Abstract
The COVID-19 pandemic has accelerated the shift towards online education, making it a critical focus for educational institutions. Understanding students’ adaptability to this new learning environment is crucial for ensuring their academic success. This study aims to predict students’ adaptability levels in online education using a dataset of 1205 observations that incorporates sociodemographic factors and information collected across different educational levels (school, college, and university). Various machine learning (ML) and deep learning (DL) models, including decision tree (DT), random forest (RF), support vector machine (SVM), K-nearest neighbors (KNN), XGBoost, and artificial neural networks (ANNs), are applied for adaptability prediction. The proposed ensemble model achieves superior performance with 95.73% accuracy, significantly outperforming traditional ML and DL models. Furthermore, explainable AI (XAI) techniques, such as LIME and SHAP, were employed to uncover the specific features that significantly impact the adaptability level predictions, with financial condition, class duration, and network type emerging as key factors. By combining robust predictive modeling and interpretable AI, this study contributes to the ongoing efforts to enhance the effectiveness of online education and foster student success in the digital age.
1. Introduction
The rapid digital transformation of education, accelerated by the COVID-19 pandemic, has fundamentally altered how students engage with learning environments. This shift has highlighted the critical importance of understanding and predicting students’ adaptability to online education platforms. While the transition to virtual learning environments has provided unprecedented accessibility and flexibility, it has also revealed significant disparities in students’ capacity to adapt to these new educational paradigms [1].
Student adaptability in online education encompasses various dimensions, including technological readiness, socioeconomic factors, and individual learning capabilities [2]. Recent studies have shown that successful adaptation to online learning environments is crucial for academic success [3], with students’ ability to adjust to virtual platforms directly impacting their learning outcomes [4]. However, the complex interplay of factors that affect student adaptability presents a significant challenge for educational institutions in providing targeted support and interventions.
Recent advances in ML have opened new avenues for analyzing student performance and adaptability in online education [5,6,7]. Studies have demonstrated the effectiveness of algorithms like random forest, support vector machine (SVM), and artificial neural networks (ANNs) in predicting student outcomes [8,9]. Furthermore, XAI techniques such as SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) have added interpretability to these predictive models, making them more transparent and actionable [10,11]. Although existing research highlights the potential of ML and XAI in education, there is a significant need for models that balance predictive accuracy with interpretability in diverse educational contexts. Previous studies often focus on standalone algorithms, overlooking the complementary strengths of ensemble approaches. Additionally, few models provide actionable insights into the sociodemographic and behavioral factors influencing adaptability.
The primary objective of this study is to develop and validate an interpretable ensemble model to predict student adaptability in online education environments. The main contributions of this research are as follows:
- Development of a novel ensemble model that combines multiple machine learning classifiers through a soft voting mechanism, achieving superior prediction accuracy (95.73%) compared to traditional standalone models.
- Integration of explainable AI techniques (SHAP and LIME) to provide transparent insights into the model’s decision-making process, making the predictions more interpretable and actionable for educational stakeholders.
- Identifying and quantifying key factors influencing student adaptability, including financial condition, class duration, and network type, provides valuable information for policy development and resource allocation.
- Validation of the model’s effectiveness using a comprehensive dataset collected during the pandemic, offering insights into student adaptability under extraordinary circumstances.
The remainder of this paper is organized as follows: Section 2 presents a comprehensive review of the existing literature in the field of student adaptability prediction and machine learning applications in education. Section 3 details the methodology, including dataset characteristics, preprocessing techniques, and the architecture of the proposed ensemble model. Section 4 presents various machine learning models’ experimental results and comparative analysis. Section 5 discusses the integration of explainable AI techniques and their insights. Finally, Section 6 provides a detailed discussion of the findings, implications, and limitations of this study. Section 7 concludes this study with future research directions.
2. Literature Review
The rapid transition to online education, primarily driven by the COVID-19 pandemic, has amplified the need for innovative approaches to analyzing and enhancing student adaptability and performance in virtual learning environments [12]. Existing research underscores the transformative potential of machine learning (ML) and explainable AI (XAI) in achieving these goals, with studies ranging from predictive modeling to in-depth interpretability analysis.
The authors of [13] highlighted the benefits of online education by demonstrating comparable student performance and satisfaction across on-campus and off-campus environments. Their findings emphasize the growing necessity of integrating ML tools to maintain educational quality in diverse learning settings. Similarly, a comprehensive study conducted at Bradley University [14] tested eight ML algorithms, including decision trees, support vector machines (SVMs), and logistic regression, for predictive analytics in STEM education. The research revealed that careful algorithm selection and parameter tuning could significantly enhance educational outcomes, setting the stage for the widespread adoption of ML-based systems.
