
Beyond Weisfeiler–Lehman with Local Ego-Network Encodings †


Abstract
:1. Introduction
- C1
- We present a novel structural encoding scheme for graphs, describing its relationship with existing graph representations and MP-GNNs.
- C2
- We formally show that the proposed encoding has more expressive power than the 1-WL test, and identify expressivity upper bounds for graphs that match subgraph GNN state-of-the-art methods.
- C3
- We experimentally assess the performance of nine model architectures enriched with our proposed method on six tasks and thirteen graph data sets and find that it consistently improves downstream model performance.
2. Notation and Related Work
2.1. Message Passing Graph Neural Networks
2.2. Expressivity of Weisfeiler–Lehman and
| Algorithm 1 1-WL (Color refinement). |
|
2.3. Graph Neural Networks beyond 1-WL
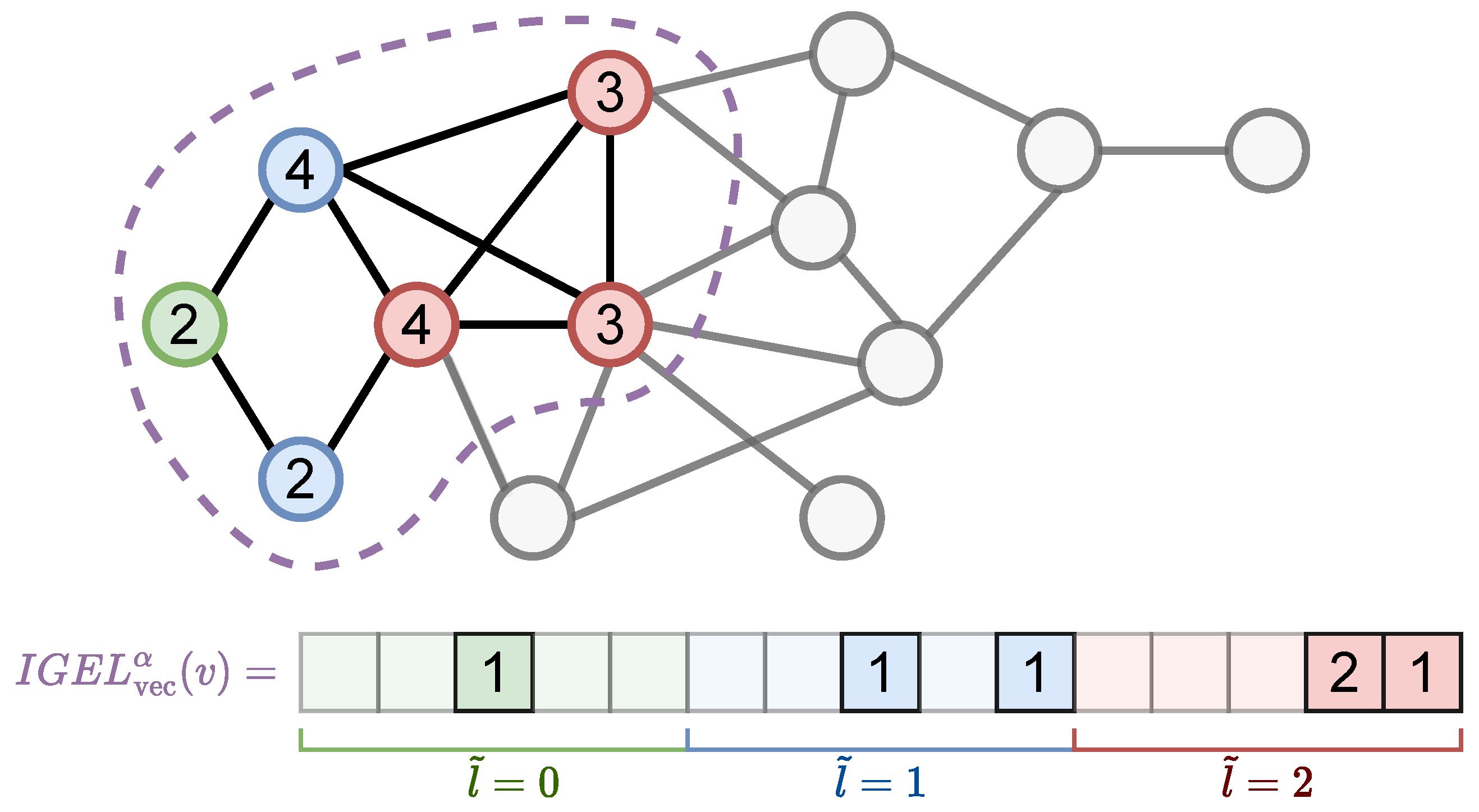
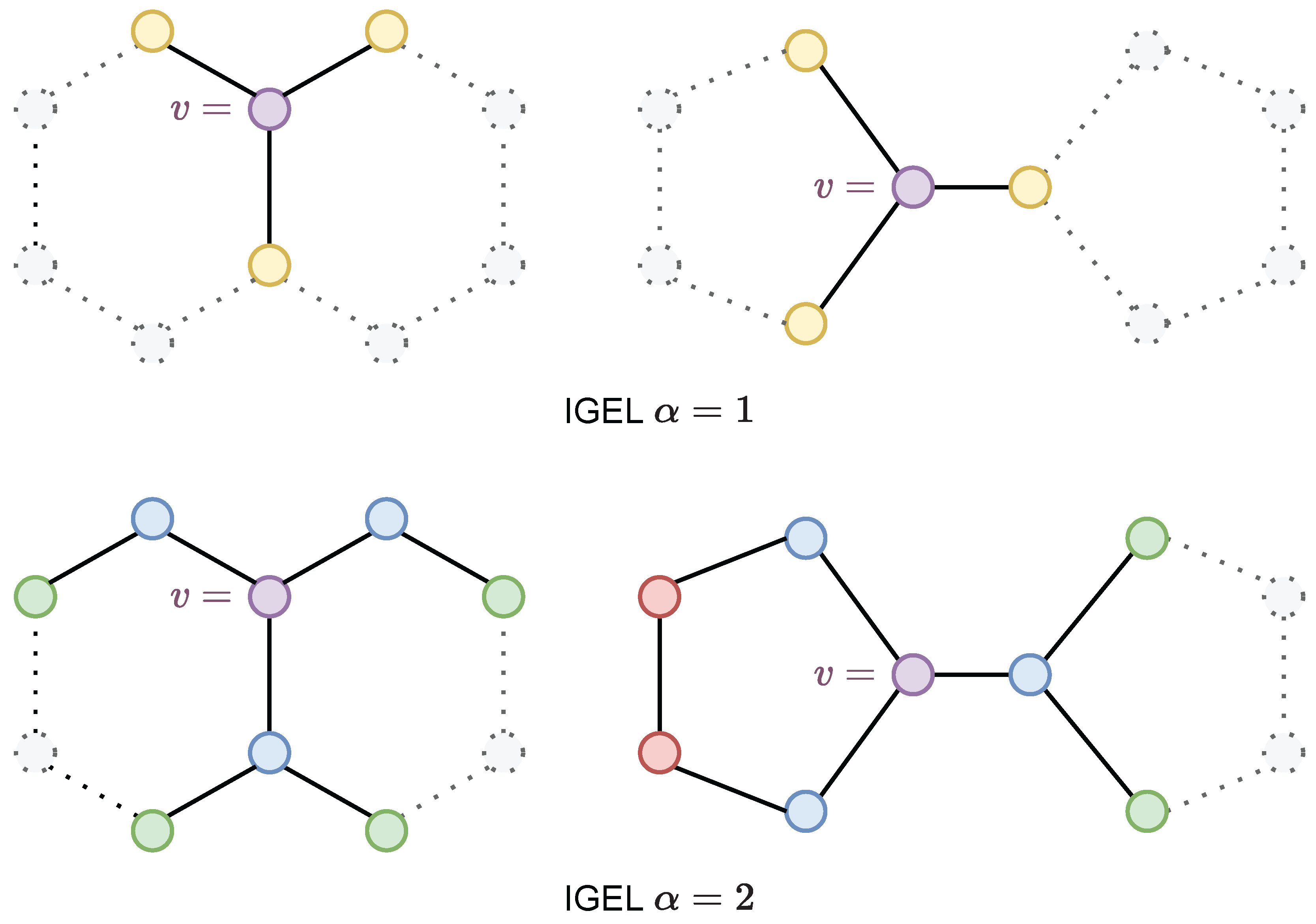
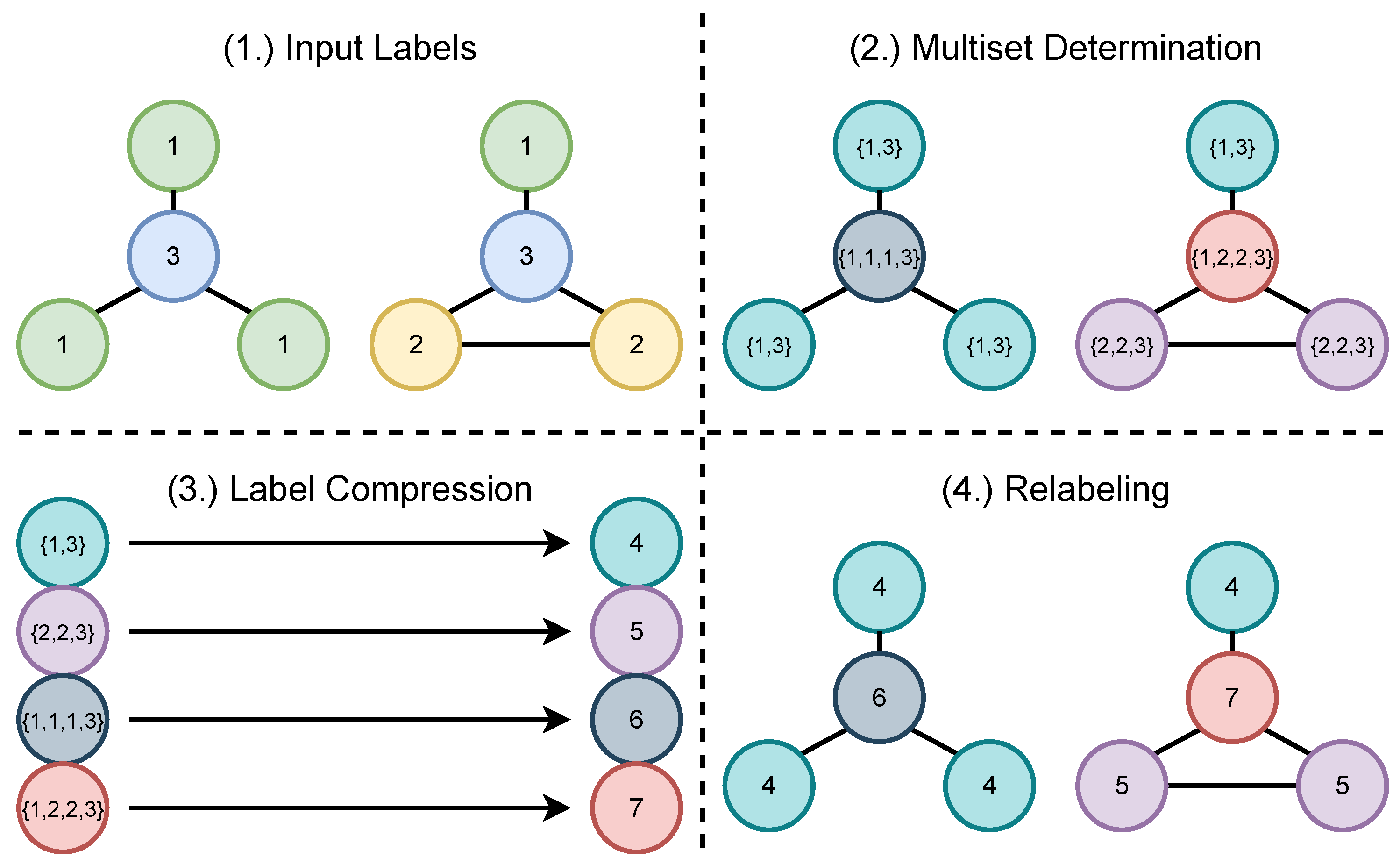
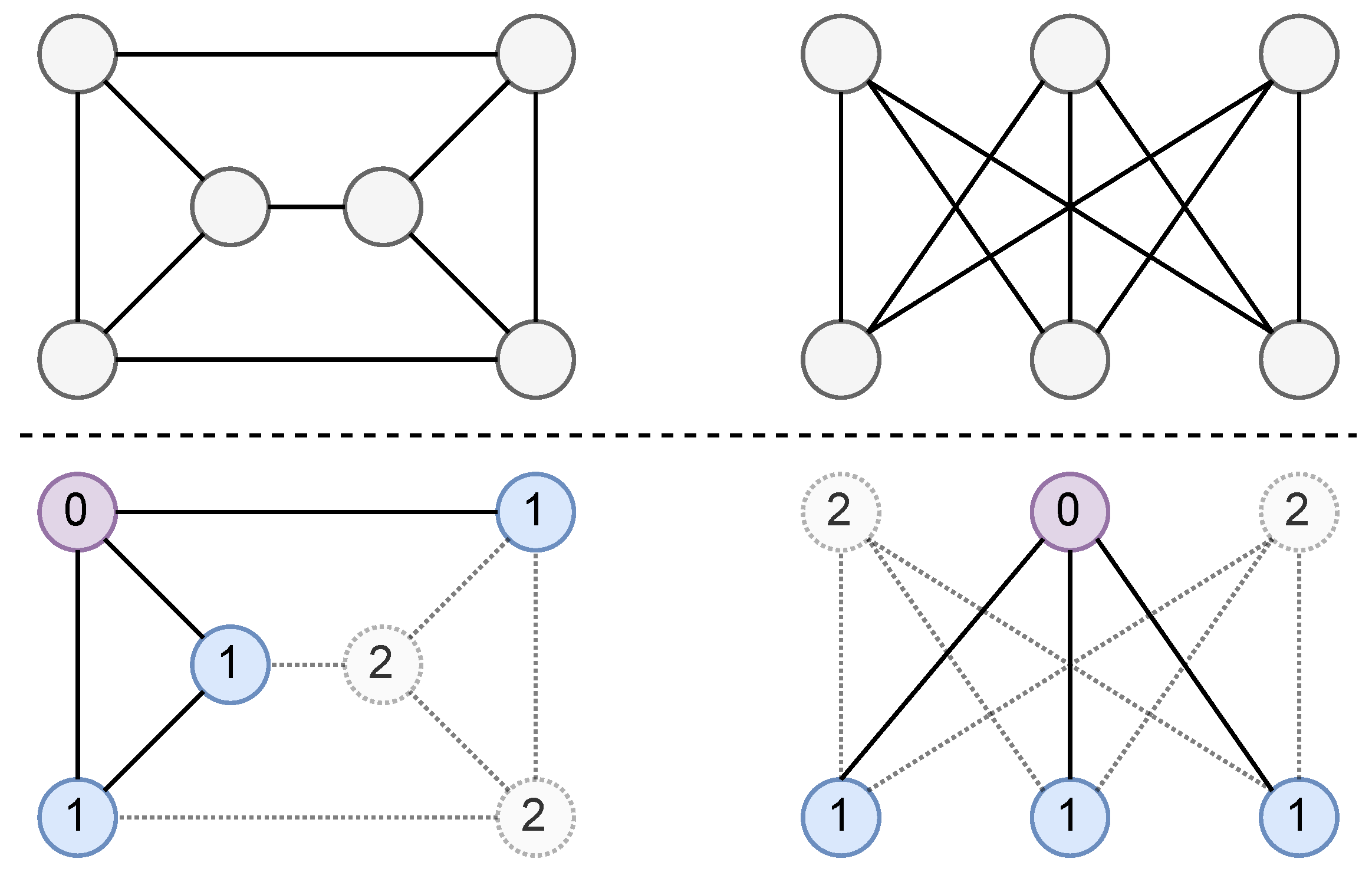
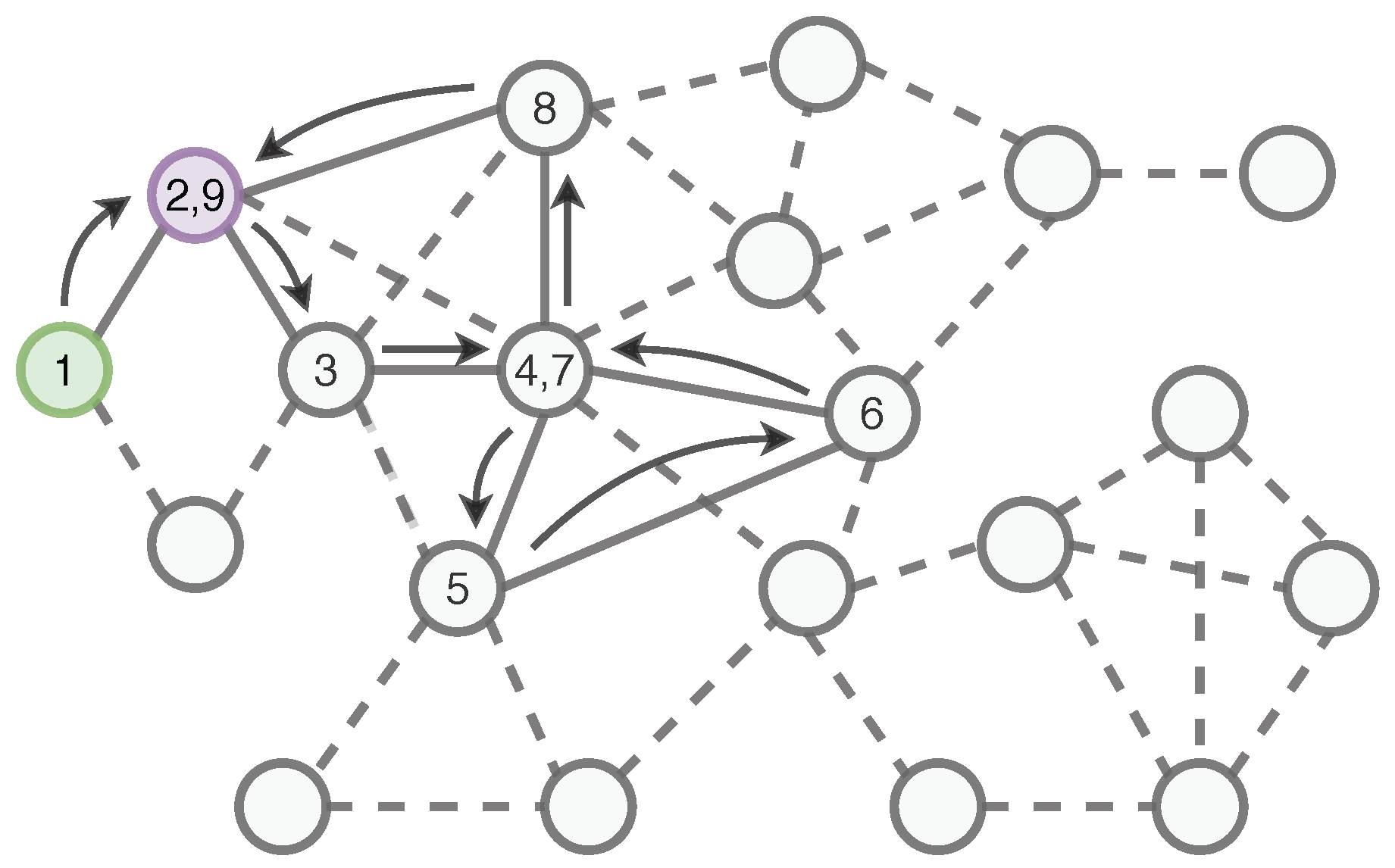
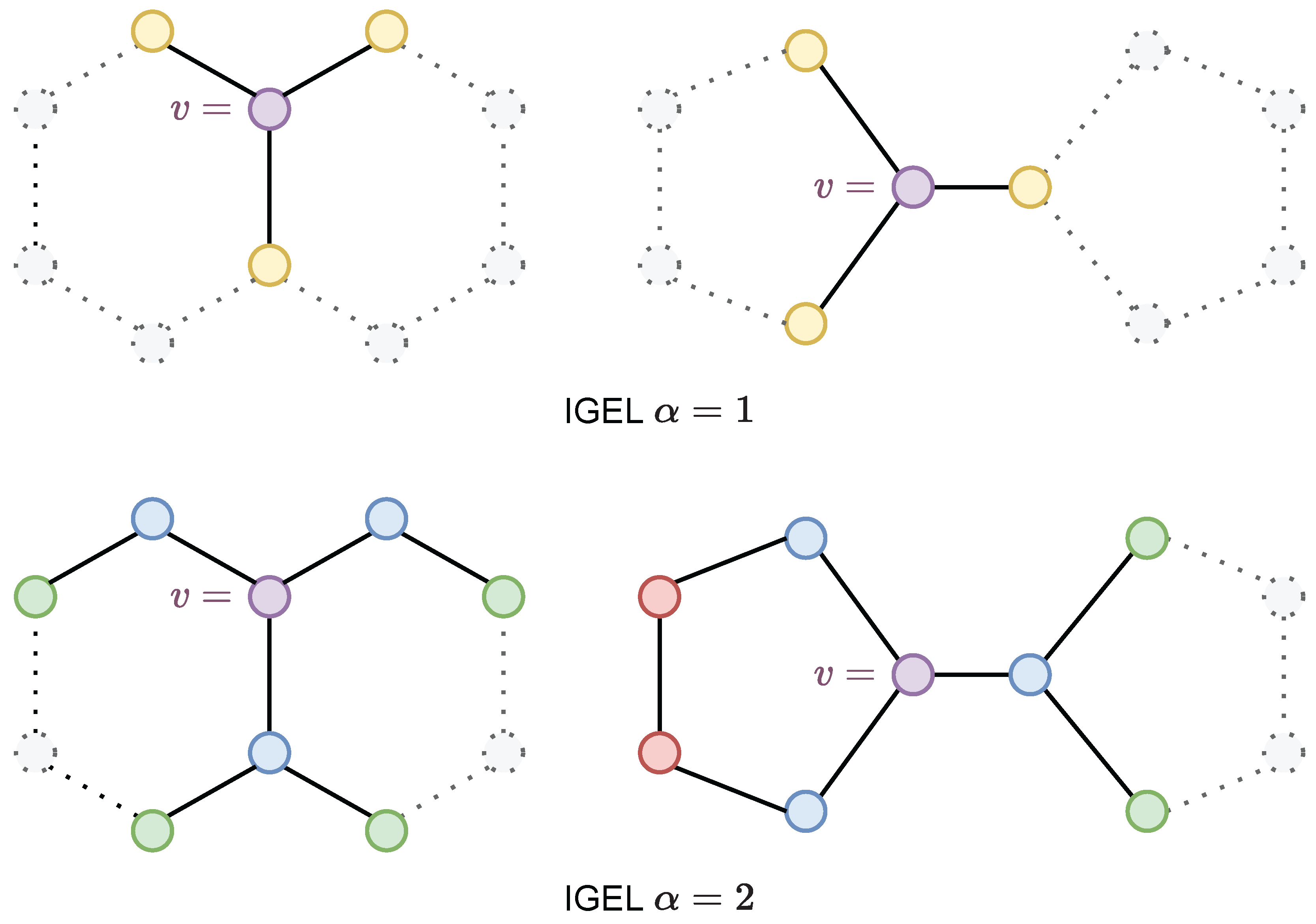
3. Local Ego-Network Encodings
| Algorithm 2 Encoding. |
|
4. Which Graphs Are -Distinguishable?
4.1. Distinguishability on 1-WL Equivalent Graphs
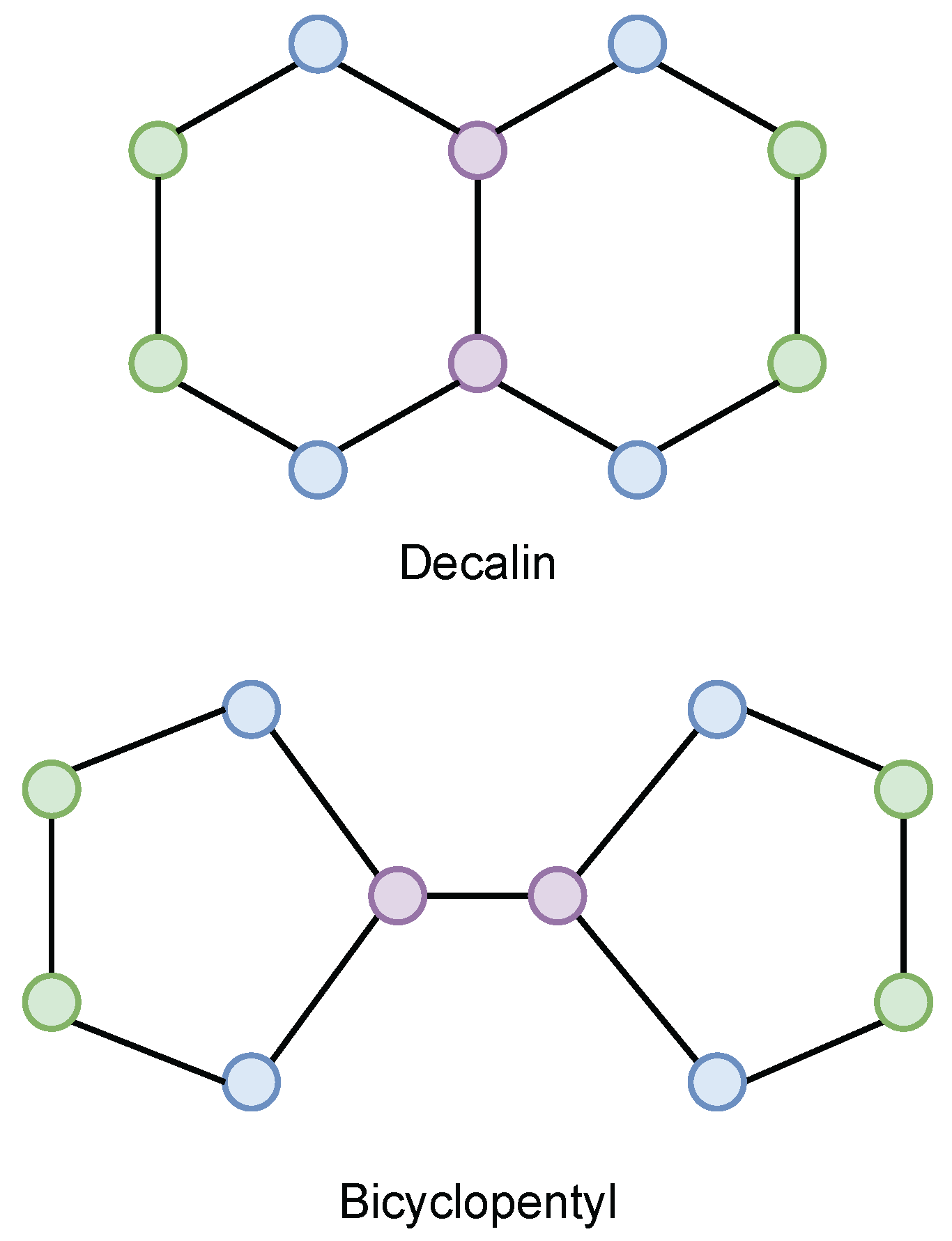
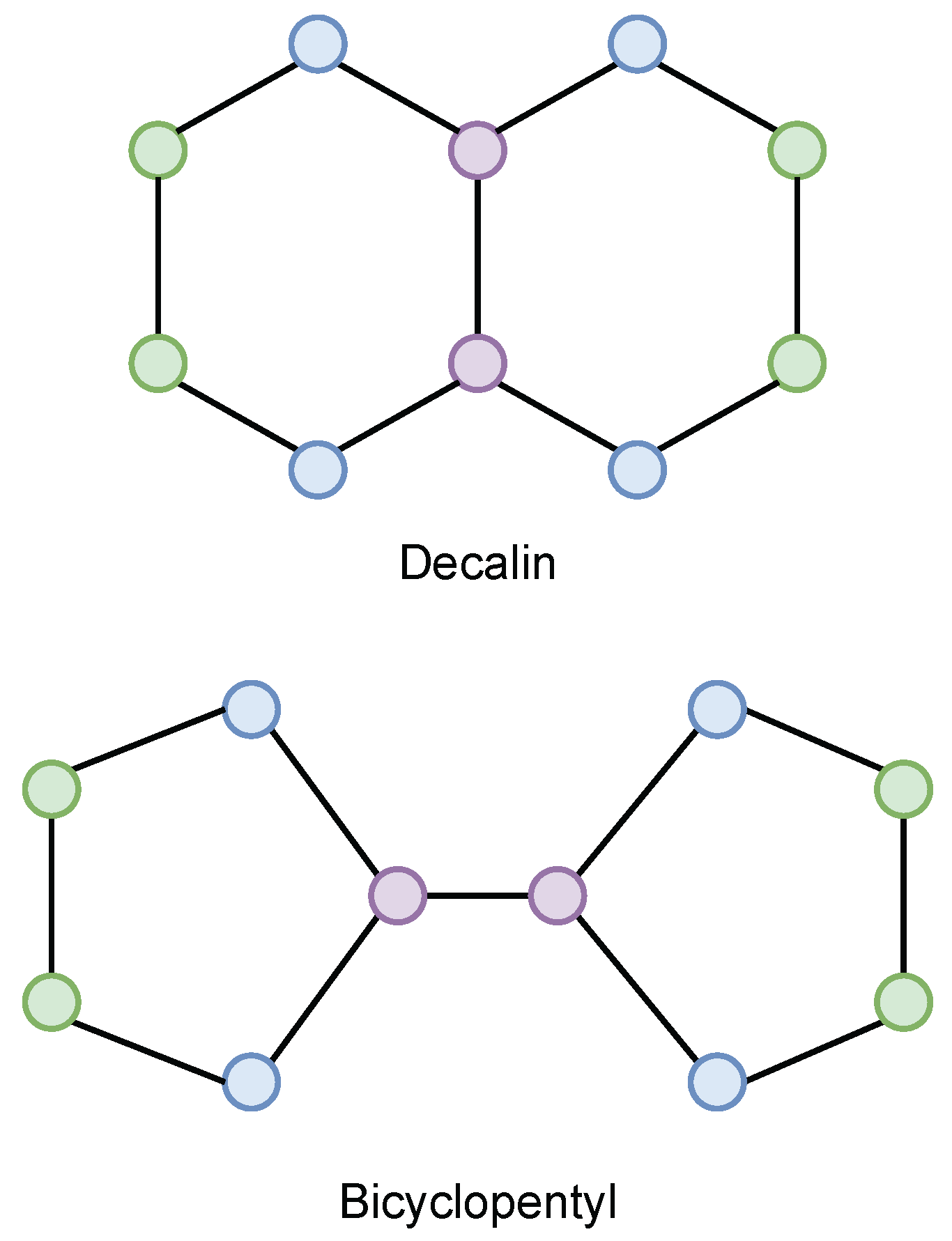
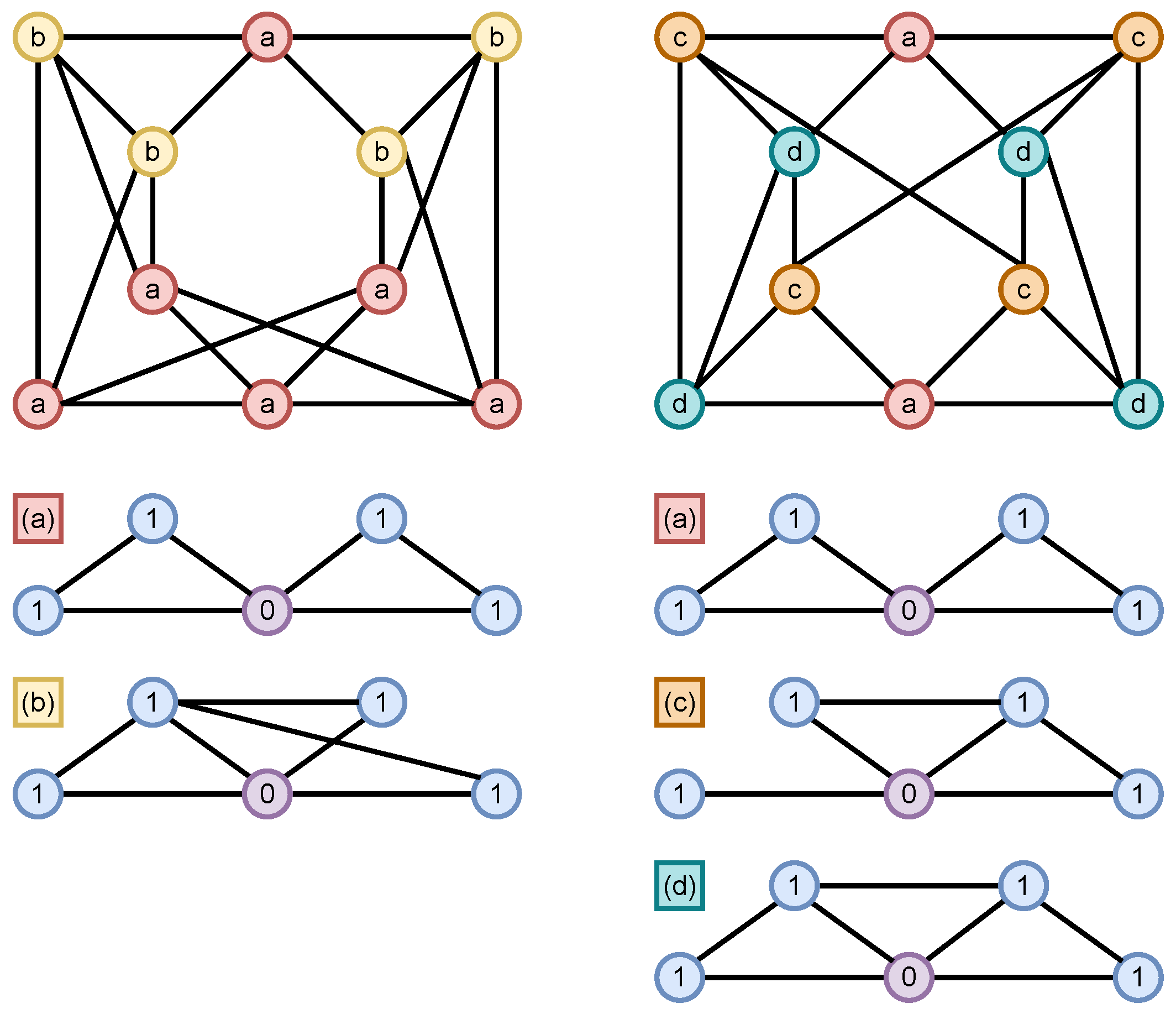
4.1.1. /1-WL Expressivity: Decalin and Bicyclopentyl
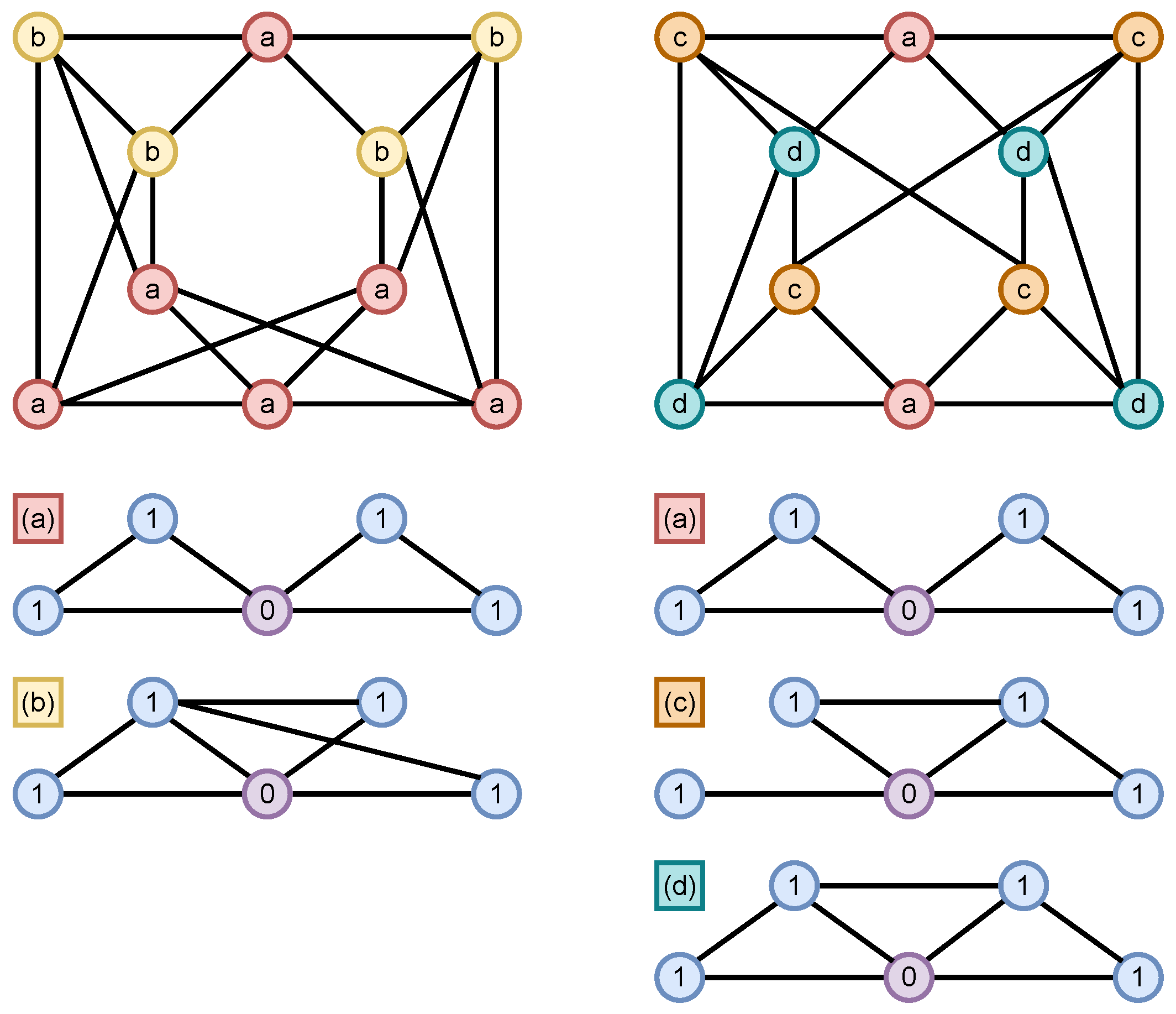
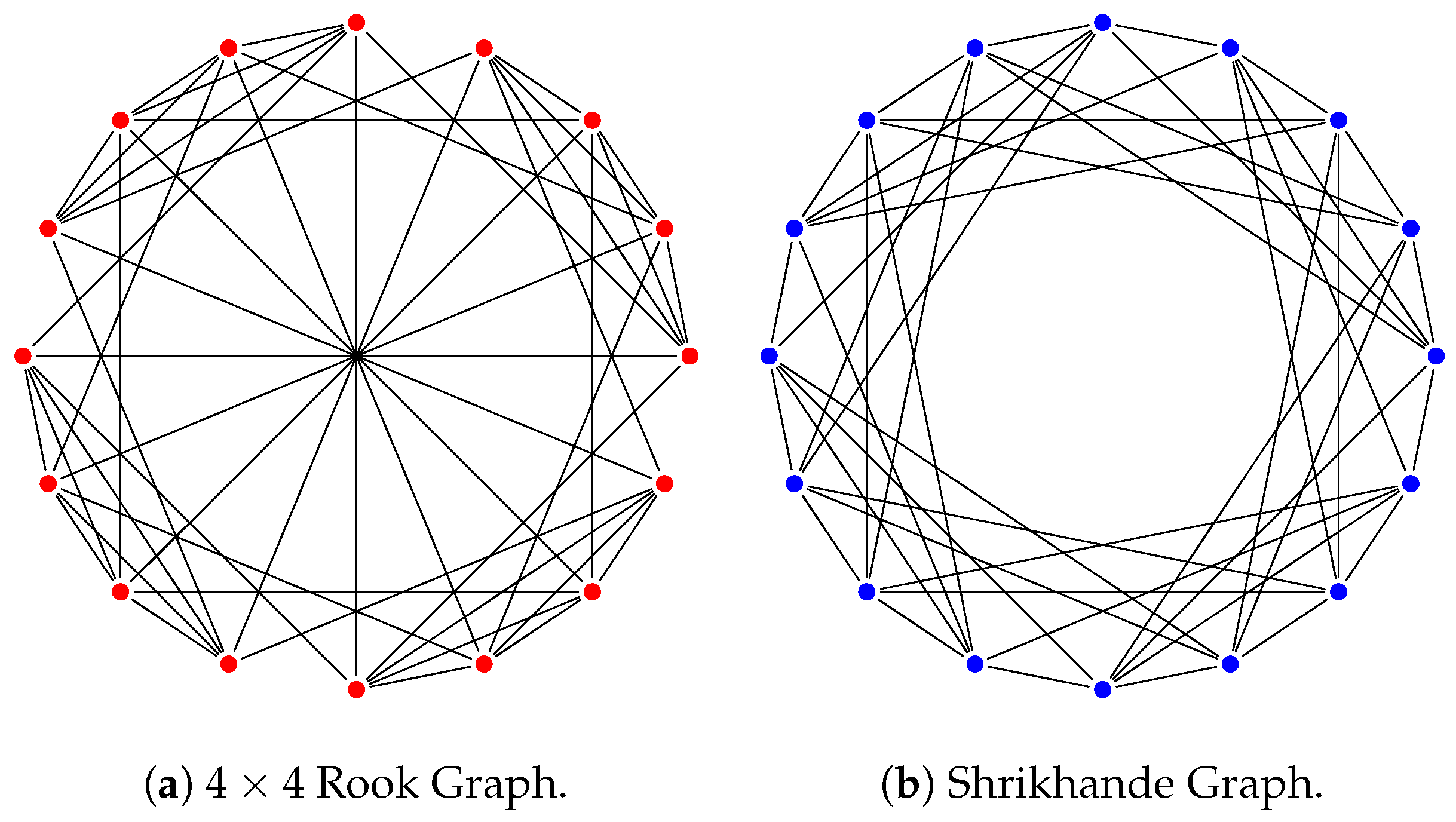
4.1.2. Expressivity: Cospectral 4-Regular Graphs
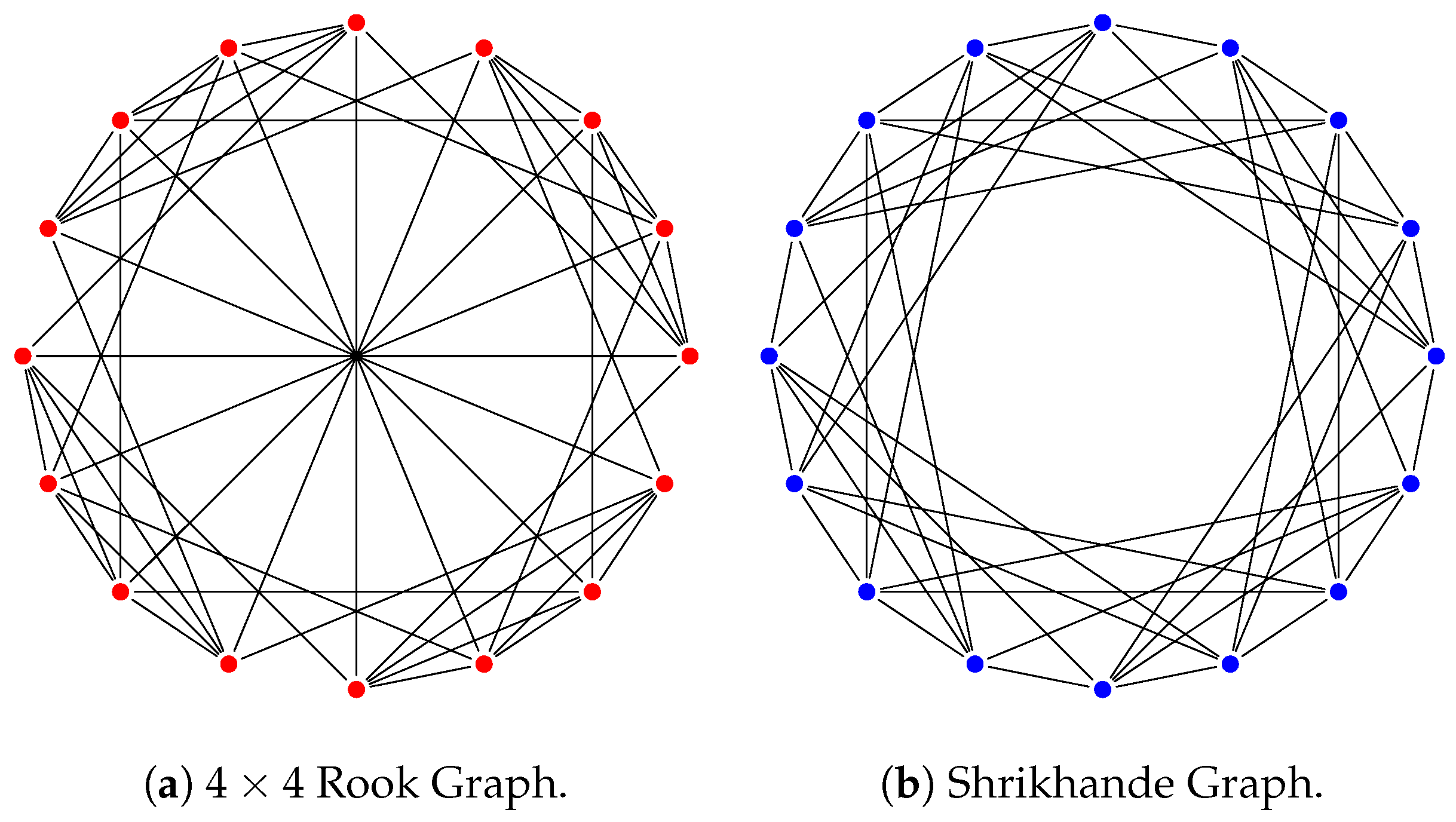
4.2. Indistinguishability on Strongly Regular Graphs
- —
- ;
- —
- ;
- —
- no values of γ can be distinguished by or .
- -
- Let : . Since G is d-regular, v is the center of , and has d-neighbors. By definition, d neighbors of v have shared neighbors with v each, plus an edge with v, and does not include edges beyond its neighbors. Thus, for SRGs where , , and , where
- -
- Let : as when . G is d-regular, so . Thus, for any SRGs s.t. and , where
4.3. Expressivity Implications
5. Empirical Validation
- Q1.
- Does improve MP-GNN performance on standard graph-level tasks?
- Q2.
- Can we empirically validate our results on the expressive power of compared to 1-WL?
- Q3.
- Are encodings appropriate features to learn on unattributed graphs?
- Q4.
- How do GNN models compare with more traditional neural network models when they are enriched with features?
5.1. Overview of the Experiments
5.2. Experimental Methodology
5.3. Results and Notation
5.4. Graph Classification: TU Graphs
5.5. Graph Isomorphism Detection
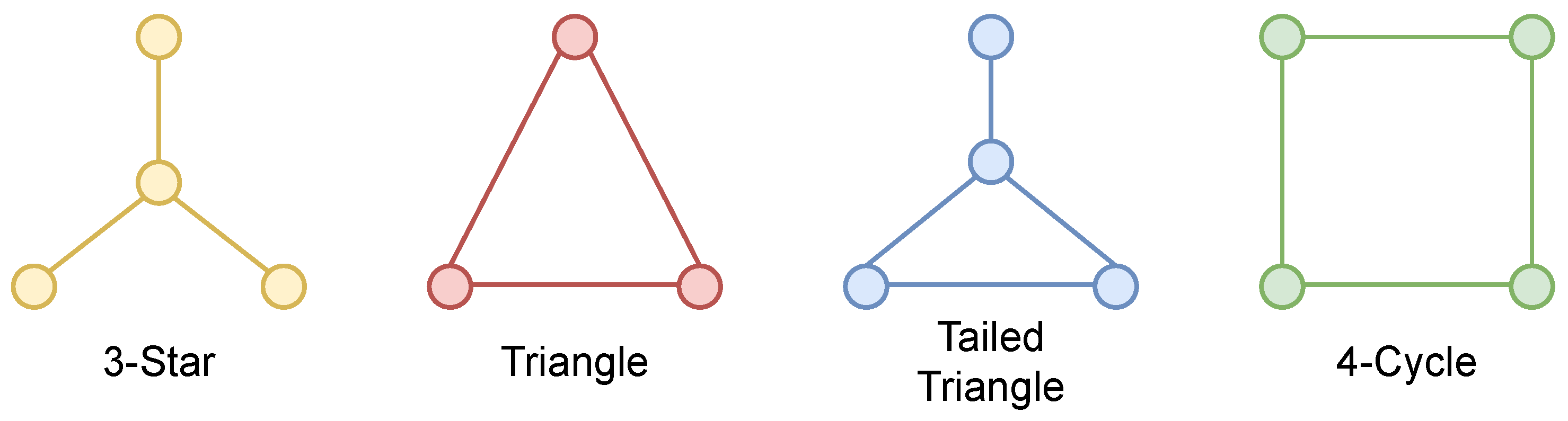
5.6. Graphlet Counting
5.7. Benchmark Results with Subgraph GNNs
5.8. Link Prediction
5.9. Vertex Classification
