Abstract
Road anomaly detection is essential for intelligent transportation systems and road maintenance. This work presents a MATLAB-native hybrid Convolutional Neural Network–Bidirectional Long Short-Term Memory (CNN–BiLSTM) framework for context-aware road event detection using multiaxial acceleration and vibration signals. The proposed architecture integrates short-term feature extraction via one-dimensional convolutional layers with bidirectional LSTM-based temporal modeling, enabling simultaneous capture of instantaneous signal morphology and long-range dependencies across driving trajectories. Multiaxial data were acquired at 50 Hz using an AQ-1 On-Board Diagnostics II (OBDII) Data Logger during urban and suburban routes in San Andrés Cholula, Puebla, Mexico. Our hybrid CNN–BiLSTM model achieved a global accuracy of 95.91% and a macro F1-score of 0.959. Per-class F1-scores ranged from 0.932 (none) to 0.981 (pothole), with specificity values above 0.98 for all event categories. Qualitative analysis demonstrates that this architecture outperforms previous CNN-only vibration-based models by approximately 2–3% in macro F1-score while maintaining balanced precision and recall across all event types. Visualization of BiLSTM activations highlights enhanced interpretability and contextual discrimination, particularly for events with similar short-term signatures. Further, the proposed framework’s low computational overhead and compatibility with MATLAB Graphics Processing Unit (GPU) Coder support its feasibility for real-time embedded deployment. These results demonstrate the effectiveness and robustness of our hybrid CNN–BiLSTM approach for road anomaly detection using only acceleration and vibration signals, establishing a validated continuation of previous CNN-based research. Beyond the experimental validation, the proposed framework provides a practical foundation for real-time pavement monitoring systems and can support intelligent transportation applications such as preventive road maintenance, driver assistance, and large-scale deployment on low-power embedded platforms.
1. Introduction
The detection of surface irregularities such as pothole, speed bump, and sudden braking events plays an important role in modern transportation systems and infrastructure maintenance [1,2,3,4,5]. Identifying these anomalies in real time contributes to safer driving, reduces maintenance expenses, and enables proactive management of road networks. At the same time, it is important to emphasize that road traffic safety is a multifactorial problem influenced not only by road surface conditions, but also by human behavior, vehicle dynamics, traffic density, and environmental factors. Previous studies have systematically analyzed these aspects, highlighting their combined impact on accident occurrence and severity, including pedestrian-related risk factors in vehicle–pedestrian interactions [6,7].
Regarding surface irregularities detection, recent developments in deep learning have improved the analysis of vibration and acceleration signals for this purpose [8,9]. Convolutional neural networks (CNNs) can extract informative vibration patterns associated with different road events; then most existing approaches focus only on short segments of the signal. This constraint limits robustness when there is noise from the sensor or dynamic driving conditions. Events with similar transient profiles, such as pothole and sudden braking, are particularly difficult to distinguish without explicitly modeling temporal relationships [10].
To overcome these challenges, several studies have proposed hybrid architectures that merge convolutional and recurrent layers [11,12]. This combination leverages the spatial feature extraction of CNNs and the contextual representation capabilities of long short-term memory (LSTM) networks. Despite these advances, few implementations are available that exploit this design for multiaxial vibration data.
The present work introduces a hybrid CNN–BiLSTM framework aimed at context-aware classification of road events using multiaxial acceleration and vibration signals. The model captures both short-term signal morphology and long-range dependencies across driving trajectories, which enhances interpretability and discrimination between events. The system was developed in MATLAB R2024a with Graphics Processing Unit (GPU) acceleration and supports automatic code generation through MATLAB GPU Coder [13], facilitating its deployment on embedded devices.
Experimental validation was carried out using a balanced dataset of six-channel vibration and acceleration signals sampled at 50 Hz along various urban and suburban routes in San Andrés Cholula, Puebla, Mexico. Our hybrid CNN–BiLSTM model achieved a global precision of 95.91% and a macro F1-score of 0.959, confirming balanced performance across the four event categories (none, pothole, speed bump, sudden braking). The bidirectional LSTM layer provided temporal awareness and improved discrimination between overlapping vibration patterns, while also offering greater transparency through activation visualization.
The remainder of this paper is organized as follows. Section 2 reviews related work on road anomaly detection using sensor-based and deep learning approaches. Section 3 describes the proposed methodology, including data acquisition, preprocessing, model architecture, and training procedure. Section 4 presents the experimental results and discussion, covering quantitative performance, generalization aspects, and interpretability through contextual activation analysis. Finally, Section 5 concludes the paper and outlines current limitations and directions for future research.
2. Related Work
Recent studies on road anomaly detection reveal two dominant paradigms: vision-based systems that analyze road imagery and sensor-based systems that interpret vibration or inertial data. Each strategy offers distinct advantages, and both have benefited from the adoption of deep-learning models in recent years.
Vision-based approaches commonly rely on object-detection and semantic-segmentation models to identify surface anomalies such as pothole and speed bump. Architectures derived from the YOLO family are among the most widely used due to their favorable accuracy–speed trade-off. Several studies report detection accuracies exceeding 85% mean average precision at an intersection-over-union threshold of 0.5 (mAP@0.5), with inference rates above 100 FPS on embedded platforms such as the Jetson AGX Xavier [14,15]. These results demonstrate that modern vision models can achieve real-time performance under controlled conditions. However, their reliability decreases in adverse scenarios that involve poor illumination, shadows, occlusions, or weather variability, and their computational demands remain significant despite the use of pruning, quantization, and mixed-precision inference [16,17].
