Abstract
In a multiple linear regression model, the ordinary least squares estimator is inefficient when the multicollinearity problem exists. Many authors have proposed different estimators to overcome the multicollinearity problem for linear regression models. This paper introduces a new regression estimator, called the Dawoud–Kibria estimator, as an alternative to the ordinary least squares estimator. Theory and simulation results show that this estimator performs better than other regression estimators under some conditions, according to the mean squares error criterion. The real-life datasets are used to illustrate the findings of the paper.
1. Introduction
Consider the following linear regression model:
where is an vector of the dependent variable, is a known full rank matrix of explanatory variables, and is a vector of unknown regression parameter. The ordinary least squares estimator (OLS) of in (1) is defined by
where and is an vector of disturbances with zero mean and variance–covariance matrix, is an identity matrix of order nxn. Under the normality assumption of the disturbances, follows distribution.
In a multiple linear regression model, it is assumed that the explanatory variables are independent. However, in real-life situations, there may be strong or near-to-strong linear relationships among the explanatory variables. This causes the problem of multicollinearity. In the presence of multicollinearity, it is difficult to estimate the unique effect of individual variables in the regression equations. Moreover, the OLS estimator becomes unstable or inefficient and may produce the wrong sign (see Hoerl and Kennard) [1]. To overcome these problems, many authors have introduced different kinds of one- and two-parameter estimators: to mention a few, Stein [2], Massy [3], Hoerl and Kennard [1], Mayer and Willke [4], Swindel [5], Liu [6], Akdeniz and Kaçiranlar [7], Ozkale and Kaçiranlar [8], Sakallıoglu and Kaçıranlar [9], Yang and Chang [10], Roozbeh [11], Akdeniz and Roozbeh [12], Lukman et al. [13,14], and, very recently, Kibria and Lukman [15], among others.
The objective of this paper is to introduce a new class of two-parameter estimator for the regression parameter when the explanatory variables are correlated and then to compare the performance of the new estimator with the OLS estimator, the ordinary ridge regression (ORR) estimator, the Liu estimator, the Kibria–Lukman (KL) estimator, the two-parameter (TP) estimator proposed by Ozkale and Kaciranlar [8], and the new two-parameter (NTP) estimator that is proposed by Yang and Chang [10].
Some Alternative Biased Estimators and the Proposed Estimator
The canonical form of Equation (1) is as follows:
where and . Here, is an orthogonal matrix such that The OLS estimator of is as follows:
and the mean squared error matrix (MSEM) of is given by
The ORR of [1] is given by
where , is the biasing parameter, and
The Liu estimator of [6] is given by
where , is the biasing parameter of Liu estimator, and
The KL estimator of [15] is given by
where and
The two-parameter (TP) estimator of (Ozkale and Kaçiranlar [8]) is given by
where , and are the biasing parameters, and
The new two-parameter (NTP) estimator of (Yang, H.; Chang [10]) is given by
The proposed new class of two-parameter estimator of is obtained by minimizing , subject to , where is a constant,
Here, and are the Lagrangian multipliers.
The solution of minimizing the objective function
is obtained by Kibria and Lukman [15] for getting the KL estimator and defined in Equation (10).
Now, the solution to (16) gives the proposed estimator as follows:
where and .
The proposed estimator will be called the Dawoud–Kibria (DK) estimator and is denoted by .
Moreover, the proposed DK estimator is also obtained by augmenting to (3) and then using the OLS estimate. The MSEM of the DK estimator is given by
The main differences between the KL estimator and the proposed DK estimator are as follows:
- -
- The KL is a one-parameter estimator, while the proposed DK is a two-parameter estimator.
- -
- The KL estimator is obtained based on the objective function , while the proposed DK estimator is obtained from a different objective function, which is .
- -
- The KL estimator is a function of the shrinkage estimator , while the proposed DK estimator is a function of and .
- -
- Since the KL estimator has one parameter and the proposed DK estimator has two parameters, their MSEs are different.
- -
- In the KL estimator, shrinkage parameter needs to be estimated, while in the proposed DK estimator, both and need to be estimated.
- -
- The KL estimator is a special case of the proposed DK estimator when , so the proposed DK estimator is the general estimator.
The following lemmas will be used to make some theoretical comparisons among estimators in the following section.
Lemma 1 [16].
Letmatricesand (or
), thenif and only if, whereis the maximum eigenvalue of matrix
Lemma 2 [17].
Letbe anpositive definite matrix that isandbe some vector, thenif and only if.
Lemma 3 [18].
Let,be two linear estimators of. Suppose that, whereis the covariance matrix ofand, . Consequently,
if and only if, where.
The rest of this article is organized as follows: In Section 2, we give the theoretical comparisons among the abovementioned estimators and derive the biasing parameters of the proposed DK estimator. A simulation study is conducted in Section 3. Two numerical examples are illustrated in Section 4. Finally, some concluding remarks are given in Section 5.
2. Comparison among the Estimators
2.1. Theoretical Comparisons among the Proposed DK Estimator and the OLS, ORR, Liu, KL, TP, and NTP Estimators
Theorem 1.
The proposed estimator is superior to estimator if and only if
Proof.
The difference of the dispersion matrices is given by
where
will be positive definite (pd) if and only if
We observed that for and ,
Consequently, is positive definite. □
Theorem 2.
When, the proposed estimator is superior to estimator if and only if
where
Proof.
It is clear that for and , and . It is obvious that if and only if
where is the maximum eigenvalue of the matrix . Consequently, is positive definite. □
Theorem 3.
The proposed estimator is superior to estimator if and only if
where .
Proof.
Using the difference between the dispersion matrices
where
will be pd if and only if
So, if and , . Consequently,
is positive definite. □
Theorem 4.
The proposed estimator is superior to estimatorif and only if
where .
Proof.
Using the difference between the dispersion matrices
where
will be pd if and only if
Obviously, for and ,
Consequently,
is positive definite. □
Theorem 5.
The proposed estimator is superior to estimator if and only if
where .
