Abstract
This study presents WoolGAN, a lightweight texture style transfer method based on a generative adversarial network (GAN), with wool felting texture as the primary example. Unlike conventional convolutional approaches, it requires only a small training dataset of approximately 300 images and is capable of preserving the shape of the target object in the image. To achieve this, color hints and edge maps with background separation are used as inputs during both training and generation phases. Experimental results demonstrate that the generated images are highly realistic and well-received by human evaluators. Moreover, this method can be broadly applied to other texture styles, especially when only limited datasets are available.
1. Introduction
Texture style transfer is a key topic in image generation; however, many deep learning methods suffer from shape distortion and demand large-scale datasets. This study introduces WoolGAN, a lightweight texture style transfer method based on a generative adversarial network and a texture style transfer model that performs well with small datasets while preserving the original shape of objects. Through improvements in preprocessing and model architecture, WoolGAN enables better control, making it ideal for applications such as consistent branding or visual identity.
WoolGAN can also be integrated with shape transfer models to provide flexible manipulation of both shape and texture. Built on the GAN framework [1], it tackles the limitations of shape distortion and data scarcity found in existing approaches.
The proposed system is designed around the following five core objectives:
- Generate stylistically consistent textures;
- Realistically reproduce the visual characteristics of specific materials;
- Maintain color consistency with the original image;
- Preserve the shape and proportions of the target object;
- Perform effectively with limited data availability.
This study aims to deliver a versatile, low-barrier, and high-fidelity solution for texture style transfer, enhancing its practicality and relevance across a wide range of real-world use cases.
2. Materials and Methods
The overall architecture of the proposed WoolGAN model is illustrated in Figure 1. The primary innovations of this study lie in the input image preprocessing pipeline and the customized loss function design. Both the generator and discriminator are implemented using the pix2pix framework [2], ensuring texture consistency and the preservation of fine details throughout the image translation process.
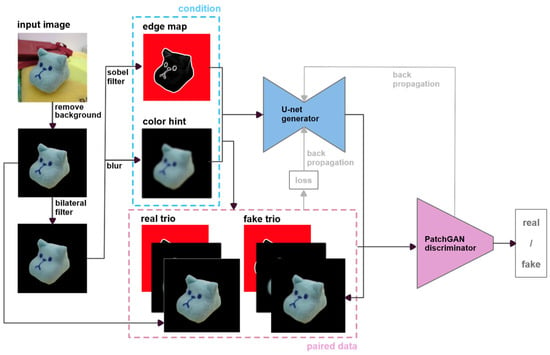
Figure 1.
Architecture of proposed WoolGAN model.
2.1. Preprocessing and Stylization Pipeline
In the data preprocessing stage, input images are first subjected to background removal and bilateral filtering to reduce noise and texture interference. The preprocessed images are then transformed into two separate inputs: an edge map and a color hint image. These are paired with the original (unfiltered) image as the target output to form the training dataset.
This setup enables the model to jointly learn contour and color information, thereby improving structural stability and enhancing the wool felt texture in the generated images.
The preprocessing pipeline consists of the following steps:
- Background removal. Removes background content to ensure that style transfer focuses solely on the primary object;
- Smoothing. Applies bilateral filtering to suppress noise and fine textures, facilitating more effective stylization;
- Edge map generation. Uses Sobel edge detection to extract object contours, with a red mask applied to the background region to help the model distinguish between foreground and background;
- Color hint generation. Applies a mean blur with a kernel size of (5,5) to generate smooth and coherent color guidance.
The generator employs a U-Net architecture to preserve the input’s structure and texture, while the discriminator utilizes a PatchGAN [3] to enhance the realism of local details.
Figure 2 illustrates the application pipeline. After background removal and the generation of edge and color hint images, WoolGAN stylizes only the foreground object. The stylized result is then merged with the original background, producing the appearance of a real object rendered as a wool felt replica.
