Abstract
Background: Understanding how accident risk escalates during unfolding industrial events is essential for developing intelligent safety systems. This study proposes a large language model (LLM)-based framework that simulates human-like risk reasoning over sequential accident precursors. Methods: Using 100 investigation reports from the U.S. Chemical Safety Board (CSB), two Generative Pre-trained Transformer (GPT) agents were developed: (1) an Accident Precursor Extractor to identify and classify time-ordered events, and (2) a Subjective Probability Estimator to update perceived accident likelihood as precursors unfold. Results: The subjective accident probability increases near-linearly, with an average escalation of 8.0% ± 0.9% per precursor (). A consistent tipping point occurs at the fourth precursor, marking a perceptual shift to high-risk awareness. Across 90 analyzed cases, Agent 1 achieved 0.88 precision and 0.84 recall, while Agent 2 reproduced human-like probabilistic reasoning within ±0.08 of expert baselines. The magnitude of escalation differed across precursor types. Organizational factors were perceived as the highest risk (median = 0.56), followed by human error (median = 0.47). Technical and environmental factors demonstrated comparatively smaller effects. Conclusions: These findings confirm that LLM agents can emulate Bayesian-like updating in dynamic risk perception, offering a scalable and explainable foundation for adaptive, sequence-aware safety monitoring in safety-critical systems.
1. Introduction
The concept of precursors, defined as early signs or warnings that indicate potential outcomes, has historically played a crucial role in how humans interpret and respond to unfolding events. Historical examples, from ancient China’s fallen battle flags to medieval omens [1,2], illustrate humanity’s enduring tendency to interpret early signs as indicators of danger. These signs, often subtle or coincidental, were perceived as precursors that, once observed, profoundly influenced human judgment and action. In industrial, military, and high-reliability systems, early indicators such as minor alarms, deviations from standard procedure, or near-misses play a crucial role in shaping human and organizational responses [3,4].
Precursors may not guarantee that an accident will follow, but they shift the observer’s belief, consciously or unconsciously, about the likelihood of failure [5]. Subsequently, precursor-based probabilistic risk assessment (PRA), an approach that quantitatively evaluates near-miss or minor events to forecast and mitigate larger system failures, has become an established topic in the safety and risk management field [6,7,8]. For example, a notable successful case analysis is the U.S. Nuclear Regulatory Commission’s (NRC) Accident Sequence Precursor (ASP) Program [9]. Since its launch in 1988, the ASP Program has reviewed all Licensee Event Reports from U.S. power reactors, utilizing PRA models to screen and rank each event based on its conditional core damage probability (CCDP) or incremental core damage probability (CDP) [10]. The NRC has identified and catalogued a total of 954 precursors to date [11].
The creation of comprehensive precursor-event repositories has become a practical strategy for assessing potential major accidents in complex systems and scenarios [12,13,14,15]. Leveraging precursors as proxies to infer the likelihood of rare events is a powerful approach for estimating low-probability risks [16,17,18]. Innovative, scenario-based risk assessment methods integrate precursor event databases with advanced computational algorithms, such as dynamic Bayesian networks (BN), guided probabilistic simulation, and sequence analysis models, to generate, evaluate, and prioritize accident scenarios in complex systems [19,20,21,22].
However, a critical unresolved question is whether human judgments, based on either lay perceptions or expert opinions, can be rigorously translated into numerical probability values suitable for formal PRA [23]. Following the seminal WASH-1400 Reactor Safety Study in 1975, the estimation of precursor event probabilities and their conditional likelihood of core damage has predominantly relied on structured expert judgment elicitation—currently termed subjective probability—reflecting the paucity of empirical data. This expert-elicitation framework was later formalized within PRA via Bayesian and uncertainty-analysis methods [24]. However, the translation of expert judgments into precise numerical subjective probabilities for use in formal probabilistic risk assessments has long been a matter of contention within the safety and risk analysis communities [25,26]. While ongoing debate persists, a consensus has emerged within the academic community that subjective probability, when applied with appropriate caution, can serve as a valid component of risk assessment [24,27].
Nevertheless, the topic remains underexplored in both research and education. Most university-level probability theory courses continue to focus predominantly on classical and empirical probability, offering limited attention to subjective likelihood [28]. This gap stands in contrast to engineering practice, where the use of subjective probability is often necessary to account for uncertainty in complex or data-sparse environments. It is important to note that Bayesian probability, particularly the use of BN, has become increasingly prevalent in risk assessment [29,30,31]. A critical methodological issue persists. For example, in BN, each node’s outcome is determined by its conditional probability table (CPT), which quantifies the probabilistic relationships with its parent nodes. Mostly, such CPT is populated through expert judgment. Yet, the subjective process by which these expert judgments are translated into quantitative probability estimates is often inadequately specified or justified [32]. Developing systematic methods to elicit, calibrate, and validate expert-derived subjective probabilities remains an important area for further research.
Thus, prior research has focused on static or expert-elicited probabilities, lacking empirical modeling of how perceived accident likelihood evolves dynamically through sequential cues. To address these limitations, this study investigates how subjective accident probability evolves as precursors are revealed sequentially in industrial incident narratives. Specifically, we ask the following questions:
- i.
- How does risk perception change with each additional precursor?
- ii.
- How do precursor types and their sequential order influence the magnitude of this escalation?
- iii.
- Can large language models (LLMs) replicate human-like reasoning in assessing such risk dynamics?
To answer these questions and fill these gaps, this study develops two Generative Pre-trained Transformer (GPT) agents that replicate human-like probability updating across real industrial narratives. It is due to GPT’s unique ability to process structured narratives, apply heuristic reasoning, and simulate human-like cognitive patterns. To ensure the integrity and reliability of each agent’s functionality, and to prevent any cross-interference or contamination of prompt data, we employed two independent GPT agents rather than one. This approach also eliminates the ethical concerns associated with collecting data from human participants through interviews or questionnaires. On the other hand, we acknowledge that recent advances in LLMs have enabled new approaches to AI-assisted reasoning in domains involving unstructured data and decision-making. While their application in safety science is still emerging, early studies show promise in hazard analysis [33,34], fault detection [35], assisted scenario simulation [36], and automated safety insight extraction [37,38]. However, few efforts have explored LLMs for simulating human-like probabilistic reasoning over sequential events [39,40]. This study addresses that gap by modeling dynamic risk perception through GPT agents, offering a novel application of LLMs in precursor-based safety forecasting.
