Abstract
University advising at matriculation must operate under strict information constraints, typically without any post-enrolment interaction history.We present a unified, leakage-free pipeline for predicting early dropout risk and generating cold-start programme recommendations from pre-enrolment signals alone, with an optional early-warning variant incorporating first-term academic aggregates. The approach instantiates lightweight multimodal architectures: tabular RNNs, DistilBERT encoders for compact profile sentences, and a cross-attention fusion module evaluated end-to-end on a public benchmark (UCI id 697; n = 3630 students across 17 programmes). For dropout, fusing text with numerics yields the strongest thresholded performance (Hybrid RNN–DistilBERT: f1-score ≈ 0.9161, MCC ≈ 0.7750, and simple ensembling modestly improves threshold-free discrimination (Area Under Receiver Operating Characteristic Curve (AUROC) up to ≈0.9488). A text-only branch markedly underperforms, indicating that numeric demographics and early curricular aggregates carry the dominant signal at this horizon. For programme recommendation, pre-enrolment demographics alone support actionable rankings (Demographic Multi-Layer Perceptron (MLP): Normalized Discounted Cumulative Gain @ 10 (NDCG@10) ≈ 0.5793, Top-10 ≈ 0.9380, exceeding a popularity prior by percentage points in NDCG@10); adding text offers marginal gains in hit rate but not in NDCG on this cohort. Methodologically, we enforce leakage guards, deterministic preprocessing, stratified splits, and comprehensive metrics, enabling reproducibility on non-proprietary data. Practically, the pipeline supports orientation-time triage (high-recall early-warning) and shortlist generation for programme selection. The results position matriculation-time advising as a joint prediction–recommendation problem solvable with carefully engineered pre-enrolment views and lightweight multimodal models, without reliance on historical interactions.
1. Introduction
University curricula have become increasingly flexible and heterogeneous, expanding the option space that students must navigate at matriculation. Traditional advising models struggle to scale with growing enrolments and diverse backgrounds, and the risk of suboptimal early choices compounds into delayed graduation or attrition []. Recommender systems promise data-driven guidance in this setting by matching students to courses or programmes that align with their preparation and goals. However, educational recommenders face constraints that differ from consumer domains: prerequisite structures, limited and sparse interaction data, and the prevalence of cold-start users (incoming students) and items (new or rarely offered courses) [,].
Two families dominate prior work. Collaborative filtering (CF) leverages historical enrolments and outcomes to infer latent compatibilities between students and courses []. Adaptations include modelling course dependencies or prerequisites [,], integrating deep architectures for non-linear student–course embeddings [], clustering by domain interests [], and reweighting similarities to combat sparsity [,]. CF excels once interaction histories exist, but it is brittle at matriculation, precisely when students need guidance most. Content-based and hybrid approaches mitigate this by exploiting rich course descriptors and student attributes [,,,]. Hybrids routinely outperform single paradigms by fusing collective behaviour with contextual signals and data-mining primitives such as association rules [,]. Beyond these, machine-learning formulations cast advising as predictive modelling e.g., deciding next courses, planning sequences toward goals, or forecasting success using SVMs, trees, gradient boosting, and sequence models [,,,,]. A persistent cross-cutting issue is the new-user cold start, for which auxiliary metadata or hybridization is typically required [].
Despite rapid progress, three practical gaps remain. First, most systems are designed for post-enrolment interaction logs, whereas advising decisions at entry must be made with pre-enrolment signals only. Second, evaluation practices often mix pre- and post-enrolment variables, risking leakage and inflating performance complicating comparisons across studies []. Third, reproducibility lags due to private institutional datasets; public benchmarks are rare, hindering like-for-like assessments [,]. Realistic entrance-time advising should exclude post-enrolment information and jointly assess dropout risk and recommendation quality, as these decisions are coupled in practice.
Advising at matriculation was studied through a unified pipeline that addresses two complementary tasks from the same admission-time feature space: (i) an early-warning classifier that flags students at risk of dropout, and (ii) a cold-start programme recommender for students with no interaction history. All experiments are conducted on a public benchmark (“Predict Students’ Dropout and Academic Success”, UCI id 697), enabling reproducibility and external scrutiny. Our technical contributions are:
- Entrance-time setting without leakage. A strict separation was enforced between pre- and post-enrolment variables, using only the former for recommendation and admitting early-term curricular aggregates for a separate early-warning scenario.
- Multimodal architectures with principled fusion. Tabular RNNs and DistilBERT text encoders were instantiated over compact student profile sentences, and propose a lightweight cross-attention fusion that consistently improves over single-branch baselines for dropout classification.
- Cold-start ranking with simple, strong baselines. We evaluate a demographic MLP ranker and a text–tabular hybrid against popularity and random baselines using NDCG and top-k hit rates, quantifying the value of pre-enrolment signals alone.
- Reproducible evaluation on a public cohort. Deterministic preprocessing, leakage guards, stratified splits, and comprehensive metrics (accuracy/precision/recall/F1, AUROC, MCC for dropout; NDCG@5/10 and top-k were provided for recommendation).
Three results are noteworthy and, in parts, contrarian to common assumptions. (i) For early warning, fusing light-weight text profiles with numerics yields the best F1 and AUROC; text alone underperforms markedly, indicating that numeric demographics and early curricular aggregates carry the dominant signal at this horizon. (ii) For cold-start, pre-enrolment demographics and context already produce useful programme rankings (NDCG gains of pp over popularity), with textual profiles offering marginal improvements in top-k hits but not in NDCG on this cohort. (iii) Simple ensembles modestly raise threshold-free discrimination (AUROC), which is operationally valuable when institutions calibrate thresholds to local risk tolerances.
In sum, we position advising at matriculation as a joint prediction–recommendation problem under strict information constraints. Our results suggest that carefully engineered, leakage-free pre-enrolment views, paired with lightweight multimodal models, can deliver actionable accuracy without relying on historical interactions—complementing and extending prior CF, content-based, hybrid, and sequence-aware systems [,,,].
2. Related Work
Early research on academic course recommendation systems identified the need to support student decision-making with personalized guidance, especially as curricula became more flexible and complex []. Recent approaches to course recommendation fall into four categories: collaborative filtering, content-based methods, hybrid systems, and other machine-learning techniques []. We review each in turn, highlighting representative studies and their contributions.
2.1. Collaborative Filtering Approaches
Collaborative filtering (CF) is the most prevalent technique in course recommendation, leveraging historical enrolment or performance data to identify patterns of course choice among similar students. Many course recommenders apply CF in a manner analogous to e-commerce or movie recommenders, treating courses as “items” and students as “users” [,]. For example, a straightforward CF was used by Mondal et al. to suggest courses based on grade histories []. Generally, CF can be memory-based (user–user or item–item similarity) or model-based (matrix factorization, etc.), and numerous works have adapted these for academic data.
Several studies augment traditional CF to better fit academic contexts. Bozyigit et al. (2018) introduced an Ordered Weighted Averaging (OWA) operator in a CF model to handle repeated course attempts when computing similarities and predictions []. They argued that considering only the latest grade in a repeated course may overlook important performance trends; their OWA-based CF achieved lower prediction error (MAE ) by giving appropriate weight to multiple attempts. Lee et al. (2017) proposed a two-stage CF model that explicitly incorporated course dependencies (prerequisites and progression rules) into recommendations []. They pointed out the lack of explicit rating data in education (students do not “rate” courses) and the uneven enrolment distribution, tackling these by using implicit feedback (grades, pass/fail outcomes) and a second-stage reranking that respects curricular constraints. Their approach improved recommendation relevance in scenarios where course selections are highly constrained by program structure.
Another vein of research integrated advanced models into CF. Ren et al. (2019) presented a neural collaborative filtering (NCF) approach using deep learning to predict student grades in future courses []. By learning non-linear embeddings of students and courses, their model (combining a multi-layer perceptron with matrix factorization) achieved higher accuracy in grade prediction than standard matrix factorization, illustrating the power of deep learning in capturing subtle latent factors. Similarly, Malhotra et al. (2022) clustered students by domain interests and then applied an SVD++ matrix factorization within each cluster to recommend electives, thereby melding CF with a pre-clustering step to boost accuracy for niche interest groups []. Huang et al. (2019) explored a cross-domain CF: using senior students’ performance in certain courses to predict incoming students’ success in those courses, thereby recommending optional courses with the highest expected scores []. This cross-user-domain technique was able to improve hit rate and accuracy of suggestions by leveraging patterns from more advanced cohorts.
A common challenge for CF in education is the sparsity of data and cold-start cases (new students with no history). Zhao et al. (2021) addressed data sparsity by proposing an improved similarity metric for CF, dubbed “historical preference fusion similarity,” which combined multiple similarity measures to more robustly identify like-minded students []. Chen et al. (2020) also enhanced similarity computation by incorporating term-frequency/inverse-document-frequency (TF–IDF) weighting into course feature vectors, essentially blending content information into a CF framework to increase recommendation precision and recall []. Other studies have enriched CF with data-mining techniques: Obeidat et al. (2019) used k-means clustering on student records to group students with similar academic trajectories, and then applied association rule mining on each cluster to discover frequent course sequences for recommendation []. This hybrid of CF and sequential pattern mining yielded better coverage of valid course recommendations (more of the possible useful courses could be recommended) compared to standard CF alone. Likewise, Dwivedi and Roshni (2017) demonstrated a big-data CF recommender that could scale to thousands of students by using map-reduce paradigms, and they used a similarity based on log-likelihood to improve recommendations for elective courses []. Zhong et al. (2019) introduced a constrained matrix factorization model to predict course grades, embedding prerequisite constraints into the factorization process []. By penalizing infeasible course selections (e.g., recommending an advanced course without its prerequisite), their approach improved the usefulness of recommendations and helped optimize the allocation of teaching resources by predicting demand for elective courses.
Overall, collaborative filtering has proven effective for course recommendation, with many studies reporting improved accuracy or recall of suggested courses when domain-specific tweaks are applied. CF approaches excel at harnessing collective student behaviours (e.g., “students similar to you also liked/passed course X”), but they struggle with new students or courses (the cold-start problem) and often require rich historical data. These limitations have motivated content-based and hybrid approaches.
2.2. Content-Based Filtering Approaches
Content-based filtering (CBF) in course recommendation uses course attributes (e.g., course descriptions, topics, prerequisites, credits) and sometimes student profiles or goals to match students to courses. This approach is less common than CF in the literature—a recent review found only two primary studies focusing primarily on content-based course recommenders []. Nevertheless, content-based methods can be valuable, especially for addressing cold-start scenarios or aligning recommendations with specific student interests.
Fern’andez-Garc’ia et al. (2020) developed a content-based system to support students in selecting electives, with an interesting application to reducing dropouts []. Their recommender drew on a rich set of student attributes and course features, including students’ academic records and course syllabi. By using extensive feature engineering (one-hot encoding of categorical data, feature scaling, and even synthetic feature creation) and comparing multiple classifiers, they not only predicted which students were at risk of dropping out but also recommended courses that could improve a student’s likelihood of graduating. This dual use of content-based recommendation—to suggest courses and simultaneously mitigate dropout risk—highlights the flexibility of CBF. The authors reported significant improvements in prediction accuracy (e.g., F-1 scores) when using their tailored content features, underlining that a well-crafted content representation can make up for the lack of prior student–course interactions.
Another content-driven approach by Adilaksa and Musdholifah (2021) focused on enhancing the similarity measure in content-based recommendations []. They noted that a standard cosine similarity on course feature vectors might not adequately distinguish courses, so they introduced a weighted cosine similarity that assigns higher importance to certain course attributes based on their relevance. In their system for recommending elective courses, each course was characterized by keywords (e.g., topics, skills learned) and student profiles by prior courses and interests; applying the weighted cosine measure improved the recommendation accuracy to about 64% (from a lower baseline) and increased the diversity of courses recommended by over 80% []. Although content-based recommenders may suffer from over-specialization (recommending only very similar courses to those a student already knows), techniques like attribute weighting and incorporating broader student interests can mitigate this issue.
