Abstract
The article discusses approaches to building parallel data storage systems in high- performance clusters. The features of building data structures in parallel file systems for various applied tasks are analyzed. Approaches are proposed to improve the efficiency of access to data by computing nodes of the cluster due to the correct distribution of data in parallel file storage.
1. Introduction
The growing need of scientific teams, industrial enterprises, and commercial firms in solving problems that require high-performance computing resources demands the creation of computing tools provided to users using cloud and platform technologies. At present, such computing resources are supercomputers and HPC clusters that make it possible to carry out calculations using parallel computing technologies. So, the tasks of mathematical modeling, global optimization, big data analysis, and the training of neural networks cannot be solved using a single server; powerful multi-node clusters united by high-performance computing networks are required. The workflow management in such clusters is a research task aimed at optimizing the computing resources load, minimizing the waiting and computing time, managing job priorities, and providing computing jobs with initial data.
Based on HPC clusters, it is possible to create a research infrastructure that provides tools for miscellaneous scientific calculations to teams of scientists, industry, and developers of high-tech commercial products [1]. The creation of shared research facilities on the basis of scientific centers, enterprises, organizations of the Russian Academy of Sciences and universities makes it possible to increase the efficiency of using computing facilities and expand the circle of consumers of high-performance computing resources [2]. This approach to the use of computational tools involves the parallel execution of miscellaneous types of computational tasks within a single high-performance cluster. In this case, in order to efficiently use computing resources and minimize the loss of time and money for re-configuring the HPC cluster, it is necessary to develop a technology that allows creating individual software environments for various computing tasks and ensuring their parallel execution in a HPC cluster [3], wherein each computational task obtains access to the parallel processing information means and inter-process communication. The means of HPC cluster workflow management create an individual profile for inter-process interaction in a dynamic virtual environment for each computational task.
The optimization of the loading of the shared research HPC cluster is generally aimed at ensuring the maximum loading of computing modules, reducing the waiting time for tasks in the queue, and minimizing equipment downtime.
To implement such requirements for a HPC cluster, it is of particular importance to provide computing tasks with initial data. The performance of the means of providing data to computational jobs should, for example, minimize the processing downtime by waiting for data to be provided. The tasks of providing data to computational tasks in multi-node computing systems are solved by creating a specialized file storage that provides parallel access to cluster computing nodes and data. Thus, the data exchange height speed is ensured in the conditions of parallel operation of virtual software environments for the execution of miscellaneous types of computational tasks.
The classical scheme for organizing parallel file access is the use of a group of data storage nodes connected to computing nodes by a high-speed network. A parallel file system deployed on storage nodes creates a single data space, ensures information consistency, the duplication of information on different nodes, and control of access to files by computing nodes.
Both proprietary and open-source implementations of parallel file systems are available today. For example, proprietary solutions include
- General Parallel File System (GPFS)—developed by IBM;
- Google File System.
IBM GPFS is used by the manufacturer as part of a commercial product, the elastic storage system, which is a scalable hardware and software data storage system. The Google File System is used by Google in the company’s high-performance computing clusters.
Among open source parallel file systems, the Lustre project is currently actively developing, originating from Carnegie University, now supervised by Intel Corporation. Another open-source project is the Ceph parallel file system supervised by RedHat (IBM).
The direction of providing parallel access to data is currently an actively developing area of informatics [4,5,6]. The main efforts of developers and researchers are concentrated in the following areas:
- Maximizing the volume of data storage;
- Ensuring the required performance during data transfer, taking into account the number of computing nodes and data storage nodes;
- Development of methods for scaling the file system while maintaining or increasing performance;
- Development of methods for improving the reliability of parallel file systems.
The architectures and ways of representing data in parallel file systems are discussed below.
2. Parallel File System Architecture
Consider the architecture of a parallel file system using the Lustre project as an example.