Proof.
where
will be positive definite if and only if
Clearly, for and , . Consequently, is pd. □
Theorem 6.
The proposed estimator is superior to estimatorif and only if
where .
Proof.
where
will be pd if and only if
Clearly, for and ,
Consequently, is positive definite. □
2.2. Determination of the Parameters k and d
Since both biasing parameters and are unknown and need to be estimated from the observed data, we will give a short discussion on the estimation of the parameters in this subsection. The biasing parameter in the ORR estimator and the biasing parameter in the Liu estimator were derived by Hoerl and Kennard [1] and Liu [6], respectively. Different authors for different kinds of models have proposed different estimators of and : to mention a few, Hoerl et al. [19], Kibria [20], Kibria and Banik [21], Lukman and Ayinde [22], Mansson et al. [23], and Khalaf and Shukur [24], among others.
Now, we will discuss the estimation of the optimal values of and for the proposed DK estimator. First, we assume that is fixed, then the optimal value of can be obtained by minimizing
Differentiating with respect to and setting , we obtain
Since the optimal value of in (33) depends on the unknown parameters and , we replace them with their corresponding unbiased estimators. Consequently, we have
and
Furthermore, the optimal value of can be obtained by differentiating with respect to for a fixed and setting , and we obtain
where .
Additionally, the optimal with known parameters is
where .
In addition,
The estimator determination of the parameters and in is obtained iteratively as follows:
Step 1: Obtain an initial estimate of using .
Step 2: Obtain from (35) using in Step 1.
Step 3: Estimate in (38) by using in Step 2.
Step 4: In case is not between 0 and 1, use .
Additionally, Hoerl et al. [19] defined the biasing parameter k for the ORR estimator as
The biasing parameter d is given by Ozkale and Kaciranlar [8] and adopted for the Liu estimator
Then, Kibria and Lukman [15] found the biasing parameter estimator for the KL estimator as
In addition, of the KL estimator is also obtained when in the derived biasing parameter estimator for the proposed DK estimator.
3. Simulation Study
To support a theoretical comparison of the estimators, a Monte Carlo simulation study was conducted to compare the performance of the estimators in this section. As such, this section will contain (i) the simulation technique and (ii) a discussion of the results.
3.1. Simulation Technique
Following Gibbons [25] and Kibria [20], we generated the explanatory variables using the following equation:
where are independent standard normal pseudo-random numbers, and represents the correlation between any two explanatory variables and is considered here to be 0.90 and 0.99. We consider in the simulation. These variables are standardized so that and are in correlation forms. The observations for the dependent variable are determined by the following equation:
where are . The values of are chosen such that [26]. Since we aimed to compare the performance of the DK estimator with OLS, ORR, Liu, KL, TP, and NTP estimators, we chose (0.3, 0.6, 0.9) between 0 and 1, as did Wichern and Churchill [27] and Kan et al. [28], where ORR gives better results and (0.2, 0.5, 0.8). The replication of this simulation study is 1000 times for the sample sizes and 100 and 1, 25, and 100. For each replicate, we computed the mean square error (MSE) of the estimators by using the equation below:
where is the estimator values and is the true parameter values. The estimated MSEs of the estimators are shown in Table 1, Table 2, Table 3 and Table 4.

Table 1.
Estimated MSE for ordinary least squares estimator (OLS), ordinary ridge regression (ORR), Liu, Kibria–Lukman (KL), two-parameter (TP), new two-parameter (NTP), and Dawoud–Kibria (DK).
Table 2.
Estimated MSE for OLS, ORR, Liu, KL, TP, NTP, and DK.
Table 3.
Estimated MSE for OLS, ORR, Liu, KL, TP, NTP, and DK.
Table 4.
Estimated MSE for OLS, ORR, Liu, KL, TP, NTP, and DK.
3.2. Simulation Results Discussions
From Table 1, Table 2, Table 3. Table 4, it appears that as and increase, the estimated MSE values increase, while as increases, the estimated MSE values decrease. As expected, when the multicollinearity problem exists, the OLS estimator gives the highest MSE values and performs the worst among all estimators. Additionally, the results show that the proposed DK estimator is performing better than the rest of the estimators, followed by NTP and KL estimators, most of the time for all conditions. The NTP estimator gives better results in MSE values when and are near zero. The proposed DK estimator always performs better than the KL estimator. The NTP estimator performance is between the KL and DK estimators most of the time, while the KL estimator performance is between the NTP estimator and the proposed DK estimator some of the time. Thus, simulation results are consistent with the theoretical results.
To see the effect of various parameters on MSE, we plotted MSE vs. the parameters in Figure 1, Figure 2, Figure 3, Figure 4, Figure 5 and Figure 6.
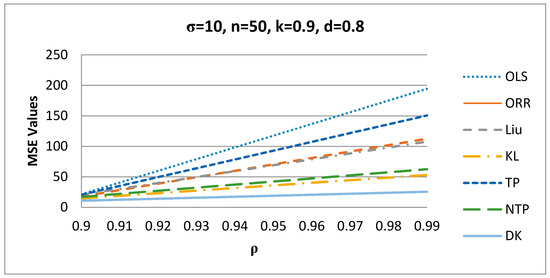
Figure 1.
MSE values versus values.
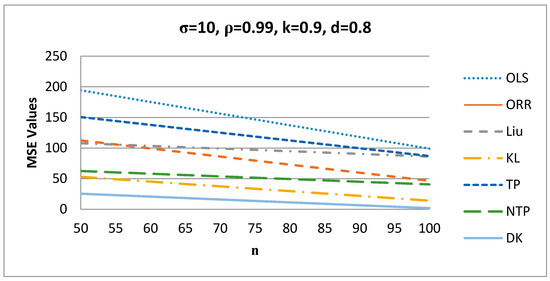
Figure 2.
MSE values versus values.