Another study focused on predicting student pass rates in online education environments [15]. It introduced a feature-based model that leveraged decision tree (DT) and SVM algorithms optimized using grid search alongside deep neural networks (DNNs). Among these, DNNs demonstrated superior accuracy, reinforcing the importance of advanced ML techniques in improving student success rates and optimizing online educational management. In another study, the authors [16] proposed a novel classification method for blended courses based on students’ online learning behaviors using the expectation–maximization algorithm, improving the accuracy of learning outcome predictions via random forest models. The findings highlight that higher prediction accuracy is achieved when students engage diversely in online activities rather than focusing on a single type. Leveraging a dataset of 30,000 students, another work [17] explored random forest and regression models to predict academic success in online courses, identifying critical behaviors, such as assignment submission and forum activity, and offering actionable insights to reduce dropout rates in smart university platforms. The emergence of explainable AI (XAI) has added a critical layer of interpretability to predictive models. For instance, a study on student adaptability [8] employed random forest (RF) models combined with XAI methods such as SHAP and LIME, achieving an impressive 91% accuracy. The analysis identified key influencing factors, including financial condition and class duration, providing actionable insights for educators and policymakers. Another investigation into virtual learning environments [10] expanded on this by using demographic and behavioral data to predict performance across various stages of course completion. By achieving 91% accuracy with RF and leveraging global and local interpretability, the study facilitated targeted instructor interventions, demonstrating the power of XAI in educational settings.
Research also explores the future implications of AI-driven education, particularly with the integration of Industry 4.0 technologies. One study [18] highlighted the benefits and challenges of implementing AI in classroom settings during the pandemic. This research leveraged neural networks (NNs) to predict student adaptability, achieving a classification accuracy of 93%. The study emphasized the potential of explainable machine learning (XML) techniques in providing transparency to AI-driven decisions, addressing the ethical concerns often associated with “black box” algorithms.
Early prediction frameworks have also gained prominence as tools for identifying at-risk students. A robust framework [19] utilized ML models like logistic regression, decision trees, and ensemble methods (e.g., XGBoost), achieving 83.77% accuracy by the 8th week of the course. This framework incorporated XAI techniques, allowing for educators to tailor interventions effectively. Similarly, another study analyzed student adaptability during the COVID-19 pandemic [9] employed sociodemographic and learning environment data, evaluating models such as decision trees, random forest, and artificial neural networks (ANNs). The random forest model achieved the best accuracy of 89.63%, emphasizing the importance of model selection and data representation.
Building on these advancements, the authors [11] proposed a comprehensive framework that integrates regression, classification, and predictive models to analyze and predict student performance. This framework employed algorithms like random forest, SVM, and neural networks, achieving a precision of up to 95%. By incorporating SHAP and LIME analysis, the framework identified critical performance indicators, such as financial condition, class duration, and network type, enabling educators to design targeted interventions. Additionally, the framework’s use of synthetic oversampling techniques to address class imbalances underscores its robustness in handling real-world datasets.
While previous research has made significant strides in applying ML and XAI techniques to online education, there remains a crucial gap in developing comprehensive ensemble models that can accurately predict student adaptability and provide interpretable insights across diverse learning contexts. The current study addresses this gap by proposing a novel interpretable ensemble model to predict student adaptability in online education.
3. Methodology
Figure 1 demonstrates a comprehensive flowchart illustrating the complete methodological framework of this study.
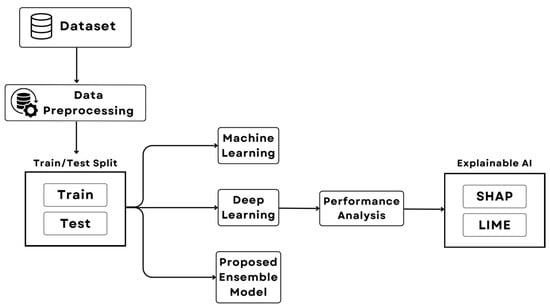
Figure 1.
Overview of the methodological workflow followed in this study, detailing the stages of data collection, preprocessing, model experimentation, and evaluation using performance metrics and explainable AI techniques.
3.1. Dataset
The dataset [9] used in this study encompasses 1205 observations, with each entry representing a student and their corresponding sociodemographic and educational attributes. Comprising 13 distinct features, along with the target variable “Adaptivity Level”, the data categorizes students into three different groups: High, Low, and Moderate adaptability levels. The data collection was conducted during the implementation of pandemic-related restrictions, presenting an unprecedented opportunity to examine student adaptability under extraordinary circumstances. This period of significant educational disruption, characterized by the rapid transition to remote learning environments, provides a valuable context for understanding students’ capacity to adapt to sudden systemic changes.
The dataset comprises various attributes reflective of students’ demographics, educational background, and technological access. The characteristics are summarized as follows:
- Gender: The dataset includes 1205 entries, with “Boy” being the most frequent category (603 instances).
- Age: The data spans six categories, with the most common age group being “21–25” (374 instances).
- Education Level: Distributed across three categories, with “School” as the most frequent (530 instances).
- Institution Type: Predominantly comprising “non-Government” institutions (623 instances).
- IT Student: Most are not IT students, with 501 entries labeled “No”.
- Location: Predominantly urban areas, with 135 entries labeled “Yes”.
- Load-shedding: A significant portion reported “Low” load-shedding (1004 entries).
- Financial Condition: Students categorized as Poor, Mid, and Rich, with “Mid” being the most common (676 instances).
- Internet Type: Most students reported using “Mobile Data” (655 instances).
- Network Type: “4G” is the dominant category (775 instances).
