Abstract
In an e-learning platform, information retrieval plays an enormous role through efficient processing. Recently, the education sector has increased its trend in online learning systems by generating a large amount of educational content based on student’s criteria. For this sophisticated data analysis scheme, several methods have been employed in recent studies; however, they have suffered from various limitations, including reliability issues, security problems, unauthorized disclosure of data, cost consumption, and interpretability challenges. To tackle these issues, a proposed framework, named the war strategy optimization-based bidirectional long short-term memory (WSO-BiLSTM) model, is designed in this research to reduce sensitivity to local optima and improve convergence stability, thereby achieving robust retrieval performance. With this perspective, the BiLSTM model captures the semantic information of documents in a dual direction for effective retrieval outcomes. Moreover, the model’s key features are extracted effectively by various feature extraction methods. The dynamic movement towards the optimal solution of the WSO algorithm enables the proposed model to retrieve the information more accurately in the information retrieval system. Experiments on an e-learning dataset show that, with a 90% training split, the proposed method achieves 97.90% accuracy, 98.45% precision, 97.90% F1-score, and 97.35% recall.
1. Introduction
Nowadays, information is one of the most important assets for many organizations and industries to perform processing, scheduling, effective storage, and retrieval functions [1]. Conceptually, a large amount of information is stored in a cloud and can be retrieved in the future for further processing. Therefore, the retrieval process is performed by various search engines such as Wiki, Bing, Google, and Yahoo [2]. Generally, the information retrieval process is achieved by two major phases: indexing and querying. In the indexing phase, the obtained initial information is secured in the cloud storage, whereas in the querying phase, the retrieving process is achieved significantly [3]. To retrieve the information, the user enters a query about a specific term in a search engine, which explores several locations and documents that were secured in a cloud system with diverse file formats, and the most related information was explicitly displayed. The user continuously queries the needs and interacts with the search engine until the user is fully satisfied with the results [4,5]. Thus, the querying phase is widely used for data-retrieving functions.
Numerous conventional methods were developed for retrieving the information [6]. The traditional algorithm methods are fuzzy clustering, k-means clustering [6], Chaotic Spin Phase Function (CSPF) [7], Advanced Encryption Standard (AES) algorithm, and Full Harmonic Encryption (FHE) [8]. Similarly, the data retrieval process under deep-learning (DL)-based techniques includes Bidirectional Long Short-Term Memory (BiLSTM), Deep Q-Network (DQN) [9], Convolutional Neural Network (CNN), VGGNet-19, and the distributed External Data Storage Retrieval System (DISTOR) [10]. Although these deep-learning-based retrieval models have demonstrated promising performance [11,12,13], their effectiveness often depends on careful manual hyperparameter tuning and gradient-based optimization, which are sensitive to initialization and may converge to suboptimal solutions in complex, non-convex search spaces [14,15]. To address these limitations, this study proposes a war strategy optimization-based bidirectional long short-term memory (WSO-BiLSTM) framework that integrates population-based metaheuristic optimization with deep sequential modeling to improve convergence stability, reduce sensitivity to initialization, and enhance retrieval robustness. Under the evaluation of clustering methods, the retrieved results easily fluctuated and caused local optima issues [6]. Further, the fuzzy clustering algorithm caused a minimal convergence rate and ended with the wrong retrieved results. Moreover, the other conventional algorithms suffered from unauthorized disclosure of data, minimal security concerns, and high complexity issues. To overcome the challenges faced in the traditional algorithm techniques, DL-based methods are specifically designed for effective information retrieval functions [14,15].
The research model effectively retrieves the information for e-learning purposes in an online environment. The input information is acquired and refined to extract the optimal features, which enables the model to increase performance efficiency through accurate retrieval of information in the learning environment. The main contribution of the research is furnished below.
War strategy optimization (WSO): The WSO algorithm is effectively utilized for retrieval systems due to its dynamic behavior in moving towards the optimal solution. The good balancing behavior in exploring and exploiting WSO enables the proposed framework to increase the robustness and convergence rate of the solution in the information retrieval process.
War strategy optimization-based bidirectional long short-term memory classifier (WSO-BiLSTM): The BiLSTM model has a unique facility for analyzing the input from both directions, such as the past and the future. Also, the learning rate of this model moves to a greater extent, and this feature helps the proposed framework to obtain the best global solution at a better learning rate.
The remainder of the research article is structured as follows: Section 2 presents a review of recent articles on various techniques and acquired challenges. Section 3 describes the proposed methodology with its specialized functions and architecture for retrieving data processing. Section 4 elaborates on the achieved results and provides a detailed comparison with other existing methods. Finally, Section 5 serves as the conclusion, along with the future directions of the research.
2. Literature Review
The section describes the review of recent articles in the field of information retrieval under e-learning appliances, along with their problem specifications.
Ruei-Shan Lu et al. [16] implemented an augmentation-based retrieval generator that captures the data securely from the storage area. The developed model strengthened the generation capabilities and specific domain contexts with improved knowledge performance. However, the model maximized the potential and applicability challenges, which gradually reduced the effectiveness of the personalized learning path. Tianyuan Shi et al. [17] developed a dual-feedback knowledge scheme to retrieve the information from a task-oriented system. In the developed model, both generator and retriever systems achieved the retrieval process. The method attained superior performance by capturing the negative and positive feedback of the information. However, observing the negative feedback reduced the training efficacy of the model, which caused an enormous gap in the fine-tuning progress. Adnan Tahir et al. [18] established an optimization algorithm with the integration of hybrid pelican billiards to retrieve the information precisely. Initially, the important data was stored in a cloud environment that was effectively retrieved by the model with enhanced performance. However, the method faced certain disadvantages, such as interpretability, scalability, and optimization errors.
Eunaicy and Vadivelu [19] introduced a semantic word approach (SEMWORD) to retrieve the data of an educational resource context from the anonymous environment system. This model effectively identified a semantic context that enhanced the potential effectiveness with improved accessible advances. However, the model suffered from security-related problems and high-cost consumption during validation of the retrieval process. Venkatachalam and Venkatachalam [11] employed an information retrieval and reliable storage process with the integration of an optimization algorithm to achieve robust results. The optimized model enhanced the search accuracy with the acquisition of high-performance efficacy. However, the model has a complexity issue that affects the performance and results of performance degradation.
Trabelsi et al. [20] provides a comprehensive survey of neural ranking models for document retrieval, comparing a wide range of deep-learning-based approaches across multiple dimensions, including model architecture, neural components, and feature extraction strategies. However, despite its thorough comparative analysis, the study primarily focuses on architectural design and performance evaluation, while giving limited attention to computational efficiency, optimization strategies, and adaptability to resource-constrained or real-time environments. Specifically, the utilization of advanced optimization techniques and/or hybrid learning strategies to tackle challenges such as the cost of training, scalability, and robustness remains underexplored. This gap indicates the demand for more studies to perform the analysis of effective and optimized neural ranking frameworks, especially for deployment in practical systems such as e-learning platforms, large-scale information retrieval systems, or dynamic environments where efficiency and adaptability are critical.
