Abstract
We examine in this paper the implementation of Bayesian point predictors of order statistics from a future sample based on the lower record values from a generalized exponential distribution.
Keywords:
interval prediction; point prediction; order statistics; kth record values; generalized exponential distribution MSC:
62G30; 62E15; 62N02
1. Introduction
Let be a sequence of independent and identically distributed (iid) random variables with a cumulative distribution function (cdf) and a probability density function (pdf) , where could be a real-valued vector. We will say that is an upper (lower) record value if it exceeds all previous random variables, i.e., if for all . By definition, is the first upper and lower record value.
The origin of the record value theory goes back to [1], where record values were introduced as a model of the successive extreme sequence of iid random variables. Record value theory for the iid case has been studied quite extensively in the literature. See, e.g., [2,3] for a detailed survey and the references inside.
In the continuous case, the definition of the record values is as follows: For a fixed k, we define the sequence , of the lower record times of as follows:
where denotes the order statistic of the sample . The sequence is called the sequence of the lower record values of . In [2], these records are denoted as the Type 2 -record sequence. Note that for , ordinary lower record times and values are recovered.
Record values can be found in many events in our everyday lives. We are especially interested in observing new records in meteorology, hydrology, sports, and so on. Their usefulness is found for characterization purposes, entropy measures, goodness-of-fit procedures, and various other statistical inferences.
The joint density function of the first n lower records is obtained as (see [2]):
where is denoted as an observed realization of .
Suppose that are iid observations with cdf and pdf , which are independent of the X-model. The order statistics of the sample are defined by the increasing order of , denoted as . Order statistics have a broad use in statistics; their usefulness arises for characterization purposes, robust estimation, goodness-of-fit tests, reliability theory, quality control, and so on. Various literature works on order statistics can be found; for a detailed analysis, we recommend [4,5] and the references therein.
Prediction of future events based on current knowledge is a huge issue in statistics. It can be expressed in various contexts, and it can be generated in different forms. Several papers have been published on predicting future record values based on current records (see [2,3,6]) and prediction of future order statistics based on current order statistics (see [4,5,7]). The problem of predicting record values and order statistics from two independent sequences following two parameter exponential distributions was extensively discussed in [8].
The motivation behind this research follows from the point predictors of order statistics of a future sample from an exponential distribution based on the upper record values published in [9]. In this paper, we deal with point predictors of order statistics based on the lower record values from the generalized exponential distribution. Using a monotone transformation between the generalized exponential distribution and exponential distribution, we extend the associated inference and methodology found in [9] to our problem of interest.
This paper is organized as follows: In Section 2, we present a formal structure of the prior model distribution with related posterior densities of the order statistics. The construction of predictive intervals and the expressions for point predictors of the order statistics from a future sample, with the maximum as a special case, is addressed in Section 3 and Section 4. The overall analysis of derived estimators is illustrated on a real data example and presented in Section 5.
2. Prior Information and Predictive Distributions
In general, the two parameter generalized exponential distribution with the shape parameter and scale parameter , denoted as , is determined by the pdf and cdf of the form:
where .
In this work, we deal with the one-parameter generalized exponential distribution, denoted as GED(), with pdf and cdf given, respectively, by:
where is a shape parameter.
The generalized exponential distribution (GED) is often recognized as a good alternative in situations when the Gamma and Weibull distributions lack efficient fits for skew data. For a detailed discussion about the GED, we refer to [10]. One of the several properties of this distribution family is that its nature (concave density, simple form of the pdf and cdf, behavior of the hazard rate function, simple procedure for generating random numbers) leads to easier modeling of skew data (see [11,12]). Specifically, we note that the GED distribution is a generalization of the standard exponential distribution (which can be obtained for ). The connection between and is established by a monotone transformation . Several papers deal with estimation procedures for the parameters of the GE distribution based on records and order statistics (see, for example, Raqab and Ahsanullah [13]) and prediction inference for order statistics from the GED (see [7]).
Let us suppose we observed the first n lower record values from GED(). From (4), (5), and (1), we can easily construct the likelihood function for , given , as:
where and . Here, we denote log as the natural logarithm.
Further, we can extend the reasoning about the parameter by supposing that it is a realization of a random variable with prior distribution:
where are parameters of the prior distribution. These parameters are chosen in most cases based on realizations of previous experiments or relying on the knowledge that the researcher owns. With this in mind, it is easy to obtain the posterior distribution of , given , as:
where is the complete gamma function. It is well known (see [14]) that the Bayes estimator of , with respect to squared error loss (SEL), is the mean of the posterior density (8), i.e.,
The marginal density function of the order statistic from a sample of size m from GED is given by (see [15]):
where is the complete beta function.
The Bayesian predictive density of X, given , is obtained as an integral of the posterior density (8) multiplied by the density function (4) with respect to , i.e.,
By proceeding as before, the Bayesian predictive density of , given , is obtained as an integral of the posterior density (8) multiplied by the conditional density (10) with respect to , i.e.,
For special cases and , the previous formulae reduce to:
and:
which represent the predictive densities of the minimum and the maximum of a future sample of size m, given .
