Abstract
The rapid development of unmanned aerial vehicles (UAVs) and deep learning has accelerated the application of semantic segmentation in precision agriculture (SSPA). A key driver of this progress lies in multimodal fusion, which leverages complementary structural, spectral, and physiological information to enhance the representation of complex agricultural scenes. Despite advancements, the efficacy of multimodal fusion in SSPA is limited by modality heterogeneity and the difficulty of simultaneously retaining fine details and capturing global context. To address these challenges, we propose AgriFusion, a dual-encoder framework based on convolutional and transformer architectures for SSPA tasks. Specifically, convolutional and transformer encoders are first used to extract crop-related local structural details and global contextual features from multimodal inputs. Then, an attention-based fusion module adaptively integrates these complementary features in a modality-aware manner. Finally, a MLP-based decoder aggregates multi-scale representations to generate accurate segmentation results efficiently. Experiments conducted on the Agriculture-Vision dataset demonstrate that AgriFusion achieves a mean Intersection over Union (mIoU) of 49.31%, Pixel Accuracy (PA) of 81.72%, and F1 score of 67.85%, outperforming competitive baselines including SegFormer, DeepLab, and AAFormer. Ablation studies further reveal that unimodal or shallow fusion strategies suffer from limited discriminative capacity, whereas AgriFusion adaptively integrates complementary multimodal features and balances fine-grained local detail with global contextual information, yielding consistent improvements in identifying planting anomalies and crop stresses. These findings validate our central claims that modality-aware spectral fusion and balanced multi-scale representation are critical to advancing agricultural semantic segmentation, and establish AgriFusion as a principled framework for enhancing remote sensing-based monitoring with practical implications for sustainable crop management and precision farming.
1. Introduction
In modern precision agriculture, timely and accurate monitoring of farmland is crucial for ensuring food security and enhancing agricultural sustainability [1]. In recent years, deep learning has become the dominant paradigm for analyzing agricultural remote sensing imagery, particularly for tasks such as semantic segmentation of crops and field structures. However, most existing studies rely primarily on RGB imagery, which, although widely accessible and low cost, is inherently limited in capturing crop physiological and spectral information beyond the visible range. In contrast, near-infrared (NIR) and other multispectral bands provide complementary cues related to vegetation health and structural patterns, enabling deep learning models to extract richer and more discriminative features [2]. Nevertheless, differences between modalities, as well as the design of effective fusion strategies, remain significant challenges; how to align heterogeneous feature spaces, exploit complementary information, and mitigate redundancy or noise continues to be a bottleneck restricting the full potential of multi-modal fusion in agricultural semantic segmentation. In this study, we focus on the fusion of two complementary modalities, RGB and NIR imagery. RGB provides structural and textural information such as canopy geometry and field patterns, while NIR captures spectral and physiological signals related to vegetation vigor and stress. Their combination enriches the representation of agricultural scenes and enhances the detection of anomalies that are difficult to identify with a single modality.
Within deep learning-based approaches for remote sensing semantic segmentation, two dominant paradigms have emerged: convolutional neural networks (CNNs) and Transformers. CNN-based methods remain the backbone of current research due to their strong capability in capturing local textures and hierarchical spatial features. A number of remote sensing-specific CNN variants have been proposed to adapt to the challenges of high-resolution aerial imagery. For example, Hi-ResNet enhances boundary and detail extraction through multi-branch aggregation and edge-aware loss [3], while IARU-Net integrates Inception modules and attention gates into a U-shaped CNN to better capture multi-scale context [4]. Further refinements include adaptations of DeepLab architectures that reduce model parameters while maintaining accuracy in land-cover segmentation [5], as well as HRNet-based approaches that enhance building and land-cover extraction via high-resolution multi-branch aggregation [6] or dynamic feature selection to mitigate class imbalance and scale variation [7]. Despite these advances, CNN-based methods are inherently limited by their restricted receptive field, which hampers their ability to capture long-range dependencies and effectively model cross-modal interactions, thereby motivating exploration of alternative architectures such as Transformers.
Transformer-based models have recently shown strong capabilities in capturing global context and aggregating multi-scale information for remote sensing semantic segmentation. For instance, UNetFormer combines a CNN encoder with a Transformer decoder to efficiently capture global dependencies for real-time aerial scene segmentation [8,9], while AMTNet enhances multi-scale attention to integrate long-range context with local structural cues [10]. At the application level, Swin-UNet [11] combined with UPerNet [12] improves coastal vegetation and mangrove delineation in complex shoreline environments [13], and hybrid diffusion with SegFormer [14] strengthens land-use segmentation by producing sharper boundaries and stronger priors [15]. In the agricultural domain, HSI-TransUNet demonstrates the benefits of coupling spatial and spectral modeling to improve crop plot extraction from UAV-based hyperspectral imagery [16]. A recent survey further highlights how Transformers are reshaping optical, SAR, and hyperspectral image interpretation, while also noting practical challenges related to training data and computational costs [17].
Despite the progress of both CNN- and Transformer-based models, most existing approaches still rely on single-modality inputs, typically RGB imagery. However, RGB alone is inherently limited in capturing the full range of information critical for agricultural monitoring, particularly missing spectral cues beyond the visible range. This limitation has motivated increasing interest in spectral–spatial fusion, where complementary data such as NIR, multispectral, or hyperspectral imagery are integrated with RGB to enrich feature representation. Early fusion strategies often relied on simply stacking multi-band images as multi-channel inputs for convolutional networks [18,19], yet this naive approach is insufficient for leveraging the distinctive characteristics of spectral and spatial domains. More recent research has therefore explored mid- and late-fusion schemes, which assign dedicated modality-specific branches and perform fusion at the feature or decision level, generally achieving more robust results [20]. For instance, dual-branch RGB–NIR networks with cross-modal feature fusion, such as CMFNet, significantly improve weed delineation compared to RGB-only or simple concatenation [21]. Attention-based designs like YOLACTFusion further demonstrate that hierarchical attention mechanisms can effectively merge RGB spatial detail with NIR spectral cues, boosting segmentation of small structures in agricultural scenes [22]. Empirical evidence also supports the benefit of spectral–spatial fusion; combining visible and multispectral UAV data yields consistent accuracy gains of 1–4 percentage points in crop classification [23], while crop classification and field delineation using RGB and NIR fusion [24] and field-scale phenotyping frameworks integrating multimodal UAV imagery [25] further demonstrate the effectiveness of this approach across different agricultural scenarios. Recent hybrid CNN–Transformer architectures extend this direction by coupling modality-specific encoders with dynamic or attention-based fusion modules that adaptively weight RGB, NIR, and red-edge information, showing promising results in crop and weed segmentation [26].