Sensor-based approaches have emerged as a robust and cost-effective alternative, as they are largely insensitive to visual disturbances and require only lightweight hardware. Acceleration and gyroscope signals capture dynamic responses induced by irregularities on the road surface, enabling effective event detection using compact datasets. Ozoglu and Gökgöz [10] trained a convolutional neural network on vibration and gyroscope data acquired from smartphone sensors, achieving a validation accuracy of 93.24% for pothole detection and field precision between 80% and 87%. Related works using acceleration-only data have reported accuracies greater than 90% to classify pothole and speed bump [9,18,19]. Despite their efficiency, CNN-based models primarily learn short-term signal characteristics and often struggle to discriminate events with similar transient signatures, such as pothole and sudden braking, when the temporal context is not explicitly modeled.
To address these limitations, recent studies have increasingly explored temporal modeling strategies that extend beyond standard convolutional processing. Hybrid architectures combining CNNs with recurrent units such as LSTM, GRU, and bidirectional LSTM have demonstrated improved robustness by explicitly capturing long-range temporal dependencies in inertial and vibration signals [11,19,20]. Bidirectional variants, in particular, leverage both past and future contextual information to enhance discrimination in continuous driving sequences. More recent works have investigated temporal convolutional networks (TCNs) and lightweight attention-based mechanisms for sequential sensor data, achieving extended temporal receptive fields and improved contextual representation [21,22]. However, these approaches often increase architectural complexity, require extensive hyperparameter tuning, or rely on large-scale datasets, limiting their suitability for real-time embedded deployment.
In parallel, multi-sensor fusion approaches have been proposed to further enhance road anomaly detection by integrating inertial measurements with complementary modalities such as GPS, vehicle speed, suspension data, or camera-based perception [1,3]. Fusion strategies range from early feature-level integration to late decision-level aggregation, generally improving detection robustness across heterogeneous driving conditions. Nevertheless, multi-sensor systems introduce additional challenges related to sensor synchronization, hardware cost, and increased data bandwidth, which can hinder scalability and deployment in resource-constrained or low-cost environments. As a result, there remains strong interest in single-modality solutions that can achieve competitive performance while preserving simplicity and robustness.
Regarding embedded capabilities, the integration of deep-learning models into edge and embedded platforms is a key requirement for real-time road anomaly detection. Vision-based systems have achieved high throughput in devices such as the Jetson AGX Xavier through aggressive optimization techniques [23,24]. On the other hand, sensor-based solutions benefit from lower computational overhead and reduced data transmission requirements, making them inherently suitable for mobile and embedded deployment. Nevertheless, incorporating advanced temporal modeling layers, including bidirectional recurrent networks, into embedded pipelines continues to pose practical challenges.
Motivations and Scope
The existing literature demonstrates that both vision-based and sensor-based deep-learning approaches can effectively detect road surface anomalies. Vision-based methods offer high accuracy under favorable visual conditions but suffer from sensitivity to environmental factors and substantial computational demands. Sensor-based CNN models are lightweight and robust but lack explicit temporal reasoning. In contrast to recent multi-sensor fusion and vision-based approaches that rely on image-based object detection, the framework presented in this work combines convolutional feature extraction with bidirectional LSTM-based temporal modeling using only multiaxial acceleration and vibration signals. This design enables improved discrimination between temporally overlapping events, enhanced interpretability through activation visualization, and feasibility for real-time embedded deployment.
In addition, beyond the sensing modality, the proposed contribution also differs from existing hybrid CNN–LSTM approaches reported in the literature. Unlike generic CNN–LSTM models designed for activity recognition or long-sequence prediction, the proposed CNN–BiLSTM architecture is specifically tailored to short, overlapping inertial windows under strict real-time constraints. Bidirectional temporal modeling is applied at the segment level rather than across full driving trajectories, preserving low latency while still capturing contextual dependencies that are critical for discriminating road events with similar short-term vibration signatures.
In summary, the current state of the art in road anomaly detection reflects a clear trade-off between sensing modality, model complexity, and deployment feasibility. Vision-based approaches achieve high detection accuracy under favorable conditions but remain sensitive to environmental variability and require substantial computational resources. Sensor-based methods relying on acceleration and vibration signals offer a lightweight and robust alternative, particularly suitable for embedded and large-scale deployment; however, many existing solutions are limited by their reliance on short-term convolutional representations. Recent hybrid CNN–LSTM architectures demonstrate improved temporal reasoning and robustness, yet often introduce increased complexity or depend on multi-sensor fusion strategies. Within this context, there remains a need for compact, single-modality frameworks that explicitly model temporal context while preserving interpretability and real-time capability, motivating the hybrid CNN–BiLSTM approach proposed in this work.
3. The Proposed Approach
This section describes the methodological framework of the proposed context-aware road event detection system, developed entirely within a native MATLAB R2024a environment. The approach integrates convolutional and recurrent neural components to capture both short-term signal morphology and long-range temporal dependencies from multiaxial vehicular sensor data, allowing accurate and interpretable classification of road anomalies. Figure 1 provides a high-level overview of the complete methodological pipeline, illustrating the main stages of data acquisition, preprocessing, feature extraction, model training, and performance evaluation. This flowchart is intended to facilitate understanding of the overall workflow and the interaction between its core components.
