
Gait-Driven Pose Tracking and Movement Captioning Using OpenCV and MediaPipe Machine Learning Framework †



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Literature Survey
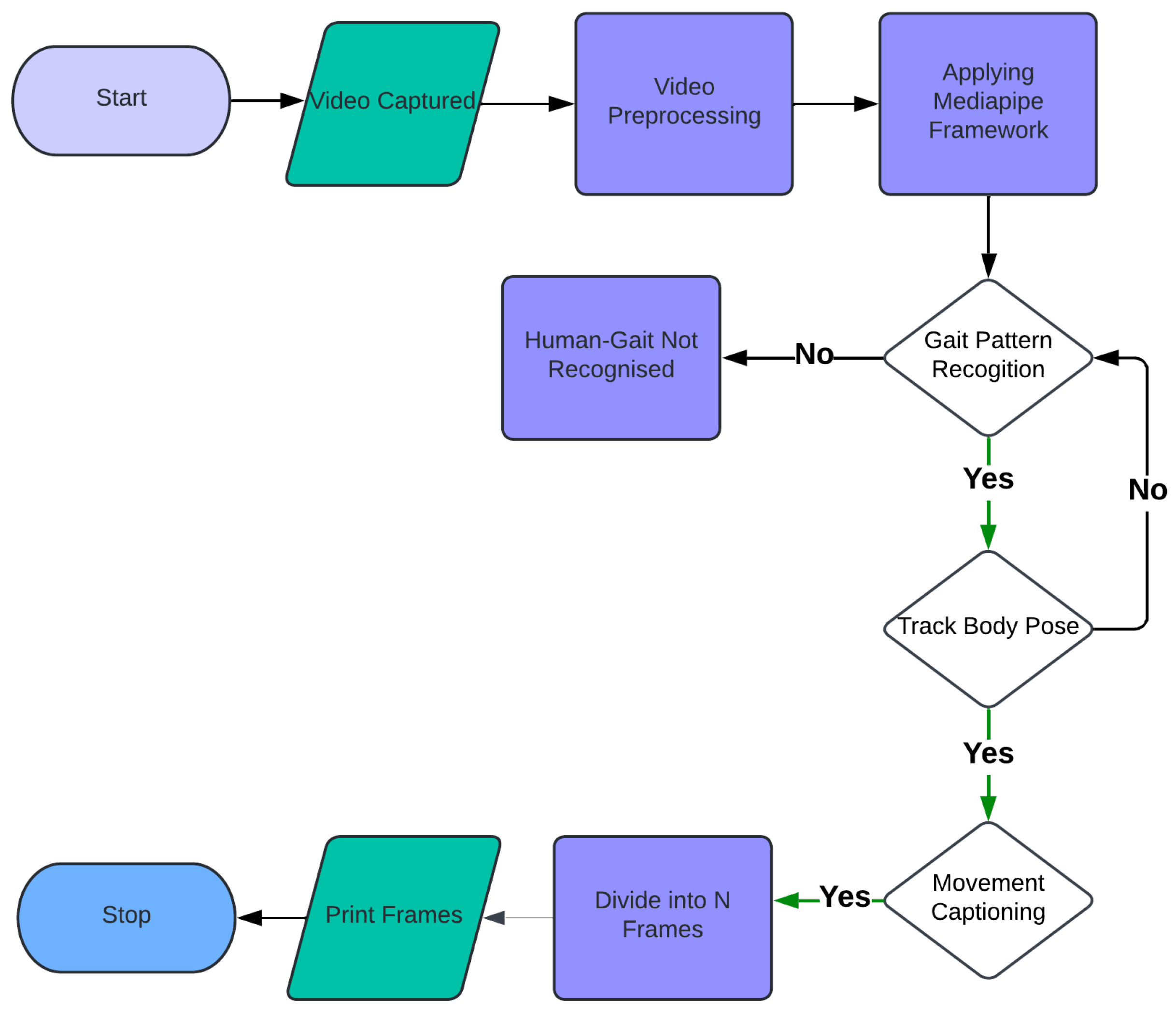
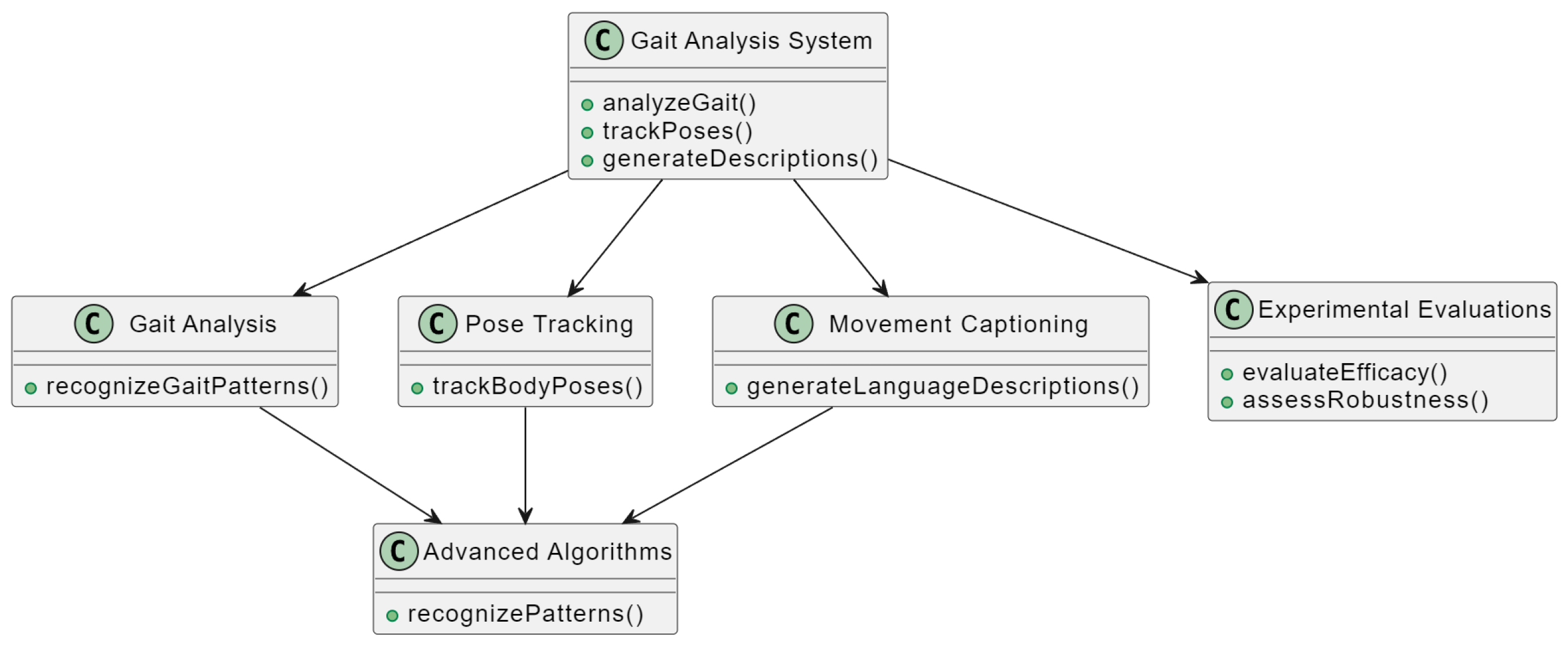
3. Methodology
3.1. GHUM 3D for Skeleton Recognition
3.2. Python for Categorizing Movements
3.3. Human Activity Recognition
3.4. Video Analysis by Dividing Video Data into 15 Frames
3.5. Streamlit for UI Development
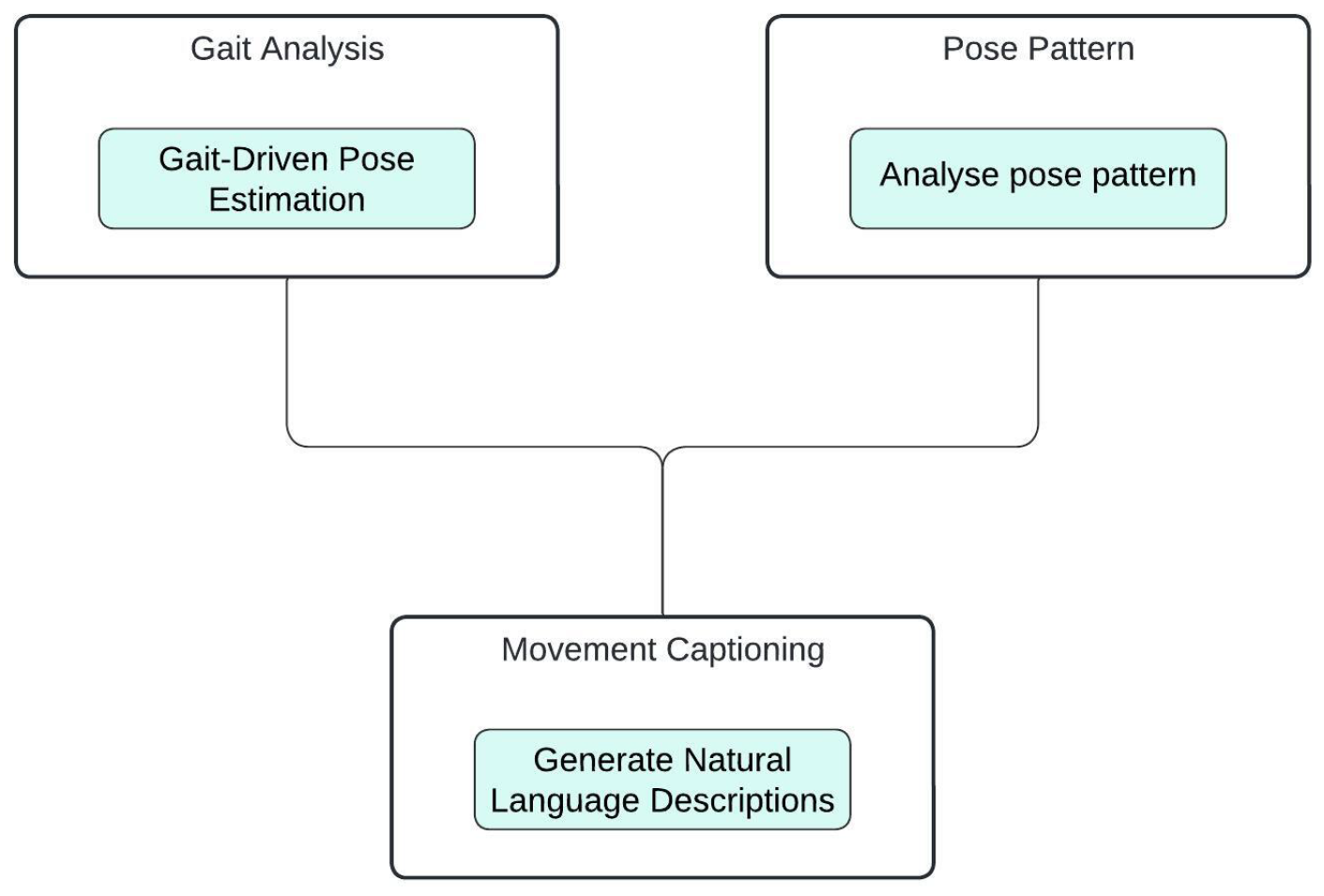
3.6. Integration of Gait Analysis, Pose Tracking, and Movement Captioning
3.7. Feature Extraction
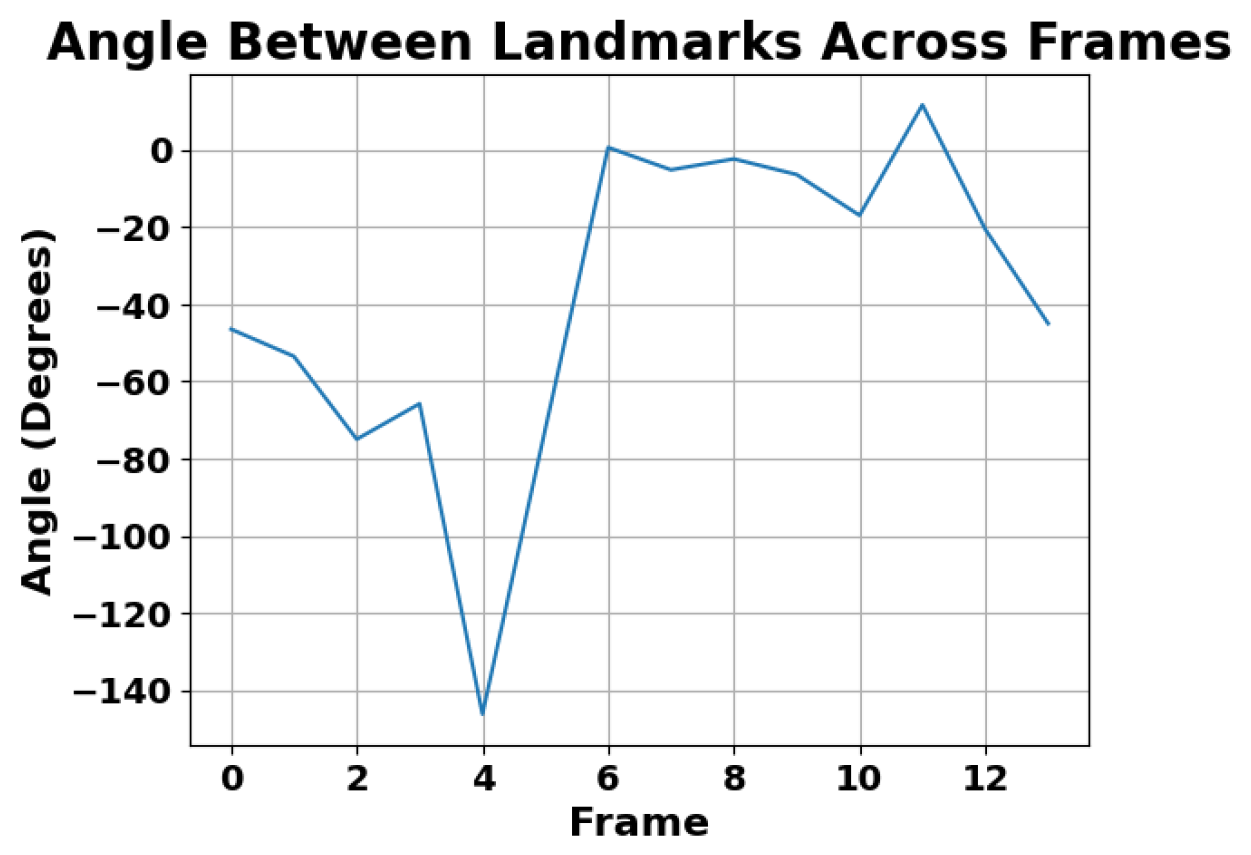
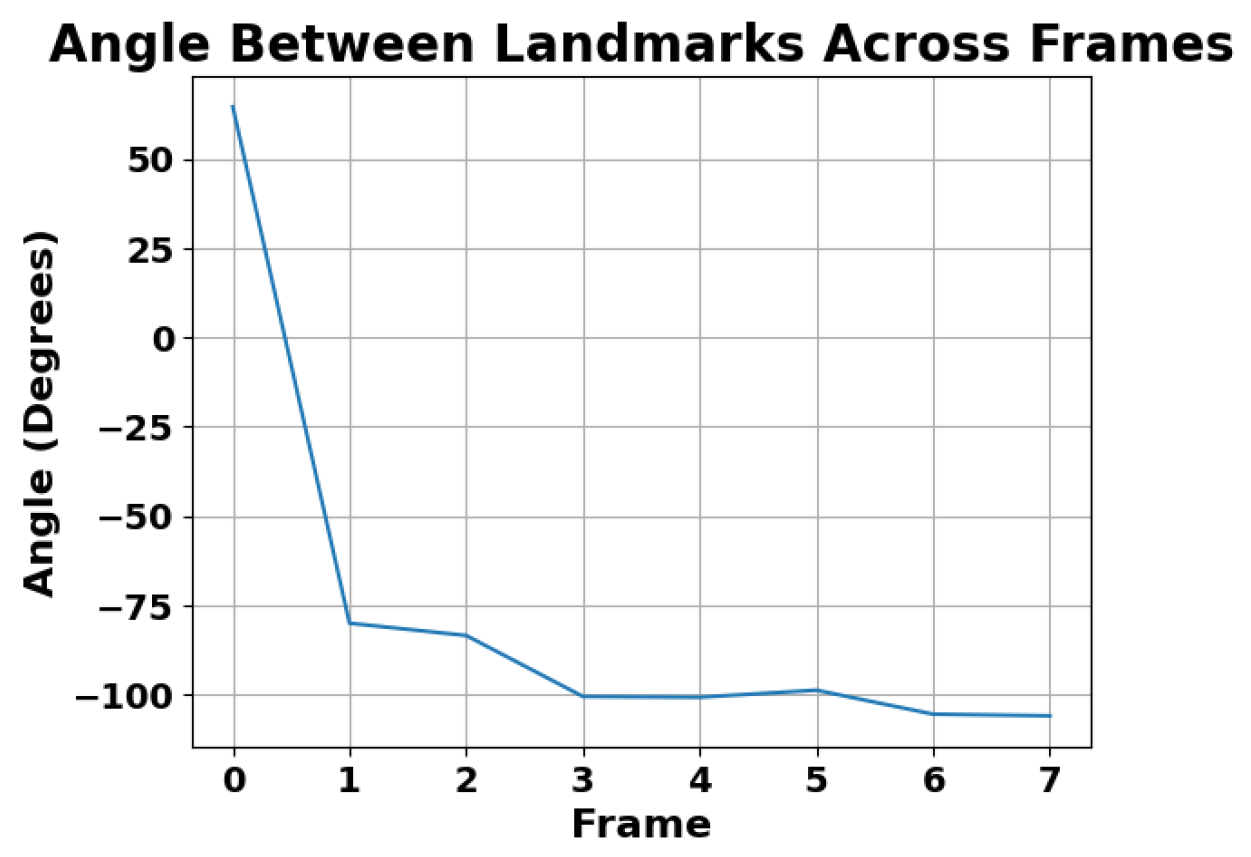
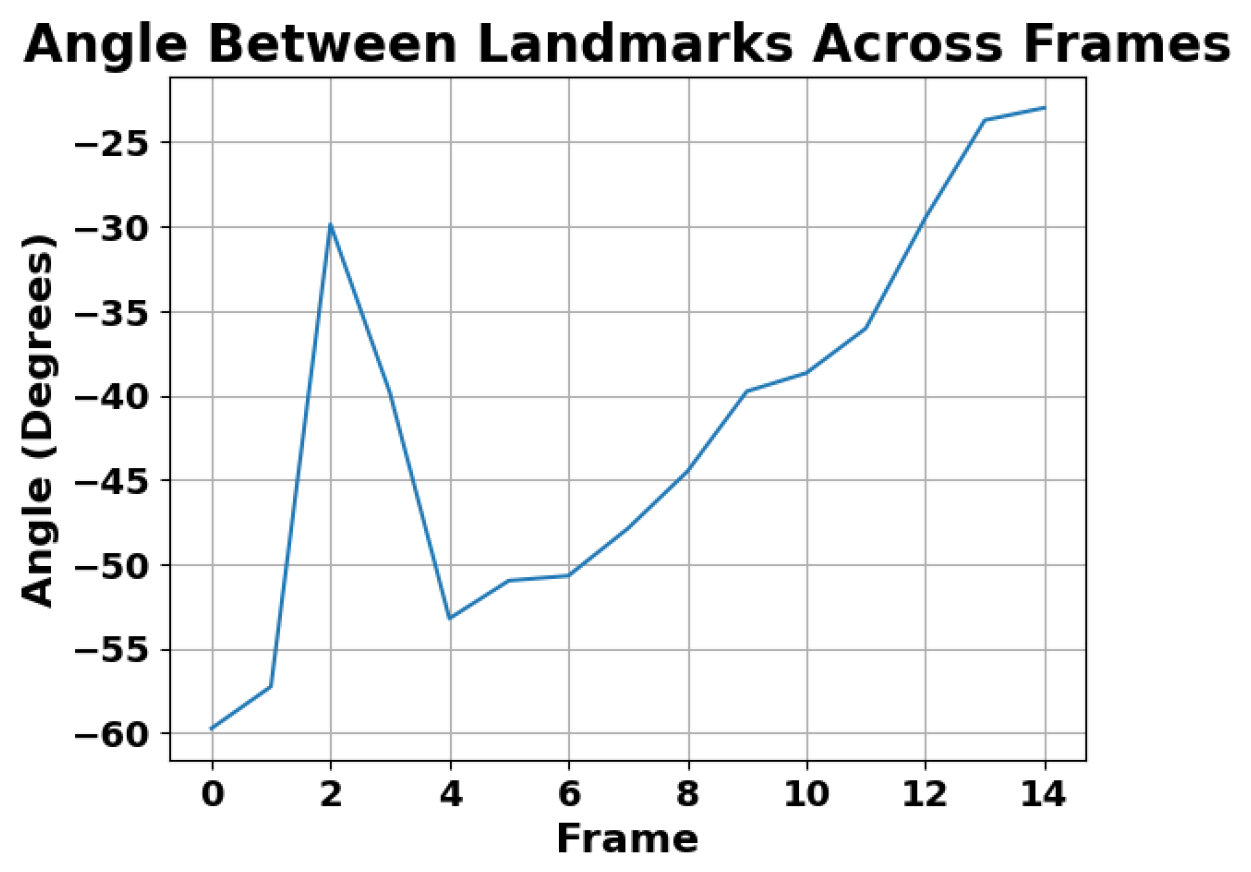
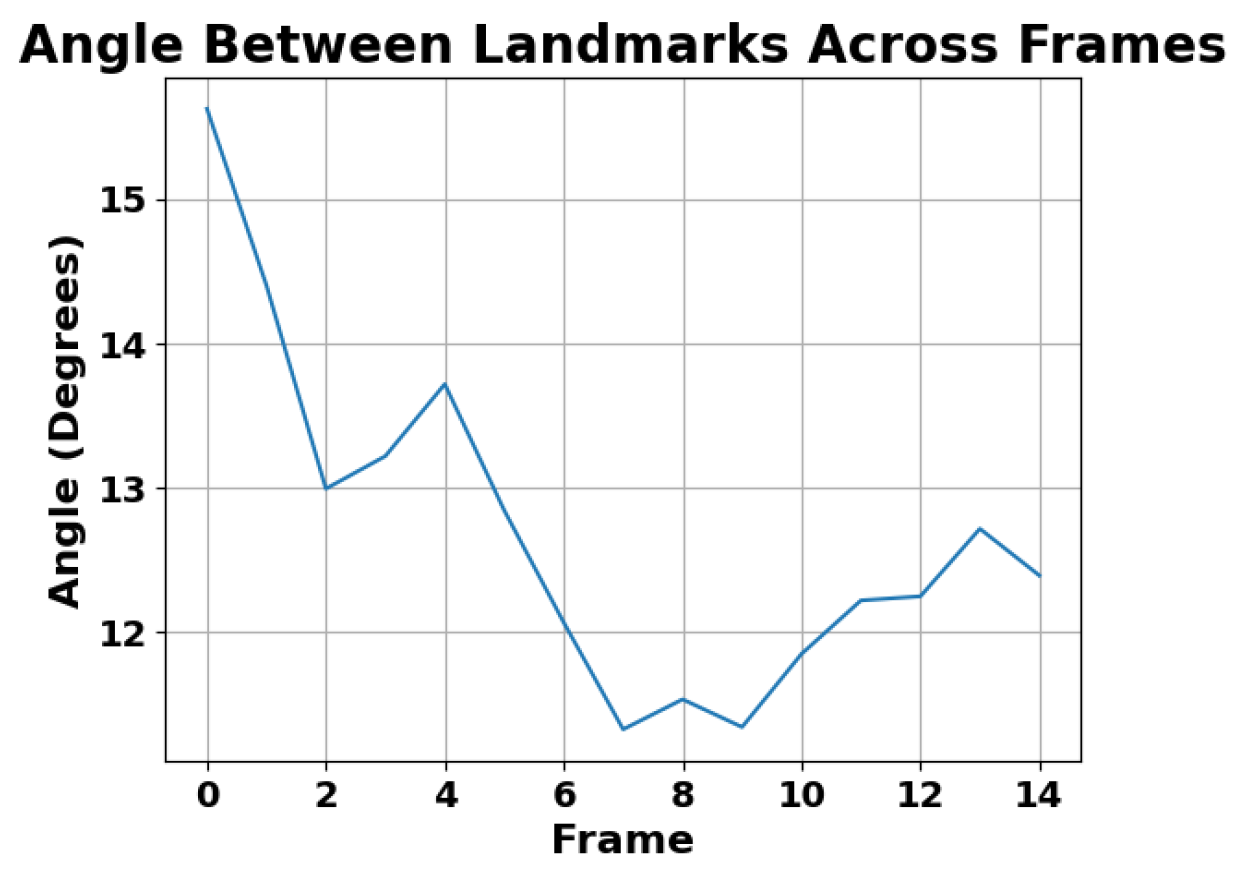
4. Results
5. Conclusions and Future Work