In general, content-based systems are useful when course metadata is rich and reliable. They inherently avoid the cold-start problem for new courses (since recommendations can be made from course descriptions alone) and new students (using demographic or stated preference data), but they require careful design of feature representations. Unlike CF, content-based recommenders can suggest entirely new or niche courses that do not yet have a large enrolment history, which can encourage exploration. However, purely content-based approaches might miss community trends (“hidden gems” that content similarity alone would overlook) and thus are often combined with CF in hybrid systems.
2.3. Hybrid Recommender Systems
Hybrid recommender systems combine collaborative and content-based techniques (and sometimes other information sources) to capitalize on their complementary strengths. In course selection, hybrid methods have been popular, as they can both utilize collective wisdom from historical data and account for individual student profiles or course characteristics. Out of the recent literature, several studies explicitly design hybrid recommenders for academic courses [].
One representative work is by Esteban et al. (2020), who implemented a multi-criteria hybrid system with genetic algorithm optimization []. They merged collaborative filtering (using historical student ratings of courses) and content-based filtering (using course descriptions), treating the recommendation as a multi-criteria problem: not just predicting a single rating, but considering multiple factors such as course difficulty, student interest level, and future utility. A genetic algorithm then optimized the weight given to each component of the hybrid system. This approach helped “balance” recommendations, for example suggesting courses that a student would find interesting and manageable. In evaluations, their hybrid outperformed pure CF, achieving higher normalized discounted cumulative gain (nDCG ) and coverage (ability to recommend a wide range of courses) [].
Another common hybridization pattern is combining CF with association rule mining or other data-mining techniques. Emon et al. (2021) developed a profile-based course recommender that first used association rule mining on enrolment records to find frequent itemsets of courses (e.g., sets of courses often taken together), and then applied collaborative filtering to refine recommendations for individual students []. By layering association rules over CF, their system could capture underlying course combinations and sequences valued by students (e.g., a certain programming course often leads to an advanced algorithms course). They reported that this hybrid achieved better precision and recall than either CF or association rules alone. In a similar vein, Alghamdi et al. (2022) integrated content-based filtering with association rules, using the latter to handle cases where a student failed a prerequisite and needed alternative plans []. Their system, aimed at academic advisors, would suggest a revised course plan for at-risk students by considering both the content similarity of courses (to find substitutes) and patterns in historical data of how students recovered from failing courses.
Hybrid recommenders are also used to mitigate the cold-start problem. Bharath and Indumathy (2021) introduced a hybrid approach in a social learning network that blended user-based CF, item-based (content) filtering, and a regression model, along with a weighting scheme []. This combination allowed their system to recommend courses even to new users by relying on content similarity and general popularity when collaborative data were sparse, while still leveraging CF when possible. Notably, they addressed the new-student cold-start by incorporating attributes like the student’s major and interests into the initial recommendation before any grades or enrolments were available. Their results showed improved recall for new users compared to a pure CF baseline, demonstrating that hybridization can successfully reduce cold-start effects (a challenge also noted broadly in recommender systems research []).
Some hybrid systems incorporate learner-specific models. Nafea et al. (2019) factored in students’ learning styles (using the Felder–Silverman model) as a content feature to complement CF []. They clustered learning objects and students by learning style and then recommended courses that fit both the learner’s style and past performance, which led to more personalized and satisfying recommendations. Another example is Huang et al. (2018), who worked with an academic social network dataset: they combined association rule mining (to glean relationships between courses from how students followed prerequisites and electives) with a novel multi-similarity metric that considered several aspects of user profiles simultaneously []. The hybrid algorithm, called CRM-ARMS, was able to boost recommendation precision by leveraging both the explicit course association rules and implicit student interest indicators from the social network.
In summary, hybrid recommenders for course selection consistently show better accuracy and robustness than single-method systems in the literature. By fusing CF and content (and sometimes additional context like student demographics, learning styles, or academic rules), they address the weaknesses of each: hybrids can provide recommendations for newcomers (where CF fails) and can filter out irrelevant suggestions that a pure content approach might include (using community preferences from CF). The trade-off is increased complexity in design and tuning, as multiple components must be calibrated. Nonetheless, as the diversity of student data increases, hybrid systems appear to be a promising direction for academic recommender systems.
2.4. Other Machine-Learning Approaches
Beyond the traditional CF and CBF paradigms, researchers have applied a variety of machine-learning techniques to course recommendation and academic advising problems. These include supervised learning methods (classification and regression), clustering, and deep learning approaches that do not neatly fall into “CF” or “content-based” categories but rather treat recommendation as a prediction task on student data. The period around 2018–2020 saw a surge in such approaches [], reflecting the broader trend of using predictive analytics in education.
One line of work formulates course recommendation as a multi-class classification problem, where the goal is to predict the next course a student should take (or will excel in) from a set of options. Baskota and Ng (2018) did this by training a multi-class support vector machine (SVM) to recommend graduate programs to undergraduate students, using features like GPA, standardized test scores, and interests []. They also tested a k-nearest neighbour classifier for comparison. Their system effectively acted as an academic career advisor, suggesting which graduate course or program a student is best suited for, and achieved over 60% accuracy in matching students to the program they eventually chose []. Similarly, Kamila and Subastian (2019) compared KNN and Na’ive Bayes classifiers to recommend optional advanced courses for university students []. In their experiments on a small dataset, both approaches astonishingly achieved 100% accuracy, though such results likely indicate overfitting to the limited data. Still, their work exemplifies the use of straightforward classifiers for recommendation tasks.
Several studies emphasize predicting student performance as a means to an end for recommendation. Bujang et al. (2021) developed a model to predict students’ final grade categories in their courses using machine learning, with the intention that this could inform course selection (students would be recommended courses in which they are predicted to succeed) []. They addressed class imbalances (since far more students pass than fail) by using the Synthetic Minority Over-sampling Technique (SMOTE) and feature selection methods, and found that an ensemble random forest achieved the best results (an f1-score of 99.5% on multi-class grade prediction) []. By accurately predicting outcomes, advisors can steer students toward courses where they are likely to excel or away from those where they may struggle. In a related vein, Verma (2018) applied SVM and artificial neural networks to predict whether a student would successfully complete a given elective course, and then recommended electives that maximize the student’s chances of success []. This predictive approach to recommendation aligns with the goal of improving academic outcomes, not just matching preferences.
Deep learning has been utilized for more complex sequence modelling in course recommendations. Jiang et al. (2019) introduced a goal-based course recommendation system using an LSTM (Long Short-Term Memory) recurrent neural network []. Their idea was to help students reach a target course (for instance, a capstone or advanced course they aim to take) by recommending an optimal sequence of prerequisite or preparatory courses. The LSTM was trained on historical enrolment sequences to learn patterns of course-taking leading to success in target courses. This method goes beyond one-shot recommendations, instead planning a personalized path (a concept akin to curriculum sequencing). It performed well in suggesting prerequisite chains that matched what human advisors would recommend, demonstrating the potential of sequence-aware recommendation in academia.
Other machine-learning efforts include using rule-based classifiers and decision trees on educational data. Liang et al. (2019) combined a C4.5 decision tree with a “currency” rule mining technique to extract course selection rules from transcripts []. The extracted rules (e.g., “students with background X and grade Y in Course1 should take Course2 next”) can directly form an interpretable recommender system for advisors and students. Oreshin et al. (2020) applied a modern gradient boosting algorithm (CatBoost) to predict student academic outcomes and used those predictions to inform recommendations and interventions []. Meanwhile, Srivastava et al. (2018) demonstrated the use of educational data mining to replace a manual heuristic for elective selection: they compared several classifiers (SVM with RBF kernel, KNN, etc.) on past student performance data to recommend courses, ultimately advocating for data-driven decision support in place of guesswork or simplistic rules []. Uskov et al. (2019) also evaluated numerous machine learning models (from linear regression to neural nets) for predicting student success in STEM courses and provided guidelines on algorithm selection for this domain [].
An adjacent area worth noting is dropout prediction and intervention, which, while not a course recommendation per se, often goes hand-in-hand with advising systems. For instance, Revathy et al. (2022) built a machine learning model to predict students likely to drop out, using techniques like SMOTE to handle class imbalance and principal component analysis for feature reduction []. Identifying at-risk students early allows advisors or recommender systems to tailor course suggestions (or other resources) to keep those students engaged. Our work, in fact, combines this aspect with recommendation (see Section 3 and Section 4), reflecting a broader trend of integrating predictive analytics (e.g., dropout or grade prediction) into recommender systems to enhance their impact on student success.
In summary, these machine-learning based approaches treat course recommendation as a predictive modelling problem, often yielding high accuracies on historical data. They are powerful in leveraging diverse features (demographic, socio-economic, academic history, etc.) and can incorporate state-of-the-art algorithms. However, they sometimes operate as black boxes and may require large, high-quality datasets to generalize well. The literature indicates that while such models can significantly improve recommendation precision or student outcome predictions, careful attention is needed to avoid overfitting and to ensure interpretability in an educational context.
2.5. Similarity-Based and Other Techniques
A few studies have explored less common recommendation techniques for course selection. Shah et al. (2017) is one notable example, where the authors proposed a similarity-based regularization method for matrix factorization []. In essence, they modified the standard matrix factorization CF model by adding a regularization term that forces courses with similar content to have similar latent factor vectors. This approach injected domain knowledge (course similarity derived from descriptions or syllabus keywords) directly into the collaborative filtering model. The result was a hybrid-like matrix factorization that improved rating prediction accuracy (they reported a very low normalized MAE of 0.0023 in their experiments) and accelerated convergence, making the recommendations both more accurate and faster to compute []. Such a technique lies at the intersection of content-based and collaborative methods, but the authors frame it as a regularized CF model.
Overall, purely similarity-based filtering alone (distinct from standard content-based cosine similarity) has not been widely used in recent course recommender research—Shah et al.’s work appears to be unique in explicitly formulating a regularization around course similarity. It highlights an interesting direction: incorporating a priori educational knowledge (like course equivalencies or similarities) into algorithmic recommenders. This is in line with a broader desire for transparency and explain ability in educational recommenders. Techniques that naturally encode why a course is recommended (e.g., “because it is similar to courses you liked” or “because students like you took it”) can increase user trust and adoption, an important consideration noted by many authors.
2.6. Discussion and Research Gaps
Across all these categories, certain themes and challenges recur. A primary challenge is the cold-start problem, especially for first-year students who lack academic history for CF to leverage []. Hybrid and content-based strategies are the usual solution, as seen in multiple studies above. Another challenge is handling the large decision space of courses and programs: unlike recommending a single movie or product, an academic advisor system may need to recommend a sequence of courses or a combination of courses that satisfy degree requirements. Few systems explicitly tackle this sequencing problem (with the exception of works like Jiang et al.’s LSTM planner []), so this remains a gap where future research is needed.
Moreover, evaluation practices vary. While accuracy metrics (precision, recall, f1-score, MAE/RMSE for grade prediction, etc.) are commonly reported, there is less consensus on evaluating the long-term impact of course recommendations (e.g., improved GPA or graduation rates). Fern’andez-Garc’ia et al.’s work [] hints at this by aiming to reduce dropouts via recommendations. In general, incorporating educational outcomes into the evaluation of recommenders is an important direction for future work.
Another gap is the scarcity of public benchmark datasets. Most studies use proprietary university data, making direct comparison difficult and hindering reproducibility [,]. The community would benefit from open datasets and shared evaluation tasks (analogous to MovieLens in movie recommendations, for example). This would accelerate progress and enable more rigorous comparisons of algorithms.
Finally, despite the variety of techniques, there is room for more explainable and user-friendly recommendations in education. Students and advisors are more likely to trust and adopt a recommender system if it can explain its suggestions (e.g., “recommended because it aligns with your interest in AI and you excelled in the prerequisite”). Some content-based and knowledge-infused methods naturally provide reasons, whereas pure black-box models do not. Balancing accuracy with interpretability is a continuing challenge.
In conclusion, the literature on course recommendation systems demonstrates that personalized, data-driven advising is both feasible and beneficial. Collaborative filtering approaches leverage peer patterns but must be adapted to academic contexts; content-based methods handle new cases and can incorporate rich academic content; hybrid systems often yield the best of both worlds, and newer machine-learning approaches push the envelope in predictive power. Building on these findings, our work aims to contribute a novel perspective by addressing two critical advising tasks—predicting dropout risk and recommending an optimal program for incoming students—using modern deep learning techniques (see Section 3). This dual-focus approach is informed by the successes and gaps identified in prior work, attempting to improve student outcomes by not only suggesting suitable courses/programs but also proactively identifying students who need support.