Nevertheless, despite the progress of spectral–spatial fusion, most existing methods still suffer from inadequate integration of heterogeneous features and limited ability to aggregate multi-scale information. Simple concatenation or late-fusion designs often fail to fully exploit the complementary properties of RGB and NIR modalities, while attention-based fusion modules are typically applied only at a single scale, overlooking the hierarchical nature of feature representations. These limitations restrict the discriminative power of current models in complex agricultural environments, where fine-grained boundaries and subtle spectral–spatial variations are critical. To simultaneously address the challenges of insufficient heterogeneous feature fusion, this paper proposes a novel Asymmetric Dual-Encoder Network, named AgriFusion. Specifically, we design an asymmetric dual-encoder architecture where a Transformer model (Mix Transformer (MiT)) captures the global context from RGB images while a CNN model (ResNet) extracts features from single-channel NIR images, enabling targeted modeling of heterogeneous data. In addition, a multi-level Attention Fusion Feature (AFF) module with local and global attention mechanisms is introduced to selectively and synergistically combine complementary features from the CNN and Transformer backbones. Furthermore, a MLP-based decoder is employed to efficiently aggregate the fused multi-scale features and generate fine-grained segmentation maps while reducing computational complexity. By organically integrating these three innovations, AgriFusion produces more discriminative feature representations, leading to more accurate and robust semantic segmentation in complex agricultural environments.
2. Method
2.1. Dataset
To rigorously evaluate the effectiveness of the proposed AgriFusion model, we employed the Agriculture-Vision dataset [27], which has become a widely used benchmark for semantic segmentation in agricultural remote sensing. This dataset was curated to accelerate methodological advances in precision agriculture by providing a standardized and challenging evaluation platform. It consists of 94,986 high-quality aerial images collected from 3432 agricultural fields across the United States, with a ground sampling distance of up to 10 cm/pixel that enables fine-grained observation of crop conditions at the parcel level. A notable strength of Agriculture-Vision lies in its multi-spectral composition: unlike many traditional agricultural datasets that provide only RGB imagery, it includes both RGB and Near-Infrared (NIR) channels. The RGB channels contain visible light information (red, green, and blue), which captures fine structural details of farmland such as planting rows, field boundaries, and texture patterns. The NIR channel reflects physiological and spectral variations related to plant health, allowing the detection of vegetation vigor and stress conditions that are not visible in the RGB spectrum. Combining these two modalities provides both geometric accuracy and sensitivity to crop physiological status, which is essential for robust detection of diverse agricultural anomalies such as planter skips, nutrient deficiencies, and weed clusters. The NIR band is particularly sensitive to vegetation vigor and stress, offering critical physiological information that complements the structural and textural cues captured by RGB imagery [28]. By jointly exploiting these two modalities, the dataset supports more comprehensive semantic segmentation and provides a robust benchmark for evaluating fusion-based methods such as our AgriFusion network.
As illustrated in Figure 1, expert annotators manually labeled nine anomaly categories that are highly relevant to crop growth and field management: double plant (DP), dry down (DD), end row (DR), nutrient deficiency (ND), planter skip (PS), storm damage (SD), water (WT), waterway (WW), and weed cluster (WC). These categories encompass the most common anomalies and stressors encountered during the agricultural cycle, ensuring that the dataset reflects realistic and diverse farming scenarios. In our study, however, we adopted eight categories for training, validation, and testing because the storm damage class suffers from incomplete and inconsistent annotations, which may compromise fair evaluation. Following the official protocol, the dataset is divided into training (70%), validation (15%), and test (15%) subsets, a partition that ensures sufficient data for model optimization while preserving separate sets for hyperparameter tuning and unbiased evaluation.

Figure 1.
Representative examples of anomaly categories in the Agriculture-Vision dataset. RGB and NIR images are shown for each class. Colored regions indicate the annotated anomaly areas.
2.2. The Proposed Model
Our proposed framework, AgriFusion, addresses two major challenges in agricultural remote sensing segmentation: (1) the heterogeneous nature of multi-spectral data, particularly the complementary yet distinct characteristics of RGB–NIR bands, and (2) the need for robust multi-scale feature aggregation to handle targets ranging from fine-grained weeds to large-scale canopy damage. As shown in Figure 2, AgriFusion integrates three key components: an Asymmetric Dual-Encoder, which uses MiT-B1 (RGB) with ResNet-18 (NIR) to extract modality-specific features; Attention Fusion Feature (AFF) modules, inserted at multiple stages to selectively integrate both modalities through local–global attention; and an MLP-based Decoder, inspired by SegFormer, which aggregates fused multi-scale features via MLP projection plus bilinear upsampling to generate high-resolution segmentation with minimal computational cost. This modular design ensures efficiency while enhancing the discriminative power of the model for complex farmland damage segmentation tasks.
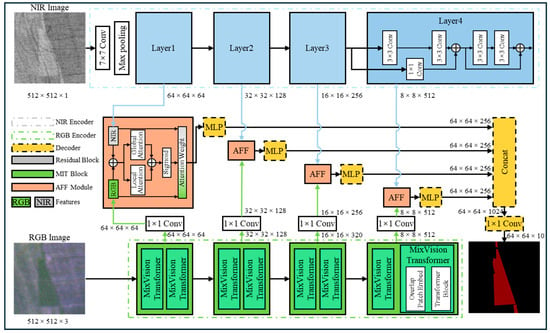
Figure 2.
Overall architecture of the proposed AgriFusion network.
2.2.1. Encoder
AgriFusion employs an asymmetric dual-encoder that processes RGB and NIR inputs in parallel and produces multi-scale features for subsequent fusion and decoding. Let . The RGB branch adopts a hierarchical MiT whose overlapped patch embedding and stagewise self-attention are effective at modeling long-range dependencies with competitive efficiency, which is important for large homogeneous regions and elongated structures in aerial scenes [29]. The NIR branch is a compact residual network that begins with a 7 × 7 convolution and a pooling layer followed by four residual stages. This choice reflects the fact that NIR is a single-channel modality with highly concentrated physiological signals [30]; assigning a lightweight CNN avoids over-allocating capacity while preserving strong local inductive biases [31,32]. The two encoders produce feature tuples and at strides with spatial sizes . Prior to fusion we align channels with 1 × 1 projections and use bilinear resizing if minor stride mismatches occur:
where and denote modality-specific 1 × 1 convolutional projections used for channel alignment, are the spatial dimensions at stage s, and is the unified channel width after projection. As shown in Equation (1), this operation ensures that both modalities are projected into a unified feature space with compatible resolutions and channel dimensions, preparing them for subsequent fusion.