Ethical Considerations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, S.; Fang, J.; Hu, X.; Ngai, E.; Wang, W.; Guo, Y.; Leung, V.C.M. Emotion recognition from gait analyses: Current research and future directions. arXiv 2020, arXiv:2003.11461. [Google Scholar] [CrossRef]
- Karg, M.; Kühnlenz, K.; Buss, M. Recognition of affect based on gait patterns. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2010, 40, 1050–1061. [Google Scholar] [CrossRef] [PubMed]
- Bhattacharya, U.; Roncal, C.; Mittal, T.; Chandra, R.; Kapsaskis, K.; Gray, K.; Bera, A.; Manocha, D. Take an emotion walk: Perceiving emotions from gaits using hierarchical attention pooling and affective mapping. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020; pp. 145–163. [Google Scholar]
- Sheng, W.; Li, X. Multi-task learning for gait-based identity recognition and emotion recognition using attention enhanced temporal graph convolutional network. Pattern Recognit. 2021, 114, 107868. [Google Scholar] [CrossRef]
- Roether, C.L.; Omlor, L.; Christensen, A.; Giese, M.A. Critical features for the perception of emotion from gait. J. Vis. 2009, 9, 15. [Google Scholar] [CrossRef] [PubMed]
- Cui, L.; Li, S.; Zhu, T. Emotion detection from natural walking. In Proceedings of the Human Centered Computing: Second International Conference, HCC 2016, Colombo, Sri Lanka, 7–9 January 2016; Revised Selected Papers 2. Springer International Publishing: Cham, Switzerland, 2016; p. 2333. [Google Scholar]
- Fan, Y.; Mao, S.; Li, M.; Wu, Z.; Kang, J. CM-YOLOv8: Lightweight YOLO for Coal Mine Fully Mechanized Mining Face. Sensors 2024, 24, 1866. [Google Scholar] [CrossRef] [PubMed]