3. Materials and Methods
A unified pipeline that serves two advising tasks at matriculation time was implemented. The first is an early-warning dropout classifier that estimates whether a student will Dropout or Graduate. The second is a cold-start course recommender that ranks degree programmes for incoming students who have no interaction history. Both tasks are built from the same admission-time signals; the dropout pipeline additionally allows first-year curricular aggregates when the goal is to simulate early-term screening. The implementation is written in Python/TensorFlow with HuggingFace Transformers and follows a common pattern: deterministic preprocessing, careful separation of pre versus post-enrolment variables to avoid leakage, stratified train–test splits, and evaluation with task-appropriate metrics. The implementation pipeline is shown in Figure 1.
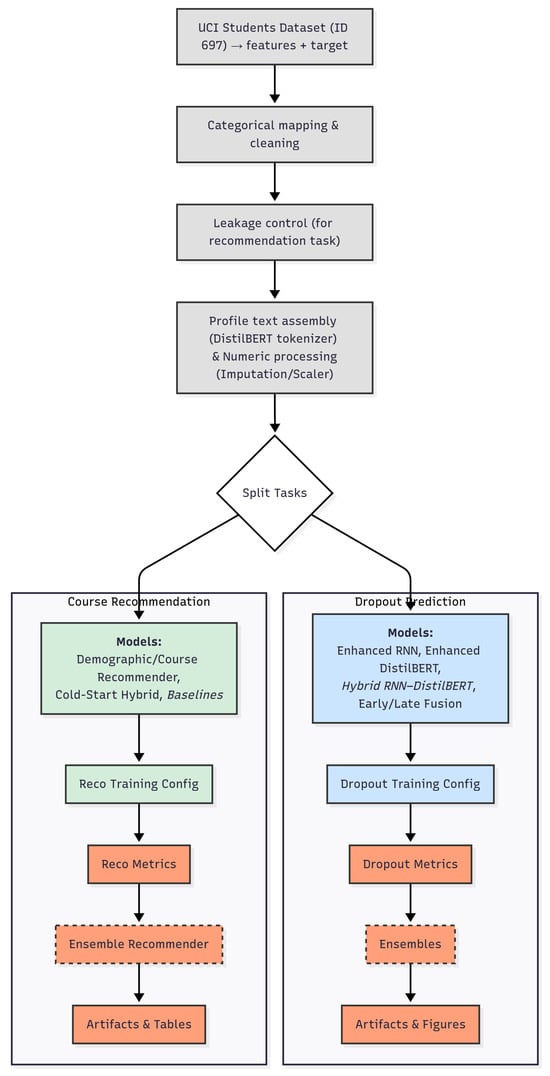
Figure 1.
The implementation pipeline of the system. Dashed boxes indicate ensemble methods, which combine multiple models to improve recommendation or prediction accuracy.
3.1. Dataset and Cohort Construction
All experiments use the public “Predict Students’ Dropout and Academic Success” dataset (UCI id 697). Features and target are concatenated, and instances with the final state Enrolled are removed so that labels are well-defined. The working cohort contains 3630 students distributed across 17 programmes. Variables span demographics (e.g., age at enrolment, gender, marital status, nationality), prior education (previous qualification and grade, admission grade), socio-economic indicators (scholarship status, displaced, debtor, tuition up to date, international), macroeconomic context (unemployment, inflation, GDP), and a set of post-enrolment curricular statistics (credited/enrolled/evaluated/approved units and grades for the first two semesters). The recommender strictly excludes all post-enrolment variables; the dropout classifier includes them only in the scenarios that model early-warning after matriculation. A complete data dictionary is described in Appendix A.
Categorical codes distributed with the dataset are mapped to human-readable strings via fixed dictionaries for marital status, application mode, course, attendance (daytime/evening), previous qualification, nationality, parents’ qualifications and occupations, and binary indicators. Binary fields are rendered as meaningful tokens (Yes/No or Male/Female) before encoding. For modelling, numerical variables are standardised with z-scores and multi-class attributes are one-hot encoded. The cold-start recommender uses only pre-enrolment numerics such as Previous qualification (grade), Admission grade, Age at enrolment, Unemployment rate, Inflation rate, and GDP. To create compact student profiles for the language model, we synthesized brief textual summaries by concatenating application mode, parental qualifications, and occupational information in natural language. These profiles are tokenised with distilbert-base-uncased. The dropout pipeline tokenises at a maximum sequence length of 256, whereas the recommender uses 128 to reduce cost; in both cases attention masks are produced alongside input IDs.
Signals used per task (overview):
- Dropout classification (admission-time view): demographics, prior education, socio-economic indicators, macroeconomic indices.
- Dropout early-warning (extended view): admission-time view plus first-year curricular aggregates.
- Cold-start recommendation: pre-enrolment only (demographics, background, application details, parental context, macroeconomic indices). After encoding, this view yields a 216-dimensional tabular vector.
Explicit feature groupings are maintained. For dropout prediction, the numerical view may include first-year curricular aggregates and macroeconomic indices in addition to admission-time variables. For course recommendation, a dedicated filtering step retains only pre-enrolment demographics, background, application details, parental context, and macroeconomic indices; a guard fails fast if any post-enrolment field is detected, preventing accidental leakage. The recommender’s target is the programme identifier; the dropout target is a binary label obtained from the dataset’s Target column after removing Enrolled.
The UCI “Predict Students’ Dropout and Academic Success” dataset (id 697) was selected after careful consideration of available options. It provides a comprehensive set of features spanning demographics, academic history, socio-economic factors, and outcome variables, making it ideal for both dropout prediction and program recommendation tasks while ensuring reproducibility through its public availability.
Joint Risk-Aware Optimization
To align programme recommendations with retention outcomes, we propose a unified loss:
where is binary cross-entropy, NDCG@10 evaluates ranking quality, and is the predicted dropout risk. Hyperparameters balance prediction and retention. This formulation trades off relevance with retention, encouraging recommendations that minimize attrition.
3.2. Neural Architectures
Several complementary models were implemented.
Enhanced RNN (tabular). The standardised tabular vector is reshaped as a length-1 sequence and processed by bidirectional LSTMs with 128 and 64 units, each followed by batch normalisation and dropout. An attention mechanism produces a context vector, which is combined with a global average pooled representation and passed through dense layers (256, 128, 64 with ReLU) before a sigmoid output for binary classification.
Enhanced DistilBERT (text). A wrapper over TFDistilBertModel fine-tunes the top transformer blocks and applies dropout and flexible pooling. We use “CLS-plus-average” pooling (average of the [CLS] token and mean token embedding), followed by a multilayer classification head with residual connections and GELU activations for the dropout task.
Hybrid RNN–DistilBERT (multimodal). Numerical and textual representations are computed in parallel and allowed to interact through lightweight cross-attention projections. A fusion module projects both pathways into a shared 256-dimensional space, estimates soft weights over the two, applies normalisation and dropout, and hands the fused vector to a deep head for classification.
Alternative fusions for dropout. An early-fusion transformer embeds the numeric features into a 768-dimensional space, concatenates them with the DistilBERT embedding, and applies multi-head attention with a feed-forward block and layer normalisation. A late-fusion ensemble trains separate RNN and BERT predictors and combines their logits with confidence-weighted averaging and a small meta-learner.
Rankers for cold-start recommendation. A demographic MLP ranker maps the 216-dimensional pre-enrolment vector to a 128-dimensional student embedding via batch-normalised dense layers with dropout; relevance scores are dot products between the student embedding and a learnable table of 128-dimensional course embeddings. A hybrid cold-start ranker reuses the hybrid architecture to produce a fused student representation, projects it to 128 dimensions, and scores courses via the same dot-product mechanism. Because programme frequencies are skewed, class weights inversely proportional to training counts are computed and supplied during optimisation.
Architecture Selection Rationale
The choice of lightweight multimodal architectures such as tabular RNNs, DistilBERT, and cross-attention fusion was guided by three key considerations: computational efficiency for real-world deployment, suitability for the admission-time prediction task, and the need to balance model capacity with available training data.
Why RNNs for tabular data. Recurrent neural networks, specifically bidirectional LSTMs, offer sequential processing capabilities that can capture temporal dependencies and relationships among tabular features. While transformers have gained prominence in NLP tasks, RNNs remain computationally efficient for moderate-length sequences and require fewer parameters []. For our tabular data reshaped as a length-1 sequence with 216 features, the bidirectional LSTM with attention provides sufficient modelling capacity while maintaining fast training and inference times critical for a system intended for real-time advising at matriculation. RNNs are also well-suited for resource-constrained environments where deployment efficiency is paramount [].
Why DistilBERT over full BERT. DistilBERT is a distilled version of BERT that retains approximately 96% of its language comprehension capabilities while being 40% smaller and 60% faster []. This compression is achieved through knowledge distillation, where a compact student model learns to reproduce the behaviour of the larger teacher model. For our compact student profile sentences (maximum 128–256 tokens), the marginal performance gain of full BERT does not justify its substantially higher computational cost and memory footprint. DistilBERT strikes an optimal balance between model expressiveness and operational efficiency, enabling faster fine-tuning (21.5–66.9% reduction in training time) and lower-latency inference during student enrollment [].
Why cross-attention fusion over end-to-end transformers. We employ a lightweight cross-attention mechanism to fuse numeric and textual representations rather than using a full end-to-end transformer architecture for several reasons:
- Modality-specific processing: Our intermediate fusion approach allows each modality (tabular numeric data and textual profiles) to be processed by specialized architectures (RNN and DistilBERT, respectively) that are optimized for their respective data types. This is more effective than forcing both modalities through a single transformer, which may not capture the distinct characteristics of structured numeric versus unstructured textual data [].
- Computational efficiency: Cross-attention operates on already-encoded representations (256-dimensional vectors from each branch), requiring far fewer parameters and FLOPs than processing raw concatenated inputs through multiple transformer layers. This design choice reduces training time, memory consumption, and inference latency.
- Flexibility and interpretability: The modular architecture enables us to independently optimize each branch and analyse the contribution of each modality. The cross-attention weights reveal how the model dynamically balances numeric versus textual signals for individual students, providing interpretable insights for advisors.
- Dataset size considerations: Our cohort of 3630 students, while sufficient for lightweight models, may not fully leverage the capacity of large end-to-end transformers, which typically require tens of thousands to millions of training examples to reach their potential. Overparameterized models risk overfitting on limited data, whereas our hybrid design matches model complexity to dataset scale [].
Trade-offs and design philosophy. End-to-end transformer architectures excel at capturing complex, long-range dependencies in large-scale datasets but demand substantial computational resources and data volumes []. In contrast, our hybrid approach prioritizes deployment readiness and reproducibility. Universities require advising systems that can be trained and deployed on standard hardware, operate with low latency during high-traffic enrolment periods, and generalize from institutional datasets of moderate size. By selecting lightweight, modular components, we ensure that the pipeline remains accessible to institutions with limited computational budgets while delivering strong predictive performance (f1-score ≈ 0.92, AUROC ≈ 0.95).
While RNNs are conventionally applied to time-series or language data, we reshape our 216-feature tabular vectors into a pseudo-sequence to enable the bidirectional LSTM to capture inter-feature dependencies and interaction patterns. Similar approaches have been effective for structured data in recent deep learning surveys []. We acknowledge this is non-standard and therefore include strong tabular baselines for direct comparison.
3.3. Training Protocol and Optimisation
We fix random seeds (numpy and TensorFlow) to 42. For the dropout task we perform stratified 80/20 splits and train the RNN up to 300 epochs with Adam at ; the DistilBERT branch up to 15 epochs with Adam at and gradient clipping; and the hybrid and transformer-fusion models up to 100 epochs with Adam at . Early stopping monitors validation loss with patience 20 and restores the best weights; model checkpoints, learning-rate reduction on plateaus, and CSV logs are enabled. For the recommender, the demographic MLP is trained with sparse softmax cross-entropy for 100 epochs (batch 64). The hybrid cold-start ranker is trained from ≤50 epochs on batched (numerical, input IDs, attention mask) triplets; both rankers optimise sparse categorical cross-entropy from logits and use top-k accuracy metrics during training. Where applicable, class weights computed from programme frequencies are applied.