Ilić et al. [21] conducted a detailed literature review on intelligent methods used in e-learning systems, focusing on AI-powered applications in personalization, adaptive learning, learner modeling, and assessment automation. However, the review provides no performance comparison for the proposed methods or comparison regarding the efficiency, scalability, or computational cost in real-world e-learning systems. Also, the paper lacks a focused discussion on advanced deep-learning-based information retrieval and ranking models and their impact on learning content recommendation and search effectiveness.
Challenges
The attained challenges for the existing methods are furnished below:
- The major limitation of the dual-feedback knowledge scheme was decreased training efficacy; negative feedback reduced the efficacy of training samples and resulted in minimal investigation outcomes [17].
- The augmented-based retrieval method suffered from minimal content relevance that affects the learning pathways for retraining and scalability infrastructure; the method caused an issue in data privacy and bias mitigation [16].
- The model faced certain disadvantages in the SEMWORD-based data retrieval method, such as security-based issues and high computation cost problems while validating the retrieval process [19].
3. WSO Enabled Bidirectional Long Short-Term Memory Classifier for Information Retrieval
This article’s main motivation is to retrieve intelligent information for the E-learning process in web resource systems. Conceptually, the research undergoes two phases: indexing and querying. In this model, the input for the research is observed from the CISI dataset [22], the Benchmark E-learning dataset [23], and the Course Recommendation System dataset [24]. In the indexing phase, the collected data is extracted effectively, and the encryption process is performed to store them in the cloud system. The feature extraction process extracts the instructive information and encrypts the file using the Rivest–Shamir–Adleman (RSA) encryption algorithm. After performing the encryption process, the security concern of the data documents is enhanced by securing them in the cloud storage system [25]. Furthermore, in the querying phase, the user sends a query message to the web page to gather additional information about various terms in the E-learning process by the utilization of a search engine. After entering the query message to the web page in the cloud system, the search engine performs text pre-processing tasks, which transform the raw text data into an easily understandable format by eliminating the noise artifacts. Further, the enhanced text quality is allowed into the feature extraction phase, where the significant features are extracted by modified similarity-based graph features that indulge cosine and sine similarity features, term frequency-inverse document frequency (TFIDF) features, and bag of words features. Based on these methods, the important features are effectually extracted and subjected to an information-retrieval-based BiLSTM model for retrieving the actual related files, based on the user’s query. The WSO-BiLSTM effectively evaluates long-range dependent information in both forward and backward directions and provides robust outcomes. Thus, the complexity and overfitting issues acquired in the WSO-BiLSTM are effectively reduced by the implementation of WSO. Therefore, the imposed optimization achieves a better convergence rate with minimal error. Due to this evaluation, the WSO-BiLSTM retrieves the information precisely with an increased accuracy rate. Moreover, the schematic illustration of the WSO-BiLSTM is expressed in Figure 1.
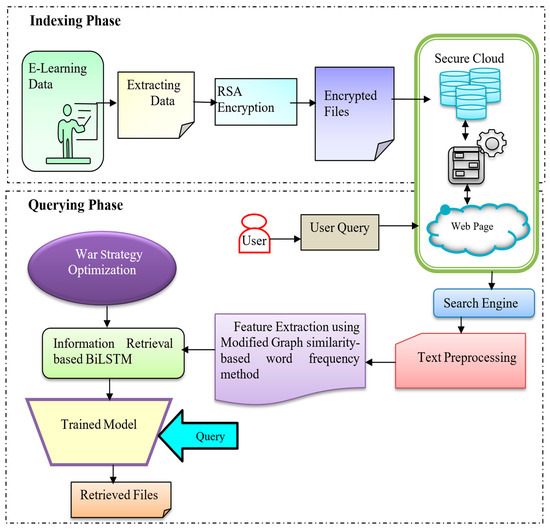
Figure 1.
Schematic illustration of the proposed WSO-BiLSTM framework.
3.1. Indexing Phase
In the indexing phase, initially, the research process undergoes data observation, extraction, and encryption and is secured in a cloud storage system. These processes are significantly performed in the indexing phase, which is briefly described in the upcoming section.
3.1.1. Input E-Learning Data
The input for the proposed research is collected from the CISI dataset, the Benchmark E-learning dataset, and the Course Recommendation System dataset, which are text-based datasets that are mainly used for the information retrieval process. Generally, the dataset file contains CSV text data documents and query associations to perform effective information retrieval functions.
3.1.2. Extracting Data
The input data received from e-learning moves toward the extracting phase. Here, the important pieces of information are extracted from the input data. Further, the extracted feature has a dimension of . In this context, data security is a major issue that occurs in cloud storage systems. Generally, the information is categorized as public, private, and confidential and is widely stored in a cloud system for future retrieval processes. Therefore, to overcome this issue, the research utilized the RSA encryption algorithm to encrypt the data and store it in a cloud storage system that is most reliable and secure.
3.1.3. RSA-Based Encryption
Generally, the RSA algorithm is widely used for data encryption purposes, which involves three stages: key generation, encryption, and decryption [26]. In the key generation stage, the algorithm generates public and private keys, in which the information is encrypted with the public key and decrypted by a private key. The steps that indulge in the key generation phase are given below:
- Select the prime numbers , where .
- Demonstrate .
- By considering Euler’s totient function, evaluate .
- After evaluating the function, select an integer value as and compute a function as , and .
- Calculate as .
- Generate the public key as and private key as .
For the encryption process, the data is converted into a cipher text with the utilization of a public key. Thus, the cipher text format is measured as shown in Equation (1),
where represents the plaintext data, denotes the ciphertext data, is the public exponent, and represents the modulus.
Similarly, during the decryption process, the encrypted ciphertext is converted back into the original data, as expressed in Equation (2).
where represents the private exponent and denotes the modulus.
Therefore, the encrypted data is securely stored in a cloud storage system for future retrieval functions. These processes are specifically acquired in the indexing phase.
3.2. Querying Phase
In the querying phase, the user sends a query message to the web page with the utilization of a search engine to capture additional information about the learning process. After evaluating the query, the phase performs the retrieval function precisely, with an improved accuracy rate.
3.2.1. Text Preprocessing
The extracted files are subjected to the text pre-processing phase, which eliminates the noise and other artifacts in the extracted files. When the user asks a query about the requirement of information that the user wants to know, the query in the search engine evaluates the cloud storage system for the information and extracts some identical files significantly. Additionally, this pre-processing phase organized the unstructured data into structural form data for easy analysis. The text pre-processing task in the research involves lemmatization, stemming, stopping word removal, and using special character removal methods. Based on these methods, it eliminates the redundant text data, prefixes’ and suffixes’ root words, stop words, symbols, and other punctuation marks, specifically.
