1. Introduction
In recent years, high-speed trains in China have gained widespread popularity among passengers due to their advantages in speed, comfort, stability, safety, and environmental sustainability. However, with the continuous increase in operating velocities, aerodynamic challenges have become increasingly prominent [
1,
2]. When a high-speed train passes through a tunnel, the confined tunnel walls significantly alter the surrounding flow field, giving rise to compression and expansion waves. These pressure waves propagate at the speed of sound within the tunnel, undergoing repeated reflections and superpositions, which in turn cause cyclic fluctuations in the aerodynamic pressure on the train’s surface. Prolonged and alternating exposure to such positive and negative aerodynamic loads [
3] can lead to local stress concentrations, particularly at critical structural interfaces, such as welded joints. These stress concentrations may induce fatigue damage in the welded regions and other local structures, ultimately compromising both the structural integrity of the train and passenger safety. Therefore, it is essential to investigate the characteristics of external pressure variations during high-speed train passage through tunnels, as such studies are of great significance in ensuring the safe operation of high-speed rail systems.
Extensive research has been conducted by scholars, both in China and abroad, to investigate the characteristics of the external pressure fluctuations induced by high-speed trains passing through tunnels. These studies, based on experimental investigations and numerical simulations, have provided in-depth insights into the influencing factors. The experimental results have demonstrated that the peak-to-peak value of the external pressure increases with the train formation length [
4]. Moreover, both the amplitude of the external pressure variation and its peak-to-peak value have been shown to be proportional to the square of the train speed [
5,
6,
7]. Additionally, the absolute values of the pressure peak-to-peak amplitude, maximum positive pressure, and maximum negative pressure tend to first increase and then decrease with increasing tunnel length [
8]. A systematic analysis of available full-scale experimental data indicates that when the tunnel length is below a certain critical threshold, the peak-to-peak value of pressure increases with tunnel length. However, once this critical length is exceeded, the pressure fluctuation tends to reach a steady state [
9].
Numerical simulation studies on the pressure waves generated by high-speed trains passing through tunnels have revealed several key patterns. It has been shown that the peak-to-peak value of external pressure is proportional to the square of train speed and exhibits an approximately linear relationship with the blockage ratio [
10]. Both the amplitude and the peak-to-peak value of external pressure increase with the train formation length [
11,
12]. Furthermore, the maximum external pressure amplitudes experienced by the leading, intermediate, and trailing cars initially increase and then decrease as tunnel length increases. Conversely, the external pressure amplitude decreases with increasing tunnel clearance area [
13]. Niu et al. [
14] investigated the pressure fluctuation patterns on the surface of train bodies during tunnel passage. Their findings indicate that for the constant cross-sectional regions of the train, the amplitude of negative pressure exceeds that of positive pressure, whereas for the streamlined regions, the positive and negative pressure amplitudes are comparable. Additionally, as the measurement point shifts toward the rear of the train, the positive pressure amplitude decreases, while the negative pressure amplitude increases. Zhou et al. [
15] employed a three-dimensional numerical approach to investigate the characteristics of the pressure waves generated by trains operating at different speed levels during tunnel passage. Their findings indicate that varying speed regimes exert a significant influence on the maximum negative pressure observed on the surfaces of all train cars, while the impact on the maximum positive pressure is pronounced only on the trailing cars. Luo et al. [
16] utilized a two-dimensional numerical simulation to examine the formation process of pressure waves when a high-speed train suddenly enters a tunnel. Previous studies have also investigated a variety of operational parameters affecting pressure wave behavior. Commonly considered input variables include the train speed, train length, tunnel length, blockage ratio, measurement point location, and train head or tail geometry. For instance, Niu et al. [
14] emphasized the importance of the measurement location and the train geometry, while Zhou et al. [
15] highlighted the train speed as a critical factor. These variables form the basis for most simulation-based or data-driven predictive models in the field and serve as a reference for the input features used in the present study. Uystepruyst et al. [
17], adopting the Euler equations in conjunction with non-reflecting boundary conditions, proposed a novel numerical method for simulating the pressure waves induced by high-speed trains in tunnels, which effectively reduced the computational resource demands. However, these conventional approaches still suffer from several inherent limitations. For instance, full-scale field tests are significantly affected by environmental factors, are restricted to existing tunnel infrastructures, and involve high costs and complex logistical coordination. Scaled model tests require extensive preliminary preparation, are time-consuming, and incur substantial expenses. Although numerical simulations can offer high-precision predictions, they are computationally intensive and demand considerable processing time and resources [
18,
19]. Therefore, there is a pressing need to explore more efficient and accessible research methodologies.
Although substantial progress has been made in numerical simulations and experimental studies on external pressure fluctuations caused by train operations in tunnels, these predictive methods typically rely on large-scale Computational Fluid Dynamics (CFD) simulations. While CFD simulations provide highly accurate pressure fluctuation data, their high computational cost and complex modeling process limit the efficient prediction and comprehensive assessment of external pressure responses under multi-condition and complex environmental scenarios. This limitation makes it difficult to meet practical engineering needs, such as train operation safety analysis and tunnel structural protection design. In recent years, with the rapid development of deep learning and artificial intelligence technologies, data-driven approaches have increasingly become a research focus in complex flow problems. Especially in fields such as high-speed rail, aerospace, wind energy, construction, shipbuilding, and drone design, data-driven methods, with their efficient predictive capabilities and interdisciplinary applicability, have shown great potential. Chen et al. [
20] used an autoregressive moving average (ARMA) model to predict tunnel pressure waves for high-speed trains, achieving a certain level of prediction accuracy when compared with actual measurements. Chen et al. [
21] proposed a combined prediction model using the Autoregressive Integrated Moving Average (ARIMA) model and BP neural network. A comparative analysis between the combined model and individual models revealed that the combined model provided a superior prediction performance. Cui et al. [
22] employed a PSO-BP neural network model to predict aerodynamic pressure amplitudes within tunnels. By selecting the optimal parameters through K-fold cross-validation, they demonstrated the optimization effect of Particle Swarm Optimization (PSO) on the BP neural network. Recent advances have emphasized the use of deep learning-based surrogate models and hybrid techniques for improving efficiency in complex engineering problems. For example, Zhang et al. [
23] developed a deep learning-based surrogate model for the probabilistic analysis of tunnel crown settlement in high-speed railways, considering spatial soil variability and construction processes. Similarly, Zhang et al. [
24] proposed an efficient reliability analysis method for tunnel convergence under uncertainty. Other studies have explored integrating CFD with deep learning models [
25], and combining CFD with variational auto-encoder (VAE) techniques to capture complex physical features while reducing dimensionality [
26]. These developments inspire our approach of coupling numerical simulations with machine learning to accurately and efficiently predict pressure wave effects in tunnel environments. While data-driven and deep learning models offer high computational efficiency and predictive accuracy, they also have limitations. These include a strong dependence on the quantity and quality of training data, limited generalization to unseen scenarios, and a lack of physical interpretability in some models. Furthermore, deep models often require extensive hyperparameter tuning and may lack robustness in extrapolating beyond the training domain. Therefore, it remains essential to balance model accuracy, interpretability, and computational feasibility when designing predictive frameworks.
