Abstract
To address the demand for lightweight, high-precision, real-time, and low-computation detection of targets with limited samples—such as laboratory instruments in portable AR devices—this paper proposes a small dataset object detection algorithm based on a hierarchically deployed attention mechanism. The algorithm adopts Rep-YOLOv8 as its backbone. First, an ECA channel attention mechanism is incorporated into the backbone network to extract image features and adaptively adjust channel weights, improving performance with only a minor increase in parameters. Second, a CBAM-spatial module is integrated to enhance region-specific features for small dataset objects, highlighting target characteristics and suppressing irrelevant background noise. Then, in the neck network, the SE attention module is replaced with an eSE attention module to prevent channel information loss caused by dimensional changes. Experiments conducted on both open-source and self-constructed small datasets show that the proposed hierarchical Rep-YOLOv8 model effectively meets the requirements of lightweight design, real-time processing, high accuracy, and low computational cost. On the self-built small dataset, the model achieves a mAP@0.5 of 0.971 across 17 categories, outperforming the baseline Rep-YOLOv8 (0.871) by 11.5%, demonstrating effective recognition and segmentation capability for small dataset objects.
1. Introduction
Object detection, as one of the core tasks in the field of computer vision [1], holds significant application value in scenarios such as autonomous driving [2], industrial quality inspection [3], and intelligent security [4]. This technology involves detecting the presence of target objects in an input image, determining their semantic categories, and locating their positions, i.e., the process of classifying, localizing, sizing, and segmenting objects within an image [5]. The development of object detection can be divided into two major technical paradigms: traditional object detection algorithms [6] and deep learning-based object detection algorithms [7].
Traditional object detection algorithms can be primarily categorized into feature-based and segmentation-based approaches. Among them, feature-based traditional object detection algorithms mainly achieve detection and recognition by identifying certain attributes of objects in images; these attributes can be hand-crafted features or abstract features extracted by algorithms. Segmentation-based traditional object detection algorithms, on the other hand, achieve detection and recognition through the regional, color, and edge characteristics of objects in images. For instance, Viola et al. [8] introduced the Viola-Jones detector in 2001, which core components are Haar-like features, integral images, AdaBoost classifiers, and cascade classifiers, primarily used for face detection. Dalal et al. [9] proposed the HOG detector in 2005 based on Histogram of Oriented Gradients (HOG) feature extraction and SVM classifiers, mainly applied to pedestrian detection. The DPM detector proposed by Felzenszwalb et al. [10] in 2009 further developed HOG. These methods provided a solid foundation for the further development and optimization of object detection algorithms and are suitable for detection scenarios with simple backgrounds. However, they exhibit significant limitations when dealing with real-world scenarios involving occlusions and complex backgrounds.
Deep learning-based object detection techniques employ Convolutional Neural Networks (CNNs) to automatically learn multi-scale feature representations [11]. Leveraging large datasets for deep training, they significantly enhance detection performance in complex scenes. The R-CNN framework proposed by Girshick et al. [12] in 2014 achieved 53.7% mAP on the PASCAL VOC2012 dataset, an 18.6 percentage point improvement over traditional methods. The YOLO series algorithms developed by Redmon et al. [13,14,15] in 2015 pioneered the single-stage detection paradigm, achieving real-time detection speeds through end-to-end training, followed by subsequent versions like YOLOv2 and YOLOv3. The YOLOv8 model [16,17,18,19] released by Ultralytics in 2023, through architectural innovations (such as replacing the C3 module with the C2f module and streamlining the FPN-PAN structure), achieved 53.9% mAP on the COCO dataset while maintaining an inference speed of 45 FPS.
With the expanding application of Augmented Reality (AR) technology in fields such as industrial inspection [20], medical assistance [21], and educational simulation [22], object detection faces new technical challenges: it must simultaneously meet requirements for high accuracy, real-time performance, lightweight design, and low computational power on devices with limited resources. Current mainstream algorithms often excessively pursue accuracy improvements, leading to a sharp increase in model complexity and computational overhead, making them difficult to adapt to mobile devices like AR glasses. To address the above issues, this paper proposes an improved scheme based on the YOLOv8 architecture. By hierarchically deploying attention mechanisms, it aims to achieve lightweight, low-computation, and high-accuracy recognition on small-sample datasets, such as those for laboratory equipment. This algorithm adopts the Rep-YOLOv8 architecture as the baseline and incorporates optimized attention mechanisms to achieve efficient recognition on a small-sample database of self-built laboratory instruments and equipment.
2. Materials and Methods
2.1. Network Model
2.1.1. YOLOv8 Network Model
With the emergence of portable visual inspection devices, detection algorithms need to achieve a dynamic balance between accuracy and efficiency. YOLOv8 is a model from the YOLO series developed by Ultralytics (5001 Judicial Way, Frederick, MD 21703, USA). Its overall structure is roughly divided into three parts: the Backbone network, the Neck network, and the Head network. The overall structure of YOLOv8 is shown in Figure 1.
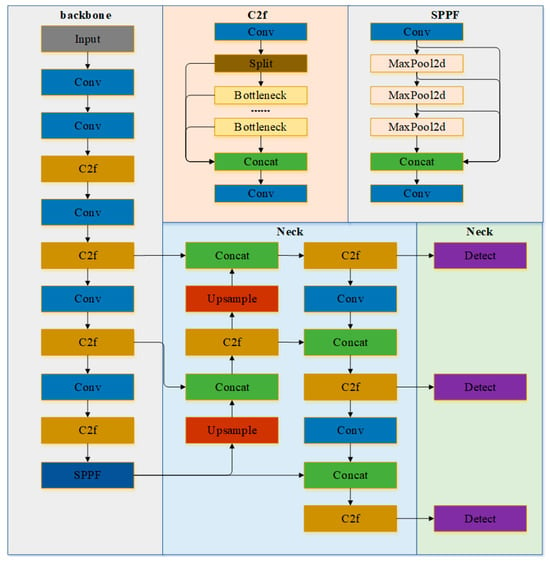
Figure 1.