Default widths follow MiT-B1 on the RGB branch and a reduced setting on the NIR branch, which allocates computation in proportion to modality bandwidth. The asymmetric design departs from early concatenation pipelines that stack RGB and NIR at the input and pass them through a single shared backbone. Such homogeneous processing has been shown to under-utilize modality-specific semantics and to blur the complementary roles of appearance and physiology in multi-spectral imagery [33]. By contrast, separate encoders enable tailored capacity and inductive biases for each modality while keeping their output scales compatible for fusion.
2.2.2. Attention Fusion Feature Module
The Attention-based Fusion Feature (AFF) module integrates RGB and NIR representations at several resolutions while learning where local detail or global context should dominate. For each stage we take the aligned features and and produce a fused output . Different from AAFormer [34], which employs a squeeze-and-excitation attention mechanism [35] to optimize the decoder but often suffers from limited cross-modal interaction and an overemphasis on channel reweighting, our AFF module is explicitly designed to address heterogeneous fusion. As shown in Figure 3, it contains a local attention branch, a global attention branch, and a gated modality mixer, enabling the model to simultaneously capture fine-grained spatial cues, long-range contextual dependencies, and adaptive modality weighting.
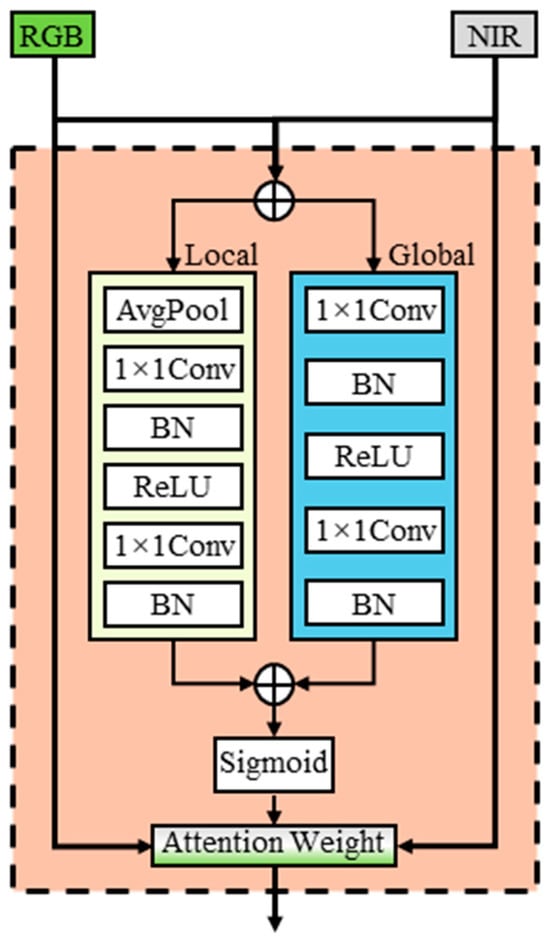
Figure 3.
Overall architecture of AFF module.
Formally, given modality-specific features , AFF module first initializes a shared representation through element-wise addition:
where and denote the projected RGB and NIR features at stride s, and is the aligned channel dimension.
The local attention branch applies two sequential 1 × 1 convolutions with batch normalization and ReLU activation to generate pixel-wise channel-sensitive responses, as formulated in Equation (3). This branch emphasizes spatially fine structures such as thin weed patches, irregular field boundaries, and planter skips [36].
where are learnable kernels, is ReLU, and , are batch normalization layers.
In parallel, the global attention branch aggregates context using global average pooling followed by two 1 × 1 convolutions with LayerNorm and ReLU activation, as expressed in Equation (4). The resulting descriptor reweights channels, improving robustness to illumination variability and class-level bias. This design is inspired by the success of squeeze-and-excitation (SE) attention in highlighting channel dependencies [35], and by subsequent evidence that global context enhances semantic segmentation in remote sensing imagery [37].
where GAP(⋅) denotes global average pooling, , are convolution kernels, and , are LayerNorm layers.
The outputs of the local and global branches are first aggregated and normalized through a sigmoid activation, which produces an adaptive fusion weight map:
where denotes the learned attention weights, is the element-wise sigmoid function. Intuitively, acts as a modality gate at every spatial location and channel. When , the gate favors RGB features, which are typically more reliable for structural patterns such as row boundaries, tillage marks, and man-made objects [14]. When , the gate emphasizes NIR features, which are more sensitive to vegetation vigor, stress, and other physiological signals [38,39]. For intermediate values, the model adaptively blends the two inputs, yielding a data-driven balance between geometric texture and spectral physiology. Building on this interpretation, the fused representation is then computed as
where denotes the element-wise sigmoid, ⊙ indicates element-wise multiplication, are the aligned RGB and NIR features at stride sss, and , are the local and global attention responses, with broadcast along the spatial dimensions before addition in Equation (5). The map provides per-pixel, per-channel weights, and the factor 2 stabilizes gradient magnitudes so that both modalities retain sufficient contribution during optimization [40,41]. In practice, In practice, Equations (5) and (6) can be viewed as a gated residual blend between the two modality streams. RGB dominates where structural evidence is decisive, while NIR takes precedence in vegetation-sensitive regions. This balance allows the AFF module to perform robust fusion across heterogeneous agricultural patterns, consistent with recent multimodal fusion strategies in remote sensing and medical imaging [42,43].
In summary, the AFF module provides a compact yet powerful mechanism for modality-aware feature integration. By explicitly combining local spatial attention with global contextual reweighting, it enables the network to dynamically adjust the relative importance of RGB and NIR signals in a category- and region-specific manner. Unlike simple concatenation or channel recalibration approaches, AFF learns fine-grained gating maps that preserve boundary precision while simultaneously enhancing vegetation sensitivity. This design ensures that spectral and structural cues are not treated uniformly but rather fused adaptively according to scene content, thereby strengthening the model’s ability to detect heterogeneous agricultural anomalies. As demonstrated in later experiments, this fusion strategy consistently improves segmentation performance across both structural and physiological categories, underscoring the central role of AFF in the AgriFusion architecture [44].
