Abstract
In linear regression analysis, the independence assumption is crucial and the ordinary least square (OLS) estimator generally regarded as the Best Linear Unbiased Estimator (BLUE) is applied. However, multicollinearity can complicate the estimation of the effect of individual variables, leading to potential inaccurate statistical inferences. Because of this issue, different types of two-parameter estimators have been explored. This paper compares t-tests for assessing the significance of regression coefficients, including several two-parameter estimators. We conduct a Monte Carlo study to evaluate these methods by examining their empirical type I error and power characteristics, based on established protocols. The simulation results indicate that some two-parameter estimators achieve better power gains while preserving the nominal size at 5%. Real-life data are analyzed to illustrate the findings of this paper.
1. Introduction
In linear regression analysis, the independence assumption of the explanatory variables is crucial, as the ordinary least square (OLS) estimator is commonly used as the Best Linear Unbiased Estimator (BLUE). However, multicollinearity presents a significant obstacle, complicating the estimation of unique effects for individual variables. This often leads to OLS producing inefficient and unreliable estimates, marked by high standard errors and inaccurate confidence intervals (Kibria, 2003) [1]. To overcome these challenges, researchers have developed various alternative biasing estimators to replace OLS, each with unique approaches to improve estimation accuracy. Pioneering efforts in this area include contributions from Hoerl and Kennard (1970) [2] and subsequent enhancements by Ehsanes Saleh and Kibria (1993) [3], Kibria (2003) [1], Alheety et al. (2025) [4], Dawoud and Kibria (2020) [5], Hoque and Kibria (2023) [6], Hoque and Kibria (2024) [7], Nayem et al. (2024) [8], and Yasmin and Kibria (2025) [9], among others.
Hypothesis testing is another aspect of statistical inference, especially in regression models, where it is necessary to test the significance of the coefficients. This procedure helps identify which variables are significant predictors of the outcome.
Our main objective is to find out the statistical significance of the regression coefficients within our model using hypothesis testing. However, the current body of research on this topic is somewhat limited. Halawa and Bassiouni (2000) [10] were instrumental in presenting approximate t-tests for regression coefficients within the framework of ridge regression, with a focus on empirical sizes and powers. Building on this, Cule et al. (2011) [11] assessed these tests for linear and logistic ridge regression frameworks, further advancing our understanding of their effectiveness across different types of regression models. Gokpinar and Ebegil (2016) [12] also contributed by evaluating the effectiveness of t-tests across various estimators of the ridge parameter , based on insights from the existing literature. Additionally, Kibria and Banik (2019) [13] as well as Perez-Melo and Kibria (2020) [14] investigated the robustness of t-tests across different ridge parameters. Despite these advancements, continued research is essential to deepen our understanding and enhance methodologies for testing the significance of regression coefficients.
Additionally, within the context of the Liu estimator, Ullah et al. (2017) [15] focused on testing coefficients specific to this regression framework. Expanding on this work, Perez-Melo et al. (2022) [16] conducted a comparative analysis of Ridge, Liu, and Kibria Lukman estimators, enhancing our understanding of regression coefficient testing across different estimation methods. These studies underscore the significance of exploring diverse regression techniques and their implications for hypothesis testing in regression analysis.
This study aims to thoroughly contrast various t-test statistics for testing different regression coefficients across multiple two-parameter estimation methods. We will evaluate the performance of these tests within several frameworks, for example the Yang and Chang (2010) [17] estimator, Modified Ridge Type (MRT) estimator, and other two-parameter estimators, and compare them to ordinary least square (OLS). By employing Monte Carlo simulation, we will examine the empirical type I error for each and then estimate the power properties of each method, guided by procedures established by Halawa and Bassiouni (2000) [10] and Gokpinar and Ebegil (2016) [12]. We will look at different two-parameter estimators together to see which one performs better than others. Previous work has not comprehensively compared all two-parameter methods against OLS, so our objective is to examine most of them and recommend the ones that hold type I error rates and demonstrate gains in power. This research also seeks to enhance the understanding of regression coefficient testing methods and offer valuable insights for practitioners in model selection and interpretation in regression analysis.
This paper is structured as follows: Section 2 outlines the statistical methodology, detailing various estimators for different parameters and . Section 3 presents the methods and explains the results of the simulation study. Section 4 provides an applied example to demonstrate the performance of several best selected methods compared to OLS. Finally, Section 5 offers a summary and concluding remarks.
2. Statistical Framework
In this section, we will explain the structure of the linear regression model and explore the estimators used in this context.
2.1. Framework of Model and Several Established Estimators
We consider the following model:
where is an vector representing a response variable, is an regressor matrix, assumed to have a full rank, is a vector of regression coefficients, and is an vector of normally distributed residuals, satisfying and , with being an identity matrix.
The ordinary least square (OLS) estimator of in the linear regression model is given by the following:
To test whether the th component of is equivalent to zero, i.e., , the test statistics is defined based on the OLS estimator:
where is the th component of , and is the standard error of , which is the square root of the th diagonal entry of the covariance matrix , where
The test statistic in Equation (3) follows Student’s t-distribution with degrees of freedom under the null hypothesis. However, if becomes ill conditioned when multicollinearity arises, the OLS estimator may yield unbalanced estimates with excessively high variances. To mitigate this issue, Hoerl and Kennard (1970) [2] established other shrinkage regression estimators.
2.2. Two Parameter Estimators
In this section, we will consider various two-parameter estimators that are available in the literature.
2.2.1. Liu Type of Two-Parameter Estimator
To overcome the multicollinearity problem, Liu (2003) [18] proposed a two-parameter estimator,
where is any estimator of ; if we choose and then we can obtain
The expected value and covariance matrix are given, respectively, as follows:
where , and is estimated as follows:
From Liu (2003) [18], we will consider the following values of and :
2.2.2. Ozkale and Kaciranlar Two-Parameter Estimator
Ozkale and Kaciranlar (2007) [19] consider the following estimator,
where .
We have the expected value and covariance matrix for as follows:
is estimated as follows:
Following Ozkale and Kaciranlar (2007) [19], we have the optimal and as follows:
and
Hoerl et al. (1975) [20] used the harmonic mean of values which is identified by Hoerl and Kennard (1970) [2]. Also, Kibria (2003) [1] proposed the arithmetic mean of the same values. Therefore, both arithmetic and harmonic means of values can be used for estimating this shrinkage parameter . Then,
We can see that depends on k and also depends on . So, we can select parameters and by applying the following iterative method.
Step 1. First, we will calculate .
Step 2. Then, we will obtain or by using from Step 1.
Step 3. We will estimate from estimators or from Step 2.
Step 4. If we find that is negative, we need to use because is always less than one and bigger than zero, i.e., .