Overall Structure of YOLOv8.
The input end of YOLOv8 uses adaptive image scaling to adjust the input image to a suitable size before passing the processed image to the backbone network. The backbone network of YOLOv8 consists of CBS modules, C2f modules, and SPPF modules. It generally follows the CSP concept of YOLOv5, but to meet lighter weight requirements, the C3 module is replaced with the C2f module. The CBS module comprises Convolution, Batch Normalization, and SiLU activation function; this combination improves model stability, accelerates convergence, and prevents gradient vanishing. Compared to the C3 module, the C2f module adds skip connections and an additional Split operation, enriching the gradient flow of the model. In the SPPF module, feature fusion is performed through pooling and convolution operations, adaptively integrating feature information at various scales to enhance the model’s feature extraction capability. In the neck network of YOLOv8, features extracted from the backbone network are processed using PAN and FPN [23] structures. These employ top-down and bottom-up cross-layer connections to achieve more thorough feature fusion. In the final prediction head network, a mainstream decoupled head structure is used, separating the classification and detection heads. Positive and negative samples are determined based on scores weighted by classification and regression scores, effectively improving model performance. It also abandons the Anchor-Based approach, using a more flexible and accurate Anchor-Free method to adapt to targets of different sizes and shapes.
2.1.2. Rep-YOLOv8 Network Model
The RepVGG network [24] is a simple and efficient network structure constructed by continuously stacking RepVGG blocks. Compared to other networks that increase depth to improve accuracy, leading to excessive complexity and slow inference speed, RepVGG exhibits a good balance between speed and accuracy, enhancing model accuracy while improving detection speed and reducing the number of parameters. In its core concept, the RepVGG network uses structural re-parameterization to separate the training model from the inference model. As shown in Figure 2, during training, it employs a multi-branch structure similar to ResNet, containing two convolution operations, one BN layer, and a ReLU activation function. During inference, it can be transformed into a single-path structure similar to VGG. The multi-branch structure allows the network to maintain good performance during training, while the single-path serial structure significantly improves inference speed during the inference phase.
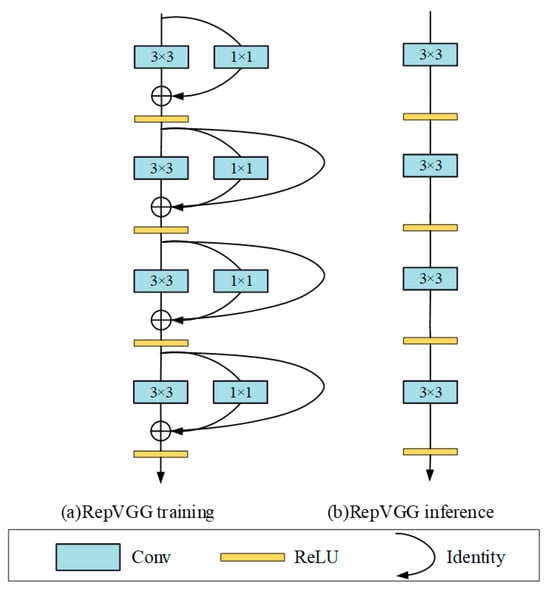
Figure 2.
RepVGG Network Structure.
The backbone network of the Rep-YOLOv8 model is improved based on the principles of the RepVGG network, replacing the original convolution modules in the YOLOv8 backbone with RepVGG modules. Figure 3 shows the structure of the RepVGG module. It can be seen that during training, the RepVGG module parallels three branches: a main branch with a 3 × 3 convolution kernel, a branch with a 1 × 1 convolution kernel, and an identity branch connected only to a BN layer. During training, the outputs of the three branches are summed to obtain the final output. When performing detection tasks, the branches are merged using structural re-parameterization methods to form a simple serial structure, avoiding computational waste.
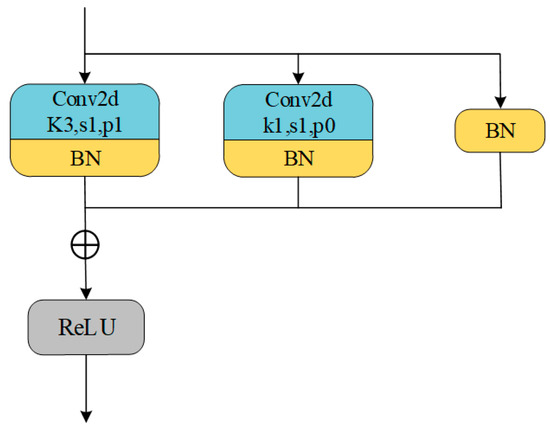
Figure 3.
RepVGG Module Structure.
2.1.3. Structural Re-Parameterization
During the training of deep neural networks, the inclusion of BN layers brings many advantages, such as alleviating gradient vanishing and explosion, accelerating network convergence, but it also inevitably introduces computational complexity. RepVGG extensively uses structures combining convolution and BN layers. If the convolution and BN layers are merged into a single-path structure, it can save computational resources, improve model performance, and increase the network’s forward inference speed. This is the conceptual basis of structural re-parameterization. The following is the derivation process for merging convolution and BN layers in structural re-parameterization. First, convolution is performed. The calculation formula for the convolution layer is shown in Equation (1):
where w is the weight kernel, x is the input, b is the bias, and * denotes the convolution operation.