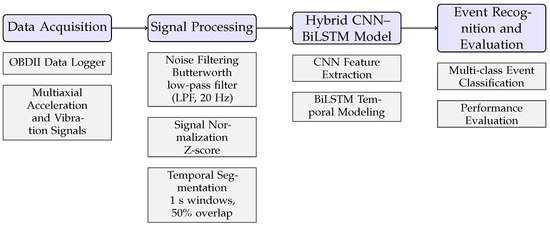
Figure 1.
Overview of the proposed road event detection pipeline. The methodology is organized into four main stages: (1) multiaxial data acquisition using an On-Board Diagnostics II (OBDII) data logger, (2) signal preprocessing including filtering, normalization, and temporal segmentation, (3) contextual feature learning using a hybrid CNN–BiLSTM architecture, and (4) multi-class event recognition and performance evaluation.
3.1. Data Acquisition and Preprocessing
Multiaxial acceleration and vibration data were collected using an AQ-1 On-Board Diagnostics II (OBDII) Data Logger configured to record six synchronized channels at 50 Hz, comprising triaxial acceleration (accel_x, accel_y, accel_z) and triaxial vibration (vib_x, vib_y, vib_z). The dataset employed in this study corresponds to a real-world acquisition campaign conducted on public roads under normal driving conditions.
Data acquisition was performed across urban, suburban, and peripheral routes in San Andrés Cholula, Puebla, Mexico. Two representative trajectories were selected: one covering the central urban area and another focused on suburban and peripheral roads. Each trajectory was recorded in both outbound and return directions to increase variability in road surface conditions, traffic flow, and driving behavior.
The complete dataset is organized into four JSON files:
- urban_trip_puebla_1.json: Outbound urban trajectory.
- urban_trip_puebla_2.json: Return urban trajectory.
- urban_trip_puebla_3.json: Outbound suburban and peripheral trajectory.
- urban_trip_puebla_4.json: Return suburban trajectory.
Each sensor sample was manually annotated with one of four event labels: none, pothole, speed bump, or sudden braking. Annotations were assigned based on synchronized inspection of the sensor signals and driving context, following consistent labeling criteria across all routes. At the raw signal level, the dataset comprises over 360,000 labeled samples corresponding to the 50 Hz sampling rate across six sensor channels.
The raw sample counts per class are as follows: 327,846 for none, 15,892 for pothole, 9518 for speed bump, and 7952 for sudden braking. This reflects the natural distribution of driving conditions, where most time is spent on normal road segments. To mitigate potential bias from this imbalance, class weights were computed inversely proportional to class frequencies and applied during model training. The weighting ensures that minority classes (pothole, speed bump, sudden braking) contribute proportionally more to the loss function, preventing the model from overfitting to the majority none class. For a more detailed description of the data acquisition setup, annotation protocol, and route characteristics, the reader is referred to our previous work [9]. All dataset files are provided as Supplementary Materials to ensure full reproducibility and to facilitate further benchmarking on road event detection using multiaxial acceleration and vibration signals. During window segmentation, special care was taken to prevent data leakage: each 1 s window (50 samples) inherits the label of its central sample, and windows are constructed such that no window contains samples from more than one original trajectory file. This ensures that temporally adjacent samples from the same continuous recording do not appear in both training and test splits after dataset partitioning.
To reduce high-frequency noise while preserving event-related signal content, all channels were filtered using a second-order Butterworth low-pass filter with a cutoff frequency of 20 Hz. This cutoff was selected based on spectral analysis of the recorded events, which showed that meaningful energy for pothole, speed bump, and sudden braking events resides predominantly below 20 Hz. Higher frequencies contained primarily sensor noise and uninformative vibrational components. The second-order design provides adequate roll-off (−40 dB/decade) while maintaining approximately linear phase response, minimizing distortion of the transient signatures critical for event discrimination.
Filtered signals were then standardized via z-score normalization per channel to ensure stable training dynamics across sensors with different measurement ranges and baseline characteristics.
The preprocessed signals were segmented into overlapping temporal windows of 1 s (50 samples) with 50% overlap. The 1 s duration balances two requirements: it is sufficiently long to capture the full temporal envelope of sustained maneuvers like braking (1–2 s), yet short enough to maintain temporal resolution for brief impacts such as pothole (200–400 ms). The 50% overlap ensures that event onsets are not missed due to window boundary effects and increases the effective size of the training set, improving model generalization while avoiding excessive redundancy. Each window forms a tensor representing the six sensor channels across 50 time steps.
3.2. Feature Extraction and Model Architecture
The proposed framework relies on a hybrid neural network that combines convolutional feature extraction with bidirectional long short-term memory (BiLSTM) contextual modeling. This architecture was implemented in MATLAB R2024a using the Deep Learning Toolbox, (The MathWorks, Natick, MA, USA), which supports GPU acceleration and facilitates deployment through MATLAB GPU Coder [13].
The network structure consists of the following:
- Input layer: sequenceInputLayer(6, MinLength, 50) configured for input tensors of six-channels, 50-samples. Where MinLength specifies the minimum sequence length (50 samples).
