Abstract
Chest X-ray radiology report generation is a challenging task that involves techniques from medical natural language processing and computer vision. This paper provides a comprehensive overview of recent progress. The annotation protocols, structure, linguistic characteristics, and size of the main public datasets are presented and compared. Understanding their properties is necessary for benchmarking and generalization. Both clinically oriented and natural language generation metrics are included in the model evaluation strategies to assess their performance. Their respective strengths and limitations are discussed in the context of radiology applications. Recent deep learning approaches for report generation and their different architectures are also reviewed. Common trends such as instruction tuning and the integration of clinical knowledge are also considered. Recent works show that current models still have limited factual accuracy, with a score of 72% reported with expert evaluations, and poor performance on rare pathologies and lateral views. The most important challenges are the limited dataset diversity, weak cross-institution generalization, and the lack of clinically validated benchmarks for evaluating factual reliability. Finally, we discuss open challenges related to data quality, clinical factuality, and interpretability. This review aims to support researchers by synthesizing the current literature and identifying key directions for developing more clinically reliable report generation systems.
1. Introduction
Chest radiography [1] is the most frequently performed medical imaging procedure worldwide [2]. However, its central role is increasingly challenged by a global lack of radiologists and rising workloads. The capacity of specialists to interpret medical images is often surpassed by demand in many areas [3]. In the United States, the high volume of imaging examinations is reported to surpass the current capacity of radiologists [3]. In resource-limited countries, the situation is more severe. For instance, in 2015, Rwanda had only 11 radiologists for a population of 12 million people [4], and similarly, Liberia had just two practicing radiologists for its population of four million [5]. This lack of radiologists contributes to reporting delays and makes the diagnosis prone to human error. Consequently, there is an increasing interest in using deep learning solutions to assist with radiological interpretation. To reduce human error and reporting delays, the use of automated medical reporting systems is a promising solution [3].
The development of deep learning for creating chest X-ray reports has seen significant progress lately. It is largely due to vision–language models that simultaneously analyze images and generate reports. These are essentially computer vision systems combined with advanced natural language processing techniques that are able to understand the X-ray images and generate their clinical report to ensure it closely mimics the radiologist’s workflow [6,7]. Advanced approaches have been developed recently, such as transformer-based architectures [8], contrastive vision-text learning [9,10,11], models enhanced with medical knowledge bases [12], memory-enhanced models [13], anatomically and expert-guided models [14,15], and Multi-View and longitudinally guided models [16].
While significant progress has been made, generating reliable and clinically accurate reports is still difficult. Current models are susceptible to hallucinations (producing findings absent from the image) and the omission of clinically significant abnormalities [17,18]. Many models are trained and evaluated on a limited number of public datasets, such as MIMIC-CXR, IU X-rays, and CheXpert [19,20,21]. Although useful, these datasets represent certain demographic and reporting patterns and thus cannot be effectively generalized to other institutions. Furthermore, the training of most current systems is primarily performed on the frontal. As a result, these models show limited performance with lateral views. This reduces their applicability in real-world clinical workflows [22]. The evaluation methodology is another major limitation. Standard natural language generation metrics such as BLEU (Bilingual Evaluation Understudy) or ROUGE (Recall-Oriented Understudy for Gisting Evaluation) are still widely used, but they correlate poorly with clinical accuracy and often fail to capture factual errors. Despite the availability of multiple clinically oriented metrics like CheXbert F1 [17], RadGraph F1 [23], and other studies on LLM evaluation [22], there is no consensus on a robust and standardized framework for evaluation. Finally, a persistent challenge of these models is their interpretability and trustworthiness. The lack of transparency of deep learning models makes it challenging for clinicians to verify the reasoning behind generated reports. Also, variable accuracy across different datasets and patient subgroups remains a major barrier to clinical adoption.
Multiple reviews of radiology report generation for chest X-rays have been published recently. While early studies discussed general diagnostic tasks [24], more recent reviews have focused more specifically on radiology report generation [3,25]. Some studies specifically addressed multi-modal inputs [6], or gave a global overview of current practices and future directions [26]. However, the need for an updated review is motivated by the rapid evolution of the field and the emergence of new strategies to improve the clinical factuality of the generated reports. Our work provides an analysis with a focus on the most recent architectures (2024–2025), different improvement strategies, and evaluation practices. It also discusses the current challenges and future perspectives, complementing the existing reviews.
The main contributions of this paper are as follows:
- We describe the key public datasets and benchmarks, including their characteristics, strengths, and limitations, as well as details on dataset diversity and the availability of multi-view or follow-up data.
- We review the evaluation metrics and methodologies, including standard natural language metrics like BLEU and ROUGE, clinically oriented ones such as RadGraph and CheXbert, and LLM-based evaluation protocols. We also discuss their correlation with human and radiologist judgment.
- We present the latest architectures and approaches used in current vision–language models with a focus on encoder-decoder architectures, joint image-text generation, and large vision–language models (LVLMs). We cover key approaches such as transformer-based models, contrastive learning, knowledge augmentation, memory, and variants guided by anatomy, experts, and multi-stage or conversational methods.
- We investigate recent key methodologies proposed to improve factual accuracy and domain adaptation. This includes retrieval-augmented generation, bootstrapping of large language models, and automated preference-based alignment.
- We discuss actual persistent challenges and gaps, including generalization across institutions, limitations of using only frontal X-rays, reliance on single or non-longitudinal exams, interpretability, and clinical trust.
The rest of the paper is organized as follows: Section 2 describes the overall review methodology. Section 3 reviews the public datasets and benchmarks used for chest X-ray report generation. The evaluation metrics and methodologies are discussed in Section 4. Section 5 presents deep learning-based architectures. Recent methodologies designed to improve factuality and domain adaptation are described in Section 6. In Section 7, current challenges and open research directions are highlighted. Finally, Section 8 concludes the review and outlines perspectives for future work. Additional details on the mathematical formulations of NLG metrics and complementary evaluation metrics are provided in Appendices Appendix A and Appendix B.
2. Methodology
In the process of reviewing the literature, we conducted searches on Google Scholar, PubMed, IEEE Xplore, arXiv, and the ACL Anthology using wide combinations of keywords such as radiology report generation, chest X-ray, medical vision–language models, multimodal learning, evaluation metrics, and clinical factuality. Combinations of these keywords were used to retrieve the articles, including “chest X-rays + radiology report generation”, “vision-language model + chest X-rays”, “CXR + deep learning”, “radiology report generation + LLM + chest X-rays”, “report generation + evaluation metrics” and “retrieval-augmented generation + radiology report generation + chest X-rays”. Our review focuses on the period from 2018 through September 2025, with particular attention to 2024–2025. This focus captures the recent shift to large, transformer-based vision–language models and methods designed to improve clinical factuality. For inclusion, we selected peer-reviewed papers and influential preprints that reported clear methods and quantitative experiments on public or institutional datasets. We included studies addressing report generation for chest X-rays written in English and publicly available. Work on non-medical captioning without text generation, such as unimodal classification, segmentation, and detection, was excluded. Non-English papers, duplicates, and inaccessible articles were also removed. To reduce bias, we first removed duplicates across databases. We then expanded our coverage by tracing references and papers that cited key studies. From each study, we extracted key information such as model family, training data and scale, and pretraining or alignment strategies. We also noted the evaluation setup and metrics, clinical factuality checks, expert or radiologist evaluation, and data availability. A total of 82 records were initially identified across all databases. This large number of articles was then refined by deleting duplicates (n = 6); 76 articles remained. During the screening phase, we eliminated articles that were not publicly available (n = 8) and out-of-scope (n = 17). A total of 51 studies were included in the final review. The PRISMA flow diagram (Figure 1) summarizes the identification, screening, eligibility assessment, and final inclusion of studies.
Figure 1.
PRISMA flow diagram of records identification and selection for this review.
3. Medical Datasets for Report Generation
An important component of recent advances in automatic chest X-ray radiology report generation is public, large-scale, annotated datasets. The most popular used datasets contain chest X-rays paired with free-text or structured radiology reports of specialists and radiologists. This data is required for the training and validation of the models and also for the comparative evaluation across diverse clinical tasks, including visual question answering (VQA) and report generation. The design and performance of generation models are influenced by the differences in dataset size, report format, annotation quality, and pathology coverage. In this section, we will review the most widely used public datasets used for radiology report generation. Characteristics such as size, content, and clinical relevance are presented. A summary table (Table 1) reports key properties of each discussed dataset.
3.1. MIMIC-CXR
Developed by Johnson et al. [19], MIMIC-CXR represents one of the largest publicly available datasets of chest X-ray images. It contains 377,110 images and 227,835 radiographic studies, collected from 65,379 patients between 2011 and 2016 at the Beth Israel Deaconess Medical Center in Boston, MA, USA [2]. The dataset split consists of a training set (270,790 studies), a validation set (2130 studies), and a test set (3858 studies) [27]. Each study in the dataset is paired with a free-text radiology report written by board-certified radiologists. In accordance with the Health Insurance Portability and Accountability Act (HIPAA) Safe Harbor requirements, the dataset is completely de-identified to protect patient privacy. Because of its size, detailed content, and real-world clinical nature, this dataset has become a reference benchmark for vision–language research in radiology, particularly for report generation and visual question answering (VQA). An extension of MIMIC-CXR was later introduced to simplify image processing and labeling: MIMIC-CXR-JPG [28].
3.2. MIMIC-CXR-JPG
MIMIC-CXR-JPG [28,29] is a large-scale extension of MIMIC-CXR that provides 377,110 chest radiographs in JPG format, complemented with structured labels automatically extracted from 227,827 free-text radiology reports. All images are converted from DICOM format to JPG using a standardized process involving normalization, histogram equalization, and lossy compression with a quality factor of 95. Structured labels were automatically extracted from the original reports using two open-source NLP (Natural Language Processing) tools: CheXpert [20] and NegBio [30]. These labels include 14 categories, consisting of 13 pathologies such as cardiomegaly, pleural effusion, and pneumothorax, as well as the “No Finding” class. Custom Python 3.7 code was employed to identify and isolate the impressions, findings, or final sections of each report, from which labels were derived. MIMIC-CXR-JPG includes predefined training, validation, and test splits, along with metadata on view position, patient orientation, and acquisition time. The multi-modal data structure, which leverages both the free-text reports from MIMIC-CXR and the structured labels from MIMIC-CXR-JPG, is exemplified in Figure 2. It shows a single radiographic study in which the paired chest X-ray views (a,b) and the corresponding narrative report (c) originate from MIMIC-CXR, while the structured pathology labels (d) are automatically derived from the report using the tools provided in MIMIC-CXR-JPG.
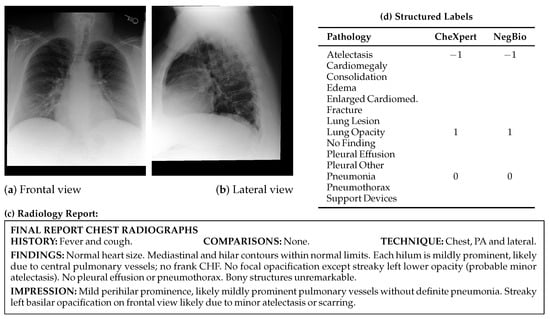
Figure 2.
Illustrative example from the MIMIC-CXR dataset, including radiographic views (a) frontal and (b) lateral, (c) the corresponding full-text radiology report, and (d) structured pathology labels automatically extracted using the CheXpert and NegBio labelers from MIMIC-CXR-JPG. Label values: 1 = positive, 0 = negative, −1 = uncertain, and blank = not mentioned. “Cardiomed.” is an abbreviation for “Cardiomediastinum”.
3.3. IU X-Ray (Open-I)
The IU Chest X-ray Collection [21] is a publicly available dataset released by the U.S. National Library of Medicine. The dataset consists of 7470 frontal chest radiographs paired with 3955 de-identified radiology reports collected from two large hospital systems within the Indiana Network for Patient Care. Most reports include dedicated sections for findings, impressions, and the clinical indication for the exam. Reports were manually annotated with MeSH supplemented by RadLex [31] codes. Both DICOM and PNG versions of the images are provided. Despite its smaller scale compared to datasets like MIMIC-CXR, IU X-ray (Open-I) is frequently used due to its accessibility and real-world clinical content.
3.4. ChestX-Ray14 (NIH)
The NIH Chest X-ray dataset was first introduced as ChestX-ray8 [32]. It was later extended and re-released as ChestX-ray14, with more images and refined annotations to include six additional thoracic diseases [32]. The ChestX-ray14 dataset, collected between 1992 and 2015, consists of 112,120 frontal-view chest radiographs originating from 30,805 unique patients. The disease labels were automatically extracted from corresponding radiology reports using two automated NLP tools: MetaMap [33] and DNorm. The quality of these automated labels was validated on a subset of 900 reports that were manually annotated by two annotators [32]. Provided as 1024 × 1024 PNG files, each image is annotated with a maximum of 14 binary pathology labels. In contrast to datasets such as MIMIC-CXR or IU X-ray (Open-I), this collection does not provide the corresponding full-text radiology reports. However, no radiologist validation was performed on the full dataset, which makes its use as a benchmark potentially problematic [20].
3.5. CheXpert (Stanford)
The CheXpert dataset [20] comprises 224,316 chest radiographs from 65,240 patients, collected from Stanford Hospital between October 2002 and July 2017. Each study is annotated with labels for 14 observations, including common thoracic pathologies such as Cardiomegaly, Edema, and Pleural Effusion, in addition to a “No Finding” class. An automated, rule-based labeler was developed to extract observations from free-text radiology reports. Each mention of a finding as positive, negative, uncertain, or blank in the report is categorized by the labeler. The blank is assigned if a specific finding is not mentioned in the report. In an evaluation on a dedicated set of reports across multiple tasks, the CheXpert labeler outperformed the NIH labeler, achieving higher F1 scores [32]. This higher performance can be explained by its use of a three-phase pipeline to classify mentions and manage uncertainty in the reports. A validation and test set of 200 and 500 studies, respectively, are provided in the dataset. To establish a reliable ground-truth benchmark, the validation and test studies are manually annotated by 3 and 5 certified radiologists, respectively. The model trained on CheXpert surpassed at least two of three radiologists on four of five selected pathologies, showing higher diagnostic accuracy compared to the radiologists.