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Additional Settings and Results
Appendix A.1. Data Set Details
Appendix A.2. Hyper-Parameters and Experiment Details

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chebnet | GAT | GCN | GIN | GNNML3 | Linear | MLP | |
|---|---|---|---|---|---|---|---|
| Star | 2 | 1 | 2 | 1 | 1 | 2 | 1 |
| Tailed Triangle | 1 | 1 | 1 | 1 | 2 | 1 | 1 |
| Triangle | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4-Cycle | 2 | 1 | 1 | 1 | 1 | 1 | 1 |
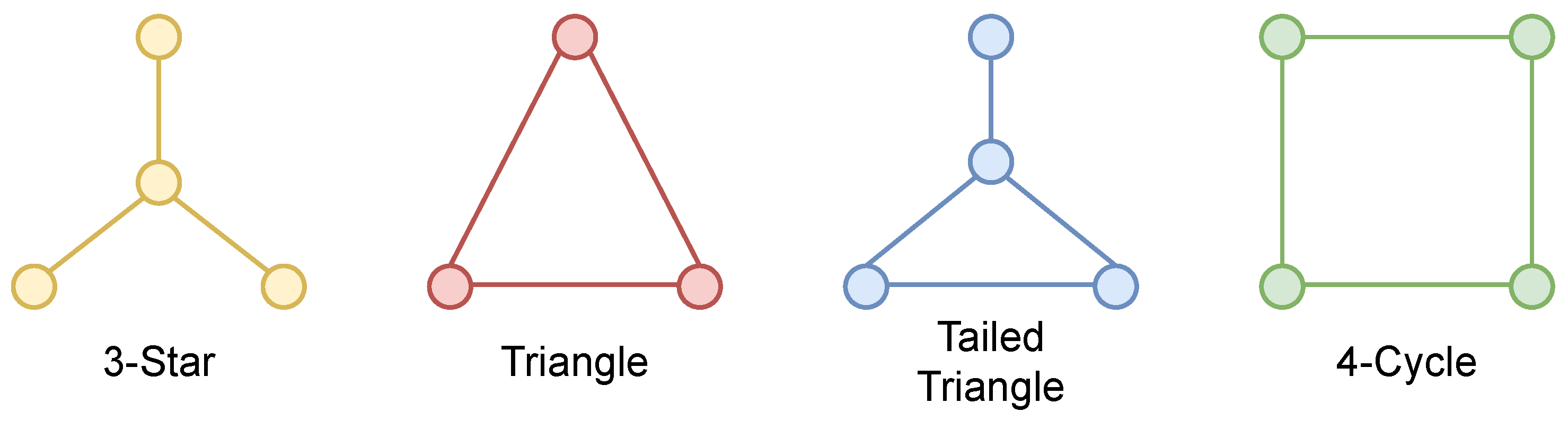
| Custom Graphlet | 2 | 1 | 1 | 1 | 2 | 2 | 2 |
| Enzymes | 1 | 2 | 2 | 1 | 2 | 2 | 2 |
| Mutag | 1 | 1 | 1 | 1 | 1 | 1 | 2 |
| Proteins | 2 | 2 | 2 | 1 | 2 | 1 | 1 |
| PTC | 1 | 1 | 2 | 1 | 1 | 2 | 2 |
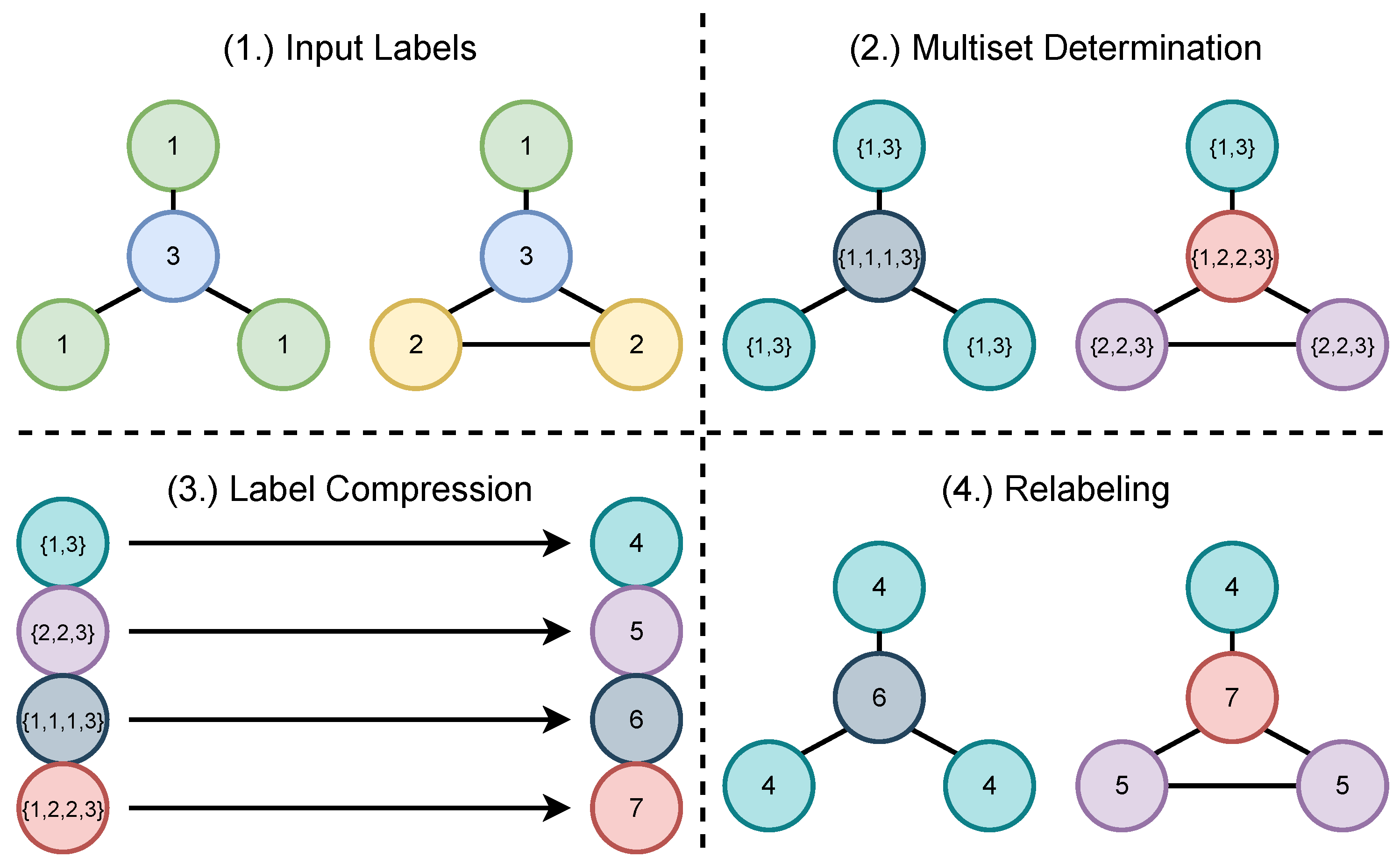
Appendix B. Relationship to Weisfeiler–Lehman Graph Kernels
Appendix C. IGEL Is Permutation Equivariant
Appendix D. Connecting IGEL and SPNNs

Appendix E. IGEL and MATLANG
Appendix E.1. MATLANG Sub-Languages
Appendix E.2. Can IGEL Be Represented in MATLANG?
- (a)
- , the ego network of v in G at depth .
- (b)
- The degrees of every node in .
- (c)
- The shortest path lengths from every node in to v.
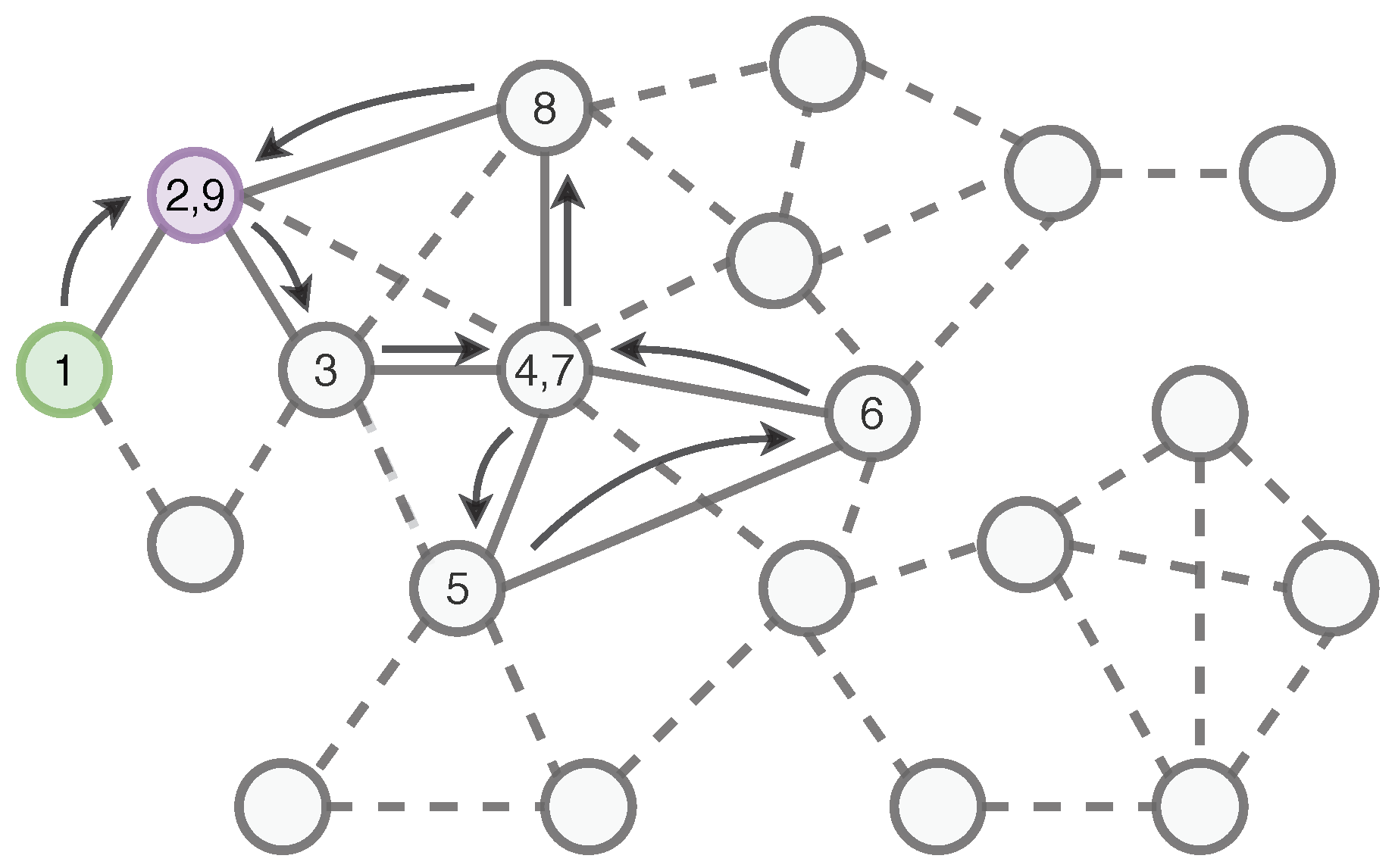
Appendix F. Implementing IGEL through Breadth-First Search
| Algorithm A1 Encoding (BFS). |
|
Appendix G. Extending IGEL beyond Unattributed Graphs
Appendix G.1. Application to Labelled Graphs
Appendix G.2. Application to Attributed Graphs
Appendix G.3. IGEL and Subgraph MP-GNNs
Appendix H. Self-Supervised IGEL
IGEL & Self-Supervised Node Representations
| Param. | Description |
|---|---|
| Random walks per node | |
| Steps per random walk | |
| # of neg. samples | |
| Context window size |
Appendix I. Comparison of Existing Methods
| Approach | Model Architectures | Message Passing Extensions | Limitations |
|---|---|---|---|
| Distance-Aware | PGNNs [15] DE-GNNs [38] SPNNs [40] | Introduce distance to target nodes, ego network roots as an encoded variables, or as the explicit distance as part of the message passing mechanism. | Considers a fixed set of target nodes or requires architecture modifications to introduce permutation equivariant distance signals. |
| subgraph | k-hop GNNs [16] Nested-GNNs [20] ESAN [22] GNN-AK [21] SUN [23] | Propagate information through subgraphs around k-hops, either applying GNNs on the subgraphs, pooling subgraphs, and introducing distance/context signals within the subgraph. | Requires learning over subgraphs with an increased time and memory cost and architecture modifications to propagate messages across subgraphs (incl. distance, context, and node attribute information). |
