Abstract
Phishing websites pose a major cybersecurity threat, exploiting unsuspecting users and causing significant financial and organisational harm. Traditional machine learning approaches for phishing detection often require extensive feature engineering, continuous retraining, and costly infrastructure maintenance. At the same time, proprietary large language models (LLMs) have demonstrated strong performance in phishing-related classification tasks, but their operational costs and reliance on external providers limit their practical adoption in many business environments. This paper presents a detection pipeline for malicious websites and investigates the feasibility of Small Language Models (SLMs) using raw HTML code and URLs. A key advantage of these models is that they can be deployed on local infrastructure, providing organisations with greater control over data and operations. We systematically evaluate 15 commonly used SLMs, ranging from 1 billion to 70 billion parameters, benchmarking their classification accuracy, computational requirements, and cost-efficiency. Our results highlight the trade-offs between detection performance and resource consumption. While SLMs underperform compared to state-of-the-art proprietary LLMs, the gap is moderate: the best SLM achieves an F1-score of 0.893 (Llama3.3:70B), compared to 0.929 for GPT-5.2, indicating that open-source models can provide a viable and scalable alternative to external LLM services.
1. Introduction
Website phishing remains one of the most prevalent and damaging forms of online fraud, enabling attackers to steal user credentials, financial data, or other sensitive information by imitating legitimate websites [1,2] . The Anti-Phishing Working Group (APWG) reported over 1.1 million unique phishing websites detected in Q2 2025, representing a 13% increase compared to Q1 in 2025, continuing a multi-year upward trend in attack frequency [3]. Unlike email phishing, web-based phishing exploits users’ trust in domains, brands, and website structures, making it difficult to detect through superficial inspection [4]. As phishing websites become more sophisticated, automated and adaptive detection techniques are essential [2,5].
Classical machine learning and deep learning approaches for website phishing detection, such as URL-based classifiers [6,7] or visual similarity models based on Convolutional Neural Networks (CNNs) [8,9,10] have shown promising detection rates under controlled conditions. However, they face several limitations in practice. Models trained on static features are vulnerable to adversarial evasion, such as obfuscating malicious scripts or dynamically generating HTML content [11,12,13]. Furthermore, Machine Learning (ML) classifiers require continuous retraining or feature updates to remain effective against rapidly evolving phishing tactics. Challenges such as high false-positive rates, susceptibility to adversarial attacks, and data imbalances limit the usefulness of ML-based detection approaches [14].
Recent work has proposed using Large Language Models (LLMs) in many cybersecurity applications [15]. Regarding phishing website detection, the models are used by treating the HTML structure and embedded text as natural language input. Proprietary LLMs, such as GPT-4 or Gemini, have demonstrated strong performance in classifying phishing websites and even generating natural-language explanations of their reasoning [16,17]. However, these approaches are often impractical in commercial settings, as they depend on vendor-controlled APIs, incur high inference costs, and make fine-tuning or customisation expensive. They also pose data privacy risks, as sensitive information must be sent to external systems, and may suffer from availability issues due to varying request latencies that can range from a few seconds to minutes [18,19].
SLMs, which we define as models with ≤70b parameters, present a promising alternative for phishing website detection, especially when they are open source and deployed locally. They offer several advantages, including significantly reduced operating costs, independence from vendor APIs, improved data privacy and confidentiality, easier compliance, and the ability to fine-tune models on-premise for domain-specific needs. However, to the best of our knowledge, no study outlines the utility, performance, costs, and benefits of using SLMs in comparison to large proprietary models.
In this work, we present a website phishing detection methodology and systematically benchmark a diverse set of 15 commonly used SLMs, ranging from 1 billion to approximately 70 billion parameters. The selected models include different sizes of Gemma (https://ollama.com/library/gemma3, (accessed on 2 March 2026)), Deepseek (https://ollama.com/library/deepseek-r1, (accessed on 2 March 2026)), Qwen (https://ollama.com/library/qwen3, (accessed on 2 March 2026)) and Llama (https://ollama.com/library/llama3.1, (accessed on 2 March 2026), https://ollama.com/library/llama3.2, (accessed on 2 March 2026), https://ollama.com/library/llama3.3, (accessed on 2 March 2026)), as well as models that are only available in one size, such as Mistral (https://ollama.com/library/mistral-nemo, (accessed on 2 March 2026)), gpt-oss (https://ollama.com/library/gpt-oss, (accessed on 2 March 2026)), phi (https://ollama.com/library/phi3, (accessed on 2 March 2026)), and dolphin (https://ollama.com/library/dolphin3, (accessed on 2 March 2026)). We evaluate those models along three axes: time to analyse website HTML and produce results, phishing classification correctness, and output coherence. To generate this benchmark, each model classifies 1000 websites (500 phishing and 500 benign) sampled from a freely available dataset [20].
To determine the suitability of local SLMs for phishing detection, we structure our approach along the following research questions:
- RQ1: Do SLMs deliver coherent and reliable outputs, including meaningful reasoning for phishing website detection?
- RQ2: How do the costs and benefits of local models compare to state-of-the-art proprietary models such as GPT4?
- RQ3: How does the length of the HTML code influence both analysis runtime and detection performance?
The main contributions of this article are:
- 1.
- We design an LLM-based phishing website detection pipeline and benchmark 15 SLMs, regarding various numeric and text-based criteria.
- 2.
- The benchmarking methodology, dataset, and source code are publicly available on Github (https://github.com/sbaresearch/benchmarking-SLMs, (accessed on 2 March 2026)), so other researchers and practitioners can reproduce the results and test new models in the future.
- 3.
- We discuss the benefits and challenges of small, local models compared to commercially available options and provide recommendations for applying SLMs to website phishing detection.
This work presents a website phishing detection approach and provides a detailed analysis of the capabilities of SLMs. Rather than focusing solely on classification performance relative to larger proprietary models, we conduct a comprehensive evaluation of cost, performance trade-offs, and privacy considerations when deploying SLMs for phishing detection. Based on these findings, we derive practical application recommendations.
Section 2 presents related work, followed by the experimental design (Section 3). Section 4 presents results, Section 5 discusses the advantages and costs of local LLMs compared to commercial applications, and Section 6 reflects on limitations. Finally, Section 7 concludes the work and outlines future research directions.
2. Related Work
Although the field of LLM-based website phishing detection has only recently gained traction, several studies have reported promising results using different models and analysis strategies. Table 1 provides an overview of these studies, highlighting input data modalities, models, and their reported classification performance.

Table 1.
Summary of related work classified into data modes, LLMs used, dataset size, and reported classification performance (F1-score).
For a broader overview of the current state of website phishing detection, ref. [25] summarise various approaches, including LLMs and beyond.
Ref. [26] focuses on the relevance of LLMs in Explainable AI (XAI) for phishing website detection. Using a multimodal detection pipeline that includes many ML models, such as CatBoost, CNN1D, and EfficientNetB7, alongside the CodeBert transformer, the detection performance achieves an F1-score between 0.953 and 0.989 across datasets. Since the LLM is mainly used in the XAI part of the pipeline and is not directly involved in the decision, we did not include this work in the practical applications, which are listed in Table 1.
Regarding input data, two main approaches are commonly used in the literature: text-only, which consists of website HTML code and URLs, and text combined with screenshot images. The choice of data modality typically depends on data availability and the capabilities of the selected models. Since most LLMs are designed to process and generate text, relying solely on HTML code is frequently chosen as a starting point for a phishing detection framework. Combining text and images is a common next step and a method often used to detect brand impersonations.
The most frequently used models are versions of GPT-3.5 and GPT-4, followed by iterations of the Gemini models. Open-source alternatives, such as Llama and Qwen, are less commonly chosen. The dataset sizes used in the different studies vary but generally range from a few thousand websites. Typically, researchers use balanced datasets, with an equal number of phishing and benign websites. As a comparative performance measure in phishing detection setups, the F1-score is commonly reported. The reported F1-scores range from 0.72 to 0.99.
In [21] a multimodal approach is used that involves both brand identification and domain verification. An LLM analyses the given input (Screenshot, HTML) and returns a list of indicators, like brand, has credentials, or a confidence score. The dataset used in their work is freely available in a GitHub repository (https://github.com/JehLeeKR/Multimodal_LLM_Phishing_Detection/tree/main/data/MMLLM_Benign/1, (accessed on 2 March 2026)).
Ref. [17] uses a different approach for handling the website screenshot, utilising an OCR model to extract text elements from the image. Their prompt instructs the LLM to analyse the input data and output a JSON-style document containing, e.g., ’phishing score’, ’brands’, or ’suspicious domain’. Although the method for deriving the dataset is provided, the final dataset is not available. Ref. [27] provides an extension to this detection system by using LLMs to derive optimal crawling strategies for websites that use cloaking techniques. The LLM, which is supported by prior examples stored in a RAG, is the deciding factor in providing an optimal crawling environment. As the best-performing model, GPT-4o-mini achieved an F1-score of 0.933 for detecting phishing websites.
Compared to other approaches that rely on a single agent (or multiple non-collaborating agents), ref. [22] presents a multi-agent system where each model represents a different expert to analyse website HTML code, content, URL, and screenshot. A moderator agent tracks if a common answer has been found, and if yes, provides the result to a judge agent who makes the final decision. The dataset is derived from various sources that can be accessed for free, but the final version is not available.
Unlike other related work, ref. [23] does not analyse each website in separation, instead 50 URLs are batched together and simultaneously analysed by an LLM, producing boolean phishing indicators as output. To enhance model performance, a classification head is added to the model architecture, whose weights are trained using a sample of the utilised URL dataset. The base dataset is online available [28].
Ref. [24] has a different focus, testing the resilience of phishing detection systems to evasion strategies. Based on the original HTML code of legitimate websites, deviating versions are created, which incorporate phishing techniques.
Ref. [16] emphasise brand recognition as a mechanism to collect potential URLs a brand might use and also account for changes such as logo or web presence that a brand might have gone through. This is done to build a dependable database for each brand, with the goal of reducing detection errors and minimising reliance on a reference database. In their pipeline, LLMs are used to detect the brand and predict whether a website is credential taking or not. For both tasks, the prompting technique relies on structured prompts, including few-shot examples. The datasets used to answer their research questions is available (https://sites.google.com/view/phishllm/experimental-setup-datasets, (accessed on 2 March 2026)).
Overall, related work demonstrates promising results and identifies several effective approaches for phishing website detection using LLMs. However, important gaps remain, including the lack of structured benchmarking of SLMs, limited analysis of cost, performance, and deployment trade-offs between SLMs and large proprietary models, and the absence of application-oriented recommendations that account for these factors in real-world settings. This work addresses these gaps and provides a systematic assessment of the usability of SLMs for website phishing detection.