2.2.3. New Biased Estimator Based on Ridge
Sakallıoglu˘ and Kiciranlar (2008) [21] proposed the following two-parameter estimator:
The expected value and covariance matrix are given, respectively, as
where and is estimated as
For estimating the unknown parameters and , we can choose
where for fixed , we use and .
2.2.4. Yang and Chang Two-Parameter Estimator
Yang and Chang (2010) [17] consider the following estimator:
where , and and are biasing parameters.
The expected value and covariance matrix of are as follows:
and is estimated as
For , we fix , and based on Yang and Chang (2010) [17], we obtain the optimal as
We apply different formulas for this parameter, such as arithmetic mean, harmonic mean, and median.
Then, we obtain
The estimators of parameters and in are acquired by using the following iterative method:
Step 1: Obtain an initial estimate using .
Step 2: Estimate using in Step 1.
Step 3: Find using in Step 2.
Step 4. If does not hold, use .
2.2.5. Almost Unbiased Two-Parameter Estimator
Wu and Yang (2011) [22] consider the following estimator:
The expected value and covariance matrix of are as follows:
where and is estimated as
Now, and .
We apply the arithmetic mean and harmonic mean for this parameter.
We can select parameters and by using the following approach.
Step 1: We compute using .
Step 2: We obtain using .
Step 3: We find using from Step 2.
Step 4. If is negative, we need because it is always less than 1 but it may be smaller than 0.
2.2.6. Unbiased Two-Parameter Estimator
Wu (2014) [23] considers the following two-parameter estimator:
where and for , , and is called the prior information and is a random vector which has a specified mean and covariance.
The expected value and covariance matrix of are as follows:
and is estimated as
Now, for fixed , we need to obtain an estimator of as follows:
where .
If then
Otherwise, .
Parameter is defined as
If , then
Otherwise,
The selection of parameters and can be obtained by using the following approach.
Step 1: Estimate .
Step 2: Compute a random vector J.
Step 3: Compute using J and .
Step 4: Compute .
2.2.7. Dorugade Modified Two-Parameter Estimator
Dorugade (2014) [24] considers the following modified estimator:
where .
The expected value and covariance matrix of are as follows:
and is estimated as
For unknow values of and , some well know methods are and .
The optimal can be considered as follows:
2.2.8. Modified Almost Unbiased Liu Estimator
Arumairajan and Wijekoon (2017) [25] consider the following two-parameter estimator:
where .
The expected value and covariance matrix of are as follows:
and is estimated as
Now, , and .
For the optimal value, we use the arithmetic mean value of .
2.2.9. Modified Almost Unbiased Two-Parameter Estimator
Lukman et al. (2019) [26] consider the following estimator:
where .
The expected value and covariance matrix of are as follows:
and is estimated as
For the estimation of and , following Hoerl and Kennard (1970) [2], , and the harmonic version of the proposed is , and .
2.2.10. Modified New Two-Parameter Estimator
Lukman et al. (2019) [27] consider the following estimator:
where is the prior information on and it tends to become if approaches infinity.
Let us recall that and let .
The expected value and covariance matrix of are as follows:
and is estimated as
For , we fix , based on Lukman et al. (2019) [27], and we obtain the optimal as
and the harmonic mean is
Then, we obtain
The selection of parameters and in is obtained using the following method:
Step 1: First, we will obtain an initial estimate of using .
Step 2: We will obtain using .
Step 3: We will estimate using .
Step 4. If is negative, we must use . However, takes a value between 0 and 1.
2.2.11. Modified Ridge Type
Lukman et al. (2019) [28] consider the following two-parameter estimator:
where , with and as biasing parameters.
The expected value and covariance matrix of are as follows:
and is estimated as
As the shrinkage parameters and are both unknown, it is necessary to estimate them from the observed data. This section provides the formulas for various shrinkage parameter regression estimators.
Lukman et al. (2019) [28] proposed an estimator as follows:
We can obtain the harmonic mean of as
and
Also, the harmonic means of is
The selection of parameters and in is obtained by using the following method:
Step 1: We need to obtain an initial estimate of using .
Step 2: We obtain using from Step 1.
Step 3: We estimate using from Step 2.
Step 4. If is negative, we use .
2.2.12. A New Biased Estimator by Dawoud and Kibria
Dawoud and Kibria (2020) [5] consider the following two-parameter estimator:
where .
The expected value and covariance matrix of are as follows:
and is estimated as
For , we fix , and we obtain the optimal as
where .
Then, for the optimal , we obtain
where .
In addition, .
The selection of parameters and in is obtained by using the following method:
Step 1: Obtain an initial estimate of using .
Step 2: Obtain using .
Step 3: Estimate using .
Step 4. If is not between 0 and 1, use .
2.2.13. Generalized Two-Parameter Estimator
Zeinal (2020) [29] proposed the following two-parameter estimator:
where .
The expected value and covariance matrix of are as follows:
where .
and is estimated as
For the unknown parameter, we obtain the optimal for fixed as
Then, we obtain
and take the arithmetic mean of the above-mentioned .
The selection of parameters and in is obtained by using the following method:
Step 1: We need an initial estimate of using
Step 2: We obtain using .
Step 3: W estimate using .
Step 4. If is negative, we use .
2.2.14. Siray Two-Parameter Estimator
Şiray et al. (2021) [30] consider the following two-parameter estimator:
where .
The expected value and covariance matrix of are as follows:
and is estimated as
Now, , so we can find the harmonic mean and median of ,
and , so we can also find the harmonic mean and median of .
The estimation procedure for the biasing parameters is obtained by using the following method.
Step 1: Take an initial estimate of from .
Step 2: Obtain using .
Step 3: Estimate using .
Step 4. If is negative, use .
2.2.15. Unbiased Modified Two-Parameter Estimator
Proposed by Abidoye, Ajayi, Adewale, and Ogunjobi (2022) [31], this estimator is defined as
where and for with being uncorrelated with .
The expected value and covariance matrix of are as follows:
and is estimated as
In this study, we choose and .
2.2.16. Ahamd and Aslam’s Modified New Two-Parameter Estimator
Ahmad and Aslam (2022) [32] consider the following two-parameter estimator:
where .
The expected value and covariance matrix of are as follows:
and is estimated as
Now, .
We use the harmonic mean of values, and
The selection of parameters and in is obtained by using the following method:
Step 1: We need an initial estimate of using .
Step 2: We obtain using .
Step 3: We estimate using .
Step 4. If is negative, we use .
2.2.17. Modified Liu Ridge Type
Aslam and Ahmad (2022) [33] consider the following two-parameter estimator:
where .
The expected value and covariance matrix of are as follows:
and is estimated as
Now, , and we can find the max value of , with .
The selection of parameters and is obtained by using the following method:
Step 1: We need to obtain an initial estimate of using .
Step 2: We obtain using .
Step 3: We estimate using .
Step 4. If is negative, we use .
2.2.18. New Biased Regression Two-Parameter Estimator
Proposed by Dawoud, Lukman, and Haadi (2022) [34], the estimator is defined as:
where , with from KL, and and .