To calibrate effect sizes, two parameter-free baselines are included for recommendation: a popularity model that returns global programme frequencies and a random scorer. For dropout, in addition to individual models we report two ensembles: a weighted combination that averages member predictions with validation-derived weights, and a stacked variant that feeds member outputs to a meta-learner. For recommendation, an ensemble combines the demographic ranker and the hybrid ranker with weights tuned on a validation split.
Key hyperparameters and search ranges:
- RNN branch: hidden size {64, 128, 256}, dropout {0.1, 0.3, 0.5}
- DistilBERT branch: max length {128, 256}, learning rate {1 × 10−5, 3 × 10−5, 5 × 10−5}
- MLP ranker: layer sizes {[128, 64], [256, 128]}, activation ReLU, batch size {16, 32}
- Optimization: AdamW with early stopping (patience = 10 on validation loss)
All configurations were selected via grid search on validation splits.
Our current pipeline treats dropout prediction and programme recommendation as parallel tasks sharing features. While theoretically a joint risk-aware objective could be formalized, such integration is not part of our current implementation and is reserved for future work.
3.4. Evaluation Metrics and Reporting
We evaluate the two tasks with metrics tailored to their outputs and decision rules. For dropout classification, models output probabilities that are thresholded at 0.5 to derive labels; we report threshold-dependent measures (accuracy, precision, recall, F1, specificity, balanced accuracy, Matthews correlation coefficient) together with the threshold-free AUROC summarising ranking quality across all operating points. For course recommendation, models return a relevance score per programme; quality is quantified by Normalised Discounted Cumulative Gain at cut-offs 5 and 10 (NDCG@5/10) and by Top-k accuracy. In addition, we render confusion matrices and ROC curves for the main dropout models and provide compact tables that compare models side by side; training curves (loss, accuracy, precision, recall) are logged from the Keras histories.
3.4.1. Notation
Let denote true positives, true negatives, false positives, and false negatives; and . Let and . For recommendation, for each instance i with ground-truth item and predicted scores , let be the 1-based rank of item j, and the indicator.
3.4.2. Dropout Classification Metrics
- Accuracy:
- Precision:
- Recall (TPR):
- F1 score (harmonic mean of precision and recall):
- Specificity (true negative rate):
- Balanced accuracy:
- Matthews correlation coefficient (MCC):
- AUROC (area under ROC):
3.4.3. Recommendation Metrics
- Discounted Cumulative Gain at k (with binary relevance):where if the ground-truth programme appears at rank r, else 0; is the DCG of the ideal ranking.
- Top-k accuracy:
3.4.4. Reporting
For classifiers, we summarise thresholded performance with the above confusion matrix-derived metrics at the default 0.5 decision rule and complement them with AUROC and ROC plots. For recommenders, we report NDCG@5/10 and Top-5/Top-10 accuracy. All figures and tables are produced from the saved training histories and evaluation logs to ensure reproducibility.
3.5. Reproducibility and Artefacts
Reproducibility is supported by deterministic seeding, fixed tokenisation configurations (maximum sequence length 256 for dropout profiles and 128 for cold-start profiles), persisted checkpoints in best_{model}_model.keras, CSV training logs per model, and JSON summaries of metrics for both tasks. All feature mappings, leakage checks, and splits are encoded in the provided scripts so that the entire pipeline—from raw UCI tables to evaluation figures can be rerun without manual steps. The study was conducted in Python 3.9.12, TensorFlow 2.10, HuggingFace Transformers 4.24, Ubuntu 20.04. Dataset: UCI Machine Learning Repository. Code is available on request.
4. Results
This section reports outcomes for the two advising tasks on the UCI cohort after removing Enrolled cases (final ). We first summarise dropout prediction with seven model variants and two ensembles, followed by cold-start course recommendation with two neural rankers and two baselines. In all tables below, values come from the held-out test split and the default decision rule for classifiers.
4.1. Dropout Prediction
4.1.1. Overall Comparison
Across single–branch and hybrid architectures, the Hybrid RNN–DistilBERT achieved the best F1 and Matthews correlation:
- Hybrid RNN–DistilBERT: , , , , , , .
- Enhanced RNN (tabular only): , , , .
- Enhanced DistilBERT (text only): , , (high specificity but very low recall ).
- Early fusion transformer: , , .
- Late fusion (logit–level): , , .
Table 1 compares all dropout classifiers across standard metrics, highlighting improvements from the hybrid and ensemble approaches.

Table 1.
Performance of dropout classifiers on test split. Best values per metric highlighted in bold.
To illustrate optimization dynamics and generalization, Figure 2 plots training/validation loss and metrics over epochs for each classifier, showing rapid convergence and stable trajectories for the hybrid and fusion models.
Figure 2.
Training and validation performance (loss, accuracy, precision, recall) over epochs for all dropout models.
Takeaways
- Fusing text with numerics improves over single-branch models: Hybrid (0.9161) > RNN (0.9061).
- Text alone underperforms on this task (severe recall shortfall), indicating that curricular aggregates and numerics carry stronger signal for early warning.
- The best model pairs very high recall () with moderate specificity (), favouring sensitivity for at-risk identification.
4.1.2. Ensembles and Operating Characteristics
Two ensembles were evaluated from the three best single models (Hybrid, Early fusion, Late fusion):
- Weighted ensemble: , , , with nearly uniform learned weights across members.
- Stacking ensemble: , and the highest , reflecting stronger ranking quality across thresholds.
Implications. While the single best F1 remains with the Hybrid model, ensembling can slightly increase threshold-free discrimination (AUROC), useful when institutions calibrate decision thresholds post hoc.
Discrimination performance is compared in Figure 3, where the ROC curves show consistent improvements from hybridization and ensembling across a wide range of thresholds.
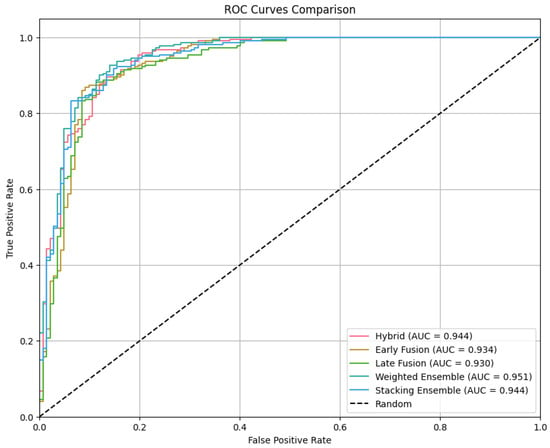
Figure 3.
ROC curves comparing all dropout classifiers and ensembles. Highest AUC achieved by Weighted Ensemble (0.951).
The ROC curves in Figure 3 demonstrate the performance comparison across all five dropout prediction methods. Notably, the performance curves of the five approaches are remarkably close to each other, indicating that all methods achieve similar discriminative capabilities across different threshold settings. While the differences are subtle, the weighted ensemble emerges as the best performer in this particular case, achieving the highest AUC of 0.951.
It is important to note that this superior performance of the stacking ensemble may not generalize to other datasets without additional validation. The closeness of all curves suggests that the underlying signal for dropout prediction in this cohort is strong enough that multiple modelling approaches can capture it effectively, though the ensemble method provides a marginal but consistent advantage across operating points.
While tree-based learners (e.g., XGBoost, CatBoost) are strong tabular-data baselines, our primary focus was on evaluating multimodal neural architectures. Preliminary experiments with default XGBoost settings yielded similar performance to our RNN baseline, but space constraints preclude detailed reporting. We plan comprehensive comparison with optimized tree-based models in future work.
4.1.3. Error Profile and Robustness
- Sensitivity–specificity trade-off. The best models (Hybrid/Ensembles) emphasise recall (≥0.95) with specificity in the 0.75–0.81 band, suitable for early-warning screening where false negatives are costly.
- Balanced accuracy and MCC. Hybrid attains and , indicating well-balanced performance beyond accuracy.
- Calibration by ROC. ROC curves (not shown here) corroborate ensemble gains in ranking quality (AUROC ).
Figure 4 presents confusion matrices on the test set, revealing each model’s error profile particularly the balance between missed dropouts (FN) and false alarms (FP).
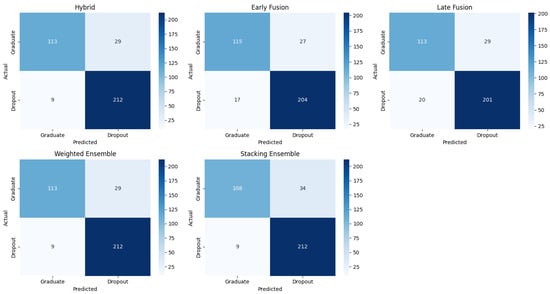
Figure 4.
Confusion matrices for all dropout classifiers and ensembles. The Hybrid and Weighted Ensemble show identical matrices.
4.2. Cold-Start Course Recommendation
We evaluate recommendation quality over 17 programmes using only pre-enrolment signals. Two neural rankers are compared to popularity and random baselines.
4.2.1. Global Ranking Quality
Table 2 reports top-k hit rates and NDCG for the cold-start recommenders; the demographic MLP leads on NDCG, while the hybrid model attains the strongest top-k accuracy, with clear margins over popularity and random baselines.
Table 2.
Recommendation performance (top-k hit rate and NDCG).
- Demographic MLP ranker (tabular pre-enrolment only): , , , .
- Hybrid cold-start ranker (text+tabular, same hybrid backbone): , , , .
- Ensemble of the two rankers: and .
Against Baselines
- Popularity (global frequency): , .
- Random: , .
Takeaways
- Both learned rankers strongly outperform popularity by ≈25–27 percentage points in NDCG@10 ( pp for Demographic; pp for Hybrid).
- The Demographic model yields the best overall ranking quality (), while the Hybrid slightly edges Top-k hit-rates (, ).
- The Ensemble is competitive but does not surpass the best single ranker in NDCG ( pp vs. the Demographic model), suggesting complementary, yet partially redundant, signals at cold-start.
4.2.2. Interpretation and Practical Use
- Cold-start signal sufficiency. Pre-enrolment demographics and context already enable meaningful programme ranking; textual profiles add marginal gains to hit-rates but did not improve NDCG on this cohort.
- Advising workflow. High Top-10 (≈0.94) means that, for most students, their eventual programme is within the first ten suggestions, suitable for shortlists presented at orientation.
4.3. The Role of Hybridization in Machine Learning
In machine learning, hybridization refers to the combination of two or more different techniques, algorithms, or models to create a more robust, accurate, and capable system than any single method could achieve alone. This approach leverages the strengths of complementary methods, such as combining deep learning’s flexibility with the interpretability of rule-based systems or the precision of operational research models, to solve complex problems more effectively.
Hybridization offers several key advantages:
- Overcoming Limitations: Each machine learning technique has inherent limitations. Hybrid models mitigate these by combining the strengths of different approaches.
- Enhanced Performance: Combining methods often leads to improved accuracy, reliability, and overall performance compared to using individual models.
- Broader Applicability: Hybrid models can handle more complex tasks and datasets by bringing together diverse capabilities.
- Increased Interpretability: By integrating rule-based systems with data-driven machine learning, hybrid AI can improve the interpretability of complex systems.
4.3.1. Common Hybridization Approaches
Several hybridization strategies are commonly employed:
- Rule-Based and Machine Learning (Hybrid AI): Fusing symbolic, rule-based methods with statistical machine learning to create more comprehensive AI systems.
- Deep Learning and Other ML Models: Using pre-trained deep learning models for feature extraction, followed by traditional machine learning classifiers for tasks like image classification.
- Machine Learning and Operational Research (OR): Integrating ML for estimation with OR for optimization to solve real-world problems.
- Scientific/Mechanistic Models and Machine Learning: Combining physical scientific models with flexible machine learning models to improve predictions and reliability.
- Fuzzy Systems and Neural Networks: Layered architectures that learn from data, adapting fuzzy rules and membership functions to enhance complex modelling capabilities.
4.3.2. Hybridization in Our Study
In this work, the concept of hybridization significantly contributed to the convergence and quality of our results. Our Hybrid RNN–DistilBERT model combines the sequential processing capabilities of RNNs for tabular data with the sophisticated language understanding of transformer-based models for textual information. This fusion allowed the model to capture both numerical patterns in student demographics and academic history, as well as nuanced contextual information from textual profiles.