- Convolutional blocks: two sequential one-dimensional convolutional layers (convolution1dLayer(3, 64, Padding, same)), each followed by batch normalization and ReLU activation, extract short-term temporal features. A max pooling layer (maxPooling1dLayer(2, Stride, 2)) reduces the temporal dimensionality.
- Contextual encoding: a bidirectional LSTM layer (bilstmLayer(64, OutputMode, last)) models long-range dependencies and contextual transitions, improving discrimination between event classes with similar short-term vibration patterns.
- Classification head: a fully connected layer (fullyConnectedLayer(4)), followed by softmax and classification layers, generates categorical predictions for the four event types.
The complete layer sequence is illustrated in Figure 2. This configuration was designed to capture both local and global temporal structures within the multiaxial sensor signals, a property typically absent in purely convolutional approaches.
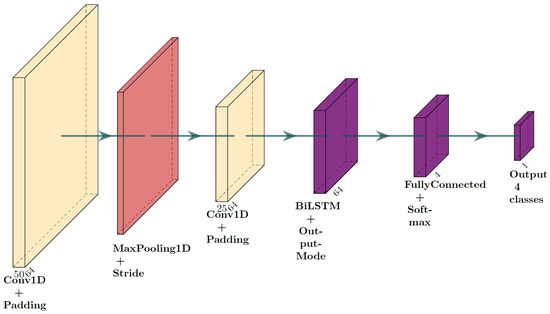
Figure 2.
Schematic representation of the proposed hybrid CNN–BiLSTM architecture for context-aware road event detection. The network combines convolutional layers for short-term feature extraction with a bidirectional LSTM encoder for temporal context modeling, followed by a fully connected and softmax classification head.
3.3. Model Training
Training was carried out using the Adam optimizer with a fixed learning rate of 0.001 over 80 epochs and a mini-batch size of 32. The dataset was divided into 80% for training and 20% for validation. The samples were shuffled at each epoch to encourage generalization. All experiments were performed on a single GPU-equipped workstation using MATLAB’s GPU Coder for accelerated computation and embedded compatibility. In addition, a categorical cross-entropy loss function was used to optimize the multi-class classification objective. The batch normalization layers mitigated the internal covariate shift and contributed to faster convergence. Explicit data augmentation was not applied, as the overlapping window strategy and balanced class distribution provided sufficient signal diversity for robust learning.
3.4. Event Classification and Evaluation
During inference, each preprocessed [6 × 50] segment was classified into one of the four target categories. The sequence of window-level predictions was aggregated to reconstruct the temporal evolution of road events along each driving trajectory, allowing a direct visual correspondence between predicted and actual events.
The trained model was evaluated using accuracy, macro-averaged precision, recall, F1-score, specificity, and the area under the receiver operating characteristic curve (AUC). All metrics were calculated both globally and per-class to ensure a balanced and unbiased assessment of performance under potential class imbalance.
To assess the robustness of the reported results, both the proposed CNN–BiLSTM framework and the CNN-only baseline were trained and evaluated multiple times using identical data splits but different random initializations. The reported performance values reflect the average behavior across these runs, exhibiting low variability and consistently higher scores for the hybrid architecture. This confirms that the observed performance improvements are stable and not attributable to stochastic effects in model initialization or training. Visual summaries of the results include confusion matrices, Receiver operating characteristic (ROC) curves, bar graphs of performance metrics per-class, and BiLSTM activation maps, which together provide both quantitative validation and qualitative insight into the contextual decision-making behavior of the proposed model [25,26,27].
3.5. Implementation and Deployment Considerations
To validate the practical feasibility of real-time deployment, the trained CNN–BiLSTM model was exported and profiled. The final model has a compact size of 298 KB (305,162 bytes), making it suitable for storage on most embedded systems and microcontrollers. Inference latency was measured on a mid-range embedded GPU (NVIDIA Jetson Nano) using TensorRT (The MathWorks, Natick, MA, USA), optimization. The model processes a single input window (100 samples @ 50 Hz) in approximately 1.2 ms, well below the 20 ms available per sample for real-time operation at the original sampling rate. The maximum RAM usage during inference remains below 15 MB. These metrics confirm that the proposed architecture is not only accurate, but also efficient enough for real-time execution on low-power edge devices, fulfilling the design goal of a deployable pavement monitoring system.
4. Experimental Results and Analysis
This section reports on the experimental evaluation of the proposed hybrid CNN–BiLSTM framework for context-aware road event detection. The results encompass quantitative and qualitative analysis, per-class performance, comparative benchmarking with existing approaches, and the interpretability of the contextual reasoning of the model. In addition, this section provides an explicit discussion of the main strengths and current limitations of the proposed framework in order to objectively assess its practical applicability and scope.
4.1. Overall Classification Performance
Our CNN–BiLSTM model demonstrates consistently high classification accuracy in all four event categories: none, pothole, speed bump, and sudden braking. As summarized in Table 1 and visualized in Figure 3 and Figure 4, the model achieves a global precision of 95.91%, with macro-averaged precision, recall and F1-score values of 0.959, 0.9591, and 0.959, respectively. These results confirm a balanced predictive performance, with no single class dominating the error distribution. A key strength of the proposed model lies in its ability to achieve high and well-balanced performance across all event classes using only inertial signals, without relying on vision-based cues or multi-sensor fusion.

Table 1.
Per-class performance metrics of the proposed CNN–BiLSTM framework on the validation set.