3. Methodology
This work examines the costs and benefits of using small local LLMs for phishing detection compared to commonly used proprietary models. To gain detailed insights into the advantages and disadvantages of using such models two experiments are conducted, which cover different input data and data processing steps. In the Model Selection experiment (Experiment 1), the behaviour of a local LLMs is examined on a small subset of the full dataset used in the Scaled Evaluation experiment (Experiment 2). The goals of the first experiment are to uncover random behaviour, model runtime, and model output quality in terms of completeness and formatting. In experiment 2, models that performed satisfactorily in experiment 1 are used to classify a larger set of websites. In this experiment, the focus lies on the actual phishing detection performance, output coherence and the incurred analysis cost. Figure 1 summarises the overall pipeline and the relationship between models, datasets, and experiments. The concrete dataset construction and experimental execution are described in Section 4.
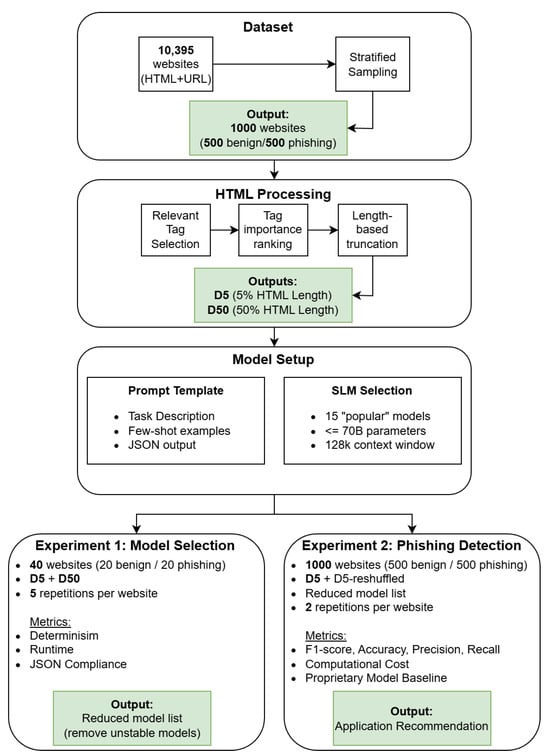
Figure 1.
Methodological approach and experimental design of the SLM benchmarking pipeline.
3.1. Model Selection
Given the large number of local LLMs—Ollama alone lists over 1000 models, versions, and specialisations—it is infeasible to evaluate all options exhaustively (https://ollama.com, (accessed on 2 March 2026)). Therefore, a subset of models was selected for this study, based on clearly defined inclusion and exclusion criteria, summarised in Table 2.
Table 2.
SLM selection Criteria.
Two key constraints informed our selection process. First, only models up to 70 billion parameters were included to focus on LLMs that can run locally on limited hardware. This allows organisations to retain sensitive data on-premise, thereby addressing privacy and compliance concerns, while also reducing operational costs. Furthermore, studies evaluating commercial LLMs (e.g., GPT) for phishing detection already exist (see Section 2), hence, our work focuses on local, open-source alternatives to provide a complementary perspective. Second, a minimum context window of 128,000 tokens was chosen , as all models support this window size and to ensure that the HTML input could be fully processed, avoiding automatic truncation by the model itself. Despite the truncation process, the HTML code often remains very long. Allowing models with smaller windows to internally truncate prompts would compromise comparability. Based on the above model selection criteria, 15 models were selected, spanning a diverse range of architectures and parameter sizes: deepseek-r1: 1.5b, 14b, 70b; gemma3: 4b, 12b, 27b; qwen3: 4b, 30b; llama: 3.2:1b, 3.1:8b, 3.3:70b; mistral-nemo:12b; phi3-medium: 14b; dolphin3: 8b and gpt-oss: 20b. Considerations:
- Since no singular llama3.x model on Ollama comes with all required parameter sizes; multiple versions were included to represent a range of models.
- The chosen Qwen3 models feature an exceptionally large context window length of 256,000 tokens, which allows them to process more input. To maintain comparability, the maximum prompt length was capped at 128,000 tokens.
- Since LLM-based phishing detection research often relies on GPT-family models, we decided to include gpt-oss:20b as an open-source GPT alternative with a comparable model size to the other models tested in our experiments.
3.2. Prompt Design
Designing an effective prompt is a critical step in LLM-based phishing website detection. The primary objective of the prompt is to instruct the model to analyse a given HTML document and corresponding URL [29], identify potential phishing indicators, and produce a structured, interpretable output that can be used for quantitative evaluation. The final prompt (see Prompt Template Appendix A.1) is based on the template proposed by [17] and was iteratively refined through multiple design cycles. The prompt consists of three core elements: (1) the detailed task description, which instructs the model to classify a website as benign or phishing based on the provided HTML code and URL, (2) guidance examples (few-shot prompting) that outline common phishing indicators to guide the model’s reasoning, and (3) the output specification, which defines the required JSON output format, including fields and score ranges. While the models are clearly instructed on how to deliver their output, any JSON-parsable response is accepted during the analysis phase. We anticipate inaccuracies when working with smaller models, and therefore do not discard results solely due to minor formatting deviations.
The following considerations shaped the final design:
- Flat Prompt Design: We use the generate mode (no conversation history), since each website must be analysed independently. As a result, the prompt had to be written in a flattened format, i.e., without explicit role labels like system or user.
- Few-Shot Prompting: To guide the model in detecting phishing characteristics, the prompt includes a limited number of examples of common phishing indicators (e.g., suspicious URLs, hidden forms, misleading redirects). These examples provide context and decision-making cues.
- Output Formatting: A strict JSON-parsable output format was defined to standardise model responses. The output contains three fields: phishing_score (an integer from 0 to 10, segmented into predefined risk brackets to reduce ambiguity and facilitate consistent interpretation across different models). is_phishing (boolean classification), reasoning (brief textual explanation citing key indicators). Furthermore, the output length is limited to 1000 tokens in an attempt to encourage models to retain the required output formatting and obtain concise answers.
4. Evaluation Design
This section describes the evaluation design, including the dataset, experimental setup, and hardware environment.
4.1. Dataset
The dataset used as a basis for this work can be accessed freely online and is provided to improve phishing detection techniques [20]. The full dataset contains detailed information on 10,395 websites, comprising 5244 legitimate and 5151 phishing websites. This dataset includes HTML files, URLs, screenshots, CSS files, and information about JavaScript components and their execution. In this work, only the index HTML file, which displays the page with all JavaScript code executed, and the URL were used, to keep it simple and comparable. The data repository was chosen because, with approximately 12,000 downloads (As of February 2026), it is frequently used and contains an extensive data collection that does not need to be further processed, and comes with clear documentation, which makes it also interesting for use in future work. Furthermore, the dataset was created recently (2023), thus containing more state-of-the-art website structures and phishing attempts. Based on this initial dataset, a stratified sample of 1000 websites consisting of 500 benign and 500 phishing websites was selected and further processed for use in the two experiments. This sampling strategy ensures a balanced and representative distribution, regarding HTML code length, across different website characteristics. We also conducted manual checks of the HTML code to rule out dataset-specific errors and ensure that we were working on a reliable database.
Selecting 1000 websites as the overall sample size is consistent with related work, such as [22,23]. Furthermore, using this sample size ensures that the classification performance metrics rely on a sufficiently large data basis to provide stable statistical estimates.
It is noteworthy that balanced datasets were used throughout this work, even though in real-world scenarios, the vast majority of websites encountered are expected to be benign. Unlike supervised learning approaches, LLMs analyse each website independently and do not rely on aggregated training data. Using a balanced dataset for analysis in this setting offers two key advantages: (1) it simplifies the interpretation of classification metrics, as results are not affected by class skew, and (2) it ensures a sufficient number of phishing samples, enabling more robust analysis of the LLMs’ phishing detection capabilities.
Experiment 1: For the initial Model Selection experiment, we sampled 20 benign and 20 phishing websites of the 1000 website large sample using a stratified random sampling approach. This ensured that the dataset covers a broad range of HTML document lengths, thereby reducing the risk of bias in the evaluation and still allowing a reliable runtime estimate with respect to HTML code length. For the 40 sampled websites, we created two different truncated versions, referred to as the D5 and D50 datasets. Both datasets contain only the HTML code elements most relevant for phishing detection, as these provide key information about the contents and structure of the websites [17]. The two datasets differ in the amount of HTML code retained: the D5 dataset includes only a maximum of 5% of the original websites’ HTML code, while the D50 dataset includes a maximum of 50%. This truncation serves two purposes: (1) to avoid information that is unnecessary for phishing detection, and (2) to reduce the computational costs when processing the data with LLMs.
Dataset Truncation Details: To generate the D5 or D50 dataset, first, for each website’s HTML code, the most phishing-relevant HTML code elements are selected. Choosing these elements builds on the work of [17], who selected the following tags for a similar phishing detection task: head, title, meta, body, h1, h2, h3, h4, h5, h6, p, strong, a, img, hr, table, tbody, tr, th, td, ol, ul, li, ruby, and label. Second, beyond just selecting relevant tags, our truncation approach extends this by ranking the tags by their importance for phishing detection [24]. Specifically, the elements: a, img, meta and link are deemed the most important, followed by HTML and head, while all remaining elements were assigned the lowest importance. Third, in case when, after the selection process described in the first step, too much code beyond a required percentage threshold remains, tags are removed from the HTML code according to their importance. The additional removal starts with the least important tags until the required percentage threshold of the original HTML code length is reached (i.e., 5% to get the D5 dataset and 50% to get the D50 dataset).
Experiment 2: For this experiment, all of the 1000 websites of the sampled dataset were used. Based on the findings from Experiment 1, this dataset was truncated following the D5 dataset, retaining a maximum of 5% of the original HTML content per website. In an additional analysis step, for the same 1000 websites, the HTML tags within each importance score group were randomly shuffled before truncation, resulting in a D5-reshuffled dataset. This preserves the importance of ordering but accounts for potential biases arising from tag ordering.
4.2. Experiments
To ensure a clear structure for this work, the phishing detection evaluation process is divided into two experiments. The first experiment focuses on randomness, runtime, and output completeness, establishing a baseline for model stability and feasibility. The second experiment then evaluates the models’ phishing classification performance and computational costs.