3.2.2. Feature Extraction Using Modified Graph Similarity-Based Word Frequency Method
The pre-processed data is applied to the feature extraction phase, where the informative features of the text data are extracted by a modified similarity-based graph feature method. The method indulges cosine–sine similarity features, TF-IDF features, and bag of words methods to extract the features separately. Therefore, a detailed explanation of these methods is given as follows.
The sine–cosine features calculate the similarity among the inner product space of two vectors and evaluate the sine and cosine angles of the vectors. In this context, the cosine angle attains the value of one only when the two vectors are identical, and for other cases, the value is less than one. These values represent the orientation magnitude of the vectors. Conceptually, sine–cosine similarity features are mainly used to enhance the accuracy of classification. In the research, the utilization of sine–cosine similarity features significantly enhanced the user’s query classification [27]. The expression of similarity measurement is illustrated in Equation (3):
where and indicate the two vectors in which the similarity is being measured properly.
The TF-IDF numerical statistical method generates text summarization and categorization techniques to help the user read the document effectively. Generally, the method performs information retrieval and text mining processes with the utilization of a weighting factor and eliminates filtering words specifically. Moreover, TF-IDF proportionally increases the number of word counts in the document, based on the word frequency value. Thus, this method helps to control some more common words. Conceptually, TF-IDF is evaluated by two terms: frequency term and inverse document frequency term. In this context, the frequency term evaluates the raw frequency of a term that is present in the selected document. Furthermore, the inverse document frequency term measures the common word that is present in the entire document set, divided by the total number of documents in which the word appears [28]. Thus, the expression of the TF-IDF method is depicted as shown in Equation (4),
where represents the frequency term phase, mentions the inverse document frequency term phase [29], and denotes the total number of documents.
The bag-of-words (BoW) method is widely used to classify and categorize text data by measuring the weights and number of occurrences of every word. Conceptually, the BoW method converts the normal text data into a machine-understandable form with numerical values that efficiently identify all the words present in every document. Additionally, the method counts the word occurrence in the document. The BoW method is mainly used for text classification and information retrieval: a simple feature extraction method that effectively understands text data during validation [30]. Thus, the achieved outcome is represented as shown in Equation (5),
where denotes the vocabulary size and indicates the count of the -th word in the document.
3.2.3. Proposed War Strategy Optimization-Based Bidirectional Long Short-Term Memory Classifier
In the traditional data retrieval process, several learning techniques were introduced to retrieve the information, but they suffer from complexity issues, unauthorized disclosure of data, minimal security concerns, maximal optimization problems, and outlier data sensitivity. To overcome these problems, a BiLSTM model was developed to retrieve information properly and enhance the overall performance for large-range dependencies [31,32]. The proposed model effectively captures the non-linear data source, along with the past and future information by its forward and backward evaluation process [33]. The war strategy optimization (WSO) algorithm is applied as a metaheuristic optimization technique to improve convergence stability and fine-tune model parameters. Conceptually, the WSO is developed from the inspiration of ancient military attacks that protect their kingdom from other dynasties’ attacks.
The obtained extracted feature is fed into the WSO-BiLSTM to retrieve the information effectively. The feature vector is formed by concatenating the BoW, TF-IDF, and cosine similarity features extracted in Equations (3)–(5). The BiLSTM model has a long short-term memory, which effectively evaluates the information in both forward and backward directions and provides an efficient information retrieval process [34]. In this context, the classification and categorization accuracy are improved, and better performance is attained, specifically.
The BiLSTM output has the dimension of [N × 328 × 200], which is expressed as shown in Equation (6),
More specifically, the utilization of the WSO algorithm handles the complexity and overfitting issues. The WSO algorithm finetunes the model to perform better convergence and minimize errors. The outcome of the developed model is expressed as , having the dimension of , which is evaluated as shown in Equation (7),
The concatenated feature vector A is reshaped to dimension before being fed into the WSO-BiLSTM to retrieve the information effectively. The BiLSTM model has a long short-term memory, which effectively evaluates the information in both forward and backward directions and provides an efficient information retrieval process. In this context, the classification and categorization accuracy are improved, and better performance is attained, specifically. The BiLSTM output has the dimension of . More specifically, the utilization of the WSO algorithm handles the complexity and overfitting issues. The WSO algorithm finetunes the model to perform better convergence and minimize errors. The outcome of the developed model is expressed as with the dimension of . where denotes the number of output classes. After feature selection, the dimensionality is reduced from 374 to 328 by eliminating redundant and low-relevance features before reshaping. Thus, the architectural representation of the WSO-BiLSTM is illustrated in Figure 2.
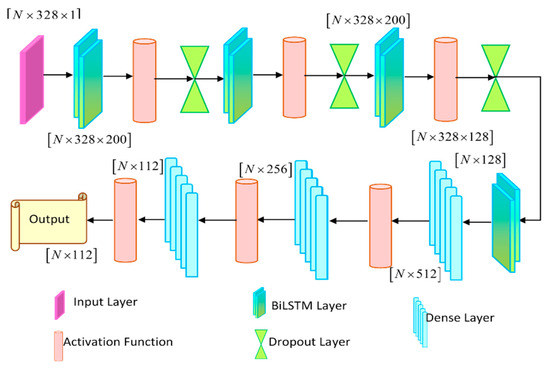
Figure 2.
Architecture representation of BiLSTM model classifier.
Inspiration
The idea behind the implemented war strategy optimization (WSO) algorithm stems from the old ways of military strategy that sent troops into organized, multi-layered tactical units. Within these units, commanders would direct single units like infantry, archers, and cavalry in an elastic and strategic combination that was intended to vanquish enemy troops. Likewise, the WSO algorithm applies the principles of strategic exploration, exploitation, and dynamic maneuvering in order to enhance model performance.
Mathematical Procedure of War Strategy Optimization
War strategy optimization is an effective and unique strategy to defeat the opposite parties during wartime. Generally, the WSO encountered the actual target and reached the goal precisely, with the help of the commander strategy, in every pattern. Moreover, the WSO has the strategy of a random attack, signaling by drums, attack strategy, defense strategy, replacing weak agents, and opposition traps to achieve an accurate information retrieval process. Based on these strategies, the WSO strengthens its ability and progressive condition by reducing the local optima error and overtiring challenges [35]. To perform these executions, the developed WSO is implemented in the layer of the model that tunes the weights and biases and achieves effective outcome results. Each candidate solution vector represents a concatenation of selected BiLSTM parameters, including network weights, bias terms, and the learning rate, which are jointly optimized by the WSO algorithm.