The calculation formula for the BN layer for the i-th channel of the feature map is shown in Equation (2):
where μi is the mean, σ2 is the variance, γi is the scale factor, βi is the shift factor, and ε is a constant for numerical stability.
Substituting Equation (1) into Equation (2) yields the combined calculation formula shown in Equation (3):
The new weight corresponding to the merged convolution layer is shown in Equation (4):
The new bias for the corresponding convolution kernel is shown in Equation (5):
Substituting Equation (4) into Equation (5) yields the combined calculation formula shown in Equation (6):
According to the derivation, the BN layer is directly merged into the convolution operation: the convolution kernel is scaled by a certain factor, and the bias is modified, reducing the parameter count of the original BN layer. The principle of structural re-parameterization is shown in Figure 4. From Figure 4 (left), it can be seen that the 3 × 3 convolution and BN layer are fused into a single 3 × 3 convolution; the 1 × 1 convolution is zero-padded to 3 × 3 and then fused with the BN layer into a 3 × 3 convolution; for the branch with only BN (identity branch), since there is no convolution layer, an identity mapping is performed, and the BN layer can be converted into a 3 × 3 convolution (with the kernel being an identity matrix scaled by BN parameters). Finally, multi-branch fusion is performed to obtain the fused 3 × 3 convolutional layer. Figure 4 (right) shows the process of parameter change. It can be seen that after structural re-parameterization, the parameters are reduced from one 3 × 3 conv, one 1 × 1 conv, and three BN layers (considering the three branches) to just one 3 × 3 convolutional layer, both reducing the model’s parameter count and accelerating the model’s inference speed.
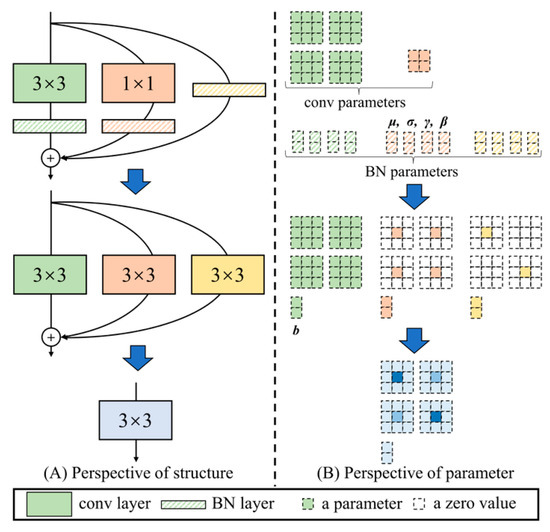
Figure 4.
Schematic Diagram of Structural Re-parameterization.
2.2. Algorithm
2.2.1. Attention Mechanism
As YOLOv8 still has room for optimization in terms of feature extraction capability, channel information screening mechanism, computational resource consumption rate, and feature fusion effectiveness in complex scenarios where multi-scale targets coexist and occlusions cause interference, adding attention mechanisms has become one of the core strategies for improving model performance in deep learning models, especially in object detection tasks.
Attention mechanisms play an important role in computer vision tasks such as image recognition, object detection, and semantic segmentation. They perform weighted processing on input data, enhancing the focus on important information and ignoring unnecessary information when performing deep convolutional neural network tasks. By calculating the correlation weights between features, they guide the model to focus on task-relevant highly effective regions, thereby enhancing the discriminative power of feature representations. Based on the dimension of focus, they can be divided into spatial attention, channel attention, and hybrid attention.
To address this, this paper proposes a hierarchical deployment scheme of hybrid attention mechanisms based on the Rep-YOLOv8 architecture (as shown in Figure 5).
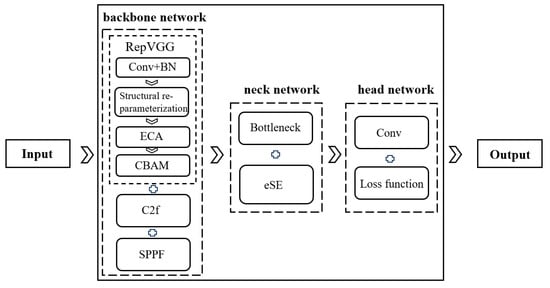
Figure 5.
Structure Diagram of Rep-YOLOv8 with Hierarchically Deployed Attention Mechanisms.
First, the ECA (Efficient Channel Attention) mechanism is embedded into the RepVGG modules of the shallow network (backbone) to enhance the model’s screening ability for key features and reduce computational resource consumption through the synergistic optimization of structural re-parameterization and lightweight channel attention. Then, following the ECA attention mechanism, a dual-attention architecture working in conjunction with the CBAM-spatial (spatial attention unit from the Convolutional Block Attention Module) is added. This utilizes dual-path feature fusion via global average pooling and max pooling, combined with convolution operations to generate spatial weight maps, strengthening the feature response of target regions. Finally, in the deep network (neck), the eSE (effective Squeeze and Extraction) attention module replaces the original SE (Squeeze-and-Excitation) module [25] in the C2f modules to mitigate the channel information loss problem caused by channel dimensionality reduction.