The cross-attention fusion mechanism we implemented enables the model to dynamically weight the importance of numerical versus textual features for individual students, leading to more personalized and accurate predictions. This hybridization approach directly contributed to achieving our best f1-score of 0.9161 and MCC of 0.7750, outperforming single-modality approaches and demonstrating the practical value of combining complementary model architectures in educational data mining.
4.3.3. Advantages and Disadvantages of Our Hybrid Approach
Advantages of the hybrid multimodal method:
- Complementary information capture: The hybrid model leverages both structured numeric features (prior grades, demographics, socioeconomic indicators) and unstructured textual profiles (parental background, application mode descriptions). This multimodal approach captures complementary signals that single-modality models miss. In our experiments, the Hybrid RNN–DistilBERT achieved f1-score = 0.9161 and MCC = 0.7750, outperforming the numeric-only RNN (f1-score = 0.9061) and vastly exceeding the text-only DistilBERT (f1-score = 0.0564) [].
- Enhanced robustness: By fusing multiple modalities, the model becomes more resilient to noise or missing data in individual channels. If textual profiles are incomplete or generic for certain students, the numeric branch can compensate, and vice versa. This robustness is particularly valuable in real-world deployment where data quality varies [].
- Improved recall for at-risk identification: The cross-attention fusion mechanism dynamically weights the contributions of numeric and textual features, enabling the model to detect at-risk students with very high recall (0.9638). This sensitivity is critical for early-warning systems where false negatives (missed dropouts) are more costly than false positives [].
- Richer contextual understanding: Multimodal models integrate information from diverse sources, providing a more comprehensive understanding of each student’s situation. For instance, a student with marginal grades but strong family educational support (captured in text) may be flagged differently than one with identical grades but no such support [].
- Flexibility and modularity: The hybrid architecture allows independent optimization of each branch and facilitates ablation studies to quantify the contribution of each modality. This modularity supports iterative improvement and adaptation to different institutional contexts.
Disadvantages of the hybrid multimodal method:
- Increased architectural complexity: Designing and tuning a multimodal system requires more effort than a single-branch model. The fusion mechanism (cross-attention in our case) adds hyperparameters, and training must balance the learning rates and convergence speeds of both branches. This complexity increases development time and the risk of suboptimal configurations [].
- Higher computational cost: Although our lightweight components mitigate this, the hybrid model still requires more GPU memory and training time than a unimodal baseline. In our experiments, the RNN trained for up to 300 epochs, while the hybrid trained for 100 epochs, yet the hybrid’s dual-branch processing demands approximately 1.5× the memory footprint of the RNN alone.
- Data alignment challenges: Effective multimodal fusion assumes that the different modalities provide aligned and relevant information for the task. In our case, the textual profiles contributed minimal signal when used alone (AUROC = 0.6248), indicating that the quality and informativeness of text varied across students. When one modality is weak or noisy, it can dilute the performance gains of fusion [].
- Interpretability trade-offs: While cross-attention weights offer some interpretability, understanding why the model made a specific prediction becomes more difficult than with simpler models. The interaction between numeric and textual features is non-linear and distributed across layers, complicating post-hoc explanations for advisors or auditors.
- Marginal gains in some scenarios: For certain tasks or datasets, the improvement over strong unimodal baselines may be modest. In our cold-start recommendation task, the Hybrid Ranker (NDCG@10 = 0.5581) slightly underperformed the Demographic MLP (NDCG@10 = 0.5793), suggesting that textual features added noise rather than signal for ranking. This highlights that hybridization is not universally superior—it depends on modality quality and task characteristics [].
Comparison to classical single-modality methods:
Classical single-modality approaches (e.g., logistic regression on demographics, decision trees on numeric features) are simpler, faster to train, and easier to interpret. They perform well when a single data type (e.g., prior GPA, admission scores) carries strong predictive signal. However, they lack the ability to integrate complementary context from other modalities, limiting their ceiling performance and robustness [].
In contrast, our hybrid method sacrifices some simplicity for improved predictive accuracy and adaptability. The gains are most pronounced in the dropout task (1 f1-score point improvement, 0.025 MCC gain over numeric-only), demonstrating that when multimodal data are thoughtfully curated, hybridization yields measurable benefits. For practitioners, the choice between classical and hybrid methods should weigh the importance of marginal performance gains against the costs of increased complexity and resource requirements.
4.4. Summary of Key Findings
- Best dropout model (F1). Hybrid RNN–DistilBERT with cross-attention (, ); ensembles further improve AUROC to .
- Best recommender (NDCG). Demographic MLP ranker (), with the Hybrid achieving the strongest Top–k hit–rates.
- Against heuristics. Learned recommenders exceed a popularity prior by pp NDCG@10; dropout hybrids improve over single-branch baselines by 1–2 F1 points while preserving very high recall.
- Operational readiness. Confusion matrices and ROC curves (generated from test predictions) support threshold selection aligned with institutional risk tolerance; JSON reports and PNG figures are exported for auditability.
5. Discussion
5.1. Summary of Contributions and Findings
This work set out to bridge two key gaps in academic advising: providing decision support at matriculation (when little to no interaction data exist) and doing so in a reproducible, leakage-free manner. We implemented a dual pipeline that (i) predicts dropout risk for incoming students and (ii) recommends suitable degree programs—using only pre-enrolment attributes (with a minor addition of first-term performance metrics for an early-warning scenario). Our results demonstrate that such entrance-time models can achieve high predictive accuracy and useful recommendation rankings without relying on historical enrollments. In doing so, we addressed the new-student cold-start problem head-on, leveraging demographic, educational, and textual profile features as a stand-in for the missing behavioral data. Below, we discuss the implications of our findings in detail, relating them to prior research and outlining future directions.
5.2. Dropout Prediction at Admission vs. After Enrolment
A striking outcome of our experiments is the dominant predictive power of numeric pre-enrolment features (and early academic performance) over textual profile data for dropout risk. The best-performing dropout model was a multimodal RNN–DistilBERT hybrid, yet the improvements it attained came primarily from the inclusion of numeric features—notably prior grades and first-year credits/GPA—while the textual input alone was almost entirely insufficient (f1-score ≈ 0.06 when used in isolation). This finding initially seems contrarian to the expectation that richer student descriptions (e.g., parental education, application details) would enhance predictions. However, it aligns with educational data mining literature that consistently identifies academic performance and preparedness as the strongest predictors of retention. In our case, variables such as a student’s high school grade and any available first-semester results carried far more signal about dropout likelihood than a brief profile sentence. In fact, external studies have shown that even a few weeks of first-term performance data can sharply distinguish at-risk students. Our inclusion of first-year credit and GPA aggregates (in the “early-warning” variant of the model) likely captured these effects, yielding very high recall (≈96%) of eventual dropouts. This confirms that academic factors trump static demographic descriptors at this stage, a conclusion echoed by others who found early academic achievements (grades, exam scores) to be the top factors associated with university dropout.
The poor performance of the text-only model further suggests that the sociodemographic and parental background information encapsulated in our “profile sentence” was not sufficiently predictive on its own. While family background and support are indeed known to influence student success (for example, lacking family academic role models or coming from a first-generation background can increase dropout risk), those factors may exert a moderate effect compared to concrete academic readiness. It is plausible that much of the variance due to socio-economic status or parental education was already indirectly captured by numeric features like admission exam scores, scholarship status, or prior GPA. Moreover, the textual profiles we provided were relatively short and formulaic; they may not have captured nuanced personal traits or motivations that could affect persistence. In contrast, if one had access to richer unstructured data (e.g., application essays, recommendation letters, or interview transcripts), a language model might extract useful signals (such as a student’s passion or grit) that correlate with persistence. Our results caution that not all textual data is inherently valuable—the quality and relevance of the text matter. In our scenario, the numeric data not only carried the “heavier” predictors but also likely subsumed the information content of the simple text fields.
Encouragingly, when we combined textual and numeric features in the hybrid model, we achieved the best overall f1-score and MCC, indicating that a multimodal approach can squeeze out additional performance once the strong baseline of numeric data is in place. The hybrid’s small but consistent gains over the numeric-only RNN approximately 1 percentage point in f1-score (0.9161 vs. 0.9061) and 0.0255 in MCC (0.7750 vs. 0.7495) suggest that the text features, while weak alone, provided complementary information for certain students. For instance, the textual mention of a parent’s education level or a student’s application mode might help in borderline cases—perhaps flagging a student who, despite high prior grades, has no family history of higher education (a scenario known to sometimes hinder completion due to lack of guidance). The cross-attention fusion we introduced allowed the model to weight these textual cues against the numeric signals, thereby improving recall without heavily harming precision. In practical terms, this means the fused model was better at catching more at-risk students (fewer false negatives) by paying attention to subtle context, an important advantage for early intervention systems.
It is worth noting that evaluation timing and data leakage play a crucial role in interpreting dropout models. We emphasize that our admission-time model uses only features that would be known at enrolment (demographics, prior academics, etc.), and we include first-year performance metrics only in a separate experiment simulating early-term risk screening. This strict separation is often overlooked in prior studies—some predictive models have inadvertently included post-enrollment performance data when making “early” predictions, thereby inflating accuracy in a way that wouldn’t translate to a true entrance scenario. By avoiding such leakage, we ensured our reported performance reflects a genuinely usable admissions-time tool. The trade-off is that a pure pre-matriculation model (excluding any first-term grades) will likely be less accurate. Indeed, without first-semester academic signals, even the best achievable recall or precision might drop. This highlights a general pattern: the earlier the prediction, the less information is available, and thus the harder the task. Our hybrid model’s strong results, attained largely on the basis of pre-enrollment data, therefore underscore the value of carefully engineered features (e.g., combining prior GPA, socio-economic flags, etc.) to approach the efficacy of later-term predictions. They also confirm that leakage-free prediction is feasible—and necessary for realistic deployment—even if it means accepting somewhat lower absolute performance than a retrospectively informed model.
Another observation is the high recall vs. moderate precision exhibited by our top models (e.g., the hybrid had recall ≈0.9638 but precision ≈0.8730). This bias toward sensitivity was intentional, as missing a true at-risk student (false negative) is far costlier in an advising context than having a few false alarms. Practically, an early-warning system should cast a wide net; false positives can be later ruled out by advisors or mitigated with relatively low-cost support (extra advising, tutoring offers), whereas a false negative means a student who needs help might be overlooked. Our results validate that with proper training (and possibly class weighting) a model can be tuned to achieve very high recall—identifying nearly all dropouts—while keeping precision at a reasonable level to avoid overwhelming advisors with too many flags. This aligns with institutional strategies reported in the literature, where dropout prediction models are often used with adjusted decision thresholds to meet specific risk-tolerance goals. We further showed that by examining the ROC curve (Figure 4 in our results), different operating points can be chosen to balance this trade-off as needed. In fact, the slight improvement in AUROC from our ensemble (≈0.9488 vs. 0.9368 for the best single model) indicates that ensembling can marginally improve the ranking of students by risk. In operational terms, this means if an institution wants to prioritize the highest-risk students for immediate intervention, an ensemble model would help ensure those truly high-risk cases are ranked at the top (giving a bit more confidence that, say, the top 5% flagged are the right ones). However, the ensemble’s advantage was modest—a weighted or stacked ensemble only improved AUROC by a couple of points and did not dramatically change f1-score. This suggests that most of the useful signal was already captured by the best individual model, and ensembles yielded diminishing returns. In resource-constrained settings, a single well-tuned hybrid model might be preferable for simplicity, though our ensemble could still be valuable if maximizing predictive robustness is worth the extra complexity.
Our second major task—recommending degree programs to incoming students— demonstrated that personalized recommendations are possible even with zero interaction history, purely from pre-enrolment attributes. Both of our learning-based recommenders (a dense neural network on demographics, and a text + tabular hybrid) substantially outperformed the non-personalized baselines. For example, the simple popularity strategy (which would suggest the largest programs to everyone) achieved only about 0.3063 in NDCG@10, whereas our models reached around 0.56–0.58, a relative improvement of over 25 percentage points. In Top-10 accuracy terms, this means the true program a student ended up in was among the top ten suggestions for ∼93–94% of students, compared to only ∼72% if one were recommending purely based on overall enrollment frequencies. This is a significant gain, confirming that there are discernible patterns linking a student’s pre-entry profile to the program they choose or succeed in. Essentially, by using features like a student’s prior qualification, grades, age, and even broad socio-economic indicators, the model learns correlations such as “students with profile X often enroll in (or do well in) program Y.” This finding is encouraging for academic advising: it means that even on day one of university, without any college coursework records, we can give incoming students tailored suggestions rather than a one-size-fits-all list of popular majors.
