
Developing a Model for the Automated Identification and Extraction of Agricultural Terms from Unstructured Text †




Abstract
:1. Introduction
2. Related Work
3. Methods
3.1. Text Corpus Construction
3.2. Dataset
3.3. Model Setup
3.4. Model Training, Validation, and Testing
4. Results
4.1. Insights into the Manual Annotation of the Dataset
4.2. Model Performance
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, G.; He, Y.; Hu, X. Entity linking: An issue to extract corresponding entity with knowledge base. IEEE Access 2018, 6, 6220–6231. [Google Scholar] [CrossRef]
- Kolitsas, N.; Ganea, O.E.; Hofmann, T. End-to-end neural entity linking. In Proceedings of the 22nd Conference on Computational Natural Language Learning (CoNLL 2018), Brussels, Belgium, 31 October–1 November 2018. [Google Scholar]
- Shelar, H.; Kaur, G.; Heda, N.; Agrawal, P. Named entity recognition approaches and their comparison for custom ner model. Sci. Technol. Libr. 2020, 39, 324–337. [Google Scholar] [CrossRef]
- Zhang, Z.; Iria, J.; Brewster, C.; Ciravegna, F. A Comparative Evaluation of Term Recognition Algorithms. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08), Marrakech, Morocco, 26 May–1 June 2008. [Google Scholar]
- Zhang, Z.; Petrak, J.; Maynard, D. Adapted TextRank for Term Extraction: A Generic Method of Improving Automatic Term Extraction Algorithms. Procedia Comput. Sci. 2018, 137, 102–108. [Google Scholar] [CrossRef]
- Popovski, G.; Seljak, B.K.; Eftimov, T. A survey of named-entity recognition methods for food information extraction. IEEE Access 2020, 8, 31586–31594. [Google Scholar] [CrossRef]
- Jimeno-Yepes, A.; MacKinlay, A.; Han, B.; Chen, Q. Identifying Diseases, Drugs, and Symptoms in Twitter. Stud. Health Technol. Inf. 2015, 216, 643–647. [Google Scholar]