2.2.3. Decoder
The decoder aggregates fused features from multiple scales and produces dense predictions with minimal overhead. We do not adopt an FPN- or UPerNet-style feature pyramid. Instead, we use a progressive upsampling-and-concatenation strategy with a lightweight MLP projection to effectively integrate multi-scale representations from the dual encoders. For each stage we first project to a common embedding width E using a linear layer implemented as a 1 × 1 convolution:
where denotes a 1 × 1 convolution (optionally followed by normalization and a nonlinearity, depending on implementation), are the spatial dimensions at stride s. We then upsample to the stride-4 resolution , concatenate them along the channel axis, and compress the concatenated tensor back to width E with another 1 × 1 convolution:
where is bilinear interpolation to the stride-4 spatial size , ∥ denotes channel-wise concatenation, and Γ(⋅) is a 1 × 1 convolution that re-compresses the concatenated features back to width E. The stride-4 reference grid corresponds to the highest-resolution encoder output used by the decoder. A final 1 × 1 classifier maps Z to class logits, which are bilinearly upsampled to the input size to obtain the segmentation:
where is a 1 × 1 convolution producing K channels, K is the number of semantic classes, is applied along the channel dimension, and resizes the logits to the input resolution H × W. This MLP-style head follows the observation that, given strong multi-scale encoder features, heavy deconvolutions and pyramid pooling are not necessary. Lightweight projections and simple upsampling suffice to achieve strong accuracy with low overhead, in line with prior designs such as SegFormer’s decoder. In contrast with classical decoder heads such as FPN [36] and ASPP [45] that provide strong context aggregation at higher computational cost, our decoder keeps floating-point operations and memory usage low while preserving multi-scale information provided by the encoders and AFF module.
2.3. Experiment
2.3.1. Implementation Details
All experiments were conducted on a workstation equipped with an NVIDIA RTX 2080Ti GPU (22 GB memory). To initialize the encoders, we adopted pre-trained weights to accelerate convergence: ResNet-18 was used for the NIR branch, and MiT-B1 was used for the RGB branch. During training, we set the batch size to 64 and trained the model for 100 epochs to ensure convergence. The optimizer was Adam with an initial learning rate of 0.001. For supervision, we employed a composite loss function that combines cross-entropy loss with a Dice loss term, following common practice in semantic segmentation [46], which helps balance class distribution and improves boundary delineation. Standard data augmentation techniques, including random flipping and rotation, were applied to improve generalization.
2.3.2. Evaluation Metrics
To comprehensively evaluate the performance of the proposed model, we adopt the mean Intersection over Union (mIoU) as the primary metric. mIoU is widely used in semantic segmentation as it measures the average overlap between the predicted regions and ground truth across all classes (Everingham et al., 2010) [47]. In addition to mIoU, we also report Pixel Accuracy (PA) and F1-score to provide a more comprehensive evaluation. PA measures the proportion of correctly classified pixels across the entire image, reflecting the overall segmentation correctness, while the F1-score balances precision and recall for each class, offering deeper insights into class-level performance, especially for minority categories such as planter skips or storm damage. By jointly considering mIoU, PA, and F1-score, we ensure a robust and fair assessment of both global accuracy and per-class discriminability.
where N is the number of classes, and denote the true positives, false positives, and false negatives for class i, respectively.
3. Result
3.1. Comprehensive Performance Comparison
To comprehensively evaluate the effectiveness of the proposed AgriFusion framework, we first compared AgriFusion against representative segmentation models from three architectural families: CNN-based methods (DeepLabV3 [48], DeepLabV3+ [49]), Transformer-based methods (SegFormer [14] with MiT-B1 and MiT-B3 backbones), and Hybrid methods (AAFormer [34]). The quantitative results are summarized in Table 1.

Table 1.
Comparison of AgriFusion with CNN-, Transformer-, and Hybrid-Based Methods.
Overall, AgriFusion achieves the best performance across all evaluation metrics, with an mIoU of 49.31%, PA of 81.72%, and F1 score of 67.85%. Compared with SegFormer (MiT-B3), one of the strongest Transformer baselines, AgriFusion improves mIoU by +4.43% and F1 score by +8.64%. Against the Hybrid AAFormer, AgriFusion achieves +3.85% mIoU and +7.66% F1, indicating the superiority of the proposed dual-encoder fusion design. CNN-based approaches lag significantly behind, with DeepLabV3+ reaching 43.43% mIoU and 57.35% F1, highlighting their limited capacity to model complex agricultural scenes.
To further ensure the reliability of these results and verify that the observed improvements are not caused by random fluctuations, each experiment was repeated five times with different random seeds. Table 2 reports the mean and standard deviation of mIoU and F1 for each method, as well as the results of paired two-sided t-tests comparing each baseline with AgriFusion.
Table 2.
Statistical analysis over 5 runs (mean ± std) and significance testing against AgriFusion.
The standard deviation of each model is below 0.5%, indicating stable training dynamics across different initializations. More importantly, the performance improvements of AgriFusion over all baselines are statistically significant (p < 0.001) for both mIoU and F1. The large effect sizes (Cohen’s d > 10) further confirm the practical significance of the improvements. These results demonstrate that AgriFusion consistently and significantly outperforms CNN-, Transformer-, and hybrid-based approaches, providing a more robust and reliable multimodal fusion strategy for agricultural semantic segmentation.
Class-wise comparisons are provided in Table 3. AgriFusion consistently outperforms baseline methods across most anomaly categories. For planter skip, AgriFusion achieves 55.36% IoU, which is nearly +10% higher than SegFormerB3 (45.35%) and substantially higher than AAFormer (41.35%). For waterway, AgriFusion obtains 41.46% IoU, significantly outperforming AAFormer (26.89%), demonstrating its strength in detecting narrow, irregular structures. Similarly, in water, AgriFusion achieves 75.05% IoU, improving over AAFormer (69.19%) and SegFormerB3 (62.08%). These results confirm that AgriFusion effectively integrates both spectral cues and multi-scale contextual information, enabling robust segmentation of both fine-grained and large-scale anomalies.
Table 3.
Per-Class IoU Comparison Between AgriFusion and Baseline Models.
The qualitative comparisons in Figure 4 further corroborate these findings. CNN-based models (DeepLabV3/+) often miss subtle vegetation stress regions and fail to delineate boundaries in classes such as end row and planter skip. Transformer-based SegFormer produces smoother predictions but struggles with fragmented small objects, while AAFormer partially alleviates this issue yet still produces noisy masks in challenging cases such as weed cluster. In contrast, AgriFusion generates predictions that are both spatially coherent and semantically precise, capturing fine row structures as well as large-area vegetation anomalies. These consistent improvements across metrics, categories, and qualitative outputs demonstrate the overall effectiveness of the proposed approach.

Figure 4.
Qualitative comparison of segmentation results. White boxes highlight important local details, and the colors represent different anomaly categories.