Specifically, the first agent extracts time-ordered precursors from 90 U.S. Chemical Safety Board (CSB) reports, while the second simulates a human-like observer who estimates accident probability at each step. Through this approach, we aim to (1) model risk escalation as a function of precursor sequence, (2) analyze the influence of precursor types on subjective probability, and (3) assess the potential of LLMs as tools for simulating cognitive risk assessment. In doing so, we contribute to the growing intersection of artificial intelligence (AI) and safety science, offering both theoretical insights and practical implications for the design of next-generation safety systems. Specifically, this study is grounded in cognitive theories of risk perception, particularly the notion that humans evaluate danger through Bayesian-like reasoning, updating their beliefs in response to new evidence over time. As precursors accumulate, individuals reassess the likelihood of failure based on both the quantity and nature of observed warnings. Accordingly, the study tests the following hypotheses:
H1.
Subjective accident probability increases monotonically as precursors accumulate.
H2.
Precursor type and order significantly affect the escalation magnitude.
H3.
GPT-based agents can replicate human-like probabilistic reasoning with statistically comparable accuracy.
In this context, this paper is organized as follows. The next section, Section 2, outlines the methodological framework. Section 3 presents the results derived from our empirical investigation. Section 4 presents a discussion of the findings, including their relevance to existing literature and theoretical implications. Finally, Section 5 highlights the key conclusions and contributions of the study.
2. Methodology
This study investigates whether the subjective probability of an accident increases continuously as precursors are observed sequentially. To simulate human-like risk estimation, we developed AI agents based on ChatGPT 4o. As shown in Figure 1, the methodology consists of a four-step process: (1) data collection, (2) precursor extractor agent, (3) subjective probability estimator agent, and (4) statistical analysis.
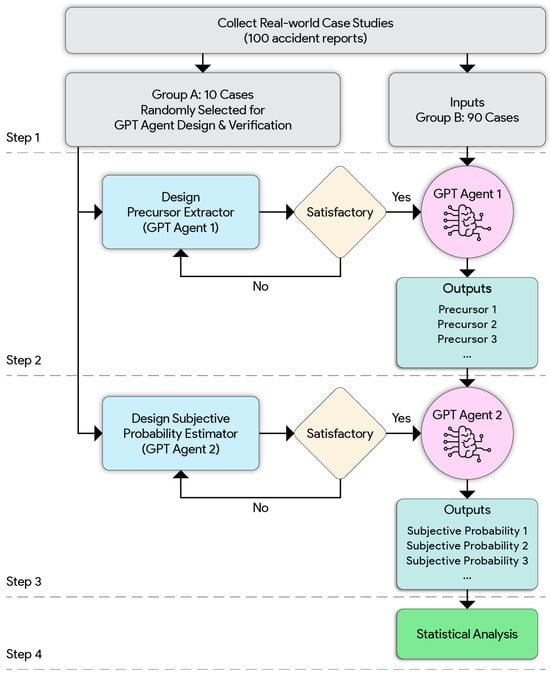
Figure 1.
Research methodological framework.
2.1. Step 1: Data Collection
To ensure broad applicability and relevance, we collected data from real-world incident reports published by the U.S. Chemical Safety and Hazard Investigation Board. Specifically, we focused on the 100 most recent investigation reports, with the final report released between 16 August 2000, and 1 May 2025. These reports were selected based on their completeness, the availability of a detailed incident timeline, and the inclusion of operational context leading up to the event. Each report was verified to include a structured narrative format with key sections (e.g., “Background,” “Incident Description,” “Timeline,” and “Findings”), which are the standard formats for CSB reports. All contextual “Background” information from the accident report was extracted independently and stored in a separate file, distinct from the original report, to facilitate its use in subsequent prompt-based processes. As illustrated in Figure 1, we divided the reports into two groups:
- i.
- Group (A) with 10 cases for GPT agent design and verification. This number was adequate to allow iteratively improving prompts and probability mappings, convey variation across representative precursor-risk scenarios, and conform to accepted procedures for model validation before extensive testing.
- ii.
- Group (B) with 90 cases for the research experiment. This larger dataset enabled the systematic assessment of the GPT agent’s scalability, consistency, robustness, and capacity to mimic human-like reasoning across a range of precursor types, sequences, and escalation patterns.
Specifically, the 10-case validation set (Group A) was used to design and evaluate the two GPT agents in an iterative manner. They were not used for model training as in traditional machine learning; instead, they served solely to validate the performance of the GPT agents within the LLM framework. These cases yielded a total of 52 manually labeled precursors and corresponding probability estimation points, providing diverse coverage of precursor types (technical, human, organizational, and environmental) and escalation patterns. This sample size was selected to balance practical constraints with the need for sufficient variation in scenario structure. Additionally, the U.S. CSB has historically published 128 investigation reports. That said, our research sample covers 78% of all public CSB reports. From these, we randomly selected 10 cases to form the verification set, providing a reasonable balance in terms of sample size and representativeness. It is noted that the verification set differs from the training set in traditional machine learning, which typically requires a 30% sample. They were just used to validate GPT-Agent’s functionality. Across these 10 cases, both agents were assessed for stability, logical consistency, and agreement with human-labeled outputs. Performance convergence was observed after iterative refinement, with Agent 1 achieving over 85% precision in precursor extraction and Agent 2 producing probability trajectories within ±0.08 mean absolute deviation from expert baselines. These results provided sufficient confidence to proceed with the full-scale deployment on Group B.
2.2. Step 2: Precursor Extractor (Agent 1)
We designed a GPT-powered agent, referred to as the Accident Precursor Extractor (Agent 1), to identify and extract discrete precursor events from the incident reports (Figure 1). Agent 1 was developed in the ChatGPT store using conversational, interactive, instruction-based design. A precursor is defined as a concrete, observable condition or event that occurred within one week before the adverse event.
Agent 1 is developed using a built-in, structured prompt framework. To ensure consistency in results, it requires only a single input—the upload of the CSB incident report. It is important to emphasize that all agents in this study were developed entirely through conversational interaction, without the need for programming or coding. This approach leveraged the convenience of development afforded by the ChatGPT store itself. Furthermore, the study did not require elaborate prompt engineering; uploading a case file and issuing a straightforward prompt was sufficient to generate the desired outputs.
Subsequently, it can generate precursor outputs without requiring explicit prompt text. Subsequently, each identified precursor is summarized in a generalized form for pattern comparison, using a neutral and factual tone. Time markers (e.g., “3 days before incident”) are preserved when available. The structured output is as follows:
Precursor 1: [General Description]—[Brief event with time marker]
Precursor 2: …
The extractor identifies and classifies precursors into four general categories:
- i.