In summary, current methods for predicting external pressure fluctuations still face certain limitations in terms of rapid responses under multiple operational conditions and complex environmental scenarios, as well as in providing physical mechanism explanations. To address these issues, this paper proposes a machine learning prediction model that integrates optimization algorithms and explainability analysis methods. Firstly, a dataset of external pressure amplitude during high-speed train passage through tunnels was constructed using a numerical simulation. This dataset incorporates various typical operational conditions, including different tunnel lengths, train speeds, train lengths, blockage ratios, and measurement point positions. Subsequently, after completing data preprocessing, four representative machine learning models—random forest (RF), support vector regression (SVR), XGBoost, and Multilayer Perceptron (MLP)—were employed to model and predict external pressure fluctuation amplitudes. A systematic comparison of the models was conducted based on their prediction accuracy and generalization ability during the testing phase, leading to the selection of the best-performing model. Optimization algorithms were then applied to adaptively adjust the hyperparameters of this model, further enhancing its predictive performance. At the same time, a SHAP (SHapley Additive exPlanations) explainability analysis was integrated to quantitatively assess the contribution of different operational parameters to the pressure fluctuation amplitude predictions. This analysis helped identify the key features driving the predictions, providing data support and theoretical foundations for a subsequent aerodynamic characteristic analysis and the optimization design of tunnels.
2. Experimental Design
Given the limited data available in the existing literature regarding the external pressure amplitudes during the passage of a high-speed train through a tunnel, it is challenging to meet the demands for the high-quality sample data required for subsequent machine learning prediction models. To address this, this study employs Computational Fluid Dynamics (CFD) methods to numerically simulate the train operation process under typical conditions, thereby constructing a comprehensive and representative dataset. Through a controlled variable approach, simulation schemes are designed to systematically capture external pressure variation data under different combinations of tunnel and train parameters. This data will provide a solid foundation for subsequent model training and performance evaluation.
In this section, we will first introduce the governing equations, numerical calculation models, and boundary condition settings used in the simulations. The reliability and accuracy of the established models will be validated, and the process of dataset construction will be described in detail.
2.1. Governing Equations
The aerodynamic behavior of the train follows the fundamental fluid dynamics equations, which include the continuity equation, the momentum equation, and the energy equation. These governing equations describe the conservation of mass, momentum, and energy in the fluid flow around the train, forming the basis for the numerical simulation of the external pressure fluctuations during the train’s passage through the tunnel.
Continuity Equation (Conservation of Mass):
In the equation, t represents time; represents the component of the fluid velocity along the i-th direction, where i = 1, 2, 3 corresponds to the , , and directions, respectively.
Momentum Equation (Conservation of Momentum):
In the equation, p denotes the static pressure, represents the stress tensor, is the gravitational force component in the i-th direction, and denotes other energy terms arising from resistance and energy sources.
Energy Equation (Conservation of Energy):
In the equation, h denotes the entropy, k represents the molecular conductivity, corresponds to the turbulent conductivity induced by turbulent transport, and denotes the volumetric source term.
In this study, we employed the SST k-ω turbulence model, which combines the advantages of the standard k-ε and k-ω models. The SST k-ω turbulence model adopts the standard k-ω formulation in the low Reynolds number regions near the train surface, while transitioning to the standard k-ε model in regions farther away from the wall. A blending function is employed to gradually shift from the wall-adjacent k-ω model to the outer k-ε model, thereby combining the advantages of both models. Due to its robustness and accuracy in capturing flow characteristics near walls and in the free stream, the SST k-ω model is widely used in engineering applications. Accordingly, this study adopts the SST k-ω turbulence model for the computational analysis of the high-speed train.
The transport equation for the turbulent kinetic energy
k in the SST
k-ω model is given as follows:
In the equation, represents the generation of turbulent kinetic energy; is the cross-diffusion term; and are the effective diffusivity terms for k and ω, respectively; and denote the dissipation terms of k and ω, respectively; and and are user-defined source terms.
2.2. Computational Model
According to relevant studies [
27], a two-dimensional, revolving–axisymmetric train/tunnel model offers significant advantages in computational efficiency while maintaining a high level of accuracy comparable to that of three-dimensional simulations. Therefore, in this study, a two-dimensional, revolving–axisymmetric train/tunnel model is adopted to perform numerical simulations on a full-scale high-speed train. The SST