- Class Duration: The majority report a duration of “1–3 h” (840 instances).
- Self LMS: A large majority do not use LMS platforms (955 entries labeled “No”).
- Device: Most students access online education via mobile devices (1013 entries).
Figure 2 depicts the distribution of the target variable, “Adaptivity Level”, which is imbalanced with “Moderate” adaptability being the most frequent class (625 instances, 51.9%), followed by “Low” (480 instances, 39.8%), and “High” (100 instances, 8.3%).
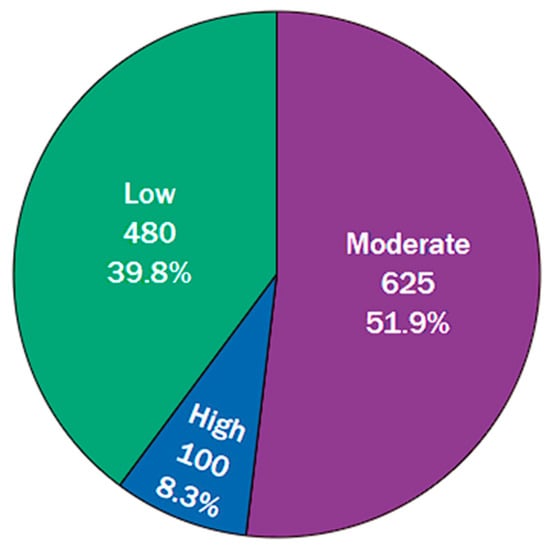
Figure 2.
Distribution of Adaptivity Levels in the dataset. The pie chart illustrates the proportions of students categorized as “High”, “Moderate”, and “Low” adaptability.
Data Preprocessing
To ensure the dataset was suitable for machine learning and deep learning models, preprocessing steps were undertaken, including encoding categorical variables and balancing the target variable.
Categorical features were encoded using an Ordinal Encoding method, which assigned numerical values to categories based on a predefined order. This method ensured that the encoding reflected natural or domain-specific hierarchies within the data. The following are examples of the encoding applied:
- Gender: “Boy” was encoded as 0, and “Girl” as 1.
- Age: Categories ranged from “1–5” (0) to “26–30” (5).
- Financial Condition: Encoded as “Poor” (0), “Mid” (1), and “Rich” (2).
- Adaptivity Level: Encoded as “High” (0), “Low” (1), and “Moderate” (2).
To address the imbalance in the “Adaptivity Level” target variable, the Synthetic Minority Oversampling Technique (SMOTE) was applied. This method generates synthetic samples for the minority classes to create a balanced dataset. After applying SMOTE, each class had an equal number of 625 instances, ensuring that the model was not biased toward the majority class. The balancing improved the dataset’s representativeness and enhanced the predictive performance of the models.
3.2. ML and DL Models
The analysis included several machine learning (ML) and deep learning (DL) models, each with its unique characteristics and strengths:
- Multinomial Logistic Regression: This linear model serves as a baseline classifier for multiclass problems. While it demonstrated moderate accuracy, its simplicity makes it suitable for understanding linear separability in the data.
- Decision Tree: This interpretable model creates decision boundaries based on feature splits. It showed high accuracy, demonstrating its ability to capture complex feature interactions.
- Random Forest: An ensemble of decision trees, this model mitigates overfitting and improves generalization, achieving strong performance in accuracy and F1-score.
- K-Nearest Neighbors (KNN): This non-parametric method classifies based on proximity to labeled instances in the feature space. It performed well, balancing simplicity and effectiveness.
- XGBoost: A gradient-boosted decision tree model, XGBoost demonstrated robust performance by optimizing for speed and accuracy, especially in handling tabular data.
- Gradient Boosting: Similar to XGBoost, this ensemble method incrementally builds models to minimize errors, yielding competitive results.
- Gaussian Naïve Bayes: Based on Bayes’ theorem, this probabilistic model performed modestly due to its strong feature independence assumption.
- Support Vector Machine (SVM): This algorithm creates hyperplanes for classification in high-dimensional spaces. It achieved moderate accuracy, highlighting its suitability for linearly separable data.
- AdaBoost: This adaptive boosting algorithm combines weak classifiers to form a strong learner. Its moderate performance reflects its sensitivity to noise in the data.
- CatBoost: A gradient boosting algorithm designed for categorical data, CatBoost delivered strong results, emphasizing its suitability for datasets with mixed feature types.
- Artificial Neural Network (ANN): This deep learning model captures non-linear patterns in the data, showing competitive performance. Its ability to model complex relationships makes it a versatile choice.
3.3. Proposed Ensemble Model
The proposed ensemble model is designed to leverage the strengths of multiple machine learning classifiers, combining their predictions using a soft voting mechanism to achieve robust and accurate results. By integrating diverse algorithms, the model capitalizes on their complementary strengths and reduces the risk of overfitting or underfitting. This section details the architecture, components, and configuration of the proposed model.