4.2.1. Experiment 1—Syntactic Performance and Runtime
When using LLMs, randomness is a critical factor, especially when aiming to build a reliable and reproducible solution. Output variability arises because models predict the next output token based on a probability distribution learned during training. Even when presented with identical prompts, the model may select different tokens, leading to variations in output [30,31]. For our experiments, the parameters for each model are set to temperature = 0, top_p = 0, top_k = 1, ensuring outputs are as deterministic as possible.
Using these settings, each model uses the prompt from Section 3.2 and analyses both the D5 and D50 phishing websites datasets, truncated to different levels (5% and 50% of the original HTML length). Each model analyses the same website five times to measure model output variability and to estimate the total runtime. This results in 3000 total runs per dataset (40 websites × 15 models × 5 repetitions). For testing the variability and stability of the model results, using the small sample dataset already provides valuable insights that can be applied to larger samples without requiring days of waiting for the results to be computed. At the end of Experiment 1, models that fail to produce consistent and correctly formatted output are excluded from Experiment 2.
The goals for this experiment are to answer the following questions:
- Is the output deterministic or do variations occur?
- How long are the model runtimes, and how does the prompt length influence it?
- To what extent do models adhere to the specified JSON output format?
4.2.2. Experiment 2—Phishing Detection Performance
The findings of Experiment 1 directly inform the design of Experiment 2. Only the models that passed Experiment 1 are included in the analysis, ensuring the evaluation focuses on practical and reliable candidates. At this stage, the full data sample of 1000 websites is utilised, comprising 500 benign and 500 phishing sites. Due to computational resource constraints, only the D5 version (truncated to 5% of the original HTML length) is utilised. The prompt remains identical to the one from Experiment 1 (see Section 3.2).
The primary goal of this experiment is to evaluate the classification performance of the models using standard metrics such as accuracy, precision, recall, and F1-score. Furthermore, the output coherence is examined by comparing the output variables to ensure that they lead to consistent decisions. For instance, if the boolean phishing variable is False, a corresponding low phishing score should be obtained, and the reasoning should reflect this decision. Finally, the experiment assesses the computational costs of running these models, enabling a comparison to commercial approaches. Ultimately, the experiment provides insights into the practical trade-offs between small open-source LLMs in phishing detection and commercial alternatives. To establish a baseline, we compared three state-of-the-art proprietary language models. Furthermore, to assess the robustness of our findings with respect to the data truncation procedure, the best-performing model on the D5 dataset is also tested on a D5-reshuffled dataset.
4.3. Used Hardware
For all computations, initially, the Nvidia A100 80 GB PCIe GPU and an AMD EPYC 9554 CPU were tested. For the 70b models, a switch to the Nvidia H100 80 GB PCIe GPU was necessary. All experiments were conducted on cloud infrastructure from runpod.io (https://www.runpod.io/, (accessed on 2 March 2026)).
5. Results
This section presents the results of the two experiments.
5.1. Results Experiment 1
The goal of the first experiment is to assess the practicality of different LLMs for phishing detection scenarios. To this end, the focus lies on three key aspects: runtime performance, output variability, and output correctness. These factors offer initial insights into the stability, reliability, and suitability of each model for potential deployment in productive environments.
5.1.1. LLM Runtime
A first consideration is runtime, i.e., the time it takes a model to analyse a single website. Runtime is critical in operational settings, where many websites must be processed quickly to prevent phishing attacks. Figure 2 shows the total runtime per model for both datasets. The two 70b models (llama3.3:70b and deepseek-r1:70b) exceeded A100 GPU VRAM capacity, requiring a switch to a more powerful H100 GPU and a reduced context window length of 65,536 tokens (vs. 128k for others). Still, for Experiment 1, none of the websites exceed the reduced context window, therefore avoiding any unintended information loss.
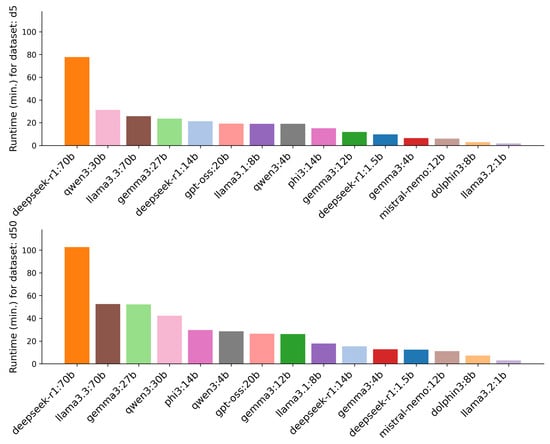
Figure 2.
Runtime for each model with D5 and D50 dataset.
Finally, the experiment assesses the computational costs of running these models, allowing a comparison to commercial approaches. Ultimately, the experiment provides insights into the practical trade-offs between small open-source LLMs in phishing detection and commercial alternatives, which are also obtained by using three proprietary language models as a comparison baseline. To assess the reliability of the results with respect to the data truncation steps, the best-performing model on the D5 dataset was used to analyse the D5-reshuffled dataset.
Analysing the 40 websites in the D5 dataset took 291 min (∼5 h), while analysing the same websites in the D50 dataset took 440.5 min (∼7 h 25 min), which is about 51.4% longer, thus showing that prompt length clearly affects runtime. This is a key consideration for Experiment 2, where the dataset size increases to 1000 websites.
As expected, larger models, such as the 70b models, needed the most time for both datasets (25.8 to 102.5 min), whereas the smallest models, like llama3.2:1b and dolphin3:8b, completed the task within just 1.8 to 7 min. Deepseek-r1:70b averaged 23.3 and 30.8 s per analysis run for the D5 and D50 datasets, respectively, while llama3.2:1b was the fastest, with averages of 0.5 and 0.9 s. Despite hardware and context window advantages, the two 70b models remained among the slowest. Table A1 in Appendix A contains the mean runtime per analysis run for all models.
Interestingly, runtime is influenced not only by model size but also by model family. For instance, the Gemma and Llama models exhibit significantly lower runtimes compared to other models, such as DeepSeek or Qwen. DeepSeek, Qwen, and gpt-oss are the only tested “thinking” models.
Prompt length was another factor for runtime, possibly due to several factors such as the tokenisation process, which takes longer for longer prompts, the quadratic scaling of the self-attention mechanism with respect to sequence length [32,33] and the key-value (KV) caches, which need to be built and get larger for longer prompts [34]. Figure 3 illustrates the relationship between HTML token count and analysis runtime, with 400 data points (five runs per website across D5 and D50 for each model). The dot overlap is high due to repeated analyses.
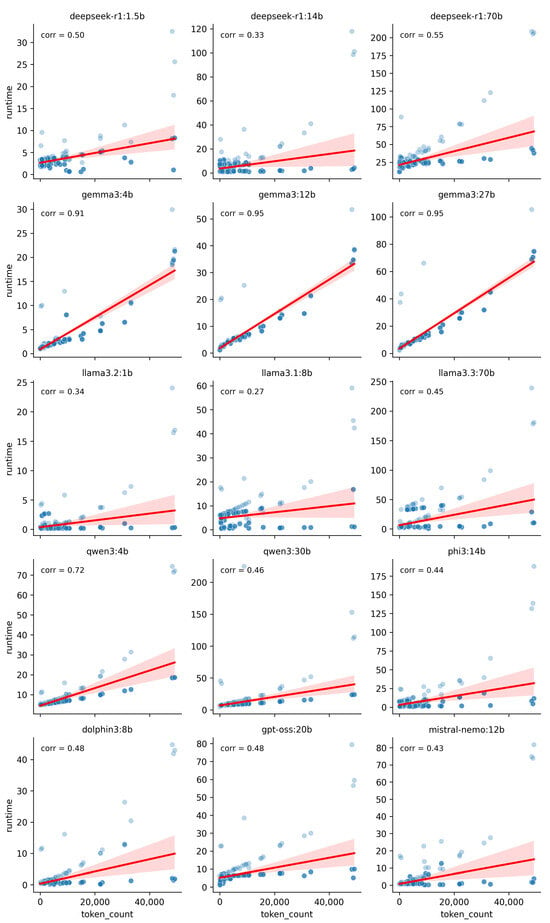
Figure 3.
Correlation between model analysis runtime and prompt length. Each dot represents the token count of one website’s HTML code and the corresponding analysis time.
The large discrepancy in the HTML token count is due to the dataset sampling scheme, which exactly aimed at including websites of all lengths. Most models show a positive correlation between token count and runtime (coefficients 0.27–0.95), but the strength of this relationship depended more on the model family than size. For example, Gemma3 and DeepSeek models had similar correlations within their families, highlighting the importance of architecture.
Another way to compare the runtime is to compute the relative runtime, which was calculated by dividing D5 runtime by D50 runtime for each model and website, then logarithmising results to handle outliers and improve interpretability. Figure 4 shows the resulting boxplots.
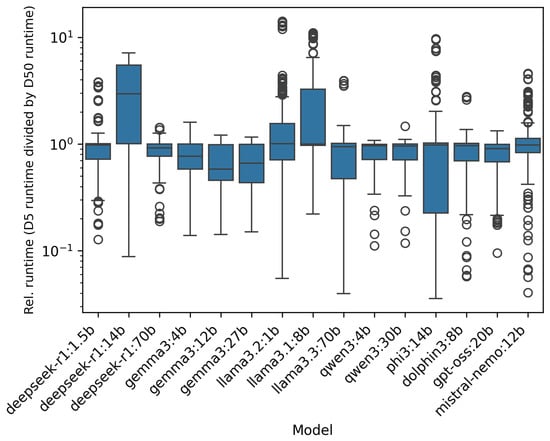
Figure 4.
Distribution of the logarithm of the relative analysis time differences between the D5 and D50 datasets for each model.
For most models, the boxes fall below , indicating smaller token counts (D5) yield lower runtimes. Notable exceptions include deepseek-r1:14b and llama3.1:8b, which had reduced runtimes for longer prompts. The smallest models (llama3.2:1b, llama3.1:8b) analyse a website in about 1 s, so small timing changes can skew results, making the D5 website analyses take longer. Deepseek-r1:14b’s behaviour and Mistral-Nemo’s many outliers cannot be explained as easily, but may be due to model structure, optimisations, or quantisation. Quantisation could explain why the other DeepSeek models performed as expected. Boxplots also highlight runtime variability: Gemma3 has low variability, while mistral-nemo and deepseek-r1:1.5b show high variance and many outliers.
The key findings of malicious website detection runtime are:
- Prompt length strongly affects runtime, with longer inputs leading to higher computational costs, for almost all models.
- Model family, rather than model size alone, is a key determinant of runtime efficiency.
- Gemma and Llama models are generally faster and more consistent than DeepSeek and Qwen models.
- Runtime variability plays a crucial role in determining model practicality, with low-variance models being more predictable.