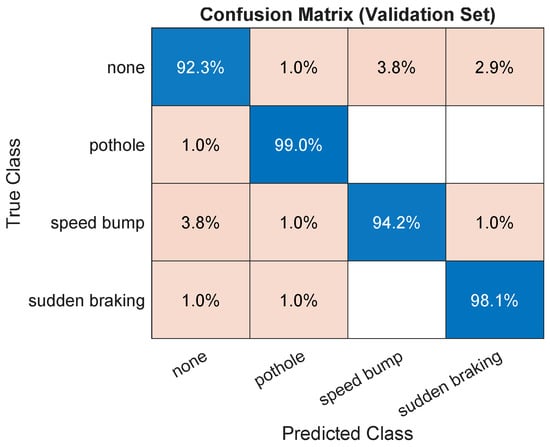
Figure 3.
Confusion matrix for validation data showing balanced classification and minimal cross-class confusion.
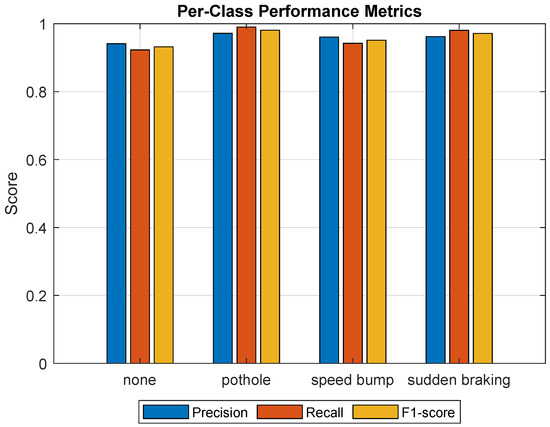
Figure 4.
Per-class performance metrics (Precision, Recall, and F1-score) for the four road event categories.
From a methodological perspective, the novelty of the proposed framework resides in the explicit incorporation of bidirectional temporal modeling on top of a compact 1D convolutional backbone. Unlike CNN-only approaches, including our prior work, the proposed architecture exploits both past and future temporal context within each segment, enabling the model to capture event evolution patterns that cannot be resolved using local convolutional features alone. Although the observed improvement of approximately 2–3% in macro F1-score may appear modest numerically, it is practically significant in continuous road monitoring scenarios. Even small reductions in false positives and false negatives accumulate over long driving sessions, leading to improved system reliability, fewer spurious alerts, and more consistent event detection in real-world deployments.
4.2. Per-Class Metrics
Detailed per-class statistics (Table 1) demonstrate consistent precision and recall values that exceed 0.94 for all types of events. The confusion matrix (Figure 3) indicates a minimal misclassification between pothole and sudden braking, events that typically exhibit overlapping vibration patterns. The high specificity (≥0.98) in all classes confirms a low false-positive rate, essential for reliable embedded applications.
This behavior highlights one of the main advantages of incorporating bidirectional temporal modeling, which mitigates ambiguity in events that share similar short-term signal morphology. In contrast to CNN-only architectures that classify each temporal window largely independently, the proposed CNN–BiLSTM framework explicitly models contextual continuity across consecutive segments. This temporal reasoning capability is particularly beneficial for events that exhibit similar instantaneous vibration signatures but differ in their temporal evolution.
4.3. ROC Analysis and Generalization
The receiver operating characteristic (ROC) curves for each category of events (Figure 5) reveal a high discriminative capacity, with AUC values of 0.986 (none), 1.000 (pothole), 0.994 (speed bump) and 0.998 (sudden braking). All ROC curves are presented within a single multi-class plot using a one-vs-rest evaluation strategy, where class-wise curves are superimposed for direct and fair comparison under the same CNN–BiLSTM model configuration. The convergence behavior shown in the validation curves confirms stable learning and negligible overfitting throughout the 80 training epochs, reflecting well-calibrated optimization dynamics.
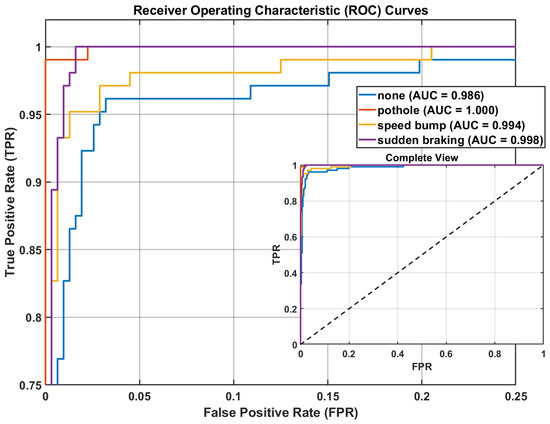
Figure 5.
ROC curves (the dotted diagonal line represents the chance-level performance of a random classifier) for the proposed hybrid CNN–BiLSTM model. The figure shows the one-vs-rest ROC curves for all event classes superimposed in a single plot, enabling a direct comparison of class-wise discriminative performance.