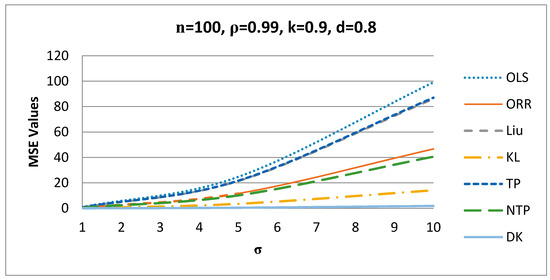
Figure 3.
MSE values versus values.
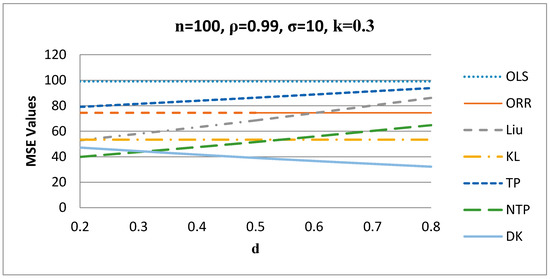
Figure 4.
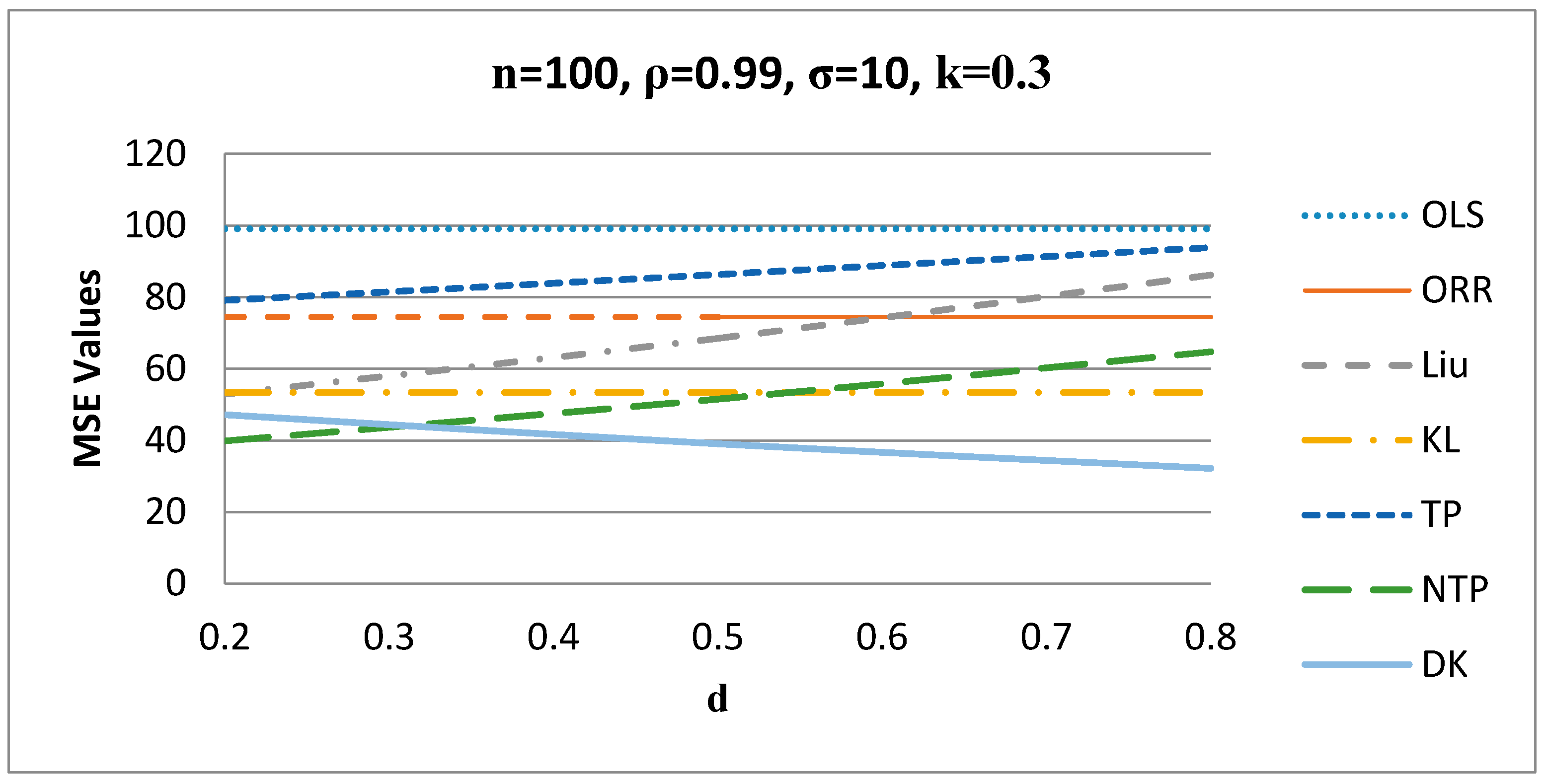
MSE values versus values when k = 0.3.