3.2. Comparison with Early, Late, and Advanced Fusion Strategies
To further verify the effectiveness of the proposed adaptive fusion mechanism, we additionally compared AgriFusion with three representative multimodal fusion strategies: Early Fusion, Late Fusion, and the advanced CMX framework [50]. In the Early Fusion configuration, RGB and NIR channels are concatenated along the channel dimension to form a 4-channel input, which is then fed directly into a single encoder–decoder network without any modality-specific processing. This represents the most straightforward multimodal strategy, relying on the backbone to implicitly learn cross-modal interactions from the input level. In contrast, the Late Fusion configuration employs two independent encoders for the RGB and NIR modalities, and the feature maps extracted from both streams are concatenated at the final encoding stage before being passed to the decoder. No adaptive weighting or attention is applied during the fusion, making this setting equivalent to the “W/O AFF” variant used in the ablation study. Finally, CMX serves as a strong representative of state-of-the-art multimodal fusion approaches. Originally designed for RGB–Depth/Thermal tasks, CMX employs cross-modal interaction modules to enhance representation learning. Given that NIR provides dense spectral information similar to Depth and Thermal, CMX offers a competitive and relevant baseline for our task.
Table 4 presents the comparison results. Early Fusion and Late Fusion yield only modest improvements compared with single-modality baselines, confirming that simple concatenation strategies are insufficient to fully exploit multimodal complementarity. Late Fusion performs slightly better than Early Fusion due to its ability to preserve modality-specific representations through separate encoders, but it still lacks explicit interaction mechanisms. CMX achieves stronger results through its dedicated cross-modal fusion modules, while AgriFusion further improves mIoU by 5.19% over Early Fusion, 4.43% over Late Fusion, and 0.75% over CMX, demonstrating the effectiveness of the proposed adaptive fusion strategy.
Table 4.
Comparison with early, late, and advanced fusion strategies.
3.3. Ablation Study
The results of the first ablation study (Table 5) provide strong evidence for the necessity of heterogeneous spectral fusion. The unimodal baselines, RGB-only and NIR-only, achieved 40.60% mIoU, 76.73% PA, and 55.13% F1 and 37.64% mIoU, 73.20% PA, and 50.14% F1, respectively. These results indicate that, while RGB imagery provides rich structural and textural information, it lacks sensitivity to vegetation vigor and physiological stress. Conversely, the NIR modality excels at capturing crop health indicators but suffers from reduced discriminative power in the absence of structural context.
Table 5.
Ablation study of AgriFusion on spectral fusion and multi-scale feature balance.
When the attention-based fusion module was removed (W/O AFF), performance reached 44.88% mIoU, 79.27% PA, and 59.57% F1, which, although better than unimodal inputs, still lags behind the full model. In contrast, the complete AgriFusion (Full) model that integrates the asymmetric dual-encoder with attention-based feature fusion achieved 49.31% mIoU, 81.72% PA, and 67.85% F1. Relative to the baselines, AgriFusion improves over RGB-only by +8.71 mIoU, +4.99 PA, and +12.72 F1; over NIR-only by +11.67 mIoU, +8.52 PA, and +17.71 F1; and over W/O AFF by +4.43 mIoU, +2.45 PA, and +8.28 F1. These gains across all metrics strongly support our first claim that modality-aware attention fusion is indispensable for leveraging the complementary properties of RGB and NIR imagery in agricultural semantic segmentation.
The second ablation study further highlights the importance of balancing local detail preservation with global contextual modeling. The Local-only configuration, where only the local attention branch of AFF is activated, achieved 46.12% mIoU, 79.35% PA, and 65.32% F1. This setting favors fine structures such as weed clusters and boundaries but lacks long-range contextual reasoning. The Global-only configuration, where the local branch is removed and only the global attention branch is retained, yielded 46.58% mIoU, 80.04% PA, and 65.41% F1. This variant provides stronger scene-level coherence by aggregating global context and channel importance, yet it is less effective at capturing small or irregular targets that require fine spatial sensitivity.
The complete AgriFusion (Full) model attained 49.31% mIoU, 81.72% PA, and 67.85% F1, outperforming Local-only by +3.19 mIoU, +2.37 PA, and +2.53 F1; and Global-only by +2.73 mIoU, +1.68 PA, and +2.44 F1. These consistent improvements confirm that joint local and global feature aggregation provides a more balanced representation, simultaneously enhancing the segmentation of small objects and maintaining large-scale consistency. In addition, the decoder design ensures these gains are achieved without unnecessary architectural complexity. This evidence reinforces our second claim that adaptive multi-scale fusion combined with efficient decoding is a critical mechanism for advancing agricultural semantic segmentation.
4. Discussion
4.1. Spectral–Spatial Fusion and Modality Complementarity
The ablation study, detailed in Table 5, highlights the critical role of heterogeneous spectral fusion in agricultural semantic segmentation. To further analyze modality contributions, Table 6 presents the per-class IoU comparison across different variants. The RGB-only baseline achieves a mIoU of 40.60%. It shows relative strength in categories where geometric texture and row alignment are prominent, such as Dry Down (60.33%), Planter Skip (48.21%), and Waterway (60.25%). Performance is notably weaker for targets defined by vegetation stress or small irregularities, including Nutrient Deficiency (30.12%) and Weed Cluster (16.85%). These observations are consistent with prior studies [51], indicating that RGB imagery captures geometric detail well but is less sensitive to subtle physiological stress signals.
Table 6.
Per-Class IoU Comparison Between AgriFusion and Its Variants (RGB-only, NIR-only, and W/O AFF).
By contrast, the NIR-only variant shows a decline in overall performance, achieving an mIoU of 37.64%. This model struggles with structure-dependent anomalies, with scores for Planter Skip (41.54%) and End Row (19.30%) falling below the RGB-only baseline. This indicates that the NIR signal alone cannot provide sufficient geometric context for all segmentation tasks.
The model without the attention fusion (W/O AFF) module, which relies on a more basic spectral combination, achieves an mIoU of 44.88%. This result is a significant improvement over both single-modality baselines, demonstrating that even a simple fusion strategy is highly beneficial. For instance, the IoU for Weed Cluster improves to 31.87%, substantially outperforming both the RGB-only (16.85%) and NIR-only (13.32%) models. This confirms that integrating heterogeneous spectral data is a crucial step toward robust performance.
AgriFusion (Full) achieves the highest accuracy (49.31% mIoU), consistently outperforming unimodal baselines across nearly all categories. The most notable gains appear in categories requiring both structural and spectral cues, such as weed cluster (41.46%, compared to 16.85% in RGB-only and 31.87% in NIR-only) and planter skip (55.36%). These results, further corroborated by the qualitative comparisons in Figure 5, validate that the attention-based fusion mechanism can dynamically exploit modality complementarity, enhancing both local detail and physiological sensitivity [52]. Together, these findings strongly support the hypothesis that effective spectral fusion is essential for robust agricultural anomaly detection.