3. Prediction Intervals of Order Statistics
In this section, we construct prediction intervals for , given
For the Bayesian two-sided equi-tailed interval, we need to obtain the solutions of the following equations
where L and U are lower and upper interval bounds, respectively, with as the predictive distribution function of , given . Its form is given by:
for . Due to a rather complicated form of (14), we can only find the solutions of (13) numerically.
If (12) possesses a unimodal shape, the highest posterior density (HPD) interval for given , could be presented by the set:
where is the largest constant such that . The lower and upper bounds of the HPD interval for this case, denoted as , are the solutions of the following optimization problem (see [16], Theorem 1).
In Section 5, we present the construction of these posterior intervals on an example.
Case When (Maximum of the Future Sample)
Within this special case, (14) simplifies to:
so we can express the lower quantile of (16) explicitly as:
Therefore, it is then reasonable to think of the interval as the upper one-sided Bayesian predictive interval for , given .
Moreover, we can directly obtain the Bayesian two-sided equi-tailed prediction interval for the maximum of a future sample of size m by:
4. Point Predictors of Order Statistics
In this section, we obtain Bayes point predictors for order statistics from a future sample of size m based on the observed lower record values, with respect to the squared error loss (SEL) function, as:
where we have , according to ([17], p. 543), and where .
Let us denote:
For special cases and , we have:
and:
Further, we find the mean squared prediction error (MSPE) of , for , as:
The value of can only be estimated numerically because of its complicated form. For case , the MSPE (22) slightly reduces its complexity.
Remark 1. When applying absolute error loss function, the point predictor of the maximum of a future sample is the median of the predictive density (12), i.e.,
Remark 1.
The flexibility of the shape of the prior density is allowed by considering mixtures of prior distributions. Following the same construction principle of (8), if we take as a prior distribution, then , where and for . The Bayes point predictor , in this case, is given by:
where is a digamma function.
5. An Illustrative Examples
In this section, we investigate and compare the performances, through an illustrative example, of the inferential procedures presented in this paper.
For illustrating the usefulness of our proposed predictors, we used a dataset representing time to failure of steel specimens subjected to cyclical stress loading of 35.5 stress amplitudes. The dataset goes as follows:
In [18], the authors assumed that these data followed the two-parameter GED(4.1016,0.0062).
Therefore, when all elements of this dataset are multiplied by 0.0062, we have a dataset that follows the one parameter GE(4.1016); see [10].
The lower records from newly formed data:
provide us the basis for the Bayesian inferential procedures developed in previous sections.
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 0.9672 | 0.7750 | 0.6944 | |||||
| 1.0726 | 0.9672 | 0.8246 | 0.775 | ||||
| 1.0726 | 1.0416 | 1.0292 | 0.9672 | 0.8246 | |||
| 5.2824 | 3.4658 | 2.7404 | 1.0726 | 1.0416 | 1.0292 | 0.9672 |
It is interesting to make results comparable with those found in [9], where the observed upper record values are used as the basis of Bayesian inferential procedures for the exponential distribution. Therefore, we consider three cases with as the parameter values of prior distribution, denoted as Cases I, II, and III, respectively. Jeffrey’s non-informative prior with is considered as well.
To compare the proposed methods, a numerical study was conducted in statistical software R [19], up to four digit accuracy. It is important to note that the shape of the posterior density function for all cases under consideration followed a similar uni-modal shape as the one presented in Figure 1. Therefore, using the nominal value , we obtained the Bayesian two-sided equi-tailed and HPD intervals for the order statistics from future samples of size , and 20.
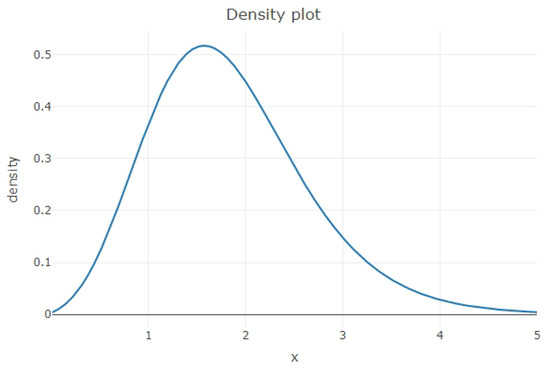
Figure 1.
Posterior density function for Case I when
The data analysis indicated that the corresponding Bayesian credible intervals differed notably when compared with the case of non-informative priors in the sense that they provided more accurate results. Furthermore, when the prior information became available, the width of the intervals decreased. Case III dominated in these circumstances, which was quite reasonable due to the mean and variance of the prior distribution for this case. Furthermore, the HPD method was seen to be more precise than the other method. However, it was seen that the HPD method had several drawbacks when considering the minimum of the sample as the size of the future sample increased. Therefore, the Bayesian equi-tailed interval was adopted as preferable for considerations in practice. Since the MSPEs of the point predictors depend on , we evaluated the estimate of from (9). These results are presented in Table 1, Table 2, Table 3 and Table 4 for Cases I, II, and III and for the case of non-informative priors, respectively, when and 2.