- Technical anomalies (e.g., alarms, sensor faults, pressure deviations);
- ii.
- Environmental triggers (e.g., poor visibility, abnormal weather conditions);
- iii.
- Human errors (e.g., procedural violations, miscommunication);
- iv.
- Organizational factors (e.g., staffing shortages, deferred maintenance).
This typology for precursors is based on established frameworks in the accident precursor literature [3,14,15] and observations from the human-labeled results in the 10-case verification set. These categories provide a practical and interpretable framework for analyzing the influence of precursors on perceived risk escalation.
Moreover, the agent excludes any speculative, interpretive, or causal inferences. To maintain temporal relevance and reduce analytical noise, a 7-day window is employed; long-term system deficiencies are excluded unless explicitly linked to this period, though critical information preceding it is still considered. Root cause analysis, latent factors, and cultural issues are beyond the scope of this extraction.
Typically, the 7-day window for precursor identification was chosen based on both empirical precedent and practical considerations. Prior studies in high-reliability settings, such as rail and construction safety [3,14,15], have employed similar timeframes to capture actionable, near-term precursors. Short-term signals are more cognitively salient and reduce interference from latent conditions that may not influence immediate risk perception. During agent verification, a 7-day window consistently captured the majority of relevant events while minimizing noise. However, we acknowledge this may limit applicability in domains with long-latency failures, and future work should consider adaptive windows based on system dynamics.
To assess the reliability of Agent 1, we conducted a validation exercise using 10 reports (Group A). Two human coders (the first two authors) independently reviewed and labeled all precursors within the 7-day window for each case. The third author supervised the whole process. These human-labeled sequences were then compared against the outputs of Agent 1. Precision and recall were calculated based on matching descriptions and correct temporal placement. Agent 1 achieved an average precision of 0.88 and a recall of 0.84, indicating high alignment with human judgment (being 1.00 as a benchmark). Discrepancies were typically due to minor semantic differences or overlooked ambiguous indicators. This evaluation confirmed the agent’s readiness for broader application across the Group B dataset. Next, Agent 1 is used to extract precursors from the 90 cases of Group B. More detailed descriptions of the design and configuration of Agents 1 and 2 are provided in Appendix A.
2.3. Step 3: Subjective Probability Estimator (Agent 2)
In this phase, we designed another GPT agent, named Subjective Probability Estimator (Agent 2), to simulate human-like reasoning and to estimate the evolving subjective probability of an accident as precursors unfold sequentially. Unlike traditional quantitative models, this system emulates the cognitive processes of an informed, yet non-expert human observer, incorporating intuitive reasoning, heuristic cues, and contextual awareness.
GPT Agent 2 operates according to a structured, multi-stage inference process grounded in principles of conditional and Bayesian probability. Users first upload background information, followed by individual precursors in sequence. No additional instructions are needed, ensuring consistent, context-aware outputs without manual prompt engineering. The logic unfolds as follows:
- i.
- Contextual Initialization (Background Encoding)
Agent 2 first receives detailed background information regarding the facility, including plant layout, process systems, and operational context. At this stage, the agent does not produce any output. The purpose is solely to internalize the contextual environment in which subsequent precursors will be evaluated.
- ii.
- Initial Precursor Processing (Single-Precursor Inference)
Agent 2 is then prompted with the first accident precursor. Based on the background context and the nature of this precursor, the agent generates a subjective probability estimate representing the likelihood of a major accident. It represents a fundamental form of conditional probability estimation.
- iii.
- Sequential Precursor Integration (Bayesian Updating)
As each additional precursor is introduced, prompted one at a time, the agent updates its probability estimates. Each update reflects the integration of the new precursor into the existing inference structure, forming a fully connected Bayesian network (Figure 2). The agent incrementally refines its subjective probability of a major accident, capturing the compounding influence of multiple precursors. In addition, this study employs such a fully connected BN structure to model the potential interdependencies among all identified precursors. While the use of BNs is not novel in the field of safety science, our implementation serves to support the reasoning mechanism within Agent 2. Specifically, when each precursor is sequentially prompted, the agent incorporates prior contextual information and inferred dependencies from previously processed precursors. This structure is implemented through conversational interaction in ChatGPT store for Agent 2 design, enabling it to simulate conditional reasoning across event sequences without requiring manual specification of probabilistic dependencies.
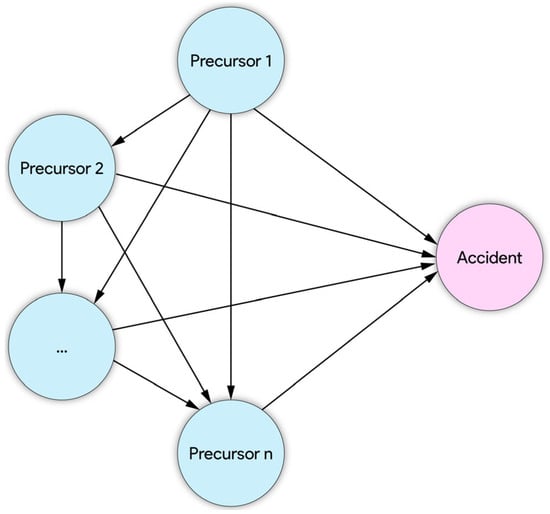
Figure 2.
A fully connected BN.
Similarly, Agent 2’s subjective probability estimates were verified through comparison with baseline estimates from the first two authors, who have domain expertise in process safety and risk assessment. For each of the 10 validation cases, probability values were independently assigned at each precursor stage by human evaluators, using the same background and sequential prompts provided to the GPT agent. The agent’s estimates matched or closely approximated the human values in 87% of cases, with mean absolute differences of less than 0.08. Deviations primarily occurred in complex scenarios involving organizational or compound failures. These results support the validity of using GPT agents as proxies for human-like probability reasoning, while also highlighting areas for potential improvement through calibrated prompt engineering or hybrid systems incorporating expert feedback.
- iv.
- Cumulative Risk Estimation (Dynamic Bayesian Modeling):
This iterative process continues until all relevant precursors have been considered. The resulting trajectory of probability estimates reflects the Agent’s evolving perception of accident risk, informed by both the static background context and the dynamic precursor sequence.
