Abstract
The digitization of electoral processes requires robust systems for processing handwritten numerical data from voting documents. This paper presents a convolutional neural network study for handwritten digit recognition in Mexico’s PREP (Programa de Resultados Electorales Preliminares) system. Rather than individual digit classification, we approach the problem as direct 1000-class classification, treating each three-digit combination as a single class to maximize accuracy and simplify inference. We evaluated eight CNN architectures including ResNet variants, MobileNetV3, ShuffleNetV2, and EfficientNet, with ResNet-18 emerging as optimal for balancing accuracy and computational efficiency under CPU-only deployment. To address dataset challenges including class imbalance and image artifacts, we developed a customized RandAugment strategy applying photometric and limited geometric transformations that preserve semantic integrity. Our methodology demonstrates feasibility of deploying robust digit recognition systems in resource-constrained electoral environments while maintaining high accuracy. The research provides a practical framework for automated electoral data processing adaptable to similar systems across Latin America.
1. Introduction
In Mexico, the National Electoral Institute (INE) serves as the autonomous public institution responsible for organizing federal elections, including the election of the President of the Republic, deputies, and senators who comprise the Congress of the Union. The INE also coordinates with federal electoral institutions to organize local elections in the states of the Republic and Mexico City [1].
The Mexican electoral system incorporates the Preliminary Electoral Results Programme (PREP), a system that provides preliminary election results by capturing and publishing data recorded by polling station officials in vote counting and tallying reports (Figure 1). These reports are transmitted from polling stations to Data Collection and Transmission Centers (CATD) [2]. The primary function of PREP is to publish real-time preliminary election results on Election Day night, ensuring security, transparency, reliability, credibility, and information integrity throughout all electoral phases. It is important to note that these results serve informational purposes only and carry no legal effect.

Figure 1.
Vote counting and tabulation report (AEC), copy for the PREP system.
The PREP operation involves handwritten Actas de Escrutinio y Cómputo (AEC) forms completed by polling station officials, which are subsequently digitized at CATDs. The INE has developed a system that segments regions containing numerical voting results within these documents. This data is presented to data entry clerks at record entry terminals (Figure 2), with candidate or coalition identifiers hidden to prevent bias during manual transcription.
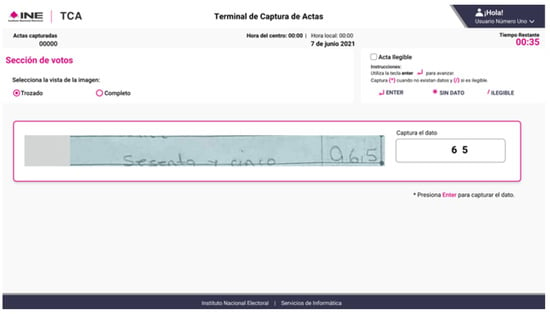
Figure 2.
Official PREP data entry interface used by clerks at record entry terminals.
The fundamental objective of this work is to collaborate with the INE in developing an automated system for recognizing handwritten numerical values from the same regions of interest currently processed by human data entry clerks. This automated recognition system would operate in parallel with the existing PREP infrastructure, enabling evaluation and validation in real-world electoral environments while potentially improving processing speed and reducing human error in the digitization process.
2. Materials and Methods
2.1. Data Collection and Preprocessing
We used the test split, which comprises 1.13 million ROI images representing one of 1000 three-digit classes. A direct multiclass approach improves joint probability over separate digit predictions. All images were resized to 64 × 192 pixels and normalized to [0, 1].
The dataset exhibits natural class imbalance inherent to real-world handwritten digit collection—common digit combinations dominate the distribution while some classes contain few or zero samples. No stratified sampling or resampling techniques were applied, preserving the authentic distribution of the original assessment data. This approach ensures that model performance reflects real deployment conditions where such imbalance naturally occurs.
Images were captured primarily via smartphone camera and, in limited cases, via document scanner, resulting in realistic artifacts including partial crops at ROI boundaries, ink marks, and dividing lines between digit regions. To enhance model robustness against these naturally occurring variations, controlled augmentation was applied during training (see Section 2.3). The weighted metric used for evaluation (macro-average accuracy) explicitly accounts for class imbalance, penalizing misclassification of underrepresented classes to provide a fair assessment across all digit combinations.