| Structural | SMP [18] GSNs [19] | Explicitly introduce structural information in the message passing mechanism, e.g., counts of cycles or stars where a node appears. | Requires identifying and introducing structural features (e.g., node roles in the network) during message passing through architecture modifications. |
| Spectral | GNN-ML3 [26] | Introduce features from the spectral domain of the graph in the message passing mechanism. | Requires cubic-time eigenvalue decomposition to construct spectral features and architecture modifications to introduce them during message passing. |
| Avg. n | Avg. m | Num. Graphs | Task | Output Shape | Splits (Train/Valid/Test) | |
|---|---|---|---|---|---|---|
| Enzymes | 32.63 | 62.14 | 600 | Multi-class Graph Class. | 6 (multi-class probabilities) | 9-fold/1 fold (Graphs, Train/Eval) |
| Mutag | 17.93 | 39.58 | 188 | Binary Graph Class. | 2 (binary class probabilities) | 9-fold/1 fold (Graphs, Train/Eval) |
| Proteins | 39.06 | 72.82 | 1113 | Binary Graph Class. | 2 (binary class probabilities) | 9-fold/1 fold (Graphs, Train/Eval) |
| PTC | 25.55 | 51.92 | 344 | Binary Graph Class. | 2 (binary class probabilities) | 9-fold/1 fold (Graphs, Train/Eval) |
| Graph8c | 8.0 | 28.82 | 11,117 | Non-isomorphism Detection | N/A | N/A |
| EXP Classify | 44.44 | 111.21 | 600 | Binary Class. (pairwise graph distinguishability) | 1 (non-isomorphic graph pair probability) | Graph pairs 400/100/100 |
| SR25 | 25 | 300 | 15 | Non-isomorphism Detection | N/A | N/A |
| RandomGraph | 18.8 | 62.67 | 5000 | Regression (Graphlet Counting) | 1 (graphlet counts) | Graphs 1500/1000/2500 |
| ZINC-12K | 23.1 | 49.8 | 12,000 | Molecular prop. regression | 1 | Graphs 10,000/1000/1000 |
| PATTERN | 118.9 | 6079.8 | 14,000 | Recognize subgraphs | 2 | Graphs 10,000/2000/2000 |
| ArXiv ASTRO-PH | 18,722 | 198,110 | 1 | Binary Class. (Link Prediction) | 1 (edge probability) | Randomly sampled edges 50% train/50% test |
| 4039 | 88,234 | 1 | Binary Class. (Link Prediction) | 1 (edge probability) | Randomly sampled edges 50% train/50% test | |
| PPI | 2373 | 68,342.4 | 24 | Multi-label Vertex Class. | 121 (binary class probabilities) | Graphs 20/2/2 |
References
- Bronstein, M.M.; Bruna, J.; Cohen, T.; Veličković, P. Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges. arXiv 2021, arXiv:2104.13478. [Google Scholar]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 974–983. [Google Scholar]
- Duvenaud, D.K.; Maclaurin, D.; Iparraguirre, J.; Bombarell, R.; Hirzel, T.; Aspuru-Guzik, A.; Adams, R.P. Convolutional Networks on Graphs for Learning Molecular Fingerprints. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural Message Passing for Quantum Chemistry. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; 2017; Volume 70, pp. 1263–1272. [Google Scholar]