- Ramachandran, R.; Arutchelvan, K. Named entity recognition on bio-medical literature documents using hybrid based approach. J. Ambient Intell. Humaniz. Comput. 2021, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Tarcar, A.K.; Tiwari, A.; Dhaimodker, V.N.; Rebelo, P.; Desai, R.; Rao, D. Healthcare NER Models Using Language Model Pretraining. In Proceedings of the 13th ACM International WSDM Conference (WSDM 2020), Houston, TX, USA, 3–7 February 2020. [Google Scholar]
- Malarkodi, C.S.; Lex, E.; Devi, S.L. Named Entity Recognition for the Agricultural Domain. Res. Comput. Sci. 2016, 117, 121–132. [Google Scholar]
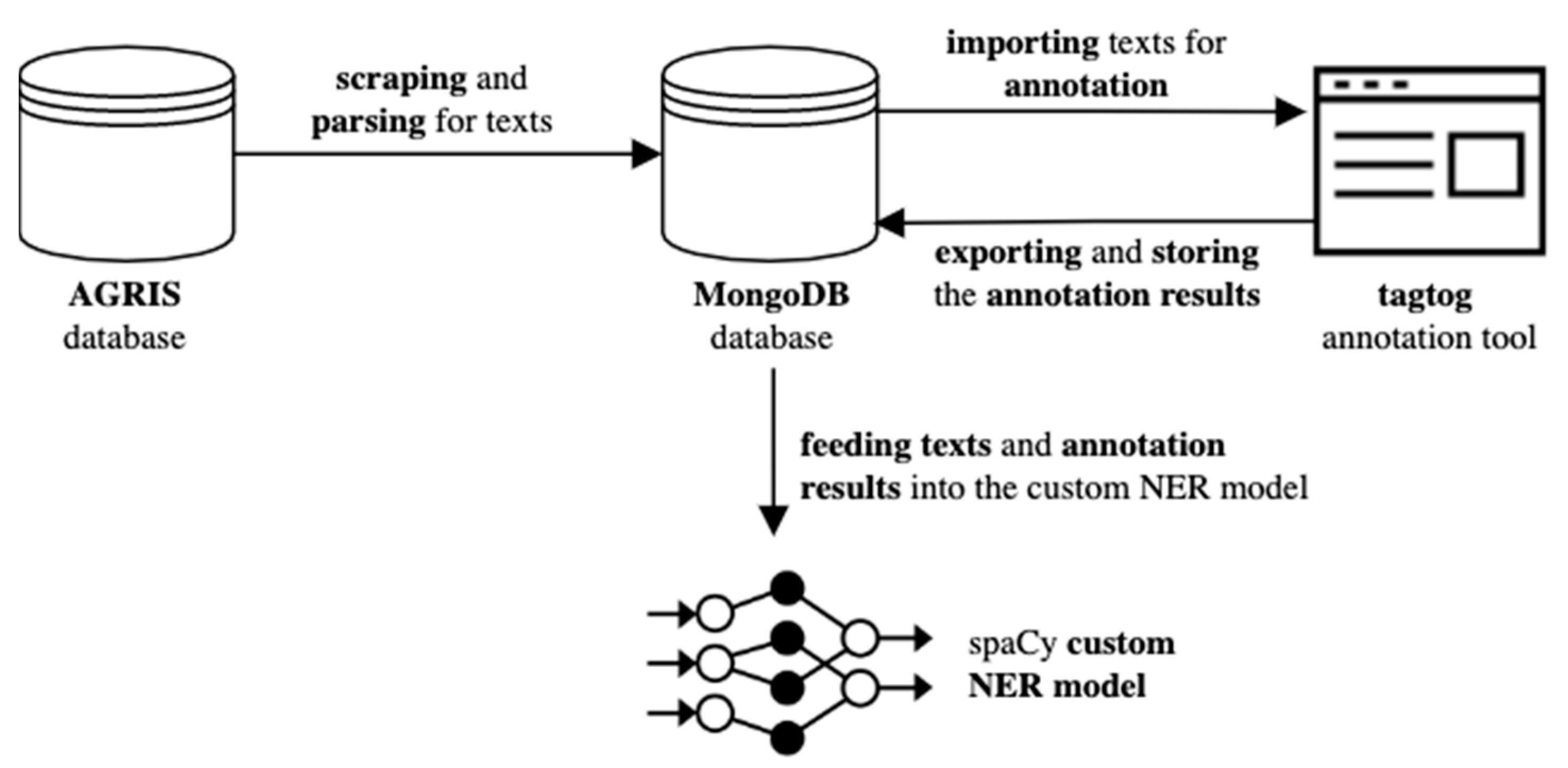

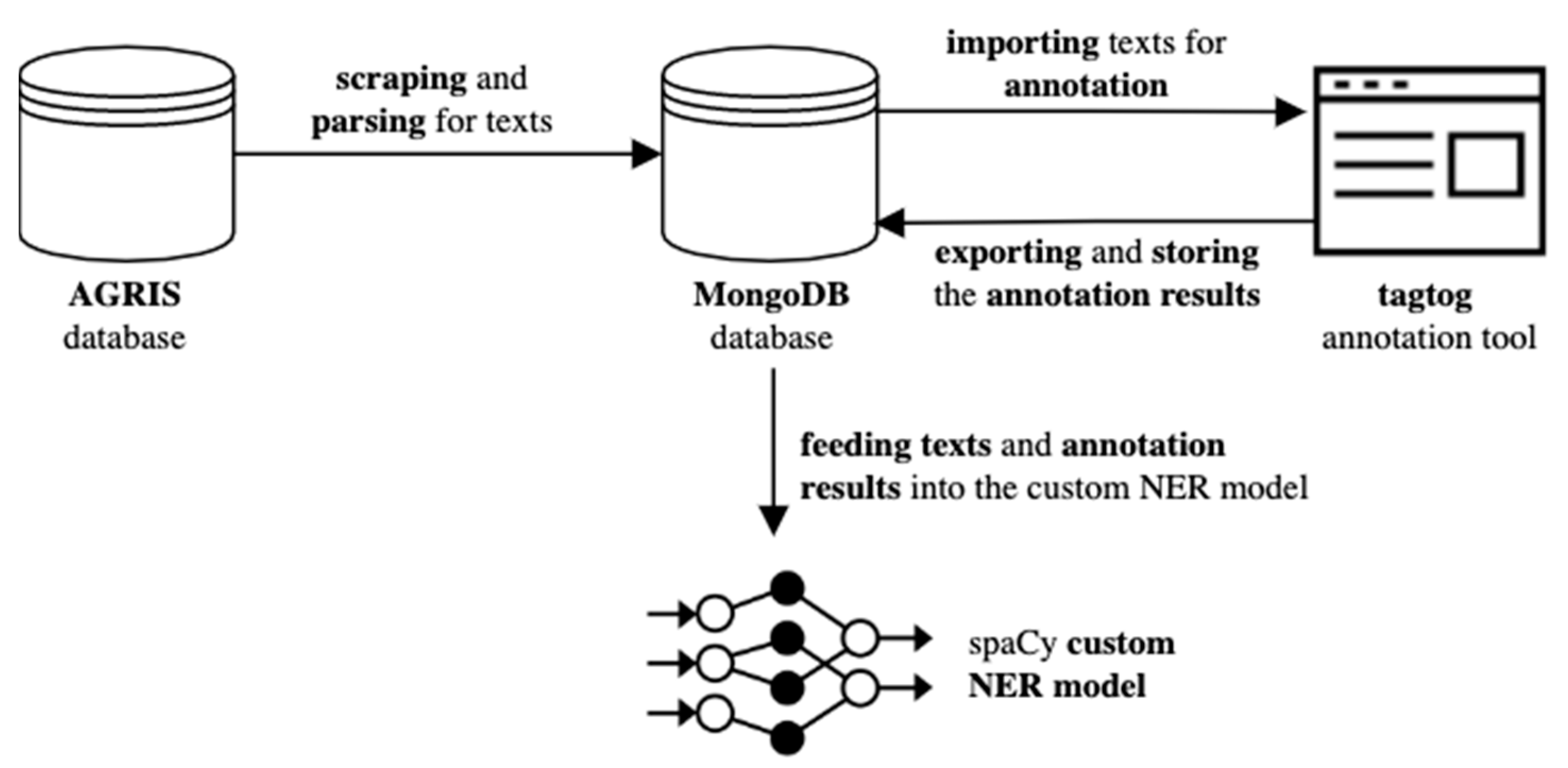{kind=link}
| Characteristic | Average Value | Minimum Value | Maximum Value |
|---|---|---|---|
| Length in characters | 1762 | 163 | 4751 |
| Length in words | 352 | 33 | 950 |
| Annotator #1 | Annotator #2 | Annotator #3 | Annotator #4 | Annotator #5 | |
|---|---|---|---|---|---|
| Annotator #1 | - | 57.89% | 62.54% | 39.96% | 30.96% |
| Annotator #2 | 57.89% | - | 64.00% | 37.53% | 36.03% |
| Annotator #3 | 62.54% | 64.00% | - | 35.83% | 32.42% |
| Annotator #4 | 36.96% | 37.53% | 35.83% | - | 13.30% |
| Annotator #5 | 30.96% | 36.03% | 32.42% | 13.30% | - |
| Minimum Value | Maximum Value | Average Value | Standard Dev. | |
|---|---|---|---|---|
| Precision | 40.85% | 50.73% | 47.82% | 2.73% |
| Recall | 46.54% | 54.52% | 49.22% | 2.30% |
| F1-score | 44.18% | 51.81% | 48.45% | 1.93% |
| Minimum Value | Maximum Value | Average Value | Standard Dev. | |
|---|---|---|---|---|
| Precision | 40.85% | 49.73% | 46.44% | 2.91% |