Similar to the design of Agent 1, Agent 2 was iteratively verified using the Group A cases until its outputs aligned with human expectations, ultimately demonstrating reasonable probability estimates consistent with the authors’ observations.
Overall, a brief interaction protocol for Agent 2 is as follows:
- Inputs:
Background Context: The system ingests this silently, with no immediate output.
Sequential Precursors: Each triggers a probability update with narrative justification.
- Outputs:
Numeric Probability Estimates (0–1.00)
Narrative Rationale for each estimate
Temporal Risk Evolution Plot (optional, for visualization)
Finally, Agent 2 is used to process the 90 cases of Group B.
2.4. Step 4: Statistical Analysis
In this step, we evaluated how subjective accident probability evolves with the sequential presentation of precursors. To this end, a structured statistical analysis comprising four methodological components was conducted: (1) descriptive statistics, (2) monotonicity testing, (3) linear regression modeling, and (4) typology-based comparison.
First, we compiled all the outputs of Agent 1 and Agent 2 into a structured dataset. For each case, we recorded:
- Case ID
- Precursor index
- Precursor description
- Time of precursor
- Subjective probability
- Precursor category
Next, we applied Spearman’s rank correlation coefficient to each case to assess whether subjective probabilities tend to increase in a consistent pattern as additional precursors are revealed. This non-parametric test evaluates the monotonic relationship between the order of precursor appearance and the associated probability values. In parallel, we employed simple linear regression modeling to quantify the rate of risk escalation. This approach allowed us to estimate both the strength and consistency of linear escalation patterns in perceived risk over time.
We also examined how different types of precursors influence subjective probability. We classified each precursor into one of four categories: (1) technical anomaly, (2) human error, (3) environmental trigger, and (4) organizational factor. We then aggregated probability estimates by precursor type and conducted comparative statistical analysis to identify how the precursor category affects perceived risk escalation. Finally, a one-way analysis of variance (ANOVA) was performed to compare the mean escalation slopes across the four precursor categories. This multi-faceted analytical approach provides a robust framework for quantifying trends, escalation rates, and category-specific effects in subjective accident probability estimation.
3. Results
3.1. GPT Agent Output Overview
Following the methodology, two GPT-based agents were deployed: Agent 1 (Accident Precursor Extractor) and Agent 2 (Subjective Probability Estimator). Agent 1 successfully extracted discrete precursors per case from 90 real-world accident reports (Group B). A sample interface is shown in Figure 3. When the Agent is prompted with one example of accident reports, it will export the lists of precursors (see Figure 4), confirming its ability to deliver structured, time-tagged precursor sequences.
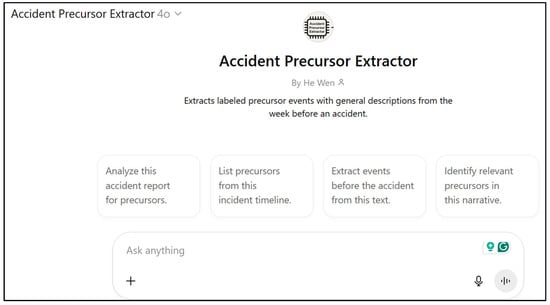
Figure 3.
Screenshot of Accident Precursor Extractor (Agent 1).

Figure 4.
Results by Accident Precursor Extractor.
Agent 2 produced evolving subjective probability estimates (0–1.00) for each case, updated sequentially as precursors were introduced. Figure 5 displays the screenshot of the Subjective Probability Estimator (Agent 2).

Figure 5.
Screenshot of Subjective Probability Estimator (Agent 2).
Subsequently, GPT Agent 2 is prompted with the background information of the chemical plant presented in Figure 6. Then, GPT Agent 2 is sequentially prompted with the precursors. The results of the first two are illustrated in Figure 7 and Figure 8.
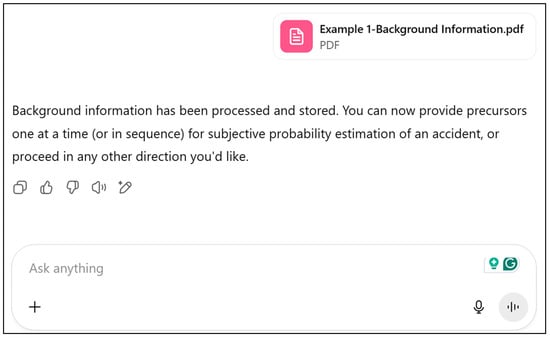
Figure 6.
Prompted with background information.

Figure 7.
Prompted with precursor 1.

Figure 8.
Prompted with precursor 2.
3.2. Results of Statistical Analysis
3.2.1. Number of Precursors
The Group B dataset comprises 90 cases, each with a time series of precursor-triggered probability estimates. Each record includes case ID, precursor index, precursor description, time of precursor, subjective probability, and precursor category. The number of discrete precursors identified per case for the 90 accidents is analyzed. Table 1 summarizes the descriptive statistics. There are 479 distinct precursors identified from 90 cases. The findings indicate a mean of 5.32 precursors per case, underscoring the complex and multifactorial nature of accident correlation. The minimum number of precursors observed in any single case was four, affirming that major industrial incidents seldom arise from a single-point failure. The maximum number of precursors recorded was 15, reflecting the high degree of systemic interaction and failure accumulation in certain events. The median number of precursors was five, confirming the traditional understanding of the domino effect with 5 blocks [41].

Table 1.
Descriptive statistics of the precursor number.
3.2.2. Value of Subjective Probability
The quantitative analysis focuses on the numerical value of subjective probabilities. Figure 9 depicts the heatmap of the 90 cases. Based on the observation of the range, the values of subjective probability vary from 0.02 to 0.95, indicating a wide variation in risk perception depending on the precursors present. This variability justifies the use of personalized or adaptive risk modeling tools, rather than rigid threshold-based systems.
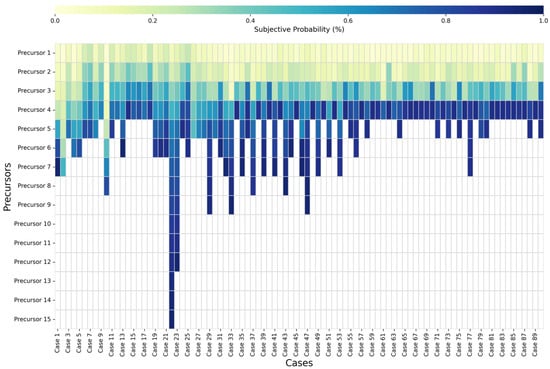
Figure 9.