3.6. CheXpert Plus
The CheXpert Plus dataset [34] is an upgraded version of the original CheXpert dataset [20]. The dataset consists of 223,228 chest radiographs from 64,725 patients. Each image is annotated for 14 distinct clinical observations. It includes additional information, like DICOM images, radiology reports, patient demographics, and pathology labels. It contains a total of 36 million tokens, with 13 million tokens specifically from the impression sections of the reports. CheXpert Plus is the largest dataset for impression-level text-image tasks, surpassing MIMIC-CXR. Despite MIMIC-CXR containing 377,095 chest X-rays, the CheXpert Plus dataset provides a larger collection of text data, with a total of 36 million tokens versus MIMIC’s 34 million. Compared to the 8 million tokens in the impression sections found in MIMIC-CXR, CheXpert plus contains 13.4 million tokens.
3.7. PadChest
The PadChest dataset [35] is a publicly available dataset released in Alicante, Spain. The dataset includes 160,868 images from 67,625 patients, paired with 109,931 free-text radiology reports. The chest X-rays of this dataset were collected at the Hospital San Juan from 2009 to 2017. The dataset has six different types of projections and metadata on acquisition factors and patient demographics. Reports were annotated with 174 radiographic findings, 19 differential diagnoses, and 104 anatomical locations. The labels are structured in a hierarchical taxonomy and mapped to the Unified Medical Language System (UMLS) [35]. Trained physicians manually validated approximately 27% of the annotations, while the remainder were generated using a recurrent neural network with attention mechanisms. A micro-F1 score of 0.93 on an independent test set confirms the overall quality of the labels. Unlike other datasets, PadChest reports are written in Spanish, making it suitable for developing and testing models in multilingual settings.
3.8. PadChest-GR
PadChest-GR [36] extends the original PadChest dataset, facilitating research in grounded radiology report generation. The dataset contains 4555 bilingual chest X-ray studies (3099 abnormal and 1456 normal) in both Spanish and English, which makes the dataset suitable for multilingual training and evaluation. For each positive sentence, radiologists independently provided up to two sets of manual bounding-box annotations. These annotations also include categorical labels that describe the finding type, anatomical location, and progression. A key feature of this dataset is spatial grounding, where each clinical finding is linked to its precise location on the image. This level of detailed localization is largely absent from other public datasets. The spatial grounding provided by this dataset helps make report generation models more transparent and less prone to errors like hallucinations.
3.9. VinDr-CXR
Sourced from two of Vietnam’s largest hospitals: Hospital 108 (H108) and Hanoi Medical University Hospital (HMUH). VinDr-CXR [37] is a publicly available dataset of posteroanterior chest radiographs. The dataset has a training set of 15,000 images and a test set of 3000 images totaling 18,000 de-identified chest X-rays. To establish a high-quality benchmark, test set images were labeled by a consensus of five radiologists, a more rigorous process than the independent annotation by three radiologists used for the training set. Each image from the training set was annotated by three radiologists independently, while in the test set it is a consensus of five radiologists. The dataset provides both 6 global image-level diagnoses and 22 specific local abnormalities precisely annotated with bounding boxes. Images are provided in DICOM format, while their expert-generated annotations are distributed as structured CSV files. VinDr-CXR relies on manual annotations of expert radiologists, which are more trustworthy than NLP-based label extraction. In order to enhance the clinical accuracy of the final text, the combination of local and global labels makes the dataset valuable for pretraining report generation models.
3.10. Rad-ReStruct
Rad-ReStruct [38] was developed using the IU X-ray dataset and contains 3720 chest X-ray images paired with 3597 structured patient reports organized into a hierarchy of over 180,000 questions. MeSH and RadLex coded findings have been parsed into a multi-level template to construct each report. The template is composed of anatomical, pathological, and descriptive terms from a controlled vocabulary of 178 concepts. The dataset was partitioned using an 80%, 10%, and 10% split, representing the training, validation, and test sets, respectively. All images from a single patient were constrained to the same set in order to avoid data leakage [39].
3.11. FG-CXR
In the field of RRG (Radiology Report Generation) for chest X-rays, the interpretability of the models is one of the main challenges. To address this challenge, the FG-CXR [14] dataset has been developed, providing detailed annotations at the anatomical level instead of a full image with an entire report. The dataset consists of 2951 frontal chest X-rays. Each CXR is associated with gaze-tracking sequences from REFLACX [40] and EGDdatasets [41]. These gaze sequences are converted into both temporal coordinates and attention heatmaps. Region-specific findings, covering seven anatomical areas, such as the heart and the upper and lower lungs, are reported. These findings are either directly extracted from original reports or derived from MIMIC-CXR annotations. Multimodal annotations enable the development of gaze-supervised report generation frameworks, including Gen-XAI. The dataset is publicly available and includes predefined divisions for training, validation, and testing. Furthermore, the dataset incorporates additional data, comprising disease labels and anatomical segmentation masks.

Table 1.
Summary of public datasets used for radiology report generation.
Table 1.
Summary of public datasets used for radiology report generation.
| Dataset | Images | Reports | Labels | Data Type | Source |
|---|---|---|---|---|---|
| MIMIC-CXR [19] | 377,110 | 227,835 | 14 1 | Free-text reports, DICOM images | PhysioNet |
| MIMIC-CXR-JPG [28] | 377,110 | – | 14 1 | JPG images, structured labels | PhysioNet |
| IU X-ray (Open-I) [21] | 7470 | 3955 | 189 [42] | Free-text reports, DICOM/PNG | Open-I |
| ChestX-ray14 [32] | 112,120 | – | 14 2 | PNG images, binary labels | NIH CC |
| CheXpert [20] | 224,316 | – | 14 3 | JPEG images, structured labels | Stanford AIMI |
| CheXpert Plus [34] | 223,228 | 187,711 | 14 3 | Free-text reports, DICOM images, structured labels | Stanford AIMI |
| PadChest [35] | 160,868 | 109,931 | 193 4 | Free-text reports (Spanish), DICOM images | BIMCV |
| PadChest-GR [36] | 4555 | 4555 | 24 | Bilingual reports, bounding boxes, spatial annotations | BIMCV |
| VinDr-CXR [37] | 18,000 | – | 22 | DICOM images, bounding boxes | PhysioNet |
| Rad-ReStruct [38] | 3720 | 3597 | 178 5 | PNG images, Structured reports, hierarchical QA pairs | GitHub |
| FG-CXR [14] | 2951 | – | 7 6 | Frontal chest X-ray, gaze-tracking, region findings | GitHub |
1 13 pathologies plus a “No Finding” class, automatically extracted from free-text reports using CheXpert and NegBio. 2 14 binary pathology labels automatically extracted using NLP tools (MetaMap, DNorm). Full-text reports are not provided. 3 14 observations extracted from reports using a rule-based labeler. Includes uncertainty labels and expert-labeled test sets. 4 Includes 174 radiographic findings and 19 differential diagnoses. 5 Comprises 178 terms categorized as anatomies, diseases, pathological signs, foreign objects, and attributes. 6 Seven anatomical regions with region-specific findings derived from MIMIC-CXR annotations and gaze-tracking data.
4. Evaluation Metrics
The problem of metric selection is very important in medical report generation. These metrics provide an evaluation of the quality of language and clinical accuracy of the generated reports. The evaluation metrics can be organized into three main families. First, Natural Language Generation (NLG) metrics such as BLEU, ROUGE, METEOR, and CIDEr are used to evaluate the surface-level lexical, semantic, and syntactic similarity between generated and reference reports. However, factual errors and clinical correctness cannot be detected by these metrics. Second, Clinical Efficacy (CE) metrics, including CheXbert-based scores, RadGraph F1, and GREEN, evaluate the correctness of medical content. These CE metrics provide a more reliable assessment of medical factuality by extracting and comparing pathology labels. Finally, to assess clinical utility, coherence, and error severity, which remain difficult to quantify automatically, human evaluations by expert radiologists and LLM-based evaluations are increasingly adopted. A robust evaluation protocol for radiology report generation requires combining these complementary metrics rather than relying on a single metric or family of metrics.
4.1. Natural Language Generation Metrics
These metrics assess the syntactic and semantic similarity between the generated report and the reference text, typically without explicitly considering clinical correctness. To assess the textual quality of generated reports, most studies adopt standard NLG metrics originally developed for tasks such as machine translation or summarization. Mathematical formulations for these metrics are provided in Appendix A. These include:
- Bilingual Evaluation Understudy (BLEU) [43]: BLEU is a widely adopted metric to evaluate the surface-level linguistic similarity of generated texts, particularly in medical report generation [23]. Originally developed for machine translation, BLEU measures the n-gram co-occurrence between generated and reference texts, which reflects the n-gram lexical overlap. As a result, BLEU tends to reward surface-level lexical similarity, leading to inflated scores for outputs that reuse reference wording, even when the clinical content is inaccurate. At the same time, it may penalize reports that are clinically accurate but use different wording because BLEU does not account for semantic or clinical correctness. This can lead to overestimating the quality of clinically incorrect outputs, and underestimating clinically valid findings expressed with alternative wording.
- Recall-Oriented Understudy for Gisting Evaluation (ROUGE) [44,45]: ROUGE, like BLEU, is a widely adopted family of evaluation metrics designed to assess the quality of generated texts by comparing them with reference texts [23]. In medical report generation, ROUGE is frequently used to quantify lexical overlap between model-generated and expert-written reports. Although ROUGE provides useful insight into lexical overlap, it does not account for semantic similarity or factual correctness, which is a major limitation in medical contexts. For instance, two clinically different findings (e.g., “no pneumothorax” vs. “pneumothorax present”) may share overlapping words but convey opposite clinical information. As noted in recent studies, high ROUGE scores do not necessarily reflect semantic or clinical correctness. Therefore, while ROUGE is commonly reported in medical report generation tasks, it is often complemented by domain-specific metrics that aim to capture clinical correctness more directly.
- Metric for Evaluation of Translation with Explicit ORdering (METEOR) [46,47]: METEOR was developed to address specific weaknesses identified in BLEU and ROUGE metrics by incorporating flexible matching strategies that are not limited to exact lexical matching, including stemmed forms, synonyms, and paraphrases [47]. METEOR demonstrates a stronger correlation with human judgment of adequacy and fluency in shared evaluation tasks [48] because of recall and flexible matching, which lowers lexical bias in favor of the exact matches. Nevertheless, its reliability in medical contexts remains limited, since it does not explicitly evaluate the clinical accuracy or factual correctness of the generated reports. Consequently, METEOR is often used in combination with domain-specific clinical metrics in medical report generation tasks.
Additional NLG metrics including CIDEr, BERTScore, and GLEU are described in Appendix B. These metrics are widely reported but are known to have limited correlation with clinical correctness, since they evaluate surface form similarity.
4.2. Clinical Efficacy Metrics
Given the limitations of text-only metrics, recent works increasingly evaluate models using clinically informed metrics. These are computed using the rule-based CheXpert labeler [20], its BERT-based successor CheXbert [17], or RadGraph [49], which extracts structured pathology labels from generated and reference reports. Specifically, the widely used Clinical Efficacy (CE) metrics, including precision, recall, and F1-score, are calculated for 14 pathologies, typically using the CheXbert labeler [17,50].
- RadGraph F1 [23,51]: RadGraph F1 is a recent automatic, clinically aware metric designed to evaluate radiology reports by computing the overlap in clinical entities and relations between a generated and a reference report. It relies on RadGraph [49], a clinical information extraction system that represents each report as a graph composed of labeled entities (findings, anatomical sites) and relations. RadGraph is trained on expert-annotated radiology reports and is specifically tailored to capture radiology-specific semantics.Two entities are matched if both their tokens and labels (entity type) match. Similarly, relations are matched if the relation type and their start and end entities match.This metric better captures the clinical correctness of radiology-specific content than traditional NLG metrics. Yu et al. [23] demonstrate that RadGraph F1 correlates more strongly with radiologist judgments than BLEU or CheXbert vector similarity, especially for identifying clinically significant errors. However, RadGraph F1 requires an accurate information extraction system and does not directly account for linguistic fluency or coherence.
- CheXbert Vector Similarity [17]: CheXbert vector similarity is an automatic clinical evaluation metric that assesses the alignment between a generated and a reference radiology report based on 14 predefined pathologies. It evaluates only the clinical content of reports without consideration for language fluency or coherence. For each report, the CheXbert model produces a 14-label vector using BioBERT [52], first fine-tuned on rule-based labels from CheXpert, then further fine-tuned on an expert-annotated set augmented via backtranslation. Each label corresponds to one of four classes: positive, negative, uncertain, or blank. For the evaluation, a 14-label vector [27,53] is extracted from the reference and the generated reports using the CheXbert labeler. This vector is then used to compute the following evaluation metrics, including precision, recall, and F1-score.
- GREEN Score [54,55]: Ostmeier et al. [54] introduced GREEN (Generative Radiology Report Evaluation and Error Notation) to handle the limitations of the actual metrics in measuring clinical correctness. The GREEN metric identifies and explains clinically significant errors by providing both quantitative and qualitative analysis in the generated reports. GREEN uses fine-tuned language models to detect and categorize six types of errors: false positives (hallucinations), omissions, localization errors, severity misassessments, irrelevant comparisons, and omitted comparisons. Unlike traditional lexical metrics, GREEN provides both a numerical score and a human-readable summary. This allows for an evaluation that is interpretable and clinically relevant. GREEN is a more reliable measure of clinical factuality because it correlates more strongly with radiologists’ error counts than existing metrics such as BLEU, ROUGE, and RadGraph F1.
- LC GREEN score [54,56]LC-GREEN (Length-Controlled GREEN) [56] was introduced to address the issue of verbosity bias in report generation. This bias can lead to an artificial overestimation of GREEN scores. As shown in the Equation (1), LC-GREEN has a length penalty.where is the length (in words) of the candidate report relative to the reference report. By penalizing reports that are too verbose, LC-GREEN offers a more robust evaluation of generated radiology reports.