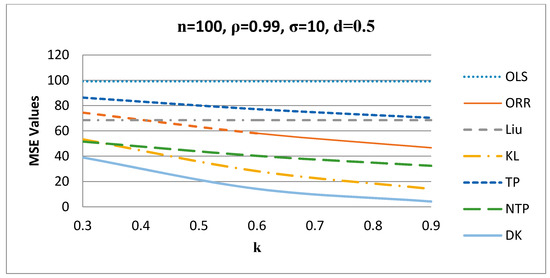
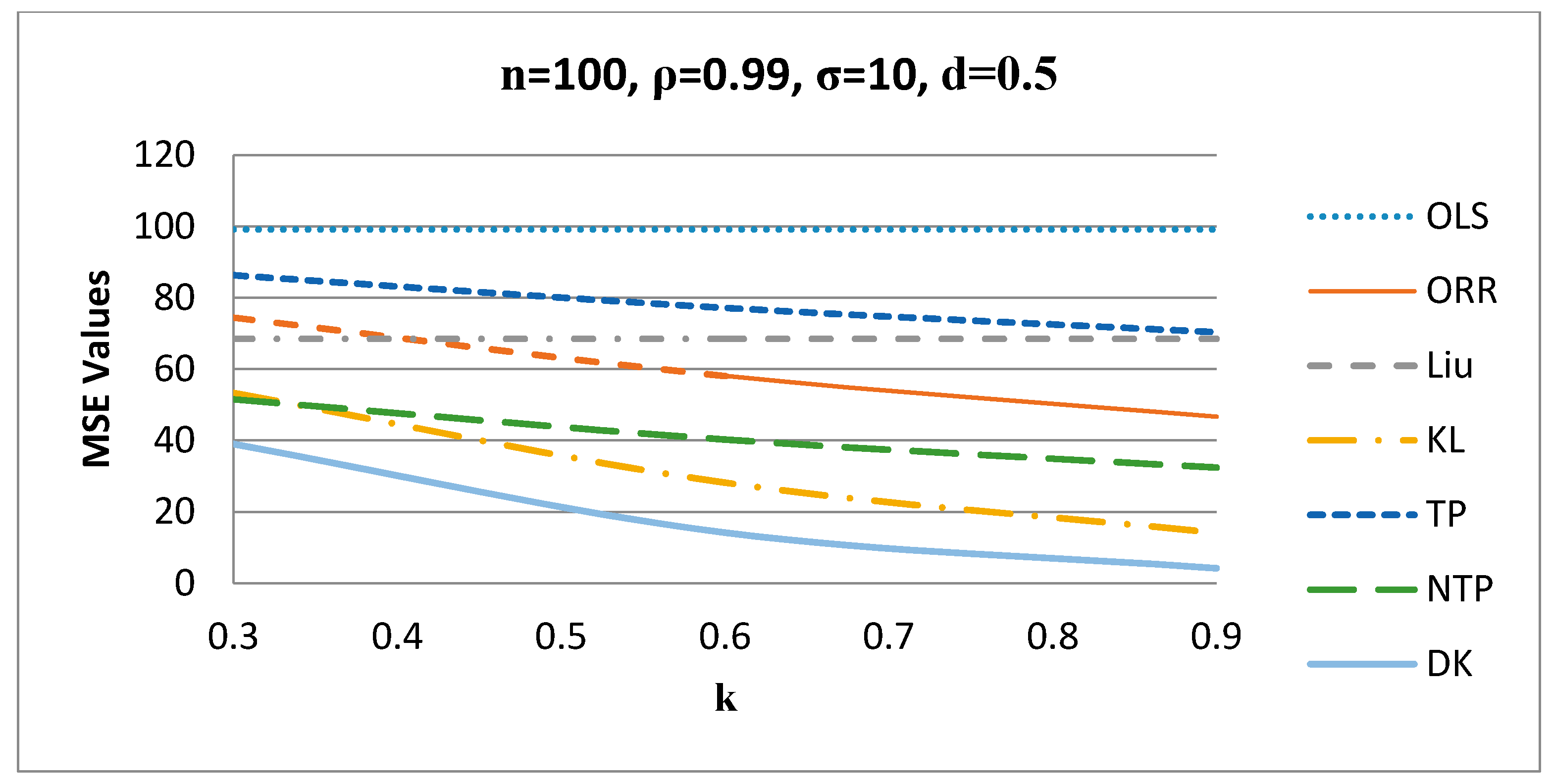
Figure 5.
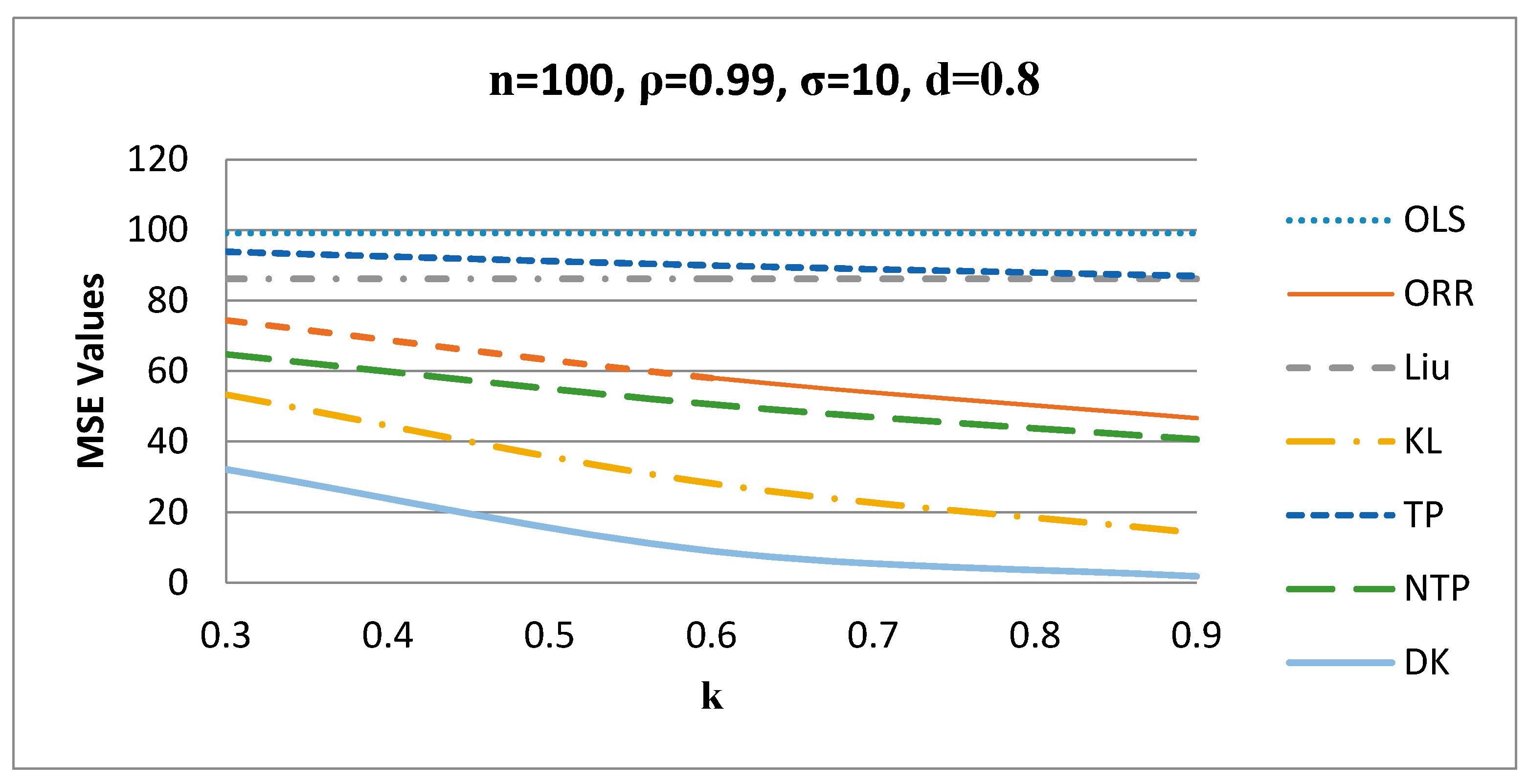
MSE values versus values when d = 0.5.