is adopted to simulate the turbulent flow field, given its proven robustness and computational efficiency in predicting the aerodynamic characteristics of high-speed trains, and this is combined with an all-
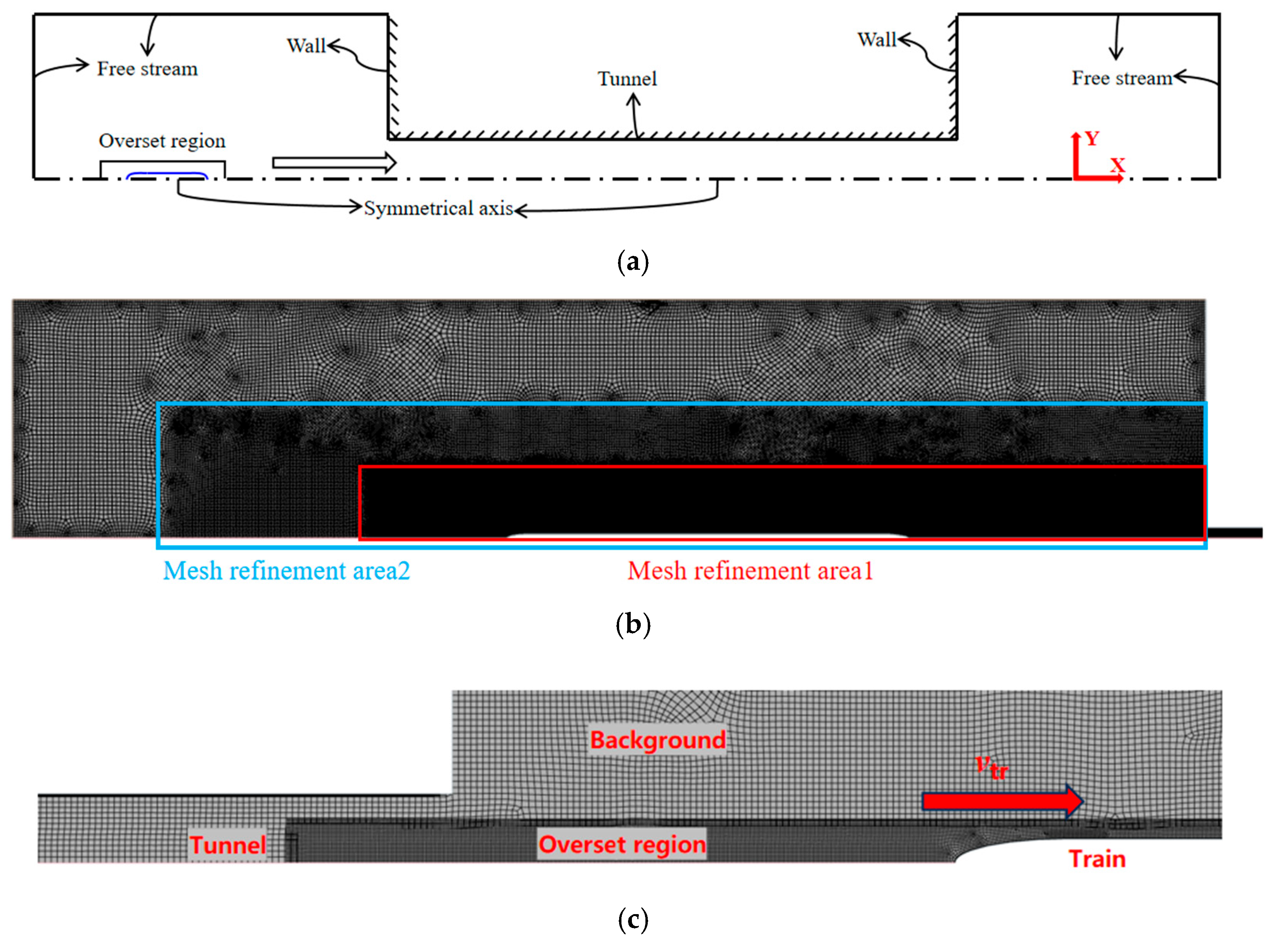
y+ wall treatment approach and an all-wall treatment approach to ensure the accurate capture of near-wall flow characteristics. The numerical simulations are performed using a finite volume method (FVM), with second-order spatial discretization schemes applied to enhance the solution accuracy. Temporal discretization is conducted using an implicit unsteady solver to ensure numerical stability during the simulation of transient pressure variations. The computational domain incorporates three types of boundary conditions: free-stream boundaries, wall boundaries, and overset mesh boundaries. Specifically, the tunnel walls and train surfaces are defined as wall boundaries, the region surrounding the train body is treated with overset mesh boundaries, and the remaining domain is designated as free-stream boundaries. At the free-stream boundaries, the inflow velocity is set according to the air velocity far away (e.g., 0 m/s), and the pressure is initialized at atmospheric conditions. Turbulence is specified using the intensity–length scale method, with a turbulence intensity of 5% and a length scale of 0.07 times the tunnel hydraulic diameter. The free-stream condition ensures realistic external flow behavior and avoids non-physical reflections. Combined with the overset mesh method, it enables the accurate simulation of the train’s movement and pressure wave propagation in the tunnel. The train model consists of eight carriages, with a total length of
= 201.4 m, a cross-sectional area of
= 11.85 m
2, and a body height of
= 3.7 m. Following industry standards, the computational domain is constructed as shown in
Figure 1a to minimize boundary effects and ensure sufficient flow development. The computational domain height is set to 31.25
, with a distance of 600
from the tunnel entrance to the upstream boundary and 300
from the tunnel exit to the downstream boundary. This domain configuration effectively minimizes boundary-induced disturbances to the main flow region, thereby enhancing the accuracy and physical reliability of the simulation results.
A structured quadrilateral mesh was employed to discretize the entire computational domain, resulting in a total of approximately 206,000 cells. The mesh distribution of the computational domain is illustrated in
Figure 1b. The first-layer thickness was set to 0.25 m, which corresponds to a dimensionless wall distance
y+ > 30. This value places the first mesh point well within the log-law region, allowing for the use of wall function approaches in the SST
k-ω turbulence model. We have adopted this mesh resolution intentionally to reduce the computational cost while maintaining acceptable accuracy, as our study focuses primarily on far-field external pressure wave propagation, rather than near-wall shear stress prediction. This strategy is commonly used in railway aerodynamics studies. To enhance the computational accuracy in critical regions, mesh refinement was applied around the train body and in areas with significant flow feature variations, ensuring the accuracy and stability of the numerical simulation results.
Figure 1c shows the mesh layout around the train model. During the simulation, the overset mesh moves synchronously with the train in the positive velocity direction to accurately capture the dynamic evolution of the external flow field during the train’s motion.
Figure 2 illustrates the pressure–time histories obtained under different mesh densities. By comparing the simulation results using coarse (99,000 cells), medium (206,000 cells), and fine (438,000 cells) meshes, it is evident that the overall trends of the pressure curves remain consistent across all the mesh configurations, indicating a certain degree of stability in the simulation results concerning mesh resolution. Although the coarse mesh exhibits noticeable deviations in peak pressure compared to the medium and fine meshes, the medium mesh achieves a level of accuracy close to that of the fine mesh while significantly reducing the computational cost. Therefore, considering both accuracy and efficiency, the medium-density mesh is selected for subsequent simulations in this study.
2.3. Method Validation
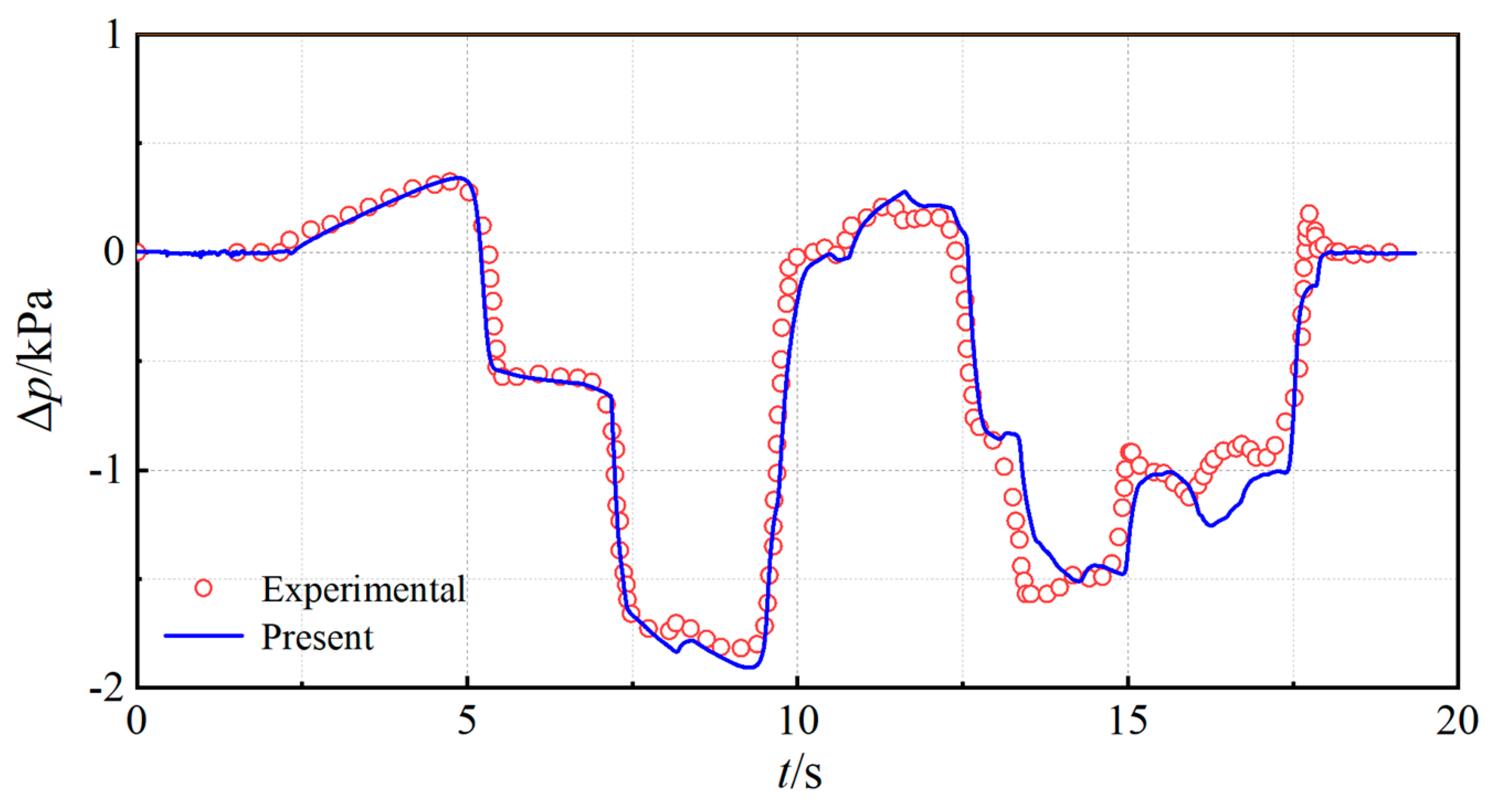
To verify the accuracy and applicability of the established numerical model, the full-scale experimental data of a high-speed train reported in Ref. [
28] were selected for comparison. The test conditions were as follows: a train speed of 250 km/h, a tunnel length of 1080 m, and a tunnel cross-sectional area of 92 m
2. The pressure monitoring point was located on the train surface, 38 m from the train head. The pressure variations on the train surface during tunnel entry and passage obtained from the numerical simulation in this study were compared with the experimental measurements. The comparison results are shown in
Figure 3. As shown in
Figure 3, the numerical simulation results demonstrate a high degree of consistency with the experimental data in terms of the overall trend of pressure fluctuations, with the primary characteristic points closely matching.