Lustre is a high-performance file system composed of servers and storage. The Metadata Server (MDS) keeps track of metadata (such as ownership and access rights to a file or directory). Object storage servers provide file I/O services for object storage targets that host the actual data store. The storage targets are typically a single disk array. Lustre’s parallel file system achieves its performance by automatically splitting data into chunks known as “stripes” and writing the stripes in a round-robin fashion across multiple storage objects. This process, called “striping”, can significantly increase file I/O speed by eliminating single disk bottlenecks [7].
A parallel storage system consists of many components, including drives, storage controllers, I/O cards, storage servers, SAN switches, and related management software. Combining all of these components together and tuning them for optimal performance comes with significant challenges. Figure 1 shows the Lustre parallel file system architecture.
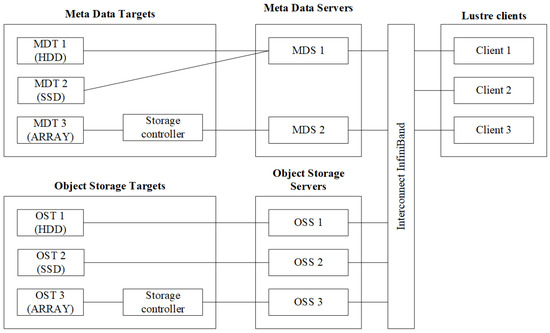
Figure 1.
Lustre parallel file system architecture.
The elements of architecture are as follows:
- Control nodes—meta data servers (MDSs);
- Data storage and provision nodes—object storage servers (OSSs);
- Data storage elements—object storage target (OST);
- Metadata storage elements—meta data targets (MDTs);
- High-speed data-processing network.
Metadata servers (MDSs) are the control components of a parallel file system that store information about all the data in the system, as well as serving client requests for access to data. Metadata are stored on information resources called metadata targets (MDTs), implemented either as physical disks or as block devices in a data storage system. To ensure fault tolerance, metadata servers can be duplicated.
Access to parallel file system clients data is carried out through the metadata server. When servicing requests, the metadata server identifies the client and selects one of the nodes for storing and providing data—OSS. The choice is made based on meta-information about the availability of the requested data on storage elements available to this OSS, as well as based on information about OSS loading by requests from other clients. After that, the interaction between the client and the selected OSS is carried out directly through a high-performance data network. This solves the problem of the formation of “bottlenecks” in the access of computing nodes to a single data storage [8].
Data storage elements are disk drives directly connected to the OSS as well as logical drives formed by storage systems based on disk arrays. Data storage and provision nodes provide the caching of information contained on disks and high-speed exchange with the data transmission network.
Thus, the architecture of a parallel file system makes it possible to provide data for a group of computational tasks due to the parallel operation of a group of storage nodes.
3. Data Storage Structure in A Parallel File System
As noted above, the parallel file storage architecture allows you to provide computing nodes with access to different storage nodes, which allows you to avoid “bottlenecks” and prevent performance degradation.
Note that different application tasks may have different requirements for the data structure stored in the file system.
For big data-processing tasks—telemetry streams, the analysis of accumulated information arrays in order to obtain new knowledge (data mining)—where parallel processes of one computing task performed on different computing nodes require access to independent data arrays, it is enough to place one application data copy on each storage node and ensure the interaction of each pair of “computing node–storage node” over a high-speed data transmission network.
For data-intensive tasks (e.g., preparing training sets for neural networks, and training neural networks [9]), a more complex structure data storage is required, allowing different computing nodes to access the same file from several computing nodes. This feature is supported by the parallel file system by fragmenting files into separate blocks (stripes) [10].
The term “number of stripes” refers to the number of fragments into which a file is divided; in other words, the number of OSTs that are used to store the file. So, each stripe of the file will be in a different OST. The “stripe size” refers to the size of a stripe recorded as a single block in the OST.
The benefits of striping include the following:
- Increased I/O throughput due to multiple file areas being read or written in parallel;
- Helping to balance the use of the OST pool.