2.2. Model Selection
We evaluated eight CNN backbones (ResNet-18/34 [3], MobileNetV3-S/M [4], EfficientNet-B0/B1 [5], and ShuffleNetV2 1.5×/2.0× [6]) under identical settings, comparing weighted Top-1 accuracy, parameter count, and GPU inference time. ResNet-18 delivered the best trade-off and was chosen for subsequent experiments.
2.3. Training Strategy and Data Augmentation
Models were trained for 10 epochs using a modified RandAugment strategy [7], with the Adam optimizer [8] (lr = 0.001) and a batch size of 64, using a 70/30 train/test split. To enhance robustness, we applied RandAugment during training only (num_ops = 3, magnitude = 6), using photometric filters (AutoContrast, Equalize, Posterize, Brightness, Contrast, Color) and limited geometric transforms (ShearX, TranslateX, Sharpness). Rotations and vertical shifts were excluded to preserve class integrity. No augmentation was applied at test time.
2.4. Implementation Details
All models were implemented in PyTorch 2.7.0 [9] on Python 3.13.7 and trained on an NVIDIA RTX 2080 Ti GPU. Training experiments ran on an ASUS WS Z390 PRO workstation with 32 GiB RAM, an Intel® Core™ i9-9900K × 16 cores, a 2 TB disk, and EndeavourOS 2025.03.19 (64-bit, GNOME 48, X11, Linux 6.16.4-arch1-1).
CPU inference times (Table 1) were measured on three diverse computing environments to assess real-world deployment feasibility: (1) Intel Xeon @ 2.20 GHz via Google Colab; (2) Apple Silicon M4 Max on a MacBook Pro; and (3) Apple Silicon M2 Pro on a MacBook Pro. Measurements were conducted using 100 random input images at the target resolution (64 × 192 pixels) with torch.no_grad() to disable gradient computation. CPU inference represents the primary deployment scenario outlined in the Abstract, where resource constraints preclude GPU availability.

Table 1.
Average inference time per image (Per Image, in seconds) and total inference time for 100 images (Total, in seconds) for each model on three different computing environments: Environment 1—Intel Xeon @ 2.20 GHz (Google Colab); Environment 2—Apple Silicon M4 Max (MacBook Pro); Environment 3—Apple Silicon M2 Pro (MacBook Pro).
3. Results
All performance metrics reported here were obtained using an NVIDIA RTX 2080 Ti GPU for model comparison and accuracy evaluation, with supplementary CPU inference measurements taken on Intel Xeon and Apple Silicon architectures to assess real-world deployment feasibility. Although primary deployment inference will run on CPU-only infrastructure (see Abstract), these comprehensive benchmarks across both GPU and CPU environments allow for rapid experimentation, fair model comparison, and practical assessment of computational demands.
Figure 3 shows Top-1 accuracy (weighted average across all classes) versus parameter count for eight CNN architectures. The weighted metric was used because macro-average accuracy penalizes underrepresented or absent classes, skewing results in this highly imbalanced dataset. ResNet-34 achieved the highest accuracy (98.04%), while ResNet-18 closely follows with 98.00% accuracy, offering substantially better computational efficiency. Lightweight models such as MobileNetV3-Small and ShuffleNetV2 2.0 exhibited modest accuracy drops (97.20% and 97.72%), respectively.
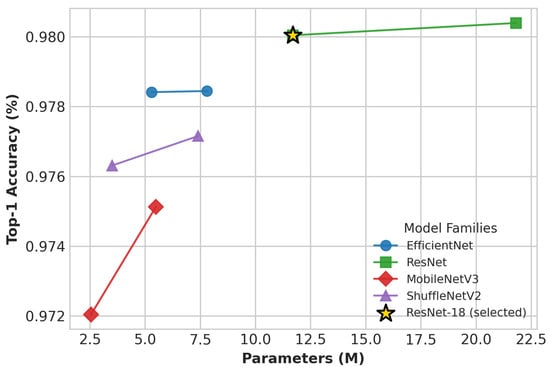
Figure 3.
Weighted Top-1 accuracy vs. parameter count for CNN families on PREP digit classification. Lines connect family variants; ResNet-18 (star) marks the selected model.