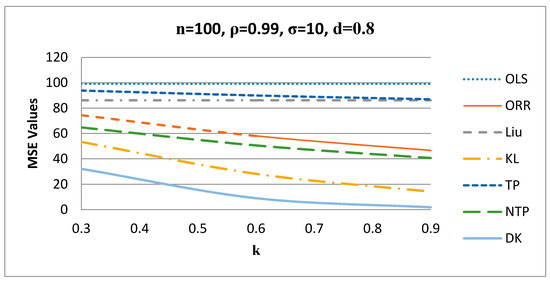
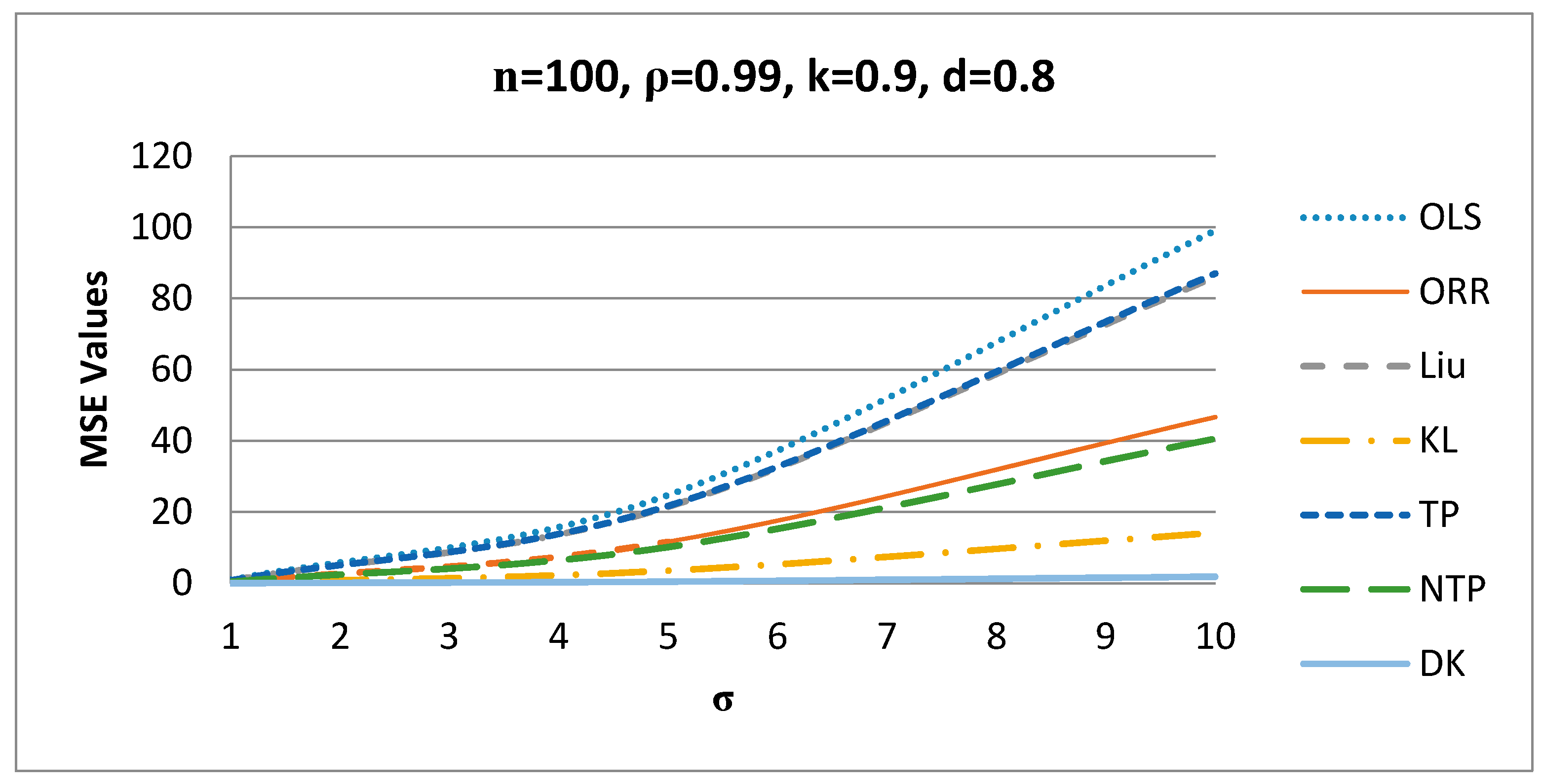
Figure 6.
MSE values versus values when d = 0.8.