Moreover, to enhance BiLSTM’s performance and mitigate its limitations (e.g., slow convergence and sensitivity to initialization), we apply war strategy optimization (WSO) to learn model parameters, including weights, learning rate, and biases, dynamically. WSO mimics adaptive combat tactics such as leadership switching, attack–defense positioning, and rank-based reinforcement to successfully search and exploit the solution space. The algorithm avoids local optima, accelerates convergence, and improves generalization performance. In general, WSO updates the model parameters iteratively by calculating a fitness function based on validation accuracy and guiding the search through strategic operations such as exploration (for global search) and exploitation (for local fine-tuning), as detailed in Equations (8)–(12).
Initially, the parameters are initialized and the fitness value is determined for each solution. The iterative process is continued until the maximum iteration is reached. During each iteration, for each solution, the algorithm checks the condition to perform either the exploration or exploitation phase. Here, represents a uniformly distributed random coefficient and denotes the predefined exploitation phase is performed.
When , the exploration phase is updated as shown in Equation (8),
where indicates the current position of the -th solution, le denotes the leader position, co indicates the commander position, represents a random coefficient, denotes the control threshold, , and denotes the scaling factor.
Otherwise, when , the exploitation phase is updated, as shown in Equation (9),
After updating the positions, the fitness for each solution is computed, as shown in Equation (10),
where represents the fitness value of the -th solution and denotes the fitness function.
Then, the best solution is updated based on the computed fitness, which is expressed as shown in Equation (11),
Finally, the iteration counter is updated, as shown in Equation (12),
Therefore, based on these attack and defense strategies, the WSO algorithm updates the solutions iteratively and achieves a better convergence rate.
In the proposed framework (Figure 3), war strategy optimization (WSO) is employed as a metaheuristic optimizer to fine-tune selected parameters of the BiLSTM model, including network weights, bias terms, and learning rate. As illustrated in the WSO flowchart, the algorithm iteratively updates candidate solutions through alternating phases of exploration and exploitation, guided by a fitness evaluation based on model performance. By continuously reinforcing high-quality solutions and replacing weaker ones, WSO effectively steers the BiLSTM parameter search toward stable and well-converged configurations. This optimization strategy reduces sensitivity to initialization and mitigates the risk of entrapment in local optima, leading to improved and consistent retrieval performance across datasets.
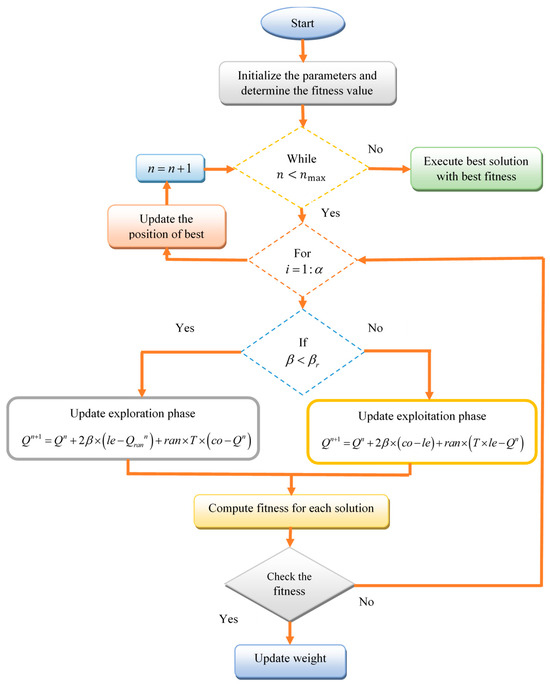
Figure 3.
Flowchart of war strategy optimization.
4. Results
The achieved performance effectiveness of the WSO-BiLSTM for the information retrieval process is briefly explained in this section.
4.1. System Implementation
The information retrieval experiments using the proposed WSO-BiLSTM framework were conducted on a Windows 11 Pro 64-bit system equipped with an Intel® Core™ i7-10710U processor, 16 GB of RAM, and 100 GB of storage. The WSO-BiLSTM model was implemented in Python 3.10.12, using PyCharm Professional 2024.2.1 as the development environment. These implementation settings were consistently applied across all experiments reported in the Results section.
Implementation and Reproducibility Details
The proposed WSO-BiLSTM framework was implemented in Python, using a standard deep learning environment. All experiments were conducted using fixed random seeds to ensure consistent initialization across runs. The BiLSTM network consists of bidirectional recurrent layers followed by a fully connected output layer with a softmax activation function. Cross-entropy loss was used as the optimization objective. For each experiment, training was performed until convergence or until the maximum number of epochs was reached. To ensure robustness, results were obtained through repeated runs, using different random seeds, and the best-performing outcomes were reported.
4.2. Dataset Specification
The input for the information retrieval research is garnered from the CISI dataset, E-learning dataset, and Course Recommendation System dataset, which are elaborately detailed as follows.
The CISI dataset [22] is a text-based dataset that is effectively used for information retrieval, which is captured from the Centre for Inventions and Scientific Information (CISI). The collected text documents from the center contain 1460 data content with 112 associate queries. Based on the user query, associate the matched documents and perform the retrieval process specifically.
The E-learning dataset [23] is captured from an introductory class at a Brazilian university that contains the estimation of various student performances in the online environment, classification of productions, and skill-based projects. Based on this information, the developed model performs the retrieval process.
The Course Recommendation System dataset [24] consists of udemey course data CSV text files in 18 columns based on course ID, course title, URL, paid, month, year, number of subscribers, number of reviews, and number of lectures, etc. This dataset recommends courses for users, based on their requirements.
4.3. Comparative Methods
All the experiments described in the Results part used the same experimental procedures. The WSO-BiLSTM model was repeatedly trained until convergence, and the data represent the performance obtained after stable learning behavior, rather than during an arbitrary run. For performing experiments involving cross-validation, a 10-fold strategy was adopted, using random partitioning of the data and testing after each fold. As reported in the original contributions, the baseline methods of comparison developed are aligned with algorithmic descriptions and experimental settings, and results reported in the literature were utilized to ensure a fair comparison when the same datasets and evaluation protocols are used.
The proposed WSO-BiLSTM model is compared with other existing methods, such as the dual-feedback system [17], HP-BOA [18], RAG [16], Felder-Silverman Learning Style Model (FSLSM) [36], SEMWORD [19], Deep Learning and Information Fusion (DLIF) [34] and OIIRS [11] to achieve effective performance using the CISI dataset [22], E-learning dataset [23] and Course Recommendation System dataset [24].