Table 1 presents a comparison of errors between the numerical computation results. It is evident that the pressure amplitude obtained from the two-dimensional numerical calculation exhibits an error of 4.9% compared to the experimental pressure amplitude reported in the literature, which is within the reasonable error range of 10%. This indicates that the employed two-dimensional computational model demonstrates high predictive accuracy, providing strong support and reference for the subsequent construction of the external pressure dataset in tunnels.
2.4. Dataset Construction
During the process of a high-speed train traversing a tunnel, the external pressure fluctuations are influenced by a combination of factors. Previous studies have indicated that the structural form of the tunnel entrance significantly affects the pressure gradient, though its impact on the pressure amplitude is relatively limited [
29]. Moreover, for high-speed trains with a streamlined design, the length of the train’s front section has a negligible effect on the pressure amplitude [
30]. Given that the focus of this study is on a streamlined high-speed train and the variation in external pressure amplitude, the influence of the tunnel entrance structure and the train’s front length are disregarded in the experimental design to reduce variable interference and enhance the specificity of the analysis. This approach helps simplify the research model while emphasizing other key parameters that play a dominant role in pressure amplitude.
This study thoroughly considers five key factors influencing the external pressure fluctuations of a high-speed train as it passes through a tunnel during the experimental design phase. These factors include the tunnel length (
), train length (
), train speed (
), blockage ratio (
, defined as the ratio of the train cross-sectional area to the tunnel cross-sectional area), and the relative position of the measurement point (
). Based on two common train configurations, an 8-carriage train (train length = 200 m) and a 16-carriage train (train length = 400 m), a total of 2016 experiments were designed and completed. The specific initial conditions for the experiments are detailed in
Table 2. The tunnel length range was set from 500 m to 10,000 m; the train speeds covered typical operational ranges from 200 km/h to 350 km/h; the tunnel cross-sectional areas included common specifications, such as 52, 58, 70, 80, 92, and 100 m
2; and the pressure measurement points are located at the midpoint on the exterior of each high-speed train carbody.
By combining different initial conditions for simulation, all results converged, yielding the external pressure amplitude dataset. A portion of the dataset is presented in
Table 3. The dataset was derived based on the governing equations of fluid dynamics used in the numerical model, which describe the conservation of mass, momentum, and energy in the flow field, as shown in Equations (1)–(5). These equations were solved numerically using the finite volume method implemented in STAR-CCM+. The input features for the predictive model include the following five parameters: tunnel length (
), train length (
), train speed (
), blockage ratio (
), and measurement point location (
). The output consists of multiple target variables, including the positive peak value (
), negative peak value (
), and peak-to-peak value (