5.1.2. Syntactic Performance
Adhering to the specified output format is vital for a model’s reliability and usability. Consistent formatting enables automatic analysis and systematic comparison. Here, models were instructed to output strictly in JSON format with three items: is_phishing, phishing_score, and reasoning.
Table 3 lists, per model, the number of analysis runs (per website) with successful JSON output. Some models, especially DeepSeek, included additional information (e.g., thought process) with the JSON object, as shown in Model Output 1 in Appendix A. As long as the JSON was in the correct format, the run was counted as successful.
Table 3.
This table shows, for each model and website (40 from the D5 dataset and 40 from the D50 dataset), how many of the five analysis runs produced valid JSON output.
All model parameters were set for deterministic results (see Section 4.2.1). If determinism held, each model would always produce either correct or incorrect output for the same website, which is represented by categories 0 or 5 in Table 3). However, some models exhibit inconsistent behaviour, producing correct JSON output only in some of the five runs (once, twice, or four times), indicating output instability. Often, the first run differed from later ones (see Model Output 2 for gemma3:4b in Appendix A).
This likely results from loading/warm-up behaviour, kernel caching, and background telemetry in the Ollama inference framework [35]. To address this, we discarded the first run and treated subsequent runs as deterministic
GPT-oss was an exception: it produced correct JSON only twice out of five for one website, likely due to our token output limit. Some models ignored the instruction and included additional explanatory text before the actual JSON output. If the token limit was reached, the output was truncated, making the JSON unparsable. We decided that models that failed to produce the required output format at least four times per website across more than half of all analysed websites will be excluded from Experiment 2.
5.1.3. Output Stability
This section examines output stability, specifically whether models consistently produce the same decisions across all runs. Each model is required to generate a JSON format output containing three items (see Section 3.2): is_phishing, phishing_score, and reasoning. When models provided the required format, we extracted these variables to check consistency. Coherent output is crucial for evaluating a model’s reliability and building trust in its decisions. There are two desirable scenarios:
- is_phishing = True, phishing_score ≥ 5, reasoning says it is phishing,
- is_phishing = False, phishing_score < 5, reasoning says it is not phishing.
Since the phishing score ranges from 0 to 10, it is unclear whether a score of five should count as phishing. In cybersecurity, it is often debatable which type of error is worse: missing a phishing attempt or falsely flagging a benign website [14,36,37]. We deem the missed phishing attempt as more costly than disrupting the user experience, which is why we treat a score of five as True.
We analyse coherence from two complementary perspectives: (i) quantitative consistency between the binary decision (is_phishing) and the certainty score (phishing_score), and (ii) qualitative coherence, examining the reasoning texts, for keywords linked to phishing or benign websites.
Quantitative Analysis
Table 4 presents the quantitative consistency analysis, highlighting the relationship between the boolean decision and phishing score.
Table 4.
The table presents phishing scores and classification decisions (Phishing Cat) assigned by the models over five analysis runs per website (200 runs per dataset). Scores that do not match the corresponding decision are highlighted in red.
Model outputs were mostly coherent; nearly all inconsistencies occurred when the decision was False, but the score was 5. The Mistral model was an exception, assigning a score of 6 to a False decision. NaN rows/columns indicate failed JSON outputs.
Notably, no model ever assigned the highest score of 10, while 0 was common. Four times, llama3.1:8b gave an erroneous score of 12 (should be ≤ 10). Models tended to assign low scores, possibly finding it easier to classify a website as benign if phishing indicators were absent. This may also result from prompt design, where models rely too heavily on the provided examples, or from similarities in website design, where phishing websites share indicators with benign websites, which can create decision uncertainty.
Overall, models behaved similarly in scoring for the respective boolean decision, as well as the amount of missing JSON outputs (NaNs). This indicates that using longer HTML code does not guarantee a different (or better) classification result.
Although there are a few exceptions: gemma3:4b gave significantly more scores <5 for the D5 dataset than the D50, and gpt-oss:20b, llama3.2:1b, and qwen3:4b had noticeably fewer NaNs for the D50 websites. Overall, the D5 dataset appears sufficient for reasonable analysis.
Most models retained their assessment for the same website between datasets, as shown in Table 5. Eight models scored 30 or more (out of 40) in column “0”, meaning that for 75% or more of the websites, the boolean result was identical in all five runs. Most models were consistent between datasets, except llama3.2:1b, which mostly produced NaNs in both cases. The second most common case is that models changed all five of their assessments, shown in column “5”. Table 3 highlights that the number of NaN classifications for the concerned models varies notably across the two datasets, suggesting that the differences were due to missing JSON output rather than model opinion. The remaining observed differences, denoted in columns “1” to “4”, reflect output consistency only after the first run.
Table 5.
Classification consistency across models for the D5 and D50 analyses. For each website, the number of differing classifications across five runs is counted. A value of 0 indicates identical results in all runs, while a value of 5 means that each run produced different results.
Qualitative Analysis of Reasoning Outputs
To complement the coherence checks, we conducted a qualitative analysis of the models’ reasoning outputs, i.e., the explanatory texts contained in the reasoning key of the JSON output. We focused on language used in the models’ reasoning text to justify decisions by scanning for predefined keywords: (i) phishing indicators–terms associated with malicious or suspicious behaviour (e.g., “phishing”, “suspicious”, “fraudulent”, “deceptive”), and (ii) legitimacy indicators–terms associated with safe or trusted websites (e.g., “legitimate”, “safe”, “no phishing indicators”, “trusted”). These keywords were derived by manually analysing model outputs during experimentation. For each model–dataset pair, we counted the total mentions of each category and reported them as phishing_score_tendency and legit_score_tendency, respectively. While this keyword-based approach is inherently high-level and depends on the defined keyword set, it provides an indication of the style and focus of the models’ explanations.
Table A2 (in Appendix A) summarises differences in how models frame their reasoning. Some models, such as gemma3:4b, use many phishing-related terms, matching their tendency to classify most sites as phishing. Others, such as mistral-nemo, return a more balanced mix of keywords associated with phishing or benign websites, aligning with a more balanced Boolean decision profile. We also observe variability across datasets: for instance, dolphin3:8b uses more language associated with phishing websites on the D5 dataset compared to the D50 dataset.
5.1.4. Consequences for the Setup of Experiment 2
The results from Experiment 1 were instrumental in determining an efficient and reliable setup for Experiment 2. We excluded the following models due to their failures to generate the required JSON result format: llama3.1:8b, llama3.2:1b, gpt-oss:20b, qwen3:4b, qwen3:30b and deepseek.r1:1.5b.
Furthermore, we observed that models are consistent after the first analysis run (Section 5.1.2). To account for this, only two runs per website will be conducted. The first run serves as initiation and will be discarded, while the second run will be used as the final decision output. To maintain reasonable runtimes analysing the larger dataset, all websites will be truncated using the D5 truncation scheme, retaining at most 5% of the original HTML code for analysis. This choice is supported by the quantitative coherence check, which showed minimal performance differences between the D5 and the D50 datasets. Finally, while the context window size could be reduced due to the smaller token number in the D5 scheme, we decided against modifying model parameters, as doing so could negatively impact comparability between the experiments.
5.2. Results Experiment 2
In this experiment, the objective is to evaluate the classification performance of the models on a larger dataset comprising 1000 websites. Performance is measured using well-established evaluation metrics, namely accuracy, precision, recall, and F1-score. Although models with excessive NaN outputs were excluded after Experiment 1, some missing predictions still occur in Experiment 2. These NaN values affect the computation of performance metrics and were therefore omitted from the metric calculations. However, the resulting reduction in sample size is minor and does not compromise the interpretability of the results. Table 6 and Table 7 show the performance results.
Table 6.
Summary of performance metrics per model based on the boolean classification decision, sorted in descending order by F1-score. Bold numbers indicate the highest value per metric.
Table 7.
Summary of performance metrics per model based on the numeric classification decision, sorted in descending order by F1-score. Bold numbers indicate the highest value per metric.
For Table 6, the boolean decision was taken as the predicted label, whereas Table 7 shows the metrics based on the numeric decision of the models. Numeric values smaller than five correspond to a decision of “not phishing”, and all values of five or larger correspond to the decision “phishing”.
The evaluation in Table 6, based on the boolean decision output, highlights the relative strengths of the different models in phishing website classification. When prioritising overall effectiveness, the F1-score and accuracy are particularly informative, as both false positives and false negatives can have serious consequences in this domain.
Llama3.3:70b emerges as the strongest overall model, achieving the highest F1-score (0.893) and accuracy (0.887). It maintains a good balance between precision (0.845) and recall (0.948), with an almost negligible proportion of NaNs (0.001), making it highly reliable for deployment. Similarly, deepseek-r1:70b achieves a strong F1-score (0.873) and accuracy (0.865), balancing precision (0.824) and recall (0.929), while maintaining consistent output formatting (NaN proportion: 0.073).
Mistral-nemo:12b also performs strongly, with an F1-score of 0.858 and accuracy of 0.849. It emphasises a balanced trade-off between precision (0.811) and recall (0.909), and a low rate of missing predictions (0.009). The best-performing models all exhibit higher recall than precision, indicating greater success in identifying actual phishing sites than in correctly identifying benign websites.
Mistral-nemo:12b, deepseek-r1:14b, gemma3:27b and gemma3:12b show solid all-round performance (F1-score 0.828–0.858, accuracy 0.804–0.865), and similar error patterns compared to the top models. While the overall performance is slightly worse than for the 70b models, this tier of models is considerably smaller, which affects deployability and analysis runtime.
At the lower end, gemma3:4b, dolphin3:8b, and phi3:14b show the weakest results, with F1-scores (0.462–0.690) and accuracies (0.562–0.729).
Overall, models such as llama3.3:70b and deepseek-r1:70b provide the most balanced and reliable performance, excelling in both F1-score and accuracy. Mistral-nemo:12b and gemma3:27b also perform strongly when maximising recall is essential, while deepseek-r1:14b offers dependable, balanced detection. Overall, model size impacts the result performance, with the largest models performing the best. However, considerably smaller models only perform marginally worse.
The results in Table 7 present a similar picture, where instead of the Boolean decision, the numeric categorisation was taken as the decision criterion. Consistent with Experiment 1, we observe that models only rarely assign conflicting boolean decisions and numeric assessments. Overall, however, measuring the model’s performance based on the phishing score results in a slightly worse performance across most performance metrics in almost all cases. A notable outlier is gemma3:27b, which now achieves only a 0.764 F1-score, down from 0.835 for the boolean decision. In conclusion, the models’ binary decisions yield better results across almost all tested models, indicating that relying solely on a binary decision can be sufficient.