Table 1.
The 95% Bayesian prediction interval and point predictor for of a future sample of size m when . HPD, highest posterior density.
Table 2.
The 95% Bayesian prediction interval and point predictor for of a future sample of size m when .
Table 3.
The 95% Bayesian prediction interval and point predictor for of a future sample of size m when .
Table 4.
The 95% Bayesian prediction interval and point predictor for of a future sample of size m when .
MSPEs were increasing with respect to k, while the equi-tailed credible interval width was decreasing with respect to k. Case III did not dominate other cases. Case III did not have the smallest values of the MSPEs, and it did not have the shortest intervals everywhere. In the most cases, the HPD intervals were shorter than the equi-tailed ones.
6. Conclusions
In this paper, we addressed the problem of presenting Bayesian point predictors of order statistics of a future sample of size m based on the lower record values from a GED. With respect to the SEL, we investigated the point prediction of order statistics from a future sample. Furthermore, we presented the construction of Bayesian and HPD intervals. An illustrative example was given to show the implementation of the procedures developed.
It may be interesting to compare point predictors for order statistics based on lower record values from GED with those point predictors of order statistics when upper record values are observed from the exponential distribution. This may motivate researchers to transform data from the exponential distribution to the GED in order to obtain better point predictors.
Funding
This research received no external funding.
Acknowledgments
The author would like to thank the referees for their valuable comments and suggestions, which significantly improved the quality of the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Chandler, K.N. The distribution and frequency of record values. J. R. Stat. Soc. Ser. (Methodol.) 1952, 14, 220–228. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Arnold, B.C.; Nagaraja, H.N. Records; Wiley: Hoboken, NJ, USA, 1998. [Google Scholar]
- Nevzorov, V.B. Records: Mathematical Theory; Translations of Mathematical Monographs; AMS: Providence, RI, USA, 2000. [Google Scholar]
- Arnold, B.C.; Balakrishnan, N.; Nagaraja, H.N. A First Course in Order Statistics; SIAM: Philadelphia, PA, USA, 2008. [Google Scholar]
- David, H.A.; Nagaraja, H.N. Order Statistics; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2003. [Google Scholar]
- Ahsanullah, M. Linear prediction of record values for the two parameter exponential distribution. Ann. Inst. Stat. Math. 1980, 32, 363–368. [Google Scholar] [CrossRef]
- Ahmad, A.A.; Raqab, M.Z.; Madi, M.T. Bayesian prediction intervals for future order statistics from the generalized exponential distribution. J. Iran. Stat. Soc. 2007, 6, 17–30. [Google Scholar]
- Ahmadi, J.; Balakrishnan, N. Prediction of order statistics and record values from two independent sequences. Statistics 2010, 44, 417–430. [Google Scholar] [CrossRef]
- Ahmadi, J.; MirMostafaee, S.M.T.K.; Balakrishnan, N. Bayesian prediction of order statistics based on k-record values from exponential distribution. Statistics 2011, 45, 375–387. [Google Scholar] [CrossRef]
- Gupta, R.D.; Kundu, D. Theory & methods: Generalized exponential distributions. Aust. N. Z. J. Stat. 1999, 41, 173–188. [Google Scholar]
- Gupta, R.D.; Kundu, D. Closeness of gamma and generalized exponential distribution. Commun. -Stat.-Theory Methods 2003, 32, 705–721. [Google Scholar] [CrossRef]
- Gupta, R.D.; Kundu, D. Discriminating between Weibull and generalized exponential distributions. Comput. Stat. Data Anal. 2003, 3, 179–196. [Google Scholar] [CrossRef]
- Raqab, M.M.; Ahsanullah, M. Estimation of the location and scale parameters of generalized exponential distribution based on order statistics. J. Stat. Comput. Simul. 2001, 69, 109–123. [Google Scholar] [CrossRef]
- Jaheen, Z.F. Empirical Bayes inference for generalized exponential distribution based on records. Commun.-Stat.-Theory Methods 2004, 33, 1851–1861. [Google Scholar] [CrossRef]
- Raqab, M.Z. Generalized exponential distribution: moments of order statistics. Statistics 2004, 38, 29–41. [Google Scholar] [CrossRef]
- Chen, M.H.; Shao, Q.M. Monte Carlo estimation of Bayesian credible and HPD intervals. J. Comput. Graph. Stat. 1999, 8, 69–92. [Google Scholar]
- Gradshteyn, I.S.; Ryzhik, I.M. Table of Integrals, Series, and Products; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Asgharzadeh, A.; Valiollahi, R.; Raqab, M.Z. Estimation of Pr(Y<X) for the two-parameter generalized exponential records. Commun. -Stat.-Simul. Comput. 2017, 46, 379–394. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2015. [Google Scholar]
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).