The proposed ensemble model integrates six machine learning classifiers, random forest (RF), gradient boosting (GB), logistic regression (LR), support vector machine (SVM), K-nearest neighbors (KNN), and decision tree (DT), through a soft voting mechanism to optimize predictive performance. This approach leverages the complementary strengths of diverse algorithms, ensuring robustness against individual model limitations while enhancing generalization. The ensemble employs a soft voting strategy, aggregating the probabilistic predictions of all classifiers and selecting the class with the highest average probability. Soft voting is particularly effective because it leverages the probability scores from each model, allowing for the ensemble to weigh predictions based on confidence levels. Each classifier contributes probabilistic predictions for the three adaptability classes (High, Moderate, Low). The final prediction is derived by averaging these probabilities across all models and selecting the class with the highest aggregated probability.
The classifiers were selected to balance interpretability, non-linear pattern capture, and computational efficiency:
- Tree-based models (RF, GB, DT) excel at modeling hierarchical feature interactions and handling non-linear decision boundaries.
- LR provides a linear baseline, identifying globally significant features through coefficient magnitudes.
- SVM with a radial basis function (RBF) kernel projects data into a high-dimensional space, resolving complex separations.
- KNN leverages local similarity patterns, complementing global models like LR.
The ensemble’s superiority arises from its ability to mitigate individual model weaknesses. For example, while SVM may overfit noisy samples, its errors are counterbalanced by RF’s bagging mechanism and KNN’s locality-driven predictions. Similarly, DT’s inherent variance is stabilized by GB’s sequential error correction. This synergy reduces both bias (via GB and LR) and variance (via RF and SVM), resulting in a model that generalizes effectively across diverse student profiles.
3.3.1. Hyperparameter Configuration
Each classifier in the ensemble was configured with carefully chosen hyperparameters to optimize performance. The configurations are summarized in Table 1.

Table 1.
Hyperparameter configuration of the ensemble model components.
Hyperparameters were standardized to ensure reproducibility and fairness in contribution. For instance, RF and GB used n_estimators = 100, optimizing the trade-off between bias reduction and computational overhead. LR employed max_iter = 1500 to guarantee convergence, while SVM used probability = True to enable probabilistic outputs for voting.
3.3.2. Evaluation Measures
The models were evaluated using standard classification metrics: accuracy, precision, recall, and F1-score.
Accuracy measures the proportion of total correct predictions:
Precision indicates how many of the positively predicted cases were actually positive:
Recall reflects how many actual positives were correctly identified:
F1-score is the harmonic mean of precision and recall:
4. Result Analysis
In this study, the dataset was divided into training and testing sets in an 80:20 ratio to ensure a robust evaluation of the models. Multiple machine learning (ML) and deep learning (DL) models were employed to predict students’ adaptability levels in online education. The results of the experiments, presented in terms of accuracy, precision, recall, and F1-score, offer a comparative analysis of model performances. Table 2 demonstrates the experimental results of different ML and DL models, including the proposed ensemble model of this study.
Table 2.
Model performance results.
From the experimental results, the decision tree (accuracy: 91.20%) and random forest (accuracy: 91.73%) classifiers emerged as strong performers among traditional ML models, demonstrating high recall and precision values. Ensemble-based models such as XGBoost (accuracy: 90.47%) and gradient boosting (accuracy: 87.47%) also achieved competitive results, highlighting the effectiveness of ensemble techniques in capturing complex patterns within the dataset.
K-nearest neighbors (accuracy: 88.00%) provided a balanced trade-off between simplicity and performance. Meanwhile, the performance of Gaussian naïve Bayes (accuracy: 66.67%) and AdaBoost (accuracy: 65.87%) was comparatively lower, reflecting their limitations in handling the dataset’s underlying structure. Support vector machine (accuracy: 75.73%) and artificial neural network (accuracy: 84.80%) models performed moderately well, with ANN showing slight advantages due to its ability to capture non-linear relationships. CatBoost, a gradient boosting model optimized for categorical data, achieved an accuracy of 90.33%, indicating its suitability for the task.
The proposed ensemble model achieved superior performance with an accuracy of 95.73%, precision of 95.70%, recall of 95.53%, and F1-score of 95.54%. These results outperform all other tested models, including strong contenders like random forest and CatBoost. The proposed model effectively leverages the strengths of multiple algorithms, combining their outputs to yield robust predictions. This improvement can be attributed to the ensemble’s ability to mitigate individual model biases and harness diverse learning patterns, resulting in a highly generalized predictive model. Compared to the baseline models, the proposed ensemble model’s enhancements in both accuracy and F1-score signify a significant step forward in predicting student adaptability levels in online education environments.
Figure 3 further highlights the proposed model’s exceptional performance. For the adaptability levels (High, Low, Moderate), the model accurately classified the majority of instances within each category with minimal misclassifications. Specifically, 119 out of 120 instances for the “High” level were correctly identified, while 137 out of 140 instances for the “Low” level and 103 out of 115 instances for the “Moderate” level were accurately predicted. These results underscore the model’s strong predictive capabilities and its effectiveness in differentiating between the varying levels of adaptability.