However, striping has disadvantages if performed incorrectly, such as increased overhead due to internal network operations and contention between servers, and throughput degradation due to inappropriate striping settings.
The default number and sizes of stripes are chosen to balance the I/O performance needs of multiple parallel execution scales and file sizes. Small files should be striped at a value of 1. However, setting the stripe number too low can degrade I/O performance for large files and parallel I/O. Thus, the user must carefully select strip specifications according to application data.
The striping must be compatible with the application’s I/O strategy and output size. The increase in the number of stripes and/or the size of the stripes should be proportional to the number of nodes used for I/O. As a general rule, an application should try to use as many OSTs as possible. Thus, when writing a large single file in parallel, the maximum allowable value for the stripe counter is set. Alternatively, when writing a large number of small files in parallel, set the interleave counter to 1. The intermediate number of concurrent output files may work better if the number of stripes is greater than 1. An experimental estimate of the number of stripes is advisable for best performance. Note that for a number of tasks, the file size correlates with the number of computing nodes that perform parallel writing to it. Therefore, adjusting interleaving based on file size is usually sufficient, and a simpler starting point for estimating the number of lanes for subsequent processing optimization.
Figure 2 shows an example of file distribution across six storage elements.
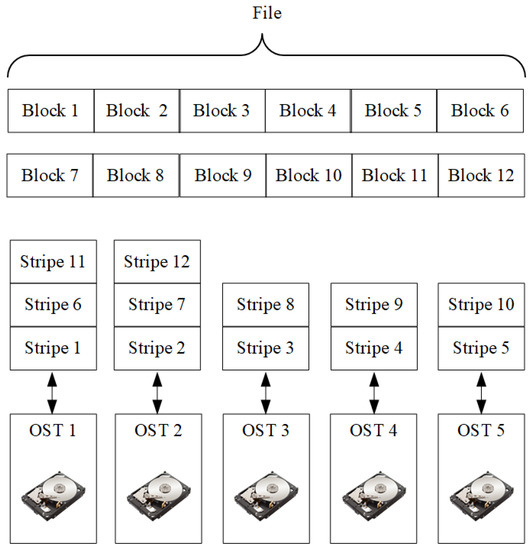
Figure 2.
The file distribution example.
5. Conclusions
A parallel file system is an integral part of a high-performance computing system designed to solve a wide range of scientific and scientific–practical problems. The parallel file system effectively prevents the formation of “bottlenecks” that reduce the performance of the HPC clusters due to delays in disk operations. Its application in the shared research facilities, providing high-performance computing services, allows to provide sufficient throughput of the disk subsystem for all scientific tasks performed in parallel by the HPC cluster.
The tasks of processing big data, extracting knowledge, and mathematical modeling impose different requirements on the organization of data exchange with disk storage when performed on a group of computing nodes.
At the same time, in order to optimize and increase the efficiency of the functioning of the HPC cluster as a whole, it is necessary to take measures to adapt data storage patterns in a parallel file system to the specifics of the applied problems being solved.
An analysis of computational tasks from various fields of science and technology shows that the requirements for the throughput of access to the file system for various applied tasks differ significantly. So the tasks of optimization, quantum mechanical calculations, aerodynamics do not require significant resources of the file system while loading the computing unit.
The tasks of training neural networks are more demanding on the performance of the file system, which ensures the timely loading of training data on computing nodes, but the ratio between data volumes and calculations is not the maximum.
The greatest requirements for the performance of the file system are observed in the tasks of preparing data for training neural networks and in the tasks of extracting knowledge (data mining). These tasks require a high-speed exchange of large data arrays between a large number of data storage and processing nodes.
Depending on the task type and file storage characteristics, a data storage template is selected. In general, maximizing file system performance requires maximizing the number of storage objects used.
Thus, when deploying projects designed to solve computing problems that require high disk efficiency, you should allocate the maximum number of storage elements, mainly NVMe SSD.
For tasks with medium and low disk intensity, it is enough to allocate a small number of SAS or SATA storage elements.