4.3.1. Comparative Analysis Based on TP with CISI Dataset
The research estimates the performance efficacy of the WSO-BiLSTM under various evaluation metrics such as precision, accuracy, F1-score, and recall. From these evaluations, the attained effectiveness is compared with other conventional techniques under a training percentage maximal value of 90%. In this context, the achieved value for a precision metric for the proposed WSO-BiLSTM model is 98.5%, which shows an improvement as 2.37%, 2.30%, 2.28%, 1.36%, 0.45%, 0.34%, and 0.23% for the dual feedback system, HP-BOA, RAG, FSLSM, SEMWORD, DLIF, and OIIRS methods. The achieved accuracy value for the WSO-BiLSTM model is 97.87%, which shows a 1.99% higher improvement than the dual feedback system, 1.66% higher than HP-BOA, 1.48% greater than RAG, 0.93% more than FSLSM, 0.38% higher than SEMWORD, 0.30% higher than DLIF, and 0.21% more effective than OIIRS. Meanwhile, the obtained value of the F1-score for the WSO-BiLSTM model is 97.86%, which shows an improvement of 1.98%, 1.65%, 1.47%, 0.93%, 0.38%, 0.29%, and 0.20% for the above-mentioned conventional methods. Moreover, the attained value for the recall metric of the WSO-BiLSTM model is 97.23%, which is 1.61% higher than the dual feedback system, 1% greater than HP-BOA, 0.67% higher than RAG, 0.49% more than FSLSM, 0.31% higher than SEMWORD, 0.25% higher than DLIF, and 0.17% greater than OIIRS methods. Therefore, the overall estimation of the WSO-BiLSTM model is demonstrated in Figure 4.
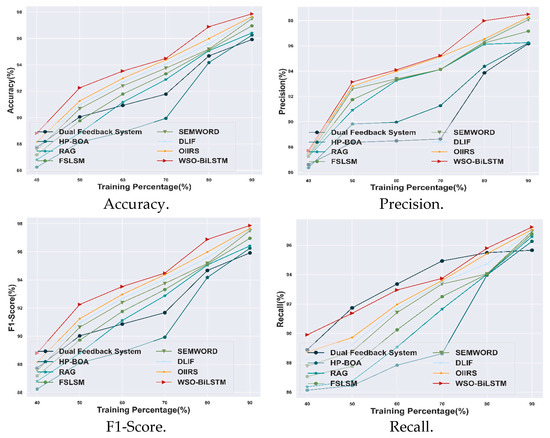
Figure 4.
Comparative analysis based on TP with CISI dataset.
4.3.2. Comparative Analysis Based on K-Fold with CISI Dataset
The comparative analysis of the proposed WSO-BiLSTM model compared with other existing models based on K-fold value is illustrated in Figure 5. The WSO-BiLSTM model achieved high efficiency with a K-fold value of 10. The proposed WSO-BiLSTM model achieved a high accuracy of 96.88%, which shows a 3.14% higher improvement than the dual feedback system, 2.32% higher than HP-BOA, 2.06% greater than RAG, 1.17% more than FSLSM, 0.60% higher than SEMWORD, 0.40% higher than DLIF and 0.32% more effective than OIIRS.
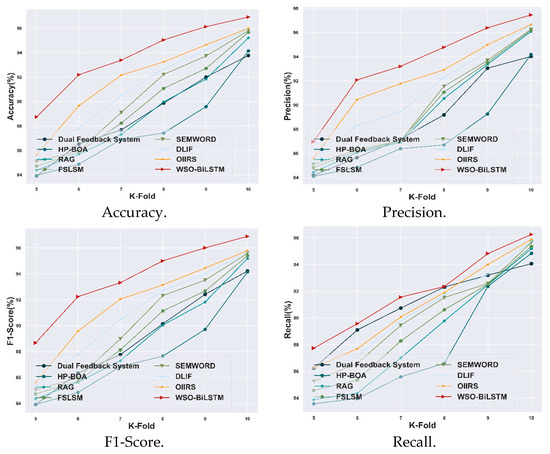
Figure 5.
Comparative analysis based on K-fold with CISI dataset.
The proposed model gained a high F1-score value of 96.86% compared with 0.62% higher than the DLIF model. The proposed WSO-BiLSTM model achieved a high precision value of 97.51%, surpassing other existing methods in optimal information retrieval systems, with the DLIF model displaying a performance improvement of 0.63%. The proposed model results in better information retrieval when compared to the DLIF model. The proposed WSO-BiLSTM model gained a high recall value of 96.26% and outperformed the DLIF model with an improvement of 0.52% with a K-fold value of 10. The proposed WSO-BiLSTM model showed superior performance compared to all the other existing methods for retrieving information in e-learning.
4.3.3. Comparative Assessment Based on TP Using E-Learning Dataset
The proposed WSO-BiLSTM model is evaluated based on evaluation metrics and compared with other existing techniques under a training percentage value of 90%. The achieved accuracy value for the WSO-BiLSTM model is 97.9%, which shows a 0.85% improvement over the OIIRS model. The precision value of the WSO-BiLSTM model is 98.45%, which shows a 0.56% improvement over the OIIRS model. Meanwhile, the obtained value of the F1-score for the WSO-BiLSTM model is 97.9%, which shows an improvement of 0.86% with the model. Moreover, the attained value for the recall metric of the WSO-BiLSTM model is 97.35%, which is 1.14% higher than the OIIRS methods. Therefore, the overall estimation of the WSO-BiLSTM model is illustrated in Figure 6.
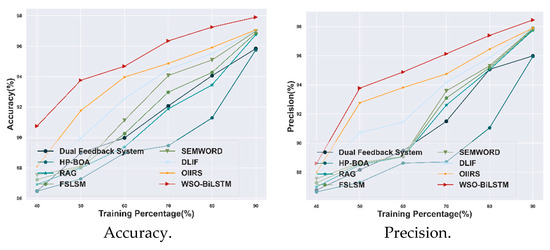
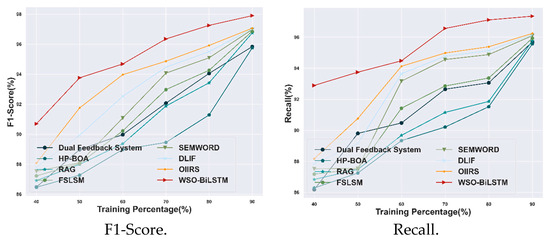
Figure 6.
Comparative analysis based on TP with the E-learning dataset.
4.3.4. Comparative Assessment Based on K-Fold Using E-Learning Dataset
The proposed WSO-BiLSTM model is evaluated with other existing models using the E-learning dataset based on the K-fold value, which is illustrated in Figure 7. The proposed model achieved a high accuracy of 96.92%: an improvement of 0.96% compared with the OIIRS model. The WSO-BiLSTM model results in a high precision value of 97.46%, which shows a 0.82% improvement over the OIIRS model. Meanwhile, the obtained value of the F1-score for the WSO-BiLSTM model is 96.89%, which shows an improvement of 1.14% with the OIIRS model. Moreover, the attained value for the recall metric of the WSO-BiLSTM model is 96.38%, which is 1.34% higher than the OIIRS methods. Therefore, the overall evaluation of the WSO-BiLSTM model is illustrated in Figure 7.