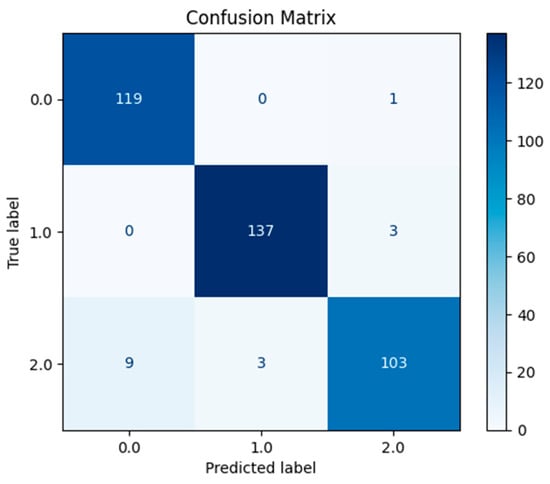
Figure 3.
Confusion matrix representing the classification results of the proposed ensemble model.
Additionally, the precision–recall curve analysis from Figure 4 for the proposed model demonstrates its robustness across all adaptability levels. The precision–recall curves for classes “High” (Class 0), “Low” (Class 1), and “Moderate” (Class 2) exhibit high area under the curve (AUC) values of 0.99, 1.00, and 0.98, respectively. This indicates that the model maintains high precision and recall across all classes, even for cases with imbalanced class distributions. The near-perfect PR AUC for the “Low” level highlights the model’s exceptional ability to correctly identify this class, while the high AUC values for the “High” and “Moderate” levels further validate the model’s effectiveness. These findings reinforce the proposed model’s applicability in practical scenarios requiring precise and reliable adaptability predictions.
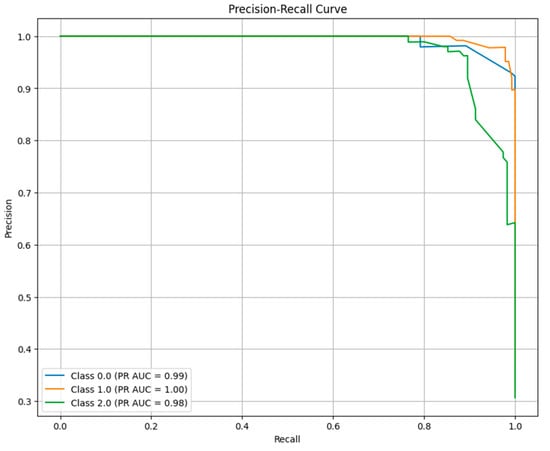
Figure 4.
Precision–recall (PR) curves for each class (“High”, “Low”, “Moderate”) predicted by the ensemble model.
5. Explainable AI Integration
5.1. SHAP Analysis of Feature Importance
SHAP is a widely used explainable AI (XAI) technique that provides insights into the contributions of individual features to model predictions [20]. By assigning Shapley values to features, SHAP quantifies the average impact of each feature on the model’s output, thereby enhancing the interpretability of complex models.
The SHAP analysis for the proposed ensemble model, as depicted in Figure 5, highlights the key features influencing the model’s decisions across different adaptability levels. “Financial Condition” emerged as the most critical feature, showcasing its significant role in determining adaptability levels for all classes (Class 0: High; Class 1: Moderate; Class 2: Low). Other influential features include “Class Duration”, “Network Type”, “Age”, and “Education Level”, which collectively contribute to the model’s predictive accuracy. The SHAP values indicate varying feature importance across adaptability classes, reflecting the model’s nuanced decision-making process.
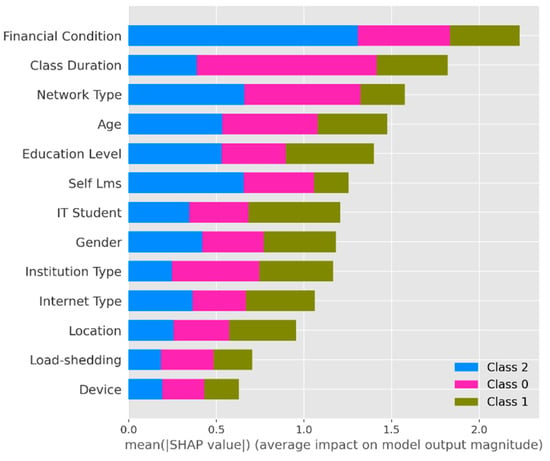
Figure 5.
SHAP summary plot illustrating the global feature importance in predicting adaptability levels. Financial condition, class duration, and network type emerge as the most influential predictors. The plot also highlights class-specific feature impacts, reflecting the nuanced interpretability of the ensemble model.
For instance, “Class Duration” and “Network Type” show higher importance for moderate and low adaptability levels, while “Financial Condition” remains consistently impactful across all levels. Features like “Self LMS” and “IT Student” also appear prominently, particularly for moderate adaptability levels, suggesting that students’ familiarity with learning management systems and technology-based learning tools strongly influences adaptability. Similarly, demographic variables such as “Age” and “Gender” indicate subtle but notable impacts, with younger students adapting more readily to certain conditions. This analysis underscores the ability of the model to identify and leverage feature-specific patterns, ensuring robust and interpretable predictions. By incorporating SHAP-based insights, the proposed model achieves superior accuracy and offers an actionable understanding of the underlying factors driving adaptability in online education. Furthermore, these insights can guide educators and policymakers in designing targeted interventions to address specific challenges, such as improving financial aid for needy students or optimizing network accessibility for remote learners.