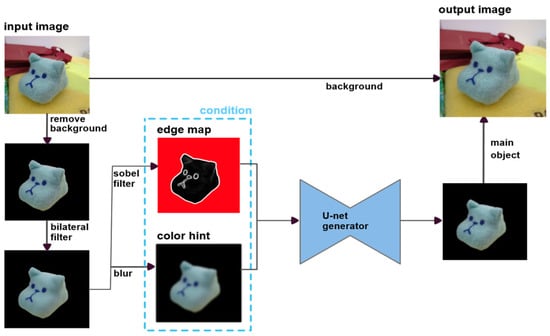
Figure 2.
The application pipeline of WoolGAN. The input image undergoes background removal, edge map extraction, and color hint generation. WoolGAN then applies texture stylization to the foreground object only. The stylized object is finally composited with the original background to produce a wool felt-like rendering.
Notably, WoolGAN focuses exclusively on texture transformation without altering the object’s shape. For scenarios that require shape modification (e.g., stylized avatars), an external shape-modifying model can be applied first, followed by WoolGAN for texture transfer. This two-step approach is particularly suitable for applications involving human figures, where maintaining high visual consistency is critical.
2.2. Loss Function Design
To ensure the realism and material fidelity of the generated wool felt images, WoolGAN integrates multiple loss components. Each loss contributes to improving specific aspects of texture, structure, and perceptual quality. The total generator loss is defined as the weighted sum of the following six components.
2.2.1. Adversarial Loss (GAN Loss)
To encourage the generator to produce realistic wool felt images, we adopt the standard adversarial loss from the pix2pix framework. This loss drives the generator G to produce outputs that can fool the discriminator D, aligning the distribution of generated images with real samples.
2.2.2. L1 Loss
The L1 loss penalizes pixel-wise differences between the generated image y and the ground truth x, maintaining structural consistency and preventing excessive blurring. It is defined as:
2.2.3. Gram Matrix Loss
Inspired by Gatys et al. [4], Gram matrix loss compares the texture statistics between generated and reference images using feature correlation maps. This helps to preserve the wool felt texture style while maintaining content structure. The loss is computed as follows:
where denotes the Gram matrix of feature maps at layer l.
2.2.4. Laplacian Loss
To enhance edge sharpness and fine textures, we introduce Laplacian loss, which captures high-frequency image components using the Laplacian operator [5]. This loss enforces better multi-scale detail consistency:
2.2.5. Structural Similarity Loss (SSIM Loss)
To better reflect human perceptual judgment, we adopt SSIM loss [6] to measure the similarity of structure, contrast, and luminance between the generated and target images. The SSIM loss is defined as Equation (4). This ensures perceptual consistency and visual naturalness of the output:
2.2.6. Depth Gradient Loss
Following Godard et al. [7], the depth gradient loss constrains spatial gradient continuity to maintain depth coherence and suppress unnatural shape artifacts. It is defined by the differences in x and y directional gradients between the output and reference:
2.2.7. Total Loss Function
The final generator loss is a weighted combination of all the above components:
To enhance learning dynamics, we apply a progressive weighting strategy: decreasing the influence of Gram loss over training epochs while increasing the weight of the Laplacian loss. This ensures gradual refinement of texture details and overall visual realism. The details of hyperparameters are listed in Table 1.

Table 1.
Hyperparameters of training process.
2.3. Dataset and Training Setup
This study employed a training dataset consisting of 200 wool felt craft images captured by the authors and 100 AI-generated images produced using SDXL 1.0 [8], along with an additional 20 non-overlapping real photographs as the test set. All images were taken using Google Pixel 7a, uniformly preprocessed through background removal and resizing to 256 × 256 pixels, and then converted into edge maps and color hint images based on the model’s input requirements.
Model training was conducted on Google Colab with an NVIDIA L4 GPU. The training lasted for 180 epochs, using a batch size of 1 and a buffer size of 16,224. The objective was to enable the model to effectively learn wool felt texture characteristics and generate stylistically consistent outputs, even under limited data conditions, through appropriate preprocessing and tailored loss function design.