The hierarchical deployment creates a complementary pipeline. The shallow combo (ECA + CBAM-spatial) acts as a “feature enhancer and spatial filter” for low-level information, ensuring that only the most relevant primitive features are passed forward. The deep eSE module then acts as a “semantic channel selector” on these refined features, ensuring that the final classification and detection heads are driven by the most task-relevant high-level concepts.
2.2.2. ECA Module in Shallow Network
In convolutional neural networks, the shallow network is responsible for capturing the main content of low-level image features (such as edges, textures, geometric contours), which form the basis for high-level semantic understanding. However, traditional convolution operations lack a dynamic screening mechanism for the importance of feature channels and spatial locations, making shallow features susceptible to background noise interference. Especially in small-sample detection or complex scenes, key detailed information may be lost due to uneven weight distribution. To address this issue, this paper introduces a hybrid channel and spatial attention mechanism in the shallow network, achieving refined expression of low-level features and noise suppression through dual-path synergistic optimization.
Channel attention is a mechanism focused on the important allocation of channels in the feature maps of convolutional neural networks. It assigns different weights to each channel to emphasize those most contributing to the task and suppress irrelevant or redundant channels. However, most common algorithms achieve better performance at the expense of model complexity. Therefore, this paper introduces a distribution mechanism that lightweight the model. The ECA attention mechanism [26] is a lightweight channel attention module designed to enhance the CNN’s ability to screen key channel features at a very low computational cost. Its core idea is to replace the fully connected operation in the traditional SE module with local cross-channel interaction, significantly reducing parameters and computational complexity while ensuring performance, as shown in Figure 6.
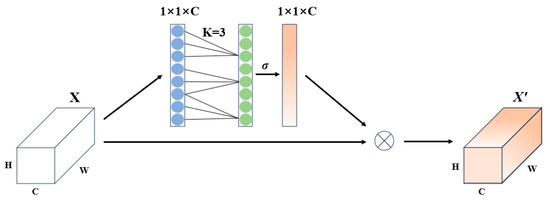
Figure 6.
ECA Attention Module.
The structure design of the ECA module is concise and efficient, comprising three key steps:
- Perform Global Average Pooling (GAP) on the input feature map to compress spatial information, generating a global feature descriptor vector for each channel.
- Use 1D convolution (1D Conv) for local cross-channel interaction on the channel vector, dynamically adjusting the local range of cross-channel interaction to avoid the high parameter count and information redundancy of traditional fully connected layers. The adaptive formula for the convolution kernel size k is:where k represents the size of the convolution kernel, C represents the number of channels, γ and b are hyperparameters (default γ = 2, b = 1), and | |odd means taking the nearest odd integer.
- Use the Sigmoid function to map the convolution output to values between 0 and 1, generating weight coefficients for each channel. These weight coefficients are then multiplied channel-wise with the original input feature map to complete feature recalibration, enhancing the response of key channels and suppressing secondary information. The output maintains the same dimensions as the input.
2.2.3. CBAM-Spatial Module in Shallow Network
The CBAM-spatial module [27], as the spatial unit of CBAM, is a lightweight attention structure specifically designed for optimizing features in the spatial dimension. Its core function is to dynamically assign weights to strengthen spatial regions in the feature map that are highly relevant to the task. It effectively addresses the difficulty in capturing salient features caused by insufficient data samples while also highlighting spatial regions and suppressing irrelevant background interference.
As shown in Figure 7, the CBAM-spatial module first takes the spatial positions from the output of the channel attention (preceding CBAM channel attention, though the text describes adding CBAM-spatial after ECA here, which might imply a standalone use or a specific integration; the figure reference is CBAM-spatial) as the feature quantity. It then performs global average pooling and global max pooling along the channel dimension separately, generating two-channel spatial description matrices. These two feature maps are concatenated, encoded for spatial context information through a single 3 × 3 convolutional kernel, and finally normalized by a Sigmoid function to generate a spatial weight matrix. This matrix is multiplied element-wise with the original feature map to achieve feature recalibration. The calculation formula for the CBAM-spatial module is:
where F is the input feature map, σ is the sigmoid function, f3×3 denotes a convolution operation with a 3 × 3 filter, [ ; ] denotes concatenation, and and are the average-pooled and max-pooled features across the channel dimension, respectively.

Figure 7.
Spatial Attention Module.
Compared to traditional spatial attention mechanisms, the advantages of CBAM-spatial are mainly reflected in three aspects:
- It integrates multi-granularity spatial information through a dual-pooling strategy, capturing both the overall distribution characteristics of target regions (average pooling) and retaining the salient responses of local details (max pooling), overcoming the information bias problem of single pooling operations.
- It uses a fixed-size 3 × 3 convolutional kernel instead of complex branch structures, reducing parameters by 60% (compared to more complex spatial attention designs).
- The module overall follows the lightweight principle and can be seamlessly embedded into the RepVGG network architecture.
2.2.4. eSE Module in Deep Network
The shallow network has successively deployed ECA channel attention and CBAM-spatial attention, achieving strong feature screening capability, low computational cost, and strong feature response through dual-path collaboration. To further strengthen the global channel relationships in high-level semantic features, this paper adopts the eSE attention module in the deep network to replace the original SE attention module.
The SE attention module adaptively adjusts the weight of each channel and contains two fully connected (FC) layers. To avoid high model complexity, the first FC layer uses a reduction ratio r to reduce the number of input feature channels from C to C/r. The second FC layer then needs to expand the number of channels back to the original size C. In this process, the reduction in channel dimensionality leads to loss of channel information. Compared to the SE module, the eSE module improves upon it by using only one FC layer with C channels to replace the two FC layers in the original module. By reducing the number of FC layers, it preserves more of the original channel information, thereby enhancing model performance. The structures of both are shown in Figure 8.