5.2. LIME Analysis of Model Predictions
LIME is another explainable AI technique that explains individual predictions by approximating the complex model with a simpler, interpretable model in the prediction’s local region [21]. LIME generates explanations by perturbing the input features and observing their impact on the prediction, thus identifying the features most responsible for the model’s decision for a specific instance.
The LIME analysis for the proposed ensemble model, as shown in Figure 6, provides detailed insights into the feature contributions for a single instance classified as “High” adaptability. Key features such as “Class Duration”, “Financial Condition”, and “Institution Type” played significant roles in driving the prediction towards the “High” class, with positive contributions noted for these features. On the other hand, features like “Self LMS” and “IT Student” were found to have negligible or no influence on this particular prediction, suggesting that their importance may vary depending on the instance.

Figure 6.
LIME explanation for a specific instance predicted as “High” adaptability. Key contributing features include class duration, financial condition, and institution type.
The LIME plot also reveals the nuanced interplay of features in shaping the model’s decision boundary. For example, a high “Class Duration” and a favorable “Financial Condition” contribute positively, reinforcing the model’s prediction of “High” adaptability. The local interpretability offered by LIME complements the global insights from SHAP by enabling a case-by-case analysis, thus enhancing the understanding of individual predictions.
By leveraging LIME, educators and stakeholders can gain actionable insights into specific cases, allowing for personalized interventions. For instance, if a student’s adaptability level is predicted to be “Low”, LIME can help identify the features that need to be addressed, such as improving internet access or adjusting class durations. This case-specific interpretability bridges the gap between machine learning predictions and real-world applications, ensuring that the proposed model achieves high accuracy and provides practical value in enhancing online education strategies.
6. Discussion
6.1. Key Factors Contributing to Performance
While prior studies [8,11] have employed ensemble methods with XAI, our approach introduces several key novelties. Unlike existing works that focus on homogeneous ensembles, such as tree-based models only, our approach uniquely integrates six algorithmically distinct classifiers, spanning linear (LR), kernel-based (SVM), instance-based (KNN), and tree-based (RF, GB, DT) paradigms, to capture complementary patterns in adaptability determinants.
The experimental results demonstrate the superior performance of the proposed ensemble model compared to individual machine learning and deep learning approaches in predicting student adaptability levels in online education. The ensemble model achieved remarkable accuracy (95.73%), precision (95.70%), recall (95.53%), and F1-score (95.54%), significantly outperforming standalone models, including Random Forest (91.73%) and CatBoost (90.33%). This enhanced performance can be attributed to several key factors:
First, the soft voting mechanism effectively leverages the probabilistic predictions of six diverse classifiers, allowing for the model to capture different aspects of the relationship between input features and adaptability levels. Second, the combination of different algorithmic approaches—from simple linear models to complex tree-based ensembles—enables the model to handle both linear and non-linear patterns in the data while mitigating individual model biases. Third, each component classifier’s carefully selected hyperparameter configurations ensure optimal individual performance before integration into the ensemble.
6.2. Incorporation of Explainable AI Techniques
The incorporation of explainable AI (XAI) techniques, specifically SHAP and LIME analyses, proved invaluable in understanding the model’s decision-making process. SHAP analysis revealed that financial condition, class duration, and network type are the most influential features across all adaptability levels, providing crucial insights into the socioeconomic and infrastructural factors affecting online learning success. LIME analysis complemented these findings by offering instance-level explanations, demonstrating how different feature combinations influence individual predictions. This dual approach to model interpretability validates the model’s learning patterns and ensures transparency in its predictions, making it more trustworthy and actionable for educational stakeholders.
SHAP and LIME’s interpretability can be utilized for non-technical stakeholders via structured validation frameworks and user-focused translation of model insights [22]. Educators can validate instance-level explanations by comparing model-identified factors, such as “low financial condition” or “3G network limitations”, with direct student feedback obtained through surveys or interviews. For instance, if the model assigns a student’s anticipated low adaptability to financial limitations, instructors could discreetly validate this through counseling sessions or needs-assessment forms, guaranteeing coherence between algorithmic insights and actual obstacles. Administrators can verify global SHAP trends, such as “class duration” as a primary characteristic, by implementing pilot interventions, such as modifying course schedules for a select group of students and assessing variations in adaptability scores. To bridge the technical–practical gap, model explanations should be integrated into decision support dashboards that convert raw feature importance scores into plain-language recommendations.
6.3. Real-World Implications and Policy Impact
The real-world implications of this study are substantial and multifaceted. Educational institutions can utilize the model’s predictions and feature essential insights to develop targeted interventions for students at risk of low adaptability. For instance, knowing that financial conditions significantly impact adaptability, institutions might allocate additional financial aid or resources to students in need [23]. Similarly, understanding the importance of network type and class duration can guide infrastructure investments and course scheduling decisions [24]. The model’s high accuracy in identifying different adaptability levels enables proactive support systems, allowing for educators to intervene before students face significant challenges in their online learning journey.