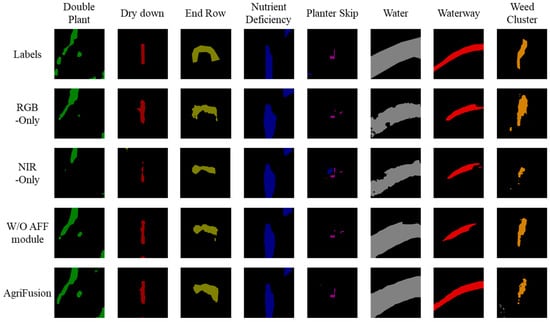
Figure 5.
Qualitative Segmentation Results of AgriFusion and Its Variants (RGB-only, NIR-only, and W/O AFF). Colors represent different anomaly categories.
Qualitative comparisons (Figure 5) further confirm this conclusion. While RGB-only predictions preserve field boundaries but fail to detect stressed vegetation, and NIR-only predictions highlight stressed regions but neglect structural alignment, the AgriFusion outputs exhibit both geometric consistency and physiological sensitivity. Taken together, these results affirm that attention-guided spectral fusion provides a synergistic, rather than additive, benefit, validating our first scientific claim: effective integration of RGB and NIR modalities is essential for robust agricultural anomaly detection.
4.2. Multi-Scale Representation and Feature Balance
The ablation study on multi-scale feature processing, summarized in Table 5, demonstrates that accurate segmentation of agricultural anomalies requires a careful balance between local detail preservation and global contextual understanding. To more clearly isolate the contributions of local and global representations, Table 7 reports the per-class IoU comparison between the Local-only and Global-only variants. The Local-only configuration achieved an mIoU of 46.12 percent, with relatively strong performance in categories where fine-grained boundary information is critical. For example, the model performed well on weed cluster with 35.14 percent and waterway with 29.65 percent, both of which involve small and irregular structures that benefit from high-resolution spatial detail. However, performance was less satisfactory on large-scale conditions such as dry down at 66.04 percent and nutrient deficiency at 37.10 percent. This indicates that an exclusive reliance on local filters cannot fully capture long-range dependencies, a limitation consistent with prior studies [53] showing that convolutional networks without explicit global aggregation struggle in large and heterogeneous scenes.
Table 7.
Per-Class IoU Comparison Between AgriFusion and Its Variants (Local-only and Global-only).
The Global-only configuration slightly improved the overall mean IoU to 46.58 percent, providing better results in spatially coherent anomalies. For example, dry down improved to 63.29 percent and nutrient deficiency to 38.56 percent, highlighting the advantage of long-range dependencies in modeling extensive field-level conditions. At the same time, performance declined for classes requiring fine spatial resolution, such as weed cluster at 36.41 percent and waterway at 28.72 percent. These results support findings from transformer-based segmentation methods that global attention enhances scene-level reasoning but risks losing sharpness at class boundaries when not combined with localized feature representations [9].
The complete AgriFusion delivered the best performance with a mean IoU of 49.31 percent, surpassing all ablated variants across nearly every category. It achieved notable improvements in weed cluster with 41.46 percent and nutrient deficiency with 39.69 percent, while also achieving higher accuracy in large-scale categories such as dry down with 68.92 percent. These results, supported by qualitative examples in Figure 6, demonstrate that AgriFusion effectively integrates both local and global attention pathways within a lightweight decoder. The outcome is a representation that preserves fine structural boundaries while maintaining holistic contextual consistency. This design principle resonates with the rationale behind feature pyramid networks and atrous spatial pyramid pooling, yet the proposed model achieves a more adaptive balance by explicitly learning to combine complementary receptive fields [54,55]. Collectively, the evidence substantiates our second claim: balanced multi-scale representation is indispensable for robust segmentation of diverse agricultural anomalies.

Figure 6.
Qualitative Segmentation Results of AgriFusion and Its Variants (Local-only and Global-only).
4.3. Limitations and Future Work
Although AgriFusion demonstrates promising results, several limitations remain. First, the current design only fuses RGB and NIR imagery; while effective, other modalities such as hyperspectral [56], thermal [57], or LiDAR [58] can capture biochemical and structural attributes beyond RGB–NIR, yet integrating such heterogeneous sources poses challenges in alignment and adaptive weighting. Second, the framework is primarily data-driven, and agricultural monitoring could benefit from embedding external knowledge such as crop growth models, soil properties, and weather dynamics, in line with recent calls for physics- or theory-guided machine learning [59]. Third, the current dataset only covers farmland in the United States, which may limit the model’s generalizability to other regions with different crop types, planting structures, and environmental conditions [60]. Domain shifts across regions, for example, when applying the model to farmlands in China, may lead to performance degradation. This highlights the need for multi-regional data and domain adaptation strategies in future work. Focusing on modality extension and knowledge integration will further enhance the robustness and scientific impact of AgriFusion and accelerate its deployment in sustainable agriculture.
In addition, since the Agriculture-Vision dataset is derived from airborne imagery, the proposed AgriFusion framework is inherently suitable for UAV-based agricultural monitoring. Although the network is not explicitly designed as a lightweight model, its relatively efficient architecture and reliance on only two spectral modalities (RGB and NIR) reduce sensor payload requirements and facilitate deployment on UAV platforms equipped with multispectral cameras. This aligns with recent advances demonstrating the feasibility of deep-learning inference on UAVs and the integration of multi-modal sensing in precision agriculture [61,62,63]. Future work will focus on validating the model’s performance in UAV-based operational scenarios and exploring strategies to integrate additional sensor modalities such as hyperspectral, thermal, or LiDAR imagery to improve adaptability under diverse field conditions.
5. Conclusions
This study introduced AgriFusion, a novel semantic segmentation framework designed to address two key challenges in agricultural remote sensing: effective spectral–spatial fusion and balanced multi-scale representation of complex field structures. By employing an asymmetric dual-encoder architecture that separately processes RGB and NIR imagery, coupled with an attention-based fusion mechanism and a MLP-based decoder, the model effectively integrates complementary spectral feature while maintaining a robust balance between local detail and global context.
Extensive experiments on the Agriculture-Vision public benchmark, including five repeated runs with different random seeds, confirmed the advantages of the proposed approach and demonstrated the stability and statistical significance of the improvements. Compared with unimodal baselines, AgriFusion significantly improved segmentation accuracy in categories requiring both structural patterns and physiological signals, such as planter skips and waterway, thereby validating the necessity of modality-aware spectral fusion. Furthermore, comparative studies with early, late, and advanced fusion strategies (e.g., CMX) further verified the effectiveness of the proposed adaptive fusion mechanism. Ablation studies also demonstrated that neither local nor global representations alone were sufficient to capture the heterogeneity of agricultural anomalies. Instead, the joint modeling of fine-scale details and long-range dependencies produced the highest overall performance, substantiating the importance of multi-scale feature balance.