- Singh, J.P.; Jain, S.; Arora, S.; Singh, U.P. Vision-based gait recognition: A survey. IEEE Access 2018, 6, 70497–70527. [Google Scholar] [CrossRef]
- Zhang, R.; Vogler, C.; Metaxas, D. Human gait recognition. In Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004; IEEE: Piscataway, NJ, USA, 2004; p. 18. [Google Scholar]
- Bashir, K.; Xiang, T.; Gong, S. Gait recognition without subject cooperation. Pattern Recognit. Lett. 2010, 31, 2052–2060. [Google Scholar] [CrossRef]
- Liu, Z.; Sarkar, S. Improved gait recognition by gait dynamics normalization. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 863–876. [Google Scholar] [PubMed]
- Bobick, A.F.; Johnson, A.Y. Gait recognition using static, activity-specific parameters. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 8–14 December 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 1. [Google Scholar]
- Shakhnarovich, G.; Lee, L.; Darrell, T. Integrated face and gait recognition from multiple views. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 8–14 December 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 1. [Google Scholar]
- Xu, D.; Yan, S.; Tao, D.; Zhang, L.; Li, X.; Zhang, H.J. Human gait recognition with matrix representation. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 896–903. [Google Scholar]
- Gafurov, D. A survey of biometric gait recognition: Approaches, security, and challenges. In Proceedings of the Annual Norwegian Computer Science Conference, Oslo, Norway, 13–16 May 2007; pp. 19–21. [Google Scholar]