- Samanta, B.; De, A.; Jana, G.; Gómez, V.; Chattaraj, P.; Ganguly, N.; Gomez-Rodriguez, M. NEVAE: A Deep Generative Model for Molecular Graphs. J. Mach. Learn. Res. 2020, 21, 1–33. [Google Scholar] [CrossRef]
- Battaglia, P.; Pascanu, R.; Lai, M.; Jimenez Rezende, D.; Kavukcuoglu, K. Interaction Networks for Learning about Objects, Relations and Physics. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Weisfeiler, B.; Leman, A. The Reduction of a Graph to Canonical Form and the Algebra which Appears Therein. Nauchno-Tech. Inf. 1968, 2, 12–16. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful are Graph Neural Networks? In Proceedings of the 7th International Conference on Learning Representations ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Morris, C.; Ritzert, M.; Fey, M.; Hamilton, W.L.; Lenssen, J.E.; Rattan, G.; Grohe, M. Weisfeiler and Leman Go Neural: Higher-Order Graph Neural Networks. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19), Honolulu, HI, USA, 27 January–1 February 2019; 2019; 33, pp. 4602–4609. [Google Scholar]
- Grohe, M. Descriptive Complexity, Canonisation, and Definable Graph Structure Theory; Lecture Notes in Logic; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Brijder, R.; Geerts, F.; Bussche, J.V.D.; Weerwag, T. On the Expressive Power of Query Languages for Matrices. ACM Trans. Database Syst. 2019, 44, 1–31. [Google Scholar] [CrossRef]
- Barceló, P.; Kostylev, E.V.; Monet, M.; Pérez, J.; Reutter, J.; Silva, J.P. The Logical Expressiveness of Graph Neural Networks. In Proceedings of the International Conference on Learning Representations, Virtual Conference, 26 April–1 May 2020. [Google Scholar]
- Geerts, F. On the Expressive Power of Linear Algebra on Graphs. Theory Comput. Syst. 2021, 65, 1–61. [Google Scholar] [CrossRef]
- Morris, C.; Lipman, Y.; Maron, H.; Rieck, B.; Kriege, N.M.; Grohe, M.; Fey, M.; Borgwardt, K. Weisfeiler and Leman go machine learning: The story so far. arXiv 2021, arXiv:2112.09992. [Google Scholar]
- You, J.; Ying, R.; Leskovec, J. Position-aware Graph Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 7134–7143. [Google Scholar]
- Nikolentzos, G.; Dasoulas, G.; Vazirgiannis, M. k-hop graph neural networks. Neural Netw. 2020, 130, 195–205. [Google Scholar] [CrossRef] [PubMed]
- Bodnar, C.; Frasca, F.; Otter, N.; Wang, Y.; Liò, P.; Montufar, G.F.; Bronstein, M. Weisfeiler and Lehman Go Cellular: CW Networks. Adv. Neural Inf. Process. Syst. 2021, 34, 2625–2640. [Google Scholar]
- Vignac, C.; Loukas, A.; Frossard, P. Building powerful and equivariant graph neural networks with structural message-passing. Adv. Neural Inf. Process. Syst. 2020, 33, 14143–14155. [Google Scholar]
- Bouritsas, G.; Frasca, F.; Zafeiriou, S.; Bronstein, M.M. Improving Graph Neural Network Expressivity via Subgraph Isomorphism Counting. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 657–668. [Google Scholar] [CrossRef]