Although the experimental data were collected within a limited geographic region, the model was exposed to diverse road conditions, including varying pavement materials, traffic densities, and driving speeds across urban and suburban environments. The use of multiaxial acceleration and vibration signals enables the network to learn physics-driven response patterns associated with road irregularities rather than location-specific features. Furthermore, the bidirectional temporal modeling allows the CNN–BiLSTM architecture to capture invariant contextual signatures across driving trajectories, which supports generalization beyond the specific routes used during data acquisition. Nevertheless, the authors acknowledge that large-scale cross-city or cross-country validation remains an important direction for future work to further assess robustness under different vehicle types, road construction standards, and sensor mounting configurations. Despite these strengths, a current limitation of the proposed framework is the absence of explicit mechanisms to compensate for domain shifts caused by different vehicle dynamics, suspension systems, or sensor mounting configurations. Addressing such variability through adaptive normalization or domain generalization techniques represents a relevant direction for future research.
4.4. Contextual Feature Interpretation
To examine the interpretability of the contextual layer, BiLSTM activations were visualized along the temporal axis (Figure 6). The activation profiles reveal three distinct temporal motifs that leverage sequential context for classification. For pothole, activations exhibit high-magnitude, sporadic spikes (e.g., ) superimposed on a moderately active baseline (), reflecting the impulse-like yet irregular nature of road-impact events. sudden braking triggers a characteristic asymmetric envelope: a gradual ascent from baseline () to peak () over ∼45 samples, followed by a rapid decay and a prolonged tail of low-amplitude oscillations, capturing the anticipatory rise and subsequent damped vibrations of vehicle deceleration. none segments show predominantly low-level activity () interspersed with occasional moderate perturbations (), corresponding to minor road irregularities during normal driving. The BiLSTM’s discrimination capability stems from its evaluation of the full temporal morphology, not merely instantaneous amplitude. It distinguishes the intermittent, high-energy spikes of a pothole from the sustained, structured envelope of braking, while correctly attributing isolated moderate peaks in the none class to background noise rather than significant events. This contextual reasoning accounts for the consistent 2–3% improvement in macro F1-score over CNN-only baselines, which lack explicit sequential modeling. Thus, the framework offers not only performance gains but also interpretable insights into its temporal decision logic, moving beyond black-box classification.
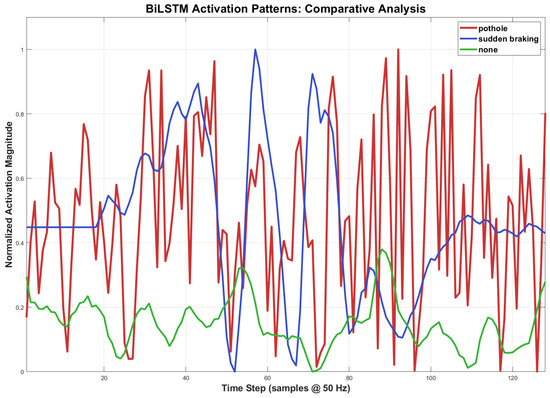
Figure 6.
Normalized BiLSTM activation patterns for pothole (intermittent high-magnitude spikes), sudden braking (asymmetric envelope with gradual rise and prolonged decay), and none (low-level baseline with occasional moderate perturbations) events. The temporal signatures illustrate how contextual modeling discriminates between impulse-like impacts, sustained maneuvers, and background driving conditions.
4.5. Comparative Analysis with Prior Work
Road anomaly detection has been addressed in the literature using fundamentally different sensing paradigms, which directly affect the scope and validity of quantitative comparisons. Recent large-scale studies focus on city-wide or nationwide deployment using vision-based pipelines and crowdsourced image datasets [3,4,14]. These approaches typically rely on high-resolution RGB imagery, object-detection or semantic-segmentation models, extensive manual annotation, and substantial computational resources. Due to the differences in sensing modality, data representation, labeling strategy, and evaluation protocols, a direct quantitative comparison with such vision-based systems is not methodologically appropriate for the present work.
Table 2 therefore summarizes representative and methodologically comparable approaches based on vibration, acceleration, or inertial signals, as well as selected vision-based methods included solely for contextual reference. Most signal-based methods can be categorized into traditional machine learning pipelines or modern deep learning architectures. The traditional approach, exemplified by Martinelli et al. [28], relies on time-frequency signal transformations and manually engineered features, achieving moderate accuracy (86.4%) but requiring domain expertise for feature design. In contrast, modern deep learning methods automatically learn discriminative features from raw or preprocessed signals. However, many recent vibration-based works still employ shallow or standard CNN architectures that focus on short temporal windows. For instance, Ozoglu and Gökgöz [10] reported a validation accuracy of 93.24% with a shallow 1D-CNN, while a similar CNN-only architecture [9] achieved 93.5% accuracy but inherently lacks explicit temporal modeling. This limitation is critical, as it can hinder the model’s ability to discriminate between transient events with overlapping vibration signatures, such as pothole and sudden braking. Vision-based approaches such as YOLOv5 [15] achieve competitive performance (87.0% mean average precision at an intersection-over-union threshold of 0.5, mAP@0.5), but at the cost of high computational complexity, sensitivity to environmental conditions, and reliance on expensive hardware, making them less suitable for lightweight embedded deployment.
Table 2.
Comparison of the proposed CNN–BiLSTM framework with prior state-of-the-art methods.
The comparison also includes works that, while methodologically different, provide relevant context. Raslan et al. [29] explored deep learning with CNN variants, focusing on the impact of data representation and achieving an average accuracy of 85.4%. Compared to this method, the proposed hybrid CNN–BiLSTM framework achieves a superior accuracy of 95.91% using only inertial signals. More importantly, the integration of the BiLSTM layer provides explicit temporal modeling, a key advantage that allows the network to learn contextual patterns across sequential vibration windows, which is absent in pure CNN or traditional feature-based architectures.