3. Results
3.1. Wool Felt Texture Transfer Results
The results of WoolGAN’s texture transfer, in comparison with other models, are presented in Figure 3. Unlike existing methods, the proposed approach preserves both the original shape and background of the input image. Although the texture realism may appear less refined than that produced by more advanced models, this trade-off contributes to improved structural consistency. Public perception of texture quality is further examined through questionnaire responses and interview-based evaluations in subsequent sections.


Figure 3.
Comparison of wool felt texture transfer results generated by WoolGAN and SDXL [8].
3.2. User Study: Questionnaire and Interview
To evaluate the effectiveness of WoolGAN, a user study was conducted combining a structured questionnaire with follow-up interviews. A total of 23 valid responses were collected; seven participants were selected for in-depth interviews. Most respondents were aged between 20 and 30, with a gender distribution of 14 females and 9 males. Among them, 12 had a background or interest in art or design, and 17 reported some familiarity with wool felt crafts, ensuring basic material recognition capabilities.
The questionnaire employed a 7-point Likert scale (1 = strongly disagree, 7 = strongly agree) and evaluated five key dimensions: material realism, feature preservation, color consistency, aesthetic preference fit, and style coherence. The full questionnaire is provided in Appendix A.
The evaluation was divided into three sections:
- Realism and style consistency of wool felt conversion. Participants compared stylized figures generated by WoolGAN and SDXL using the same base images;
- Similarity assessment. Participants rated the resemblance between generated and original images, with the image order randomized;
- Material realism by object type. Participants assessed the felt-like quality of the converted images across various categories (e.g., dolls, vehicles).
Overall, the results indicated that WoolGAN received high ratings in style coherence, color fidelity, and shape preservation. Although it was slightly outperformed by some existing methods in terms of material realism, participants generally perceived the generated images as visually coherent and representative of wool felt texture. Follow-up interviews further supported WoolGAN’s suitability for stylization tasks under limited data conditions, highlighting its potential in creative applications within low-resource environments.
3.3. Survey and Interview Results
3.3.1. Realism and Style Consistency of Wool Felt Conversion
This evaluation was based on a series of character images stylized into wool felt using four different methods. Participants provided subjective ratings (Figure 4). Error bars in all figures represent 95% confidence intervals. Although WoolGAN received slightly lower average scores in terms of realism (Figure 4a) and exhibited greater variability in responses, the results still suggest that the overall output quality remained within an acceptable range. In terms of style consistency (Figure 4b), WoolGAN achieved the highest average score with the lowest standard deviation, indicating stable visual style across outputs.
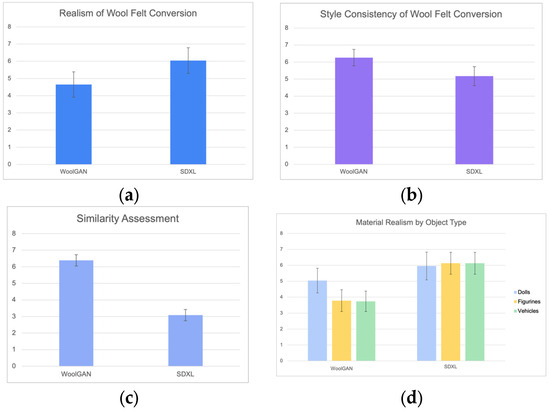
Figure 4.
Results of subjective evaluation across four assessment categories: (a) realism of wool felt conversion: WoolGAN (mean = 4.65, variance = 1.80) vs. SDXL (mean = 6.04, variance = 1.19); (b) style consistency of wool felt conversion: WoolGAN (mean = 6.39, variance = 0.84) vs. SDXL (mean = 3.09, variance = 1.62); (c) similarity assessment: WoolGAN (mean = 6.26, variance = 1.18) vs. SDXL (mean = 5.17, variance = 1.77); and (d) material realism by object type: WoolGAN—dolls (mean = 5.04, variance = 1.89), figurines (mean = 3.78, variance = 1.68), vehicles (mean = 3.74, variance = 1.57); SDXL—dolls (mean = 5.96, variance = 1.11), figurines (mean = 6.13, variance = 1.58), vehicles (mean = 6.13, variance = 1.22). Error bars represent 95% confidence intervals.