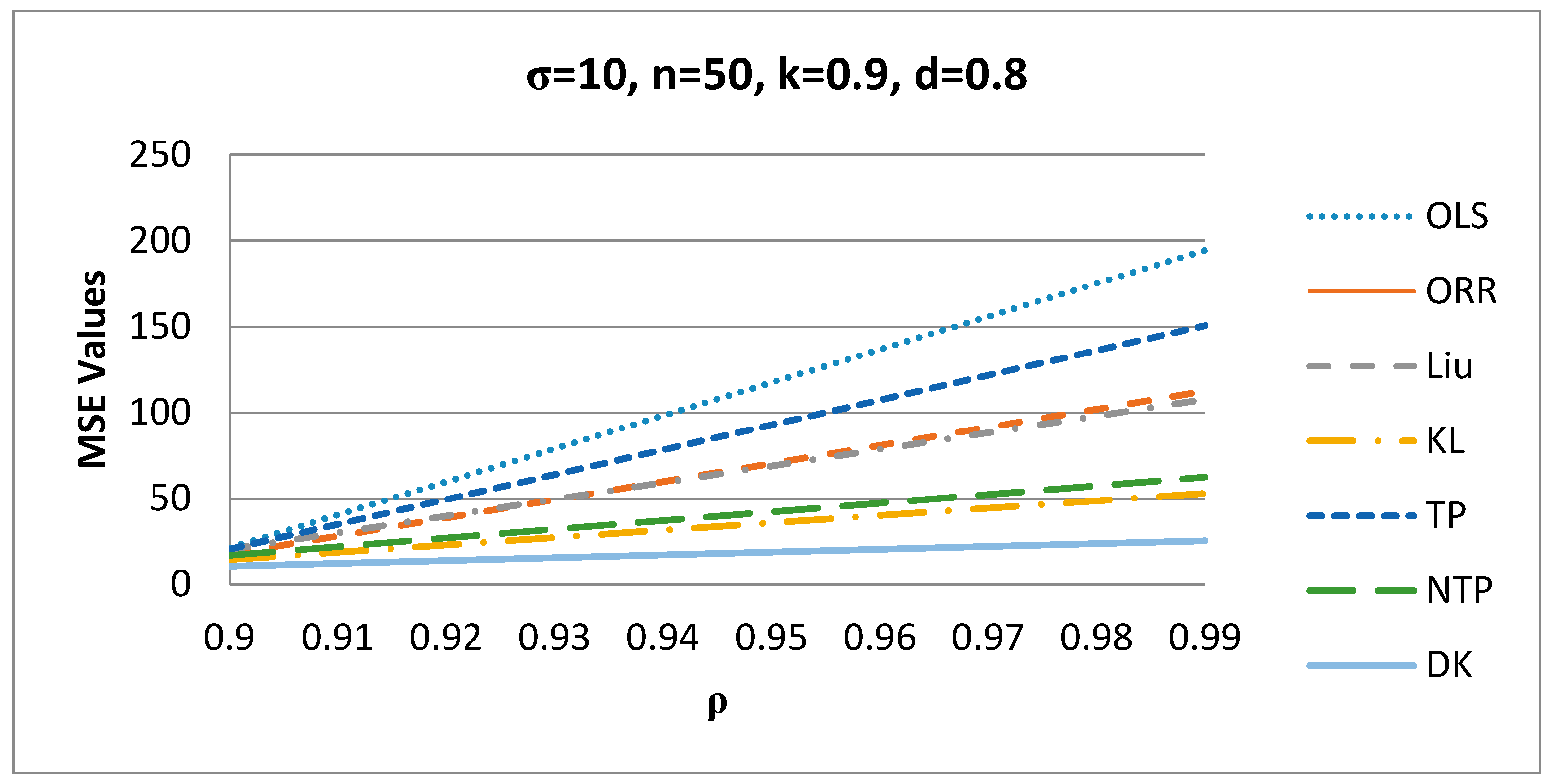
It appears from Figure 1 that as increases, the MSE values of the estimators increase for σ = 10, n = 50, k = 0.9, and d = 0.8, and the proposed DK estimator has the smallest MSE value among all estimators.
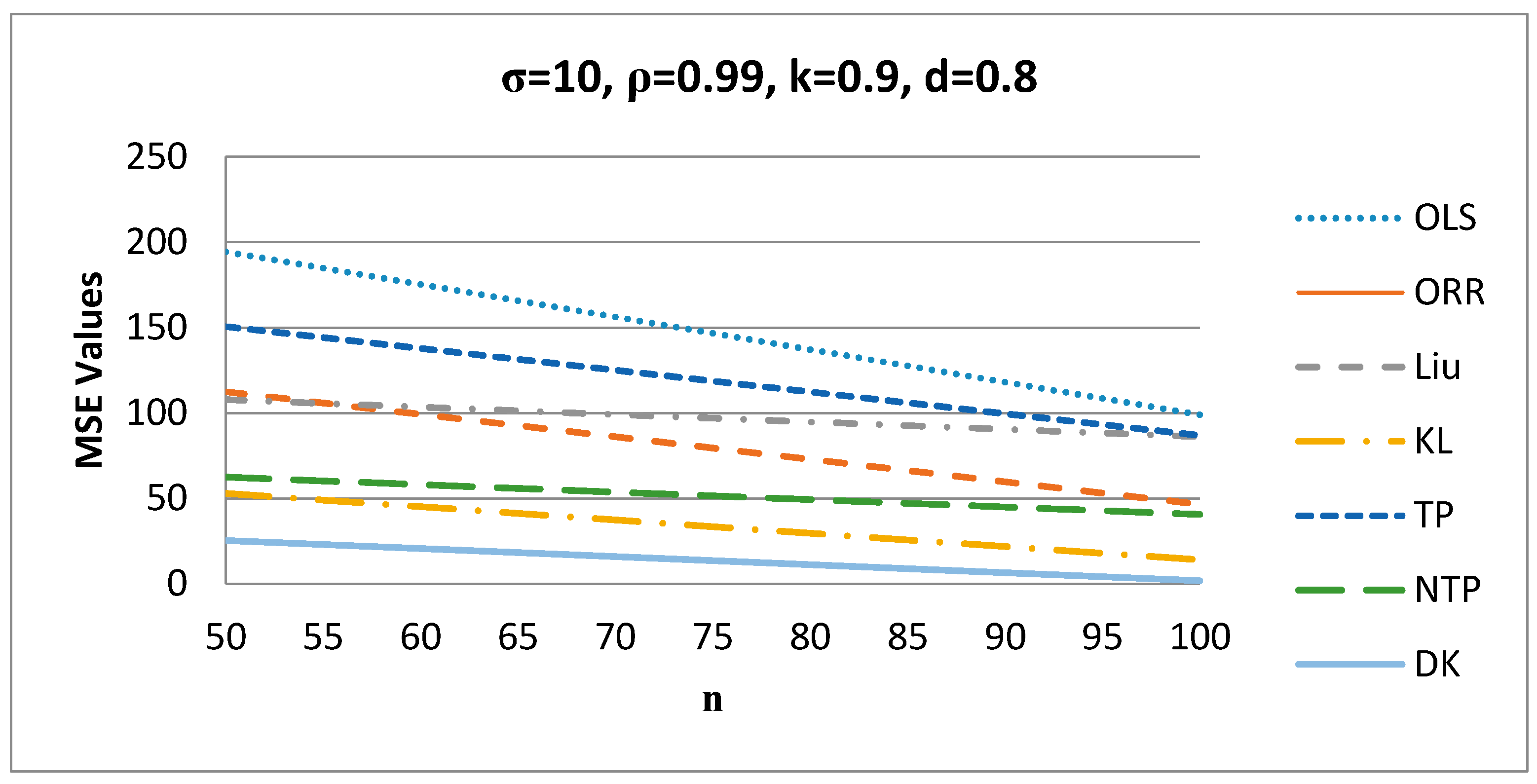
Figure 2 shows that as increases, the MSE values of the estimators decrease for σ = 10, ρ = 0.99, k = 0.9, and d = 0.8, and the proposed DK estimator has the smallest MSE value among all estimators.
Figure 3 shows the behavior of , where as increases, the MSE values of the estimators increase for n = 100, ρ = 0.99, k = 0.9, d = 0.8, and for other values of these factors.
Figure 4 shows the behavior of the estimators for different values of when . It is evident from Figure 4 that the proposed DK estimator gives the smallest MSE values when d is greater than 0.3, while the NTP estimator gives better results when d is less than 0.3 for n = 100, ρ = 0.99, σ = 10, and for other values of these factors.
Figure 5 shows the behavior of the estimators for different values of when , such that the proposed DK estimator gives the smallest MSE values among all other estimators for n = 100, ρ = 0.99, σ = 10, and for other values of these factors.
Figure 6 shows the behavior of the estimators for different values of when , such that the proposed DK estimator gives the smallest MSE values among all other estimators for n = 100, ρ = 0.99, σ = 10, and for other values of these factors.
4. Application
4.1. Portland Cement Data
We use the Portland cement data, which was originally adopted by Woods et al. [29] to explain their theoretical results. The data were analyzed by various researchers: to mention a few, Kaciranlar et al. [30], Li and Yang [31], Lukman et al. [13], and, recently, Kibria and Lukman [15], among others.
The regression model for these data is defined as
For more details about these data, see Woods et al. [29].
The variance inflation factors are , , , and . Eigenvalues of are , , , and , and the condition number of is approximately 20.58. The VIFs, the eigenvalues, and the condition number all indicate that severe multicollinearity exists. The estimated parameters and the MSE values of the estimators are presented in Table 5. It appears from Table 5 that the proposed DK estimator performs the best among the mentioned estimators as it gives the smallest MSE value.