In addition, XAI insights can inform policymaking at the institutional and governmental levels. The clear relationship between socioeconomic factors and the adaptability of online learning suggests the need for comprehensive support systems that address technical and financial barriers to education [25]. The model’s ability to provide interpretable predictions makes it a valuable tool for educational administrators in resource allocation and program design decisions.
However, the deployment of such predictive models necessitates careful ethical considerations. Automated predictions of student adaptability should not be used to penalize or stigmatize students labeled as having low adaptability. Instead, these insights must guide the provision of targeted support, such as additional resources, counseling, or tailored learning plans. Educational institutions must establish ethical guidelines to ensure that the model’s outputs foster inclusive and supportive environments, prioritizing student welfare over punitive measures.
6.4. Limitations of This Study
However, several limitations of this study should be acknowledged. First, the scope of the dataset may not fully represent the diverse global student population, potentially limiting the generalizability of the model across different cultural and educational contexts. While the proposed model achieves high accuracy on the Bangladeshi student population, its generalizability to other cultural and demographic contexts warrants careful consideration. The dataset’s focus on a single national cohort introduces potential biases tied to region-specific factors. To enhance cross-cultural applicability, future work should validate the model on multinational datasets and incorporate culture-invariant features. Transfer learning techniques could also adapt the model to new contexts without full retraining. Second, while the model captures static features effectively, it does not account for temporal changes in student adaptability or dynamic factors that might influence learning outcomes over time. Third, the reliance on self-reported data for certain features might introduce response biases that could affect the model’s predictions. Additionally, while the ensemble model performs excellently, its computational complexity and resource requirements might pose challenges for real-time applications in resource-constrained environments.
7. Conclusions
This study presented an interpretable ensemble model for predicting student adaptability in online education environments. The proposed model combines six diverse machine learning classifiers through a soft voting mechanism, achieving superior performance with 95.73% accuracy, 95.70% precision, 95.53% recall, and 95.54% F1-score. This significant improvement over traditional models demonstrates the effectiveness of the ensemble approach in capturing complex patterns within educational data.
Integrating explainable AI techniques, specifically SHAP and LIME analysis, provided valuable insights into the model’s decision-making process. Financial condition emerged as the most influential factor in determining student adaptability, followed by class duration and network type. These findings highlight the critical role of socioeconomic and infrastructural factors in online learning success.
Several promising directions for future research emerge from this study. Future studies could incorporate longitudinal data to capture changes in student adaptability over time, potentially revealing patterns in adaptation processes and learning trajectories. Developing more sophisticated features that capture student engagement patterns, learning behaviors, and psychological factors could enhance the model’s predictive capabilities. Testing the model’s performance across different cultural and educational contexts would help establish its generalizability and identify culture-specific adaptation factors. Additionally, developing lightweight versions of the model suitable for real-time prediction and intervention in resource-constrained environments would increase its practical applicability. Finally, future work could focus on implementing the model within existing educational platforms to provide automated, timely support for students at risk of low adaptability. These advancements would further contribute to the development of more effective and equitable online education systems, ultimately supporting student success in increasingly digital learning environments.
Author Contributions
Conceptualization, S.S.S. and A.I.J.; methodology, S.S.S. and A.I.J.; software, S.S.S.; formal analysis, S.S.S. and A.I.J.; investigation, S.S.S. and A.I.J.; resources, S.S.S.; data curation, S.S.S.; writing—original draft preparation, S.S.S.; writing—review and editing, A.I.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not appliable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset utilized in this study was obtained from a publicly accessible repository hosted on Kaggle. The complete dataset is available at: https://www.kaggle.com/datasets/mdmahmudulhasansuzan/students-adaptability-level-in-online-education/data (accessed on 23 May 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Srivastava, S. The Evolution of Education: Navigating 21st-Century Challenges. Int. J. Multidiscip. Res. 2023, 5. [Google Scholar] [CrossRef]
- Manca, S.; Delfino, M. Adapting educational practices in emergency remote education: Continuity and change from a student perspective. Br. J. Educ. Technol. 2021, 52, 1394–1413. [Google Scholar] [CrossRef]