4.3. Limitations and Human Evaluation
Despite these metrics, many studies still lack human evaluations by radiologists, which are critical for assessing factuality, coherence, and diagnostic utility. Few works perform expert scoring or error categorization, though these are crucial to ensure clinical deployment readiness.
Furthermore, metrics like BLEU or ROUGE may penalize medically correct but lexically diverse outputs. There is growing interest in aligning metrics with clinical needs (e.g., factual correctness, coverage of critical findings).
For instance, Lee et al. [57] also performed a human evaluation where three radiologists rated report acceptability on the following 4-point scale: (1) totally acceptable without any revision, (2) acceptable with minor revision, (3) acceptable with major revision, and (4) unacceptable. Based on this scale, they defined successful autonomous reporting as reports receiving a score of (1) or (2), and reported a success rate of 72.7 % for their CXR-LLaVA model.
4.4. LLM-Based Evaluation Protocols
Recent studies have introduced the use of large language models [55] (LLMs) such as GPT-3.5 for automatic evaluation of radiology report generation. Instead of comparing texts using lexical overlap, these models assess the semantic quality and factual coherence of generated reports via prompt-based role simulation. For instance, XrayGPT [22] uses GPT-3.5 Turbo to compare outputs from different models by asking which response is closer to the reference. This setup enables comparative evaluation based on clinical coherence and informativeness [22]. As such, they are typically used to complement, rather than replace, traditional metrics or expert-based evaluations.
5. Deep Learning-Based Report Generation Models
Deep learning models for generating radiology reports have evolved quickly. The field has progressed from classical encoder-decoder architectures to more advanced approaches that leverage alignment strategies, instruction tuning, and large vision–language models. This section provides an overview of representative approaches, grouping them by their primary methodological innovations. These include prompt- and knowledge-augmented, memory-enhanced, anatomically guided, Multi-View and longitudinally guided, transformer-based, and joint image-text generation models. We also cover more recent advancements, like conversational LVLMs, expert-guided models, and unified multimodal models. To complement this overview, the key features, datasets, and results of these models are summarized in Table 2 and Table 3.
5.1. Encoder-Decoder Architectures
Encoder-decoder models are still a key part of many systems used to generate medical reports today. First, the encoder processes chest X-rays to extract their spatial features. The decoder then generates a report based on these extracted visual features. While building on this framework, recent models also incorporate structural and clinical enhancements. Table 2 summarizes the architectures, innovations, and performance metrics of encoder-decoder models across different datasets.
5.1.1. Prompt- and Knowledge-Augmented Models
For instance, PromptMRG employs an ImageNet-pretrained ResNet-101 encoder, a BERT-base decoder [58], and three auxiliary modules: Diagnosis-Driven Prompts (DDP), Cross-Modal Feature Enhancement (CFE), and Self-adaptive Disease-balanced Learning (SDL) [27] (Figure 3). Specifically, a disease classification module operates in parallel with the encoder and outputs diagnostic labels for each pathology. These labels are converted into token-level prompts ([BLA], [POS], [NEG], and [UNC], which represent absent, positive, negative, or uncertain findings, respectively). The symbolic prompts are prepended to the decoder input sequence and learned jointly during training. Each prompt corresponds to one disease (specific pathology category) and guides the report generation of the language model toward clinically consistent output. The model also introduces a cross-modal retrieval module that uses CLIP-based embeddings to fetch similar reports and augment the classification branch and employs self-adaptive logit-adjusted loss [59] to compensate for the decoder’s inability to control disease distributions and to mitigate class imbalance during training. The decoder leverages both visual features and diagnostic prompts to generate reports that are more clinically accurate. When evaluated using the CheXpert labeler on the official MIMIC-CXR [19] test split, PromptMRG reaches CE-Precision 0.501, CE-Recall 0.509, and CE-F1 0.476, with BLEU-4 0.112, ROUGE-L 0.268, and METEOR 0.157. When evaluated on the IU X-ray (Open-I) [21] dataset, it obtains CE-Precision 0.213, CE-Recall 0.229, CE-F1 0.211, BLEU-4 0.098, ROUGE-L 0.281, and METEOR 0.160.
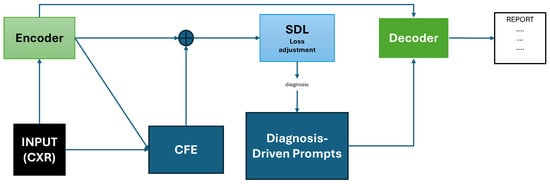
Figure 3.
Schematic representation of the PromptMRG [27] architecture adapted from Jin et al. The model includes an encoder producing visual features, a parallel classification branch with CFE (which retrieves similar reports via CLIP embeddings), Diagnosis-Driven Prompts (DDP) guiding the decoder, and Self-Adaptive Disease-balanced Learning (SDL) applied on the classification loss. Prompts and visual features are combined in the decoder to generate clinically accurate reports.
ChestBioX-Gen [60] is a CNN-RNN encoder-decoder designed for radiology report generation from chest X-ray images. The encoder uses the CheXNet model [61] (DenseNet121) to extract visual features from each image. To improve report coherence and clinical specificity, ChestBioX-Gen employs a co-attention mechanism to align visual regions of interest with textual embeddings produced by BioGPT [62], a language model pretrained on 15 million PubMed abstracts. When evaluated on the IU X-ray dataset, the model achieved BLEU-1, BLEU-2, BLEU-3, BLEU-4, and ROUGE-L scores of 0.6685, 0.6247, 0.5689, 0.4806, and 0.7742, respectively. However, to further improve performance, the authors suggest exploring transformer-based decoders and validation on larger datasets such as MIMIC-CXR. The architecture of ChestBioX-Gen is illustrated in Figure 4.
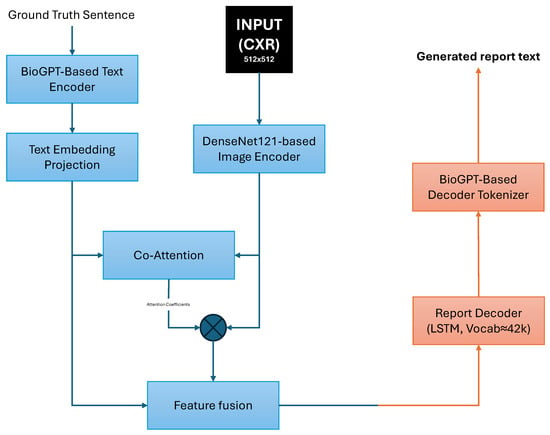
Figure 4.
ChestBioX-Gen architecture overview. Visual features from a DenseNet121-based encoder and text embeddings from a BioGPT-based encoder are aligned via co-attention. The fused features are passed to an RNN decoder to generate the radiology report text.
Another approach to knowledge augmentation is proposed by He et al. [63], who introduce a framework that leverages keywords extracted from existing radiology reports to guide report generation. First, relevant keywords are predicted from chest X-ray images by a ConvNeXt multi-label classification network. Subsequently, based on these predicted words, a Text-to-Text Transfer Transformer (T5) generates the radiology report. This method adapts medical knowledge from existing reports to align the keyword setting with ground truth clinical scenarios. The predicted keywords serve as prompts to filter non-related information and guide the pre-trained language model toward generating more clinically relevant reports. The model achieves BLEU-1, BLEU-2, and BLEU-3 scores of 0.627, 0.516, and 0.440, respectively, on IU X-ray and 0.462, 0.335, and 0.257 on MIMIC-CXR.
Another framework that uses a cross-modal attention mechanism has been proposed by Li et al. [64]. It is context-enhanced and integrates clinical text context, including comparison, the reason for the examination and clinical history. The model employs a multi-label classification to identify relevant medical knowledge (14 CheXpert diseases + 100 extracted medical terms), which are then embedded to guide report generation. GPT-4 improves generated reports by incorporating the findings of a disease diagnosis. On the MIMIC-CXR dataset, the model achieved BLEU-1, BLEU-2, BLEU-3, and BLEU-4 scores of 0.411, 0.284, 0.195, and 0.138, respectively, with a ROUGE-L of 0.312 and a clinical efficacy F1 score of 0.431.
5.1.2. Memory-Enhanced and Anatomically-Guided Models
This group of models integrates significant enhancements, including relational memory for long-range coherence (AERMNet), hierarchical anatomical knowledge (HKRG), and gaze-guided supervision (Gen-XAI). AERMNet, an encoder-decoder architecture, was proposed by Zeng et al. [13] to enhance word correlation and contextual representation for medical report generation. A common issue with current models is their weak word correlation and poor contextual representation, which reduce the accuracy of the generated reports. AERMNet improves upon the AOANet baseline [65] through the addition of a dual-layer LSTM decoder, based on the Mogrifier LSTM [66]. It also includes an attention-enhanced relational memory module to better capture long-term dependencies between words. The chest X-ray features are extracted using a ResNet101 [67] pretrained on ImageNet [68]. The relational memory module is continually updated, which strengthens the correlation between the generated words. AERMNet showed higher performance than some existing models after being trained on four datasets. These include IU X-ray, MIMIC-CXR, fetal heart ultrasound, and an ultrasound dataset collected in collaboration with a hospital in Chongqing.
On the MIMIC-CXR dataset, AERMNet achieved scores of BLEU-1 = 0.273, BLEU-4 = 0.169, METEOR = 0.157, ROUGE-L = 0.232, and CIDEr = 0.253.
Another novel approach is the HKRG (Hierarchical Knowledge Radiology Generator) with its hierarchical reasoning structure. The model uses a multi-level framework to associate features in a CXR to a specific anatomical part and clinical knowledge [12]. HKRG operates in two distinct stages: first, a vision–language pretraining stage, followed by a report generation stage. To encode images, the model uses a Swin Transformer [69], and a knowledge-enhanced BERT [70] (KEBERT) for text encoding. A cross-modal attention mechanism is integrated to combine the visual and textual features. This combination is then decoded by a 12-layer Transformer decoder. This structure mimics how radiologists interpret images by systematically integrating knowledge of organs and pathologies. The model is optimized with a multi-task loss function. This function combines three objectives: masked image modeling, masked language modeling, and a contrastive loss. The HKRG model was evaluated on the IU X-ray and MIMIC-CXR datasets. On the IU X-ray dataset, the model outperformed the previous SOTA, achieving scores of 0.538 (BLEU-1), 0.213 (BLEU-4), 0.244 (METEOR), and 0.418 (ROUGE-L). On the larger MIMIC-CXR dataset, its performance was highly competitive, with scores of 0.417, 0.143, 0.167, and 0.310 for the same metrics, though it did not surpass the SOTA on all of them. This approach provides two main benefits: it significantly improves anatomical precision and reduces overgeneralization. However, its performance depends on the quality and completeness of the external knowledge bases used during training. We have included the HKRG model in the category of anatomically-guided models, even though it uses a transformer-based encoder-decoder structure. This is due to its primary contribution, which involves the hierarchical integration of information about organs and diseases.
Also, to enhance the interpretability of RRG, Pham et al. developed Gen-XAI [14]. It is a gaze-supervised encoder-decoder model based on the FG-CXR dataset. The model uses eye-tracking heatmaps and region-level textual findings as supervision signals. This design choice promotes explainable visual-textual alignment. Gen-XAI has three main components. To align with radiologist fixations, a Gaze Attention Predictor generates anatomical attention maps. The heatmaps predicted for each anatomical region are then used by a Spatial-Aware Attended Encoder to modify image features. Finally, a GPT-2-based [71] decoder produces a single sentence for each anatomical region. The model mimics the visual interpretation of anatomical areas of the radiologists by constraining specific regions. Gen-XAI outperforms the state-of-the-art (SOTA) in both clinical efficacy and Natural Language Generation (NLG) metrics. On the FG-CXR test set, its scores are BLEU-4 = 0.561, METEOR = 0.386, ROUGE-L = 0.692, CIDEr = 4.026, and F1-micro = 0.497. Another quality of the model is that it offers a region-level visual explanation.
In addition to anatomical or memory-guided methods, a new line of work leverages temporal and multi-view information to capture disease progression, which better reflects clinical workflows.
5.1.3. Multi-View and Longitudinally Guided Models
The MLRG (Multi-view Longitudinal Report Generation) [16] model was proposed by Liu et al. to address the limitations of single-image and dual-view methods. The model operates in two stages. The first stage involves a multi-view longitudinal contrastive learning framework. It includes spatiotemporal information from radiology reports. In the second stage, the missing patient-specific knowledge is managed by a tokenized absence encoding mechanism. This stage lets the generator flexibly use the available context. MLRG uses RAD-DINO [72] for vision encoding, a CXR-BERT [73] for text encoding, and a DistilGPT2-based text generator [74]. These visual and textual representations are then correlated with a multi-view longitudinal fusion network. MLRG achieves BLEU-4, ROUGE-L, RadGraph F1, and F1 scores of: 0.158, 0.320, 0.291, and 0.505 on MIMIC-CXR [2], 0.094, 0.248, 0.219, and 0.515 on MIMIC-ABN [75], and 0.154, 0.331, 0.328, and 0.501 on two-view CXR [76]. With these scores, this model outperforms prior SOTA models on all three datasets. By incorporating multi-view and longitudinal data, the model can better mimic the workflow of radiologists and generate more clinically accurate reports.
5.1.4. Transformer-Based Encoder-Decoder
CheXReport [8] architecture was designed for radiology report generation from chest X-ray images. It relies entirely on transformers. CLAHE [77] is used to pre-process the CXR images before resizing them to 224 × 224 pixels. Afterward, the local and global visual features of the input image are extracted using pretrained Swin-T, Swin-S, and Swin-B model blocks in the encoder. These features are then projected into a 256-dimensional visual embedding space. To combine the visual and textual features, GloVe [78] word embeddings and Swin Transformer blocks are integrated into the decoder. Using a beam search, the decoder suggests reports with a beam of 5. On the MIMIC-CXR dataset, the model achieved scores of 0.127, 0.286, 0.147, and 0.130 on BLEU-4, ROUGE-L, METEOR, and GLEU. CheXReport outperforms the SOTA on BLEU-4 and ROUGE-L scores. However, CheXReport does not appear to incorporate anatomical priors, disease-specific prompts, or structured medical knowledge. Furthermore, its performance is not assessed using clinical factuality metrics, such as CheXbert or RadGraph. Unlike traditional CNN-RNN methods, CheXReport uses a pure transformer-based encoder-decoder architecture. This demonstrates the effectiveness of vision–language transformer architectures for generating radiology reports.