- Zhang, M.; Li, P. Nested graph neural networks. Adv. Neural Inf. Process. Syst. 2021, 34, 15734–15747. [Google Scholar]
- Zhao, L.; Jin, W.; Akoglu, L.; Shah, N. From Stars to Subgraphs: Uplifting Any GNN with Local Structure Awareness. In Proceedings of the International Conference on Learning Representations, Virtual Conference, 25–29 April 2022. [Google Scholar]
- Bevilacqua, B.; Frasca, F.; Lim, D.; Srinivasan, B.; Cai, C.; Balamurugan, G.; Bronstein, M.M.; Maron, H. Equivariant Subgraph Aggregation Networks. In Proceedings of the International Conference on Learning Representations, Virtual Conference, 25–29 April 2022. [Google Scholar]
- Frasca, F.; Bevilacqua, B.; Bronstein, M.M.; Maron, H. Understanding and Extending Subgraph GNNs by Rethinking Their Symmetries. In Proceedings of the Advances in Neural Information Processing Systems, Virtual/New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Michel, G.; Nikolentzos, G.; Lutzeyer, J.; Vazirgiannis, M. Path Neural Networks: Expressive and Accurate Graph Neural Networks. In Proceedings of the 40th International Conference on Machine Learning (ICML), Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Maron, H.; Ben-Hamu, H.; Serviansky, H.; Lipman, Y. Provably Powerful Graph Networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Balcilar, M.; Héroux, P.; Gaüzère, B.; Vasseur, P.; Adam, S.; Honeine, P. Breaking the Limits of Message Passing Graph Neural Networks. In Proceedings of the 38th International Conference on Machine Learning (ICML), Virtual conference, 18–24 July 2021. [Google Scholar]
- Hu, W.; Fey, M.; Zitnik, M.; Dong, Y.; Ren, H.; Liu, B.; Catasta, M.; Leskovec, J. Open Graph Benchmark: Datasets for Machine Learning on Graphs. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Virtual conference, 6–12 December 2020; Volume 33. [Google Scholar]
- Morris, C.; Kriege, N.M.; Bause, F.; Kersting, K.; Mutzel, P.; Neumann, M. TUDataset: A collection of benchmark datasets for learning with graphs. In Proceedings of the ICML 2020 Workshop on Graph Representation Learning and Beyond (GRL+ 2020), Virtual conference, 12–18 July 2020. [Google Scholar]
- You, J.; Ying, Z.; Leskovec, J. Design Space for Graph Neural Networks. Adv. Neural Inf. Process. Syst. 2020, 33, 17009–17021. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, USA, 4–9 December 2017. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, Canada, 30 April–3 May 2018. [Google Scholar]
- Gao, H.; Wang, Z.; Ji, S. Large-Scale Learnable Graph Convolutional Networks. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1416–1424. [Google Scholar]