The expected value and covariance matrix of are as follows:
and is estimated as
Here, and we find the minimum value of .
With , we find the minimum value of .
The selection of parameters and is carried out as follows:
Step 1: Obtain an initial estimate of using .
Step 2: Obtain using .
Step 3: Estimate using .
Step 4. If is negative, use
2.2.19. Biased Two-Parameter Estimator
Proposed by Idowu, Oladapo, Owolabi, and Ayinde (2022) [35], this estimator is defined as follows:
where and .
The expected value and covariance matrix of are as follows:
and is estimated as
Now, .
And
2.2.20. New Two-Parameter Estimator
Owolabi, Ayinde, Idowu, Oladapo, and Lukman (2022) [36] consider the following new two-parameter estimator:
where .
The expected value and covariance matrix of are as follows:
and is estimated as
Now, and the harmonic mean is , while .
The selection of parameters and is obtained by using the following method:
Step 1: We can obtain an initial estimate of using .
Step 2: We can obtain using from Step 1.
Step 3: We can estimate using from Step 2.
Step 4. If is negative, we must use .
2.2.21. New Ridge-Type Estimator
The two-parameter estimator proposed by Owolabi, Ayinde, and Alabi (2022) [37] is defined as
where .
The expected value and covariance matrix of are as follows:
and is estimated as
Now, and .
The selection of parameters and is carried out as follows:
Step 1: We obtain an initial estimate of using .
Step 2: We obtain using from Step 1.
Step 3: We estimate using from Step 2.
Step 4. If is negative, we use .
2.2.22. Modified Two-Parameter Estimator
Proposed by Owolabi, Ayinde, and Alabi (2022) [38], this estimator is defined as
The expected value and covariance matrix of are as follows:
where and is estimated as
Here, and we use the arithmetic mean of , while .
In cases where is not between 0 and 1, we must use .
2.2.23. Modified Two-Parameter Liu Estimator by Abonazel
Abonazel (2023) [39] considers the following estimator which they use for the Conway–Maxwell Poisson regression model and Abdelwahab et al. (2024) [40] use it for the Poisson regression model, so we extended it for the Gaussian linear regression model:
where .
The expected value and covariance matrix of are as follows:
and is estimated as
Now, and .
2.2.24. Liu–Kibria–Lukman Two-Parameter Estimator
Idowu et al. (2023) [41] proposed the following estimator:
where and .
The expected value and covariance matrix of are as follows:
and is estimated as
Now, .
For parameter which is proposed by Kibria and Lukman (2020) [42], it is given as follows:
2.2.25. Two-Parameter Ridge Estimator
Proposed by Shakir Khan, Ali, Suhail et al. (2024) [43], this estimator is defined as
where .
The expected value and covariance matrix of are as follows:
and is estimated as
Now, and .
The above values is utilized for for computing the value of .
The above values of are used to compute the optimum values of .
We provide a summary in Table 1, which shows the name and parameters for every two-parameter estimation method, to facilitate better understanding.

Table 1.
Summary table for each estimator.
To test whether the th component of is equivalent to zero, we use the approach of Halawa and Bassiouni (2000) [10]. The t-test statistic for this test is defined as follows:
where represents the th component of various estimators such as . The term is the standard error of , which is calculated from the square root of the th diagonal element of the covariance matrix . Under the null hypothesis, the test statistics in Equation (55) follows an approximate Student’s t-distribution with degrees of freedom.
3. A Monte Carlo Simulation Study
We conduct a Monte Carlo study to compare the performance of the test statistics in this section. First, we present the empirical type I error rates of the tests in Section 3.1. Then, we discuss the empirical powers of the tests in Section 3.2.
3.1. Type I Error-Rated Simulation Procedure
3.1.1. Simulation Methodology
In the simulation technique, the explanatory variables X are generated from the formula , where is an matrix with orthogonal columns, is the diagonal matrix containing the eigenvalues of the correlation matrix, and is the matrix of normalized eigenvectors of the correlation matrix. This systematic generation of explanatory variables allows for a comprehensive evaluation of type I errors in regression analysis.
In this study, we generate observations for the explanatory variables according to
where is an independent normal (). We can check the performance based on the type I error rates across various biasing parameters. The comparison considers different values of sample sizes , and 100, and a varying number of explanatory variables = 3, 5, and 10. Also, several correlation levels , and 0.99 are chosen, along with the assumed standard deviations of errors . The experiment is replicated 5000 times using R software [44].
Following Halawa and Bassiouni (2000) [10], the determination of the most and least favorable orientations () is carried out using the eigenvectors after normalization, which corresponds to the largest and smallest eigenvalues of in their correlation form. The most favorable (MF) orientation is , where represents a vector of ones, and the least favorable (LF) orientation is any normalized vector orthogonal to . In the MF orientation, all components of are equal, whereas in the LF orientation, all components are equally likely.
Studies have shown that the LF orientation yields tests that maintain the nominal type I error level regardless of the estimator used. Conversely, under the MF orientation, some tests exhibit higher type I error rates than expected. Thus, for practical purposes, the MF orientation helps to identify and discard tests that are too liberal in rejecting the null hypothesis. Consequently, our simulations are conducted based on the MF orientation of .
To begin, we compare the type I error rates under the component of the orientation vector of . For this purpose, the th component is replaced by zero, denoted as , . Subsequently, the test statistics are derived from the models, and the type I error rates are estimated by calculating the proportion of test statistic values which are more than the critical values from the t-distribution with d.f. This procedure helps us to evaluate the performance of the test in correctly rejecting null hypotheses when they are true, thereby providing the empirical size of the tests. The simulated type I error rates for different sample sizes and regressors are presented in Table 2, Table 3 and Table 4 for , and 0.99, respectively.
Table 2.
Type I error rate for ρ = 0.80 and α = 0.05 under MF orientation.
Table 3.
Type I error rate for ρ = 0.90 and α = 0.05 under MF orientation.
Table 4.
Type I error rate for ρ = 0.99 and α = 0.05 under MF orientation.
3.1.2. Interpretation of Simulation Results for Type I Error
Assuming a nominal type I error rate of 5%, and using a simulation of 5000 iterations, we anticipate that the observed type I error will typically lie within the interval of , approximately (4.4%, 5.6%). To maintain consistency, tests with an average observed type I error exceeding 0.06 were excluded from the comparison.
3.2. Statistical Power Simulation Procedure
3.2.1. Monte Carlo Approach for Statistical Power
In this section, we conduct a comparative analysis of various test statistics with a focus on their power. Building upon the methodology outlined by Gokpinar and Ebegil (2016) [12], our objective is to evaluate the efficacy of these tests by computing their empirical power. By assessing each test’s ability to correctly reject false null hypotheses, we gain insights into their relative performance and robustness in detecting true effects. This analysis provides valuable information for researchers and practitioners in choosing the most suitable test statistic for their regression models based on power considerations.