- dos Santos, C.F.G.; de Souza Oliveira, D.; Passos, L.A.; Pires, R.G.; Santos, D.F.S.; Valem, L.P.; Moreira, T.P.; Santana, M.C.S.; Roder, M.; Papa, J.P. Gait recognition based on deep learning: A survey. ACM Comput. Surv. (CSUR) 2022, 55, 1–34. [Google Scholar] [CrossRef]
- Dudekula, K.V.; Chalapathi, M.M.V.; Kumar, Y.V.P.; Prakash, K.P.; Reddy, C.P.; Gangishetty, D.; Solanki, M.; Singhu, R. Physiotherapy assistance for patients using human pose estimation with Raspberry Pi. ASEAN J. Sci. Technol. Rep. 2024, 27, e251096. [Google Scholar] [CrossRef]
- Mangone, M.; Marinelli, E.; Santilli, G.; Finanore, N.; Agostini, F.; Santilli, V.; Bernetti, A.; Paoloni, M.; Zaami, S. Gait analysis advancements: Rehabilitation value and new perspectives from forensic application. Eur. Rev. Med. Pharmacol. Sci. 2023, 27, 3–12. [Google Scholar] [PubMed]
- Xu, D.; Zhou, H.; Quan, W.; Jiang, X.; Liang, M.; Li, S.; Ugbolue, U.C.; Baker, J.S.; Gusztav, F.; Ma, X.; et al. A new method proposed for realizing human gait pattern recognition: Inspirations for the application of sports and clinical gait analysis. Gait Posture 2024, 107, 293–305. [Google Scholar] [CrossRef] [PubMed]
- Fang, P.; Zhu, M.; Zeng, Z.; Lu, W.; Wang, F.; Zhang, L.; Chen, T.; Sun, L. A Multi-Module Sensing and Bi-Directional HMI Integrating Interaction, Recognition, and Feedback for Intelligent Robots. Adv. Funct. Mater. 2024, 34, 2310254. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Janapati, M.; Allamsetty, L.P.; Potluri, T.T.; Mogili, K.V. Gait-Driven Pose Tracking and Movement Captioning Using OpenCV and MediaPipe Machine Learning Framework. Eng. Proc. 2024, 82, 4. https://doi.org/10.3390/ecsa-11-20470
Janapati M, Allamsetty LP, Potluri TT, Mogili KV. Gait-Driven Pose Tracking and Movement Captioning Using OpenCV and MediaPipe Machine Learning Framework. Engineering Proceedings. 2024; 82(1):4. https://doi.org/10.3390/ecsa-11-20470
Chicago/Turabian StyleJanapati, Malathi, Leela Priya Allamsetty, Tarun Teja Potluri, and Kavya Vijay Mogili. 2024. "Gait-Driven Pose Tracking and Movement Captioning Using OpenCV and MediaPipe Machine Learning Framework" Engineering Proceedings 82, no. 1: 4. https://doi.org/10.3390/ecsa-11-20470
APA StyleJanapati, M., Allamsetty, L. P., Potluri, T. T., & Mogili, K. V. (2024). Gait-Driven Pose Tracking and Movement Captioning Using OpenCV and MediaPipe Machine Learning Framework. Engineering Proceedings, 82(1), 4. https://doi.org/10.3390/ecsa-11-20470