Table 1 reports CPU inference times across three different computing environments: a server-class Intel Xeon processor, an Apple M4 Max (ARM-based), and an Apple M2 Pro (ARM-based). These measurements simulate real-world CPU-only deployment scenarios with 100 random input images at the target resolution (64 × 192 pixels). ResNet-18 demonstrates superior efficiency on CPU, averaging 0.0288 s per image on the Intel Xeon and 0.0082 s on the M2 Pro, significantly outperforming ResNet-34 (0.0500 s and 0.0186 s, respectively). Among all tested architectures, MobileNetV3-S demonstrates the fastest CPU inference times, averaging 0.0112 s per image on Intel Xeon, 0.0876 s on Apple M4 Max, and 0.0925 s on Apple M2 Pro. ShuffleNetV2 1.5 follows with comparable performance (0.0188 s on Intel Xeon), confirming the suitability of lightweight models for CPU-only deployment while maintaining competitive accuracy.
These results confirm that under GPU evaluation, ResNet-34 achieves the highest accuracy, while ResNet-18 provides the best balance of accuracy and efficiency for both GPU and CPU inference. Considering CPU-only deployment requirements, ResNet-18’s strong performance on diverse computing platforms makes it the preferred architecture for the PREP digit recognition system, ensuring robust operation across server, mobile, and edge computing environments.
4. Discussion
ResNet-18 provides the optimal balance of weighted Top-1 accuracy (98.00%) and inference speed for PREP’s CPU-only deployment. Although ResNet-34 offers marginally higher accuracy, its longer latency limits practicality. ShuffleNetV2 2.0× runs faster but at 97.72% accuracy, risking reliability.
Limitations include GPU-based evaluation and no field testing under varied conditions. Future work will explore lightweight attention mechanisms and extensive class-balancing techniques to improve performance on underrepresented classes.
Prioritizing compact, high-performing architectures like ResNet-18 ensures efficient, reliable large-scale vote recognition in resource-constrained settings.
Ethical Implications and Institutional Framework
The Comité Técnico Asesor de la Plataforma Tecnológica de la Encuesta de Resultados Preliminares (COTAPREP, Technical Advisory Committee for the PREP Technological Platform) is the institutional body responsible for comprehensive evaluation of legal, ethical, and technological considerations regarding the current PREP electoral counting workflow. All data used in this study—handwritten digit images from past elections—originates from material previously approved and vetted within this institutional framework. This research does not modify, propose changes to, or directly engage with the existing PREP processes; rather, it represents an independent technical feasibility study of digit recognition capabilities using approved electoral data (institutional collaboration frameworks supporting this research have been discontinued due to recent changes in governmental policies and priorities).
Our contribution is purely exploratory, demonstrating whether automated digit recognition can function reliably within the technical constraints of the electoral domain. This proof of concept provides evidence that could inform future policy discussions, should decision-makers at institutional or governmental levels consider such automation. Any actual deployment would necessarily involve institutional review, policy changes, and implementation of auditable mechanisms—decisions that extend entirely beyond the scope of this technical work. By validating model performance transparently across diverse computing environments, we support informed decision-making while respecting established institutional frameworks and maintaining the integrity of the current electoral process.
Author Contributions
M.A.C.R., G.S.P., J.P.-P., L.K.T.M., A.H.S., J.O.M., H.M.P.M. and L.J.G.V. contributed equally to the conception, writing, and review of the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data supporting the reported results are available upon request from the corresponding author. The data are not publicly available due to privacy restrictions.
Acknowledgments
The authors would like to thank the organizers of the First Summer School on Artificial Intelligence in Cybersecurity for providing the academic framework that inspired this research.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Instituto Nacional Electoral. ¿Qué Hace el INE? 2024. Available online: https://portal.ine.mx/que-hace-el-ine/ (accessed on 15 March 2025).
- Instituto Nacional Electoral. Ley General de Instituciones y Procedimientos Electorales. Diario Oficial de la Federación. 2 June 2023. Available online: https://www.diputados.gob.mx/LeyesBiblio/pdf/LGIPE.pdf (accessed on 11 February 2026).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical guidelines for efficient CNN architecture design. arXiv 2018, arXiv:1807.11164. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. RandAugment: Practical automated data augmentation with a reduced search space. arXiv 2019, arXiv:1909.13719. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- PyTorch Team. PyTorch. Ver. 2.7.0, PyTorch Foundation. 2024. Available online: https://pytorch.org/ (accessed on 8 September 2025).



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.