Regarding dataset-related biases, gemma3.3:70b achieved an F1-score of 0.897 when performing the analysis on the D5-reshuffled dataset, indicating that there are only minor result consistency effects regarding the tag order.
In Section 2, the results of comparable approaches are summarised. Most prior studies report results using large, proprietary models, such as Gemini Pro 1.0 or GPT-4, with F1-scores reaching up to 0.99. However, due to differences in the analysis architecture and datasets, these results should be interpreted with caution, as direct comparisons are not always meaningful. Therefore, we additionally evaluated state-of-the-art proprietary large language models to assess whether the performance gap can also be observed within the same analysis framework used for the SLMs. Table 8 reports the corresponding results and confirms that these models achieve higher classification performance than the best-performing SLMs. Notably, NaN values occur in some cases when provider-specific safety mechanisms prevent the prompt from being executed, and consequently, no prediction is returned for the respective website.
Table 8.
Summary of performance metrics per proprietary model based on the boolean classification decision, sorted in descending order by F1-score.
Overall, the evidence suggests that large models tend to outperform smaller ones, which is consistent with expectations. It is, however, encouraging to see that the tested 70b models come close to 90% F1-score and accuracy, while more compact models sit around 85% for both metrics. This shows the improvement in small open-source models, which previously achieved only around 74% accuracy or were worse, for state-of-the-art models one or two years ago [17]. This suggests that smaller, more efficient models are closing the performance gap, making them increasingly viable for practical phishing detection scenarios.
Threshold Sensitivity Analysis
Although the primary evaluation relies on the models’ native Boolean classification outputs, the numeric phishing score allows for analysing threshold sensitivity. In the main experiments, the cut-off was set to 5; however, alternative thresholds may change the precision–recall trade-off. We therefore evaluated all thresholds between 0 and 10 and recomputed the performance metrics for each model.
For most models, the threshold maximising the F1-score is slightly above 5 (see Table A3 in Appendix A). However, as shown in Figure A1, the performance differences compared to the fixed cut-off of 5 are marginal. At a threshold of 10, recall collapses to 0 for several models, as no instance is assigned the maximum score.
The numeric score also enables incorporating asymmetric misclassification costs. To emphasise the higher cost of false negatives, we evaluate (i) the score with and (ii) minimisation of an empirical expected cost function: Expected cost , using an asymmetric cost matrix with . Both criteria yield similar recall-oriented operating points (see Table A3).
To assess deployment implications under realistic phishing prevalence, we additionally compute the expected Positive Predictive Value (PPV) using Bayes’ rule for . PPV decreases at very low prevalence levels despite stable True Positive Rate (TPR) and False Positive Rate (FPR), highlighting the sensitivity of rare-event detection to false positives, as shown in Table A4 in the Appendix A. Low PPV rates do not mean that language models are not fit for the task of phishing detection, but rather that user experience might suffer as benign websites are misclassified too frequently. Focusing on controlling FPR rates or using language models as a secondary instance in multi-stage detection systems might mitigate the problem.
Overall, the models achieve their best performance in operating regions with relatively high recall, which is desirable for phishing detection, where missing a phishing website is typically more harmful than incorrectly flagging a benign website. This holds for both SLMs and proprietary LLMs.
6. Discussion
The goal of this study was to evaluate how small, non-fine-tuned LLMs perform on a phishing detection task. While the detection performance of SLMs is promising, these models still lag behind proprietary large-scale models. In the following, we discuss the advantages and disadvantages of both approaches, highlighting the trade-offs related to performance, feasibility, costs, and data privacy.
6.1. Costs
One of the primary advantages of small local LLMs is their low operational cost. Running models locally eliminates recurring API fees that are typical of proprietary services, making them particularly attractive for organisations with limited budgets that aim for large-scale deployments, where models are queried almost continuously. The following hosting options are typically available:
- Proprietary API: In related literature, GPT4o and GPT4-turbo are frequently used for phishing detection. At the time of writing (September 2025), GPT4o is priced at $2.5 per million input tokens and $10 per million output tokens, while GPT4-turbo costs $10 per million input tokens and $30 per million output tokens. The newer and comparable GPT5 models, such as GPT5, GPT5.1, and GPT5.2, are priced at a similar level (as of February 2026), with $1.25 to $1.75 per million input tokens and $10 to $14 per million output tokens. The most expensive GPT5.2-pro model sits at $21 per million input tokens, and $168 per million output tokens [38]. More precisely, to obtain the results in Experiment 2, which includes two analysis runs for each of the 1000 websites, or 3.8 million tokens in total, per model, for the three proprietary models, we paid $11.26 for GPT4.1, $10.09 for GPT5.2 and $10.05 for gemini2.5-flash.Across both experiments in this study, each model processed approximately 8 million input tokens. While output token counts varied between models, using gpt-oss as an example, which belongs to the same family as GPT-4, generated roughly 1.6 million output tokens in total. Using these figures, the total cost of running the experiments for commonly used models in related work would be approximately $36 (31€) for GPT4o, or $128 (109€) for GPT4o-turbo.
- Renting GPUs: In this study, models were executed on rented GPUs via runpod, with the following rates: Nvidia A100, 1.4 EUR per GPU hour, and Nvidia H100, 2.03 EUR per GPU hour. The total runtime for Experiments 1 and 2 was slightly over 28 h, resulting in a total cost of approximately 41 EUR for the A100 setup, including disc storage fees. For the two largest 70b models, which required an H100 GPU, the total runtime was 22 h and 20 min, amounting to roughly 46 EUR, including disk storage.
- Fully local Setup: As the Nvidia A100 is no longer widely available, the latest GPU generation (H100 series) is an option, which costs between 27,000 EUR and 39,000 EUR, depending on the provider and specifications (https://www.newegg.com/p/pl?d=h100 (accessed on 11 September 2025), https://geizhals.at/nvidia-h100-nvl-900-21010-0020-000-a3356480.html (accessed on 11 September 2025)). In addition to the initial investment, electricity, cooling, and maintenance costs must be factored in, which can vary significantly by region and infrastructure.
Taking all these factors into account, the break-even point where investing in local hardware becomes more economical than relying on proprietary APIs ranges between 625 million and 3.6 billion tokens (input and output combined). This range depends on both the GPU price and the selected GPT model. With a high GPU price and a cheaper GPT version, the hardware costs only balance out after a substantial number of tokens are processed. For perspective, in this study, gpt-oss processed about 9.6 million tokens to analyse 2400 websites. At this rate, the break-even point would be reached after roughly 160,000 to 900,000 analysis runs. Considering that the APWG reported over 1 million phishing websites in Q2 2025 alone [3], running a GPU with local LLMs becomes economically viable compared to using commercial models within just a few months. However, the results in Section 5.2 show that models take several seconds to analyse a website. Therefore, (repeated) scans of hundreds of thousands of websites call for more efficient models or, more likely, parallelised analysis setups. Considering the costs for the three approaches, none of them remains economically feasible. A potential solution is to reduce the number of websites to analyse by combining classical ML approaches as preselectors and LLMs as final decision-makers.
6.2. Benefits of SLMs
The following advantages make (locally hosted) SLMs attractive for phishing detection and similar security-critical applications.
- Data Privacy, Control and Security: Running all inference on local infrastructure ensures that sensitive information such as URLs, HTML content, and user metadata remains internal and is not transmitted to external providers. This is particularly important for organisations subject to strict data protection regulations or operating in sensitive domains. In the context of phishing detection, local models allow organisations to maintain full control over their data, reducing exposure to external systems. Furthermore, keeping the analysis methods and intellectual property (IP) in-house provides a competitive advantage, preventing sensitive prompts and detection strategies from being shared with third parties. It also lowers the risk of manipulation or infiltration by adversaries.
- Customisability: Although models in this study were evaluated in their out-of-the-box state, local models can be fine-tuned for phishing detection. Organisations with relevant expertise can leverage their proprietary data to partially retrain model weights or implement a retrieval-augmented generation (RAG) system to improve performance. The current open-source LLM ecosystem offers a wide variety of models for domain-specific adaptations. Furthermore, fine-tuned models for related tasks are often shared on platforms such as Hugging Face. However, to the best of our knowledge, no fine-tuned models specifically for phishing detection are publicly available at this time.
- Independence and Availability: Local model deployment eliminates vendor lock-in, ensuring that operations are not dependent on the availability, pricing policies, or strategic decisions of external providers. Local models can also offer greater reliability, as they are not affected by cloud service outages or external network issues. In addition, they can deliver lower latency and faster response times, which is particularly beneficial for time-critical applications such as real-time phishing detection.
6.3. Challenges of SLMs
Despite these benefits, small local LLMs come with a set of limitations that must be acknowledged.
- Performance: The most evident drawback is the lower performance of small models compared to larger proprietary ones. The results achieved in this study are promising; the tested 70b models, for instance, demonstrated solid overall performance, while other models excelled in specific areas such as precision or recall. However, the best proprietary large models used in related work outperformed local models across all performance metrics. We could confirm these results by using state-of-the-art large models in the same analysis framework that was used for the SLMs. Even though the performance gap is relatively small (F1-score difference of 0.036), it still could have practical implications, leading to higher rates of false positives or false negatives. Such errors can have severe consequences, including missed threats or unnecessary disruptions.
- Customisability: Customisability is one of the key strengths of local models, but realising it is non-trivial. First, a suitable base model must be selected, which requires in-depth knowledge of available models and careful evaluation of their strengths and weaknesses. Second, high-quality, domain-specific data is needed to achieve a meaningful fine-tuning result. Finally, fine-tuning itself can be a computationally intensive process, requiring specialised hardware and expertise.
- Hardware cost: Running even relatively small models locally requires specialised hardware, and the technical expertise to set up, optimise, and maintain the infrastructure. For organisations without existing ML infrastructure, the initial hardware investment can be substantial. In short-term or exploratory projects, this upfront investment may be too high, making proprietary models or rental GPU services more cost-effective alternatives. Ultimately, the exact cost must be carefully calculated based on the organisation’s specific strategy.
- Scalability: Proprietary cloud-based solutions offer elastic scaling with demand. In contrast, local deployments are constrained by on-site hardware capacity. Handling sudden spikes in phishing detection workloads may require over-provisioning hardware or accepting degraded performance.
Both SLMs and proprietary LLMs exhibit low PPV rates when the dataset has only a low prevalence of phishing websites, which negatively affects user experience as benign websites are misclassified. Combating this challenge either involves focusing on reducing the FPR, as it is the main driver of PPV, or increasing the prevalence of phishing websites within a dataset, for instance, when pre-filtering is available.