5.1.5. Multi-Modal Data Fusion Models
Beyond visual information, a novel approach proposed by Aksoy et al. [79] uses unstructured clinical notes and structured patient data, such as oxygen saturation, acuity level, blood pressure, and temperature, in addition to chest X-ray images. Another novelty is the conditioned cross-multi-head attention module, which fuses these different data modalities. The framework uses an EfficientNetB0 CNN as an encoder and a transformer architecture with cross-attention mechanisms to generate reports conditioned on all the available patient information. The dataset used for training and evaluation was created by combining the MIMIC-CXR, MIMIC-IV, and MIMIC-IV-ED datasets. On this combined dataset, the model achieved scores of 0.351, 0.231, 0.162, and 0.107 on BLEU-1, BLEU-2, BLEU-3, and BLEU-4 metrics, respectively, and a ROUGE-L score of 0.331. The model’s factual accuracy was evaluated by a board-certified radiologist. The model got a score of 4.24/5 for language fluency, 4.12/5 for content selection and 3.89/5 for correctness and abnormal findings confirming the performance but highlighting the need for improvement.
Table 2.
Summary of Encoder-Decoder Architectures for chest X-ray report generation. metrics abbreviated: CE-F1 stands for Clinical Efficacy-F1, RG-F1 indicates RadGraph-F1. Hum. corresponds to human evaluation.
Table 2.
Summary of Encoder-Decoder Architectures for chest X-ray report generation. metrics abbreviated: CE-F1 stands for Clinical Efficacy-F1, RG-F1 indicates RadGraph-F1. Hum. corresponds to human evaluation.
| Model | Category | Key Innovation | Dataset | BLEU-4 | ROUGE-L | METEOR | CIDER | CE-F1 | Other |
|---|---|---|---|---|---|---|---|---|---|
| PromptMRG [27] | Prompt/Knowledge | Diagnosis-driven | MIMIC-CXR | 0.112 | 0.268 | 0.157 | - | 0.476 | - |
| prompts, CFE | IU X-ray | 0.098 | 0.281 | 0.160 | - | 0.211 | - | ||
| ChestBioX-Gen [60] | Prompt/Knowledge | BioGPT co-attention | IU X-ray | 0.481 | 0.774 | 0.189 | 0.416 | - | - |
| AERMNet [13] | Memory-Enhanced | Relational memory, Mogrifier LSTM | MIMIC-CXR | 0.090 | 0.232 | 0.157 | 0.253 | - | - |
| IU X-ray | 0.183 | 0.398 | 0.219 | 0.560 | - | - | |||
| HKRG [12] | Anatomy-Guided | Hierarchical anatomical knowledge | IU X-ray | 0.213 | 0.418 | 0.244 | - | - | - |
| MIMIC-CXR | 0.143 | 0.310 | 0.167 | - | 0.339 | - | |||
| Gen-XAI [14] | Anatomy-Guided | Gaze supervision, eye-tracking | FG-CXR | 0.561 | 0.692 | 0.386 | 4.026 | 0.497 | - |
| MLRG [16] | Multi-View/Long. | Spatiotemporal contrastive learning | MIMIC-CXR | 0.158 | 0.320 | 0.176 | - | 0.505 | RG-F1 = 0.291 |
| MIMIC-ABN | 0.094 | 0.248 | 0.136 | - | 0.515 | RG-F1 = 0.219 | |||
| Two-view CXR | 0.154 | 0.331 | 0.178 | - | 0.501 | RG-F1 = 0.328 | |||
| CheXReport [8] | Pure Transformer | Swin Transformer encoder-decoder | MIMIC-CXR | 0.127 | 0.286 | 0.147 | - | - | GLEU = 0.130 |
| He et al. (2024) [63] | Prompt/Knowledge | Keywords extraction + Multi-label filtering | IU X-ray | - | - | - | - | - | B-1 = 0.627 |
| - | - | - | - | - | B-2 = 0.516 | ||||
| MIMIC-CXR | - | - | - | - | - | B-1 = 0.462 | |||
| - | - | - | - | - | B-2 = 0.335 | ||||
| Aksoy et al. (2024) [79] | Multi-Modal Fusion | Cross-attention fusion of clinical data | combined dataset | 0.107 | 0.331 | - | - | - | Hum. eval. |
| Context-Enhanced Framework [64] | Prompt/Knowledge | Clinical text fusion + Knowledge embedding + LLM refinement | IU X-ray | 0.209 | 0.408 | 0.212 | 0.396 | - | - |
| MIMIC-CXR | 0.138 | 0.312 | 0.203 | 0.195 | 0.431 | - |
5.2. Joint Image-Text Generation
CXR-IRGen [80] adopts a modularized structure with a vision module and a language module that jointly generates the chest X-ray radiology reports and images. The vision module is based on a latent diffusion model [81] (LDM). This conditioning strategy improves the clinical realism and diagnostic relevance of the generated images. The authors demonstrate that using the reference image improves the image quality (Fréchet Inception Distance [82], Peak Signal-to-Noise Ratio, and Structural Similarity Index [83]), and increases diagnostic performance (AUROC) by about 1.84 %. The language module generates the reports using a two-stage CXR report generation method. First, a pretrained LLM (BART [84]) with an encoder-decoder architecture encodes the text into a sequence of text embeddings and then reconstructs the report from the average value of all text embeddings. Then, a prior model aligns the image and text by projecting image embeddings into the text embedding space, optimized using a joint loss combining cosine similarity and Mean Squared Error (MSE), thereby ensuring that the report aligns with the image content. Furthermore, CXR-IRGen integrates reference image embeddings into its vision module prompts to improve the clinical relevance of generated reports. However, this approach risks overfitting, as shown by abnormally high classification scores (AUROC) compared to real clinical data. Instead of using raw images as input, CXR-IRGen formats CheXpert-style disease labels into textual prompts, which are then used to condition the generation of both synthetic chest X-ray images and corresponding reports. This method combines the benefits of both image captioning and retrieval-based methods [85].
5.3. Large Vision–Language Models for Radiology
This section reviews recent large multimodal models specifically designed for chest X-ray interpretation, which often rely on encoder-decoder principles but extend them through vision–language alignment and instruction-tuned LLMs. Table 3 provides a comprehensive comparison of LVLM architectures and their performance across clinical and lexical metrics.
5.3.1. Task-Specific Models for Chest X-Ray
The CXR-LLaVA [57] represents a specialized open-source vision–language model designed for chest X-ray interpretation. Its architecture is influenced by the LLaVA network [86] and integrates two core components, as shown in Figure 5: a Vision Transformer (ViT-L/16) as the visual encoder and a LLaMA-2-7B [87] language model. The model is trained using a two-stage methodology, which involves visual encoder pretraining and then vision–language alignment. In the initial training stage, the visual encoder is pretrained on 374,881 image-label pairs from a public chest X-ray dataset. Then, the model uses 217,699 image-report pairs from MIMIC-CXR to perform feature alignment between the visual and textual modalities. For instruction tuning, the authors generated question answering and multi-turn dialogue samples from MIMIC-CXR reports via the GPT-4 model. During evaluation, CXR-LLaVA surpassed general-purpose models such as GPT-4-vision [88] and Gemini-Pro-Vision on multiple benchmarks, achieving an F1-score of 0.81 on MIMIC-CXR, 0.57 on CheXpert, and 0.56 on the Indiana external test set. The model demonstrates high efficacy for frequently encountered findings such as edema and cardiomegaly. In contrast, it exhibits poor performance for pneumothorax, with an F1-score of 0.05. The quality of the generated reports was evaluated through a human study, where a panel of three board-certified radiologists rated each report on a 4-point scale. Reports with scores of 1 (fully acceptable) or 2 (minor revisions) were considered successful, leading to a 72.7 % success rate for CXR-LLaVA.
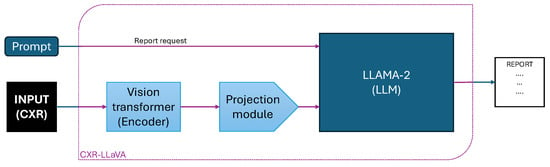
Figure 5.
Schematic overview of the CXR-LLaVA architecture. The model uses a Vision Transformer encoder to process the chest X-ray image, a projection module to align visual features, and an LLM (LLaMA-2) that integrates the prompt request and visual embeddings to generate the final radiology report.
5.3.2. Conversational and Interactive Models
RaDialog is a dual-branch large vision–language model developed for chest X-ray report generation and conversational clinical assistance. The architecture is composed of a visual feature extractor and a structured findings extractor, as illustrated in Figure 6. Their outputs are combined within a prompt construction module to query the Vicuna-7B large language model [89], which was fine-tuned via LoRA [90]. Functionally, RaDialog includes two task-specific variants: RaDialog-align uses a BERT-based alignment module to convert visual embeddings into 32 LLM-compatible tokens, while RaDialog-project employs a direct projection of 196 image tokens via an MLP adapter. RaDialog includes two training configurations: RaDialog-rep is trained on the MIMIC-CXR dataset for report generation only, while RaDialog-ins is fine-tuned using RaDialog-Instruct, a large instruction tuning dataset comprising ten tasks such as report generation, correction, simplification, and region-grounded question answering. RaDialog-Instruct includes both real and pseudo-labeled data, and training incorporates context-dropping augmentation to enhance robustness. On MIMIC-CXR, RaDialog achieves a clinical efficacy score of 39.7 and a BERTScore of 0.40, outperforming prior medical LVLMs like CheXagent and R2GenGPT. In addition, RaDialog was preferred by radiologists in 84% of cases for report generation and 71% for conversational performance in human evaluation.
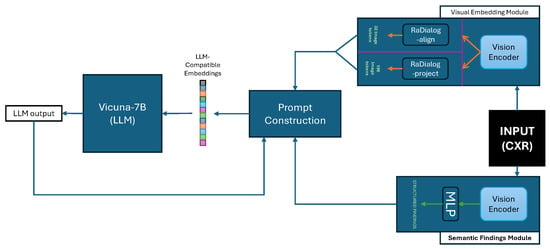
Figure 6.
Overview of the RaDialog architecture. Chest X-ray images are processed through a Visual Embedding Module, followed by either the RaDialog-align or RaDialog-project path. Simultaneously, semantic findings are extracted via a Semantic Findings Module. Both branches are merged in the Prompt Construction block to generate input sequences for the Vicuna-7B LLM, which produces the final report or dialog response.
Recent research introduces another conversational VLM that summarizes chest X-ray reports named XrayGPT [22]. The model involves a Vicuna-based LLM and a medical image encoder (MedCLIP [9]), which are aligned by a lightweight transformation layer. This alignment allows joint vision–language learning. The model is trained in two stages. First, 213,514 image-report pairs from MIMIC-CXR [19] are used for training, and then 3000 high-quality summaries from the IU X-ray (Open-I) dataset [21] are used for fine-tuning. During the preprocessing of the summaries, GPT-3.5 Turbo is used to remove incomplete phrases, historical comparisons, and technical metadata. A specific prompt schema is followed in order to simulate a medical dialogue for multiple radiological tasks. XrayGPT achieved scores of 0.3213, 0.0912, and 0.1997 for ROUGE-1, ROUGE-2, and ROUGE-L, respectively. It outperforms the MiniGPT-4 baseline by 19% in the ROUGE-1 score. An automatic comparison using GPT-3.5 Turbo showed that XrayGPT was preferred in 82% of the cases compared to 6% for the baseline. 72% of the generated reports by the model were judged as factually accurate by certified medical doctors, with an average score of 4 out of 5. In comparison, the baseline got only 20% factual accuracy with an average score of 2 out of 5. The authors noted that one of the limitations is that the performance is lower on lateral views, probably because of the dominance of frontal images in the training data. XrayGPT demonstrates that vision–language alignment and LLM-based simulation of clinical dialogue can enhance the coherence and reliability of radiology report generation.
RadVLM [91] is a compact multitask conversational vision–language model designed for interpreting chest X-rays. Based on the LLaVA-OneVision-7B backbone [92], the model combines a SigLIP vision encoder [93] with a Qwen2 language model [94], linked by a two-layer MLP adapter. To enhance representation quality, the model encodes multiple patches of the input image at various resolutions, including the full image, using the Higher AnyRes strategy [95]. These patches are then concatenated before being processed by the language model. The vision encoder, adapter, and language model are all jointly fine-tuned end-to-end using the curated instruction dataset. With a dataset of more than one million image-instruction pairs, the model was trained to perform tasks, including report generation, abnormality classification, visual grounding, and multi-turn conversational interactions. The dataset for the report generation task comprises 232,344 image-report pairs from MIMIC-CXR and 178,368 pairs from CheXpert Plus. The generated reports were evaluated using both lexical metrics (BERTScore and ROUGE-L) and clinical metrics (RadGraph F1 and GREEN). Using the MIMIC-CXR test set, RadVLM achieved the best lexical results with a BERTScore of 51.0 and a ROUGE-L of 24.3, while also scoring 17.7 on RadGraph F1 and 24.9 on GREEN. While RadVLM outperforms baseline models like RaDialog and MAIRA-2 [96] on both lexical and clinical metrics, CheXagent maintains a lead in clinical correctness.