The numerical data for the 90 cases.
Comparing the subjective probability of Precursor 1 for each case, the initial estimates vary significantly, ranging from 0.02 to 0.25, with the majority clustered between 0.02 and 0.10. This variation highlights that even the first observable warning sign can trigger a broad spectrum of perceived risk, depending on its nature and the context in which it is presented.
The mean probability across all observations is approximately 0.48, suggesting that evaluators often perceive a moderate risk as precursors accumulate. The median is 0.45, closely aligned with the mean, indicating a relatively symmetric distribution of subjective risk perceptions. It also means most cases reach a perceived risk level approaching or exceeding a 50-50 chance of a major incident. It suggests that operators, investigators, or analysts often recognize the tipping point well before the actual event, highlighting missed opportunities for intervention.
3.2.3. Monotonicity and Escalation Trends
The macroscopic observation of the values indicates a generally upward trend in subjective probabilities as the number of precursors increases (Figure 10). In most cases, subjective probabilities increase progressively with each additional precursor. Many cases reach a high probability (≥0.60) by Precursor 5. These likely represent severe or compound-risk scenarios. Some cases (e.g., Case 2 and Case 26) maintain relatively low probabilities throughout (also see Figure 9), suggesting that even with multiple precursors, the perceived risk remained moderate.
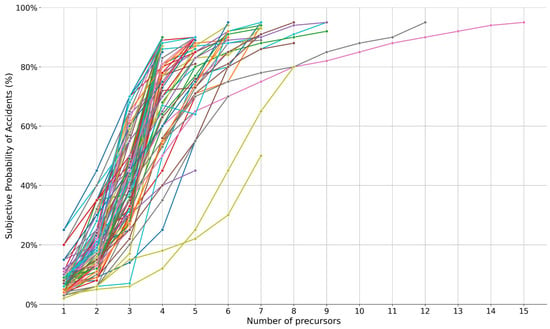
Figure 10.
Monotonicity and escalation trends. Since this figure presents all cases together to illustrate the overall trends, legends are omitted to reduce clutter and improve readability.
The monotonicity test was conducted to evaluate this pattern statistically. Spearman’s rank correlation coefficients were calculated for each case to assess the monotonic relationship between the precursor index and subjective probability. The monotonicity test results are summarized in Table 2, showing strong positive correlations across all 90 cases. Spearman’s values ranged from 0.75 to 1.00 ( < 0.05), with a mean of 0.89 ± 0.07, confirming that subjective accident probability consistently increases as additional precursors are introduced. These findings support the hypothesis that the subjective probability of an accident rises continuously as additional warning signs are observed.
Table 2.
Spearman’s rank correlation coefficients between precursor order and subjective probability.
Simple linear regression for each case yielded slopes ranging from a 5% to 12% increase in subjective probability per precursor, with a mean slope of 8.0%, standard deviation (SD) of 0.9%, and a 95% confidence interval (CI) . Adjusted values were higher (0.70–0.95), confirming a strong linear escalation pattern across most cases.
3.2.4. Risk Escalation Stages
The escalation pattern is illustrated by the distribution of each precursor (see Figure 11). Most trajectories show a clear upward trend, often approaching or reaching near-certainty after the final few precursors. Some variability in slope steepness and baseline levels was observed, reflecting differences in scenario characteristics or precursor severity.
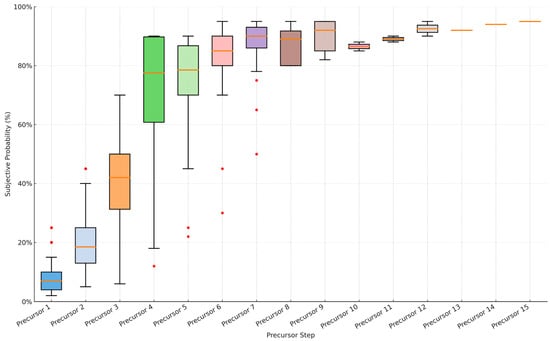
Figure 11.
Distribution of subjective probabilities per precursor.
In addition, while most cases yielded no more than 9 identifiable precursors, two outlier cases produced 12 and 15 precursors, respectively. These outliers slightly extend the upper bound but do not alter the overall three-stage division. If we exclude the two outliers, the detailed values are displayed in Table 3, and then it will show a three-stage pattern:
Table 3.
Subjective probabilities per precursor.
- i.
- Early stage (Precursors 1–2): Represents a lower initial risk, indicating that early warnings are often perceived as less critical.
- ii.
- Middle stage (Precursors 3–4): Represents a critical threshold where probabilities markedly escalate, reflecting accumulated perception of risk. Median probability jumps significantly from Precursor 3 (0.42) to Precursor 4 (0.77), suggesting a critical shift point.
- iii.
- Late stage (Precursors 5–9): Represent approach certainty, emphasizing urgency and severity, likely involving compounding human or organizational factors. Precursor 5–9 shows narrower ranges and consistently high values (>0.60), indicating emergency-level risk awareness.
3.2.5. Influence of Precursor Types
The research examined how different categories of precursors contribute to the escalation of subjective accident probability. Table 4 summarizes the frequency distribution of precursors across the four standardized categories. The results highlight that organizational factors were the most frequent, making up 38% of all precursors, and were associated with the highest median subjective probability (0.56). It suggests that systemic management failures, such as inadequate oversight, missing procedures, or poor communication, are perceived as highly consequential.
Table 4.
Frequency and Distribution of Precursor Types.
In addition, human errors and technical anomalies appeared in comparable numbers but elicited different responses. Human errors had a higher median probability (0.47) than technical anomalies (0.41), indicating greater concern about human unpredictability and the erosion of defense layers. Environmental triggers, though rare (4% of total), were perceived as least critical individually (median = 0.35), but may still exacerbate risk when interacting with other factors. Generally, physical precursors have a lower impact on subjective accident probability compared to human-related precursors.
As demonstrated above, Precursor 4 marks a critical shift point in perceived risk. Moreover, the first four precursors typically consist of a mix of different types rather than a single category, suggesting that sharp increases in subjective accident probability, rising from 0.08 at Precursor 1 to 0.77 at Precursor 4, are often driven by the compounding effects of diverse precursor types.
3.2.6. ANOVA and Mixed-Effects Analysis
To complement the correlation and regression analyses, additional statistical tests were conducted to verify the robustness of escalation patterns across precursor categories.