6.4. Application Recommendation
Based on the highlighted advantages and disadvantages in Section 6, determining an optimal setup is challenging, as the decision depends heavily on organisational priorities and operational constraints. With the results, two primary paths emerge:
- (i)
- Proprietary models: for high performance: If high performance and accuracy are the primary objectives and economic considerations are less critical, proprietary models are the preferred choice. This is particularly true when the dataset size of websites to analyse is small to moderate, or if the analysis is only performed infrequently. Ease of deployment, scalability, and superior performance outweigh the recurring costs.
- (ii)
- Local LLMs: for cost efficiency and privacy: The results show that there is potential in running smaller local LLMs for phishing detection, particularly when cost, data control, and privacy are key priorities. Using local models in combination with customisation techniques could become sustainable long-term solutions. While the initial investment may be substantial, these upfront costs can be offset over time. Furthermore, having full ownership of the model enables continuous improvements through iterative fine-tuning.Among the tested local models, llama3.3:70b, deepseek-r1:70b and mistral-nemo:12b stand out as the most promising options out of the box. The two 70b models demonstrated particularly strong performance. While all three models are small enough to be fine-tuned at a reasonable computational cost, especially the Mistral model, which only consists of 12 billion parameters, it is a promising candidate. Regarding analysis runtime, Llama, Gemma, and the Mistral model are among the fastest.
Another consideration that needs to be accounted for is the type of response variable that the models should use. In Experiment 2, we observed that relying on a boolean classification decision yielded better results than relying on the numeric score. A potential reason may originate from the chosen few-shot prompt design. Models may base their score just on the provided (non-exhaustive) examples by matching them to the techniques found in the HTML code. The llama3.2:1b model at some point responded with a Python script, which basically counted the number of occurrences of the phishing techniques mentioned in the prompt. Furthermore, we observed interesting patterns regarding the model warm-up, where the first of the analysis runs differed from all subsequent runs. To ensure stable results, each website should be analysed twice, and the first result should be discarded to avoid unwanted behaviour when the model first analyses a new website. Generally, models with high runtime variability are harder to manage in production environments, as their runtime behaviour is less consistent and may lead to uncertainty in planning.
Regarding large-scale deployment, simulating low phishing website prevalence in the data indicates that using language models as a secondary step after a prefiltering stage might improve user experience compared to using them as the only classification tool.
7. Limitations
Although we carefully conducted this work, we acknowledge some limitations. A more detailed investigation into the linguistic patterns of the reasoning outputs could provide additional insights (e.g., with more advanced Natural Language Processing (NLP) methods or LLMs). In this study, we focused exclusively on HTML code and URLs as input for phishing detection. While we expect performance improvements from incorporating multimodal data (e.g., text and screenshots), a careful analysis of such approaches is left for future research. Adversarial attacks on the model or specific HTML code alterations that hinder a correct website analysis were not tested. Conducting such experiments could provide further insights into the resilience of SLMs when they are specifically targeted. Diving deeper into thresholding of the numerical value as well as considering the PPV, for both SLMs and proprietary LLMs, choosing optimal threshold values can improve detection accuracy, and low phishing website prevalence may require additional filtering steps before the final classification can be made. While our results indicate that efficient HTML code truncation retains classification performance and reduces analysis runtime, our framework allows for reproducible results, only starting with the second analysis run. These gains in stability come at the cost of doubling the analysis runtime. We hope that for future frameworks for language model-based phishing detection, reproducible model output can be achieved after the first analysis run.
8. Conclusions and Future Work
In this work, we evaluated and benchmarked 15 small, local (non-fine-tuned) LLMs for the task of website phishing detection. The tested models represent a diverse selection of frequently used architectures, ranging from 1b to 70b parameters. Over the course of two experiments, we systematically assessed analysis runtime, output coherence and classification performance. Of the 15 models, nine were deemed practical and provided accurate results on a small sample dataset. These models were then further evaluated on a larger dataset of 1000 websites.
The results show that overall classification accuracy for most models ranges from 56% to 89%, with most models achieving 80% or more. However, more substantial differences were observed in precision. For example, the gpt:oss model achieved an impressive precision of 98% in test runs, but numerous missing JSON outputs and a low recall score hinder its applicability; it was therefore excluded. Models with a more balanced F1-score, such as llama3.3:70, deepseek-r1:70b or mistral-nemo:12b, are more practical in most use cases, as they strike a balance between relatively high accuracy and moderate error rates.
A key observation is that even some mid-sized models in the 10b–20b parameter range achieve F1-scores comparable to those of previous generations of 70b models. While the current-generation 70b models can outperform proprietary models such as GPT3.5. This reflects a promising trend toward smaller, more efficient models becoming increasingly viable for phishing detection. Tracking future developments of these models will be particularly interesting.
While the out-of-the-box local models tested in this work do not fully match the performance of state-of-the-art large proprietary LLMs, they offer several advantages, including greater data privacy, customisation potential, and operational independence. Regarding deployment cost, SLMs becomes a viable option when a heavy workload over an extended period of time is expected, as then the upfront cost of the hardware levels out with the API cost of proprietary alternatives.
While the results offer valuable insights, several opportunities for future research remain. First, customisation is a key advantage of open-source models. Future work could focus on fine-tuning these models or integrating RAG techniques to improve performance. Second, the dataset used in this work includes additional information, such as website screenshots and other website components, which could be utilised for (multimodal) phishing detection. Another interesting research avenue is a deeper investigation into HTML truncation, especially a structured analysis of HTML tag importance and their order. A key point regarding larger-scale deployment is also to assess the resilience of SLMs towards adversary attacks like evasion tactics contained in the website’s structure or through attacks targeting the language model directly. Finally, integrating LLMs into a larger framework for phishing detection, combining multiple tools and analysis stages, could further improve the results.
Author Contributions
Conceptualization, G.G. and A.E.; methodology, G.G. and A.E.; software, G.G.; validation, G.G., P.K., S.R. and A.E.; formal analysis, G.G. and A.E.; investigation, G.G.; resources, G.G. and A.E.; data curation, G.G.; writing—original draft preparation, G.G. and A.E.; writing—review and editing, G.G., P.K., S.R. and A.E.; visualisation, G.G.; supervision, A.E.; project administration, A.E.; funding acquisition, A.E. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Austrian Research Promotion Agency (FFG) under the “Digitale Technologien 2023” programme (FFG Project No. FO999915293–LLM4CTI). SBA Research (SBA-K1 NGC) is a COMET Center within the COMET—Competence Centers for Excellent Technologies Programme and funded by BMIMI, BMWET, and the federal state of Vienna. The COMET Programme is managed by FFG.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data openly available through in a repository as shown in our corresponding repository at https://github.com/sbaresearch/benchmarking-SLMs, (accessed on 2 March 2026).
Acknowledgments
We also thank Johannes Kosche for working on the infrastructure and assisting with early experiments. We used Grammarly to check the manuscript for correct spelling and grammar, typographical errors, and clarity. All scientific content, interpretations, and conclusions reflect the authors’ work and judgment. We thank the University of Vienna for providing Open Access funding.
Conflicts of Interest
Author Georg Goldenits was employed by the company SBA Research gGmbH. Author Sebastian Raubitzek was employed by the company SBA Research gGmbH. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Appendix A. Additional Materials
Appendix A.1. Prompt Template
Prompt Template 1 shows the complete, non-truncated prompt template used in this work, which includes the detailed list of the few-shot examples provided to the model.
Prompt:
You are a cybersecurity expert analysing websites for phishing attempts. Your task is to examine the provided HTML code and the original website URL to determine if the website is likely a phishing site.
**Important:** The HTML may be truncated to reduce costs, so CSS styles and JavaScript code may be missing. Focus on the HTML structure, text content, URLs, and the original URL.
Original URL: ’{original_url}’
HTML: ’{html_text}’
Original HTML character count: ’{original_character_count}’
When assessing the likelihood of phishing, consider both your general knowledge of phishing techniques and the evidence you see in the data - focus on HTML structure, content, and domain/URL consistency.
Below are common examples of phishing indicators you may find useful, but you are not limited to them:
1. **Suspicious URLs/domains**—Check href attributes, form actions, image sources for:
- -
- -
2. **Form analysis**—Login/input forms with:
- -
- -
- -
3. **Content and language**—Text containing:
- -
- -
- -
4. **HTML structure issues**:
- -
- -
- -
5. **Link analysis**—Check all href attributes for:
- -
- -
- -
6. **Brand impersonation**—Look for:
- -
- -
- -
7. **Missing legitimacy markers**:
- -
- -
- -
**Note:** Since CSS/JS may be truncated, focus on HTML tags, text content, and URL analysis rather than visual styling or dynamic behaviour.
*Scoring guide:**
- -
- -
- -
- -
- -
**Required output format (JSON only):**
{
phishing_score: int [0–10],
is_phishing: boolean [true/false],
reasoning: string [Brief explanation of your decision based on specific indicators found]
}
**Output Constraints:**
Do only output the JSON-formatted output and nothing else.
Appendix A.2. Runtime Analysis
Table A1 is referenced in Section 5.1.1, where only the fastest and slowest models are discussed.
Table A1.
Average analysis runtime (in seconds) per model and website run for the D5 and the D50 dataset. The table is sorted by dataset and in ascending order according to runtime.
Table A1.
Average analysis runtime (in seconds) per model and website run for the D5 and the D50 dataset. The table is sorted by dataset and in ascending order according to runtime.
| Dataset | Model | Runtime |
|---|---|---|
| d5 | llama3.2:1b | 0.550 |
| d5 | dolphin3:8b | 0.892 |
| d5 | mistral-nemo:12b | 1.793 |
| d5 | gemma3:4b | 1.966 |
| d5 | deepseek-r1:1.5b | 2.916 |
| d5 | gemma3:12b | 3.545 |
| d5 | phi3:14b | 4.515 |
| d5 | qwen3:4b | 5.725 |
| d5 | llama3.1:8b | 5.729 |
| d5 | gpt-oss:20b | 5.784 |
| d5 | deepseek-r1:14b | 6.386 |
| d5 | gemma3:27b | 7.077 |
| d5 | llama3.3:70b | 7.731 |
| d5 | qwen3:30b | 9.375 |
| d5 | deepseek-r1:70b | 23.318 |
| d50 | llama3.2:1b | 0.876 |
| d50 | dolphin3:8b | 2.162 |
| d50 | mistral-nemo:12b | 3.358 |
| d50 | deepseek-r1:1.5b | 3.752 |
| d50 | gemma3:4b | 3.840 |
| d50 | deepseek-r1:14b | 4.618 |
| d50 | llama3.1:8b | 5.353 |
| d50 | gemma3:12b | 7.846 |
| d50 | gpt-oss:20b | 7.946 |
| d50 | qwen3:4b | 8.601 |
| d50 | phi3:14b | 8.913 |
| d50 | qwen3:30b | 12.709 |
| d50 | gemma3:27b | 15.658 |
| d50 | llama3.3:70b | 15.748 |
| d50 | deepseek-r1:70b | 30.775 |
Appendix A.3. Qualitative Analysis
The qualitative reasoning output analysis in Table A2 is part of Section 5.1.3 and contains the complete information of the phishing and benign wording tendencies per model and dataset.