Based on the previous analysis of type I error, we have discarded the tests that significantly exceeded the nominal size of 5%. The remaining test statistics will now be compared in terms of power. To calculate power, we modify the th component of the vector by replacing it with , where is a positive integer and . We choose such that for each combination of correlation level and number of predictors, the maximum power achieved by the most powerful test is 100%. For this comparison, we select . This procedure allows us to evaluate the relative power of the remaining tests under various conditions, providing insights into their ability to detect true effects in the data.
Using 5000 simulation iterations, we estimate the power of these tests by calculating the proportion of times that the absolute value of the test statistic is more than the critical value . We explore different combinations of sample sizes, with , and 100, and different numbers of regressors, with and 10. These computations are conducted across correlation levels of 0.80, 0.90, and 0.99. By systematically varying these parameters, we obtain a comprehensive understanding of the power of each test under different conditions, allowing us to assess their relative effectiveness in detecting true effects in the data. The simulated power of the tests for different sample sizes and regressors is presented in Table 5, Table 6 and Table 7 for , and 0.99, respectively.
Table 5.
Statistical power of test for ρ = 0.80 and α = 0.05.
Table 6.
Statistical power of test for ρ = 0.90 and α = 0.05.
Table 7.
Statistical power of test for ρ = 0.99 and α = 0.05.
3.2.2. Interpretation of Simulation Results for Power
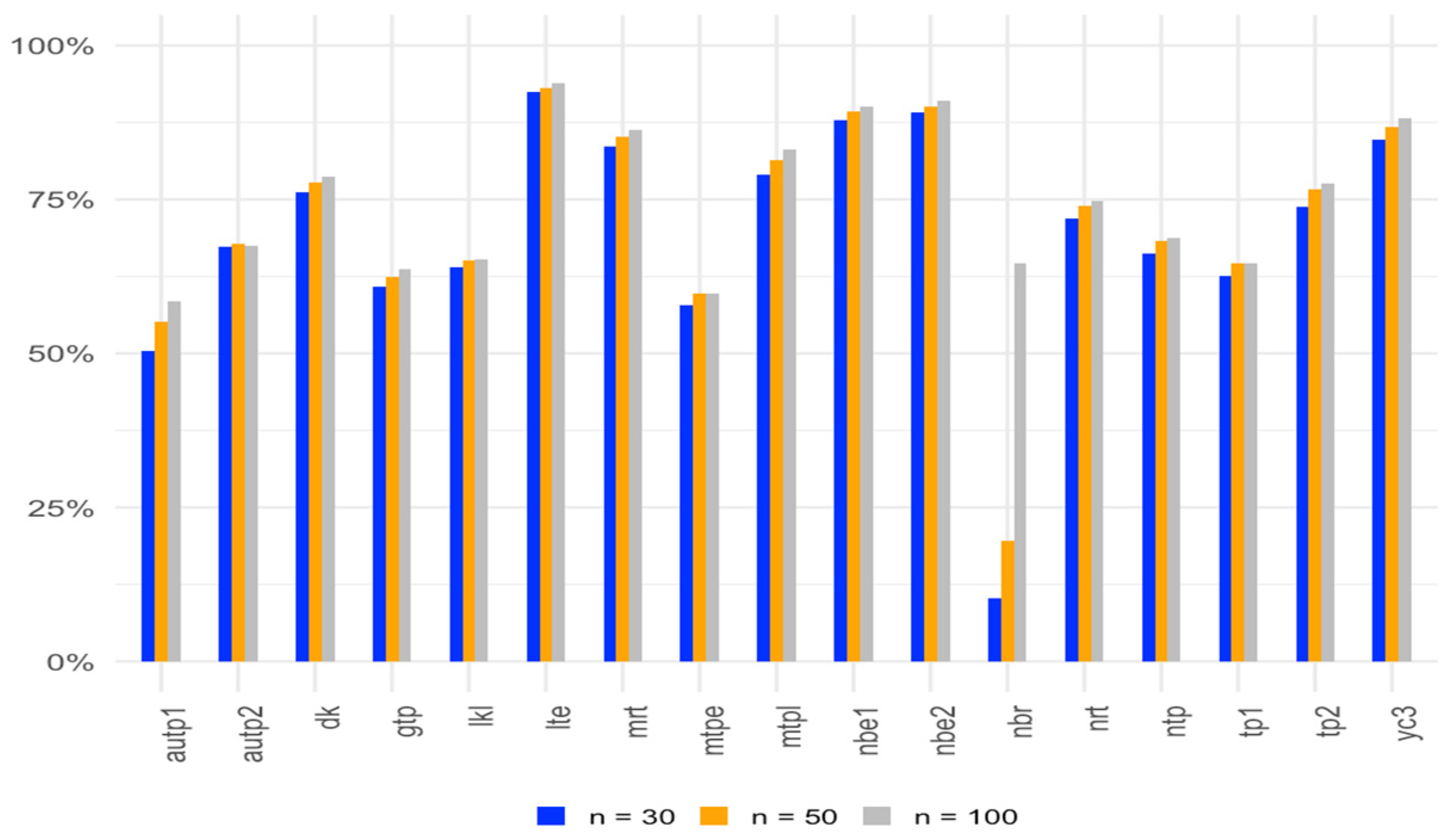
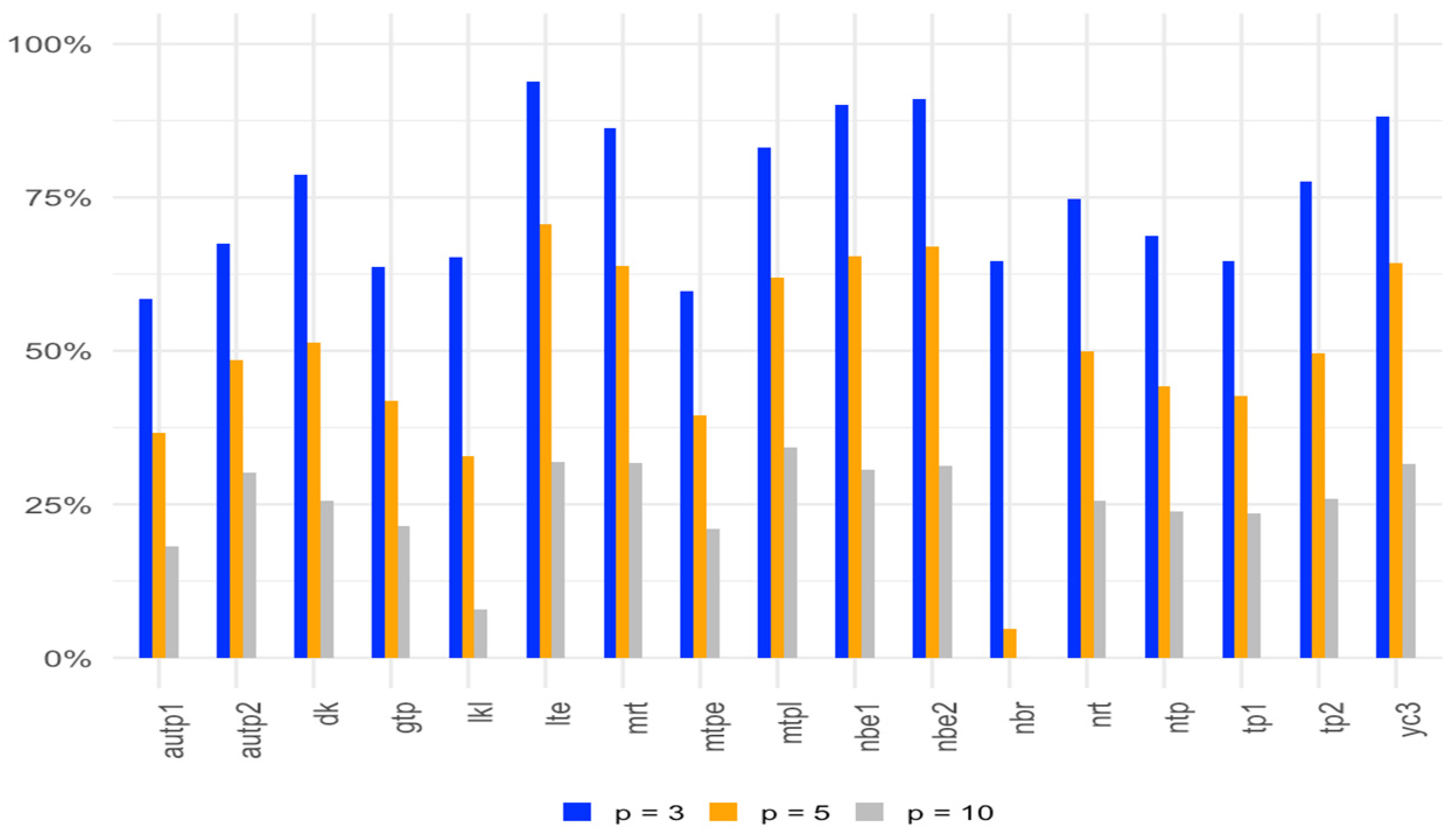
Based on the results from Table 5, Table 6 and Table 7, we observe that as the sample size increases, while keeping the other conditions constant, the power of the tests generally increases, as expected. Additionally, it is apparent that most of the tests exhibit greater power compared to the t-test across correlation levels of 0.80, 0.90, and 0.99. It is noted that for a given sample size, a smaller number of regressors results in higher power than a large number of regressors. Among them, some two-parameter methods such as LTE, NBE2, MRT, and LKL exhibit higher power than others compared to OLS. Additionally, YC3 and DK also show better power. These findings underscore the effectiveness of the related estimators in enhancing the power of hypothesis tests in regression analysis, particularly in the presence of multicollinearity.
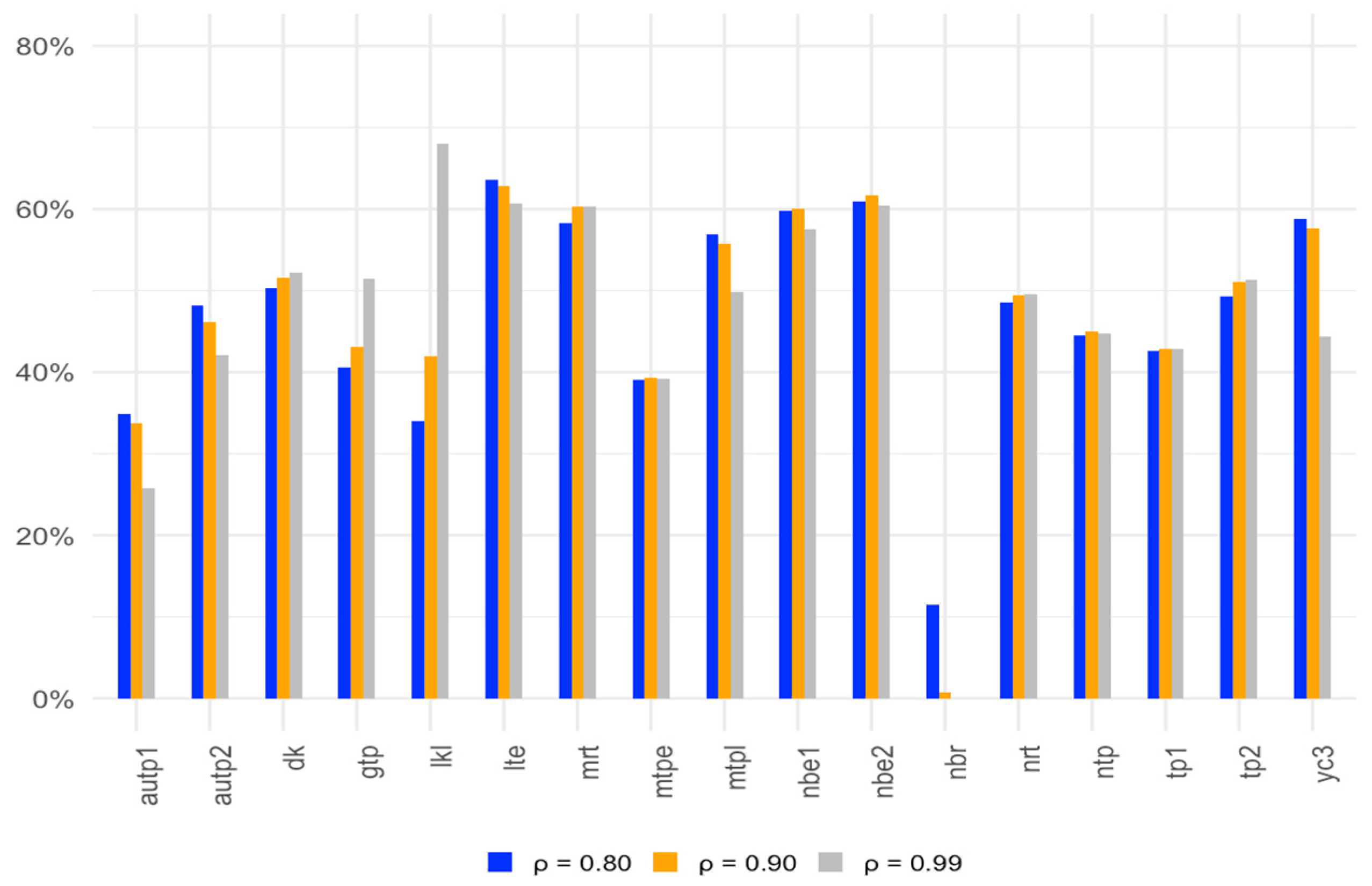
Figure 1, Figure 2 and Figure 3 show the average gain in power for two-parameter estimators over the OLS test for with different correlation levels, sample sizes, and numbers of regressors.