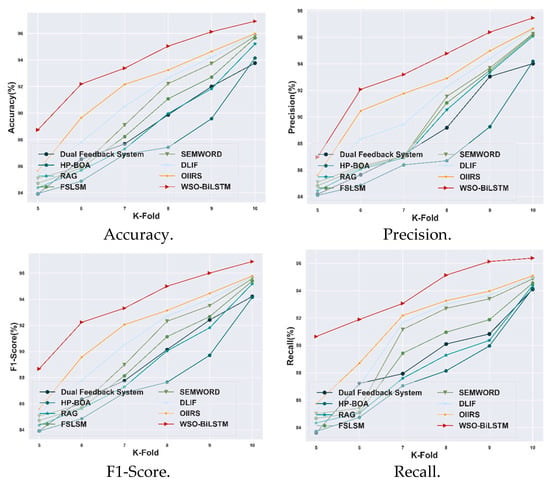
Figure 7.
Comparative analysis based on K-fold with the E-learning dataset.
4.3.5. Comparative Analysis Based on TP with Course Recommendation System Dataset
The proposed WSO-BiLSTM model is evaluated with other existing models using the Course Recommendation System dataset, based on the training percentage of 90%, which is illustrated in Figure 8. The proposed model achieved a high accuracy of 97.88%: an improvement of 0.52% compared with the OIIRS model. The WSO-BiLSTM model gained a high precision value of 98.47%, which shows a 0.40% improvement over the OIIRS model. Moreover, the obtained value of the F1-score for the WSO-BiLSTM model is 97.88%, which shows an improvement of 0.53% with the OIIRS model. Moreover, the attained value for the recall metric of the WSO-BiLSTM model is 97.29%, which is 0.66% higher than the OIIRS methods. Therefore, the overall evaluation of the WSO-BiLSTM model with other existing models is illustrated in Figure 8.
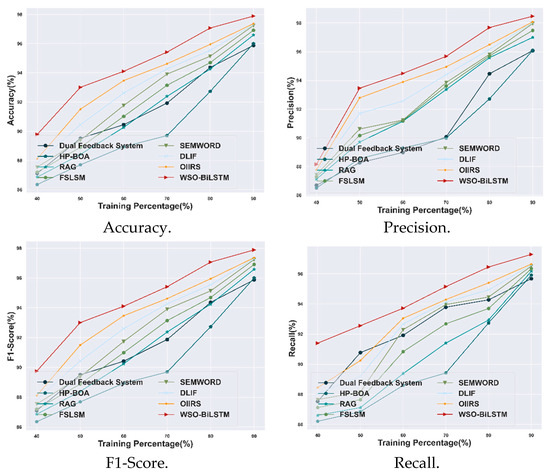
Figure 8.
Comparative analysis based on TP with Course Recommendation System dataset.
4.3.6. Comparative Evaluation Using Course Recommendation System Dataset
The proposed WSO-BiLSTM model is evaluated with other existing models using the Course Recommendation System dataset, based on the K-fold value, which is illustrated in Figure 9. The proposed model achieved a high accuracy of 96.9%: an improvement of 0.64% compared with the OIIRS model. The WSO-BiLSTM model achieved a precision value of 97.48%, which shows a 0.65% improvement over the OIIRS model. Meanwhile, the obtained value of the F1-score for the WSO-BiLSTM model is 96.87%, which shows an improvement of 0.82% with the OIIRS model. Moreover, the attained value for the recall value of the WSO-BiLSTM model is 96.32%, which is 0.86% higher than the OIIRS methods. Therefore, the evaluation of the WSO-BiLSTM model is illustrated in Figure 9.
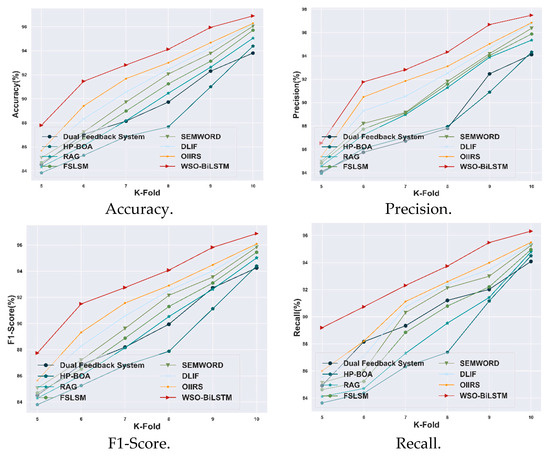
Figure 9.
Comparative analysis based on K-fold with Course Recommendation System dataset.
4.4. Comparative Discussion
The research demonstrates the information retrieval process with the utilization of the WSO-BiLSTM approach. To prove its effectiveness, the developed WSO-BiLSTM model is compared with other existing models. In this context, the other existing models faced difficulties such as scalability, interpretability issues, optimization errors, security issues, computational costs, complexity problems, and degradation in personalization. Therefore, to overcome these challenges, the WSO-BiLSTM model is developed. Thus, the complete comparative discussion of the WSO-BiLSTM model is displayed in Table 1. The information retrieval systems must retrieve relevant content, which is pedagogically suitable and adaptive in feedback, based on user progress and context. The WSO algorithm employs dynamically adjusted leadership and ranking methods to avoid local optima and imposes well-balanced search conduct in complex, high-dimensional environments. This is particularly suitable for fine-tuning deep learning models with high-dimensional parameter spaces and non-convex error landscapes. The integration of WSO with a bidirectional long short-term memory (BiLSTM) network is chosen strategically. BiLSTM excels in learning bidirectional sequential dependency and semantic context, which is critical in determining query purpose and educational information. WSO is even more reinforced, because it makes learning process optimization feasible, achieving faster convergence, reduced overfitting, and better accuracy in fetching pedagogically relevant information. The proposed WSO-BiLSTM model uses an effective feature extraction process and war strategy optimization to eliminate local optima and effectively enhance convergence speed. The integration of the Bidirectional LSTM model learns and processes both future and past contexts in semantic data streams. This two-fold approach improves retrieval accuracy. These advancements combined represent a significant upgrade over the current works by simultaneously addressing the performance, optimization stability, and model flexibility of dynamic e-learning retrieval contexts.

Table 1.
Comparative discussion of the WSO-BiLSTM classifier model.
Methodologically, the effectiveness of the implemented WSO-BiLSTM framework is due to the complementing roles of its main components. The BiLSTM is particularly useful for modeling bidirectional semantic dependencies in text that are relevant for precisely representing query-document relationships in e-learning scenarios. However, traditional gradient-based training can be vulnerable to initialization and local optima. This constraint is overcome by the integration of war strategy optimization with a population-based search mechanism, which balances exploration and exploitation for a more stable convergence in complex, non-convex optimization landscapes. These properties have been combined to enable the proposed method to jointly leverage deep sequential modeling and metaheuristic optimization to yield improved robustness and consistent retrieval performance across datasets.