Beyond quantitative gains, qualitative analysis highlighted that AgriFusion generates segmentation maps that are both structurally coherent and sensitive to vegetation stress signals. These improvements directly address practical needs in precision agriculture, where early detection of anomalies such as nutrient deficiency, water stress, and weed invasion can support timely intervention and enhance crop management strategies.
In summary, AgriFusion provides a principled solution to two long-standing scientific challenges in agricultural semantic segmentation. By advancing both spectral fusion and multi-scale modeling, the framework establishes a foundation for more accurate and reliable monitoring of crop conditions using remote sensing imagery. While several limitations remain, including the need for validation on diverse datasets, integration of additional sensing modalities, and further efficiency optimization, the findings presented here demonstrate the potential of fusion-based models to contribute meaningfully to sustainable agriculture.
Author Contributions
X.L.: Data curation, Methodology, Formal analysis, Investigation, Visualization, Writing—original draft, and Writing—review & editing. L.Q.: Conceptualization, Methodology, Supervision, and Writing—review & editing. C.Y.: Conceptualization, Methodology, Supervision, Funding acquisition, and Writing—review & editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Acknowledgments
The authors acknowledge the Minnesota Supercomputing Institute (MSI) at the University of Minnesota for providing resources that contributed to the research results reported within this paper. URL: http://www.msi.umn.edu (accessed on 6 October 2025).
Conflicts of Interest
The authors declare that they have no known competing financial interest or personal relationships that could have appeared to influence the work reported in this study.
References
- Wang, J.; Zhang, S.; Lizaga, I.; Zhang, Y.; Ge, X.; Zhang, Z.; Zhang, W.; Huang, Q.; Hu, Z. UAS-based remote sensing for agricultural Monitoring: Current status and perspectives. Comput. Electron. Agric. 2024, 227, 109501. [Google Scholar] [CrossRef]
- Paul, N.; Sunil, G.; Horvath, D.; Sun, X. Deep learning for plant stress detection: A comprehensive review of technologies, challenges, and future directions. Comput. Electron. Agric. 2025, 229, 109734. [Google Scholar] [CrossRef]
- Chen, Y.; Fang, P.; Zhong, X.; Yu, J.; Zhang, X.; Li, T. Hi-ResNet: Edge detail enhancement for high-resolution remote sensing segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 15024–15040. [Google Scholar] [CrossRef]
- Gonthina, N.; Narasimha Prasad, L. An enhanced convolutional neural network architecture for semantic segmentation in high-resolution remote sensing images. Discov. Comput. 2025, 28, 91. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, L.; Liu, X.; Yan, P. An improved semantic segmentation algorithm for high-resolution remote sensing images based on DeepLabv3+. Sci. Rep. 2024, 14, 9716. [Google Scholar] [CrossRef] [PubMed]
- Che, Z.; Shen, L.; Huo, L.; Hu, C.; Wang, Y.; Lu, Y.; Bi, F. MAFF-HRNet: Multi-attention feature fusion HRNet for building segmentation in remote sensing images. Remote Sens. 2023, 15, 1382. [Google Scholar] [CrossRef]
- Guo, S.; Yang, Q.; Xiang, S.; Wang, P.; Wang, X. Dynamic high-resolution network for semantic segmentation in remote-sensing images. Remote Sens. 2023, 15, 2293. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Zhang, M.; Dong, Q.; Zhang, G.; Wang, Z.; Wei, P. SugarcaneGAN: A novel dataset generating approach for sugarcane leaf diseases based on lightweight hybrid CNN-Transformer network. Comput. Electron. Agric. 2024, 219, 108762. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Liu, W.; Lin, Y.; Liu, W.; Yu, Y.; Li, J. An attention-based multiscale transformer network for remote sensing image change detection. ISPRS J. Photogramm. Remote Sens. 2023, 202, 599–609. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. segmentation. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 205–218. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Wang, Z.; Li, J.; Tan, Z.; Liu, X.; Li, M. Swin-upernet: A semantic segmentation model for mangroves and spartina alterniflora loisel based on upernet. Electronics 2023, 12, 1111. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Fan, J.; Shi, Z.; Ren, Z.; Zhou, Y.; Ji, M. DDPM-SegFormer: Highly refined feature land use and land cover segmentation with a fused denoising diffusion probabilistic model and transformer. Int. J. Appl. Earth Obs. Geoinf. 2024, 133, 104093. [Google Scholar] [CrossRef]
- Niu, B.; Feng, Q.; Chen, B.; Ou, C.; Liu, Y.; Yang, J. HSI-TransUNet: A transformer based semantic segmentation model for crop mapping from UAV hyperspectral imagery. Comput. Electron. Agric. 2022, 201, 107297. [Google Scholar] [CrossRef]
- Aleissaee, A.A.; Kumar, A.; Anwer, R.M.; Khan, S.; Cholakkal, H.; Xia, G.-S.; Khan, F.S. Transformers in remote sensing: A survey. Remote Sens. 2023, 15, 1860. [Google Scholar] [CrossRef]
- Cheng, X.; Li, B.; Deng, Y.; Tang, J.; Shi, Y.; Zhao, J. Mmdl-net: Multi-band multi-label remote sensing image classification model. Appl. Sci. 2024, 14, 2226. [Google Scholar] [CrossRef]
- Zhao, R.; Zhang, C.; Xue, D. A multi-scale multi-channel CNN introducing a channel-spatial attention mechanism hyperspectral remote sensing image classification method. Eur. J. Remote Sens. 2024, 57, 2353290. [Google Scholar] [CrossRef]
- Cunha, N.; Barros, T.; Reis, M.; Marta, T.; Premebida, C.; Nunes, U.J. Multispectral image segmentation in agriculture: A comprehensive study on fusion approaches. In Iberian Robotics Conference; Springer Nature: Cham, Switzerland, 2023; pp. 311–323. [Google Scholar]
- Fan, X.; Ge, C.; Yang, X.; Wang, W. Cross-modal feature fusion for field weed mapping using RGB and near-infrared imagery. Agriculture 2024, 14, 2331. [Google Scholar] [CrossRef]
- Liu, C.; Feng, Q.; Sun, Y.; Li, Y.; Ru, M.; Xu, L. YOLACTFusion: An instance segmentation method for RGB-NIR multimodal image fusion based on an attention mechanism. Comput. Electron. Agric. 2023, 213, 108186. [Google Scholar] [CrossRef]
- Zheng, Z.; Yuan, J.; Yao, W.; Kwan, P.; Yao, H.; Liu, Q.; Guo, L. Fusion of uav-acquired visible images and multispectral data by applying machine-learning methods in crop classification. Agronomy 2024, 14, 2670. [Google Scholar] [CrossRef]