Interview feedback revealed that most participants found WoolGAN’s results visually similar to wool felt dolls. However, those unfamiliar with the material had more difficulty identifying the stylization. SDXL was frequently noted for producing fluffier textures, which aligned better with participants’ mental image of wool felt and contributed to its higher realism scores.
3.3.2. Similarity Assessment
Figure 4c presents a comparison of the perceived similarity between generated images and original inputs across different methods. The results indicate that SDXL deviated most from the original input in the object category, with a larger visual gap, suggesting limited ability to preserve original features. In contrast, WoolGAN received higher average similarity scores and lower standard deviation, indicating stronger feature retention and greater output consistency as perceived by most participants.
3.3.3. Material Realism by Object Type
Figure 4d shows ratings of material realism across different object categories after wool felt stylization. WoolGAN generally received higher scores for doll-like items compared to other object types.
Interview feedback suggested that the rounded shapes of the dolls align well with the typical look of wool felt, thereby enhancing perceived realism. In contrast, human figures received slightly lower scores due to their rigid appearance; vehicles were also rated lower, likely because their complex or sharp-edged designs reduced the felt-like impression. Nevertheless, most participants agreed that WoolGAN effectively conveyed the wool felt texture across different object types.
4. Conclusions
The proposed WoolGAN framework effectively transfers wool felt textures while preserving the original shape and background of the target object. It demonstrates consistent texturing, accurate color reproduction, and minimal artifacts, exhibiting stable performance even under limited data conditions. User feedback from questionnaires and visual analysis indicated strong positive responses, particularly regarding color consistency and shape preservation—attributes largely attributed to the structured use of edge and color hint inputs. However, the model’s rendering of fine material realism remains slightly less detailed compared to more advanced methods. Importantly, the strict preservation of object shape may reduce the perceived authenticity of the wool felt texture, especially for objects where roundness is typically associated with the material. Future work could explore shape simplification or controlled stylized deformation to enhance the plausibility of wool felt appearance. Overall, WoolGAN presents a promising approach to texture style transfer in data-scarce environments and shows strong potential for broader applications in creative and stylization tasks.
Author Contributions
Conceptualization, W.-C.C. and M.-H.T.; methodology, W.-C.C.; software, W.-C.C.; validation, W.-C.C. and M.-H.T.; formal analysis, W.-C.C.; investigation, W.-C.C.; resources, M.-H.T.; data curation, W.-C.C.; writing—original draft preparation, W.-C.C.; writing—review and editing, M.-H.T.; visualization, W.-C.C.; supervision, M.-H.T.; project administration, M.-H.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
All results are contained within the article.
Acknowledgments
During the preparation of this manuscript, the authors used generative AI tools, including ChatGPT and GitHub Copilot, for purposes such as translation, editing, and text refinement. The authors have reviewed and edited all outputs and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
The evaluation questionnaire used in this study is available through the following link: https://docs.google.com/forms/d/e/1FAIpQLSdA33lGhw7fv_sopz3fdeyprkZwcwX4JfiCeWO0MnPxa3KHIQ/viewform (accessed on 17 July 2025).
References
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 27th Conference on Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 8–13 December 2014; p. 27. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A Neural Algorithm of Artistic Style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Bojanowski, P.; Joulin, A.; Lopez-Paz, D.; Szlam, A. Optimizing the Latent Space of Generative Networks. arXiv 2017, arXiv:1707.05776. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised Monocular Depth Estimation with Left-Right Consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Podell, D.; Saxena, S.; Savarese, S.; Shih, K.; Lucieri, A.; Highley, D.; Drozd, I.; von Platen, P.; Wolf, T.; Hu, H.; et al. SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. arXiv 2023, arXiv:2307.01952. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.