Ensuring reliability and fault tolerance through the use of a redundant storage architecture is provided on data object storage servers or storage systems.
Author Contributions
Conceptualization, S.D., K.V. and A.Z.; methodology, S.D., K.V. and A.Z.; validation, S.D.; formal analysis, K.V.; investigation, S.D., K.V. and A.Z.; writing—original draft preparation, S.D. and K.V.; writing—review and editing, S.D. and K.V.; supervision, A.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The research was carried out using the infrastructure of the Shared Research Facilities “High Performance Computing and Big Data” (CKP “Informatics”) of FRC CSC RAS (Federal Research Center ”Computer Science and Control” of the Russian Academy of Sciences, Moscow).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zatsarinnyy, A.A.; Abgaryan, K.K. Current problems of creation of research infrastructure for synthesis of new materials in the framework of the digital transformation of society. In Proceedings of the II International Conference Mathematical Modeling in Materials Science of Electronic Components, Online, 19–20 October 2020; pp. 8–13. [Google Scholar]
- Zatsarinny, A.A.; Volovich, K.I.; Denisov, S.A.; Ionenkov, Y.S.; Kondrashev, V.A. Methodological approaches to evaluating the effectiveness of the center collective use “Informatics”. Highly Available Syst. 2020, 16, 44–51. [Google Scholar]
- Volovich, K.; Zatsarinnyy, A.; Frenkel, S.; Denisov, S. High Performance Computing in a Shared Virtual Infrastructure. In Proceedings of the VI International Conference on Information Technologies and High-Performance Computing (ITHPC 2021), Khabarovsk, Russia, 14–16 September 2021; Volume 2930, pp. 38–46. [Google Scholar]
- Kartsev, A.; Malkovsky, S.; Volovich, K.; Sorokin, A. Study of the performance and scalability of the Quantum ESPRESSO package in the study of low-dimensional systems on hybrid computing systems. In Proceedings of the I International Conference Mathematical Modeling in Materials Science of Electronic Components, Moscow, Russia, 21–23 October 2019; pp. 18–21. [Google Scholar]
- Abgaryan, K.K. Information technology is the construction of multi-scale models in problems of computational materials science. Highly Available Syst. 2018, 14, 9–15. [Google Scholar]
- Abgaryan, K.K.; Gavrilov, E.S.; Marasanov, A.M. Multiscale modeling for composite materials computer simulation support. Int. J. Open Inf. Technol. 2017, 5, 24–28. [Google Scholar]
- Kokorev, A.; Belyakov, D.; Lyubimova, M. Data storage systems of “hybrilit” heterogeneous computing platform for scientific research carried out in JINR: Filesystems and raids performance research CEUR Workshop Proceedings. In Proceedings of the 9th International Conference “Distributed Computing and Grid Technologies in Science and Education” (GRID’2021), Dubna, Russia, 5–9 July 2021; Volume 3041, pp. 296–303. [Google Scholar]
- Seiz, M.; Offenhäuser, P.; Andersson, S.; Hötzer, J.; Hierl, H.; Nestler, B.; Resch, M. Lustre I/O performance investigations on Hazel Hen: Experiments and heuristics. J. Supercomput. 2021, 77, 12508–12536. [Google Scholar]
- Tipu, A.J.S.; Conbhuí, P.Ó.; Howley, E. Applying neural networks to predict HPC-I/O bandwidth over seismic data on lustre file system for ExSeisDat. Clust. Comput. 2022, 25, 2661–2682. [Google Scholar] [PubMed]
- Rybintsev, V. Optimizing the parameters of the Lustre-file-system-based HPC system for reverse time migration. J. Supercomput. 2020, 76, 536–548. [Google Scholar]
- Volovich, K. Estimation of the workload of a hybrid computing cluster in tasks of modeling in materials science. In Proceedings of the II International Conference Mathematical Modeling in Materials Science of Electronic Components, Online, 19–20 October 2020; pp. 30–33. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).