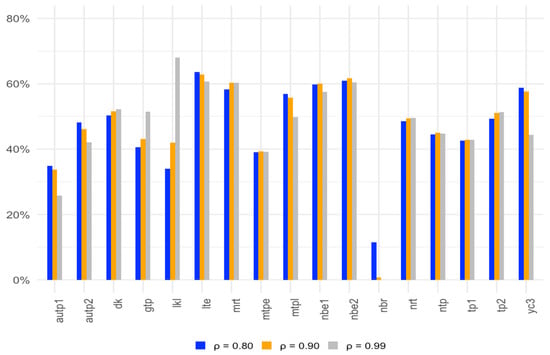
Figure 1.
Average gain in power over the OLS test for α = 0.05 at correlation levels of 0.80, 0.90, and 0.99.
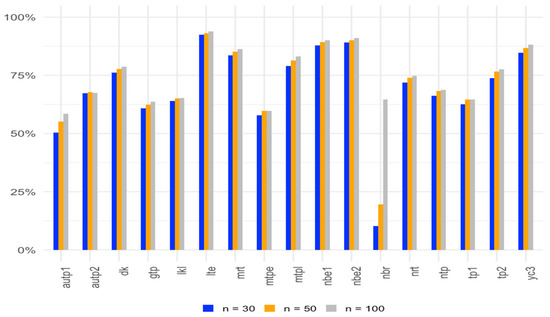
Figure 2.
Average gain in power over the OLS test for α = 0.05 with sample sizes of 30, 50, and 100.
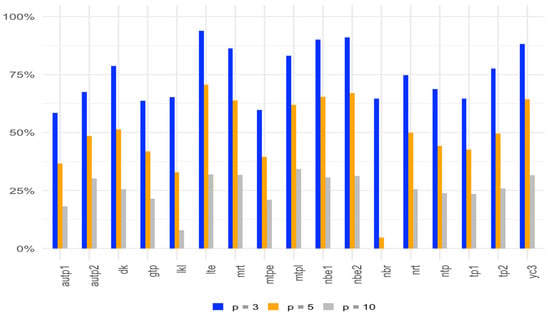
Figure 3.
Average gain in power over the OLS test for α = 0.05 with 3, 5, and 10 parameters.
As we have only considered , we examine two additional values, and 10, which are given in Table 8, Table 9 and Table 10.
Table 8.
Statistical power for and 10 for .
Table 9.
Statistical power for and 10 for .
Table 10.
Statistical power for and 10 for .
For additional levels of variance, the results show the decrease in power with the increase in variance. They also result in higher power than the OLS estimator.
We also want to consider sample sizes of 200 and 300 so that we can determine the power for the test compared to the lower sample sizes which are given in Table 11, Table 12 and Table 13. For the power, we take the same procedure as that followed by Gokpinar and Ebegil (2016) [12] and choose to find the higher power.
Table 11.
Statistical power for n = 200 and 300 and .
Table 12.
Statistical power for n = 200 and 300 and .
Table 13.
Statistical power for n = 200 and 300 and .
As sample size increases to 200 and 300, the results suggest that the power increases with the increase in sample sizes. As the number of regressors increases, the power reduces while keeping the sample size constant.
We also introduce additional simulation scenarios where errors are drawn from alternative distributions—such as the t-distribution with a low degree of freedom in Table 14 and the exponential distribution with a rate of 1 in Table 15.
Table 14.
Statistical power for ρ = 0.80 using errors from t-distribution.
Table 15.
Statistical power for ρ = 0.90 using errors from exponential distribution.
4. Application to Real-Life Data
To illustrate the simulation results and findings of this paper, we analyze a pollution dataset which was originally published by McDoland and Schwing (1973) [45] in this section. These data model the total age-adjusted mortality rate for the years 1959–1961 across 201 Standard Metropolitan Statistical Areas (SMSAs), with the data sourced from Duffy and Carroll (1967) [46]. The dataset has 60 observations and 15 independent variables measuring demographic, socioeconomic, and environmental factors.
We consider the following model:
where = total age-adjusted mortality rate, = PREC (mean annual precipitation), = JANT (mean January temperature), = JULT (mean July temperature), = OVR65 (percent of population which is 65 years of age or over), = POPN (population per household), = EDUC (median school years), = HOUS (percent of housing units), = DENS (population per square mile), = NONW (percent of population which is non-white), = WWDRK (percent employment in white color occupation), = POOR (percent of families with low income), = HC (relative population potential of hydrocarbons), = NOX (relative population potential of oxides of nitrogen), = SOx (relative population potential of sulfur dioxide), and = HUMID (percent relative humidity).
Independent variables in this dataset exhibit high levels of correlation, or multicollinearity. For multicollinearity, we can use the variance inflation factor (VIF), calculated as
where is the multiple correlation coefficient obtained from regression of the explanatory variable. The VIF values are given in Table 16.
Table 16.
Variance inflation factor.
Based on the VIF values, it can be seen that variables such as HC (98.64) and NOX (104.98) exhibit a high level of multicollinearity; therefore, we can state that there is a dependency among explanatory variables.
To detect multicollinearity, we obtain the condition number value calculated as . We can see that the CN value is 35,406.49, which is more than 10, so it confirms that severe multicollinearity among the variables exists.
To evaluate the significance of the regression coefficients, we want to test the null hypothesis. We calculate the p values as . If (typically), we reject the null hypothesis, indicating that the regression coefficients are statistically significant. In Table 17, we present the parameter estimates, standard errors, and p-values for each regression coefficient.
Table 17.
Results of pollution data analysis comparing two-parameter models with OLS.
Based on the previous simulation results for type I errors and test power, certain two-parameter estimators, such as LTE, NBE2, MRT, and LKL, demonstrate higher power than others compared to OLS. Additionally, YC3 and DK also show improved power. Therefore, we want to evaluate the performance of these estimators with the real-life data affected by multicollinearity.
The corresponding parameter estimates, standard errors, and p-values are presented in Table 17. From the table, we can see that variables PREC, JANT, JULT, HOUS, POOR, and HUMID are not significant at the alpha level of 0.05 for the OLS estimator. However, under the YC3 estimator, all of these variables are statistically significant. Also, for the MRT estimator, the variables JANT, JULT, and HUMID are significant, and for the LKL estimator, the variables JANT, JULT, HOUS, POOR, and HUMID are significant.