5.3.3. Expert-Guided Models
Recent research introduces VILA-M3 [15] as a novel method that uses expert-guided mechanisms. It is designed in a four-stage scheme: (1) vision encoder pretraining, (2) vision-language pretraining, (3) instruction fine-tuning (IFT), and (4) a specialized IFT stage that injects outputs from medical expert models. The innovation of this architecture is that VILA-M3 can activate external expert models during inference. This technique, which is not used in previous models such as Med-Gemini [97], improves model reasoning by using the expert models’ outputs. For segmentation, MONAI-BraTS [98] and VISTA3D [99] tools are used, and for chest X-ray classification, TorchXRayVision [100] is used. Conversational prompts are made from the outputs of the expert models, which are used by VILA-M3 to refine its generated text with structured clinical information. On different tasks, including classification on CheXpert, RRG on MIMIC-CXR, and multiple VQA datasets, VILA-M3 outperforms the previous SOTA Med-Gemini by nearly 9%. In the RRG task on MIMIC-CXR, the model shows a BLEU-4 score of 21.6 where Med-Gemini achieves only 20.5. The F1 score for the classification task on CheXpert is 61.0 versus 48.3. VILA-M3 achieved an average score of 64.3, outperforming Med-Gemini’s 55.7. The clinical accuracy improvement is partly due to the guidance of the VLMs by the clinical signals from expert models. Finally, ablation studies confirm that the model’s performance is improved by both expert-model prompts and domain-aligned instruction tuning. These results demonstrate that the combination of modular expert components with instruction-tuned LLMs improves the clinical accuracy of RRG models.
5.3.4. Multi-Stage Vision–Language Models
The first large-scale benchmark created using the CheXpert Plus dataset [34] is CXPMRG-Bench [10]. It investigates 19 report generation algorithms, with 14 LLMs and 2 VLMs. Various pre-training strategies have been followed, including supervised fine-tuning, self-supervised autoregressive generation and contrastive learning for X-ray and report pairs. First, chest X-ray scans are divided into patches, which are then processed using autoregressive generation by a vision model based on Mamba. This improves perception efficiency with complexity. The second step involves aligning image and report pairs using contrastive learning. For this, the model uses language encoders such as Bio-ClinicalBERT [101] or LLaMA2 [87]. In the final stage, the model undergoes supervised fine-tuning using downstream datasets and is then evaluated on the IU X-ray, MIMIC-CXR, and CheXpert Plus datasets. The large variant, MambaXray-VL-L, achieved SOTA results on CheXpert Plus. It achieved 0.112 on BLEU-4, 0.276 on ROUGE-L, 0.157 on METEOR, 0.139 on CIDEr, 0.377 on precision, 0.319 on recall, and 0.335 on F1.
5.3.5. Unified Medical Vision–Language Models
Unlike prior LVLMs in radiology that mainly focus on specific tasks, such as report generation or VQA, HealthGPT is introduced as the first unified medical LVLM capable of addressing both multimodal comprehension and generation across diverse medical tasks via H-LoRA, HVP, and a three-stage learning strategy (TLS). This training method separates the tasks of understanding and creating information to avoid task conflict and improve efficiency. HealthGPT adopts the LLaVA architecture [102] for its simplicity and portability. It integrates CLIP-L/14 [103] to extract visual features, and subsequently combines shallow (concrete) and deep (abstract) features with alignment adapters. Furthermore, three variants were developed: HealthGPT-M3, HealthGPT-L14, and HealthGPT-XL32, which are based on Phi-3-mini (3.8 B) [104], Phi-4 (14 B) [105], and Qwen2.5-32B (32 B), respectively. The vocabulary was expanded with 8192 VQ indices derived from VQGAN-f8-8192 [106], serving as multi-modal tokens. The model was trained on VL-Health, a dataset curated by the authors to unify seven comprehension and five generation tasks. It includes medical VQA datasets like VQA-RAD [107], SLAKE [108], PathVQA [109], MIMIC-CXR-VQA [110], LLaVA-Med [86], and PubMedVision [111]. It also integrates generation datasets, specifically MIMIC-CXR for text-to-image, IXI [112] for super-resolution, SynthRAD2023 [113] for modality conversion, and LLaVA-558k [114] for image reconstruction. The evaluation was limited to comprehension and generation tasks, excluding radiology report generation metrics. Experimental results nevertheless demonstrated performance gains compared to the SOTA.
Table 3.
Summary of Large Vision–Language Models (LVLMs) for chest X-ray report generation. metrics abbreviated: CE-F1 stands for Clinical Efficacy-F1, RG-F1 indicates RadGraph-F1, Hum. corresponds to human evaluation.
Table 3.
Summary of Large Vision–Language Models (LVLMs) for chest X-ray report generation. metrics abbreviated: CE-F1 stands for Clinical Efficacy-F1, RG-F1 indicates RadGraph-F1, Hum. corresponds to human evaluation.
| Model | Category | Base LLM | Vision Enc. | Dataset | BLEU-4 | ROULE-L | BERTScore | CE-F1 | Other |
|---|---|---|---|---|---|---|---|---|---|
| CXR-LLaVA [57] | Task-Specific | LLaMA-2-7B | ViT-L/16 | MIMIC-CXR | - | - | - | 0.81 | - |
| CheXpert | - | - | - | 0.57 | - | ||||
| IU X-ray | - | - | - | 0.56 | Hum. = 72.7% | ||||
| RaDialog-align [39] | Conversational | Vicuna-7B | BERT-based | MIMIC-CXR | 0.097 | 0.271 | 0.40 | 0.394 | - |
| IU X-ray | 0.102 | 0.310 | 0.47 | 0.226 | - | ||||
| RaDialog-project [39] | Conversational | Vicuna-7B | MLP adapter | MIMIC-CXR | 0.094 | 0.267 | 0.36 | 0.397 | - |
| IU X-ray | 0.110 | 0.304 | 0.45 | 0.231 | - | ||||
| XrayGPT [22] | Conversational | Vicuna | MedCLIP | MIMIC-CXR | - | 0.200 | - | - | R-1 = 0.321 Hum. = 72% |
| RadVLM [91] | Conversational | Qwen2 | SigLIP | MIMIC-CXR | - | 0.243 | 0.510 | - | RG-F1 = 0.177 GREEN = 0.249 |
| VILA-M3 [15] | Expert-Guided | - | - | MIMIC-CXR | 0.216 | 0.322 | - | - | GREEN = 0.392 |
| CheXpert | - | - | - | - | - | ||||
| MambaXray-VL-L [10] | Multi-Stage | - | Mamba-based | CheXpert Plus | 0.112 | 0.276 | - | 0.335 | METEOR = 0.157 CIDEr = 0.139 |
| MambaXray-VL-B [10] | Multi-Stage | - | Mamba-based | CheXpert Plus | 0.105 | 0.267 | - | 0.273 | METEOR = 0.149 CIDEr = 0.117 |
| HealthGPT [115] | Unified | Phi-3/4, Qwen2.5 | CLIP-L/14 | Multi-datasets | - | - | - | - | Multimodal comprehension + generation |
5.4. Critical Analysis and Performance Comparison
A comparison of architectures for chest X-ray radiology report generation based on clinical metrics shows clear performance patterns.
First, MLRG [16] shows strong clinical performance with a CE-F1 of 0.505 on MIMIC-CXR, outperforming encoder-decoder baselines like PromptMRG [27] (CE-F1 = 0.476). This suggests that multi-view and longitudinally-guided models improve factual accuracy compared to the other encoder-decoder architectures by incorporating temporal information and multiple views.
Second, some models are difficult to compare due to their evaluation on NLG metrics only. For example, ChestBioX-Gen [60] achieves high scores of BLEU-4 (0.481) and ROUGE-L (0.774) on IU X-ray. Similarly, CheXReport [8] reports competitive lexical scores but lacks clinical efficacy metrics, which makes it difficult to evaluate the clinical accuracy and utility of these models. The NLG metric scores do not always correlate with clinical accuracy, and hallucinations and clinical errors are not often detected by these metrics.
Finally, large vision–language models show competitive performance on clinical efficacy metrics. CXR-LLaVA [57] achieves CE-F1 = 0.81 on MIMIC-CXR but only 0.57 and 0.56 on CheXpert and IU X-ray datasets, while RadVLM [91] achieves BERTScore = 0.510. These models show variable performance across different clinical tasks and datasets.
This analysis shows that clinical accuracy is highly impacted by architectural choices. Models with clinical grounding—through multi-view information, longitudinal data, or anatomical knowledge outperform standard encoder-decoder architectures on clinical metrics. However, future work should prioritize a unified evaluation protocol for both NLG and clinical correctness for a better comparison between architectures.
6. Methodologies for Factuality and Domain Adaptation
In addition to the core model architectures reviewed in the previous sections, certain methodological strategies have been proposed to improve factual accuracy and domain adaptation in radiology report generation.
These techniques are model-agnostic and can be integrated into diverse frameworks, including encoder-decoder systems, joint image-text generation pipelines, and large vision–language models.
6.1. RULE: A Retrieval-Augmented Generation Framework
One emerging strategy for enhancing the factual consistency of radiology report generation involves retrieval-augmented generation (RAG) frameworks, as demonstrated by RULE [116]. To minimize hallucinations, RULE uses image features and textual prompts to retrieve pertinent radiology reports with its multimodal RAG architecture. The system’s final report is guided by the external knowledge from these retrieved reports. Even with its performance on NLG metrics showing that the method is promising for reducing lexical inconsistencies, its clinical reliability remains difficult to quantify, since its evaluation lacks domain-specific metrics such as CheXbert or RadGraph. Integrating retrieval-based mechanisms with clinically grounded supervision can be a reliable approach for increasing the factuality and quality of RRG. RULE adopts a retrieval method without relying on fine-grained visual grounding or anatomical supervision. The combination of clinical supervision and retrieval-augmented frameworks can be a promising path for further future improvements.
6.2. Bootstrapping General LLMs to RRG
The adaptation of general-domain large language models to the medical domain remains a persistent challenge in RRG. A method proposed by Liu et al. [11] to address this challenge is bootstrapping LLMs specifically for this task. Coarse-to-fine decoding (C2FD) and in-domain instance induction (I3) are combined in this approach. Contrastive semantic ranking and related instance retrieval are used to adapt the LLM during the induction phase. Related instance retrieval provides in-domain reports from the training data and public medical corpora to serve as task-specific and ranking-support references. The LLM is instructed to create intermediate reports that are semantically close to high-ranking instances by the contrastive semantic ranking component. To refine intermediate reports, the coarse-to-fine decoding process uses a text generator. This generator takes the visual representation, a refinement prompt, and the intermediate report to produce the final output. When tested on the IU X-ray and MIMIC-CXR datasets, this method showed superior performance over baselines and reached SOTA results. For example, on the IU X-ray dataset, applying the full bootstrapping approach (I3 + C2FD) to a fine-tuned MiniGPT-4 improves the BLEU-4 score from 0.134 to 0.184, demonstrating a gain in linguistic quality.
6.3. Preference-Based Alignment Without Human Feedback (CheXalign)
To solve the problem of getting costly radiologist feedback, CheXalign [56] introduces an automated preference fine-tuning pipeline for chest X-ray report generation. The method uses large public datasets like MIMIC-CXR and CheXpert Plus. In these datasets, radiologist reports are paired with metrics like GREEN and BERTScore to create preference pairs. The authors introduced LC-GREEN, a version of the GREEN metric with explicit length control, to solve the problem of reward hacking caused by excessive verbosity. The results on the MIMIC-CXR and CheXpert Plus test set show that preference fine-tuning improved the performance of the baseline CheXagent model. The best configuration (Kahneman-Tversky Optimization [117] with GREEN Judge) raised the GREEN score from 0.249 to 0.328 (+31.9%), the LC-GREEN score from 0.218 to 0.293 (+34.1%), and the BERTScore from 0.856 to 0.867 (+1.27%). On the CheXpert Plus test set, this fine-tuning process raised the GREEN score from 0.248 to 0.341 (+37.2%), the LC-GREEN score from 0.202 to 0.266 (+31.4%), and the BERTScore from 0.851 to 0.863 (+1.42%). For the stronger baseline CheXagent-2, preference fine-tuning with Direct Preference Optimization [118] and GREEN Judge further improved performance on the MIMIC-CXR test set. The scores rose from GREEN = 0.326, LC-GREEN = 0.297, and BERTScore = 0.888 to 0.387 (+18.9%), 0.339 (+14.1%), and 0.891 (+0.30%), respectively. Similarly, on the CheXpert Plus test set, the CheXagent-2 baseline had scores of 0.349, 0.304, and 0.892. After DPO fine-tuning, these scores improved to 0.387 (+10.9%), 0.320 (+5.34%), and 0.888 (−0.38%). Finally, the clinical effectiveness was confirmed using CheXbert scores. On MIMIC-CXR, CheXalign improved CheXagent’s macro-F1 score from 38.9 to 44.0 and the micro-F1 score from 50.9 to 58.0.
7. Discussion and Open Challenges
Building on the previous analysis of datasets, metrics, and models, this section identifies key challenges and suggests a roadmap for future work in chest X-ray report generation. Our analysis is structured around six topics: data quality and supervision, factuality and generalization, methodological innovations, interpretability and clinical integration, the consequences and risks of LLM generation, and future perspectives.
7.1. Data Quality and Supervision
The dataset content composition and the quality of supervision signals can highly affect the performance of RRG models. The supervision quality in RRG is improved when techniques such as LLM-assisted preprocessing (XrayGPT [22]) and domain-specific pretraining (ChestBioX-Gen [60]) are applied. Also, handling the class imbalance led to an improvement of the absolute F1 score by 8% on rare pathologies (minority class) with the PromptMRG model [27], showing the importance of macro-averaged metrics. Nevertheless, the dominance of datasets with English language reports and the lack of lateral view radiographs mean that the models still have some limitations in generalization across various institutions and demographics.
7.2. Factuality and Generalization
For the clinical adoption of AI, the factual reliability of RRG models must be maximized. For instance, the accuracy of the generated reports may be limited if the training relies on visual features without clinical priors. In contrast, relational memory improves coherence across datasets, as illustrated by AERMNet [13]. Another recent method, demonstrated in CXR-IRGen [80], generates images and reports simultaneously with diffusion-based conditioning. However, the model is probably overfitting, since the AUROC scores on synthetic data are inflated. During an expert evaluation, LVLMs, including XrayGPT [22] and LLaVA [57], achieve approximately 72% factual accuracy with poor performance on the lateral views and uncommon pathologies, which represent the minority classes in the dataset. A recent study showed that RRG models capture pathology evolution and generate more clinically reliable reports with the incorporation of multi-view and temporal information [16]. The remaining challenges are achieving more robust generalization and ensuring factual consistency.