, the difference between the positive and negative peaks), which comprehensively reflect the characteristics of external pressure variation as the train enters the tunnel.
5. Results
5.1. Model Performance
To reduce the risk of model overfitting and enhance the model’s generalization capability, this study incorporates an L2 regularization strategy during model training. L2 regularization introduces a penalty term—the sum of squared weight parameters—into the loss function, which suppresses excessively large weights and prevents the model from over-relying on a small number of features. During the feature selection phase, L2 regularization promotes a more balanced distribution of weights, enabling the model to fully exploit the available feature information, thereby improving its robustness and generalization performance.
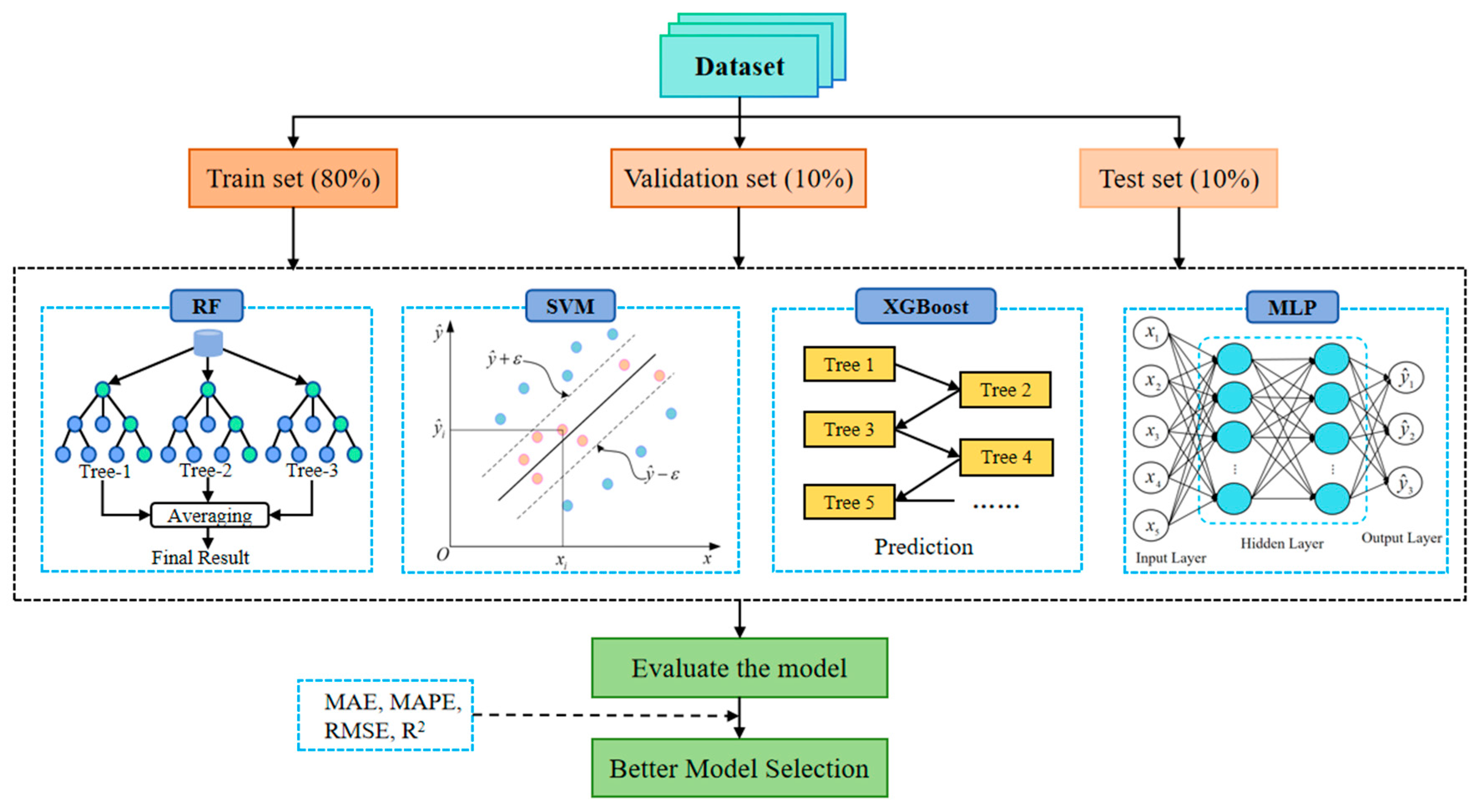
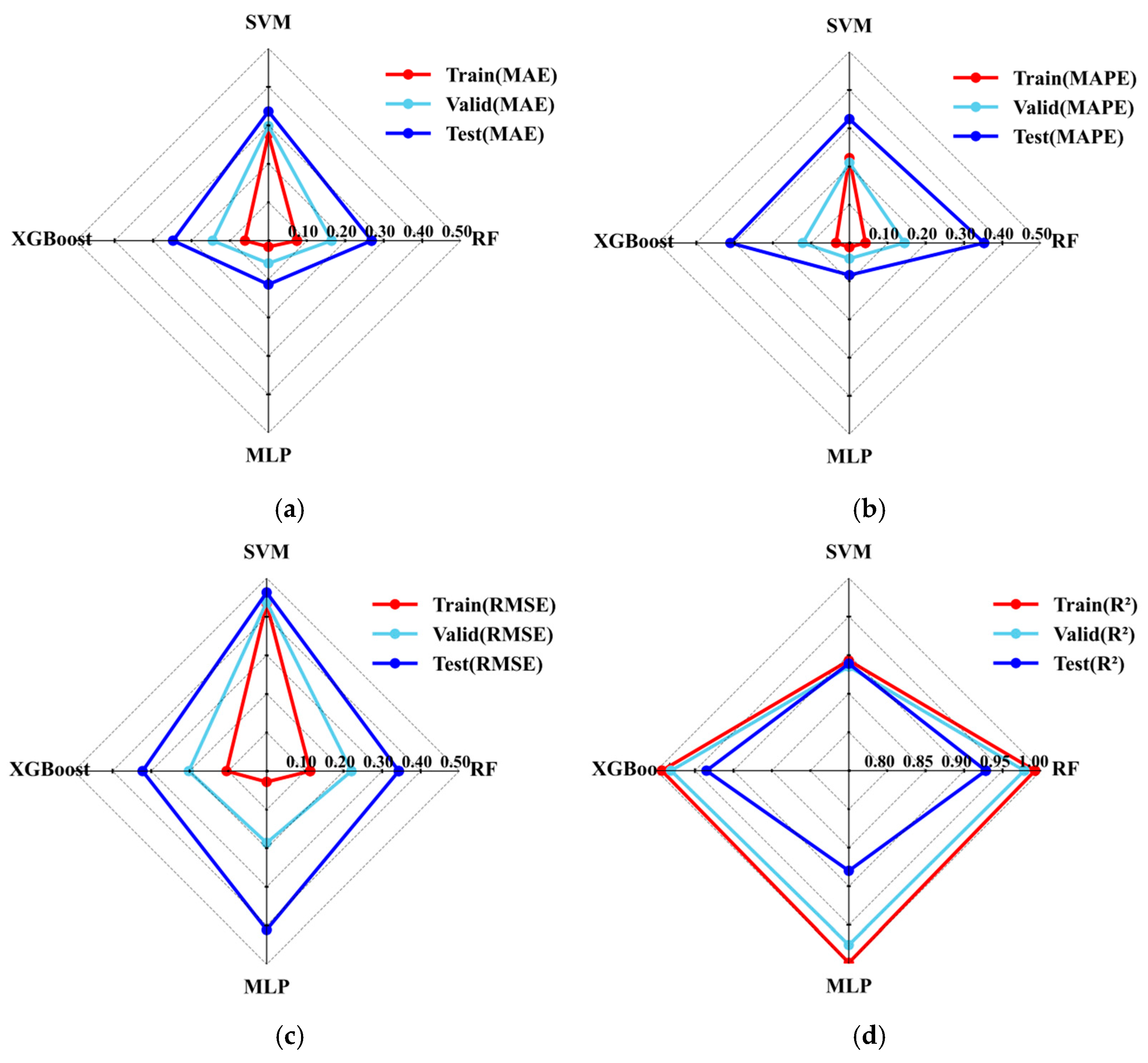
Given the varying suitability of different machine learning models, this study evaluates the performance of four representative models—random forest (RF), support vector regression (SVR), XGBoost, and Multilayer Perceptron (MLP)—in predicting external pressure. The models’ predictive performances are quantitatively compared on the training, validation, and test datasets, with the results illustrated in
Figure 6.
As shown in the figure, the random forest model exhibits noticeably lower errors on the training set compared to the validation and test sets, indicating a certain degree of overfitting during training. Although RF fits the training data well, its generalization ability is limited. Moreover, the relatively low coefficient of determination (R2) on the test set further reflects its lack of robustness. Therefore, the random forest model is not considered the optimal choice for this task.
The SVM model exhibits similar error levels across the training, validation, and test sets, indicating the absence of overfitting, as the training error is not significantly lower than the validation error. However, the overall prediction error remains relatively high, suggesting that the model struggles to accurately capture the nonlinear relationships between the input parameters and the external pressure amplitude. Consequently, SVM is not well-suited for the current prediction task.
The XGBoost model demonstrates a balanced distribution of errors across the training, validation, and test sets, reflecting its strong generalization ability. Nonetheless, its overall error is slightly higher than that of the MLP model, indicating that its predictive performance for the external pressure amplitude is somewhat inferior to that of MLP.
Although the RMSE value of the MLP model on the test set is slightly higher compared to XGBoost and RF, its performance in terms of the MAE and the MAPE remains the best, and it also achieves the highest R2 score. Considering that the RMSE is more sensitive to outliers, the higher RMSE value may be attributed to a few extreme cases, while the overall error distribution remains low and stable. Thus, the MLP model is considered more robust and generalizable for this task.
In summary, the MLP model outperforms the other methods in terms of prediction accuracy in this study. However, its stability and precision under complex operating conditions still have room for improvement. To enhance the model’s robustness and predictive performance across diverse scenarios, future work will consider the integration of intelligent optimization algorithms.