In general, the proposed hybrid CNN–BiLSTM configuration demonstrates a favorable balance between accuracy, interpretability, and computational efficiency. By relying on invariant inertial signal characteristics and temporal context rather than location-dependent cues, the model exhibits strong generalization potential across different road scenarios, making it suitable for real-time deployment in embedded and mobile systems.
5. Conclusions
This work introduces a native MATLAB framework for context-sensitive road event detection based on a hybrid one-dimensional convolutional neural network and bidirectional long short-term memory (CNN–BiLSTM). By combining convolutional feature extraction with bidirectional temporal reasoning, the model captures both the local morphology and contextual evolution of vibration signals, leading to reliable discrimination among road anomalies such as pothole, speed bump, and sudden braking events.
Experimental evaluation on a balanced dataset collected in urban and suburban trajectories validates the robustness of the approach. Our CNN–BiLSTM model reached an overall accuracy of 95.91% and a macro-averaged F1-score of 0.959, with class-specific F1-scores consistently above 0.93. Inclusion of the BiLSTM layer improves temporal awareness, allowing the system to classify events that exhibit similar short-term signal patterns. Visualization of internal BiLSTM activations corroborates the interpretability and stability of the learned temporal representations.
A key strength of the proposed framework lies in its ability to achieve high and balanced classification performance using only multiaxial acceleration and vibration signals, avoiding the need for camera-based perception or complex multi-sensor fusion pipelines. This results in reduced computational overhead, lower hardware requirements, and increased robustness to adverse environmental conditions such as poor lighting or weather variability.
Compared with earlier CNN-only implementations, the proposed hybrid network achieves an improvement of approximately 2–3% in macro F1-score while preserving a compact structure suitable for real-time deployment through MATLAB GPU Coder. Against the state-of-the-art image-based approaches derived from YOLO which typically report mean precision values of 81–87% (mean average precision at an intersection-over-union threshold of 0.5, mAP@0.5), the present vibration-driven framework achieves a higher balanced accuracy with markedly lower computational and data acquisition requirements. Furthermore, compared to previous vibration-based CNN models, which reached validation accuracies near 93.24%, the proposed approach provides a measurable improvement in both accuracy and cross-environment generalization.
At the same time, several limitations of the current study should be acknowledged. First, the experimental validation was conducted within a limited geographic region and using a single vehicle and sensor configuration, which may constrain direct generalization to different road infrastructures, vehicle dynamics, or sensor mounting setups. Second, although the bidirectional temporal modeling improves contextual discrimination, it introduces a modest increase in model complexity compared to purely convolutional architectures, which may impact deployment on extremely resource-constrained platforms.
Future work may therefore focus on large-scale cross-region validation, domain adaptation across vehicle types, and selective multi-sensor fusion to further enhance robustness while preserving the lightweight nature of the framework. Additionally, transfer learning strategies and adaptive domain generalization could be explored to broaden applicability in heterogeneous intelligent transportation systems.
Supplementary Materials
The following supporting information can be downloaded at https://www.mdpi.com/article/10.3390/vehicles8010004/s1: the full dataset used for model training and evaluation, comprising multiaxial acceleration and vibration recordings collected during real-world driving experiments.
Author Contributions
Conceptualization, Investigation: A.A.-G. Validation and Writing—Original Draft: A.M.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data supporting the findings of this study are publicly available and have been included as Supplementary Materials with the manuscript.
Acknowledgments
Acknowledgments to INAOE for supporting the development of this postdoctoral research under the supervision of Alejandro Medina Santiago (Researcher for Mexico); this work will strengthen Project 882 of Conahcyt.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kim, Y.M.; Kim, Y.G.; Son, S.Y.; Lim, S.Y.; Choi, B.Y.; Choi, D.H. Review of recent automated pothole-detection methods. Appl. Sci. 2022, 12, 5320. [Google Scholar] [CrossRef]
- Asaduzzaman; Rana, S. Smart monitoring of pavement condition utilizing vehicle vibration and smartphone sensor. In Advances in Civil Engineering: Select Proceedings of ICACE 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 199–209. [Google Scholar]
- Parasnis, G.; Chokshi, A.; Jain, V.; Devadkar, K. Roadscan: A novel and robust transfer learning framework for autonomous pothole detection in roads. In Proceedings of the 2023 IEEE 7th Conference on Information and Communication Technology (CICT), Jabalpur, India, 15–17 December 2023; pp. 1–6. [Google Scholar]