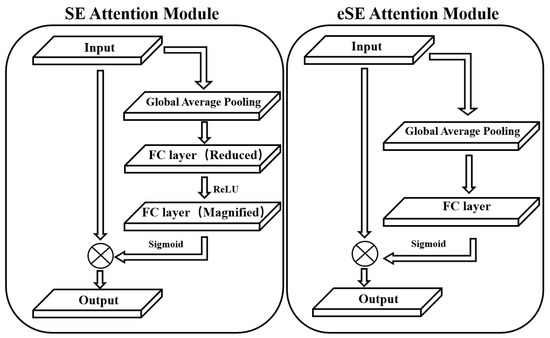
Figure 8.
SE Attention Module and eSE Attention Module.
3. Results and Discussion
3.1. Algorithm Validation
3.1.1. Ablation Study
To verify the effectiveness of the hierarchically deployed hybrid attention mechanism, ablation experiments were conducted using a public dataset (Pascal VOC) [28]. The experiments employed three metrics for a comprehensive performance evaluation of the model: Precision (P), Recall (R), and Average Precision (AP).
Precision represents the ratio of correctly detected positive samples to the total number of detected samples, as shown in Equation (9):
Recall represents the ratio of correctly detected positive samples to the total number of actual positive samples in the test set, as shown in Equation (10):
where TP (True Positive) denotes the number of objects correctly identified and accurately classified by the model; FP (False Positive) denotes the number of objects incorrectly marked by the model where no target should exist, falsely classified as positive samples; FN (False Negative) denotes the number of actual positive samples that the model failed to identify.
Average Precision (AP) is calculated as the average precision across different recall levels within the sorted prediction results. It is primarily used to evaluate the model’s performance for a specific category. Its formula is shown in Equation (11):
The Average Precision measures the average precision for the predictions of one category; its value is the area under the Precision-Recall (PR) curve. The mean Average Precision (mAP) represents the average of the AP values across all categories. This metric reflects the overall performance of the model across all categories. For example, mAP@0.5 refers to the mAP value when the IoU threshold is set to 0.5, and mAP@0.5:0.95 refers to the average mAP value as the IoU threshold varies from 0.5 to 0.95 in steps (usually 0.05).
To evaluate the rationality of various improvements integrated into YOLOv8, an ablation study was conducted under identical conditions, with the model parameter count at 10.7M and FPS at 80. The ablation experiments performed on the Pascal VOC dataset yielded the results shown in Table 1. These results demonstrate the improvement in training accuracy after the separate incorporation of the ECA, CBAM-spatial, and eSE attention modules. The ECA attention module enhances the focus on crucial information, significantly boosting the post-training accuracy performance. The eSE module effectively mitigates the issue of channel information loss caused by channel dimensionality reduction, also contributing notably to the overall improvement in network accuracy.

Table 1.
Ablation Study on Pascal VOC Dataset.
The results of the ablation study are shown in Table 1. It can be observed that the mAP@0.5 of the YOLOv8 algorithm incorporating the RepVGG structure reaches 78.9%. After sequentially adding the ECA, CBAM-spatial, and finally the eSE attention modules, the mAP@0.5 shows significant improvement. The proposed hierarchical deployment of hybrid attention mechanisms achieves 89.6%. The ECA attention module enhances the focus on important information, greatly improving post-training accuracy performance. The CBAM-spatial attention module strengthens the feature representation of target regions. The eSE module effectively mitigates the channel information loss problem caused by channel dimensionality reduction. The hierarchical deployment and mixing of these three also have a positive effect on the overall network accuracy improvement.
3.1.2. Multi-Sample Object Recognition
To verify the performance improvement of the hierarchically deployed Rep-YOLOv8 on multi-sample object detection, two models (before and after improvement) were trained under the same dataset, same training environment, and same training parameters, and their results were evaluated. This paper uses the PASCAL VOC dataset for controlled experiments. Its target detection objects include 20 different categories such as people, vehicles, and furniture, totaling 11,540 images with 27,450 annotated objects. This paper selects 5823 images as the test set for validation. To more intuitively demonstrate the model’s performance, a confusion matrix is used as an evaluation tool, with results shown in Figure 9.
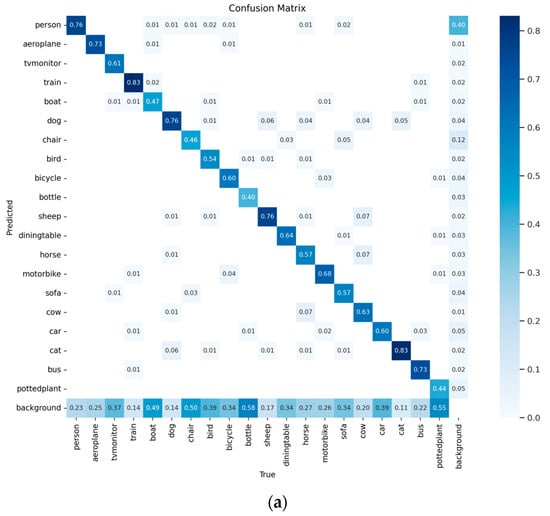
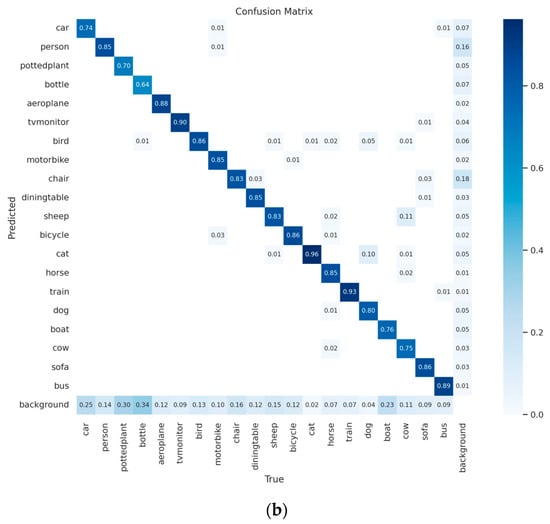
Figure 9.