- Babai, L.; Kucera, L. Canonical labelling of graphs in linear average time. In Proceedings of the 20th Annual Symposium on Foundations of Computer Science (sfcs 1979), San Juan, PR, USA, 29–31 October 1979; pp. 39–46. [Google Scholar] [CrossRef]
- Huang, N.T.; Villar, S. A Short Tutorial on The Weisfeiler–Lehman Test And Its Variants. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 8533–8537. [Google Scholar]
- Veličković, P. Message passing all the way up. In Proceedings of the Workshop on Geometrical and Topological Representation Learning, International Conference on Learning Representations, Virtual Conference, 25–29 April 2022. [Google Scholar]
- Li, P.; Wang, Y.; Wang, H.; Leskovec, J. Distance Encoding: Design Provably More Powerful Neural Networks for Graph Representation Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 4465–4478. [Google Scholar]
- You, J.; Gomes-Selman, J.M.; Ying, R.; Leskovec, J. Identity-aware graph neural networks. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), Virtual conference, 2–9 February 2021; 2021; 35, pp. 10737–10745. [Google Scholar]
- Abboud, R.; Dimitrov, R.; Ceylan, İ.İ. Shortest Path Networks for Graph Property Prediction. In Proceedings of the First Learning on Graphs Conference (LoG), Virtual Conference, 9–12 December 2022. [Google Scholar]
- Maron, H.; Ben-Hamu, H.; Shamir, N.; Lipman, Y. Invariant and Equivariant Graph Networks. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Zhang, B.; Luo, S.; Wang, L.; He, D. Rethinking the Expressive Power of GNNs via Graph Biconnectivity. In Proceedings of the International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Papp, P.A.; Wattenhofer, R. A Theoretical Comparison of Graph Neural Network Extensions. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; 162, pp. 17323–17345. [Google Scholar]
- Albert, R.; Barabási, A.L. Statistical mechanics of complex networks. Rev. Mod. Phys. 2002, 74, 47–97. [Google Scholar] [CrossRef]
- Shervashidze, N.; Schweitzer, P.; Jan, E.; Leeuwen, V.; Mehlhorn, K.; Borgwardt, K. Weisfeiler–Lehman Graph Kernels. J. Mach. Learn. Res. 2010, 1, 1–48. [Google Scholar]
- Alvarez-Gonzalez, N.; Kaltenbrunner, A.; Gómez, V. Beyond 1-WL with Local Ego-Network Encodings. In Proceedings of the First Learning on Graphs Conference (LoG), Virtual Conference, 9–12 December 2022. Non-archival Extended Abstract track. [Google Scholar]
- Van Dam, E.R.; Haemers, W.H. Which Graphs Are Determined by Their Spectrum? Linear Algebra Its Appl. 2003, 373, 241–272. [Google Scholar] [CrossRef]
- Brouwer, A.E. and Van Maldeghem, Hendrik. Strongly Regular Graphs; Cambridge University Press: Cambridge, UK, 2022; Volume 182, p. 462. [Google Scholar]
- Arvind, V.; Fuhlbrück, F.; Köbler, J.; Verbitsky, O. On Weisfeiler-Leman invariance: Subgraph counts and related graph properties. J. Comput. Syst. Sci. 2020, 113, 42–59. [Google Scholar] [CrossRef]
