions of Scientific Papers with p-Values? Am. Stat. 2019, 73, 20–25. [Google Scholar] [CrossRef] [Green Version]
- Button, K.S.; Ioannidis, J.P.; Mokrysz, C.; Nosek, B.A.; Flint, J.; Robinson, E.S.; Munafò, M.R. Power failure: Why small sample size undermines the reliability of neuroscience. Nat. Rev. Neurosci. 2013, 14, 365–376. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kelter, R. Bayesian alternatives to null hypothesis significance testing in biomedical research: A non-technical introduction to Bayesian inference with JASP. BMC Med. Res. Methodol. 2020, 20, 1–12. [Google Scholar] [CrossRef]
- Kelter, R. Analysis of Bayesian posterior significance and effect size indices for the two-sample t-test to support reproducible medical research. BMC Med. Res. Methodol. 2020, 20, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Kelter, R. Bayesian survival analysis in STAN for improved measuring of uncertainty in parameter estimates. Meas. Interdiscip. Res. Perspect. 2020, 18, 101–119. [Google Scholar] [CrossRef]
- Wagenmakers, E.J.; Morey, R.D.; Lee, M.D. Bayesian Benefits for the Pragmatic Researcher. Curr. Dir. Psychol. Sci. 2016, 25, 169–176. [Google Scholar] [CrossRef]
- Edwards, W.; Lindman, H.; Savage, L.J. Bayesian statistical inference for psychological research. Psychol. Rev. 1963, 70, 193–242. [Google Scholar] [CrossRef]
- Hendriksen, A.; de Heide, R.; Grünwald, P. Optional Stopping with Bayes Factors: A Categorization and Extension of Folklore Results, with an Application to Invariant Situations. Bayesian Anal. 2020, in press. [Google Scholar] [CrossRef]
- Berger, J.; Wolpert, R.L. The Likelihood Principle; Institute of Mathematical Statistics: Hayward, CA, USA, 1988. [Google Scholar]
- Pereira, C.A.d.B.; Stern, J.M. Evidence and credibility: Full Bayesian significance test for precise hypotheses. Entropy 1999, 1, 99–110. [Google Scholar] [CrossRef]
- Pereira, C.A.d.B.; Stern, J.M.; Wechsler, S. Can a Significance Test be genuinely Bayesian? Bayesian Anal. 2008, 3, 79–100. [Google Scholar] [CrossRef]
- Pereira, C.A.d.B.; Stern, J.M. The e-value: A fully Bayesian significance measure for precise statistical hypotheses and its research program. São Paulo J. Math. Sci. 2020, 1–19. [Google Scholar] [CrossRef]
- Kelter, R. Simulation data for the analysis of Bayesian posterior significance and effect size indices for the two-sample t-test to support reproducible medical research. BMC Res. Notes 2020, 13, 1–3. [Google Scholar] [CrossRef]
- Kelter, R. fbst: An R package for the Full Bayesian Significance Test for testing a sharp null hypothesis against its alternative via the e-value. Behav. Res. Methods 2021, in press. [Google Scholar] [CrossRef]
- Madruga, M.R.; Esteves, L.G.; Wechsler, S. On the Bayesianity of Pereira-Stern tests. Test 2001, 10, 291–299. [Google Scholar] [CrossRef]
- Diniz, M.; Pereira, C.A.B.; Polpo, A.; Stern, J.M.; Wechsler, S. Relationship between Bayesian and frequentist significance indices. Int. J. Uncertain. Quantif. 2012, 2, 161–172. [Google Scholar] [CrossRef]
- Ly, A.; Wagenmakers, E.J. A Critical Evaluation of the FBST ev for Bayesian Hypothesis Testing. Comput. Brain Behav. 2021, 1–8. [Google Scholar] [CrossRef]
- Kelter, R. On the Measure-Theoretic Premises of Bayes Factor and Full Bayesian Significance Tests: A Critical Reevaluation. Comput. Brain Behav. 2021, 1–11. [Google Scholar] [CrossRef]
- Kleijn, B. The Frequentist Theory of Bayesian Statistics; Springer: Amsterdam, The Netherlands, 2020. [Google Scholar]
- Rosenman, R.H.; Brand, R.J.; Jenkins, D.; Friedman, M.; Straus, R.; Wurm, M. Coronary heart disease in Western Collaborative Group Study. Final follow-up experience of 8 1/2 years. JAMA 1975, 233, 872–877. [Google Scholar] [CrossRef]
- Rouder, J.N.; Speckman, P.L.; Sun, D.; Morey, R.D.; Iverson, G. Bayesian t tests for accepting and rejecting the null hypothesis. Psychon. Bull. Rev. 2009, 16, 225–237. [Google Scholar] [CrossRef]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed.; Routledge: Hillsdale, NJ, USA, 1988. [Google Scholar]
- Schervish, M.J. Theory of Statistics; Springer Verlag: New York, NY, USA, 1995. [Google Scholar]
- Bauer, H. Measure and Integration Theory; De Gruyter: Berlin, Germany, 2001. [Google Scholar]
- Robert, C.P. The Bayesian Choice, 2nd ed.; Springer New York: Paris, France, 2007. [Google Scholar] [CrossRef]
- Jeffreys, H. Theory of Probability, 1st ed.; The Clarendon Press: Oxford, UK, 1939. [Google Scholar]
- Haldane, J.B.S. A note on inverse probability. Math. Proc. Camb. Philos. Soc. 1932, 28, 55–61. [Google Scholar] [CrossRef]
- Popper, K. The Logic of Scientific Discovery; Routledge: London, UK; New York, NY, USA, 1959. [Google Scholar] [CrossRef]
- Berger, J. Statistical Decision Theory and Bayesian Analysis; Springer: New York, NY, USA, 1985. [Google Scholar]
- Rousseau, J. Approximating Interval hypothesis: P-values and Bayes factors. In Bayesian Statistics; Bernado, J., Berger, J., Dawid, A., Smith, A., Eds.; Oxford University Press: Valencia, Spain, 2007; Volume 8, pp. 417–452. [Google Scholar]
- Rao, C.R.; Lovric, M.M. Testing point null hypothesis of a normal mean and the truth: 21st Century perspective. J. Mod. Appl. Stat. Methods 2016, 15, 2–21. [Google Scholar] [CrossRef]
- Kelter, R. Bayesian and frequentist testing for differences between two groups with parametric and nonparametric two-sample tests. Wires Comput. Stat. 2020, 13, e1523. [Google Scholar] [CrossRef]
- Good, I. Surprise index. In Encyclopedia of Statistical Sciences; Kotz, S., Johnson, N., Reid, C., Eds.; John Wiley & Sons: New York, NY, USA, 1988; Volume 7. [Google Scholar]
- Good, I. C332. Surprise indexes and p-values. J. Stat. Comput. Simul. 1989, 32, 90–92. [Google Scholar] [CrossRef]
- Good, I.J. C420. The existence of sharp null hypotheses. J. Stat. Comput. Simul. 1994, 49, 241–242. [Google Scholar] [CrossRef]
- Stern, J.M. Significance tests, Belief Calculi, and Burden of Proof in legal and Scientific Discourse. Front. Artif. Intell. Its Appl. 2003, 101, 139–147. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).