Confusion Matrices of the Two Models: (a) Rep-YOLOv8 Confusion Matrix; (b) Hierarchically Deployed Rep-YOLOv8 Confusion Matrix.
From the figure, it can be seen that the prediction results of the Rep-YOLOv8 model are more dispersed, and its classification precision is relatively lower. In contrast, the prediction results of the hierarchically deployed Rep-YOLOv8 model are mainly concentrated on the diagonal of the confusion matrix, showing higher precision. Thus, it can be concluded that the hierarchically deployed Rep-YOLOv8 model has higher precision in classifying various categories, better overall model performance, and a lower probability of misjudging targets.
Simultaneously, to verify the applicability of the hierarchical deployment algorithm, a comparative analysis experiment was conducted with other widely used methods in the field of object detection. The results are shown in Table 2.
Table 2.
Model Performance Comparison Experiment on Pascal VOC Dataset.
This paper selected YOLOv5m, YOLOv8s, Faster R-CNN, SSD, and Cascade R-CNN for comparison. From the table, it can be seen that the average precision (mAP@0.5) of the hierarchically deployed Rep-YOLOv8 is significantly higher than other algorithms, while the model’s parameter count is also relatively low. Therefore, the algorithm adopted in this paper makes the model more lightweight and high-performance, with faster detection speed and lower computational cost, making it suitable for real-time object detection tasks.
3.1.3. Small Dataset Object Detection
Given that this paper uses portable AR devices for real-time detection of experimental instruments, under the premises of lightweight design, high efficiency, and low computational power, the detection task also faces challenges of small sample size and multiple targets per image. To verify the algorithm’s performance under small dataset object detection, this paper uses the Cityscapes dataset as the test subject for small dataset targets. It includes approximately 5000 finely annotated high-resolution images, of which 1525 are selected as the test set to validate the recognition and segmentation performance of target objects.
The loss function can reflect the deviation between the predicted values and the true values in the model; a smaller deviation indicates better model robustness. Through calculation, the convergence curves of the loss functions for various metrics of Rep-YOLOv8 and the hierarchically deployed Rep-YOLOv8 are shown in Figure 10.

Figure 10.
Convergence curves for Precision, Recall, mAP@0.5, and mAP@0.5:0.95 metrics: (a) Convergence curves for the four metrics of Rep-YOLOv8; (b) Convergence curves for the four metrics of Hierarchical Rep-YOLOv8.
From the figure, it can be seen that in both object classification and segmentation tasks, the hierarchical Rep-YOLOv8 algorithm shows improvement over the Rep-YOLOv8 algorithm across all four metrics.
To validate the feasibility of the proposed approach, a series of advanced models were compared with the hierarchical Rep-YOLOv8. As shown in the data from Table 3, on the Cityscapes dataset, the hierarchical Rep-YOLOv8 demonstrates a more outstanding balance between model size and accuracy. Compared to SegNet, CCNet, DANet, UperNet, OCRNet, and DeepLabv3+, it achieves improvements in mAP@0.5 by 8.8%, 4.1%, 1.6%, 3.0%, 2.1%, and 1.3%, respectively. Although it shows a slight decrease of 0.4% and 0.6% compared to SegFormer and SETR-MLA, the hierarchical Rep-YOLOv8 has a significantly smaller number of parameters than these two models, making it more lightweight and compact, and thus better suited for the requirements of mobile device optimization.
Table 3.
Comparative Experiment on Cityscapes Dataset.
To better demonstrate the recognition and segmentation performance of the hierarchical Rep-YOLOv8 when multiple scales and multiple detection targets exist in the same image, tests were conducted on pedestrians and vehicles in this dataset. The results are shown in Figure 11.

Figure 11.
Detection results of the three models: (a) Hierarchical Rep-YOLOv8; (b) Rep-YOLOv8; (c) YOLOv8.
The results show: for the scenario with multi-scale targets in the first row, all three models demonstrate good recognition and segmentation effects for nearby targets, but exhibit varying degrees of missing distant small targets. For the scenario with multiple detection targets in the second row, compared to the Rep-YOLOv8 model which mistakenly identifies a distant sign as a person and the YOLOv8 model which misses the person target on the right side of the image, the hierarchical Rep-YOLOv8 model performs better in handling the recognition and segmentation of such small, multiple detection targets. For the scenario involving both multiple scales and multiple targets in the third row, whether in vehicle segmentation (left vehicle) or target recognition in complex environments (right electric bike and trees), the hierarchical Rep-YOLOv8 model performs better than both the Rep-YOLOv8 and YOLOv8 models.
Therefore, it can be concluded that the hierarchical Rep-YOLOv8 model has better recognition and segmentation effects in complex environments with multiple scales and multiple detection targets.