- Baroudi, U.; BaHamid, A.; Elalfy, Y.; Alami, Z.A. Enhancing Pothole Detection and Characterization: Integrated Segmentation and Depth Estimation in Road Anomaly Systems. arXiv 2025, arXiv:2504.13648. [Google Scholar] [CrossRef]
- Bello-Salau, H.; Aibinu, A.; Onumanyi, A.; Onwuka, E.; Dukiya, J.; Ohize, H. New road anomaly detection and characterization algorithm for autonomous vehicles. Appl. Comput. Inform. 2020, 16, 223–239. [Google Scholar] [CrossRef]
- Macioszek, E.; Granà, A.; Krawiec, S. Identification of factors increasing the risk of pedestrian death in road accidents involving a pedestrian with a motor vehicle. Arch. Transp. 2023, 65, 7–25. [Google Scholar] [CrossRef]
- Sharma, S.N.; Dehalwar, K. A systematic literature review of pedestrian safety in urban transport systems. J. Road Saf. 2025, 36, 55–78. [Google Scholar] [CrossRef]
- Martinez-Ríos, E.A.; Bustamante-Bello, M.R.; Arce-Sáenz, L.A. A review of road surface anomaly detection and classification systems based on vibration-based techniques. Appl. Sci. 2022, 12, 9413. [Google Scholar] [CrossRef]
- Aguilar-González, A.; Medina Santiago, A. CNN-Based Road Event Detection Using Multiaxial Vibration and Acceleration Signals. Appl. Sci. 2025, 15, 10203. [Google Scholar] [CrossRef]
- Ozoglu, F.; Gökgöz, T. Detection of road potholes by applying convolutional neural network method based on road vibration data. Sensors 2023, 23, 9023. [Google Scholar] [CrossRef] [PubMed]
- Arce-Saenz, L.A.; Izquierdo-Reyes, J.; Bustamante-Bello, R. Exploring single-head and multi-head CNN and LSTM-based models for road surface classification using on-board vehicle multi-IMU data. Sci. Rep. 2025, 15, 24595. [Google Scholar] [CrossRef]
- Zhao, J.; Yang, W.; Zhu, F. A CNN-LSTM-attention model for near-crash event identification on mountainous roads. Appl. Sci. 2024, 14, 4934. [Google Scholar] [CrossRef]
- MathWorks. GPU Coder User’s Guide, R2024a; The MathWorks, Inc.: Natick, MA, USA, 2024. [Google Scholar]
- Zuo, H.; Li, Z.; Gong, J.; Tian, Z. Intelligent road crack detection and analysis based on improved YOLOv8. In Proceedings of the 2025 8th International Conference on Advanced Algorithms and Control Engineering (ICAACE), Shanghai, China, 21–23 March 2025; pp. 1192–1195. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Thompson, E.M.; Ranieri, A.; Biasotti, S.; Chicchon, M.; Sipiran, I.; Pham, M.K.; Nguyen-Ho, T.L.; Nguyen, H.D.; Tran, M.T. SHREC 2022: Pothole and crack detection in the road pavement using images and RGB-D data. Comput. Graph. 2022, 107, 161–171. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2021, 17, 168–192. [Google Scholar] [CrossRef]
- Khan, M.; Raza, M.A.; Abbas, G.; Othmen, S.; Yousef, A.; Jumani, T.A. Pothole detection for autonomous vehicles using deep learning: A robust and efficient solution. Front. Built Environ. 2024, 9, 1323792. [Google Scholar] [CrossRef]
- Yaqoob, S.; Cafiso, S.; Morabito, G.; Pappalardo, G. Detection of anomalies in cycling behavior with convolutional neural network and deep learning. Eur. Transp. Res. Rev. 2023, 15, 9. [Google Scholar] [CrossRef] [PubMed]
- Hadj-Attou, A.; Kabir, Y.; Ykhlef, F. Hybrid deep learning models for road surface condition monitoring. Measurement 2023, 220, 113267. [Google Scholar] [CrossRef]
- Reza, S.; Ferreira, M.C.; Machado, J.; Tavares, J.M.R. Road Traffic Events Monitoring Using a Multi-Head Attention Mechanism-Based Transformer and Temporal Convolutional Networks. IEEE Trans. Intell. Transp. Syst. 2025, 26, 13011–13024. [Google Scholar] [CrossRef]
- Guirguis, K.; Schorn, C.; Guntoro, A.; Abdulatif, S.; Yang, B. SELD-TCN: Sound event localization & detection via temporal convolutional networks. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–21 January 2021; pp. 16–20. [Google Scholar]
- Ilahi, A.H.Z.; Irwansyah, A.; Oktavianto, H. Comparative Study of CNN Architectures for Real-Time Audio-Based Car Accident Detection on Edge Devices. JOIV Int. J. Inform. Vis. 2025, 9, 1310–1318. [Google Scholar] [CrossRef]
- Kim, G.; Kim, S. A road defect detection system using smartphones. Sensors 2024, 24, 2099. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In Proceedings of the European Conference on Information Retrieval, Santiago de Compostela, Spain, 21–23 March 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 345–359. [Google Scholar]
- Ling, C.X.; Huang, J.; Zhang, H. AUC: A statistically consistent and more discriminating measure than accuracy. In Proceedings of the IJCAI, Acapulco, Mexico, 9–15 August 2003; Volume 3, pp. 519–524. [Google Scholar]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef]
- Martinelli, A.; Meocci, M.; Dolfi, M.; Branzi, V.; Morosi, S.; Argenti, F.; Berzi, L.; Consumi, T. Road surface anomaly assessment using low-cost accelerometers: A machine learning approach. Sensors 2022, 22, 3788. [Google Scholar] [CrossRef] [PubMed]
- Raslan, E.; Alrahmawy, M.F.; Mohammed, Y.; Tolba, A.S. Evaluation of data representation techniques for vibration based road surface condition classification. Sci. Rep. 2024, 14, 11620. [Google Scholar] [CrossRef] [PubMed]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.