7.3. Beyond Architectures: Optimizing Factuality
The reliability and the clinical factuality of chest X-ray RRG are not necessarily improved with new designs and architectures. It can also be improved with techniques including alignment and optimization methods. Model hallucinations and factual errors can be reduced by including information from external datasets, using retrieval-augmented generation (RAG) frameworks, such as RULE [116]. Retrieving relevant instances and then using a coarse-to-fine decoding process is a bootstrapping technique that helps to adapt LLMs to the radiology field. Another preference-based optimization method, CheXalign [56], improves factual alignment. Even if its validation remains limited to a few datasets, this approach avoids costly radiologist feedback.
7.4. Interpretability and Clinical Integration
To gain clinical professionals’ trust and move toward clinical integration, the model’s reasoning has to be transparent in order to improve reliability. Models such as HKRG [12] and Gen-XAI [14] use gaze maps or hierarchical reasoning. This makes the generated reports more anatomically accurate and easier to interpret and trace back to specific data points. The clinical utility of vision–language models is still limited. While benchmarks like CXPMRG-Bench [10] and systems like CheXReport [8] have demonstrated their scalability, they still rely on a limited selection of English datasets and NLG metrics. Some models, including RaDialog [39], enable human-in-the-loop tasks through their interactive architecture, including refining impressions, answering clinical questions, and report correction. This progress helps to bring AI models closer to real-world clinical applications.
7.5. Consequences and Risks of LLM Generation
Despite the potential of large language models (LLMs), their clinical use requires specific safety measures beyond performance metrics. These models have critical challenges that must be addressed before their clinical integration.
First, LLMs are prone to the generation of hallucinations, such as findings that can be categorized as anatomical misidentifications, non-existent pathologies, or false quantitative measurements [119,120,121]. These errors are generated with high model confidence, which is a threat to clinical safety and requires specific frameworks to evaluate their diagnostic impact [122]. For instance, Asgari et al. [123] reported a 1.47% hallucination rate in clinical documentation tasks, with 44% classified as major errors. Second, there is a risk of automation bias, which means that radiologists may over-rely on the AI models for report generation and neglect error verification. Studies demonstrate that the professional’s critical diagnostic accuracy may diminish because of an over-reliance on LLMs for report generation [51]. Maintaining an expert systematic verification of the generated reports is essential to ensure that the AI output serves as a drafting tool under the final accountability of the radiologists [124]. Finally, the clinical adoption of generative models raises some ethical issues about the responsibility distribution between clinicians and developers in cases of errors, patient harm, or misdiagnosis [119,125].
7.6. Future Perspectives
A recent ambition towards creating general-purpose medical AI is exemplified by HealthGPT [115]. These architectures demonstrate their versatility for various clinical tasks by interpreting and generating content across different modalities. Some remaining challenges still persist, for instance, the lack of clinically grounded evaluation, the management of heterogeneous datasets, and balancing task performance. The next important steps include prospective studies with radiologists, the use of multi-institutional datasets with diverse demographics and acquisition views, and the prioritization of clinically validated benchmarks. Furthermore, agentic AI systems are a promising path to address current constraints related to reasoning and self-correction without human intervention. Agentic AI could verify and improve the generated reports by interacting with medical knowledge bases. To move forward in chest X-ray radiology report generation, models must ensure factual accuracy, interpretability, generalizability, and smooth integration into clinical workflows. The transition of automated report generation from benchmark success to safe clinical deployment requires meeting these conditions.
8. Conclusions
This paper reviews recent progress in chest X-ray radiology report generation. The study focuses on deep learning-based architectures and techniques, evaluation metrics, and datasets used in this field. Some limitations, such as the lack of prospective clinical validation, restricted dataset diversity, and limited factual reliability, prevent clinical adoption despite promising results. Among the most promising directions is the creation of diverse, multi-institutional datasets to improve generalization. In addition, establishing clinically validated benchmarks is necessary to better evaluate factual accuracy. Finally, to gain clinicians’ trust, the model’s design must be transparent and interpretable. Furthermore, strategies like retrieval-augmented learning or preference-based fine-tuning may further improve clinical factuality.
Addressing these challenges is essential to move beyond benchmark performance toward reliable, clinically integrated systems that can reduce reporting delays and expand global access to radiological expertise.
Author Contributions
Conceptualization, M.S. and M.A.A.; methodology, M.S. and M.A.A.; validation, M.S. and M.A.A.; formal analysis, M.S. and M.A.A.; writing—original draft preparation, M.S.; writing—review and editing, M.A.A.; funding acquisition, M.A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by the Natural Sciences and Engineering Research Council of Canada (NSERC), under funding reference number RGPIN-2024-05287, and by the AI in Health Research Chair at the Université de Moncton.
Data Availability Statement
No new data were created or analyzed in this study.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AUROC | Area Under the Receiver Operating Characteristic Curve |
| BLEU | Bilingual Evaluation Understudy |
| BERT | Bidirectional Encoder Representations from Transformers |
| BERTScore | BERT-based Semantic Similarity Metric |
| CE | Clinical Efficacy |
| CIDEr | Consensus-based Image Description Evaluation |
| CLIP | Contrastive Language-Image Pretraining |
| CNN | Convolutional Neural Network |
| CXR | Chest X-ray |
| DPO | Direct Preference Optimization |
| GPT | Generative Pretrained Transformer |
| HIPAA | Health Insurance Portability and Accountability Act |
| IFT | Instruction Fine-Tuning |
| IU X-ray | Indiana University Chest X-ray dataset |
| LLaVA | Large Language and Vision Assistant |
| LLM | Large Language Model |
| LVLM | Large Vision–Language Model |
| LSTM | Long Short-Term Memory |
| METEOR | Metric for Evaluation of Translation with Explicit ORdering |
| MIMIC-CXR | Medical Information Mart for Intensive Care Chest X-ray |
| MLP | Multilayer Perceptron |
| NLG | Natural Language Generation |
| NLP | Natural Language Processing |
| PA | Posteroanterior (Projection) |
| ResNet | Residual Network |
| RNN | Recurrent Neural Network |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation |
| RRG | Radiology Report Generation |
| SOTA | State-of-the-Art |
| Swin | Shifted Window Transformer |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| TLS | Three-Stage Learning Strategy |
| VLM | Vision–Language Model |
| VQA | Visual Question Answering |
| VQGAN | Vector Quantized Generative Adversarial Network |
| ViT | Vision Transformer |
Appendix A. Mathematical Formulations of NLG Metrics
- Bilingual Evaluation Understudy (BLEU) [43]:BLEU is calculated as the geometric mean of modified n-gram precisions, weighted by a brevity penalty (BP) to discourage overly short candidate sentences. BLEU’s mathematical formulation is defined in Equation (A1).where is the clipped precision for n-grams of size n, are uniform weights, and BP is the brevity penalty given by Equation (A2).with c the generated sentence length and r the reference sentence length. BLEU variants such as BLEU-1 to BLEU-4 correspond to uni- to 4-gram precision, respectively.
- Recall-Oriented Understudy for Gisting Evaluation (ROUGE) [44,45]:The most widely used variants include:
- –
- ROUGE-L is based on the Longest Common Subsequence (LCS) and defined in Equation (A3). ROUGE-L is particularly favored because of its ability to capture sentence-level structural similarity without requiring consecutive matches.where , , m and n being the lengths of the reference and generated sentences, respectively, and the parameter balances recall and precision, typically set to .
- –
- ROUGE-N (based on n-gram overlap), where n denotes the size of the n-grams, is defined in Equation (A4).
- Metric for Evaluation of Translation with Explicit ORdering (METEOR) [46,47]: The METEOR score is computed from a harmonic mean (F-score) of unigram precision (P) and recall (R), with greater importance given to recall, as shown in Equation (A5) [46]:In order to account for differences in word order, METEOR calculates a penalty based on the number of matched chunks and matched unigrams, defined in Equation (A6), where represents the number of chunks, m the number of matched unigrams, and parameters and are empirically tuned to optimize correlation with human judgments [126]:This penalty is included in the final calculation of the mean of the METEOR score to give a balanced score of precision, recall, and fluency as represented by Equation (A7) [46]:
Appendix B. Additional Natural Language Generation Metrics
This appendix provides detailed descriptions of supplementary NLG metrics referenced in Section 4.
- Consensus-based Image Description Evaluation (CIDEr) [127,128]: CIDEr evaluates the similarity between a generated report and a set of reference reports based on term frequency-inverse document frequency (TF-IDF) weighted n-gram vectors. For each n-gram length n, it computes the average cosine similarity between the candidate (generated) and reference set :The final score is computed as a weighted average over to 4, using uniform weights :CIDEr correlates more strongly with human judgments than BLEU or ROUGE, particularly in tasks involving diverse but semantically similar outputs. However, in medical report generation, it may overweight lexical variation and overlook clinical correctness, and is thus often complemented by clinically oriented metrics.
- BERTScore [129]: BERTScore evaluates the similarity between a generated and a reference report based on contextualized embeddings from BERT. Each token in the candidate and reference is encoded using a pretrained BERT model. Then, for every token in the candidate, the maximum cosine similarity to tokens in the reference is computed, and vice versa. Precision (P) measures the average of the maximum similarities from candidate to reference, and recall (R) the reverse. The final score is computed as the harmonic mean of P and R, as shown in Equation A10.Unlike lexical metrics such as BLEU or ROUGE, BERTScore captures semantic similarity and has been shown to correlate more closely with human judgment [129]. However, in medical report generation, it does not account for clinical correctness and may be influenced by the pretraining domain of the underlying language model [130]. Consequently, BERTScore is often used alongside complementary clinical evaluation metrics to account for factual correctness.
- Google BLEU (GLEU): GLEU [131] is a metric initially developed to address specific limitations of BLEU when applied to sentence-level evaluation, particularly within neural machine translation. While BLEU’s evaluation relies solely on n-gram precision, GLEU incorporates both precision and recall through the computation of clipped counts of matched n-grams between the candidate and reference sentences. The final score is defined as the minimum value between n-gram precision and recall, calculated across n-grams from orders 1 to 4. By offering this dual perspective, GLEU can penalize both under-generation and over-generation. This capability makes it more appropriate for concise, informative texts, like those found in medical sentences. Unlike BLEU, which favors longer texts, GLEU was specifically designed for single-sentence evaluation and correlates better with human judgments in these scenarios. Recent research has applied GLEU in medical image captioning and radiology report generation. It is used to evaluate the local fidelity of specific phrases, especially when assessing the correctness of individual sentences in clinical reports [8].