3.2. Experiment and Analysis
3.2.1. Database Construction
This paper collected common laboratory instruments and tools to create a small-sample object detection dataset comprising 500 images. It includes 17 categories such as interferometers, Abbe comparators, optometers-B, length measuring machines, projection length measuring machines, and coordinate measuring machines (CMM). Samples of these 17 common experimental instruments were collected from multiple angles, at different distances, under different lighting conditions, and with multiple target occlusions. During the collection of single images, the simultaneous appearance of multiple experimental instruments was the main focus, supplemented by detailed shots of individual instruments. The dataset was split in a 4:1 ratio into 400 training set images and 100 validation set images.
Before training, target objects in the images need to be manually annotated to generate label files so that the model can correctly identify objects of different categories and positions. This paper used LabelImg as the data annotation tool, including key information such as image file path, bounding box size, object category, and specific location. An annotation example is shown in Figure 12.

Figure 12.
LabelImg Annotation Example.
Preprocessing operations such as Mosaic augmentation and MixUp augmentation were applied to the annotated images to improve the quality and efficiency of data mining during the training of the hierarchical Rep-YOLOv8 algorithm. However, because feature information of some small targets in the dataset is harder to extract, and certain local key information might be cropped during data processing, it is necessary to disable these augmentation techniques in the final stages of training the hierarchical Rep-YOLOv8 model. Image data during model training is shown in Figure 13.

Figure 13.
(a) Image data without augmentation techniques; (b) Image data with augmentation techniques.
3.2.2. Self-Built Database Experiment
Through the systematic evaluation on the PASCAL VOC dataset, the deployment scheme proposed in this paper has been effectively validated in terms of architectural rationality. Meanwhile, tests on the Cityscapes dataset further verified the algorithm’s advantages for complex environments with multiple scales and multiple detection targets. To deeply investigate the effect of the improved algorithm on experimental instrument detection, this paper uses the self-built dataset for transfer training and validation evaluation.
The AP results for the 17 categories are shown in Table 4. Each target category is represented by an English abbreviation. The experimental results indicate that while there are individual cases of reduced precision, the hierarchical Rep-YOLOv8 architecture overall demonstrates superior detection performance on the custom dataset. Comparative analysis based on the mAP@0.5 evaluation criterion shows that the mAP@0.5 values for Rep-YOLOv8 and hierarchical Rep-YOLOv8 are 0.871 and 0.971, respectively, achieving an improvement rate of 11.5%. This statistically significant difference fully validates the enhancing effect of the network structure adjustment on feature extraction capability.
Table 4.
AP results for various categories in the custom dataset.
To more intuitively represent the experimental results, the PR curves for Rep-YOLOv8 and the hierarchical Rep-YOLOv8 are shown in Figure 14, respectively. It can be seen that the recognition results of the hierarchical Rep-YOLOv8 are higher degree of overlap to Rep-YOLOv8, exhibiting higher recognition precision.
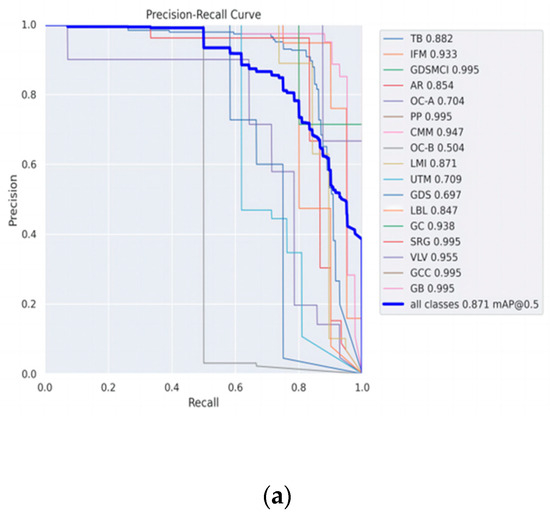
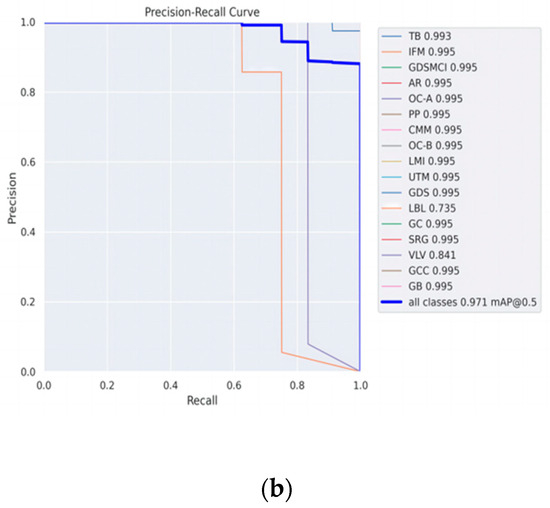
Figure 14.
Comparison of PR curves for the two models: (a) PR curve for Rep-YOLOv8; (b) PR curve for Hierarchical Rep-YOLOv8.
In summary, the model trained on the custom dataset was used to detect common instruments in the laboratory. Example detection results are shown in Figure 15 below. The experimental results show that when detecting the 17 categories of laboratory instruments, the target objects can be accurately identified, segmented, and effectively classified, demonstrating good performance for small dataset object detection of experimental instruments.

Figure 15.
Detection results of Hierarchical Rep-YOLOv8 on the self-built dataset.