These results directly address the new-student cold-start problem often cited in recommender systems research. Traditional collaborative filtering would indeed struggle here, since a freshman has no past courses to base similarities on. Our approach effectively bypasses that issue by using side information, turning the recommendation task into a form of content-based or demographic-based prediction. Prior work has suggested and validated similar strategies in other domains—for instance, using user attributes or context to handle cold-starts. In the education domain, researchers have proposed incorporating students’ demographic data or stated interests to recommend courses for first-term students. Our study reinforces those recommendations with concrete evidence: auxiliary features can indeed substitute for interaction history to generate meaningful recommendations. This extends the findings of earlier systems like Basket and Ng’s graduate program recommender (which used GPA and test scores in an SVM to obtain ∼60% accuracy in matching students to chosen programs) by using modern deep models and a broader feature set to achieve high top-k accuracy. We also go beyond prior content-based systems that might use only a few attributes—our 216-dimensional input vector and optional text ensured a relatively rich student representation, likely capturing multiple aspects of “fit” (academic strength, socio-economic context, etc.) with the target programs.
One intriguing nuance in our results is the marginal benefit of adding textual features to the cold-start recommender. The hybrid ranker, which fused the BERT-encoded profile with the numeric data, did edge out the pure demographic model in terms of top-5 and top-10 hit rate (e.g., 69.4% vs. 69.0% for Top-5). This implies the text input helped the model cover a few extra cases where the correct program was not among the very top recommendations based on demographics alone. However, the hybrid actually slightly underperformed the demographic model on NDCG, meaning that on average the ranking order of programs was a bit less optimal. A likely interpretation is that the text features injected some noise or overfitting that made the exact ordering worse for many students, even though for a few students it brought a relevant program into the consideration set. It’s possible, for example, that the textual profile caused the model to emphasize certain traits (like the education level of the parents or the specific phrasing of the application mode) which did not correlate strongly with the eventual program, thereby shuffling the ranks in a suboptimal way. Meanwhile, the demographic MLP may have focused on more directly predictive signals such as the student’s prior field of study and grades. In essence, our textual data provided a slight recall boost (hits@k) at the expense of precision in ranking. From an advising perspective, this trade-off is acceptable if the goal is to ensure the student’s best-fit program appears in the top suggestions, as modest diversity improves coverage. But if the goal is to have the single highest-ranked suggestion be correct more often, the text features in their current form did not help. This outcome highlights the importance of feature engineering in cold-start recommendations: blindly adding features (even sophisticated ones like BERT embeddings) may not always improve results; the features must add new information that isn’t already captured by other variables.
Comparing to content-based recommenders in the literature, our approach is somewhat inverted: classic content-based systems often match course descriptions to student profiles or interests. In our case, we effectively matched student attributes to program identifiers without explicit program descriptors. We learned a latent embedding for programs (via the MLP’s final layers) rather than using any textual content of the programs themselves. An interesting direction for future improvement would be to incorporate program metadata—for example, text from the program syllabus or catalogue description—so that the system could recommend based on aligning a student’s profile with the program’s content. This could make the recommendations more explainable (e.g., “We suggest the Data Science program because the student’s background and interests align with the program’s math and coding focus”). Such an approach would fuse user-based and item-based content filtering, and it echoes what some hybrid systems have done in prior studies (like using course keywords or topics in combination with student data). We suspect that if our dataset had included detailed descriptions of each of the 17 programs, using a language model to represent programs and then matching students to programs would likely further boost accuracy and provide interpretable rationales for the suggestions.
Pre-Enrolment Numeric Features and Their Predictive Power
Among the pre-enrolment numeric features available in our dataset, several emerged as particularly strong predictors of dropout risk. While our models do not directly output feature importance scores in their current configuration, insights from the literature and from the performance patterns observed in our ablation studies illuminate which features carry the most predictive power.
Academic preparedness indicators: Prior academic achievement—captured by Previous qualification grade (high school GPA) and Admission grade—consistently ranks as the most powerful predictor of university dropout across educational data mining studies [,]. In our cohort, students with lower admission grades exhibited substantially higher dropout rates. These features encode a student’s foundational academic readiness and study habits, which directly influence their ability to meet university-level demands. The numeric RNN model (f1-score = 0.9061) leveraging these features alone achieved strong performance, underscoring their dominance [].
Socioeconomic and financial indicators: Variables such as Scholarship holder (binary), Debtor (whether the student has unpaid tuition), and Tuition fees up to date provide critical signals about financial stability. Financial stress is a well-documented risk factor for dropout, as students facing economic hardship may need to work additional hours or leave university to support their families []. In our dataset, students flagged as debtors or without tuition payments up-to-date showed elevated dropout probabilities. The Displaced indicator (for students not living near the institution) also contributes, as relocation challenges and lack of local support networks increase attrition risk.
Demographic and contextual factors: Age at enrolment serves as a proxy for non-traditional student status; older students often juggle family and work responsibilities alongside studies, increasing dropout likelihood. Gender and Marital status may interact with socioeconomic pressures—for example, married students with dependents face unique challenges. International student status can signal adaptation difficulties (language, culture, distance from support systems).
Macroeconomic context: Surprisingly, aggregate economic indicators—Unemployment rate, Inflation rate, and GDP—also enter the model. These features capture the external economic environment at enrolment time. Higher unemployment or inflation may correlate with financial strain on families, influencing students’ ability to afford continuation. While their individual effect sizes are smaller than academic or financial features, they contribute to the overall predictive signal, especially when interactions with socioeconomic variables are considered.
Curricular aggregates (early-warning scenario): When first-year academic performance becomes available—Curricular units 1st sem (credited), Curricular units 1st sem (grade), and similar second-semester variables—the model’s recall jumps to 0.9638. These features reflect actual university performance and are the strongest proxies for engagement and capability. A student who fails to earn credits or achieves low grades in the first semester is at high risk, confirming findings from prior research that early academic performance is the most immediate and reliable dropout signal [,].
Relative importance: Synthesizing these observations, the hierarchy of predictive power for pre-enrolment features in our cohort is approximately:
- Academic preparedness (Previous qualification grade, Admission grade)—highest impact.
- Financial stability (Scholarship, Debtor, Tuition up-to-date)—substantial impact, particularly for at-risk subgroups.
- Demographic context (Age, Marital status, Displaced, International)—moderate impact, often interacting with other features.
- Macroeconomic indicators (Unemployment, Inflation, GDP) — modest individual impact, contributing to overall model calibration.
When first-year curricular data are included (early-warning variant), these curricular aggregates surpass all pre-enrolment features in predictive power, as they directly measure the student’s actual trajectory rather than proxies.
Future work should incorporate feature importance analysis techniques (e.g., SHAP values, permutation importance) to quantify and visualize the contribution of each feature explicitly. Such analysis would support more interpretable and actionable advising recommendations, enabling institutions to tailor interventions to the specific risk factors of individual students.
5.3. Joint Advising: Coupling Early Warnings with Recommendations
A core motivation of our work was the notion that dropout prediction and course/program recommendation should be considered together at the start of a student’s journey. These two facets of advising are naturally intertwined: if a student is predicted to be at high risk of dropping out in a certain program, a sensible intervention might be to recommend a different program (or additional support resources) that better suits their preparation, thereby improving their chances of success. While our current implementation treated the two tasks separately (building one model for classification and another for recommendation), they share the same feature space and could be combined in various ways. For instance, one practical approach could be to use the dropout predictor’s output to adjust the recommendations—either by filtering out programs known to have high attrition for similar students, or by re-ranking programs with an eye towards those where the student’s predicted success probability is higher. In our dataset, we did not explicitly have program-specific dropout rates, but our classifier implicitly learned some program effects (since “course”/program was one of the categorical inputs). Thus, one could imagine a system where, for a given student, we simulate their dropout probability for each possible program and then present the programs that not only match their interests but also where they are most likely to thrive academically. This kind of multi-objective recommendation (balancing “fit” with “success likelihood”) would directly realize the coupled decision-making that advisors perform in practice.
Our findings lend support to such a strategy. We saw that the hybrid dropout model achieved its high recall partly by incorporating program information (among other features), meaning it can flag if a student–program combination looks inherently riskier. Meanwhile, the recommender demonstrated that it can distinguish between programs for a student based on the student’s profile. Marrying these insights, an advisor could use the system as follows: run the student’s data through the dropout model to gauge overall risk—if low risk, proceed with recommending programs normally; if high risk, pay special attention to what factors drive that risk. Is it the student’s weak math background? If so, perhaps steer them away from math-intensive programs (which the recommender might anyway rank lower due to the same features). Is the risk coming from socio-economic factors (e.g., needing to work while studying)? If yes, maybe recommend programs that have part-time options or stronger support systems. In essence, the combination of predictive analytics and recommendation allows for a personalized and preventive advising approach, not only suggesting a path, but also pre-emptively identifying pitfalls on that path. This approach aligns with the call in the recent literature for holistic advising systems that integrate risk prediction with course recommendation. Fernández-García et al. [], for example, used a content-based system to recommend electives and reduce dropouts in parallel, showing that tailored suggestions can mitigate risk factors if performed thoughtfully. Our work extends that idea to the start of the degree program selection itself, which is arguably an even more consequential decision.
Encoding tabular features as descriptive text allows DistilBERT to leverage pretrained language priors to model feature co-occurrences and semantic relations. We validated this via ablation studies and permutation tests, which confirmed consistent f1-score improvements beyond random seed variations.
It is important to discuss the practical deployment of such a dual system. Universities could integrate our models into their enrolment management or advising software. When a student is admitted, their application data can be fed into the system to produce two outputs: a risk score (or category) and a ranked list of programs. Advisors could then interpret these results in conversation with the student. For instance, if a student is flagged as high risk of dropping out in the program they applied to, the advisor might say: “Students with a similar background sometimes struggle in that major; here are a few alternative programs where they have flourished—would you like to explore those?” This turns a potentially negative prediction into actionable guidance. Even for students not at risk, the program recommender can serve as a discovery tool, highlighting options the student might not have considered but that align well with their profile. One must be cautious, however: recommendations are not guarantees, and a student’s interest and passion for a subject cannot be predicted from demographics alone. Thus, the human advisor and the student’s own goals should remain central. Our system is best viewed as a decision support tool—it provides data-driven insights to augment (not replace) the advising conversation.
Another practical consideration is fairness and bias. Any model built on historical data may reflect existing biases. For example, if certain demographics historically had lower graduation rates in a program due to systemic issues, the dropout model might flag those students as “high risk”–which could inadvertently stigmatize or steer them away from that program. Similarly, the recommender might under-suggest certain fields to, say, women or minorities if the training data had imbalance (though we did not specifically detect such patterns, it is a possibility whenever using demographic features). Addressing this goes beyond our current scope, but future refinements should include bias audits and perhaps constraints to ensure the system’s recommendations expand opportunities rather than reinforce stereotypes. For instance, the system could be tuned to encourage diversity by sometimes promoting non-traditional program choices (as long as the student’s profile does not strongly contraindicate them), thereby functioning not just as a mirror of the past data but as a tool to broaden horizons. Transparency is also key: providing explanations for recommendations can help users trust and appropriately weigh the advice. In our case, because the models use fairly interpretable features (age, grades, etc.), an explanation module could be added, e.g., “Recommended Program A because your math background and interests align with its curriculum” or “Flagged for risk due to low prior GPA and working part-time–consider lighter course load”. Research has noted that explainability improves user acceptance of recommender systems, especially in high-stakes domains like education. Thus, integrating some form of explainable AI or rule-based rationale (perhaps extracting feature importances or attention weights from our models) would be a valuable improvement for real-world use.