Table A2.
Overview of the qualitative output analysis per model and dataset, summarised in the Phishing Score and Benign Score tendencies.
Table A2.
Overview of the qualitative output analysis per model and dataset, summarised in the Phishing Score and Benign Score tendencies.
| Model | Dataset | Phishing Score Tendency | Benign Score Tendency |
|---|---|---|---|
| deepseek-r1:1.5b | d5 | 336 | 86 |
| deepseek-r1:14b | d5 | 322 | 109 |
| deepseek-r1:70b | d5 | 333 | 127 |
| dolphin3:8b | d5 | 257 | 125 |
| gemma3:12b | d5 | 485 | 212 |
| gemma3:27b | d5 | 483 | 186 |
| gemma3:4b | d5 | 518 | 123 |
| gpt-oss:20b | d5 | 194 | 95 |
| llama3.1:8b | d5 | 116 | 19 |
| llama3.2:1b | d5 | 10 | 0 |
| llama3.3:70b | d5 | 306 | 151 |
| mistral-nemo:latest | d5 | 219 | 166 |
| phi3:medium | d5 | 304 | 117 |
| qwen3:30b | d5 | 14 | 2 |
| qwen3:4b | d5 | 101 | 106 |
| deepseek-r1:1.5b | d50 | 207 | 31 |
| deepseek-r1:14b | d50 | 301 | 166 |
| deepseek-r1:70b | d50 | 318 | 176 |
| dolphin3:8b | d50 | 197 | 83 |
| gemma3:12b | d50 | 475 | 190 |
| gemma3:27b | d50 | 425 | 195 |
| gemma3:4b | d50 | 470 | 115 |
| gpt-oss:20b | d50 | 107 | 63 |
| llama3.1:8b | d50 | 170 | 19 |
| llama3.2:1b | d50 | 18 | 0 |
| llama3.3:70b | d50 | 246 | 113 |
| mistral-nemo:latest | d50 | 156 | 112 |
| phi3:medium | d50 | 235 | 57 |
| qwen3:30b | d50 | 0 | 0 |
| qwen3:4b | d50 | 164 | 239 |
Appendix A.4. Model Output Example
Model Output 1 shows the typical result of the DeepSeek models, highlighting the combination of the thinking process and the required JSON output. Although other models used in this work are also reasoning models, only the DeepSeek models provide a thinking process in this way.
Result Samples:
“\n\nOkay, so I need to analyze this website’s HTML code for phishing attempts. The user provided an HTML snippet that seems very minimal—just a title link. But since CSS and JS might be missing, I have to focus on the structure and content.\n\nFirst, let me look at the HTML structure. It starts with <html>, then <head> which includes meta tags, charset, and a title. The body is empty except for some empty <body/body/html>. So, no actual content in the page beyond the title link.\n\nNow, looking at the phishing indicators:\n\n1. **Suspicious URLs/Domain**: The HTML doesn’t have any links or href attributes because it’s just an empty body. But wait, maybe there are other elements? No, the structure is very minimal—probably no form fields or images either since they’re not present.\n\n2. **Form Analysis**: There are no login inputs or forms in this snippet. So, that’s probably not a concern here.\n\n3. **Content and Language**: The only text is the title: \“Amazon\”. That doesn’t seem like it contains any phishing indicators. It’s just a link to an account sign-in page for Amazon. I don’t see any urgency, threats, or reward baits here.\n\n4. **HTML Structure Issues**: There are no errors in the HTML structure because there are no tags beyond what’s already present. So, that doesn’t add anything.\n\n5. **Link Analysis**: The only link is to \“Amazon\”, which is a legitimate account sign-in page for Amazon. It doesn’t point to any other domain or have any suspicious links.\n\n6. **Brand impersonation**: The text has \“Amazon\” in the title, but it’s just a regular brand name. There are no references to other companies or services on this page. So, that’s not a phishing indicator either.\n\n7. **Missing Legitimacy Markers**: The HTML doesn’t have any meta tags like title or description. It does have a link tag, which is fine because it’s pointing to a legitimate domain. There are no proper company details in the footer or any privacy policy links. So, that’s not an issue here.\n\nPutting this all together: The website has very minimal HTML structure and content. It doesn’t contain any phishing indicators like suspicious URLs, form fields, incorrect domains, or references to other companies. The only link is to a legitimate account sign-in page for Amazon, which isn’t phishing material.\n\nTherefore, based on the analysis, there are no clear signs of phishing attempts here. So, the phishing score should be 0–2, indicating very unlikely. \n</think>\n\n“‘json\n{\n \“phishing_score\”: 0,\n \“is_phishing\”: false,\n \“reasoning\”: \“The website’s HTML code is minimal and lacks any links or content that would indicate phishing attempts. The only link points to a legitimate Amazon account sign-in page, which does not contain phishing indicators.\”\n}\n""’
Model Output 2 illustrates a common occurrence, where the model’s first output differs from all subsequent runs, which are then identical.
Result Samples:
Run 1: ““json\n{\n“phishing_score”: 3,\n“is_phishing”: false,\n“reasoning”: “The HTML code is minimal and lacks significant content. It contains basic HTML tags for a webpage, but there are no suspicious URLs, forms, or text content that would immediately indicate a phishing attempt. The lack of content makes it difficult to assess the legitimacy of the site.“\n}\n””
Run 2: ““‘json\n{\n\“phishing_score\”: 3,\n\“is_phishing\”: false,\n\“reasoning\”: \“The HTML code is minimal and lacks significant content. It contains basic HTML tags for a webpage, but no suspicious URLs, forms, or text content are present. It’s difficult to assess the legitimacy of the site without more information. The score reflects the lack of indicators, but it’s not a definitive determination of legitimacy.\”\n}\n”””
Run 3: ““‘json\n{\n\“phishing_score\”: 3,\n\“is_phishing\”: false,\n\“reasoning\”: \“The HTML code is minimal and lacks significant content. It contains basic HTML tags for a webpage, but no suspicious URLs, forms, or text content are present. It’s difficult to assess the legitimacy of the site without more information. The score reflects the lack of indicators, but it’s not a definitive determination of legitimacy.\”\n}\n””’
Run 4: ““‘json\n{\n\“phishing_score\”: 3,\n\“is_phishing\”: false,\n\“reasoning\": \“The HTML code is minimal and lacks significant content. It contains basic HTML tags for a webpage, but no suspicious URLs, forms, or text content are present. It’s difficult to assess the legitimacy of the site without more information. The score reflects the lack of indicators, but it’s not a definitive determination of legitimacy.\"\n}\n””’
Run 5: ““‘json\n{\n\“phishing_score\": 3,\n\“is_phishing\": false,\n\“reasoning\": \“The HTML code is minimal and lacks significant content. It contains basic HTML tags for a webpage, but no suspicious URLs, forms, or text content are present. It’s difficult to assess the legitimacy of the site without more information. The score reflects the lack of indicators, but it’s not a definitive determination of legitimacy.\"\n}\n””’
Table A3.
Optimal numerical cut-off thresholds according to F1, F and expected cost metrics per model.
Table A3.
Optimal numerical cut-off thresholds according to F1, F and expected cost metrics per model.
| Model | F1-Score | F1-Threshold | F2-Score | F2-Treshold | Exp. Cost | Exp. Cost Threshold |
|---|---|---|---|---|---|---|
| llama3.3:70b | 0.901 | 8 | 0.925 | 5 | 349 | 6 |
| deepseek-r1:70b | 0.871 | 6 | 0.910 | 3 | 267 | 2 |
| mistral-nemo:12b | 0.854 | 7 | 0.902 | 5 | 377 | 3 |
| deepseek-r1:14b | 0.842 | 5 | 0.888 | 3 | 337 | 1 |
| gemma3:27b | 0.850 | 7 | 0.920 | 6 | 277 | 6 |
| gemma3:12b | 0.832 | 6 | 0.897 | 5 | 385 | 4 |
| gemma3:4b | 0.694 | 7 | 0.840 | 4 | 498 | 3 |
| dolphin3:8b | 0.791 | 3 | 0.863 | 2 | 450 | 2 |
| phi3:14b | 0.664 | 0 | 0.832 | 0 | 496 | 0 |
| gpt-5.2 | 0.972 | 4 | 0.987 | 3 | 39 | 3 |
| gpt-4.1 | 0.910 | 4 | 0.931 | 3 | 280 | 2 |
| gemini-2.5-flash | 0.920 | 7 | 0.952 | 3 | 164 | 3 |

Figure A1.
F1-score, precision and recall for all possible numerical decision cut-off values.
Figure A1.
F1-score, precision and recall for all possible numerical decision cut-off values.

Table A4.
PPV rates for each model at three phishing website prevalence levels . The table is sorted according to the maximum PPV rate per model. PPV values are listed in the order .
Table A4.
PPV rates for each model at three phishing website prevalence levels . The table is sorted according to the maximum PPV rate per model. PPV values are listed in the order .
| Model | TPR | FPR | PPV list |
|---|---|---|---|
| gpt-4.1-url | 0.910 | 0.066 | [0.420, 0.122, 0.014] |
| dolphin3:8b | 0.506 | 0.048 | [0.357, 0.096, 0.010] |
| gpt-5.2-url | 0.960 | 0.162 | [0.238, 0.057, 0.006] |
| gemini-2.5-flash-url | 0.978 | 0.175 | [0.227, 0.053, 0.006] |
| llama3.3:70b | 0.948 | 0.174 | [0.223, 0.052, 0.005] |
| deepseek-r1:70b | 0.929 | 0.199 | [0.197, 0.045, 0.005] |
| deepseek-r1:14b | 0.877 | 0.189 | [0.196, 0.045, 0.005] |
| mistral-nemo:12b | 0.909 | 0.213 | [0.184, 0.041, 0.004] |
| gemma3:27b | 0.964 | 0.347 | [0.128, 0.027, 0.003] |
| gemma3:12b | 0.951 | 0.340 | [0.128, 0.027, 0.003] |
| phi3:medium | 0.345 | 0.145 | [0.111, 0.023, 0.002] |
| gemma3:4b | 0.980 | 0.853 | [0.057, 0.011, 0.001] |
References
- Federal Bureau of Investigation, Internet Crime Complaint Center (IC3). Internet Crime Report 2024; Federal Bureau of Investigation: Washington, DC, USA, 2025. Available online: https://www.ic3.gov/AnnualReport/Reports/2024_IC3Report.pdf (accessed on 25 September 2025).