4. Conclusions
Aiming at the problems of portable AR devices in experimental instrument detection, this paper takes Rep-YOLOv8 as the base model and hierarchically deploys different attention mechanisms in the shallow and deep networks, adopting a hybrid attention mechanism to achieve effective detection of small dataset experimental instruments. Experimental results show that the hierarchical Rep-YOLOv8 algorithm demonstrates higher average precision in multiple validations, indicating that the hybrid attention mechanism not only significantly improves channel learning efficiency, feature enhancement, small dataset learning performance, and effective transmission of feature information but also enables effective recognition and segmentation of small dataset experimental instruments in complex environments with multiple scales and multiple targets on the custom dataset, meeting the requirements of portable AR devices for lightweight design, high precision, real-time performance, and low computational power.
Author Contributions
Conceptualization, Y.Z. and H.H.; methodology, Y.Z. and H.H.; software, H.H.; validation, J.L., J.X. and J.M.; formal analysis, H.H.; investigation, J.L.; resources, Y.Z. and J.L.; data curation, Y.Z. and H.H.; writing—original draft preparation, Y.Z. and H.H.; writing—review and editing, H.H.; visualization, J.X.; supervision, J.M.; project administration, J.L.; funding acquisition, J.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Zhejiang Provincial Administration for Market Regulation, grant number ZC2023057.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
We would like to thank the editor and the reviewers for their comments which helped us improve the paper. During the preparation of this manuscript, the author used Deepseek to polish and refine the English language. The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
Author Yonggang Zhao, Jiongming Lu, Jixia Xu and Jiechu Miu were employed by Hangzhou of Supervising Testing Center for Quality & Metrology. The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Shuai, Z.H. Adaptive Neuroevolutionary Methods for Deep Neural Networks in Computer Vision; Dalian Maritime University: Dalian, China, 2023. [Google Scholar]
- Li, Y.P.; Hou, L.Y.; Wang, C. Moving Object Detection in Autonomous Driving Based on YOLOv3. Comput. Eng. Des. 2019, 4, 1139–1144. [Google Scholar]
- Jiao, R.D.; Gao, D.H.; Huang, Y.H.; Liu, S.; Duan, X.P.; Wang, R.; Liu, W.D. Research and Validation of Few-Shot Evaluation Method for Production Line AI Quality Inspection. Comput. Sci. 2024, S1, 1161–1168. [Google Scholar]
- Xu, K. Research on Intelligent Security Video Surveillance Based on Multi-object Recognition. Tech. Autom. Appl. 2024, 7, 168–171. [Google Scholar]
- Shi, Z. Object detection models and research directions. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics and Computer Engineering (ICCECE), Virtual, 15–17 January 2021; pp. 546–550. [Google Scholar]
- Bustos, N.; Mashhadi, M.; Lai-Yuen, S.K.; Mashhadi, M.; Lai-Yuen, S.K.; Sarkar, S.; Das, T.K. A systematic literature review on object detection using near infrared and thermal images. Neurocomputing 2023, 560, 126804. [Google Scholar] [CrossRef]
- Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y.; Liu, S.; Du, S.; Lan, X. A review of object detection based on deep learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001; Volume 1. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Tang, H.; Li, Z.; Zhang, D.; He, S.; Tang, J. Divide-and-Conquer: Confluent Triple-Flow Network for RGB-T Salient Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 1958–1974. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Gao, H.; Jia, Z.; Li, Z. BL-YOLOv8: An Improved Road Defect Detection Model Based on YOLOv8. Sensors 2023, 23, 8361. [Google Scholar] [CrossRef] [PubMed]
- Xiao, X.; Feng, X. Multi-object pedestrian tracking using improved YOLOv8 and OC-SORT. Sensors 2023, 23, 8439. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Ye, K. YOLO-IMF: An Improved YOLOv8 Algorithm for Surface Defect Detection in Industrial Manufacturing Field. In International Conference on Metaverse; Springer Nature: Cham, Switzerland, 2023; pp. 15–28. [Google Scholar]
- Du, J. Research on the Design of Assembly System for Complex Equipment Based on Augmented Reality; Nanjing University of Posts and Telecommunications: Nanjing, China, 2023. [Google Scholar]
- Liu, H. Innovative Design and Application Research of Minimally Invasive Spinal Surgery Guidance System Based on Augmented Reality Technology; Army Medical University of the Chinese People’s Liberation Army: Chongqing, China, 2021. [Google Scholar]
- Hu, Y. Research on AR Game Design for Children’s Safety Education Based on Interactive Narrative; Jiangsu University: Zhenjiang, China, 2021. [Google Scholar]
- Kirillova, A.; Girshick, R.; He, K.; Dollar, P. Panoptic feature pyramid networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 15–20 June 2019; pp. 6399–6408. [Google Scholar]
- Huang, Y.; Chen, R.; Chen, Y.; Ding, S.; Yao, J. A Fast bearing Fault diagnosis method based on lightweight Neural Network RepVGG. In Proceedings of the 4th International Conference on Advanced Information Science and System, Sanya, China, 25–27 November 2022; pp. 1–6. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Duan, X.; Sun, Y.; Wang, J. ECA-UNet for coronary artery segmentation and three-dimensional reconstruction. Signal Image Video Process 2023, 17, 783–789. [Google Scholar] [CrossRef]
- Niu, C.; Nan, F.; Wang, X. A super resolution frontal face generation model based on 3DDFA and CBAM. Displays 2021, 69, 102043. [Google Scholar] [CrossRef]
- Hoiem, D.; Divvala, S.K.; Hays, J.H. Pascal VOC 2008 challenge. World Lit. Today 2009, 24, 1–4. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).