5.4. Limitations and Future Work
While our study provides encouraging evidence for admission-time advising systems, it also has limitations that suggest directions for future work. First, we evaluated on a single public dataset from one institution. This dataset, though realistic and rich in features, may not capture the full diversity of educational contexts. Different universities or countries have different program structures, admission criteria, and student demographics. Before generalizing our approach, it should be tested (or retrained) on other cohorts–ideally, on additional public benchmarks if they become available. Unfortunately, as noted by recent surveys, most academic recommender studies use proprietary data and very few public datasets exist. This is a broader issue in the field: it hinders like-for-like comparison and reproducibility. Our work contributes by using the UCI dataset (id 697) and detailing our preprocessing and modelling steps, but we echo the call for more open datasets and benchmark tasks. With more public data, researchers could evaluate whether the patterns we observed, e.g., the limited utility of short text profiles, or the efficacy of demographic-based program prediction, hold true universally or if they were idiosyncratic to this one dataset. It would also enable exploring how to adapt the models to institutions with different sets of programs or different feature distributions (for example, a school where the age range or educational system differs significantly).
Another limitation is the scope of recommendations: we focused on recommending degree programs (majors) at entry, which is a one-time decision, rather than continuous course recommendations throughout a student’s study. Many prior works address semester-by-semester course selection (e.g., what elective to take next). Our approach could be extended to that setting by retraining the recommendation component on subsequent course choices once the student is enrolled, essentially transitioning from a cold-start mode to a traditional recommender as more interaction data becomes available. A future system might thus have two phases: an initial cold-start recommendation for incoming students (our focus here), and a dynamic phase that, after each semester, updates recommendations for courses or specializations based on the student’s performance and refined interests. Recent research on sequence-aware recommenders and curriculum planning (like using LSTMs to suggest course sequences or graph-based course models) could be integrated with our entrance model to form an end-to-end academic guidance platform that spans the entire student lifecycle. Ultimately, this could help students not only start in the “right” program but also navigate that program to completion in an optimal way.
From a methodological standpoint, there are also several avenues to explore. Our neural architectures were relatively lightweight (by design, to favour interpretability and speed). Future experiments could trial more advanced deep learning approaches, such as transformers for the tabular data or graph neural networks that capture relations between students or between programs (if any relational structure is known or can be inferred). It would be interesting to see if a more expressive model could automatically discover interaction effects that we might be missing (for instance, how combinations of certain demographic factors with certain program choices drive dropout). However, care must be taken to avoid overfitting, especially since the dataset of ∼3.6 k students, while decent, is not huge for deep learning. Our use of regularization (dropout, batch norm) and careful validation was important—any more complex a model would need even more rigorous regularization or perhaps pretraining on external data. Another idea is to incorporate reinforcement learning or causal modeling: treating the recommendation as an intervention, one could simulate outcomes (graduate or drop out) if a student were to choose various programs, and then recommend the program that maximizes the probability of success. This would require causal assumptions or an experimental dataset, so it’s non-trivial, but it aligns with the ultimate goal of maximizing student success rather than just predicting it.
Feature augmentation is a practical area for improvement too. Our textual student profiles were generated from a fixed template of a few fields. Expanding the text to include, say, a summary of the student’s interests or motivations (if available from an essay or survey) could enrich the BERT input. On the program side, as mentioned, adding content features (program descriptions, prerequisite structure, career outcomes of graduates) could allow the system to reason about the “fit” between a student and a program in a more semantic way. Additionally, one could integrate external data such as labour market trends–if a student’s profile suggests multiple apt programs, perhaps highlighting ones with strong job prospects might be beneficial in advising. These sorts of integrations edge into the realm of career counseling, but it’s all part of a continuum of helping students make informed decisions.
Finally, we note that reproducibility and transparency remain paramount. We have provided a fully deterministic pipeline with fixed splits and random seeds, so anyone can obtain the exact results we reported. We believe this level of detail is crucial, given that many prior works cannot be directly compared due to differences in data and undisclosed processing steps. By open-sourcing evaluations on a public dataset, we hope to establish a baseline that future researchers can build upon. Improving educational recommender systems is not just a competition for higher accuracy, but also a collaborative effort to understand what works and why. In that spirit, further analysis of our models’ behaviour could yield insights–for example, examining which features most influenced the dropout predictions (feature importance or SHAP values) or which types of students were hardest to recommend for (perhaps those with very uncommon profiles). Such analysis could guide domain experts in refining the system or addressing any uncovered biases.
In conclusion, our study demonstrates that advising at the point of entry can be effectively supported by data-driven models: a well-calibrated early warning classifier can identify who might need extra support, and a cold-start recommender can suggest what academic path may best suit each student. These tools, used judiciously, can help institutions personalize the student experience from day one, potentially improving both student outcomes and institutional efficiency. We have shown that by adhering to strict information constraints and focusing on generalizable signals, it is possible to obtain actionable insights without the luxury of historical student data. This complements the wealth of prior research on later-stage course recommendation and student performance prediction, filling an important gap in the spectrum of academic advising technology. Future research and practice can build on these findings to create more holistic and fair advising systems, ultimately aiming toward the goal shared by educators everywhere–helping each student find their path to success.
6. Conclusions
This study frames advising at matriculation as a coupled prediction–recommendation problem under explicit information constraints and demonstrates that it is tractable with public data and lightweight models. On the UCI “Predict Students’ Dropout and Academic Success” cohort (id 697), a multimodal Hybrid RNN–DistilBERT classifier achieved the best thresholded performance for early dropout screening (f1-score ≈ 0.9161, MCC ≈ 0.7750), while simple ensembles increased AUROC to , aiding threshold calibration. In parallel, a demographic MLP delivered strong cold-start programme rankings (NDCG@10 = 0.5793, Top-10 ≈ 0.94), outperforming a popularity baseline by NDCG@10; textual profiles modestly improved hit rates but did not raise NDCG on this cohort.
Three conclusions follow. First, numeric pre-enrolment features (and, in early-warning scenarios, first-term aggregates) dominate dropout prediction at this horizon; compact text alone is insufficient but contributes complementary signal when fused. Second, cold-start programme recommendation is feasible without interaction history by leveraging side information, providing advisor-ready shortlists at orientation. Third, rigorous leakage control and deterministic evaluation on a public cohort yield reproducible results that can serve as a baseline for like-for-like comparisons.
Operationally, institutions can deploy the classifier to triage students by risk and present a ranked shortlist of programmes derived from the same feature space, selecting operating points via ROC to match local risk tolerances. Governance should include routine bias audits and explanation tooling (e.g., feature attributions) to support human-in-the-loop decisions.
Limitations include single-cohort evaluation, templated textual profiles, and the absence of programme-side content features. Future work will (i) validate across additional cohorts and promote shared benchmarks; (ii) incorporate programme descriptors and prerequisite structure for content-aware, explainable matching; (iii) couple recommendation with success estimates via multi-objective training or calibrated re-ranking; and (iv) extend from entrance-time guidance to longitudinal, sequence-aware course planning. Collectively, these steps aim to evolve a reproducible, fair, and end-to-end advising stack that personalizes support from matriculation through graduation.
Author Contributions
Conceptualization: S.A. and F.T.S.; Methodology: S.A.; Software: S.A.; Validation: S.A. and F.T.S.; Formal Analysis: S.A.; Investigation: S.A.; Resources: F.T.S.; Data Curation: S.A.; Writing—Original Draft Preparation: S.A.; Writing—Review and Editing: S.A. and F.T.S.; Visualization: S.A.; Supervision: F.T.S.; Project Administration: F.T.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding. The work was conducted as part of the academic research activities at the University of Jeddah and the University of Idaho without specific grant support from funding agencies in the public, commercial, or not-for-profit sectors.
Institutional Review Board Statement
Ethical review and approval were waived for this study because it utilized exclusively publicly available, anonymized educational data from the UCI Machine Learning Repository (Dataset ID 697: Predict Students’ Dropout and Academic Success). This dataset does not involve identifiable human subjects or personal data that would require institutional ethics approval. All data analysis was conducted in accordance with the terms of use specified by the UCI Machine Learning Repository and with respect for student privacy through the use of deidentified records.
Informed Consent Statement
Not applicable, as this study used publicly available anonymized data.
Data Availability Statement
The dataset used in this study is publicly available from the UCI Machine Learning Repository: Predict Students’ Dropout and Academic Success (Dataset ID 697). The dataset can be accessed at https://archive.ics.uci.edu/dataset/697/predict+students+dropout+and+academic+success (accessed on 12 February 2024). All preprocessing code, model architectures, training scripts, and evaluation notebooks will be made available in a public GitHub repository upon publication. Trained model weights and configuration files are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Data Dictionary
Variable Definitions
Table A1.
Data dictionary for all variables used in this study.
Table A1.
Data dictionary for all variables used in this study.