- Zhao, L.; Zhang, J.; Yang, H.; Xiao, C.; Wei, Y. A Multi-Branch Deep Learning Network for Crop Classification Based on GF-2 Remote Sensing. Remote Sens. 2025, 17, 2852. [Google Scholar] [CrossRef]
- Li, Y.; Li, T.; Zhao, Y.; Jiang, K.; Ye, Y.; Wang, S.; Zhou, Z.; Wei, Q.; Zhu, R.; Chen, Q.; et al. Multimodal fusion of UAV-based computer vision and plant water content dynamics for high-throughput soybean maturity classification. Crop Environ. 2025. [Google Scholar] [CrossRef]
- Hruška, A.; Hamouz, P.; Lev, J.; Pavlíček, J.; Kroulík, M.; Hamouzová, K.; Košnarová, P.; Holec, J.; Kouřím, P. Weed detection in cabbage fields using RGB and NIR images. Smart Agric. Technol. 2025, 12, 101232. [Google Scholar] [CrossRef]
- Chiu, M.T.; Xu, X.; Wei, Y.; Huang, Z.; Schwing, A.G.; Brunner, R.; Khachatrian, H.; Karapetyan, H.; Dozier, I.; Rose, G.; et al. Agriculture-vision: A large aerial image database for agricultural pattern analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2828–2838. [Google Scholar]
- Berger, K.; Machwitz, M.; Kycko, M.; Kefauver, S.C.; Van Wittenberghe, S.; Gerhards, M.; Verrelst, J.; Atzberger, C.; Van der Tol, C.; Damm, A.; et al. Multi-sensor spectral synergies for crop stress detection and monitoring in the optical domain: A review. Remote Sens. Environ. 2022, 280, 113198. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Chen, H.-Y.; Sang, I.-C.; Norris, W.R.; Soylemezoglu, A.; Nottage, D. Terrain classification method using an NIR or RGB camera with a CNN-based fusion of vision and a reduced-order proprioception model. Comput. Electron. Agric. 2024, 227, 109539. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Khan, U.; Khan, M.K.; Latif, M.A.; Naveed, M.; Alam, M.M.; Khan, S.A.; Su’ud, M.M. A Systematic Literature Review of Machine Learning and Deep Learning Approaches for Spectral Image Classification in Agricultural Applications Using Aerial Photography. Comput. Mater. Contin. 2024, 78, 2967. [Google Scholar] [CrossRef]
- Zhao, F.; Zhang, C.; Geng, B. Deep multimodal data fusion. ACM Comput. Surv. 2024, 56, 1–36. [Google Scholar] [CrossRef]
- Shen, Y.; Wang, L.; Jin, Y. AAFormer: A multi-modal transformer network for aerial agricultural images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1705–1711. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhang, J.; Lin, S.; Ding, L.; Bruzzone, L. Multi-scale context aggregation for semantic segmentation of remote sensing images. Remote Sens. 2020, 12, 701. [Google Scholar] [CrossRef]
- Li, K.; Qiang, Z.; Lin, H.; Wang, X. A Multi-Branch Attention Fusion Method for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2025, 17, 1898. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Zhang, S.; Zhang, G.; Zhang, M.; Shang, H. SLViT: Shuffle-convolution-based lightweight Vision transformer for effective diagnosis of sugarcane leaf diseases. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 101401. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Cai, Z.; Fang, H.; Jiang, F.; Yang, J.; Ji, T.; Hu, Y.; Wang, X. AMFFNet: Asymmetric Multi-Scale Feature Fusion Network of RGB-NIR for Solid Waste Detection. IEEE Trans. Instrum. Meas. 2023, 72, 2522610. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5518615. [Google Scholar] [CrossRef]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional feature fusion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3560–3569. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhang, J.; Liu, H.; Yang, K.; Hu, X.; Liu, R.; Stiefelhagen, R. CMX: Cross-modal fusion for RGB-X semantic segmentation with transformers. IEEE Trans. Intell. Transp. Syst. 2023, 24, 14679–14694. [Google Scholar] [CrossRef]
- Kior, A.; Yudina, L.; Zolin, Y.; Sukhov, V.; Sukhova, E. RGB imaging as a tool for remote sensing of characteristics of terrestrial plants: A review. Plants 2024, 13, 1262. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J. CrossFuse: A novel cross attention mechanism based infrared and visible image fusion approach. Inf. Fusion 2024, 103, 102147. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, H.; Hu, Q. Transfuse: Fusing transformers and cnns for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; pp. 14–24. [Google Scholar]
- Deng, Y.; Cao, Y.; Chen, S.; Cheng, X. Residual Attention Network with Atrous Spatial Pyramid Pooling for Soil Element Estimation in LUCAS Hyperspectral Data. Appl. Sci. 2025, 15, 7457. [Google Scholar] [CrossRef]
- Lei, J.; Shu, C.; Xu, Q.; Yu, Y.; Yang, S. FCPFNet: Feature complementation network with pyramid fusion for semantic segmentation. Neural Process. Lett. 2024, 56, 60. [Google Scholar] [CrossRef]
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent advances of hyperspectral imaging technology and applications in agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Wooster, M.J.; Roberts, G.; Smith, A.M.; Johnston, J.; Freeborn, P.; Amici, S.; Hudak, A.T. Thermal remote sensing of active vegetation fires and biomass burning events. In Thermal Infrared Remote Sensing: Sensors, Methods, Applications; Springer: Dordrecht, The Netherlands, 2013; pp. 347–390. [Google Scholar]
- Goodwin, N.R.; Coops, N.C.; Culvenor, D.S. Assessment of forest structure with airborne LiDAR and the effects of platform altitude. Remote Sens. Environ. 2006, 103, 140–152. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat, F. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Csurka, G. Domain adaptation for visual applications: A comprehensive survey. arXiv 2017, arXiv:1702.05374. [Google Scholar] [CrossRef]
- Liu, J.; Wang, F.; Argaman, E.; Zhao, Z.; Shi, P.; Shi, S.; Han, J.; Ge, W.; Chen, H. Application of UAV Multimodal Data and Deep Learning for Estimating Soil Salt Content at the Small Catchment Scale. Int. Soil Water Conserv. Res. 2025. [Google Scholar] [CrossRef]
- Pengpeng, Y.; Teng, F.; Zhu, W.; Shen, C.; Chen, Z.; Song, J. Cloud–edge–device collaborative computing in smart agriculture: Architectures, applications, and future perspectives. Front. Plant Sci. 2025, 16, 1668545. [Google Scholar]
- Zhang, S.; Wang, X.; Lin, H.; Qiang, Z. A Review of the Application of UAV Multispectral Remote Sensing Technology in Precision Agriculture. Smart Agric. Technol. 2025, 12, 101406. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).