References
- Broder, J. Chapter 5—Imaging the Chest: The Chest Radiograph. In Diagnostic Imaging for the Emergency Physician; W.B. Saunders: Philadelphia, PA, USA, 2011; pp. 185–296. [Google Scholar] [CrossRef]
- Johnson, A.E.W.; Pollard, T.J.; Berkowitz, S.J.; Greenbaum, N.R.; Lungren, M.P.; Deng, C.y.; Mark, R.G.; Horng, S. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports. Sci. Data 2019, 6, 317. [Google Scholar] [CrossRef]
- Li, Y.; Kong, C.; Zhao, G.; Zhao, Z. Automatic radiology report generation with deep learning: A comprehensive review of methods and advances. Artif. Intell. Rev. 2025, 58, 344. [Google Scholar] [CrossRef]
- Rosman, D.A.; Nshizirungu, J.J.; Rudakemwa, E.; Moshi, C.; de Dieu Tuyisenge, J.; Uwimana, E.; Kalisa, L. Imaging in the land of 1000 hills: Rwanda radiology country report. J. Glob. Radiol. 2015, 1, 5. [Google Scholar] [CrossRef]
- Ali, F.; Harrington, S.; Kennedy, S.; Hussain, S. Diagnostic Radiology in Liberia: A Country Report. J. Glob. Radiol. 2015, 1, 6. [Google Scholar] [CrossRef]
- Wang, X.; Figueredo, G.; Li, R.; Zhang, W.E.; Chen, W.; Chen, X. A survey of deep-learning-based radiology report generation using multimodal inputs. Med. Image Anal. 2025, 103, 103627. [Google Scholar] [CrossRef]
- Hartsock, I.; Rasool, G. Vision-language models for medical report generation and visual question answering: A review. Front. Artif. Intell. 2024, 7, 1430984. [Google Scholar] [CrossRef]
- Zeiser, F.A.; da Costa, C.A.; de Oliveira Ramos, G.; Maier, A.; da Rosa Righi, R. CheXReport: A transformer-based architecture to generate chest X-ray reports suggestions. Expert Syst. Appl. 2024, 255, 124644. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, Z.; Agarwal, D.; Sun, J. MedCLIP: Contrastive learning from unpaired medical images and text. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 3876–3887. [Google Scholar] [CrossRef]
- Wang, X.; Wang, F.; Li, Y.; Ma, Q.; Wang, S.; Jiang, B.; Tang, J. CXPMRG-Bench: Pre-training and Benchmarking for X-ray Medical Report Generation on CheXpert Plus Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 11–15 June 2025; pp. 5123–5133. [Google Scholar]
- Liu, C.; Tian, Y.; Chen, W.; Song, Y.; Zhang, Y. Bootstrapping Large Language Models for Radiology Report Generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; AAAI: Washington, DC, USA, 2024; Volume 38, pp. 18635–18643. [Google Scholar] [CrossRef]
- Wang, B.; Teng, P.; Zhang, H.; Yang, F.; Wang, Z.; Yi, X.; Zhang, T.; Wang, C.; Tavares, A.J.; Xu, H. HKRG: Hierarchical knowledge integration for radiology report generation. Expert Syst. Appl. 2025, 271, 126622. [Google Scholar] [CrossRef]
- Zeng, X.; Liao, T.; Xu, L.; Wang, Z. AERMNet: Attention-enhanced relational memory network for medical image report generation. Comput. Methods Programs Biomed. 2024, 244, 107979. [Google Scholar] [CrossRef]
- Pham, T.T.; Ho, N.V.; Bui, N.T.; Phan, T.; Brijesh, P.; Adjeroh, D.; Doretto, G.; Nguyen, A.; Wu, C.C.; Nguyen, H.; et al. FG-CXR: A Radiologist-Aligned Gaze Dataset for Enhancing Interpretability in Chest X-Ray Report Generation. In Proceedings of the Asian Conference on Computer Vision (ACCV), Hanoi, Vietnam, 8–12 December 2024; pp. 941–958. [Google Scholar]
- Nath, V.; Li, W.; Yang, D.; Myronenko, A.; Zheng, M.; Lu, Y.; Liu, Z.; Yin, H.; Law, Y.M.; Tang, Y.; et al. VILA-M3: Enhancing Vision-Language Models with Medical Expert Knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 11–15 June 2025; pp. 14788–14798. [Google Scholar]
- Liu, K.; Ma, Z.; Kang, X.; Li, Y.; Xie, K.; Jiao, Z.; Miao, Q. Enhanced Contrastive Learning with Multi-view Longitudinal Data for Chest X-ray Report Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 11–15 June 2025; pp. 10348–10359. [Google Scholar]
- Smit, A.; Jain, S.; Rajpurkar, P.; Pareek, A.; Ng, A.; Lungren, M. Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1500–1519. [Google Scholar]
- Heiman, A.; Zhang, X.; Chen, E.; Kim, S.E.; Rajpurkar, P. FactCheXcker: Mitigating Measurement Hallucinations in Chest X-ray Report Generation Models. In Proceedings of the 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 10–17 June 2025; pp. 30787–30796. [Google Scholar] [CrossRef]
- Johnson, A.; Pollard, T.; Mark, R.; Berkowitz, S.; Horng, S. MIMIC-CXR Database (version 2.1.0). PhysioNet 2024, 6. [Google Scholar] [CrossRef]
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K.; et al. CheXpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 590–597. [Google Scholar] [CrossRef]
- Demner-Fushman, D.; Kohli, M.D.; Rosenman, M.B.; Shooshan, S.E.; Rodriguez, L.; Antani, S.; Thoma, G.R.; McDonald, C.J. Preparing a collection of radiology examinations for distribution and retrieval. J. Am. Med. Inform. Assoc. 2015, 23, 304–310. [Google Scholar] [CrossRef]
- Thawakar, O.C.; Shaker, A.M.; Mullappilly, S.S.; Cholakkal, H.; Anwer, R.M.; Khan, S.; Laaksonen, J.; Khan, F. XrayGPT: Chest Radiographs Summarization using Large Medical Vision-Language Models. In Proceedings of the 23rd Workshop on Biomedical Natural Language Processing, Bangkok, Thailand, 16 August 2024; pp. 440–448. [Google Scholar] [CrossRef]
- Yu, F.; Endo, M.; Krishnan, R.; Pan, I.; Tsai, A.; Reis, E.P.; Fonseca, E.K.U.N.; Lee, H.M.H.; Abad, Z.S.H.; Ng, A.Y.; et al. Evaluating progress in automatic chest X-ray radiology report generation. Patterns 2023, 4, 100802. [Google Scholar] [CrossRef]
- Çallı, E.; Sogancioglu, E.; van Ginneken, B.; van Leeuwen, K.G.; Murphy, K. Deep learning for chest X-ray analysis: A survey. Med. Image Anal. 2021, 72, 102125. [Google Scholar] [CrossRef]
- Ouis, M.Y.; A. Akhloufi, M. Deep learning for report generation on chest X-ray images. Comput. Med. Imaging Graph. 2024, 111, 102320. [Google Scholar] [CrossRef]
- Rehman, M.; Shafi, I.; Ahmad, J.; Garcia, C.O.; Barrera, A.E.P.; Ashraf, I. Advancement in medical report generation: Current practices, challenges, and future directions. Med. Biol. Eng. Comput. 2025, 63, 1249–1270. [Google Scholar] [CrossRef]
- Jin, H.; Che, H.; Lin, Y.; Chen, H. PromptMRG: Diagnosis-Driven Prompts for Medical Report Generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 2607–2615. [Google Scholar] [CrossRef]
- Johnson, A.; Lungren, M.; Peng, Y.; Lu, Z.; Mark, R.; Berkowitz, S.; Horng, S. MIMIC-CXR-JPG—Chest Radiographs with Structured Labels (Version 2.1.0); PhysioNet, MIT Laboratory for Computational Physiology: Cambridge, MA, USA, 2024. [Google Scholar] [CrossRef]
- Johnson, A.E.W.; Pollard, T.J.; Greenbaum, N.R.; Lungren, M.P.; ying Deng, C.; Peng, Y.; Lu, Z.; Mark, R.G.; Berkowitz, S.J.; Horng, S. MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs. arXiv 2019, arXiv:1901.07042. [Google Scholar] [CrossRef]
- Peng, Y. NegBio: A high-performance tool for negation and uncertainty detection in radiology reports. AMIA Summits Transl. Sci. Proc. 2018, 2018, 188–196. [Google Scholar]
- Langlotz, C.P. RadLex: A New Method for Indexing Online Educational Materials. RadioGraphics 2006, 26, 1595–1597. [Google Scholar] [CrossRef]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. ChestX-Ray8: Hospital-Scale Chest X-Ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3462–3471. [Google Scholar] [CrossRef]
- Aronson, A.R.; Lang, F.M. An overview of MetaMap: Historical perspective and recent advances. J. Am. Med. Inform. Assoc. 2010, 17, 229–236. [Google Scholar] [CrossRef]
- Chambon, P.; Delbrouck, J.B.; Sounack, T.; Huang, S.C.; Chen, Z.; Varma, M.; Truong, S.Q.; Chuong, C.T.; Langlotz, C.P. CheXpert Plus: Augmenting a Large Chest X-ray Dataset with Text Radiology Reports, Patient Demographics and Additional Image Formats. arXiv 2024, arXiv:2405.19538. [Google Scholar] [CrossRef]
- Bustos, A.; Pertusa, A.; Salinas, J.M.; de la Iglesia-Vayá, M. PadChest: A large chest x-ray image dataset with multi-label annotated reports. Med. Image Anal. 2020, 66, 101797. [Google Scholar] [CrossRef] [PubMed]
- de Castro, D.C.; Bustos, A.; Bannur, S.; Hyland, S.L.; Bouzid, K.; Wetscherek, M.T.; Sánchez-Valverde, M.D.; Jaques-Pérez, L.; Pérez-Rodríguez, L.; Takeda, K.; et al. PadChest-GR: A Bilingual Chest X-Ray Dataset for Grounded Radiology Report Generation. NEJM AI 2025, 2, AIdbp2401120. [Google Scholar] [CrossRef]
- Nguyen, H.Q.; Lam, K.; Le, L.T.; Pham, H.H.; Tran, D.Q.; Nguyen, D.B.; Le, D.D.; Pham, C.M.; Tong, H.T.T.; Dinh, D.H.; et al. VinDr-CXR: An open dataset of chest X-rays with radiologist’s annotations. Sci. Data 2022, 9, 429. [Google Scholar] [CrossRef]
- Pellegrini, C.; Keicher, M.; Özsoy, E.; Navab, N. Rad-ReStruct: A Novel VQA Benchmark and Method for Structured Radiology Reporting. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2023, Vancouver, BC, Canada, 8–12 October 2023; pp. 409–419. [Google Scholar]
- Pellegrini, C.; Özsoy, E.; Busam, B.; Wiestler, B.; Navab, N.; Keicher, M. RaDialog: Large Vision-Language Models for X-Ray Reporting and Dialog-Driven Assistance. In Proceedings of the Medical Imaging with Deep Learning, Salt Lake City, UT, USA, 9–11 July 2025. [Google Scholar]
- Bigolin Lanfredi, R.; Zhang, M.; Auffermann, W.; Chan, J.; Duong, P.; Srikumar, V.; Drew, T.; Schroeder, J.; Tasdizen, T. REFLACX: Reports and Eye-Tracking Data for Localization of Abnormalities in Chest X-Rays (Version 1.0.0); PhysioNet, MIT Laboratory for Computational Physiology: Cambridge, MA, USA, 2021. [Google Scholar] [CrossRef]
- Karargyris, A.; Kashyap, S.; Lourentzou, I.; Wu, J.; Tong, M.; Sharma, A.; Abedin, S.; Beymer, D.; Mukherjee, V.; Krupinski, E.; et al. Eye Gaze Data for Chest X-Rays (Version 1.0.0); PhysioNet, MIT Laboratory for Computational Physiology: Cambridge, MA, USA, 2020. [Google Scholar] [CrossRef]
- Kale, K.; Bhattacharyya, P.; Jadhav, K. Replace and Report: NLP Assisted Radiology Report Generation. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 10731–10742. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Barbella, M.; Tortora, G. Rouge metric evaluation for text summarization techniques. SSRN Electron. J. 2022, 4120317. [Google Scholar] [CrossRef]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Denkowski, M.; Lavie, A. Meteor Universal: Language Specific Translation Evaluation for Any Target Language. In Proceedings of the Ninth Workshop on Statistical Machine Translation, Baltimore, MD, USA, 26–27 June 2014; pp. 376–380. [Google Scholar]
- Denkowski, M.; Lavie, A. Meteor 1.3: Automatic metric for reliable optimization and evaluation of machine translation systems. In Proceedings of the Sixth Workshop on Statistical Machine Translation, Edinburgh, UK, 30–31 July 2011; pp. 85–91. [Google Scholar]
- Jain, S.; Agrawal, A.; Saporta, A.; Truong, S.; Duong, D.N.D.N.; Bui, T.; Chambon, P.; Zhang, Y.; Lungren, M.; Ng, A.; et al. RadGraph: Extracting Clinical Entities and Relations from Radiology Reports. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, Virtual, 6–14 December 2021. [Google Scholar]
- Miura, Y.; Zhang, Y.; Tsai, E.; Langlotz, C.; Jurafsky, D. Improving Factual Completeness and Consistency of Image-to-Text Radiology Report Generation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Virtual, 6–11 June 2021; pp. 5288–5304. [Google Scholar] [CrossRef]
- Tanno, R.; Barrett, D.G.; Sellergren, A.; Ghaisas, S.; Dathathri, S.; See, A.; Welbl, J.; Lau, C.; Tu, T.; Azizi, S.; et al. Collaboration between clinicians and vision-language models in radiology report generation. Nat. Med. 2025, 31, 599–608. [Google Scholar] [CrossRef]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2019, 36, 1234–1240. [Google Scholar] [CrossRef]
- Nicolson, A.; Dowling, J.; Koopman, B. Improving chest X-ray report generation by leveraging warm starting. Artif. Intell. Med. 2023, 144, 102633. [Google Scholar] [CrossRef]
- Ostmeier, S.; Xu, J.; Chen, Z.; Varma, M.; Blankemeier, L.; Bluethgen, C.; Md, A.E.M.; Moseley, M.; Langlotz, C.; Chaudhari, A.S.; et al. GREEN: Generative Radiology Report Evaluation and Error Notation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024; pp. 374–390. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, X.; Abderezaei, J.; Bauml, J.; Boodoo, R.; Haghighi, F.; Ganjizadeh, A.; Brattain, E.; Van Veen, D.; Meng, Z.; et al. RadEval: A framework for radiology text evaluation. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Suzhou, China, 4–9 November 2025; pp. 546–557. [Google Scholar] [CrossRef]
- Hein, D.; Chen, Z.; Ostmeier, S.; Xu, J.; Varma, M.; Reis, E.P.; Md, A.E.M.; Bluethgen, C.; Shin, H.J.; Langlotz, C.; et al. CheXalign: Preference fine-tuning in chest X-ray interpretation models without human feedback. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vienna, Austria, 27 July–1 August 2025; pp. 27679–27702. [Google Scholar] [CrossRef]
- Lee, S.; Youn, J.; Kim, H.; Kim, M.; Yoon, S.H. CXR-LLaVA: A multimodal large language model for interpreting chest X-ray images. Eur. Radiol. 2025, 35, 4374–4386. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Menon, A.K.; Jayasumana, S.; Rawat, A.S.; Jain, H.; Veit, A.; Kumar, S. Long-tail learning via logit adjustment. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Ouis, M.Y.; Akhloufi, M.A. ChestBioX-Gen: Contextual biomedical report generation from chest X-ray images using BioGPT and co-attention mechanism. Front. Imaging 2024, 3, 1373420. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning. arXiv 2017, arXiv:1711.05225. [Google Scholar]
- Luo, R.; Sun, L.; Xia, Y.; Qin, T.; Zhang, S.; Poon, H.; Liu, T.Y. BioGPT: Generative pre-trained transformer for biomedical text generation and mining. Brief. Bioinform. 2022, 23, bbac409. [Google Scholar] [CrossRef]
- He, M.Z.; yin Anson Cheung, D.H.; Hei, D.T.; Wong, E.; Yoo, D.J.S. 338 - Enhancing Chest X-Ray Report Generation in Radiology through Deep Learning: Leveraging Keywords from Existing Reports and Multi-Label Classification. J. Med. Imaging Radiat. Sci. 2024, 55, 101657. [Google Scholar] [CrossRef]
- Li, H.; Wang, H.; Sun, X.; He, H.; Feng, J. Context-enhanced framework for medical image report generation using multimodal contexts. Knowl.-Based Syst. 2025, 310, 112913. [Google Scholar] [CrossRef]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.Y. Attention on Attention for Image Captioning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4633–4642. [Google Scholar] [CrossRef]
- Melis, G.; Kočiský, T.; Blunsom, P. Mogrifier LSTM. In Proceedings of the International Conference on Learning Representations, Virtual, 26 April–1 May 2020. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, C.; Zhang, Y.; Xie, W.; Wang, Y. Knowledge-enhanced visual-language pre-training on chest radiology images. Nat. Commun. 2023, 14, 4542. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Pérez-García, F.; Sharma, H.; Bond-Taylor, S.; Bouzid, K.; Salvatelli, V.; Ilse, M.; Bannur, S.; Castro, D.C.; Schwaighofer, A.; Lungren, M.P.; et al. Exploring scalable medical image encoders beyond text supervision. Nat. Mach. Intell. 2025, 7, 119–130. [Google Scholar] [CrossRef]
- Boecking, B.; Usuyama, N.; Bannur, S.; Castro, D.C.; Schwaighofer, A.; Hyland, S.; Wetscherek, M.; Naumann, T.; Nori, A.; Alvarez-Valle, J.; et al. Making the Most of Text Semantics to Improve Biomedical Vision–Language Processing. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 1–21. [Google Scholar] [CrossRef]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2020, arXiv:1910.01108. [Google Scholar] [CrossRef]
- Ni, J.; Hsu, C.N.; Gentili, A.; McAuley, J. Learning Visual-Semantic Embeddings for Reporting Abnormal Findings on Chest X-rays. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Virtual, 16–20 November 2020; pp. 1954–1960. [Google Scholar] [CrossRef]
- Miao, Q.; Liu, K.; Ma, Z.; Li, Y.; Kang, X.; Liu, R.; Liu, T.; Xie, K.; Jiao, Z. EVOKE: Elevating Chest X-ray Report Generation via Multi-View Contrastive Learning and Patient-Specific Knowledge. arXiv 2025, arXiv:2411.10224. [Google Scholar] [CrossRef]
- Zuiderveld, K. VIII.5.—Contrast Limited Adaptive Histogram Equalization. In Graphics Gems; Academic Press: Cambridge, MA, USA, 1994; pp. 474–485. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Aksoy, N.; Sharoff, S.; Baser, S.; Ravikumar, N.; Frangi, A.F. Beyond images: An integrative multi-modal approach to chest x-ray report generation. Front. Radiol. 2024, 4, 1339612. [Google Scholar] [CrossRef] [PubMed]
- Shentu, J.; Al Moubayed, N. CXR-IRGen: An Integrated Vision and Language Model for the Generation of Clinically Accurate Chest X-Ray Image-Report Pairs. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2024; pp. 5212–5221. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; IEEE: New York, NY, USA, 2017; Volume 30, pp. 6626–6637. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Endo, M.; Krishnan, R.; Krishna, V.; Ng, A.Y.; Rajpurkar, P. Retrieval-Based Chest X-Ray Report Generation Using a Pre-trained Contrastive Language-Image Model. In Proceedings of the Machine Learning for Health, Virtual, 4 December 2021; pp. 209–219. [Google Scholar]
- Li, C.; Wong, C.; Zhang, S.; Usuyama, N.; Liu, H.; Yang, J.; Naumann, T.; Poon, H.; Gao, J. LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; Volume 36, pp. 28541–28564. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar] [CrossRef]
- Javan, R.; Kim, T.; Mostaghni, N. GPT-4 vision: Multi-modal evolution of ChatGPT and potential role in radiology. Cureus 2024, 16, e68298. [Google Scholar] [CrossRef]
- Chiang, W.L.; Li, Z.; Lin, Z.; Sheng, Y.; Wu, Z.; Zhang, H.; Zheng, L.; Zhuang, S.; Zhuang, Y.; Gonzalez, J.E.; et al. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality, March 2023. Available online: https://lmsys.org/blog/2023-03-30-vicuna/ (accessed on 24 July 2025).