A one-way ANOVA revealed significant differences in mean escalation slopes among the four precursor types (). Post hoc Tukey comparisons revealed that organizational factors led to steeper escalation than both technical anomalies () and environmental triggers (), while the difference between organizational and human-error precursors was marginal ().
A mixed-effects linear model with precursor order as a fixed effect and case ID as a random effect confirmed a strong positive relationship (), consistent with an average escalation rate of 8.0% per precursor. The random-effects variance () indicated moderate between-case variability. The mean slope was 8.0 ± 0.9% (95% CI: 6.3–9.8%), confirming the reliability of the estimated escalation rate.
Together, these results demonstrate that dynamic risk perception is both monotonic and typology-sensitive, with organizational and human-factor precursors exerting the greatest influence.
4. Discussion
This study demonstrates that subjective accident probability escalates systematically with the sequential appearance of precursors. Several topics warrant further discussion.
First, whether the risk escalation patterns reflect human-like Bayesian updating, this study provides empirical support for the notion that subjective accident probability escalates systematically as precursors are observed sequentially. The findings reveal a consistent monotonic increase across cases. It aligns with Bayesian reasoning, in which each new input updates the perceived likelihood of failure. Particularly, Precursor 4 often marks a significant “tipping point,” triggering a sharp transition in perceived risk. This observation is consistent with findings from a systematic literature review, which indicate that even in the absence of proven causal links, the emergence of three distinct precursors or the repeated occurrence of the same precursor on three occasions without effective mitigation can elevate the perceived probability of a major accident to above 90% [5].
Second, this study demonstrates the typology and sequence sensitivity of precursors. Our analysis confirms that both the type of precursor and order play decisive roles in shaping subjective risk perception. Organizational factors were most frequent and associated with the highest perceived risk. Human errors following technical anomalies also led to sharp increases in probability, underscoring the importance of compound escalation. Temporal order further amplified perceived risk, especially when early technical issues were not promptly mitigated. This sensitivity to escalation patterns reinforces the need for sequence-aware AI risk models.
Nevertheless, it shows the limitations and the role of time. This study deliberately focused on short-term precursors within a 7-day window, consistent with prior research. However, we recognize that this may omit long-latency conditions relevant to other domains. Although time markers (e.g., days or hours before the event) were captured, our model does not yet incorporate temporal spacing between precursors into probability estimates. Future work should explore time-weighted or time-sensitive models to better reflect temporal urgency.
Third, while some safety analysis models emphasize causal chains or fault trees, this study focuses on perceived risk as it evolves through sequential, observable precursors. Causal relationships among precursors are often constructed post hoc by investigators; in contrast, our approach aims to model the “subjective risk response” to precursor accumulation in real time. As such, the GPT-based system emphasizes correlation and temporal proximity over causality. We believe this perspective is especially relevant for applications in proactive safety monitoring, where early warning signs must be interpreted before causes are fully known.
Furthermore, this study aims to extend the application of logic graphs to language-based reasoning. Though BNs are widely used in safety science, this study does not implement a dynamic BN (DBN) formalism. Instead, we adopt a simplified fully connected BN structure to support narrative-based reasoning. Each time a precursor is introduced, Agent 2 recalculates subjective probability based on all prior inputs. This approach mimics Bayesian updating while avoiding the need to manually specify CPTs or time slices, thereby making the method more robust for unstructured narratives. Our intent is not to replace PRA tools but to complement them, particularly in data-sparse or narrative-rich contexts. GPT-based agents used here perform implicit Bayesian updating through language-based reasoning, integrating contextual information and sequential precursors without predefined structures. It enables flexible interpretation in data-sparse environments or when expert judgment is embedded in unstructured narratives. The use of GPT-4o reflects state-of-the-art at the time, with newer models like DeepSeek and Gemini Pro advancing in lightweight deployment and contextual fidelity [42].
Although this study avoids human data collection, future applications must incorporate transparent model auditing, explainable outputs, and compliance with AI ethics frameworks such as ISO/IEC 42001 to ensure accountability in industrial contexts, especially in safety-critical scenarios. The GPT-based framework exhibits strong alignment with human-like reasoning; however, its outputs remain probabilistic and may vary slightly across runs due to model stochasticity. Results depend on the clarity of input narratives, and incomplete or ambiguous reports may bias outcomes [43,44,45].
Despite its contributions, this study has several limitations that warrant careful consideration. First, the verification set used to calibrate and validate the two GPT agents consisted of only 10 cases. While this aligns with common qualitative validation practices, it limits the statistical generalizability of the results. Second, although the agents processed time-tagged precursors, the current framework does not explicitly model the time intervals between precursors. This omission may overlook critical temporal dynamics, such as urgency or variability in escalation rates. Future work should address these limitations by (1) expanding the verification set to include a more diverse and representative sample, and (2) incorporating time-weighted or interval-sensitive models to better reflect the real-world temporal progression of risk.
5. Conclusions
This study provides empirical evidence that subjective accident probability escalates systematically as precursors are observed sequentially, confirming the hypothesized relationship between precursor accumulation and perceived risk. In summary, the key findings of this study can be outlined as follows:
- i.
- Monotonic escalation: Subjective accident probability increases consistently with precursor accumulation, exhibiting an average escalation rate of 8.0 ± 0.9% per precursor (p < 0.05).
- ii.
- Critical tipping point: The fourth precursor marks a consistent perceptual transition from moderate concern to high-risk awareness, indicating a critical stage in dynamic risk perception.
- iii.
- Typology sensitivity: Organizational and human-factor precursors exert the strongest effects on perceived risk, while technical and environmental factors contribute more modest increments.
- iv.
- Human-like reasoning: The dual GPT-agent framework effectively replicates human probabilistic reasoning, with close correspondence to expert judgments (mean deviation ± 0.08).
Accordingly, all three hypotheses proposed prior to this study were supported. The results also reveal that both the type and temporal position of precursors significantly affect subjective probability estimates. Early-stage precursors (e.g., Precursor 1 and 2) tend to set the initial frame of risk perception but generally result in lower probability values. In contrast, Precursor 4 consistently marks a critical inflection point, often signaling a shift toward urgency or crisis. This transition from low- to high-risk perception may reflect the psychological tipping point at which observers begin to interpret the situation as deviating significantly from routine and approaching a state of failure. This finding reinforces the importance of mid-sequence precursors in real-time monitoring systems. It supports the notion that risk escalation is not only additive but may also be sensitive to sequence structure.