- Dwivedi, V.P.; Joshi, C.K.; Laurent, T.; Bengio, Y.; Bresson, X. Benchmarking Graph Neural Networks. arXiv 2020, arXiv:2003.00982. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online Learning of Social Representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. Node2Vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Abboud, R.; Ceylan, I.I.; Grohe, M.; Lukasiewicz, T. The Surprising Power of Graph Neural Networks with Random Node Initialization. In Proceedings of the International Joint Conferences on Artificial Intelligence Organization, Virtual Conference, 19–26 August 2021; pp. 2112–2118. [Google Scholar]
- Chen, Z.; Chen, L.; Villar, S.; Bruna, J. Can Graph Neural Networks Count Substructures? Adv. Neural Inf. Process. Syst. 2020, 33, 10383–10395. [Google Scholar]
- Hu, W.; Liu, B.; Gomes, J.; Zitnik, M.; Liang, P.; Pande, V.; Leskovec, J. Strategies for Pre-training Graph Neural Networks. In Proceedings of the International Conference on Learning Representations, Virtual Conference, 26 April–1 May 2020. [Google Scholar]
- Leskovec, J.; Krevl, A. SNAP Datasets: Stanford Large Network Dataset Collection. 2014. Available online: https://snap.stanford.edu/data/index.html (accessed on 16 September 2023).
- Niepert, M.; Ahmed, M.; Kutzkov, K. Learning Convolutional Neural Networks for Graphs. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 2014–2023. [Google Scholar]
- Shervashidze, N.; Borgwardt, K. Fast subtree kernels on graphs. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, Canada, 7–12 December 2009; Volume 22. [Google Scholar]
- Rieck, B.; Bock, C.; Borgwardt, K. A Persistent Weisfeiler–Lehman Procedure for Graph Classification. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; 2019; Volume 97, pp. 5448–5458. [Google Scholar]
- Togninalli, M.; Ghisu, E.; Llinares-López, F.; Rieck, B.; Borgwardt, K. Wasserstein Weisfeiler–Lehman Graph Kernels. Adv. Neural Inf. Process. Syst. 2019, 32, 6436–6446. [Google Scholar]
- Kriege, N.M.; Morris, C.; Rey, A.; Sohler, C. A Property Testing Framework for the Theoretical Expressivity of Graph Kernels. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; 2018; Volume 7, pp. 2348–2354. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, USA, 5–10 December 2013; Volume 2, pp. 3111–3119. [Google Scholar]

| Model | Enzymes | Mutag | Proteins | PTC |
|---|---|---|---|---|
| MLP | 41.10 > 26.18⋄ | 87.61 > 84.61⋄ | 75.43 ~ 75.01 | 64.59 > 62.79 ⋄ |
| GCN | 54.48 > 48.60⋄ | 89.61 > 85.42⋄ | 75.67 > 74.50 * | 65.76 ~ 65.21 |
| GAT | 54.88 ~ 54.95 | 90.00 > 86.14⋄ | 73.44 > 70.51⋄ | 66.29 ~ 66.29 |
| GIN | 54.77 > 53.44 * | 89.56 ~ 88.33 | 73.32 > 72.05⋄ | 61.44 ~ 60.21 |
| Chebnet | 61.88 ~ 62.23 | 91.44 > 88.33⋄ | 74.30 > 66.94⋄ | 64.79 ~ 63.87 |