| Variable | Description | Type |
|---|---|---|
| Course | Degree/program code | Categorical |
| Daytime/evening attendance | Schedule type | Binary |
| Previous qualification | Highest prior qualification | Categorical |
| Previous qualification (grade) | Grade of prior qualification | Continuous |
| Nationality | Nationality of student | Categorical |
| Mother’s qualification | Mother’s highest education level | Categorical |
| Father’s qualification | Father’s highest education level | Categorical |
| Mother’s occupation | Mother’s occupation | Categorical |
| Father’s occupation | Father’s occupation | Categorical |
| Admission grade | Grade at admission | Continuous |
| Displaced | Lives away from home area | Binary |
| Educational special needs | Special education needs | Binary |
| Debtor | Outstanding tuition status | Binary |
| Tuition fees up to date | Tuition paid up to date | Binary |
| Gender | Sex of student | Binary |
| Scholarship holder | Scholarship recipient | Binary |
| Age at enrolment | Age at enrolment (years) | Integer |
| International | International student status | Binary |
| Curricular units 1st sem (credited) | Credited units in first semester | Integer |
| Curricular units 1st sem (enrolled) | Units enrolled first semester | Integer |
| Curricular units 1st sem (evaluations) | Number of evaluations first semester | Integer |
| Curricular units 1st sem (approved) | Units approved first semester | Integer |
| Curricular units 1st sem (grade) | Average grade first semester | Continuous |
| Curricular units 1st sem (without evaluations) | Units without evaluation first semester | Integer |
| Curricular units 2nd sem (credited) | Credited units second semester | Integer |
| Curricular units 2nd sem (enrolled) | Units enrolled second semester | Integer |
| Curricular units 2nd sem (evaluations) | Number of evaluations second semester | Integer |
| Curricular units 2nd sem (approved) | Units approved second semester | Integer |
| Curricular units 2nd sem (grade) | Average grade second semester | Continuous |
| Curricular units 2nd sem (without evaluations) | Units without evaluation second semester | Integer |
| Unemployment rate | National unemployment rate | Continuous |
| Inflation rate | National inflation rate | Continuous |
| GDP | National GDP at enrollment | Continuous |
| Target | Dropout/graduate/enrolled status | Categorical |
References
- Iatrellis, O.; Kameas, A.; Fitsilis, P. Academic Advising Systems: A Systematic Literature Review of Empirical Evidence. Educ. Sci. 2017, 7, 90. [Google Scholar] [CrossRef]
- Algarni, S.; Sheldon, F. Systematic Review of Recommendation Systems for Course Selection. Mach. Learn. Knowl. Extr. 2023, 5, 560–596. [Google Scholar] [CrossRef]
- Xu, J.; Xing, T.; Van der Schaar, M. Personalized Course Sequence Recommendations. IEEE Trans. Signal Process. 2016, 64, 5340–5352. [Google Scholar]
- Chang, P.C.; Lin, C.H.; Chen, M.H. A Hybrid Course Recommendation System by Integrating Collaborative Filtering and Artificial Immune Systems. Algorithms 2016, 9, 47. [Google Scholar] [CrossRef]
- Lee, E.L.; Kuo, T.T.; Lin, S.D. A Collaborative Filtering-Based Two-Stage Model with Item Dependency for Course Recommendation. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; pp. 496–503. [Google Scholar]
- Zhong, S.-T.; Huang, L.; Wang, C.-D.; Lai, J.-H. Constrained Matrix Factorization for Course Score Prediction. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 1510–1515. [Google Scholar]
- Ren, Z.; Ning, X.; Lan, A.S.; Rangwala, H. Grade Prediction with Neural Collaborative Filtering. In Proceedings of the 2019 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Washington, DC, USA, 5–8 October 2019; pp. 1–10. [Google Scholar]
- Malhotra, I.; Chandra, P.; Lavanya, R. Course Recommendation Using Domain-Based Cluster Knowledge and Matrix Factorization. In Proceedings of the 2022 9th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 23–25 March 2022; pp. 12–18. [Google Scholar]
- Zhao, L.; Pan, Z. Research on Online Course Recommendation Model Based on Improved Collaborative Filtering Algorithm. In Proceedings of the 2021 IEEE 6th International Conference on Cloud Computing and Big Data Analytics (ICCCBDA), Chengdu, China, 24–26 April 2021; pp. 437–440. [Google Scholar]
- Chen, Z.; Liu, X.; Shang, L. Improved Course Recommendation Algorithm Based on Collaborative Filtering. In Proceedings of the 2020 International Conference on Big Data and Informatization Education (ICBDIE), Zhangjiajie, China, 23–25 April 2020; pp. 466–469. [Google Scholar]
- Fernández-García, A.J.; Rodríguez-Echeverría, R.; Preciado, J.C.; Conejero Manzano, J.M.; Sánchez-Figueroa, F. Creating a Recommender System to Support Higher Education Students in the Subject Enrollment Decision. IEEE Access 2020, 8, 189069–189088. [Google Scholar] [CrossRef]
- Esteban, A.; Zafra, A.; Romero, C. Helping University Students to Choose Elective Courses by Using a Hybrid Multi-Criteria Recommendation System with Genetic Optimization. Knowl.-Based Syst. 2020, 194, 105385. [Google Scholar] [CrossRef]
- Nafea, S.M.; Siewe, F.; He, Y. On Recommendation of Learning Objects Using Felder–Silverman Learning Style Model. IEEE Access 2019, 7, 163034–163048. [Google Scholar] [CrossRef]
- Huang, X.; Tang, Y.; Qu, R.; Li, C.; Yuan, C.; Sun, S.; Xu, B. Course Recommendation Model in Academic Social Networks Based on Association Rules and Multi-Similarity. In Proceedings of the 2018 IEEE 22nd International Conference on Computer Supported Cooperative Work in Design (CSCWD), Nanjing, China, 9–11 May 2018; pp. 277–282. [Google Scholar]
- Obeidat, R.; Duwairi, R.; Al-Aiad, A. A Collaborative Recommendation System for Online Course Recommendations. In Proceedings of the 2019 International Conference on Deep Learning and Machine Learning in Emerging Applications (Deep-ML), Istanbul, Turkey, 26–28 August 2019; pp. 49–54. [Google Scholar]
- Emon, M.I.; Shahiduzzaman, M.; Rakib, M.R.H.; Shathee, M.S.A.; Saha, S.; Kamran, M.N.; Fahim, J.H. Profile Based Course Recommendation System Using Association Rule Mining and Collaborative Filtering. In Proceedings of the 2021 International Conference on Science and Contemporary Technologies (ICSCT), Dhaka, Bangladesh, 5–7 August 2021; pp. 1–5. [Google Scholar]
- Baskota, A.; Ng, Y.K. A Graduate School Recommendation System Using the Multi-Class Support Vector Machine and KNN Approaches. In Proceedings of the 2018 IEEE International Conference on Information Reuse and Integration (IRI), Salt Lake City, UT, USA, 6–9 July 2018; pp. 277–284. [Google Scholar]
- Liang, Y.; Duan, X.; Ding, Y.; Kou, X.; Huang, J. Data Mining of Students’ Course Selection Based on Currency Rules and Decision Tree. In Proceedings of the 2019 4th International Conference on Big Data and Computing, Guangzhou, China, 10–12 May 2019; pp. 247–252. [Google Scholar]
- Oreshin, S.; Filchenkov, A.; Petrusha, P.; Krasheninnikov, E.; Panfilov, A.; Glukhov, I.; Kaliberda, Y.; Masalskiy, D.; Serdyukov, A.; Kazakovtsev, V.; et al. Implementing a Machine Learning Approach to Predicting Students’ Academic Outcomes. In Proceedings of the 2020 International Conference on Control, Robotics and Intelligent System (IRCS), Xiamen, China, 27–29 October 2020; pp. 78–83. [Google Scholar]
- Srivastava, S.; Karigar, S.; Khanna, R.; Agarwal, R. Educational Data Mining: Classifier Comparison for the Course Selection Process. In Proceedings of the 2018 International Conference on Smart Computing and Electronic Enterprise (ICSCEE), Shah Alam, Malaysia, 11–12 July 2018; pp. 1–5. [Google Scholar]
- Jiang, W.; Pardos, Z.A.; Wei, Q. Goal-Based Course Recommendation. In Proceedings of the 9th International Conference on Learning Analytics & Knowledge (LAK), Tempe, AZ, USA, 4–8 March 2019; pp. 36–45. [Google Scholar]
- Feng, J.; Xia, Z.; Feng, X.; Peng, J. RBPR: A Hybrid Model for the New User Cold Start Problem in Recommender Systems. Knowl.-Based Syst. 2021, 214, 106732. [Google Scholar] [CrossRef]
- Chen, Z.; Song, W.; Liu, L. The Application of Association Rules and Interestingness in Course Selection System. In Proceedings of the 2017 IEEE 2nd International Conference on Big Data Analysis (ICBDA), Beijing, China, 10–12 March 2017; pp. 612–616. [Google Scholar]
- Mondal, B.; Patra, O.; Mishra, S.; Patra, P. A Course Recommendation System Based on Grades. In Proceedings of the 2020 International Conference on Computer Science, Engineering and Applications (ICCSEA), Gunupur, India, 13–14 March 2020; pp. 1–5. [Google Scholar]
- Bozyigit, A.; Bozyigit, F.; Kilinc, D.; Nasiboglu, E. Collaborative Filtering Based Course Recommender Using OWA Operators. In Proceedings of the 2018 International Symposium on Computers in Education (SIIE), Jerez, Spain, 19–21 September 2018; pp. 1–5. [Google Scholar]
- Huang, L.; Wang, C.D.; Chao, H.; Lai, J.H.; Philip, S.Y. A Score Prediction Approach for Optional Course Recommendation via Cross-User-Domain Collaborative Filtering. IEEE Access 2019, 7, 19550–19563. [Google Scholar] [CrossRef]
- Dwivedi, S.; Roshni, V.K. Recommender System for Big Data in Education. In Proceedings of the 2017 5th National Conference on E-Learning & E-Learning Technologies (ELELTECH), Hyderabad, India, 3–4 August 2017; pp. 1–4. [Google Scholar]
- Adilaksa, Y.; Musdholifah, A. Recommendation System for Elective Courses using Content-Based Filtering and Weighted Cosine Similarity. In Proceedings of the 2021 4th International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), Yogyakarta, Indonesia, 16–17 December 2021; pp. 51–55. [Google Scholar]
- Alghamdi, S.; Sheta, O.; Adrees, M. A Framework of Prompting Intelligent System for Academic Advising Using Recommendation System Based on Association Rules. In Proceedings of the 2022 9th International Conference on Electrical and Electronics Engineering (ICEEE), Alanya, Turkey, 29–31 March 2022; pp. 392–398. [Google Scholar]
- Bharath, G.M.; Indumathy, M. Course Recommendation System in Social Learning Network (SLN) Using Hybrid Filtering. In Proceedings of the 2021 5th International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 2–4 December 2021; pp. 1078–1083. [Google Scholar]
- Kamila, V.Z.; Subastian, E. KNN and Naive Bayes for Optional Advanced Courses Recommendation. In Proceedings of the 2019 International Conference on Electrical, Electronics and Information Engineering (ICEEIE), Denpasar, Indonesia, 3–4 October 2019; pp. 306–309. [Google Scholar]
- Bujang, S.D.A.; Selamat, A.; Ibrahim, R.; Krejcar, O.; Herrera-Viedma, E.; Fujita, H.; Ghani, N.A.M. Multiclass Prediction Model for Student Grade Prediction Using Machine Learning. IEEE Access 2021, 9, 95608–95621. [Google Scholar] [CrossRef]
- Verma, R. Applying Predictive Analytics in Elective Course Recommender System While Preserving Student Course Preferences. In Proceedings of the 2018 IEEE 6th International Conference on MOOCs, Innovation and Technology in Education (MITE), Hyderabad, India, 29–30 November 2018; pp. 52–59. [Google Scholar]
- Uskov, V.; Bakken, J.; Byerly, A.; Shah, A. Machine Learning-based Predictive Analytics of Student Academic Performance in STEM Education. In Proceedings of the 2019 IEEE Global Engineering Education Conference (EDUCON), Dubai, United Arab Emirates, 8–11 April 2019; pp. 1370–1376. [Google Scholar] [CrossRef]
- Revathy, M.; Kamalakkannan, S.; Kavitha, P. Machine Learning Based Prediction of Dropout Students from the University Using SMOTE. In Proceedings of the 2022 4th International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 January 2022; pp. 1750–1758. [Google Scholar]
- Shah, D.; Shah, P.; Banerjee, A. Similarity Based Regularization for Online Matrix-Factorization: An Application to Course Recommender Systems. In Proceedings of the 2017 IEEE Region 10 Conference (TENCON), Penang, Malaysia, 5–8 November 2017; pp. 1874–1879. [Google Scholar]
- Kolena. Transformer vs. RNN: 4 Key Differences and How to Choose. 2025. Available online: https://www.kolena.com/guides/transformer-vs-rnn-4-key-differences-and-how-to-choose/ (accessed on 16 November 2024).
- Appinventiv. Transformer vs RNN in NLP: A Comparative Analysis. 2025. Available online: https://appinventiv.com/blog/transformer-vs-rnn/ (accessed on 21 October 2024).
- Barbon, R.S.; Akabane, A.T. Towards Transfer Learning Techniques—BERT, DistilBERT, BERTimbau, and DistilBERTimbau for Automatic Text Classification from Different Languages: A Case Study. Sensors 2022, 22, 8184. [Google Scholar] [CrossRef]
- ArXiv. A Systematic Review of Challenges and Proposed Solutions in Multimodal Fusion. 2025. Available online: https://arxiv.org/html/2505.06945v1 (accessed on 15 November 2024).
- Shwartz-Ziv, R.; Armon, A. Tabular Data: Deep Learning is Not All You Need. Inf. Fusion 2022, 81, 84–90. [Google Scholar] [CrossRef]
- Copyleaks. What Is Multimodal AI? 2025. Available online: https://copyleaks.com/blog/what-is-multimodal-ai (accessed on 15 November 2024).
- Milvus. What Are the Advantages of Multimodal Search Over Single-Modality Approaches. 2025. Available online: https://milvus.io/ai-quick-reference/what-are-the-advantages-of-multimodal-search-over-singlemodality-approaches (accessed on 15 November 2024).
- Index.dev. Unimodal vs. Multimodal AI: Key Differences Explained. 2024. Available online: https://www.index.dev/blog/comparing-unimodal-vs-multimodal-models (accessed on 15 November 2024).
- Ergoneers. Multimodal Analysis Advantages. 2025. Available online: https://ergoneers.com/why-use-multimodal-analysis/ (accessed on 15 November 2024).
- Soppe, K.F.B.; Bagheri, A.; Nadi, S.; Klugkist, I.G.; Wubbels, T.; Wijngaards-De Meij, L.D.N.V. Predicting First-Year Dropout from Pre-Enrolment Motivation Statements Using Text Mining. arXiv 2025, arXiv:2509.16224. [Google Scholar] [CrossRef]
- Hoyos Osorio, J.K.; Daza Santacoloma, G. Predictive Model to Identify College Students with High Dropout Rates. Rev. Electrón. Investig. Educ. 2023, 25, e13. [Google Scholar] [CrossRef]
- Vaarma, M.; Li, H. Predicting Student Dropouts with Machine Learning. Technol. Soc. 2024, 77, 102214. [Google Scholar] [CrossRef]
- Rebelo Marcolino, M.; Porto, T.R.; Primo, T.T.; Targino, R.; Ramos, V.; Queiroga, E.M.; Cechinel, R.M.C. Student Dropout Prediction Through Machine Learning and Administrative Data. Sci. Rep. 2025, 15, 93918. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).