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Deperrois, N.; Matsuo, H.; Ruipérez-Campillo, S.; Vandenhirtz, M.; Laguna, S.; Ryser, A.; Fujimoto, K.; Nishio, M.; Sutter, T.M.; Vogt, J.E.; et al. RadVLM: A Multitask Conversational Vision-Language Model for Radiology. arXiv 2025, arXiv:2502.03333. [Google Scholar] [CrossRef]
- Li, B.; Zhang, Y.; Guo, D.; Zhang, R.; Li, F.; Zhang, H.; Zhang, K.; Zhang, P.; Li, Y.; Liu, Z.; et al. LLaVA-OneVision: Easy Visual Task Transfer. Trans. Mach. Learn. Res. 2025, 2025. Available online: https://researchportal.hkust.edu.hk/en/publications/llava-onevision-easy-visual-task-transfer/ (accessed on 24 July 2025).
- Zhai, X.; Mustafa, B.; Kolesnikov, A.; Beyer, L. Sigmoid Loss for Language Image Pre-Training. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 11975–11986. [Google Scholar]
- Yang, A.; Yang, B.; Hui, B.; Zheng, B.; Yu, B.; Zhou, C.; Li, C.; Li, C.; Liu, D.; Huang, F.; et al. Qwen2 Technical Report. arXiv 2024, arXiv:2407.10671. [Google Scholar] [CrossRef]
- Chai, L.; Gharbi, M.; Shechtman, E.; Isola, P.; Zhang, R. Any-Resolution Training for High-Resolution Image Synthesis. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 170–188. [Google Scholar] [CrossRef]
- Bannur, S.; Bouzid, K.; Castro, D.C.; Schwaighofer, A.; Thieme, A.; Bond-Taylor, S.; Ilse, M.; Pérez-García, F.; Salvatelli, V.; Sharma, H.; et al. MAIRA-2: Grounded Radiology Report Generation. arXiv 2024, arXiv:2406.04449. [Google Scholar] [CrossRef]
- Yang, L.; Xu, S.; Sellergren, A.; Kohlberger, T.; Zhou, Y.; Ktena, I.; Kiraly, A.; Ahmed, F.; Hormozdiari, F.; Jaroensri, T.; et al. Advancing Multimodal Medical Capabilities of Gemini. arXiv 2024, arXiv:2405.03162. [Google Scholar] [CrossRef]
- Myronenko, A. 3D MRI Brain Tumor Segmentation Using Autoencoder Regularization. In Proceedings of the Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, Granada, Spain, 16 September 2018; pp. 311–320. [Google Scholar]
- He, Y.; Guo, P.; Tang, Y.; Myronenko, A.; Nath, V.; Xu, Z.; Yang, D.; Zhao, C.; Simon, B.; Belue, M.; et al. VISTA3D: A Unified Segmentation Foundation Model For 3D Medical Imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 11–15 June 2025; pp. 20863–20873. [Google Scholar]
- Cohen, J.P.; Viviano, J.D.; Bertin, P.; Morrison, P.; Torabian, P.; Guarrera, M.; Lungren, M.P.; Chaudhari, A.; Brooks, R.; Hashir, M.; et al. TorchXRayVision: A library of chest X-ray datasets and models. In Proceedings of the 5th International Conference on Medical Imaging with Deep Learning, Zurich, Switzerland, 6–8 July 2022; PMLR: London, UK, 2022; Volume 172, pp. 231–249. [Google Scholar]
- Alsentzer, E.; Murphy, J.; Boag, W.; Weng, W.H.; Jindi, D.; Naumann, T.; McDermott, M. Publicly Available Clinical BERT Embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, Minneapolis, MN, USA, 7 June 2019; pp. 72–78. [Google Scholar] [CrossRef]
- Liu, H.; Li, C.; Li, Y.; Li, B.; Zhang, Y.; Shen, S.; Lee, Y.J. LLaVA-NeXT: Improved Reasoning, OCR, and World Knowledge. 2024. Available online: https://llava-vl.github.io/blog/2024-01-30-llava-next/ (accessed on 14 October 2025).
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 8748–8763. [Google Scholar]
- Abdin, M.; Aneja, J.; Awadalla, H.; Awadallah, A.; Awan, A.A.; Bach, N.; Bahree, A.; Bakhtiari, A.; Bao, J.; Behl, H.; et al. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv 2024, arXiv:2404.14219. [Google Scholar] [CrossRef]
- Abdin, M.; Aneja, J.; Behl, H.; Bubeck, S.; Eldan, R.; Gunasekar, S.; Harrison, M.; Hewett, R.J.; Javaheripi, M.; Kauffmann, P.; et al. Phi-4 Technical Report. arXiv 2024, arXiv:2412.08905. [Google Scholar] [CrossRef]
- Esser, P.; Rombach, R.; Ommer, B. Taming Transformers for High-Resolution Image Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 12873–12883. [Google Scholar]
- Lau, J.J.; Gayen, S.; Ben Abacha, A.; Demner-Fushman, D. A dataset of clinically generated visual questions and answers about radiology images. Sci. Data 2018, 5, 180251. [Google Scholar] [CrossRef]
- Liu, B.; Zhan, L.M.; Xu, L.; Ma, L.; Yang, Y.; Wu, X.M. Slake: A Semantically-Labeled Knowledge-Enhanced Dataset For Medical Visual Question Answering. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France (Virtual), 13–16 April 2021; pp. 1650–1654. [Google Scholar] [CrossRef]
- He, X.; Zhang, Y.; Mou, L.; Xing, E.; Xie, P. PathVQA: 30000+ Questions for Medical Visual Question Answering. arXiv 2020, arXiv:2003.10286. [Google Scholar] [CrossRef]
- Bae, S.; Kyung, D.; Ryu, J.; Cho, E.; Lee, G.; Kweon, S.; Oh, J.; JI, L.; Chang, E.; Kim, T.; et al. MIMIC-Ext-MIMIC-CXR-VQA: A Complex, Diverse, and Large-Scale Visual Question Answering Dataset for Chest X-Ray Images (Version 1.0.0); PhysioNet, MIT Laboratory for Computational Physiology: Cambridge, MA, USA, 2024. [Google Scholar] [CrossRef]
- Chen, J.; Gui, C.; Ouyang, R.; Gao, A.; Chen, S.; Chen, G.H.; Wang, X.; Cai, Z.; Ji, K.; Wan, X.; et al. Towards Injecting Medical Visual Knowledge into Multimodal LLMs at Scale. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; pp. 7346–7370. [Google Scholar] [CrossRef]
- The IXI Dataset. 2014. Available online: https://brain-development.org/ixi-dataset/ (accessed on 15 October 2025).
- Thummerer, A.; van der Bijl, E.; Galapon, A., Jr.; Verhoeff, J.J.C.; Langendijk, J.A.; Both, S.; van den Berg, C.N.A.T.; Maspero, M. SynthRAD2023 Grand Challenge dataset: Generating synthetic CT for radiotherapy. Med. Phys. 2023, 50, 4664–4674. [Google Scholar] [CrossRef]
- Liu, H.; Li, C.; Li, Y.; Lee, Y.J. Improved Baselines with Visual Instruction Tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 26296–26306. [Google Scholar]
- Lin, T.; Zhang, W.; LI, S.; Yuan, Y.; Yu, B.; Li, H.; He, W.; Jiang, H.; Li, M.; xiaohui, S.; et al. HealthGPT: A Medical Large Vision-Language Model for Unifying Comprehension and Generation via Heterogeneous Knowledge Adaptation. In Proceedings of the Forty-second International Conference on Machine Learning, Vancouver, BC, Canada, 13–19 July 2025. [Google Scholar]
- Xia, P.; Zhu, K.; Li, H.; Zhu, H.; Li, Y.; Li, G.; Zhang, L.; Yao, H. RULE: Reliable Multimodal RAG for Factuality in Medical Vision Language Models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; pp. 1081–1093. [Google Scholar] [CrossRef]
- Ethayarajh, K.; Xu, W.; Muennighoff, N.; Jurafsky, D.; Kiela, D. Model alignment as prospect theoretic optimization. In Proceedings of the 41st International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Rafailov, R.; Sharma, A.; Mitchell, E.; Ermon, S.; Manning, C.D.; Finn, C. Direct preference optimization: Your language model is secretly a reward model. In Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Salehi, S.; Singh, Y.; Horst, K.K.; Hathaway, Q.A.; Erickson, B.J. Agentic AI and Large Language Models in Radiology: Opportunities and Hallucination Challenges. Bioengineering 2025, 12, 1303. [Google Scholar] [CrossRef]
- Huang, L.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H.; Chen, Q.; Peng, W.; Feng, X.; Qin, B.; et al. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. ACM Trans. Inf. Syst. 2025, 43, 42. [Google Scholar] [CrossRef]
- Kim, Y.; Jeong, H.; Chen, S.; Li, S.S.; Park, C.; Lu, M.; Alhamoud, K.; Mun, J.; Grau, C.; Jung, M.; et al. Medical Hallucination in Foundation Models and Their Impact on Healthcare. medRxiv 2025. [Google Scholar] [CrossRef]
- Roustan, D.; Bastardot, F. The Clinicians’ Guide to Large Language Models: A General Perspective with a Focus on Hallucinations. Interact. J. Med. Res. 2025, 14, e59823. [Google Scholar] [CrossRef]
- Asgari, E.; Montaña-Brown, N.; Dubois, M.; Khalil, S.; Balloch, J.; Yeung, J.A.; Pimenta, D. A framework to assess clinical safety and hallucination rates of LLMs for medical text summarisation. npj Digit. Med. 2025, 8, 274. [Google Scholar] [CrossRef]
- Artsi, Y.; Sorin, V.; Glicksberg, B.S.; Korfiatis, P.; Freeman, R.; Nadkarni, G.N.; Klang, E. Challenges of Implementing LLMs in Clinical Practice: Perspectives. J. Clin. Med. 2025, 14, 6169. [Google Scholar] [CrossRef]
- Tung, T.; Hasnaeen, S.M.N.; Zhao, X. Ethical and practical challenges of generative AI in healthcare and proposed solutions: A survey. Front. Digit. Health 2025, 7, 1692517. [Google Scholar] [CrossRef] [PubMed]
- Lavie, A.; Denkowski, M.J. The METEOR metric for automatic evaluation of machine translation. Mach. Transl. 2009, 23, 105–115. [Google Scholar] [CrossRef]
- Vedantam, R.; Zitnick, C.L.; Parikh, D. CIDEr: Consensus-based image description evaluation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Oliveira dos Santos, G.; Colombini, E.L.; Avila, S. CIDEr-R: Robust Consensus-based Image Description Evaluation. In Proceedings of the Seventh Workshop on Noisy User-Generated Text (W-NUT 2021), Online, 11 November 2021; pp. 351–360. [Google Scholar] [CrossRef]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. In Proceedings of the International Conference on Learning Representations, Online, 26 April–1 May 2020. [Google Scholar]
- Hanna, M.; Bojar, O. A Fine-Grained Analysis of BERTScore. In Proceedings of the Sixth Conference on Machine Translation, Online, 10–11 November 2021; pp. 507–517. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.