| GNNML3 | 61.42 < 62.79⋄ | 92.50 > 91.47 * | 75.54 > 62.32⋄ | 64.26 < 66.10⋄ |
| Model | Mutag | Proteins | PTC |
|---|---|---|---|
| Igel (ours) | |||
| k-hop [16] † | 87.9 ± 1.2⋄ | — | |
| GSN [19] † | |||
| NGNN [20] † | — | ||
| ID-GNN [39] † | * | ||
| GNN-AK [21] † | |||
| ESAN [22] † |
| Model | + | Graph8c | EXP Class. |
|---|---|---|---|
| (#Errors) | (Accuracy) | ||
| Linear | No | 6.242M | 50% |
| Yes | 1571 | 97.25% | |
| MLP | No | 293K | 50% |
| Yes | 1487 | 100% | |
| GCN | No | 4196 | 50% |
| Yes | 5 | 100% | |
| GAT | No | 1827 | 50% |
| Yes | 5 | 100% | |
| GIN | No | 571 | 50% |
| Yes | 5 | 100% | |
| Chebnet | No | 44 | 50% |
| Yes | 1 | 100% | |
| GNNML3 | No | 0 | 100% |
| Yes | 0 | 100% |
| Model | + | Star | Triangle | Tailed Tri. | 4-Cycle | Custom |
|---|---|---|---|---|---|---|
| Linear | No | |||||
| Yes | ||||||
| MLP | No | |||||
| Yes | ||||||
| GCN | No | |||||
| Yes | ||||||
| GAT | No | |||||
| Yes | ||||||
| GIN | No | |||||
| Yes | ||||||
| Chebnet | No | |||||
| Yes | ||||||
| GNNML3 | No | |||||
| Yes | ||||||
| GIN-AK+ [21] | No | — | ||||
| SUN [23] | No | — |
| Model | + | Zinc-12K (Mean Squared Error, ↓) | Pattern (Accuracy, ↑) |
|---|---|---|---|
| GIN | No | ||
| Yes | |||
| GIN-AK+ | No | ||
| Yes | 86.737 ± 0.062 |
| Method | arXiv | |
|---|---|---|
| DeepWalk [51] | 0.968 | 0.934 |
| node2vec [52] | 0.968 | 0.937 |
| () | 0.976 | 0.984 |
| Method | PPI | |
|---|---|---|
| Only Features (MLP, ours) | 0.558 | |
| GraphSAGE-GCN [32] | 0.500 | |
| GraphSAGE-mean [32] | 0.598 | |
| GraphSAGE-LSTM [32] | 0.612 | |
| GraphSAGE-pool [32] | 0.600 | |
| GraphSAGE (no sampling) [33] | 0.768 | |
| LGCL [34] | 0.772 | |
| () | Graph Only | 0.736 |
| Graph + Feats | 0.850 | |
| () | Graph Only | 0.506 |
| Graph + Feats | 0.741 | |
| Const-GAT [33] | 0.934 | |
| GAT [33] | 0.973 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alvarez-Gonzalez, N.; Kaltenbrunner, A.; Gómez, V. Beyond Weisfeiler–Lehman with Local Ego-Network Encodings. Mach. Learn. Knowl. Extr. 2023, 5, 1234-1265. https://doi.org/10.3390/make5040063
Alvarez-Gonzalez N, Kaltenbrunner A, Gómez V. Beyond Weisfeiler–Lehman with Local Ego-Network Encodings. Machine Learning and Knowledge Extraction. 2023; 5(4):1234-1265. https://doi.org/10.3390/make5040063
Chicago/Turabian StyleAlvarez-Gonzalez, Nurudin, Andreas Kaltenbrunner, and Vicenç Gómez. 2023. "Beyond Weisfeiler–Lehman with Local Ego-Network Encodings" Machine Learning and Knowledge Extraction 5, no. 4: 1234-1265. https://doi.org/10.3390/make5040063
APA StyleAlvarez-Gonzalez, N., Kaltenbrunner, A., & Gómez, V. (2023). Beyond Weisfeiler–Lehman with Local Ego-Network Encodings. Machine Learning and Knowledge Extraction, 5(4), 1234-1265. https://doi.org/10.3390/make5040063