- Konstantinidou, A.; Nisiforou, E. Assuring the quality of online learning in higher education: Adaptations in design and implementation. Australas. J. Educ. Technol. 2022, 38, 127–142. [Google Scholar] [CrossRef]
- Noor, U.; Younas, M.; Aldayel, H.S.; Menhas, R.; Qingyu, X. Learning behavior, digital platforms for learning and its impact on university students’ motivations and knowledge development. Front. Psychol. 2022, 13, 933974. [Google Scholar] [CrossRef] [PubMed]
- Malik, A.; Onyema, E.M.; Dalal, S.; Lilhore, U.K.; Anand, D.; Sharma, A.; Simaiya, S. Forecasting students’ adaptability in online entrepreneurship education using modified ensemble machine learning model. Array 2023, 19, 100303. [Google Scholar] [CrossRef]
- Pallathadka, H.; Wenda, A.; Ramirez-Asís, E.; Asís-López, M.; Flores-Albornoz, J.; Phasinam, K. Classification and prediction of student performance data using various machine learning algorithms. Mater. Today Proc. 2023, 80, 3782–3785. [Google Scholar] [CrossRef]
- Shanto, S.S.; Ahmed, Z.; Jony, A.I. Enriching Learning Process with Generative AI: A Proposed Framework to Cultivate Critical Thinking in Higher Education using Chat GPT. Tuijin Jishu/J. Propuls. Technol. 2024, 45, 3019–3029. [Google Scholar]
- Nnadi, L.C.; Watanobe, Y.; Rahman, M.M.; John-Otumu, A.M. Prediction of Students’ Adaptability Using Explainable AI in Educational Machine Learning Models. Appl. Sci. 2024, 14, 5141. [Google Scholar] [CrossRef]
- Suzan, M.H.; Samrin, N.A.; Biswas, A.A.; Pramanik, A. Students’ Adaptability Level Prediction in Online Education using Machine Learning Approaches. In Proceedings of the 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Adnan, M.; Uddin, M.I.; Khan, E.; Alharithi, F.S.; Amin, S.; Alzahrani, A.A. Earliest Possible Global and Local Interpretation of Students’ Performance in Virtual Learning Environment by Leveraging Explainable AI. IEEE Access 2022, 10, 129843–129864. [Google Scholar] [CrossRef]
- Gligorea, I.; Yaseen, M.U.; Cioca, M.; Gorski, H.; Oancea, R. An Interpretable Framework for an Efficient Analysis of Students’ Academic Performance. Sustainability 2022, 14, 8885. [Google Scholar] [CrossRef]
- Khan, A.B.F.; Samad, A. Evaluating Online Learning Adaptability in Students Using Machine Learning-Based Techniques: A Novel Analytical Approach. Educ. Sci. Manag. 2024, 2, 25–34. [Google Scholar] [CrossRef]
- Afrouz, R.; Crisp, B.R. Online Education in Social Work, Effectiveness, Benefits, and Challenges: A Scoping Review. Aust. Soc. Work 2020, 74, 55–67. [Google Scholar] [CrossRef]
- Uskov, V.L.; Bakken, J.P.; Byerly, A.; Shah, A. Machine Learning-based Predictive Analytics of Student Academic Performance in STEM Education. In Proceedings of the 2019 IEEE Global Engineering Education Conference (EDUCON), Dubai, United Arab Emirates, 8–11 April 2019; pp. 1370–1376. [Google Scholar] [CrossRef]
- Ma, X.; Yang, Y.; Zhou, Z. Using Machine Learning Algorithm to Predict Student Pass Rates in Online Education. In Proceedings of the 3rd International Conference on Multimedia Systems and Signal Processing—ICMSSP ’18, Shenzhen, China, 28–30 April 2018. [Google Scholar] [CrossRef]
- Luo, Y.; Han, X.; Zhang, C. Prediction of learning outcomes with a machine learning algorithm based on online learning behavior data in blended courses. Asia Pac. Educ. Rev. 2022, 25, 267–285. [Google Scholar] [CrossRef]
- Abujadallah, M.S.; Abudalfa, S.I. Predicting Student Retention in Smart Learning Environments Using Machine Learning. In Technical and Vocational Education and Training; Springer: Berlin/Heidelberg, Germany, 2024; pp. 153–160. [Google Scholar] [CrossRef]
- Tiwari, R.G.; Jain, A.K.; Kukreja, V.; Ujjwal, N. Education 4.0: Explainable Machine Learning for Classification of Student Adaptability. In Proceedings of the 2022 International Conference on Data Analytics for Business and Industry (ICDABI), Sakhir, Bahrain, 25–26 October 2022; pp. 6–10. [Google Scholar] [CrossRef]
- Jang, Y.; Choi, S.; Jung, H.; Kim, H. Practical early prediction of students’ performance using machine learning and eXplainable AI. Educ. Inf. Technol. 2022, 27, 12855–12889. [Google Scholar] [CrossRef]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining Explanations: An Overview of Interpretability of Machine Learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. ‘Why Should I Trust You?’: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’16, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Khosravi, H.; Shum, S.B.; Chen, G.; Conati, C.; Tsai, Y.-S.; Kay, J.; Knight, S.; Martinez-Maldonado, R.; Sadiq, S.; Gašević, D. Explainable Artificial Intelligence in education. Comput. Educ. Artif. Intell. 2022, 3, 100074. [Google Scholar] [CrossRef]
- Moore, A.; Nguyen, A.; Rivas, S.; Bany-Mohammed, A.; Majeika, J.; Martinez, L. A Qualitative Examination of the Impacts of Financial Stress on College Students’ well-being: Insights from a large, Private Institution. SAGE Open Med. 2021, 9, 205031212110181. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Huang, X.; Chen, H.; Su, X.; Yur-Austin, J. Data driven course scheduling to ensure timely graduation. Int. J. Prod. Res. 2021, 61, 336–361. [Google Scholar] [CrossRef]
- Careemdeen, J.D. The Impact of Socio-Economic Factors in the Virtual Learning Environment on Student Learning. Int. J. Acad. Res. Bus. Soc. Sci. 2023, 13, 802–814. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).