- Europol. Internet Organised Crime Threat Assessment (IOCTA) 2024; European Union Agency for Law Enforcement Cooperation: Luxembourg, 2024. [Google Scholar] [CrossRef]
- Anti-Phishing Working Group (APWG). Phishing Activity Trends Report: 2nd Quarter 2025; APWG: Lexington, MA, USA, 2025. Available online: https://docs.apwg.org/reports/apwg_trends_report_q2_2025.pdf (accessed on 25 September 2025).
- Chiew, K.L.; Yong, K.S.C.; Tan, C.L. A survey of phishing attacks: Their types, vectors and technical approaches. Expert Syst. Appl. 2018, 106, 1–20. [Google Scholar] [CrossRef]
- Mahboubi, A.; Luong, K.; Aboutorab, H.; Bui, H.T.; Jarrad, G.; Bahutair, M.; Camtepe, S.; Pogrebna, G.; Ahmed, E.; Barry, B.; et al. Evolving techniques in cyber threat hunting: A systematic review. J. Netw. Comput. Appl. 2024, 232, 104004. [Google Scholar] [CrossRef]
- Yang, R.; Zheng, K.; Wu, B.; Wu, C.; Wang, X. Phishing Website Detection Based on Deep Convolutional Neural Network and Random Forest Ensemble Learning. Sensors 2021, 21, 8281. [Google Scholar] [CrossRef]
- Bahaghighat, M.; Ghasemi, M.; Ozen, F. A high-accuracy phishing website detection method based on machine learning. J. Inf. Secur. Appl. 2023, 77, 103553. [Google Scholar] [CrossRef]
- Yerima, S.Y.; Alzaylaee, M.K. High Accuracy Phishing Detection Based on Convolutional Neural Networks. In Proceedings of the 2020 3rd International Conference on Computer Applications & Information Security (ICCAIS); IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Abdelnabi, S.; Krombholz, K.; Fritz, M. VisualPhishNet: Zero-Day Phishing Website Detection by Visual Similarity. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security (CCS ’20); Association for Computing Machinery: New York, NY, USA, 2020; pp. 1681–1698. [Google Scholar] [CrossRef]
- Lin, Y.; Liu, R.; Divakaran, D.M.; Ng, J.Y.; Chan, Q.Z.; Lu, Y.; Si, Y.; Zhang, F.; Dong, J.S. Phishpedia: A Hybrid Deep Learning Based Approach to Visually Identify Phishing Webpages. In 30th USENIX Security Symposium (USENIX Security 21); USENIX Association: Berkeley, CA, USA, 2021; pp. 3793–3810. Available online: https://www.usenix.org/conference/usenixsecurity21/presentation/lin (accessed on 25 September 2025).
- Panum, T.K.; Hageman, K.; Hansen, R.R.; Pedersen, J.M. Towards Adversarial Phishing Detection. In Proceedings of the 13th USENIX Workshop on Cyber Security Experimentation and Test (CSET ’20); USENIX Association: Berkeley, CA, USA, 2020; Available online: https://www.usenix.org/conference/cset20/presentation/panum (accessed on 25 September 2025).
- Nahapetyan, A.; Khare, K.; Schwarz, K.; Reaves, B.; Kapravelos, A. Characterizing Phishing Pages by JavaScript Capabilities. arXiv 2025, arXiv:2509.13186. [Google Scholar] [CrossRef]
- Abuadbba, A.; Wang, S.; Almashor, M.; Ahmed, M.E.; Gaire, R.; Camtepe, S.; Nepal, S. Towards Web Phishing Detection Limitations and Mitigation. arXiv 2022, arXiv:2204.00985. [Google Scholar] [CrossRef]
- Kavya, S.; Sumathi, D. Staying ahead of phishers: A review of recent advances and emerging methodologies in phishing detection. Artif. Intell. Rev. 2024, 58, 50. [Google Scholar] [CrossRef]
- Yao, Y.; Duan, J.; Xu, K.; Cai, Y.; Sun, Z.; Zhang, Y. A survey on large language model (LLM) security and privacy: The Good, The Bad, and The Ugly. High-Confid. Comput. 2024, 4, 100211. [Google Scholar] [CrossRef]
- Liu, R.; Lin, Y.; Teoh, X.; Liu, G.; Huang, Z.; Dong, J.S. Less Defined Knowledge and More True Alarms: Reference-based Phishing Detection without a Pre-defined Reference List. In 33rd USENIX Security Symposium (USENIX Security 24); USENIX Association: Berkeley, CA, USA, 2024; pp. 523–540. Available online: https://www.usenix.org/conference/usenixsecurity24/presentation/liu-ruofan (accessed on 25 September 2025).
- Koide, T.; Nakano, H.; Chiba, D. ChatPhishDetector: Detecting Phishing Sites Using Large Language Models. IEEE Access 2024, 12, 154381–154400. [Google Scholar] [CrossRef]
- Barberá, I. AI Privacy Risks & Mitigations—Large Language Models (LLMs); European Data Protection Board: Brussels, Belgium, 2025; Available online: https://www.edpb.europa.eu/system/files/2025-04/ai-privacy-risks-and-mitigations-in-llms.pdf (accessed on 25 September 2025).
- Irugalbandara, C.; Mahendra, A.; Daynauth, R.; Arachchige, T.K.; Dantanarayana, J.L.; Flautner, K.; Tang, L.; Kang, Y.; Mars, J. Scaling Down to Scale Up: A Cost-Benefit Analysis of Replacing OpenAI’s LLM with Open Source SLMs in Production. In 2024 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS); IEEE: Piscataway, NJ, USA, 2024; pp. 280–291. [Google Scholar] [CrossRef]
- Putra, I.K.A.A. Phishing Website Dataset, version v1; Zenodo: Geneva, Switzerland, 2023. [Google Scholar] [CrossRef]
- Lee, J.; Lim, P.; Hooi, B.; Divakaran, D.M. Multimodal Large Language Models for Phishing Webpage Detection and Identification. In 2024 APWG Symposium on Electronic Crime Research (eCrime), Boston, MA, USA, 24–26 September 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–13. Available online: https://ieeexplore.ieee.org/document/10896256 (accessed on 25 September 2025).
- Li, W.; Manickam, S.; Chong, Y.-W.; Karuppayah, S. PhishDebate: An LLM-Based Multi-Agent Framework for Phishing Website Detection. arXiv 2025, arXiv:2506.15656. [Google Scholar] [CrossRef]
- Trad, F.; Chehab, A. Prompt Engineering or Fine-Tuning? A Case Study on Phishing Detection with Large Language Models. Mach. Learn. Knowl. Extr. 2024, 6, 367–384. [Google Scholar] [CrossRef]
- Kulkarni, A.; Balachandran, V.; Divakaran, D.M.; Das, T. From ML to LLM: Evaluating the Robustness of Phishing Web Page Detection Models against Adversarial Attacks. Digit. Threat. Res. Pract. 2025, 6, 10. [Google Scholar] [CrossRef]
- Li, W.; Manickam, S.; Chong, Y.-W.; Leng, W.; Nanda, P. A state-of-the-art review on phishing website detection techniques. IEEE Access 2024, 12, 187976–188012. [Google Scholar] [CrossRef]
- Vulfin, A.; Sulavko, A.; Vasiliev, V.; Minko, A.; Kirillova, A.; Samotuga, A. A multimodal phishing website detection system using explainable artificial intelligence technologies. Mach. Learn. Knowl. Extr. 2026, 8, 11. [Google Scholar] [CrossRef]
- Nakano, H.; Koide, T.; Chiba, D. PhishParrot: LLM-driven adaptive crawling to unveil cloaked phishing sites. arXiv 2025, arXiv:2508.02035. [Google Scholar] [CrossRef]
- Hannousse, A.; Yahiouche, S. Web Page Phishing Detection, version v3; Mendeley Data; Elsevier: Amsterdam, The Netherlands, 2021. [Google Scholar] [CrossRef]
- Aljofey, A.; Bello, S.A.; Lu, J.; Xu, C. Comprehensive phishing detection: A multi-channel approach with variants TCN fusion leveraging URL and HTML features. J. Netw. Comput. Appl. 2025, 238, 104170. [Google Scholar] [CrossRef]
- Google Developers. Introduction to Large Language Models. 2025. Available online: https://developers.google.com/machine-learning/resources/intro-llms (accessed on 25 September 2025).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems 30 (NIPS 2017); Curran Associates, Inc.: Long Beach, CA, USA, 2017; pp. 5998–6008. Available online: https://papers.neurips.cc/paper/7181-attention-is-all-you-need.pdf (accessed on 25 September 2025).
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-Attention with Linear Complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar] [CrossRef]
- Keles, F.D.; Wijewardena, P.M.; Hegde, C. On The Computational Complexity of Self-Attention. In Proceedings of the 34th International Conference on Algorithmic Learning Theory; PMLR: New York, NY, USA, 2023; pp. 597–619. Available online: https://proceedings.mlr.press/v201/duman-keles23a.html (accessed on 25 September 2025).
- Fu, Y. Challenges in Deploying Long-Context Transformers: A Theoretical Peak Performance Analysis. arXiv 2024, arXiv:2405.08944. [Google Scholar] [CrossRef]
- Ratul, I.J.; Zhou, Y.; Yang, K. Accelerating Deep Learning Inference: A Comparative Analysis of Modern Acceleration Frameworks. Electronics 2025, 14, 2977. [Google Scholar] [CrossRef]
- Dalvi, S.; Gressel, G.; Achuthan, K. Tuning the False Positive Rate/False Negative Rate with Phishing Detection Models. Int. J. Eng. Adv. Technol. 2019, 9, 7–13. [Google Scholar] [CrossRef]
- Bold, R.; Al-Khateeb, H.; Ersotelos, N. Reducing False Negatives in Ransomware Detection: A Critical Evaluation of Machine Learning Algorithms. Appl. Sci. 2022, 12, 12941. [Google Scholar] [CrossRef]
- OpenAI. OpenAI API Pricing. 2025. Available online: https://platform.openai.com/docs/pricing (accessed on 25 September 2025).




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.