Table 5.
The results of regression coefficients and the corresponding MSE values.
4.2. Longley Data
Longley data were originally used by Longley [32] and then by other authors (Yasin and Murat [33]; Lukman and Ayinde [22]). The regression model of this data is defined as
For more details about these data, see Longley [32].
The variance inflation factors are , , , , and . Eigenvalues of are as follows: 2.76779 × 1012, 7,039,139,179, 11,608,993.96, 2,504,761.021, 1738.356, 13.309, and the condition number of is approximately 456,070. The VIFs, the eigenvalues, and the condition number all indicate that severe multicollinearity exists. The estimated parameters and the MSE values of the estimators are presented in Table 6. It appears from Table 6 that the proposed DK estimator performs the best among the mentioned estimators as it gives the smallest MSE value.
Table 6.
The results of regression coefficients and the corresponding MSE values.
5. Summary and Concluding Remarks
In this paper, we introduced a new class of two-parameter estimator, namely, the Dawoud–Kibria (DK) estimator, to solve the multicollinearity problem for linear regression models. We theoretically compared the proposed DK estimator with some existing estimators, for example, the ordinary least squares (OLS) estimator, the ordinary ridge regression (ORR) estimator, the Liu (1993) estimator, the new modified ridge-type estimator of Kibria and Lukman (KL; 2020), the two-parameter (TP) estimator of Ozkale and Kaciranlar (2007), and the new two-parameter (NTP) estimator of Yang and Chang (2010), and derived the biasing parameters and of the proposed DK estimator. A simulation study has been conducted to compare the performance of the OLS, ORR, Liu, KL, TP, NTP, and the proposed DK estimators. It is evident from simulation results that the proposed DK estimator gives better results than the rest of the estimators under some conditions. Real-life datasets were analyzed to illustrate the findings of the paper. Hopefully, the paper will be useful for practitioners of various fields.