5.2. Comparison of MLP Model Performance Before and After Hyperparameter Optimization
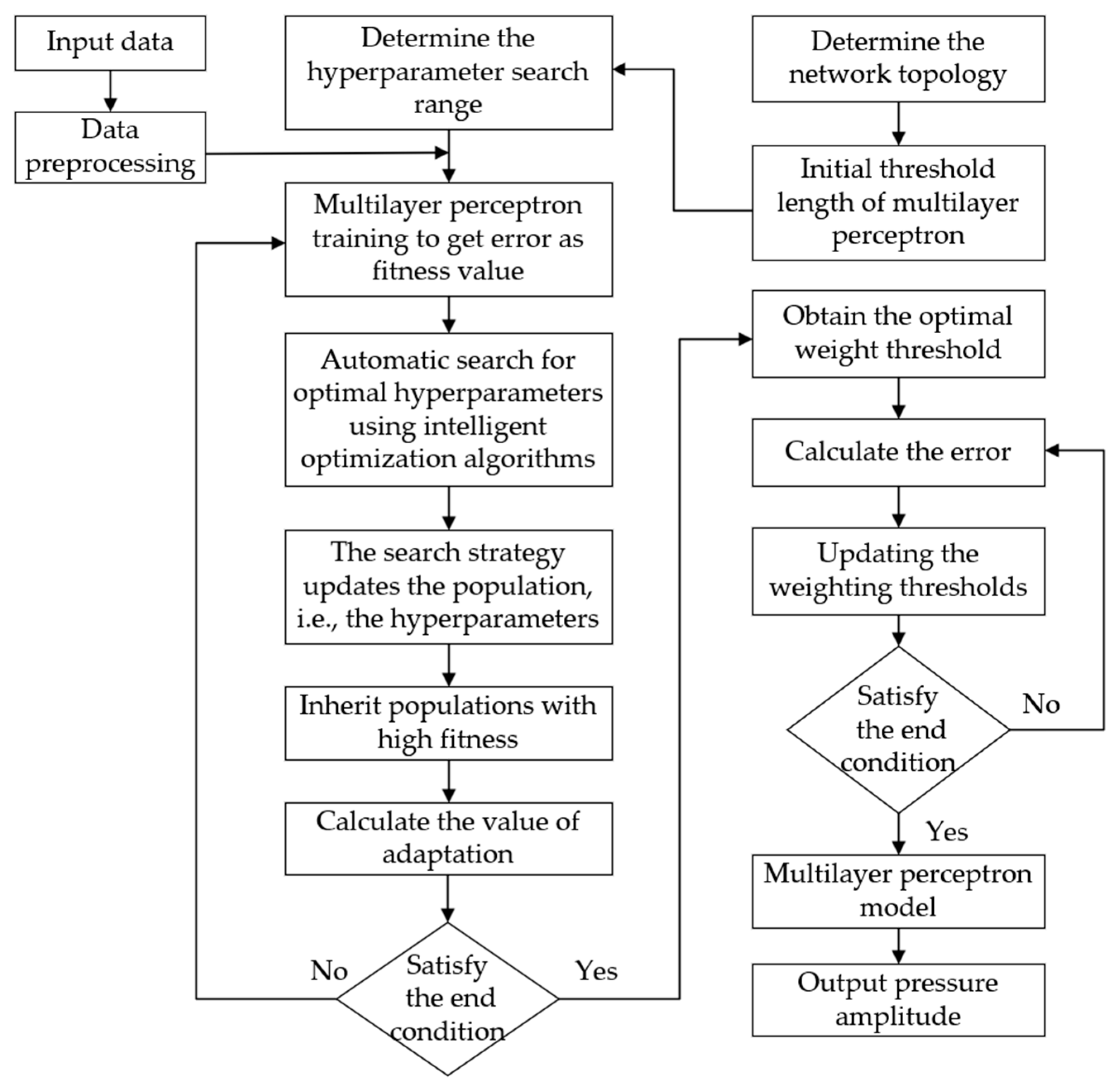
To further improve the prediction accuracy and generalization capability of the MLP model, this study introduces intelligent optimization algorithms to enhance both its architecture and hyperparameter settings. Specifically, adaptive optimization techniques, such as the sparrow search algorithm (SSA) [
40], Simulated Annealing (SA) [
41], Particle Swarm Optimization (PSO) [
42], the Snake Optimization Algorithm (SOA) [
43], and the Sine–Cosine Algorithm (SCA) [
44] are employed to automatically tune key hyperparameters, including the number of hidden layers, the number of neurons per layer, and the regularization coefficient. This approach aims to mitigate the limitations of manual parameter tuning, accelerate convergence, and improve the overall stability of the model. The optimization workflow of MLP using intelligent algorithms is illustrated in
Figure 7.
During the optimization process, an early stopping mechanism is introduced to prevent overfitting. In addition, the Levenberg–Marquardt algorithm is employed for weight updates, with the Mu parameter dynamically adjusted during training to enhance the optimization performance. The hyperparameter search space is defined as follows: the learning rate is set within the range of [0.0001, 0.1], and the number of neurons in the hidden layer is selected from [10, 200]. The mean squared error (MSE) is used as the fitness function to guide the model’s training and optimization.
The optimized MLP model with the improved optimization algorithm is compared with the unoptimized MLP model, and the performance is evaluated using various metrics.