Furthermore, the highest VIF variables, HC and NOX, are not significant under any estimation method. But some other high VIF variables, such as JANT and POOR, are significant under specific estimators. Also, the NONW variable is statistically significant across all of them, indicating its consistent impact. Therefore, we observe that all of the estimators perform better than the OLS estimator, but among them YC3 (Yang and Chang estimator) performs better than the other estimators on these data.
Another example we use are “body data” which can be found in the textbook Biostatistics for the Biological and Health Sciences, 2nd edition by Triola et al. (2006) [47]. These data are also available at “www.triolastats.com (accessed on 24 February 2015)”. The dataset consists of body and exam measurements for 300 subjects. The outcome variable for our model is HDL cholesterol (mg/dL). The explanatory variables are x1: weight (kg), x2: height (cm), x3: waist circumference (cm), x4: arm circumference (cm), and x5: BMI (Body Mass Index). The VIF values for the body dataset are given in Table 18.
Table 18.
VIF for body data.
There is evidence of multicollinearity in the data, as evidenced by several of the variance inflation factors (VIFs) being greater than 10 (see the paper by Ozkale and Kacıranlar (2007) [19], which is in practice considered the threshold for multicollinearity.
We can also see that the condition number is 143.6735, which also indicates that there is severe multicollinearity.
From Table 19, we can see that variable x3 is significant and variable x4 has a p-value of around 0.06 for most models, including the OLS estimator. Using the YC3 estimator, both x3 and x4 variables are highly non-significant; the MRT estimator shows non-significant results for the x4 variable. So, YC3 and MRT estimators provide better results for multicollinear independent variables.
Table 19.
Results of body data analysis.
5. Concluding Remarks
In this paper, we examined various test statistics derived from two-parameter estimators to address multicollinearity issues when testing regression coefficients within a linear regression model. We conducted a simulation study under several conditions and compared these test statistics empirically, evaluating their performance in terms of empirical size and power. Our findings show that several two-parameter estimators consistently outperformed other tests, demonstrating their effectiveness in managing multicollinearity and producing more reliable results. Specifically, the LTE, NBE2, YC3, MRT, and LKL estimators exhibited higher power than the others. These results provide valuable insights for selecting appropriate test statistics for regression coefficient testing in multicollinearity settings, contributing to the refinement of regression analysis methodology and more accurate inference for practitioners. Finally, we analyzed a pollution dataset and body data to illustrate the findings of this paper, which supported the simulation results to some extent. We can suggest that some estimators like YC3 and MRT work better than other estimators and OLS when there is multicollinearity. They can help to determine which variables are significant and perform better than OLS in the presence of multicollinearity.
In the future, we can use these estimators to test parameters for other types of regression models, like logistic and Poisson regression, and in more complex settings like mixed models. Another area of research is to investigate hypothesis testing for survival regression models like Weibull, exponential, and Cox Proportional Hazards models in the presence of multicollinearity.
Author Contributions
Conceptualization, M.A.H. and B.M.G.K.; methodology, M.A.H. and B.M.G.K.; software, M.A.H.; validation, M.A.H., Z.B. and B.M.G.K.; formal analysis, M.A.H. and B.M.G.K.; investigation, M.A.H., Z.B. and B.M.G.K.; resources, M.A.H., Z.B. and B.M.G.K.; data curation, M.A.H.; writing—original draft preparation, M.A.H.; writing—review and editing, M.A.H., Z.B. and B.M.G.K.; visualization, B.M.G.K. and Z.B.; project administration, Z.B. and B.M.G.K.; funding acquisition, N/A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Kibria, B.M.G. Performance of some new ridge regression estimators. Commun. Stat. Simul. Comput. 2003, 32, 419–435. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Ehsanes Saleh, A.M.; Kibria, B.M.G. Performance of some new preliminary test ridge regression estimators and their properties. Commun. Stat. Theory Methods 1993, 22, 2747–2764. [Google Scholar] [CrossRef]
- Alheety, M.I.; Nayem, H.M.; Kibria, B.M.G. An Unbiased Convex Estimator Depending on Prior Information for the Classical Linear Regression Model. Stats 2025, 8, 16. [Google Scholar] [CrossRef]
- Dawoud, I.; Kibria, B.M.G. A new biased estimator to combat the multicollinearity of the Gaussian linear regression model. Stats 2020, 3, 526–541. [Google Scholar] [CrossRef]
- Hoque, M.A.; Kibria, B.M.G. Some one and two parameter estimators for the multicollinear gaussian linear regression model: Simulations and applications. Surv. Math. Its Appl. 2023, 18, 183–221. [Google Scholar]
- Hoque, M.A.; Kibria, B.M.G. Performance of some estimators for the multicollinear logistic regression model: Theory, simulation, and applications. Res. Stat. 2024, 2, 2364747. [Google Scholar] [CrossRef]
- Nayem, H.M.; Aziz, S.; Kibria, B.M.G. Comparison among Ordinary Least Squares, Ridge, Lasso, and Elastic Net Estimators in the Presence of Outliers: Simulation and Application. Int. J. Stat. Sci. 2024, 24, 25–48. [Google Scholar] [CrossRef]
- Yasmin, N.; Kibria, B.M.G. Performance of Some Improved Estimators and their Robust Versions in Presence of Multicollinearity and Outliers. Sankhya B 2025, 2025, 1–47. [Google Scholar] [CrossRef]
- Halawa, A.M.; El Bassiouni, M.Y. Tests of regression coefficients under ridge regression models. J. Stat. Comput. Simul. 2000, 65, 341–356. [Google Scholar] [CrossRef]
- Cule, E.; Vineis, P.; De Iorio, M. Significance testing in ridge regression for genetic data. BMC Bioinform. 2011, 12, 372. [Google Scholar] [CrossRef]
- Gökpınar, E.; Ebegil, M. A study on tests of hypothesis based on ridge estimator. Gazi Univ. J. Sci. 2016, 29, 769–781. [Google Scholar]
- Kibria, B.M.G.; Banik, S. A simulation study on the size and power Properties of some ridge regression Tests. Appl. Appl. Math. Int. J. (AAM) 2019, 14, 7. [Google Scholar]