4.5. Statistical Analysis
Statistical analysis is utilized to determine the patterns in text data, and concluding those patterns might help to explain the variation in the results from one experiment to the next. Furthermore, several statistical measures such as best, mean, and variance are computed for the various evaluation metrics. The proposed WSO-BiLSTM model achieved a high best value in comparison to other existing models, demonstrating the effectiveness of the suggested model. Table 2 depicts the statistical analysis of the proposed WSO-BiLSTM model, using the accuracy, precision, F1-score, and recall metrics based on best, mean, and variance, respectively.
Table 2.
Statistical analysis.
The statistical investigation is shown in Table 2, which also strengthens the stability and robustness performance of the proposed WSO-BiLSTM model. The superior best and mean values and lower variance compared to the baseline methods are observed across all three datasets. This suggests that the enhanced performance is not due to randomness or any one training case, but rather to stable learning behavior when training multiple times. Notably, the decreased variance observed in accuracy, F1-score, and recall indicates that the optimization performed in accordance with the WSO has successfully mitigated sensitivity to initialization and local optima, which are well-known challenges in deep-learning-based retrieval models. Again, showing a statistically significant superior performance across datasets underlines the generalizability of the proposed framework and its applicability to dynamic and heterogeneous e-learning information retrieval scenarios.
5. Conclusions
The WSO-BiLSTM is utilized to retrieve information from various dynamic environments. The model is efficiently integrated with the WSO algorithm to reduce the local optimal issues and computational cost and achieve robust retrieving outcomes. The input observed from various information sources is subjected to several feature extraction methods for extracting the important features used for further retrieval. Furthermore, the efficacy of the performance is improved by the implementation of WSO strategy optimization, which reduces the overfitting and complexity issues that are acquired in the proposed model. Moreover, the developed BiLSTM model captured the semantic information of the data documents and attained effective results in the retrieval process. The achieved effectiveness is further compared with other conventional techniques with various evaluation measures. The proposed approach reduces sensitivity to local optima and improves convergence stability, leading to more consistent retrieval performance. Experimental results across multiple datasets demonstrate strong performance, achieving up to 97.90% accuracy and 98.45% precision on the e-learning dataset with a 90% training split.
We have presented a WSO-BiLSTM framework which achieves constant performance gains and stable behavior across different datasets. The population nature of war strategy optimization adds a further computational burden with respect to traditional gradient-based training, which can limit the scalability in large-scale or time-critical retrieval situations. Moreover, as shown in this paper, in a selected subset of model parameters, the utility of WSO is limited, and the optimization of network components (including a few additional NN components) may achieve additional growth at the cost of computational overhead. Moreover, the experimental evaluation data is restricted to text-based e-learning data, and how this proposed approach can be adapted to multimodal or highly dynamic learning environments has not been studied.
Further work would be in optimization, optimization techniques, optimization strategies, and reduction for the population. Translating the framework for multimodal e-learning contexts and including explainability systems to gain a better level of transparency and user trust are also exciting futures in studies. Furthermore, by enabling the integration of online and incremental learning capabilities, the proposed model can be more flexible in changing educational environments.
Author Contributions
Conceptualization, H.B.A.; methodology, H.B.A.; software, H.B.A.; validation, H.B.A. and A.A.; formal analysis, H.B.A.; investigation, H.B.A. and A.A.; resources, H.B.A.; data curation, A.A.; writing—original draft preparation, H.B.A.; writing—review and editing, H.B.A. and A.A.; visualization, H.B.A. and A.A.; supervision, H.B.A.; project administration, H.B.A.; funding acquisition, H.B.A. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Leading Talents of Provincial Colleges and Universities, Zhejiang-China (Grant No: KY20220214000024) and General Program-Education Department of Zhejiang Province (Grant No. Y202045131).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
The authors give the publisher permission to publish the work.
Data Availability Statement
The datasets used in this study are publicly available from Kaggle and are cited in the References section (CISI dataset, E-learning dataset, and Course Recommendation System dataset).
Acknowledgments
The authors gratefully acknowledge the financial support from Wenzhou-Kean University.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Goldner, H.; Erdelić, T.; Carić, T.; Erdelić, M. Using Industry-based Spatio-Temporal Databases to Store and Retrieve Big Traffic Data. Transp. Res. Procedia 2023, 73, 265–272. [Google Scholar] [CrossRef]
- Jain, S.; Seeja, K.R.; Jindal, R. A fuzzy ontology framework in information retrieval using semantic query expansion. Int. J. Inf. Manag. Data Insights 2021, 1, 100009. [Google Scholar] [CrossRef]
- Bobillo, F.; Straccia, U. Fuzzy ontology representation using OWL 2. Int. J. Approx. Reason. 2011, 52, 1073–1094. [Google Scholar] [CrossRef]
- Diriye, A.; White, R.; Buscher, G.; Dumais, S. Leaving so soon? Understanding and predicting web search abandonment rationales. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Redmond, WA, USA, 29 October–2 November 2012; pp. 1025–1034. [Google Scholar]
- Wang, P.; Hou, Y.; Li, Z.; Zhang, Y. QIRM: A quantum interactive retrieval model for session search. Neurocomputing 2021, 451, 57–66. [Google Scholar] [CrossRef]
- Xing, C.; Wang, K. Website information retrieval of web database based on symmetric encryption algorithm. J. Ambient. Intell. Humaniz. Comput. 2021, 1–12. [Google Scholar] [CrossRef]
- Abuturab, M.R. Securing multiple information using wavelet transform and Yang-Gu mixture amplitude-phase retrieval algorithm. Opt. Lasers Eng. 2019, 118, 42–51. [Google Scholar] [CrossRef]