Building on the present findings, future research can extend the framework to other large language models such as Gemini Pro, Claude 3, and DeepSeek, enabling comparative evaluation of reasoning consistency and contextual fidelity. Additionally, cross-domain studies can investigate the applicability of the approach in aviation, healthcare, and construction safety, where sequential precursors and dynamic decision-making are crucial. Integrating time-weighted modeling, uncertainty quantification, and explainable AI techniques can further enhance the interpretability and robustness of models in real-world deployments.
Author Contributions
Conceptualization, H.W. and M.P.; methodology, H.W., M.P. and Z.S.; software, H.W.; validation, H.W., M.P. and Z.S.; formal analysis, H.W.; investigation, H.W.; resources, H.W., M.P. and Z.S.; data curation, H.W.; writing—original draft preparation, H.W.; writing—review and editing, M.P. and Z.S.; visualization, H.W., M.P. and Z.S.; supervision, Z.S.; project administration, H.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Some or all data, models, or code that support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Agent Design and Configuration Details
To enhance transparency and reproducibility, this appendix provides the key configurations, prompt structures, and operational parameters used in developing the two GPT-based agents through the ChatGPT Store interface.
(1) Agent 1—Accident Precursor Extractor:
- Platform: ChatGPT 4o
- Development method: Instruction-based conversational design (no coding required)
- Core system prompt:
- i.
- You are an accident precursor extractor.
- ii.
- Identify and summarize all observable conditions or events that occurred within seven days before the incident.
- iii.
- Present outputs in the format: Precursor [number] − [description + time marker].
- iv.
- Classify each precursor as technical, human, organizational, or environmental.
- Constraints: 7-day window, factual summarization only, exclusion of speculative or causal inference.
- Validation: 10 CSB cases manually labeled and cross-checked; achieved precision = 0.88, recall = 0.84.
(2) Agent 2—Subjective Probability Estimator:
- Platform: ChatGPT 4o
- Development method: Sequential conversational reasoning (background + precursor inputs).
- Core system prompt:
- i.
- You are a safety analyst estimating the subjective probability of a major accident given sequential precursors.
- ii.
- For each new precursor, update the probability (0–1.00) and provide a brief rationale. Assume Bayesian-like reasoning that integrates prior context and newly observed events.
- Output format: {Probability Value (0–1.00); Narrative Rationale}.
- Verification: Compared against expert-assigned baselines across 10 cases (mean absolute deviation ± 0.08).
The prompt examples and full agent scripts are available from the corresponding author upon reasonable request.
References
- Galvany, A. Signs, Clues and Traces: Anticipation in Ancient Chinese Political and Military Texts. Early China 2015, 38, 151–193. [Google Scholar] [CrossRef]
- Kieckhefer, R. Magic in the Middle Ages; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar]
- Gnoni, M.G.; Saleh, J.H. Near-miss management systems and observability-in-depth: Handling safety incidents and accident precursors in light of safety principles. Saf. Sci. 2017, 91, 154–167. [Google Scholar] [CrossRef]
- Gnoni, M.G.; Tornese, F.; Guglielmi, A.; Pellicci, M.; Campo, G.; De Merich, D. Near miss management systems in the industrial sector: A literature review. Saf. Sci. 2022, 150, 105704. [Google Scholar] [CrossRef]
- Wen, H. A new perspective on precursors and rare events from a systematic review. J. Loss Prev. Process Ind. 2025, 99, 105785. [Google Scholar] [CrossRef]
- Khakzad, N.; Khan, F.; Amyotte, P. Quantitative risk analysis of offshore drilling operations: A Bayesian approach. Saf. Sci. 2013, 57, 108–117. [Google Scholar] [CrossRef]
- Perez, P.; Tan, H. Accident Precursor Probabilistic Method (APPM) for modeling and assessing risk of offshore drilling blowouts—A theoretical micro-scale application. Saf. Sci. 2018, 105, 238–254. [Google Scholar] [CrossRef]
- Garrick, B.J.; Christie, R.F. Probabilistic risk assessment practices in the USA for nuclear power plants. Saf. Sci. 2002, 40, 177–201. [Google Scholar] [CrossRef]
- Johnson, J.W.; Rasmuson, D.M. The US NRC’s accident sequence precursor program: An overview and development of a Bayesian approach to estimate core damage frequency using precursor information. Reliab. Eng. Syst. Saf. 1996, 53, 205–216. [Google Scholar] [CrossRef]
- Jang, S.; Park, S.; Jae, M. Development of an Accident Sequence Precursor Methodology and its Application to Significant Accident Precursors. Nucl. Eng. Technol. 2017, 49, 313–326. [Google Scholar] [CrossRef]
- Accident Sequence Precursor (ASP) Program|Nuclear Regulatory Commission. Available online: https://www.nrc.gov/about-nrc/regulatory/research/asp (accessed on 14 October 2025).