| Recall | 46.54% | 54.52% | 48.51% | 2.05% |
| F1-score | 44.18% | 49.95% | 47.38% | 1.67% |
| Minimum Value | Maximum Value | Average Value | Standard Dev. | |
|---|---|---|---|---|
| Precision | 48.14% | 50.73% | 49.53% | 1.00% |
| Recall | 46.77% | 52.96% | 50.11% | 2.36% |
| F1-score | 47.78% | 51.81% | 49.79% | 1.30% |
| Model Configuration (Language Model—Batch Size—Learning Rate) | Precision | Recall | F1-Score |
|---|---|---|---|
| “en_core_web_lg”—128—0.01 | 50.73% | 47.34% | 48.97% |
| “en_core_web_sm”—64—0.0001 | 46.08% | 54.52% | 49.95% |
| “en_core_web_sm”—64—0.0001 | 50.70% | 52.96% | 51.81% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panoutsopoulos, H.; Brewster, C.; Espejo-Garcia, B. Developing a Model for the Automated Identification and Extraction of Agricultural Terms from Unstructured Text. Chem. Proc. 2022, 10, 94. https://doi.org/10.3390/IOCAG2022-12264
Panoutsopoulos H, Brewster C, Espejo-Garcia B. Developing a Model for the Automated Identification and Extraction of Agricultural Terms from Unstructured Text. Chemistry Proceedings. 2022; 10(1):94. https://doi.org/10.3390/IOCAG2022-12264
Chicago/Turabian StylePanoutsopoulos, Hercules, Christopher Brewster, and Borja Espejo-Garcia. 2022. "Developing a Model for the Automated Identification and Extraction of Agricultural Terms from Unstructured Text" Chemistry Proceedings 10, no. 1: 94. https://doi.org/10.3390/IOCAG2022-12264
APA StylePanoutsopoulos, H., Brewster, C., & Espejo-Garcia, B. (2022). Developing a Model for the Automated Identification and Extraction of Agricultural Terms from Unstructured Text. Chemistry Proceedings, 10(1), 94. https://doi.org/10.3390/IOCAG2022-12264