- El-Ansari, A.; Beni-Hssane, A.; Saadi, M.; El Fissaoui, M. PAPIR: Privacy-aware personalized information retrieval. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 9891–9907. [Google Scholar] [CrossRef]
- Lee, H.Y.; Chung, P.H.; Wu, Y.C.; Lin, T.H.; Wen, T.H. Interactive spoken content retrieval by deep reinforcement learning. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 2447–2459. [Google Scholar] [CrossRef]
- Xue, J.; Xu, C.; Bai, L. DStore: A distributed system for outsourced data storage and retrieval. Future Gener. Comput. Syst. 2019, 99, 106–114. [Google Scholar] [CrossRef]
- Venkatachalam, C.; Venkatachalam, S. Optimal intelligent information retrieval and reliable storage scheme for cloud environment and E-learning big data analytics. Knowl. Inf. Syst. 2024, 66, 6643–6673. [Google Scholar] [CrossRef]
- Izacard, G.; Caron, M.; Hosseini, L.; Riedel, S.; Bojanowski, P.; Joulin, A.; Grave, E. Unsupervised dense information retrieval with contrastive learning. arXiv 2021, arXiv:2112.09118. [Google Scholar]
- Zhu, R.; Tu, X.; Huang, J.X. Deep learning on information retrieval and its applications. In Deep Learning for Data Analytics; Academic Press: Cambridge, MA, USA, 2020; pp. 125–153. [Google Scholar]
- Punithavathi, R.; Ramalingam, A.; Kurangi, C.; Reddy, A.S.K.; Uthayakumar, J. Secure content-based image retrieval system using deep learning with a multi-share creation scheme in a cloud environment. Multimed. Tools Appl. 2021, 80, 26889–26910. [Google Scholar] [CrossRef]
- Mahalakshmi, P.; Fatima, N.S. Ensembling of text and images using deep convolutional neural networks for intelligent information retrieval. Wirel. Pers. Commun. 2022, 127, 235–253. [Google Scholar] [CrossRef]
- Lu, R.S.; Lin, C.C.; Tsao, H.Y. Empowering Large Language Models to Leverage Domain-Specific Knowledge in E-Learning. Appl. Sci. 2024, 14, 5264. [Google Scholar] [CrossRef]
- Shi, T.; Li, L.; Lin, Z.; Yang, T.; Quan, X.; Wang, Q. Dual-feedback knowledge retrieval for task-oriented dialogue systems. arXiv 2023, arXiv:2310.14528. [Google Scholar]
- Tahir, A.; Chen, F.; Hayat, B.; Shaheen, Q.; Ming, Z.; Ahmad, A.; Kim, K.I.; Lim, B.H. Hybrid hp-boa: An optimized framework for reliable storage of cloud data using a hybrid meta-heuristic algorithm. Appl. Sci. 2023, 13, 5346. [Google Scholar] [CrossRef]
- Eunaicy, J.I.C.; Vadivelu, V.S. A SEMWORD-based Semantic Secure Content Retrieval System in E-learning. Indian J. Sci. Technol. 2023, 16, 2447–2457. [Google Scholar]
- Trabelsi, M.; Chen, Z.; Davison, B.D.; Heflin, J. Neural ranking models for document retrieval. Inf. Retr. J. 2021, 24, 400–444. [Google Scholar] [CrossRef]
- Ilić, M.; Mikić, V.; Kopanja, L.; Vesin, B. Intelligent techniques in e-learning: A literature review. Artif. Intell. Rev. 2023, 56, 14907–14953. [Google Scholar] [CrossRef]
- CISI Dataset. Available online: https://www.kaggle.com/datasets/dmaso01dsta/cisi-a-dataset-for-information-retrieval (accessed on 15 July 2025).
- E-Learning Dataset. Available online: https://www.kaggle.com/datasets/marlonferrari/elearning-student-reactions (accessed on 15 July 2025).
- Course Recommendation System Dataset. Available online: https://www.kaggle.com/datasets/shailx/course-recommendation-system-dataset (accessed on 15 July 2025).
- Abdalla, H.B.; Lin, J.; Li, G. NoSQL: A collection of documents and cloud by using a dynamic web query form. In Proceedings of the Seventh International Conference on Digital Image Processing (ICDIP 2015), Los Angeles, CA, USA, 6 July 2015; SPIE: Bellingham, WA, USA, 2015; Volume 9631, pp. 534–542. [Google Scholar]
- Bonde, S.Y.; Bhadade, U.S. Analysis of encryption algorithms (RSA, SRNN, and 2 key pair) for information security. In Proceedings of the 2017 International Conference on Computing, Communication, Control and Automation (ICCUBEA), Pune, India, 17–18 August 2017; IEEE: New York, NY, USA, 2017; pp. 1–5. [Google Scholar]
- Jayakodi, K.; Bandara, M.; Perera, I.; Meedeniya, D. WordNet and cosine similarity-based classifier of exam questions using Bloom’s taxonomy. Int. J. Emerg. Technol. Learn. 2016, 11, 142. [Google Scholar] [CrossRef]
- Christian, H.; Agus, M.P.; Suhartono, D. Single document automatic text summarization using the term frequency-inverse document frequency (TF-IDF). ComTech: Comput. Math. Eng. Appl. 2016, 7, 285–294. [Google Scholar] [CrossRef]
- Nafis, N.S.M.; Awang, S. An enhanced hybrid feature selection technique using term frequency-inverse document frequency and support vector machine-recursive feature elimination for sentiment classification. IEEE Access 2021, 9, 52177–52192. [Google Scholar] [CrossRef]
- Qader, W.A.; Ameen, M.M.; Ahmed, B.I. An overview of bag of words; importance, implementation, applications, and challenges. In Proceedings of the 2019 International Engineering Conference (IEC), Erbil, Iraq, 23–25 June 2019; IEEE: New York, NY, USA, 2019; pp. 200–204. [Google Scholar]
- Abdalla, H.B.; Gheisari, M.; Awlla, A.H. Hybrid self-attention BiLSTM and incentive learning-based collaborative filtering for e-commerce recommendation systems. Electron. Commer. Res. 2024, 25, 4947–4970. [Google Scholar] [CrossRef]
- Abdalla, H.B.; Gheisari, M.; Ahmed, A.; Mehmed, B.; Cheraghy, M.; Liu, Y. An Efficient Recommendation System in E-commerce Using Passer Learning Optimization Based on Bi-LSTM. J. Comput. Cogn. Eng. 2025, 4, 513–534. [Google Scholar] [CrossRef]
- Mahalakshmi, P.; Fatima, N.S. Collaborative text and image-based information retrieval model using Bilstm and residual networks. In Proceedings of the 2020 3rd International Conference on Intelligent Sustainable Systems (ICISS), Thoothukudi, India, 3–5 December 2020; IEEE: New York, NY, USA, 2020; pp. 958–964. [Google Scholar]
- Guo, X.; Yang, J.; Yang, L. Retrieval and Analysis of Multimedia Data of Robot Deep Neural Network Based on Deep Learning and Information Fusion. Informatica 2024, 48, 13. [Google Scholar] [CrossRef]
- Ayyarao, T.S.; Ramakrishna, N.S.S.; Elavarasan, R.M.; Polumahanthi, N.; Rambabu, M.; Saini, G.; Khan, B.; Alatas, B. War strategy optimization algorithm: A new effective metaheuristic algorithm for global optimization. IEEE Access 2022, 10, 25073–25105. [Google Scholar] [CrossRef]
- Felder–Silverman Learning Style Model (FSLSM); Hussain, T.; Yu, L.; Asim, M.; Ahmed, A.; Wani, M.A. Enhancing e-learning adaptability with automated learning style identification and sentiment analysis: A hybrid deep learning approach for smart education. Information 2024, 15, 277. [Google Scholar] [CrossRef]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.