- Kirchsteiger, C. Impact of accident precursors on risk estimates from accident databases. J. Loss Prev. Process Ind. 1997, 10, 159–167. [Google Scholar] [CrossRef]
- de las Heras-Rosas, C.; Suárez-Cebador, M.; Salguero-Caparrós, F.; Rubio-Romero, J.C. Analysis of the main components precursors of occupational accidents in the construction industry in Spain (2003–2022). Saf. Sci. 2025, 190, 106902. [Google Scholar] [CrossRef]
- Kyriakidis, M.; Hirsch, R.; Majumdar, A. Metro railway safety: An analysis of accident precursors. Saf. Sci. 2012, 50, 1535–1548. [Google Scholar] [CrossRef]
- Wu, W.; Gibb, A.G.F.; Li, Q. Accident precursors and near misses on construction sites: An investigative tool to derive information from accident databases. Saf. Sci. 2010, 48, 845–858. [Google Scholar] [CrossRef]
- Yang, M.; Khan, F.; Lye, L.; Amyotte, P. Risk assessment of rare events. Process Saf. Environ. Prot. 2015, 98, 102–108. [Google Scholar] [CrossRef]
- Bier, V.M. Statistical methods for the use of accident precursor data in estimating the frequency of rare events. Reliab. Eng. Syst. Saf. 1993, 41, 267–280. [Google Scholar] [CrossRef]
- Goossens, L.H.J.; Cooke, R.M. Applications of some risk assessment techniques: Formal expert judgement and accident sequence precursors. Saf. Sci. 1997, 26, 35–47. [Google Scholar] [CrossRef]
- Guo, Z.; Haimes, Y.Y. Risk Assessment of Infrastructure System of Systems with Precursor Analysis. Risk Anal. 2016, 36, 1630–1643. [Google Scholar] [CrossRef]
- Khakzad, N.; Khakzad, S.; Khan, F. Probabilistic risk assessment of major accidents: Application to offshore blowouts in the Gulf of Mexico. Nat. Hazards 2014, 74, 1759–1771. [Google Scholar] [CrossRef]
- Sajid, Z. A dynamic risk assessment model to assess the impact of the coronavirus (COVID-19) on the sustainability of the biomass supply chain: A case study of a US biofuel industry. Renew. Sustain. Energy Rev. 2021, 151, 111574. [Google Scholar] [CrossRef]
- Dao, U.; Sajid, Z.; Khan, F.; Zhang, Y. Dynamic Bayesian network model to study under-deposit corrosion. Reliab. Eng. Syst. Saf. 2023, 237, 109370. [Google Scholar] [CrossRef]
- Slovic, P. Perception of Risk. Science 1987, 236, 280–285. [Google Scholar] [CrossRef] [PubMed]
- Apostolakis, G. The Concept of Probability in Safety Assessments of Technological Systems. Science 1990, 250, 1359–1364. [Google Scholar] [CrossRef] [PubMed]
- Watson, S.R. The meaning of probability in probabilistic safety analysis. Reliab. Eng. Syst. Saf. 1994, 45, 261–269. [Google Scholar] [CrossRef]
- Yellman, T.W.; Murray, T.M. Comment on ‘The meaning of probability in probabilistic safety analysis’. Reliab. Eng. Syst. Saf. 1995, 49, 201–205. [Google Scholar] [CrossRef]
- Apostolakis, G.E. The interpretation of probability in probabilistic safety assessments. Reliab. Eng. Syst. Saf. 1988, 23, 247–252. [Google Scholar] [CrossRef]
- D’Agostini, G. Teaching statistics in the physics curriculum: Unifying and clarifying role of subjective probability. Am. J. Phys. 1999, 67, 1260–1268. [Google Scholar] [CrossRef]
- Animah, I. Application of Bayesian network in the maritime industry: Comprehensive literature review. Ocean. Eng. 2024, 302, 117610. [Google Scholar] [CrossRef]
- Zhang, G.; Thai, V.V. Expert elicitation and Bayesian Network modeling for shipping accidents: A literature review. Saf. Sci. 2016, 87, 53–62. [Google Scholar] [CrossRef]
- Wang, Q.-A.; Chen, J.; Ni, Y.; Xiao, Y.; Liu, N.; Liu, S.; Feng, W. Application of Bayesian networks in reliability assessment: A systematic literature review. Structures 2025, 71, 108098. [Google Scholar] [CrossRef]
- Wen, H.; Khan, F.; Amin, M.T.; Halim, S.Z. Myths and misconceptions of data-driven methods: Applications to process safety analysis. Comput. Chem. Eng. 2022, 158, 107639. [Google Scholar] [CrossRef]
- Charalampidou, S.; Zeleskidis, A.; Dokas, I.M. Hazard analysis in the era of AI: Assessing the usefulness of ChatGPT4 in STPA hazard analysis. Saf. Sci. 2024, 178, 106608. [Google Scholar] [CrossRef]
- Sujan, M.; Slater, D.; Crumpton, E. How can large language models assist with a FRAM analysis? Saf. Sci. 2025, 181, 106695. [Google Scholar] [CrossRef]
- Wu, H.; Triebe, M.J.; Sutherland, J.W. A transformer-based approach for novel fault detection and fault classification/diagnosis in manufacturing: A rotary system application. J. Manuf. Syst. 2023, 67, 439–452. [Google Scholar] [CrossRef]
- Dang, P.; Zhu, J.; Li, W.; Xie, Y.; Zhang, H. Large-language-model-driven agents for fire evacuation simulation in a cellular automata environment. Saf. Sci. 2025, 191, 106935. [Google Scholar] [CrossRef]
- Sabetta, N.; Costantino, F.; Stabile, S. A comparative analysis for automated information extraction from OSHA Lockout/Tagout accident narratives with Large Language Model. Procedia Comput. Sci. 2025, 253, 1362–1372. [Google Scholar] [CrossRef]
- Baek, S.; Park, C.Y.; Jung, W. Automated safety risk management guidance enhanced by retrieval-augmented large language model. Autom. Constr. 2025, 176, 106255. [Google Scholar] [CrossRef]
- Gu, J.; Pang, L.; Shen, H.; Cheng, X. Do LLMs Play Dice? Exploring Probability Distribution Sampling in Large Language Models for Behavioral Simulation. In Proceedings of the 31st International Conference on Computational Linguistics, Abu Dhabi, United Arab Emirates, 19–24 January 2025; Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Di Eugenio, B., Schockaert, S., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2025; pp. 5375–5390. Available online: https://aclanthology.org/2025.coling-main.360/ (accessed on 14 October 2025).
- Pournemat, M.; Rezaei, K.; Sriramanan, G.; Zarei, A.; Fu, J.; Wang, Y.; Eghbalzadeh, H.; Feizi, S. Reasoning Under Uncertainty: Exploring Probabilistic Reasoning Capabilities of LLMs. arXiv 2025, arXiv:2509.10739. [Google Scholar] [CrossRef]
- Heinrich, H.W. Industrial Accident Prevention. A Scientific Approach; McGraw-Hill: New York, NY, USA, 1931. [Google Scholar]
- Sun, K.; Wang, X.; Miao, X.; Zhao, Q. A review of AI edge devices and lightweight CNN and LLM deployment. Neurocomputing 2025, 614, 128791. [Google Scholar] [CrossRef]
- Jonnala, S.; Swamy, B.; Thomas, N.M. Geopolitical Bias in Sovereign Large Language Models: A Comparative Mixed-Methods Study. J. Res. Innov. Technol. 2025, 4, 173–192. [Google Scholar] [CrossRef]
- Osborne, M.R.; Bailey, E.R. Me vs. the machine? Subjective evaluations of human- and AI-generated advice. Sci. Rep. 2025, 15, 3980. [Google Scholar] [CrossRef]
- Zhuang, N.; Cao, B.; Yang, Y.; Xu, J.; Xu, M.; Wang, Y.; Liu, Q. LLM Agents Can Be Choice-Supportive Biased Evaluators: An Empirical Study. In Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI-25), Philadelphia, PA, USA, 25 February–4 March 2025; pp. 26436–26444. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).