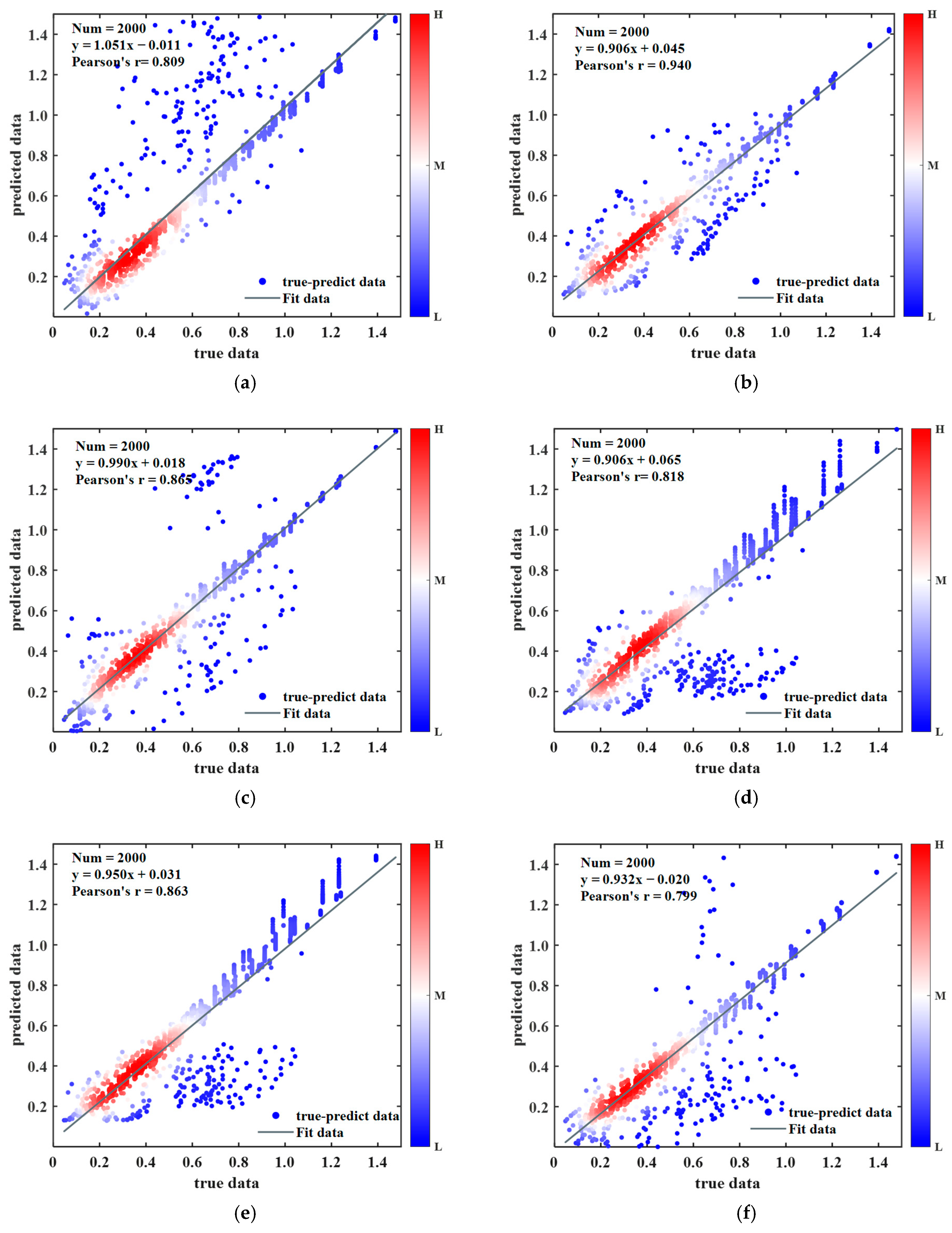
Figure 8 illustrates the prediction performance of six different models on the test set, where the horizontal axis represents the true data values, and the vertical axis represents the model’s predicted values. The color of the data points indicates the density distribution, with high-density areas shown in red and low-density areas in blue. From
Figure 8, it can be observed in subplot (b) that most of the data points are tightly clustered near the ideal diagonal line, indicating that the SSA-MLP model achieves a higher predictive accuracy. The slope of the regression fit line is close to one, and the intercept is small, reflecting a low overall bias. Additionally, the correlation coefficient of this model is higher than that of other models, further confirming its stability and generalization ability on the test set. Overall, SSA-MLP outperforms other methods in accurately capturing the variation trend of the true data, with predictions showing a higher degree of alignment with the true values. Therefore, this method demonstrates superior performance in this task, providing an effective optimization strategy to enhance the predictive capability of the MLP model.
Table 4 shows the comparison of the
R2,
RMSE, and
MAPE metrics for the MLP model with different optimization algorithms on the training set, validation set, and test set. As shown in
Table 4, the
R2 of the MLP model reaches 0.999 on the training set, indicating an extremely high fit. However, the
R2 drops to 0.880 on the test set, suggesting that the model may suffer from overfitting. The
RMSE is 0.028 on the training set, but increases to 0.411 on the test set, further demonstrating the model’s lack of generalization ability. The
MAPE is 0.012 on the training set, but rises to 0.085 on the test set, indicating a substantial error in the unseen data.
The SSA-MLP model achieves an R2 of greater than 0.99 across all the datasets, with a notable improvement on the test set, where the R2 increases to 0.993: a 12.8% increase compared to the MLP model. The RMSE drops to 0.112, a 72.7% decrease, and the MAPE decreases to 0.052, a 38.8% reduction, significantly enhancing the model’s generalization ability. The SA-MLP model achieves an R2 of 0.989 on the test set, with an RMSE of 0.135 and a MAPE of 0.063. While these metrics are slightly lower than those of SSA-MLP, they still outperform the original MLP model. The PSO-MLP model has an R2 of 0.988 on the training set, slightly lower than the original MLP, but the R2 on the test set improves to 0.974. However, the RMSE (0.213) and the MAPE (0.099) on the test set are noticeably higher than those of SA-MLP and SSA-MLP, suggesting that the optimization effect is relatively limited, possibly due to convergence to a local optimum. The SOA-MLP model performs well on the test set, with an R2 of 0.984, an RMSE of 0.169, and a MAPE of 0.075, showing improvements over PSO-MLP, though its metrics are still slightly lower than those of SSA-MLP. The SCA-MLP model achieves an R2 of 0.982, an RMSE of 0.179, and a MAPE of 0.083 on the test set, performing slightly worse than SOA-MLP, but still outperforming the original MLP model.
In conclusion, the SSA-MLP model outperforms all the other models across all the metrics, demonstrating a strong generalization ability and effectively reducing the test error. The SA-MLP model follows closely, particularly excelling in the MAPE, showcasing its robust generalization capability. The PSO-MLP, SOA-MLP, and SCA-MLP models all show improvements over the original MLP, but their optimization effects are not as effective as those of SSA-MLP and SA-MLP. Therefore, MLP models optimized with algorithms like SSA and SA can effectively mitigate overfitting, enhance the generalization ability, and maintain a high prediction accuracy on the test set.