Author Contributions
I.D.: Conceptualization, methodology, original draft preparation. B.M.G.K.: Conceptualization, Results Discussion and Review and Editing. Both authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
Authors are grateful to three anonymous referees and the editor for their valuable comments and suggestions, which certainly improved the presentation and quality of the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Stein, C. Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. In Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability; MR0084922; University California Press: Berkeley, CA, USA, 1956; Volume 197–206, pp. 1954–1955. [Google Scholar]
- Massy, W.F. Principal components regression in exploratory statistical research. J. Am. Stat. Assoc. 1965, 60, 234–256. [Google Scholar] [CrossRef]
- Mayer, L.S.; Willke, T.A. On biased estimation in linear models. Technometrics 1973, 15, 497–508. [Google Scholar] [CrossRef]
- Swindel, B.F. Good ridge estimators based on prior information. Commun. Stat. Theory Methods 1976, 5, 1065–1075. [Google Scholar] [CrossRef]
- Liu, K. A new class of biased estimate in linear regression. Commun. Stat. Theory Methods 1993, 22, 393–402. [Google Scholar]
- Akdeniz, F.; Kaçiranlar, S. On the almost unbiased generalized liu estimator and unbiased estimation of the bias and mse. Commun. Stat. Theory Methods 1995, 24, 1789–1797. [Google Scholar] [CrossRef]
- Ozkale, M.R.; Kaçiranlar, S. The restricted and unrestricted two-parameter estimators. Commun. Stat. Theory Methods 2007, 36, 2707–2725. [Google Scholar] [CrossRef]
- Sakallıoglu, S.; Kaçıranlar, S. A new biased estimator based on ridge estimation. Stat. Pap. 2008, 49, 669–689. [Google Scholar] [CrossRef]
- Yang, H.; Chang, X. A new two-parameter estimator in linear regression. Commun. Stat. Theory Methods 2010, 39, 923–934. [Google Scholar] [CrossRef]
- Roozbeh, M. Optimal QR-based estimation in partially linear regression models with correlated errors using GCV criterion. Comput. Stat. Data Anal. 2018, 117, 45–61. [Google Scholar] [CrossRef]
- Akdeniz, F.; Roozbeh, M. Generalized difference-based weighted mixed almost unbiased ridge estimator in partially linear models. Stat. Pap. 2019, 60, 1717–1739. [Google Scholar] [CrossRef]
- Lukman, A.F.; Ayinde, K.; Binuomote, S.; Clement, O.A. Modified ridge-type estimator to combat multicollinearity: Application to chemical data. J. Chemother. 2019, 33, e3125. [Google Scholar] [CrossRef]
- Lukman, A.F.; Ayinde, K.; Sek, S.K.; Adewuyi, E. A modified new two-parameter estimator in a linear regression model. Model. Eng. Simul. 2019, 2019, 6342702. [Google Scholar] [CrossRef]
- Kibria, B.M.G.; Lukman, A.F. A New Ridge-Type Estimator for the Linear Regression Model: Simulations and Applications. Hindawi Sci. 2020, 2020, 9758378. [Google Scholar] [CrossRef]
- Wang, S.G.; Wu, M.X.; Jia, Z.Z. Matrix Inequalities; Science Chinese Press: Beijing, China, 2006. [Google Scholar]
- Farebrother, R.W. Further results on the mean square error of ridge regression. J. R. Stat. Soc. B 1976, 38, 248–250. [Google Scholar] [CrossRef]
- Trenkler, G.; Toutenburg, H. Mean squared error matrix comparisons between biased estimators-an overview of recent results. Stat. Pap. 1990, 31, 165–179. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kannard, R.W.; Baldwin, K.F. Ridge regression: Some simulations. Commun. Stat. 1975, 4, 105–123. [Google Scholar] [CrossRef]
- Kibria, B.M.G. Performance of some new ridge regression estimators. Commun. Stat. Simul. Comput. 2003, 32, 419–435. [Google Scholar] [CrossRef]
- Kibria, B.M.G.; Banik, S. Some ridge regression estimators and their performances. J. Mod. Appl. Stat. Methods 2016, 15, 206–238. [Google Scholar] [CrossRef]
- Lukman, A.F.; Ayinde, K. Review and classifications of the ridge parameter estimation techniques. Hacet. J. Math. Stat. 2017, 46, 953–967. [Google Scholar] [CrossRef]
- Månsson, K.; Kibria, B.M.G.; Shukur, G. Performance of some weighted Liu estimators for logit regression model: An application to Swedish accident data. Commun. Stat. Theory Methods 2015, 44, 363–375. [Google Scholar] [CrossRef]
- Khalaf, G.; Shukur, G. Choosing ridge parameter for regression problems. Commun. Stat. Theory Methods 2005, 21, 2227–2246. [Google Scholar] [CrossRef]
- Gibbons, D.G. A simulation study of some ridge estimators. J. Am. Stat. Assoc. 1981, 76, 131–139. [Google Scholar] [CrossRef]
- Newhouse, J.P.; Oman, S.D. An evaluation of ridge estimators. In A Report Prepared for United States Air Force Project; RAND: Santa Monica, CA, USA, 1971. [Google Scholar]
- Wichern, D.W.; Churchill, G.A. A comparison of ridge estimators. Technometrics 1978, 20, 301–311. [Google Scholar] [CrossRef]
- Kan, B.; Alpu, O.; Yazıcı, B. Robust ridge and robust Liu estimator for regression based on the LTS estimator. J. Appl. Stat. 2013, 40, 644–655. [Google Scholar] [CrossRef]
- Woods, H.; Steinour, H.H.; Starke, H.R. Effect of composition of Portland cement on heat evolved during hardening. J. Ind. Eng. Chem. 1932, 24, 1207–1214. [Google Scholar] [CrossRef]
- Kaciranlar, S.; Sakallioglu, S.; Akdeniz, F.; Styan, G.P.H.; Werner, H.J. A new biased estimator in linear regression and a detailed analysis of the widely-analysed dataset on portland cement. Sankhya Indian J. Stat. B 1999, 61, 443–459. [Google Scholar]
- Li, Y.; Yang, H. Anew Liu-type estimator in linear regression model. Stat. Pap. 2012, 53, 427–437. [Google Scholar] [CrossRef]
- Longley, J.W. An appraisal of least squares programs for electronic computer from the point of view of the user. J. Am. Stat. Assoc. 1967, 62, 819–841. [Google Scholar] [CrossRef]
- Yasin, A.; Murat, E. Influence Diagnostics in Two-Parameter Ridge Regression. J. Data Sci. 2016, 14, 33–52. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).