- Perez-Melo, S.; Kibria, B.M.G. On some test statistics for testing the regression coefficients in presence of multicollinearity: A simulation study. Stats 2020, 3, 40–55. [Google Scholar] [CrossRef]
- Ullah, M.I.; Aslam, M.; Altaf, S. lmridge: A Comprehensive R Package for Ridge Regression. R J. 2018, 10, 326. [Google Scholar] [CrossRef]
- Perez-Melo, S.; Bursac, Z.; Kibria, B.M.G. Comparison of Test Statistics for Testing the Regression Coefficients in the OLS, Ridge, Liu and Kibria-Lukman Linear Regression Model: A Simulation Study. In JSM Proceedings, Biometrics Section; American Statistical Association: Alexandria, VA, USA, 2022; pp. 59–80. [Google Scholar]
- Yang, H.; Chang, X. A new two-parameter estimator in linear regression. Commun. Stat. Theory Methods 2010, 39, 923–934. [Google Scholar] [CrossRef]
- Liu, K. Using Liu-type estimator to combat collinearity. Commun. Stat. Theory Methods 2003, 32, 1009–1020. [Google Scholar] [CrossRef]
- Özkale, M.R.; Kaciranlar, S. The restricted and unrestricted two-parameter estimators. Commun. Stat. Theory Methods 2007, 36, 2707–2725. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W.; Baldwin, K.F. Ridge regression: Some simulations. Commun. Stat. Theory Methods 1975, 4, 105–123. [Google Scholar] [CrossRef]
- Sakallıoğlu, S.; Kaçıranlar, S. A new biased estimator based on ridge estimation. Stat. Pap. 2008, 49, 669–689. [Google Scholar] [CrossRef]
- Wu, J.; Yang, H. Efficiency of an almost unbiased two-parameter estimator in linear regression model. Statistics 2013, 47, 535–545. [Google Scholar] [CrossRef]
- Wu, J. An Unbiased Two-Parameter Estimation with Prior Information in Linear Regression Model. Sci. World J. 2014, 1, 206943. [Google Scholar] [CrossRef] [PubMed]
- Dorugade, A.V. A modified two-parameter estimator in linear regression. Stat. Transit. New Ser. 2014, 15, 23–36. [Google Scholar] [CrossRef]
- Arumairajan, S.; Wijekoon, P. Modified almost unbiased Liu estimator in linear regression model. Commun. Math. Stat. 2017, 5, 261–276. [Google Scholar] [CrossRef]
- Lukman, A.F.; Adewuyi, E.; Oladejo, N.; Olukayode, A. Modified almost unbiased two-parameter estimator in linear regression model. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2019; Volume 640, p. 012119. [Google Scholar]
- Lukman, A.F.; Ayinde, K.; Siok Kun, S.; Adewuyi, E.T. A modified new two-parameter estimator in a linear regression model. Model. Simul. Eng. 2019, 2019, 6342702. [Google Scholar] [CrossRef]
- Lukman, A.F.; Ayinde, K.; Binuomote, S.; Clement, O.A. Modified ridge-type estimator to combat multicollinearity: Application to chemical data. J. Chemom. 2019, 33, e3125. [Google Scholar] [CrossRef]
- Zeinal, A. Generalized two-parameter estimator in linear regression model. J. Math. Model. 2020, 8, 157–176. [Google Scholar] [CrossRef]
- Üstündağ Şiray, G.; Toker, S.; Özbay, N. Defining a two-parameter estimator: A mathematical programming evidence. J. Stat. Comput. Simul. 2021, 91, 2133–2152. [Google Scholar] [CrossRef]
- Abidoye, A.O.; Ajayi, I.M.; Adewale, F.L.; Ogunjobi, J.O. Unbiased Modified Two-Parameter Estimator for the Linear Regression Model. J. Sci. Res. 2022, 14, 785–795. [Google Scholar] [CrossRef]
- Ahmad, S.; Aslam, M. Another proposal about the new two-parameter estimator for linear regression model with correlated regressors. Commun. Stat. Simul. Comput. 2022, 51, 3054–3072. [Google Scholar] [CrossRef]
- Aslam, M.; Ahmad, S. The modified Liu-ridge-type estimator: A new class of biased estimators to address multicollinearity. Commun. Stat. Simul. Comput. 2022, 51, 6591–6609. [Google Scholar] [CrossRef]
- Dawoud, I.; Lukman, A.F.; Haadi, A.R. A new biased regression estimator: Theory, simulation and application. Sci. Afr. 2022, 15, e01100. [Google Scholar] [CrossRef]
- Idowu, J.I.; Oladapo, O.J.; Owolabi, A.T.; Ayinde, K. On the biased Two-Parameter Estimator to Combat Multicollinearity in Linear Regression Model. Afr. Sci. Rep. 2022, 1, 188–204. [Google Scholar] [CrossRef]
- Owolabi, A.T.; Ayinde, K.; Idowu, J.I.; Oladapo, O.J.; Lukman, A.F. A new two-parameter estimator in the linear regression model with correlated regressors. J. Stat. Appl. Probab. 2022, 11, 185–201. [Google Scholar]
- Owolabi, A.T.; Ayinde, K.; Alabi, O.O. A new ridge-type estimator for the linear regression model with correlated regressors. Concurr. Comput. Pract. Exp. 2022, 34, e6933. [Google Scholar] [CrossRef]
- Owolabi, A.T.; Ayinde, K.; Alabi, O.O. A Modified Two Parameter Estimator with Different Forms of Biasing Parameters in the Linear Regression Model. Afr. Sci. Rep. 2022, 1, 212–228. [Google Scholar] [CrossRef]
- Abonazel, M.R. New modified two-parameter Liu estimator for the Conway–Maxwell Poisson regression model. J. Stat. Comput. Simul. 2023, 93, 1976–1996. [Google Scholar] [CrossRef]
- Abdelwahab, M.M.; Abonazel, M.R.; Hammad, A.T.; El-Masry, A.M. Modified Two-Parameter Liu Estimator for Addressing Multicollinearity in the Poisson Regression Model. Axioms 2024, 13, 46. [Google Scholar] [CrossRef]
- Idowu, J.I.; Oladapo, O.J.; Owolabi, A.T.; Ayinde, K.; Akinmoju, O. Combating multicollinearity: A new two-parameter approach. Nicel Bilim. Derg. 2023, 5, 90–116. [Google Scholar] [CrossRef]
- Kibria, B.M.G.; Lukman, A.F. A new ridge-type estimator for the linear regression model: Simulations and applications. Scientifica 2020, 2020, 9758378. [Google Scholar] [CrossRef]
- Khan, M.S.; Ali, A.; Suhail, M.; Kibria, B.M.G. On some two parameter estimators for the linear regression models with correlated predictors: Simulation and application. Commun. Stat. Simul. Comput. 2024, 2024, 1–15. [Google Scholar] [CrossRef]
- R Core Team. _R: A Language and Environment for Statistical Computing_; R Foundation for Statistical Computing: Vienna, Austria, 2024; Available online: https://www.R-project.org/ (accessed on 11 August 2024).
- McDonald, G.C.; Schwing, R.C. Instabilities of regression estimates relating air pollution to mortality. Technometrics 1973, 15, 463–481. [Google Scholar] [CrossRef]
- Duffy, E.A.; Carroll, R.E. United States Metropolitan Mortality, 1959–1961; PHS Publication No. 1967, 999-AP-39; U.S. Public Health Service, National Center for Air Pollution Control: Philadelphia, PA, USA, 1967.
- Triola, M.M.; Triola, M.F.; Roy, J.A. Biostatistics for the Biological and Health Sciences; Pearson Addison-Wesley: Boston, MA, USA, 2006. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).