5.3. Model Interpretation
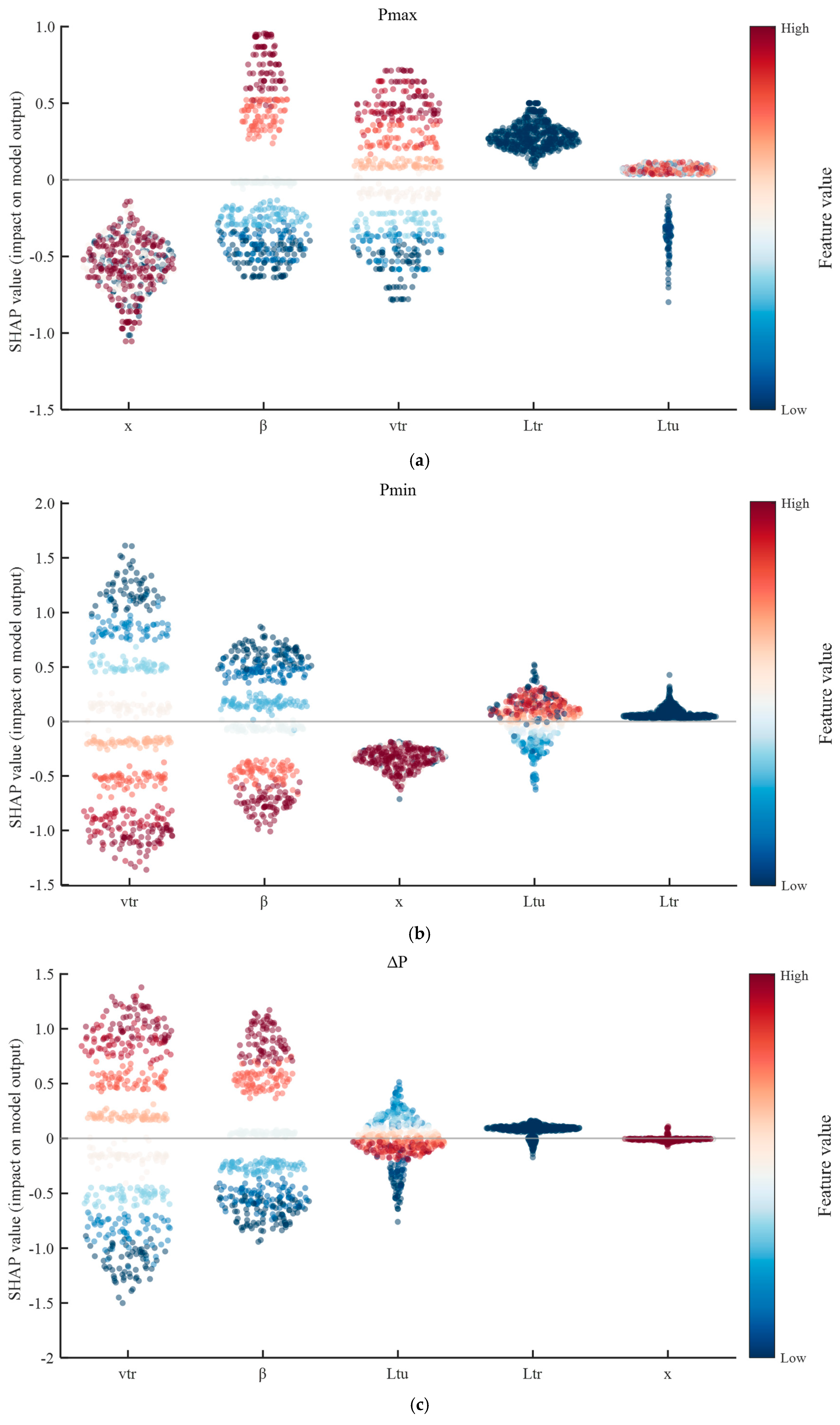
To enhance the model’s interpretability, the SHAP method is employed, grounded in cooperative game theory. Its mathematical basis is detailed in Equation (16), which underpins the analysis results shown in this section. To further explore the influence of each input feature on the SSA-MLP model’s prediction of the external pressure amplitude, SHAP values are used for the interpretability analysis of the model results, as shown in
Figure 9. The horizontal axis represents the input features, while the vertical axis shows the SHAP values, reflecting the contribution of each feature to the model output. A larger SHAP value indicates a greater positive contribution of the feature to the prediction, whereas a smaller SHAP value represents a negative contribution. The color of the points indicates the feature’s value, with red representing higher values and blue representing lower values.
As shown in
Figure 9, for the positive peak value,
, the SHAP value distribution reveals that the relative measurement position,
x, and the blockage ratio,
, have the most significant influences on the prediction results. High feature values are primarily distributed in the region with positive SHAP values, indicating that an increase in these features substantially enhances the predicted value. Train speed,
, also exhibits a strong impact; its SHAP values tend to be positive as the speed increases, suggesting that higher speeds contribute more to the prediction of the
. The influence of train length,
, is moderate, with SHAP values distributed around zero and showing a balanced mix of positive and negative contributions. Tunnel length,
, has the weakest impact, with the SHAP values highly concentrated near zero and exhibiting minimal fluctuation, indicating a limited contribution to the prediction of the
. In summary, the relative measurement position, blockage ratio, and train speed are the dominant factors influencing the prediction of the
, while the effects of train length and tunnel length are comparatively weaker.
For the negative peak value, , train speed, , is the most influential factor, as evidenced by the widest SHAP value distribution. High feature values are mainly associated with negative SHAP values, indicating that a higher train speed corresponds to a larger negative peak amplitude. The blockage ratio ranks second in importance and exhibits a similar trend—larger blockage ratios result in greater negative peak amplitudes. The SHAP values for the relative measurement position are concentrated around zero, suggesting a limited contribution to the prediction. Similarly, the effects of tunnel length and train length are minimal, as indicated by the narrow and centered SHAP distributions. These results demonstrate that train speed and the blockage ratio are the primary factors influencing the prediction of the negative peak value, while the impact of other features is relatively weak.
For the peak-to-peak value, , the SHAP value distribution indicates that train speed, , is the most influential factor. It exhibits the widest SHAP value range, with higher speeds corresponding to positive SHAP values, suggesting that greater speeds lead to larger values. The blockage ratio, , is the second-most important factor, showing that the increases with the increasing blockage ratio. Tunnel length, , ranks next in importance, where longer tunnels are generally associated with negative SHAP values, implying that the decreases as the tunnel length increases—possibly due to the attenuation effect of pressure wave propagation. In contrast, train length, , and the relative measurement position, , have SHAP values concentrated around zero, indicating their limited contribution to the prediction of the . These results demonstrate that train speed and the blockage ratio are the primary factors affecting the prediction of the , followed by tunnel length, while train length and the measurement position have relatively minor impacts.
In summary, train speed and the blockage ratio are identified as the core features influencing the prediction of the external pressure amplitude, while the importance of other features varies depending on the specific prediction target. This conclusion provides a theoretical basis for feature selection and model optimization and further validates the physical consistency and reliability of the SSA-MLP model. The SHAP analysis not only enhances interpretability but also provides actionable engineering insights. For instance, the identification of key influencing factors can guide tunnel and train designers in prioritizing parameters during the early stages of design and optimization. Furthermore, understanding the marginal effects of each input variable supports data-driven decisions in model refinement, contributing to both accuracy and robustness. It is worth noting that although tunnel length exhibits relatively low importance in the SHAP analysis, it was deliberately retained as an input variable. This decision is grounded in its physical relevance to the development and propagation of pressure waves, especially in scenarios involving long tunnels. While its marginal contribution to prediction accuracy may be limited under certain conditions, excluding such a physically meaningful parameter could compromise the model’s generalizability across broader engineering contexts.
6. Conclusions
Based on the findings, this study proposes a hybrid modeling strategy that integrates numerical simulations with machine learning. While CFD provides high-fidelity pressure amplitude data, its high computational cost limits large-scale scenario exploration. To address this, an SSA-MLP model was trained on CFD-generated data under varying tunnel lengths, train speeds, and blockage ratios, enabling fast and reliable pressure predictions across multiple conditions. To improve the model’s transparency, a SHAP analysis was used to quantify the influence of each input. The results show that train speed and the blockage ratio are the most influential factors, followed by tunnel length and measurement position; train length has a minimal effect. These insights support future integrated tunnel–train design and operational optimization.
Several limitations are acknowledged. This study uses a 2D, axisymmetric CFD model, which omits 3D effects, such as crosswinds and lateral flows. Future work should explore full 3D simulations for enhanced accuracy. Additionally, due to time and space constraints, statistical significance testing (e.g., confidence intervals) was not included. Such analyses would strengthen the performance validation and are planned for future studies. Moreover, fixed train nose and tunnel entrance profiles were adopted based on standard references to reduce complexity. While prior studies suggest nose geometry may have a limited impact under certain conditions, this assumption requires further validation. Future work should incorporate a sensitivity analysis of geometric parameters to enhance the model’s generalizability.
Despite these limitations, the hybrid simulation–ML framework developed herein demonstrates a strong potential for practical engineering applications. It can serve as an efficient surrogate model, enabling the rapid evaluation of pressure wave impacts under diverse operational conditions and supporting iterative design and scenario-based assessments for tunnel and rolling stock engineers.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}